#Data Deduplication Software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
B2B Database Contacts: Achieving the Precise Harmony Between Quality and Quantity

In the ever-evolving landscape of B2B sales, the tapestry of effective B2B Lead Generation, targeted Sales Leads, and strategic Business Development is intricately woven with the threads of the B2B Contact Database. This comprehensive article embarks on an exploration to unravel the profound interplay between quality and quantity – the pulse that resonates within B2B Database Leads. Join us on this journey as we traverse the pathways, strategies, and insights that guide you towards mastering the equilibrium, steering your Sales Prospecting initiatives towards finesse and success.
DOWNLOAD THE INFOGRAPHIC HERE
The Essence of Quality
Quality emerges as the cornerstone in the realm of B2B Lead Generation, encapsulating the essence of depth, precision, and pertinence that envelops the contact data nestled within the B2B Contact Database. These quality leads, much like jewels in a treasure trove, possess the capacity to metamorphose into valuable clients, etching a definitive impact on your revenue stream. Every contact entry isn't a mere data point; it's a capsule that encapsulates an individual's journey – their role, industry, buying tendencies, and distinctive preferences. Cultivating a repository of such high-caliber contacts is akin to nurturing a reservoir of prospects, where each interaction holds the promise of meaningful outcomes.
Deciphering the Role of Quantity
Yet, even in the pursuit of quality, quantity emerges as a steadfast ally. Quantity embodies the expanse of contacts that populate your B2B Database Leads. Imagine casting a net wide enough to enfold diverse prospects, broadening your scope of engagement. A higher count of contacts translates to an amplified potential for interaction, heightening the probability of uncovering those latent prospects whose untapped potential can blossom into prosperous business alliances. However, it's imperative to acknowledge that quantity, devoid of quality, risks transforming into an exercise in futility – a drain on resources without yielding substantial outcomes.
Quality vs. Quantity: The Artful Balancing Act
In the fervor of database compilation, the allure of sheer quantity can occasionally overshadow the crux of strategic B2B Sales and Sales Prospecting. An extensive, indiscriminate list of contacts can rapidly devolve into a resource drain, sapping efforts and diluting the efficacy of your marketing endeavors. Conversely, an overemphasis on quality might inadvertently curtail your outreach, constraining the potential for growth. The true artistry lies in achieving a symphony – a realization that true success unfolds from the harmonious interaction of quality and quantity.
youtube
Navigating the Equilibrium
This path towards equilibrium demands a continual commitment to vigilance and meticulous recalibration. Consistent audits of your B2B Contact Database serve as the bedrock for maintaining data that is not only up-to-date but also actionable. Removing outdated, duplicated, or erroneous entries becomes a proactive stride towards upholding quality. Simultaneously, infusing your database with fresh, relevant contacts injects vibrancy into your outreach endeavors, widening the avenues for engagement and exploration.
Harnessing Technology for Exemplary Data Management
In this era of technological prowess, an array of tools stands ready to facilitate the intricate choreography between quality and quantity. Step forward Customer Relationship Management (CRM) software – an invaluable ally empowered with features such as data validation, deduplication, and enrichment. Automation, the pinnacle of technological innovation, elevates database management to unparalleled heights of precision, scalability, and efficiency. Embracing these technological marvels forms the bedrock of your B2B Sales and Business Development strategies.
Collaborating with Esteemed B2B Data Providers
In your pursuit of B2B Database Leads, consider forging collaborations with esteemed B2B data providers. These seasoned professionals unlock a treasure trove of verified leads, tailor-made solutions for niche industries, and a portal to global business expansion. By tapping into their expertise, you merge the realms of quality and quantity, securing a comprehensive toolkit poised to reshape your sales landscape.
As we draw the curtains on this exploration, remember that the compass steering your B2B Sales, Sales Prospecting, and Business Development endeavors is calibrated by the delicate interplay of quality and quantity. A B2B Contact Database enriched with high-value leads, accompanied by a robust quantity, stands as the axis upon which your strategic maneuvers pivot. Equipped with insights, tools, and allies like AccountSend, your pursuit to strike this harmonious equilibrium transforms into an enlightening journey that propels your business towards enduring growth and undeniable success.
#AccountSend#B2BLeadGeneration#B2B#LeadGeneration#B2BSales#SalesLeads#B2BDatabases#BusinessDevelopment#SalesFunnel#SalesProspecting#BusinessOwner#Youtube
14 notes
·
View notes
Text
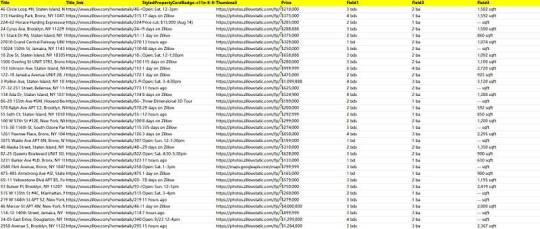
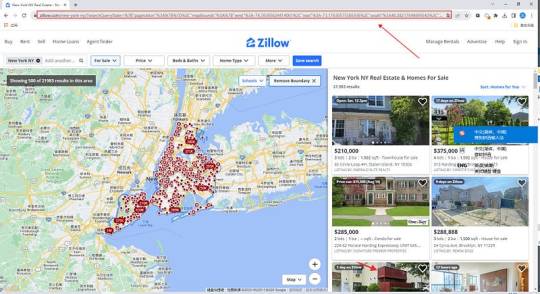
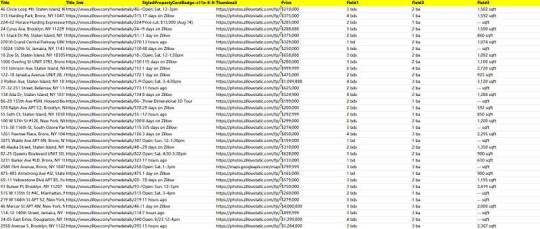
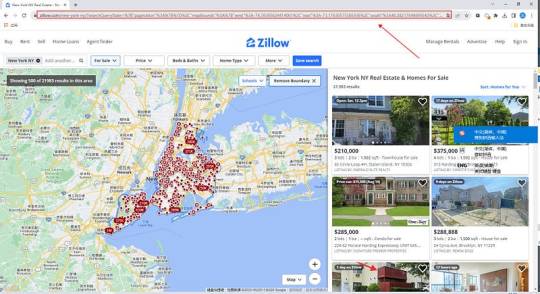
Easy way to get job data from Totaljobs
Totaljobs is one of the largest recruitment websites in the UK. Its mission is to provide job seekers and employers with efficient recruitment solutions and promote the matching of talents and positions. It has an extensive market presence in the UK, providing a platform for professionals across a variety of industries and job types to find jobs and recruit staff.
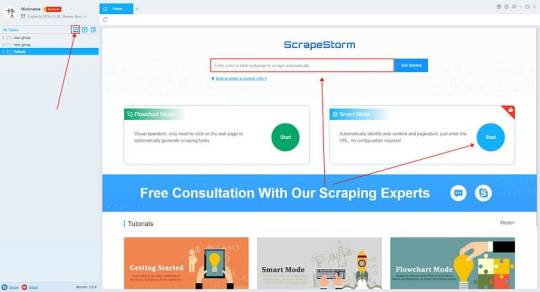
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
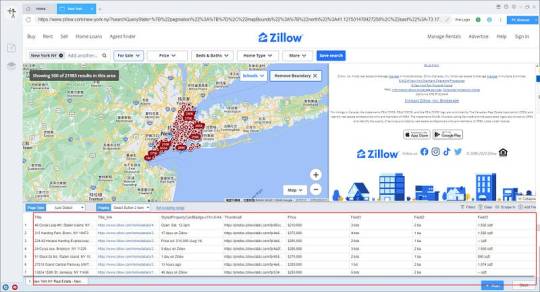
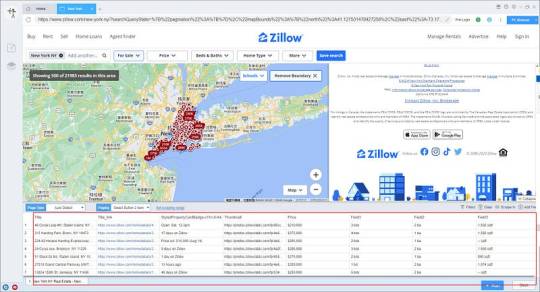
Preview of the scraped result
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
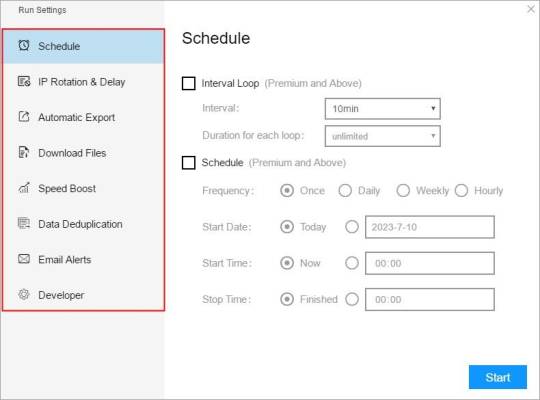
(1) Run settings
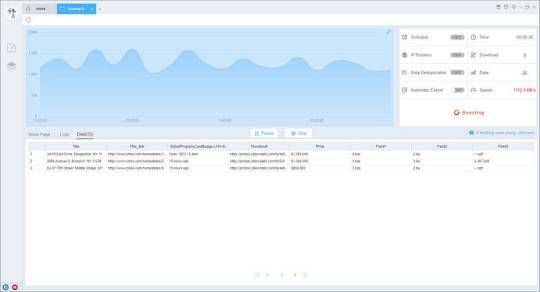
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
4. Export and view data
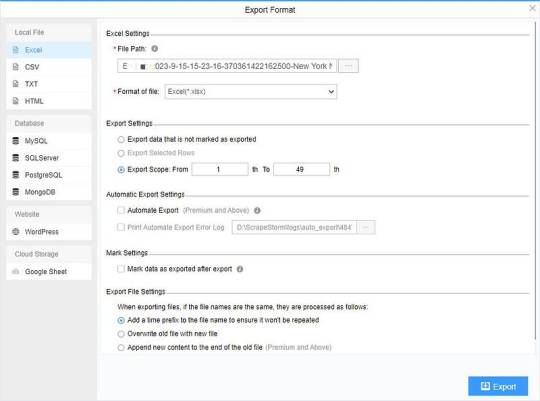
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
2 notes
·
View notes
Text
Control Structured Data with Intelligent Archiving

Control Structured Data with Intelligent Archiving
You thought you had your data under control. Spreadsheets, databases, documents all neatly organized in folders and subfolders on the company server. Then the calls started coming in. Where are the 2015 sales figures for the Western region? Do we have the specs for the prototype from two years ago? What was the exact wording of that contract with the supplier who went out of business? Your neatly organized data has turned into a chaotic mess of fragmented information strewn across shared drives, email, file cabinets and the cloud. Before you drown in a sea of unstructured data, it’s time to consider an intelligent archiving solution. A system that can automatically organize, classify and retain your information so you can find what you need when you need it. Say goodbye to frantic searches and inefficiency and hello to the control and confidence of structured data.
The Need for Intelligent Archiving of Structured Data
You’ve got customer info, sales data, HR records – basically anything that can be neatly filed away into rows and columns. At first, it seemed so organized. Now, your databases are overloaded, queries are slow, and finding anything is like searching for a needle in a haystack. An intelligent archiving system can help you regain control of your structured data sprawl. It works by automatically analyzing your data to determine what’s most important to keep active and what can be safely archived. Say goodbye to rigid retention policies and manual data management. This smart system learns your data access patterns and adapts archiving plans accordingly. With less active data clogging up your production systems, queries will run faster, costs will decrease, and your data analysts can actually get work done without waiting hours for results. You’ll also reduce infrastructure demands and risks associated with oversized databases. Compliance and governance are also made easier. An intelligent archiving solution tracks all data movement, providing a clear chain of custody for any information that needs to be retained or deleted to meet regulations. Maybe it’s time to stop treading water and start sailing your data seas with an intelligent archiving solution. Your databases, data analysts and CFO will thank you. Smooth seas ahead, captain!
How Intelligent Archiving Improves Data Management
Intelligent archiving is like a meticulous assistant that helps tame your data chaos. How, you ask? Let’s explore:
Automated file organization
Intelligent archiving software automatically organizes your files into a logical folder structure so you don’t have to spend hours sorting through documents. It’s like having your own personal librarian categorize everything for easy retrieval later.
Efficient storage
This software compresses and deduplicates your data to free up storage space. Duplicate files hog valuable storage, so deduplication removes redundant copies and replaces them with pointers to a single master copy. Your storage costs decrease while data accessibility remains the same.
Compliance made simple
For companies in regulated industries, intelligent archiving simplifies compliance by automatically applying retention policies as data is ingested. There’s no danger of mistakenly deleting information subject to “legal hold” and avoiding potential fines or sanctions. Let the software handle the rules so you can avoid data jail.
Searchability
With intelligent archiving, your data is indexed and searchable, even archived data. You can quickly find that invoice from five years ago or the contract you signed last month. No more digging through piles of folders and boxes. Search and find — it’s that easy. In summary, intelligent archiving brings order to the chaos of your data through automated organization, optimization, compliance enforcement, and searchability. Tame the data beast once and for all!
Implementing an Effective Data Archiving Strategy
So you have a mind-boggling amount of data accumulating and you’re starting to feel like you’re drowning in a sea of unstructured information. Before you decide to throw in the towel, take a deep breath and consider implementing an intelligent archiving strategy.
Get Ruthless
Go through your data and purge anything that’s obsolete or irrelevant. Be brutally honest—if it’s not useful now or in the foreseeable future, delete it. Free up storage space and clear your mind by ditching the digital detritus.
Establish a Filing System
Come up with a logical taxonomy to categorize your data. Group similar types of info together for easy searching and access later on. If you have trouble classifying certain data points, you probably don’t need them. Toss ‘em!
Automate and Delegate
Use tools that can automatically archive data for you based on your taxonomy. Many solutions employ machine learning to categorize and file data accurately without human input. Let technology shoulder the burden so you can focus on more important tasks, like figuring out what to have for lunch.
Review and Refine
Revisit your archiving strategy regularly to make sure it’s still working for your needs. Make adjustments as required to optimize how data is organized and accessed. Get feedback from other users and incorporate their suggestions. An effective archiving approach is always a work in progress. With an intelligent data archiving solution in place, you’ll gain control over your information overload and find the freedom that comes from a decluttered digital space. Tame the data deluge and reclaim your sanity!
Conclusion
So there you have it. The future of data management and control through intelligent archiving is here. No longer do you have to grapple with endless spreadsheets, documents, files and manually track the relationships between them.With AI-powered archiving tools, your data is automatically organized, categorized and connected for you. All that structured data chaos becomes a thing of the past. Your time is freed up to focus on more meaningful work. The possibilities for data-driven insights and optimization seem endless. What are you waiting for? Take back control of your data and unleash its potential with intelligent archiving. The future is now, so hop to it! There’s a whole new world of data-driven opportunity out there waiting for you.
2 notes
·
View notes
Text
Streamline Your Data Accuracy with Entity Resolution Software and Data Match Tools
In today’s data-driven economy, organizations are constantly challenged with inconsistent, duplicate, and mismatched records. Whether it’s customer information, supplier databases, or transactional logs—clean, reliable data is essential for analytics, automation, and decision-making. This is where Match Data Pro LLC steps in, offering enterprise-grade Entity Resolution Software, intelligent Data Match Software, and smart contact matching services built around precise data profiling metrics.
Data deduplication automation
0 notes
Text
Flash Based Array Market Emerging Trends Driving Next-Gen Storage Innovation
The flash based array market has been undergoing a transformative evolution, driven by the ever-increasing demand for high-speed data storage, improved performance, and energy efficiency. Enterprises across sectors are transitioning from traditional hard disk drives (HDDs) to solid-state solutions, thereby accelerating the adoption of flash based arrays. These storage systems offer faster data access, higher reliability, and scalability, aligning perfectly with the growing needs of digital transformation and cloud-centric operations.

Shift Toward NVMe and NVMe-oF Technologies
One of the most significant trends shaping the FBA market is the shift from traditional SATA/SAS interfaces to NVMe (Non-Volatile Memory Express) and NVMe over Fabrics (NVMe-oF). NVMe technology offers significantly lower latency and higher input/output operations per second (IOPS), enabling faster data retrieval and processing. As businesses prioritize performance-driven applications like artificial intelligence (AI), big data analytics, and real-time databases, NVMe-based arrays are becoming the new standard in enterprise storage infrastructures.
Integration with Artificial Intelligence and Machine Learning
Flash based arrays are playing a pivotal role in enabling AI and machine learning workloads. These workloads require rapid access to massive datasets, something that flash storage excels at. Emerging FBAs are now being designed with built-in AI capabilities that automate workload management, improve performance optimization, and enable predictive maintenance. This trend not only enhances operational efficiency but also reduces manual intervention and downtime.
Rise of Hybrid and Multi-Cloud Deployments
Another emerging trend is the integration of flash based arrays into hybrid and multi-cloud architectures. Enterprises are increasingly adopting flexible IT environments that span on-premises data centers and multiple public clouds. FBAs now support seamless data mobility and synchronization across diverse platforms, ensuring consistent performance and availability. Vendors are offering cloud-ready flash arrays with APIs and management tools that simplify data orchestration across environments.
Focus on Energy Efficiency and Sustainability
With growing emphasis on environmental sustainability, energy-efficient storage solutions are gaining traction. Modern FBAs are designed to consume less power while delivering high throughput and reliability. Flash storage vendors are incorporating technologies like data reduction, deduplication, and compression to minimize physical storage requirements, thereby reducing energy consumption and operational costs. This focus aligns with broader corporate social responsibility (CSR) goals and regulatory compliance.
Edge Computing Integration
The rise of edge computing is influencing the flash based array market as well. Enterprises are deploying localized data processing at the edge to reduce latency and enhance real-time decision-making. To support this, vendors are introducing compact, rugged FBAs that can operate reliably in remote and harsh environments. These edge-ready flash arrays offer high performance and low latency, essential for applications such as IoT, autonomous systems, and smart infrastructure.
Enhanced Data Security Features
As cyber threats evolve, data security has become a critical factor in storage system design. Emerging FBAs are being equipped with advanced security features such as end-to-end encryption, secure boot, role-based access controls, and compliance reporting. These features ensure the integrity and confidentiality of data both in transit and at rest. Additionally, many solutions now offer native ransomware protection and data immutability, enhancing trust among enterprise users.
Software-Defined Storage (SDS) Capabilities
Software-defined storage is redefining the architecture of flash based arrays. By decoupling software from hardware, SDS enables greater flexibility, automation, and scalability. Modern FBAs are increasingly adopting SDS features, allowing users to manage and allocate resources dynamically based on workload demands. This evolution is making flash storage more adaptable and cost-effective for enterprises of all sizes.
Conclusion
The flash based array market is experiencing dynamic changes fueled by technological advancements and evolving enterprise needs. From NVMe adoption and AI integration to cloud readiness and sustainability, these emerging trends are transforming the landscape of data storage. As organizations continue their journey toward digital maturity, FBAs will remain at the forefront, offering the speed, intelligence, and agility required for future-ready IT ecosystems. The vendors that innovate in line with these trends will be best positioned to capture market share and lead the next wave of storage evolution.
0 notes
Text
Reliable Data Recovery

Our engineers have an outstanding track record of retrieving misplaced or deleted files, including photographs. We pride ourselves on cutting-edge proprietary methods paired with straightforward solutions. Tap into our vast experience retrieving lost data from all data storage devices. Whether you have a non-responsive hard drive, a compromised server, or a malfunctioning device, data recovery engineers excel at addressing these concerns and ensuring that you or your business don’t face data loss. Each data loss situation is unique. The improper use of data recovery software could put your data at risk. We have developed proprietary tools and data recovery techniques that allow us to deliver custom recovery solutions for every data loss scenario, including - Data Recovery Company.
All leading manufacturers authorize to open sealed storage device mechanisms without voiding the original warranty. Our data recovery allows you to receive an in-warranty device replacement from the manufacturer. Our Data Recovery is one of the leading data recovery company in India with over two decades of experience in Data recovery services. We are also one of the most renowned and trusted names in and around and the whole of for providing reliable and affordable data recovery service - Best Data Recovery.
We get good data from SD cards to complete information centers and everything in between. Having carried out data recoveries, we have expertise in recovering information from all types of storage media. This can rely upon the type of storage gadget concerned in the recovery and the severity of the damage. Our Data Recovery is an ISO-accredited business who are consultant in information recovery. Our data recovery offered us reassurance from the start that they may recover the information. We also allows users to access and restore data from any device, failover IT systems, and virtualize the business from a deduplicated copy. For low-value data or losses caused by deletion or corruption, data recovery software is a good first step.
We offer skilled, reliable data recovery providers communication was all the time prompt and defined intimately the steps within the restoration process. Repair corrupted or damaged records data - Some information may be broken or corrupted ultimately and we are in a position to restore some of these where possible. For more information please visit our site https://www.nowdatarecovery.com/
0 notes
Text
Why Kabir Amperity Is a Key Figure in Enterprise Data Solutions?
Kabir Amperity is recognized as a key figure in enterprise data solutions due to his visionary leadership and deep understanding of customer data management. As a driving force behind Amperity, Kabir Amperity has played a pivotal role in developing advanced data platforms that unify and activate customer data across channels. His innovative approach helps large enterprises make data-driven decisions, enhance customer experiences, and drive growth through actionable insights. Under his guidance, Amperity has become a trusted partner for some of the world’s leading brands, offering scalable and intelligent solutions tailored for complex data environments. Kabir Amperity’s influence continues to shape the future of enterprise data strategy, making him a standout leader in the technology and data space.
Leading Data Innovation Through Strategic Product Vision
Kabir Amperity plays a vital role in shaping the landscape of enterprise data solutions through his strong product vision. His strategic insight into customer data challenges has fueled the continuous evolution of Amperity’s platform. By identifying real-world pain points in enterprise environments, Kabir ensures that Amperity develops tools that address the fragmented nature of customer data. His approach centers around usability, scalability, and accuracy, enabling businesses to leverage their data more effectively. As a result, enterprises are empowered to build unified customer profiles, personalize engagement, and enhance retention. Kabir Amperity's leadership is instrumental in delivering high-performance software solutions that meet the growing demands of data-centric industries.
Championing Customer-Centric Data Unification Strategies
One of the hallmarks of Kabir Amperity’s leadership is his commitment to putting customers at the center of data strategy. Rather than relying solely on outdated, cookie-based data tracking methods, Kabir advocates for a unified customer view driven by first-party data. This philosophy has helped Amperity differentiate itself from other platforms by focusing on real-time, people-based identity resolution. Through innovative tools that cleanse, deduplicate, and connect customer records, Kabir has enabled businesses to gain clear, actionable insights. His work is changing the way large enterprises understand and interact with their customers—making every touchpoint more meaningful and efficient in today’s competitive digital landscape.
Driving Enterprise Growth Through Scalable Architecture
Scalability is a core requirement for enterprise software, and Kabir Amperity has prioritized it within every layer of Amperity’s infrastructure. By building a cloud-native platform capable of ingesting and processing billions of data points, Kabir ensures that the solution can meet the needs of organizations of any size. This scalability also extends to flexibility, enabling seamless integration with various data sources and marketing platforms. As a result, enterprises can operationalize data across departments without major disruptions. Kabir’s focus on building a foundation for sustainable growth allows businesses to scale their customer intelligence strategies in alignment with their evolving goals.
Advancing Machine Learning in Customer Data Platforms
Kabir Amperity has been at the forefront of applying machine learning in the enterprise data space. His leadership at Amperity has resulted in the creation of intelligent algorithms that enhance data accuracy and customer matching. Machine learning models developed under his direction continually improve as they ingest more data, helping to refine customer profiles and uncover valuable behavioral patterns. This approach not only reduces manual data effort but also ensures faster time to insight. Kabir’s dedication to AI-driven development has transformed how enterprises extract value from customer data, setting a new benchmark for software companies building data-first platforms.
Building Trusted Partnerships With Leading Global Brands
A key indicator of Kabir Amperity’s influence is the trust he has cultivated with global brands across retail, travel, finance, and other industries. Through Amperity, he has partnered with household names that rely on the platform to drive their customer engagement strategies. These partnerships are built on performance, security, and a deep understanding of each brand’s unique challenges. Kabir emphasizes collaboration and long-term success, which has helped Amperity maintain strong client relationships and achieve high satisfaction ratings. His ability to understand enterprise needs and deliver measurable results has made him a go-to leader for companies seeking dependable software solutions.
Promoting Ethical Use and Governance of Data
As the digital landscape evolves, data privacy and ethical use have become top concerns for enterprises. Kabir Amperity has taken a clear stance on these issues by embedding strong governance capabilities into the Amperity platform. His leadership ensures that the software complies with global regulations such as GDPR and CCPA, and empowers companies to maintain transparent data practices. Kabir champions the responsible use of customer data, aligning business objectives with ethical considerations. This focus on integrity not only builds consumer trust but also helps organizations future-proof their data strategies in an increasingly regulated environment.
Inspiring a Culture of Innovation and Collaboration
Inside Amperity, Kabir fosters a culture where innovation, curiosity, and teamwork thrive. His leadership style emphasizes open communication and continuous learning, enabling teams to experiment, fail fast, and iterate quickly. By encouraging cross-functional collaboration, he ensures that product development remains aligned with customer feedback and real-world needs. This dynamic work environment has helped Amperity attract top talent and stay ahead in the fast-moving software industry. Kabir’s influence goes beyond technical innovation—he is shaping a company culture that values creativity, inclusion, and purpose, which contributes directly to the platform’s continued success in enterprise markets.
Conclusion
Kabir Amperity’s leadership has been instrumental in positioning Amperity as a trailblazer in enterprise data solutions. From driving innovation in machine learning to building scalable, customer-centric platforms, his strategic approach addresses the complex challenges facing today’s businesses. He combines technical expertise with a deep commitment to ethics and user trust, making the platform both powerful and responsible. Through strong partnerships, smart architecture, and a vibrant internal culture, Kabir continues to lead Amperity toward new heights. As enterprises increasingly rely on data to drive growth, his vision ensures that they do so with clarity, confidence, and competitive advantage.
0 notes
Text
The Future of Data Centers: Why Hyperconverged Infrastructure (HCI) Is the Next Big Thing in IT
In an era where digital transformation is at the heart of nearly every business strategy, traditional data centers are under unprecedented pressure to evolve. Organizations need IT infrastructure that can support modern workloads, ensure high availability, enable seamless scalability, and reduce operational complexity. This has led to the rapid rise of Hyperconverged Infrastructure (HCI)—a paradigm shift in how data centers are architected and managed.
HCI is not just a trend—it represents a foundational shift in IT infrastructure that is shaping the future of the data center. Let’s explore what makes HCI such a compelling choice and why it is poised to become the standard for next-generation IT environments.
What is Hyperconverged Infrastructure (HCI)?
Hyperconverged Infrastructure is a software-defined IT framework that combines compute, storage, and networking into a tightly integrated system. Traditional infrastructure requires separate components for servers, storage arrays, and networking hardware, each with its own management interface. HCI collapses these components into a unified platform that can be managed centrally, often through a single pane of glass.
At the heart of HCI is virtualization. Resources are abstracted from the underlying hardware and pooled together, allowing IT teams to provision and manage them dynamically. These systems typically run on industry-standard x86 servers and use intelligent software to manage workloads, data protection, and scalability.
Key Drivers Behind HCI Adoption
1. Operational Simplicity
One of the most compelling advantages of HCI is the reduction in complexity. By consolidating infrastructure components into a unified system, IT teams can dramatically streamline deployment, management, and troubleshooting. The simplified architecture allows for faster provisioning of applications and services, reduces the need for specialized skills, and minimizes the risk of configuration errors.
2. Scalability on Demand
Unlike traditional infrastructure, where scaling often involves costly overprovisioning or complex re-architecting, HCI offers linear scalability. Organizations can start small and scale out incrementally by adding additional nodes to the cluster—without disrupting existing workloads. This makes HCI an ideal fit for both growing enterprises and dynamic application environments.
3. Lower Total Cost of Ownership (TCO)
HCI delivers cost savings across both capital and operational expenses. Capital savings come from using off-the-shelf hardware and eliminating the need for dedicated storage appliances. Operational cost reductions stem from simplified management, reduced power and cooling needs, and fewer personnel requirements. HCI also enables automation, which reduces manual tasks and enhances efficiency.
4. Improved Performance and Reliability
With storage and compute co-located on the same nodes, data does not have to travel across disparate systems, resulting in lower latency and improved performance. HCI platforms are built with high availability and data protection in mind, often including features like automated failover, snapshots, replication, deduplication, and compression.
5. Cloud-Like Flexibility, On-Premises
HCI bridges the gap between on-premises infrastructure and the public cloud by offering a cloud-like experience within the data center. Self-service provisioning, software-defined controls, and seamless integration with hybrid and multi-cloud environments make HCI a cornerstone for cloud strategies—especially for businesses looking to retain control over sensitive workloads while embracing cloud agility.
Strategic Use Cases for HCI
The versatility of HCI makes it suitable for a wide range of IT scenarios, including:
Virtual Desktop Infrastructure (VDI): Supports thousands of virtual desktops with consistent performance, simplified deployment, and strong security.
Edge Computing: Compact, self-contained HCI systems are ideal for remote or branch offices where IT support is limited.
Disaster Recovery (DR): Integrated backup, replication, and failover features make HCI a powerful platform for DR strategies.
Private and Hybrid Clouds: HCI provides a robust foundation for organizations building private clouds or integrating with public cloud providers like AWS, Azure, or Google Cloud.
Application Modernization: Simplifies the migration and deployment of modern, containerized applications and legacy workloads alike.
Potential Challenges and Considerations
While HCI offers significant benefits, organizations should also be aware of potential challenges:
Vendor Lock-In: Many HCI platforms are proprietary, which can limit flexibility in choosing hardware or software components.
Initial Learning Curve: Shifting from traditional infrastructure to HCI requires new skills and changes in operational processes.
Not Always Cost-Effective at Scale: For extremely large environments with very high-performance needs, traditional architectures may still offer better economics or flexibility.
That said, many of these challenges can be mitigated with proper planning, vendor due diligence, and a clear understanding of business goals.
The Road Ahead: HCI as a Foundation for Modern IT
According to industry analysts, the global HCI market is projected to grow significantly over the next several years, driven by increasing demand for agile, software-defined infrastructure. As organizations prioritize flexibility, security, and cost-efficiency, HCI is emerging as a key enabler of digital transformation.
Forward-looking businesses are leveraging HCI not only to modernize their data centers but also to gain a competitive edge. Whether supporting a hybrid cloud strategy, enabling edge computing, or simplifying IT operations, HCI delivers a robust, scalable, and future-ready solution.
Final Thoughts
Hyperconverged Infrastructure represents more than a technical evolution—it’s a strategic shift toward smarter, more agile IT. As the demands on infrastructure continue to rise, HCI offers a compelling alternative to the complexity and limitations of traditional architectures.
Organizations that embrace HCI are better positioned to respond to change, scale rapidly, and deliver superior digital experiences. For IT leaders seeking to align infrastructure with business goals, HCI is not just the next big thing—it’s the next right step.
0 notes
Text
Integration Of E2e Testing In A Ci/Cd Pipeline

E2E Testing
E2E Testing is a method to test a software from the consumer's perspective. It involves simulating real scenarios, including user interfaces, backend testing. The purpose of E2E testing is to validate the application’s overall behavior, including its functionality, reliability, performance, and security.
E2E Testing helps in identifying issues when one or more components interact with each other. It is usually done after integration testing, which tests individual component. Then E2E tests determines if the components interact well or not, which ensures that the application meets the user’s requirements.
For an in-depth comparison between system testing and integration testing, you can read the article titled "System Testing vs Integration Testing: Why They Matter?"
Automation Of E2E Tests with CI/CD Workflows
As your project grows, manual E2E Tests become less manageable. This is especially true of testing user interfaces, because a single action in a UI can lead to many other actions. This complexity makes automating tests essential. End-to-end tests can help automate user-interaction testing, saving valuable time.
With the speed software changes nowadays, automated tests have become absolutely necessary for developing a good software.
Once we have the parameters and test cases to work upon, we can implement it via code in a CI/CD Pipeline to run on every push event in a software repository. It helps you in identifying bugs earlier making a reliable software to use.
Steps to automate E2E Tests:
Analyse and make it clear on the aspects the application is supposed to be tested.
Setup test environment.
Analyse requirements and dependencies
List down what response should happen during the test.
Design test cases
Setup Workflow and define the events for the workflow to run(eg. on commit and push)
Run, test and revise
Challenges During Automated Testing
Here are the 3 most common test automation challenges that teams usually face while adopting automation testing:
Test Script Issues: Test scripts can be brittle, breaking with minor changes in the UI or API endpoints. This is especially true for tests that rely heavily on specific selectors or expected responses that are subject to change.
Test Code Duplication: Duplication in test scripts can lead to maintenance nightmares, where a change in the application requires updates in multiple places within the test suite.
Over-reliance on UI for Data Verification: Relying too much on UI elements for data verification can make tests slower and more prone to failure due to rendering issues or changes in the UI.
Unnecessary Noisy Data: Unnecessary noisy data in test scripts and test results can obscure important information, making it difficult to identify actual issues and understand the state of the application under test leading to flaky tests.
How Keploy solves these challenges:
A few months ago, I discovered Keploy, an open-source utility designed to transform user traffic into test cases and data stubs. Keploy simplifies the process of testing backend applications using authentic data by generating mocks and stubs, enhancing testing efficiency and accuracy.
Keploy streamlines the process of capturing and converting real-world user traffic into mocks and stubs for subsequent replay testing. It also introduces Test Deduplication, effectively eliminating redundant tests, thus addressing a significant challenge in the testing domain. Moreover, Keploy enhances its utility by offering native integration with leading testing frameworks, including JUnit, gotest, pytest, and Jest, further simplifying the testing workflow.
To demonstrate how Keploy works, let's outline a simplified workflow to illustrate its capabilities in capturing user traffic and converting it into test cases and data stubs for a backend application.
To install Keploy, run the following command:
curl -Ohttps://raw.githubusercontent.com/keploy/keploy/main/keploy.sh&& sourcekeploy.shkeploy
(On MacOS and Windows, additional tools are required for Keploy due to the lack of native eBPF support.)
You should see something like this: ▓██▓▄ ▓▓▓▓██▓█▓▄ ████████▓▒ ▀▓▓███▄ ▄▄ ▄ ▌ ▄▌▌▓▓████▄ ██ ▓█▀ ▄▌▀▄ ▓▓▌▄ ▓█ ▄▌▓▓▌▄ ▌▌ ▓ ▓█████████▌▓▓ ██▓█▄ ▓█▄▓▓ ▐█▌ ██ ▓█ █▌ ██ █▌ █▓ ▓▓▓▓▀▀▀▀▓▓▓▓▓▓▌ ██ █▓ ▓▌▄▄ ▐█▓▄▓█▀ █▓█ ▀█▄▄█▀ █▓█ ▓▌ ▐█▌ █▌ ▓ Keploy CLI Available Commands: example Example to record and test via keploy generate-config generate the keploy configuration file record record the keploy testcases from the API calls test run the recorded testcases and execute assertions update Update Keploy Flags: --debug Run in debug mode -h, --help help for keploy -v, --version version for keploy Use "keploy [command] --help" for more information about a command.
Clone this sample application and move to the application directory and download its dependencies using go mod download . (You would need Golang)
In the application directory, run the following command to start PostgresDB instance:
docker-compose up -d
Now, we will create the binary of our application:-
go build
Now we are ready to record user-traffic to generate tests:bash sudo -E PATH=$PATH keploy record -c "./echo-psql-url-shortener"
Generate testcases
To generate testcases we just need to make some API calls. You can use Postman, Hoppscotch, or simply curl:bash curl --request POST \ --url http://localhost:8082/url \ --header 'content-type: application/json' \ --data '{ "url": "https://google.com" }'
this will return the shortened url.bash { "ts": 1645540022, "url": "http://localhost:8082/Lhr4BWAi" }
GET Request:bash curl --request GET \ --url http://localhost:8082/Lhr4BWAi
Now, let's see the magic! 🪄💫
Now both these API calls were captured as a testcase and should be visible on the Keploy CLI. You should be seeing an app named keploy folder with the test cases we just captured and data mocks created:

This is a single generated mock sample:yaml version: api.keploy.io/v1beta1 kind: Postgres name: mock-0 spec: metadata: type: config postgresrequests: - identifier: StartupRequest length: 102 payload: AAAAZgADAABkYXRhYmFzZQBwb3N0Z3JlcwB1c2VyAHBvc3RncmVzAGNsaWVudF9lbmNvZGluZwBVVEY4AGV4dHJhX2Zsb2F0X2RpZ2l0cwAyAGRhdGVzdHlsZQBJU08sIE1EWQAA startup_message: protocolversion: 196608 parameters: client_encoding: UTF8 database: postgres datestyle: ISO, MDY extra_float_digits: "2" user: postgres auth_type: 0 postgresresponses: - header: [R] identifier: ServerResponse length: 102 authentication_md5_password: salt: [217, 186, 178, 46] msg_type: 82 auth_type: 5 reqtimestampmock: 2024-03-30T00:14:05.937758635+05:30 restimestampmock: 2024-03-30T00:14:05.938960021+05:30 connectionId: "0" ---
Run the captured testcases
Now that we have our testcase captured, run the generated tests:bash sudo -E PATH=$PATH keploy test -c "./echo-psql-url-shortener" --delay 10
So no need to setup dependencies like Postgres, web-go locally or write mocks for your testing.
The application thinks it's talking to Postgres
We will get output something like this:

A reports folder will be generated in the Keploy directory to see the generated test results and it will look something like this :yaml version: api.keploy.io/v1beta1 name: test-set-0-report status: PASSED success: 1 failure: 0 total: 1 tests: - kind: Http name: test-set-0 status: PASSED started: 1711738084 completed: 1711738084 test_case_path: /home/erakin/Desktop/samples-go/echo-sql/keploy/test-set-0 mock_path: /home/erakin/Desktop/samples-go/echo-sql/keploy/test-set-0/mocks.yaml test_case_id: test-1 req: method: POST proto_major: 1 proto_minor: 1 url: http://localhost:8082/url header: Accept: '*/*' Content-Length: "33" Content-Type: application/json Host: localhost:8082 User-Agent: curl/8.2.1 body: |- { "url": "https://github.com" } timestamp: 2024-03-30T00:14:20.849621269+05:30 resp: status_code: 200 header: Content-Length: "66" Content-Type: application/json; charset=UTF-8 Date: Fri, 29 Mar 2024 18:44:20 GMT body: | {"ts":1711737860850126711,"url":"http://localhost:8082/4KepjkTT"} status_message: OK proto_major: 0 proto_minor: 0 timestamp: 2024-03-30T00:14:22.932135785+05:30 noise: header.Date: [] result: status_code: normal: true expected: 200 actual: 200 headers_result: - normal: true expected: key: Content-Length value: - "66" actual: key: Content-Length value: - "66" - normal: true expected: key: Content-Type value: - application/json; charset=UTF-8 actual: key: Content-Type value: - application/json; charset=UTF-8 - normal: true expected: key: Date value: - Fri, 29 Mar 2024 18:44:20 GMT actual: key: Date value: - Fri, 29 Mar 2024 18:48:04 GMT body_result: - normal: false type: JSON expected: | {"ts":1711737860850126711,"url":"http://localhost:8082/4KepjkTT"} actual: | {"ts":1711738084114782375,"url":"http://localhost:8082/4KepjkTT"} dep_result: [] test_set: test-set-0
Additionally, if writing Keploy's command, seems repetitive and boring, we can also leverage its configuration file to list everything in one-go.
Generate keploy-config:bash keploy config --generate --path "./config-dir/"
Here is the keploy-config file:yaml path: "" command: "" port: 0 proxyPort: 16789 dnsPort: 26789 debug: false disableTele: false inDocker: false containerName: "" networkName: "" buildDelay: 30s test: selectedTests: {} globalNoise: global: {} test-sets: {} delay: 5 apiTimeout: 5 coverage: false coverageReportPath: "" ignoreOrdering: true mongoPassword: "default@123" language: "" removeUnusedMocks: false record: recordTimer: 0s filters: [] configPath: "" bypassRules: [] keployContainer: "keploy-v2" keployNetwork: "keploy-network" # Example on using tests #tests: # filters: # - path: "/user/app" # urlMethods: ["GET"] # headers: { # "^asdf*": "^test" # } # host: "dc.services.visualstudio.com" #Example on using stubs #stubs: # filters: # - path: "/user/app" # port: 8080 # - port: 8081 # - host: "dc.services.visualstudio.com" # - port: 8081 # host: "dc.services.visualstudio.com" # path: "/user/app" # #Example on using globalNoise #globalNoise: # global: # body: { # # to ignore some values for a field, # # pass regex patterns to the corresponding array value # "url": ["https?://\S+", "http://\S+"], # } # header: { # # to ignore the entire field, pass an empty array # "Date": [], # } # # to ignore fields or the corresponding values for a specific test-set, # # pass the test-set-name as a key to the "test-sets" object and # # populate the corresponding "body" and "header" objects # test-sets: # test-set-1: # body: { # # ignore all the values for the "url" field # "url": [] # } # header: { # # we can also pass the exact value to ignore for a field # "User-Agent": ["PostmanRuntime/7.34.0"] # }
You can also filter out the noisy data(e.g Date) to have accurate tests
Now that you are aware of Keploy's capabilites, let's go ahead and see what else can it do!
Keploy Integration with native frameworks
As mentioned earlier, we can integrate Keploy with native frameworks like JUnit, go-test, pytest as well as Jest to do more stuff like Test Coverage etc.
For example, here is how we can integrate Keploy with Jest:
Pre-requisites
Node.js
nyc: npm inyc
Get Keploy jest sdk
Install the latest release of the Keploy Jest SDKnpm i @keploy/sdk
Update package file
Update the package.json file that runs the application:bash "scripts": { //other scripts "test": "jest --coverage --collectCoverageFrom='src/**/*.{js,jsx}'", "coverage": "nyc npm test && npm run coverage:merge && npm run coverage:report", "coverage:merge": "mkdir -p ./coverage && nyc merge ./coverage .nyc_output/out.json", "coverage:report": "nyc report --reporter=lcov --reporter=text" //other scripts }
Usage
For the code coverage for the keploy API tests using the jest integration, you need to add the following test to your Jest test file. It can be called as Keploy.test.js.bash const {expect} = require("@jest/globals"); const keploy = require("@keploy/sdk"); const timeOut = 300000; describe( "Keploy Server Tests", () => { test( "TestKeploy", (done) => { const cmd = "npm start"; const options = {}; keploy.Test(cmd, options, (err, res) => { if (err) { done(err); } else { expect(res).toBeTruthy(); // Assert the test result done(); } }); }, timeOut ); }, timeOut );
Now let's run jest tests along keploy using command:-bash keploy test -c "npm test" --delay 15 --coverage
To get Combined coverage:bash keploy test -c "npm run coverage" --delay 10 --coverage
Integrating Keploy into workflows for automated testing
Keploy integration into CI/CD workflows enables automated testing by capturing API requests and responses during development. It generates test cases based on this captured data, allowing for continuous testing without manual intervention. This ensures that any changes in the codebase are automatically validated, enhancing the reliability and efficiency of the development process.
Let's perform a simple demonstration for automated testing using Keploy:
In this demo, we are going to run Keploy with a sample go application using echo framework and Postgres.
This is the Github workflow I created:bash name: Golang On Linux on: [push] jobs: golang_linux: runs-on: ubuntu-latest steps: - name: Checkout repository uses: actions/checkout@v2 - name: Set up Go uses: actions/setup-go@v2 with: go-version: '^1.16' - name: Clone Keploy repository run: git clone https://github.com/keploy/keploy.git - name: Build Keploy from source run: | cd keploy go build -o keploy env: GO111MODULE: on - name: Move Keploy binary to accessible location run: sudo mv ./keploy/keploy /usr/local/bin - name: Verify Keploy installation run: keploy - name: Run shell script for application setup and testing run: | chmod +x ./.github/workflows/test_workflow_scripts/golang-linux.sh ./.github/workflows/test_workflow_scripts/golang-linux.sh
Along with a script:bash #!/bin/bash # Ensure the script stops on any error set -e # Assuming .github/workflows/test_workflow_scripts/test-iid.sh is executable and has the needed shebang sudo bash ./.github/workflows/test_workflow_scripts/test-iid.sh # Start a MongoDB container for the application's database needs docker-compose up -d # Clean existing Keploy configuration if present # Generate a new Keploy configuration file # Ensure keployv2 binary is in the PATH or provide an absolute path keploy config --generate # Update Keploy configuration for test specifics sed -i 's/global: {}/global: {"body": {"ts":[]}}/' "./keploy.yml" sed -i 's/ports: 0/ports: 5432/' "./keploy.yml" # Remove old Keploy test data to start fresh rm -rf ./keploy/ # Build the application binary go build -o echoSql # Record test cases and mocks with Keploy, adjusting for the application's startup for i in {1..2}; do # Ensure Keploy and the application are available in the PATH or use absolute paths sudo keploy record -c "./echoSql" & sleep 10 # Adjust based on application start time # Make API calls to record curl --request POST \ --url http://localhost:8082/url \ --header 'content-type: application/json' \ --data '{ "url": "https://google.com" }' curl --request GET \ --url http://localhost:8082/Lhr4BWAi sleep 5 # Allow time for recording sudo kill $(pgrep echoSql) sleep 5 done # Run recorded tests # Ensure Keploy is in the PATH or use an absolute path sudo keploy test -c "./echoSql" --delay 7 # Process test results for CI/CD feedback report_file="./keploy/reports/test-run-0/test-set-0-report.yaml" test_status1=$(grep 'status:' "$report_file" | head -n 1 | awk '{print $2}') report_file2="./keploy/reports/test-run-0/test-set-1-report.yaml" test_status2=$(grep 'status:' "$report_file2" | head -n 1 | awk '{print $2}') if [ "$test_status1" = "PASSED" ] && [ "$test_status2" = "PASSED" ]; then echo "Tests passed" exit 0 else echo "Some tests failed" exit 1 fi
The workflow activates upon a push event to the repository. Here's the sequence it follows:
The code is built.
A Postgres instance is initiated.
The applications run, with Keploy recording all API calls.
Test sets are executed to validate the changes.
A report file is generated and reviewed to conclude the workflow.
This process is easily replicable on GitHub by cloning the repository and re-triggering the workflows using GitHub Runners. Similarly, this workflow can be adapted and implemented with other CI/CD tools like Jenkins and CircleCI, ensuring broad compatibility and flexibility for automated testing and integration.
Conclusion
In conclusion, automating End-to-End (E2E) testing within CI/CD workflows represents a pivotal advancement in the realm of software development and quality assurance. By leveraging tools like Keploy, developers can overcome traditional challenges associated with manual testing, such as inefficiency, inaccuracy, and the inability to keep pace with rapid development cycles. Keploy, with its innovative approach to generating test cases and data stubs from real user traffic, not only simplifies the testing process but also significantly enhances its effectiveness and reliability. Integrating such automation into CI/CD pipelines ensures that applications are rigorously tested from the end user's perspective, guaranteeing that each component functions harmoniously within the broader system. This shift towards automated E2E testing facilitates the delivery of high-quality software that meets user requirements and withstands the demands of the modern digital landscape, ultimately leading to more reliable, secure, and user-friendly applications.
Faq’s
1. What is E2E testing in the context of CI/CD pipelines?
End-to-end (E2E) testing verifies the entire application flow from frontend to backend. It ensures all integrated parts work as expected before deployment. In CI/CD, E2E tests run automatically during builds or pre-deployment stages. This helps catch bugs early and avoid post-release issues.
2. Why should E2E tests be integrated into the CI/CD pipeline?
Integrating E2E tests ensures your application works as a whole before going live. It reduces manual testing effort and increases deployment confidence. Bugs are caught earlier in the development lifecycle. This leads to faster releases and higher-quality software.
3. When should E2E tests be triggered in a CI/CD pipeline?
E2E tests are typically run after unit and integration tests pass. They are often triggered in staging or pre-production environments. Running them before deployment prevents faulty code from reaching users. You can also schedule nightly runs for broader regression coverage.
4. What tools can help run E2E tests in CI/CD pipelines?
Popular tools include Cypress, Playwright, Selenium, and Keploy for API-based E2E. CI platforms like GitHub Actions, GitLab CI, and Jenkins integrate easily with them. Docker or Kubernetes can be used to mimic production environments. Choose tools that support automation and parallel execution.
5. What are common challenges in E2E testing in CI/CD, and how to solve them?
Challenges include flakiness, long test durations, and environment inconsistency. Use stable test data, mocks, and retry logic to reduce flakiness. Parallelization and test prioritization speed up pipelines. Containerized environments ensure reliable test execution.
#testing#unit testing#ai tools#e2e#code coverage#testing tools#software testing#software development
0 notes
Text
Quick way to extract job information from Reed
Reed is one of the largest recruitment websites in the UK, covering a variety of industries and job types. Its mission is to connect employers and job seekers to help them achieve better career development and recruiting success
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.

4. Export and view data
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

2 notes
·
View notes
Text
Scraping Capterra.com Product Details: Unlock B2B Software Insights for Smarter Decisions

Scraping Capterra.com Product Details: Unlock B2B Software Insights for Smarter Decisions
In the competitive world of B2B software, informed decision-making is everything. Whether you're a SaaS provider, market researcher, or software reseller, having access to accurate product details can drive strategic choices and better customer engagement. At Datascrapingservices.com, we offer professional Capterra.com Product Details Scraping Services that provide you with structured, reliable, and up-to-date data from one of the most trusted software directories in the world.
Why Scrape Capterra.com?
Capterra.com is a leading platform where users explore, compare, and review software across thousands of categories like CRM, project management, accounting, HR, marketing automation, and more. It’s a goldmine of information for businesses looking to analyze the software landscape, monitor competitors, or identify partnership opportunities. That’s where our automated Capterra scraping services come in—extracting key product data at scale, with accuracy and speed.
Key Data Fields Extracted from Capterra.com:
Product Name
Vendor Name
Product Description
Category
Pricing Details
Deployment Type (Cloud, On-Premise, etc.)
Features List
User Ratings and Reviews
Review Count and Score
Product URL and Website Links
This structured data can be delivered in your preferred format—CSV, Excel, JSON, or directly into your CRM or BI tool.
Benefits of Capterra Product Details Extraction
✅ Competitive Intelligence
Track your competitors' positioning, pricing, features, and user sentiment. Understand where you stand and how to differentiate your product more effectively.
✅ Lead Generation and Market Research
Identify new software vendors and solutions within specific categories or regions. Perfect for consultants and analysts seeking data-driven insights.
✅ SaaS Product Comparison
If you run a product comparison site or software review platform, you can enrich your database with verified, regularly updated listings from Capterra.
✅ Content Strategy
Use extracted reviews, features, and product overviews to create detailed blog posts, product comparisons, and buyer guides.
✅ Business Development
Target emerging or established vendors for partnerships, integrations, or channel sales opportunities using real-time insights from Capterra.
Why Choose DataScrapingServices.com?
Custom Scraping Solutions: Tailored to your needs—whether you want to track only one category or extract data across all Capterra listings.
Real-time or scheduled extraction: Receive updated data on a daily, weekly, or monthly basis—whenever you need it.
Accurate and Clean Data: We ensure the scraped data is deduplicated, validated, and formatted for immediate use.
Compliant and Ethical Practices: We follow best practices and adhere to web scraping guidelines and data privacy laws.
Best eCommerce Data Scraping Services Provider
Macys.com Product Listings Scraping
Scraping Argos.co.uk Home and Furniture Product Listings
Coles.com.au Product Information Extraction
Extracting Product Details from eBay.de
Scraping Currys.co.uk Product Listings
Target.com Product Prices Extraction
Wildberries.ru Product Price Scraping
Extracting Product Data from Otto.de
Extracting Amazon Product Listings
Extracting Product Details from BigW.com.au
Best Capterra Product Details Extraction Services in USA:
Fort Worth, Washington, Orlando, Mesa, Indianapolis, Long Beach, Denver, Fresno, Bakersfield, Atlanta, Austin, Houston, San Jose, Tulsa, Omaha, Philadelphia, Louisville, Chicago, San Francisco, Colorado, Wichita, San Antonio, Fresno, Long Beach, New Orleans, Oklahoma City, Raleigh, Seattle, Memphis, Sacramento, Virginia Beach, Columbus, Jacksonville, Las Vegas, El Paso, Charlotte, Milwaukee, Sacramento, Dallas, Nashville, Boston, Tucson and New York.
Final Thoughts
Scraping product details from Capterra.com empowers your business with valuable market intelligence that manual methods simply can't deliver. Whether you’re streamlining competitive analysis, fueling lead generation, or enriching your SaaS insights, DataScrapingServices.com is your trusted partner.
📧 Get in touch today: [email protected]🌐 Visit us at: Datascrapingservices.com
Let’s transform Capterra data into your next competitive advantage.
#scrapingcapterraproductdetails#extractingproductinformationfromcapterra#ecommercedataextraction#webscraping#pricemonitoring#ecommercestrategy#dataextraction#marketintelligence#retailpricing#competitortracking#datascrapingservices
0 notes
Text
Maximizing Data Accuracy and Speed with Modern Data Ops Software and Fuzzy Matching Tools – A Match Data Pro LLC Guide
Explore how Match Data Pro LLC empowers businesses through cutting-edge data ops software, secure on-premise data software, fast bulk data processing, and intelligent fuzzy matching online solutions to streamline and scale operations.
Introduction
In today’s data-driven world, businesses handle massive volumes of information across various platforms and departments. But without proper tools to manage, clean, and align this data, even the most valuable insights can slip through the cracks. That’s where Match Data Pro LLC steps in—offering advanced solutions like data ops software, on-premise data software, bulk data processing, and fuzzy matching online to bring order and accuracy to your operations.
Data Ops Software: The Backbone of Modern Data Strategy
Data ops software is a critical component of any organization’s digital infrastructure. It bridges the gap between data engineering and operations, helping teams automate, orchestrate, and monitor data workflows efficiently.
Match Data Pro LLC provides powerful data ops software that allows companies to:
Automate repetitive data workflows
Maintain pipeline health
Ensure data quality in real-time
Improve collaboration between data and IT teams
Whether you're in finance, healthcare, eCommerce, or logistics, our platform is designed to scale with your data challenges—helping you move from manual fixes to streamlined, automated processes.
On-Premise Data Software: Complete Control, Maximum Security
Not every business can rely on cloud-based solutions—especially those in regulated industries or enterprises that prioritize data sovereignty. That’s why Match Data Pro LLC offers flexible, secure on-premise data software options for companies that want full control over their infrastructure.
Our on-premise data software enables:
Compliance with strict data governance requirements
Offline or air-gapped deployments
Direct integration with internal tools and servers
Enhanced security and privacy protection
With our customizable solutions, organizations don’t have to compromise between control and performance.
Bulk Data Processing: Speed at Scale
Time is of the essence when you’re working with large datasets. Waiting hours—or even days—for your system to complete tasks is no longer an option. That’s why bulk data processing is at the core of Match Data Pro’s platform.
We help teams:
Clean, validate, and transform millions of records in minutes
Merge and deduplicate contact databases
Process log files, spreadsheets, CRM records, and more
Streamline back-office operations with automation
Our bulk data processing tools deliver unmatched speed and accuracy, giving you the freedom to handle large datasets without slowdowns or system errors.
Fuzzy Matching Online: Find Matches Others Miss
One of the most powerful features of our platform is fuzzy matching online—an essential tool for resolving data inconsistencies. Whether you’re dealing with typos, variations in naming, or incomplete records, fuzzy matching uses intelligent algorithms to connect the dots.
Match Data Pro LLC's fuzzy matching online capabilities include:
Real-time contact, address, and record matching
Tolerance for misspellings and formatting differences
Scoring and confidence levels to validate results
Seamless integration into existing systems via API
This technology is especially useful in CRM cleanup, marketing segmentation, and database consolidation—ensuring data is not just connected, but accurate and actionable.
Why Choose Match Data Pro LLC?
We’re more than a tool—we’re a partner in your digital transformation. Here’s why clients across industries choose us:
Custom Solutions: Tailored for your environment, whether cloud, hybrid, or on-premise.
Scalable Architecture: Grows with your business needs and volume.
Intuitive Interface: No-code and low-code tools for easy onboarding.
Reliable Support: Access to data experts who help you get the most out of your stack.
Use Case Spotlight
A national retail chain used Match Data Pro LLC to deploy on-premise data software to stay compliant with internal security policies. Within weeks, they automated their bulk data processing for loyalty program enrollments and implemented fuzzy matching online to reconcile millions of duplicate customer records. The result? 70% less manual effort and a 40% improvement in data integrity.
Final Thoughts
Your data is only as valuable as your ability to manage it. With Match Data Pro LLC, you gain access to enterprise-ready tools like data ops software, secure on-premise data software, ultra-fast bulk data processing, and highly accurate fuzzy matching online—so you can transform disorganized information into business intelligence.
0 notes
Text
Your Trusted Partner for Advanced Data Storage Solutions
Your data deserves the best — and that’s exactly what Esconet Technologies Ltd. delivers.
At Esconet, we provide advanced data storage solutions that are designed to meet the evolving demands of today’s businesses. Whether you need ultra-fast block storage, flexible file and object storage, or software-defined storage solutions, we have you covered.
1. High-Performance Block Storage — Designed for low-latency, high-speed access with NVMe-over-Fabrics. 2. File and Object Storage — Handle massive datasets easily with NFS, SMB, S3 support, and parallel file systems for up to 40 GB/s throughput. 3. Software-Defined Storage (SDS) — Enjoy scalability, auto-tiering, load balancing, deduplication, and centralized management. 4. Data Protection and Security — Advanced encryption, RAID, and erasure coding to safeguard your critical information. 5. Strategic Partnerships — We collaborate with Dell Technologies, HPE, NetApp, Hitachi Vantara, and others to bring you the best solutions, including our own HexaData Storage Systems.
For more details, visit: Esconet's Data Storage Systems Page
#EsconetTechnologies#DataStorage#EnterpriseIT#SecureStorage#SoftwareDefinedStorage#HexaData#BusinessSolutions#DataSecurity
0 notes
Text
SaaS Acceleration Techniques: Boosting Cloud App Performance at the Edge

As businesses increasingly rely on software-as-a-service (SaaS) applications, ensuring optimal performance becomes a strategic imperative. Cloud-based applications offer significant flexibility and cost efficiency, yet their performance often hinges on the underlying network infrastructure. Latency issues, bandwidth constraints, and inefficient routing can slow down critical SaaS platforms, negatively impacting user experience and productivity. Fortunately, WAN optimization techniques—when extended to the network's edge—can dramatically enhance performance, ensuring fast, reliable access to cloud apps.
The Need for WAN Optimization in a SaaS World
SaaS applications are central to modern business operations, from CRM and collaboration tools to analytics and enterprise resource planning (ERP) systems. However, these applications can experience latency and inconsistent performance if the data must travel long distances or traverse congested networks. A poorly optimized WAN may result in delayed page loads, sluggish response times, and a frustrating user experience.
Optimizing WAN performance is critical not only for internal operations but also for customer-facing services. In a world where every millisecond counts, businesses must take proactive steps to ensure that SaaS applications perform at their best. Enhancing network paths and reducing latency can lead to faster decision-making, increased productivity, and a competitive edge.
Key Techniques for SaaS Acceleration
Dynamic Path Selection
One of the most effective WAN optimization techniques is dynamic path selection. This method uses real-time analytics to assess multiple network paths continuously and automatically routes traffic via the most optimal route. By leveraging technologies such as Software-Defined WAN (SD-WAN), organizations can ensure that latency-sensitive SaaS traffic, like video conferencing or real-time collaboration tools, always takes the fastest route. Dynamic routing reduces delays and prevents network congestion, providing smooth, uninterrupted access to cloud applications.
Local Breakout
Local breakout is another critical strategy for accelerating SaaS performance. Instead of routing all traffic back to a centralized data center, local breakout allows branch offices or remote locations to access the internet for SaaS applications directly. This approach significantly reduces the round-trip time and minimizes latency by reducing the distance data must travel. Local breakout is particularly effective in multi-site organizations where remote teams require fast and reliable access to cloud-based services.
Traffic Shaping and QoS Policies
Traffic shaping and Quality of Service (QoS) policies help prioritize critical SaaS traffic over less important data flows. By prioritizing real-time applications and essential business functions, IT teams can ensure mission-critical data gets the bandwidth it needs—even during peak usage periods. Implementing these policies reduces the impact of bandwidth contention and improves overall network performance, thereby enhancing the user experience for cloud applications.
Caching and Data Deduplication
Edge caching is another technique that significantly enhances SaaS performance. By storing frequently accessed data locally at the network edge, caching reduces the need to repeatedly fetch information from distant cloud data centers. This function not only speeds up access times but also alleviates bandwidth congestion. In addition, data deduplication techniques can optimize data transfers by eliminating redundant information, ensuring that only unique data travels over the network. Caching and deduplication help streamline data flows, improve efficiency, and reduce operational costs.
Continuous Monitoring and Real-Time Analytics
Proactive monitoring is essential for maintaining high-quality WAN performance. Continuous real-time analytics track key metrics such as latency, packet loss, throughput, and jitter. These metrics provide IT teams with immediate insights into network performance, allowing them to identify and address any issues quickly. Automated alerting systems ensure that any deviation from SLA benchmarks triggers a swift response, preventing minor glitches from evolving into major disruptions. With ongoing monitoring, businesses can effectively maintain optimal performance levels and plan for future capacity needs.
Best Practices for Implementing WAN Optimization
Adopting these techniques requires careful planning and a strategic approach. First, conduct a comprehensive assessment of your existing network infrastructure. Identify areas where latency is highest and determine which segments can benefit most from optimization. Use this data to develop a roadmap prioritizing dynamic routing, local breakout, and caching in key locations.
Next, invest in a robust SD-WAN solution that integrates seamlessly with your current infrastructure. An effective SD-WAN platform facilitates dynamic path selection and offers centralized control for consistent policy enforcement across all sites. This centralized approach helps reduce configuration errors and ensures all network traffic adheres to predefined QoS rules.
In addition to the technical implementations, it is vital to establish clear service level agreements (SLAs) with your vendors. Use real-time monitoring data to enforce these SLAs, ensuring that every link in your WAN meets the expected performance standards. This proactive approach optimizes network performance and provides the leverage needed for effective vendor negotiations.
Training and support are also crucial components of a successful WAN optimization strategy. Equip your IT staff with the necessary skills to manage and monitor advanced SD-WAN tools and other optimization technologies. Regular training sessions and access to technical support help maintain operational efficiency and ensure your team can respond quickly to network issues.
Real-World Impact: A Theoretical Case Study
Consider the case of a mid-market enterprise that experienced frequent performance issues with its cloud-based CRM and collaboration platforms. The company struggled with high latency and intermittent service interruptions due to a congested WAN that routed all traffic through a single, overloaded data center.
By deploying an SD-WAN solution with dynamic path selection and local breakout, the enterprise restructured its network traffic. The IT team rerouted latency-sensitive applications to use the fastest available links and directed non-critical traffic over less expensive, slower connections. Lastly, they implemented edge caching to store frequently accessed data locally, reducing the need for repeated downloads from the central cloud data center.
The result? The company observed a 35% reduction in average latency, improved application response times, and significantly decreased bandwidth costs. These improvements enhanced employee productivity and boosted customer satisfaction as response times for online support and real-time updates improved dramatically. This case study illustrates how thoughtful WAN optimization can transform network performance and yield tangible cost savings.
Optimize Your WAN for Peak Cloud Performance
In today's digital-first world, balancing latency and bandwidth is crucial for delivering fast and reliable cloud application experiences. Real-time WAN monitoring, dynamic routing, and intelligent traffic management ensure that SaaS applications perform optimally, even during peak usage. Organizations can optimize their networks to meet the demands of multi-cloud environments and emerging technologies, such as 5G, by adopting strategies like SD-WAN, local breakout, caching, and continuous performance analytics. Partnering with a telecom expense management professional is essential for success. A company like zLinq offers tailored telecom solutions that help mid-market enterprises implement these advanced strategies effectively. With comprehensive network assessments, proactive vendor negotiations, and seamless integration of cutting-edge monitoring tools, zLinq empowers organizations to transform their WAN from a cost center into a strategic asset that drives innovation and growth. Ready to optimize your WAN for peak cloud performance? Contact zLinq today to unlock the full potential of your network infrastructure.
0 notes