#SRE Certification Course
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
SRE Online Training | Site Reliability Engineering Training
The Concept of "Retry, Timeout, and Circuit Breaker" patterns

Introduction:
Site Reliability engineering software systems, resilience and fault tolerance are crucial for ensuring smooth user experiences and optimal system performance. Among the key strategies for improving reliability, Retry, Timeout, and Circuit Breaker patterns stand out as essential techniques for handling failures and improving system robustness. These patterns help prevent cascading failures, reduce downtime, and enhance the overall reliability of applications. By understanding how these patterns work, developers can design systems that can gracefully recover from errors and continue providing service to users. Site Reliability Engineering Online Training
What Are Retry, Timeout, and Circuit Breaker Patterns?
At their core, Retry, Timeout, and Circuit Breaker patterns aim to ensure that software systems remain operational even in the face of transient or unexpected failures. Each pattern has a distinct role and can be used independently or together depending on the complexity of the system being developed.
Retry Pattern: The Retry pattern is employed when a request fails due to temporary issues like network instability or service unavailability. The idea is simple—rather than immediately returning an error, the system attempts the request again after a brief delay. This pattern is particularly useful for addressing intermittent failures in remote services, APIs, or external dependencies.
Timeout Pattern: The Timeout pattern focuses on avoiding endless waits in case of service delays or failures. When a system makes a request, it sets a predefined period for the operation to complete. If the request doesn’t respond within the specified time, it is aborted and an error is returned. This pattern helps prevent the system from getting stuck and ensures that users aren't left waiting for an unreasonable amount of time.
Circuit Breaker Pattern: The Circuit Breaker pattern protects the system from being overwhelmed by continuous failures. When a certain threshold of consecutive failed attempts is reached, the circuit breaker trips and the system stops making calls to the failing service for a predefined "cool-off" period. This allows the service to recover, preventing it from being flooded with requests and improving overall system stability.
How Do Retry, Timeout, and Circuit Breaker Patterns Improve System Resilience?
These three patterns work together to create a more resilient and fault-tolerant system. By implementing Retry, Timeout, and Circuit Breaker patterns, developers can handle failures more effectively, resulting in a better user experience and a more reliable application.
1. Reducing the Impact of Temporary Failures with Retry
The Retry pattern is designed to address temporary failures that are often caused by external systems or services. When a request fails, such as during network timeouts or when a service is momentarily unavailable, the system does not immediately report an error to the user. Instead, it retries the operation after a brief pause, increasing the likelihood that the request will succeed if the failure is only transient.
In some cases, the system can implement exponential back off, where the time between retries gradually increases. This strategy helps avoid overwhelming the failing service with too many requests in a short period, giving the service time to recover.
2. Preventing Endless Waits with Timeout
While retries help with temporary failures, there are situations where an operation may take too long to complete due to persistent issues. The Timeout pattern ensures that the system doesn't waste resources waiting for an operation that isn't responding within a reasonable period.
For instance, if a request is made to an external service, but the service is down or experiencing heavy load, the Timeout pattern ensures that the system doesn't continue to wait indefinitely. By setting an appropriate timeout value, developers can avoid slow performance and ensure that users receive a response within an acceptable timeframe. SRE Course
3. Protecting Systems from Cascading Failures with Circuit Breaker
The Circuit Breaker pattern is especially critical when dealing with failures that could lead to cascading issues across the system. When one part of the system fails repeatedly, it can put excessive strain on other components that depend on it. This could lead to a complete system failure, which is where the Circuit Breaker comes into play.
Once the circuit breaker detects a certain number of consecutive failures, it "trips," halting further attempts to interact with the failing service. The system enters a "half-open" state where it periodically tests the health of the service. If the service is functioning properly, the circuit breaker is reset and normal operation resumes. However, if the service continues to fail, the system remains "closed", and no further requests are made.
By implementing this pattern, a system can avoid overloading a failing service and give it time to recover. This prevents a localized failure from escalating into a system-wide breakdown, improving overall resilience.
Key Benefits of Using Retry, Timeout, and Circuit Breaker Patterns
Each of these patterns brings unique advantages to a software system. Here are some key benefits of implementing Retry, Timeout, and Circuit Breaker patterns in your applications:
Increased Fault Tolerance: By incorporating these patterns, systems can better handle errors, ensuring that they continue functioning even when failures occur.
Improved User Experience: These patterns reduce downtime and ensure that users experience fewer interruptions, even in the event of service failures.
System Stability: With a combination of retries, timeouts, and circuit breakers, systems can maintain their stability by preventing cascading failures and overloading.
Faster Recovery: In the event of a failure, these patterns allow systems to recover more quickly, ensuring a more reliable and efficient service.
Best Practices for Implementing Retry, Timeout, and Circuit Breaker Patterns
To effectively implement these patterns, there are several best practices to follow:
Tune Retry Settings: While retries can help with temporary issues, setting too many retries or insufficient wait times can cause further problems. It's crucial to find a balance between retry attempts and back-off times to prevent unnecessary strain on the system.
Set Appropriate Timeout Values: The timeout values should be set by the expected response time of the external services. Short timeouts may lead to premature failures, while long timeouts may cause delays in the system.
Monitor Circuit Breaker States: Regular monitoring of the circuit breaker states is essential to ensure that services are properly recovering after failures. Metrics and logs can help track the health of services and adjust the configuration as necessary.
Implement Fullback Strategies: In conjunction with the Circuit Breaker pattern, fall back mechanisms should be put in place. This could include providing default responses when the service is unavailable or offering a reduced level of functionality. SRE Certification Course
Conclusion
In conclusion, Retry, Timeout, and Circuit Breaker patterns are indispensable tools for building resilient software systems. These patterns work together to enhance the fault tolerance, stability, and user experience of modern applications. By carefully implementing these patterns, developers can create systems that gracefully handle failures, recover quickly, and ensure continuous service even in the face of errors. Their strategic use helps safeguard against cascading failures, prevents unnecessary delays, and ensures the long-term reliability of software systems.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Site Reliability Engineering (SRE) worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://sitereliabilityengineering123.blogspot.com/
Visit: https://www.visualpath.in/online-site-reliability-engineering-training.html
#Site Reliability Engineering Training#SRE Course#Site Reliability Engineering Online Training#SRE Training Online#Site Reliability Engineering Training in Hyderabad#SRE Online Training in Hyderabad#SRE Courses Online#SRE Certification Course
0 notes
Text
Is Your Team Ready for the SRE Mindset?
In the ever-evolving world of IT and software development, ensuring system reliability, performance, and scalability is more critical than ever. That’s where SRE, or Site Reliability Engineering, comes into play. This discipline bridges the gap between development and operations by applying software engineering principles to infrastructure and operations problems.

In this article, we’ll uncover the full form of the SRE process, explain its core components, and explore why it’s vital for modern IT organizations.
What is SRE? (Full Form & Definition)
SRE stands for Site Reliability Engineering. It is a set of principles and practices that incorporates software engineering approaches to solve IT operations problems. Originally pioneered by Google, SRE helps organizations build and maintain highly reliable and scalable systems.
In simpler terms, SRE ensures that websites, applications, and services remain up and running efficiently, even as they scale to support millions of users.
Core Components of the SRE Process
The SRE process is not a one-time activity; it’s a continuous lifecycle that focuses on balancing system reliability with feature velocity. Below are the key pillars that make up the SRE process:
1. Service Level Objectives (SLOs) and Service Level Indicators (SLIs)
SLIs are metrics that measure aspects like latency, availability, and error rates.
SLOs are targets for these indicators, providing a threshold for acceptable performance.
Together, they help define what reliability looks like for a given system.
2. Error Budgets
The difference between 100% availability and your SLO target (e.g., 99.9%) is the error budget.
It allows developers to take risks and innovate without compromising reliability.
3. Incident Management & Postmortems
SRE teams handle incident response, including detection, mitigation, and communication.
After resolving an issue, a blameless postmortem is conducted to understand root causes and improve systems.
4. Monitoring and Observability
Real-time monitoring tools and logs help detect anomalies.
Observability enables understanding why a system is behaving a certain way, not just that it’s behaving differently.
5. Automation & Elimination of Toil
SRE emphasizes automating repetitive tasks and manual operations to reduce human error and increase efficiency.
This “toil reduction” helps engineers focus on engineering solutions rather than firefighting.
Why the SRE Process Matters
✅ Improved System Reliability
SRE ensures systems stay up and available. Downtime costs businesses money and trust—SRE helps minimize both.
✅ Faster Product Releases
With a structured balance between reliability and speed (via error budgets), SRE enables faster deployment without sacrificing quality.
✅ Better Incident Response
SRE teams are prepared for outages. Their incident handling playbooks and tools allow them to restore services quickly.
✅ Enhanced Collaboration
SRE promotes DevOps culture by encouraging collaboration between developers and operations, resulting in more reliable software delivery.
✅ Customer Satisfaction
End-users experience fewer bugs, less downtime, and better performance, leading to increased trust and retention.
Who Should Implement SRE?
Tech Startups aiming for scale
Large Enterprises managing distributed systems
E-commerce Platforms, Fintech Apps, Cloud Service Providers, and others, where uptime and performance are critical
If your business relies on digital services, adopting the SRE process can be a game-changer.
Ready to start your SRE journey? Join the growing community of Site Reliability Engineers with NovelVista’s SRE Foundation Certification and gain the skills to power next-generation IT systems.
👉 SRE Certification
Final Thoughts
Site Reliability Engineering isn’t just a trend—it’s a proven approach to building and managing resilient systems. By uncovering the SRE process and understanding its components, organizations can deliver robust, scalable, and efficient digital services.
Whether you're an IT leader, engineer, or business stakeholder, integrating the SRE mindset into your operations is essential for long-term success in the digital age.
0 notes
Text
Why the SRE Certification Is Blowing Up in 2025
In the fast-evolving world of DevOps and cloud, one role is making serious waves: Site Reliability Engineer (SRE). And if you’re looking to break into high-impact IT roles, the SRE Foundation certification is your launchpad.
💡 Why Everyone’s Talking About It From startups to tech giants, companies are on the hunt for professionals with solid Site Reliability Engineer certification skills. Why? Because they need pros who can ensure system reliability, scalability, and performance—especially in a world where downtime = lost dollars.
📘 What You’ll Learn The SRE certification course offered by GSDC is more than just a training—it’s a deep dive into real-world SRE principles and practices like:
Monitoring and observability
Incident response and blameless post-mortems
Automation strategies for reliability
🎯 The SRE Certification Benefits ✅ High-demand career path ✅ Globally recognized credentials ✅ Hands-on knowledge through Site Reliability Engineering training ✅ Prepares you for real-world challenges in DevOps and cloud environments
🌐 Why Choose SRE Foundation? Whether you're starting your journey or formalizing your experience, the Site Reliability Engineering (SRE) Foundation program gives you a structured, globally respected framework. It’s a perfect match for developers, sysadmins, and IT pros aiming to level up.
Want to become the person everyone calls when systems go sideways? The sre certification is trending—and it's your ticket into the future of IT.
For information visit: -
Contact : +41444851189
#SRECertification #SiteReliabilityEngineerCertification #SREFoundation #SiteReliabilityEngineeringTraining #SRECourse #SREPrinciples #SRECertificationBenefits #DevOpsCareers #TrendingInTech #GSDC
#Site Reliability Engineer certification#sre certification#SRE Foundation certification#Site Reliability Engineering training#SRE certification course
0 notes
Text
Why SRE Certification is a must have for IT professionals
In order to guarantee the stability, performance, and dependability of IT systems, the position of SRE foundation certification has grown more and more important. In order to succeed in this ever changing area, IT workers must hold the SRE certification. Here are some reasons why everyone who is serious about an IT profession should get this certification, since it is not only helpful but also necessary.
Let's dive into the primary advantages of acquiring CSERF
1. Understanding the Core Principles of SRE - The SRE Foundation certification offers a thorough comprehension of the fundamental ideas that underpin the SRE certificate field. Site reliability engineering certified professional is a methodology that combines software engineering with IT operations with an emphasis on creating scalable and dependable systems.
2. Bridging the Gap Between Development and Operations - There has always been a major separation in IT between the development and operations teams. Through encouraging cooperation, automation, and shared duties, site reliability engineering certification methods seek to close this gap. IT workers may enhance communication, accelerate deployment cycles, and create more robust systems by learning how to use these principles successfully with the help of the site reliability engineering course.
3. Contributing to Organizational Success -SRE course is about more than simply keeping systems operational; it's about making a positive impact on the company as a whole. The SRE training and certification is a great advantage for both the individual and the business since it gives them the skills and frameworks they need to significantly improve the bottom line of the corporation.
For more information Visit our-
Also visit -
For more inquiries - +91 7796699663.

#SRE certification#SRE certificate#SRE Foundation Certification#site reliability engineering certified professional#site reliability engineering certification#SRE course#site reliability engineering course#site reliability engineer certification#SRE training and certification#site reliability engineering#CSERF.
0 notes
Text

The Site Reliability Engineering Certification offered by GSDC is a testament to the skills and expertise of an SRE. It demonstrates that the candidate has a comprehensive understanding of SRE principles, practices, and methodologies and can apply them to real-world scenarios. The SRE Certification is important for professionals who want to enhance their job prospects and advance their careers in the field of Site Reliability Engineering. It provides a competitive edge in the job market and shows that the candidate is committed to ongoing learning and development. Organizations that wish to be sure that their SREs have the ability to manage and maintain complex systems can also benefit from the certification.It assures that the candidate can design, build, and operate reliable systems that meet or exceed the required service level objectives.
#site reliability engineering certification#site reliability engineer certification#sre course#site reliability engineer foundation certification#site reliability engineering certification online#sre foundation certificaiton
0 notes
Text

Site Reliability Engineering (SRE) aims to ensure service reliability and performance. It balances rapid innovation with system stability using tools like error budgets and SLOs. SRE emphasizes automation, blameless postmortems, and continuous improvement, bridging the gap between development and operations. Embark on a transformative journey with our Site Reliability Engineer (SRE) Certification program.
#sre certification#site reliability engineer certification#sre foundation certification#sre course#sre certification cost
0 notes
Text
Site Reliability Engineer (SRE) Certification: Engineering High-Availability Systems
Embark on a transformative journey with our Site Reliability Engineer (SRE) Certification program. Designed for aspirants and professionals alike, this course delves into the core principles of maintaining, building, and ensuring scalable and highly reliable software systems. Grasp the fundamental tenets of SRE, from managing incident responses and reducing organizational toil to enhancing service performance and monitoring system health.

#sre certification#site reliability engineer certification#sre foundation certification#sre certification cost#sre course
0 notes
Text
this day couldn't have been worse
Firstly my parents. Literally 19 but i need to get their permission for a haircut. For a haircut?
Then they give me lame excuses about how my hair is thinning. Like genetics?😑 look at your own hair pl. And then why the hell can i not get short hair. What difference is it going to make. As it is I have a scarf no one sees my hair so why can't i do it for my own sake. The thing which pisses me off is not hair. Tbh i don't eveb care about hair now it's more about my independence. Why do i need to ask someone else if i can cut my own hair, a grown adult. Not speaking to anyone. If thwy sre going to act like kids then go ahead.
And then i've been speaking to a few people working in fintech. Two men, both their names sound so similar and begin with A. Already spoken to one a while back but I had asked someone for the second one' number. They misheard and gave me the first one's. I messaged the fi4st one again. As if i didn' speak to him last month. He probably thinks i'm such a dumb ass for acting all new. Messaged the second one again.
Wanted to speak to the first one but the fact thst i approqched him all new is such a fuckup.
Gosh
Then. I got restricted on linkedin? Bruh wtff
Linkedin??? What sketchy shit did i even do. Goodness. Now i've put my details for verification. Idk when will it get verified.
Then i was supposed to fast today. But yesterdsy i was in a pissy mood wnd slept late and because of the whole 'drama' and thwn i got up late ans missed. Thank you for ruining my day.
This day cannot get more dumb now.
Only.good thing tjis week was i got an 8/8 on an assignment which i did in like 2 hours it wasn't eveb necessary foe the course but had to do it for the certificate. But niw i'm just getting so bored to complete the whole thing. My linkedin profile being restricted is really pissing me off tho. Like heck u. Why th and i had to updatw so many things.
2 notes
·
View notes
Text
DevOps Training in Marathahalli Bangalore – Build a Future-Proof Tech Career

Are you looking to transition into a high-growth IT role or strengthen your skills in modern software development practices? If you're in Bangalore, particularly near Marathahalli, you're in one of the best places to do that. eMexo Technologies offers a detailed and industry-ready DevOps Training in Marathahalli Bangalore designed for beginners, professionals, and career changers alike.
Explore DevOps Course in Marathahalli Bangalore – Key Skills You’ll Gain
This DevOps Course in Marathahalli Bangalore is structured to give you both theoretical knowledge and hands-on experience. Here’s what the curriculum typically covers:
Core Modules:
Step into the world of DevOps Training Center in Marathahalli Bangalore, where you'll discover how this powerful approach bridges the gap between development and operations to streamline processes and boost efficiency in today’s tech-driven environment.
✅ Linux Basics: Learn command-line fundamentals essential for DevOps engineers.
✅ Version Control with Git & GitHub: Master source code management.
✅ Automate your software build and deployment: workflows seamlessly using Jenkins as a powerful Continuous Integration tool.
✅ Configuration Management with Ansible: Manage infrastructure more efficiently.
✅ Containerization using Docker: Package apps with all their dependencies.
✅ Orchestration with Kubernetes: Manage containers at scale.
✅ Cloud Computing with AWS: Get started with DevOps in cloud environments.
✅ Monitoring & Logging with Prometheus, Grafana: Gain insights into application performance.
✅ CI/CD Pipeline Implementation: Build end-to-end automation flows.
✅ Everything is taught with real-time: examples, project work, and lab exercises.
Get Recognized with a DevOps Certification Course in Marathahalli Bangalore – Boost Your Industry Credibility
Upon completing the course, you'll be awarded a DevOps Certification Course in Marathahalli Bangalore issued by eMexo Technologies, validating your expertise in the field. This certification is designed to validate your expertise and improve your credibility with hiring managers. It’s especially useful for roles like:
✅ DevOps Engineer
✅ Site Reliability Engineer (SRE)
✅ Build & Release Engineer
✅ Automation Engineer
✅ System Administrator with DevOps skills
Top-Rated Best DevOps Training in Marathahalli Bangalore – Why eMexo Technologies Stands Out from the Rest
When it comes to finding the Best DevOps Training in Marathahalli Bangalore, eMexo Technologies ticks all the boxes:
✅ Up-to-Date Curriculum: Constantly refreshed to include the latest industry tools and practices.
✅ Experienced Trainers: Learn from industry professionals with 8–15 years of real-world experience.
✅ Real Projects: Work on case studies and scenarios inspired by actual DevOps environments.
✅ Flexible Timings: Choose from weekday, weekend, and online batches.
✅ Affordable Pricing: With the current 40% discount, this course is great value for money.
✅ Lifetime Access to Materials: Revise and revisit anytime.
DevOps Training Institute in Marathahalli Bangalore – Why Location Matters
Located in one of Bangalore’s biggest IT hubs, eMexo Technologies is a top-rated DevOps Training Institute in Marathahalli Bangalore. Proximity to major tech parks and MNCs means better networking opportunities and access to local job openings right after your course.
DevOps Training Center in Marathahalli Bangalore – Hands-On, Tech-Ready Lab Environment
At the DevOps Training Center in Marathahalli Bangalore, students don’t just watch tutorials—they do the work. You’ll have access to a fully equipped lab environment where you’ll implement DevOps pipelines, configure cloud environments, and monitor system performance.
DevOps Training and Placement in Marathahalli Bangalore – Start Working Faster
Job support is one of the biggest advantages here. The DevOps Training and Placement in Marathahalli Bangalore equips you with everything you need to launch a successful career in DevOps, including:
✅ 1:1 career counseling
✅ Resume building support
✅ Mock interviews with real-time feedback
✅ Interview scheduling and referrals through their hiring partners
✅ Post-course job alerts and updates
Many past students have successfully secured roles at top companies like Infosys, Wipro, TCS, Mindtree, and Accenture.
youtube
Don’t Miss This Opportunity!
If you're serious about breaking into tech or advancing in your current role, now is the perfect time to act. With expert-led training, hands-on labs, and full placement support, eMexo Technologies' DevOps Training in Marathahalli Bangalore has everything you need to succeed.
👉 Enroll now and grab an exclusive 30% discount on our DevOps training – limited seats available!
🔗 Click here to view course details and enroll
#DevOps#DevOpsTraining#DevOpsCourse#LearnDevOps#DevOpsEngineer#DevOpsSkills#DevOpsCulture#Git#Jenkins#Docker#Kubernetes#Ansible#Terraform#Prometheus#Grafana#CI/CD#Automation#ITTraining#CloudComputing#SoftwareDevelopment#CareerGrowth#DevOpsTrainingcenterinBangalore#DevOpsTrainingInMarathahalliBangalore#DevOpsCourseInMarathahalliBangalore#DevOpsTrainingInstitutesInMarathahalliBangalore#DevOpsClassesInMarathahalliBangalore#BestDevOpsTrainingInMarathahalliBangalore#DevOpsTrainingandPlacementinMarathahalliBangalore#Youtube
1 note
·
View note
Text
Site Reliability Engineering: Tools, Techniques & Responsibilities
Introduction to Site Reliability Engineering (SRE)
Site Reliability Engineering (SRE) is a modern approach to managing large-scale systems by applying software engineering principles to IT operations. Originally developed by Google, SRE focuses on improving system reliability, scalability, and performance through automation and data-driven decision-making.

At its core, SRE bridges the gap between development and operations teams. Rather than relying solely on manual interventions, SRE encourages building robust systems with self-healing capabilities. SRE teams are responsible for maintaining uptime, monitoring system health, automating repetitive tasks, and handling incident response.
A key concept in SRETraining is the use of Service Level Objectives (SLOs) and Error Budgets. These help organizations balance the need for innovation and reliability by defining acceptable levels of failure. SRE also emphasizes observability—the ability to understand what's happening inside a system using metrics, logs, and traces.
By embracing automation, continuous improvement, and a blameless culture, SRE enables teams to reduce downtime, scale efficiently, and deliver high-quality digital services. As businesses increasingly depend on digital infrastructure, the demand for SRE practices and professionals continues to grow. Whether you're in development, operations, or IT leadership, understanding SRE can greatly enhance your approach to building resilient systems.
Tools Commonly Used in SRE
Monitoring & Observability
Prometheus – Open-source monitoring system with time-series data and alerting.
Grafana – Visualization and dashboard tool, often used with Prometheus.
Datadog – Cloud-based monitoring platform for infrastructure, applications, and logs.
New Relic – Full-stack observability with APM and performance monitoring.
ELK Stack (Elasticsearch, Logstash, Kibana) – Log analysis and visualization.
Incident Management & Alerting
PagerDuty – Real-time incident alerting, on-call scheduling, and response automation.
Opsgenie – Alerting and incident response tool integrated with monitoring systems.
VictorOps (now Splunk On-Call) – Streamlines incident resolution with automated workflows.
Automation & Configuration Management
Ansible – Simple automation tool for configuration and deployment.
Terraform – Infrastructure as Code (IaC) for provisioning cloud resources.
Chef / Puppet – Configuration management tools for system automation.
CI/CD Pipelines
Jenkins – Widely used automation server for building, testing, and deploying code.
GitLab CI/CD – Integrated CI/CD pipelines with source control.
Spinnaker – Multi-cloud continuous delivery platform.
Cloud & Container Orchestration
Kubernetes – Container orchestration for scaling and managing applications.
Docker – Containerization tool for packaging applications.
AWS CloudWatch / GCP Stackdriver / Azure Monitor – Native cloud monitoring tools.
Best Practices in Site Reliability Engineering (SRE)
Site Reliability Engineering (SRE) promotes a disciplined approach to building and operating reliable systems. Adopting best practices in SRE helps organizations reduce downtime, manage complexity, and scale efficiently.
A foundational practice is defining Service Level Indicators (SLIs) and Service Level Objectives (SLOs) to measure and set targets for performance and availability. These metrics ensure teams understand what reliability means for users and how to prioritize improvements.
Error budgets are another critical concept, allowing controlled failure to balance innovation with stability. If a system exceeds its error budget, development slows to focus on reliability enhancements.
SRE also emphasizes automation. Automating repetitive tasks like deployments, monitoring setups, and incident responses reduces human error and improves speed. Minimizing toil—manual, repetitive work that doesn’t add long-term value—is essential for team efficiency.
Observability is key. Systems should be designed with visibility in mind using logs, metrics, and traces to quickly detect and resolve issues.
Finally, a blameless post mortem culture fosters continuous learning. After incidents, teams analyze what went wrong without pointing fingers, focusing instead on preventing future issues.
Together, these practices create a culture of reliability, efficiency, and resilience—core goals of any successful SRE team.
Top 5 Responsibilities of a Site Reliability Engineer (SRE)
Maintain System Reliability and Uptime
Ensure services are available, performant, and meet defined availability targets.
Automate Operational Tasks
Build tools and scripts to automate deployments, monitoring, and incident response.
Monitor and Improve System Health
Set up observability tools (metrics, logs, traces) to detect and fix issues proactively.
Incident Management and Root Cause Analysis
Respond to incidents, minimize downtime, and conduct postmortems to learn from failures.
Define and Track SLOs/SLIs
Establish reliability goals and measure system performance against them.
Know More: Site Reliability Engineering (SRE) Foundation Training and Certification.
0 notes
Text
Why Site Reliability Engineer (SRE) Certification Is in High Demand Right Now
In today’s cloud-driven world, uptime isn’t optional—it’s mission-critical. That’s exactly why the Site Reliability Engineer certification is one of the hottest credentials in tech right now.
From startups to global enterprises, companies are looking for certified pros who understand SRE principles and practices. If you're eyeing a career upgrade, the SRE Foundation certification is your gateway to high-impact roles in modern IT environments.
🚀 What’s the Hype About SRE Certification?
It bridges the gap between software development and IT operations
Equips you with real-world skills to enhance system reliability, scalability, and performance
Backed by top-tier Site Reliability Engineering training programs
💡 What You'll Learn in the SRE Certification Course:
Core SRE principles and practices like SLAs, SLOs, and error budgets
Incident management, monitoring, and automation
Strategies for continuous improvement and reducing system toil
🌐 Why Tech Teams Are Prioritizing This Now:
Businesses can't afford downtime—SRE certification benefits include stronger system resilience and faster recovery
Certified professionals earn more and move faster up the ladder
It’s a must-have if you want to lead site reliability or DevOps initiatives
📚 Whether you're starting with the SRE Foundation certification or upskilling with full Site Reliability Engineering training, now’s the time to make your move.
For information visit: -
Contact : +41444851189
#SRECertification #SiteReliabilityEngineer #SREFoundation #DevOpsCareers #SREPrinciples #TechTrends #UptimeMatters #EngineeringExcellence #CertificationGoals #SRETraining
#Site Reliability Engineer certification#sre certification#SRE Foundation certification#Site Reliability Engineering training#SRE certification course#SRE principles and practices#SRE certification benefits
0 notes
Text
Embarking on a Digital Journey: Your Guide to Learning Coding
In today's fast-paced and ever-evolving technology landscape, DevOps has emerged as a crucial and transformative field that bridges the gap between software development and IT operations. The term "DevOps" is a portmanteau of "Development" and "Operations," emphasizing the importance of collaboration, automation, and efficiency in the software delivery process. DevOps practices have gained widespread adoption across industries, revolutionizing the way organizations develop, deploy, and maintain software. This paradigm shift has led to a surging demand for skilled DevOps professionals who can navigate the complex and multifaceted DevOps landscape.

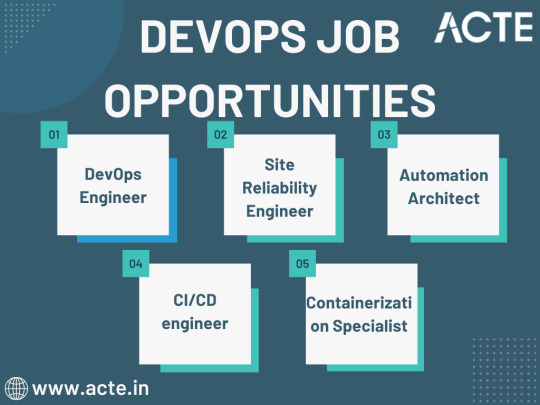
Exploring DevOps Job Opportunities
DevOps has given rise to a spectrum of job opportunities, each with its unique focus and responsibilities. Let's delve into some of the key DevOps roles that are in high demand:
1. DevOps Engineer
At the heart of DevOps lies the DevOps engineer, responsible for automating and streamlining IT operations and processes. DevOps engineers are the architects of efficient software delivery pipelines, collaborating closely with development and IT teams. Their mission is to accelerate the software delivery process while ensuring the reliability and stability of systems.
2. Site Reliability Engineer (SRE)
Site Reliability Engineers, or SREs, are a subset of DevOps engineers who specialize in maintaining large-scale, highly reliable software systems. They focus on critical aspects such as availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning. SREs play a pivotal role in ensuring that applications and services remain dependable and performant.
3. Automation Architect
Automation is a cornerstone of DevOps, and automation architects are experts in this domain. These professionals design and implement automation solutions that optimize software development and delivery processes. By automating repetitive and manual tasks, they enhance efficiency and reduce the risk of human error.
4. Continuous Integration/Continuous Deployment (CI/CD) Engineer
CI/CD engineers specialize in creating, maintaining, and optimizing CI/CD pipelines. The CI/CD pipeline is the backbone of DevOps, enabling the automated building, testing, and deployment of code. CI/CD engineers ensure that the pipeline operates seamlessly, enabling rapid and reliable software delivery.
5. Containerization Specialist
The rise of containerization technologies like Docker and orchestration tools such as Kubernetes has revolutionized software deployment. Containerization specialists focus on managing and scaling containerized applications, making them an integral part of DevOps teams.
Navigating the DevOps Learning Journey
To embark on a successful DevOps career, individuals often turn to comprehensive training programs and courses that equip them with the necessary skills and knowledge. The DevOps learning journey typically involves the following courses:
1. DevOps Foundation
A foundational DevOps course covers the basics of DevOps practices, principles, and tools. It serves as an excellent starting point for beginners, providing a solid understanding of the DevOps mindset and practices.
2. DevOps Certification
Advanced certification courses are designed for those who wish to delve deeper into DevOps methodologies, CI/CD pipelines, and various tools like Jenkins, Ansible, and Terraform. These certifications validate your expertise and enhance your job prospects.
3. Docker and Kubernetes Training
Containerization and container orchestration are two essential skills in the DevOps toolkit. Courses focused on Docker and Kubernetes provide in-depth knowledge of these technologies, enabling professionals to effectively manage containerized applications.
4. AWS or Azure DevOps Training
Specialized DevOps courses tailored to cloud platforms like AWS or Azure are essential for those working in a cloud-centric environment. These courses teach how to leverage cloud services in a DevOps context, further streamlining software development and deployment.
5. Advanced DevOps Courses
For those looking to specialize in specific areas, advanced DevOps courses cover topics like DevOps security, DevOps practices for mobile app development, and more. These courses cater to professionals who seek to expand their expertise in specific domains.
As the DevOps landscape continues to evolve, the need for high-quality training and education becomes increasingly critical. This is where ACTE Technologies steps into the spotlight as a reputable choice for comprehensive DevOps training.
They offer carefully thought-out courses that are intended to impart both foundational information and real-world, practical experience. Under the direction of knowledgeable educators, students can quickly advance on their path to become skilled DevOps engineers. They provide practical insights into industrial practises and issues, going beyond theory.
Your journey toward mastering DevOps practices and pursuing a successful career begins here. In the digital realm, where possibilities are limitless and innovation knows no bounds, ACTE Technologies serves as a gateway to a thriving DevOps career. With a diverse array of courses and expert instruction, you'll find the resources you need to thrive in this ever-evolving domain.
3 notes
·
View notes
Text
The Site Reliability Engineering Certification offered by GSDC is a testament to the skills and expertise of an SRE. It demonstrates that the candidate has a comprehensive understanding of SRE principles, practices, and methodologies and can apply them to real-world scenarios. The SRE Certification is important for professionals who want to enhance their job prospects and advance their careers in the field of Site Reliability Engineering. It provides a competitive edge in the job market and shows that the candidate is committed to ongoing learning and development.
#site reliability engineering certification#site reliability engineer certification#sre course#site reliability engineer foundation certification#site reliability engineering certification online#sre foundation certificaiton#sre certification#sre certification cost#sre foundation accrediation
0 notes
Text

Embark on a transformative journey with our Site Reliability Engineer (SRE) Certification program. Designed for aspirants and professionals alike, this course delves into the core principles of maintaining, building, and ensuring scalable and highly reliable software systems.
#sre certification#site reliability engineer certification#sre foundation certification#sre course#sre certification cost
0 notes
Text
What is B.Tech CSE with Cloud Computing? Everything You Need to Know
As industries rapidly shift toward cloud-first and digital strategies, the demand for skilled professionals in cloud technologies has surged. From powering enterprise applications to enabling remote work and global collaboration, cloud computing is at the heart of this transformation.
To meet this growing need, academic institutions have introduced specialized engineering programs tailored to cloud technologies. Among them, B.Tech CSE with Cloud Computing has emerged as one of the most relevant and future-oriented courses for tech-savvy students.
In this article, we’ll explore what this program entails, the curriculum, the career opportunities it opens up, and why Jaipur is becoming a hotspot for cloud-focused engineering education.
What Is B.Tech CSE with Cloud Computing?
B.Tech in Computer Science and Engineering (CSE) with a specialization in Cloud Computing is a 4-year undergraduate program that combines the foundational concepts of computer science with an in-depth focus on cloud technology.
This course prepares students to design, implement, and manage scalable and secure cloud solutions. It moves beyond traditional computer science by teaching how businesses deploy applications and infrastructure using platforms like AWS, Microsoft Azure, and Google Cloud.
The specialization is ideal for students who want to work in cutting-edge fields such as DevOps, cloud architecture, cloud security, and scalable software development.
Why Cloud Computing Matters More Than Ever
Cloud computing has evolved into a critical pillar of modern IT infrastructure. Companies of every size and industry are shifting from on-premise systems to cloud environments to take advantage of scalability, reliability, and cost efficiency.
Here’s why this field is booming:
High demand across industries: Healthcare, finance, retail, education, and even governments rely on cloud platforms.
Global skill shortage: There's a growing gap between demand and supply of cloud professionals.
Innovation at scale: Cloud powers AI, machine learning, big data analytics, and more.
Remote work enablement: Cloud platforms make remote collaboration seamless.
With these trends accelerating, professionals with cloud expertise are becoming indispensable.
What You’ll Study in This Course
The B.Tech CSE with Cloud Computing curriculum is structured to include both core computer science subjects and cloud-focused modules. Some of the core subjects include:
Data Structures & Algorithms
Operating Systems
Software Engineering
Database Management Systems
Computer Networks
Specialized cloud topics covered in the later semesters include:
Virtualization and Cloud Infrastructure
Cloud Services (IaaS, PaaS, SaaS)
DevOps and Automation
Cloud Security and Compliance
Serverless Computing
Real-time Project in Cloud Deployment
The course includes workshops, labs, internships, and capstone projects, offering students practical exposure in cloud environments.
Career Opportunities After Graduation
Graduates of this program can pursue a variety of high-demand roles in the tech industry. The skillset acquired during the degree aligns with current trends in software deployment, automation, and cloud-based services.
Popular job roles include:
Cloud Developer
Solutions Architect
DevOps Engineer
Site Reliability Engineer (SRE)
Cloud Infrastructure Specialist
Cloud Security Analyst
Data Engineer (Cloud Platforms)
Many of these roles come with lucrative salaries, especially for those with certifications and hands-on project experience.
Pursuing the Right Institute
Choosing the right college is crucial. Look for institutions that offer strong industry tie-ups, updated curricula, cloud lab access, and placement support. If you’re planning to enroll in a cloud engineering course in Jaipur, you’ll find several top-tier private and public institutions offering excellent learning environments.
Universities like Gyan Vihar (AESTR), JECRC University, Poornima University, and Manipal University Jaipur have gained recognition for integrating cloud computing into their B.Tech CSE programs. These colleges emphasize hands-on experience, industry certifications, and live projects.
Skills You’ll Build Through the Course
This program isn't just about theory — it prepares you to build, deploy, and manage cloud systems in real-world settings. Key skills include:
Cloud platform management (AWS, Azure, GCP)
CI/CD pipelines and DevOps tools (Jenkins, GitLab, Docker, Kubernetes)
Infrastructure as Code (Terraform, Ansible)
Cloud security policies and best practices
Serverless application development
Monitoring, logging, and incident response in cloud environments
These are the very skills that companies are actively hiring for in today’s competitive tech market.
Why Jaipur Is Emerging as a Cloud Tech Education Hub
Jaipur is fast becoming a go-to destination for students pursuing engineering and technology degrees. With a growing tech ecosystem, modern infrastructure, and an affordable cost of living, the city offers a balanced environment for learning and innovation.
Many colleges in Jaipur have established partnerships with global cloud providers like AWS and Microsoft, ensuring that students graduate with relevant industry-ready skills. Additionally, the city is home to a growing number of tech startups and incubators, offering hands-on internship and placement opportunities.
Students opting for b.tech cse in cloud engineering in Jaipur not only benefit from academic knowledge but also from access to local and national job markets, certifications, and project-based learning.
Admission Process and Eligibility
The typical eligibility criteria for this program include:
Completion of 10+2 with Physics, Mathematics, and Computer Science or Chemistry
Minimum 50–60% marks in qualifying exams (may vary by institution)
Admissions via JEE Main, REAP (Rajasthan), or direct university entrance exams
Application cycles usually begin around April and may extend till August or September. Many private colleges also offer merit-based scholarships and early bird discounts.
Certifications That Add Value
Students are encouraged to supplement their degree with cloud certifications such as:
AWS Certified Solutions Architect
Microsoft Azure Administrator
Google Associate Cloud Engineer
Certified Kubernetes Administrator (CKA)
DevOps Engineer Professional
These globally recognized credentials significantly improve job prospects and salary potential.
Conclusion
Cloud computing is more than a buzzword—it's the foundation of today’s and tomorrow’s digital economy. A degree like B.Tech CSE with Cloud Computing equips students with the technical depth, practical knowledge, and industry exposure needed to thrive in this evolving landscape.
From world-class colleges in Jaipur to growing opportunities across the country, this course can set you on a high-growth career path in tech. If you're passionate about cloud systems, automation, and building digital solutions at scale, this specialization is worth considering.
0 notes
Text
Mastering Enterprise Kubernetes: Why DO380 is a Game-Changer for OpenShift Admins
As Kubernetes becomes the enterprise standard for container orchestration, administrators are facing new challenges in scaling, managing, and automating OpenShift clusters. If you've already completed DO180 and DO280, the next step in your Red Hat OpenShift journey is DO380 — the course that equips you with advanced administration, GitOps practices, and cluster automation skills.
🔍 What is DO380?
DO380 - Red Hat OpenShift Administration III is an advanced course designed to teach you how to operate and automate large-scale OpenShift container platforms in production environments. This course builds on the skills you acquired in DO180 (Foundations of OpenShift) and DO280 (OpenShift Administration II).
💡 What You'll Learn:
✅ Cluster scaling & resilience: Manage large OpenShift clusters with High Availability and node tuning.
✅ Advanced GitOps with ArgoCD: Deploy and manage workloads using Git-based pipelines.
✅ Custom Metrics & Auto-scaling: Enable horizontal pod autoscaling based on custom metrics.
✅ Infrastructure as Code: Use Ansible Automation with Red Hat Enterprise Linux and OpenShift.
✅ Security & compliance: Apply security policies at scale using OpenShift compliance operators.
✅ Monitoring & Observability: Implement cluster monitoring with Prometheus, Grafana, and Alertmanager.
🎯 Who Should Take DO380?
🔧 DevOps Engineers & Site Reliability Engineers (SREs) looking to automate OpenShift at scale.
☁️ Cloud Platform Administrators managing hybrid or multi-cloud container platforms.
🎓 Red Hat Certified System Administrators (RHCSA) preparing for RHCA path.
📈 Career Impact:
With DO380 certification, you're not just another Kubernetes admin — you're an enterprise-grade OpenShift expert, capable of designing resilient, secure, and automated container platforms. This positions you for roles like:
🔹 OpenShift Platform Engineer
🔹 SRE (Site Reliability Engineer)
🔹 DevOps Architect
🔹 Hybrid Cloud Administrator
🎓 Certification Path:
📚 DO180 + DO280 + DO380 = OpenShift Admin Level
Once you complete DO380, you're one step away from achieving Red Hat Certified Architect (RHCA).
🔥 Final Thoughts:
In 2025 and beyond, enterprises will demand automation-first, GitOps-enabled, and security-aware administrators. DO380 prepares you to lead that transformation. Ready to level up?
🧠 Want to Learn DO380 with Hands-On Labs?
Join our expert-led batch at Hawkstack — Get instructor-led training, lab access, real-world projects, and certification guidance.
📅 New batch starts 19th July 📍 100% Practical | Live Sessions | RHCA Roadmap For more details www.hawkstack.com
0 notes