#OSI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
Sometimes I forget that there’s legitimately an agent named “Snoopy” in the OSI. And he’s a corporal.

34 notes
·
View notes
Text




Alpine Marbon CRV, 1966, by OSI. The Cycolac Research Vehicle was commissioned by US company Marbon-Chemical to showcase their ABS plastic material Cycolac for automotive applications. The car toured Europe's car makers and found a taker at Citroën who used Marbon's ABS for their Mehari
#Alpine#Alpine Marbon CRV#OSI#Cycolac Research Vehicle#research vehicle#test vehicle#prototype#Marbon-Chemical#ABS Plastic#1966#coachbuilt#rear engine#1960
392 notes
·
View notes
Text
I really, really, REALLY wish Doc & Jackson would tell us what Shore Leave’s name is. Like…I need to know. For no reason other than it would make me happy.
61 notes
·
View notes
Text

General Gathers for Pride Month :)
Reference under the cut

53 notes
·
View notes
Text

Next in the Pokemon crossover lineup!
They absolutely talk shit about you after kicking your ass
(ngl I totally picked Primarina as my starter because of how pretty she is lol. Work has stolen all my free time)
58 notes
·
View notes
Text




OSI 20M TS 1968. - source Bring a Trailer.
43 notes
·
View notes
Text
I swear I can understand so many of Hunter’s actions if we frame it as revenge on Rusty for stealing her precious boychick.
Assassinanny 911 on roids, basically
25 notes
·
View notes
Text


Finally finished up the last ones from this crew because I'm making TH profiles for them :V
#bionicle#matoran#onu matoran#ko matoran#osi#aklavu#oc#ocs#lego#bonkle#bonkles#digital#art#sketchbook#lagou#av matoran
185 notes
·
View notes
Text
Nostalgia hit me like a train here Is one of my Pokemon oc.
They are a grass poison type!!

15 notes
·
View notes
Text





NEW VISITOR FILES: OSI CLERGY [COLONY: BYZANTIUM, LOWER DISTRICT]
We've got our eye on a visiting OSI group; give them one hell of a vacation and follow 'Visiting OSI Protocol' until further instructions. I don't believe they're up to anything, but we can never be too careful. Oh, and make sure to figure out their vices.- WEST
BASIC DETAILS UNDER CUT
TOP ROW:
NAME: EDMUND WEBB AGE: 34 OSI RANK: DEACON YEARS DEDICATED TO OSI: 10 SPECIALTY: YOUTH STUDIES/GUIDANCE
NAME: ELINAH FIRYALI AGE: 32 OSI RANK: DEACON YEARS DEDICATED TO OSI: 6 SPECIALTY: VODIAL RHETORIC
NAME: ALYA VOSTRONOYSKI AGE: 59 OSI RANK: BISHOP YEARS DEDICATED TO OSI: 37 SPECIALTY: STATISTICAL CANON AND PROBABILITY
BOTTOM ROW:
NAME: ISSAK DIMITRIOU AGE: 32 OSI RANK: VICAR YEARS DEDICATED TO OSI: 8 SPECIALTY: NON-SPECIALIZED/GENERAL STUDY
NAME: VICTOR SUBEDI AGE: 22 OSI RANK: PASTOR YEARS DEDICATED TO OSI: ~1 SPECIALTY: CLERGY APPRENTICE
12 notes
·
View notes
Text
"Open" "AI" isn’t

Tomorrow (19 Aug), I'm appearing at the San Diego Union-Tribune Festival of Books. I'm on a 2:30PM panel called "Return From Retirement," followed by a signing:
https://www.sandiegouniontribune.com/festivalofbooks

The crybabies who freak out about The Communist Manifesto appearing on university curriculum clearly never read it – chapter one is basically a long hymn to capitalism's flexibility and inventiveness, its ability to change form and adapt itself to everything the world throws at it and come out on top:
https://www.marxists.org/archive/marx/works/1848/communist-manifesto/ch01.htm#007
Today, leftists signal this protean capacity of capital with the -washing suffix: greenwashing, genderwashing, queerwashing, wokewashing – all the ways capital cloaks itself in liberatory, progressive values, while still serving as a force for extraction, exploitation, and political corruption.
A smart capitalist is someone who, sensing the outrage at a world run by 150 old white guys in boardrooms, proposes replacing half of them with women, queers, and people of color. This is a superficial maneuver, sure, but it's an incredibly effective one.
In "Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," a new working paper, Meredith Whittaker, David Gray Widder and Sarah B Myers document a new kind of -washing: openwashing:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543807
Openwashing is the trick that large "AI" companies use to evade regulation and neutralizing critics, by casting themselves as forces of ethical capitalism, committed to the virtue of openness. No one should be surprised to learn that the products of the "open" wing of an industry whose products are neither "artificial," nor "intelligent," are also not "open." Every word AI huxters say is a lie; including "and," and "the."
So what work does the "open" in "open AI" do? "Open" here is supposed to invoke the "open" in "open source," a movement that emphasizes a software development methodology that promotes code transparency, reusability and extensibility, which are three important virtues.
But "open source" itself is an offshoot of a more foundational movement, the Free Software movement, whose goal is to promote freedom, and whose method is openness. The point of software freedom was technological self-determination, the right of technology users to decide not just what their technology does, but who it does it to and who it does it for:
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
The open source split from free software was ostensibly driven by the need to reassure investors and businesspeople so they would join the movement. The "free" in free software is (deliberately) ambiguous, a bit of wordplay that sometimes misleads people into thinking it means "Free as in Beer" when really it means "Free as in Speech" (in Romance languages, these distinctions are captured by translating "free" as "libre" rather than "gratis").
The idea behind open source was to rebrand free software in a less ambiguous – and more instrumental – package that stressed cost-savings and software quality, as well as "ecosystem benefits" from a co-operative form of development that recruited tinkerers, independents, and rivals to contribute to a robust infrastructural commons.
But "open" doesn't merely resolve the linguistic ambiguity of libre vs gratis – it does so by removing the "liberty" from "libre," the "freedom" from "free." "Open" changes the pole-star that movement participants follow as they set their course. Rather than asking "Which course of action makes us more free?" they ask, "Which course of action makes our software better?"
Thus, by dribs and drabs, the freedom leeches out of openness. Today's tech giants have mobilized "open" to create a two-tier system: the largest tech firms enjoy broad freedom themselves – they alone get to decide how their software stack is configured. But for all of us who rely on that (increasingly unavoidable) software stack, all we have is "open": the ability to peer inside that software and see how it works, and perhaps suggest improvements to it:
https://www.youtube.com/watch?v=vBknF2yUZZ8
In the Big Tech internet, it's freedom for them, openness for us. "Openness" – transparency, reusability and extensibility – is valuable, but it shouldn't be mistaken for technological self-determination. As the tech sector becomes ever-more concentrated, the limits of openness become more apparent.
But even by those standards, the openness of "open AI" is thin gruel indeed (that goes triple for the company that calls itself "OpenAI," which is a particularly egregious openwasher).
The paper's authors start by suggesting that the "open" in "open AI" is meant to imply that an "open AI" can be scratch-built by competitors (or even hobbyists), but that this isn't true. Not only is the material that "open AI" companies publish insufficient for reproducing their products, even if those gaps were plugged, the resource burden required to do so is so intense that only the largest companies could do so.
Beyond this, the "open" parts of "open AI" are insufficient for achieving the other claimed benefits of "open AI": they don't promote auditing, or safety, or competition. Indeed, they often cut against these goals.
"Open AI" is a wordgame that exploits the malleability of "open," but also the ambiguity of the term "AI": "a grab bag of approaches, not… a technical term of art, but more … marketing and a signifier of aspirations." Hitching this vague term to "open" creates all kinds of bait-and-switch opportunities.
That's how you get Meta claiming that LLaMa2 is "open source," despite being licensed in a way that is absolutely incompatible with any widely accepted definition of the term:
https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
LLaMa-2 is a particularly egregious openwashing example, but there are plenty of other ways that "open" is misleadingly applied to AI: sometimes it means you can see the source code, sometimes that you can see the training data, and sometimes that you can tune a model, all to different degrees, alone and in combination.
But even the most "open" systems can't be independently replicated, due to raw computing requirements. This isn't the fault of the AI industry – the computational intensity is a fact, not a choice – but when the AI industry claims that "open" will "democratize" AI, they are hiding the ball. People who hear these "democratization" claims (especially policymakers) are thinking about entrepreneurial kids in garages, but unless these kids have access to multi-billion-dollar data centers, they can't be "disruptors" who topple tech giants with cool new ideas. At best, they can hope to pay rent to those giants for access to their compute grids, in order to create products and services at the margin that rely on existing products, rather than displacing them.
The "open" story, with its claims of democratization, is an especially important one in the context of regulation. In Europe, where a variety of AI regulations have been proposed, the AI industry has co-opted the open source movement's hard-won narrative battles about the harms of ill-considered regulation.
For open source (and free software) advocates, many tech regulations aimed at taming large, abusive companies – such as requirements to surveil and control users to extinguish toxic behavior – wreak collateral damage on the free, open, user-centric systems that we see as superior alternatives to Big Tech. This leads to the paradoxical effect of passing regulation to "punish" Big Tech that end up simply shaving an infinitesimal percentage off the giants' profits, while destroying the small co-ops, nonprofits and startups before they can grow to be a viable alternative.
The years-long fight to get regulators to understand this risk has been waged by principled actors working for subsistence nonprofit wages or for free, and now the AI industry is capitalizing on lawmakers' hard-won consideration for collateral damage by claiming to be "open AI" and thus vulnerable to overbroad regulation.
But the "open" projects that lawmakers have been coached to value are precious because they deliver a level playing field, competition, innovation and democratization – all things that "open AI" fails to deliver. The regulations the AI industry is fighting also don't necessarily implicate the speech implications that are core to protecting free software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
Just think about LLaMa-2. You can download it for free, along with the model weights it relies on – but not detailed specs for the data that was used in its training. And the source-code is licensed under a homebrewed license cooked up by Meta's lawyers, a license that only glancingly resembles anything from the Open Source Definition:
https://opensource.org/osd/
Core to Big Tech companies' "open AI" offerings are tools, like Meta's PyTorch and Google's TensorFlow. These tools are indeed "open source," licensed under real OSS terms. But they are designed and maintained by the companies that sponsor them, and optimize for the proprietary back-ends each company offers in its own cloud. When programmers train themselves to develop in these environments, they are gaining expertise in adding value to a monopolist's ecosystem, locking themselves in with their own expertise. This a classic example of software freedom for tech giants and open source for the rest of us.
One way to understand how "open" can produce a lock-in that "free" might prevent is to think of Android: Android is an open platform in the sense that its sourcecode is freely licensed, but the existence of Android doesn't make it any easier to challenge the mobile OS duopoly with a new mobile OS; nor does it make it easier to switch from Android to iOS and vice versa.
Another example: MongoDB, a free/open database tool that was adopted by Amazon, which subsequently forked the codebase and tuning it to work on their proprietary cloud infrastructure.
The value of open tooling as a stickytrap for creating a pool of developers who end up as sharecroppers who are glued to a specific company's closed infrastructure is well-understood and openly acknowledged by "open AI" companies. Zuckerberg boasts about how PyTorch ropes developers into Meta's stack, "when there are opportunities to make integrations with products, [so] it’s much easier to make sure that developers and other folks are compatible with the things that we need in the way that our systems work."
Tooling is a relatively obscure issue, primarily debated by developers. A much broader debate has raged over training data – how it is acquired, labeled, sorted and used. Many of the biggest "open AI" companies are totally opaque when it comes to training data. Google and OpenAI won't even say how many pieces of data went into their models' training – let alone which data they used.
Other "open AI" companies use publicly available datasets like the Pile and CommonCrawl. But you can't replicate their models by shoveling these datasets into an algorithm. Each one has to be groomed – labeled, sorted, de-duplicated, and otherwise filtered. Many "open" models merge these datasets with other, proprietary sets, in varying (and secret) proportions.
Quality filtering and labeling for training data is incredibly expensive and labor-intensive, and involves some of the most exploitative and traumatizing clickwork in the world, as poorly paid workers in the Global South make pennies for reviewing data that includes graphic violence, rape, and gore.
Not only is the product of this "data pipeline" kept a secret by "open" companies, the very nature of the pipeline is likewise cloaked in mystery, in order to obscure the exploitative labor relations it embodies (the joke that "AI" stands for "absent Indians" comes out of the South Asian clickwork industry).
The most common "open" in "open AI" is a model that arrives built and trained, which is "open" in the sense that end-users can "fine-tune" it – usually while running it on the manufacturer's own proprietary cloud hardware, under that company's supervision and surveillance. These tunable models are undocumented blobs, not the rigorously peer-reviewed transparent tools celebrated by the open source movement.
If "open" was a way to transform "free software" from an ethical proposition to an efficient methodology for developing high-quality software; then "open AI" is a way to transform "open source" into a rent-extracting black box.
Some "open AI" has slipped out of the corporate silo. Meta's LLaMa was leaked by early testers, republished on 4chan, and is now in the wild. Some exciting stuff has emerged from this, but despite this work happening outside of Meta's control, it is not without benefits to Meta. As an infamous leaked Google memo explains:
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/
Thus, "open AI" is best understood as "as free product development" for large, well-capitalized AI companies, conducted by tinkerers who will not be able to escape these giants' proprietary compute silos and opaque training corpuses, and whose work product is guaranteed to be compatible with the giants' own systems.
The instrumental story about the virtues of "open" often invoke auditability: the fact that anyone can look at the source code makes it easier for bugs to be identified. But as open source projects have learned the hard way, the fact that anyone can audit your widely used, high-stakes code doesn't mean that anyone will.
The Heartbleed vulnerability in OpenSSL was a wake-up call for the open source movement – a bug that endangered every secure webserver connection in the world, which had hidden in plain sight for years. The result was an admirable and successful effort to build institutions whose job it is to actually make use of open source transparency to conduct regular, deep, systemic audits.
In other words, "open" is a necessary, but insufficient, precondition for auditing. But when the "open AI" movement touts its "safety" thanks to its "auditability," it fails to describe any steps it is taking to replicate these auditing institutions – how they'll be constituted, funded and directed. The story starts and ends with "transparency" and then makes the unjustifiable leap to "safety," without any intermediate steps about how the one will turn into the other.
It's a Magic Underpants Gnome story, in other words:
Step One: Transparency
Step Two: ??
Step Three: Safety
https://www.youtube.com/watch?v=a5ih_TQWqCA
Meanwhile, OpenAI itself has gone on record as objecting to "burdensome mechanisms like licenses or audits" as an impediment to "innovation" – all the while arguing that these "burdensome mechanisms" should be mandatory for rival offerings that are more advanced than its own. To call this a "transparent ruse" is to do violence to good, hardworking transparent ruses all the world over:
https://openai.com/blog/governance-of-superintelligence
Some "open AI" is much more open than the industry dominating offerings. There's EleutherAI, a donor-supported nonprofit whose model comes with documentation and code, licensed Apache 2.0. There are also some smaller academic offerings: Vicuna (UCSD/CMU/Berkeley); Koala (Berkeley) and Alpaca (Stanford).
These are indeed more open (though Alpaca – which ran on a laptop – had to be withdrawn because it "hallucinated" so profusely). But to the extent that the "open AI" movement invokes (or cares about) these projects, it is in order to brandish them before hostile policymakers and say, "Won't someone please think of the academics?" These are the poster children for proposals like exempting AI from antitrust enforcement, but they're not significant players in the "open AI" industry, nor are they likely to be for so long as the largest companies are running the show:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4493900

I'm kickstarting the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#llama-2#meta#openwashing#floss#free software#open ai#open source#osi#open source initiative#osd#open source definition#code is speech
255 notes
·
View notes
Text
FOUND ANOTHER FUCKING SOLDER BRIDGE


See those areas marked in red? Those were holding back my OSI 540B replica video board from generating video. This board is of a design where solder mask was not always a given so it's very easy to bridge traces. I found one last spring (left), and I found another one this morning thru tracing the weirdness of the video signal, until I noticed that a pair of 74LS174's weren't passing any signals.
Turns out they were locked up, because master reset was pulled low by another solder bridge (right). See that middle line marked Q3? That should be similar to D3, but it wasn't.
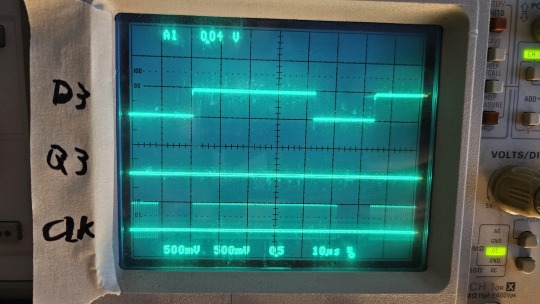
I wasn't sure I had fixed it, until I started tweaking analog video levels again, and suddenly I had something visible on the screen! A few keystrokes later and... BASIC!
FUCK YEAH, BASIC!

And so I decided to run my usual SIN COS test:

The video signal is a bit low voltage, so it appears kinda dark. I need to tweak alot of the analog parts of the circuit, possibly modify a few things to get it playing nice. I also need to run test programs for the color video modes, the whole point of doing this replica build. Here's an original 540B built for monochrome video:

And here's one built for color video:

I built this thing in summer of 2020, it's nice to see it finally video-ing.
FUCK YEAH, I needed that win. I really did.
83 notes
·
View notes
Text

ART FOR THE TEN YEAR ANNIVERSARY OF OBJECT SURVIVAL ISLAND - APRIL 29TH - one of my favourites watch.
#osc#object shows#osc art#object show#object survival island#osi#pillowy osi#object show community#osc community#digital art#art
18 notes
·
View notes
Text
youtube

youtube
youtube

youtube

youtube

youtube

youtube


youtube
youtube

youtube
#PRND.fn__def__(@)#ParaMetR.¡ç(@$@)#$EX.T🌃🗾💈🎰🌌♨️🚇🚲🚜🛣🚨🚨🚨🚧🛳⚓🛫🛎🚪🕧🚽⌛🌚🕘🌟🌞🌟🕋❄⚡⚡🌈🌀⛄🌀🌬🌪🌊💧🔥🔥..;@%¶∆∆∆#You#Whome#WiP#SubjectiPredicate Blob#PenultiM8.chk P&L “ Pleas ” & 'TU'#SVio.sampL/3-🎙#OSI#IEEE.℅ⁿ$ol' [9001] {TQM}. KAN.spReⁿt.. 🎶 🎻S🎷H🎸O🎹.Tau-ru s HEN-r🔮☢🔜 1c2SEA.tac NAM FDMA TDMA AMPS.pcs1900 ∅ⁿ∅.reg ret 24-60 xGPSì#CDMA#Trax#[ ' STACK ' .]#Token.rng#*-.b@ (Auto-)#CHiR¶π^😘.$exẞ.$read#C.O.G.Sold.#Spread_ ° _SpecTrum 🤖.ℹ 🆔 🆚 :-* 📡 🔋📸 📺 📀.📀#o.obj
11 notes
·
View notes
Text

O.S.I Love You ♥️ 💀
#venture bros#go team venture#Osi#o.s.I#hunter gathers#destiny#hank venture#tank top#shore leave#my favorite episode of season 5#I hope you guys like these as much as I do
309 notes
·
View notes
Text
Rusty discovers he’s in a simulation by himself, when he allucinates Tiger coming to him with a better dildo— but the wank machine only does the front which prompts a glitch in the matrix.
Once again Lust Venture’s incurable horniness saves the day
8 notes
·
View notes