#ClickHouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
Интеграции ClickHouse: работа с MySQL, S3, Kafka и внешними словарями. Урок 7
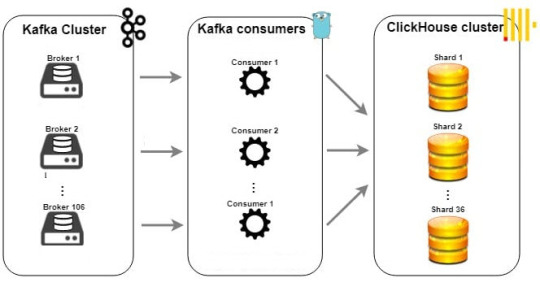
ДлДо сих пор мы рассматривали ClickHouse как самостоятельную систему: создавали в нем таблицы и загружали данные. Однако в реальном мире данные редко живут в одном месте. Транзакционная информация находится в реляционных базах вроде MySQL или PostgreSQL, архивы ло��ов — в объектных хранилищах типа Amazon S3, а потоки событий в реальном времени — в Apache Kafka. Перемещать все эти данные в ClickHouse с помощью сложных ETL-процессов — долго и дорого. К счастью, ClickHouse спроектирован как открытый аналитический хаб и умеет работать с внешними данными напрямую. В этой статье мы рассмотрим самые важные механизмы интеграции, которые превращают ClickHouse из просто быстрой базы данных в центр вашей аналитической экосистемы. Движки для внешних баз данных: Запросы без перемещения Частая задача — объединить аналитические данные из ClickHouse (например, логи событий) со справочной информацией из основной, транзакционной базы данных. ClickHouse позволяет делать это "на лету" с помощью специальных движков таблиц. Как это работает? Вы создаете в ClickHouse таблицу, которая не хранит данные сама, а выступает в роли "прокси" или коннектора к таблице во внешней базе. Каждый раз, когда вы делаете SELECT к такой таблице, ClickHouse перенаправляет запрос во внешнюю систему. Пример: Подключение к MySQL Предположим, в MySQL у нас есть таблица users с информацией о пользователях. Создадим ее "отражение" в ClickHouse: CREATE TABLE users_from_mysql ( user_id UInt64, user_name String, registration_date Date ) ENGINE = MySQL('mysql_host:3306', 'mysql_db', 'users', 'mysql_user', 'password'); Важные оговорки: Производительность: Этот способ не предназначен для высоконагруженных запросов к внешней базе. Он отлично подходит для JOIN'ов с небольшими справочниками. Predicate pushdown: ClickHouse старается "проталкивать" WHERE условия во внешнюю базу, чтобы фильтровать данные на ее стороне, но это работает не для всех типов запросов. Интеграция ClickHouse при работе с файлами в S3: Анализируем архивы на месте Объектные хранилища, такие как Amazon S3, — популярное место для хранения огромных архивов логов. Загружать терабайты таких данных в ClickHouse для разового анализа неэффективно. И этого не нужно делать! Интеграция ClickHouse может помочь выполнять запросы напрямую к файлам в S3 с помощью табличной функции s3() Пример: Запрос к CSV файлу в S3 SELECT request_method, status_code, count() FROM s3( 'https://my-bucket.s3.us-east-1.amazonaws.com/logs/archive-*.csv.gz', 'AWS_ACCESS_KEY_ID', 'AWS_SECRET_ACCESS_KEY', 'CSVWithNames', 'request_method String, status_code UInt16' ) GROUP BY request_method, status_code; Это невероятно мощный инструмент для работы с "холодными" данными. Потоковая обработка: Интеграция ClickHouse с Apache Kafka Для аналитики в реальном времени данные часто поступают через брокеры сообщений, и Apache Kafka — самый популярный из них. ClickHouse имеет нативный движок Kafka для создания эффективных real-time пайплайнов. Более подробно мы рассматриваем примеры построения pipelinов на наших курсах, посвященных созданию хранилищ данных на ClickHouse и Kafka для инженеров данных Архитектура пайплайна: Стандартный подход состоит из трех компонентов: Таблица с движком Kafka: Она подключается к топику Kafka и работает как потребитель (consumer). Целевая таблица с движком MergeTree: Это основная, оптимизированная таблица, где данные будут храниться постоянно. Материализованное представление (Materialized View): Это "клей", который автоматически читает новые данные из таблицы Kafka и вставляет их в таблицу MergeTree. Теперь любой JSON, отправленный в топик в Kafka, будет автоматически распарсен и практически мгновенно попадет в нашу основную аналитическую таблицу.
Обогащение данных: Внешние словари Еще одна частая задача — обогащение данных. Ваши основные таблицы содержат идентификаторы (user_id), а в отчетах нужны имена (user_name). Делать JOIN каждый раз может быть неэффективно. Решение — внешние словари. Это справочники (key-value), которые ClickHouse подгружает из внешнего источника и кэширует в оперативной памяти для сверхбыстрого доступа.

Как это работает? Для этого Вам нужно описать словарь (в XML или DDL), указывая его структуру, источник (например, таблица в MySQL) и правила обновления. В запросах вы используете специальную функцию dictGet() для получения значения по ключу. Функция dictGet() работает невероятно быстро, так как обращается к данным в оперативной памяти. Заключение Бесспорно, ClickHouse — это не изолированная база данных, а мощный аналитический процессор. Освоив эти инструменты интеграции ClickHouse, вы сможете решать гораздо более широкий класс задач, сокращая затраты на разработку сложных ETL-пайплайнов и строя по-настоящему современные аналитические системы. Использованные референсы и материалы Официальный сайт Apache Kafka. Документация ClickHouse по табличной функции s3(). Документация ClickHouse по Внешним словарям. Статья HTTP Analytics for 6M requests per second using ClickHouse на Cloudflare SQL-блокнот к Уроку 7 бесплатного курса доступен в нашем репозитории на GitHub Read the full article
0 notes
Text
🌟 Why Choose Open Source Databases in 2025?
As businesses continue to grow and scale, the demand for efficient and reliable data management systems increases. Open source databases are:
Highly scalable and suitable for enterprise-grade workloads
Flexible and customizable for specific business use cases
Backed by active developer communities and regular updates
Cost-effective with no expensive licensing fees
Compatible with modern tech stacks, including cloud-native apps and AI-driven platforms

🏆 Top Open Source Databases for Enterprises in 2025
Here’s a breakdown of the most powerful and enterprise-ready open source databases in 2025:
1. PostgreSQL
Known for: Advanced querying, full ACID compliance, strong security features
Ideal for: Complex web applications, analytics, enterprise software
Highlights: JSONB support, partitioning, indexing, high extensibility
2. MySQL
Known for: Speed and reliability
Ideal for: Web and mobile applications, e-commerce platforms
Highlights: Replication, clustering, strong community support
3. MariaDB
Known for: Enterprise level security and speed
Ideal for: Businesses seeking MySQL compatibility with better performance
Highlights: ColumnStore for big data, Galera clustering
4. MongoDB
Known for: NoSQL architecture and flexibility
Ideal for: Applications needing rapid development and large-scale unstructured data
Highlights: Document-oriented model, horizontal scaling, sharding
5. Redis
Known for: Ultra-fast performance and in-memory storage
Ideal for: Real-time applications, caching, session storage
Highlights: Pub/Sub messaging, data persistence, AI model support
6. ClickHouse
Known for: Lightning fast OLAP queries
Ideal for: Data warehousing and real-time analytics
Highlights: Columnar storage, parallel query processing, compression
✅ Benefits of Using Open Source Databases for Enterprises
💰 Cost Savings: No licensing costs; lower TCO
🔧 Customization: Tailor the database to fit unique business needs
🚀 Performance: Handle massive datasets with high speed and reliability
📈 Scalability: Easily scale horizontally or vertically as data grows
🔐 Security: Enterprise ready databases with encryption, access control, and auditing features
🌐 Community & Ecosystem: Global support, extensive documentation, and regular enhancements
🤔 FAQs on Open Source Databases
🔹 Are open source databases suitable for large enterprises?
Absolutely. Many global enterprises, including Fortune 500 companies, rely on open source databases for mission-critical workloads.
🔹 Can open source databases handle high-transaction volumes?
Yes. Databases like PostgreSQL, MySQL and MongoDB are capable of processing millions of transactions per second.
🔹 What if we need enterprise support?
Many open source projects offer commercial support through enterprise editions or certified service providers.
🔹 Are these databases cloud-ready?
Most open source databases are compatible with cloud platforms like AWS, Azure, and Google Cloud, and many even offer Kubernetes support.
🔹 How do open source databases compare to commercial databases?
They often match or exceed commercial solutions in performance and flexibility, without the vendor lock in or heavy licensing costs.
🛠️ Additional Tips for Adopting Open Source Databases
Start with a pilot project to test database performance in a controlled environment
Leverage containerization (Docker, Kubernetes) for deployment flexibility
Ensure your team is trained or partner with a database consulting provider
Monitor and tune performance regularly using tools like pgAdmin, Percona Toolkit, or Prometheus
🧩 Conclusion
Open source databases are no longer just an alternative they are essential tools for modern enterprises. Whether you’re looking for high performance, cost-efficiency, scalability, or agility, the open source ecosystem has a solution tailored for your business needs in 2025.
At Simple Logic, we help enterprises implement, optimize, and manage open source databases with unmatched efficiency and expertise. Whether it’s PostgreSQL, MongoDB, or Redis we ensure your data is always secure, accessible, and scalable.
🚀 Ready to Transform Your Database Strategy?
👉 Switch to enterprise grade open source databases with Simple Logic today! 📩 Reach out now at [email protected] or call +91 86556 16540 💡 Let’s build a database ecosystem that fuels your digital transformation in 2025 and beyond!
#simplelogic#makingitsimple#simplelogicit#makeitsimple#itservices#itconsulting#itcompany#manageditservices#blog#opensource#opensourcedatabase#database#data#databasestrategy#mongodb#mariadb#redis#clickhouse#mysql
0 notes
Text

ClickHouse adquiere HyperDX para acelerar el futuro de la observabilidad
ClickHouse, la empresa detrás de la base de datos analítica más rápida del mundo, anunció hoy la adquisición de HyperDX, una plataforma de observabilidad de código abierto basada en ClickHouse. Esta adquisición estratégica refuerza el compromiso de ClickHouse por ofrecer las soluciones más rápidas, rentables y escalables para desarrolladores y empresas de todo el mundo, incluida la observabilidad.
La adquisición combina el rendimiento y la escalabilidad inigualables de ClickHouse con la experiencia orientada al desarrollador de HyperDX para crear una plataforma de observabilidad completa que integra de manera transparente reproducción de sesiones, excepciones, registros, métricas de infraestructura y rastreo distribuido a través de un enfoque nativo de OpenTelemetry.
“Las funcionalidades de análisis y el ecosistema abierto de ClickHouse la convierten en una tecnología potente para la observabilidad. No obstante, la experiencia de usuario final carecía de algunas características integrales presentes en soluciones más establecidas. HyperDX es muy interesante, ya que combina una experiencia de consultas mejorada con una interfaz de usuario más intuitiva para flujos de trabajo de observabilidad exploratorios”. Viktor Eriksson, Lovable
"La observabilidad es fundamentalmente un problema de datos", indicó Tanya Bragin, vicepresidenta de producto y marketing de ClickHouse. "El tamaño del conjunto de datos dicta qué tan difícil y costoso será diseñar una plataforma de observabilidad. Por ese motivo, ClickHouse ha sido la columna vertebral de las plataformas de observabilidad durante años, con tecnología para soluciones de registros, métricas y rastreo para firmas como eBay y Netflix".
Originalmente, ClickHouse exploró nuevas soluciones de observabilidad durante su transición de Datadog a su pila de LogHouse interna (Cómo diseñamos una plataforma 19 PiB Logging con ClickHouse y ahorramos millones), que se basó en ClickHouse para manejar sus cargas de trabajo a escala de petabytes. Durante este proceso, descubrieron HyperDX y observaron la facilidad con la que podía transformar una implementación de ClickHouse existente en una plataforma de observabilidad completa.
"Cuando comenzamos HyperDX, teníamos dos principios fundamentales: queríamos diseñar la mejor plataforma de observabilidad de código abierto posible, y ClickHouse era la ÚNICA base de datos con la tecnología para lograrlo", explicó Michael Shi, director ejecutivo de HyperDX. "Nuestra misión siempre ha sido ayudar a que los ingenieros diagnostiquen y resuelvan problemas de producción más rápido, y ClickHouse ha sido una parte muy importante de ese camino desde el primer día".
El futuro de la observabilidad de código abierto
A través de conversaciones, las empresas descubrieron que compartían la misma visión:
La observabilidad debe ser rentable y fácil de usar para los desarrolladores
El rendimiento y la escalabilidad de ClickHouse la convierten en la mejor base para la observabilidad
La experiencia orientada al desarrollador de HyperDX permite que los equipos la implementen sin esfuerzo
La integración ofrece numerosos beneficios, entre ellos:
Recopilación de datos basada en estándares: tanto ClickHouse como HyperDX han asumido un compromiso con OpenTelemetry, y actualmente ClickHouse mantiene el exportador ClickHouse OpenTelemetry
Priorización del código abierto: hacer que una observabilidad sólida sea accesible para todos, con productos de nube que ofrezcan una experiencia operativa simple y rentable
Acceso a datos flexible: acceso directo a datos de observabilidad con varias opciones de análisis
Rendimiento de datos ultrarrápido: consulte terabytes en cuestión de segundos para solucionar problemas en tiempo real
HyperDX Cloud seguirá prestando servicios a los clientes existentes e incorporando nuevos, y el proyecto de código abierto seguirá siendo mantenido y desarrollado de forma activa. Al mismo tiempo, la hoja de ruta conjunta está pensada para sumar herramientas de observabilidad aún más potentes para los ingenieros.
0 notes
Text
DeepSeek, Compromis de o Breșă Majoră de Securitate: Peste un Milion de Conversații Expuse Online
🚨 Un nou scandal de securitate zguduie lumea AI: DeepSeek, startup-ul chinez care a provocat neliniște pe burse la începutul săptămânii, a fost prins într-un incident grav de securitate. O bază de date neprotejată a fost descoperită expusă online, permițând accesul neautorizat la peste un milion de conversații private între utilizatori și chatbot-ul său, alături de informații tehnice…
#AI chatbot#AI data breach#AI vulnerability#API security#atac cibernetic#bam#breșă de date#chei API#ClickHouse#Conversații private#cyber threat#cybersecurity#cybersecurity incident#data privacy#database exposure#date confidențiale#DeepSeek#diagnoza#exposed data#expunere date#hacking#hacking risk#neamt#roman#securitate cibernetică#security breach#user privacy#vulnerabilitate AI#Wiz Research
1 note
·
View note
Text
1 note
·
View note
Text
ClickHouse Meetup London, July 20, 2022
Slides: 18:00 Doors Open – Networking & Snacks … source
0 notes
Text
ClickHouse or StarRocks? Here is a Detailed Comparison While StarRocks and ClickHouse have a lot in common, there are also differences in functions, performance, and application scenarios. Check out this breakdown of both! A New Choice of Column DBMS Hadoop was developed 13 years ago.
— https://ift.tt/OuPeUFB
0 notes
Link
Apache Kafka became the de facto standard for data streaming. However, the combination of an event-driven architecture with request-response APIs is crucial for most enterprise architectures. This blog post explores how Tinybird innovates with a REST/HTTP layer on top of the open source analytics database ClickHouse in the cloud. Integrating Kafka with Tinybird, the benefits of fully managed services like Confluent Cloud, and customer stories from Factorial, FanDuel and Hard Rock Digital show why Kafka and analytics databases complement each other for more innovation and faster time-to-market. The post Apache Kafka and Tinybird (ClickHouse) for Streaming Analytics HTTP APIs appeared first on Kai Waehner.
#Analytics#Apache Kafka#ClickHouse#Cloud#database#Tinybird#api#data lake#data warehouse#HTTP#kafka#open source#Request Response#REST#sql#WebSockets
0 notes
Text
Within minutes, we found a publicly accessible ClickHouse database linked to DeepSeek, completely open and unauthenticated, exposing sensitive data. It was hosted at oauth2callback.deepseek.com:9000 and dev.deepseek.com:9000.
This database contained a significant volume of chat history, backend data and sensitive information, including log streams, API Secrets, and operational details.
More critically, the exposure allowed for full database control and potential privilege escalation within the DeepSeek environment, without any authentication or defense mechanism to the outside world.
lol
43 notes
·
View notes
Text
Глубокое погружение в движки MergeTree: Replacing, Summing, Aggregating и Collapsing. Урок 5
Если вы работаете с аналитикой больших данных и пользуетесь ClickHouse, то уж точно сталкивались с мощнейшим семейством движков MergeTree. В прошлых статьях мы уже коснулись базового MergeTree и его специализированных братьев, но сейчас пришло время глубже разобраться в самых важных и полезных из них. Почему это стоит сделать? Потому что правильный выбор движка — это не просто формальность, а ключ к эффективной, быстрой и экономной работе с вашими данными! В этой статье я расскажу, как работают четыре кита семейства MergeTree: ReplacingMergeTree, SummingMergeTree, AggregatingMergeTree и CollapsingMergeTree. Эти движки специально разработаны для автоматизации части работы с данными, значительно упрощая ваши запросы и повышая производительность. Давайте подробно разбираться, в каких сценариях какой движок точно станет вашим лучшим помощником. 🔍 ReplacingMergeTree: храним только самые свежие данные Представьте, у вас есть таблица профилей пользователей, где постоянно меняется email или время последнего входа. Вам важно хранить только актуальные записи — упрощаем это с ReplacingMergeTree! Этот движок при фоновых слияниях удаляет старые версии с одинаковым ключом, оставляя только последнюю. Как определить «последнюю»? Просто: укажите дополнительный столбец-версию (например, обновление по времени), и ClickHouse оставит запись с самой свежей версией. Если версия не указана — он просто сохранил последнюю вставленную. Но будьте внимательны! Дедупликация происходит не сразу после вставки, а только в фоне при слиянии, так что недолго можно увидеть дубли. Если хотите ускорить процесс — используйте команду OPTIMIZE TABLE ... FINAL. 📌 Пример создания таблицы: CREATE TABLE user_profiles ( user_id UInt64, email String, updated_at DateTime ) ENGINE = ReplacingMergeTree(updated_at) ORDER BY user_id; 🛠️ Такое решение идеально, если вы храните справочники или иные обновляющиеся данные. 📊 SummingMergeTree: поднимаем агрегацию на новый уровень А если собирать массу сырых метрик — кликов, просмотров или показов — и постоянно надо быстро получать их суммы по дате, кампании или региону? Хранить каждый клик необязательно — SummingMergeTree сделает агрегацию за вас. Как работает? При фоне слияния все строки с одним и тем же ключом сортировки "свариваются" в одну, а числовые столбцы складываются. В итоге — меньше данных, меньше места и сверхскоростные запросы. 📌 Пример создания таблицы для подсчёта просмотров и кликов: CREATE TABLE campaign_stats ( event_date Date, campaign_id UInt32, views UInt64, clicks UInt64 ) ENGINE = SummingMergeTree() ORDER BY (event_date, campaign_id); Такой движок просто незаменим в маркетинговой аналитике для больших объемов событий. ⚙️ AggregatingMergeTree: агрегации любой сложности без потерь А что делать, если нужны не просто суммы, а уникальные пользователи, средние значения или другие продвинутые вычисления? Здесь на сцену выходит AggregatingMergeTree! Он не хранит сырые данные, а сохраняет промежуточные состояния агрегатных функций, что позволяет моментально получать сложные метрики. Работает через специальные типы столбцов AggregateFunction. Вы сохраняете состояния с помощью функций с суффиксом -State, а получаете итог благодаря функциям с суффиксом -Merge. 📌 Например, считаем уникальных посетителей по страницам за день: CREATE TABLE daily_unique_users ( day Date, url String, visitors AggregateFunction(uniq, UInt64) ) ENGINE = AggregatingMergeTree() ORDER BY (day, url); INSERT INTO daily_unique_users SELECT toDate(timestamp) AS day, url, uniqState(user_id) AS visitors FROM access_logs GROUP BY day, url; SELECT day, url, uniqMerge(visitors) AS unique_visitors FROM daily_unique_users GROUP BY day, url; Этот способ экономит ресурсы и время по сравнению с обычным вычислением на огромных сырых данных. 🔄 CollapsingMergeTree: контроль парных событий и балансов Особая категория задач — отслеживание событий, где важно знать начало и конец, например, сессии пользователей или приход-расход товаров. CollapsingMergeTree поможет автоматически «схлопывать» пары событий с противоположными значениями в специальном столбце Sign (1 и -1). Ваша таблица будет содержать столбец Sign Int8, где положительные события — с Sign=1, а отрицательные с Sign=-1. При фоновых слияниях пары удаляются, оставляя только фактическое состояние. 📌 Создание такой таблицы требует продуманной логики записи, но она незаменима для поддержки целостности данных и в кейсах сложного учета. ✅ Итоги и рекомендации Выбор движка из семейства MergeTree — это ваш мощный рычаг оптимизации в ClickHouse. Если вам нужно хранить только последние версии записей — берите ReplacingMergeTree. Для быстрой агрегации численных метрик идеально подойдет SummingMergeTree. Нужны сложные агрегаты, такие как уникальные значения или средние — упрощайте себе жизнь с AggregatingMergeTree. А для задач, где важен учет парных событий и балансов — CollapsingMergeTree ваш верный союзник. Освоив эти четыре движка, вы существенно сократите объем хранимых данных, упростите запросы и повысите скорость обработки — и это только начало! В следующей статье мы рассмотрим, как оптимизировать запросы и применять индексы для ещё более крутых результатов. До новых встреч и удачи в анализе! 🚀 Источники и полезные материалы: Официальная документация ClickHouse по MergeTree Altinity блог о SummingMergeTree Alibaba SQL-блокнот к бесплатному курсу — репозиторий GitHub #ClickHouse #MergeTree #BigDataAnalytics #DataEngineering #ClickHouseTips Read the full article
0 notes
Text
ClickHouse acquires PeerDB to expand its Postgres support
https://techcrunch.com/2024/07/30/real-time-database-startup-clickhouse-acquires-peerdb-to-expand-its-postgres-support/
2 notes
·
View notes
Text
This Week in Rust 513
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.72.1
Foundation
Announcing the Rust Foundation’s Associate Membership with OpenSSF
Project/Tooling Updates
This month in Servo: upcoming events, new browser UI, and more!
Pagefind v1.0.0 — Stable static search at scale
Open sourcing the Grafbase Engine
Announcing Arroyo 0.6.0
rust-analyzer changelog #199
rumqttd 0.18.0
Observations/Thoughts
Stability without stressing the !@#! out
The State of Async Rust
NFS > FUSE: Why We Built our own NFS Server in Rust
Breaking Tradition: Why Rust Might Be Your Best First Language
The Embedded Rust ESP Development Ecosystem
Sifting through crates.io for malware with OSSF Package Analysis
Choosing a more optimal String type
Changing the rules of Rust
Follow up to "Changing the rules of Rust"
When Zig Outshines Rust - Memory Efficient Enum Arrays
Three years of Bevy
Should I Rust or should I go?
[audio] What's New in Rust 1.68 and 1.69
[audio] Pitching Rust to decision-makers, with Joel Marcey
Rust Walkthroughs
🤗 Calling Hugging Face models from Rust
Rust Cross-Compilation With GitHub Actions
tuify your clap CLI apps and make them more interactive
Enhancing ClickHouse's Geospatial Support
[video] All Rust string types explained
Research
A Grounded Conceptual Model for Ownership Types in Rust
Debugging Trait Errors as Logic Programs
REVIS: An Error Visualization Tool for Rust
Miscellaneous
JetBrains, You're scaring me. The Rust plugin deprecation situation.
Crate of the Week
This week's crate is RustQuant, a crate for quantitative finance.
Thanks to avhz for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
r3bl_rs_utils - [tuify] Use nice ANSI symbols instead of ">" to decorate what row is currently selected
r3bl_rs_utils - [all] Use nu shell scripts (not just or fish) and add Github Actions to build & test on mac & linux
r3bl_rs_utils - [tuify] Use offscreen buffer from r3bl_tui to make repaints smooth
Ockam - make building of ockam_app create behind a feature flag
Ockam - Use the Terminal to print out RPC response instead of printlns
Hyperswitch - add domain type for client secret
Hyperswitch - separate payments_session from payments core
Hyperswitch - move redis key creation to a common module
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
342 pull requests were merged in the last week
#[diagnostic::on_unimplemented] without filters
repr(transparent): it's fine if the one non-1-ZST field is a ZST
accept additional user-defined syntax classes in fenced code blocks
add explicit_predicates_of to SMIR
add i686-pc-windows-gnullvm triple
add diagnostic for raw identifiers in format string
add source type for invalid bool casts
cache reachable_set on disk
canonicalize effect vars in new solver
change unsafe_op_in_unsafe_fn to be warn-by-default from edition 2024
closure field capturing: don't depend on alignment of packed fields
consistently pass ty::Const through valtrees
coverage: simplify internal representation of debug types
disabled socketpair for Vita
enable varargs support for AAPCS calling convention
extend rustc -Zls
fallback effects even if types also fallback
fix std::primitive doc: homogenous → homogeneous
fix the error message for #![feature(no_coverage)]
fix: return early when has tainted in mir pass
improve Span in smir
improve PadAdapter::write_char
improve invalid let expression handling
inspect: closer to proof trees for coherence
llvm-wrapper: adapt for LLVM API changes
make .rmeta file in dep-info have correct name (lib prefix)
make ty::Const debug printing less verbose
make useless_ptr_null_checks smarter about some std functions
move required_consts check to general post-mono-check function
only suggest turbofish in patterns if we may recover
properly consider binder vars in HasTypeFlagsVisitor
read from non-scalar constants and statics in dataflow const-prop
remove verbose_generic_activity_with_arg
remove assert that checks type equality
resolve: mark binding is determined after all macros had been expanded
rework no_coverage to coverage(off)
small wins for formatting-related code
some ConstValue refactoring
some inspect improvements
treat host effect params as erased in codegen
turn custom code classes in docs into warning
visit ExprField for lint levels
store a index per dep node kind
stabilize the Saturating type
stabilize const_transmute_copy
make Debug impl for ascii::Char match that of char
add minmax{,_by,_by_key} functions to core::cmp
specialize count for range iterators
impl Step for IP addresses
add implementation for thread::sleep_until
cargo: cli: Add '-n' to dry-run
cargo: pkgid: Allow incomplete versions when unambigious
cargo: doc: differentiate defaults for split-debuginfo
cargo: stabilize credential-process and registry-auth
cargo: emit a warning for credential-alias shadowing
cargo: generalise suggestion on abiguous spec
cargo: limit cargo add feature print
cargo: prerelease candidates error message
cargo: consolidate clap/shell styles
cargo: use RegistryOrIndex enum to replace two booleans
rustfmt: Style help like cargo nightly
clippy: ignore #[doc(hidden)] functions in clippy doc lints
clippy: reuse rustdoc's doc comment handling in Clippy
clippy: extra_unused_type_parameters: Fix edge case FP for parameters in where bounds
clippy: filter_map_bool_then: include multiple derefs from adjustments
clippy: len_without_is_empty: follow type alias to find inherent is_empty method
clippy: used_underscore_bindings: respect lint levels on the binding definition
clippy: useless_conversion: don't lint if type parameter has unsatisfiable bounds for .into_iter() receiver
clippy: fix FP of let_unit_value on async fn args
clippy: fix ICE by u64::try_from(<u128>)
clippy: trigger transmute_null_to_fn on chain of casts
clippy: fix filter_map_bool_then with a bool reference
clippy: ignore closures for some type lints
clippy: ignore span's parents in collect_ast_format_args/find_format_args
clippy: add redundant_as_str lint
clippy: add extra byref checking for the guard's local
clippy: new unnecessary_map_on_constructor lint
clippy: new lint: path_ends_with_ext
clippy: split needless_borrow into two lints
rust-analyzer: field shorthand overwritten in promote local to const assist
rust-analyzer: don't skip closure captures after let-else
rust-analyzer: fix lens location "above_whole_item" breaking lenses
rust-analyzer: temporarily skip decl check in derive expansions
rust-analyzer: prefer stable paths over unstable ones in import path calculation
Rust Compiler Performance Triage
A pretty quiet week, with relatively few statistically significant changes, though some good improvements to a number of benchmarks, particularly in cycle counts rather than instructions.
Triage done by @simulacrum. Revision range: 7e0261e7ea..af78bae
3 Regressions, 3 Improvements, 2 Mixed; 2 of them in rollups
56 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
[disposition: merge] RFC: Unicode and escape codes in literals
Tracking Issues & PRs
[disposition: merge] stabilize combining +bundle and +whole-archive link modifiers
[disposition: merge] Stabilize impl_trait_projections
[disposition: merge] Tracking Issue for option_as_slice
[disposition: merge] Amend style guide section for formatting where clauses in type aliases
[disposition: merge] Add allow-by-default lint for unit bindings
New and Updated RFCs
[new] RFC: Remove implicit features in a new edition
[new] RFC: const functions in traits
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-09-20 - 2023-10-18 🦀
Virtual
2023-09-20 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
SurrealDB for Rustaceans
2023-09-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Nightly Night: Generators
2023-09-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-09-21 | Virtual (Cologne, DE) | Cologne AWS User Group #AWSUGCGN
AWS User Group Cologne - September Edition: Stefan Willenbrock: Developer Preview: Discovering Rust on AWS
2023-09-21 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 33rd Edition
2023-09-21 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2023-09-25 | Virtual (Dublin, IE) | Rust Dublin
How we built the SurrealDB Python client in Rust.
2023-09-26 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-09-26 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-09-26 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
(Hybrid - online & in person) September 2023 Rust Melbourne Meetup
2023-10-03 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-10-04 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2023-10-04 | Virtual (Various) | Ferrous Systems
A Decade of Rust with Ferrous Systems
2023-10-05 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-10-07 | Virtual (Kampala, UG) | Rust Circle Kampala
Rust Circle Meetup: Mentorship (First Saturday)
2023-10-10 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-10-10 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-10-11| Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-10-11 - 2023-10-13 | Virtual (Brussels, BE) | EuroRust
EuroRust 2023
2023-10-12 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-10-18 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
Asia
2023-09-25 | Singapore, SG | Metacamp - Web3 Blockchain Community
Introduction to Rust
2023-09-26 | Singapore, SG | Rust Singapore
SG Rustaceans! Updated - Singapore First Rust Meetup!
2023-10-03 | Taipei, TW | WebAssembly and Rust Meetup (Wasm Empowering AI)
WebAssembly Meetup (Wasm Empowering AI) in Taipei
Europe
2023-09-21 | Aarhus, DK | Rust Aarhus
Rust Aarhus - Rust and Talk at Concordium
2023-09-21 | Bern, CH | Rust Bern
Rust Bern Meetup #3 2023 🦀
2023-09-28 | Berlin, DE | React Berlin
React Berlin September Meetup: Creating Videos with React & Remotion & More: Integrating Rust with React Native – Gheorghe Pinzaru
2023-09-28 | Madrid, ES | MadRust
Primer evento Post COVID: ¡Cervezas MadRust!
2023-09-28 | Paris, FR | Paris Scala User Group (PSUG)
PSUG #114 Comparons Scala et Rust
2023-09-30 | Saint Petersburg, RU | Rust Saint Petersburg meetups
Rust Community Meetup: A tale about how I tried to make my Blitz Basic - Vitaly; How to use nix to build projects on Rust – Danil; Getting to know tower middleware. General overview – Mikhail
2023-10-10 | Berlin, DE | OpenTechSchool Berlin
Rust Hack and Learn
2023-10-12 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-10-17 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
SIMD in Rust
North America
2023-09-21 | Lehi, UT, US | Utah Rust
A Cargo Preview w/Ed Page, A Cargo Team Member
2023-09-21 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2023-09-21 | Nashville, TN, US | Music City Rust Developers
Rust on the web! Get started with Leptos
2023-09-26 | Mountain View, CA, US | Rust Breakfast & Learn
Rust: snacks & learn
2023-09-26 | Pasadena, CA, US | Pasadena Thursday Go/Rust
Monthly Rust group
2023-09-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-09-28 | Boulder, CO, US | Solid State Depot - The Boulder Makerspace
Rust and ROS for Robotics + Happy Hour
2023-10-11 | Boulder, CO, US | Boulder Rust Meetup
First Meetup - Demo Day and Office Hours
2023-10-12 | Lehi, UT, US | Utah Rust
The Actor Model: Fearless Concurrency, Made Easy w/Chris Mena
2023-10-17 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
Oceania
2023-09-26 | Canberra, ACT, AU | Rust Canberra
September Meetup
2023-09-26 | Melbourne, VIC, AU | Rust Melbourne
(Hybrid - online & in person) September 2023 Rust Melbourne Meetup
2023-09-28 | Brisbane, QLD, AU | Rust Brisbane
September Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
This is the first programming language I've learned that makes it so easy to make test cases! It's actually a pleasure to implement them.
– 0xMB on rust-users
Thanks to Moy2010 for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
Efficient Data Management for Predictive Models – The Role of Databases in Handling Large Datasets for Machine Learning
Predictive modelling thrives on data—lots of it. Whether you are forecasting demand, detecting fraud, or personalising recommendations, the calibre of your machine-learning (ML) solutions depends on how efficiently you store, organise, and serve vast amounts of information. Databases—relational, NoSQL, and cloud-native—form the backbone of this process, transforming raw inputs into ready-to-learn datasets. Understanding how to architect and operate these systems is, therefore, a core competency for every aspiring data professional and hence, a part of every data science course curriculum.
Why Databases Matter to Machine Learning
An ML workflow usually spans three data-intensive stages:
Ingestion and Storage – Collecting data from transactional systems, IoT devices, logs, or third-party APIs and landing it in a durable store.
Preparation and Feature Engineering – Cleaning, joining, aggregating, and reshaping data to create meaningful variables.
Model Training and Serving – Feeding training sets to algorithms, then delivering real-time or batch predictions back to applications.
Databases underpin each stage by enforcing structure, supporting fast queries, and ensuring consistency, and hence form the core module of any data science course in Mumbai. Without a well-designed data layer, even the most sophisticated model will suffer from long training times, stale features, or unreliable predictions.
Scaling Strategies for Large Datasets
Horizontal vs. Vertical Scaling Traditional relational databases scale vertically—adding more CPU, RAM, or storage to a single machine. Modern workloads often outgrow this approach, prompting a shift to horizontally scalable architectures such as distributed SQL (e.g., Google Spanner) or NoSQL clusters (e.g., Cassandra, MongoDB). Sharding and replication distribute data across nodes, supporting petabyte-scale storage and parallel processing.
Columnar Storage for Analytics Column-oriented formats (Parquet, ORC) and columnar databases (Amazon Redshift, ClickHouse) accelerate analytical queries by scanning only the relevant columns. This is especially valuable when feature engineering requires aggregations across billions of rows but only a handful of columns.
Data Lakes and Lakehouses Data lakes offer schema-on-read flexibility, letting teams ingest semi-structured or unstructured data without upfront modelling. Lakehouse architectures (Delta Lake, Apache Iceberg) layer ACID transactions and optimised metadata on top, blending the reliability of warehouses with the openness of lakes—ideal for iterative ML workflows.
Integrating Databases with ML Pipelines
Feature Stores To avoid re-computing features for every experiment, organisations adopt feature stores—specialised databases that store versioned, reusable features. They supply offline batches for training and low-latency look-ups for online inference, guaranteeing training-serving consistency.
Streaming and Real-Time Data Frameworks like Apache Kafka and Flink pair with databases to capture event streams and update features in near real time. This is crucial for applications such as dynamic pricing or anomaly detection, where stale inputs degrade model performance.
MLOps and Automation Infrastructure-as-code tools (Terraform, Kubernetes) and workflow orchestrators (Airflow, Dagster) automate database provisioning, data validation, and retraining schedules. By codifying these steps, teams reduce manual errors and accelerate model deployment cycles.
Governance, Quality, and Cost
As datasets balloon, so do risks:
Data Quality – Referential integrity, constraints, and automatic checks catch nulls, duplicates, and outliers early.
Security and Compliance – Role-based access, encryption, and audit logs protect sensitive attributes and meet regulations such as GDPR or HIPAA.
Cost Management – Partitioning, compression, and lifecycle policies curb storage expenses, while query optimisers and materialised views minimise compute costs.
A modern data science course walks students through these best practices, combining theory with labs on indexing strategies, query tuning, and cloud-cost optimisation.
Local Relevance and Hands-On Learning
For learners taking a data science course in Mumbai, capstone projects frequently mirror the city’s fintech, media, and logistics sectors. Students might design a scalable order-prediction pipeline: ingesting transaction data into a distributed warehouse, engineering temporal features via SQL window functions, and serving predictions through a feature store exposed by REST APIs. Such end-to-end experience cements the role of databases as the silent engine behind successful ML products.
Conclusion
Efficient data management is not an afterthought—it is the foundation upon which predictive models are built and maintained. By mastering database design, scaling techniques, and MLOps integration, data professionals ensure that their models train faster, score accurately, and deliver value continuously. As organisations double down on AI investments, those who can marry machine learning expertise with robust database skills will remain at the forefront of innovation.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].
0 notes
Text
Corporate Bank Technology – Cash Management Domain – Java Engineer - Assistant Vice President
Job Description: Job Title Corporate Bank Technology – Cash Management Domain – Java Engineer Corporate Title… of Clickhouse and BigQuery, Java / Kotlin microservices development for Cloud deployment Participate in code reviews, providing… Apply Now
0 notes
Text
#ばばさん通信ダイジェスト : Langfuse 用の ClickHouse 冗長構成を AWS Fargate で実現する
賛否関わらず話題になった/なりそうなものを共有しています。
Langfuse 用の ClickHouse 冗長構成を AWS Fargate で実現する
https://tech.layerx.co.jp/entry/2025/05/02/123428
0 notes