#Datastage
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Data Stage Training in Hyderabad
Master Data Stage with RS Trainings – The Best Training Institute in Hyderabad
Data Stage is a leading ETL (Extract, Transform, Load) tool designed to streamline the data integration process in complex enterprise environments. It enables businesses to efficiently extract data from diverse sources, transform it according to business requirements, and load it into target systems. With its user-friendly interface and robust scalability, Data Stage is a preferred choice for data professionals worldwide.

If you're looking to gain expertise in Data Stage, RS Trainings in Hyderabad is the ideal destination. Renowned for delivering top-notch IT training, RS Trainings is the best institute for Data Stage training in Hyderabad.
Why Choose RS Trainings for Data Stage Training?
Training by Industry Experts Learn Data Stage from seasoned professionals working in top MNCs. They bring real-world insights to the classroom, ensuring you get industry-aligned training.
Comprehensive Curriculum RS Trainings offers a meticulously designed syllabus covering all aspects of Data Stage, from basic ETL concepts to advanced data integration techniques.
Hands-On Practical Sessions Gain hands-on experience with real-time projects and scenarios, helping you master Data Stage functionalities like job design, debugging, and optimization.
Flexible Learning Options RS Trainings provides flexible schedules and online learning options to cater to students, professionals, and data enthusiasts.
Certification Assistance RS Trainings supports you in obtaining certifications, enhancing your credibility and career prospects in the data engineering domain.
What You Will Learn
Introduction to ETL and Data Stage
Designing, Developing, and Debugging Jobs
Data Integration and Transformation Techniques
Performance Tuning and Optimization
Integration with Databases and Cloud Platforms
Real-Time Project Implementation
By enrolling in Data Stage training at RS Trainings, you’ll acquire the skills needed to excel in the competitive field of data integration and data engineering.
Take the first step toward a successful data engineering career. Join RS Trainings – the best place for learning Data Stage training in Hyderabad by Industry IT experts!
#datastage training in Hyderabad#datastage online training#datastage online training with placement#datastage training center#datastage course online#datastage training institute in Hyderabad
0 notes
Text
Fitbit Sleep Data Links Health And Sleep In A Recent Study
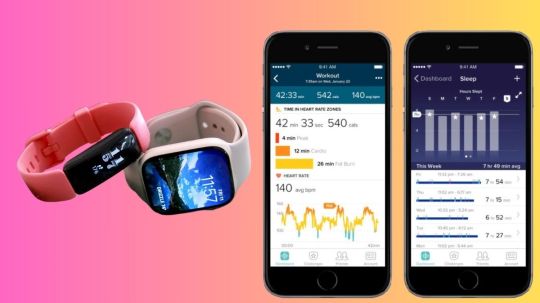
A recent study that makes use of Fitbit sleep data finds links between illness and sleep. The largest study of its sort emphasizes how valuable it may be to use Fitbit sleep data that is collected over time for research on health and illness.
They can all agree that getting a good night’s sleep is crucial, but most individuals might not be aware of the long-term health effects of daily fluctuations in sleep duration and quality. Based on data from Fitbit users, a recent study published in Nature Medicine provides insight into the ways that sleep regularity, quality, and length affect a variety of health consequences.
Researchers from Google, the NIH’s All of Us Research Program, and Vanderbilt University Medical Centre collaborated on the largest study of its kind to date. This work deviates from earlier sleep research, which were frequently small-scale and focused on self-reported sleep diaries, short-term movement monitor sessions, or costly in-lab sleep studies that lasted for a short while.
Rather, the study was based on about 6.5 million sleep nights gathered over an average of 4.5 years of wear from over 6,700 Fitbit sleep data users who were part of the All of Us Research Program.
Fitbit sleep data analysis
The study does not concentrate on a specific group of health outcomes; rather, it examines the connections between sleep and the full range of human diseases. Six major conclusions from the studies on the effects of sleep on people’s health are as follows:
Sleep duration: A substantial reduction in the likelihood of obesity and sleep apnoea was found for every additional hour of sleep. It has been discovered that numerous illnesses are linked not only to insufficient sleep but also to excessive sleep.
Sleep stages: Heart health and mental wellness appear to be significantly impacted by the balance of REM, light, and deep sleep, as indicated by Fitbit sleep data.
Sleep disturbances: Elevations in the Fitbit restlessness measure have been associated with an increased risk of hypothyroidism and sleep difficulties.
Sleep irregularity: A variety of problems affecting almost all organ systems have been linked to irregular sleep patterns. High blood pressure, obesity, psychiatric problems (depression, anxiety, bipolar disorder), and migraine headaches were found to have strong correlations with irregular sleep patterns.
Demographic variations: The study discovered notable variations in the median amount of sleep time among various groups. For instance, White participants slept longer than Black participants, and women tended to sleep longer than men. This emphasises that when studying and improving sleep health, individual variables and potential health inequities must be taken into account.
Lifestyle role: The research discovered a correlation between variations in sleep duration and lifestyle factors such as alcohol and tobacco use. This emphasises how interrelated health behaviours are and how crucial it is to address a variety of lifestyle factors in order to enhance sleep and general well-being.
The study also provided a very fascinating look at the typical time that people sleep. The average time for participants to fall asleep was 11:10 pm, and throughout their primary sleep window of the day, they slept for almost 6.7 hours. A considerable number of people even sneak in a nap in the afternoon, usually about 2:30.
Although the purpose of this study is not to propose Fitbit sleep data as a therapeutic tool, we believe that some of these findings will demonstrate to researchers the value of using affordable wearables and sleep monitors to investigate the potential effects of changing sleep patterns on population health over time.
The study also serves as a reminder that getting regular sleep is just as crucial as getting enough sleep.
A Complete Guide to Fitbit Sleep Data
Sleep is essential to health. Wearable technology makes sleep tracking easier and more enlightening. Wearable fitness technology leader Fitbit offers thorough sleep tracking to help customers understand and improve their sleep patterns. Fitbit sleep data, interpretation, and sleep improvement strategies will be covered in this guide.
How Fitbit Sleep Data
Fitbits measure sleep stages via heart rate and accelerometers. Fitbit Sleep Data can identify if you’re asleep, waking, or experiencing different sleep stages.
Fitbit Sleep Data Stages
Fitbit tracks four sleep stages:
Nighttime awakeness.
Light sleep is non-REM when your heart rate slows and you relax.
Immune function and recovery depend on deep sleep, the most peaceful non-REM state.
Memory and learning depend on dreaming and REM sleep.
Understanding Sleep Score
Fitbit’s Sleep Score evaluates sleep quality. This score is 0–100 and based on:
Total sleep time.
Restoration: Deep and REM sleep duration.
Consistency and balance of sleep stages.
The Meaning of Your Sleep Score.
Great (90-100): Your sleep is restful and regulated.
Good (80-89): Restful sleep with few disruptions.
Fair (60-79): Your sleep could be enhanced for greater repair.
Poor (<60): Restorative sleep requires significant improvements.
Detailed Sleep Analysis
Sleep Time: Total sleep time per night. Adults should sleep 7-9 hours per night, per Fitbit.
In Bed vs. Asleep: This measure relates in-bed time to sleep time. Significant differences may suggest sleep disruptions or trouble falling asleep.
Sleep Regularity: Sleep quality is affected by schedule consistency. Fitbit measures bedtime and wake-up time to promote sleep.
Fitbit measures HRV during sleep: To assess autonomic nervous system function. Better health and recovery are linked to higher HRV.
Improve Sleep Using Fitbit: Fitbit monitors your sleep and provides personalized advice to improve it.
Establish Sleep Routine: The same bedtime and waketime enhances your body’s schedule and sleep consistency.
Make Bedtime Relaxing: To relax your body, try reading, meditating, or having a warm bath before bed.
Optimize Sleep Environment: Keep your bedroom dark, quiet, and cold for sleep. Buying a comfy mattress and pillows can also improve sleep.
Restrict Screen Time: Phones, tablets, and laptops emit blue light that disrupts melatonin. Avoid screens an hour before bed.
Watch Your Coffee and Alcohol: Caffeine and alcohol affect sleep. Reduce intake, especially before bed.
Fitbit Premium Improves Sleep Insights
Advanced features like: Fitbit Premium provides deeper insights and assistance.
Personalized Sleep Reports: Long-term sleep analysis.
Guided programs: Customized sleep programs.
Advanced sleep metrics include respiration and oxygen saturation.
Conclusion
Sleep tracking from Fitbit helps you understand and improve sleep. Understand and use Fitbit data to improve sleep and health.
Read more on govindhtech.com
#DataLinks#FitbitSleep#healtheffects#Google#dataanalysis#Hearthealth#Wearabletechnology#heartrate#laptops#ImprovesSleep#DataStages#data#technology#technews#news#govindhtech
1 note
·
View note
Text

Automating the Modernization and Migration of ETLs: A Tech Odyssey
Datametica’s Raven is a proven code conversion service that comes with a 100% code conversion guarantee. Datametica has used Raven in numerous projects, from end to end cloud migration to just code conversion and optimization.
Visit: https://www.datametica.com/automating-the-modernization-and-migration-of-etls-a-tech-odyssey/
#datametica raven#raven migration#etl migration tool#etl tools for data migration#datastage etl tool
0 notes

Text

0 notes
Text
DataStage Training in Hyderabad
RS Trainings is proud to offer the best DataStage training in Hyderabad, providing comprehensive knowledge and real-time project explanations. DataStage is a powerful ETL (Extract, Transform, Load) tool that enables organizations to efficiently extract, transform, and load data from various sources into their data warehouses or other target systems. With our industry-expert trainers and hands-on approach, we ensure that you gain the skills and practical experience necessary to excel in the field of DataStage.

Why Choose RS Trainings for DataStage Training?
Expert Trainers: Our training sessions are conducted by experienced professionals who have extensive knowledge and hands-on experience in working with DataStage. They bring their real-world expertise and industry insights into the classroom, helping you understand the practical applications of DataStage in different scenarios and industries.
Comprehensive Curriculum: Our DataStage training program is designed to provide you with a solid foundation in DataStage concepts and techniques. We cover various topics such as data extraction, data transformation, data loading, parallel processing, job sequencing, and error handling. You will also learn about advanced features like change data capture and data integration with other tools.
Real-Time Project Explanation: At RS Trainings, we believe in a practical approach to learning. Along with theoretical concepts, we provide real-time project explanations that simulate actual industry scenarios. This hands-on experience allows you to apply the knowledge gained during the training to real-world situations, giving you a deeper understanding of DataStage implementation.
Hands-On Learning: We provide access to the DataStage software during the training, allowing you to practice and implement what you have learned. You will work on hands-on exercises, assignments, and real-time projects to strengthen your skills and build confidence in using DataStage.
Customized Training Options: We understand that each individual or organization may have unique requirements. Therefore, we offer flexible training options to suit your needs. Whether you prefer classroom training or online sessions, we have options available for both. We can also customize the training program to focus on specific aspects of DataStage based on your organization's requirements.
Ongoing Support: Our commitment to your success doesn't end with the completion of the training program. We provide ongoing support even after the training is over. Our trainers are available to answer your queries, clarify doubts, and provide guidance whenever needed. We also offer access to valuable learning resources, including updated course materials and reference guides.
Enroll in RS Trainings for the Best DataStage Training in Hyderabad:
If you are looking to enhance your ETL skills and master DataStage, RS Trainings is your ideal training partner. With our best-in-class training program, industry-expert trainers, and real-time project explanations, you will acquire the knowledge and practical experience required to become proficient in DataStage.
Take the first step towards a successful career in ETL and data integration by enrolling in our DataStage training program. Contact RS Trainings today and unlock the power of DataStage to streamline data processing and drive valuable insights for your organization.
#datastage online training#datastage training in hyderabad#datastage training with placement#datastage course online
0 notes
Text
DATASTAGE 11x, PYTHON , Unix Scripting , Oracle, SQL/PL SQL /Consultant Specialist
. Requirements To be successful in this role, you should meet the following requirements: DATASTAGE 11x, PYTHON , Unix Scripting… Apply Now
0 notes
Text
Best Practices to Protect Personal Data in 2024

In today’s digital landscape, protecting personally identifiable information (PII) demands attention. Individuals and businesses face a growing number of data breaches and cyberattacks, as well as strict data privacy laws. To keep PII secure, you must apply clear, effective cybersecurity strategies, including the following.
Start by focusing on data minimization. Only collect the PII essential to your operations, and avoid storing or asking for data you don’t need. For example, “refrain from requesting an individual's Social Security number if it is unnecessary.” Keeping less data on hand reduces the risk of exposure during a cyber incident.
One other consideration, it's only "PII" if you have more than 1 tidbit…for example, if you know my DOB yet NOT my mothers maiden name or my current address? Suddenly, "PII" is less threatening. Mr. Valihora can coach an organization on how to identify "PII" - in terms of how it's stored, and also develop a "Data Masking" strategy in order that not enough pieces of the puzzle - are available for potential data breaches or threats etc.
Tim Valihora is an expert on: Cloud PAK for Data (CP4D) v3.x, v4.x, v5.1 IBM InfoSphere Information Server (over 200 successful installs of IIS.) Information Governance Catalog Information Governance Dashboard FastTrack(tm) Information Analyzer SAP PACK for DS/QS DS "Ready To Launch" (RTL) DS SAP PACK for SAP Business Warehouse IBM IIS "Rest API" IBM IIS "DSODB" IBM Business Process Manager (BPM) MettleCI DataStage DevOps Red Hat Open Shift Control Plane Watson Knowledge Catalog Enterprise Search Data Quality Data Masking PACK for DataStage + QualityStage OPTIM Data Masking CASS - Postal Address Certification SERP - Postal Address Certification QualityStage (QS) Matching strategies + Data Standardization / Cleansing DataStage GRID Toolkit (GTK) installs
Mr. Valihora has more than 200 successful IBM IIS installs in his career and worked with 120 satisfied IBM IIS clients.
Encrypt all sensitive PII, whether it moves through systems or stays stored. Encryption blocks unauthorized access to the data without the decryption key. Use strong encryption protocols like AES-256 to keep PII private.
Apply firm access controls to limit who can interact with PII. Grant access only to those who need it. Use role-based access controls (RBAC) and multi-factor authentication (MFA) to ensure that only authorized personnel have access to or control over sensitive data. In addition, keep audit logs to track any access or changes, and hold individuals accountable.
Finally, carry out regular risk assessments and data audits. These reviews help you identify weak spots and confirm that your data practices align with current privacy regulations. By assessing risk, you can detect areas where PII may be at risk and apply proper safeguards.
Tim Valihora currently resides in Vero Bech, FL - and also enjoys golf, darts, tennis and guitar playing - during work outages!
0 notes
Text
Are you Looking Salesforce Data Migration Services In India, USA

Availability of data across CRMs is essential for all business tools to function at their full potential. We are providers of complete Data migration services in India. Our Salesforce data migration services are secure, seamless, reliable and are customized to meet your specific needs. As a leading Salesforce data migration service provider in India, we ensure the smooth transfer of data from your legacy systems to Salesforce, maintaining accuracy and integrity throughout the process. Depending on the complexity, we follow best practices using native tools like APEX Data Loader for straightforward migrations or ETL tools such as Data Loader.io, Informatica Cloud, Jitterbit, IBM DataStage, Pervasive and Boomi for more advanced requirements. Our experts for Salesforce data migration services in India and Salesforce data migration services in the USA are trained to assist you with data extraction and transformation from any existing legacy system such as SugarCRM, SalesforceIQ, Microsoft Dynamics CRM, Siebel and existing data sources such as MS SQL Server, Oracle Database, Flat Files, MS Access etc. as well as from Salesforce.com. Additionally, we provide Data processing services in USA, that ensures the migration and smooth processing of your data across multiple business platforms.
Let's connect: https://www.kandisatech.com/service/data-migration
#Salesforce#DataMigration#BusinessGrowth#SalesforceDataMigration#salescloud#sfdc#salesforcelearning#CRM#salesforceconsultant#salesforcedevelopers#salesforcepartner#india#usa
0 notes
Text
Discover the Future of IT with IBM
Ever wanted to unlock the power of IBM technologies but weren't sure where to start? Look no further! In this blog, we will dive into the world of IBM training, showing you how to master everything from IBM Cognos Analytics for data analysis to IBM Maximo for managing your assets.
Why Choose Ascendient Learning for IBM Training?
Ascendient Learning, a trusted IBM Global Training Provider, is a one-stop shop for all your IBM training needs. Here is what sets us apart:
Massive Course Selection: From IBM Cloud and IBM Watson to IBM Security and WebSphere, Ascendient Learning covers the entire IBM technology stack. Regardless of your expertise, Ascendient Learning has a course to fit your needs.
Flexible Learning Options: Learn at your own pace and on your own schedule. Ascendient Learning offers a variety of learning formats to suit different preferences and learning styles. Choose from self-paced online courses that you can access anytime, anywhere. Or, if you prefer a more traditional setting, attend in-person classes (depending on availability) and network with other learners and instructors.
Award-Winning Expertise: Our instructors are IBM-certified professionals with real-world experience, ensuring you get practical, applicable skills. You won't be lectured by someone who has just read a textbook. Ascendient Learning instructors know how to apply their knowledge to solve real-world problems.
Top-Notch Quality: Ascendient Learning has consistently won awards for quality scores, schedule availability, and student satisfaction. We are committed to providing a top-notch learning experience, and our track record speaks for itself. When you choose Ascendient Learning for your IBM training, you can be confident that you are investing in quality education that will help you achieve your goals.
Finding the Perfect Course for You
We categorize our courses to make finding what you need a breeze. Here are some popular categories to explore:
Analytics: Master data analysis with courses on Cognos Analytics, SPSS Statistics, and more. Become an expert at turning raw data into actionable insights.
Business Automation: Streamline your workflows with training on IBM Business Automation Workflow and Process Manager. Learn how to automate repetitive tasks, improve efficiency, and free up your team to focus on more strategic initiatives.
Cloud Pak: Learn about IBM Cloud Paks, pre-built software that helps you build and manage applications across any cloud. This is a perfect option if you are looking to embrace the flexibility and scalability of cloud computing.
Data Platform: Keep your data skills sharp with courses on InfoSphere DataStage and DB2.
Maximo: Become an expert in asset management with training on Maximo Asset Management, System Administration, and Development. Learn how to optimize the performance and lifespan of your physical assets, maximizing their return on investment.
Security: Protect your data with courses on QRadar and Security Access Manager. These courses will equip you with the skills you need to identify and mitigate security threats.
Watson & AI: Embrace the future of AI with training on the innovative IBM Watson platform. Learn how to leverage AI for tasks like natural language processing, machine learning, and data analysis.
More Than Just Courses
Ascendient Learning offers more than just training courses. We also provide valuable resources like free webinars, personalized learning paths, and certification support to help you succeed.
Your Future Starts Here
The future of IT is IBM. Don't miss out on the chance to be at the forefront of innovation. Enroll in an Ascendient Learning IBM training course today and start your journey toward a brighter future.
For more details, visit: https://www.ascendientlearning.com/it-training/ibm
1 note
·
View note
Text
Top 5 Data Center Virtualization Software Of 2024

The Office, an iconic sitcom, offers an amusing yet insightful glimpse into the lives of office workers at Dunder Mifflin, a paper company. Through characters like Michael Scott, Jim Halpert, and Dwight Schrute, the show highlights the dynamics of a workplace where diverse personalities come together. Their interactions, from Michael's erratic management style to Jim's pranks and Dwight’s unconventional ideas, create a unique office culture that mirrors the complexity and collaboration found in many real-world settings.
Similarly, Data Center Virtualization Software reflects this blend of variety and integration in the business world. Just as the characters in The Office each contribute their unique traits to the team, these software platforms centralize data from diverse sources into a unified virtual environment. This eliminates the need for multiple physical data centers, enhancing efficiency and performance. Data Center Virtualization Software allows businesses to gather, manage, and analyze data from various origins through a single platform, thereby improving accessibility and operational scalability.
For 2024, the leading Data Center Virtualization Software includes AWS Glue, IBM DataStage, SAP HANA Cloud, Red Hat JBoss Enterprise Application, and TIBCO Data Virtualization. These tools offer advanced capabilities for integrating and managing data in a digital format, facilitating remote access and reducing reliance on traditional physical infrastructure. Each platform brings its own set of features, such as serverless data integration, cloud-native insights, and real-time analytics, making them valuable for businesses looking to streamline their data operations and enhance productivity in an increasingly digital world.
Read More - https://www.techdogs.com/td-articles/product-mine/top-5-data-center-virtualization-software-of-2024
0 notes
Text
IBM lotus notes domino Training Courses Malaysia
Lotus Domino uses a document-oriented database called a notes storage facility to manage data such as rich text documents (formatted text and images) and other document files with attachments. This database is the central component of the Domino architecture. https://lernix.com.my/ibm-lotus-notes-domino-datastage-training-courses-malaysia/
0 notes
Text
IBM lotus notes domino Training Courses Malaysia
Lotus Domino uses a document-oriented database called a notes storage facility to manage data such as rich text documents (formatted text and images) and other document files with attachments. This database is the central component of the Domino architecture. https://lernix.com.my/ibm-lotus-notes-domino-datastage-training-courses-malaysia/
0 notes
Text
Modern Tools Enhance Data Governance and PII Management Compliance

Modern data governance focuses on effectively managing Personally Identifiable Information (PII). Tools like IBM Cloud Pak for Data (CP4D), Red Hat OpenShift, and Kubernetes provide organizations with comprehensive solutions to navigate complex regulatory requirements, including GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). These platforms offer secure data handling, lineage tracking, and governance automation, helping businesses stay compliant while deriving value from their data.
PII management involves identifying, protecting, and ensuring the lawful use of sensitive data. Key requirements such as transparency, consent, and safeguards are essential to mitigate risks like breaches or misuse. IBM Cloud Pak for Data integrates governance, lineage tracking, and AI-driven insights into a unified framework, simplifying metadata management and ensuring compliance. It also enables self-service access to data catalogs, making it easier for authorized users to access and manage sensitive data securely.
Advanced IBM Cloud Pak for Data features include automated policy reinforcement and role-based access that ensure that PII remains protected while supporting analytics and machine learning applications. This approach simplifies compliance, minimizing the manual workload typically associated with regulatory adherence.
The growing adoption of multi-cloud environments has necessitated the development of platforms such as Informatica and Collibra to offer complementary governance tools that enhance PII protection. These solutions use AI-supported insights, automated data lineage, and centralized policy management to help organizations seeking to improve their data governance frameworks.
Mr. Valihora has extensive experience with IBM InfoSphere Information Server “MicroServices” products (which are built upon Red Hat Enterprise Linux Technology – in conjunction with Docker\Kubernetes.) Tim Valihora - President of TVMG Consulting Inc. - has extensive experience with respect to:
IBM InfoSphere Information Server “Traditional” (IIS v11.7.x)
IBM Cloud PAK for Data (CP4D)
IBM “DataStage Anywhere”
Mr. Valihora is a US based (Vero Beach, FL) Data Governance specialist within the IBM InfoSphere Information Server (IIS) software suite and is also Cloud Certified on Collibra Data Governance Center.
Career Highlights Include: Technical Architecture, IIS installations, post-install-configuration, SDLC mentoring, ETL programming, performance-tuning, client-side training (including administrators, developers or business analysis) on all of the over 15 out-of-the-box IBM IIS products Over 180 Successful IBM IIS installs - Including the GRID Tool-Kit for DataStage (GTK), MPP, SMP, Multiple-Engines, Clustered Xmeta, Clustered WAS, Active-Passive Mirroring and Oracle Real Application Clustered “IADB” or “Xmeta” configurations. Tim Valihora has been credited with performance tuning the words fastest DataStage job which clocked in at 1.27 Billion rows of inserts\updates every 12 minutes (using the Dynamic Grid ToolKit (GTK) for DataStage (DS) with a configuration file that utilized 8 compute-nodes - each with 12 CPU cores and 64 GB of RAM.)
0 notes
Text
The 4 Best Data Cleaning Tools of 2024
The main reason for low data quality is the existence of dirty data in the database and data input errors. Different representation methods and inconsistencies between data caused by data from different sources are the cause of dirty data. Therefore, before data analysis, we should first perform data cleaning. Data cleaning is a process of collecting and analyzing data, re-examining and verifying data. Its purpose is to deal with different types of data, such as missing, abnormal, duplicate and illegal, to ensure the accuracy, completeness, consistency, validity and uniqueness of the data.
Let’s take a look at 4 commonly used data cleaning tools.

IBM InfoSphere DataStage is an ETL tool and part of the IBM Information Platforms Solutions suite and IBM InfoSphere. It uses a graphical notation to construct data integration solutions and is available in various versions such as the Server Edition, the Enterprise Edition, and the MVS Edition. It uses a client-server architecture. The servers can be deployed in both Unix as well as Windows.
It is a powerful data integration tool, frequently used in Data Warehousing projects to prepare the data for the generation of reports.

Pycharm is a PythonIDE integrated development environment. It has a set of tools that can help users improve efficiency when using Python language development, such as debugging, syntax highlights, project management, code jumps, smart prompts, automatic completion, unit testing, version control, etc. .

Excel is the main analysis tool for many data-related practitioners. It can handle all kinds of data. Statistical analysis and auxiliary decision-making operations. If performance and data volume are not considered, most data-related processing can be handled.

Python language is concise, easy to read, and extensible. It is an object-oriented dynamic language. It was originally designed to write automated scripts. It is increasingly used to develop independent large-scale projects, because the version is constantly updated and new language features are also increasing.
0 notes
Text
Enterprise AI Data Ingestion and Integration Importance
Data Ingestion Methods
As generative AI gained traction, a number of well-known businesses decided to limit its application due to improper handling of confidential internal data. As they work to gain a deeper understanding of the technology, several companies have implemented internal bans on generative AI tools, and many have also prohibited the use of internal ChatGPT. This information is reported by CNN.
When investigating large language models (LLMs), companies still frequently take the chance of using internal data because LLMs can transform from general-purpose to domain-specific knowledge thanks to this contextual data. Data intake is the first step in the development cycle of either generative AI or conventional AI. Here, raw data customized to an organization’s needs can be gathered, preprocessed, hidden, and formatted for use with LLMs or other models. At present, there is no established procedure to address the difficulties associated with data ingestion; however, the accuracy of the model relies on it.
Four hazards of incomplete data ingestion
Creation of misinformation an LLM may produce inaccurate results when trained on contaminated data, or data containing errors or inaccuracies. This could result in poor decision-making and possible cascading problems.
Increased variance: Consistency is gauged by variance. Inadequate data can result in inconsistent responses over time or deceptive outliers, which are especially harmful to smaller data sets. A model with a high variance may be suitable for training data but not for use in real-world industry scenarios.
Restrictive data coverage and non-representative responses: When data sources are restrictive, homogeneous or contain mistaken duplicates, statistical errors like sampling bias can skew all results. This could lead to the model leaving out of the discussion entire regions, departments, populations, businesses, or sources.
Difficulties in correcting biased data: “Retraining the algorithm from scratch is the only way to retroactively remove a portion of that data if the data is biased from the start.” When answers are vectorized from unrepresentative or contaminated data, it is challenging for LLM models to unlearn them. These models frequently use previously learned responses to support their understanding.
Challenges in rectifying biased data: Data ingestion needs to be done correctly from the beginning since improper handling can result in a number of new problems. An AI model’s foundational training data is like learning to fly an aircraft. One degree off on the takeoff angle could land you on a different continent than anticipated.
The data pipelines that power generative AI are the foundation of the entire pipeline, so taking the right precautions is essential.
Four essential elements to guarantee dependable data ingestion
Data governance and quality: Ensuring the security of data sources, preserving comprehensive data, and offering unambiguous metadata are all examples of data quality. Working with fresh data through techniques like web scraping or uploading might also be necessary for this. Throughout the data lifecycle, data governance is a continuous process that helps guarantee adherence to legal requirements and business best practices.
Data integration: With the use of these tools, businesses can bring together various data sources in a safe, single location. Extract, load, and transform is a widely used technique (ELT). In an ELT system, data sets are selected from siloed warehouses, transformed and then loaded into source or target data pools. Fast and secure transformations are made possible by ELT tools like IBM DataStage, which use parallel processing engines. By 2023, the typical enterprise will be receiving hundreds of different data streams, so developing new and traditional AI models will depend heavily on accurate and efficient data transformations.
Preprocessing and data cleaning: This covers data formatting to adhere to particular data types, orchestration tools, or LLM training requirements. While image data can be stored as embedding’s, text data can be tokenized or chunked. Data integration tools can be used to perform extensive transformations. Additionally, it might be necessary to alter the data types or remove duplicates from the raw data directly.
Data storage: The problem of data storage emerges when the data has been cleaned and processed. Since most data is hosted either on-premises or in the cloud, businesses must decide where to keep their data. When handling sensitive data, such as customer, internal, or personal information, it’s crucial to exercise caution when utilizing external LLMs. On the other hand, LLMs are essential for optimizing or putting into practice a retrieval-augmented generation (RAG) based strategy. It’s crucial to execute as many data integration procedures on internal servers as you can to reduce risks. Using remote runtime options such as can be one possible solution.
With IBM, begin your data ingestion process
By combining different tools, IBM DataStage simplifies data integration and makes it simple to pull, organize, transform, and store data in a hybrid cloud environment that is required for AI training models. All levels of data practitioners can use the tool by utilizing guided custom code to access APIs or by utilizing no-code GUIs.
You now have more flexibility in running your data transformations with the DataStage as a Service Anywhere remote runtime option. It gives you unparalleled control over the parallel engine’s location and allows you to use it from any location. With DataStage as a Service Anywhere, you can run all data transformation features in any environment thanks to its lightweight container design. As you perform data integration, cleaning, and preprocessing within your virtual private cloud, you can steer clear of many of the pitfalls associated with subpar data ingestion. You have total control over security, efficacy, and quality of data with DataStage, which meets all of your data requirements for generative AI projects.
Although generative AI has virtually no bounds to what it can accomplish, there are restrictions on the types of data that a model can use, and those constraints could be crucial.
Read more on Govindhtech.com
0 notes