#AmazonRDS
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text

We are proud to announce that AllCode has achieved the status of Certified AWS Advanced Consulting Partner! This significant milestone underscores our commitment to delivering exceptional AWS Solutions and services
#aws services#AWS#CloudComputing#AWSAdvancedPartner#CloudSolutions#Innovation#SecureCloud#PublicSector#AmazonRDS#QuickSight#AWSExperts#AllCode
0 notes
Text
What Is Amazon RDS? Amazon RDS Best Practices, Benefits

What is Amazon RDS?
The service for relational databases Designed to minimize total cost of ownership, Amazon Relational Database Service (Amazon RDS) is easy to use. Setting up, running, and scaling to meet demand is easy. Tasks related to provisioning, configuration, backup, and patching are among the undifferentiated database management tasks that are automated by Amazon RDS. With Amazon RDS, users can quickly establish a new database and personalize it to suit their needs using two deployment options and eight engines. Customers can optimize performance with features including AWS Graviton3-based instances, optimized writes and reads, and Multi-AZ with two readable standbys. They can also select from a variety of pricing choices to efficiently control expenses.
New developments with Amazon RDS
Aurora
Fully compatible with MySQL and PostgreSQL, Amazon Aurora offers unmatched performance and availability on a global scale for a tenth of the price of commercial databases. With features like Amazon Aurora Serverless, which can scale to hundreds of thousands of transactions in a split second, Amazon Aurora I/O-Optimized, which predicts prices, and zero-ETL integrations to Amazon Redshift, which provide near-real-time analytics on your transactional data, you can take advantage of improved capabilities that delight your users.
The Amazon RDS
When you utilize Amazon RDS, you may start using the same commercial and open source database software that you are accustomed to and trust, like MariaDB, PostgreSQL, MySQL, SQL Server, Oracle, and Db2. With support for AWS Graviton3-based instances, Amazon Elastic Block Store (Amazon EBS), and io2 Block Express storage, you can take advantage of the innovation of the AWS stack and eliminate the burden of undifferentiated administrative duties.
Creating applications for generative AI
The performance of your generative AI applications can be enhanced by using Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Amazon Aurora PostgreSQL-Compatible Edition. You can accomplish 20 times better queries per second than with pgvector_IVFFLAT when you combine the capabilities of Amazon Aurora Optimized Reads and pgvector_hnsw.
ML and analytics with integrations at zero ETL
With zero-ETL integrations, the laborious task of creating and overseeing ETL pipelines from live databases to data warehouses is eliminated. In order to achieve desired business objectives, zero-ETL enables clients to access their transactional data in almost real-time for analytics and machine learning (ML) purposes.
Possibilities for deployment
Deployment choices are flexible with Amazon RDS. Applications that need to customize the underlying database environment and operating system can benefit from the managed experience offered by Amazon Relational Database Service (Amazon RDS) Custom. Fully managed database instances can be set up in your on-premises environments using Amazon Relational Database Service (Amazon RDS) on AWS Outposts.
Use Cases
Construct mobile and web applications
Provide high availability, throughput, and storage scalability to accommodate expanding apps. Utilize adaptable pay-per-use pricing to accommodate different application usage trends.
Use managed databases instead
Instead of worrying about self-managing your databases, which may be costly, time-consuming, and complex, experiment and create new apps with Amazon RDS.
Become independent of legacy databases
By switching to Aurora, you can get rid of costly, punitive, commercial databases. When you switch to Aurora, you can obtain commercial databases’ scalability, performance, and availability for a tenth of the price.
Amazon RDS advantages
One type of managed database service is Amazon RDS. It is in charge of the majority of management duties. Amazon RDS allows you to concentrate on your application and users by removing time-consuming manual procedures.
The following are the main benefits that Amazon RDS offers over partially managed database deployments:
You can utilize database engines like IBM Db2, MariaDB, Microsoft SQL Server, MySQL, Oracle Database, and PostgreSQL, which you are already familiar with.
Backups, software patching, automatic failure detection, and recovery are all handled by Amazon RDS.
You have the option to manually create backup snapshots or enable automated backups. These backups can be used to restore a database. The Amazon RDS restoration procedure is dependable and effective.
With a primary database instance and a synchronous backup database instance that you may switch to in case of issues, you can achieve high availability. To improve read scaling, you may also employ read replicas.
In addition to the security features included in your database package, you may manage access by defining users and permissions using AWS Identity and Access Management (IAM). Putting your databases in a virtual private cloud (VPC) can also help protect them.
Read more on Govindhtech.com
#AmazonRDS#RDS#RelationalDatabaseService#PostgreSQL#MySQL#AmazonAurora#databases#AmazonEBS#New#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Video
youtube
(via Amazon Relation Database Service RDS Explained for Cloud Developers) Full Video Link - https://youtube.com/shorts/zBv6Tcw6zrUHi, a new #video #tutorial on #amazonrds #aws #rds #relationaldatabaseservice is published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #codeonedigest #aws #amazonwebservices #aws #awscloud #cloudcomputing #amazonrdsvsaurora #amazonrdsbackupandrestore #amazonrdssnapshotexporttos3 #amazonrdsbackup #amazonrdsaurora #amazonrdsautomatedbackup #amazonrdsaccessfromoutside #amazonrdsguide #awsrdsauroratutorial #awsrdsvsaurora #awsrdsperformanceinsights #awsrdsexplained #awsrdstutorial #awsrdsengine #relationaldatabaseservice #relationaldatabasemanagementsystem #relationaldatabase #rdbms
1 note
·
View note
Video
youtube
Amazon RDS for Oracle | Simplify Your Database Management
RDS for Oracle offers a managed Oracle Database environment, providing the full capabilities of Oracle’s powerful database platform. It supports both Standard and Enterprise Editions, making it suitable for a wide range of use cases.
- Key Features: - Automated backups, patching, and monitoring. - Support for Oracle-specific features like Data Guard, Real Application Clusters (RAC), and Automatic Storage Management (ASM). - Transparent Data Encryption (TDE) for enhanced security. - Flexible licensing options, including Bring Your Own License (BYOL).
- Use Cases: - Mission-critical enterprise applications. - Financial and ERP systems. - Applications requiring robust security, performance, and reliability.
Key Benefits of Choosing the Right Amazon RDS Database:
1. Optimized Performance: Select an engine that matches your performance needs, ensuring efficient data processing and application responsiveness. 2. Scalability: Choose a database that scales seamlessly with your growing data and traffic demands, avoiding performance bottlenecks. 3. Cost Efficiency: Find a solution that fits your budget while providing the necessary features and performance. 4. Enhanced Features: Leverage advanced capabilities specific to each engine to meet your application's unique requirements. 5. Simplified Management: Benefit from managed services that reduce administrative tasks and streamline database operations.
Conclusion:
Choosing the right Amazon RDS database engine is critical for achieving the best performance, scalability, and functionality for your application. Each engine offers unique features and advantages tailored to specific use cases, whether you need the speed of Aurora, the extensibility of PostgreSQL, the enterprise features of SQL Server, or the robustness of Oracle. Understanding these options helps ensure that your database infrastructure meets your application’s needs, both now and in the future.
#AWS #AWSSummitNYC #awsxon #awssummitny #awscloud #awsreinvent #aws_jr_champions #cloudolus #cloudolupro #Oracle #dbs #database #rds
#youtube#AmazonRDS OracleOnAWS RDSforOracle AWSDatabase ManagedDatabase DatabaseManagement CloudDatabase OracleDatabase AWSRDS DatabaseAdmin AWSTutor#AWS AWSSummitNYC awsxon awssummitny awscloud awsreinvent aws_jr_champions cloudolus cloudolupro Oracle dbs database rds
1 note
·
View note
Text

What is Amazon RDS? . . . visit: http://bit.ly/3JCREfe for more information
#aws#AmazonRDS#DataPipeline#VPCEndpoint#AWSBastionHost#amazon#AWSRedshift#AWSElasticache#awsaurora#azure#cloudcomputing#cloudtechnology#amazonemr#amazons3#amazonlightsail#amazonec2#javatpoint
0 notes
Photo

MOST POPULAR AWS PRODUCTS
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon SNS
- AWS Cloudtrail
Visit www.connectio.in
0 notes
Photo
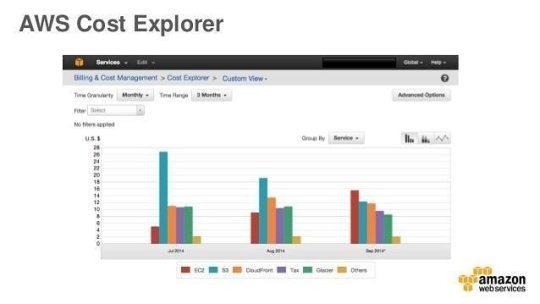
Monitor your Amazon Redshift, Amazon RDS, and Amazon ElastiCache reservations using AWS Cost Explorer’s RI Utilization report.⠀ ⠀ 💲💲Cost Explorer is an essential feature in AWS to predict and forecast monthly budgets, total spent each month and get details on what services are costing you 💰 money.⠀ ⠀ Starting today, you can monitor your Amazon Redshift, Amazon RDS, and Amazon ElastiCache reservations, in addition to your Amazon EC2 Reserved Instances (RI), using the RI Utilization report, available in AWS Cost Explorer.⠀ https://buff.ly/2zGK0wJ⠀ ⠀ #aws #cloud #amazonwebservices #cost #budget #cloudcost #cloudbudget #amazon #cloudmanagment #redshift #amazonrds #elasticcache
#cost#aws#cloudcost#cloudbudget#amazon#redshift#cloud#budget#amazonwebservices#amazonrds#cloudmanagment#elasticcache
0 notes
Text
Verwendung von Amazon RDS für Cloud Computing: "Rationalisieren Sie Ihr Cloud Computing mit Amazon RDS von MHM Digitale Lösungen UG"
#CloudComputing #AmazonRDS #MHMDigitaleLösungenUG #Skalierung #Kosteneffizienz #Sicherheit #Datenbanklösungen #Datenhaltung #Datenmanagement #Datenübertragung
Cloud Computing ist ein sehr wichtiger Bestandteil der IT-Branche. Amazon RDS bietet eine skalierbare, sichere und kostengünstige Plattform für die Entwicklung und Verwaltung von Datenbanken. Amazon RDS ermöglicht es IT-Profis, ihre Cloud-Computing-Lösungen auf einer zentralen und sicheren Umgebung zu entwickeln, zu debuggen und zu verwalten. Dank seiner vielen nützlichen Funktionen können…
View On WordPress
#Amazon RDS#Cloud Computing#Datenübertragung.#Datenbanklösungen#Datenhaltung#Datenmanagement#Kosteneffizienz#MHM Digitale Lösungen UG#Sicherheit#Skalierung
0 notes
Text
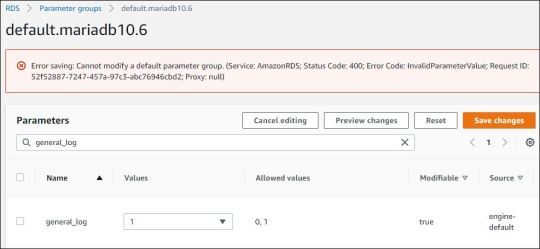
Error saving: Cannot modify a default parameter group. (Service: AmazonRDS; Status Code: 400; Error Code: InvalidParameterValue; Request ID: 52f52887-7247-457a-97c3-abc76946cbd2; Proxy: null)
Error saving: Cannot modify a default parameter group. (Service: AmazonRDS; Status Code: 400; Error Code: InvalidParameterValue; Request ID: 52f52887-7247-457a-97c3-abc76946cbd2; Proxy: null)
In AWS when we try to edit the Default parameter for the Amazon RDS server for MariaDB then we get the error. Cause: We cannot change the default parameter. Solution: We need to create the new parameter group and associate that with the database and reboot the database. Steps as follows: Create the New Parameter Group. 2. Create a Parameter group as you required, which I named as General…
View On WordPress
0 notes
Text
VMware workloads to AWS: Optimize, migrate and modernize

Optimization, migration, and modernization of VMware workloads to AWS.
Based on strategy and results, IBM clients’ transformation journeys are unique. Businesses must ensure that its infrastructure supports strategic goals like cost optimization, performance improvement, and cloud adoption as technology and business needs change.
After Broadcom acquired VMware, VMware clients confront transformational decisions in a shifting marketplace. IBM Consulting understands. IBM Consulting can assist VMware clients succeed through a variety of hybrid cloud transformation pathways using its expertise. These include on-premises modernization, cloud modernization, containerization with cloud-native technologies, or a mix.
VMware Modernization Assessment is a Rapid Strategy and Assessment that explores VMware’s future paths to achieve business success and manage risk.
IBM Cloud For VMWare Regulated Workloads
IBM will discuss how IBM Consulting can help organizations who prefer AWS-based cloud-native solutions using AWS’s modern tools and cloud services in this blog.
AWS offers VMware a complete platform with cloud services, global infrastructure, and strong security. This method avoids hardware dependence, scalability issues, and high operational costs of on-premises infrastructure. Organizations can use AWS’s scalability, pay-as-you-go pricing, and wide range of services to construct VMware workloads to AWS.
Clients considering data centre (DC) exits want to cut costs and simplify operations while improving security, compliance, and innovation.
Data centre consolidation can be accelerated by moving from VMware to the cloud or hybrid. IBM Consulting provides data centre migration (DC exit), a comprehensive solution to help organizations efficiently and strategically migrate from their data centre infrastructure to their cloud of choice, including AWS. IBM’s generative AI and IBM–AWS collaborative investments enable scaled migration.
AWS Cloud migration scenarios
To build new capabilities, boost operational efficiency, and implement cloud-native architecture on AWS Cloud, enterprises can explore numerous scenarios to relocate and modernize VMware workloads to AWs:
Clients can move VMware VMs to AWS instances first. This requires rehosting apps on Amazon Elastic Compute Cloud (Amazon EC2) instances and maybe reconfiguring them for the cloud. After migration, organisations can modernise their applications to use AWS native services like Amazon RDS for database management, AWS Lambda for serverless computing, and Amazon S3 for scalable storage.
IBM’s container-first approach provides an end-to-end stack of solutions and services to satisfy modern organisations’ complex needs. From cloud infrastructure and AI to cybersecurity and data management, it covers it all. This product centres on ROSA and OpenShift Virtualization. These technologies demonstrate IBM’s commitment to flexible, scalable, and integrated business innovation and efficiency.
ROSA, EKS, and Amazon ECS on AWS Fargate may containerize workloads across the AWS Cloud to reduce vendor lock-in. Businesses can execute and manage containerized and virtual machine (VM) workloads on a single platform using Red Hat OpenShift virtualization.
Software as a service (SaaS): VMware applications can be migrated to AWS. The flexible, cost-effective, and efficient way to deliver software applications is SaaS.
Offered managed services: IBM is an AWS-certified MSP that can migrate VMware workloads to AWS managed services. AWS managed services automate and simplify cloud management. IBM services help organizations adapt and operate in the AWS Cloud with best practices, security, and compliance. Managed services let companies focus on their core business while IBM manages cloud infrastructure.
IBM Migration Factory speeds cloud migration
IBM understands AWS technologies from years of collaboration and expertise, enabling enterprise integration and optimisation. IBM provides a tailored strategy to meet clients’ needs.
AWS Migration Factory, based on IBM Garage Methodology, is a unique app modernization engagement approach from IBM Consulting. This squad-based, workstream-centric strategy uses gen AI and automation to scale rapid transformation.
The structured and efficient AWS Migration Factory framework migrates huge VMware workloads to AWS. Organizations may reduce risks, costs, and time for cloud migration by using automated technologies, best practices, and a phased strategy. The manufacturing speeds client engagements with cooperative incentive programmes.
IBM thoroughly evaluates the client’s VMware setup before migrating. This includes workload dependencies, performance metrics, and migration needs. Based on the assessment, a complete migration strategy should include timetables, resource allocation, and risk mitigation. The IBM Consulting Cloud Accelerator, IBM Consulting Delivery Curator, IBM Consulting developer experience platform, and IBM Consulting AIOps solutions help plan, design, and execute end-to-end migration and modernization journeys.
These assets are supported by IBM Delivery Central. Digitising and improving delivery procedures and providing real-time oversight, this end-to-end delivery execution platform transforms delivery. Powered by generative AI, these assets and assistants serve key personas’ consumption modes.
Other AWS tools and services for VMware workload migration include AWS Migration Hub. It accelerates and automates application migration to AWS, offering visibility, tracking, and coordination, incorporating AWS Application Migration Services.
IBM’s Generative-AI migration tools
IBM used Amazon Bedrock to create migration tools and assets. Using Amazon Bedrock and generative AI, this unique approach migrates applications and workloads to the cloud.
Service-based AI-powered discovery: Extracts crucial data from client data repositories to speed up application discovery.
Artificial intelligence-powered migration aid: Transforms natural language questions into SQL queries to retrieve application and server migration status from a centralised data lake (Delivery Curator) during migration.
Generative AI design assistant: Uses models like llama2 on Delivery Curator’s centralised data store and the design assistant to speed up design.
IBM helped a worldwide manufacturer move VMware workloads to AWS
Moving to AWS may save costs, scale, and innovate for companies. IBM assisted a worldwide consumer products manufacturer in migrating 400 applications to AWS in two years as part of its product strategy shift. To increase agility, scalability, and security, the customer moved to AWS.
The customer also needed to train personnel on new data handling techniques and the architectural transition. To achieve these goals, the customer moved their technology from on-premises to AWS, which improved business performance by 50% and saved up to 50% utilising Amazon RDS.
Read more on govindhtech.com
#vmwareworkloads#aws#modernize#assistvmware#ibmcloud#generativeai#amazonec2#amazonrds#amazons2#redhat#genai#ibmhelped#migrationtools#cloudmigration#technology#technews#news#govindhtech
0 notes
Text
Amazon Aurora Database Explained for AWS Cloud Developers
Full Video Link - https://youtube.com/shorts/4UD9t7-BzVM Hi, a new #video #tutorial on #amazonrds #aws #aurora #database #rds is published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #cod
Amazon Aurora is a relational database management system (RDBMS) built for the cloud & gives you the performance, availability of commercial-grade databases at one-tenth the cost. Aurora database comes with MySQL & PostgreSQL compatibility. Amazon Aurora provides built-in security, continuous backups, serverless compute, up to 15 read replicas, automated multi-Region replication, and…

View On WordPress
#amazon aurora#amazon aurora mysql#amazon aurora postgresql#amazon aurora serverless#amazon aurora tutorial#amazon web services#amazon web services tutorial#aurora database aws#aurora database tutorial#aurora database vs rds#aurora db#aurora db aws#aurora db aws tutorial#aurora db cluster#aurora db with spring boot#aws#aws aurora#aws aurora mysql#aws aurora postgresql#aws aurora tutorial#aws aurora vs rds#aws cloud#what is amazon web services
0 notes
Video
youtube
Amazon RDS for SQL Server | Managed Database Service for Efficiency
RDS for SQL Server provides a managed environment for Microsoft SQL Server, offering enterprise-grade features like business intelligence, data warehousing, and advanced analytics. It integrates seamlessly with other Microsoft products, making it a robust choice for enterprise applications.
- Key Features: - Support for SQL Server features like SSRS, SSIS, and SSAS. - Automated backups and Multi-AZ deployments. - Integration with Active Directory for secure authentication. - Easy scaling of resources and storage.
- Use Cases: - Large-scale enterprise applications. - Business intelligence and reporting. - Applications requiring advanced analytics and integration with Microsoft ecosystems.
Key Benefits of Choosing the Right Amazon RDS Database:
1. Optimized Performance: Select an engine that matches your performance needs, ensuring efficient data processing and application responsiveness. 2. Scalability: Choose a database that scales seamlessly with your growing data and traffic demands, avoiding performance bottlenecks. 3. Cost Efficiency: Find a solution that fits your budget while providing the necessary features and performance. 4. Enhanced Features: Leverage advanced capabilities specific to each engine to meet your application's unique requirements. 5. Simplified Management: Benefit from managed services that reduce administrative tasks and streamline database operations.
Conclusion:
Choosing the right Amazon RDS database engine is critical for achieving the best performance, scalability, and functionality for your application. Each engine offers unique features and advantages tailored to specific use cases, whether you need the speed of Aurora, the extensibility of PostgreSQL, the enterprise features of SQL Server, or the robustness of Oracle. Understanding these options helps ensure that your database infrastructure meets your application’s needs, both now and in the future.
📢 Subscribe to ClouDolus for More AWS & DevOps Tutorials! 🚀 🔹 ClouDolus YouTube Channel - https://www.youtube.com/@cloudolus 🔹 ClouDolus AWS DevOps - https://www.youtube.com/@ClouDolusPro
*THANKS FOR BEING A PART OF ClouDolus! 🙌✨*
***************************** *Follow Me* https://www.facebook.com/cloudolus/ | https://www.facebook.com/groups/cloudolus | https://www.linkedin.com/groups/14347089/ | https://www.instagram.com/cloudolus/ | https://twitter.com/cloudolus | https://www.pinterest.com/cloudolus/ | https://www.youtube.com/@cloudolus | https://www.youtube.com/@ClouDolusPro | https://discord.gg/GBMt4PDK | https://www.tumblr.com/cloudolus | https://cloudolus.blogspot.com/ | https://t.me/cloudolus | https://www.whatsapp.com/channel/0029VadSJdv9hXFAu3acAu0r | https://chat.whatsapp.com/BI03Rp0WFhqBrzLZrrPOYy *****************************
#youtube#aws rdsawscloudamazon web servicesAmazon RDS for SQL Server | Managed Database Service for Efficiencyamazon awsAmazon RDSSQL ServerDatabasec#AmazonRDS SQLServerOnAWS RDSforSQLServer AWSDatabase ManagedDatabase DatabaseEfficiency CloudDatabase AWSRDS SQLServerAdmin DatabasePerforma
0 notes
Text
RDS Proxy with Lambda
Amazon recently announced that the RDS Proxy service was in General Availability and therefore can be used for Prod. I am essite. I’m going to document my experience as I go through the process.
As usual, Amazon’s documentation is... lacking. It provides paragraph on paragraph of words, but at the end you’re still wondering how to actually use the Proxy in any meaningful way. There was only one dedicated page that I could find:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/rds-proxy.html
However, some others have created good tutorials and explanations of how and why to use it:
https://www.percona.com/community-blog/2020/01/07/a-first-look-at-amazon-rds-proxy/
https://idk.dev/improving-application-availability-with-amazon-rds-proxy/
Once you have the Proxy setup, you can simply connect to it without needing any special changes. Just point your ORM at the proxy URL instead of the Reader URL and you’re off to the races.
Function Speeds
The speed was... impressive to say the least. A cold start of a very simple Node function took around 300ms. Subsequent calls took less than 10ms. This is much better than the 5 second cold starts (and slow calls) previously seen.
Caveats
You can’t change the DB instance size once the proxy is created, meaning you can’t scale your database tier up. It’s not a big deal as long as you plan for the right amount of traffic.
The proxy can’t be public, which means you need special logic when running your serverless applications offline. I detailed my solution below.
There is still a cold start if the RDS Proxy has shut down. You can specify the idle time when configuring the proxy. Keep in mind that you pay for the time it’s active, so this could become a cost that doesn’t scale well with your infrastructure.
Working Locally or with Serverless Offline
When using the excellent Serverless Offline plugin (or just executing locally), you need to perform special logic to determine whether your Lambda function is running in AWS or locally. Thankfully, the Serverless framework provides a variable for that:
https://www.serverless.com/plugins/serverless-offline#the-processenvis_offline-variable
So you can do some magic like:
host: (process.env.IS_OFFLINE === "false") ? `YOUR_READER_URL` : process.env.DB_CREDS_HOST,
Weird/Infuriating Issue With VPC Setup
I tried using the same VPC as an existing database so I didn’t have to setup a bunch of new stuff for this test. For some reason, when trying to save the RDS proxy, I’m getting this error:
Minimum 2 AZs are needed to be covered by subnets but found only 1 AZs, requested subnet 'subnet-0b504b629635cdee0' is in an unsupported availability zone 'us-east-1e
I confirmed that the subnet in question was in us-east-1e. You can’t change the AZ for a subnet once it’s created, so I made a new one, in the same VPC, with the same Route Table, using private IPs... but they refused to show up in the list when creating a new Proxy. So I deleted the entire database and started a new one and allowed it to create it’s own VPC settings.
0 notes
Text
Deploy ML Models On AWS Lambda - Code Along
Introduction
The site Analytics Vidhya put out an article titled Deploy Machine Learning Models on AWS Lambda on Medium on August 23, 2019.
I thought this was a great read, and thought I might do a code along and share some of my thoughts and takeaways!

[ Photo by Patrick Brinksma on Unsplash ]
You should be able to follow along with my article and their article at the same time (I would read both) and my article should help you through their article. Their sections numbers don’t make sense (they use 2.3 twice) so I choose to use my own section numbers (hopefully you don’t get too confused there).
Let’s get going!

Preface - Things I Learned The Hard Way
You need to use Linux!
This is a big one. I went through all the instructions using a Windows OS thinking it would all work the same, but numpy on Windows is not the same as numpy on Linux, and AWS Lambda is using Linux.
After Windows didn’t work I switched to an Ubuntu VirtualBox VM only to watch my model call fail again! (Note that the issue was actually with how I was submitting my data via cURL, and not Ubuntu, but more on that to come). At the time I was able to deploy a simple function using my Ubuntu VM, but it seemed that numpy was still doing something weird. I thought maybe the issue was that I needed to use AWS Linux (which is actually different from regular Ubuntu).
To use AWS Linux, you have a few options (from my research):
Deploy an EC2 instance and do everything from the EC2 instance
Get an AWS Linux docker image
Use Amazon Linux WorkSpace
I went with option #3. You could try the other options and let me know how it goes. Here is an article on starting an Amazon Linux WorkSpace:
https://aws.amazon.com/blogs/aws/new-amazon-linux-workspaces/
It takes a while for the workspace to become available, but if you’re willing to wait, I think it’s a nice way to get started. It’s also a nice option if you’re running Windows or Mac and you don’t have a LOT of local memory (more on that in a minute).
Funny thing is that full circle, I don’t think I needed to use Amazon Linux. I think the problem was with how I was submitting my cURL data. So in the end you could probably use any flavor of Linux, but when I finally got it working I was using Amazon WorkSpace, so everything is centered around Amazon Linux WorkSpace (all the steps should be roughly the same for Ubuntu, just replace yum with apt or apt-get and there are a few other changes that should be clear).
Another nice thing about running all of this from Amazon WorkSpace is that it also highlights another service from AWS. And again, it’s also a nice option if you’re running Windows or Mac and you don’t have a LOT of local memory to run a VM. VMs basically live in RAM, so if your machine doesn’t have a nice amount of RAM, your VM experience is going to be ssslllooowwwww. My laptop has ~24GB of RAM, so my VM experience is very smooth.
Watch our for typos!
I reiterate this over and over throughout the article, and I tried to highlight some of the major ones that could leave you pulling your hair out.
Use CloudWatch for debugging!
If you’re at the finish line and everything is working but the final model call, you can view the logs of your model calls under CloudWatch. You can add print statements to your main.py script and this should help you find bugs. I had to do this A LOT and test almost every part of my code to find the final issue (which was a doozy).
Okay, let’s go!

#1 - Build a Model with Libraries SHAP and LightGBM.
The article starts off by building and saving a model. To do this, they grab a open dataset from the package SHAP and use LightGBM to build their model.
Funny enough, SHAP (SHapley Additive exPlanations) is a unified approach to explain the output of any machine learning model. It happens to also have datasets that you can play with. SHAP has a lot of dependencies, so it might be easier to just grab any play dataset rather than installing SHAP if you’ve never installed SHAP before. On the other hand, it’s a great package to be aware of, so in that sense it’s also worth installing (although it’s kind of overkill for our needs here).
Here is the full code to build and save a model to disk using their sample code:
import shap import lightgbm as lgbm
data,labels = shap.datasets.adult()
params = {'objective':'binary', 'booster_type':'gbdt', 'max_depth':6, 'learning_rate':0.05, 'metric':'auc'}
dtrain = lgbm.Dataset(data,labels)
model = lgbm.train(params,dtrain,num_boost_round=100,valid_sets=[dtrain])
model.save_model('saved_adult_model.txt')
Technically you can do this part on any OS, either way I suggest creating a Python venv.
Note that I’m using AWS Linux, which is RedHat based so I’ll be using yum instead of apt or apt-get. First I need python3, so I’ll run:
sudo yum -y install python3
Then I created a new folder, and within that new folder I created a Python venv.
python3 -m venv Lambda_PyVenv
To activate your Python venv just type the following:
source Lambda_PyVenv/bin/activate
Now we need shap and lightgbm. I had some trouble installing shap, so I had to run the following first:
sudo yum install python-devel
sudo yum install libevent-devel
sudo easy_install gevent
Which I got from:
https://stackoverflow.com/questions/11094718/error-command-gcc-failed-with-exit-status-1-while-installing-eventlet
Next I ran:
pip3 install shap
pip3 install lightgbm
And finally I could run:
python3 create_model.py
Note: For file creating and editing I use Atom (if you don’t know how to install atom on Ubuntu, open a new terminal, then I would check out the documentation and just submit the few lines of code from command line).
#2 - Install the Serverless Framework
Next thing you need to do is open a new terminal and install the Serverless Framework on your Linux OS machine.
Something else to keep in mind, if you try to test out npm and serverless from Atom or Sublime consoles, it’s possible you might hit errors. You might want to use your normal terminal from here on out!
Here is a nice article on how to install npm using AWS Linux:
https://tecadmin.net/install-latest-nodejs-and-npm-on-centos/
In short, you need to run:
sudo yum install -y gcc-c++ make
curl -sL https://rpm.nodesource.com/setup_10.x | sudo -E bash -
sudo yum install nodejs
Then to install serverless I just needed to run
sudo npm install -g serverless
Don’t forget to use sudo!
And then I had serverless running on my Linux VM!

#3 - Creating an S3 Bucket and Loading Your Model
The next step is to load your model to S3. The article does this by command line. Another way to do this is to use the AWS Web Console. If you read the first quarter for my article Deep Learning Hyperparameter Optimization using Hyperopt on Amazon Sagemaker I go through a simple way of creating an S3 bucket and loading data (or in this case we’re loading a model).
#4 - Create the Main.py file
Their final main.py file didn’t totally work for me, it was missing some important stuff. In the end my final main.py file looked something like:
import boto3 import lightgbm import numpy as np
def get_model(): bucket= boto3.resource('s3').Bucket('lambda-example-mjy1') bucket.download_file('saved_adult_model.txt','/tmp/test_model.txt') model= lightgbm.Booster(model_file='/tmp/test_model.txt') return model
def predict(event): samplestr = event['body'] print("samplestr: ", samplestr) print("samplestr str:", str(samplestr)) sampnp = np.fromstring(str(samplestr), dtype=int, sep=',').reshape(1,12) print("sampnp: ", sampnp) model = get_model() result = model.predict(sampnp) return result
def lambda_handler(event,context): result1 = predict(event) result = str(result1[0]) return {'statusCode': 200,'headers': { 'Content-Type': 'application/json' },'body': result }
I had to include the ‘header’ section and the body. These needed to be returned as a string in order to not get ‘internal server error’ type errors.
You’ll also notice that I’m taking my input and converting it from a string to a 2d numpy array. I was feeding a 2d array similar to the instructions and this was causing an error. This was the error that caused me to leave Ubuntu for AWS Linux because I thought the error was still related to the OS when it wasn’t. Passing something other than a string will do weird things. It’s better to pass a string and then just convert the string to any format required.
(I can’t stress this enough, this caused me 1.5 days of pain).
#5 - YML File Changes
Next we need to create our .yml file which is required for the serverless framework, and gives necessary instructions for the framework.
For the most part I was able to use their YML file, but below are a few properties I needed to change:
runtime: python3.7
region : us-east-1
deploymentBucket: name : lambda-example-mjy1
iamRoleStatements: - Effect : Allow Action: - s3:GetObject Resource: - "arn:aws:s3:::lambda-example-mjy1/*"
WARNING!!!
s3.GetObject should be s3:GetObject
Don’t get that wrong and spend hours on a blog typo like I did!

If you need to find your region, you can use the following link as a resource:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.html
Also, make sure the region you specify is the same region that your S3 bucket is located in.
#6 - Test What We Have Built Locally
Before you test locally, I think you need your requirements.txt file. For now you could just run:
pip freeze > requirements.txt
Now, if you’re like me and tried to run it locally at this point, you probably hit an error because they never walked you through how to add the serverless-python-requirements plugin!

I found a nice article that walks you through this step:
https://serverless.com/blog/serverless-python-packaging/
You want to follow the section that states ...
“ Our last step before deploying is to add the serverless-python-requirements plugin. Create a package.json file for saving your node dependencies. Accept the defaults, then install the plugin: “
In short, you want to:
submit ‘npm init’ from command line from your project directory
I gave my package name the same as my service name: ‘test-deploy’
The rest I just left blank i.e. just hit enter
Last prompt just enter ‘y’
Finally you can enter ‘sudo npm install --save serverless-python-requirements’ and everything so far should be a success.
Don’t forget to use sudo!
BUT WE’RE NOT DONE!!! (almost there...)
Now we need to do the following (if you haven’t already):
pip3 install boto3
pip3 install awscli
run “aws configure” and enter our Access Key ID and Secret Access Key
Okay, now if we have our main.py file ready to go, we can test locally (’again’) using the following command:
serverless invoke local -f lgbm-lambda --path data.txt
Where our data.txt file contains
{"body":[[3.900e+01, 7.000e+00, 1.300e+01, 4.000e+00, 1.000e+00,
0.000e+00,4.000e+00, 1.000e+00, 2.174e+03, 0.000e+00, 4.000e+01,
3.900e+01]]}
Also, beware of typos!!!!

Up to this point, make sure to look for any typos, like your model having the wrong name in main.py. If you’re using their main.py file and saved your model with the name “saved_adult_model.txt”, then the model name in main.py should be “saved_adult_model.txt”. Watch out for plenty of typos, especially if you’re following along with their code! They didn’t necessarily clean everything :(. If you get stuck, there is a great video at the end of this blog that could help with typo checking.
#7 - The Moment We’ve All Been Waiting For, AWS Lambda Deployment!
Now we need to review our requirements.txt file and remove anything that doesn’t need to be in there. Why? Well, this is very important because AWS Lambda has a 262MB storage limit! That’s pretty small!
If you don’t slim down your requirements.txt you’ll probably hit storage limit errors.
With that in mind, I recommend taking only the files and folders needed and move them to some final folder location where you’ll run “serverless deploy”. You should only need the following:
main.py
package.json
requirements.txt
serverless.yaml
node_modules
package-lock.json
Now from command line within our final folder, we just run ..
serverless deploy
If all goes well, this should deploy everything! This might take a minute, in which case get some coffee and enjoy watching AWS work for you!

And if everything went as planned, then we should be able to test our live deployment using cURL!
curl -X POST https://xxxxxxxxxx.execute-api.xx-xxxx-1.amazonaws.com/dev/predictadult -d "39,7,13,4,1,0,4,1,2174,0,4,33"
Hopefully in the end you receive a model response like I did!
Resources:
https://medium.com/analytics-vidhya/deploy-machine-learning-models-on-aws-lambda-5969b11616bf
https://serverless.com/framework/docs/providers/aws/guide/installation/
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.html
https://serverless.com/blog/serverless-python-packaging/
And here is a great live demo from PyData Berlin!
youtube
0 notes
Text
Actcastのアーキテクチャ紹介
まえがき
2020年になり、弊社の提供するIoTプラットフォームサービスであるActcastも正式版をリリースしました。まだまだ改善余地はありますが、現状のActcastを支えているAWS上のアーキテクチャを紹介します。
参考
エッジコンピューティングプラットフォームActcastの正式版をリリース - PR TIMES
全体の概要
データをやり取りする主要なコンポーネントとしては、以下の3つがあげられます。下記の図を参照する際にこれを念頭においてください。
User API: ウェブのダッシュボードから使用され、グループやデバイスの管理などに使われます。
Device API: エッジデバイスから使用され、デバイスの設定や認証情報などを取得するのに使われます。
AWS IoT Core: MQTTを用いてデバイス側へ通知を送ったり、デバイス側からデータを送信するのに使われます。
すべてを記載しているわけではないですが典型的なデータのながれに着目して図にしたものがこちらになります。(WAFやCognitoなどはスペースの都合でアイコンだけになっています)
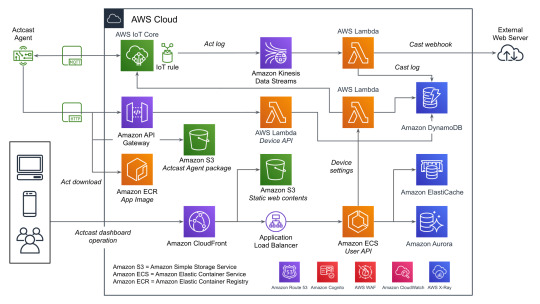
Actcast特有の概念であるActやCastという用語についてドキュメントから引用し、そのあと全体の説明をします。
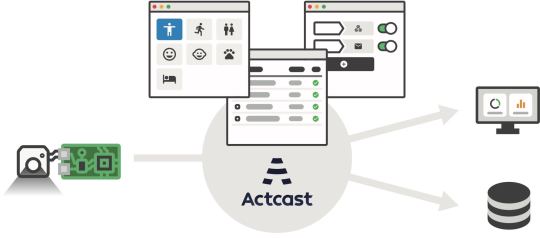
Actとは
デバイス上で実行され、デバイスに様々な振舞いをさせるソフトウェアを Act と呼んでいます。 Actcast に用意されているアプリケーションに、お好みの設定を与えたものが Act になります。
注: 上記の図ではアプリケーションはAppと記載されています。
Castとは
Cast とは Act から届いたデータをインターネットにつなげるものです。 Cast は「どのような場合にインターネットにつなげるか」を指定するトリガー部分と「どのようにインターネットにつなげるか」を指定するアクション部分からなります。
Actcastでのデータの流れ
ユーザーの操作とエッジデバイス上でのデータの流れに着目すると以下のようになります。
Actcastのユーザーはダッシュボードを通じてActのインストールやCastの設定をおこなう
エッジデバイス上で実行されているActcast Agentが設定に基づいたアプリケーションを起動する(Act)
Actが必要に応じてデータを生成する
Castの設定に基づいて生成されたデータを外部システムへ送信する(webhook)
先程の図に上記の番号を記載したのがこちらの図です。
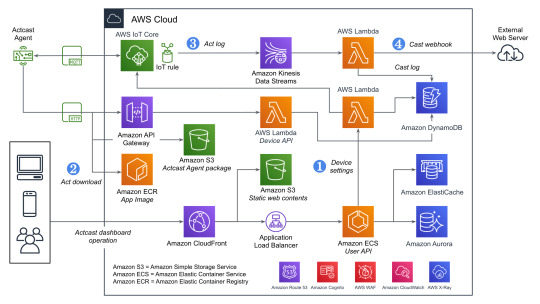
それぞれについて実際のAWSのリソースと絡めながら説明していきます。
1. Device Settings
良くあるウェブアプリケーションと同じ部分は箇条書きで簡単に説明します。
負荷分散はCloudFrontやAWS WAFなどをはさみつつALBを使用
アプリケーションの実行環境としてはECSをFargateで実行(User API)
データの永続化は基本的にAmazon Aurora(PostgreSQL)
キャッシュはElastiCache(Redis)
一部のデータはエッジデバイスから参照されるためワークロードの変化が読めなかったり、スケーラビリティが重要になったりするためDynamoDBを使用する形になっています。ECSのタスクから直接DynamoDBを触っていないのはDynamoDBに関するアクセス権をLambda側に分離するためです。もともとはすべてのDynamoDBへのアクセスパターンごとにLambdaを分けていましたが、さまざまな理由から最近は統合されました。
また、ダッシュボードでユーザー操作があった際にその設定をDynamoDBに保存すると同時にAWS IoTのMQTT経由でActcast Agentに通知を送り、それを契機にAgent自身でDevice APIを使って設定を取得します。Device API自体はAWS IoTのデバイス証明書を用いて認証を行っています。
2. Act download
DynamoDBから設定を取得したActcast Agentは、実行対象のアプリケーションイメージをECRから取得します。(ECRの認証情報はDevice APIから取得しています)
その後、設定に基づきイメージをActとして実行します。設定はアプリケーションによってことなり、典型的には後述のAct logを生成する条件が指定できます(推論結果の確度などを用いて)。
3. Act log
Actは条件によってデータ(Act log)を生成することがあります。 例えば、年齢性別推定を行うActはカメラに写った画像から以下のようなデータを生成します。
{ "age": 29.397336210511124, "style": "Male", "timestamp": 1579154844.8495722 }
生成したデータはAWS IoTを経由して一旦Kinesisのシャードに追加されていきます。Kinesisを挟むことでDynamoDBに対する負荷が急激に上昇した場合でもデータの欠損が発生しにくいようにしています。
4. Cast webhook
Kinesisのシャードに追加されたデータをLambdaのコンシューマーが処理していきます。 この際に、Castの設定(TriggerとAction)をもとにwebhookをするかや送信先を決定します。
Triggerではいくつかの条件が満たされているときに限りActionを実行するように設定することができます。
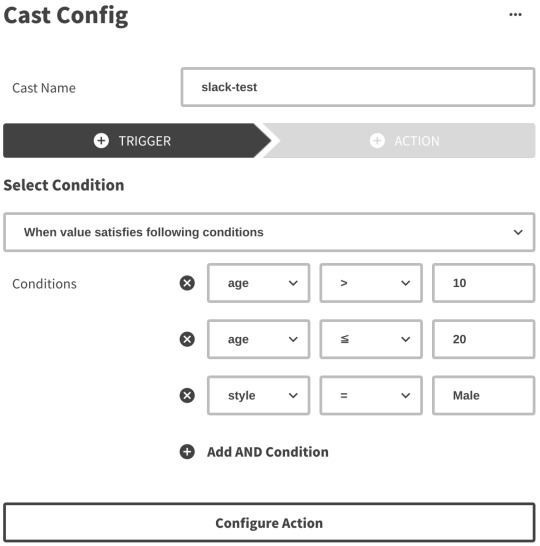
Actionではwebhook先のURLや送信するHTTPリクエストのボディなどを設定できますが詳細はドキュメントを確認してください。
ユーザー設定に基づきリクエスト先が変わるためSSRFなどが起きないような対策もしています。
苦労話
AWS IoT
Device Shadow
AWS IoTのDeviceとして登録するとそれに対応したShadowというものがAWS IoT上から操作できます。 これはShadowに設定した状態をDevice側に同期させるような場合に使えますが、このShadowで保持できるデータのサイズがなかなか厳しく最終的にはDynamoDB側に自前で同じようなデータをもたせる方針に切り替えました。
Job
AWS IoTにはJobというものがありますが、同時実行数の制限などが厳しく(Active continuous jobs: max 100)Actcastのようにデバイス数がどんどん増えていくような場合には使えませんでした。こちらもDevice Shadowと同じようにDynamoDB上に自前で似たような仕組みを作っています。
Amazon Aurora
Amazon Aurora with PostgreSQL Compatibility
MySQLではなくPostgreSQLのAuroraを使っていると直面する課題ですが、Auroraの機能としてメジャーバージョンを更新する方法が提供されていないということが挙げられます。
Upgrading an Aurora PostgreSQL DB Cluster Engine Version - Amazon Aurora
ダウンタイムを抑えつつバージョンを更新するためには新旧のAuroraクラスタを用意し、データを同期しつつどこかのタイミングでアプリケーションから接続する先を変更するということが必要です(本当はもう少し複雑です)。
更新元のバージョンが9.xか10.xかでPostgreSQLのロジカルレプリケーションが使えるかが変わってくるのも難しいポイントです。もし9.x系であれば外部のツール(bucardoなど)を使う必要があります。
pg_upgrade相当の機能を実現してもらえればダウンタイムがあるとはいえ運用負荷は相当下がるのですがなかなか実現されていないようです。
今後の改善
ログの追跡
現状でもX-Rayを導入したり、CloudWatch Logsからログを確認したりなどは行っていますが今回紹介していないものも含め全体を構成する要素が非常に多いため問題が起きたさいに関連箇所を調べるのはなかなか大変な状態です。この部分を改善していくための手法を検討している段階です。
まとめ
AWS上には様々なサービスがあり、IoT関係も含めてすべてAWSのサービスだけで構築することができました。 今後は安定性やスケーラビリティの観点で改善を続けていきます。
ここでは言及していませんが、ECSやLambdaの上でRustを使う話も別途記事として公開する予定なのでお楽しみに。
この記事はwatikoがお送りしました。
0 notes
Link
You can encrypt your Amazon RDS DB instances and snapshots at rest by enabling the encryption option for your Amazon RDS DB instances. Data that is encrypted at rest includes the underlying storage for a DB instances, its automated backups, Read Replicas, and snapshots. via Pocket
0 notes