#DBT and Sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
What is DBT and what are it’s pros and cons?
Certainly! Here’s a content piece on DBT (Data Build Tool), including its pros and cons:
Understanding DBT (Data Build Tool): Pros and Cons
In the realm of data engineering and analytics, having efficient tools to transform, model, and manage data is crucial. DBT, or Data Build Tool, has emerged as a popular solution for data transformation within the modern data stack. Let’s dive into what DBT is, its advantages, and its drawbacks.
What is DBT?
DBT, short for Data Build Tool, is an open-source command-line tool that enables data analysts and engineers to transform data within their data warehouse. Instead of extracting and loading data, DBT focuses on transforming data already stored in the data warehouse. It allows users to write SQL queries to perform these transformations, making the process more accessible to those familiar with SQL.
Key features of DBT include:
SQL-Based Transformations: Utilize the power of SQL for data transformations.
Version Control: Integrate with version control systems like Git for better collaboration and tracking.
Modularity: Break down complex transformations into reusable models.
Testing and Documentation: Include tests and documentation within the transformation process to ensure data quality and clarity.
Pros of Using DBT
Simplicity and Familiarity:
DBT leverages SQL, a language that many data professionals are already familiar with, reducing the learning curve.
Modular Approach:
It allows for modular transformation logic, which means you can build reusable and maintainable data models.
Version Control Integration:
By integrating with Git, DBT enables teams to collaborate more effectively, track changes, and roll back when necessary.
Data Quality Assurance:
Built-in testing capabilities ensure that data transformations meet predefined criteria, catching errors early in the process.
Documentation:
DBT can automatically generate documentation for your data models, making it easier for team members to understand the data lineage and structure.
Community and Support:
As an open-source tool with a growing community, there’s a wealth of resources, tutorials, and community support available.
Cons of Using DBT
SQL-Centric:
While SQL is widely known, it may not be the best fit for all types of data transformations, especially those requiring complex logic or operations better suited for procedural languages.
Limited to Data Warehouses:
DBT is designed to work with modern data warehouses like Snowflake, BigQuery, and Redshift. It may not be suitable for other types of data storage solutions or traditional ETL pipelines.
Initial Setup and Learning Curve:
For teams new to the modern data stack or version control systems, there can be an initial setup and learning curve.
Resource Intensive:
Running complex transformations directly in the data warehouse can be resource-intensive and may lead to increased costs if not managed properly.
Dependency Management:
Managing dependencies between different data models can become complex as the number of models grows, requiring careful organization and planning.
Conclusion
DBT has revolutionized the way data teams approach data transformation by making it more accessible, collaborative, and maintainable. Its SQL-based approach, version control integration, and built-in testing and documentation features provide significant advantages. However, it’s important to consider its limitations, such as its SQL-centric nature and potential resource demands.
For teams looking to streamline their data transformation processes within a modern data warehouse, DBT offers a compelling solution. By weighing its pros and cons, organizations can determine if DBT is the right tool to enhance their data workflows.
0 notes
Text
Google BigQuery and DBT| Build SQL Data Pipeline [Hands on Lab]
In this hands on lan we will be teaching you how to Transform data in google bigquery database using DBT tool . In this lab you … source
0 notes
Text
[FAQ] What I've been learning about dbt
Data transforming made easy with dbt! 🚀 Say goodbye to ETL headaches and hello to efficient analytics. Dive into seamless data transformations that work for you! 💻✨ #DataTransformation #dbt
Recently I had this need to create a new layer in my personal DW. This DW runs in a postgreSQL and gets data from different sources, like grocy (a personal grocery ERP. I talked about how I use grocy in this post), firefly (finance data), Home Assistant (home automation). So, I’ve been using dbt to organize all these data into a single data warehouse. Here’s what I’ve learned so far: FAQ Is…

View On WordPress
0 notes
Text
Snowflake DBT Developer
Job title: Snowflake DBT Developer Company: NTT Data Job description: a Snowflake DBT Developer to join our team in Hyderabad, Telangana (IN-TG), India (IN). Snowflake and Data Vault 2 (optional…) Consultant Extensive expertise in DBT, including macros, modeling, and automation techniques. Proficiency in SQL, Python… Expected salary: Location: Hyderabad, Telangana Job date: Wed, 18 Jun 2025…
0 notes
Text
Data Lakehouse

Data Lakehouse: революция в мире данных, о которой вы не знали. Представьте себе мир, где вам больше не нужно выбирать между хранилищем структурированных данных и озером неструктурированной информации.
Data Lakehouse — это как швейцарский нож в мире данных, объединяющий лучшее из двух подходов. Давайте разберёмся, почему 75% компаний уже перешли на эту архитектуру и как она может изменить ваш бизнес.
Что такое Data Lakehouse на самом деле?
Data Lakehouse — это не просто модное словечко. Это принципиально новый подход к работе с данными, который ломает традиционные барьеры. В отличие от старых систем, где данные приходилось постоянно перемещать между разными хранилищами, здесь всё живёт в одной экосистеме. Почему это прорыв? - Больше никакой головной боли с ETL — данные доступны сразу после поступления. - Один источник правды — все отделы работают с одинаковыми данными. - Масштабируемость без ограничений — растёт бизнес, растёт и ваше хранилище.
Как работает эта магия?
Секрет Data Lakehouse в трёх китах. Единый слой хранения Вместо разделения на data lakes и warehouses — общее хранилище для всех типов данных. Apache Iceberg (тот самый, за который Databricks выложили $1 млрд) — это лишь один из примеров технологий, делающих это возможным.
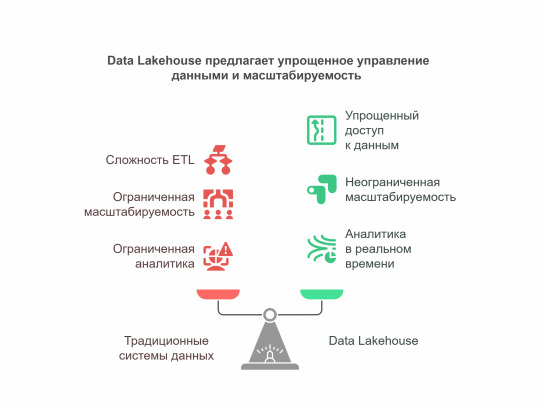
Революция в мире данных, о которой вы не знали Реальное время — не просто слова 56% IT-директоров подтверждают: аналитика в реальном времени сокращает их расходы вдвое. Финансовые операции, маркетинговые кампании, обнаружение мошенничества — всё это теперь можно делать мгновенно. SQL и не только Старые добрые запросы работают бок о бок с машинным обучением и сложной аналитикой. Никаких "или-или" — только "и то, и другое".
Кто двигает этот рынок?
Три компании, за которыми стоит следить: - SingleStore — анализирует петабайты данных за миллисекунды ($464 млн инвестиций). - dbt Labs — превращает сырые данные в готовые для анализа без перемещения (60 тыс. клиентов). - Tinybird — создание приложений для работы с данными в реальном времени ($70 млн финансирования).
Почему вам стоит задуматься об этом уже сегодня?
70% технологических лидеров называют доступность данных для реальной аналитики критически важной. Data Lakehouse — это не будущее, это настоящее. Компании, которые внедряют эти решения сейчас, получают: - Конкурентное преимущество — быстрее принимают решения. - Экономию — до 50% на инфраструктуре. - Гибкость — работа с любыми данными в любом формате.
Динамика тренда С чего начать? Попробуйте облачные решения от Databricks или Amazon Redshift. Начните с малого — одного проекта или отдела. Убедитесь сами, как это работает, прежде чем масштабировать на всю компанию. Data Lakehouse — это не просто технология. Это новый образ мышления о данных. Как вы планируете использовать этот подход в своем бизнесе?
Часто задаваемые вопросы (ЧаВо)
Что такое Data Lakehouse и чем он отличается от традиционных хранилищ данных? Data Lakehouse — это современная архитектура данных, объединяющая преимущества Data Lakes (хранение неструктурированных данных) и Data Warehouses (структурированная аналитика). В отличие от традиционных систем, он обеспечивает единое хранилище для всех типов данных с поддержкой SQL-запросов, машинного обучения и аналитики в реальном времени без необходимости перемещения данных между системами. Какие ключевые преимущества Data Lakehouse для бизнеса? Основные преимущества включают: 1) Снижение затрат на инфраструктуру до 50% 2) Возможность аналитики в реальном времени 3) Устранение необходимости сложных ETL-процессов 4) Поддержка всех типов данных (структурированных, полуструктурированных и неструктурированных) 5) Единый источник данных для всей организации. Какие технологии лежат в основе Data Lakehouse? Ключевые технологии включают: 1) Apache Iceberg, Delta Lake и Apache Hudi для управления таблицами 2) Облачные хранилища (S3, ADLS) 3) Вычислительные движки (Spark, Presto) 4) SQL-интерфейсы 5) Инструменты машинного обучения. Эти технологии обеспечивают ACID-транзакции, версионность данных и высокую производительность. Как начать внедрение Data Lakehouse в моей компании? Рекомендуется начинать с пилотного проекта: 1) Выберите одну бизнес-задачу или отдел 2) Оцените облачные решения (Databricks, Snowflake, Amazon Redshift) 3) Начните с миграции части данных 4) Обучите команду 5) Измерьте результаты перед масштабированием. Многие провайдеры предлагают бесплатные пробные версии. Какие компании являются лидерами в области Data Lakehouse? Ключевые игроки рынка: 1) Databricks (Delta Lake) 2) Snowflake 3) AWS (Redshift, Athena) 4) Google (BigQuery) 5) Microsoft (Fabric). Также стоит обратить внимание на инновационные стартапы: SingleStore для аналитики в реальном времени, dbt Labs для трансформации данных и Tinybird для приложений реального времени. Какие проблемы решает Data Lakehouse? Data Lakehouse решает ключевые проблемы: 1) Фрагментация данных между разными системами 2) Задержки в аналитике из-за ETL 3) Высокая стоимость содержания отдельных хранилищ и озер данных 4) Сложность работы с неструктурированными данными 5) Ограничения масштабируемости традиционных решений. Каковы основные варианты использования Data Lakehouse? Типичные сценарии: 1) Аналитика в реальном времени (финансы, маркетинг) 2) Обнаружение мошенничества 3) Персонализация клиентского опыта 4) IoT и обработка потоковых данных 5) Машинное обучение и AI 6) Консолидация корпоративных данных 7) Управление клиентскими данными (CDP). Read the full article
0 notes
Text
10 Must-Have Skills for Data Engineering Jobs

In the digital economy of 2025, data isn't just valuable – it's the lifeblood of every successful organization. But raw data is messy, disorganized, and often unusable. This is where the Data Engineer steps in, transforming chaotic floods of information into clean, accessible, and reliable data streams. They are the architects, builders, and maintainers of the crucial pipelines that empower data scientists, analysts, and business leaders to extract meaningful insights.
The field of data engineering is dynamic, constantly evolving with new technologies and demands. For anyone aspiring to enter this vital domain or looking to advance their career, a specific set of skills is non-negotiable. Here are 10 must-have skills that will position you for success in today's data-driven landscape:
1. Proficiency in SQL (Structured Query Language)
Still the absolute bedrock. While data stacks become increasingly complex, SQL remains the universal language for interacting with relational databases and data warehouses. A data engineer must master SQL far beyond basic SELECT statements. This includes:
Advanced Querying: JOIN operations, subqueries, window functions, CTEs (Common Table Expressions).
Performance Optimization: Writing efficient queries for large datasets, understanding indexing, and query execution plans.
Data Definition and Manipulation: CREATE, ALTER, DROP tables, and INSERT, UPDATE, DELETE operations.
2. Strong Programming Skills (Python & Java/Scala)
Python is the reigning champion in data engineering due to its versatility, rich ecosystem of libraries (Pandas, NumPy, PySpark), and readability. It's essential for scripting, data manipulation, API interactions, and building custom ETL processes.
While Python dominates, knowledge of Java or Scala remains highly valuable, especially for working with traditional big data frameworks like Apache Spark, where these languages offer performance advantages and deeper integration.
3. Expertise in ETL/ELT Tools & Concepts
Data engineers live and breathe ETL (Extract, Transform, Load) and its modern counterpart, ELT (Extract, Load, Transform). Understanding the methodologies for getting data from various sources, cleaning and transforming it, and loading it into a destination is core.
Familiarity with dedicated ETL/ELT tools (e.g., Apache Nifi, Talend, Fivetran, Stitch) and modern data transformation tools like dbt (data build tool), which emphasizes SQL-based transformations within the data warehouse, is crucial.
4. Big Data Frameworks (Apache Spark & Hadoop Ecosystem)
When dealing with petabytes of data, traditional processing methods fall short. Apache Spark is the industry standard for distributed computing, enabling fast, large-scale data processing and analytics. Mastery of Spark (PySpark, Scala Spark) is vital for batch and stream processing.
While less prominent for direct computation, understanding the Hadoop Ecosystem (especially HDFS for distributed storage and YARN for resource management) still provides a foundational context for many big data architectures.
5. Cloud Platform Proficiency (AWS, Azure, GCP)
The cloud is the default environment for modern data infrastructures. Data engineers must be proficient in at least one, if not multiple, major cloud platforms:
AWS: S3 (storage), Redshift (data warehouse), Glue (ETL), EMR (Spark/Hadoop), Lambda (serverless functions), Kinesis (streaming).
Azure: Azure Data Lake Storage, Azure Synapse Analytics (data warehouse), Azure Data Factory (ETL), Azure Databricks.
GCP: Google Cloud Storage, BigQuery (data warehouse), Dataflow (stream/batch processing), Dataproc (Spark/Hadoop).
Understanding cloud-native services for storage, compute, networking, and security is paramount.
6. Data Warehousing & Data Lake Concepts
A deep understanding of how to structure and manage data for analytical purposes is critical. This includes:
Data Warehousing: Dimensional modeling (star and snowflake schemas), Kimball vs. Inmon approaches, fact and dimension tables.
Data Lakes: Storing raw, unstructured, and semi-structured data at scale, understanding formats like Parquet and ORC, and managing data lifecycle.
Data Lakehouses: The emerging architecture combining the flexibility of data lakes with the structure of data warehouses.
7. NoSQL Databases
While SQL handles structured data efficiently, many modern applications generate unstructured or semi-structured data. Data engineers need to understand NoSQL databases and when to use them.
Familiarity with different NoSQL types (Key-Value, Document, Column-Family, Graph) and examples like MongoDB, Cassandra, Redis, DynamoDB, or Neo4j is increasingly important.
8. Orchestration & Workflow Management (Apache Airflow)
Data pipelines are often complex sequences of tasks. Tools like Apache Airflow are indispensable for scheduling, monitoring, and managing these workflows programmatically using Directed Acyclic Graphs (DAGs). This ensures pipelines run reliably, efficiently, and alert you to failures.
9. Data Governance, Quality & Security
Building pipelines isn't enough; the data flowing through them must be trustworthy and secure. Data engineers are increasingly responsible for:
Data Quality: Implementing checks, validations, and monitoring to ensure data accuracy, completeness, and consistency. Tools like Great Expectations are gaining traction.
Data Governance: Understanding metadata management, data lineage, and data cataloging.
Data Security: Implementing access controls (IAM), encryption, and ensuring compliance with regulations (e.g., GDPR, local data protection laws).
10. Version Control (Git)
Just like software developers, data engineers write code. Proficiency with Git (and platforms like GitHub, GitLab, Bitbucket) is fundamental for collaborative development, tracking changes, managing different versions of pipelines, and enabling CI/CD practices for data infrastructure.
Beyond the Technical: Essential Soft Skills
While technical prowess is crucial, the most effective data engineers also possess strong soft skills:
Problem-Solving: Identifying and resolving complex data issues.
Communication: Clearly explaining complex technical concepts to non-technical stakeholders and collaborating effectively with data scientists and analysts.
Attention to Detail: Ensuring data integrity and pipeline reliability.
Continuous Learning: The data landscape evolves rapidly, demanding a commitment to staying updated with new tools and technologies.
The demand for skilled data engineers continues to soar as organizations increasingly rely on data for competitive advantage. By mastering these 10 essential skills, you won't just build data pipelines; you'll build the backbone of tomorrow's intelligent enterprises.
0 notes
Text
How Digital Public Infrastructure is Revolutionizing Financial Inclusion in India
India’s rapid digital transformation has caught the world’s attention—not just in terms of tech innovation, but in how it has reshaped financial access for millions. The backbone of this change is India’s Digital Public Infrastructure (DPI): a stack of interoperable systems like Aadhaar, UPI, DigiLocker, and the Account Aggregator framework. Together, they’ve created a financial ecosystem that is inclusive, scalable, and data-rich.
But to truly harness the power of DPI, professionals need strong analytical capabilities. That’s where Certification Courses for Financial Analytics in Thane come into play—offering individuals the skillset to decode vast financial datasets and contribute to India’s inclusive growth story.
What Is Digital Public Infrastructure (DPI)?
Digital Public Infrastructure refers to core systems that facilitate identity, payments, and data exchange in an open, scalable, and secure way. India’s DPI includes:
Aadhaar – Biometric-based unique digital ID for over 1.3 billion people.
UPI (Unified Payments Interface) – A real-time payment system processing over 13 billion transactions monthly (as of May 2025).
DigiLocker – A cloud-based platform for issuing and verifying documents.
Account Aggregator – A consent-based data-sharing framework enabling individuals to share financial data securely.
Together, these form the foundation for delivering banking, insurance, credit, and welfare services across the socio-economic spectrum.
The DPI Impact on Financial Inclusion
✅ Banking the Unbanked
Over 500 million people have been brought into the formal banking system via Jan Dhan accounts linked to Aadhaar and mobile numbers. DPI has eliminated barriers like physical documentation and geographical access.
✅ Seamless Credit Access
With the Account Aggregator (AA) framework, lenders can now access verified financial data (with consent) to underwrite loans faster. This is revolutionizing credit access for MSMEs, gig workers, and rural entrepreneurs.
✅ Cost Reduction & Efficiency
Traditional banking and KYC costs have significantly dropped thanks to eKYC and digital documentation via DigiLocker, making financial services more affordable.
✅ Direct Benefit Transfers (DBT)
Government subsidies and welfare payments are now seamlessly deposited into beneficiary accounts through Aadhaar-based DBT, cutting out middlemen and leakage.
Why Financial Analytics Matters in DPI-Driven Finance
India’s DPI generates massive amounts of transactional and behavioral data every second. Banks, fintechs, NBFCs, and policymakers rely on financial analysts to make sense of this data and design effective, inclusive solutions.
Here’s how Certification Courses for Financial Analytics in Thane help bridge the gap:
Learn to work with UPI and AA datasets
Use tools like Python, SQL, Power BI, and Excel for data modeling
Understand financial inclusion metrics and risk scoring models
Apply statistical techniques to assess DPI’s impact on credit access or savings behavior
Train with case studies based on Indian financial systems
Use Cases: Analytics in Action
📊 Predicting Creditworthiness in Rural Lending
By analyzing income patterns from bank statements (via Account Aggregator), analysts can develop credit scoring models tailored for non-salaried borrowers.
📊 Optimizing DBT Programs
Government agencies use analytics to track whether welfare funds are reaching the intended beneficiaries, ensuring more efficient use of taxpayer resources.
📊 Fraud Detection in UPI Payments
Machine learning models help detect anomalies in UPI transaction patterns, flagging potential fraud and increasing trust in the system.
📊 Product Design for Financial Inclusion
Fintechs use location, behavior, and transaction data to create products like sachet insurance or micro-loans, tailored to low-income users.
Why Choose Certification Courses for Financial Analytics in Thane?
Thane, located near Mumbai—the financial capital of India—offers proximity to top banks, fintech companies, and startups. Choosing a financial analytics course in Thane gives learners access to:
Industry-Experienced Faculty: Learn from experts with hands-on experience in digital finance.
Live Projects & Internships: Apply learning to real-time DPI-related financial datasets.
Job Placement Support: Career services geared toward roles in analytics, risk, and product strategy.
Peer Learning: Interact with professionals from finance, data science, and public policy sectors.
Career Paths in DPI-Powered Finance
Role
Key Skills
Where You Fit In
Financial Data Analyst
SQL, Tableau, Python
Analyze trends in UPI usage, DBT effectiveness
Credit Analyst (AA Model)
Risk scoring, ML models
Design credit solutions for underserved segments
Policy Analyst
Statistics, policy understanding
Evaluate impact of DPI on financial inclusion
Product Analyst – Fintech
UX + Data
Build better digital banking products for Bharat
Conclusion: Building India’s Financial Future
India’s DPI is one of the most ambitious digital inclusion projects globally—and it’s working. But its true power lies in how well we use the data it generates to build more equitable financial systems.
By enrolling in Certification Courses for Financial Analytics in Thane, you gain the ability to turn raw data into real-world financial impact—improving access, reducing risk, and helping millions achieve financial stability.
0 notes
Text
Engenheiro a de dados pleno presencial
Engenheiro a de dados pleno presencial
Sobre a Beyond
Nosso maior diferencial é que não enxergamos profissionais como meros recursos, e sim, como pessoas reais, com sonhos, ambições e vontade de fazer o seu melhor. Buscamos Talentos que vão ALÉM de capacidades técnicas excepcionais, perseverança, olhar crítico e novas ideias são qualidades que nos movem diariamente em direção a um futuro cada vez mais tecnológico. Aqui as pessoas são o nosso maior ativo, nosso maior orgulho e são verdadeiramente valorizadas por suas habilidades.
Estamos presentes como Outsourcing e Projetos em grandes nomes do mercado financeiro!
Requisitos
Domínio avançado de SQL;
Experiência prévia com grandes volumes de dados e modelagem de dados;
Desejável experiência no setor financeiro;
Conhecimento em Ciência de Dados e Inteligência Artificial será um diferencial;
Capacidade analítica, proatividade e foco em resolução de problemas.
Diferenciais
Familiaridade com pipelines de dados, ETL, ferramentas como Airflow, DBT, ou similares;
Experiência com ferramentas de Big Data (Spark, Hadoop, etc.).
Benefícios
Plano de Saúde;
Vale Alimentação ou Refeição: R$ 30,80 por dia;
Vale Transporte ou Auxílio Combustível;
Bonificação atrativa MENSAL por resultados distribuído a todos os colaboradores;
Plano de Cargos & Salários;
Local: 100% presencial em Santo André/SP;
Jornada de trabalho: de Segunda à Sexta, das 8h às 17h.
Processo Seletivo
Primeiro contato a fim de entender se nossas posições dão match com o seu momento de carreira;
Bate Papo com alguém do nosso time de Pessoas para te conhecer melhor e apresentar as nossas oportunidades;
Entrevista Técnica com as lideranças da área.
A Beyond promove o melhor ambiente para se trabalhar e o mais humano possível! Queremos conosco pessoas que mudem o jogo e façam bonito, por isso vem fazer parte do #melhortimedasgalaxias!
Conheça Mais Sobre Nossa História
Veja nossa avaliação no Glassdoor (4.9 Estrelas)!
Imagine e Go #beyond
Candidatar-se
0 notes
Text
Stop Drowning in Data: How Data Engineering Consulting Services Solve the Bottlenecks No One Talks About
Introduction: What If the Problem Isn’t Your Data... But How You're Handling It?
Let’s get real. You’ve invested in BI tools, hired data analysts, and built dashboards. But your reports still take hours (sometimes days) to generate. Your engineers are constantly firefighting data quality issues. Your data warehouse looks more like a junk drawer than a strategic asset. Sound familiar?
You're not alone. Organizations sitting on mountains of data are struggling to extract value because they don't have the right engineering backbone. Enter Data Engineering Consulting Services — not as a quick fix, but as a long-term strategic solution.
In this blog, we’re going beyond the surface. We’ll dissect real pain points that plague modern data teams, explore what effective consulting should look like, and arm you with actionable insights to optimize your data engineering operations.
What You'll Learn:
💡 Why modern data challenges need engineering-first thinking
💡 Key signs you need Data Engineering Consulting Services (before your team burns out)
💡 Frameworks and solutions used by top consulting teams
💡 Real-world examples of high-ROI interventions
💡 How to evaluate and implement the right consulting service for your org
1. The Hidden Chaos in Your Data Infrastructure (And Why You Can’t Ignore It Anymore)
Behind the shiny dashboards and modern data stacks lie systemic issues that paralyze growth:
🔹 Disconnected systems that make data ingestion slow and error-prone
🔹 Poorly defined data pipelines that break every time schema changes
🔹 Lack of data governance leading to compliance risks and reporting discrepancies
🔹 Engineering teams stretched too thin to focus on scalability
This is where Data Engineering Consulting Services step in. They provide a structured approach to cleaning the mess you didn’t know you had. Think of it like hiring an architect before you build — you may have the tools, but you need a blueprint that works.
Real-World Scenario:
A fintech startup was pushing daily transaction data into BigQuery without proper ETL validation. Errors built up, reports failed, and analysts spent hours troubleshooting. A data engineering consultant redesigned their ingestion pipelines with dbt, automated quality checks, and implemented lineage tracking. Result? Data errors dropped 80%, and reporting time improved by 60%.
Actionable Solution:
🔺 Conduct a pipeline health audit (consultants use tools like Monte Carlo or Great Expectations)
🔺 Implement schema evolution best practices (e.g., schema registry, versioned APIs)
🔺 Use metadata and lineage tools to track how data flows across systems
2. Stop Making Your Analysts Do Engineering Work
How often have your analysts had to write complex SQL joins or debug ETL scripts just to get a working dataset?
This isn’t just inefficient — it leads to:
📌 Delayed insights 📌 Burnout and attrition 📌 Risky shadow engineering practices
Data Engineering Consulting Services help delineate roles clearly by building reusable, well-documented data products. They separate transformation logic from business logic and promote reusability.
Actionable Steps:
🔺 Centralize transformations using dbt and modular SQL
🔺 Implement a semantic layer using tools like Cube.js or AtScale
🔺 Create governed data marts per department (sales, marketing, product)
Example:
An eCommerce company had 12 different versions of "customer lifetime value" across teams. A consulting team introduced a unified semantic layer and reusable dbt models. Now, every team references the same, validated metrics.
3. Scaling Without Burning Down: How Consultants Build Resilient Architecture
Growth is a double-edged sword. What works at 10 GB breaks at 1 TB.
Consultants focus on making your pipelines scalable, fault-tolerant, and cost-optimized. This means selecting the right technologies, designing event-driven architectures, and implementing automated retries, monitoring, and alerting.
Actionable Advice:
🔺 Switch from cron-based batch jobs to event-driven data pipelines using Kafka or AWS Kinesis
🔺 Use orchestration tools like Airflow or Dagster for maintainable workflows
🔺 Implement cost monitoring (especially for cloud-native systems like Snowflake)
Industry Example:
A logistics firm working with Snowflake saw a 3x spike in costs. A consultant restructured the query patterns, added role-based resource limits, and compressed ingestion pipelines. Outcome? 45% cost reduction in 2 months.
4. Compliance, Security, and Data Governance: The Silent Time Bomb
As data grows, so do the risks.
📢 Regulatory fines (GDPR, HIPAA, etc.) 📢 Insider data leaks 📢 Poor audit trails
Data Engineering Consulting Services don’t just deal with data flow — they enforce best practices in access control, encryption, and auditing.
Pro Strategies:
🔺 Use role-based access control (RBAC) and attribute-based access control (ABAC)
🔺 Encrypt data at rest and in transit (with key rotation policies)
🔺 Set up data cataloging with auto-tagging for PII fields using tools like Collibra or Alation
Real Use-Case:
A healthcare analytics firm lacked visibility into who accessed sensitive data. Consultants implemented column-level encryption, access logs, and lineage reports. They passed a HIPAA audit with zero findings.
5. Choosing the Right Data Engineering Consulting Services (And Getting ROI Fast)
The consulting industry is saturated. So, how do you pick the right one?
Look for:
🌟 Proven experience with your stack (Snowflake, GCP, Azure, Databricks)
🌟 Open-source contributions or strong GitHub presence
🌟 A focus on enablement — not vendor lock-in
🌟 References and case studies showing measurable impact
Red Flags:
🚫 Buzzword-heavy pitches with no implementation roadmap
🚫 Proposals that skip over knowledge transfer or training
Quick Tip:
Run a 2-week sprint project to assess fit. It’s better than signing a 6-month contract based on slide decks alone.
Bonus Metrics to Track Post Engagement:
📊 Time-to-insight improvement (TTR) 📊 Data freshness and uptime 📊 Number of breakages or rollbacks in production 📊 Cost per query or per pipeline
Conclusion: From Data Chaos to Clarity — With the Right Engineering Help
Data isn’t the new oil — it’s more like electricity. It powers everything, but only if you have the infrastructure to distribute and control it effectively.
Data Engineering Consulting Services are your strategic partner in building this infrastructure. Whether it’s untangling legacy systems, scaling pipelines, enforcing governance, or just helping your team sleep better at night — the right consultants make a difference.
Your Next Step:
Start with an audit. Identify the single biggest blocker in your data pipeline today. Then reach out to a consulting firm that aligns with your tech stack and business goals. Don’t wait until your data team is in firefighting mode again.
📢 Have questions about what type of consulting your organization needs? Drop a comment or connect with us to get tailored advice.
Remember: You don’t need more data. You need better data engineering.
0 notes
Text
Why Every Data Team Needs a Modern Data Stack in 2025
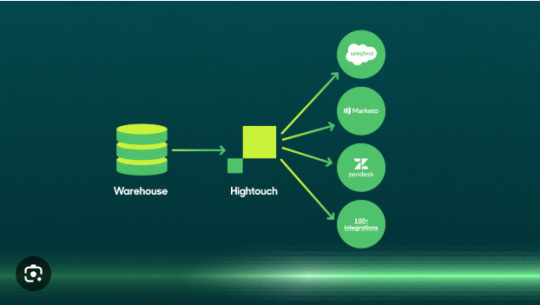
As businesses across industries become increasingly data-driven, the expectations placed on data teams are higher than ever. From real-time analytics to AI-ready pipelines, today’s data infrastructure needs to be fast, flexible, and scalable. That’s why the Modern Data Stack has emerged as a game-changer—reshaping how data is collected, stored, transformed, and analyzed.
In 2025, relying on legacy systems is no longer enough. Here’s why every data team needs to embrace the Modern Data Stack to stay competitive and future-ready.
What is the Modern Data Stack?
The Modern Data Stack is a collection of cloud-native tools that work together to streamline the flow of data from source to insight. It typically includes:
Data Ingestion/ELT tools (e.g., Fivetran, Airbyte)
Cloud Data Warehouses (e.g., Snowflake, BigQuery, Redshift)
Data Transformation tools (e.g., dbt)
Business Intelligence tools (e.g., Looker, Tableau, Power BI)
Reverse ETL and activation platforms (e.g., Hightouch, Census)
Data observability and governance (e.g., Monte Carlo, Atlan)
These tools are modular, scalable, and built for collaboration—making them ideal for modern teams that need agility without sacrificing performance.
1. Cloud-Native Scalability
In 2025, data volumes are exploding thanks to IoT, user interactions, social media, and AI applications. Traditional on-premise systems can no longer keep up with this scale.
The Modern Data Stack, being entirely cloud-native, allows data teams to scale up or down based on demand. Whether you’re dealing with terabytes or petabytes of data, cloud warehouses like Snowflake or BigQuery handle the load seamlessly and cost-effectively.
2. Faster Time to Insight
Legacy ETL systems often result in slow, rigid pipelines that delay analytics and business decisions. With tools like Fivetran for ingestion and dbt for transformation, the Modern Data Stack significantly reduces the time it takes to go from raw data to business-ready dashboards.
This real-time or near-real-time capability empowers teams to respond quickly to market trends, user behavior, and operational anomalies.
3. Democratization of Data
A key advantage of the Modern Data Stack is that it makes data more accessible across the organization. With self-service BI tools like Looker and Power BI, non-technical stakeholders can explore, visualize, and analyze data without writing SQL.
This democratization fosters a truly data-driven culture where insights aren’t locked within the data team but are shared across departments—from marketing and sales to product and finance.
4. Simplified Maintenance and Modularity
Gone are the days of monolithic, tightly coupled systems. The Modern Data Stack follows a modular architecture, where each tool specializes in one part of the data lifecycle. This means you can easily replace or upgrade a component without disrupting the entire system.
It also reduces maintenance overhead. Since most modern stack tools are SaaS-based, the burden of software updates, scaling, and infrastructure management is handled by the vendors—freeing up your team to focus on data strategy and analysis.
5. Enables Advanced Use Cases
As AI and machine learning become core to business strategies, the Modern Data Stack lays a solid foundation for these advanced capabilities. With clean, centralized, and structured data in place, data scientists and ML engineers can build more accurate models and deploy them faster.
The stack also supports reverse ETL, enabling data activation—where insights are not just visualized but pushed back into CRMs, marketing platforms, and customer tools to drive real-time action.
6. Built for Collaboration and Governance
Modern data tools are built with collaboration and governance in mind. Platforms like dbt enable version control for data models, while cataloging tools like Atlan or Alation help teams track data lineage and maintain compliance with privacy regulations like GDPR and HIPAA.
This is essential in 2025, where data governance is not optional but a critical requirement.
Conclusion
The Modern Data Stack is no longer a “nice to have”—it’s a must-have for every data team in 2025. Its flexibility, scalability, and speed empower teams to deliver insights faster, innovate more efficiently, and support the growing demand for data-driven decision-making.
By adopting a modern stack, your data team is not just keeping up with the future—it's helping to shape it.
0 notes
Text
Implementing CI/CD for Snowflake Projects

Introduction
Continuous Integration and Continuous Deployment (CI/CD) for Snowflake enables teams to automate development, testing, and deployment of Snowflake SQL scripts, schemas, stored procedures, and data pipelines. By integrating with DevOps tools, you can ensure version control, automated testing, and seamless deployment of Snowflake objects.
1. Why CI/CD for Snowflake?
Traditional data warehouses lack modern DevOps automation. Implementing CI/CD for Snowflake helps:
Automate schema management (tables, views, procedures).
Improve collaboration with version-controlled SQL scripts.
Reduce errors through automated testing and validation.
Enable faster deployments using pipeline automation.
2. CI/CD Pipeline Architecture for Snowflake
A typical CI/CD pipeline for Snowflake consists of:
Version Control (GitHub, GitLab, Bitbucket) — Stores SQL scripts.
CI Process (Jenkins, GitHub Actions, Azure DevOps) — Validates and tests SQL changes.
Artifact Repository (S3, Nexus, Artifactory) — Stores validated scripts.
CD Process (dbt, Flyway, Liquibase, Terraform) — Deploys changes to Snowflake.
Monitoring & Alerts (Datadog, Prometheus) — Tracks performance and errors.
3. Setting Up CI/CD for Snowflake
Step 1: Version Control with Git
Store Snowflake DDL, DML, and stored procedure scripts in a Git repository.bashgit init git add schema.sql git commit -m "Initial commit" git push origin main
Step 2: CI Pipeline — Linting & SQL Validation
Use SQLFluff to check for syntax issues.bashpip install sqlfluff sqlfluff lint schema.sql
Step 3: Automated Testing
Create a test environment in Snowflake and execute test cases.sqlCREATE DATABASE test_db CLONE production_db;
Run test queries:sqlSELECT COUNT(*) FROM test_db.orders WHERE status IS NULL;
Step 4: CD Pipeline — Deploy to Snowflake
Use Liquibase or dbt to manage database changes.
Liquibase Example
bashliquibase --changeLogFile=schema.xml update
dbt Example
bashdbt run --profiles-dir .
Step 5: Automating with Jenkins
Define a Jenkins Pipeline (Jenkinsfile):groovypipeline { agent any stages { stage('Checkout') { steps { git 'https://github.com/org/snowflake-repo.git' } } stage('Lint SQL') { steps { sh 'sqlfluff lint schema.sql' } } stage('Deploy to Snowflake') { steps { sh 'liquibase update' } } } }
4. Best Practices for Snowflake CI/CD
✅ Use separate environments (Dev, Test, Prod). ✅ Implement automated rollback for failed deployments. ✅ Integrate monitoring tools for performance tracking. ✅ Follow Git branching strategies (feature branches, main branch).
5. Conclusion
CI/CD for Snowflake enables automated, secure, and version-controlled deployments of SQL-based data solutions. By integrating Git, Jenkins, Liquibase, or dbt, you can streamline database development and ensure data consistency.
WEBSITE: https://www.ficusoft.in/snowflake-training-in-chennai/
0 notes
Text

#Visualpath Teaching the best #DBT (Data Build Tool) Training in Ameerpet. It is the NO.1 Institute in Hyderabad Providing Online Training Classes. Our faculty has experienced in real time and provides DBT Real time projects and placement assistance. Contact us +91-9989971070.
Join us on WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit: https://visualpath.in/dbt-online-training-course-in...
Read Our blog: https://visualpathblogs.com/
#DataBuildTool#DBT#DataTransformation#DataEngineering#SQL#DataAnalytics#ETL#DataPipeline#DataWarehouse#DataQuality#BigData#DataScience#DataModeling#DataTesting#DataOps
0 notes
Text
Snowflake DBT Developer
Job title: Snowflake DBT Developer Company: NTT Data Job description: a Snowflake DBT Developer to join our team in Hyderabad, Telangana (IN-TG), India (IN). Snowflake and Data Vault 2 (optional…) Consultant Extensive expertise in DBT, including macros, modeling, and automation techniques. Proficiency in SQL, Python… Expected salary: Location: Hyderabad, Telangana Job date: Wed, 18 Jun 2025…
0 notes
Text

#Visualpath offers the Best Online DBT Courses, designed to help you excel in data transformation and analytics. Our expert-led #DBT Online Training covers tools like Matillion, Snowflake, ETL, Informatica, Data Warehousing, SQL, Talend, Power BI, Cloudera, Databricks, Oracle, SAP, and Amazon Redshift. With flexible schedules, recorded sessions, and hands-on projects, we provide a seamless learning experience for global learners. Master advanced data engineering skills, prepare for DBT certification, and elevate your career. Call +91-9989971070 for a free demo and enroll today!
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
Visit: https://www.visualpath.in/online-data-build-tool-training.html
#visualpathedu #testing #automation #selenium #git #github #JavaScript #Azure #CICD #AzureDevOps #playwright #handonlearning #education #SoftwareDevelopment #onlinelearning #newtechnology #software #education #ITskills #training #trendingcourses #careers #students #typescript
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
dbt Labs Acquires SDF Labs to Offer Robust SQL Comprehension
http://securitytc.com/THLzCw
0 notes
Text
Engenheiro a de dados pleno presencial
Engenheiro a de dados pleno presencial
Sobre a Beyond
Nosso maior diferencial é que não enxergamos profissionais como meros recursos, e sim, como pessoas reais, com sonhos, ambições e vontade de fazer o seu melhor. Buscamos Talentos que vão ALÉM de capacidades técnicas excepcionais, perseverança, olhar crítico e novas ideias são qualidades que nos movem diariamente em direção a um futuro cada vez mais tecnológico. Aqui as pessoas são o nosso maior ativo, nosso maior orgulho e são verdadeiramente valorizadas por suas habilidades.
Estamos presentes como Outsourcing e Projetos em grandes nomes do mercado financeiro!
Requisitos
Domínio avançado de SQL;
Experiência prévia com grandes volumes de dados e modelagem de dados;
Desejável experiência no setor financeiro;
Conhecimento em Ciência de Dados e Inteligência Artificial será um diferencial;
Capacidade analítica, proatividade e foco em resolução de problemas.
Diferenciais
Familiaridade com pipelines de dados, ETL, ferramentas como Airflow, DBT, ou similares;
Experiência com ferramentas de Big Data (Spark, Hadoop, etc.).
Benefícios
Plano de Saúde;
Vale Alimentação ou Refeição: R$ 30,80 por dia;
Vale Transporte ou Auxílio Combustível;
Bonificação atrativa MENSAL por resultados distribuído a todos os colaboradores;
Plano de Cargos & Salários;
Local: 100% presencial em Santo André/SP;
Jornada de trabalho: de Segunda à Sexta, das 8h às 17h.
Processo Seletivo
Primeiro contato a fim de entender se nossas posições dão match com o seu momento de carreira;
Bate Papo com alguém do nosso time de Pessoas para te conhecer melhor e apresentar as nossas oportunidades;
Entrevista Técnica com as lideranças da área.
A Beyond promove o melhor ambiente para se trabalhar e o mais humano possível! Queremos conosco pessoas que mudem o jogo e façam bonito, por isso vem fazer parte do #melhortimedasgalaxias!
Conheça Mais Sobre Nossa História
Veja nossa avaliação no Glassdoor (4.9 Estrelas)!
Imagine e Go #beyond
Candidatar-se
0 notes