#Captcha Solver
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Video
youtube
ScrapingBypass Web Scraping API Bypass Cloudflare Captcha Verification
ScrapingBypass API can bypass Cloudflare Captcha verification for web scraping using Python, Java, NodeJS, and Curl. $3 for 3-day trial: https://www.scrapingbypass.com/pricing ScrapingBypass: https://scrapingbypass.com Telegram: https://t.me/CloudBypassEN
#scrapingbypass#bypass cloudflare#cloudflare bypass#web scraping api#captcha solver#web scraping#web crawler#extract data
1 note
·
View note
Text
Captcha Solver: What It Is and How It Works
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a common online security tool used to block bots and verify that a user is human. While useful for cybersecurity, CAPTCHAs can be frustrating and time-consuming—especially for people with disabilities, or when they appear too frequently. This is where Captcha Solver come in, offering solutions that can bypass or automate CAPTCHA challenges.
What is a Captcha Solver?
A Captcha Solver is a tool, software, or service that automatically solves CAPTCHA challenges—such as identifying objects in images, typing distorted text, or checking a box labeled “I’m not a robot.” These solvers are used for different purposes, both legitimate and illegitimate.
There are two main types:
Automated Captcha Solvers – These use AI, OCR (optical character recognition), and machine learning to analyze and solve CAPTCHAs without human intervention.
Human-Based Captcha Solvers – These services outsource CAPTCHA solving to real people (often paid workers) who solve them in real time.
How Do Captcha Solvers Work?
Captcha Solvers typically work through one of the following methods:
AI and Image Recognition: For image-based CAPTCHAs (e.g., “Click all squares with traffic lights”), AI algorithms are trained to recognize and respond correctly.
OCR for Text-Based CAPTCHAs: For CAPTCHAs that involve reading distorted text, OCR software can interpret and convert the images into readable text.
Browser Extensions and Bots: Some solvers are embedded into bots or browser extensions that automatically detect and bypass CAPTCHA fields.
API Integration: Many commercial solvers offer APIs that developers can plug into scripts or apps, allowing automated CAPTCHA resolution.
Legitimate Uses of Captcha Solvers
Not all uses of CAPTCHA solvers are unethical. Legitimate scenarios include:
Accessibility: People with visual or motor impairments may use CAPTCHA solvers to access websites and services.
Testing Automation: Developers and QA testers use solvers during automated testing of web applications that include CAPTCHA barriers.
Data Collection: Companies that collect public data (like for SEO or research) may use solvers to streamline the process while complying with terms of use.
Risks and Ethical Concerns
However, CAPTCHA solvers are also used for unethical or illegal activities, such as:
Spam Bots: Bypassing CAPTCHA to post spam on forums, social media, or comment sections.
Credential Stuffing: Automating login attempts with stolen credentials.
Web Scraping Violations: Bypassing site protections to extract large amounts of data without permission.
Using CAPTCHA solvers against a site's terms of service can lead to IP bans, legal consequences, or security breaches.
Conclusion
Captcha Solver are a double-edged sword. They offer convenience and accessibility in some cases but can also enable abuse and automation for malicious purposes. As AI continues to evolve, so will CAPTCHA and its solvers—sparking an ongoing cat-and-mouse game between cyber defense and those trying to bypass it. For ethical users, it’s crucial to use these tools responsibly and only where permitted.
0 notes
Text
Looking back on the entire show after watching the finale makes me realize just the insane amount of detail and foreshadowing present.
Whenever N’s memory gets brought up, it’s usually paired with him being beheaded
Ep 1: Gets his head blasted off by Uzi and loses 2 hours of memory
Ep 3: Brings up his memory to V who slices his head off
Ep 5: The episode is all about N’s memories and we briefly see his worker drone body missing it’s head when they get to the basement
Ep 8: The Solver rips N’s head off, and after regrowing it, he recalls another memory of the Solver tearing him apart as a worker
The constant emphasis on hands in the show
The disassembly drones having swappable hands
Uzi gets stabbed in the hand in episode one
The Solver and eldritch J with the weird human hand tentacles
The fact that characters are constantly losing hands and arms
V’s weird monster arm from the flashback
The handlights indicating whether a drone is possessed
The constant close ups of whenever N and Uzi hold hands
The secret handshake
Uzi’s hand burning in ep4 and her hand burning as she destroys Cyn’s heart in ep8
The Solver using Tessa’s hand and fingerprint to get past a Captcha Test
The solver powers revolving around hand movement
The hands on Uzi’s wings
Doll’s knife going through Uzi’s hand
Alice chopping Uzi’s finger off
N chopping Uzi’s hand off to save her
There’s more here, and it happens in the other Glitch shows too. For example, Pomni’s glitched hand, the Meta Runner arms being the main catalyst for the conflict in MR, and meme guardians holding hands for power in SMG4
The constant foreshadowing for CynTessa and the little details that make so much more sense in hindsight
Episodes 6 and 7 we see N, V, and J’s yellow eyes reflected in Tessa’s helmet
The creepy apparition of CynTessa in Ep4
Cyn and Tessa having the exact same haircut
The whole entire scene with Tessa and the sentinels
Without the context of ep7, that scene plays out like Uzi’s stress at seeing N get attacked by the Sentinels causes her to be briefly possessed by Solver in order to override the controls
Looking back at it, however, the Solver only fully possessed Uzi when Tessa got bitten by the sentinel. It was trying to save itself not N.
It literally saved itself and disguised the attempt as Uzi trying to protect N. If that’s not a perfect metaphor for who and what the Absolute Solver is, idk what is.
And it did it again at the end of the episode where it yet again it possessed Uzi to get the door open right when the sentinel charged at Tessa.
The Sentinel briefly shutting down and getting confused at what it thought was human blood, and then a few scenes later it comes back and guns directly for Tessa, with her blood no longer working to distract it.
Tessa and Cyn’s matching fondness for N in particular.
Tessa outright beheading a drone in her first introduction which contradicts her character in ep5
Then there’s the Solver/Cyn’s almost stalker-like obsession with N
N being the only DD to not feel pain. J and V grunt and yell when they get stabbed or lose a limb, but N gets ripped apart and doesn’t even blink
Cyn calling N “big brother” which the Solver does as well. V and J are never once called “big sister”.
N being the only DD to have lost his memories, possibly so the Solver could control him better. N is a sweetheart by nature and by continuing to override his memories every time he tries to protect the Workers, the Solver can keep him bloodthirsty and feral.
The weird hologram of Maid V that the Solver used to taunt him
The Cyn hologram hugging him
The Solver purposely exploiting N’s feelings for Uzi to keep him from fully attacking her while she’s possessed.
The whole puppy dog eyes thing
“Your backups will forgive me” and the fact that she has backups of N even before the mansion massacre.
The Solver N, V, and J retain their personalities only because it liked N’s in particular
The fact that it sent the nicest, kindest drone in the entire show to slaughter its own kind
The low, annoyed “Hello Uzi” followed by the high pitched, upbeat “Hi N :D”
How the Solver plays around with Tessa’s corpse and her affection for N
Again with how it plays with N’s relationship with Uzi by using Tessa’s voice to tell him that he has to kill Uzi to save the universe
The Solver using a hologram of N to fuck with Uzi twice
The Solver using the hologram of N to fool V into calling out for him so it could lure the real N out
The Solver’s obsession with N technically never going away. With Cyn as the main host it was a sibling bond, but with Uzi now the main host it’ll likely latch onto her romantic love for N
The absolute insane foreshadowing to Uzi becoming the Solver itself
The occasional reflection of N and V’s yellow eyes in Uzi’s visor
Uzi overwriting Cyn’s admin control and replacing it with her own
Uzi possessing the Solver cameras while in N’s memories, and the cameras having purple eyes
The protagonist’s journey graph in presentation in the very first episode alluding to a big fight and monstrous transformation at the end.
Uzi overpowering CynTessa with her own Solver
Uzi breaking through possession via the powers of angst and teenage rebellion, without even needing the patch like Nori and Yeva
Uzi and Tessa having the same fleshy bat wings
Uzi’s core number being 1001 just like Cyn’s
Uzi’s tail chewing on N’s head for some reason in episode 6, likely foreshadowing to Cyn being in her tail
Uzi possessing Braiden just like the Solver would
Other little details
Uzi’s purple being a perfect complement to N’s yellow which also matches their personalities
The background posters having just the stupidest/funniest notes on them
Uzi’s tail looking like a sentinel head
Lizzy having seemingly infinite phones
The drones treating the school bus like it’s an animal with sentience
Braiden’s head literally always being on fire, even in death
The references to Until Dawn and Friday the Thirteenth in episode 4
The soundtracks having just the stupidest fucking titles (affectionate), with some of them even referencing each other.
N going from being J’s doormat in episode 1 to outright beheading Tessa in episode 7 when he realized she lied to him
The Solver making its biggest mistake asking N to choose “the universe over the life of one little drone” because it didn’t account for the “one little drone” being Cyn, not Uzi
The Protagonist’s Journey chart foreshadowing Nori being alive with the “help from an unexpected source” close to the end of the timeline
Khan going from leaving Uzi for dead to rebuilding her rail gun and directly attacking the Solver in the hopes of saving her
Also Khan’s behavior and bad parenting suddenly making a lot more sense once we finally see a full photo of Nori and realize that Uzi is damn near identical to her mother.
Uzi’s teeth aren’t sharp until after her transformation in ep4
In a roundabout way, the humans on Copper-9 were successful is making something that could stop the Solver, as they caused the incidents that would eventually lead to Nori meeting Khan and passing down her genetics to Uzi
#hoo boy this got long#and this still isn’t all of the crazy details and foreshadowing that are in this show#murder drones#long post#uzi doorman#serial designation n#serial designation v#serial designation j#cyn#the absolute solver#khan doorman#nori doorman#Md lizzy#md braiden#even as I’m typing out the notes I’m still remember more details
157 notes
·
View notes

Text
Buster: Captcha Solver for Humans
https://github.com/dessant/buster
2 notes
·
View notes
Text
Mass Destruction Liveblog
haha we're all gonna die
Ads lol
Oh god no No No No No Whao new intro goes hard Its real NORI NO DEAWEED LADY poor mitchell Oh gof the dhadows Summing leds Oh usd cross Welp thats not spooky Someones dropping sick beats Oh god poor yeva IS SHE DEAD oh fucking hell naw Poor mitchell Badass seaweeed woman Oof dude CATGIRL CORE HUH ARE YOU NORI casual flesh hole ITS THEM YAY oh no n POOR BABYGIRL NAW i hate you tessa "Robots like boxes" N tell your gf the truth onvious foreshadowing is obvious I was kinda right BLONDE KIDS lizzy's voice? Oh yay they live MORE DDS YAY MORE DDS v clone? Swearing hah Its giving saw Mayor v Meme time Oh fod poor man Trauma ghost lol CYN N killed a man oh god no JESUS FUCKING CHRIST ourple NO BOY solver uzi is love Girly The demon core CATGIRL SPIDER ooh oil Well she traumatized Flesh tunnel CORE TO THE RESCUE ARE YOU NORI familiar? N KILLED NORI ITS NOTI NORI NORI YAY SHE HAS CRINGE TASTE IN MEN oh its j Why wasnt she the pilot She can actually fly it KHAN HAS A GUN HES COOL lizzy? Im not well Get a captcha Badass explosion WAIT DID SHE DESTROY IT poor baby no Oh so shes evil NOOOO DOLL NOOOOOOO yeva comimg in clutch Oh god not the hole n-nori? Classic arm chopping oh, so thats what happened NORI'S COOL no girlypop Oh yay doll No, doll, no I HATE YOU TESSA WHY cool girl No nori your cool SO THAT'S WHERE SHE GOT IT oh god no not that Oh god Well that happened Yay blood Nonononono JESES FUCK NO NORI CORE YAY taha Ooh yay fight Hellfuck Black hole boomerang Badass soundtrack NO BOY he'll be fine… right Oh yay Wait shes mad Punt her like a football SCREAMING tessa just… just stay dead Oh god no Doll… please HEY FREAK LIAM V CLASSIC SHES SO COOL I LOVE DEMON TESSA oh no Please J COMING IN CLUTCH RONATHON? OH NO EAIT THEY'RE COOL RAILGUN TIME je… sus NO PLEASE oh Falling Drone heaven?
#kitty's kooky insane ramblings#murder drones#MURDER DRONES SPOILERS#MURDER DRONES episode 7#murder drones mass destruction
4 notes
·
View notes
Text
The Truth About CAPTCHA Bypass: Is It Ethical, Legal, and Worth It?

CAPTCHAs—short for Completely Automated Public Turing test to tell Computers and Humans Apart—are an integral part of online security. They're meant to distinguish human users from bots by presenting tasks that are easy for people but difficult for machines. However, as technology advances, so does the sophistication of CAPTCHA bypass methods.
In this article, we explore the evolving landscape of CAPTCHA bypass—how it works, who uses it, the tools and methods involved, and the ethical and legal implications surrounding its use.
What Is CAPTCHA Bypass?
CAPTCHA bypass refers to any method used to defeat or circumvent CAPTCHA verification systems, allowing bots or scripts to access content, forms, or services without human interaction. It's widely used in web scraping, automated form submissions, data harvesting, and sometimes for malicious purposes like spamming or credential stuffing.
While some use CAPTCHA bypass for legitimate business automation, others exploit it to carry out unethical or illegal activities.
Types of CAPTCHA Systems
Before discussing bypass methods, let’s review common CAPTCHA types:
Text-based CAPTCHAs – Users type distorted characters.
Image-based CAPTCHAs – Users click on specific images (e.g., "select all traffic lights").
Audio CAPTCHAs – Used for accessibility.
Invisible CAPTCHAs – Detect behavior (like mouse movement) to infer human presence.
reCAPTCHA v2 & v3 – Google’s advanced CAPTCHA versions that evaluate risk scores and behavioral patterns.
Each CAPTCHA type requires different bypass approaches.
Common CAPTCHA Bypass Techniques
1. Optical Character Recognition (OCR)
OCR engines can read distorted text from image-based CAPTCHAs. Tools like Tesseract (an open-source OCR engine) are trained to decode common fonts and noise patterns.
2. Machine Learning (ML)
ML models, especially Convolutional Neural Networks (CNNs), can be trained on thousands of CAPTCHA examples. These systems learn to identify patterns and bypass even complex image-based CAPTCHAs with high accuracy.
3. Human-in-the-Loop Services
Services like 2Captcha and Anti-Captcha outsource CAPTCHA solving to low-cost human labor, solving them in real-time via APIs. While controversial, they are legal in many jurisdictions.
4. Browser Automation (Selenium, Puppeteer)
Automating browser actions can trick behavioral-based CAPTCHAs. Combining Selenium with CAPTCHA solving APIs creates a powerful bypass system.
5. Token Reuse or Session Hijacking
Some CAPTCHAs generate session tokens. If these are stored or reused improperly, attackers can replay valid tokens to bypass the system.
CAPTCHA Bypass Tools and APIs
Here are popular tools and services in 2025:
2Captcha – Crowdsourced human solvers.
Anti-Captcha – AI-based and human-based CAPTCHA solving.
CapMonster – AI-driven CAPTCHA solver with browser emulation.
Buster – A browser extension for solving reCAPTCHAs via audio analysis.
Death by CAPTCHA – Another human-powered solving API.
Legal and Ethical Considerations
While bypassing CAPTCHA may sound clever or harmless, the legal and ethical landscape is more complex:
✅ Legitimate Use Cases
Automation for accessibility: Helping disabled users bypass complex CAPTCHAs.
Web scraping with permission: For competitive research or data aggregation.
Testing and QA: Developers use CAPTCHA bypass to test form behavior.
❌ Illegitimate Use Cases
Spam bots and credential stuffing.
Bypassing terms of service on platforms like Google or Facebook.
Data harvesting without permission.
Most websites have terms that prohibit automated bypasses. Violating them may result in legal action or IP bans. In some countries, large-scale CAPTCHA bypass for malicious use could violate cybercrime laws.
How Websites Are Fighting Back
Web developers and security professionals continuously adapt to evolving bypass techniques. New defenses include:
Fingerprinting & behavioral analysis – Tracking mouse movement, typing rhythm, etc.
Rate limiting & honeypots – Limiting requests and setting traps for bots.
Advanced bot detection services – Tools like Cloudflare Bot Management and Akamai Bot Manager.
Best Practices for Ethical CAPTCHA Use
Avoid scraping or automating tasks on sites without permission.
Use CAPTCHA-solving APIs only where legally allowed.
Inform users or clients when using bypass tools during development or testing.
Stay updated on laws in your country about bot activity and scraping.
The Future of CAPTCHA and Bypass
CAPTCHAs are evolving. In 2025, we're seeing movement toward:
Invisible CAPTCHAs with behavioral scoring.
Biometric authentication instead of traditional CAPTCHAs.
Decentralized bot protection via blockchain-like verification systems.
But as long as there's automation, there will be ways to bypass CAPTCHAs—the challenge is balancing innovation with responsibility.
Conclusion
CAPTCHA bypass is a fascinating, ever-evolving field that combines artificial intelligence, web automation, and cybersecurity. While the tools and techniques are powerful, they come with ethical and legal responsibilities.
If you're a developer, business owner, or security professional, understanding CAPTCHA bypass can help you protect your systems—or responsibly automate tasks. But always keep in mind: just because you can bypass a CAPTCHA doesn’t mean you should.
0 notes
Text
Integration of AI and Machine Learning into Web Scraping APIs

Introduction
Artificial Intelligence (AI) and Machine Learning (ML) have recently advanced rapidly and revolutionized several industries. One of the most dramatic changes with these advancements is the transformation of web scraping. Web scraping was considered the traditional coding suite for data extraction from websites. However, the latest developments in AI and ML have turned this into something much more efficient, accurate, and adaptable. This blog will venture into the integration of AI and ML into Web Scraping APIs, along with discussing its advantages, challenges, and prospects for the future.
Understanding the Web Scraping APIs
Web Scraping APIs are specialized tools that give access to developers for extracting data from a website in a programmatic manner. These APIs considerably simplify the web scraping process by allowing automated mechanisms to fetch, parse, and structure data. Conventional web scraping is dependent upon static scripts able to parse HTML structures to retrieve specific data. However, because of the dynamic nature of today's web, classical methods struggle in the face of dealing with contemporary JavaScript-powered web pages, CAPTCHAs, and anti-scraping mechanisms.
The Role of AI in Web Scraping APIs
Artificial Intelligence within Web Scraping APIs has been a game changer for data collection, data processing, and data use. AI-powered scraping tools are able to withstand complex challenges such as modification in website structure, dynamic content load, and anti-scraping mechanisms. How AI supports Web Scraping APIs are:
1. Pre-empt Data Extraction
AI-enabled web scrapers may analyze page structures and extract relevant data without any predefined rules.
ML models may recognize patterns that help them to make changes according to the changes in website layouts.
2. Counter Anti-Scraping Measures
To prevent automated access, websites implement various anti-scraping measures, including CAPTCHA, blocking specific IP addresses, and user-agent detection.
AI bots could use CAPTCHA solvers, IP rotation, and human-like patterns to bypass these barriers.
3. Understanding the Data with Natural Language Processing (NLP)
NLP models enable scrapers to comprehend unstructured text, extract relevant information, and even summarize content.
While sentiment analysis, keyword extraction, and named entity recognition can enhance the usability of data successfully scraped otherwise.
4. Adaptive Learning for Changing Web Structures
Machine learning algorithms can track and learn from ongoing changes in a concerned website so that data can be collected freely without constant script updating.
Deep learning models can also analyze DOM elements and infer patterns dynamically.
5. Intelligent Data Cleaning and Pre-Processing
AI techniques will delete duplicates, fix inconsistencies, and fill in missing values from scraped data.
Anomaly detection identifies and corrects erroneous data points.
Key Technologies Enabling AI and ML in Web Scraping APIs
Several technologies and frameworks empower AI and ML in Web Scraping APIs:
Python libraries: BeautifulSoup, Scrapy, or Selenium, combined with TensorFlow, PyTorch, or Scikit-learn.
AI-Based Browsers: Puppeteer and Playwright for headless browsing with ML enhancements.
Cloud Computing and APIs: Google Cloud AI, AWS AI services, and OpenAI APIs for intelligent scraping.
Data Annotation and Reinforcement Learning: Using human-labeled datasets to train ML models for better accuracy.
Benefits of AI and ML in Web Scraping APIs
Applications of AI and ML in Web Scraping APIs bring advantages, including:
Faster- AI-based scrapers can deliver results in an instant.
Scalability- ML algorithms enable web scraping tools to scale to various domains and handle huge datasets.
Reduced Maintenance- Reinforced learning will lead to reduced script-update requirements.
Better Accuracy- AI filtering can effectively sort noise and deliver upper-rend data.
Even exploitable security- AI approaches help avoid any anti-bot mechanisms and follow the principle of ethical scraping.
Challenges and Ethical Considerations
However, AI web scraping challenges are offset by apparent advantages:
1. Legal and Ethical Issues Unsurprisingly
Most web places deny scraping in their terms of service.
Any scraping carried out by AI needs to be mindful of data privacy issues such as GDPR and CCPA.
2. Complex Website Structures
AI scrapers need to cope with dynamic page rendering with JavaScript and AJAX-based content or rendering.
3. Computational Costs
Running ML models for web scraping entails high computational costs and therefore running costs.
4. Validation and Data Quality
The AI scrapers need to have a strong mechanism for validation to confirm the accuracy of the data being extracted.
Best Practices for Using AI in Web Scraping APIs
To get the best out of AI in Web Scraping APIs, developers are expected to follow these best practices:
Respect Website Terms and Policies- Always check the site's robots.txt file, and respect its rules.
Implement Conscious Scraping Approach- Avoid hammering the website with too many requests; set limits for the bot to follow.
Implement Smart Proxy Rotations and User Agents- Rotate IP addresses and user-agent strings that mirror real users.
Monitor Pageload Activities- Have some ML-powered monitoring to track alterations to websites' structures.
Ensure Data Privacy- Follow the existing legal regimes to protect user data and avoid unauthorized collection of data.
Future Possibilities of AI and ML in Web Scraping APIs
The integration of AI and ML into Web Scraping APIs would expand with improvements in:
Self-Learning Web Scrapers- Full autonomic scrapers learning & adapting without human help.
AI-Powered Semantic Understanding- In other words, using more advanced NLP paradigms like GPT-4 for extracting context insight.
Decentralized Scrapping Networks- A distributed AI-driven scraping that minimizes the risk of detection and scales up easily.
Frameworks for Ethical AI Scraping- Formulating common norms for responsible web scraping practices.
Conclusion
AI and ML in Web Scraping APIs have transformed data extraction, making it more intelligent, resilient, and efficient. Despite challenges such as legal concerns and computational demands, AI-powered web scraping is set to become an indispensable tool for businesses and researchers. By leveraging adaptive learning, NLP, and automation, the future of Web Scraping APIs will be more sophisticated, ensuring seamless data extraction while adhering to ethical standards.
Know More : https://www.crawlxpert.com/blog/ai-and-machine-learning-into-web-scraping-apis
0 notes
Text
Captcha Solver : Quick and Easy Ways to Bypass Captchas!
youtube
0 notes
Video
youtube
Captcha Solver : Quick and Easy Ways to Bypass Captchas!
0 notes
Text
How ArcTechnolabs Builds Grocery Pricing Datasets in UK & Australia

Introduction
In 2025, real-time grocery price intelligence is mission-critical for FMCG brands, retailers, and grocery tech startups...
ArcTechnolabs specializes in building ready-to-use grocery pricing datasets that enable fast, reliable, and granular price comparisons...
Why Focus on the UK and Australia for Grocery Price Intelligence?
The grocery and FMCG sectors in both regions are undergoing massive digitization...
Key Platforms Tracked by ArcTechnolabs:

How ArcTechnolabs Builds Pre-Scraped Grocery Pricing Datasets
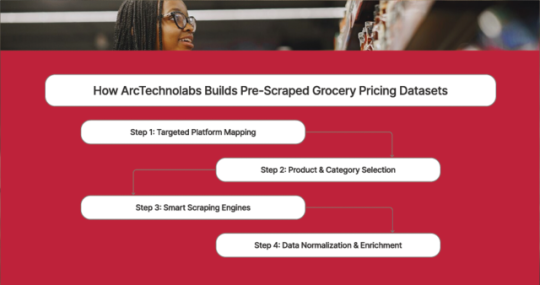
Step 1: Targeted Platform Mapping
UK: Tesco (Superstore), Ocado (Online-only)
AU: Coles (urban + suburban), Woolworths (nationwide chain)
Step 2: SKU Categorization
Dairy
Snacks & Beverages
Staples (Rice, Wheat, Flour)
Household & Personal Care
Fresh Produce (location-based)
Step 3: Smart Scraping Engines
Rotating proxies
Headless browsers
Captcha solvers
Throttling logic
Step 4: Data Normalization & Enrichment
Product names, pack sizes, units, currency
Price history, stock status, delivery time
Sample Dataset: UK Grocery (Tesco vs Sainsbury’s)
ProductTesco PriceSainsbury’s PriceDiscount TescoStock1L Semi-Skimmed Milk£1.15£1.10NoneIn StockHovis Wholemeal Bread£1.35£1.25£0.10In StockCoca-Cola 2L£2.00£1.857.5%In Stock
Sample Dataset: Australian Grocery (Coles vs Woolworths)
Product Comparison – Coles vs Woolworths
Vegemite 380g
--------------------
Coles: AUD 5.20 | Woolworths: AUD 4.99
Difference: AUD 0.21
Discount: No
Dairy Farmers Milk 2L
---------------------------------
Coles: AUD 4.50 | Woolworths: AUD 4.20
Difference: AUD 0.30
Discount: Yes
Uncle Tobys Oats
------------------------------
Coles: AUD 3.95 | Woolworths: AUD 4.10
Difference: -AUD 0.15 (cheaper at Coles)
Discount: No
What’s Included in ArcTechnolabs’ Datasets?
Attribute Overview for Grocery Product Data:
Product Name: Full title with brand and variant
Category/Subcategory: Structured food/non-food grouping
Retailer Name: Tesco, Sainsbury’s, etc.
Original Price: Base MRP
Offer Price: Discounted/sale price
Discount %: Auto-calculated
Stock Status: In stock, limited, etc.
Unit of Measure: kg, liter, etc.
Scrape Timestamp: Last updated time
Region/City: London, Sydney, etc.
Use Cases for FMCG Brands & Retailers
Competitor Price Monitoring – Compare real-time prices across platforms.
Retailer Negotiation – Use data insights in B2B talks.
Promotion Effectiveness – Check if discounts drive sales.
Price Comparison Apps – Build tools for end consumers.
Trend Forecasting – Analyze seasonal price patterns.
Delivery & Formats
Formats: CSV, Excel, API JSON
Frequencies: Real-time, Daily, Weekly
Custom Options: Region, brand, platform-specific, etc.
Book a discovery call today at ArcTechnolabs.com/contact
Conclusion
ArcTechnolabs delivers grocery pricing datasets with unmatched speed, scale, and geographic depth for brands operating in UK and Australia’s dynamic FMCG ecosystem.
Source >> https://www.arctechnolabs.com/arctechnolabs-grocery-pricing-datasets-uk-australia.php
#ReadyToUseGroceryPricingDatasets#AustraliaGroceryProductDataset#TimeSeriesUKSupermarketData#WebScrapingGroceryPricesDataset#GroceryPricingDatasetsUKAustralia#RetailPricingDataForQCommerce#ArcTechnolabs
0 notes
Text
How Automated Web Scraping Powers Real-Time Market Intelligence in 2025
In 2025, the race for data-driven dominance has only accelerated. Businesses are no longer just making data-informed decisions—they’re expected to respond to market shifts in real time. The key to unlocking this agility lies in one technology: automated web scraping. From tracking competitor pricing and new product launches to monitoring regional customer sentiment, automated web scraping allows organizations to collect and analyze high-impact data continuously. It's not just about gathering more information; it's about getting the right insights faster and feeding them directly into strategies.

What is Automated Web Scraping?
At its core, web scraping involves extracting data from websites. While manual scraping is possible, it's neither scalable nor consistent for modern enterprise needs. Automated web scraping takes it a step further by using bots, scripts, and intelligent systems to collect data from thousands of web pages simultaneously, without human intervention.
Unlike traditional data gathering, automation enables continuous, real-time access to dynamic web data. Whether it's product listings, stock prices, news articles, or social media trends, automated web scraping allows businesses to stay informed and agile.
Why Real-Time Market Intelligence Matters in 2025
The business landscape in 2025 is dynamic, decentralized, and deeply influenced by digital trends. As consumer behaviors evolve rapidly, staying updated with static reports or slow-moving data sources is no longer sufficient.
Key Reasons Real-Time Intelligence Is a Business Imperative:
Instant Reactions to Consumer Trends: Viral content, influencer campaigns, or trending hashtags can reshape demand within hours.
Hyper-competitive Pricing: E-commerce giants change prices by the hour—being reactive is no longer enough.
Supply Chain Volatility: Real-time monitoring of supplier availability, shipping conditions, and raw material costs is essential.
Localized Customer Preferences: Consumers in different geographies engage differently, tracking regional trends in real-time enables better personalization.
Key Use Cases of Automated Web Scraping for Market Intelligence
1. Competitor Monitoring
Businesses use automated scrapers to track competitor pricing, promotions, and inventory levels in real time. This helps them make dynamic pricing decisions and spot opportunities to win over customers.
2. Product Development Insights
Scraping product reviews, Q&A forums, and social chatter enables product teams to understand what features customers like or miss across similar offerings in the market.
3. Sentiment Analysis
Real-time scraping of reviews, social media, and news comments allows for up-to-date sentiment analysis. Brands can detect PR risks or emerging product issues before they escalate.
4. Localized Trend Tracking
Multilingual and region-based scraping helps companies understand local search trends, demand patterns, and user behavior, essential for international businesses.
5. Financial & Investment Research
Web scraping helps investors gather information on companies, mergers, leadership changes, and market movement without waiting for quarterly reports or outdated summaries.
Challenges in Real-Time Market Data Collection (And How Automation Solves Them)
Despite its power, real-time data scraping comes with technical and operational challenges. However, automation, with the right infrastructure, solves these issues efficiently:
Website Blocking & CAPTCHAs: Many websites implement anti-scraping mechanisms that detect and block bots. Automated tools use rotating IPs, proxy servers, and CAPTCHA solvers to bypass these restrictions ethically.
High Volume of Data: Collecting large datasets from thousands of sources is impractical manually. Automated scraping allows data collection at scale—scraping millions of pages without human effort.
Frequent Web Page Changes: Websites often change layouts, breaking scrapers. Advanced automation frameworks use AI-based parsers and fallback mechanisms to adapt and recover quickly.
Data Formatting and Clean-Up: Raw scraped data is usually unstructured. Automated systems use rule-based or AI-driven cleaning processes to deliver structured, ready-to-use data for analytics tools or dashboards.
Maintaining Compliance: Automation ensures that scraping practices align with privacy regulations (like GDPR) by excluding personal or sensitive data and respecting robots.txt protocols.
Technologies Driving Web Scraping in 2025
The evolution of scraping tech is driven by AI, cloud computing, and data engineering advancements.
AI-Powered Extraction Engines
Modern scrapers now use AI and NLP to not just extract text but understand its context, identifying product specifications, customer emotions, and competitive differentiators.
Headless Browsers & Smart Bots
Tools like headless Chrome replicate human behavior while browsing, making it difficult for sites to detect automation. Bots can now mimic mouse movement, scroll patterns, and form interactions.
Serverless & Scalable Architectures
Cloud-native scraping solutions use auto-scaling functions that grow with demand. Businesses can scrape 10,000 pages or 10 million, with no performance trade-off.
API Integration & Real-Time Feeds
Scraped data can now flow directly into CRM systems, BI dashboards, or pricing engines, offering teams real-time visibility and alerts when anomalies or changes are detected.
How TagX is Redefining Real-Time Market Intelligence
At TagX, we specialize in delivering real-time, high-precision web scraping solutions tailored for businesses looking to gain a data advantage. Our infrastructure is built to scale with your needs—whether you're monitoring 100 products or 1 million.
Here’s how TagX supports modern organizations with market intelligence:
End-to-End Automation: From data extraction to cleaning and structuring, our scraping pipelines are fully automated and monitored 24/7.
Multi-Source Capabilities: We extract data from a variety of sources—ecommerce platforms, social media, job boards, news outlets, and more.
Real-Time Dashboards: Get your data visualized in real-time with integrations into tools like Power BI, Tableau, or your custom analytics stack.
Ethical & Compliant Practices: TagX follows industry best practices and compliance norms, ensuring data is collected legally and responsibly.
Custom-Built Scrapers: Our team builds custom scrapers that adapt to your specific vertical—be it finance, e-commerce, logistics, or media.
Whether you're an emerging tech startup or a growing retail brand, TagX helps you unlock real-time intelligence at scale, so your decisions are always ahead of the market curve.
Future Trends: What’s Next for Web Scraping in Market Intelligence
Context-Aware Web Scrapers
Next-gen scrapers will not only extract data but also interpret intent. For example, detecting a competitor’s product rebranding or analyzing tone shifts in customer reviews.
Multilingual & Cultural Insights
As companies expand globally, scraping in native languages with cultural understanding will become key to local market relevance.
Scraping + LLMs = Strategic Automation
Pairing scraping with Large Language Models (LLMs) will allow businesses to auto-summarize competitive intelligence, write reports, and even suggest strategies based on raw web data.
Predictive Intelligence
The future of scraping isn’t just about gathering data, but using it to forecast trends, demand spikes, and emerging market threats before they happen.
Final Thoughts
In 2025, reacting quickly is no longer enough—you need to anticipate shifts. Automated web scraping provides the speed, scale, and intelligence businesses need to monitor their markets and stay one step ahead. With TagX as your data partner, you don’t just collect data—you gain real-time intelligence you can trust, scale you can rely on, and insights you can act on.
Let’s Make Your Data Smarter, Together. Contact TagX today to explore how automated web scraping can power your next strategic move.
0 notes
Text
Boosting Bookings with Scraped Expedia & Priceline Data
Introduction
In the hyper-competitive travel industry, user acquisition and retention heavily rely on pricing accuracy, competitive offerings, and real-time hotel inventory. A US-based OTA startup approached Travel Scrape to develop a robust data acquisition strategy using Expedia and Priceline hotel listing data. The goal? To increase direct hotel bookings, optimize margins, and stay competitive on price.
Objectives
Monitor real-time hotel prices and promotions across top OTAs.
Compare listings and availability to identify gaps and exclusive deals.
Enable dynamic pricing and personalized offers on the client app.
Improve SEO and conversion rates by using enriched hotel metadata and user review trends.
Why Expedia & Priceline?
Expedia and Priceline are two of the largest OTAs globally, hosting millions of listings. Their platforms offer diverse hotel options with varying rates based on location, time, and user profile.
Target Use Case:
Scrape data across 50 US cities including New York, Miami, Chicago, and Los Angeles.
Focus on mid-range to premium hotels with high booking intent during holidays.
Enable filtering by price drops, free cancellations, user ratings, and last-minute deals.
Travel Scrape’s Data Strategy
1. Web Scraping Architecture
Travel Scrape deployed a custom scraping pipeline with rotating proxies, CAPTCHA solvers, and intelligent scheduling to:
Avoid detection on dynamic pages
Monitor thousands of listings daily
Collect structured data using XPath and JSON parsing
2. Key Fields Extracted
FieldExample ValueHotel NameHoliday Inn Express Downtown LACity / StateLos Angeles, CAPrice per Night$139Discount18% offAmenitiesFree WiFi, Pool, Airport ShuttleStar Rating4.2 / 5User Reviews Count3,245 reviewsCheck-in/out Time3 PM / 11 AMCancellation PolicyFree cancellation until 24 hours priorSourceExpedia / Priceline
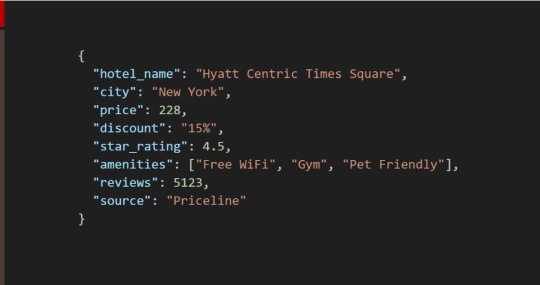
3. Sample JSON Snippet
Implementation
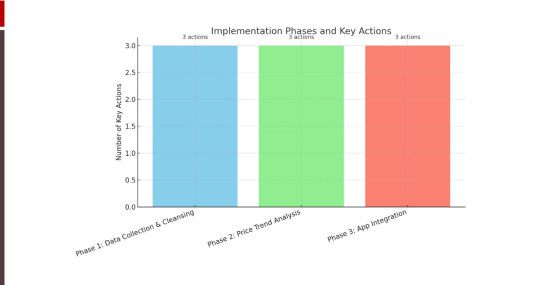
Phase 1: Data Collection & Cleansing
Collected over 500,000+ listings across Expedia and Priceline in 3 months.
Normalized hotel data to remove duplicates and match similar listings.
Tagged listings with geo-coordinates to map against app location filters.
Phase 2: Price Trend Analysis
Mapped daily fluctuations in prices during peak season.
Identified time slots when last-minute bookings dropped prices by 20-30%.
Used Python-based data models to flag competitive pricing opportunities.
Phase 3: App Integration
Integrated scraped data via internal APIs to feed the mobile app search results.
Introduced “Best Deal Now” tags on listings matching Expedia discounts.
Highlighted free cancellation deals to drive higher confidence bookings.
Results
MetricBefore Travel ScrapeAfter IntegrationHotel Booking Rate3.8%6.5%Avg. Time on Hotel Page42 seconds1 min 12 secConversion from Deal Alerts5.2%11.4%Refunds/Disputes Ratio4.9%2.1%Daily Active Users (DAU)12,00021,000
Visual Insights
Price Distribution Comparison – Expedia vs. Priceline
Expedia: Wider discount range (10–35%), skewed toward weekend bookings
Priceline: More bundled offers, especially for airport hotels
Heatmap: High-Conversion Hotel Zones (Top 5 Cities)
New York – Midtown & Downtown
Miami – South Beach
Chicago – Magnificent Mile
San Francisco – Union Square
Las Vegas – The Strip
Challenges Solved
ChallengeTravel Scrape SolutionData Blocking & CAPTCHARotating proxies + real browser renderingDynamic Content (JavaScript)Headless browser scraping with PuppeteerGeo-specific Pricing DifferencesSmart geolocation headers and city-wise scrapingHigh Duplication Across OTAsMachine learning for deduplication by hotel ID
Client Feedback
"Travel Scrape’s data feeds transformed our app’s hotel search engine. We were able to beat competitors on pricing accuracy and boost conversions in under 90 days."
- CTO, US Travel App Startup
Conclusion
With Travel Scrape’s hotel data scraping services, the client achieved significant gains in booking conversion rates, user engagement, and price competitiveness. Leveraging real-time hotel data from Expedia and Priceline enabled smarter offers, improved trust, and higher margins.
If you're an OTA, metasearch engine, or hotel chain seeking similar growth, Travel Scrape can help power your platform with precise, real-time travel data intelligence.
Source :- https://www.travelscrape.com/scraped-expedia-priceline-data.php
#ExpediaHotelScraping#PricelineDataExtraction#TravelBookingInsightsUSA#RealTimeHotelPricingData#OTADataScrapingService#WebScrapingForTravelApps#TravelAppDataIntelligence
0 notes
Text
📊 Empowering E-Commerce Brands with Real-Time Price Intelligence 🛍️

In the fast-paced world of e-commerce, staying ahead requires real-time insights into market dynamics. Actowiz Solutions collaborated with a leading FMCG brand operating across the USA, UK, and Canada to implement a real-time price intelligence system across Amazon, Walmart, and Shopify platforms.
Key Highlights:
🔍 Comprehensive Price Monitoring: Tracked pricing data across multiple platforms, ensuring consistency and identifying unauthorized discounting by resellers.
⚙️ Advanced Web Scraping: Utilized Python and Scrapy with rotating proxies and CAPTCHA solvers to extract accurate SKU-level data, including pricing, seller information, availability, promotions, and shipping details.
📈 Dynamic Pricing Strategies: Enabled the client to respond swiftly to market changes, optimizing pricing strategies and protecting brand integrity.
This strategic approach allowed the brand to maintain competitive pricing, reduce channel conflicts, and enhance overall market responsiveness.
0 notes
Video
youtube
Captcha Solver : Quick and Easy Ways to Bypass Captchas!
0 notes
Text
How to Scrape Ajio for Discounts, Deals, and New Arrivals
In the competitive arena of e-commerce, businesses must keep themselves abreast of changes in the market trends, discounts, and deals to be in the fray. One of India's popular online platforms presents a panorama of products in the categories of fashion, lifestyle, and beauty: Ajio. New arrivals, limited-time deals, and exclusive discounts frequently rekindle Ajio's course of stock, thus becoming a key source for the market intel of a competitive nature.
Web scraping helps in the bulk collection of information from websites. Scraping Ajio will offer potential insights such as discounts, new arrivals, and active campaigns. These insights will aid the striving business to mold its strategies according to market needs, change its pricing, and edge its competitors.
In this tutorial, we will talk about Ajio scraping to fetch discounts, deals, and new arrivals. We will highlight the need for scraping Ajio, the set of tools and technologies required, a step-by-step approach in scraping Ajio, and how to analyze the data to derive business-worthy insights.
Why Scrape Ajio for Discounts, Deals, and New Arrivals?
1. Real-time Tracking of Discounts and Deals
Ajio hosts regular flash sales, seasonal discounts, and exclusive offers on several products. Scraping Ajio's website for discounts is a plug to monitor real-time discounts. This plug will help keep track of the best offers, frequency of promo changes, and pricing patterns.
2. Mark New Additions
Ajio continuously adds fresh pieces to the inventory, ranging from the fashion category. Scraping new arrivals is a piece of data to keep businesses ahead of trends to see what products are being added to the platform to be updated in compliance with changing market preferences.
3. Competitive Intelligence
Through scraping the deals and discounts advertised by Ajio, firms can effectively analyze their rival strategies in terms of pricing. The data can then be used to assess whether Ajio pricing falls within the acceptable limit for any particular market or product category.
4. Pull Consumer Preference Intelligence
Scrap Ajio to find out how consumers feel towards discounts and new arrivals. Collecting this information enables businesses to analyze customer feedback and reviews in order to find out which segments of products consumers find interesting, as well as which discounts they find most appealing.
5. Further the Marketing Strategies
Accessing details associated with the product, deals, and prices enables businesses to effectively refine their marketing campaigns. You can change your promotional strategies based on competitor pricing, new arrivals, and current trends on Ajio.
Tools and Technologies for Scraping Ajio
1. Python Libraries for Web Scraping
BeautifulSoup – A Python library used to extract data from HTML and XML files. It is ideal for simple web scraping tasks where the HTML structure is relatively straightforward.
Scrapy – A more advanced Python framework that is useful for large-scale scraping. Scrapy is fast and efficient, supporting features such as crawling multiple pages, handling AJAX requests, and storing the scraped data in various formats.
Selenium –Selenium is a powerful tool for automating browsers. It’s particularly useful when scraping websites that rely heavily on JavaScript to display content dynamically (such as infinite scrolling or AJAX-based websites like Ajio).
Requests – This is a simple and easy-to-use HTTP library that sends GET requests to a website and returns HTML content, which can be parsed using libraries like BeautifulSoup.
2. Data Storage Solutions
CSV – Ideal for small-scale flat data
Databases – MySQL or PostgreSQL for larger volumes
JSON – Great for storing nested structured data
3. Captcha Solvers and Proxies
To prevent bots from scraping Ajio’s website, the platform may use anti-bot measures like CAPTCHAs or IP rate-limiting. Using services like 2Captcha or Anti-Captcha can help you bypass these measures. Additionally, rotating proxies can help prevent your IP address from being blocked by Ajio’s servers.
Ethical Considerations and Legal Aspects
1. Terms of Service for Ajio
It's imperative always to check a website's terms of service (ToS) whenever you are involved in web scraping, as most platforms prohibit any form of scraping. Ajio must have its specific rules on data extraction enforced using automatic means, and you should make sure that your actions do not violate them.
2. robots.txt
According to Ajio's robots.txt file, bots are allowed or not allowed to crawl certain pages or sections of the website. Scraping publicly available product data might not violate the robots.txt file, but ensure that your scraping activities do not put pressure on the server or interfere with the user experience.
3. Rate-Limiting
Incorporate rate-limiting within your scraping script so that Ajio's servers are not overburdened and your own IP gets blocked. This rate-limiting will guarantee that the bot executes requests at a normalized pace, imitating human browsing behavior.
4. Data Privacy
Obtain data by scraping from the public domain only. Do not scrape personal data like user information, payment info, etc., which might lead to legal liabilities.
Step-by-Step Guide to Scraping Ajio
Step 1: Inspecting Ajio’s Website Structure
Use Chrome Developer Tools (F12) to inspect elements like:
Product Name – <h1>, <span>, <a>
Price – within <span class="product-price">
Discount – often in <div> or <span>
New Arrivals – marked with special classes
Step 2: Sending HTTP Requests to Retrieve HTML
import requests from bs4 import BeautifulSoup url = 'https://www.ajio.com' response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') product_name = soup.find('h1', class_='product-name').text product_price = soup.find('span', class_='product-price').text product_discount = soup.find('span', class_='product-discount').text print(product_name, product_price, product_discount)
Step 3: Handling Dynamic Content with Selenium
from selenium import webdriver from selenium.webdriver.common.by import By import time driver = webdriver.Chrome() driver.get('https://www.ajio.com') time.sleep(5) products = driver.find_elements(By.CLASS_NAME, 'product-tile') for product in products: name = product.find_element(By.CLASS_NAME, 'product-name').text price = product.find_element(By.CLASS_NAME, 'product-price').text discount = product.find_element(By.CLASS_NAME, 'product-discount').text print(name, price, discount) driver.quit()
Step 4: Scraping New Arrivals
new_arrivals = driver.find_elements(By.CLASS_NAME, 'new-arrival-badge') for new_product in new_arrivals: name = new_product.find_element(By.CLASS_NAME, 'product-name').text print(f'New Arrival: {name}')
Step 5: Storing Data for Analysis
import csv data = [ {'Product Name': 'Leather Jacket', 'Price': '₹3,999', 'Discount': '30%'}, {'Product Name': 'Blue Jeans', 'Price': '₹1,299', 'Discount': '10%'} ] with open('ajio_data.csv', mode='w', newline='') as file: writer = csv.DictWriter(file, fieldnames=['Product Name', 'Price', 'Discount']) writer.writeheader() writer.writerows(data)
Conclusion
Scraping Ajio to fetch data for discounts, deals, and new arrivals would provide businesses with an idea about recent trends and price strategies in the fashion and lifestyle vertical. Data extraction automation helps monitor the platform's dynamic price changes and design plans around them to stay ahead in the market shift, thus making informed decisions about the business products and price strategy.
Know More : https://www.crawlxpert.com/blog/scraping-ajio-extract-discounts-deals-and-new-arrivals
0 notes