
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by edujournalblogs and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Benefits of Big Data in insurance sector

The insurance industry, as we know is founded on estimating futurestic events and accessing the risk and value for these events whick by the way require massive datasets with data from sensors, government, customer interactions and social media etc., Today big data technology has been comprehensively used to determine risks, claims, etc., with high levels of predictive accuracy. Big Data are useful in the insurance sector for the following reasons:
Risk Assessment
Understanding of customer behavior,habits, needs to anticipate future behavior and offer relevant products.
Improve Fraud Detection and criminal activity through predictive modelling
Provide targetted products and services.
Check out our master program in Data Science, Data Analytics and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#risk#customer#product#fraud_detection#services#predictive modelling#machine_learning#insight#trends#training
0 notes
Text
Importance of Big Data Analytics

Strategic decision for business forecasts and optimizing resources, such as supply chain optimization.
Product development and innovation.
Personalized Customer Service to provide enhanced customer service and increase customer satisfaction.
Risk Management to identify and mitigate risks.
Optimizing the work force hence saving work and time.
Healthcare sector support by tracking patients health records of past ailments and provide advanced diagnosis and treatment.
Providing quality services like preventing crime, improve traffic management, and predicting natural disasters, optimize supply chain processes, reduce cost, improve product quality through predictive analysis, improve teaching methods through adaptive learning etc.
Helps Banking sectors track and monitor illegal money laundering and theft.
Scalability
Check out our master program in Data Science, Data Analytics and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#Scalability#collaboration#machine_learning#training#trends#insight#data_visualization#skills#data_science#data#edujournal
0 notes
Text
Methods of Data Analysis

Sentimental Analysis
Regression Analysis
Time Series Analysis
Cluster Analysis
Predictive Analysis
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#data_science#machine_learning#data_visualization#insight#trends#regression_analysis#cluster_analysis#time_series_analysis#predictive_analysis#sentimental_analysis
0 notes
Text
Roles of a Data Engineer

A data engineer is one of the most technical profiles in the data science industry, combining knowledge and skills from data science, software development, and database management. The following are his duties :
Architecture design. While designing a company's data architecture is sometimes the work of a data architect, in many cases, the data engineer is the person in charge. This involves being fluent with different types of databases, warehouses, and analytical systems.
ETL processes. Collecting data from different sources, processing it, and storing it in a ready-to-use format in the company’s data warehouse are some of the most common activities of data engineers.
Data pipeline management. Data pipelines are data engineers’ best friends. The ultimate goal of data engineers is automating as many data processes as possible, and here data pipelines are key. Data engineers need to be fluent in developing, maintaining, testing, and optimizing data pipelines.
Machine learning model deployment. While data scientists are responsible for developing machine learning models, data engineers are responsible for putting them into production.
Cloud management. Cloud-based services are rapidly becoming a go-to option for many companies that want to make the most out of their data infrastructure. As an increasing number of data activities take place in the cloud, data engineers have to be able to work with cloud tools hosted in cloud providers, such as AWS, Azure, and Google Cloud.
Data monitoring. Ensuring data quality is crucial to make every data process work smoothly. Data engineers are responsible for monitoring every process and routines and optimizing their performance.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
Url: www.edujournal.com
#Architecture design#Data monitoring#process#machine_learning#data_visualization#data_science#trends#edujournal#data#training#testing
0 notes
Text
Machine Learning and their domain areas

Machine Language is extensively applied across industries and sectors. Various applications of machine learning are:
Prediction
ECommerce - display products based on customer preference based on past purchases
Automatic Language translation: translate text from one language to another.
Speech Recognition: translation of spoken words into text.
Image Recognition: recognize image with image segmentation techniques.
Financial sector : detect fraudelent transactions, optimization
Medical Diagnosis: detect diseases early
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
0 notes
Text
Types of Machine Learning problems
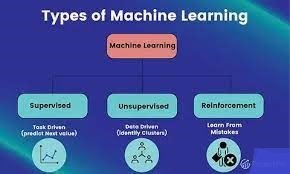
Types of Machine Learning problems:
Supervised
Un-Supervised
Reinforcement Learning
Supervised Learning: Here, we want to make certain predictions for the future. Hence, we want the machine to learn the previous historical data and forccast for the future for instance, temperature for today. We provide both the input value and output (labels) of historical data such as climate details, humidity etc and along with that output like temperature. Hence, the model can find the derivatives between input and output and generate an equation. eg regression model.
Unsupervised Learning : USL is to simply find out different patterns in data and categorize something Or group something or segment something. Here, we only provide input values not output values. We will only provide the relative features of the class but will not label them. For instance, for identifying a dog, we give long tail, sharp teeth, sharp claws, makes a boow noise etc. But we will not give the label for it. We only expect the machine to make a segregation based on the underlying features. Therefore, Unsupervised Learning does not make any predictions for the future but only makes segregation.
Reinforcement Learning: it is known as reward-based learning. For instance, we have a robot that is learning how to walk. We train the robot that walk straight and if you strike anything on your way like wall or table etc, then turn left or right and move forward or come back. Each time he strikes somewhere, we would point out his mistake and tell him where he is going wrong. Reward him in such a way that if we does not strike anywhere, he provide a rewarded system such that the robot does not commit the same mistake. So this is what Reinforced Learning is all about.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#machine_learning#Reinforced Learning#robot#Supervised_Learning#Un-Supervised_Learning#forecast#swgregation#reward_based#Data_Science#knowledge
0 notes
Text
Machine Learning and its applications

Machine Learning is an application of AI that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. it focus on development of computer programs that can access data and use it learn for themselves.. In other words, Machine learning is all about providing data to the machine and expecting the machine to learn from the data to make its decision in the future.
The difference between the traditional programming language (like Java, C#, PHP etc) and machine language is that for traditional languages we are providing instruction to the computer in the form of coding and we are generating the output from that whereas in the case of Machine Learning, we are basically dumping a whole bunch of historical data before the system and asking it to learn by itself and generate a pattern. it will do it with specific algorithms provided by us. Here, we are providing both the input and output to the model as input to the model and provides the logic as output. For instance, in the model we can use convolutional networks for identifying complicated images such as AI camera in traffic junctions to find vehicles jumping the signals or we can use a neural networks for NLP in sentimental analysis etc.
The various implementations in machine learning are Netflix (ie., suggest various movies as per your liking), amazon customer preference, Google Maps, Telsa Self Driving Cars, Object/Face/Speech Recognition, sentimental analysis on text or speech and find out the good and bad reviews, Fraud Detectiion, Virtual Assistant like Siri and Alexa etc
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#Siri#Alexa#Virtual_Assistants#neural_networks#Machine_Learning#model#algorithm#data#applications#sentiment_analysis
0 notes
Text

Data Science is the field of finding out solutions to a particular problem by analyzing the data that are fact-based and real-time in nature. For instance, suppose a company is facing problem with its sales or marketing or profit margin is shrinking etc. In such a scenario, the company will reach out to a data scientist who will execute a particular process. The process could be in the form of :
Identification the data analytical problem ie whether the fluctuation is due to pricing not set right, or specific marketing fluctuation which is constant for all other products or is it specific to this organization alone. So all these are analyzed and the data scientist will find out the actual underlined problem.
Gather all the information related to the problem in hand.
Dataset could be in a structured or unstructured form. Structured form could mean a file in a tabular form such as excel, mysql, sql server etc. Unstructured form could mean images, videos, audio, social media site etc.
Data collected from various sources must be cleaned and validated to ensure accuracy, completeness and uniformity.
Try to find out what model that fits the best for the given problem. The dataset is aligned to a particular model and algorithm is applied to this data, and the data is analyzed and different trends and patterns are extracted out of it.
Once patterns and trends are found out, the interpretation of data to discover solutions and opportunities is done for our company and find different solutions.
Communicate these findings to stakeholders using visualization for better understanding.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#patterns#algorithm#solutions#trends#Data_collection#Data_cleaning#Data_Science#machine_learning#dataset#model
0 notes
Text
Roles and Duties of a Data Engineer

A data engineer is one of the most technical profiles in the data science industry, combining knowledge and skills from data science, software development, and database management. The following are his duties :
Architecture design. While designing a company's data architecture is sometimes the work of a data architect, in many cases, the data engineer is the person in charge. This involves being fluent with different types of databases, warehouses, and analytical systems.
ETL processes. Collecting data from different sources, processing it, and storing it in a ready-to-use format in the company’s data warehouse are some of the most common activities of data engineers.
Data pipeline management. Data pipelines are data engineers’ best friends. The ultimate goal of data engineers is automating as many data processes as possible, and here data pipelines are key. Data engineers need to be fluent in developing, maintaining, testing, and optimizing data pipelines.
Machine learning model deployment. While data scientists are responsible for developing machine learning models, data engineers are responsible for putting them into production.
Cloud management. Cloud-based services are rapidly becoming a go-to option for many companies that want to make the most out of their data infrastructure. As an increasing number of data activities take place in the cloud, data engineers have to be able to work with cloud tools hosted in cloud providers, such as AWS, Azure, and Google Cloud.
Data monitoring. Ensuring data quality is crucial to make every data process work smoothly. Data engineers are responsible for monitoring every process and routines and optimizing their performance.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#cloud#data#google#machine_learning#design#data_monitoring#data_pipeline#data_science#database#warehousing
0 notes
Text
Key steps that drive decision making process

Articulate your company's goal and objectives.
Determine the source of your data viz customer feedbacks, financial report etc
Data Cleansing and Data pre-processing.
Perform Data Analytics and extrct meaningful insights, trends and corelations etc
Use data visualization tools to represent data in the form of graph, charts, automated reports, dashboard etc
Monitor the Key Performance Indicators (KPI's), that measures the progress and success of the business, and serve as a benchmark for decision making process.
Incorporate predictive analysis and move beyond retrospective analysis to forecast trends, insights and outcomes.
Collaborate with your team and other stakeholders involved and consider diverse perspectives to ensure that decisions are well informed.
Be Agile and responsive to changes in the data landscape.
Adopt your strategies and decisions based on new insights, emerging trends and outcomes and stay ahead of the competition.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#trends#predective_analysis#insight#secision_making#stakeholders#KPI#objectives#Agile#data_visualization#corelation
0 notes
Text
Time series analysis

Time series analysis is a tool for the analysis of natural systems. For eg., climatic changes or fluctations in economy.In other words, you can predict the future. it can give you valuable insight of what happend during the course of the week, weeks, months or years.
What are the 4 components of time series? Trend component. Seasonal component. Cyclical component. Irregular component.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#trend#seasonal#cyclic#irregular#time_series#predict#machine_learning#insight#data_visualization#data_science#edujournal
0 notes
Text
Agile methodology
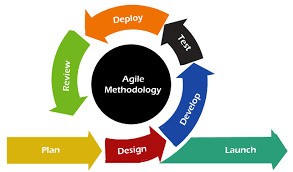
Agile methodologies such as Scrum and Kanban, focus on iterative development, customer collaboration, and responding to change. While Scrum operates in fixed-length sprints, Kanban allows for a more continuous and flow-based delivery. Teams can adapt to new requirements without waiting for a fixed iteration to complete and it supports the concept of continuous delivery, enabling teams to release features as soon as they are ready. Some teams choose to adopt a "Sprintless Agile" approach, combining Kanban's continuous flow with Agile principles.
General practices common to both Scrum and Kanban Methodologies:
Visual Management : it is the key component that makes it easy for team members to understand the status of tasks and understand the issues if any. 2.Control the Work in Progress (WIP) limits (ie., helps optimize the flow of work through the system hence preventing overflow of resources and reducing bottlenecks), improving focus and reducing multitasking hence enhancing delivering value iteratively. 3 Continuous improvement : Embrace the culture of continuous improvement through regular retrospectives with regular feedbacks. 4.Foster collaboration and collective ownership at work ie., encourage cross-functional teams and enhance communication and knowledge sharing.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#collaboration#Continuous_improvement#communication#feedback#culture#work_flow#visual_Management#work_in_progress#optimization#edujournal
0 notes
Text
Roles of Full Stack Developer

Designing User Interface (UI)
Developing Backend Business Logic
Handling Server and Database connectivity and operations
Developing API to interact with external applications
Integrating third party widgets into your application
Unit Testing and Debugging
Collaborating with cross-functional teams to deliver innovative solutions that meet customer requirement and expectations.
Testing and Hosting on Server
Software optimization.
Adapting the application to various devices.
Updating and maintaining the software after deployment.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#User_Interface#optimization#edujournal#testing#development#aoolication#software#debugging#aoi#integration#automation#seployment
0 notes
Text
Use Cases in Deep Learning
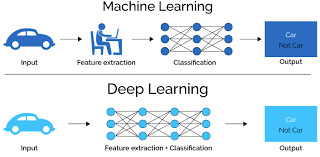
Deep Learning is a subset of Machine wherein we are training neural network models with datasets varying with complexity. We can identify patterns from our inputs which can be used to make predictions. Also, we can re-use the trained data derived from the model in other similar type of application which is known as Transfer Learning (TL).
Popular Models for doing Image Classification
MobileNetV2
ResNet50 by Microsoft Research
InceptionV3 by Google Brain team
DenseNet121 by Facebook AI Research
Smaller the algorithm, the faster the prediction time.
Use Cases:
Automatic speech recognition Image recognition Drug discovery and toxicology Customer relationship management Virtual Assistants (like Alexa, Siri, and Google Assistant). Self Driving Cars. News Aggregation and Fraud News Detection. Natural Language Processing. Entertainment Healthcare
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#Image recognition#data_visualization#data_science#trends#machine_learning#insight#edujournal#training#deep_learning#NLP
0 notes
Text
Neural Network Regression Model

Regression Analysis is a set of statistical processes, that are used for estimating the relationship between dependent variables and multiple independent variables. For eg, predicting the resale value of our house, our dependent variable is the price of our house ie the house price is the outcome you are trying to predict. The multiple indedendent variables could be the number of bedrooms in the house, sitting room, dinning room, kitchen, bathroom, car parking etc. We may have ten different houses with ten different type of bed rooms, kitchens, siitting rooms having different prices ranges depending on the size and area, place and location etc. Hence, we might require to create a model to take these information and predict the value of the house. Here, we are using Neural Networks for solving Regression Problems. We need to give the inputs and outputs to the machine learning algorithm, and the machine learning will use the algorithms at its disposal, and understanding the relationship between the inputs and outputs. In the case of inputs ie if you have 4 bedrooms in your home, the inputs have to be given in numerical encoding form such as [0 0 0 0 1 0] which are applicable for all cases. These data are sent through a neural network and the representational output is converted into a human readable form.
Anatomy of Neural Networks:
Input Layer : Data goes into Input Layer.
Hidden Layer(s) : Learns pattern in data.(We can have multiple layers here depending on complexity). We can have very deep neural networks such as resnet152 having 152 different layers which is a common computer vision algorithm. Hence, we can have how many layers as we want.
Output Layer: Learned Representation or prediction probabilities.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
0 notes
Text
Machine Learning Models
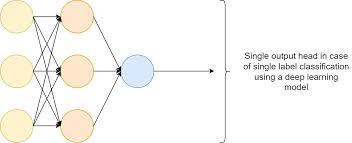
In machine learning, there are three parts to a modelling process viz.
Choosing and training a model (Training Data) (major chunk on 70%)
Validating (or tuning) the model. (about 15%)
Testing the model (Model Comparision) (about 15%)
You need to determine what kind of algorithm to use for various kind of problems. This is because some algorithms works better than others on certain kinds of data. For instance, if you are working with Structured Data, then decision trees algorithms like random forests, K-Nearest Neighbors (KNN) etc seems good. if you are working with Unstructured Data, then Deep Learning, Neural Networks, NLP etc seems good.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
0 notes
Text
Pandas for Data Science

Pandas are powerful libraries in python for data manipulation and analysis, providing data structure and functionality for efficient operations.it is well suited for working with tabular data such as spreadsheets or database. Also, Pandas help in Data Cleaning, Data manipulation, pre-processing, sorting etc. from the Data Frame. It is built on top of NumPy library and the data is used for Data Visualization in Seaborn, Matplotlib, Plotty etc.
Check out our master program in Data Science and ASP.NET- Complete Beginner to Advanced course and boost your confidence and knowledge.
URL: www.edujournal.com
#Seaborn#Matplotlob#Plotty#Data_Visualization#Pandas#Data_Cleaning#Data_Manipulation#Data_Analysis#sorting_data#data_science#machine_learning
0 notes