
Statistics
We looked inside some of the posts by idein-inc and here's what we found interesting.
Average Info
Notes Per Post
23
Likes Per Post
10
Reblog Per Post
13
Reply Per Post
0
Time Between Posts
2 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
Rustにおけるirrefutable patternを使ったイディオム
pandamanです。Rust関係のフォーラムに入り浸って知ったイディオムをこれからの記事で紹介していきます。
この記事では、場合分けを伴わないパターン(irrefutable pattern)を使ったイディオムとして
let _ = ...の形のイディオム(値の無視)
let _x = ...の形のイディオム(生存期間の調整)
の2つを紹介します。
場合分けが伴うパターンマッチ
Rustにおける代表的なパターンマッチはmatch式でしょう。
// Optionに対するパターンマッチ match opt { Some(v) => printf!("Someの場合: {}", v), None => printf!("Noneの場合"), }
match式では各パターンにマッチするかどうかで場合分けし、パターンに応じて内部の情報を取り出すこともできます。 このような場合分けと値の分解を同時に行う言語機能にはmatch式の他にif let式やwhile let式があります。
場合分けが伴わないパターンマッチ
一方で、場合分けは必要ないケースもあります。 典型的な例は値の分解だけするケースでしょう。 例えば、次のようにタプルや構造体の中身を取り出すコードを見たことがあるかもしれません1。
// タプルを分解 let (a, b) = (100, 200); // 構造体を分解 struct Point { x: i32, y: i32, z: i32, } let Point { x, y, .. // xとyだけ取り出し } = point; println!("x = {}, y = {}", x, y);
これらの例では、let文と共にパターンを利用していることに注意してください。 他にも、for式や関数の引数でもパターンを記述することができます2。 このように、Rustでは幅広い場所でパターンマッチをサポートしています。
ただし、let文のような場合分けを伴わない場所では、あらゆる値にマッチするパターンしか使えません。 そのようなパターンはirrefutable patternと呼ばれ3、上述のタプルや構造体の分解も含まれるほか、変数の導入もこのケースに当てはまります。
// 変数パターンを使ってマッチ let x = 42;
このプログラムはただの変数宣言に見えますが、芝居がかった言い方をするならば、実は「let文において変数パターンxを使って値42にパターンマッチしている」と捉えることもできます。
一方でマッチしない可能性のあるパターン(例えばパターンSome(v)は値Noneにはマッチしません)はrefutable patternと呼ばれます4。
Irrefutable patternに関連するイディオム
いくつかのIrrefutable patternはイディオムとして特殊な使われ方をすることがあります。 この記事では
let _ = ...
というケースと
let _x = ...
という2つのケースを紹介します。 これらのケースは見た目こそ似ているものの、振る舞いは異なるため注意が必要です。
let _ = ...
まずはlet _ = ...と変数名の代わりに_を使うケースを紹介します。 このアンダースコアはワイルドカードパターンと呼ばれており、値を無視するために使います。 ワイルドカードパターンはよくmatch式の最後に残りの場合分けをまとめて処理するためによく用いられます。
ワイルドカードパターンはマッチ対象の値に対して何も行わず、所有権の移動や借用も生じません。 ですから、let _ = ...という形で記述したとき、ワイルドカードパターンはプログラムの振る舞いには影響を与えません(例外は後述)。 では、なぜこのイディオムを使うのかというと、unused_must_use警告の抑制のためです。
例えば、次のプログラムはunused_must_use警告を送出します。(Playground)
fn main() { std::fs::write("foo.txt", "bar"); // unused_must_use警告 }
このプログラムでは、write関数の戻り値のResultを無視しています。 これではエラーを無視できてしまうので、Rustはunused_must_use警告によって注意を促しています。 ですが、無視することが正しいケースも存在します。 例えば、Dropによるデストラクタの実装ではエラーを通知する手段が無いため、エラーは無視するよりありません。
そのようなケースで用いるのがlet _ = ...イディオムです。 次のように、let _ = ...を使うことでコンパイラに値を無視していることを明示的に伝え、unused_must_use警告を抑制します。(Playground)
fn main() { // 警告を抑制 let _ = std::fs::write("foo.txt", "bar"); }
値の解放タイミング
let _ = ...イディオムでは、右辺の値はその文の終わり(セミコロン)で解放されます。 Rustでは、変数に代入された値を除いて、全ての値は文の終わりにて解放されます。 ワイルドカードパターンは変数ではないため、右辺の値は代入されてはいない一時的な値とみなされ、文の終わり(このイディオムの場合ではlet文の終わり)にて解放されます。
▼ 代入する変数が無いため let _ = std::fs::write("foo.txt", "bar"); ◀ ここで解放 ▲ 関数の戻り値は一時的な値とみなされ
ただし、右辺の値が既に変数に代入されている場合はワイルドカードパターンは値の所有権に影響を与えません。 ですから、次のプログラムはコンパイルが通ります。(Playground)
fn main() { let v = String::from("foo"); // ワイルドカードパターンは所有権を移動しないため以下の文はNOP。 let _ = v; // vは使用可能。 println!("{}", v); }
この特性を利用すると、let _の有無によって意味の異なるプログラムを書くこともできます😎(Playground)
fn main() { let v = String::from("foo"); // この形の文はpath statementと呼ばれ、vがdropされる。 // 分かりづらいのでdrop(v)を推奨。 v; // vはもはや使えない。 // println!("{}", v); }
実世界では目にすることは無いでしょうが。
let _x = ...
一方で、let _x = ...と変数名を_で始めるイディオムも存在します。 この_xは変数パターンであり、右辺の値を移動や借用により束縛します。 これがワイルドカードパターンとの大きな違いです。
この変数パターンは値の生存期間を調整するために使います。 特にロックのような解放のタイミングが重要となる値に対して使われます。 これは、Rustにおいて変数はブロックから脱出する際に解放されることを利用しています。
このパターンでは、変数名を_で始めることでunused_variables警告を抑制しています。 多くの場合は導入した変数を使うので、この必要はありません。 ですが、例えばグローバルリソースを排他制御する場合やtracingライブラリで実行中のコンテキストを指定する場合のように、変数を使わずその値の生存期間だけが重要になるケースでは、変数名をアンダースコアで始めるイディオムを使います。
{ // 共有リソースのロック let _lock = mutex.lock(); // 共有リソースにアクセス ... // スコープの終わりでロック解放 }
実は、アンダースコアから始まる変数は他の変数と同様に使うことができるのですが、プログラムの意図を明らかにするためにもアンダースコアから始まる変数はこのイディオムの場合にだけ使うのが良いでしょう。
GitHubに対する検索でもタプルを分解する例や構造体を分解する例がヒットします。 ↩︎
TRPLのパターンを記述できる場所の一覧もご覧ください。 ↩︎
TRPLでは論駁不可能パターンと呼ばれています。 ↩︎
ちなみに、enumでもバリアントが1つしかない場合はirrefutable扱いになるようです。(Playground) 残念ながら、現在のrustcではパターンがirrefutableかどうかの判定にinhabitedness(型に値が存在するか)を使っていません。 ですから、Result<t>に対するパターンマッチではOkとErrの両方を書く必要があります。(Playground) このチェックをもっと正確に行おうとする提案はされています(Issue)が、そもそもinhabitednessを使うのが望ましいかという点で議論が停滞しているようです。 ↩︎
9 notes
·
View notes
Text
MobileNetV2のFPGAデモ
IdeinのSitnikov Evgeniiです。読み方:シトニコフ エフゲニー。 Ideinでは深層学習をFPGAで実装をやっています。
デモの目的
MobileNetV2を試実装したい:速度と弱点を明確にしたい
新しい設計方を試してみたい
設計とRTL SimulationをC言語で実施できるようにする
Verilog言語では実装だけ
NeuralNetwork向け超速カメラインタフェース環境を開発したい
NN向けのデバッギングとI/O環境を開発したい
画像処理とNNのリアルタイム接続の経験を積みたい
モデル
TensorFlowのMobileNetV2を再学習なしで全体を16ビット整数量子化(9 bit Fractional Part)をかけたもの。
Fractional Part を8ビットではなく9ビットにした理由は,9 bitの場合に一番高いTop1精度が出ていたため
元のfp32ビットの精度:69.1851697%
16ビット量子化後の精度:69.0825304%
ImageNetの50k validation datasetでの測定
デモの動画
www.youtube.com/watch?v=MBAdPUWKZNE
youtube
FPGAの実装

MobileNetV2の前半部60%だけをFPGAで計算している: *一つ目の14x14x96ブロックも含む。
Source: https://arxiv.org/pdf/1801.04381.pdf
画像の赤枠内でFused Multiply Addの計算数の約60%になる。
残りの部分をPCのClientで計算している。
理由は後半の層はPCで並列化が簡単で効率高いため。
Hardware
FPGA Cyclone V 5CGXFC9D6F27C7:
LUT: 113k
REG: 226k
OnChipRAM: 12 200 Kbit
DSP blocks: 684
Board: Starter Platform for OpenVINO™ Toolkit
PC:
CPU: Core i7-8700 3.2 GHz
RAM: 32Gb DDR4
OS: Windows 10 pro
リソース消費

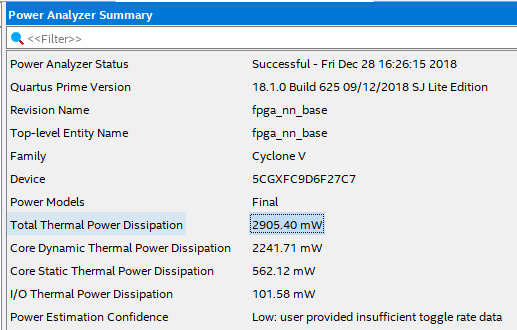
電力消費量
Info (215031): Total thermal power estimate for the design is 2375.90 mW
これがFPGAだけの電力消費量
センサの電力消費量:381 mW
合計:2756.9 mW
Top levelの設計図

画像を拡大する
ClockDomainについて
NNと画像処理の速度を合わせる為に別々の周波数を利用した。
同様にインタフェースの為に一番高い別の周波数も必要になる。
そのため、三つのClockDomainが必要になった:
NN:66.25Mhz、
画像処理:93.333Mhz、
FTDIと他のI/O:200Mhz。
データストリームがClockDomainを越える為にClockDomainCrossing FIFOが必要。上の図では「CDC FIFO」と略記。
Camera Sensor:
モデル:MT9P401 Datasheet: https://www.onsemi.cn/PowerSolutions/document/MT9P401-D.PDF
設定:一番速いFPSの為に、RowSkipとColumnSkipとGainを最上に設定したが、このせいでノイズが多くなった。
解像度:
Valid pixels: 520 x 486 (252720)
Total pixels: 1420 x 515 (731300)
FPS: ~127.5
ClockPhase: non inverted, shift =10%
このセンサの出力はRawBayerであるため画像処理も開発した。
Debugの為にUSBからセンサ設定レジスタを変更できる機能がある、
コマンドのフォーマット例:
センサのレジスタ読み込み:READ 0x0A;
センサのレジスタ書き込み:data 0x0300; WRITE 0x0A;
ターミナルの例:

Image Processor

画像を拡大する
特徴:Low latency (1ミリ秒以下)
MobileNetV2の設計
最初にこの記事でMobileNetV2の設計をしたが、改善して、新しいバージョンを実装した。新しいバージョンの主な違いは:3x3カーネルの計算でシフトレジスタの代わりにFPGAのOnChipメモリを利用するの違い。
一段の具体的な図:

画像を拡大する
NNの実装のポイント:
WeightとBiasのメモリを圧縮をしません
Dividerの設定は1だけ
MobileNetV2の60%だけ、全てはFPGA中に入らない。
量子化:全体16ビット、でも3x3カーネルのメモリ12ビットだけ(このメモリの入力がReLU6の出力で:0...0x0C00の値だけであるため不要なビットを省略)
効率と性能:
FPGAのDSPブロックの利用効率:
実装は465DSPブロックを利用している 「画像処理の周波数:93333333Mhz」と「フレームあたりのピクセル:731300」によって、FPSを計算する:
FPS=93333333/731300 =127.6266005743 (FPS)
MobileNetV2の60%は187169024乗算の演算であり。これ一枚だけについて、センサのFPSに計算したら:
187169024*127.6266005743=23,887,746,265 (23.887 GigaMults/sec)
しかし、 NNが別の周波数66,25Mhzを利用しているため:
23,887,746,265 / 66250000 = 360.5697549574,
ここから、クロックごとに360.57 DSPブロックが使用される。
FPGAのDSPブロックの利用効率:465 / 360.57 = ~77%
FPGAのメモリの利用効率:
6202Kbitを利用しているが,10Kのメモリブロックで計算したら:7460kを利用している。 理由はMemory Segmentationで FPGAのメモリの利用効率:6202/7460 = ~83%
Verilogの周波数の性能:

Verilogモジュール毎の周波数を測定した:
一番低い周波数はWeightのROMメモリで,理由はLUT中に保存しているOnChipRAMを利用していたら250Mhz位に出来る。勿論、全てを一緒にコンパイルすると周波数は少し下がる。(普通に10%内で)
結論:センサの制限しなければ、このNNの実装はこのCycloneVでは385FPSまでポテンシャルがある
実装の質
Quartusのコンパイル時にWarningを全く出力しない。
C言語のモデルとVerilog言語のモデルが互いに等しい。「BitPerfect」と言う主義の意味:出力だけではなく、各層の計算は互いに等しい。これにより開発とDebugをし易い。

PCのClientへ送るときにFPGA中でCRCを計算している。PCのClientのCRCだけで確認せず、PacketSizeとPacketの順位をチェックしている。
FPGA中にTelemetryもある。FIFOの深さについてOverfullしないかどうかのCounterもある。
元のモデルの精度と量子化後FPGAモデル精度の差は-0.1%

PCのClientはリアルタイムでストリームの動画に対しMobileNetV2を計算し、FPGAでの計算と比較している。もし等しく無いと特別のCounterを増やす:
ROMに基づいてEmulatorを接続し、動作を確認した (ROMの内容は参照の入力です)。

センサの出力RawDataの代わりに:

画像処理の出力の代わりに (画像処理をチェックする為)

画像処理のCDC FIFO出力の代わりに (画像処理のCDC FIFOをチェックする為)
この方法で画像処理とNNの動作を徹底的に確認しました。
起動と再起動の動作の録画
以下の動画はPCのClientのフォームとFPGAのターミナルを撮ったもの。
FPGAの再起動時の動作を撮影した。シーケンスとしては,
CameraのInitialization:端末にセンサのレジスタの設定値が見える。Reset後の画像処理出力の最初の2秒間は無視される。その間はPCのClientに「No Signal」を出力している。
2秒後にNNモデルが起動する。
モデル起動ともにPCのClientにストリーミングを開始する。
ポイント:再起動時にErrorCounterを少し増えている:これは間違いを検出した動作(CRCが等しくないことを見つけた)。
https://www.youtube.com/watch?v=EZBmEf0klXA
youtube
調整とエラー処理の動作の録画
悪い設定をFPGAにリアルタイムで書き込んでエラー処理を確認した。勿論、その時にErrorCounterが増やされている。
https://www.youtube.com/watch?v=ggGBex_BFK8
youtube
実装の依存
最初からPureVerilogでNNを設計と開発したので、あまりライブラリや他のソースコードに依存しない。そのため,他のFPGA(例:Xilinx)に移植し易い。
依存関係のある外部モジュール:
PLL
CDC FIFO
普通のFIFO
この3つの外部モジュールは普通FPGAのコンパイラの一部
結論
MobileNetV2を実装しました:
速度が128FPSになった(速いセンサがあれば限界は375FPS)
弱点:OnChipメモリが足りないので、もっと高いFPGAが必要。
新しい設計法を試した。設計とRTL SimulationをC言語で、Verilog言語で実装だけ:大幅な開発スピードアップ。(CからVerilogに手動で翻訳した)
NeuralNetwork向け超速カメラインタフェース環境を開発しました。Terasicのカメラの画質に不満があるため、他のカメラが必要。
NN向けのデバッギングとI/Oの環境を開発し、とても便利なものに出来上がった。ただ,USBの速度がぎりぎりで、1G~10GのEthernetとかPCIeが必要になってくる。
画像処理とNNをリアルタイムで接続しました、予定より複雑になったため、次回はもっと時間をかける必要があるとわかった。
0 notes
Text
KDDI ∞ Laboイベントで体温検知デバイスを設置
昨日、KDDI DIGITAL GATEにおいて行われた、KDDI ∞ Labo主催のパートナー向けイベントに参加させて頂きました。
イベントでは、伊藤忠テクノソリューションズ株式会社とIdeinで共同で開発した汎用的なIoTデバイスを利用した体温検知デバイスを設置頂きました。
KDDI ∞ Laboについて
新しいサービスを推進するスタートアップとともに、各業種において豊富なアセットやノウハウを有するパートナー連合と連携して、社会にインパクトのある新たな事業の共創を目指す「事業共創プラットフォーム」


イベントの様子
KDDI ∞ Laboイベント会場のエントランスに体温検知デバイスを設置、来場者の発熱者検知を行いました。

CEO中村も元気です。

COO仁藤より、オンライン参加者含めた約150名以上の参加者の皆様に向けて、Actcastをご紹介させて頂きました。

展示ブースでは Actcastを使ったRaspberry Pi Zero上で動く顔向き推定からAmazon Rekognitionに繋げる顔認証デモなど、Actcastのマーケットプレース上のアプリケーションや遠隔管理機能を体験出来るデモを展示させて頂きました。

飛沫対策としてFace Shieldが配られていました。

数多くの来場者の方々に展示ブースにお越しいただき、ありがとうございました!

最後にKDDI ∞ Laboの皆様と記念撮影。
KDDI ∞ Laboの皆様、このような素敵なイベントにご招待頂きありがとうございました!

体温検知デバイスについて
伊藤忠テクノソリューションズ株式会社様が、当社と共同で開発した体温検知デバイスの販売を開始しました。
Actcastについて
Actcastは、エッジデバイス上で画像解析AIなどを実⾏して実世界の情報を取得し、Webと連携するIoTシステムを構築・運⽤する為のプラットフォームサービスです。安価なデバイスを用いてエッジ側で解析を⾏い、不要な情報を送信しない事によって運⽤コストを⼤幅に削減し、プライバシーへの配慮も行いながらAIの普及を実現します。セキュリティ、産業IoT、リテールマーケティング、MaaSなど様々な分野でご利⽤いただく事が可能です。
0 notes
Text
GPGPUの観点から見る VideoCore VI と VideoCore IV の違い
Idein大川です.主に最適化回りを担当しています.
Raspberry Pi 4 が(技適も通過し)発売され入手可能になりましたね.これまでRaspberry Pi シリーズのGPUはVideoCore IV (以下VC4)でしたが,Pi4からは VideoCore VI (以下VC6)が採用されています.
VC4と異なり,VC6には性能を引き出す上で最大とも言える問題があります.それは「リファレンスマニュアルが公開されていない」ということです.VC4ではリファレンスマニュアルが公開されていたために py-videocore 等を作ることができ,誰でもGPGPUを嗜むことができました.しかし,VC6ではなかなかそうもいきません.幸いグラフィックライブラリMesa 3DのVideoCore対応から読み取れるものはありますが,使う必要が無いためか実装されてない(というかあるかないかもわからない)ような部分もあり,不明な部分も未だ多いです.
Ideinでも残念ながら?特別なドキュメントもらっているとかそんなことは全くありません.(VC4のように)ドキュメントを公開してもらえるのか問い合わせを行いましたが,必要な情報はMesaのVC6ドライバを参考に調査してくれ,成果は公開してもかまわないと案内頂くにとどまっています.そのため「こういう機能がきっとある筈だからたぶんこのあたりのbitに何らかのエンコーディングで入ってるだろう,本当にあるかないかもわからんそれを実装して試してみよう」とか「何らかの命令や特殊目的レジスタの存在はわかるけど具体的に何をするものなのか不明なので推測しつつ作用を調査する」といったようなエスパー行為も駆使して未解明な部分を埋めつつ,VC6 GPGPUのためのPython EDSL(embedded domain specific language)なアセンブリ py-videocore6 を開発しており,既にDNNに使うパーツの実装に足る程度には仕上がっています.また,これを利用したVC6の性能評価等も進めてみています.
たぶんこれが一番速いと思います.(フラグ)
youtube
本記事では,VC4とVC6両方に触れてみて,VC4からVC6への差分がどうなっているのかについてざっと紹介します.Pi4の性能を完全に引き出す助けにしてみて下さい.ただし,上記の通り推測が多分に含まれています.VC4同様リファレンスが公開されることを祈りましょう.
理論性能
演算器QPUが16way SIMDの32bit演算器である点はVC4と一緒です.VC4のときは3つあったスライスがVC6では2つに減っています.そのかわり(Pi3で)300MHzだったGPU動作周波数が,500MHzに向上しています.この変更により,(Pi3やPi0で)28.8Gflopsだった理論性能は32Gflopsに微増しました.ただ,Pi4ではCPUがトータルで48Gflops持っています.Pi0や旧Pi2までは圧倒していたGPU性能も新Pi2やPi3では逆転し,Pi3+,Pi4となるにつれ理論性能の差はだんだんと広がっています.実はPi3 VC4の段階で既にCPUより速く動かすのは大変なのですが,Pi4 VC6からはさらに顕著になっています.まぁ,Pi4は(Pi3とかもですが)CPUを全力全開すると一瞬でお熱になるのですが.
レジスタ/命令セット
VC4では結構いろいろな種類があった命令ですが,VC6では大まかに算術命令と分岐命令のみになりました.セマフォ命令(というかセマフォ自体)が恐らくなくなっています.また,即値ロード命令相当のものを見つけられてないだけかもしれませんが無くなっており,これはやや不便なこともありました.
VC4ではregister fileのA/B面がありましたが,VC6では総数変わらずもこの区別が無くなっています.また,1命令分のディレイも無くなっており,総じて扱い易くなる良い変更となっています.
特殊目的レジスタのうち,命令のsrcレジスタとして利用する形のものが恐らく一律で無くなりました.一部,同等機能としてdstレジスタに格納する形の命令に変化して残っているようです.同じ命令でもsrcレジスタによってストールするかどうか変わるというような挙動を嫌ったのかもしれませんが,実際の意図はわかりません.
packing/unpackingに関しては8bit整数が無くなり,絶対値unpackなどにやや顔ぶれが変わりました.また,packing/unpacking可能な命令が限定されています.というかそれらが可能な命令に対するopコードの一部として表現されているという状態です.関連して,算術命令としてfp16の乗算が追加されました.やや流行りを感じなくもないです.ただ,加算が無���ようなので,使う場合はfp32命令とpacking/unpackingを利用することになるのでしょう.
条件フラグの挙動もかなり変更されています.VC4ではznc三種類のフラグがそれぞれ同時セットされ,個別に参照することができましたが,VC6ではzncのどれか1つをセットして保持する形になり同時には参照できません.そのかわり,A面B面で長さ2の条件フラグバッファを持っており,新しくセットしたらA面に,それまでA面にあったものがB面に移動するようになっているようです.また,A面のフラグに対しand/norで更新する機能が付きました.算術命令からはA面B面両方参照でき,分岐命令からはA面のみが参照されるみたいです.
分岐命令は,相対即値,絶対即値,レジスタ内絶対値,リンクレジスタ値のいずれかに飛ぶ形になりました.VC4であったレジスタ内相対値が無くなりましたが,大きな影響は無いでしょう.VC4のときは明示的にリンクレジスタとしてregister fileのどれかを指定し,分岐時にそれに格納される形でしたが,VC6では通常のレジスタとしては参照できない暗黙のレジスタになっているようです.前述のように特殊目的レジスタでsrcとして利用できるものは消えているので,これも追加された「現在のリンクレジスタ値を引き出す命令」を使って取り出す形になっています.1段飛んで戻るだけであればregister fileを消費しなくなったということでもあります.
データの転送
VC4ではデータをTMUやuniformsでロードし,VPMを経由してDMAで書き戻していました.VC6ではTMUがロード・ストア両方に対応し,MMUも挟まっているようです.VC4では,TMUやuniformの前にはL2がありますが,DMAはそれを経由しないため,同一領域に対する読み書き読みを行うとL2キャッシュの状態によってデータの整合性が崩れることがありました(当然Ideinの変換器はこれも考慮して変換しています)が,VC6ではこの現象も発生しなくなっています.ただ,TMUでストアした直後にuniformでロードすると,どこかのキャッシュのせいなのかわかりませんがデータの整合性が崩れることがあるため,この点だけは引き続き注意しましょう.
VC4でDMA転送に使う転送元のVPM及びDMA操作には,全QPUで排他制御が必要でした.そのためVC4は書き出し(必須な処理にも関わらず!)を行うと並列性が損なわれるという性質を持ちます.VC6ではこの制約もみかけ上ありません.
TMUはスロット毎に2つだったのが1つに統合され,そのかわり同時に投入しておけるリクエスト数の限界は各4から恐らく8になっています.良い面も悪い面もある変更という感じでした.ちなみに限界数を越えてリクエストした場合の挙動はVC4よりもお行儀が悪い子です.
TMUロード時の格納先レジスタは,VC4ではr4に固定でしたが,ロードシグナルに格納先を指定できるようになりました.レジスタプレッシャーの緩和に繋がる良い変更でしょう.
uniformsは,VC4では読み出しがsrcレジスタとして使う特殊目的レジスタになっていましたが,VC6ではTMU同様シグナルで読み出しを指定するようになっています.こちらも格納先をシグナルに持たせてロードしたりすることができます.また,指定せずr5にロードすることもできます.指定する場合としない場合で同時に指定できるシグナルが変わるので使い分けになります.
uniformsの読み出し先変更は,特殊目的レジスタにアドレスを書く形であったVC4と異なり,分岐命令で行うようになりました.分岐命令が,命令列の分岐先に加えて,uniformアドレスの分岐先を指定できる形になっています.
スレッド関連
VC4ではQPUあたり2スレッド投入できましたが,切り替え時にレジスタ値を自分で退避させておく必要があり,(我々の目的に対してはですが)普通の神経で扱って性能が出せるようなものではありませんでした.VC6でも複数(ID的には4つまでありますが同時に投入される数は未確認)投入できますが,やはりレジスタを退避させる必要があるようで,引き続き性能に寄与する類のものとはあまり思えません.
命令の項でも書きましたが,セマフォは無くなったようです.そのかわりというわけでもないとは思いますが,簡易なバリア同期が入りました.もしかすると簡易じゃない特殊な使い方もあるかもしれませんが詳細不明です.
VPMは命令はあるようなのですが本当についてるのかまだよくわかってません.ただ,VC4同様排他制御が必要なのであれば,セマフォも無く,書き出しもTMU経由で行うようになってしまったVC6では使い道もあまり無さそうです.
ドライバ側の話になりますが,VC4のMailbox property interfaceでは,スレッド毎にuniformアドレスを個別に渡せていましたが,VC6では1つだけになっています.そのため,スレッド毎に別の仕事をさせるには若干の工夫が必要になっています.他にもCompute Shaderのドライバまわりはまだdispatchしたジョブの扱いに関してパフォーマンス的に少し問題を抱えていることがわかっています.
まとめ
Pi4では公式にOpenGL ES 3.1対応している(というかVC6への進化もそれをし易くする方向の変化が目立つ)ので普通にシェーダ言語が使えるようになると思います.しかし,それで期待通りのパフォーマンスを発揮させるのは難しいハードウェアになってるのではないかという印象です.
0 notes
Text
AWSで使うRust
κeenです。この記事では IdeinでのAWSの利用例の開示の一環として、どのようにRustをAWS上で動かしているかをご紹介します。
Ideinの提供しているサービスActcastではサーバの主たる部分をRustで書いています。 はじめの頃は本当にRustだけだったのですが、各方面に秀でたメンバーが集まった結果、今ではHaskellやTypeScript、一部ですがGoも動いています。
そもそもRustの採用事例が少ないことからRustをAWSで扱う知見はそこまで多くなさそうです。 そこで今回はIdeinでどのようにAWS上でRustを動かしているか、動かすにあたって必要だった知見などを紹介していきます。
全体像
全体の中で、Rustが動いている環境はECSとLambdaです。 ECSで動いているのはActcastのバックエンドAPIで、Actcastのサーバ本体とも言える部分です。
Lambdaの方は全部で4つあります。 起動トリガで分類するとAPI GatewayのAuthorizerとHandlerに1つづつ、CloudWatch EventsのEventとTimerに1つづつです。

Actcastでは今のところAWSの構成を全てterraformで管理しているのでECSジョブやLambdaもterraformからデプロイしています。 これについてはサービスリリースを乗り越えたので構成の見直しを予定しています。
ECSはdockerコンテナさえ作ってしまえば大きな懸念なく動くので以下ではLambdaでの動かしかたについて紹介します。
コード
使っているライブラリやコーディング上のテクニックを紹介します。
全般
Lambdaランタイム
LambdaのRustランタイムはありません。 しかしカスタムランタイムを使えばRustを動かすことができます。 カスタムランタイムでRustを動かすためのライブラリも公開されています。 このライブラリ(lambda-runtime)を使えばエントリポイント( main 関数)だけLambda用に作ってあげれば動くのでコードの残りの部分はあまりLambdaについて気にしなくてよくなります。 別の言い方をするとLambda特有の処理は全てエントリポイント部分に集約しています。 つまり、 main 関数の見た目は以下のようになっています。
use tokio::runtime::current_thread::block_on_all; use app::{api, App}; pub async fn handle( app: &App, event: api::CustomEvent, _ctx: Context, ) -> Result { app.do_something_with_event(event, hoge, fuga) // do other things... } fn main() { /* 初期化のコード */; let app = App::new(...); lambda!(|req, ctx| { block_on_all(handle(&app, req, ctx)) }) }
コードを少し解説すると以下のようになっています。
Lambdaのランタイムは何度か使われるので Appはメインループの外で作って使い回す
lambda! マクロでLambdaのメインループに入る
リクエストとレスポンスはserdeの Deserialize/Serialize を実装した型を書いておけばJSONから変換される
Futureを走らせるために block_on_all を呼んでいる
このうち3と4についてもう少し詳しく触れます。
出入力フォーマット
リクエストとレスポンスはAWSのドキュメントを読んで、自分の欲しいフィールドを扱えるようなデータ型を定義します。例えばAPI GatewayのCustom Authorizerであれば以下のようなデータ型を定義しています。
#[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord, Deserialize)] #[serde(rename_all = "camelCase")] pub struct CustomEvent { #[serde(rename = "type")] pub type_: String, pub authorization_token: String, pub method_arn: String, } #[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord, Serialize)] #[serde(rename_all = "camelCase")] pub struct CustomOutput { pub principal_id: String, pub policy_document: PolicyDocument, } #[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord, Serialize)] #[serde(rename_all = "PascalCase")] pub struct PolicyDocument { pub version: String, pub statement: Vec, } #[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord, Serialize)] #[serde(rename_all = "PascalCase")] pub struct Statement { pub action: String, pub effect: Effect, pub resource: String, } #[derive(Debug, Clone, PartialEq, Eq, PartialOrd, Ord, Serialize)] #[serde(rename_all = "PascalCase")] pub enum Effect { Allow, Deny, }
少し冗長ですが実行時���エラーが出るよりはマシなので1つ1つ丁寧にデータ型を定義しています。
同期と非同期
我々のコードは全て非同期で書かれていますが(cf プロダクションのRustコードを async / await に移行した話)lambda_runtimeは非同期サポートをしていないので明示的にブロックする必要があります。 非同期サポートが欲しいというissueはあるのですが、進捗芳しくないみたいです。 ここは期待せずにブロックするコードを書きましょう。
コード構成
コード構成はLambda依存の部分とビジネスロジックを完全に切り離しています。 具体的にはCargoのWorkspaceの機能を使ってコアとなるビジネスロジック部分と、それに依存するECSやLambdaのエントリポイント部分のパッケージを分けています。 他にも外部(RDBやその他のAWSリソース)とのやりとりもパッケージを分けていますがこれは普通の書き方ですね。
Rusoto
Lambdaで完結することは少なくて、他のAWSサービス群を利用しています。 RustからAWSサービス群を利用するのにはRusotoを使っています。 過去には機能が足りなくてPull-Requestを送ることもありますが、最近はおおむねそのまま使えています。
ただしasync/await対応(とそれに伴なう依存ライブラリのアップデート)がまだなのでasync/await移行してしまった我々のコードベースからは少し使いづらいものがあります。 これについてはPull-Requestが出ていますがマージされるまでもう少し掛かりそうです。 これらのPRがマージされ次第我々もRusotoを使っている部分を async/await に書き換えていく予定です。 本当はRusotoの依存ライブラリが他の依存ライブラリとコンフリクトしてバージョンの更新がブロックしているなどの問題も発生してりるので、 async / await 対応以外の更新もありますがそれはまた別の話。
DLL
Rusotoを使う際にSSLライブラリが依存に入ります。これについて注意点があります。 詳しくはビルドの節で説明しますがLambda内でopensslを使うのは非常にハードルが高いのです。 なのでLambda内でRusotoを使う際はopensslではなくpure rustのrustlsを使いたいです。 一方でECSなどopensslの使用に差し障りのない場面では枯れたライブラリであるopensslを使いたいです。
そこで、ECSでもLambdaでも使われるコアロジック部分は以下のようにopensslでもrustlsでも動くように作っています。
# Cargo.toml [dependencies] hyper = "0.12" # hyper-rustlsとhyper-tlsをoptionalにしておく hyper-rustls = { version = "0.16", optional = true } hyper-tls = { version = "0.3", optional = true } rusoto_core = { version = "0.40", default_features = false } rusoto_credential = "0.40" rusoto_ecr = { version = "0.40", default_features = false } [features] # featureで全体のtlsを切り替えられるようにしておく default = ["native-tls"] native-tls = ["hyper-tls", "rusoto_core/native-tls", "rusoto_ecr/native-tls"] rustls = ["hyper-rustls", "rusoto_core/rustls", "rusoto_ecr/rustls"]
// src/lib.rs // Rustのコード内では有効にされた方を使うようにしておく #[cfg(feature = "hyper-rustls")] use hyper_rustls as tls; #[cfg(feature = "hyper-tls")] use hyper_tls as tls;
上記のようにコードとしてはopensslまたはrustlsで動くように作っておいて、使うときに選択するようにしています。
同様にLambdaやECSのエントリポイントとなるパッケージでもフィーチャを用いてどちらでも動くようにしています。 そしてビルドするときに --no-default-features --features rustls などのオプションを渡してopensslとrustlsを使い分けています。
本当はビルド時ではなくエントリポイントの Cargo.toml 時点でフィーチャを固定したかったのですがそれは難しいようでした。 hyper-tls を有効にするECSのコードと hyper-rustls を有効にするLambdaのコードが混在する状況でワークスペースのビルド (cargo build 相当)をするとどちらのフィーチャも有効になってしまい、ビルドに失敗します。 もうちょっと言うと cargo check や cargo test もままならなくなってしまうので大変不便です。 一応、個別のパッケージ毎のビルド(cargo build -p package 相当)ではフィーチャが混在しなくなるので成功するものの、エディタ/IDEの設定ではデフォルトで -p オプションが付かないものが多いので何もせずに使える方式にしたいです。 なのでデフォルトを全て hyper-tls に寄せてしまい、Lambdaのコードをビルドするときだけ rustls を使うようにしました。
もう1つ、Lambda内からPostgreSQLにもアクセスしています。PostgreSQLを使うためにlibpqに依存しています。 これについてはビルド時に頑張ってLambda内からも使えるようにしてますので、ビルドの節を参照して下さい。
HTTP
RustでLambdaを使うときの一般論としては前項の通りですが、ALBやAPI GatewayのハンドラとしてのLambdaを使うときはもう少しライブラリのサポートがあります。 具体的にはlambda-httpクレートが用意されています。
Actcastでlambda-httpを使っているのは比較的アクセスの少ないAPIで、メインとなるエンドポイント1つとそれに付随するエンドポイント数個からなります。 小用にいくつもLambdaを作るのも管理が大変ですし、cold start問題もあります。 そこで1つのLambdaで全てのエンドポイントを処理しています。 そのLambdaではルーティングに以下のようにHTTPメソッドとリソースパスを match 式に掛けています。
let (http_method, resource_path) = match request.request_context() { RequestContext::ApiGateway { http_method, resource_path, authorizer, .. } => (http_method, resource_path), _ => unreachable!(), }; match (http_method.as_str(), resource_path.as_str()) { ("GET", "/path1") => { // ... } ("GET", "/path1/{some_id}") => { let some_id = request.get_id("some_id")?; // ... } ("POST", "/path2/{other_id}/hoge") => { let other_id = request.get_id("other_id")?; // ... } ("POST", "/path2/{other_id}/fuga") => { let other_id = request.get_id("other_id")?; // ... } _ => unreachable!(), }
マッチ対象が多くなると破綻しそうですが目で数を数えられるくらいの範囲なら問題ないでしょう。
ビルド
ECS
少しだけECSのビルドに触れておきます。
基本的にはビルドと実行のベースコンテナされ揃えればバイナリをコピーしてあげるだけで動きます。 ほとんど大したことをしないのにDockerfileを管理するのが面倒なので cargo-pack-dockerというツールを作ってCargoだけでパッケージングまで済むようにしています。
Lambda
Lambda内で動かすバイナリは普段と勝手が違うところが多くあります。 例えば何も気にせずにビルドしたバイナリをLambda環境に持っていって動かすとglibcのバージョンの問題で version `GLIBC_2.27' not found とエラーが出たりします。 また、今回の我々のようにlibpqを使いたい場合もLambdaのランタイムにlibpqが存在しないのでどうにかしないといけません。
glibcやlibpqなどのダイナミックリンクライブラリ(DLL)が上手く使えずに起動に失敗してしまう問題にはおおまかに2つの対策があります
DLLを使わない
DLLを頑張って使う
DLLを使わない
glibcが動かない環境でバイナリを動かしたいときのノウハウは古くからあります。 musl libcを使い、それをバイナリに静的にリンクしてしまえば実行時にlibcのDLLに依存しなくなります。 同様にlibpqについても静的リンクしてしまえば問題が発生しなくなります。
そのためにrust_musl_dockerのようにmusl libcや静的リンク可能なlibpqが入ったビルド用コンテナも用意されています。 このノウハウを使えばLambdaに限らず色々な場所で動かせるようになります。
しかし今回はこの方法は採用しませんでした。 一応libcとしてはglibcとmusl libcは互換性はありますが、実装は別物です。 細かい部分の挙動やパフォーマンス特性も違うため、glibc環境で開発しているアプリケーション(や、もっと言うと依存ライブラリも)をmusl libcで動かすのは一定のリスクがあります。 それに、今回はglibcが動かない環境という訳ではなくて、ビルド時に使ったglibcと実行時に利用できるglibcのバージョンが異なるだけです。 glibcのバージョンを揃える方向に舵を切ってみます。
DLLを頑張って使う
RustのLambdaランタイムlambda_runtimeのREADMEをよく見るとLambda向けのビルド方法が書かれています。 そこではsoftprops/lambda-rustというdockerコンテナでビルドしています。
このコンテナを詳細に調べると、Lambdaの実行環境と同じバージョンのAmazon Linuxのイメージを使ってRustをビルドしています。 現時点での実行環境のバージョンはドキュメントによると、2018.03.0.20181129-x86_64-gp2 と、いささか古いものになっています。 因みに、今のところRustの動くカスタムランタイムではAmazon Linux 2は使えないようです。
softprops/lambda-rustがそのままビルドに使えたら良かったのですが、残念ながら今回は使えません。 libpq などのライブラリも一緒に使う術が用意されていないからです。
しかし基本となるアイディアはそのまま流用できそうなので使います。 すなわち、以下のような方法を採ります:
Lambdaと互換性のあるAmazon LinuxのDockerイメージを使う
DockerイメージにRustのツールチェーンをインストールする
Dockerイメージにlibpqなどをインストールする
Dockerコンテナ内でRustをビルドし、成果物をZIPにまとめる
Lambdaの実行環境と同じDockerイメージを使いたいのですがどうやらピタリとバージョンの合うDockerイメージが配られているとは限らないようです。 今回は 2018.03.0.20191219.0 を使います。 余談ですがActcastではRaspbianをはじめとしてDebian系のOSを統一して使っています。しかしここだけRedHat系をOSを使っていることになります。
次はlibpqのインストールです。 我々はPostgrSQL 11の機能を使いたいので、libpqもそれに相当するものをインストールしたいです。 しかしAmazon Linuxのイメージが古いためyumではインストールできません。 仕方ないのでPostgreSQL 11のレジストリからlibpqをインストールしています(因みにAmazon Linux2なら yum で入るようです)。
ビルド用のイメージが準備できたとして、次はビルドです。ビルドは概ね以下のようなコマンドで行っています。
$ docker run --rm \ -e CARGO_TARGET_DIR=/tmp/app/your_app/target/lambda \ -v $ROOT_DIR/:/tmp/app \ -v $ROOT_DIR/.cache/cargo/registry:/root/.cargo/registry \ -v $ROOT_DIR/.cache/cargo/git:/root/.cargo/git \ -t your/build_image /tmp/app/build-script.sh your_app
ここで、 $ROOT_DIR はワークスペースのルートを指す変数です。 ポイントで解説すると
ビルド用のイメージ(your/build_image)内でビルドする
ビルド用のスクリプト(build-script.sh)を使ってビルドする(後述)
ワークスペース全体を /tmp/app にマウントする
ワークスペースのルートに .cache/ ディレクトリを作っておき、そこにCargoのキャッシュを持たせる
Cargoのターゲットディレクトリは target/ ではなく target/lambda にしてお���
となっています。
4.と5.について補足します。 コンテナ内でビルドするときにもホスト同様ビルドキャッシュは持っておいて欲しいです。 しかしホスト環境とコンテナ環境で同じキャッシュを使うと権限の問題が発生します。 コンテナ内はrootユーザで動作しているのでコンテナ内から作ったキャッシュはrootのものになり、ホストに戻ったときに取り回しが面倒になってしまうからです。 そこでコンテナ内で使うキャッシュとホストのキャッシュを分けることで問題を解決します。 それが .cache/ ディレクトリと target/lambda ディレクトリです。 また、 target/lambda はビルド成果物であるZIPファイルの受け渡し場所としての役割もあります。
さて、次はビルドに使うスクリプト(build-script.sh)です。 概ね以下のようなことをしています。
# ビルド cargo build --release # バイナリ名はbootstrapにしておく cp "$CARGO_TARGET_DIR/release/your_app" bootstrap # bootstrapが動的リンクしているライブラリをlibに入れる。ここでは `pq` 。 mkdir -p lib ldd bootstrap | grep pq | grep -o '=> [^ ]*' | sed 's/=> //' | xargs -I@ cp @ lib/ # bootstrapとlibをまとめてZIPに固める zip -X "$CARGO_TARGET_DIR/release/your_app.zip" bootstrap lib/* rm -rf bootstrap lib
ざっくりいうとビルドしてZIPに固めているだけですが、途中で動的リンクしているライブラリのパスを取得してlibディレクトリに入れています。 これでできあがるZIPファイルは以下のような構造になっています
. ├── bootstrap └── lib └── libpq.so // その他ライブラリ
LambdaのドキュメントによるとZIPの中のlibディレクトリにDLLを入れておくと LD_LIBRARY_PATH が通っているので($LAMBDA_TASK_ROOT/lib)、実行時に参照できるようになります。
これであとはLambdaにデプロイすると期待通りに動いてくれます。 我々のシステムでは今のところTerraformからデプロイしているのでTerraformが target/lambda 以下にあるZIPファイルを参照することになります。
上記の手法はlibpqに依存した箇所はないので原理的にはあらゆるDLLを同じ方法で使えるようになるはずです。 しかし何故かopensslだけは上手くいきませんでした(crypto.oがみつからないとかなんとか…)。 未だに原因が不明なのですが、現時点では前述のとおりrustlsを使って問題を回避しています。
テスト
テストについてはlambda_runtimeのドキュメントに載っている通りのコマンドが使えます。
unzip -o \ target/lambda/release/your_app.zip \ -d /tmp/lambda && \ docker run \ -i -e DOCKER_LAMBDA_USE_STDIN=1 \ --rm \ -v /tmp/lambda:/var/task \ lambci/lambda:provided
これにヒアドキュメントを使って標準入力からJSONを渡し、出力のJSONを得ています。
単体テストはこれで済むのですがインテグレーションテストはもうちょっと複雑なセットアップが必要です。 実を言うとActcastでは今のころローカル環境でのインテグレーションテストをできていません。 Lambdaは総じて多彩なAWSリソースと相互連携しながら動くのでローカルに環境を構築するのが難しいからです。 現在は開発/サンドボックス環境に実際にデプロイして動作確認や自動テストを行っています。
振り返って
RustでLambdaを使いはじめたのはカスタムランタイムとRustのサポートライブラリが発表されて間もない頃でした。 Rustを動かす情報がほとんどない上に私が個人的にLambdaを触ったのがはじめてだったこともあり、手探りで進めていって今の形に落ち着きました。
最初に作ったLambdaはAPI Gatewayの裏で動くHandlerとカスタムAuthorizerでした。 新規開発のAPIということもあり、既存のサーバとはコードベースをほとんど共有せずに作ってLambdaで動かすノウハウを獲得しました。 要するに技術的投資として新しいことを始めたのです。 PostgreSQLに接続しているのもその一環です。 複数のコンポーネントがRDBにアクセスするのはアンチパターンとされていますが、様々な状況判断からこのような選択をとりました。 そのあとに既存のコードを流用しつつ動くLambdaも作っていきました。
これらを振り返ってみます。
RustをLambdaで動かす
おおむね良さそうでした。 最初、正しく動くバイナリをビルドするのに苦戦して時間が掛かりましたが一度作り方を把握しさえしてしまえば大きな懸念なく使えます。
新規コードベースで開発した
どちらかというと良くなさそうでした。 一番最初に既存の複雑性を排して新しい技術に取り組める点は良かったです。 しかしコード(ビジネスロジック)に重複があるなどの問題がありました。 実際、他のメンバーから「最近ここに変更加えたけどLambdaの動作に影響ない?」などの問い合わせが来ることもありました。
それだけでなく、Rustのように強い静的型付言語ではコンパイラがある程度の全体整合性を検査してくれることに強みがあります。 コードベースを分けてしまうとその恩恵に与れなくなってしまいます。 コードの重複の排除だけでなく、一歩進んで積極的な整合性検査のためにもコードベースの統合が必要そうでした。
将来的に現在別のコードベース(別ディレクトリ)になっているものを1つにまとめられたらなと思っています。
まとめ
この記事ではActcastでRustをどのようにAWS上で動かしているかを紹介しました。 これで完璧と言えるものではないですし、エコシステムの今後の発展に期待すべき点もあります。 しかしある程度の規模でRustをAWS上で動かしている例として皆さまの一助になれば幸いです。
さいごに、IdeinではRustでWebサービスを作りたいエンジニアを募集しています!!
6 notes
·
View notes
Text
Actcastのアーキテクチャ紹介
まえがき
2020年になり、弊社の提供するIoTプラットフォームサービスであるActcastも正式版をリリースしました。まだまだ改善余地はありますが、現状のActcastを支えているAWS上のアーキテクチャを紹介します。
参考
エッジコンピューティングプラットフォームActcastの正式版をリリース - PR TIMES
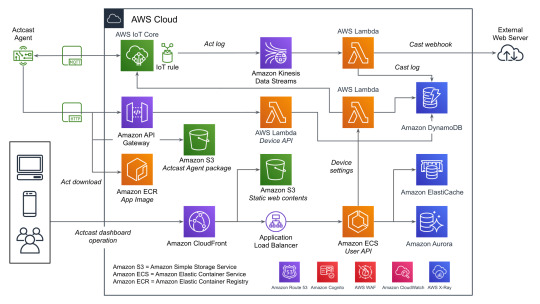
全体の概要
データをやり取りする主要なコンポーネントとしては、以下の3つがあげられます。下記の図を参照する際にこれを念頭においてください。
User API: ウェブのダッシュボードから使用され、グループやデバイスの管理などに使われます。
Device API: エッジデバイスから使用され、デバイスの設定や認証情報などを取得するのに使われます。
AWS IoT Core: MQTTを用いてデバイス側へ通知を送ったり、デバイス側からデータを送信するのに使われます。
すべてを記載しているわけではないですが典型的なデータのながれに着目して図にしたものがこちらになります。(WAFやCognitoなどはスペースの都合でアイコンだけになっています)
Actcast特有の概念であるActやCastという用語についてドキュメントから引用し、そのあと全体の説明をします。
Actとは
デバイス上で実行され、デバイスに様々な振舞いをさせるソフトウェアを Act と呼んでいます。 Actcast に用意されているアプリケーションに、お好みの設定を与えたものが Act になります。
注: 上記の図ではアプリケーションはAppと記載されています。
Castとは
Cast とは Act から届いたデータをインターネットにつなげるものです。 Cast は「どのような場合にインターネットにつなげるか」を指定するトリガー部分と「どのようにインターネットにつなげるか」を指定するアクション部分からなります。
Actcastでのデータの流れ
ユーザーの操作とエッジデバイス上でのデータの流れに着目すると以下のようになります。
Actcastのユーザーはダッシュボードを通じてActのインストールやCastの設定をおこなう
エッジデバイス上で実行されているActcast Agentが設定に基づいたアプリケーションを起動する(Act)
Actが必要に応じてデータを生成する
Castの設定に基づいて生成されたデータを外部システムへ送信する(webhook)
先程の図に上記の番号を記載したのがこちらの図です。
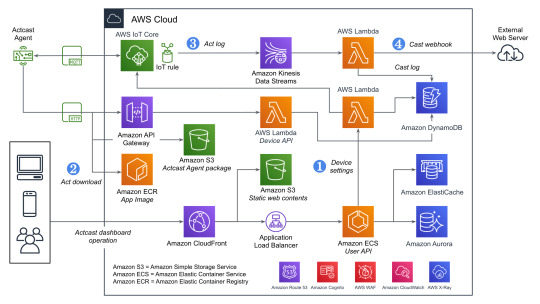
それぞれについて実際のAWSのリソースと絡めながら説明していきます。
1. Device Settings
良くあるウェブアプリケーションと同じ部分は箇条書きで簡単に説明します。
負荷分散はCloudFrontやAWS WAFなどをはさみつつALBを使用
アプリケーションの実行環境としてはECSをFargateで実行(User API)
データの永続化は基本的にAmazon Aurora(PostgreSQL)
キャッシュはElastiCache(Redis)
一部のデータはエッジデバイスから参照されるためワークロードの変化が読めなかったり、スケーラビリティが重要になったりするためDynamoDBを使用する形になっています。ECSのタスクから直接DynamoDBを触っていないのはDynamoDBに関するアクセス権をLambda側に分離するためです。もともとはすべてのDynamoDBへのアクセスパターンごとにLambdaを分けていましたが、さまざまな理由から最近は統合されました。
また、ダッシュボードでユーザー操作があった際にその設定をDynamoDBに保存すると同時にAWS IoTのMQTT経由でActcast Agentに通知を送り、それを契機にAgent自身でDevice APIを使って設定を取得します。Device API自体はAWS IoTのデバイス証明書を用いて認証を行っています。
2. Act download
DynamoDBから設定を取得したActcast Agentは、実行対象のアプリケーションイメージをECRから取得します。(ECRの認証情報はDevice APIから取得しています)
その後、設定に基づきイメージをActとして実行します。設定はアプリケーションによってことなり、典型的には後述のAct logを生成する条件が指定できます(推論結果の確度などを用いて)。
3. Act log
Actは条件によってデータ(Act log)を生成することがあります。 例えば、年齢性別推定を行うActはカメラに写った画像から以下のようなデータを生成します。
{ "age": 29.397336210511124, "style": "Male", "timestamp": 1579154844.8495722 }
生成したデータはAWS IoTを経由して一旦Kinesisのシャードに追加されていきます。Kinesisを挟むことでDynamoDBに対する負荷が急激に上昇した場合でもデータの欠損が発生しにくいようにしています。
4. Cast webhook
Kinesisのシャードに追加されたデータをLambdaのコンシューマーが処理していきます。 この際に、Castの設定(TriggerとAction)をもとにwebhookをするかや送信先を決定します。
Triggerではいくつかの条件が満たされているときに限りActionを実行するように設定することができます。
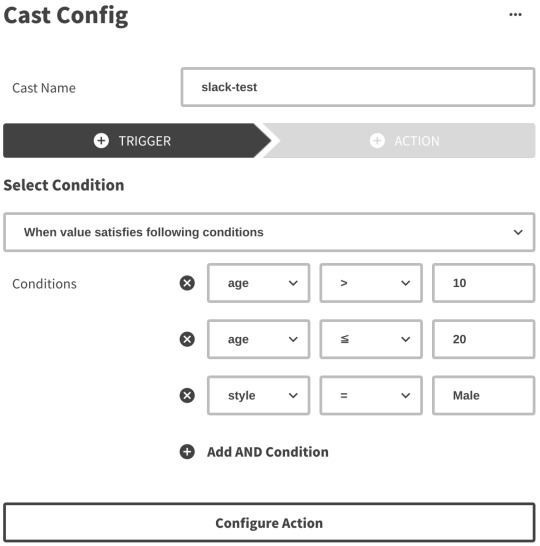
Actionではwebhook先のURLや送信するHTTPリクエストのボディなどを設定できますが詳細はドキュメントを確認してください。
ユーザー設定に基づきリクエスト先が変わるためSSRFなどが起きないような対策もしています。
苦労話
AWS IoT
Device Shadow
AWS IoTのDeviceとして登録するとそれに対応したShadowというものがAWS IoT上から操作できます。 これはShadowに設定した状態をDevice側に同期させるような場合に使えますが、このShadowで保持できるデータのサイズがなかなか厳しく最終的にはDynamoDB側に自前で同じようなデータをもたせる方針に切り替えました。
Job
AWS IoTにはJobというものがありますが、同時実行数の制限などが厳しく(Active continuous jobs: max 100)Actcastのようにデバイス数がどんどん増えていくような場合には使えませんでした。こちらもDevice Shadowと同じようにDynamoDB上に自前で似たような仕組みを作っています。
Amazon Aurora
Amazon Aurora with PostgreSQL Compatibility
MySQLではなくPostgreSQLのAuroraを使っていると直面する課題ですが、Auroraの機能としてメジャーバージョンを更新する方法が提供されていないということが挙げられます。
Upgrading an Aurora PostgreSQL DB Cluster Engine Version - Amazon Aurora
ダウンタイムを抑えつつバージョンを更新するためには新旧のAuroraクラスタを用意し、データを同期しつつどこかのタイミングでアプリケーションから接続する先を変更するということが必要です(本当はもう少し複雑です)。
更新元のバージョンが9.xか10.xかでPostgreSQLのロジカルレプリケーションが使えるかが変わってくるのも難しいポイントです。もし9.x系であれば外部のツール(bucardoなど)を使う必要があります。
pg_upgrade相当の機能を実現してもらえればダウンタイムがあるとはいえ運用負荷は相当下がるのですがなかなか実現されていないようです。
今後の改善
ログの追跡
現状でもX-Rayを導入したり、CloudWatch Logsからログを確認したりなどは行っていますが今回紹介していないものも含め全体を構成する要素が非常に多いため問題が起きたさいに関連箇所を調べるのはなかなか大変な状態です。この部分を改善していくための手法を検討している段階です。
まとめ
AWS上には様々なサービスがあり、IoT関係も含めてすべてAWSのサービスだけで構築することができました。 今後は安定性やスケーラビリティの観点で改善を続けていきます。
ここでは言及していませんが、ECSやLambdaの上でRustを使う話も別途記事として公開する予定なのでお楽しみに。
この記事はwatikoがお送りしました。
0 notes
Text
プロダクションのRustコードを async / await に移行した話
κeenです。日本時間の 11/8 日に Rust 1.39.0 が リリースされ、Rustでもいよいよ async / await が利用できるようになりました。 async / await は面倒な Future の記述をすっきり書けるようにするシンタックスシュガーであると共に、 Future をまたいだ値のライフタイムもよしなに扱ってくれるので視認性以上のメリットがあります。 可能な限り使った方が良いでしょう。
Ideinのプロダクションコードもすぐさま async / await に移行しました。 IdeinのActcastのプロジェクトにはいくつかRustのコードベースがありますが、そのうちのAPIサーバの部分を async / await に移行しました。元々非同期なWAFを使っていたこともあり、ほとんどのコードで Future を使っています。規模としてはRustだけで23パッケージ、4万行程あるようです。
$ ls */Cargo.toml | wc -l 23 $ git ls-files | grep '\.rs$' | xargs wc -l ... 39673 合計
何がどう変わるの?
移行に際してはOPTiMさんのTECH BLOGに大変お世話になりました。素晴しいブログをありがとうございます。
Rustの非同期プログラミングをマスターする - OPTiM TECH BLOG
さて、async / await に移行と言っていますが、async / await を使うには標準ライブラリの Future も必要なので厳密には同時に2つのことをやっています。さらに、Ideinのコードベースでは Future の and_then の連鎖を少しでも読みやすくするために mdoと mdo-future も利用していたのでこれらの移行を行います。 つまり、以下の3つの作業を同時に行いました
futures 0.1からfutures 0.3に移行
mdoをやめて async / await に移行
その他の Future を使うコードも async / await に移行
futures 0.1からfutures 0.3に移行
元々RustでFutureデザインパターンを書くにはfuturesクレート (futures 0.1) がデファクトスタンダード的立ち位置でした。 Rust 1.39.0で入った async / await は言語機能なので外部のクレートに依存することはなくて、標準ライブラリにある std::future::Future トレイトを使っています(async / await のために標準ライブラリに Future が入りました)。ここでよく使われる Future が2種類あることになります。 std::future::Future は本当に async / await の実現に必要な最低限の機能しか持っていません。 std::future::Future をベースとしつつfutures 0.1と同等の拡張機能を提供するのがfutures 0.3です。 同時に std::future::Future も再エクスポートしているので今までと同じような感覚でfuturesクレートを使うと、自然と async / await に対応した Future になる訳です。
とはいっても Future の定義がまるっと変わってしまっているのでそのまま自然には移行できません。 両者の定義を比べてみましょう。
futures 0.1
pub trait Future { type Item; type Error; fn poll(&mut self) -> Poll<Self::Item, Self::Error>; fn wait(self) -> Result<Self::Item, Self::Error> where Self: Sized, { ... } fn map<F, U>(self, f: F) -> Map<Self, F> where F: FnOnce(Self::Item) -> U, Self: Sized, { ... } fn map_err<F, E>(self, f: F) -> MapErr<Self, F> where F: FnOnce(Self::Error) -> E, Self: Sized, { ... } // その他19個のメソッド }
std::future::Future
pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; }
一番の違いは futures 0.1 の Future は関連型が Item と Error の2つあるのに対して標準ライブラリの Future は Output 1つしかありません。 型を impl Future<...> などと書いている箇所は全て変更が必要になります。 futures 0.1 のときに impl Future<Item = T, Error = E> と書いている箇所は Result を使って impl Future<Output = Result<T, E>> と書くと綺麗に対応が取れるでしょう。 また、futures 0.1 にはメソッドが生えているのに対して標準ライブラリのものにはメソッドが生えていません。そこはfutures 0.3がカバーしており、futures 0.3の FutureExt と TryFutureExt を使えばほとんど同じメソッドが揃うはずです。
mdoをやめて async / await に移行
mdo については貧者の async / await といったところなので省略します。
Future を使うコードを async / await に移行
まず、 Future を返していた関数は async fn に移行できます。 以下のように書かれたfutures 0.1のコードがあったとします��
fn do_async() -> impl Future<Item = T, Error = E> { // ... return future; }
これは先程紹介したように標準ライブラリの Future と Result 使ったコードに移行できます。
fn do_async() -> impl Future<Output = Result<T, E>> { // ... return future; }
これはさらに async fn に書き換えられます
async fn do_async() -> Result<T, E> { // ... return Ok(value); }
また、futures 0.1の and_then や then などを使っているコードは(async ブロックと) await で書き換えられます。 以下のように書かれたfutures 0.1のコードがあったとします。
do_async().and_then(|value| { // do something with value ... return future; }).then(|result| match result { Ok(v) => { // ... } Err(e) => { // ... } })
これは以下のように async ブロックと await を使って書き換えられます。
async { let value = do_async().await?; // do something with value ... let result = future.await; match result { Ok(v) => { // ... } Err(e) => { // ... } } }
このコードが async fn の中にある場合は async ブロックは不要です。
async fn run_async() { let value = do_async().await?; // do something with value ... let result = future.await; match result { Ok(v) => { // ... } Err(e) => { // ... } } }
コードの大部分に影響はありますが、内容としてはほとんど頭を使わずにパターンに沿って書き換えていくだけです。
ところで残念ながらトレイトのメソッドは async fn にできません。つまり、以下のようなトレイト定義は書けないということです。
trait Trait { async fn method(&self) -> Return; }
これを可能にするにはいくつかの機能をRustに追加しないと実現できないそうなので気長に待ちましょう。
ということでメソッドのシグネチャには async fn (= fn () -> impl Future 相当)ではなく、 dyn Future を使うことになります。 標準ライブラリの Future は実用するには Pin も必要になるので現実的には fn () -> Pin<Box<dyn Future<Output = Result<T, E>> + 'static + Send>> などの型を使うことになるでしょう。 async fn(&self)-> Return と書いたら裏でfn (&self) -> Pin<Box<dyn Future<Output = Return> + 'static + Send>> に変換してくれるasync-traitなどのライブラリもありますが、今回は使っていません。 まだトレイトのメソッドの async fn がどうなるか分からないことから不安定な仕様を先取りするよりは確実に動く方を選びました。 あと元のコードが後程紹介する BoxFut で書かれていたので BoxFut の中身を差し替えるだけの方が変更が少なくて済むという理由もあります。
方針
方針としてはビジネスロジックを記述する部分を互換性を補うコードなしに async / await にすることを目的に移行することにしました。 とはいってもビジネスロジックを中心に外郭のパッケージがあるのでそれはほとんどのパッケージを移行することを意味します。 外部のクレートまでは制御できないので、外郭クレートが外部のクレートを呼ぶときにfutures 0.1からfutures 0.3への互換をはさみ、自社のクレート内ではfutures 0.3しか使わない方針にしました。 ただし、1つだけ例外があって、Actcastで使っているWAF、actix-web 1.0はfutures 0.1ベースで動いているのでこれに関連するコードはfutures 0.1のまま使っています。
こういう大きな変更はタイミングを見て一気にやってしまうのがよさそうですが、 async / await がリリースされた今が一番の好機でしょう。
全体設計
方針が定まったらあとは書き換えていくだけなのですが、1つだけ重要な要素があります。 我々が使っているWAFがactix-webという点です。
冒頭で紹介したOPTiMさんのテックブログにはタスクの実行モデルがいくつか紹介されていますが、actix-webはそのうちのスレッドプールのモデルに近いものです。 クライアントからのリクエストを各スレッドに振り分けたら、レスポンスを返すまでそのスレッドが処理を担当します。
このモデルの大きな特徴の1つとして、タスクがスレッド間を移動しない点が挙げられます。Rust的にいうと + Send が必要なくなります。
+ Send の有無が全体に効いてくるのでまず最初に確認しておきましょう。さもないと全部変換し終わったあとに型が合わずに動かない、のような悲劇が起きます。作業の前に「我々のタスクはスレッドを跨ぐような設計か?」と一度見直してみるとよいでしょう。
余談ですがスレッドプールモデルだと1つ1つのタスクの粒度にバラつきがあった際にスケジューリングが平等にならないという問題が知られています。 actix-webはWebアプリケーションフレームワークということもありタスクの大きさにさほどバラつきはありませんし、そもそも非同期がタスクを細切れにして実行する仕組みなのでデメリットは薄いでしょう。 もうちょっと言うとスレッドプールモデルと対比されているワークスティーリングにも色々種類があり、スレッド毎にキューを持ちつつタスクがなくなったら他のスレッドのキューを奪うようにすることでロックを減らして効率化しているようなものもあります。興味のある方は調べてみて下さい。
先程 Pin<Box<dyn Future<Output = Result<T, E>> + 'static + Send>> という型を紹介しましたが、我々の場合ここの + Send が不要になる訳です。 現実的にはこの型を毎回書くのはしんどいので以下のように BoxFut<T> という型を定義しておいて各所でそれを使うことになるでしょう。
pub type BoxFut<T> = Pin<Box<dyn Future<Output = Result<T, Error>> + 'static>>;
これはfutures 0.1の頃からあったプラクティスなので既に(futures 0.1版の) BoxFut を定義しているプロダクトも多いかと思います。そういう場合は定義を上記のように差し替えるだけで置換できます。
実作業
おおむね、Cargo.toml にある futures = "0.1" と書かれている箇所を futures = "0.3" と書き換えて、コンパイルエラーを取りつつ async / await を導入していく作業が続きます。
futures 0.1との互換
外部クレートでfutures 0.1を使っていた箇所は互換コードを挟むことになります。 互換コードは compat フィーチャを有効にすると使えるようになります。
[dependencies] futures = { version = "0.3", features = ["compat"] }
compat を有効にした上で Future01CompatExt をインポートすると Future に compat メソッドが生えてくるのでそれでfutures 0.1の Future をfutures 0.3 の Future に変換できます。
少し実例を紹介しましょう。Reqwestを使っている部分です。
use futures::compat::{Future01CompatExt, Stream01CompatExt}; // `async fn` !! async fn get_hogehoge(arg: Arg) -> Result<Vec<HogehogeData>, Error> { // ... let resp = client .request(req) // `compat` を呼んでいる .compat() // `compat` したので `await` が呼べる .await .map_err(|err| { error!("get_hogehoge error: {:?}", err); error!("get_hogehoge cause: {:?}", err.source()); err }) .map_err(|err| err.context(ErrorKind::Http))?; debug!("get_hogehoge resp: {:?}", resp); let status = resp.status(); let body = resp .into_body() // `compat` を呼んでいる .compat() // futures 0.1にあった `concat2` は `try_concat` に置き換え .try_concat() // `compat` したので `await` が呼べる .await .map_err(|err| err.context(ErrorKind::Http))?; // ... }
コメントで書いた部分が互換コードを呼んでいる部分です。 このようにfutures 0.1を使っている外部クレートを呼ぶコードでも async / await を使ったコードと共存できます。
ところで、 await の位置が気になった方もいるかもしれません。 future.await.map_err(|e| ...)? の部分です。 futures 0.1のコードで future.map_err(|e| ...) と書いていた箇所なので、自然に書き換えるなら TryFutureExt::map_err を使って future.map_err(|e| ...).await? と書くこともできます。しかしここでは future.await で Result にしたあとに Result::map_err を呼んでいます。 元も子もないことを言えばどちらでもいいのですが、一応ここでは可能な限り標準ライブラリのAPIを使うために早めに await しています。futuresもまだ0.3で安定版ではありませんからね。 とはいえ .await? がイディオムのようになっているので .await と ? 繋げたい方もいるでしょうからあまりにするほどのことでもないです。 余談ですがfutures 0.1の map 相当のメソッドはfutures 0.3では map_ok になっているので注意して下さい。
futures 0.1との共存
我々の使っているactix-webはfutures 0.1で動いているのでサーバのエントリーポイント付近ではfutures 0.1とfutures 0.3が共存する汽水域が存在します。0.1と0.3を共存させないといけません。 そういう用途のために crates.io にfutures01 という名前でfutures 0.1のコードが登録されています。これを使って0.1系と0.3系を共存させます。
[dependencies] futures01 = "0.1" futures03 = { package = "futures", version = "0.3", features = ["compat"] }
片方がfuturesという名前だと混乱しそうなので平等に0.3の方もfutures03という名前にリネームして導入しました。
どちらともほとんど同じAPIの prelude を公開しているので名前が正面から衝突します。 Rustはグロブインポート同士で名前が衝突すると両方とも名前が見えなくなり、ユーザに名前解決を促す仕組みになっています。 prelude でよく使うのはトレイトなので名前が見えなくても多くのケースでは困らないのですが必要になったら手で解決します。
use futures01::prelude::{Future, *}; use futures03::prelude::*;
futures 0.3から0.1へ
最終的にはactix-webがfutures 0.1を要求するのでfutures 0.3から変換してあげる必要があります。 これはセオリー通りに .boxed_local().compat() で変換可能です。
mdo! { opt: Option<String> =<< self.0.get(key) .boxed_local().compat() .map_err(ErrorInternalServerError); }
wait
ほとんどの箇所では Future から中身を取り出すコードはないのですが、テストなど一部のコードで wait() を呼んでいました。
多くの場合は futures 0.3の .now_or_never().unwrap() を使うと同等のことができるのですが、名前の通り即時に返ってくる Future 以外に呼ぶとパニックしてしまいます。そういう箇所では仕方なしに一旦futures 0.1に変換してから wait() を呼んでいます。
future .boxed_local() .compat() .wait()
しかし今なら tokio 0.2 がリリースされているので test を使えばテスト内で await できるようになって不要になりそうです。
細かな点や落とし穴
boxed と boxed_local
先程紹介した通り、トレイトからの返り値には BoxFut を使うことになるでしょう。
pub type BoxFut<T> = Pin<Box<dyn Future<Output = Result<T, Error>> + 'static>>;
すると、メソッドはだいたいこういう見た目になるはずです。
fn method(&self, arg: Arg) -> BoxFut<Ret> { async { // ... Ok(ret) }.boxed() }
ここで使っているのはOPTiMさんのテックブログに紹介されている、 FutureExt のboxedです。
これで問題なくコンパイルは通るのですが、微妙に罠があります。 boxed は Self: Send を要求しているのです。なので async ブロックの内側に Send が要求されてしまいます。我々のアプリケーションでは Send が必要ないのでこれは過剰な要求です。 そこで boxed の Self: Send を要求しないバージョンとして boxed_localというAPIがあります。 これを使って以下のように書き換えると全体が破綻しなくて済みます。
fn method(&self, arg: Arg) -> BoxFut<Ret> { async { // ... Ok(ret) }.boxed_local() }
async fn とライフタイム
async fn にはライフタイム関連の罠があります。 下記のような仮想的な関数を考えましょう。
async fn reqest_data(path: &str) -> Result<Data, Error> { let url = format!("https://example.com{}", path); let data = Client::new() .request(url) .await? .response_to_data(); Ok(data) }
このタスクは理想的にはリクエストを投げてしまえばサーバからのレスポンスにしか依存しないのでライフタイムは 'static がついてほしいです。 しかし async fn の��糖ルールに従うと以下のように変換されます。
fn reqest_data(path: &str) -> impl Future<Output = Result<Data, Error>> + '_ { async { let url = format!("https://example.com{}", path); let data = Client::new() .request(url) .await? .response_to_data(); Ok(data) } }
ここで + '_ の部分は最初に紹介しませんでしたが、Rust 2018 editionで導入された匿名ライフタイムで、ライフタイムが省略されていることを明記する記法です。 関数の型のライフタイムは省略した場合は推論ではなくライフタイムの省略のルールに従って自動で決められます。 これに基いて先程のコードのライフタイムを明示すると以下のようになります。
fn reqest_data<'a>(path: &'a str) -> impl Future<Output = Result<Data, Error>> + 'a { async { let url = format!("https://example.com{}", path); let data = Client::new() .request(url) .await? .response_to_data(); Ok(data) } }
ということで残念ながら返り値のライフタイムは 'static になってくれません。 自動にまかせるとダメということが分かったので、手動で頑張ります。 結局こういうコードを書くことになります。
fn reqest_data(path: &str) -> impl Future<Output = Result<Data, Error>> + 'static { async { let url = format!("https://example.com{}", path); let data = Client::new() .request(url) .await? .response_to_data(); Ok(data) } }
'static はなくても変わりませんが明示しておいた方が意図が分かりやすいでしょう。 async / await が目の前にあるのに冗長なコードを書くのは少し歯痒いですね。
async ブロックとライフタイム
実は、先程のコードはコンパイルが通りません。コンパイルしようとすると以下のようなエラーが出ます。
--> async.rs:26:11 | 25 | fn reqest_data(path: &str) -> impl Future<Output = Result<Data, Error>> { | ----------------------------------------- this return type evaluates to the `'static` lifetime... 26 | async { | ___________^ 27 | | let url = format!("https://example.com{}", path); 28 | | let data = Client::new().request(url).await?.response_to_data(); 29 | | Ok(data) 30 | | } | |_____^ ...but this borrow... | note: ...can't outlive the anonymous lifetime #1 defined on the function body at 25:1 --> async.rs:25:1 | 25 | / fn reqest_data(path: &str) -> impl Future<Output = Result<Data, Error>> { 26 | | async { 27 | | let url = format!("https://example.com{}", path); 28 | | let data = Client::new().request(url).await?.response_to_data(); 29 | | Ok(data) 30 | | } 31 | | } | |_^ help: you can add a constraint to the return type to make it last less than `'static` and match the anonymous lifetime #1 defined on the function body at 25:1 | 25 | fn reqest_data(path: &str) -> impl Future<Output = Result<Data, Error>> + '_ { | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
これは async ブロック内にあるデータがタスクの中に放り込まれてしまうためです。 コードをよくみると async の中で path を使っていますよね?そのために async ブロック全体のライフタイムが path のライフタイムに制限されているのです。
これはシンプルに let url = ... の文を async ブロックの外に出してあげると解決します。
fn reqest_data(path: &str) -> impl Future<Output = Result<Data, Error>> { let url = format!("https://example.com{}", path); async { let data = Client::new().request(url).await?.response_to_data(); Ok(data) } }
同様に、 Client を外部から受け取る設計の場合は client.request(...) の式を async の外に出してしまえば解決します。
fn reqest_data(client: &Client, path: &str) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); let f = client.request(url); async { let data = f.await?.response_to_data(); Ok(data) } }
一時変数が必要になるのがもどかしいですね。
これくらいなら TryFutureExt::map_ok を用いて以下のように書いた方が簡潔になります。
fn reqest_data(client: &Client, path: &str) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); client.request(url).map_ok(Response::response_to_data) }
私が今回やった移行ではあえて async ブロックを残すようにしました。 async / await への移行というのは必ずしもコードだけでなく、普段からそのコードをメンテナンスしている開発者の意識も移行していく必要があるので多めに async / await を使う判断をしました。
async move ブロック
ほとんどのケースでは async ブロックで問題ないのですが、たまにライフタイムの問題が起きることがあります。 例えば先程の例の拡張で、一度リクエストを送ってURLを取得したあとにそのURLに再度データを投げるような処理を考えます。
fn put_data(path: &str, data: &str) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); // 関数の引数からリクエストデータを作成 let body = Body::from_str(data); async { let loc = Client::new().request(url).await?.location(); let data = Client::new() // ここで `async` ブロックの外側にあるデータを参照 .body(&body) .request(loc) .await? .response_to_data(); Ok(data) } }
これは async ブロックの外側にあるデータ body を参照しているのでライフタイムエラーでコンパイルが通りません。 しかし落ち着いて考えると body は関数内で生成したデータなので自分の都合で置き場所を変更しても構いません。例えば async ブロック内に移動してあげるとタスクの中に含まれるのでライフタイムの問題がなくなります。
fn put_data(path: &str, data: &str) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); // 関数の引数からリクエストデータを作成 let body = Body::from_str(data); async { let loc = Client::new().request(url).await?.location(); // `body` を一旦 `async` block内に移動 let body = body; let data = Client::new() // この参照は `async` ブロック内なので問題ない .body(&body) .request(loc) .await? .response_to_data(); Ok(data) } }
しかしこれは少し面倒ですね。 async ブロック外への参照がある度に1行増えますし、どこで参照しているかを1つ1つ把握しないといません。
そういうときに async move ブロックを使うと、 async ブロック外のデータの参照を一気にタスク内に移動できます。
fn put_data(path: &str, data: &str) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); // 関数の引数からリクエストデータを作成 let body = Body::from_str(data); // `async move` を使う async move { let loc = Client::new().request(url).await?.location(); let data = Client::new() // この参照は `async` ブロック外だが move しているので問題ない .body(&body) .request(loc) .await? .response_to_data(); Ok(data) } }
因みにActcastのレポジトリでは async ブロックが45回、 async move ブロックが10回使われているようです。
$ git grep 'async {' | wc -l 45 $ git grep 'async move {' | wc -l 10
5、6回に1回くらいは必要になる機能なようなので是非覚えておいて下さい。
コンパイルの通るコードはこちらに置いておきます。
Early return
async ブロックのおかげで型テトリスが多くの場合不要になり、条件分岐がぐっと楽になりました。
しかし、やはりどうしても型合わせをする必要があるケースがあります。そのうちの1つが async ブロックの外で行なうearly returnです。
先程のコードを変更して、JSONデータを投げてみましょう。但し Body::from_json は Result<Body, Error> を返すとします。素直にやると ? を使えばよさそうです。
fn put_json(path: &str, json: &Json) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); // from_json を呼んだあとに `?` でエラーなら即座に帰る let body = Body::from_json(json)?; async move { let loc = Client::new().request(url).await?.location(); let data = Client::new() .body(&body) .request(loc) .await? .response_to_data(); Ok(data) } }
これはあえなくコンパイルエラーになってしまいます。 返り値が impl Future なのに対して ? を使って Result を返そうとしているために起きるエラーです。
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `std::ops::Try`) --> async.rs:79:16 | 79 | let body = Body::from_json(json)?; | ^^^^^^^^^^^^^^^^^^^^^^ cannot use the `?` operator in a function that returns `impl std::future::Future` | = help: the trait `std::ops::Try` is not implemented for `impl std::future::Future` = note: required by `std::ops::Try::from_error` error: aborting due to previous error For more information about this error, try `rustc --explain E0277`.
これの解決策の1つには futures の Either を使う手があります。futures 0.1ではお馴染の方法ですね。
fn put_json(path: &str, json: &Json) -> impl Future<Output = Result<Data, Error>> + 'static { // futures 0.3の `Either` と `err` をインポート use futures::future::{err, Either}; let url = format!("https://example.com{}", path); // 関数の引数からリクエストデータを作成 let body = match Body::from_json(json) { Ok(body) => body, // エラーだった場合は `Left` として帰る。 // `Err(e)` を `Future` にするには // `err(e)` や `async { Err(e) }` などがある Err(e) => return Either::Left(err(e)), }; Either::Right(async move { let loc = Client::new().request(url).await?.location(); let data = Client::new() .body(&body) .request(loc) .await? .response_to_data(); Ok(data) }) }
ただしこれはちょと不恰好です。状況が許すなら、 async ブロック内にデータを持ち込んでから ? という手もあります。
fn put_json(path: &str, json: &Json) -> impl Future<Output = Result<Data, Error>> + 'static { let url = format!("https://example.com{}", path); // 関数の引数からリクエストデータを作成 // ここではまだ `?` しない let body = Body::from_json(json); async { // `async` ブロックの中で `?` すると問題なくなる let body = body?; let loc = Client::new().request(url).await?.location(); let data = Client::new() .body(&body) .request(loc) .await? .response_to_data(); Ok(data) } }
状況判断しながら使い分けて下さい。
まとめ
「async / await に移行する」といったときに必要になる実作業を示しました。 また、多くの場合は機械的に変換できるものの、いくつか注意点があることも紹介しました。
余談ですが、この作業は足掛け2日かかりました。とはいっても1日中 async と await を書き続けた訳ではなくて(そうだとしたら苦行ですね)、他の作業と並行して行っていたので実作業でいうと1人/日といったところじゃないでしょうか。
今回書いた async / await は1800個を数えます。
$ git grep -o -e 'async' -e 'await' | wc -l 1810
恐らく後にも先にも人生で一番 async / await と書いた2日間だったと思います。功徳も溜まったことでしょうし来世は期待できそうですね。
今のActcastは既に async / await を使って動いています。 皆さんも移行の折は今回のケースを参考にしてみて下さい。
0 notes
Text
FPGAの為のFixedPoint Int16のMobileNetV2のナイーブ設計を開発しました
自己紹介
私はSitnikov Evgeniiと申します。読み方:シトニコフ エフゲニー。 Ideinでは深層学習をFPGAで実装をやっています。
目的
MobileNetV2の設計と開発をして、設計のボトルネックを理解したい。 リソース消費を理解したい。 最適化も試してみたい。 FPGAの種類と値段を理解したい。 計算時間とLatencyを理解したい。 メモリとLutとRegを節約する方法を試してみたい。
開発プロセス
Verilog言語では開発時間がC言語より数倍遅いだけではなく、Simulation時間もとても遅いので (例えば:100x100の画像の簡単な処理に数時間かかります)、設計をC言語でレジスタ転送レベル(RTL)まで実装しました。この方法のVerilog言語とC言語の差はシンタックスです。
タイミングの単位の制限は一サイクル単位になりました。でも、周波数を自動的に計算することは出来ません。理由はAlteraがこの為に必要な具体的な情報を発表していないためです。一方、QuartusのResourceFitterのEmulatorを実装したので、リソース消費計算は自動的になりました。
設計
開発過程で5バージョンを試してみました。最後のバージョンがRTLとPipelineのバージョンとして開発しました。 私の設計の原則:
Pipelineの一段は「ExpandedConv」か「Conv」かです。
Pipeline:各段はお互い直接繋がっている、中間データを外部のメモリに保存しません。各段は同時に計算しています。
全てのWeightとBiasと中間バッファはFPGAの内部のメモリだけを利用します。
一段の入力の「in_w*in_w*in_ch」セットの計算時間:
[ExpandedConv」場合には:「6*in_w*in_w*in_ch」サイクルかかります、
[Conv](一目の段)場合には:ただの「in_w*in_w*in_ch」サイクルかかります。
一段の一般的な図
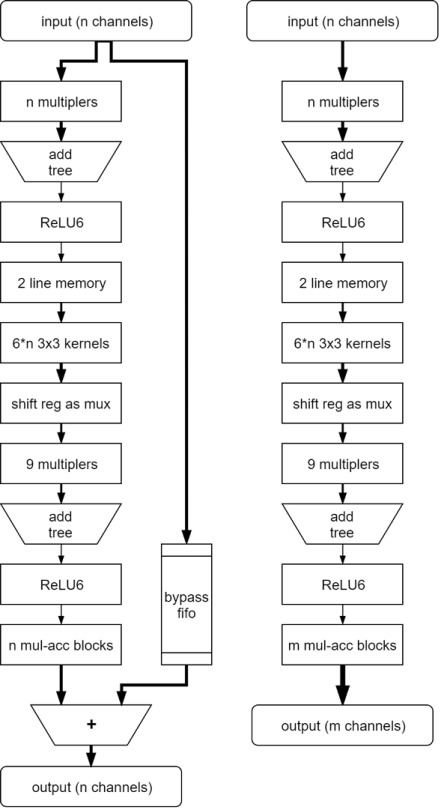
バイパスFIFOの加算有り/無しの二種類実装しました:
一段のビット幅の大きさ図
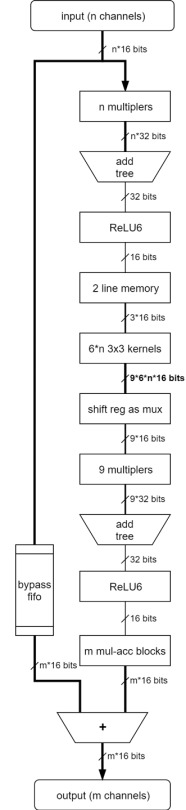
ビット幅の大きさ図によるとボトルネックは「6*n 3x3 kernels」と「Shift reg as mux」間のバスです。 1サイクルで計算を行う為に全てのin_ch*6のカーネルを保存しなければなりません。 「Stride=2」後で各サイクル計算の必要がなくなりますので、次の段は別の設計を利用するほうがよいです。
この理由で「6*n 3x3 kernels」と「Shift reg as mux」がLUTとレジスタの90%をリソース消費しています。ここが一番最適化が必要なところであると思います。
一段の具体的な図
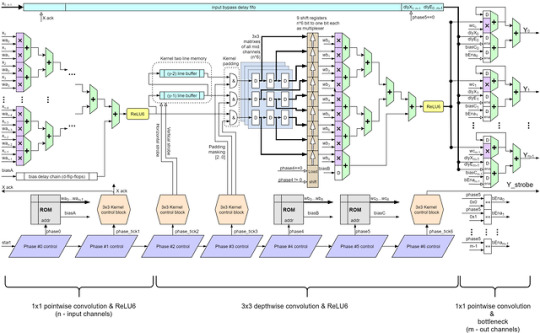
ズーム版
段の接続方法

ストライド無しの場合:中間レジスタで接続する

ストライド有りの場合:中間FIFOで接続する
パディング

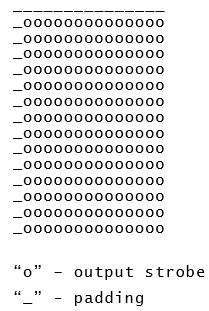
パディングでカーネルを計算する為にX軸とY軸に一つの追加サイクルを追加しました(3x3カーネル行列にデータを入力する為に)。 入力の場合には最後に追加しています(右と下端): 出力の場合には最初に追加しています(左と上端): 私の設計によって、パディングのパラメータを自動的にコンパイル時間に計算します。
段を接続する為の遅延線回路

段の出力と入力信号を一次元としてみると、出力と入力信号が同相になりません:

でも「in_w+3」サイクルでシフトすれば、同相になります: そのため、段を接続する為、段の間に起動の遅延線回路が必要です。
しかし,この段間の遅延線回路がMobileNetV2の入出力のLatencyの原因になります。 これがなければ、Latencyが数マイクロ秒になります(残りは段のLatency:約百サイクル、画像処理のLatency:画像の数ライン)。
パディングの結論
パディングがLatencyに一番重要な影響を与えます(MobileNetV2の場合はLatencyが凡その全計算時間になります)。
パディングは実装ソースコードのライン数が一番多いです。開発の上で複雑さがあります。
もしパディング無しとか、パディングのところをゼロfillしないようなNNであれば、FPGAの為の開発は大分簡単になると思います。
計算時間の見積もり
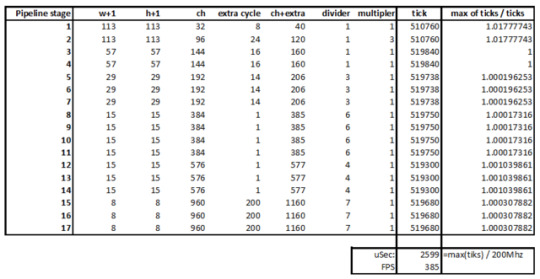
Pipelineの速さは最も遅い段で決定されるので、 各段の速度をバランスする必要があります。各段が大体同じ速度になるようバランスを取るために計算のDividerとMultiplerを追加しました。 段のDividerの意味:普通より何倍遅い計算を行っているかを表します。これがDSPブロックとレジスタの消費を節約しています。 段のMultiplierの意味:同じレベルの並列段の数を表します。逆にこれがDSPブロックとレジスタの消費を増やしています。 バランスの計算表:
速度の見積もりが385FPSになりました。 解説:「FPS」はNN実行時間の逆数です。
リソース消費
MobileNetV2、1000クラスのInt16版:
total DSP 2868 blocks total ROM 28825 Kbits total MEM 4143 Kbits total REG 2258 Kbits
そんな大量リソースはCycloneVにはありません、でもArria10とかStratixにはその量があります。 CycloneVには約10段まで入ります。 でも、段のDividerをかけると、もう少し3x3カーネルの所に最適化をかけると、全てCycloneVの中に入ると思います。
Arria10を利用したら、1000FPSまでに至ると思います。 例えば:https://arxiv.org/pdf/1809.01536.pdf この記事では最適化を全然気にしないまま最低の周波数で一番遅いArria10で266FPSという結果になりました。 私の設計では1回だけの純粋Pipeline、記事の実装が数回です。 記事の周波数では100Mhzだけ、でもArria10では余裕で300Mhzまで動作します(特別の最適化が必要がないと言う意味です)。
Stratix 10 MXを利用したら数千FPSに至ると思います。 理由はStratix 10 MXはHBM2の8196ビットの1Gメモリを搭載しています。 https://ja.wikipedia.org/wiki/High_Bandwidth_Memory https://en.wikipedia.org/wiki/High_Bandwidth_Memory
ROMとしての利用率問題
WeightとBiasのROMメモリが多過ぎる。
ROMメモリ利用率が低い:最初の段のWeightとBiasがFPGAの10kブロックに対して短すぎる、10kビットブロック中に10%だけ占有するので。
計算の質と精度
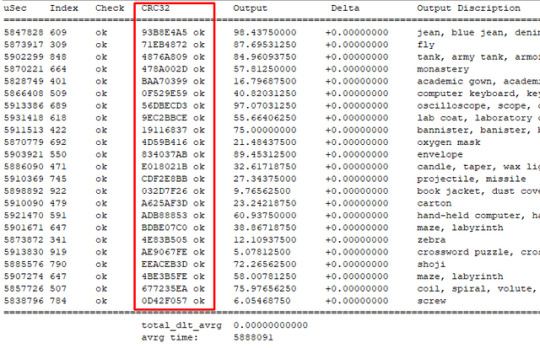
MCUの版とFPGAの版をOutputのCRC32で比較したら、CRC32が等しい: 設計を開発する時にはいつもCRC32で計算の正しさを確認しました Simulation時間が6秒かかります
全ての結果と結論がGCCで設計したSimulation結果に基づいています
結果
total DSP 2868 blocks total ROM 28825 Kbits total MEM 4143 Kbits total REG 2258 Kbits
速度の見積もりが385FPSになりました。 Latencyはほぼ計算時間と等しくなりました: 3/8 + 7/15 + 3/29+3/57+2/113 = 1.0154枚 一枚の単位は入力画像の時間です。例えば385FPSなら、Latencyが2.558mSecになりました。
結論:FPGAに適したNN設計のポイント
Weightは少ないほうがいいです。たとえばSegmentation種類. でも一個のWeightのブロック長は最低512くらいで作るほうがいいです。
チャンネルは少ないほうがいいと思います。しかし、それほど重要ではありません。
分岐は大丈夫と思います。でも大きいセットと長い遅延になる場合には多くのメモリが必要になります。
画像の解像度が256x256内であれば大丈夫です。でもHDの解像度はトップクラスのFPGAの内部メモリにさえ入りません。
FixedPoint16はFloatPoint32より速いです(Stratix以外)。
FixedPoint8試したことがありません、でもDSPブロックの単位が18ビットなので、メモリ節約だけの予感があります。
ARMより安いFPGAボードでは実装できない予感があります。(IPCoreが売れるほうがいいのかな?)
0 notes
Text
QR Code ReaderアプリとGoogle Apps Scriptを使ったActcastサンプル
Actcast開発に携わっている中山です、こんにちは。 2019/07/31にリリースしたβ versionが無事に稼働して一安心しつつ、正式リリースに向けて他メンバーとともに開発を続けています。
本記事ではActcastとGoogle Apps Script(以下、GAS)と連携させるサンプルについて紹介します。
作ったもの
今回用意したのは”イベント・勉強会の参加登録および当日受付システム”です。 IT技術系勉強会の会場受付で参加者チェックを自動化してみよう、というもので、動作としては以下のような流れになります。
Google Formsで参加登録してもらう
フォーム送信イベントにフックして受付番号を発行してスプレッドシートに記録
記録した受付番号をQRコードにしてメール送信
QR Code Reader(Act)をインストールしたRaspberry PiにQRコードを読み取らせる
Actcastが読み取った受付番号を指定したURL(ここではGASの doPost )にpostする(Cast)
GASが受け取った受付番号をスプレッドシートから検索してチェックする
実際にQR Code Readerを使ってQR Codeを読み取りスプレッドシートを更新する動作をみたい方は次のデモ動画をご覧ください。
youtube
GAS部分のコードはGitHub上で公開しています。
https://github.com/Idein/actcast-google-form-event-registration-demo
なお、このサンプルを公開するにあたってActcastのデモアプリ一覧に"QR Code Reader"が追加されました。
利点
この手の受付支援システムは他のツールやサービスでも実現可能なのですが、それらと比較しての利点は
比較的安価で入手でき他の用途にも使いやすいRaspberry Piで実現できる
イベント当日以外は別のActをインストールしておけば無駄にならない(はず)
Actcastと、Actcastからデータを受け取るサービスを疎結合にできる
といったところでしょうか。 特にActを簡単に切り替えられる点はデバイスを遊ばせておかずに済むので有用なのではないかと考えています。
意識した点
このサンプル作成にあたって意識した点は次のとおりです。
深層学習モデルを用い��い
IFTTT以上、serverless application未満のCast先
深層学習モデルを用いない
"QR Code Reader"は深層学習モデルは使用しないアプリケーションです(そりゃそうだ)。このアプリはPyPI上で公開されているQRコードライブラリとActcast SDK(ActDK)を用いて実装されており、Pythonでちょっとした物が作れてActDKのチュートリアルを試した人であれば誰でも作れるレベルです。Actcast上に公開されているものは筆者ではなく他のIdeinメンバーが実装したものですが、筆者も同様のアプリ作成を試みたところ、そこそこ短時間で実装+アップロードできました。
筆者としてはRaspberry Piで深層学習モデルを動かすアプリだけでなく、簡単に作れて役立ちそうなアプリもActcast上で公開されてほしいという気持ちでいます。"QR Code Reader"はQRコードを読み取るだけという、簡単に作れるアプリの一例としてうってつけだったわけです。
IFTTT以上、serverless application未満のCast先
サンプルを新たに作るなら、現在Actcastチュートリアルで公開しているIFFFTとの連携方法よりは凝ったものにしたいと考えていました。しかしserverless applicationはサンプルとして試すには手順が煩雑になりがちなため、もう少し簡単な例を用意したいと考えた結果、GASに落ち着きました。
実装にあたってclasp(とTypeScript)を使用している理由は、ソースコード管理と反映のしやすさを優先したためです。claspを利用しないことも考えはしたのですが、GASのスクリプトエディタにコピーしていく作業が意外と大変だったのでいったん諦めました。とはいえclaspのためだけにNode.jsをインストールする手間が増えてしまったので、もしかしたら今後JavaScript版も用意するかもしれません(確約はできませんが)。
もうひとつ、QRコード生成をGAS用に作成するリソースは持ち合わせていないため、今回はQuickChartを利用させていただきました。
結び
最後に、既存のイベント支援サービスとActcastを連携させることについて書いておきます。この場合、ユーザに送信される受付番号を読み取るアプリケーションをActDKを用いて作成し、Actcast上で公開することになるでしょう。受付番号を表示する方法がサービスごとに異なるので、おそらくデモのQR Code Readerよりは複雑なアプリになると思います。あるいは画像処理ライブラリを使って簡単に実装できるかもしれませんが……結果はいつかご自分の手で確認してください。
本記事で言及したActDKは、本記事公開時点ではパートナープログラム参加企業様に対してのみ先行提供しています。ActDKによるエッジデバイス向けアプリケーションの開発、およびActcast上でのアプリケーション公開に興味をもった方は下記資料をご覧ください。
https://actcast.io/docs/files/partner_program.pdf
0 notes
Text
Why RaspberryPi VC4 GPGPU Programming Matters
Written by: Noriyuki Ohkawa Translated by: Ryohei Tokuda
This article is the English translation from https://blog.idein.jp/post/185103625470/whyvc4matters.
The Raspberry Pi series uses a GPU called VideoCore IV (VC4) to render on display. Displaying is not necessary in most cases if we use Raspberry Pis as sensing devices. Therefore we use vacant VC4C to accelerate deep-learning inferences.
The advantages of GPGPU on VC4 are the following three:
Easy to share programs between products
Available CPU for other tasks
Less affected by over-heating
Easy to share programs between products
All of Raspberry Pi models, from pi0 to pi3, have VC4 although the frequency differs: 250MHz or 300MHz. We can say VC4 is the central unit because VC4 is initially booted, and then VC4 will kick the board's CPU.
Though all the GPUs have similar performance, the performances of CPU of pi0 and pi3 are very different. Although pi3 works fine for a substantial inference task using CPU, pi0 may not be able to execute the same program. Pi3 has SIMD ALU, but pi0 doesn't. This means we need to prepare different programs for pi0 and pi3.
In contrast, the inference performance by VC4 is almost constant. Therefore we can share the same program between the different products. We use the same program for our Actcast (currently alpha) demo program for different Raspberry Pis.
Available CPU for other tasks
On deep-learning sensing tasks, inference in itself is only one part of an application: for real applications, additional tasks such as taking a photo, pre-process, post-process, displaying (if necessary), or sending data are required. Inference by CPU exploits almost all of the CPU capacity, even though pi3 has four cores. Therefore the throughput cannot be increased.
Inference by VC4C doesn't use CPU at all. Therefore task parallel using CPU and VC4 increases the throughput by pipelining inference tasks and other tasks.
Less affected by over-heating
Pi3's CPU is powerful: if you can design and train it, a small Neural Network inference should run with the same speed on one CPU core as a VC4 version.
Theoretically, the four CPU cores are faster than VC4. For this reason, we have developed a converter to generate codes for not only VC4 but also CPU as MISRA-C.
Here we show the example of segmentation to make person-part blue. First by VC4:
youtube
Next by a CPU core of the same model:
youtube
The same model by two CPU cores:
youtube
The same model by three CPU cores:
youtube
Although we can optimize performance using multiple CPU cores by pipelining and assigning tasks to each core, execution by more than two CPU cores produces much heat. By default, the frequency of CPU cores is diminished if the temperature exceeds 80 °C. Over 85 °C, the frequency is halved. Hence the use of multiple CPU cores doesn't make speed-up without heat countermeasures. Of course, inference and other tasks by CPU cores are affected by its heat throttling.
For real operation, heat countermeasures are troublesome: driving parts such as fans are easily affected and injured by dust. A heat-sink such as metal case is desirable if it can do enough heat-release. The following picture is pi3 with a metal case. Without it, inference by CPU cores is soon affected by over-heat.
It might be interesting to check heat-design, temperature guarantee of recent "special chips" or Raspberry Pi like boards, and how the guarantee is archived.
As described above, the CPU thermal throttling starts at 80 °C, whereas the VC4 thermal throttling begins at the (relatively high) temperature of 85 °C. If the chip becomes hot during inference using VC4, CPU thermal throttling begins at first to suppress heating of the chip. For most applications, the inference (run on GPU) is the bottleneck, so thanks to the above mentioned pipelining between CPU and GPU, even if side tasks (run on CPU) spend more time than before over-heat, the overall execution time is unchanged. This is the reason why we do our demonstrations without metal cases, heat sink, or fans in exhibits.
Of course, if we pack pi0 or pi3 into a close-to-be-sealed container, like plastic cases, we can observe speed-down even with VC4. For the same reason, a Compute Module is little room for heat dissipation. Therefore, careful heat design is required.
Summary
Inference by VC4 has many advantages in addition to its speed.
For deep-learning acceleration boards, one naturally tends to focus on speed. However, for real operations, the choice of edge devices requires several considerations: costs including heat countermeasure, the ease of making applications, etc.
1 note
·
View note
Text
Why RaspberryPi VC4 GPGPU Programming Matters
Idein大川です.主に最適化回りを担当しています.
前回はお遊びのような話をしたので今回は少し真面目な話にします.
Raspberry Pi シリーズには VideoCoreIV (以下VC4) というGPUが組み込まれています. Raspberry Pi はシングルボードコンピュータなので画面表示に利用するためです.センシングデバイスとして Raspberry Pi を利用するのであれば多くの場合ディスプレイは不要なので,Ideinではこの空いてるVC4を利用して深層学習の推論を行えるようにしています.
Raspberry Pi 上VC4によるGPGPUによる推論を行う利点は主に以下の3つです.
製品間でプログラムを共通化し易い
CPUに余裕を持たせ易い
熱による性能低下を受け難い
以下,本記事では各項目について説明していきます.
製品間でプログラムを共通化し易い
pi0からpi3まで,製品によってデフォルトの動作周波数に250MHzか300MHzかの差はあるものの,どの Raspberry Pi にもVC4は乗っています.そもそも Raspberry Pi はまず最初にVC4が起動し,VC4がCPUを起こすようになっており,VC4のほうがむしろ本体であると言ってもいいかもしれません.
VC4がどの製品にも似たような性能で乗っている一方で,たとえばpi0とpi3ではCPUの性能差が大きく離れています.
重たい推論をCPUで行うプログラムでは,pi3ではまずまずの速さで動作したとしても,そのままpi0に持っていくととても遅いということになりがちです.また,pi3にはSIMD演算器がありますがpi0には無いため,pi3向けに最適化した推論部分はpi0に持ち込んでも動作しないまであります.これはpi3に対してとpi0に対してで異なるプログラムを用意しなければならないということに繋がります.
推論をVC4で行うプログラムであれば,pi0でもpi3でもさほど推論にかかる時間は変わることがありません.しかもそれを達成する推論部分のプログラムは同じものでかまいせん.実際,Actcast(現在はα版)で配信されているデモは,どのRaspberry Pi製品に対しても同じプログラムをインストールしています.
CPUに余裕を持たせ易い
深層学習の推論を伴ったセンシングを行うアプリケーションにおいて,推論はあくまでもやりたい処理の一部であり,実際にはその他の処理も行う必要があるでしょう.入力データであるカメラから撮影したり,推論のための前後処理をしたり,必要ならば画面描画をしたり,結果をどこかに送信したり,といったことです.
もしCPUで推論を行っていると,たとえpi3では4コアあると言っても,推論以外の処理のための計算能力をその間ほぼ占有してしまいます.その結果スループットが増やせなくなります.
VC4で推論を行っているなら,その間CPUは全く使っていません.そのため,CPU/VC4ヘテロ演算器環境におけるタスク並列にすることで,推論と推論以外の処理をパイプライン並列実行し,スループットを稼ぐことができるようになります.
熱による性能低下を受け難い
他はともかく実はpi3ならCPUもかなり高性能で,特に十分小さいNNが設計・訓練できるならば,1コア実行でさえVC4と同等以上の速さで推論できることがあります.そもそもpi3のCPUは理論性能では4コアでVC4より速い筈なのです.実際,我々はVC4向けに高速化したコード生成だけではなく,CPU向けに「高速なMISRA-Cコード」を吐く変換器も持っています.こちらもVC4用と同様にfloatで訓練した結果をfloatのまま結果を変えずに高速なものに変換するようになっています.
以下に人の部分を青くするようなsegmentationを行うモデルでの例を示します.まずVC4によるもの,
youtube
次に同じモデルによる推論で,VC4ではなくCPUの1コアをワーカーに使ったもの,
youtube
同じくCPUの2コアをワーカーに使ったもの,
youtube
CPUの3コアをワーカーに使ったものです.
youtube
同じ推論を複数コアで別個に並列実行することでスループットを上げられるのですが,CPUを特に2コア以上並列で常時フル稼動させるとpi3でもかなり熱が発生します.Raspbianのデフォルトでは,CPUは80度からthermal throttlingがかかって性能が低下しはじめます.85度付近まで上がってしまうとpi3上でのCPU動作周波数はおよそ半分になってしまいます.つまり,CPU複数コアを使っても熱対策ができていないと性能はCPU1コアと変わらないといった事態にもなるわけです.CPUで推論を行っていると,当然ですが推論も推論以外も全てがthrottlingに巻き込まれます.
実運用において熱対策は厄介な事項のひとつであり,特にファンのような駆動部品は粉塵等の影響を受け易く故障や寿命低下の原因にもなります.金属ケースのようなヒートシンク的なものだけで熱を発散できるならば,その程度に収めたいところです.以下の写真は先にお見せした動画の動作環境として金属ケースに収めたpi3です.このケースから出して動かすとCPU実行ではすぐに熱の影響が現れます.

最近よく出てくる「専用チップ」や Raspberry Pi と似たような位置付けのボードについても,どのくらいの温度が動作保証範囲なのか,そこに収めるためにはどのようなデバイス設計が必要になってしまうのか���あたりに着目してみるのも面白いでしょう.
前述の通りCPUのthermal throttlingは80度から始まりますが,VC4のthermal throttlingはやや高い85度からとなっています.VC4で推論を行っていると,熱が出たときにCPUで実行している部分つまり推論以外の部分の性能が先に低下してチップの発熱を抑制しにかかります.大抵のアプリケーションでは,推論部分がスループット上で律速することが多いです.つまり,推論以外の部分が多少性能低下し実行時間が伸びたとしても,並列実行される推論実行時間の影に隠蔽されてしまいます.結果として,アプリケーション全体での性能が低下し辛くなります.これは,我々が各種展示会において,ファンもヒートシンクもアルミケースも無くとも推論を伴うアプリケーションを展示することができる理由でもあります.
もちろんpi0やpi3をプラスチックケース等に入れ密閉に近いことをしてしまうとVC4での推論実行といっても性能低下を観察することはできます.また,Compute Moduleは素では配線等による熱の逃げ場が少ないため,基盤設計時に熱に対する考慮も必要になるでしょう.
まとめ
以上のように,Raspberry Piをエッジデバイスとして利用し,深層学習の推論を伴う高度なセンシングを行う場合,VC4で推論できるということには速さ以外にも利点があります.
深層学習を〜となるとどうしても推論の速いものに目が行きがちではありますが,数を設置するには熱対策等も含めたコストが問題になりますし,アプリケーションの作り易さ等,総合的に判断して目的に沿うエッジデバイスはどれなのかを選択していきたいですね.
3 notes
·
View notes
Text
機械学習におけるDifferential Privacyについて
Ideinの先崎です。
最近Tensorflowが実装を公開するなど注目を集めている、機械学習+Differential Privacyという研究分野があります。これはDifferential Privacyと呼ばれる技術を使って、機械学習におけるトレーニングデータのプライバシを保護しようというものです。 本記事では、この研究分野でどのようなことが行われているのかについて書きたいと思います。
概念・定義
まずはじめに、Differential Privacyの概念と定義について簡単に説明したいと思います。 より詳しい説明は、[1]や[2]などがわかりやすいです。
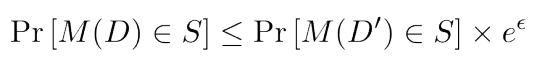
Differential Privacy(DP)はDworkによって考案された[3]概念で、あるデータセットに対する解析結果を公開する場合にそのデータのプライバシはどの程度保護されているのか、という問題を取り扱います。 Dworkはこれをパラメータεを用いて以下のように定義しました。
ここでDはデータセット、Mはこれに対する操作、SはMにより出力されうる値の集合の任意のサブセットです。 またD'はDと1レコードだけ違う、すなわちDに隣接したデータセットです。 Mがあるεに対し上式を満たす時Mはε-Differential Privacyを満たすといいます。 なんとなく式だけでは理解しにくいですが、直感的には「DとD'は1レコード分異なるはずであるがこれらに対する出力には差がない、すなわちこの1レコードのプライバシは保護されている」ということを言いたいのだと理解するとよさそうです[1]。このとき、εの値が小さければ小さいほど制限が強くなり、より強くプライバシが保護されるということになります。 このようなことを実現するためには、一般的にLaplacian NoiseやGaussian Noiseなどを解析結果に加えるということが行われます。 これにより出力が確定的に決まることを避けつつ、ノイズを加えた結果が本来のデータセットに対する操作の結果とかけ離れすぎないようにすることで、プライバシを保護しながらデータセットを解析できることが期待されます。
Deep Learningの文脈でのDP
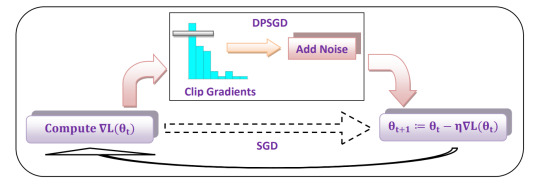
Deep Learningでは多くの場合学習に大量のデータを必要とします。もしこれが個人情報などのセンシティブなデータを含んでいる場合には、当然それらのプライバシが問題となってきます。このような背景のもと、生成されたモデルがDPを満たすように訓練する手法が活発に研究されています。例えば、[4]では確率的勾配降下法(Stochastic Gradient Descent, SGD)をDPを満たすように改変したDifferentially Private SGD(DPSGD)を用いる手法が提案されています。 (DPSGDの概要。([5]のFigure 2.))
図からもわかる通り、通常のSGDと異なる点は勾配を用いてパラメータを更新する前に勾配を一定のノルムでclipすることと、さらにそこにGaussian Noiseを加えることです。ε-Differential Privacyを満たすためにはこのノイズの強度などのパラメータをどのように設定すればいいかなどが論文中で議論されています。
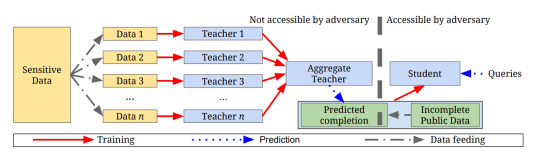
また直接勾配にノイズを加えて学習するのではなく、Knowledge Transferを利用し教師モデルのアンサンブルによってDPを満たすPrivate Aggregation of Teacher Ensembles(PATE)という手法も提案されています[6]。 (PATEの概要。([6]のFigure 1.))
この手法ではセンシティブなデータとそうでないデータがあるという仮定の元、まずセンシティブデータを分割しそれぞれでモデルを訓練します。 次にこれらのモデルの多数決にノイズを加えたものを教師モデルとして、センシティブでないデータを用いて生徒モデルを訓練します。 これにより、生徒モデルの学習にセンシティブデータは直接利用されておらず、ノイズが加えられているためDPも満たしているということになるようです。(εの値に関しての議論もなされています)
学習データプライバシの侵害

ここまでご紹介してきたように学習データのプライバシを保護するためにDPを応用する手法が研究されていますが、逆にDeep Learningにおいて学習データのプライバシはどのように侵害されうるのか?についても研究が進められています。(もし仮に誰もプライバシを侵害できないなら、プライバシ保護にコストをかける理由は薄れるでしょう。) このようなものとしては、モデルから学習データを復元するModel Inversion [7]、あるデータが学習用データセットに含まれていたかどうかを推測するMembership Inference [8]、学習データに特定のプロパティを持つものが含まれていたかどうかを推測するProperty Inference [9]などが提案されています。 (顔画像の分類を行うモデルから学習データを復元したもの(左)と元の学習データ(右)([7]のFigure 1.))
データを直接復元することは最もイメージしやすいプライバシの侵害ですが、これ以外の攻撃も脅威となりえます。例えば、ある病気の患者のデータからなんらかのモデルを構築した場合、そのデータセットに自分のデータが含まれていることが明らかになることにより自分がその病気であることが明らかになってしまう、といったシナリオが考えられます。
精度とプライバシ保護のトレードオフ
上で述べたよ��な攻撃に対し、モデルがε-DPを満たしていればその防御策になるといったことは考えられますが、実際にどの程度のεであればどの程度攻撃を緩和できるのか、といった評価についての報告は(私の知る限り)あまり多くはありません。 DPの定義より、よりεが小さくなるようにすればより攻撃を防げるようになるはずですが、本来のタスクに対する精度も低下すると考えられます。
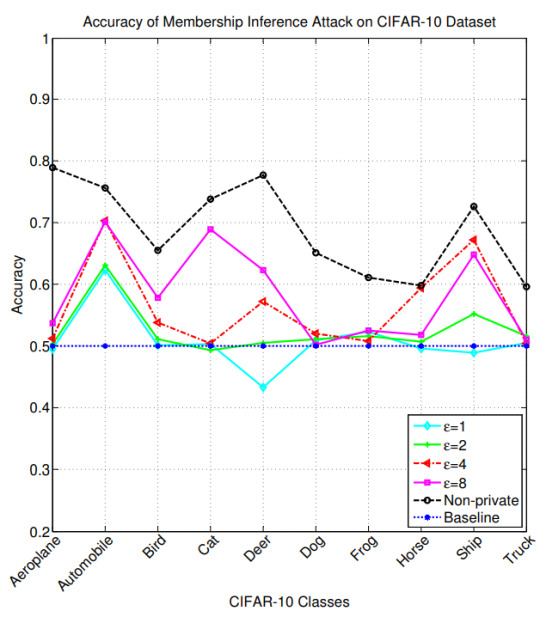
[6]では[4]で提案されたDPSGDによってDPを満たしたモデルに対しMembership Inference攻撃を行うという設定で、εの値が攻撃成功率にどの程度影響を与えるか、またそのときテスト精度にはどの程度影響を与えるかという評価実験の結果が報告されています。 (CIFAR-10で学習したモデルに対するMembership Inferenceの成功率([6]のfigure 4(a)))
確かにεを小さくするとMembership Inferenceの成功率が下がっていることがわかります(Membership Inferenceはあるデータが学習データに含まれるか否かの2値分類なので、ベースラインが50%)。 しかし一方で、CIFAR-10のテストセットの認識精度はDPを適用しないモデル、ε=8、ε=1でそれぞれ94%、68%、24%となったことも報告されており(Table 3)、εを小さくしすぎると著しく本来の機能が損なわれるということがわかります。
このように、現状ではプライバシの保護を優先すれば精度が損なわれてしまう(逆もしかり)という状態のようです。 これらの技術を実際のアプリケーション等に使うためには、εと精度のよりよいトレードオフを追求する必要がありそうです。
参考文献
[1] 注目のプライバシー Differential Privacy https://www.jstage.jst.go.jp/article/jssst/29/4/29_4_40/_pdf
[2] 差分プライバシーとは何か? (定義 & 解釈編) https://www.slideshare.net/kentarominami39/ss-64088396
[3] C. Dwork. Differential Privacy. In ICALP 2006, 2006.
[4] M. Abadi, A. Chu, I. Goodfellow, B. McMahan, I. Mironov, K. Talwar, and L. Zhang. Deep learning with differential privacy. In 23rd ACM Conference on Computer and Communications Security(ACM CCS), pp. 308–318, 2016.
[5] M. A. Rahman, T. Rahman, R. Laganiere, N. Mohammed, and Y. Wang. Membership inference attack against differentially private deep learning model. Transactions on Data Privacy, 11, 2018.
[6] N. Papernot, M. Abadi, Ú. Erlingsson, I. Goodfellow, and K. Talwar. Semi-supervised knowledge transfer for deep learning from private training data. In Proceedings of the International Conference on Learning Representations, 2017.
[7] M. Fredrikson, S. Jha, and T. Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 2015.
[8] R. Shokri, M. Stronati, C. Song, V. Shmatikov. Membership inference attacks against machine learning models. 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017.
[9] K. Ganju, Q. Wang, W. Yang, C. A. Gunter, N. Borisov. Property Inference Attacks on Fully Connected Neural Networks using Permutation Invariant Representations, Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2018.
0 notes
Text
量子化について
ideinのクリスチャンです。機械学習周りの研究開発を担当しています。
edge-computing で機械学習と言えば、量子化を利用して処理を加速する人は多いと思われます。(n.b.: 現時点の Actcast で量子化は利用されてませんが)
この記事では量子化アプローチとこの開発ノウハウをざっと紹介します。
量子化とは
機械学習で行われている量子化の実際は activations 又は weights で通常用いられる32bit 数値をbitwidth の少ない数値で代替することです。 メリットとしては、モデルサイズが小さくなるだけではなく、行列乗算を(なので畳込みも)速く処理できます。デメリットは勿論、モデルの精度が低下してしまう恐れがあることです。
どうやってビット数の少ない計算を早くするのは hardware-dependent なので、この周りの説明をするつもりはありません。
量子化をする方法の一つとして、単純に学習済みモデルの weights を取って、量子化関数を作用することです。推論の時、 activation に同じ関数を作用するだけのも可能ですが、このアプローチを使うと、モデルの精度は随分下がってしまいます。 この方法よりも器用なやり方は、学習済みモデルで学習データセットを推論することです。こうすると、レイヤーのactivations 毎に分布の平均と分散を確認できて、この情報で相応しい量子化 parameter を設定できます。
一方で、最も広く研究されている方法であり、量子化を意識している学習を使えます。実用的には、学習の時にも量子化を行って、back-propagation の時に上手く勾配を推定することです。(量子化の関数は微分不可能または微分は殆どゼロ可能性ありますので、ここで注意しないと行けません)
アプローチの紹介
良い参考になると思いますので、有名な3つアプローチを紹介します。
DoReFa-Net
この論文で、activation とweight だけでなく、勾配も量子化する手法が提案されています。こうしたら、学習も加速できるので、edge-device とかでも学習は可能となります。 それぞれのbitwidth をセットして、速度と精度の釣り合いを細かく設定出来ます。量子化数値の処理は以下のようになります:
x \\ float32 行列 k \\ bitwidth q_x = round((2^k - 1) * x) / (2^k - 1)
このアプローチで bit-width は量子化の唯一hyper parameter です。(実はweightとactivationとgradientそれぞれのパラメターあるので、3つありますが)
Integer-Arithmetic-Only Inference (gemmlowp)
tensorflow lite の組み込みquantization です。 DoreFa-Netと違って、bit-width の他にも量子化パラメターがあって、activation の分布の間の極値です。学習の時にこのparameter の調整はback-propagation でなくて、移動平均で行います。 このアプローチで整数処理で計算を加速することは目的なので、対象デバイスで使える整数型(uint8等)を設定します。(推論の時、デバイスの整数blasカーネルを呼び出したいので)bit-widthを選考するよりも、整数型で設定されてます。 量子化数値の処理は以下のようになります:
x \\ float32 行列 k \\ bitwidth a \\ float32 数値 (学習せれてる下限) b \\ float32 数値 (学習されてる上限) clamp(r) -> min(max(r, a), b) s = (b - a) / (2^k - 1) q_x = round((clamp(x) - a) / s ) * s + a
LQ-Nets
LQはLearning Quantizationの略です。上のアプローチで、k と a と bを設定したら、可能な量子化数値は {a + i * (b-a)/(2**k - 1) | i∈ [1, 2^k] }(即ち、実数から整数への変換はただのアフィン写像) のセットに限られています。 LQ-Netsではこの可能量子化数値を可変として、学習しようと提案されてます。2つparameter で設定されてなくて(aとb)、vector(size: k)で設定されてます。このベクトルを学習するため、 新たなアルゴリズム(Quantization Error Minimization)を導入されています。 量子化数値の処理は以下のようになります:
x \\ float32 行列 k \\ bitwidth l_i, i=1..2^k \\ float32 v \\ float32 vector (size: k) t_i = (l_(i-1) + l_i) / 2, i=1..2^k j = argmin_i(x <= t_(i+1)) q_x = dot(v, bit_repr(j))
実装アドバイス
実感として、論文に導入されたアプローチを実装しようとしたり、論文では評価されていないモデルの量子化をしてみたりすると、結果はイマイチなことが多いです。 ML枠組みで新しい量子化レイヤーの実装とモデルの適応に関して、ざっとノウハウを共有したいと思います。 推論処理の最適化はハードウェア依存なので、以下に記載してません。
移動平均で学習されてる parameter を warm-up
量子化特定のparameter は back-propagation でなく、移動平均で学習されてることはあります。 この場合、初期設定が理想的な数値と幅広くずれたら、モデルが精度の良くない状態へ収束する恐れがあります。このため、最初の数epoch は量子化無しで学習するのはオススメです。
量子化直前にbatch norm
様々な論文に書いてあると思いますが、activation の分布を狭い間にあるために、量子化レイヤーの前に batch normalization を取り入れると誤差は減少します。 一般的に、レイヤー順番をBatch Normalization->(k-bits) Activation-> Convolution -> Poolingにするのはオススメです。
CPUでもいい
機械学習と言えば、GPUで計算を速くするのは当たり前です。ただし、量子化特定の処理のある部分はもしかすると軽いため、周波数が高いCPUを利用した方が学習速くなる場合があります。 それを判断するには、見比べるしかなさそうです。
全レイヤーを量子化?
軽さと速度のため、全てのレイヤーを量子化したいものの、最初レイヤーと最後レイヤーの量子化は精度に大幅に影響あります。 trade-offだと思うのですが、精度を上がるように、最初と最後のlayer をfp32のままにしても良いかもしれません。 それに、モデル内で最初の layer の channel 数は少ないので、量子化しても加速はそんなにないと思われます。
入力を正規化
最初のレイヤーは量子化されたら、このレイヤーの入力はモデルの入力自体です。画像系のモデルで、数値は広く使われているuint8 の RGB (チャンネル3つ、数値 0~255)だとすると、 分布の間は広くて、量子化したら情報を失うことは多い場合があります。(量子化アプローチによって) 精度に結構に影響あるので、入力を正規化した方がいいかと思います。(もしくは、上に記載の通り、最初のレイヤーを量子化しない)
weightsよりactivations
論文にも言及されてて、weight の量子化よりも activation のが精度に影響あります。それぞれのbit-width を設定出来ますので、 act_bitwidth >= weight_bitwidth を薦めします。
最後に
上に紹介したapproachチだけでなく、様々な面白い量子化系の論文がちょいちょい投稿されてます。 使っているMLフレームワークで再現実装する場合が良くあるので、ご参考として読んでいただければと思います。
ビット数の少ない数値で速いモデルを作りましょう!
0 notes
Text
FPGAで512コア実装を試してみた。
自己紹介
私はSitnikov Evgeniiと申します。読み方:シトニコフ エフゲニー。 Ideinでは普段深層学習をFPGAで実装をやっています。 使っているボードの型番は「Terasic OpenVINO Starter Kit」です。
目的
マルチコアを実装する為に一番相応しい構造を調べたい。 リソース消費とFmaxを測りたい。(Fmaxは最高な周波数) 速度対電力の比率も調べたい。 出来るだけ多いコアを実装してみたい。
実験
時間をかけない為に、この簡単なアルゴリズムを選択しました: Long fused multiple-accumule random generator (省略:LFMArnd) このアルゴリズムはロシアの政府よく使っている、簡単で丈夫なアルゴリズムですから。
アルゴリズム:
「buf」がFinite State Machineとしてのバイトの配列変数です。 アルゴリズムの出力の8ビットのバイトを「buf」にシフトで追加し、 「buf」を二つの16ビット値としてfused multiply-accumulator(以下FMA)を計算し、 FMAの出力の32ビットを簡単なハッシュ関数で8ビットに圧縮し、 この圧縮した出力をアルゴリズムの出力にして「buf」にシフトで追加しています。
FMA数は512にしました。 理由: FPGAには342DSPブロックがあります。 各DSPブロックが二つ18ビットのFMAを行っています。 それ故に、1サイクルでFPGAが684FMAの計算を出来ます。 ですから、これより小さい一番近い2の累乗で512です。
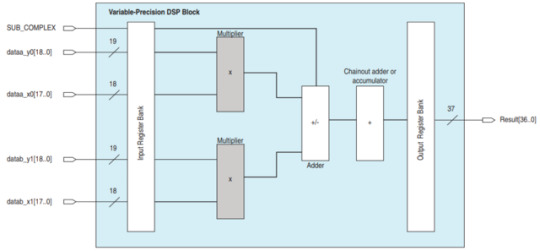
(MCUのCortexM7のSMLDA命令にぴったり似ている)
アルゴリズムのソースコード(PC版):
#define LFMA_LENGTH 512 uint8_t buf[LFMA_LENGTH*4] = {0}; static inline uint8_t LFMArnd() { int16_t *ptr = (int16_t *)buf; int32_t sum = 1; for (uint32_t i = 0; i < LFMA_LENGTH; i++) { sum += ptr[i*2 + 0] * ptr[i*2 + 1]; } uint8_t s0 = sum >> 0; uint8_t s1 = sum >> 8; uint8_t s2 = sum >> 16; uint8_t s3 = sum >> 24; uint8_t result = (s0 ^ s2) + (s1 ^ s3); for (int32_t i = ((LFMA_LENGTH * 4) - 2); i >= 0; i--) buf[i + 1] = buf[i]; buf[0] = result; return result; }
実験手順
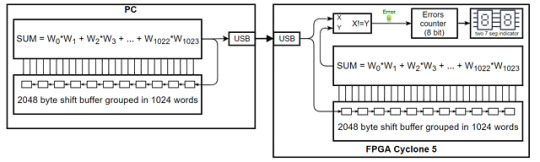
PCからUSBでFPGAにLFMArndの出力データを送り、 FPGAはPCからの受信データを「buf」にシフトする。 FPGAはこの「buf」に基づいてLFMArndの出力を計算し、 FPGAで「FPGAの計算結果」と「PCからの受信」を比較する。 等しくない場合にはエラーを数えて表す。
FPGAで実装に大事なこと
1.足し算と掛け算の実装が必ず簡単な二つだけの入力を必要とする。 2.足し算と掛け算の出力をレジスタに保存するべき。 その故に
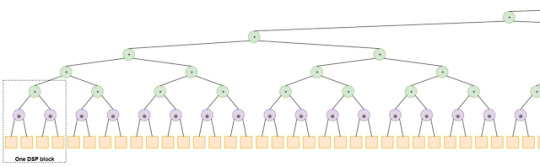
512コアの実装はこのバイナリツリー形のようになりました(保存レジスタを表示していません、でもあります):
この場合にはFmaxが100Mhzくらいになりました。 この回路がLFMArndを1サイクルで計算している。 出力のLatencyは12サイクルになりました。 でもこの速度では足りません。
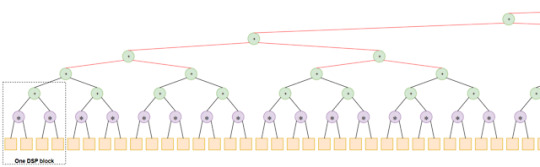
問題は: この足し算回路の距離にあります (赤線で表示しました) この回路の距離が段により長くなりますので、時間もかかる。 ですから距離を短くするために、距離に応じてPipelineレジスタの数を追加しました:
この場合にはFmaxが250Mhzくらいになりました。 でもこれが「pessimistic評価」: 現実に300Mhzまでに安定するはずです 「Optimistic評価」、 エラーが350Mhzから発生し始まる。この場合はエラー率は1/1000000なります。 エラー率の1/1000000場合はMobileNetV2の誤差は3%から4%までに上がります (エラーの影響をPCエミュレータで測りました)。
この回路がLFMArndを1サイクルで計算している。 でも出力のLatencyは20サイクルまでに上がりました。
FPGAのソースコード(Verilog):
////////////////////////////////////////////////////////////////////////////////////////////////// module tLFMArnd( input clk, input rst, output reg [7:0] out_data, output out_strobe, input [7 : 0] in_data, input in_strobe ); initial out_data = 0; reg [ 7 : 0] bytes [2047 : 0]; reg signed [15 : 0] words [1023 : 0]; reg signed [31 : 0] mults [ 511 : 0]; reg signed [31 : 0] addsZ [ 255 : 0]; reg signed [31 : 0] addsA [ 127 : 0]; reg signed [31 : 0] addsB [1 : 0] [ 63 : 0]; reg signed [31 : 0] addsC [2 : 0] [ 31 : 0]; reg signed [31 : 0] addsD [2 : 0] [ 15 : 0]; reg signed [31 : 0] addsE [2 : 0] [ 7 : 0]; reg signed [31 : 0] addsF [2 : 0] [ 3 : 0]; reg signed [31 : 0] addsG [1 : 0] [ 1 : 0]; reg signed [31 : 0] sumA; reg signed [31 : 0] sumB; integer i; integer j; initial for (i=0; i <= 2047; i = i + 1) bytes[i] = 0; initial for (i=0; i <= 1023; i = i + 1) words[i] = 0; initial for (i=0; i <= 511; i = i + 1) mults[i] = 0; initial for (i=0; i <= 255; i = i + 1) addsZ[i] = 0; initial for (i=0; i <= 127; i = i + 1) addsA[i] = 0; initial for (i=0; i <= 63; i = i + 1) for (j=0; j <= 1; j = j + 1) addsB[j][i] = 0; initial for (i=0; i <= 31; i = i + 1) for (j=0; j <= 2; j = j + 1) addsC[j][i] = 0; initial for (i=0; i <= 15; i = i + 1) for (j=0; j <= 2; j = j + 1) addsD[j][i] = 0; initial for (i=0; i <= 7; i = i + 1) for (j=0; j <= 2; j = j + 1) addsE[j][i] = 0; initial for (i=0; i <= 3; i = i + 1) for (j=0; j <= 2; j = j + 1) addsF[j][i] = 0; initial for (i=0; i <= 1; i = i + 1) for (j=0; j <= 1; j = j + 1) addsG[j][i] = 0; initial sumA = 0; initial sumB = 0; always @(posedge clk) begin //Shifter if (in_strobe) begin bytes[0] <= in_data; for (i = 1; i <= 2047; i = i + 1) bytes[i] <= bytes[i - 1]; end //Pipeline for (i=0; i <= 63; i = i + 1) for (j=1; j <= 1; j = j + 1) addsB[j][i] = addsB[j - 1][i] ; for (i=0; i <= 31; i = i + 1) for (j=1; j <= 2; j = j + 1) addsC[j][i] = addsC[j - 1][i] ; for (i=0; i <= 15; i = i + 1) for (j=1; j <= 2; j = j + 1) addsD[j][i] = addsD[j - 1][i] ; for (i=0; i <= 7; i = i + 1) for (j=1; j <= 2; j = j + 1) addsE[j][i] = addsE[j - 1][i] ; for (i=0; i <= 3; i = i + 1) for (j=1; j <= 2; j = j + 1) addsF[j][i] = addsF[j - 1][i] ; for (i=0; i <= 1; i = i + 1) for (j=1; j <= 1; j = j + 1) addsG[j][i] = addsG[j - 1][i] ; //FMA by binary tree for (i=0; i <=1023; i = i + 1) words[i] <= {bytes[i*2 + 1], bytes[i*2]}; for (i=0; i <= 511; i = i + 1) mults[i] <= words[i*2 + 1] * words[i*2]; for (i=0; i <= 255; i = i + 1) addsZ[i] <= mults[i*2 + 1] + mults[i*2]; for (i=0; i <= 127; i = i + 1) addsA[i] <= addsZ[i*2 + 1] + addsZ[i*2]; for (i=0; i <= 63; i = i + 1) addsB[0][i] <= addsA[i*2 + 1] + addsA[i*2]; for (i=0; i <= 31; i = i + 1) addsC[0][i] <= addsB[1][i*2 + 1] + addsB[1][i*2]; for (i=0; i <= 15; i = i + 1) addsD[0][i] <= addsC[2][i*2 + 1] + addsC[2][i*2]; for (i=0; i <= 7; i = i + 1) addsE[0][i] <= addsD[2][i*2 + 1] + addsD[2][i*2]; for (i=0; i <= 3; i = i + 1) addsF[0][i] <= addsE[2][i*2 + 1] + addsE[2][i*2]; for (i=0; i <= 1; i = i + 1) addsG[0][i] <= addsF[2][i*2 + 1] + addsF[2][i*2]; sumA <= addsG[1][0] + addsG[1][1]; sumB <= sumA + 1'b1; //Hashing out_data <= (sumB[7 : 0] ^ sumB[23 : 16]) + (sumB[15 : 8] ^ sumB[31 : 24]); end tREG_DELAY #(20) _clc_del(clk, in_strobe, out_strobe); endmodule
リソース消費
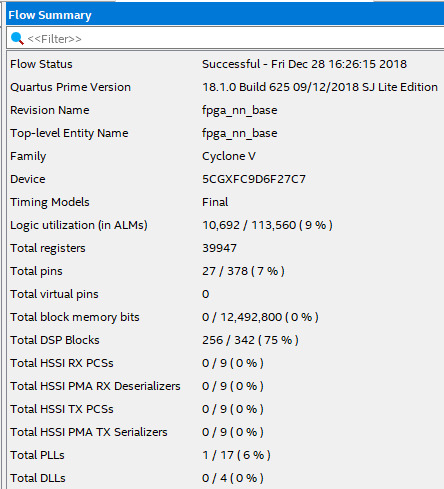
電力消費
3ワットになりました。 ヒートシンクの温度はRaspberryPiと同じくらいになりました。 でもこの回路が1サイクルで計算してFmaxが250Mhzになったら、 速度は128GigaFMAになりました。
速度対電力の比率
*PC版のコンパイラの環境と設定は
gcc -O3 -msse4.2 -mavx2 -Wall pragma GCC optimize ("unroll-all-loops") pragma GCC optimize ("tree-vectorize")
AssemblerListingの出力でAVX2とSSE命令がちゃんと利用されていることを確認しました。
PC版: 5MegaLFMArnd / Sec (one Core) = 5 * (6 Core) = 30 MegaLFMArnd / Sec
30 MegaLFMArnd / Sec * 512 (LFMA_LENGTH) = 15.36 GigaFMA / Sec
65 Watt (Core i7 8700) / 15.36 GigaFMA / Sec = 4.23177 Watt / (GigaFMA / sec)
FPGA版: 250 MegaLFMArnd / Sec * 512 (LFMA_LENGTH) = 128 GigaFMA / Sec
3 Watt (FPGA) / 128 GigaFMA / Sec = 0.0234375 Watt / (GigaFMA / Sec)
実装の回路を一覧(機能図)
https://www.youtube.com/watch?v=eJnx0aIon20 規模を分かるように:動画の始まりの「Add133~8」などが一つのDSPブロックです。 コンパイル時間が30分になりました。
纏め
一番相応しい構造は「バイナリツリーの構造」と「各段距離に応じて数の中間レジスタの構造」を組み合わせたものです。
Fmaxは250Mhzになりました。
FPGAのリソース消費率は10%になりました。
速度は128 GigaFMA / Secになりました。(PCより8倍早い)
速度対電力の比率が0.0234375 Watt / (GigaFMA / Sec)になりました。(PCより180倍低い)
0 notes
Text
ESP32の命令フェッチと性能への影響
Idein藤井です。今回はカレーの話ではなく技術的なお話です。
以前の記事「Hikey970について」でも少し触れましたが、我々はRaspberry Pi以外のSoCも調査しています。 私がESP32の性能について調べていた際に遭遇した、命令フェッチにまつわる少し変わった現象についてご紹介します。
ESP32の命令フェッチについて
ESP32とは、Espressif Systemsが開発しているSoCで、コアのISAはTensilicaのXtensa LX6です。 開発環境にはArduinoかESP-IDFがあり、今回紹介する現象はESP-IDFで確認しました。
Xtensaの命令長は基本的に24bitです。実装依存のオプションとして、プロセッサベンダは同じ命令でも16bit版を用意することができます。 例えば、ESP32には24bitのnop命令と16bitのnop.nなどが用意されています(16bit版は後ろに.nがつきます)。
コンパイラは、16bitの命令があればそちらを使ったほうがいいはずですが、そうはならないパターンがありました。 XtensaのISAリファレンスマニュアルの"4.3.1.2 Branches"に、
実装によってはジャンプ先の命令の命令フェッチが32bitのアラインメントを跨ぐと遅くなる
とあり、実測によりESP32の実装はこのパターンであるとわかりました。 このアラインメントの対応のため、16bit命令ではなく24bit命令を使ってアドレスをずらしたほうが速くなるケースがあるのですが、アドレスが決まるのはコンパイル時ではなくリンク時です。 そのため、ESP-IDFでは16bit命令と24bit命令のどちらを使うかはリンカが決定します。
ところがこのリンカの命令選択が完璧ではなく、常に速いループを生成できるとは限らないのです。
具体例
下記のようなループが、ループの前にある命令の数などによって、7サイクルかかる場合と8サイクルかかる場合があります。
for (i = 0; i < n_iter; i++) { __asm__ volatile ("add %0, %1, %2" :"=r"(a0) :"r"(a0),"r"(a1) ); __asm__ volatile ("add %0, %1, %2" :"=r"(a0) :"r"(a0),"r"(a1) ); }
遅いパターンと速いパターンを、リンク後のelfファイルをobjdumpで見比べてみます。
7サイクルの(速い)オブジェクト:
400d1e0d: 802230 add a2, a2, a3 400d1e10: 802230 add a2, a2, a3 400d1e13: 880b addi.n a8, a8, -1 400d1e15: ff4856 bnez a8, 400d1e0d
8サイクルの(遅い)オブジェクト:
400d1e0e: 802230 add a2, a2, a3 400d1e11: 802230 add a2, a2, a3 400d1e14: 880b addi.n a8, a8, -1 400d1e16: ff4856 bnez a8, 400d1e0e
7サイクルのオブジェクトの方はジャンプ先である先頭のadd命令が32bitのアラインメントを跨いでおらず、8サイクルのオブジェクトの方はジャンプ先である先頭のadd命令が32bitのアラインメントを跨いでいます。
試しに、8サイクルのオブジェクトのジャンプ先の命令を等価な16bit命令に書き換えて、下記のようにアライメントを跨がないようにしたところ、無事7サイクルで実行できました。
400d1e0e: 223a add.n a2, a2, a3 400d1e10: 802230 add a2, a2, a3 400d1e13: ffc882 addi a8, a8, -1 400d1e16: ff4856 bnez a8, 400d1e0e
zero-overheadループ
Xtensaには拡張としてzero-overheadループというものがあり、ESP32はこれを実装しています。 zero-overheadループは、予め実行回数が決まっているループを分岐のオーバーヘッドなしで実行できます。 例えば、下記のループは1周をたった2サイクルで実行できます。
400d1e11: 058876 loop a8, 400d1e1a 400d1e14: 302230 xor a2, a2, a3 400d1e17: 303320 xor a3, a3, a2
zero-overheadループでも同様の問題があるか確認するために、バイナリを書き換えてループ前後の命令を移動させ、下記のように先頭のxor命令が32bitのアラインメントを跨ぐようにすると、1周に3サイクルかかるようになりました。
400d1e13: 058876 loop a8, 400d1e1c 400d1e16: 302230 xor a2, a2, a3 400d1e19: 303320 xor a3, a3, a2
ただしzero-overheadループの場合、リンカが頑張って16bit命令と24bit命令を使い分けて配置してくれるようで、多少いじめてもジャンプ先の命令がアラインメントを跨ぐようなオブジェクトをリンカが吐くケースは見つかりませんでした。zero-overheadループを使う場合はリンカの命令選択を信用してよさそうです。
このzero-overheadループですが、コンパイラがループ内を解析しきれない場合には出力してくれません。 例えばループ中にインラインアセンブラを書くと、その内容にかかわらず普通の分岐命��を使ったループに変換されてしまいます。 現状(xtensa-esp32-elf-gcc 5.2.0)、ループ内でインラインアセンブラを使わざるを得ない状況で最速を目指すためには、下記のようにループごとインラインアセンブラを書く必要があるようです。
__asm__ goto ("loop %0, %l1" : /* no output */ : "r"(n_iter) : /* no clobber */ : end_loop ); __asm__ volatile ("add %0, %1, %2" :"=r"(a0) :"r"(a0),"r"(a1) ); __asm__ volatile ("add %0, %1, %2" :"=r"(a0) :"r"(a0),"r"(a1) ); end_loop:
まとめ
ESP32で通常の分岐命令を使う場合、ジャンプ先の命令として16bit命令と24bit命令のどちらを使うかはリンカが決定していますが、たまに遅いコードを吐きます。 zero-overheadループを使えばおそらくリンカは信用できそうなことと、そもそも命令フェッチによる1サイクルの遅れよりも分岐命令とzero-overheadループの差のほうが遥かに大きいことから、性能に大きく関わってくるようなループはzero-overheadループを使うようにしていれば問題なさそうです。
どうしても通常の分岐命令を使ってアラインメント跨ぎによる性能低下を避けるためには、ループ中の命令数と実行サイクル数を見比べて(もしくはジャンプ先のアドレスのアラインメントを見て)、遅いループになっていれば祈りNOPをループ前に入れてみていい配置になるのを期待するしかなさそうです。
0 notes
Text
Released Actcast alpha
We have released an IoT platform service named Actcast. It is free of charge alpha release. Please give it a try!
URL of the service: https://actcast.io
What is Actcast?
Actcast is an IoT platform service aiming to handle every information in the physical world by software.
Most of existing IoT systems are using relatively simple data sources such as a temperature-humidity sensor, a vibration sensor, a button switch and so on. On the other hand, with Actcast, you can use perception techniques such as image recognition based on deep learning to obtain diverse information.
Application fields are from security, in-store marketing, digital signage, visual inspection, inventory management, infrastructure monitoring and so on.

The main features of Actcast are:
Low initial costs
Low running costs
Appropriate treatment of privacy and confidential information
Remote device management and software update
Low Initial Costs
We have been doing R&D for executing deep learning inference on Raspberry Pi series to reduce costs for devices. Watch our achievements in the following video.
youtube
Usually, expensive computers are required to run deep learning inference. With our technology, the initial cost for a device becomes less than 100 USD including the camera module. Besides following facts: there are lots of information about Raspberry Pi on the Web, there are many hardware products compatible with such as camera modules, sensor modules, and cases, the supply is stable, and so on, will save cost for initial development, especially in time cost.
We realized the potential of Raspberry Pi as a hardware platform for deep learning inference 3 years ago and have been developing tools such as optimizing compiler specialized for deep learning models. In the development of Actcast, we place importance on acceleration techniques which keeps the model mathematically equivalent. Although, it is a severe condition for speeding up because it does not reduce the amount of computation, it enables automation of deployment of deep learning models to devices without trial and error process to repeat model compressions and accuracy tests for achieving accuracy.
Taking these advantages, we are designing a mechanism and a business model that allows many applications to gather on Actcast. Our goal is to make Actcast a place where a wide variety of applications are available, and every user can construct advance IoT system by just combining appropriate application.
Low Running Costs
In the Actcast’s way, inferences such as image recognition are executed on the edge devices, and only summarized information are sent to the Web. This concept is called Edge Computing.
This architecture significantly reduces the communication cost and server cost compared with that of sending data to the server and analyzing on it. Let’s consider people detection, for example. If inference with 5 fps is necessary, the number of images processed is 13 million per month. Communication and computation occur for all of these images when computation run on a server.
On the other hand, with the Actcast’s way, communication occurs only for the number of people detected by the camera. Also, since the data sent has already been analyzed, the computation cost on the server does not occur.

Appropriate Treatment of Privacy and Confidential Information
Edge Computing also has the advantage of reducing the leakage risk for privacy and confidential information. It's because devices don't have to send unnecessary data to the server. As interest in privacy is growing more and more, we think the concept of Edge Computing becomes essential.

Remote Device Management and Software Update
You can manage devices registered to Actcast remotely with the following operations:
Alive monitoring
Check the status of the device and software
Install/update/switch/configure software
We think that continuous progress is necessary for the system with machine learning technology. Because it is impossible to create an algorithm with 100% accuracy, it is important to keep using new technologies, collect data and make improvements day by day. In edge computing, the software runs on the device in the field, so the remote update of the software is an essential function.
About alpha version
With this alpha version, you can use applications we prepared in advance to experience the concept of acquiring real-world information and connecting to the web.
You can run demos like the ones on the above with Raspberry Pi on your hand. We are happy if you can report on SNS when it works as expected. Because it is under development, We think there are some problems. Please tell us in the following repository in such cases.
https://github.com/Idein/actcast-support
Toward official release
We are going to develop SDK for enabling users can create custom applications using custom models, make performance improvements, and add some features. Also, we’ll work on making application examples utilizing Actcast. Also, we need to strengthen the structure for service operation.
We think that it can be useful if users can collect data and train models as well in Actcast, so we’ll try to implement Neural Architecture Search and others.
We are looking for talented personnel. We are waiting for your application! https://idein.jp/career
Also, we are looking for partner companies since business development using Actcast requires various elements such as prototyping, production, sales, installation, operation and maintenance of devices, recognition algorithms tailored to the application, analysis, and visualization on the Web, UI, telecommunication, system integration and so on. Companies that become partners have advantages such as early access to SDKs and functions under development. For details, please see the following document.
https://actcast.io/docs/files/partner_program.pdf

1 note
·
View note
Text
Actcast α版をリリースしました
Ideinの代表の中村です。本日、弊社が開発中のIoTプラットフォームサービスActcastのα版をリリースしました。無料ですので是非お試しください。
サービスのサイトはこちら: https://actcast.io
実は昨日中にサイトを公開していたんですが、一日遅れての告知となりました。リリースが12/10と聞いていた皆さまごめんなさい。
Actcastとは
Ideinは実世界のあらゆる情報をソフトウェアで扱えるようにするという事を目標に掲げており、Actcastはそれを目指して開発を進めているIoTプラットフォームサービスです。
従来のIoTシステムでは温湿度センサー、振動センサー、スイッチなど比較的単純な情報源が使用されることが多かったのではないかと思いますが、Actcastではディープラーニングを用いた画像認識などにより多様な情報を取得する事が可能になります。応用分野はセキュリティ、店舗マーケティング、サイネージ、外観検査、在庫管理、インフラ監視など多岐に渡るでしょう。

このような応用の為のサービスは多数存在しますが、Actcastの特長は
初期コストが安い
運用コストが安い
プライバシーや機密情報の適切な取り扱いが可能
遠隔でのデバイス管理とソフトウェア更新が可能
という事です。α版は無料ですがのちに有料版になった際も従来サービスより文字通り桁違いに安価に提供できる予定です。
初期コストが安い
まず、ディープラーニングモデルを実行するデバイスのコストを安くする為、Raspberry Piを最初のターゲットに選び研究開発を行ってきました。その成果は以下の動画をご覧ください。
youtube
ディープラーニングでの推論を実行する為に高価な計算機を使われている方も多いのではないかと思いますが、Raspberry Piはカメラ込みでも1万円以下です。Web上に情報が沢山ある事、組合せて使えるカメラ・センサー・ケースなどが多数販売されている事、供給が安定している事なども初期のコスト、特に時間を節約してくれます。
弊社ではRaspberry Piのディープラーニングを実行するデバイスとしての価値に早期から注目し、ディープラーニング専用のコンパイラなどツールの開発を進めてきました。その開発においては、学習済みモデルを数学的に等価なまま高速化する事を重要視してきました。計算量を減らせないので高速化のためには厳しい条件ですが、モデルの圧縮とそれに伴い変化する精度の検証を繰り返す試行錯誤の工程が無くなり、コストを掛けずにデバイスに搭載するアプリケーションを作る事が可能になります。
この強みを生かしてActcast上に多数のアプリケーションが集まるような仕組み・ビジネスモデルを考えています。Actcastには多数の多様なアプリケーションが揃っており、ユーザーが選んで使うだけで様々な情報を取得対象にできる、という所を目指しています。
運用コストが安い
Actcastでは画像認識などの推論処理は末端のデバイス上で実行され、要約された情報のみがWebに送信されます。Edge Computingと呼ばれます。
この方法だとサーバーにデータを送って解析する方法と比べ、通信コスト・サーバーコストが著しく減ります。例えば人を検出する事を考えてみましょう。秒間5フレームの解析が必要な場合、処理する枚数は1300万枚/月となります。
サーバーで解析する方式ではこのすべてで通信と計算が発生します。一方、Actcastの方式ではカメラで検出した人数分しか通信が発生しません。また送られてきたデータは解析済みですから、サーバー側の計算コストが発生しません。
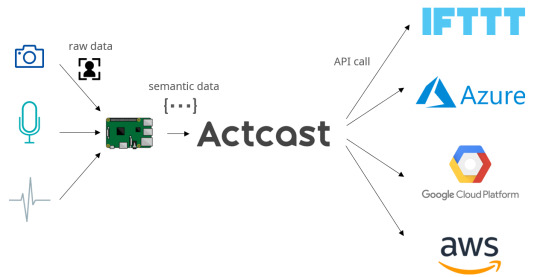
プライバシーや機密情報の適切な取り扱い
Edge Computingにはプライバシー情報や機密情報漏洩のリスクを減らせるという利点もあります。サーバーに送るのは必要最小限な情報のみで済むからです。プライバシーへの関心がますます高まってきていますので、不要なデータを通信しないEdge Computingの考え方が重要になってくると考えています。
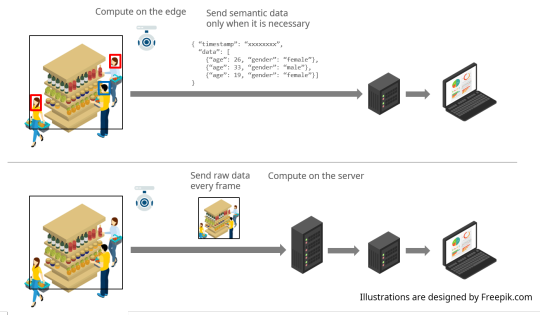
遠隔でのデバイス管理とソフトウェア更新
Actcastに登録したデバイスは以下のような管理を遠隔で行う事ができます。
死活監視
ステータスの閲覧
ソフトウェアの遠隔インストール、更新、切り替え、設定変更
私達は機械学習技術を応用したシステムは漸進的に進歩していけるものである必要があると考えています。精度100%のアルゴリズムは作り得ないものであるので、新しい技術を取り込み、データを収集し日々改善を行う事ができるものである事が必要です。エッジコンピューティングでは現場のデバイス上でソフトウェアが動作しますので、遠隔でのソフトウェアの更新がとても重要な機能となります。
α版で出来る事
α版では私達があらかじめ用意したアプリケーションを使って、実世界情報を取得しWebに接続するというコンセプトを体験してもらえるようになっています。
実際にお手持ちのRaspberry Piで上の動画にあるようなデモを動作させる事ができます。無事動きましたら是非SNS等で報告して頂けると嬉しいです。また、開発途中のサービスですので不具合が起こる事があると思います。その際は是非以下で教えて頂けますとありがたいです。
https://github.com/Idein/actcast-support
本リリースに向けて
ユーザー独自のモデルを使ってアプリケーションを作る為のSDKの開発や性能改善等に取り組んで行きます。また、Actcastを活用した応用事例を作る事にも取り組んでいきたいと考えています。また、Actcast運用の為の体制も強化していく必要があります。
学習データの収集やモデルのトレーニングなどもサービス上で出来ると便利なのではないかと考えていますので、Neural Architecture Searchなどにもチャレンジしていきたいと考えています。各分野で強い人達が必要です。
絶賛人材募集中ですので是非ご応募ください!https://idein.jp/career
また、Actcastを利用したビジネス開発はデバイスの試作・量産・販売・設置・運用・保守、用途に合わせた認識アルゴリズム、Web側での分析・可視化・UI、通信、システムインテグレーションなど様々な要素が必要になりますので、パートナー企業を募集中です。パートナーになって頂いた企業には開発中のSDKや機能に早期アクセスできるといったメリットがあります。詳しくは以下をご覧ください。
https://actcast.io/docs/files/ja/partner_program.pdf
3 notes
·
View notes