#web scraping amazon
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
📊 #CaseStudy: Enhancing Price Matching on Amazon with Hourly Web Scraping 🛒

In the competitive e-commerce landscape, staying ahead requires real-time insights. A New York-based retailer collaborated with Actowiz Solutions to implement hourly web scraping, enabling dynamic price matching on Amazon.
🔍 #KeyInsights:
#RealTimeMonitoring: Hourly data extraction allowed the retailer to track Amazon's price fluctuations promptly.
#DynamicPricing: Leveraging real-time data facilitated swift price adjustments, ensuring competitiveness.
#IncreasedProfitability: The strategy led to improved Buy Box wins and enhanced revenue streams.
📈 #StrategicApplications:
#CompetitiveAnalysis: Continuous monitoring of competitor pricing informed strategic decisions.
#InventoryManagement: Real-time insights aided in optimizing stock levels based on market demand.
#CustomerSatisfaction: Timely price adjustments contributed to better customer experiences and loyalty.
💬 #JoinTheConversation:
How is your organization leveraging real-time data to enhance pricing strategies on e-commerce platforms? Share your experiences and insights below.
1 note
·
View note
Text
How to Extract Amazon Product Prices Data with Python 3
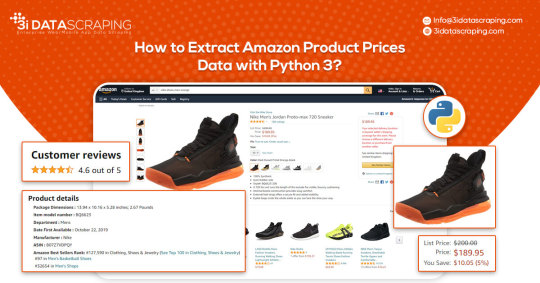
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text

Did you know that Amazon.com lists home decor items where prices range from dirt-cheap to exorbitantly expensive? Click here to read the full analysis.
0 notes
Text
Want to stay ahead of Amazon price changes? Learn how to automate price tracking using Scrapingdog’s Amazon Scraper API and Make.com. A step-by-step guide for smarter, hands-free eCommerce monitoring.
0 notes
Text
Russian Proxy Servers
Use dependable Russian proxy servers to experience a more enjoyable browsing time and access data from any location around the world. Your online activities like web surfing and downloading various forms of content can not be accessed by anyone else with these servers enabled as they provide you total privacy. Individuals who are worried about their privacy on the internet can use these solutions for various time-consuming internet activities.
1 note
·
View note
Text
Which are The Best Scraping Tools For Amazon Web Data Extraction?

In the vast expanse of e-commerce, Amazon stands as a colossus, offering an extensive array of products and services to millions of customers worldwide. For businesses and researchers, extracting data from Amazon's platform can unlock valuable insights into market trends, competitor analysis, pricing strategies, and more. However, manual data collection is time-consuming and inefficient. Enter web scraping tools, which automate the process, allowing users to extract large volumes of data quickly and efficiently. In this article, we'll explore some of the best scraping tools tailored for Amazon web data extraction.
Scrapy: Scrapy is a powerful and flexible web crawling framework written in Python. It provides a robust set of tools for extracting data from websites, including Amazon. With its high-level architecture and built-in support for handling dynamic content, Scrapy makes it relatively straightforward to scrape product listings, reviews, prices, and other relevant information from Amazon's pages. Its extensibility and scalability make it an excellent choice for both small-scale and large-scale data extraction projects.
Octoparse: Octoparse is a user-friendly web scraping tool that offers a point-and-click interface, making it accessible to users with limited programming knowledge. It allows you to create custom scraping workflows by visually selecting the elements you want to extract from Amazon's website. Octoparse also provides advanced features such as automatic IP rotation, CAPTCHA solving, and cloud extraction, making it suitable for handling complex scraping tasks with ease.
ParseHub: ParseHub is another intuitive web scraping tool that excels at extracting data from dynamic websites like Amazon. Its visual point-and-click interface allows users to build scraping agents without writing a single line of code. ParseHub's advanced features include support for AJAX, infinite scrolling, and pagination, ensuring comprehensive data extraction from Amazon's product listings, reviews, and more. It also offers scheduling and API integration capabilities, making it a versatile solution for data-driven businesses.
Apify: Apify is a cloud-based web scraping and automation platform that provides a range of tools for extracting data from Amazon and other websites. Its actor-based architecture allows users to create custom scraping scripts using JavaScript or TypeScript, leveraging the power of headless browsers like Puppeteer and Playwright. Apify offers pre-built actors for scraping Amazon product listings, reviews, and seller information, enabling rapid development and deployment of scraping workflows without the need for infrastructure management.
Beautiful Soup: Beautiful Soup is a Python library for parsing HTML and XML documents, often used in conjunction with web scraping frameworks like Scrapy or Selenium. While it lacks the built-in web crawling capabilities of Scrapy, Beautiful Soup excels at extracting data from static web pages, including Amazon product listings and reviews. Its simplicity and ease of use make it a popular choice for beginners and Python enthusiasts looking to perform basic scraping tasks without a steep learning curve.
Selenium: Selenium is a powerful browser automation tool that can be used for web scraping Amazon and other dynamic websites. It allows you to simulate user interactions, such as clicking buttons, filling out forms, and scrolling through pages, making it ideal for scraping JavaScript-heavy sites like Amazon. Selenium's Python bindings provide a convenient interface for writing scraping scripts, enabling you to extract data from Amazon's product pages with ease.
In conclusion, the best scraping tool for Amazon web data extraction depends on your specific requirements, technical expertise, and budget. Whether you prefer a user-friendly point-and-click interface or a more hands-on approach using Python scripting, there are plenty of options available to suit your needs. By leveraging the power of web scraping tools, you can unlock valuable insights from Amazon's vast trove of data, empowering your business or research endeavors with actionable intelligence.
0 notes
Text
Amazon reviews get! ScrapeStorm can help you
Amazon’s reviews mainly include product reviews and seller reviews. Product evaluation is an evaluation of purchased products, including evaluation of usage experience, performance, quality, etc. Seller evaluation is an evaluation of the seller’s service, including evaluation of logistics speed, packaging quality, after-sales service, etc.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
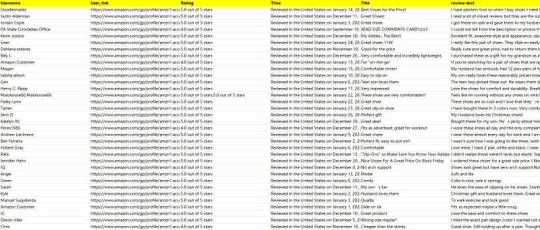
This is the demo task:
Google Drive: https://drive.google.com/file/d/1GpeTdNCV9SzAZibT_Xa1m_HT-ik0syyN/view?usp=sharing
OneDrive: https://1drv.ms/u/s!Ami6SocstkqcggMFgG2cXWI4gBI2?e=fDNx2d
1. Create a task
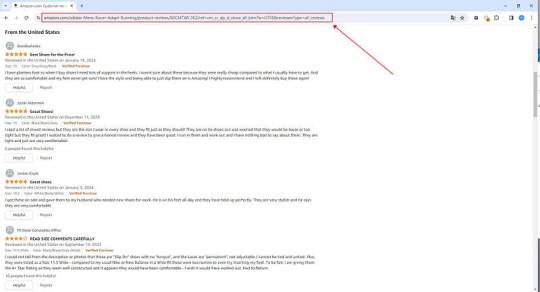
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
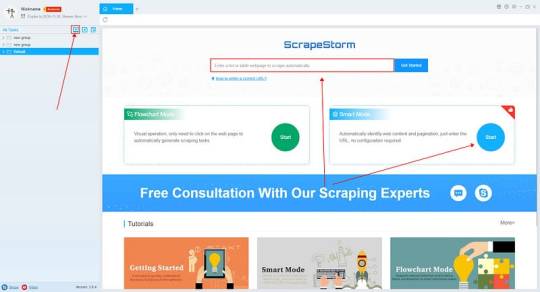
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
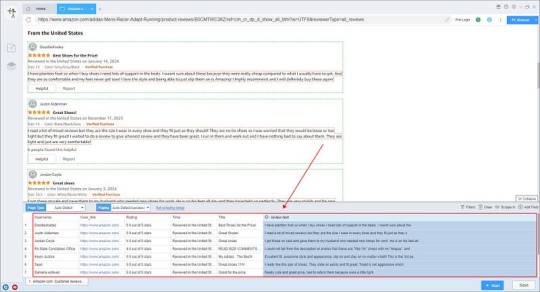
3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
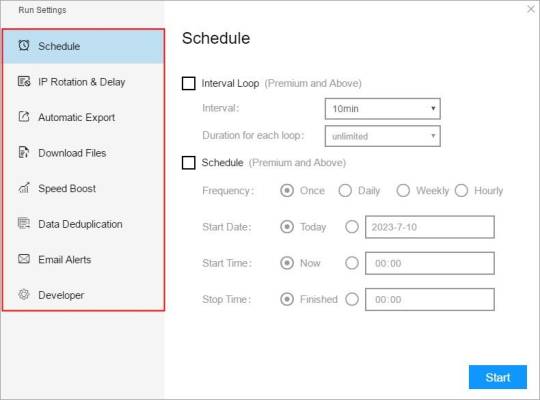
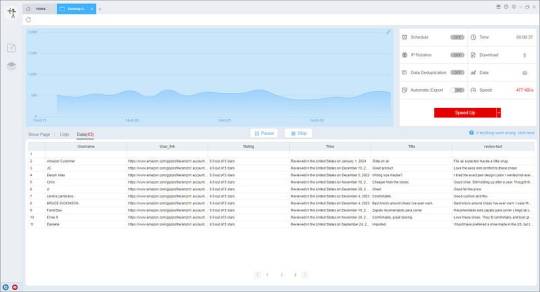
4. Export and view data
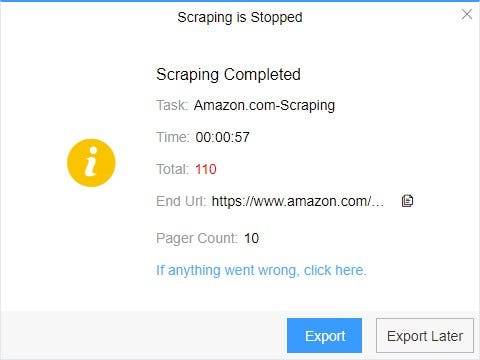
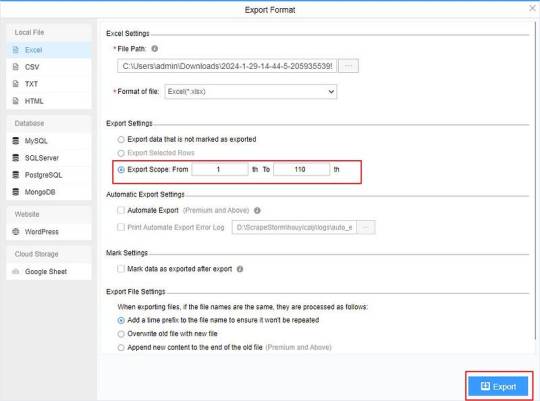
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
1 note
·
View note
Text
#proxies#proxy#proxyserver#residential proxy#amazon#amazon products#web scraping techniques#web scraping tools#web scraping services#datascience#data analytics#data#industry data
0 notes
Text
Develop your own Amazon product scraper bot in Python
How to scrape data from amazon.com? Scraping amazon products details benefits to lots of things as product details, images, pricing, stock, rating, review, etc and it analyzes how particular brand being popular on amazon and competitive analysis. Read more
1 note
·
View note
Text

🔍 Unlock Competitive Insights with Amazon Product Offers & Sellers Scraper
In today’s dynamic eCommerce world, staying ahead requires more than just listing your products - it demands continuous market intelligence. With Actowiz Solutions' #AmazonProductOffers and #SellersScraper, you can extract critical data on seller pricing, product discounts, and top deals in real time across global markets including the #USA, #UK, and #UAE.
🚀 What You Can Track:
✔️ Real-time seller offers and pricing
✔️ Competitor listings and stock levels
✔️ Discounted prices, deals, and flash sales
✔️ Marketplace fluctuations by region
💼 Perfect for:
eCommerce brands
Price benchmarking platforms
Market analysts
Retail intelligence teams
Our scraper supports high-frequency #DataCollection via #SScalableAPIs with delivery in #CSV, #JSON, or dashboard integrations. Whether you're optimizing pricing or launching a product, this tool empowers data-driven decisions across every Amazon marketplace.
📩 Contact us at: [email protected]
🌐 Learn more: www.actowizsolutions.com
0 notes
Text
Scraping Restaurant Data - Comparing Food Delivery Apps

To extract restaurant data, Foodspark provides the best restaurant delivery data scraping service. In recent years, food delivery services have been top-rated, but never more so than during the epidemic, when eating out was frowned upon by many. Despite loosened regulations, our smartphones will not take away food delivery apps soon.
#web scraping services#grocerydatascraping#food data scraping#zomato api#food data scraping services#grocerydatascrapingapi#restaurantdataextraction#fooddatascrapingservices#usa#restaurant data scraping#zomatoapi#amazon
1 note
·
View note
Text

How to Scrape Amazon Fresh
This article talks about scraping Amazon. Basically, it says if I have to scrape Amazon Fresh deals, I need to use browser automation libraries.
I can use requests to get deals, but I won't get many products as Amazon uses lazy loading.
However, after getting the product URLs, I can use requests to get reviews as that page doesn't use lazy loading.
Here's the full article.
0 notes
Text
A year in illustration, 2023 edition (part two)

(This is part two; part one is here.)

The West Midlands Police were kind enough to upload a high-rez of their surveillance camera control room to Flickr under a CC license (they've since deleted it), and it was the perfect frame for dozens of repeating clown images with HAL9000 red noses. This worked out great. The clown face is from a 1940s ad for novelty masks.
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop

I spent an absurd amount of time transforming a photo I took of three pinball machines into union-busting themed tables, pulling in a bunch of images from old Soviet propaganda art. An editorial cartoon of Teddy Roosevelt with his big stick takes center stage, while a NLRB General Counsel Jennifer Abruzzo's official portrait presides over the scene. I hand-made the eight-segment TILT displays.
https://pluralistic.net/2023/09/06/goons-ginks-and-company-finks/#if-blood-be-the-price-of-your-cursed-wealth

Working with the highest-possible rez sources makes all the difference in the world. Syvwlch's extremely high-rez paint-scraper is a gift to people writing about web-scraping, and the Matrix code waterfall mapped onto it like butter.
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/

This old TWA ad depicting a young man eagerly pitching an older man has incredible body-language – so much so that when I replaced their heads with raw meat, the intent and character remained intact. I often struggle for background to put behind images like this, but high-rez currency imagery, with the blown up intaglio, crushes it.
https://pluralistic.net/2023/10/04/dont-let-your-meat-loaf/#meaty-beaty-big-and-bouncy

I transposed Photoshop instructions for turning a face into a zombie into Gimp instructions to make Zombie Uncle Sam. The guy looking at his watch kills me. He's from an old magazine illustration about radio broadcasting. What a face!
https://pluralistic.net/2023/10/18/the-people-no/#tell-ya-what-i-want-what-i-really-really-want

The mansplaining guy from the TWA ad is back, but this time he's telling a whopper. It took so much work to give him that Pinnocchio nose. Clearly, he's lying about capitalism, hence the Atlas Shrugged cover. Bosch's "Garden of Earthly Delights" makes for an excellent, public domain hellscape fit for a nonconensual pitch about the miracle of capitalism.
https://pluralistic.net/2023/10/27/six-sells/#youre-holding-it-wrong

There's no better image for stories about techbros scamming rubes than Bosch's 'The Conjurer.' Throw in Jeff Bezos's head and an Amazon logo and you're off to the races. I boobytrapped this image by adding as many fingers as I could fit onto each of these figures in the hopes that someone could falsely accuse me of AI-generating this. No one did.
https://pluralistic.net/2023/11/06/attention-rents/#consumer-welfare-queens

Once again, it's Bosch to the rescue. Slap a different smiley-face emoji on each of the tormented figures in 'Garden of Earthly Delights' and you've got a perfect metaphor for the 'brand safety' problem of hard news dying online because brands don't want to be associated with unpleasant things, and the news is very unpleasant indeed.
https://pluralistic.net/2023/11/11/ad-jacency/#brand-safety

I really struggle to come up with images for my linkdump posts. I'm running out of ways to illustrate assortments and varieties. I got to noodling with a Kellogg's mini-cereal variety pack and I realized it was the perfect place for a vicious gorilla image I'd just found online in a WWI propaganda poster headed 'Destroy This Mad Brute.' I put so many fake AI tells in this one – extra pupils, extra fingers, a super-AI-esque Kellogg's logo.
https://pluralistic.net/2023/11/05/variegated/#nein

Bloodletting is the perfect metaphor for using rate-hikes to fight inflation. A vintage image of the Treasury, spattered with blood, makes a great backdrop. For the foreground, a medieval woodcut of bloodletting quacks – give one the head of Larry Summers, the other, Jerome Powell. For the patient, use Uncle Sam's head.
https://pluralistic.net/2023/11/20/bloodletting/#inflated-ego

I killed a long videoconference call slicing up an old pulp cover showing a killer robot zapping a couple of shrunken people in bell-jars. It was the ideal image to illustrate Big Tech's enshittification, especially when it was decorated with some classic tech slogans.
https://pluralistic.net/2023/11/22/who-wins-the-argument/#corporations-are-people-my-friend

There's something meditative about manually cutting out Tenniel engravings from Alice – the Jabberwock was insane. But it was worth it for this Tron-inflected illustration using a distorted Cartesian grid to display the enormous difference between e/acc and AI doomers, and everyone else in the world.
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
Multilayer source images for your remixing pleasure:
Scientist in chemlabhttps://craphound.com/images/scientist-in-chem-lab.psd
Humpty Dumpty and the millionaires https://craphound.com/images/humpty-dumpty-and-the-millionaires.psd
Demon summoning https://craphound.com/images/demon-summoning.psd
Killer Robot and People in Bell Jars https://craphound.com/images/killer-robot-and-bell-jars.psd
TWA mansplainer https://craphound.com/images/twa-mansplainer.psd
Impatient boss https://craphound.com/images/impatient-boss.psd
Destroy This Mad Brute https://craphound.com/images/destroy-this-mad-brute.psd
(Images: Heinz Bunse, West Midlands Police, Christopher Sessums, CC BY-SA 2.0; Mike Mozart, Jesse Wagstaff, Stephen Drake, Steve Jurvetson, syvwlch, Doc Searls, https://www.flickr.com/photos/mosaic36/14231376315, Chatham House, CC BY 2.0; Cryteria, CC BY 3.0; Mr. Kjetil Ree, Trevor Parscal, Rama, “Soldiers of Russia” Cultural Center, Russian Airborne Troops Press Service, CC BY-SA 3.0; Raimond Spekking, CC BY 4.0; Drahtlos, CC BY-SA 4.0; Eugen Rochko, Affero; modified)
201 notes
·
View notes
Text
News Extract: Unlocking the Power of Media Data Collection
In today's fast-paced digital world, staying updated with the latest news is crucial. Whether you're a journalist, researcher, or business owner, having access to real-time media data can give you an edge. This is where news extract solutions come into play, enabling efficient web scraping of news sources for insightful analysis.

Why Extracting News Data Matters
News scraping allows businesses and individuals to automate the collection of news articles, headlines, and updates from multiple sources. This information is essential for:
Market Research: Understanding trends and shifts in the industry.
Competitor Analysis: Monitoring competitors’ media presence.
Brand Reputation Management: Keeping track of mentions across news sites.
Sentiment Analysis: Analyzing public opinion on key topics.
By leveraging news extract techniques, businesses can access and process large volumes of news data in real-time.
How News Scraping Works
Web scraping involves using automated tools to gather and structure information from online sources. A reliable news extraction service ensures data accuracy and freshness by:
Extracting news articles, titles, and timestamps.
Categorizing content based on topics, keywords, and sentiment.
Providing real-time or scheduled updates for seamless integration into reports.
The Best Tools for News Extracting
Various scraping solutions can help extract news efficiently, including custom-built scrapers and APIs. For instance, businesses looking for tailored solutions can benefit from web scraping services India to fetch region-specific media data.
Expanding Your Data Collection Horizons
Beyond news extraction, companies often need data from other platforms. Here are some additional scraping solutions:
Python scraping Twitter: Extract real-time tweets based on location and keywords.
Amazon reviews scraping: Gather customer feedback for product insights.
Flipkart scraper: Automate data collection from India's leading eCommerce platform.
Conclusion
Staying ahead in today’s digital landscape requires timely access to media data. A robust news extract solution helps businesses and researchers make data-driven decisions effortlessly. If you're looking for reliable news scraping services, explore Actowiz Solutions for customized web scraping solutions that fit your needs.
#news extract#web scraping services India#Python scraping Twitter#Amazon reviews scraping#Flipkart scraper#Actowiz Solutions
0 notes
Text
LONDON (AP) — Music streaming service Deezer said Friday that it will start flagging albums with AI-generated songs, part of its fight against streaming fraudsters.
Deezer, based in Paris, is grappling with a surge in music on its platform created using artificial intelligence tools it says are being wielded to earn royalties fraudulently.
The app will display an on-screen label warning about “AI-generated content" and notify listeners that some tracks on an album were created with song generators.
Deezer is a small player in music streaming, which is dominated by Spotify, Amazon and Apple, but the company said AI-generated music is an “industry-wide issue.” It's committed to “safeguarding the rights of artists and songwriters at a time where copyright law is being put into question in favor of training AI models," CEO Alexis Lanternier said in a press release.
Deezer's move underscores the disruption caused by generative AI systems, which are trained on the contents of the internet including text, images and audio available online. AI companies are facing a slew of lawsuits challenging their practice of scraping the web for such training data without paying for it.
According to an AI song detection tool that Deezer rolled out this year, 18% of songs uploaded to its platform each day, or about 20,000 tracks, are now completely AI generated. Just three months earlier, that number was 10%, Lanternier said in a recent interview.
AI has many benefits but it also "creates a lot of questions" for the music industry, Lanternier told The Associated Press. Using AI to make music is fine as long as there's an artist behind it but the problem arises when anyone, or even a bot, can use it to make music, he said.
Music fraudsters “create tons of songs. They upload, they try to get on playlists or recommendations, and as a result they gather royalties,” he said.
Musicians can't upload music directly to Deezer or rival platforms like Spotify or Apple Music. Music labels or digital distribution platforms can do it for artists they have contracts with, while anyone else can use a “self service” distribution company.
Fully AI-generated music still accounts for only about 0.5% of total streams on Deezer. But the company said it's “evident" that fraud is “the primary purpose" for these songs because it suspects that as many as seven in 10 listens of an AI song are done by streaming "farms" or bots, instead of humans.
Any AI songs used for “stream manipulation” will be cut off from royalty payments, Deezer said.
AI has been a hot topic in the music industry, with debates swirling around its creative possibilities as well as concerns about its legality.
Two of the most popular AI song generators, Suno and Udio, are being sued by record companies for copyright infringement, and face allegations they exploited recorded works of artists from Chuck Berry to Mariah Carey.
Gema, a German royalty-collection group, is suing Suno in a similar case filed in Munich, accusing the service of generating songs that are “confusingly similar” to original versions by artists it represents, including “Forever Young” by Alphaville, “Daddy Cool” by Boney M and Lou Bega's “Mambo No. 5.”
Major record labels are reportedly negotiating with Suno and Udio for compensation, according to news reports earlier this month.
To detect songs for tagging, Lanternier says Deezer uses the same generators used to create songs to analyze their output.
“We identify patterns because the song creates such a complex signal. There is lots of information in the song,” Lanternier said.
The AI music generators seem to be unable to produce songs without subtle but recognizable patterns, which change constantly.
“So you have to update your tool every day," Lanternier said. "So we keep generating songs to learn, to teach our algorithm. So we’re fighting AI with AI.”
Fraudsters can earn big money through streaming. Lanternier pointed to a criminal case last year in the U.S., which authorities said was the first ever involving artificially inflated music streaming. Prosecutors charged a man with wire fraud conspiracy, accusing him of generating hundreds of thousands of AI songs and using bots to automatically stream them billions of times, earning at least $10 million.
6 notes
·
View notes
Text
Various web scraping tools will help you to extract Amazon data to the spreadsheet. It is a reliable solution for scraping Amazon data and fetching valuable and important information.
For More Information:-
0 notes