#Render Other Label for Pie Chart
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
Latest Java Charting Libraries are listed in this page Java offers immense flexibilities in running a number of web applications independent of the running platform and computer architecture. The two and three-dimensional representations through different types of bar graphs provided by Java have enhanced its popularity since its release. In recent years, Java libraries are being used less for web-based reporting since there are really powerful jQuery and JavaScript charting libraries available for client-side rendering. However, even now Java software is still run on millions of computers as the Java Charting Library offers varied interesting features to the users and web developers. The users can embed stunning 2D and 3D representations in the web through different types of graphs and charts imported from the Java charting library. JFreeChart This open source Java charting library offers users the maximum alternatives to represent their complex data in a simplified manner. It enables the extensive use of X-Y charts, Pie charts, Bar graphs, Gantt charts, Pareto charts, combination charts, wafer map charts and other special types of charts. In a nutshell, JFreeChart is a comprehensive charting package providing maximum charting options to the users. Axis, legends, and scales are automatically drawn and, the user can also place various markers on the plotted chart. The charts can be zoomed for a better view and can be regularly updated by the attendants of the Java charting library. The user can download the developer’s guide and follow the applications accordingly. JCC Kit This is another promising Java Charting library next to the JFree Chart. This charting library occupies very little disk space about less than 100kb and is very useful for designing charts based on scientific data. The flexibility of JCC Kit enables easy writing of applet programs that presents data on the web page without any prior knowledge of Java programming language. Automatic rescaling, creating legends and up gradation is possible with JCC Kit Charting library. OpenChart2 This Java charting is very useful and simplifies the interface for plotting 2-D charts. Following the basics of JOpenChart library, OpenChart2 offers a variety of charting features including advanced forms of bar graphs, pie charts and scatter plots. jCharts This open-source charting facility is very useful to display different types of charts through JSP’s, Servlet and Swing apps. The developer can download any Servlet container and follow the examples of jCharts. GRAL Graphing Library This Java Graphing Library enables high-quality plotting and charting. It can also import data from texts, audios, and videos and the plots can be produced in JPEG, EPS, PDF, PNG and SVG files. Users can also use GRAL for different types of data processing and this library also provides a Java Swing interface. charts4j This lightweight charts and graphs Java API enables to create charts programmatically using Google chart tools. It can be integrated into any web application or Swing, JSP, Servlet or GWT. JChart2D This charting library is meant for representing engineering data demanding high precision than colorful presentations. JChart2D, a Java component displays dynamic 2D charts offering automatic labeling scaling. Users carrying basic knowledge of Java Swing and AWT can use it to the best possible limit. It is preferred over JFreeChart due to its dynamic feature. JFreeReport This is another open source tool meant for generating reports or it can be assigned as Java Report Generator. It provides an on-screen print preview based on data via Java Swing’s Table Model Interface, and reports can either be generated from the printer or can be exported to various formats like PDF, XLS, HTML and many more. Jzy3D In designing simple three-dimensional charts like bar graphs and scatter plots, Jzy3D graphing library is very handy. This charting library is also useful in creating 2D graphs and plots.
There are also provisions to add color maps and different contours beside 3D charts. Jzy3D also enables a wide range of customization through various layout tools. JasperReports This useful open source Java reporting tool helps in delivering rich content on the screen or exporting to HTML, PDF, XML, XLS and CSV files and printer. This 100% Java-based program finds extensive use in various Web and Java applications (JEE) that produce dynamic content. The user can generate reports instantly in the most simplified manner and get them printed. Different types of projects and jobs need different projections and representations, and Java charting library offers a number of charting tools to represent their data in an understandable manner. All of these charting applications are open source software and can be downloaded for free. Hope you found this list useful. What java libraries do you use for creating reports and charts? Article Updates Article Updated on Jan 2025 - link to latest post. Article Updated on September 2021. Some HTTP links are updated to HTTPS. Updated broken links with latest URLs. Some minor text updates done. Content validated and updated for relevance in 2021. Updated on April 2019: Minor changes and updates to the introduction section, images are HTTPS now.
0 notes
Text
Next-level Data Visualization: Programmatically Creating Excel Graphs in React
In today's dynamic world of data visualization, React serves as a cornerstone for crafting immersive and interactive user interfaces. When combined with the powerful charting capabilities of ExcelJS charts, developers gain access to a robust toolkit for creating advanced data visualizations. This guide explores the process of integrating ExcelJS charts into React applications, offering developers the means to elevate their data visualization strategies.
Understanding React and ExcelJS:
React, with its component-based architecture and declarative programming paradigm, provides a flexible framework for building modern web interfaces. ExcelJS react, on the other hand, is a JavaScript library specifically designed for manipulating Excel files, including the creation of various chart types.
Leveraging ExcelJS charts in React:
By integrating ExcelJS charts into React applications, developers can enhance data visualization capabilities. ExcelJS charts offer a wide range of chart types, including bar charts, line charts, pie charts, and more, which can be seamlessly incorporated into React components.
Implementing ExcelJS charts in React Components:
Developers can utilize libraries like ExcelJS to generate Excel files containing programmatically created charts. With ExcelJS, developers have the flexibility to define data series, chart types, and styling options to create customized charts tailored to their application's needs. These Excel files, containing ExcelJS charts, can then be rendered within React components, providing users with dynamic and interactive data visualizations.
Real-time Data Binding and Updates:
React's state management capabilities enable real-time data binding, allowing developers to synchronize ExcelJS charts with live data streams. This ensures that charts update dynamically as data changes, providing users with up-to-date insights into their data.
Customization and Interactivity:
ExcelJS charts offer extensive customization options, allowing developers to tailor the appearance and interactivity of charts to meet specific requirements. Developers can customize chart styles, colors, labels, legends, and interactive features such as tooltips and data labels, enhancing the user experience.
Managing Complexity in Data Visualization:
Integrating ExcelJS charts into React applications provides developers with a scalable solution for managing complex data visualization scenarios. Whether dealing with large datasets, multiple data series, or advanced charting requirements, React's flexibility combined with ExcelJS charts's robust capabilities ensures seamless data presentation.
Practical Applications and Use Cases:
The integration of ExcelJS charts into React applications finds applications across various industries and domains. From financial analysis and business reporting to scientific research and engineering simulations, ExcelJS charts empower users to visualize and analyze data effectively.
Conclusion:
By integrating ExcelJS charts into React applications, developers can unlock a new level of sophistication in data visualization. The combination of React's flexibility and ExcelJS charts's powerful capabilities enables developers to create dynamic, interactive, and visually appealing data visualizations that enhance user engagement and facilitate data-driven decision-making. Whether building financial dashboards, business analytics tools, or scientific applications, ExcelJS charts in React offer a versatile solution for advanced data visualization needs.
0 notes
Text
Birt Pojo Data Source

Eclipse Birt Pojo Data Source
Birt Report Pojo Data Source Example
Birt Pojo Data Source Example
Birt Pojo Data Source Examples
Use esProc with BIRT. Here is the SPL script. Your BIRT reports can have a query from two data sources no matter what kind of database and go on other computations that are not convenient on BIRT.
Using POJO DataSource in BIRT 4.3 To create a report in BIRT 4.3 we can use POJO dataSource. In 4.3 this DataSource is supported. To use this we need to create a dataset class.
BIRT is an open source engine to create data visualizations that can be integrated into Java web applications. It's a top-level software project within the Eclipse Foundation and leverages contributions by IBM and Innovent Solutions. It was started and sponsored by Actuate at the end of 2004.
Eclipse Birt Pojo Data Source
Primary tabs
. Data - Databases, web services, Java objects all can supply data to your BIRT report. BIRT provides JDBC, XML, Web Services, and Flat File support, as well as support for using code to get at other sources of data. BIRTs use of the Open Data Access (ODA) framework allows anyone to build new UI and runtime support for any kind of tabular data.
= unsolved/reopened
BIRT (146)Build (4)
101416 Incorrect font format in BIRT Developer Guide in Help menu (closed/fixed)
103303 The chart engine.jar in the runtime distribution is the wrong file (closed/fixed)
105638 Rotated text report item displays in palette by default (closed/fixed)
106247 Eclpse Distro Path (closed/fixed)
Chart (46)
102417 Chart title is set to Chinese, can not be previewed correctly.(resolved/wontfix)
103130 Chart title is overlapped when previewed.(closed/worksforme)
103143 Data format doesn't work in Chart (closed/invalid)
103153 Scatter chart, if tick transposed, image does not be changed.(closed/fixed)
103168 X Axis data is lost when transposed.(closed/fixed)
103298 X series in a pie chart in wrong order (resolved/fixed)
103438 Scatter chart is displayed differently when it is transferred from another chart type.(closed/fixed)
103439 Steps in chart builder can't be restored to default setting when cleared out.(closed/fixed)
103453 Scale for 'datetime' type in chart builder doesn't work.(closed/fixed)
103460 Multiple x axis are not supported.(closed/fixed)
103463 Datetime marker line can't be set.(closed/worksforme)
103595 Datetime data in Chart axis of example are displayed inconsistently in layout.(closed/invalid)
103599 Resizing chart results in Eclipse hang up.(closed/fixed)
103602 Exception is thrown when setting chart height or width.(closed/worksforme)
103613 Linking chart by parameter causes error when a NULL param value is reached (resolved/fixed)
103617 if Label positioin is changed, then can not return initial state.(closed/fixed)
103618 Bar Chart , Label position is lack of inside item.(closed/fixed)
103770 don't use hyperlink (resolved/invalid)
103780 Chart is not displayed in layout view when transposed.(closed/fixed)
103782 Attached chart design file can't be previewed.(closed/fixed)
103787 Add a new Y-axis and set it's title to visible will cause chartException.(closed/fixed)
103960 If x axis type is 'Linear', scale should be grayed out.(closed/fixed)
103961 Marker and line doesn't work for X Axis.(closed/fixed)
103963 If there is no data for series, it should pop up a friendly error message to remind.(closed/fixed)
104248 Axis types on Chart dialog are not displayed in localized language.(verified/fixed)
104252 Sort option on Chart X-Series dialog is not displayed in localized language.(verified/fixed)
104254 Type and Action value on Chart Y-Series are not displayed in localized language.(verified/fixed)
104278 Values in Tick Style list box are not displayed in localized language.(verified/fixed)
104283 Value for Label Position on Chart dialog are not displayed in localized language.(verified/fixed)
104290 Hard coded strings on Chart Attributes>Y Series dialog (verified/fixed)
104313 Set the image to the chart label background, system throws exception (closed/fixed)
104315 Plot background image can not always take effort .(closed/worksforme)
104450 If plot background is set, data set binding is lost.(closed/fixed)
104465 Data values of Y-series cannot be displayed correctly (closed/invalid)
104613 Steps changed after chart is transposed.(closed/invalid)
104628 Chart Major.Minor Grid line style won't display in layout (closed/wontfix)
104631 If set a long title to chart X Axis,Axis type will be truncated (closed/fixed)
99331 Eclipse hangs when closing 'Chart Dialog' (resolved/fixed)
100746 Whole chart should display smaller on scale, not only display title and legend after resize (closed/invalid)
101039 Series colors do not have different default values (closed/fixed)
101179 Unfriendly error message display when preview chart with invalid data set (closed/fixed)
101806 Chart axis label background is not displayed properly in layout view.(closed/fixed)
101827 Exception should be processed before written to error log or some error message should pop up to warn user (closed/fixed)
101855 Chart title top.bottom inset should display right in layout view (closed/fixed)
101868 series value format can display as setting (closed/fixed)
102455 Pie Chart is not round (closed/fixed)
Data (22)
94542 Grouping versus Sorting (closed/invalid)
99479 After Update Birt 1.0 error Cannot load JDBC Driver class (resolved/fixed)
101553 Report Parameters are not working (resolved/duplicate)
101864 NullPointerException throws out when setting the parameter type as auto (closed/fixed)
101865 Try to set report parameter's value in beforeOpen method of data source,error occurred when save but preview was correct.(closed/duplicate)
103135 Change the name of one computed column which are used in dataset filter will cause the dataset filter invalid.(closed/fixed)
103151 When a data set parameter is generated automatically, error message doesn't always pop up.(closed/fixed)
103292 No error message when group key dismatches the interval (closed/fixed)
103296 Data set column doesn't work when it is entered by keyboard in data set filter page.(closed/fixed)
103346 Weekly interval groups by 7 day increments, not by week (resolved/fixed)
103625 Database URL will be refreshed when editing JAR files in Manage drivers dialog (closed/fixed)
104174 If I re-select csv file name, columns selected before in right pane disappeared.(closed/fixed)
104178 Linux:No file listed for '*.*' filter when new a flat file data source (closed/fixed)
104185 An additional column is generated when create a script data set (closed/fixed)
104204 Test connection fail when try to connect birt derby sample db.(closed/fixed)
104397 JDBC Data Set Editor showing empty.system schemas (resolved/fixed)
104452 IllegalArgumentException thrown out when double click on data set after change flatfile data source charset (closed/fixed)
104578 German labels are truncated on Manage JDBC drivers dialog.(verified/fixed)
104611 Smoke Test: Jdbcodbc data source can't be connected.(closed/fixed)
104616 A sql statement with parameter can not be changed if you go out of 'Edit DataSet'->'Query' (closed/fixed)
106250 POJO Data Source (closed/fixed)
103802 Aggregate function in a group footer using Total.OVERALL fails (resolved/fixed)
Data Access (16)
99872 Implementing the ODA Log Configuration in BIRT ODA Drivers (resolved/fixed)
100090 JDBC driver loaded either by data explorer or report viewer (resolved/fixed)
100495 'next' button is grayed out in 'new data source' window when create a data source.(closed/fixed)
100501 NPE thrown out when new a flat file data set (closed/fixed)
101185 NullPointerException thrown out after click on Finish in data set dailog (closed/fixed)
101372 Limit the data set to a particular schema for JDBC connection (resolved/fixed)
102405 Broken display names when Qry has Dup col names (resolved/fixed)
103531 Change data set type from Flatfile Data Set to Flat File Data Set (resolved/fixed)
103533 Change Flatfile Data Source to Flat File Data Source (resolved/fixed)
103544 Allow any filename extension for CSV files (resolved/fixed)
103598 Flat file - Use second line as data type indicator only works for String (resolved/invalid)
103600 Change spelling in error message (resolved/fixed)
103942 Cannot create a JDBC connection (resolved/invalid)
104306 ODA Consumer handling of a null argument for IQuery.prepare (resolved/fixed)
104630 Column icons don't show up in connecting derby database (closed/fixed)
105112 ODA Log Configuration's Optional Attributes (resolved/fixed)
Documentation (3)
101582 Smoke Test: NullPointerException is thrown out when open an existing report design file in which there is grid.(closed/invalid)
101969 Wrong reference in BIRT Developer Guide (closed/fixed)
101977 API document is inconsistent with real implementation (closed/fixed)
Report (7)
87022 Use preservelastmodified in Ant Copy scripts (closed/fixed)
92091 rom.def - allowsUserProperties set to false for Styles, and other entries (resolved/fixed)
101825 Set bold style to grid in property editor and it will be reflected in grid highlight box when you add a highlight rule but will not when you modify it.(closed/fixed)
102496 onRender of Data item isn't executed (resolved/fixed)
102725 DimensionHandle can not parse '1,2in' (resolved/fixed)
103517 Cannot load 'Driver' class (resolved/fixed)
104769 org.eclipse.birt.report.model.metadata.ExtensionException found in meta.log (resolved/fixed)
Report Designer (28)
87803 Data Explorer view doesn't show new data source or data set (resolved/fixed)
87804 Incorrect rendering in BIRT property editor (closed/fixed)
87830 NullPointerException in org.eclipse.birt.report.designer.internal.ui.editors.schematic.ReportDesigner.selectionChanged (resolved/fixed)
88935 Wrong string formatting (upper and lower) (resolved/fixed)
100354 '%datasource.name' is listed in data sources list when create a data source.(closed/fixed)
100964 Provide Support for the Eclipse 3.1 Platform Release (resolved/fixed)
100965 Create a RCP version of BIRT Report Designer (resolved/fixed)
100999 Ctrl+Z.Y doesn't work in expression builder (closed/fixed)
101000 Font is not sorted in order.(closed/fixed)
101586 Exception throw out when new a table group with invalid group field (closed/fixed)
101973 Digit number for ruler displays partially when setting bigger value (closed/fixed)
102598 i18n bug mulitplies numbers by 10 (resolved/fixed)
102713 Undo.Redo can't be refreshed right away after setting hyperlink.(closed/fixed)
102969 Paste should be disabled when nothing is copied (closed/wontfix)
102973 Table group interval shouldn't change after preview (closed/fixed)
103126 hyperlink content in property editor can't be cleared (closed/fixed)
103158 NPE throw out when click on edit group in cheat sheet when delete table group (closed/fixed)
103171 edit the dynamic text won't restore last expression to expression builder (closed/invalid)
103526 New Data Set dialog box has red square on right side (resolved/fixed)
103788 Display inconsistantly in BIRT GUI (closed/fixed)
103962 RCP:Project icon can not displayed (closed/wontfix)
104184 The button in Dataset.Filters can not work (closed/fixed)
104307 when group on a double type field, set interval less than zero should be permitted (closed/fixed)
104617 In chinese testing environment, translation need to be improved.(closed/fixed)
104623 Highlight preview doesn't work when change two highlight rules order.(closed/fixed)
104764 Acceptance Test: New Report repeatly produces same name of file (closed/fixed)
101403 Smoke Test: Property editor view doesn't work.(closed/fixed)
101407 NullPointerException when selecting Save As in top menu (closed/fixed)
Report Engine (14)
96357 Projects contain errors when opened in Eclipse (resolved/worksforme)
101361 Bugs in org.eclipse.birt.report.engine.extension.internal.ExtensionManager (resolved/fixed)
101685 Unable to use the Report Item Extension framework, when no query exists (resolved/fixed)
101751 Enhance IImagehandler interface to allow full customization of birt image handling mechanism (resolved/fixed)
103050 PDF Hyperlinks (resolved/fixed)
103106 Generates incompatible FOP files (resolved/fixed)
103120 Hyperlink file can't be retrived when click it in PDF page (closed/invalid)
103169 Format number with Symbol prefix should display right size when preview in Linux (closed/wontfix)
103449 Log BIRT extension loading details information (resolved/fixed)
103622 Inline for two grids doesn't work in layout view and pdf preview.(closed/duplicate)
104172 Blank pages will be generated when set Page Break to always.left.right.(closed/invalid)
104239 Value-Of Problem (resolved/fixed)
104457 Set table drop to all, preview does not take effect.(closed/worksforme)
104629 Generating report in custom plugin cause exception fop.xml malformed URL (resolved/fixed)
Report Viewer (5)
Birt Report Pojo Data Source Example
100596 DateTime parameters not functioning as report parameters (resolved/invalid)
104177 Spaces in parameter value which is entered are trimmed when previewed in html.(closed/wontfix)
104462 There is a parameter in a parameter group, 'show report parameters' button is always grayed out when previewed.(closed/fixed)
104759 Image imported from a related path in file system can't be previewed.(closed/invalid)
104962 Smoke Test: Data can't be displayed when previewed if data source type is 'sample datasource' or 'JDBC Data Source' except 'JDBCODBC driver'.(closed/fixed)
Test Suite (1)
100968 Provide Daily Build Test Reports on eclipse.org.birt Web Site (closed/fixed)
In a previous blog post I created a skeleton class for rendering a report using BIRT runtime. You can pass it the report parameters, the report definition (rptdesign) and an OutputStream and it will render HTML to that stream.
If your report definition contains graphs we run into a problem. Normally, in HTML an image is a separate resource. BIRT will generate the images containing your graphs in a temporary directory and will link to them in your HTML. For this to work, you will have to configure the Platform to write the images to a publicly accessible directory and write the links using the correct domains. Furthermore, you’ll probably need some process to clean up the images after the reports have been viewed. If your reports are being used in some website and generated on the fly, this is most likely quite difficult to determine. Maybe when the user logs out?
Luckily, in modern browsers we can embed the images in the same stream, bypassing the need of a temporary directory. The following trick will encode the image with base64 and embed it directly into the HTML stream using css data . This will work on most modern browsers but of course Internet Explorer lags a bit behind. PNG support is available up until 32kb in Internet Explorer 8 and SVG not at all. Internet Explorer 9 works fine, as well as the other major browsers.
So how does it work? First, we explicitly tell the render engine to use PNG or SVG. SVG provides sharper images but will not work in Internet Explorer 8 as mentioned above. Next, we inject our own HTMLServerImageHandler which encodes the image data to base64.
Birt Pojo Data Source Example
2
4
6
8
10
12
14
16
18
20
22
24
privateHTMLRenderOption getHtmlRenderOptions(OutputStream outs)(
HTMLRenderOption options=newHTMLRenderOption();
options.setSupportedImageFormats('SVG');
options.setSupportedImageFormats('PNG');
setupImageHandler(options);
options.setOutputFormat('html');
)
privatevoidsetupImageHandler(finalHTMLRenderOption options)(
options.setImageHandler(newHTMLServerImageHandler()(
protectedStringhandleImage(IImage image,Objectcontext,Stringprefix,booleanneedMap)(
StringembeddedImage=Base64.encode(image.getImageData(),false);
return'data:'+image.getMimeType()+';base64,'+embeddedImage;
));
Birt Pojo Data Source Examples
Some references:
1 note
·
View note
Text
Create Custom Subtotal Labels & Add Glow, 3D Effects for Shapes in Worksheet inside Android Apps
What’s new in this release?
Aspose development team is pleased to announce the new release of Aspose.Cells for Android v16.12.0. This release includes a number of new features, enhancements and bug fixes that further improve the overall stability and usability of the API. It has added the support for the creation of custom subtotal labels allowing the application developers to customize the labels according to the region or personal preferences. In order to provide this feature, the latest version of the Aspose.Cells for Android has exposed the GlobalizationSettings class offering the following 2 methods which can be overridden in a custom class to get desired labels for the Subtotals. The GlobalizationSettings class also offers the getOtherName method which is useful to give the “Other” label of Pie charts a custom value. Sometimes, application requirement could be to load just a particular type of objects while loading existing spreadsheets in Aspose.Cells’ object model. For instance, users may require to load only the cells along with formulas & formatting or just the document properties. Aspose.Cells APIs now provide a flexible yet comprehensive mechanism to achieve such requirements by exposing the LoadFilter class. The LoadFilter class along with LoadOptions.LoadFilter property can control the type of data/objects to be loaded while initializing an instance of Workbook from a template file. The constructor of the LoadFilter class can accept constant(s) from the LoadDataFilterOptions enumeration that specifies the type of objects to be loaded. It has added the support for reflection effects for a Shape object as Excel provides it via Effects tab under Format Shape dialog as shown on the blog announcement page. It has also added the support for Shadow Effects for a Shape object as Excel provides it via Effects tab under Format Shape dialog. It also supports the Glow Effects for a Shape object and 3-D Formats for Shape objects as Excel provides it via Effects tab under Format Shape dialog. Aspose.Cells for Android APIs now supports to add WordArt objects with built-in styles. In order to provide this feature, it has exposed the ShapeCollection.AddWordArt method along with PresetWordArtStyle enumeration which together allows to add preset WordArt objects since Excel 2007. It has fixed a few critical bugs as well as enhanced its core for more stability. This release includes plenty of improved features and bug fixes as listed below
Support Subtotal/Total labels in other languages
Specify Chart points' positions
Refreshing PivotTable is not working in the rendered PDF file
XLSM becomes corrupted by simple load and save operation
Hyperlinks are not working as expected after converting spreadsheet to HTML
Some characters do not render in the output PDF
Order of chart legend changed in Chart's PDF
Z order of high-low lines is not correct in PDF
Spreadsheet becomes corrupted after re-saving with Aspose.Cells
Formula is changed after inserting to a cell
Strange behaviour with simple bean using Smart Markers
Cell's text overflows to next cell
CalculateFormula has issue to recalculate cells with reference to cells with formulas
Hebrew control characters are not rendered correctly in PDF
XLS to PDF conversion is taking too much time
Layout problem when converting spreadsheet to PDF
X-axis labels are overlapping with Legend when rendered to PDF
Picture does not scale well and its SVG file is not correct
Incorrect rendering of Chart while converting spreadsheet to HTML
Spaces are omitted from text in PNG output of Chart
Selection or check state not saved when saving to PDF
Text and text alignment is messed up in the file
Extending MS Excel table/ list object changes cells formatting
Adding Arc to a new Workbook generates a potentially unsafe spreadsheet
Table column resolving broken if containing '['
Issue with extending Excel Table/List Object content regarding formulas
Incorrect formula returned from a worksheet cell
XLSM becomes corrupted after re-save operation
DataBar width is not correct while converting spreadsheet to HTML
Orange Row is not included in the Sum of Pivot Table
Image is cut off in the output HTML
Chart is missing while converting spreadsheet to HTML
Row height is not correct while converting XLSX to HTML
DCOUNTA Excel formula is not evaluated fine by Aspose.Cells formula calculation engine
Issue with DataBar Conditional Formatting when Saving an XLSM file as PDF
The space between certain characters gets removed at a few places in the output PDF file
Chart labels are not displayed/rendered the same (as per the original Excel file) in the output PDF file
Issue with font attributes of TextBox in the output PDF
TextBox's content color & size is changed while converting worksheet to EMF
TextBox's content color & size is changed while converting spreadsheet to PDF
Hebrew words are not rendered correctly when converting an Excel file to PDF file format
Content in TextBox is clipped while rendering spreadsheet to PDF
Arrowed lines are misplaced while rendering spreadsheet to PDF
Issue with the SVG image of the Chart in the rendered HTML file
Font substitution does not seem to take effect for Chart legend while using Chart.toPdf
Legend overlapping with text in Chart's PDF
Incorrect ChartPoint's ShapeXPx & ShapeYPx values
Incomplete rendering of the Rectangle shape while converting XLS to HTML
Text is getting truncated while converting spreadsheet to PDF file format
Extra pages are added due to some pages are not rendered completely in one PDF page
SheetRender - Invalid column index
Extending Excel Table modifies data
Opening and saving the file while using SheetRender corrupts the output Excel file
Setting the shape text changes the text style
Text of some cells like C2 and C3 gets unbold
Worksheet.autoFitColumns method does not seem to take effect when required font is not present in Linux
Unexpected background color applied to TextBoxes while rendering spreadsheet to PDF
Other most recent bug fixes are also included in this release.
Newly added documentation pages and articles
Some new tips and articles have now been added into Aspose.Cells for Android documentation that may guide users briefly how to use Aspose.Cells for performing different tasks like the followings.
Filtering Objects while Loading Template Spreadsheets
Managing Reflection Effects for Shapes
Overview: Aspose.Cells for Android
Aspose.Cells for Android is a MS Excel spreadsheet component that allows programmer to develop android applications for reading, writing & manipulate Excel spreadsheets (XLS, XLSX, XLSM, SpreadsheetML, CSV, tab delimited) and HTML file formats without needing to rely on Microsoft Excel. It supports robust formula calculation engine, pivot tables, VBA, workbook encryption, named ranges, custom charts, spreadsheet formatting, drawing objects like images, OLE objects & importing or creating charts.
More about Aspose.Cells for .NET
Homepage of Aspose.Cells for Android
Download Aspose.Cells for Android
#Create Custom Subtotal Labels#Render Other Label for Pie Chart#Filter Object for Loading Templates#Reflection Effects Support#Shadow Effects Support#Glow Effects Support#Android Excel API
0 notes
Text
Segoe ui font family for mac

You may use this font to create, display and print content as permitted by the license terms, or terms of use, of the Microsoft product, service or content in which this font was included. Looking inside the Segoe UI font, you can find the licensing information for the font: As such, the font is not available to you in any application running under MacOS, including Acrobat. The Segoe UI font family is not installed by Apple on MacOS nor does Microsoft install it with Microsoft Office. The font was designed by and owned by Microsoft. The font family supports a very wide range of character sets and symbols. they show up on font menus on any and all Windows applications that support TrueType font technology. Those fonts are used for system purposes but are also available for use by any and all Windows applications, i.e. Here is a view of Power BI’s available font families as seen in both Service and Desktop, and click here to learn how you can use Power BI Themes to do even more with font selection.The Segoe UI font family is available on Windows systems by virtue of that font family being installed by Microsoft as part of Windows itself. I have not checked to see if this is peculiar to my local installation, but all fonts render correctly once you publish the report to Power BI Service. ArialĬuriously, both Symbol and Wingdings do not render well in Power BI Desktop. Here is a complete list of Power BI’s currently available fonts. The Microsoft Typography site has descriptions of Power BI’s fonts (and more) as well as notes about their ideal application. Consolas has more of a distinct, “technical” appearance. By changing the font and nothing else about the report, it takes on a noticeably different character. Note how the New Hires page from Power BI’s Human Resources Sample has a slightly different visual tone when the type appears as the default Segoe UI versus a monospaced font such as Consolas. Seek out a font that reads well in the intended medium. When selecting font families, consider your audience and how they will consume the report (primarily mobile app, web browser, or print). Try not to blend too many typefaces on a report page. Even reputable authorities such as Saturday Night Live have recently jumped on the font selection bandwagon.Ĭonsistency is also important. Other fonts come with historical baggage or will be criticized by font snobs many designers (for example, Comic Sans is to font snobbery design what a pie chart is to current views about effective data visualization). Some fonts don’t work at all for common use but are available for specialized reasons, such as Wingdings. The default font family is Segoe UI for labels and Segoe UI Light for text boxes.įont selection can unintentionally make or break a report. Some fonts work well as typeface in print, others work well when viewed on the web, and others read well in a variety of media. As of January 2018, Power BI offers 23 different font families for text boxes and various types of labels. With the June 2017 Power BI Desktop update, the ability to change between font families expanded substantially. Font selection is one important but often overlooked aspect of creating content in Power BI.
0 notes
Text
Introducing Charts v3
Formally developed by SeyDesign / Nimblehost, the Charts stack has received a major update this past weekend. To check if you are eligible for a free update, you can login to your Paddle account to see if Charts is listed there. For everybody else, the latest trial version and purchase links for Charts can be found on the product page. Charts is included in the Black Friday promo.
Charts is a handy little stack if you need to convert a CSV spreadsheet file into basic line charts, bar charts, pie charts, scatterplots, area charts, meter gauges or doughnut circles. These can be useful to visually display simple data on websites or webapps. A wide choice of style options within the Charts stack allow you to customise the generated charts and graphs to match your existing theme or corporate branding.
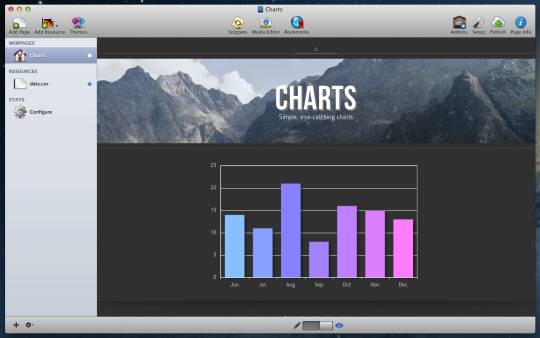
As before, the Charts stack works from a CSV file you supply. Most spreadsheet software can generate CSV files. This offers a quick method towards getting your axis labels and datasets loaded into Charts; with zero code required. Charts does all the hard work for you, to convert your CSV data into beautiful charts. You can either use CSV files added as resources in RapidWeaver or link to CSV files already stored on your web hosting account.
Changes in Charts v3 include:
Generated charts can now be previewed in RapidWeaver.
Fixed a problem that resulted in bar and line point labels missing.
Greatly improved the handling of multiple Chart stacks, when they are configured differently to each other on the same webpage.
Fixed a problem, whereby graph axis labels would always get shown on the pie and doughnut chart types, where one was not needed.
New options to specify a maximum width or height, in your preferred units of measurement (e.g. %, px, rem, vw, vh).
All colour pickers now support RGBa colour opacity.
Fixed a bug that was causing a thick black line to be rendered under chart canvases in Foundation 6.
Requested by a user, the starting angle of doughnut and pie charts can now be customised in degrees.
Updated some stack setting labels and informational tooltips, to make setup quicker and easier.
Dropped support for Internet Explorer 8 and less. These web browsers have been officially obsolete for some years. Few people use these browsers anymore. This has the benefit of greatly reducing the amount of code everybody else has to load.
Fixed a bug that caused Meter Gauges to vanish if a chart further up the page had more than 8 data points and labels enabled (yeah - I had hours of fun trying to find and fix this one)!
New background colour and font size options for chart legends.
Reorganised and regrouped a few of the stack settings, to make things easier to find.
As requested by a user, it is now possible to rotate both x-axis and y-axis ticks, on bar and line charts.
Support has been added for Area Charts. These can be accomplished by using the existing Line Chart type, and selecting the Area Plot checkbox (in Line Chart Options).
New stack icons and a few other tidbits of information required by newer versions of Stacks and RapidWeaver. Rewrote the buggy '&&' operator conditional statements.
Added the ability to toggle the chart box shadow effects on and off using a single checkbox option.
Cleaned up 'edit mode' to display less information about Charts. Important messages are still displayed if something is configured incorrectly.
New number box to change the sizing of point labels on bar charts.
Perhaps the biggest feature of all is that Charts is now fully responsive. This means that generated charts or graphs will scale-down to fit tablets and smartphones. Therefore removing the need to create multiple charts for different screen sizes. I know this has been a frequent user request for many years! Major technical hurdles had to be overcome, which meant rewriting a large portion of the underlying codebase and reconnecting all the settings. Charts will now redraw each time the screen is resized or changes orientation.
The product page for Charts has been updated with all new documentation. I have also put together a RapidWeaver 8 project file you can download. This contains several real working examples of Charts that you can experiment with. These tests work with the free trial version of Charts and the paid version.
Charts v3 will identify itself as a new stack and can be installed alongside older versions. Given the magnitude of changes, it will not attempt to convert or update older versions. This newest version of Charts has a bright orange and white icon.
Also of note, I have updated the LineGraph stack too. This one is a good option if you are only interested to making responsive line graphs (including area charts and scatterplots).
0 notes
Text
New Post has been published on Strange Hoot - How To’s, Reviews, Comparisons, Top 10s, & Tech Guide
New Post has been published on https://strangehoot.com/how-to-find-robust-library-of-flutter/
How to find robust library of Flutter - Flutter Libraries

Introduction
One of the biggest challenges in application development for larger organizations is to maintain application codebase for different client platforms. As per latest trends, most organizations develop their software products/apps for android, iOS smartphones along with Web platforms.
Technology Stack
For android native apps development, the developers use Android SDK and it’s libraries,
As for iOS apps development, the developers use Swift language.
For Web, the developers use reactJS, AngularJS or any UI framework best suited for their products/apps.
Challenges in Mobile App Development
Let us understand the real life challenges that most organizations come across while developing software products/apps for their business and operations.
Platform Specific Codebase and Maintenance
Above all, it becomes a challenge to maintain a codebase for 3 different platforms and keep updating features based on the continuously changing business demands and requirements.
Infrastructure cost is an additional overhead. Maintaining version for each platform requires additional servers and as a result, DevOps cost increases.
Need for Technical Expertise for each Platform
Another bigger challenge for organizations is developer resources having technical expertise in Android, iOS and Web may be different. Managing the changing requirements and implementing the features that should be developed on all three channels and with the same understanding is again a time consuming process in itself. Also, bug fixes and enhancements take their own time to move them into production. Even if one developer resource having expertise in all three platforms also will take the same amount of time because the codebase is different for all app platforms.

A need for a common UI framework has arised looking at the above challenges.
What is Flutter?
Analysing such complexities in app development, Google has introduced Flutter UI toolkit which is free and an open source. It is used to create a single codebase for multiple native app platforms such as Windows, Linux, Android and macOS.
Flutter is the latest app development framework that works as a single solution for making beautiful UI for Windows, Android and iOS apps. Back-end logic APIs can be integrated once for all these UI platforms to build features.
Let us understand Flutter a little more from the architectural view. Flutter is a 3-layered system comprising independent libraries. Each library belongs to underlying layers. The Flutter libraries are important because UI logic that needs to be built separately for native app platforms is done by these libraries as a single task.
Flutter Layers are –
Dart Framework
Dart is a language in which the Flutter framework is written. The framework consists of many UI libraries such as material, cupertino, widgets layer, rendering layer and commonly used abstractions such as animation, painting and gestures. The developers can add platform specific plugins such as camera and WebView to develop the domain specific features. Application widgets are composed and converted into objects and rendered on UI.
C/C++ Engine
Flutter uses Skia as a part of the graphic engine to render UI elements and does not use operating system specific rendering libraries that need lots of interaction between UI and the app logic. The flutter engine provides its own widget set that minimizes abstractions of other native platforms and improvises the performance.
Embedder
Embedder is responsible for hosting Flutter’s content and it is agnostic of operating system platforms. Input gestures, thread management, window sizing are managed by the embedder. Flutter includes embedders for android, iOS, Linux, Windows and macOS. The developer can also write a custom embedder for the specific platform that can be added to build an app for that specific platform.

Android SDK and Flutter
Android developers can install Flutter and Dart plugins in Android Studio to develop an app in Flutter framework.
To install flutter in Android SDK, follow the steps below:
Open Android Studio in your PC/laptop/macbook.
From the Configure menu, click Plugins.
Select Flutter and click Install. A prompt to install the Dart plugin appears.
Click Yes.
Click Restart once installation is complete.
Once installation is complete, create a new Flutter project and start the development. Flutter provides Material Design and Cupertino widgets to create beautiful UI design for android and iOS platforms.
To use advanced features in your flutter app, use libraries that will help you implement the functionality at fingertips.
Flutter Libraries
Business requirements to develop specific features in mobile apps are diverse and product specific. Not all features are covered in the Flutter framework or Dart plugin. Developers need to keep themselves up-to-date about the libraries that are used to implement domain specific features and take external library support.
There are libraries supporting Flutter framework in Android and iOS to implement the domain specific features.
Let us understand which type of libraries are available and useful for integrating in your Flutter app.
Chart Library
Analytics is a buzzword today. Showing data in the form of charts is a trending pattern in finance, healthcare, entertainment, sports and education industries.
flutter_charts
The chart library is written in the Dart package of Flutter. It supports column charts and line charts to show data.
The library includes data, options and classes that are used for plotting the chart, adjusting data points and showing legend. It’s iterative auto layout feature facilitates adjusting the chart data based on the UI real-estate available. Labels on X-axis and Y-axis are adjusted in the following ways –
Tilting labels
Decreasing font size of labels
Skipping some labels
This helps fitting the chart in readable format and does not overflow data points on the chart.
For more information on this library, please visit https://github.com/mzimmerm/flutter_charts
fl_chart
The library supports pie chart, line chart and bar chart with customizable parameters that gives a beautiful look and feel of the chart with animations.
To use this library with Flutter framework, please visit https://github.com/imaNNeoFighT/fl_chart for more information.
Map Library
Another most frequently used feature in apps is map. Many widget libraries for maps are available that are being used with Google Maps API.
google_maps_place_picker
The plug-in provides the place picker on Google Maps in Flutter. To use this plugin, Google Map SDK in Android and iOS needs to be enabled. In addition to that, Places API, Geolocation API and Geocoding API are required to be enabled.
For more information on this library, please visit https://github.com/fysoul17/google_maps_place_picker
Local Storage Library
Apps with more content take time to load each time a request is made on a Web server and to fetch the data. Below library is used as one of the solution to store images locally.
cached_network_image
The CachedNetworkImage library can be used to download images from the Web and store them in the cache directory. The stored images will load faster from local storage and improvise the performance. The library is used with placeholder and error widgets.
For more information, please visit https://github.com/Baseflow/flutter_cached_network_image
Errors, Warning, Notification Styling Library
Notifying the user on apps via error messages, information messages or warning messages is common, yet a very important UI feature.
flushbar
In Android, toasts and snackbars are used to show messages. The flushbar library provides lots of styling properties to show the notifications.
Customizations for styles, padding, border, text, background, shadows, icon and button actions, progress indicator, animation curves, input text are available with properties.
How to use this customer widget, please visit https://github.com/AndreHaueisen/flushbar.
Conclusion
Using the above libraries in Flutter app development helps reduce development time. In addition to that, using the right set of tools help developers to minimize the research and focus on the quality of writing the code. You can find the robust library of Flutter based on your app specific requirements and your hands-on experience of working with libraries and packages in the framework you are using.
Read More: How Is Artificial Intelligence Enabling Improved Decision Making For Oil And Gas Business?
0 notes
Text
E-Paper Module Market Overview, Growth & Advancement to (2019-2025)

Global E-Paper Module Market to 2025 based on segments, growth rate, revenue, leading players, regions and forecast. The E-Paper Module market is escalating at a rapid pace with the invention of the new dynamism that is progressing rapidly.
Objective:
The global E-Paper Module market report is comprehensive research which delivers critical predictions. Our research analysts curated the Table of Contents as per the latest trends and requirements, and the report provides the precise calculation of the E-Paper Module market regarding the advanced development which depends on the historical data and current condition of industry status. It renders the required secondary data that represents the E-Paper Module tables, figures, pie charts, diagrams, etc.
Grab Free Sample Report at: http://www.marketresearchglobe.com/request-sample/955327
Global E-Paper Module Market Segment by Manufacturers comprises:E Ink, OED, Qualcomm, Liquavistar, Plastic Logic, Pervisive Displays, LG Display, Gamma Dynamics, ITRI
E-Paper Module Market With Product Types:
Standard (1-3 Inch)
Mid-Large (3.1-6 Inch)
Large (6.1-10 Inch)
Above 10 Inch
From Applications, the E-Paper Module Market could be Put up:
E-Reader
Electronic Shelf Label
Other
E-Paper Module Market Segment by Regions comprises:
North America, Europe, Asia-Pacific, South America and The Middle East and Africa.
Points Presented in the E-Paper Module Report:
E-Paper Module Research offers businesses a list that's currently choosing the most expansion.
Shows threatening contracts and E-Paper Module impending relation between material providers and vendors and vendors.
Facets of E-Paper Module industry and success are functioned in this study.
Skilled E-Paper Module SWOT (Strengths, Weaknesses, Opportunities, and Risks) and also PESTEL (Political, Economic, Social, Technological, Environmental and Legal) research is supreme.
Import/send-out detail, E-Paper Module type analysis, prediction planning and approaches profit, and also technological progress of manufacturers are mentioned in this research.
Get it in Discounted Price at: http://www.marketresearchglobe.com/check-discount/955327
Additionally, the E-Paper Module factors highlighted in the report are revenue, sales, manufacturing cost and production, which states the competitive aspect in the lucrative idea of the market share. The E-Paper Module economic background and financial troubles across the globe are discussed in the report along with the CAGR value during the forecast period up to 2025.
Precisely What E-Paper Module Market Report Offers:
E-Paper Module market offers evaluations for your county level evaluation together using manufacture, ingestion, earnings;
Industry supplies E-Paper Module businesses with gross profit margin, merchandise classification, revenue earnings, cost, and advice;
Market predictions of five decades of the E-Paper Module segments;
In the E-Paper Module pipeline for the applicants;
Business series E-Paper Module investigation, procedures, manufacture and cost inquiry, style of transportation and price evaluation;
E-Paper Module supply chain series tendencies planning the brand new progressions;
International E-Paper Module market stocks drivers, limitations, prospects, dangers, challenges and investment prospects;
Company summarizing with E-Paper Module methodical plans, financials, and also current advancements;
Ask our Expert Enquire Here: http://www.marketresearchglobe.com/send-an-enquiry/955327
About Us: Market Research Globe is a competent consulting company in the field of Global Market Research. We provide our clients a wide range of customized Marketing and Business Research Solutions to choose from, with the help of our ingenious database developed by experts. We help our clients understand the strengths of diverse markets and how to exploit opportunities. Covering a diverse range of business scopes from Digital products to Food industry, we are your one- stop solution right from data collection to investment advices.
Contact Us: Market Research Globe Call:+1-888-376-9998 Email: [email protected] News: https://peopleheraldtoday.com
0 notes
Text
Simple Interactive Pie Chart with CSS Variables and Houdini Magic
I got the idea for doing something of the kind when I stumbled across this interactive SVG pie chart. While the SVG code is as compact as it gets (a single <circle> element!), using strokes for creating pie chart slices is problematic as we run into rendering issues on Windows for Firefox and Edge. Plus, in 2018, we can accomplish a lot more with a lot less JavaScript!
AI got the following result down to a single HTML element for the chart and very little JavaScript. The future should completely eliminate the need for any JavaScript, but more on that later.

The final pie chart result.
Some of you may remember Lea Verou's Missing Slice talk—my solution is based on her technique. This article dissects how it all works, showing what we can do in terms of graceful degradation and other ways this technique can be put to use.
The HTML
We use Pug to generate the HTML from a data object that contains unitless percentage values for the past three years:
- var data = { 2016: 20, 2017: 26, 2018: 29 }
We make all our elements reside in a .wrap element. Then, we loop through our data object and, for each of its properties, we create a radio input with a corresponding label. After these, we add a .pie element to the mix.
- var darr = [], val; .wrap - for(var p in data) { - if(!val) val = data[p]; input(id=`o${p}` name='o' type='radio' checked=val == data[p]) label(for=`o${p}`) #{p} - darr.push(`${data[p]}% for year ${p}`) - } .pie(aria-label=`Value as pie chart. ${darr.join(', ')}.` role='graphics-document group')
Note that we also made sure only the first radio input is checked.
Passing custom properties to the CSS
I normally don't like putting styles in HTML but, in this particular case, it's a very useful way to pass custom property values to the CSS and ensure that we only need to update things in one place if we need to change any of our data points—the Pug code. The CSS remains the same.
The trick is to set a unitless percentage --p on the .pie element for every radio input that might be checked:
style - for(var p in data) { | #o#{p}:checked ~ .pie { --p: #{data[p]} } - }
We use this percentage for a conic-gradient() on the .pie element after making sure neither of its dimensions (including border and padding) are 0:
$d: 20rem; .wrap { width: $d; } .pie { padding: 50%; background: conic-gradient(#ab3e5b calc(var(--p)*1%), #ef746f 0%); }
Note that this requires native conic-gradient() support since the polyfill doesn't work with CSS variables. At the moment, this limits support to Blink browsers with the Experimental Web Platform features flag enabled, though things are bound to get better.

The Experimental Web Platform features flag enabled in Chrome.
We now have a working skeleton of our demo—picking a different year via the radio buttons results in a different conic-gradient()!

The basic functionality we've been after (live demo, Blink browsers with flag enabled only).
Displaying the value
The next step is to actually display the current value and we do this via a pseudo-element. Unfortunately, number-valued CSS variables cannot be used for the value of the content property, so we get around this by using the counter() hack.
.pie:after { counter-reset: p var(--p); content: counter(p) '%'; }
We've also tweaked the color and font-size properties so that our pseudo-element is a bit more visible:

Displaying the value on the chart (live demo, Blink browsers with flag enabled only).
Smoothing things out
We don't want abrupt changes between values, so we smooth things out with the help of a CSS transition. Before we can transition or animate the --p variable, we need to register it in JavaScript:
CSS.registerProperty({ name: '--p', syntax: '<integer>', initialValue: 0, inherits: true });
Note that using <number> instead of <integer> causes the displayed value to go to 0 during the transition as our counter needs an integer. Thanks to Lea Verou for helping me figure this out!
Also note that explicitly setting inherits is mandatory. This wasn't the case until recently.
This is all the JavaScript we need for this demo and, in the future, we shouldn't even need this much as we'll be able to register custom properties from the CSS.
With that out of the way, we can add a transition on our .pie element.
.pie { /* same styles as before */ transition: --p .5s; }
And that's it for the functionality! All done with one element, one custom variable, and a sprinkle of Houdini magic!

Interactive pie chart (live demo, Blink browsers with flag enabled only).
Prettifying touches
While our demo is functional, it looks anything but pretty at this point. So, let's take care of that while we're at it!
Making the pie... a pie!
Since the presence of :after has increased the height of its .pie parent, we absolutely position it. And since we want our .pie element to look more like an actual pie, we make it round with border-radius: 50%.

Rounding up our pie (live demo, Blink browsers with flag enabled only).
We also want to display the percentage value in the middle of the dark pie slice.
In order to do this, we first position it dead in the middle of the .pie element. By default, the :after pseudo-element is displayed after its parent's content. Since .pie has no content in this case, the top-left corner of the :after pseudo-element is in the top-left corner of the parent's content-box. Here, the content-box is a 0x0 box in the center of the padding-box. Remember that we've set the padding of .pie to 50%—a value that's relative to the wrapper width for both the horizontal and the vertical direction!
This means the top-left corner of :after is in the middle of its parent, so a translate(-50%, -50%) on it shifts it to the left by half its own width and up by half its own height, making its own mid-point coincide with that of .pie.
Remember that %-valued translations are relative to the dimensions of the element they're applied on along the corresponding axis. In other words, a %-valued translation along the x-axis is relative to the element's width, a %-valued translation along the y-axis is relative to its height and a %-valued translation along the z-axis is relative to its depth, which is always 0 because all elements are flat two-dimensional boxes with 0 depth along the third axis.

Positioning the value label in the middle of the pie (live demo, Blink browsers with flag enabled only).
Next, we rotate the value such that the positive half of its x-axis splits the dark slice into two equal halves and then translate it by half a pie radius along this now-rotated x-axis.
See the Pen by thebabydino (@thebabydino) on CodePen.
What we need to figure out is how much to rotate the :after pseudo-element so that its x-axis splits the dark slice into two equal halves. Let's break that down!
Initially, the x-axis is horizontal, pointing towards the right, so in order to have it in the desired direction, we first need to rotate it so that it points up and going along the starting edge of the slice. Then it needs to rotate clockwise by half a slice.
In order to get the axis to point up, we need to rotate it by -90deg. The minus sign is due to the fact that positive values follow a clockwise direction and we're going the other way.
See the Pen by thebabydino (@thebabydino) on CodePen.
Next, we need to rotate it by half a slice.
See the Pen by thebabydino (@thebabydino) on CodePen.
But how much is half a slice?
Well, we already know what percentage of the pie this slice represents: it's our custom property, --p. If we divide that value by 100 and then multiply it by 360deg (or 1turn, it doesn't matter what unit is used), we get the central angle of our dark slice.
After the -90deg rotation, we need to rotate :after by half this central angle in the clockwise (positive) direction.
This means we apply the following transform chain:
translate(-50%, -50%) rotate(calc(.5*var(--p)/100*1turn - 90deg)) translate(.25*$d);
The last translation is by a quarter of $d, which is the wrapper width and gives us the .pie diameter as well. (Since the content-box of .pie is a 0x0 box, it has no border and both its left and right padding are 50% of its wrapper parent width.) The .pie radius is half its diameter, meaning that half the radius is a quarter of the diameter ($d).
Now the value label is positioned where we want it to be:

Positioning the value label in the middle of the slice (live demo, Blink browsers with flag enabled only).
However, there's still one problem: we don't want it to be rotated, as that can look really awkward and neck-bending at certain angles. In order to fix this, we revert the rotation at the end. To make things easier for ourselves, we store the rotation angle in a CSS variable that we'll call --a:
--a: calc(.5*var(--p)/100*1turn - 90deg); transform: translate(-50%, -50%) rotate(var(--a)) translate(.25*$d) rotate(calc(-1*var(--a)));
Much better!

Positioning the value label in the middle of the slice, now horizontal (live demo, Blink browsers with flag enabled only).
Layout
We want to have the whole assembly in the middle of the screen, so we solve this with a neat little grid trick:
body { display: grid; place-items: center center; margin: 0; min-height: 100vh }
Alright, this puts the entire .wrap element in the middle:

Positioning the whole assembly in the middle (live demo, Blink browsers with flag enabled only).
The next step is to place the pie chart above the radio buttons. We do this with a flexbox layout on the .wrap element:
.wrap { display: flex; flex-wrap: wrap-reverse; justify-content: center; width: $d; }

Placing the pie chart above the radio buttons (live demo, Blink browsers with flag enabled only).
Styling the radio buttons
...or more accurately, we're styling the radio button labels because the first thing that we do is hide the radio inputs:
[type='radio'] { position: absolute; left: -100vw; }

After hiding the radio buttons (live demo, Blink browsers with flag enabled only).
Since this leaves us with some very ugly labels that are very hard to distinguish from one another, let's give each one some margin and padding so they don't look so crammed together, plus backgrounds so that their clickable areas are clearly highlighted. We can even add box and text shadows for some 3D effects. And, of course, we can create a separate case for when their corresponding inputs are :checked.
$c: #ecf081 #b3cc57; [type='radio'] { /* same as before */ + label { margin: 3em .5em .5em; padding: .25em .5em; border-radius: 5px; box-shadow: 1px 1px nth($c, 2); background: nth($c, 1); font-size: 1.25em; text-shadow: 1px 1px #fff; cursor: pointer; } &:checked { + label { box-shadow: inset -1px -1px nth($c, 1); background: nth($c, 2); color: #fff; text-shadow: 1px 1px #000; } } }
We've also blown up the font-size a bit and set a border-radius to smooth out the corners:

After styling the radio button labels (live demo, Blink browsers with flag enabled only).
Final prettifying touches
Let's set a background on the body, tweak the font of the whole thing and add a transition for the radio labels:

The final pie chart result (live demo, Blink browsers with flag enabled only).
Graceful degradation
While our demo now looks good in Blink browsers with the flag enabled, it looks awful in all other browsers...and that's most browsers!
First off, let's put our work inside a @supports block that checks for native conic-gradient() support so the browsers that support it will render the pie chart. This includes our conic-gradient(), the padding that gives the pie equal horizontal and vertical dimensions, the border-radius that makes the pie circular, and the transform chain that positions the value label in the middle of the pie slice.
.pie { @supports (background: conic-gradient(tan, red)) { padding: 50%; border-radius: 50%; background: conic-gradient(var(--stop-list)); --a: calc(.5*var(--p)/100*1turn - 90deg); --pos: rotate(var(--a)) translate(#{.25*$d}) rotate(calc(-1*var(--a))); } } }
Now, let's construct a bar chart as a fallback for all other browsers using linear-gradient(). We want our bar to stretch across the .wrap element so that the horizontal padding is still 50%, but vertically as a narrow bar. We still want the chart to be tall enough to fit the value label. This means we will go with smaller vertical padding. We will also decrease the border-radius, since 50% would give us an ellipse and what we need is a rectangle with slightly rounded corners.
The fallback will also replace conic-gradient() with a left-to-right linear-gradient(). Since both the linear-gradient() creating the fallback bar chart and the conic-gradient() creating the pie chart use the same stop list, we can store it in a CSS variable (--stop-list) so that we don't even have it repeated in the compiled CSS.
Finally, we want the value label in the middle of the bar for the fallback since we don't have pie slices anymore. This means we store all the post-centering positioning into a CSS variable (--pos) whose value is nothing in the no conic-gradient() support case and the transform chain:
.pie { padding: 1.5em 50%; border-radius: 5px; --stop-list: #ab3e5b calc(var(--p)*1%), #ef746f 0%; background: linear-gradient(90deg, var(--stop-list)); /* same as before */ &:after { transform: translate(-50%, -50%) var(--pos, #{unquote(' ')}); /* same as before */ } @supports (background: conic-gradient(tan, red)) { padding: 50%; border-radius: 50%; background: conic-gradient(var(--stop-list)); --a: calc(.5*var(--p)/100*1turn - 90deg); --pos: rotate(var(--a)) translate(#{.25*$d}) rotate(calc(-1*var(--a))); } } }
We also switch to using a flexbox layout on the body (since, as clever as it may be, the grid one is messed up in Edge).
body { display: flex; align-items: center; justify-content: center; /* same as before */ }
This all gives us a bar chart fallback for the browsers not supporting conic-gradient().

The fallback for the final pie chart result (live demo).
Responsifying it all
The one problem we still have is that, if the viewport is narrower than the pie diameter, things don't look so good anymore.
CSS variables and media queries to the rescue!
We set the diameter to a CSS variable (--d) that gets used to set the pie dimensions and the position of the value label in the middle of our slice.
.wrap { --d: #{$d}; width: var(--d); /* same as before */ @media (max-width: $d) { --d: 95vw } }
Below certain viewport widths, we also decrease the font-size, the margin for our <label> elements, and we don't position the value label in the middle of the dark pie slice anymore, but rather in the middle of the pie itself:
.wrap { /* same as before */ @media (max-width: 265px) { font-size: .75em; } } [type='radio'] { /* same as before */ + label { /* same as before */ @media (max-width: 195px) { margin-top: .25em; } } } .pie{ /* same as before */ @media (max-width: 160px) { --pos: #{unquote(' ')} } }
This gives us our final result: a responsive pie chart in browsers supporting conic-gradient() natively. And, even though that's sadly just Blink browsers with the Experimental Web Platform features flag enabled for now, we have a solid fallback that renders a responsive bar chart for all other browsers. We also animate between values—again, that's just Blink browsers with the Experimental Web Platform features flag enabled at this point.
See the Pen by thebabydino (@thebabydino) on CodePen.
Bonus: radial progress!
We can also apply this concept to build a radial progress indicator like the one below (inspired by this Pen):

The radial progress and its fallback.
The technique is pretty much the same, except we leave the value label dead in the middle and set the conic-gradient() on the :before pseudo-element. This is because we use a mask to get rid of everything, except for a thin outer ring and, if we were to set the conic-gradient() and the mask on the element itself, then the mask would also hide the value label inside and we want that visible.
On clicking the <button>, a new value for our unitless percentage (--p) is randomly generated and we transition smoothly between values. Setting a fixed transition-duration would create a really slow transition between two close values (e.g. 47% to 49%) and a really fast transition when moving between values with a larger gap in between (e.g. 3% to 98%). We get around this by making the transition-duration depend on the absolute value of the difference between the previous value of --p and its newly generated value.
[id='out'] { /* radial progress element */ transition: --p calc(var(--dp, 1)*1s) ease-out; }
const _GEN = document.getElementById('gen'), _OUT = document.getElementById('out'); _GEN.addEventListener('click', e => { let old_perc = ~~_OUT.style.getPropertyValue('--p'), new_perc = Math.round(100*Math.random()); _OUT.style.setProperty('--p', new_perc); _OUT.style.setProperty('--dp', .01*Math.abs(old_perc - new_perc)); _OUT.setAttribute('aria-label', `Graphical representation of generated percentage: ${new_perc}% of 100%.`) }, false);
This gives us a nice animated radial progress indicator for browsers supporting all the new and shiny features. We have a linear fallback for other browsers:
See the Pen by thebabydino (@thebabydino) on CodePen.
The post Simple Interactive Pie Chart with CSS Variables and Houdini Magic appeared first on CSS-Tricks.
Simple Interactive Pie Chart with CSS Variables and Houdini Magic published first on https://brightcirclepage.tumblr.com/
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0
Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
https://ift.tt/1sYxUD0
https://ift.tt/1Hfe2Dy
https://ift.tt/2JW6rPF
https://ift.tt/1jm7smN
https://www.ccn.com/
https://www.chip.pl/
https://ift.tt/2yUaHd2
https://ift.tt/35ixPDu
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
via Blogger https://ift.tt/2OvFbNV #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
https://www.seroundtable.com/
https://letsencrypt.org/
https://www.newsbomb.gr/
https://thehackernews.com/
https://www.ccn.com/
https://www.chip.pl/
https://www.gamereactor.se/
https://www.tribes.co.uk/
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://tracking.feedpress.it/link/9375/12882884
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
https://ift.tt/1sYxUD0
https://ift.tt/1Hfe2Dy
https://ift.tt/2JW6rPF
https://ift.tt/1jm7smN
https://www.ccn.com/
https://www.chip.pl/
https://ift.tt/2yUaHd2
https://ift.tt/35ixPDu
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
http://bit.ly/2ooTMQo
http://bit.ly/311AhL4
http://bit.ly/30ZPGvr
http://bit.ly/31ZWvyv
http://bit.ly/2p3jfPp
http://bit.ly/2p3FcOi
http://bit.ly/35hHbzh
http://bit.ly/2Voi216
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
https://ift.tt/1sYxUD0
https://ift.tt/1Hfe2Dy
https://ift.tt/2JW6rPF
https://ift.tt/1jm7smN
https://www.ccn.com/
https://www.chip.pl/
https://ift.tt/2yUaHd2
https://ift.tt/35ixPDu
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
#túi_giấy_epacking_việt_nam #túi_giấy_epacking #in_túi_giấy_giá_rẻ #in_túi_giấy #epackingvietnam #tuigiayepacking
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
https://ift.tt/1sYxUD0
https://ift.tt/1Hfe2Dy
https://ift.tt/2JW6rPF
https://ift.tt/1jm7smN
https://www.ccn.com/
https://www.chip.pl/
https://ift.tt/2yUaHd2
https://ift.tt/35ixPDu
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
A Breakdown of HTML Usage Across ~8 Million Pages (& What It Means for Modern SEO)
Posted by Catalin.Rosu
Not long ago, my colleagues and I at Advanced Web Ranking came up with an HTML study based on about 8 million index pages gathered from the top twenty Google results for more than 30 million keywords.
We wrote about the markup results and how the top twenty Google results pages implement them, then went even further and obtained HTML usage insights on them.
What does this have to do with SEO?
The way HTML is written dictates what users see and how search engines interpret web pages. A valid, well-formatted HTML page also reduces possible misinterpretation — of structured data, metadata, language, or encoding — by search engines.
This is intended to be a technical SEO audit, something we wanted to do from the beginning: a breakdown of HTML usage and how the results relate to modern SEO techniques and best practices.
In this article, we’re going to address things like meta tags that Google understands, JSON-LD structured data, language detection, headings usage, social links & meta distribution, AMP, and more.
Meta tags that Google understands
When talking about the main search engines as traffic sources, sadly it's just Google and the rest, with Duckduckgo gaining traction lately and Bing almost nonexistent.
Thus, in this section we’ll be focusing solely on the meta tags that Google listed in the Search Console Help Center.
Pie chart showing the total numbers for the meta tags that Google understands, described in detail in the sections below.
<meta name="description" content="...">
The meta description is a ~150 character snippet that summarizes a page's content. Search engines show the meta description in the search results when the searched phrase is contained in the description.
SELECTOR
COUNT
<meta name="description" content="*">
4,391,448
<meta name="description" content="">
374,649
<meta name="description">
13,831
On the extremes, we found 685,341 meta elements with content shorter than 30 characters and 1,293,842 elements with the content text longer than 160 characters.
<title>
The title is technically not a meta tag, but it's used in conjunction with meta name="description".
This is one of the two most important HTML tags when it comes to SEO. It's also a must according to W3C, meaning no page is valid with a missing title tag.
Research suggests that if you keep your titles under a reasonable 60 characters then you can expect your titles to be rendered properly in the SERPs. In the past, there were signs that Google's search results title length was extended, but it wasn't a permanent change.
Considering all the above, from the full 6,263,396 titles we found, 1,846,642 title tags appear to be too long (more than 60 characters) and 1,985,020 titles had lengths considered too short (under 30 characters).
Pie chart showing the title tag length distribution, with a length less than 30 chars being 31.7% and a length greater than 60 chars being about 29.5%.
A title being too short shouldn't be a problem —after all, it's a subjective thing depending on the website business. Meaning can be expressed with fewer words, but it's definitely a sign of wasted optimization opportunity.
SELECTOR
COUNT
<title>*</title>
6,263,396
missing <title> tag
1,285,738
Another interesting thing is that, among the sites ranking on page 1–2 of Google, 351,516 (~5% of the total 7.5M) are using the same text for the title and h1 on their index pages.
Also, did you know that with HTML5 you only need to specify the HTML5 doctype and a title in order to have a perfectly valid page?
<!DOCTYPE html> <title>red</title>
<meta name="robots|googlebot">
“These meta tags can control the behavior of search engine crawling and indexing. The robots meta tag applies to all search engines, while the "googlebot" meta tag is specific to Google.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="robots" content="..., ...">
1,577,202
<meta name="googlebot" content="..., ...">
139,458
HTML snippet with a meta robots and its content parameters.
So the robots meta directives provide instructions to search engines on how to crawl and index a page's content. Leaving aside the googlebot meta count which is kind of low, we were curious to see the most frequent robots parameters, considering that a huge misconception is that you have to add a robots meta tag in your HTML’s head. Here’s the top 5:
SELECTOR
COUNT
<meta name="robots" content="index,follow">
632,822
<meta name="robots" content="index">
180,226
<meta name="robots" content="noodp">
115,128
<meta name="robots" content="all">
111,777
<meta name="robots" content="nofollow">
83,639
<meta name="google" content="nositelinkssearchbox">
“When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site. This meta tag tells Google not to show the sitelinks search box.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google" content="nositelinkssearchbox">
1,263
Unsurprisingly, not many websites choose to explicitly tell Google not to show a sitelinks search box when their site appears in the search results.
<meta name="google" content="notranslate">
“This meta tag tells Google that you don't want us to provide a translation for this page.” - Meta tags that Google understands
There may be situations where providing your content to a much larger group of users is not desired. Just as it says in the Google support answer above, this meta tag tells Google that you don't want them to provide a translation for this page.
SELECTOR
COUNT
<meta name="google" content="notranslate">
7,569
<meta name="google-site-verification" content="...">
“You can use this tag on the top-level page of your site to verify ownership for Search Console.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="google-site-verification" content="...">
1,327,616
While we're on the subject, did you know that if you're a verified owner of a Google Analytics property, Google will now automatically verify that same website in Search Console?
<meta charset="..." >
“This defines the page's content type and character set.” - Meta tags that Google understands
This is basically one of the good meta tags. It defines the page's content type and character set. Considering the table below, we noticed that just about half of the index pages we analyzed define a meta charset.
SELECTOR
COUNT
<meta charset="..." >
3,909,788
<meta http-equiv="refresh" content="...;url=...">
“This meta tag sends the user to a new URL after a certain amount of time and is sometimes used as a simple form of redirection.” - Meta tags that Google understands
It's preferable to redirect your site using a 301 redirect rather than a meta refresh, especially when we assume that 30x redirects don't lose PageRank and the W3C recommends that this tag not be used. Google is not a fan either, recommending you use a server-side 301 redirect instead.
SELECTOR
COUNT
<meta http-equiv="refresh" content="...;url=...">
7,167
From the total 7.5M index pages we parsed, we found 7,167 pages that are using the above redirect method. Authors do not always have control over server-side technologies and apparently they use this technique in order to enable redirects on the client side.
Also, using Workers is a cutting-edge alternative n order to overcome issues when working with legacy tech stacks and platform limitations.
<meta name="viewport" content="...">
“This tag tells the browser how to render a page on a mobile device. Presence of this tag indicates to Google that the page is mobile-friendly.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="viewport" content="...">
4,992,791
Starting July 1, 2019, all sites started to be indexed using Google’s mobile-first indexing. Lighthouse checks whether there's a meta name="viewport" tag in the head of the document, so this meta should be on every webpage, no matter what framework or CMS you're using.
Considering the above, we would have expected more websites than the 4,992,791 out of 7.5 million index pages analyzed to use a valid meta name="viewport" in their head sections.
Designing mobile-friendly sites ensures that your pages perform well on all devices, so make sure your web page is mobile-friendly here.
<meta name="rating" content="..." />
“Labels a page as containing adult content, to signal that it be filtered by SafeSearch results.” - Meta tags that Google understands
SELECTOR
COUNT
<meta name="rating" content="..." />
133,387
This tag is used to denote the maturity rating of content. It was not added to the meta tags that Google understands list until recently. Check out this article by Kate Morris on how to tag adult content.
JSON-LD structured data
Structured data is a standardized format for providing information about a page and classifying the page content. The format of structured data can be Microdata, RDFa, and JSON-LD — all of these help Google understand the content of your site and trigger special search result features for your pages.
While having a conversation with the awesome Dan Shure, he came up with a good idea to look for structured data, such as the organization's logo, in search results and in the Knowledge Graph.
In this section, we'll be using JSON-LD (JavaScript Object Notation for Linked Data) only in order to gather structured data info.This is what Google recommends anyway for providing clues about the meaning of a web page.
Some useful bits on this:
At Google I/O 2019, it was announced that the structured data testing tool will be superseded by the rich results testing tool.
Now Googlebot indexes web pages using the latest Chromium rather than the old Chrome 42, meaning you can mitigate the SEO issues you may have had in the past, with structured data support as well.
Jason Barnard had an interesting talk at SMX London 2019 on how Google Search ranking works and according to his theory, there are seven ranking factors we can count on; structured data is definitely one of them.
Builtvisible's guide on Microdata, JSON-LD, & Schema.org contains everything you need to know about using structured data on your website.
Here's an awesome guide to JSON-LD for beginners by Alexis Sanders.
Last but not least, there are lots of articles, presentations, and posts to dive in on the official JSON for Linking Data website.
Advanced Web Ranking's HTML study relies on analyzing index pages only. What's interesting is that even though it's not stated in the guidelines, Google doesn't seem to care about structured data on index pages, as stated in a Stack Overflow answer by Gary Illyes several years ago. Yet, on JSON-LD structured data types that Google understands, we found a total of 2,727,045 features:
Pie chart showing the structured data types that Google understands, with Sitelinks searchbox being 49.7% — the highest value.
STRUCTURED DATA FEATURES
COUNT
Article
35,961
Breadcrumb
30,306
Book
143
Carousel
13,884
Corporate contact
41,588
Course
676
Critic review
2,740
Dataset
28
Employer aggregate rating
7
Event
18,385
Fact check
7
FAQ page
16
How-to
8
Job posting
355
Livestream
232
Local business
200,974
Logo
442,324
Media
1,274
Occupation
0Product
16,090
Q&A page
20
Recipe
434
Review snippet
72,732
Sitelinks searchbox
1,354,754
Social profile
478,099
Software app
780
Speakable
516
Subscription and paywalled content
363
Video
14,349
rel=canonical
The rel=canonical element, often called the "canonical link," is an HTML element that helps webmasters prevent duplicate content issues. It does this by specifying the "canonical URL," the "preferred" version of a web page.
SELECTOR
COUNT
<link rel=canonical href="*">
3,183,575
meta name="keywords"
It's not new that <meta name="keywords"> is obsolete and Google doesn't use it anymore. It also appears as though <meta name="keywords"> is a spam signal for most of the search engines.
“While the main search engines don't use meta keywords for ranking, they're very useful for onsite search engines like Solr.” - JP Sherman on why this obsolete meta might still be useful nowadays.
SELECTOR
COUNT
<meta name="keywords" content="*">
2,577,850
<meta name="keywords" content="">
256,220
<meta name="keywords">
14,127
Headings
Within 7.5 million pages, h1 (59.6%) and h2 (58.9%) are among the twenty-eight elements used on the most pages. Still, after gathering all the headings, we found that h3 is the heading with the largest number of appearances — 29,565,562 h3s out of 70,428,376 total headings found.
Random facts:
The h1–h6 elements represent the six levels of section headings. Here are the full stats on headings usage, but we found 23,116 of h7s and 7,276 of h8s too. That's a funny thing because plenty of people don't even use h6s very often.
There are 3,046,879 pages with missing h1 tags and within the rest of the 4,502,255 pages, the h1 usage frequency is 2.6, with a total of 11,675,565 h1 elements.
While there are 6,263,396 pages with a valid title, as seen above, only 4,502,255 of them are using a h1 within the body of their content.
Missing alt tags
This eternal SEO and accessibility issue still seems to be common after analyzing this set of data. From the total of 669,591,743 images, almost 90% are missing the alt attribute or use it with a blank value.
Pie chart showing the img tag alt attribute distribution, with missing alt being predominant — 81.7% from a total of about 670 million images we found.
SELECTOR
COUNT
img
669,591,743
img alt="*"
79,953,034
img alt=""
42,815,769
img w/ missing alt
546,822,940
Language detection
According to the specs, the language information specified via the lang attribute may be used by a user agent to control rendering in a variety of ways.
The part we're interested in here is about "assisting search engines."
“The HTML lang attribute is used to identify the language of text content on the web. This information helps search engines return language specific results, and it is also used by screen readers that switch language profiles to provide the correct accent and pronunciation.” - Léonie Watson
A while ago, John Mueller said Google ignores the HTML lang attribute and recommended the use of link hreflang instead. The Google Search Console documentation states that Google uses hreflang tags to match the user's language preference to the right variation of your pages.
Bar chart showing that 65% of the 7.5 million index pages use the lang attribute on the html element, at the same time 21.6% use at least a link hreflang.
Of the 7.5 million index pages that we were able to look into, 4,903,665 use the lang attribute on the html element. That’s about 65%!
When it comes to the hreflang attribute, suggesting the existence of a multilingual website, we found about 1,631,602 pages — that means around 21.6% index pages use at least a link rel="alternate" href="*" hreflang="*" element.
Google Tag Manager
From the beginning, Google Analytics' main task was to generate reports and statistics about your website. But if you want to group certain pages together to see how people are navigating through that funnel, you need a unique Google Analytics tag. This is where things get complicated.
Google Tag Manager makes it easier to:
Manage this mess of tags by letting you define custom rules for when and what user actions your tags should fire
Change your tags whenever you want without actually changing the source code of your website, which sometimes can be a headache due to slow release cycles
Use other analytics/marketing tools with GTM, again without touching the website's source code
We searched for *googletagmanager.com/gtm.js references and saw that about 345,979 pages are using the Google Tag Manager.
rel="nofollow"
"Nofollow" provides a way for webmasters to tell search engines "don't follow links on this page" or "don't follow this specific link."
Google does not follow these links and likewise does not transfer equity. Considering this, we were curious about rel="nofollow" numbers. We found a total of 12,828,286 rel="nofollow" links within 7.5 million index pages, with a computed average of 1.69 rel="nofollow" per page.
Last month, Google announced two new link attributes values that should be used in order to mark the nofollow property of a link: rel="sponsored" and rel="ugc". I’d recommend you go read Cyrus Shepard’s article on how Google's nofollow, sponsored, & ugc links impact SEO, learn why Google changed nofollow, the ranking impact of nofollow links, and more.
A table showing how Google’s nofollow, sponsored, and UGC link attributes impact SEO, from Cyrus Shepard’s article.
We went a bit further and looked up these new link attributes values, finding 278 rel="sponsored" and 123 rel="ugc". To make sure we had the relevant data for these queries, we updated the index pages data set specifically two weeks after the Google announcement on this matter. Then, using Moz authority metrics, we sorted out the top URLs we found that use at least one of the rel="sponsored" or rel="ugc" pair:
https://ift.tt/1sYxUD0
https://ift.tt/1Hfe2Dy
https://ift.tt/2JW6rPF
https://ift.tt/1jm7smN
https://www.ccn.com/
https://www.chip.pl/
https://ift.tt/2yUaHd2
https://ift.tt/35ixPDu
AMP
Accelerated Mobile Pages (AMP) are a Google initiative which aims to speed up the mobile web. Many publishers are making their content available parallel to the AMP format.
To let Google and other platforms know about it, you need to link AMP and non-AMP pages together.
Within the millions of pages we looked at, we found only 24,807 non-AMP pages referencing their AMP version using rel=amphtml.
Social
We wanted to know how shareable or social a website is nowadays, so knowing that Josh Buchea made an awesome list with everything that could go in the head of your webpage, we extracted the social sections from there and got the following numbers:
Facebook Open Graph
Bar chart showing the Facebook Open Graph meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta property="fb:app_id" content="*"
277,406
meta property="og:url" content="*"
2,909,878
meta property="og:type" content="*"
2,660,215
meta property="og:title" content="*"
3,050,462
meta property="og:image" content="*"
2,603,057
meta property="og:image:alt" content="*"
54,513
meta property="og:description" content="*"
1,384,658
meta property="og:site_name" content="*"
2,618,713
meta property="og:locale" content="*"
1,384,658
meta property="article:author" content="*"
14,289
Twitter card
Bar chart showing the Twitter Card meta tags distribution, described in detail in the table below.
SELECTOR
COUNT
meta name="twitter:card" content="*"
1,535,733
meta name="twitter:site" content="*"
512,907
meta name="twitter:creator" content="*"
283,533
meta name="twitter:url" content="*"
265,478
meta name="twitter:title" content="*"
716,577
meta name="twitter:description" content="*"
1,145,413
meta name="twitter:image" content="*"
716,577
meta name="twitter:image:alt" content="*"
30,339
And speaking of links, we grabbed all of them that were pointing to the most popular social networks.
Pie chart showing the external social links distribution, described in detail in the table below.
SELECTOR
COUNT
<a href*="facebook.com">
6,180,313
<a href*="twitter.com">
5,214,768
<a href*="linkedin.com">
1,148,828
<a href*="plus.google.com">
1,019,970
Apparently there are lots of websites that still link to their Google+ profiles, which is probably an oversight considering the not-so-recent Google+ shutdown.
rel=prev/next
According to Google, using rel=prev/next is not an indexing signal anymore, as announced earlier this year:
“As we evaluated our indexing signals, we decided to retire rel=prev/next. Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search.” - Tweeted by Google Webmasters
However, in case it matters for you, Bing says it uses them as hints for page discovery and site structure understanding.
“We're using these (like most markup) as hints for page discovery and site structure understanding. At this point, we're not merging pages together in the index based on these and we're not using prev/next in the ranking model.” - Frédéric Dubut from Bing
Nevertheless, here are the usage stats we found while looking at millions of index pages:
SELECTOR
COUNT
<link rel="prev" href="*"
20,160
<link rel="next" href="*"
242,387
That's pretty much it!
Knowing how the average web page looks using data from about 8 million index pages can give us a clearer idea of trends and help us visualize common usage of HTML when it comes to SEO modern and emerging techniques. But this may be a never-ending saga — while having lots of numbers and stats to explore, there are still lots of questions that need answering:
We know how structured data is used in the wild now. How will it evolve and how much structured data will be considered enough?
Should we expect AMP usage to increase somewhere in the future?
How will rel="sponsored” and rel=“ugc” change the way we write HTML on a daily basis? When coding external links, besides the target="_blank" and rel=“noopener” combo, we now have to consider the rel="sponsored” and rel=“ugc” combinations as well.
Will we ever learn to always add alt attributes values for images that have a purpose beyond decoration?
How many more additional meta tags or attributes will we have to add to a web page to please the search engines? Do we really needed the newly announced data-nosnippet HTML attribute? What’s next, data-allowsnippet?
There are other things we would have liked to address as well, like "time-to-first-byte" (TTFB) values, which correlates highly with ranking; I'd highly recommend HTTP Archive for that. They periodically crawl the top sites on the web and record detailed information about almost everything. According to the latest info, they've analyzed 4,565,694 unique websites, with complete Lighthouse scores and having stored particular technologies like jQuery or WordPress for the whole data set. Huge props to Rick Viscomi who does an amazing job as its “steward,” as he likes to call himself.
Performing this large-scale study was a fun ride. We learned a lot and we hope you found the above numbers as interesting as we did. If there is a tag or attribute in particular you would like to see the numbers for, please let me know in the comments below.
Once again, check out the full HTML study results and let me know what you think!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes