#scrapy data extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Hire Expert Scrapy Developers for Scalable Web Scraping & Data Automation
Looking to extract high-value data from the web quickly and accurately? At Prospera Soft, we offer top-tier Scrapy development services to help businesses automate data collection, gain market insights, and scale operations with ease.
Our team of Scrapy experts specializes in building robust, Python-based web scrapers that deliver 10X faster data extraction, 99.9% accuracy, and full cloud scalability. From price monitoring and sentiment analysis to lead generation and product scraping, we design intelligent, secure, and GDPR-compliant scraping solutions tailored to your business needs.
Why Choose Our Scrapy Developers?
✅ Custom Scrapy Spider Development for complex and dynamic websites
✅ AI-Optimized Data Parsing to ensure clean, structured output
✅ Middleware & Proxy Rotation to bypass anti-bot protections
✅ Seamless API Integration with BI tools and databases
✅ Cloud Deployment via AWS, Azure, or GCP for high availability
Whether you're in e-commerce, finance, real estate, or research, our scalable Scrapy solutions power your data-driven decisions.
#Hire Expert Scrapy Developers#scrapy development company#scrapy development services#scrapy web scraping#scrapy data extraction#scrapy automation#hire scrapy developers#scrapy company#scrapy consulting#scrapy API integration#scrapy experts#scrapy workflow automation#best scrapy development company#scrapy data mining#hire scrapy experts#scrapy scraping services#scrapy Python development#scrapy no-code scraping#scrapy enterprise solutions
0 notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text
Tapping into Fresh Insights: Kroger Grocery Data Scraping
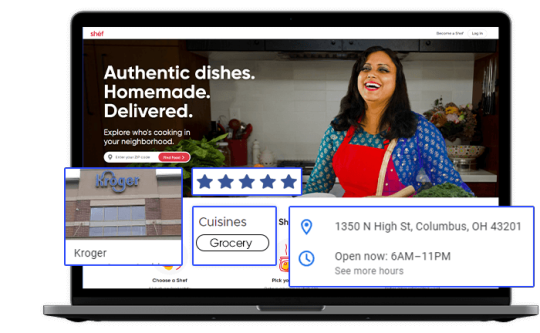
In today's data-driven world, the retail grocery industry is no exception when it comes to leveraging data for strategic decision-making. Kroger, one of the largest supermarket chains in the United States, offers a wealth of valuable data related to grocery products, pricing, customer preferences, and more. Extracting and harnessing this data through Kroger grocery data scraping can provide businesses and individuals with a competitive edge and valuable insights. This article explores the significance of grocery data extraction from Kroger, its benefits, and the methodologies involved.
The Power of Kroger Grocery Data
Kroger's extensive presence in the grocery market, both online and in physical stores, positions it as a significant source of data in the industry. This data is invaluable for a variety of stakeholders:
Kroger: The company can gain insights into customer buying patterns, product popularity, inventory management, and pricing strategies. This information empowers Kroger to optimize its product offerings and enhance the shopping experience.
Grocery Brands: Food manufacturers and brands can use Kroger's data to track product performance, assess market trends, and make informed decisions about product development and marketing strategies.
Consumers: Shoppers can benefit from Kroger's data by accessing information on product availability, pricing, and customer reviews, aiding in making informed purchasing decisions.
Benefits of Grocery Data Extraction from Kroger
Market Understanding: Extracted grocery data provides a deep understanding of the grocery retail market. Businesses can identify trends, competition, and areas for growth or diversification.
Product Optimization: Kroger and other retailers can optimize their product offerings by analyzing customer preferences, demand patterns, and pricing strategies. This data helps enhance inventory management and product selection.
Pricing Strategies: Monitoring pricing data from Kroger allows businesses to adjust their pricing strategies in response to market dynamics and competitor moves.
Inventory Management: Kroger grocery data extraction aids in managing inventory effectively, reducing waste, and improving supply chain operations.
Methodologies for Grocery Data Extraction from Kroger
To extract grocery data from Kroger, individuals and businesses can follow these methodologies:
Authorization: Ensure compliance with Kroger's terms of service and legal regulations. Authorization may be required for data extraction activities, and respecting privacy and copyright laws is essential.
Data Sources: Identify the specific data sources you wish to extract. Kroger's data encompasses product listings, pricing, customer reviews, and more.
Web Scraping Tools: Utilize web scraping tools, libraries, or custom scripts to extract data from Kroger's website. Common tools include Python libraries like BeautifulSoup and Scrapy.
Data Cleansing: Cleanse and structure the scraped data to make it usable for analysis. This may involve removing HTML tags, formatting data, and handling missing or inconsistent information.
Data Storage: Determine where and how to store the scraped data. Options include databases, spreadsheets, or cloud-based storage.
Data Analysis: Leverage data analysis tools and techniques to derive actionable insights from the scraped data. Visualization tools can help present findings effectively.
Ethical and Legal Compliance: Scrutinize ethical and legal considerations, including data privacy and copyright. Engage in responsible data extraction that aligns with ethical standards and regulations.
Scraping Frequency: Exercise caution regarding the frequency of scraping activities to prevent overloading Kroger's servers or causing disruptions.
Conclusion
Kroger grocery data scraping opens the door to fresh insights for businesses, brands, and consumers in the grocery retail industry. By harnessing Kroger's data, retailers can optimize their product offerings and pricing strategies, while consumers can make more informed shopping decisions. However, it is crucial to prioritize ethical and legal considerations, including compliance with Kroger's terms of service and data privacy regulations. In the dynamic landscape of grocery retail, data is the key to unlocking opportunities and staying competitive. Grocery data extraction from Kroger promises to deliver fresh perspectives and strategic advantages in this ever-evolving industry.
#grocerydatascraping#restaurant data scraping#food data scraping services#food data scraping#fooddatascrapingservices#zomato api#web scraping services#grocerydatascrapingapi#restaurantdataextraction
4 notes
·
View notes
Text
Making your very first Scrapy spider - 01 - Python scrapy tutorial for inexperienced persons https://www.altdatum.com/wp-content/uploads/2019/10/Making-your-very-first-Scrapy-spider-01-Python.jpg #inexperienced #Making #persons #Python #Pythoncourse #pythoncourseforbeginners #pythonforbeginners #Pythonprogramming #PythonScrapytutorial #pythonscrapywebcrawler #pythontrainingforbeginners #PythonTutorial #pythontutorialforbeginners #pythonwebscrapingtutorial #Scrapy #scrapyframework #scrapyframeworkinpython #scrapyspider #scrapyspiderexample #scrapyspiderpython #scrapyspidertutorial #Scrapytutorial #spider #tutorial #webscraping #webscrapingpython https://www.altdatum.com/making-your-very-first-scrapy-spider-01-python-scrapy-tutorial-for-inexperienced-persons/?feed_id=138456&_unique_id=687b5f7f75b7b
0 notes
Text
AI for Hourly Price Tracking on Amazon & Flipkart India – 2025

Introduction
In India's hyper-competitive eCommerce landscape, prices change every hour based on demand, stock levels, and competitor behavior. Retailers and brands often miss out on strategic pricing decisions due to lack of real-time visibility. That’s where Actowiz Solutions steps in—leveraging AI-driven web scraping to monitor hourly price fluctuations on leading platforms like Amazon and Flipkart.
Why Hourly Price Monitoring Matters
Price changes on Amazon and Flipkart occur due to:
Lightning deals and hourly discounts
Flash sales or limited-time coupons
Real-time inventory-based dynamic pricing
Third-party seller competition
AI models help businesses track these fluctuations automatically—offering an edge in price competitiveness, promotional alignment, and margin optimization.
How AI-Powered Scraping Works
Step 1: Product Mapping by SKU
Actowiz Solutions uses AI algorithms to auto-identify product listings by SKU and match variants across Amazon and Flipkart—even when naming or specs differ slightly.
Step 2: Hourly Scraping Schedules
AI bots fetch product pricing, discount info, stock availability, and seller data every hour. The system avoids IP blocks using rotating proxies and smart throttling.
Step 3: Price Pattern Detection
Machine learning models are applied to:
Identify predictable discount windows
Flag anomalies such as sudden drops or surge pricing
Benchmark competitors' pricing response during sales
Sample Data Extracted
10 AM
Amazon.in
MRP: ₹14,999
Selling Price: ₹12,499
Discount: 17%
Stock: In Stock
Flipkart
MRP: ₹14,999
Selling Price: ₹12,699
Discount: 15.3%
Stock: In Stock
11 AM
Amazon.in
MRP: ₹14,999
Selling Price: ₹11,999
Discount: 20%
Stock: In Stock
Flipkart
MRP: ₹14,999
Selling Price: ₹13,199
Discount: 12%
Stock: In Stock
Key Use Cases for eCommerce Players
1. Dynamic Pricing Engines
Brands can plug this data into dynamic pricing algorithms to auto-adjust SKUs within margins.
2. Flash Sale Monitoring
Track flash deals during festivals like Diwali or Big Billion Days—ensure your pricing matches or undercuts in real time.
3. Buy Box Optimization
Sellers get notified when their price is no longer competitive—prompting instant correction to win the Amazon buy box.
4. Brand vs Seller Analysis
Compare first-party listings vs marketplace sellers and detect unauthorized price undercuts harming brand value.
Technical Stack at Actowiz Solutions
Python + Scrapy + Puppeteer for Scraping
AI/ML Layer: Time series anomaly detection, classification
Storage: AWS S3, BigQuery
Dashboard: Custom PowerBI or Looker integration
Real Business Impact
💡 A fashion retailer using Actowiz’s hourly price feed reduced stockout loss by 22% by dynamically lowering prices on Flipkart during non-peak hours and re-aligning with Amazon flash sales.
💡 A mobile accessories brand improved daily GMV by 17% by optimizing their Flipkart pricing based on Amazon hourly tracking.
Challenges Solved by AI
Data Volume: Manually tracking 1000+ SKUs hourly is impossible
Accuracy: AI reduces noise and detects false discounts
Speed: Updates every 60 mins enable tactical moves throughout the day
Compliance & Ethics
Actowiz follows ethical scraping standards by respecting robots.txt, handling personal data securely, and offering data anonymization where needed.
Conclusion
In 2025, staying competitive in India’s eCommerce space means being faster, smarter, and more precise. With AI-powered hourly price scraping from Actowiz Solutions, brands, sellers, and retailers can make real-time pricing decisions that matter.
Learn More >>
#AIToMonitorHourlyPriceFluctuations#AIForHourlyPriceTrackingOnAmazonAndFlipkart#AIDrivenWebScraping#AIPoweredScraping#BenchmarkCompetitorsPricing#FlashSaleMonitoring#AmazonHourlyTracking#AIPoweredHourlyPriceScraping
0 notes
Text
Extract Laptop Resale Value from Cashify

Introduction
In India’s fast-evolving second-hand electronics market, Cashify has emerged as a leading platform for selling used gadgets, especially laptops. This research report investigates how to Extract laptop resale value from Cashify, using data-driven insights derived from Web scraping laptop listings from Cashify and analyzing multi-year pricing trends.
This report also explores the potential of building a Cashify product data scraping tool, the benefits of Web Scraping E-commerce Websites, and how businesses can leverage a Custom eCommerce Dataset for strategic pricing.
Market Overview: The Rise of Second-Hand Laptops in India
In India, the refurbished and second-hand electronics segment has witnessed double-digit growth over the last five years. Much of this boom is driven by the affordability crisis for new electronics, inflationary pressure, and the rising acceptance of certified pre-owned gadgets among Gen Z and millennials. Platforms like Cashify have revolutionized this space by building trust through verified listings, quality checks, and quick payouts. For brands, resellers, or entrepreneurs, the ability to extract laptop resale value from Cashify has become crucial for shaping buyback offers, warranty pricing, and trade-in deals.
Web scraping laptop listings from Cashify allows stakeholders to get a clear, real-time snapshot of average selling prices across brands, conditions, and configurations. Unlike OLX or Quikr, where listings can be inconsistent or scattered, Cashify offers structured data points — model, age, wear and tear, battery health, and more — making it a goldmine for second-hand market intelligence. By combining this structured data with a Cashify product data scraping tool, businesses can identify underpriced segments, negotiate better supplier rates, and create competitive refurbished offerings.
With millions of laptops entering the resale loop every year, the scope of scraping and analyzing Cashify’s data goes far beyond academic interest. For retailers, this data can translate into practical business actions — from customizing trade-in bonuses to launching flash sale campaigns for old stock. The bigger goal is to build an adaptive pricing model that updates dynamically. This is where Web Scraping Cashify.in E-Commerce Product Data proves indispensable for data-driven decision-making.
Technology & Tools: How to Scrape Laptop Prices from Cashify India
Building an efficient pipeline to scrape laptop prices from Cashify India demands more than just basic scraping scripts. Cashify uses dynamic content loading, pagination, and real-time pricing updates, which means your scraper must be robust enough to handle AJAX calls, handle IP blocks, and store large datasets securely. Many modern scraping stacks use Python libraries like Scrapy, Selenium, or Puppeteer, which can render JavaScript-heavy pages and pull detailed product listings, price fluctuations, and time-stamped snapshots.
Setting up a Cashify web scraper for laptop prices India can help businesses automate daily price checks, generate real-time price drop alerts, and spot sudden changes in average resale value. Combining this with a smart notification system ensures refurbishers and second-hand retailers stay one step ahead of market fluctuations.
Additionally, deploying a custom eCommerce dataset extracted from Cashify helps link multiple data points: for example, pairing model resale values with the original launch price, warranty status, or historical depreciation. This layered dataset supports advanced analytics, like predicting when a specific model’s resale value will hit rock bottom — an insight invaluable for maximizing margins on bulk procurement.
A good Cashify product data scraping tool should include error handling, proxy rotation, and anti-bot bypass methods. For larger operations, integrating this tool with CRM or ERP software automates workflows — from setting competitive buyback quotes to updating storefront listings. Ultimately, the technical strength behind web scraping e-commerce websites is what makes data actionable, turning raw pricing into real profit.
Opportunities: Turning Scraped Cashify Data into Business Strategy
Once you extract laptop resale value from Cashify, the next step is turning this raw pricing intelligence into a clear business advantage. For individual resellers, knowing the exact resale price of a MacBook Air or HP Pavilion in real-time can mean the difference between a profit and a loss. For larger refurbishing chains or online marketplaces, scraped data powers dynamic pricing engines, localized offers, and even targeted marketing campaigns for specific models or city clusters.
For instance, with a robust Cashify.com laptop pricing dataset India, a company can forecast upcoming spikes in demand — say during the start of the academic year when students buy affordable laptops — and stock up on popular mid-range models in advance. Additionally, trends in price drop alerts help predict when it’s cheaper to buy in bulk. With a Cashify web scraper for laptop prices India, these insights update automatically, ensuring no opportunity is missed.
Beyond pricing, the data can reveal supply gaps — like when certain brands or specs become scarce in specific cities. Using Web Scraping Solutions, retailers can then launch hyperlocal campaigns, offering better trade-in deals or doorstep pickups in under-supplied zones. This level of precision turns simple scraping into a strategic tool for growth.
In summary, the real power of web scraping laptop listings from Cashify lies not just in collecting prices, but in transforming them into a sustainable, profitable second-hand business model. With a solid scraping stack, well-defined use cases, and data-driven action plans, businesses can stay ahead in India’s booming refurbished laptop market.
Key Insights
Growing Popularity of Used Laptops
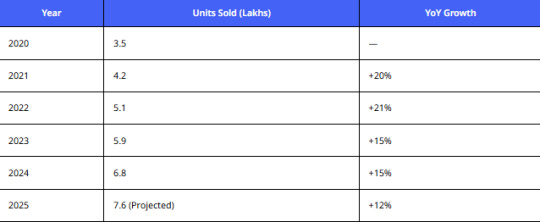
Analysis:
With over 7 million units projected for 2025, there’s a clear demand for affordable laptops, boosting the need to extract laptop resale value from Cashify for resale arbitrage and trade-in programs.
Average Resale Value Trend
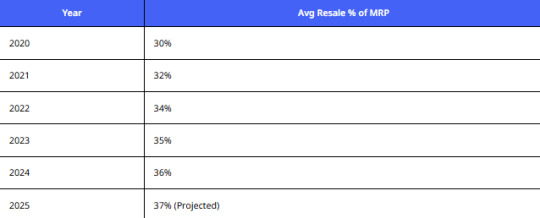
Analysis:
Consumers get back an average of 30–37% of the original price. This data justifies why many refurbishers and dealers scrape laptop prices from Cashify India to negotiate smarter buyback deals.
Brand-wise Resale Premium
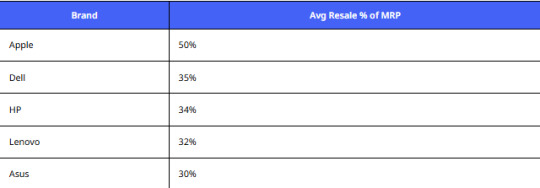
Analysis:
Apple retains the highest value — a key insight for businesses using a Cashify.com laptop pricing dataset India to optimize refurbished stock.
Price Drop Alerts Influence
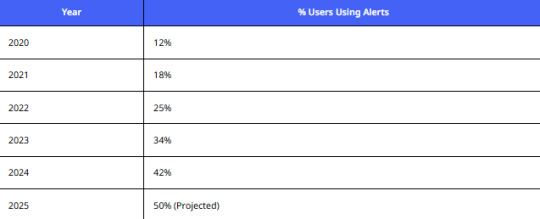
Analysis:
More users want real-time price drop alerts for laptops on Cashify, pushing resellers to deploy a Cashify web scraper for laptop prices India to monitor and react instantly.
Average Listing Time Before Sale
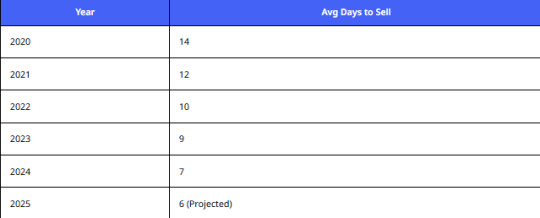
Analysis:
Faster selling cycles demand real-time tracking. Extract laptop resale value from Cashify in near real-time with a robust Cashify product data scraping tool.
Popular Price BracketsPrice Band (INR)% Share< 10,00020%10,000–20,00045%20,000–30,00025%>30,00010%
Analysis:
The ₹10k–₹20k band dominates, highlighting why Web Scraping Cashify.in E-Commerce Product Data is crucial for budget-focused segments.
Urban vs Rural Split

Analysis:
Growth in rural demand shows the need for local price intelligence via Web Scraping Solutions tailored for regional buyers.
Top Cities by Resale Listings
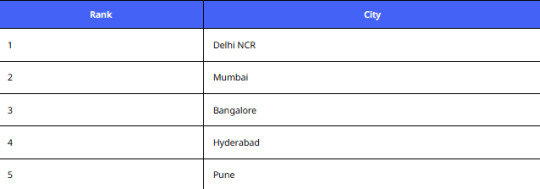
Analysis:
A Custom eCommerce Dataset from Cashify helps brands target these hubs with region-specific offers.
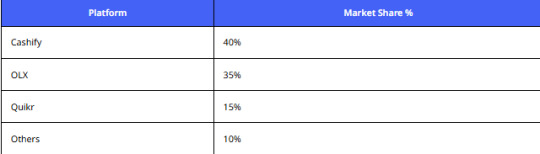
Analysis:
Cashify’s stronghold makes web scraping laptop listings from Cashify vital for second-hand market trend research.
Projected Market Value
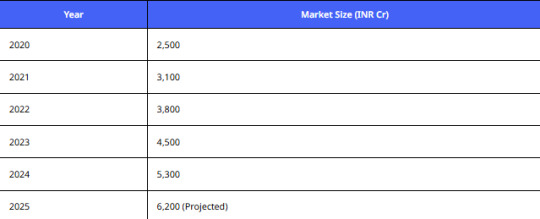
Analysis:
The second-hand laptop market will surpass INR 6,000 Cr by 2025 — a clear opportunity to build a Cashify web scraper for laptop prices India and lead the arbitrage game.
Conclusion
From real-time price tracking to building custom pricing datasets, this research shows that to stay ahead in the resale game, businesses must extract laptop resale value from Cashify with smart Web Scraping E-commerce Websites strategies. Ready to unlock hidden profits? Start scraping smarter with a custom Cashify product data scraping tool today!
Know More >> https://www.productdatascrape.com/extract-laptop-resale-value-cashify-market-trends.php
#ExtractLaptopResaleValueFromCashify#WebScrapingLaptopListingsFromCashify#ScrapeLaptopPricesFromCashifyIndia#CashifyComLaptopPricingDatasetIndia#CashifyProductDataScrapingTool#WebScrapingEcommerceWebsites
0 notes
Text
How to Scrape Data from Amazon: A Quick Guide
How to scrape data from Amazon is a question asked by many professionals today. Whether you’re a data analyst, e-commerce seller, or startup founder, Amazon holds tons of useful data — product prices, reviews, seller info, and more. Scraping this data can help you make smarter business decisions.

In this guide, we’ll show you how to do it the right way: safely, legally, and without getting blocked. You’ll also learn how to deal with common problems like IP bans, CAPTCHA, and broken scrapers.
Is It Legal to Scrape Data from Amazon?
This is the first thing you should know.
Amazon’s Terms of Service (TOS) say you shouldn’t access their site with bots or scrapers. So technically, scraping without permission breaks their rules. But the laws on scraping vary depending on where you live.
Safer alternatives:
Use the Amazon Product Advertising API (free but limited).
Join Amazon’s affiliate program.
Buy clean data from third-party providers.
If you still choose to scrape, make sure you’re not collecting private data or hurting their servers. Always scrape responsibly.
What Kind of Data Can You Scrape from Amazon?
Here are the types of data most people extract:
1. Product Info:
You can scrape Amazon product titles, prices, descriptions, images, and availability. This helps with price tracking and competitor analysis.
2. Reviews and Ratings:
Looking to scrape Amazon reviews and ratings? These show what buyers like or dislike — great for product improvement or market research.
3. Seller Data:
Need to know who you’re competing with? Scrape Amazon seller data to analyze seller names, fulfillment methods (like FBA), and product listings.
4. ASINs and Rankings:
Get ASINs, category info, and product rankings to help with keyword research or SEO.
What Tools Can You Use to Scrape Amazon?
You don’t need to be a pro developer to start. These tools and methods can help:
For Coders:
Python + BeautifulSoup/Scrapy: Best for basic HTML scraping.
Selenium: Use when pages need to load JavaScript.
Node.js + Puppeteer: Another great option for dynamic content.
For Non-Coders:
Octoparse and ParseHub: No-code scraping tools.
Just point, click, and extract!
Don’t forget:
Use proxies to avoid IP blocks.
Rotate user-agents to mimic real browsers.
Add delays between page loads.
These make scraping easier and safer, especially when you’re trying to scrape Amazon at scale.
How to Scrape Data from Amazon — Step-by-Step
Let’s break it down into simple steps:
Step 1: Pick a Tool
Choose Python, Node.js, or a no-code platform like Octoparse based on your skill level.
Step 2: Choose URLs
Decide what you want to scrape — product pages, search results, or seller profiles.
Step 3: Find HTML Elements
Right-click > “Inspect” on your browser to see where the data lives in the HTML code.
Step 4: Write or Set Up the Scraper
Use tools like BeautifulSoup or Scrapy to create scripts. If you’re using a no-code tool, follow its visual guide.
Step 5: Handle Pagination
Many listings span multiple pages. Be sure your scraper can follow the “Next” button.
Step 6: Save Your Data
Export the data to CSV or JSON so you can analyze it later.
This is the best way to scrape Amazon if you’re starting out.
How to Avoid Getting Blocked by Amazon
One of the biggest problems? Getting blocked. Amazon has smart systems to detect bots.
Here’s how to avoid that:
1. Use Proxies:
They give you new IP addresses, so Amazon doesn’t see repeated visits from one user.
2. Rotate User-Agents:
Each request should look like it’s coming from a different browser or device.
3. Add Time Delays:
Pause between page loads. This helps you look like a real human, not a bot.
4. Handle CAPTCHAs:
Use services like 2Captcha, or manually solve them when needed.
Following these steps will help you scrape Amazon products without being blocked.
Best Practices for Safe and Ethical Scraping
Scraping can be powerful, but it must be used wisely.
Always check the site’s robots.txt file.
Don’t overload the server by scraping too fast.
Never collect sensitive or private information.
Use data only for ethical and business-friendly purposes.
When you’re learning how to get product data from Amazon, ethics matter just as much as technique.
Are There Alternatives to Scraping?
Yes — and sometimes they’re even better:
Amazon API:
This is a legal, developer-friendly way to get product data.
Third-Party APIs:
These services offer ready-made solutions and handle proxies and errors for you.
Buy Data:
Some companies sell clean, structured data — great for people who don’t want to build their own tools.
Common Errors and Fixes
Scraping can be tricky. Here are a few common problems:
Error 503:
This usually means Amazon is blocking you. Fix it by using proxies and delays.
Missing Data:
Amazon changes its layout often. Re-check the HTML elements and update your script.
JavaScript Not Loading:
Switch from BeautifulSoup to Selenium or Puppeteer to load dynamic content.
The key to Amazon product scraping success is testing, debugging, and staying flexible.
Conclusion:
To scrape data from Amazon, use APIs or scraping tools with care. While it violates Amazon’s Terms of Service, it’s not always illegal. Use ethical practices: avoid private data, limit requests, rotate user-agents, use proxies, and solve CAPTCHAs to reduce detection risk.
Looking to scale your scraping efforts or need expert help? Whether you’re building your first script or extracting thousands of product listings, you now understand how to scrape data from Amazon safely and smartly. Let Iconic Data Scrap help you get it done right.
Contact us today for custom tools, automation services, or scraping support tailored to your needs.
#iconicdatascrap#howtoscrapedatafromamazon#amazondatascraping#amazonwebscraping#scrapeamazonproducts#extractdatafromamazon#amazonscraper#amazonproductscraper#bestwaytoscrapeamazon#scrapeamazonreviews#scrapeamazonprices#scrapeamazonsellerdata#extractproductinfofromamazon#howtogetproductdatafromamazon#webscrapingtools#pythonscraping#beautifulsoupamazon#amazonapialternative#htmlscraping#dataextraction#scrapingscripts#automateddatascraping#howtoscrapedatafromamazonusingpython#isitlegaltoscrapeamazondata#howtoscrapeamazonreviewsandratings#toolstoscrapeamazonproductlistings#scrapeamazonatscale
1 note
·
View note
Text
Python Automation Ideas: Save Hours Every Week with These Scripts
Tired of repeating the same tasks on your computer? With just a bit of Python knowledge, you can automate routine work and reclaim your time. Here are 10 Python automation ideas that can help you boost productivity and eliminate repetitive tasks.
1. Auto Email Sender
Use Python’s smtplib and email modules to send customized emails in bulk—perfect for reminders, reports, or newsletters.
2. File Organizer Script
Tired of a messy Downloads folder? Automate the sorting of files by type, size, or date using os and shutil.
3. PDF Merger/Splitter
Automate document handling by merging or splitting PDFs using PyPDF2 or pdfplumber.
4. Rename Files in Bulk
Rename multiple files based on patterns or keywords using os.rename()—great for photos, reports, or datasets.
5. Auto Backup Script
Schedule Python to back up files and folders to another directory or cloud with shutil or third-party APIs.
6. Instagram or Twitter Bot
Use automation tools like Selenium or APIs to post, like, or comment—ideal for marketers managing multiple accounts.
7. Invoice Generator
Automate invoice creation from Excel or CSV data using reportlab or docx. Perfect for freelancers and small businesses.
8. Weather Notifier
Set up a daily weather alert using the OpenWeatherMap API and send it to your phone or email each morning.
9. Web Scraper
Extract data from websites (news, prices, job listings) using BeautifulSoup or Scrapy. Automate market research or data collection.
10. Keyboard/Mouse Automation
Use pyautogui to simulate mouse clicks, keystrokes, and automate desktop workflows—great for repetitive UI tasks.
🎯 Want help writing these automation scripts or need hands-on guidance? Visit AllHomeworkAssignments.com for expert support, script writing, and live Python tutoring.
#PythonAutomation#TimeSavingScripts#LearnPython#ProductivityHacks#PythonProjects#AllHomeworkAssignments#AutomateWithPython
0 notes
Text
Automating Restaurant Menu Data Extraction Using Web Scraping APIs
Introduction
The food and restaurant business sector is going very heavily digital with millions of restaurant menus being made available through online platforms. Companies that are into food delivery, restaurant aggregation, and market research require menu data on a real-time basis for competition analysis, pricing strategies, and enhancement of customer experience. Manually collecting and updating this information is time-consuming and a laborious endeavor. This is where web scraping APIs come into play with the automated collection of such information to scrape restaurant menu data efficiently and accurately.
This guide discusses the importance of extracting restaurant menu data, how web scraping works for this use case, some challenges to expect, the best practices in dealing with such issues, and the future direction of menu data automation.
Why Export Restaurant Menu Data?
1. Food Delivery Service
Most online food delivery services, like Uber Eats, DoorDash, and Grubhub, need real-time menu updates for accurate pricing or availability. With the extraction of restaurant menu data, at least those online platforms are kept updated and discrepancies avoidable.
2. Competitive Pricing Strategy
Restaurants and food chains make use of web scraping restaurant menu data to determine their competitors' price positions. By tracking rival menus, they will know how they should price their products to remain competitive in the marketplace.
3. Nutritional and Dietary Insights
Health and wellness platforms utilize menu data for dietary recommendations to customers. By scraping restaurant menu data, these platforms can classify foods according to calorie levels, ingredients, and allergens.
4. Market Research and Trend Analysis
This is the group of data analysts and research firms collecting restaurant menu data to analyze consumer behavior about cuisines and track price variations with time.
5. Personalized Food Recommendations
Machine learning and artificial intelligence now provide food apps with the means to recommend meals according to user preferences. With restaurant menu data web scraping, food apps can access updated menus and thus afford personalized suggestions on food.
How Web Scraping APIs Automate Restaurant Menu Data Extraction
1. Identifying Target Websites
The first step is selecting restaurant platforms such as:
Food delivery aggregators (Uber Eats, DoorDash, Grubhub)
Restaurant chains' official websites (McDonald's, Subway, Starbucks)
Review sites (Yelp, TripAdvisor)
Local restaurant directories
2. Sending HTTP Requests
Scraping APIs send HTTP requests to restaurant websites to retrieve HTML content containing menu information.
3. Parsing HTML Data
The extracted HTML is parsed using tools like BeautifulSoup, Scrapy, or Selenium to locate menu items, prices, descriptions, and images.
4. Structuring and Storing Data
Once extracted, the data is formatted into JSON, CSV, or databases for easy integration with applications.
5. Automating Data Updates
APIs can be scheduled to run periodically, ensuring restaurant menus are always up to date.
Data Fields Extracted from Restaurant Menus
1. Restaurant Information
Restaurant Name
Address & Location
Contact Details
Cuisine Type
Ratings & Reviews
2. Menu Items
Dish Name
Description
Category (e.g., Appetizers, Main Course, Desserts)
Ingredients
Nutritional Information
3. Pricing and Discounts
Item Price
Combo Offers
Special Discounts
Delivery Fees
4. Availability & Ordering Information
Available Timings
In-Stock/Out-of-Stock Status
Delivery & Pickup Options
Challenges in Restaurant Menu Data Extraction
1. Frequent Menu Updates
Restaurants frequently update their menus, making it challenging to maintain up-to-date data.
2. Anti-Scraping Mechanisms
Many restaurant websites implement CAPTCHAs, bot detection, and IP blocking to prevent automated data extraction.
3. Dynamic Content Loading
Most restaurant platforms use JavaScript to load menu data dynamically, requiring headless browsers like Selenium or Puppeteer for scraping.
4. Data Standardization Issues
Different restaurants structure their menu data in various formats, making it difficult to standardize extracted information.
5. Legal and Ethical Considerations
Extracting restaurant menu data must comply with legal guidelines, including robots.txt policies and data privacy laws.
Best Practices for Scraping Restaurant Menu Data
1. Use API-Based Scraping
Leveraging dedicated web scraping APIs ensures more efficient and reliable data extraction without worrying about website restrictions.
2. Rotate IP Addresses & Use Proxies
Avoid IP bans by using rotating proxies or VPNs to simulate different users accessing the website.
3. Implement Headless Browsers
For JavaScript-heavy pages, headless browsers like Puppeteer or Selenium can load and extract dynamic content.
4. Use AI for Data Cleaning
Machine learning algorithms help clean and normalize menu data, making it structured and consistent across different sources.
5. Schedule Automated Scraping Jobs
To maintain up-to-date menu data, set up scheduled scraping jobs that run daily or weekly.
Popular Web Scraping APIs for Restaurant Menu Data Extraction
1. Scrapy Cloud API
A powerful cloud-based API that allows automated menu data scraping at scale.
2. Apify Restaurant Scraper
Apify provides pre-built restaurant scrapers that can extract menu details from multiple platforms.
3. Octoparse
A no-code scraping tool with API integration, ideal for businesses that require frequent menu updates.
4. ParseHub
A flexible API that extracts structured restaurant menu data with minimal coding requirements.
5. CrawlXpert API
A robust and scalable solution tailored for web scraping restaurant menu data, offering real-time data extraction with advanced anti-blocking mechanisms.
Future of Restaurant Menu Data Extraction
1. AI-Powered Menu Scraping
Artificial intelligence will improve data extraction accuracy, enabling automatic menu updates without manual intervention.
2. Real-Time Menu Synchronization
Restaurants will integrate web scraping APIs to sync menu data instantly across platforms.
3. Predictive Pricing Analysis
Machine learning models will analyze scraped menu data to predict price fluctuations and customer demand trends.
4. Enhanced Personalization in Food Apps
By leveraging scraped menu data, food delivery apps will provide more personalized recommendations based on user preferences.
5. Blockchain for Menu Authentication
Blockchain technology may be used to verify menu authenticity, preventing fraudulent modifications in restaurant listings.
Conclusion
Automating the extraction of restaurant menus from the web through scraping APIs has changed the food industry by offering real-time prices, recommendations for food based on liking, and analysis of competitors. With advances in technology, more AI-driven scraping solutions will further improve the accuracy and speed of data collection.
Know More : https://www.crawlxpert.com/blog/restaurant-menu-data-extraction-using-web-scraping-apis
#RestaurantMenuDataExtraction#ScrapingRestaurantMenuData#ExtractRestaurantMenus#ScrapeRestaurantMenuData
0 notes
Text
Python for Data Mining: Web Scraping to Deep Insights
Data is the new oil, and extracting valuable insights from it is a skill that can set you apart in today’s competitive landscape. Python, with its simplicity and powerful libraries, has become the go-to tool for data mining — a process that transforms raw data into meaningful information. In this blog, we’ll explore how Python takes you from collecting data via web scraping to deriving deep, actionable insights.
Why Python Dominates Data Mining
Python's popularity in data mining stems from its vast ecosystem of libraries, flexibility, and ease of learning. Whether you're a beginner or a seasoned programmer, Python offers a seamless learning curve and powerful tools like Pandas, NumPy, BeautifulSoup, Scrapy, Scikit-learn, and TensorFlow that make data mining efficient and effective.
Its versatility allows professionals to handle a full data pipeline: collecting, cleaning, analyzing, and visualizing data — all within a single environment.
Web Scraping: The Gateway to Raw Data
Before any analysis can happen, you need data. Often, the most valuable data isn’t readily available in clean datasets but is scattered across websites. That’s where web scraping becomes essential.
Web scraping involves programmatically extracting data from web pages. Python simplifies this process with libraries like:
BeautifulSoup: For parsing HTML and XML documents.
Scrapy: A more advanced framework for large-scale web crawling.
Selenium: For scraping dynamic content rendered by JavaScript.
For instance, if you’re researching consumer reviews or competitor pricing, Python can automate the extraction of this data from multiple web pages in a matter of minutes — a task that would take days manually.
Note: Always make sure your web scraping practices align with the site's terms of service to prevent legal issues.
Data Cleaning: Preparing for Analysis
After data collection, it often requires preparation before analysis can begin. You’ll often encounter missing values, duplicates, and inconsistencies. The Pandas library in Python proves essential, providing functions to:
Handle missing data
Remove duplicates
Convert data types
Normalize values
Proper data cleaning ensures your insights are based on reliable, high-quality information, reducing the risk of misleading conclusions.
Analyzing the Data: From Patterns to Predictions
After cleaning, the real magic begins. Python allows you to explore the data through:
Descriptive statistics: Mean, median, mode, standard deviation, etc.
Data visualization: Using Matplotlib and Seaborn for creating insightful graphs and plots.
Machine Learning models: Employing Scikit-learn for predictive modeling, clustering, classification, and regression.
For example, a retailer might use clustering to segment customers into distinct groups based on buying habits, enabling targeted marketing strategies that boost sales.
Deep Insights: Leveraging Machine Learning
When you're ready to go beyond basic analysis, Python’s deep learning libraries like TensorFlow and Keras open doors to more advanced insights. These tools can:
Predict future trends based on historical data
Recognize patterns in complex datasets
Automate decision-making processes
Imagine being able to forecast sales trends or customer churn rates with high accuracy, allowing businesses to make proactive, data-driven decisions.
Real-World Application: Training for the Future
Becoming proficient in data mining with Python is more than a skill — it’s a catalyst for career growth. As industries across healthcare, finance, e-commerce, and manufacturing increasingly rely on data, the demand for skilled data professionals continues to rise.
If you’re looking to build expertise, consider enrolling in a Python training in Aurangabad. Such programs provide hands-on experience, real-world projects, and expert mentorship, giving you the competitive edge needed in today’s data-centric job market.
Python offers a complete toolkit for data mining — from scraping raw data off the web to analyzing it for deep, actionable insights. As businesses continue to recognize the value of data-driven decision-making, mastering these skills can open countless doors. Whether you're an aspiring data scientist or a business professional looking to harness the power of data, Python stands ready to help you turn information into innovation.
At DataMites Institute, we empower individuals with crucial, industry-aligned data skills. Our courses cover core areas such as Data Science, Python, Machine Learning, and more, blending global certifications with hands-on project experience. Guided by experts and offering flexible learning options, we equip professionals for the dynamic world of analytics careers.
#python certification#python course#python training#python#python course in india#python training in india#python institute in india#pythonprogramming#python developers#python programming#python programming course#python programming language#course#certification#education
0 notes
Text
Top Options To Scrape Hotel Data From Agoda Without Coding
Introduction
In today's competitive hospitality landscape, accessing comprehensive hotel information has become crucial for businesses, researchers, and travel enthusiasts. The ability to Scrape Hotel Data From Agoda opens doors to valuable insights about pricing trends, room availability, customer reviews, and market dynamics. However, many individuals and organizations hesitate to pursue data extraction due to concerns about technical complexity and programming requirements.
The good news is that modern technology has democratized data scraping, making it accessible to users without extensive coding knowledge. This comprehensive guide explores various methods and tools that enable efficient Agoda Hotel Data Extraction while maintaining simplicity and effectiveness for non-technical users.
Understanding the Value of Agoda Hotel Data
Agoda, one of Asia's leading online travel agencies, hosts millions of hotel listings worldwide. The platform contains a treasure trove of information that can benefit various stakeholders in the tourism industry. Market researchers can analyze pricing patterns through Hotel Price Scraping , business owners can monitor competitor rates, and travel agencies can enhance their service offerings through comprehensive data analysis.
The platform's extensive database includes room rates, availability calendars, guest reviews, hotel amenities, location details, and booking policies. Extracting this information systematically allows businesses to make informed decisions about pricing strategies, marketing campaigns, and customer service improvements.
Real-Time Hotel Data from Agoda provides market intelligence that helps businesses stay competitive. By monitoring price fluctuations across different seasons, locations, and property types, stakeholders can optimize their revenue management strategies and identify market opportunities.
No-Code Solutions for Hotel Data Extraction
No-Code Solutions for Hotel Data Extraction refer to user-friendly platforms and tools that enable hotel data scraping—like reviews, room availability, and pricing—without requiring programming skills. These solutions are ideal for marketers, analysts, and business users.
1. Browser-Based Scraping Tools
Modern web scraping has evolved beyond command-line interfaces and complex programming languages. Several browser-based tools now offer intuitive interfaces that allow users to extract data through simple point-and-click operations. These tools typically record user interactions with web pages and automate repetitive tasks.
Popular browser extensions like Web Scraper, Data Miner, and Octoparse provide user-friendly interfaces where users can select specific elements on Agoda's website and configure extraction parameters. These tools automatically handle the technical aspects of data collection while presenting results in accessible formats like CSV or Excel files.
1. Cloud-Based Scraping Platforms
Cloud-based scraping services represent another excellent option for non-technical users seeking Agoda Room Availability Scraping capabilities. These platforms offer pre-built templates specifically designed for popular websites like Agoda, eliminating the need for manual configuration.
Services like Apify, Scrapy Cloud, and ParseHub provide ready-to-use scraping solutions that can be customized through simple form interfaces. Users can specify search criteria, select data fields, and configure output formats without writing a single line of code.
Key advantages of cloud-based solutions include:
Scalability to handle large-scale data extraction projects
Automatic handling of website changes and anti-scraping measures
Built-in data cleaning and formatting capabilities
Integration with popular business intelligence tools
Reliable uptime and consistent performance
Desktop Applications for Advanced Data Extraction
Desktop scraping applications offer another viable path for users seeking to extract hotel information without programming knowledge. These software solutions provide comprehensive interfaces with drag-and-drop functionality, making data extraction as simple as building a flowchart.
Applications like FMiner, WebHarvy, and Visual Web Ripper offer sophisticated features wrapped in user-friendly interfaces. These tools can handle complex scraping scenarios, including dealing with JavaScript-heavy pages, managing login sessions, and handling dynamic content loading.
Desktop applications' advantage is their ability to provide more control over the scraping process while maintaining ease of use. Users can set up complex extraction workflows, implement data validation rules, and export results in multiple formats. These applications also include scheduling capabilities for automated Hotel Booking Data Scraping operations.
API-Based Solutions and Third-Party Services
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
Companies specializing in travel data extraction often provide dedicated Agoda scraping services that can be accessed through simple web forms or API endpoints. Users can specify their requirements, such as location, date ranges, and property types, and receive Real-Time Hotel Data in return.
Benefits of API-based solutions include:
Immediate access to data without setup time
Professional-grade reliability and accuracy
Compliance with website terms of service
Regular updates to handle website changes
Customer support for troubleshooting
Automated Workflow Tools and Integrations
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
These tools are particularly valuable for businesses that must incorporate hotel data into their operations. For example, a travel agency could set up an automated workflow that scrapes Agoda data daily and updates its internal pricing database, enabling dynamic pricing strategies based on Agoda Room Availability Scraping insights.
The workflow approach seamlessly integrates with popular business tools like Google Sheets, CRM systems, and email marketing platforms. This integration capability makes it easier to act on the extracted data immediately rather than manually processing exported files.
Data Quality and Validation Considerations
Ensure data quality when implementing any Hotel Data Intelligence strategy. Non-coding solutions often include built-in validation features that help maintain data accuracy and consistency. These features typically include duplicate detection, format validation, and completeness checks.
Users should establish data quality standards before beginning extraction projects. This includes defining acceptable ranges for numerical data, establishing consistent formatting for text fields, and implementing verification procedures for critical information like pricing and availability.
Regular monitoring of extracted data helps identify potential issues early in the process. Many no-code tools provide notification systems that alert users to unusual patterns or extraction failures, enabling quick resolution of data quality issues.
Legal and Ethical Considerations
Before implementing any data extraction strategy, users must understand the legal and ethical implications of web scraping. Agoda's terms of service, robots.txt file, and rate-limiting policies should be carefully reviewed to ensure compliance.
Responsible scraping practices include:
Respecting website rate limits and implementing appropriate delays
Using data only for legitimate business purposes
Avoiding excessive server load that could impact website performance
Implementing proper data security measures for extracted information
Regularly reviewing and updating scraping practices to maintain compliance
Advanced Features and Customization Options
Modern no-code scraping solutions offer sophisticated customization options that rival traditional programming approaches. These features enable users to handle complex scenarios like multi-page data extraction, conditional logic implementation, and dynamic content handling.
Advanced filtering capabilities allow users to extract only relevant information based on specific criteria such as price ranges, star ratings, or geographic locations. This targeted approach reduces data processing time and focuses analysis on the most valuable insights.
Many platforms also offer data transformation features that can clean, format, and structure extracted information according to business requirements. These capabilities eliminate additional data processing steps and provide ready-to-use datasets.
Monitoring and Maintenance Strategies
Successful Travel Industry Web Scraping requires ongoing monitoring and maintenance to ensure consistent performance. No-code solutions typically include dashboard interfaces that provide visibility into scraping performance, success rates, and data quality metrics.
Users should establish regular review processes to validate data accuracy and identify potential issues. This includes monitoring for website changes that might affect extraction accuracy, validating data completeness, and ensuring compliance with updated service terms.
Automated alerting systems can notify users of extraction failures, data quality issues, or significant changes in scraped information. These proactive notifications enable quick responses to potential problems and maintain data reliability.
Future Trends in No-Code Data Extraction
The landscape of no-code data extraction continues to evolve rapidly, with new tools and capabilities emerging regularly. Artificial intelligence and machine learning technologies are increasingly integrated into scraping platforms, enabling more intelligent data extraction and automatic application to website changes.
These technological advances make Hotel Booking Data Scraping more accessible and reliable for non-technical users. Future developments will likely include enhanced natural language processing capabilities, improved visual recognition for data element selection, and more sophisticated automation features.
How Travel Scrape Can Help You?
We provide comprehensive hotel data extraction services that eliminate the technical barriers typically associated with web scraping. Our platform is designed specifically for users who need reliable Real-Time Hotel Data without the complexity of coding or managing technical infrastructure.
Our services include:
Custom Agoda scraping solutions tailored to your specific business requirements and data needs.
Automated data collection schedules that ensure you always have access to the most current hotel information.
Advanced data filtering and cleaning processes that deliver high-quality, actionable insights.
Multiple export formats, including CSV, Excel, JSON, and direct database integration options.
Compliance management ensures all data extraction activities adhere to legal and ethical standards.
Scalable solutions that grow with your business needs, from small-scale projects to enterprise-level operations.
Integration capabilities with popular business intelligence tools and CRM systems.
Our platform handles the technical complexities of Hotel Price Scraping while providing clean, structured data that can be immediately used for analysis and decision-making.
Conclusion
The democratization of data extraction technology has made it possible for anyone to Scrape Hotel Data From Agoda without extensive programming knowledge. Users can access valuable hotel information that drives informed business decisions through browser extensions, cloud-based platforms, desktop applications, and API services.
As the Travel Industry Web Scraping landscape evolves, businesses embracing these accessible technologies will maintain competitive advantages through better market intelligence and data-driven decision-making.
Don't let technical barriers prevent you from accessing valuable market insights; Contact Travel Scrape now to learn more about our comprehensive Travel Aggregators data extraction services and take the first step toward data-driven success.
Read More :- https://www.travelscrape.com/scrape-agoda-hotel-data-no-coding.php
#ScrapeHotelDataFromAgoda#AgodaHotelDataExtraction#HotelPriceScraping#RealTimeHotelData#HotelDataIntelligence#TravelIndustryWebScraping#HotelBookingDataScraping#TravelAggregators
0 notes
Text
NLP Sentiment Analysis | Reviews Monitoring for Actionable Insights
NLP Sentiment Analysis-Powered Insights from 1M+ Online Reviews

Business Challenge

A global enterprise with diversified business units in retail, hospitality, and tech was inundated with customer reviews across dozens of platforms:
Amazon, Yelp, Zomato, TripAdvisor, Booking.com, Google Maps, and more. Each platform housed thousands of unstructured reviews written in multiple languages — making it ideal for NLP sentiment analysis to extract structured value from raw consumer feedback.
The client's existing review monitoring efforts were manual, disconnected, and slow. They lacked a modern review monitoring tool to streamline analysis. Key business leaders had no unified dashboard for customer experience (CX) trends, and emerging issues often went unnoticed until they impacted brand reputation or revenue.
The lack of a central sentiment intelligence system meant missed opportunities not only for service improvements, pricing optimization, and product redesign — but also for implementing a robust Brand Reputation Management Service capable of safeguarding long-term consumer trust.
Key pain points included:
No centralized system for analyzing cross-platform review data
Manual tagging that lacked accuracy and scalability
Absence of real-time CX intelligence for decision-makers
Objective
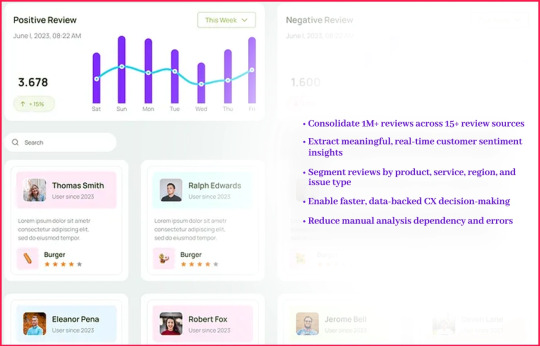
The client set out to:
Consolidate 1M+ reviews across 15+ review sources
Extract meaningful, real-time customer sentiment insights
Segment reviews by product, service, region, and issue type
Enable faster, data-backed CX decision-making
Reduce manual analysis dependency and errors
Their goal: Build a scalable sentiment analysis system using a robust Sentiment Analysis API to drive operational, marketing, and strategic decisions across business units.
Our Approach

DataZivot designed and deployed a fully-managed NLP-powered review analytics pipeline, customized for the client's data structure and review volume. Our solution included:
1. Intelligent Review Scraping
Automated scraping from platforms like Zomato, Yelp, Amazon, Booking.com
Schedule-based data refresh (daily & weekly)
Multi-language support (English, Spanish, German, Hindi)
2. NLP Sentiment Analysis
Hybrid approach combining rule-based tagging with transformer-based models (e.g., BERT, RoBERTa)
Sentiment scores (positive, neutral, negative) and sub-tagging (service, delivery, product quality)
Topic modeling to identify emerging concerns
3. Categorization & Tagging
Entity recognition (locations, product names, service mentions)
Keyword extraction for trend tracking
Complaint type detection (delay, quality, attitude, etc.)
4. Insights Dashboard Integration
Custom Power BI & Tableau dashboards
Location, time, sentiment, and keyword filters
Export-ready CSV/JSON options for internal analysts
Results & Competitive Insights

DataZivot's solution produced measurable results within the first month:
These improvements gave the enterprise:
Faster product feedback loops
Better pricing and menu optimization for restaurants
Localized insights for store/service operations
Proactive risk mitigation (e.g., before issues trended on social media)
Want to See the Dashboard in Action?
Book a demo or download a Sample Reviews Dataset to experience the power of our sentiment engine firsthand.
Contact Us Today!
Dashboard Highlights

The custom dashboard provided by DataZivot enabled:
Review Sentiment Dashboard featuring sentiment trend graphs (daily, weekly, monthly)
Top Keywords by Sentiment Type ("slow service", "friendly staff")
Geo Heatmaps showing regional sentiment fluctuations
Comparative Brand Insights (across subsidiaries or competitors)
Dynamic Filters by platform, region, product, date, language
Tools & Tech Stack

To deliver the solution at scale, we utilized:
Scraping Frameworks: Scrapy, Selenium, BeautifulSoup
NLP Libraries: spaCy, TextBlob, Hugging Face Transformers (BERT, RoBERTa)
Cloud Infrastructure: AWS Lambda, S3, EC2, Azure Functions
Dashboards & BI: Power BI, Tableau, Looker
Languages Used: Python, SQL, JavaScript (for dashboard custom scripts)
Strategic Outcome

By leveraging DataZivot’s NLP infrastructure, the enterprise achieved:
Centralized CX Intelligence: CX leaders could make decisions based on real-time, data-backed feedback
Cross-Industry Alignment: Insights across retail, hospitality, and tech units led to unified improvement strategies
Brand Perception Tracking: Marketing teams tracked emotional tone over time and correlated with ad campaigns
Revenue Impact: A/B-tested updates (product tweaks, price changes) showed double-digit improvements in review sentiment and NPS
Conclusion
This case study proves that large-scale review analytics is not only possible — it’s essential for modern enterprises managing multiple consumer-facing touchpoints. DataZivot’s approach to scalable NLP and real-time sentiment tracking empowered the client to proactively manage their brand reputation, uncover hidden customer insights, and drive growth across verticals.
If your organization is facing similar challenges with fragmented review data, inconsistent feedback visibility, or a slow response to customer sentiment — DataZivot’s sentiment intelligence platform is your solution.
#NLPSentimentAnalysis#CrossPlatformReviewData#SentimentAnalysisAPI#BrandReputationManagement#ReviewMonitoringTool#IntelligentReviewScraping#ReviewSentimentDashboard#RealTimeSentimentTracking#ReviewAnalytics
0 notes
Text
How Does Scraping Food and Menu Data from Grubhub in the USA Help in Understanding Consumer Behavior?
In the modern world, data plays a crucial role in analyzing customer behaviour and tendencies in the food industry. Companies such as Grubhub have a sea of information on ordering, preferred restaurants, and developing trends in food choices. Scraping food & menu data from Grubhub in the USA gives a method to analyze this data, which is essential for business and marketing intentions. Grubhub is a highly demanding food delivery service in the USA, with various foods from multiple eateries. Web scraping food delivery data helps collect trends in food consumption, restaurants' popularity and consumer preferences. This piece goes through the process of collecting food and menu data on Grubhub every month and discusses the importance of such data and its uses.
Necessity of Grubhub Food & Menu Data Monthly Report
Using Grubhub to scrape services every month makes monitoring shifts in customers' preferences and restaurants' relevance possible. The utilization of Grubhub food & menu data scraping services allows the comparison of data from different months and identifies seasonal shifts, promotion impacts and new trends. Such insights are helpful for restaurants, food manufacturing industries, and managers targeting their food products more effectively. It is essential to restaurant owners since knowing which meals are in demand during specific periods can assist in menu planning and advertising. Thus, food manufacturers can use Grubhub data scraper to align their product portfolios with the needs of consumers. Therefore, these insights can help marketers develop campaigns that appeal to the intended demographic. In conclusion, using food delivery data scraping services to analyze the Grubhub data offers a wealth of information about the food market environment to help make sound decisions for success.
Potential Applications of extracting food & menu data from Grubhub
However, scraping food and menu data from Grubhub benefits menu enhancement, marketing strategy, competitor analysis, supply chain and customer analysis.
Menu Optimization: Another advantage of scraping data from Grubhub is identifying the most popular meals among customers, which can help restaurants tweak their menus. This information can be valuable for adding new products to the list, excluding less popular ones, or changing the price to increase profitability.
Marketing Strategies: Based on Grubhub data, restaurants should be able to establish valuable trends in formulating specific marketing strategies. For instance, restaurants can employ this data to develop specific offers or discounts connected with definite dishes or periods of the day.
Competitor Analysis: Using a restaurant data scraper, one can decipher a competitor's performance, menu, and prices, among other factors. This can assist them in recognizing 'seamless opportunities' and ensuring they remain relevant within the market.
Supply Chain Management: The process can also assist in restaurant supply chain management by analyzing Grubhub customers' demand. This data can be employed to facilitate ordering procedures, minimize costs, and enhance productivity.
Customer Insights: The Grubhub data can be used to identify ordering patterns, preferred cuisines, and delivery options. This information can be useful for restaurants to prevent customers from going to their competitors and to ensure frequent patronage of their business establishments.
Grubhub Food & Menu Data Scraping Process:
Listed below are the steps involved in extracting Grubhub food & menu data
Identifying Target Data: The first thing to decide before scraping data from Grubhub is what we want to take from the website. It could include food preferences, restaurant ratings, customer comments, and delivery time.
Choosing a Scraping Tool: The most preferred scraping tools are BeautifulSoup, Scrapy, and Selenium. However, different tools are more beneficial depending on the intricacy of the information and the organization of the website.
Writing the Scraping Script: After the tool is chosen, we have to provide the code for a scraping script that would open the Grubhub website, find the necessary data, and take it. This script should run on a schedule to scrape data monthly.
Data Storage: You can store the data in a database, a CSV file, or any desired format for further analysis. Also, format the data properly and label it in an organized manner so that it will be easier to retrieve the information.
Analyzing the Data: After scraping and storing data, analyze it using statistical and machine learning methods to identify patterns, trends, and relationships.
Conclusion: Thus, scraping food and menu data from Grubhub is valuable in understanding consumers, restaurants, and the market. This data can improve the menu, market to specific demographics, analyze competitors, manage supplies, and tailor the customer experience. It ensures that businesses can remain relevant in the market and make necessary changes where necessary to improve their performance. Especially in the current state of the food delivery industry, the necessity of using tools and techniques for scraping and analyzing data from such sources cannot be overestimated.
Are you in need of high-class scraping services? Food Data Scrape should be your first point of call. We are undoubtedly the best in Food Data Aggregator and Mobile Grocery App Scraping service, and we render impeccable data analysis for strategic decision-making. With a legacy of excellence as our backbone, we help companies become data-driven, fueling their development. Please take advantage of our tailored solutions that will add value to your business. Contact us today to unlock the value of your data.
Source>> https://www.fooddatascrape.com/scraping-food-and-menu-data-from-grubhub-in-the-usa.php
#ScrapingFoodandMenuDatafromGrubhub#GrubhubFoodandMenuDataScrapingServices#ExtractingFoodandMenuDatafromGrubhub#ScrapingDatafromGrubhub
0 notes
Text
Making your very first Scrapy spider - 01 - Python scrapy tutorial for inexperienced persons https://www.altdatum.com/wp-content/uploads/2019/10/Making-your-very-first-Scrapy-spider-01-Python.jpg #inexperienced #Making #persons #Python #Pythoncourse #pythoncourseforbeginners #pythonforbeginners #Pythonprogramming #PythonScrapytutorial #pythonscrapywebcrawler #pythontrainingforbeginners #PythonTutorial #pythontutorialforbeginners #pythonwebscrapingtutorial #Scrapy #scrapyframework #scrapyframeworkinpython #scrapyspider #scrapyspiderexample #scrapyspiderpython #scrapyspidertutorial #Scrapytutorial #spider #tutorial #webscraping #webscrapingpython https://www.altdatum.com/making-your-very-first-scrapy-spider-01-python-scrapy-tutorial-for-inexperienced-persons/?feed_id=136746&_unique_id=686eaeaa33e4c
0 notes
Text
How to Integrate WooCommerce Scraper into Your Business Workflow
In today’s fast-paced eCommerce environment, staying ahead means automating repetitive tasks and making data-driven decisions. If you manage a WooCommerce store, you’ve likely spent hours handling product data, competitor pricing, and inventory updates. That’s where a WooCommerce Scraper becomes a game-changer. Integrated seamlessly into your workflow, it can help you collect, update, and analyze data more efficiently, freeing up your time and boosting operational productivity.

In this blog, we’ll break down what a WooCommerce scraper is, its benefits, and how to effectively integrate it into your business operations.
What is a WooCommerce Scraper?
A WooCommerce scraper is a tool designed to extract data from WooCommerce-powered websites. This data could include:
Product titles, images, descriptions
Prices and discounts
Reviews and ratings
Stock status and availability
Such a tool automates the collection of this information, which is useful for e-commerce entrepreneurs, data analysts, and digital marketers. Whether you're monitoring competitors or syncing product listings across multiple platforms, a WooCommerce scraper can save hours of manual work.
Why Businesses Use WooCommerce Scrapers
Before diving into the integration process, let’s look at the key reasons businesses rely on scraping tools:
Competitor Price Monitoring
Stay competitive by tracking pricing trends across similar WooCommerce stores. Automated scrapers can pull this data daily, helping you optimize your pricing strategy in real time.
Bulk Product Management
Import product data at scale from suppliers or marketplaces. Instead of manually updating hundreds of SKUs, use a scraper to auto-populate your database with relevant information.
Enhanced Market Research
Get a snapshot of what’s trending in your niche. Use scrapers to gather data about top-selling products, customer reviews, and seasonal demand.
Inventory Tracking
Avoid stockouts or overstocking by monitoring inventory availability from your suppliers or competitors.
How to Integrate a WooCommerce Scraper Into Your Workflow
Integrating a WooCommerce scraper into your business processes might sound technical, but with the right approach, it can be seamless and highly beneficial. Whether you're aiming to automate competitor tracking, streamline product imports, or maintain inventory accuracy, aligning your scraper with your existing workflow ensures efficiency and scalability. Below is a step-by-step guide to help you get started.
Step 1: Define Your Use Case
Start by identifying what you want to achieve. Is it competitive analysis? Supplier data syncing? Or updating internal catalogs? Clarifying this helps you choose the right scraping strategy.
Step 2: Choose the Right Scraper Tool
There are multiple tools available, ranging from browser-based scrapers to custom-built Python scripts. Some popular options include:
Octoparse
ParseHub
Python-based scrapers using BeautifulSoup or Scrapy
API integrations for WooCommerce
For enterprise-level needs, consider working with a provider like TagX, which offers custom scraping solutions with scalability and accuracy in mind.
Step 3: Automate with Cron Jobs or APIs
For recurring tasks, automation is key. Set up cron jobs or use APIs to run scrapers at scheduled intervals. This ensures that your database stays up-to-date without manual intervention.
Step 4: Parse and Clean Your Data
Raw scraped data often contains HTML tags, formatting issues, or duplicates. Use tools or scripts to clean and structure the data before importing it into your systems.
Step 5: Integrate with Your CMS or ERP
Once cleaned, import the data into your WooCommerce backend or link it with your ERP or PIM (Product Information Management) system. Many scraping tools offer CSV or JSON outputs that are easy to integrate.
Common Challenges in WooCommerce Scraping (And Solutions)
Changing Site Structures
WooCommerce themes can differ, and any update might break your script. Solution: Use dynamic selectors or AI-powered tools that adapt automatically.
Rate Limiting and Captchas
Some sites use rate limiting or CAPTCHAs to block bots. Solution: Use rotating proxies, headless browsers like Puppeteer, or work with scraping service providers.
Data Duplication or Inaccuracy
Messy data can lead to poor business decisions. Solution: Implement deduplication logic and validation rules before importing data.
Tips for Maintaining an Ethical Scraping Strategy
Respect Robots.txt Files: Always check the site’s scraping policy.
Avoid Overloading Servers: Schedule scrapers during low-traffic hours.
Use the Data Responsibly: Don’t scrape copyrighted or sensitive data.
Why Choose TagX for WooCommerce Scraping?
While it's possible to set up a basic WooCommerce scraper on your own, scaling it, maintaining data accuracy, and handling complex scraping tasks require deep technical expertise. TagX’s professionals offer end-to-end scraping solutions tailored specifically for e-commerce businesses. Whether you're looking to automate product data extraction, monitor competitor pricing, or implement web scraping using AI at scale. Key Reasons to Choose TagX:
AI-Powered Scraping: Go beyond basic extraction with intelligent scraping powered by machine learning and natural language processing.
Scalable Infrastructure: Whether you're scraping hundreds or millions of pages, TagX ensures high performance and minimal downtime.
Custom Integration: TagX enables seamless integration of scrapers directly into your CMS, ERP, or PIM systems, ensuring a streamlined workflow.
Ethical and Compliant Practices: All scraping is conducted responsibly, adhering to industry best practices and compliance standards.
With us, you’re not just adopting a tool—you’re gaining a strategic partner that understands the nuances of modern eCommerce data operations.
Final Thoughts
Integrating a WooCommerce scraper into your business workflow is no longer just a technical choice—it’s a strategic advantage. From automating tedious tasks to extracting market intelligence, scraping tools empower businesses to operate faster and smarter.
As your data requirements evolve, consider exploring web scraping using AI to future-proof your automation strategy. And for seamless implementation, TagX offers the technology and expertise to help you unlock the full value of your data.
0 notes