#and Google will control all the software
Text
A fun thing about computer skills is that as you have more of them, the number of computer problems you have doesn't go down.
This is because as a beginner, you have troubles because you don't have much knowledge.
But then you learn a bunch more, and now you've got the skills to do a bunch of stuff, so you run into a lot of problems because you're doing so much stuff, and only an expert could figure them out.
But then one day you are an expert. You can reprogram everything and build new hardware! You understand all the various layers of tech!
And your problems are now legendary. You are trying things no one else has ever tried. You Google them and get zero results, or at best one forum post from 1997. You discover bugs in the silicon of obscure processors. You crash your compiler. Your software gets cited in academic papers because you accidently discovered a new mathematical proof while trying to remote control a vibrator. You can't use the wifi on your main laptop because you wrote your own uefi implementation and Intel has a bug in their firmware that they haven't fixed yet, no matter how much you email them. You post on mastodon about your technical issue and the most common replies are names of psychiatric medications. You have written your own OS but there arent many programs for it because no one else understands how they have to write apps as a small federation of coroutine-based microservices. You ask for help and get Pagliacci'd, constantly.
But this is the natural of computer skills: as you know more, your problems don't get easier, they just get weirder.
33K notes
·
View notes
Text
Unpersoned

Support me this summer on the Clarion Write-A-Thon and help raise money for the Clarion Science Fiction and Fantasy Writers' Workshop!

My latest Locus Magazine column is "Unpersoned." It's about the implications of putting critical infrastructure into the private, unaccountable hands of tech giants:
https://locusmag.com/2024/07/cory-doctorow-unpersoned/
The column opens with the story of romance writer K Renee, as reported by Madeline Ashby for Wired:
https://www.wired.com/story/what-happens-when-a-romance-author-gets-locked-out-of-google-docs/
Renee is a prolific writer who used Google Docs to compose her books, and share them among early readers for feedback and revisions. Last March, Renee's Google account was locked, and she was no longer able to access ten manuscripts for her unfinished books, totaling over 220,000 words. Google's famously opaque customer service – a mix of indifferently monitored forums, AI chatbots, and buck-passing subcontractors – would not explain to her what rule she had violated, merely that her work had been deemed "inappropriate."
Renee discovered that she wasn't being singled out. Many of her peers had also seen their accounts frozen and their documents locked, and none of them were able to get an explanation out of Google. Renee and her similarly situated victims of Google lockouts were reduced to developing folk-theories of what they had done to be expelled from Google's walled garden; Renee came to believe that she had tripped an anti-spam system by inviting her community of early readers to access the books she was working on.
There's a normal way that these stories resolve themselves: a reporter like Ashby, writing for a widely read publication like Wired, contacts the company and triggers a review by one of the vanishingly small number of people with the authority to undo the determinations of the Kafka-as-a-service systems that underpin the big platforms. The system's victim gets their data back and the company mouths a few empty phrases about how they take something-or-other "very seriously" and so forth.
But in this case, Google broke the script. When Ashby contacted Google about Renee's situation, Google spokesperson Jenny Thomson insisted that the policies for Google accounts were "clear": "we may review and take action on any content that violates our policies." If Renee believed that she'd been wrongly flagged, she could "request an appeal."
But Renee didn't even know what policy she was meant to have broken, and the "appeals" went nowhere.
This is an underappreciated aspect of "software as a service" and "the cloud." As companies from Microsoft to Adobe to Google withdraw the option to use software that runs on your own computer to create files that live on that computer, control over our own lives is quietly slipping away. Sure, it's great to have all your legal documents scanned, encrypted and hosted on GDrive, where they can't be burned up in a house-fire. But if a Google subcontractor decides you've broken some unwritten rule, you can lose access to those docs forever, without appeal or recourse.
That's what happened to "Mark," a San Francisco tech workers whose toddler developed a UTI during the early covid lockdowns. The pediatrician's office told Mark to take a picture of his son's infected penis and transmit it to the practice using a secure medical app. However, Mark's phone was also set up to synch all his pictures to Google Photos (this is a default setting), and when the picture of Mark's son's penis hit Google's cloud, it was automatically scanned and flagged as Child Sex Abuse Material (CSAM, better known as "child porn"):
https://pluralistic.net/2022/08/22/allopathic-risk/#snitches-get-stitches
Without contacting Mark, Google sent a copy of all of his data – searches, emails, photos, cloud files, location history and more – to the SFPD, and then terminated his account. Mark lost his phone number (he was a Google Fi customer), his email archives, all the household and professional files he kept on GDrive, his stored passwords, his two-factor authentication via Google Authenticator, and every photo he'd ever taken of his young son.
The SFPD concluded that Mark hadn't done anything wrong, but it was too late. Google had permanently deleted all of Mark's data. The SFPD had to mail a physical letter to Mark telling him he wasn't in trouble, because he had no email and no phone.
Mark's not the only person this happened to. Writing about Mark for the New York Times, Kashmir Hill described other parents, like a Houston father identified as "Cassio," who also lost their accounts and found themselves blocked from fundamental participation in modern life:
https://www.nytimes.com/2022/08/21/technology/google-surveillance-toddler-photo.html
Note that in none of these cases did the problem arise from the fact that Google services are advertising-supported, and because these people weren't paying for the product, they were the product. Buying a $800 Pixel phone or paying more than $100/year for a Google Drive account means that you're definitely paying for the product, and you're still the product.
What do we do about this? One answer would be to force the platforms to provide service to users who, in their judgment, might be engaged in fraud, or trafficking in CSAM, or arranging terrorist attacks. This is not my preferred solution, for reasons that I hope are obvious!
We can try to improve the decision-making processes at these giant platforms so that they catch fewer dolphins in their tuna-nets. The "first wave" of content moderation appeals focused on the establishment of oversight and review boards that wronged users could appeal their cases to. The idea was to establish these "paradigm cases" that would clarify the tricky aspects of content moderation decisions, like whether uploading a Nazi atrocity video in order to criticize it violated a rule against showing gore, Nazi paraphernalia, etc.
This hasn't worked very well. A proposal for "second wave" moderation oversight based on arms-length semi-employees at the platforms who gather and report statistics on moderation calls and complaints hasn't gelled either:
https://pluralistic.net/2022/03/12/move-slow-and-fix-things/#second-wave
Both the EU and California have privacy rules that allow users to demand their data back from platforms, but neither has proven very useful (yet) in situations where users have their accounts terminated because they are accused of committing gross violations of platform policy. You can see why this would be: if someone is accused of trafficking in child porn or running a pig-butchering scam, it would be perverse to shut down their account but give them all the data they need to go one committing these crimes elsewhere.
But even where you can invoke the EU's GDPR or California's CCPA to get your data, the platforms deliver that data in the most useless, complex blobs imaginable. For example, I recently used the CCPA to force Mailchimp to give me all the data they held on me. Mailchimp – a division of the monopolist and serial fraudster Intuit – is a favored platform for spammers, and I have been added to thousands of Mailchimp lists that bombard me with unsolicited press pitches and come-ons for scam products.
Mailchimp has spent a decade ignoring calls to allow users to see what mailing lists they've been added to, as a prelude to mass unsubscribing from those lists (for Mailchimp, the fact that spammers can pay it to send spam that users can't easily opt out of is a feature, not a bug). I thought that the CCPA might finally let me see the lists I'm on, but instead, Mailchimp sent me more than 5900 files, scattered through which were the internal serial numbers of the lists my name had been added to – but without the names of those lists any contact information for their owners. I can see that I'm on more than 1,000 mailing lists, but I can't do anything about it.
Mailchimp shows how a rule requiring platforms to furnish data-dumps can be easily subverted, and its conduct goes a long way to explaining why a decade of EU policy requiring these dumps has failed to make a dent in the market power of the Big Tech platforms.
The EU has a new solution to this problem. With its 2024 Digital Markets Act, the EU is requiring platforms to furnish APIs – programmatic ways for rivals to connect to their services. With the DMA, we might finally get something parallel to the cellular industry's "number portability" for other kinds of platforms.
If you've ever changed cellular platforms, you know how smooth this can be. When you get sick of your carrier, you set up an account with a new one and get a one-time code. Then you call your old carrier, endure their pathetic begging not to switch, give them that number and within a short time (sometimes only minutes), your phone is now on the new carrier's network, with your old phone-number intact.
This is a much better answer than forcing platforms to provide service to users whom they judge to be criminals or otherwise undesirable, but the platforms hate it. They say they hate it because it makes them complicit in crimes ("if we have to let an accused fraudster transfer their address book to a rival service, we abet the fraud"), but it's obvious that their objection is really about being forced to reduce the pain of switching to a rival.
There's a superficial reasonableness to the platforms' position, but only until you think about Mark, or K Renee, or the other people who've been "unpersonned" by the platforms with no explanation or appeal.
The platforms have rigged things so that you must have an account with them in order to function, but they also want to have the unilateral right to kick people off their systems. The combination of these demands represents more power than any company should have, and Big Tech has repeatedly demonstrated its unfitness to wield this kind of power.
This week, I lost an argument with my accountants about this. They provide me with my tax forms as links to a Microsoft Cloud file, and I need to have a Microsoft login in order to retrieve these files. This policy – and a prohibition on sending customer files as email attachments – came from their IT team, and it was in response to a requirement imposed by their insurer.
The problem here isn't merely that I must now enter into a contractual arrangement with Microsoft in order to do my taxes. It isn't just that Microsoft's terms of service are ghastly. It's not even that they could change those terms at any time, for example, to ingest my sensitive tax documents in order to train a large language model.
It's that Microsoft – like Google, Apple, Facebook and the other giants – routinely disconnects users for reasons it refuses to explain, and offers no meaningful appeal. Microsoft tells its business customers, "force your clients to get a Microsoft account in order to maintain communications security" but also reserves the right to unilaterally ban those clients from having a Microsoft account.
There are examples of this all over. Google recently flipped a switch so that you can't complete a Google Form without being logged into a Google account. Now, my ability to purse all kinds of matters both consequential and trivial turn on Google's good graces, which can change suddenly and arbitrarily. If I was like Mark, permanently banned from Google, I wouldn't have been able to complete Google Forms this week telling a conference organizer what sized t-shirt I wear, but also telling a friend that I could attend their wedding.
Now, perhaps some people really should be locked out of digital life. Maybe people who traffick in CSAM should be locked out of the cloud. But the entity that should make that determination is a court, not a Big Tech content moderator. It's fine for a platform to decide it doesn't want your business – but it shouldn't be up to the platform to decide that no one should be able to provide you with service.
This is especially salient in light of the chaos caused by Crowdstrike's catastrophic software update last week. Crowdstrike demonstrated what happens to users when a cloud provider accidentally terminates their account, but while we're thinking about reducing the likelihood of such accidents, we should really be thinking about what happens when you get Crowdstruck on purpose.
The wholesale chaos that Windows users and their clients, employees, users and stakeholders underwent last week could have been pieced out retail. It could have come as a court order (either by a US court or a foreign court) to disconnect a user and/or brick their computer. It could have come as an insider attack, undertaken by a vengeful employee, or one who was on the take from criminals or a foreign government. The ability to give anyone in the world a Blue Screen of Death could be a feature and not a bug.
It's not that companies are sadistic. When they mistreat us, it's nothing personal. They've just calculated that it would cost them more to run a good process than our business is worth to them. If they know we can't leave for a competitor, if they know we can't sue them, if they know that a tech rival can't give us a tool to get our data out of their silos, then the expected cost of mistreating us goes down. That makes it economically rational to seek out ever-more trivial sources of income that impose ever-more miserable conditions on us. When we can't leave without paying a very steep price, there's practically a fiduciary duty to find ways to upcharge, downgrade, scam, screw and enshittify us, right up to the point where we're so pissed that we quit.
Google could pay competent decision-makers to review every complaint about an account disconnection, but the cost of employing that large, skilled workforce vastly exceeds their expected lifetime revenue from a user like Mark. The fact that this results in the ruination of Mark's life isn't Google's problem – it's Mark's problem.
The cloud is many things, but most of all, it's a trap. When software is delivered as a service, when your data and the programs you use to read and write it live on computers that you don't control, your switching costs skyrocket. Think of Adobe, which no longer lets you buy programs at all, but instead insists that you run its software via the cloud. Adobe used the fact that you no longer own the tools you rely upon to cancel its Pantone color-matching license. One day, every Adobe customer in the world woke up to discover that the colors in their career-spanning file collections had all turned black, and would remain black until they paid an upcharge:
https://pluralistic.net/2022/10/28/fade-to-black/#trust-the-process
The cloud allows the companies whose products you rely on to alter the functioning and cost of those products unilaterally. Like mobile apps – which can't be reverse-engineered and modified without risking legal liability – cloud apps are built for enshittification. They are designed to shift power away from users to software companies. An app is just a web-page wrapped in enough IP to make it a felony to add an ad-blocker to it. A cloud app is some Javascript wrapped in enough terms of service clickthroughs to make it a felony to restore old features that the company now wants to upcharge you for.
Google's defenstration of K Renee, Mark and Cassio may have been accidental, but Google's capacity to defenstrate all of us, and the enormous cost we all bear if Google does so, has been carefully engineered into the system. Same goes for Apple, Microsoft, Adobe and anyone else who traps us in their silos. The lesson of the Crowdstrike catastrophe isn't merely that our IT systems are brittle and riddled with single points of failure: it's that these failure-points can be tripped deliberately, and that doing so could be in a company's best interests, no matter how devastating it would be to you or me.
If you'd like an e ssay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/07/22/degoogled/#kafka-as-a-service
Image:
Cryteria (modified)
https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0
https://creativecommons.org/licenses/by/3.0/deed.en
519 notes
·
View notes
Text
The main reason to use Firefox and Linux and other free and open source software is that otherwise the big tech monopolies will fuck you as the customer over in search of profits. They will seek to control how you use their products and sell your data. When a company dominates the market, things can only get worse for ordinary people.
Like take Google Chrome for example, which together with its chromium reskins dominate the web browser market. Google makes a lot of money from ads, and consequently the company hates adblockers. They already are planning to move to manifest V3, which will nerf adblockers significantly. The manifest V3 compatible chrome version of Ublock Orgin is a "Lite" version for a reason. Ublock's Github page has an entire page explaining why the addon works best in Firefox.
And Google as we speak are trying to block adblockers from working on Youtube, If you want to continue blocking Youtube ads, and since Youtube ads make the site unuseable you ought to want that, it makes the most sense to not use a browser controlled by Google.
And there is no reason to think things won't get worse. There is for example nothing stopping Google from kicking adblockers off their add-on stores completely. They do regard it as basically piracy if the youtube pop-ups tell us anything, so updating the Chrome extensions terms of service to ban adblocking is a natural step. And so many people seem to think Chrome is the only browser that exists, so they are not going to switch to alternatives, or if they do, they will switch to another chrominum-based browser.
And again, they are fucking chromium itself for adblockers with Manifest V3, so only Firefox remains as a viable alternative. It's the only alternative to letting Google control the internet.
And Microsoft is the same thing. I posted before about their plans to move Windows increasingly into the cloud. This already exists for corporate customers, as Windows 365. And a version for ordinary users is probably not far off. It might not be the only version of Windows for awhile, the lack of solid internet access for a good part of the Earth's population will prevent it. But you'll probably see cheap very low-spec chromebookesque laptops running Windows for sale soon, that gets around Windows 11's obscene system requirements by their Windows being a cloud-based version.
And more and more of Windows will require Internet access or validation for DRM reasons if nothing else. Subscription fees instead of a one-time license are also likely. It will just be Windows moving in the direction Microsoft Office has already gone.
There is nothing preventing this, because again on the desktop/laptop market Windows is effectively a monopoly, or a duopoly with Apple. So there is no competition preventing Microsoft from exercising control over Windows users in the vein of Apple.
For example, Microsoft making Windows a walled garden by only permitting programs to be installed from the Microsoft Store probably isn't far off. This already exists for Win10 and 11, it's called S-mode. There seem to be more and more laptops being sold with Windows S-mode as the default.
Now it's not the only option, and you can turn it off with some tinkering, but there is really nothing stopping Microsoft from making it the only way of using Windows. And customers will probably accept it, because again the main competition is Apple where the walled garden has been the default for decades.
Customers have already accepted all sorts of bad things from Microsoft, because again Windows is a near-monopoly, and Apple and Google are even worse. That’s why there has been no major negative reaction to how Windows has increasingly spies on its users.
Another thing is how the system requirements for Windows seem to grow almost exponentially with each edition, making still perfectly useable computers unable to run the new edition. And Windows 11 is the worst yet. Like it's hard to get the numbers of how many computers running Win10 can't upgrade to Win11, but it's probably the majority of them, at least 55% or maybe even 75%. This has the effect of Windows users abandoning still perfectly useable hardware and buying new computers, creating more e-waste.
For Windows users, the alternative Windows gives them is to buy a new computer or get another operating system, and inertia pushes them towards buying another computer to keep using Windows. This is good for Windows and the hardware manufacturers selling computers with Windows 11 pre-installed, they get to profit off people buying Windows 11 keys and new computers, while the end-users have to pay, as does the environment. It’s planned obsolescence.
And it doesn’t have to be like that. Linux distros prove that you can have a modern operating system that has far lower hardware requirements. Even the most resource taxing Linux distros, like for example Ubuntu running the Gnome desktop, have far more modest system requirements than modern Windows. And you can always install lightweight Linux Distros that often have very low system requirements. One I have used is Antix. The ballooning Windows system requirements comes across as pure bloat on Microsoft’s part.
Now neither Linux or Firefox are perfect. Free and open source software don’t have a lot of the polish that comes with the proprietary products of major corporations. And being in competition with technology monopolies does have its drawbacks. The lacking website compatibility with Firefox and game compatibility with Linux are two obvious examples.
Yet Firefox and Linux have the capacity to grow, to become better. Being open source helps. Even if Firefox falls, developers can create a fork of it. If a Linux distro is not to your taste, there is usually another one. Whereas Windows and Chrome will only get worse as they will continue to abuse their monopolistic powers over the tech market.
827 notes
·
View notes
Text
Microsoft's CEO Satya Nadella has hailed the company's new Recall feature, which stores a history of your computer desktop and makes it available to AI for analysis, as “photographic memory” for your PC. Within the cybersecurity community, meanwhile, the notion of a tool that silently takes a screenshot of your desktop every five seconds has been hailed as a hacker's dream come true and the worst product idea in recent memory.
Now, security researchers have pointed out that even the one remaining security safeguard meant to protect that feature from exploitation can be trivially defeated.
Since Recall was first announced last month, the cybersecurity world has pointed out that if a hacker can install malicious software to gain a foothold on a target machine with the feature enabled, they can quickly gain access to the user's entire history stored by the function. The only barrier, it seemed, to that high-resolution view of a victim's entire life at the keyboard was that accessing Recall's data required administrator privileges on a user's machine. That meant malware without that higher-level privilege would trigger a permission pop-up, allowing users to prevent access, and that malware would also likely be blocked by default from accessing the data on most corporate machines.
Then on Wednesday, James Forshaw, a researcher with Google's Project Zero vulnerability research team, published an update to a blog post pointing out that he had found methods for accessing Recall data without administrator privileges—essentially stripping away even that last fig leaf of protection. “No admin required ;-)” the post concluded.
“Damn,” Forshaw added on Mastodon. “I really thought the Recall database security would at least be, you know, secure.”
Forshaw's blog post described two different techniques to bypass the administrator privilege requirement, both of which exploit ways of defeating a basic security function in Windows known as access control lists that determine which elements on a computer require which privileges to read and alter. One of Forshaw's methods exploits an exception to those control lists, temporarily impersonating a program on Windows machines called AIXHost.exe that can access even restricted databases. Another is even simpler: Forshaw points out that because the Recall data stored on a machine is considered to belong to the user, a hacker with the same privileges as the user could simply rewrite the access control lists on a target machine to grant themselves access to the full database.
That second, simpler bypass technique “is just mindblowing, to be honest,” says Alex Hagenah, a cybersecurity strategist and ethical hacker. Hagenah recently built a proof-of-concept hacker tool called TotalRecall designed to show that someone who gained access to a victim's machine with Recall could immediately siphon out all the user's history recorded by the feature. Hagenah's tool, however, still required that hackers find another way to gain administrator privileges through a so-called “privilege escalation” technique before his tool would work.
With Forshaw's technique, “you don’t need any privilege escalation, no pop-up, nothing,” says Hagenah. “This would make sense to implement in the tool for a bad guy.”
In fact, just an hour after speaking to WIRED about Forshaw's finding, Hagenah added the simpler of Forshaw's two techniques to his TotalRecall tool, then confirmed that the trick worked by accessing all the Recall history data stored on another user's machine for which he didn't have administrator access. “So simple and genius,” he wrote in a text to WIRED after testing the technique.
That confirmation removes one of the last arguments Recall's defenders have had against criticisms that the feature acts as, essentially, a piece of pre-installed spyware on a user's machine, ready to be exploited by any hacker who can gain a foothold on the device. “It makes your security very fragile, in the sense that anyone who penetrates your computer for even a second can get your whole history,” says Dave Aitel, the founder of the cybersecurity firm Immunity and a former NSA hacker. “Which is not something people want.”
For now, security researchers have been testing Recall in preview versions of the tool ahead of its expected launch later this month. Microsoft said it plans to integrate Recall on compatible Copilot+ PCs with the feature turned on by default. WIRED reached out to the company for comment on Forshaw's findings about Recall's security issues, but the company has yet to respond.
The revelation that hackers can exploit Recall without even using a separate privilege escalation technique only contributes further to the sense that the feature was rushed to market without a proper review from the company's cybersecurity team—despite the company's CEO Nadella proclaiming just last month that Microsoft would make security its first priority in every decision going forward. “You cannot convince me that Microsoft's security teams looked at this and said ‘that looks secure,’” says Jake Williams, a former NSA hacker and now the VP of R&D at the cybersecurity consultancy Hunter Strategy, where he says he's been asked by some of the firm's clients to test Recall's security before they add Microsoft devices that use it to their networks.
“As it stands now, it’s a security dumpster fire,” Williams says. “This is one of the scariest things I’ve ever seen from an enterprise security standpoint.”
143 notes
·
View notes
Text
Inaccessible tech is such a vicious cycle it’s beyond frustrating. My computer knowledge is dreadful for someone my age, and I know it’s dreadful but it’s incredibly hard for me to do anything about it.
Dragon, the software I use to control my computer with my voice costs £679.99. I have access to it through a scheme to help disabled people in work – without a job I’d have to pay for it myself or find another source of funding (without access to a laptop/ PC).
The software is great in many ways, but limiting in others. It’s mainly targeted at able bodied professionals as a way of dictating quickly, so while it’s absolutely brilliant for dictating into a word document, it’s a bit more tricky to control your computer with it.
One of the biggest problems though is that I can’t easily try out different software and browsers. Google docs aren’t as compatible with my software as word is. I can’t learn about alternatives because it’s a lot of time invested in something that probably won’t work well.
Each different browser requires me to download a different extension so that Dragon can interact properly with the pages. Until that’s all set up, rather than just being able to click on things I have to guide the curser through a series of increasingly small numbered grids to the right point on the screen like this: “mouse grid [pause] 3 [pause] nine [Pause] one [pause] two [pause] Mouse left click”).
But Firefox, the browser I’m most often recommended to use, I can’t use. From what I can tell there used to be an extension but Firefox now considers the Dragon extension to be a security risk and won’t allow it to be installed. I’ve looked into finding alternative ways to download the extension, but it gets really complicated really quickly – especially when each and every mouse click takes so long. After failing several times I gave up.
And it’s frustrating because if using a computer wasn’t so difficult l me, I would probably be better at finding my way around these kinds of obstacles better.
And if technology wasn’t so expensive and difficult to access more disabled people would be creating better software and hardware for disabled people.
Similarly if adaptive controllers were less expensive I might know more than I do about gaming. And more game producers might be disabled, or might create games with disabled people in mind.
But we’re stuck trying to make do with technology that’s either financially out of reach, incredibly limited or both and it means it’s incredibly hard to learn enough to come anywhere close to solving those issues (or being able to properly describe them in the first place)
135 notes
·
View notes
Text
useful information: How to get a USB Blu-Ray player to work on your computer
Not a post about vintage technology, just an explanation of what you think might be simple to do but isn't: There are Blu-Ray players that plug into your computer by USB, and you discover that just plugging it in doesn't make it work* in the same manner that CD-RWs or DVD-RWs are automatically recognised and function. You will see "BR Drive" in My Computer and the name of whatever movie you have inserted, but that's as far as you're able to go.

*There is software you can buy to make a Blu-Ray (internal or external) function, sure, and if an internal came with your computer it's likely already installed -- but if you're like me you don't have that software, you're cheap and won't pay for software, and you want to use what you have installed already or find free solutions.
Looking in the Blu-Ray drive's package, there's not a lot of info about what you're supposed to do. The above no-name Blu-Ray player cost $40 from a popular website; name-brand ones can set you back $120 or so. Looking around online for those instructions, I never saw the whole set of directions in one place, I had to cobble them together from 2 or 3 sites. And so here I share that list. To keep out of trouble, I'm not linking any files -- Google will help you.
Get VLC, the free video player available for pretty much any operating system. Thing is, it doesn't come with the internals to make it work with Blu-Ray even if when you go to the Play Media menu there is a radio button for selecting Blu-Ray.
Get MakeMKV, a decoder for reading Blu-Ray disks. This had been totally free during the beta testing period but it's come out and has a month or two trial period you can work in.
Get Java if you don't already have it. Reason for this is, the menu systems on Blu-Ray disks uses this... technically it's not required, however it does mean you don't have options such as special features, language and sound changes, or scene selection if you don't have Java installed; insert a disk, it can only play the movie.
Get the file libaacs.dll online so you have AACS decoding. I am told it hasn't been updated in awhile so there may be disks produced after 2013 that won't work right, but you won't know until you try.
There's a set of keys you will also want to have so that the player knows how to work with specific disks, and so do a search online for the "FindVUK Online Database". There will be a regularly-updated keydb.cfg archive file on that page to pick up.
Got those three programs installed and the other two files obtained? Okay, here are your instructions for assembly...
In VLC: go to Tools, Prefs, click "show all"… under the Input/Codecs heading is Access Modules then Blu-Ray: Select your region, A through C. You can change this if you need to for foreign disks. Next related action: go to My Computer and C:, click into Program Files and VLC, and this is where you copy the libaacs.dll file to.
In MakeMKV: click View, then Preferences, and under Integration - add VLC.
Confirm that Java is set up to work with VLC by going to the computer's Control Panel, going to System Properties, and into Environment Variables. Click System Variables, and click New to create this key if it doesn't already exist:
… Name: Java
… Value: [the location of the Java 'jre#.##' folder... use Browse to find it in C:\Program Files\Java]
Let's go back into My Computer and C:, this time go to Program Data, and then do a right-click in the window and select New and Folder. Rename this folder "aacs" (without the quotes), and then you click into it and copy the keydb.cfg file here.
REBOOT.
And now you should be able to recognise Blu-Ray disks in your player and play them. Three troubleshooting notes to offer in VLC:
"Disk corrupt" -- this means MakeMKV has not decoded and parsed the disk yet, or that you don't have the libaacs.dll in place so that it can decode the disk.
...After checking the VLC folder for the DLL to make sure, launch MakeMKV, then go to File, Play Disk, and select the Blu-Ray drive. Now it will grind a bit and figure out the disk's contents.
A note appears when a movie starts saying there will be no menus, but the movie plays fine -- Java isn't running.
...Invoke Java by going to the Java Settings in Start: Programs. You don't have to change anything here, so Exit, then eject the disk and put it back in to see if the movie's menu now appears.
Buffering between chapters, making the movie pause for a few seconds? There is a setting for this but I need to find that info page again for where that is. (If you find it, tell me where it is!)
I don't claim to know a lot but if you have any questions I might have some answers or suggestions. So far I've watched "Office Space" and Disney's "Coco" without any issues beside occasional buffering.
82 notes
·
View notes
Text
Sticker Cutter Research
I was looking into getting a sticker cutting machine, and I decided to start by looking into cricut which is a well known brand. I had a look at what models they had than their feature etc, but what I was most concerned about was their software. Printer companies like to lock you into a defacto subscription to support hardware you don't really own, and as I was to discover, cricut are operating in a similar way.
The cricut software is online-only*. To cut your own designs you need to use their software to upload your art to their server. There's no way to cut a new design without a logged-in cricut account and an internet connection. At one point in 2021 they flirted with limiting free accounts to 20 uploads/month but backed down after huge community backlash, as far as I can tell.
The incident spawned several community efforts to write open-source firmware for cricut hardware. Some efforts were successful for specific models/serial numbers, but require cracking open the case and hooking in to the debug contacts to flash the chip; not exactly widely accessible. Another project sought to create a python cricut server you can run locally, and then divert the app's calls to the server to your local one.
I restarted my search, this time beginning with looking for extant open-source software for driving cutters, and found this project, which looks a little awkward to use, but functional. They list a bunch of cutter hardwares and whether they're compatible or not. Of those, I recognised the sihouette brand name from other artists talking about them.
I downloaded the silhouette software to try like I did w the cricut software, and immediately it was notable that it didn't try to connect to the internet at all. It's a bit clunky, in that way printer and scanner software tends to be, but I honestly greatly preferred using it to cricut's sluggish electron app⁺. Their software has a few paid tiers above the free one, adding stuff like sgv import/export/and reading cut settings from a barcode on the input material. They're one-off payments, and seem reasonable to me.
This is not so much a review, as sharing some of the research I've done. I haven't yet used either a cricut or a silhouette, and I haven't researched other brands either. But I wanted to talk about this research because to me, cricut's aggressively online nature is a red flag. Software that must connect to a server to run is software that runs only at the whim of the server owner (and only as long as it's profitable to keep the server up). And if that software is the only thing that will make your several hundred dollars worth of plastic and (cheap, according to a teardown I read) servos run, then you have no guarantee you'll be able to run it in the future.
Do you use a desktop cnc cutter? What has your experience been like with the hardware and software? Do you have any experience from home printers with good print quality and user-refillable ink cartridges?
* Cricut's app tried to connect to more than 14 different addresses, including facebook, youtube, google analytics, datadoghq.com, and launchdarkly.com. Launch Darkly are a service provider that help software companies do a whole bunch of things I'm coming to despise, for example, they offer infrastructure for serving different features to different demographics and comparing results to control groups. You know how at various times you've gotten wildly different numbers of ads than your friends on instagram? They were using techniques like this to work out how many ads they could show without affecting their pickup/engagement rates. Scummy stuff.
⁺ Electron apps are web-pages pretending to be applications. They use heaps of ram, tend to have very poor performance, and encourage frustrating UI design that doesn't follow OS conventions. Discord's app is a notable example of an Electron app
64 notes
·
View notes
Text
After reading @kira-serialfaggot 's post about inaccessible menus and @butterfly-sapphire post about non-customizable menus figured I now had sufficient excuse to rant about how I hate how every big restaurant's ""solution"" to these two problems is somehow always the worst fucking app I've ever had to use in my life.
So, to clarify real quick. I agree with both previous posts. Places that serve food should have their menu easily accessible somewhere if they have an online presence, and places that let you customize your order need to have that as a feature of any digital ordering solution they implement. Good? Good.
So, a lot of places I've seen (Wendys, Taco Bell, and McDonald to name a few) Have tried to get around how fucking horrible the DD app itself is by making their own apps with DD integration for the actual ordering/serving of delivery orders. Great, this lets them provide their own menu customization options, serve discounts/coupons, and generally have more control over the user experience. Fantastic. As a bonus, this usually also allows you to just look at the menu whenever you want.
Small issue. All of these apps were written by the worst fucking programmers I have ever witnessed in my life. I havn't gotten angry enough to de-compile or try to reverse engineer one yet, but my user experience has been so consistently bad and I've encountered issues that, as a software engineer, I honestly could not tell you how fucked their system has to be in order to allow that to happen.
Allow me to tell you the worst of these. I'm trying to order delivery from a store. It's late, like 7pm, but I know the place is open till 10. I can confirm this on their website (I do later for reasons that will become apparent) and google maps. So I punch in my address, make my order, and go to checkout.
Unfortunately, the app tells me "Your payment method failed. Please select a new method and try again". Which was odd, but not unimaginable. I've had issues with my bank in the past. So I swap cards and try again, thinking nothing of it.
Except, my other card doesn't work either. Nor does using PayPal, or Google Pay, or any of the other payment options I tried. I'm getting desperate. I buy some games on steam just to make sure some of these are working, which they are. I was worried, but now that I've confirmed all my money hasn't been siphoned away somehow, I'm just confused and getting annoyed.
So I start going insane. I buy digital gift cards from several different sites and try using them. No dice, payment failed. I try using the website instead of the app, on my phone and PC. Payment failed. I boot up an android studio instance with a brand new virtual phone, install the app on it, and try to order. Again. Payment failed.
I'm starting to wonder if their servers are just completely down. A friend in a different state can order with no problems. A friend in the same town can order with no fanfare.
But my roommates can't. They have the same issue
Payment failed.
So. I'm going insane. I've now spent almost 3 hours attempting to order food, and I'm starving. It is at this point that my anger finally overcomes my social anxiety, and I do the one thing I never thought I'd do.
I call the store in question.
Now, in all of this there was one crucial mistake I made. See, that friend in the same town? Lived on the other side of town. And there's 2 different stores of this franchise in town. We didn't control for this, because the app doesn't let you pick a store anyways when doing delivery. It's hard locked to whatever one is closest, which isn't a terrible thing to do. You need to get the delivery address anyways, and you know where all your store are, so it cuts out a step for me. But having to choose a store might've clued us in to what was going wrong.
Because the store? Was closed.
Not just closed, like mega closed. It was being shut down. It hadn't been open for two weeks, and would never be open again. The order was failing because they'd already taken all the computer systems out, and it couldn't confirm to have received the order.
So there was nothing wrong with the payment. Literally nothing I could have done about this. I am just barred completely from ordering because the app defaults to the nearest location for orders, and my nearest location didn't exist anymore.
And you'd think that there would be some way to communicate this to the user when making the app. But for reasons I can only assume are profit motivated (Though I have no idea how the fuck this is more efficient/profitable), the app just defaults to saying the payment failed.
Now, I wouldn't be this mad if this was just "oops edge case lol" where I suffered the unfortunate consequences of some procrastinator forgetting to do the thing that removes stores from the database. Unfortunate but not really anyone I can blame for it. But no. This is just the most extreme example, and it's not even confined to the one app.
Almost every single app like this I've used defaults to saying the payment failed and to try a new payment method when anything goes wrong. No drivers out on DoorDash to actually move the order? Payment failed. You're trying to order a seasonal item that got dropped today? Payment failed. The companies servers actually are down? Payment failed. You're not connected to wi-fi like an idiot and there's actually something you can do to fix the issue that's not related to payment whatsoever? Payment failed.
What the fuck is up with this lazy ass programming? I seriously doubt there's enough technical debt from these apps to justify not having a robust error catching system that communicates with the user what the issue is. By the fucking stars these people love collecting intrusive data, I'm surprised they havn't used this as an excuse to harvest everyone's fucking location at all times and send "error data" back to central.
But just don't tell me my debit card was declined when I'm trying to order a burger and you closed that store two weeks ago.
#journal#rant#i fucking hate food delivery apps#but i'm a poor bitch with no car#and I lived for 3 months off of a BOGO burger coupon once that just never fucking removed itself from my cart even after I ordered#so I continued to cash in on that one coupon for an entire semester#so like don't fix your apps#but don't tell me my fucking bank is broken when you just can't be bothered to update your fuckin store database
58 notes
·
View notes
Text
Tidbit: Persnickety About Posters
If you want to avoid overly dark or blurry posters in your fan adventures, then follow my lead:
1) Download JPEG off of Google Images.

2) Import, scale down, and skew/shear it. Use an interpolation method such as Bilinear or Bicubic Sharper. Doing both transformations at once is better than repeatedly transforming the image (i.e. resizing it, applying the transform, and then skewing it), as it helps prevent the image and edges from becoming too blurry. This will be important later.
You can hold down Ctrl + Shift to constrain the Move tool along a single axis so it won't go out of alignment as you're skewing it. If you don't see the Transform Controls by default, enable it in the tool options bar at the top, or go to Edit>Free Transform.

3) Desaturate it. Desaturate means to turn color grayer, until it becomes black and white.

4) Adjust the brightness and contrast using the Levels adjustment tool. It's much too dark as it is! In Photoshop, it is located under Image>Adjustments>Levels..., but I recommend creating an adjustment layer from the bottom of the layers tab instead. Doing so will allow you to make edits non-destructively, meaning you can go back and change any parameters until it looks right.

You could use a Brightness/Contrast adjustment with "Use Legacy" enabled instead to achieve a similar effect, but it won't clip the shadows and highlights as easily. You would have to create an additional duplicate adjustment and turn the brightness and contrast way down on the first one to do so. It's somewhat easier to use but less efficient than Levels in this case.
5) Apply a simple sharpen to the image as it is still too blurry for our purposes. In Photoshop, it is located under Filter>Sharpen>Sharpen... Do not use any other filter, such as Unsharp Mask, unless you absolutely have to in lieu of a basic one. If you must, turn down the radius a bit and the threshold all the way to 0.

6) Make a selection around the image. Ctrl + left click on the layer's thumbnail to make a selection around it. Doing it this way makes it inherit the level of transparency any pixels have. If you can't, use the Magic Wand tool with "Anti-alias" enabled to select the transparent area outside, then invert it using Shift + Ctrl + I, or go to Select>Inverse.
Create a new layer above the image, then go to Edit>Stroke... and add a black stroke with a width of 2px located Outside. Leave everything else at the default. Doing it this way will create a stroke with anti-aliasing based on the selection you made. This should generally turn out pretty sharp if you follow my advice from Step 2. If you had used the Stroke Effect available from the Blending Options' layer styles, it will always result in a very smooth outline instead. You do not want this.
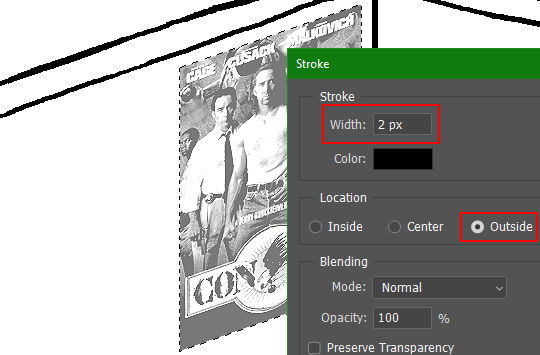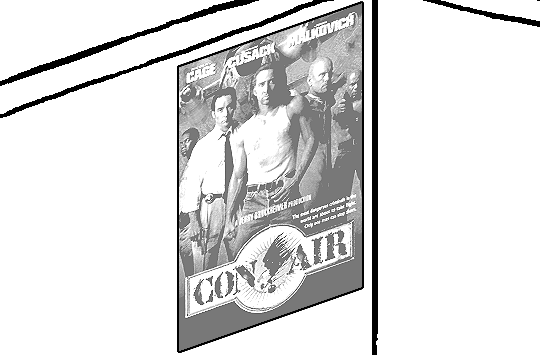
Voila, and Bob's your uncle, you're done!

The instructions above are Photoshop specific, but it should still be pretty software-agnostic. Here is the recreation PSD, and below the read-more link are additional notes, such as transferring the steps to something like GIMP.
ADDENDUM
You may be questioning why I deliberately made the stroke anti-aliased. "Isn't that an MSPArt cardinal sin??", I hear you clamoring. Well, my dear readers, let me briefly elucidate you on why your ass is wrong. Exhibit A:


The clearly semi-opaque pixels that can be found in every poster outline, which is especially pronounced here in the Little Monsters poster. I can also see that Hussie actually created a stroke on the same layer as the poster and merged it down into the white background like a dumbass. I omitted this in step 6 for the sake of convenience (and also the fact that you can't add a stroke to a smart object in Photoshop without rasterizing it first).
He had to use the magic wand tool in order to extract it from the layer for this panel, and then fill it in with the paint bucket tool. I can even tell he had the color tolerance set up very high on the magic wand to grab all those near-black and very light gray pixels, AND he had anti-alias enabled and the tolerance on the bucket tool set to be at least higher than 0 to tint similar colors. Exhibit B:


I also didn't address exactly how to desaturate something in Photoshop. Honestly it was because I was feeling pretty lazy. I would have had to rewrite step 4 to not include redundant information about adjustment layers. You can add either a Black & White adjustment layer or a Hue/Saturation one and turn the saturation all the way down to 0. The resulting tones will be slightly different from each other but I'll explain why that is in another tutorial.
Speaking of another tutorial, read this one if you believe this post is missing the step of using a posterize filter.
Now onto applying some steps to GIMP.
RE: step 2) In GIMP, there is a dedicated Unified Transform tool separate from the Move tool, unlike in Photoshop where both features are combined into one. This is how you scale and skew (AKA shear in GIMP) both at the same time, among other things such as rotating.
You'll also find that instead of any interpolation methods labeled "Bilinear" or "Bicubic", there are only ones named "Linear", "Cubic", "NoHalo", and "LoHalo". Basically, Linear and Bilinear are the same, so are Cubic and Bicubic, naturally. I guess NoHalo would be similar to Bicubic Smoother and LoHalo would be kind of similar to Bicubic Sharper as well. It's not an exact 1:1, though.
Honestly it doesn't really matter what you use to reduce the size as long as it isn't None/Nearest-Neighbor. You're going to have to sharpen it no matter what. This applies to Photoshop as well.
RE: step 3) Go to Colors>Hue-Saturation... and repeat turning the saturation down to 0, or go to Colors>Desaturate>Desaturate... and select the Lightness (HSL) method.
RE: step 4) Go to Colors>Levels... or Colors>Brightness-Contrast... The Brightness-Contrast adjustment tool already functions almost exactly like in Photoshop with "Use Legacy" enabled.
RE: step 5) In GIMP 2.10, the developers squirreled away the basic Sharpen filter, making it inaccessible from the Filters menu. To use it, hit the forward-slash (/) key or go to Help>Search and Run a Command... to bring up the Search Actions window and type in "sharpen". Select the option that just reads "Sharpen..." and has a description of "Make image sharper (less powerful than Unsharp Mask)". I find that using a sharpness value of around 40 to be similar to Photoshop's sharpen filter.
RE: step 6) Instead of holding down Ctrl, you hold down Alt and click on the layer thumbnail to make a selection around it. Make a layer underneath the image this time since there isn't an option to place the stroke outside the selection rather than the middle. Go to Edit>Stroke Selection... and create a stroke using these settings:

I recommend keeping anti-aliasing disabled however, as GIMP produces lines that are a little too smooth for my taste.

With "Antialiasing" enabled

Without
If you're using a program that doesn't have a stroke feature available, you could draw a straight 1px thick line across the top of your poster, duplicate it, and move it down 1px. Merge them together, duplicate it again, and move it all the way down to the bottom of the poster. Then repeat the exact same process for the sides. I used to do this before I even knew of the stroke feature, haha.
Another reason I had to do it this way was because my dumb ass did the thing I said not to in step 2, scaling down the image with the scale tool, and then shearing it separately with the shear tool. This caused the edges to become too blurry to be used for a stroke automatically. Oh well, live and learn.
137 notes
·
View notes
Text
Sorry peeps, but if you're genuinely out here trying to defend generative Ai because you think anyone against it is "ableist" sorry not sorry you're not just getting unfollowed you're getting fully blocked along with the OP and who you reblogged it from lmao.
"most people angry about Nanowrimo allowing AI are just being loudly ableist!!! Generative Ai is a great tool for disabled people!! Everyone should be able to use it!"
Hmm, sorry, maybe you need to curate your dash some more like I just did by blocking you, but literally the ONLY people I've seen talking about Nanowrimo's AI stance are people who are actually disabled themselves who are pointing out how fucking shitty it is for Nanowrimo to defend themselves and their sponsor using AI (and possibly scraping your works to further train their AI) By using ~Disabled People~ in concept as a shield against criticism.
Many, many people have posts on here about how they are physically or mentally disabled and they would absolutely hate having someone belittle them by telling them the only way they can accomplish something creative like writing a novel is to have a Computer spit nonsense out into a word document, or generate a "masterpiece" digital image for them from a few words typed in...
Like.
If you actually care about disabled people, you wouldn't be advocating for generative AI to be used to erase their creativity by just letting a computer churn out crap.
If you can type in a prompt on an AI generator, you can type in a word processor to write your story.
Can't physically type at all?
Use speech to text,
or do an audio recording of your novel, and have someone transcribe it,
or use actual existing Closed Caption technology to transcribe it for you!
These are all accessible technology options that actually help disabled people be creative, not just tell an AI generator "hey write me a book about x"
Disabled people have been authors and artists for millennia.
Stephen Hawking used a combination of Predictive Text, eye-control cursors, and an infrared sensor mounted on his glasses that would detect if he was tensing or relaxing the muscles in his cheek, allowing him to scroll a virtual keyboard.
Somehow, I don't think the people championing generative AI actually care about "disabled people" when they try to insist that typing a prompt into a generator and having it churn out random slop is the solution to 'allowing disabled people to be creative' instead of actually giving them the various technology and accessibility tools that have been a thing for at least 25 years, like:
Eye-tracking software that allows you to type or paint on a computer screen (this is now at the point where people can play online video games with this software!)
Having any kind of smart phone set up with speech to text and a word processing app like Google Docs or a notepad app
Using basic sound recording apps to dictate your novel for later transcription
Using other body parts than your hands (or using prosthetics) to hold paint brushes, pens, markers, digital stylus, computer mouse, etc to make art with.
And so much more!
The real ableism here is when pro-AI bros try to insist that Disabled People, categorically, are incapable of being creative and accomplishing anything without a computer doing all the work for them by generating things based on millions of stolen works, and the complete erasure of all of the disabled artists who are here *now* and existed in the past, acting like they do not and never existed, all so that rich white ai bros can continue to flood reddit with "super cool badass art I just made" which is a nonsense amalgamation, and throw tantrums when artists start using programs like Glaze and Nightshade in an attempt to protect their art from those same predatory ai tech bros.
Technology is meant to help humans be creative, not steal our works and livelyhood by replacing writers and artists entirely, because all some rich guy has to do now is type in a prompt.
14 notes
·
View notes
Text
“I’m looking at a picture of my naked body, leaning against a hotel balcony in Thailand. My denim bikini has been replaced with exposed, pale pink nipples – and a smooth, hairless crotch. I zoom in on the image, attempting to gauge what, if anything, could reveal the truth behind it. There’s the slight pixilation around part of my waist, but that could be easily fixed with amateur Photoshopping. And that’s all.
Although the image isn’t exactly what I see staring back at me in the mirror in real life, it’s not a million miles away either. And hauntingly, it would take just two clicks of a button for someone to attach it to an email, post it on Twitter or mass distribute it to all of my contacts. Or upload it onto a porn site, leaving me spending the rest of my life fearful that every new person I meet has seen me naked. Except they wouldn’t have. Not really. Because this image, despite looking realistic, is a fake. And all it took to create was an easily discovered automated bot, a standard holiday snap and £5.
This image is a deepfake – and part of a rapidly growing market. Basically, AI technology (which is getting more accessible by the day) can take any image and morph it into something else. Remember the alternative ‘Queen’s Christmas message’ broadcast on Channel 4, that saw ‘Her Majesty’ perform a stunning TikTok dance? A deepfake. Those eerily realistic videos of ‘Tom Cruise’ that went viral last February? Deepfakes. That ‘gender swap’ app we all downloaded for a week during lockdown? You’ve guessed it: a low-fi form of deepfaking.
Yet, despite their prevalence, the term ‘deepfake’ (and its murky underworld) is still relatively unknown. Only 39% of Cosmopolitan readers said they knew the word ‘deepfake’ during our research (it’s derived from a combination of ‘deep learning’ – the type of AI programming used – and ‘fake’). Explained crudely, the tech behind deepfakes, Generative Adversarial Networks (GANs), is a two-part model: there’s a generator (which creates the content after studying similar images, audio, or videos) and the discriminator (which checks if the new content passes as legit). Think of it as a teenager forging a fake ID and trying to get it by a bouncer; if rejected, the harder the teen works on the forgery. GANs have been praised for making incredible developments in film, healthcare and technology (driverless cars rely on it) – but sadly, in reality it’s more likely to be used for bad than good.
Research conducted in 2018 by fraud detection company Sensity AI found that over 90% of all deepfakes online are non-consensual pornographic clips targeting women – and predicted that the number would double every six months. Fast forward four years and that prophecy has come true and then some. There are over 57 million hits for ‘deepfake porn’ on Google alone [at the time of writing]. Search interest has increased 31% in the past year and shows no signs of slowing. Does this mean we’ve lost control already? And, if so, what can be done to stop it?
WHO’S THE TARGET?
Five years ago, in late 2017, something insidious was brewing in the darker depths of popular chatrooms. Reddit users began violating celebrities on a mass scale, by using deepfake software to blend run-of-the-mill red-carpet images or social media posts into pornography. Users would share their methods for making the sexual material, they’d take requests (justifying abusing public figures as being ‘better than wanking off to their real leaked nudes’) and would signpost one another to new uploads. This novel stream of porn delighted that particular corner of the internet, as it marvelled at just how realistic the videos were (thanks to there being a plethora of media of their chosen celebrity available for the software to study).
That was until internet bosses, from Reddit to Twitter to Pornhub, came together and banned deepfakes in February 2018, vowing to quickly remove any that might sneak through the net and make it onto their sites – largely because (valid) concerns had been raised that politically motivated deepfake videos were also doing the rounds. Clips of politicians apparently urging violence, or ‘saying’ things that could harm their prospects, had been red flagged. Despite deepfake porn outnumbering videos of political figures by the millions, clamping down on that aspect of the tech was merely a happy by-product.
But it wasn’t enough; threads were renamed, creators migrated to different parts of the internet and influencers were increasingly targeted alongside A-listers. Quickly, the number of followers these women needed to be deemed ‘fair game’ dropped, too.
Fast forward to today, and a leading site specifically created to house deepfake celebrity porn sees over 13 million hits every month (that’s more than double the population of Scotland). It has performative rules displayed claiming to not allow requests for ‘normal’ people to be deepfaked, but the chatrooms are still full of guidance on how to DIY the tech yourself and people taking custom requests. Disturbingly, the most commonly deepfaked celebrities are ones who all found fame at a young age which begs another stomach-twisting question here: when talking about deepfakes, are we also talking about the creation of child pornography?
It was through chatrooms like this, that I discovered the £5 bot that created the scarily realistic nude of myself. You can send a photograph of anyone, ideally in a bikini or underwear, and it’ll ‘nudify’ it in minutes. The freebie version of the bot is not all that realistic. Nipples appear on arms, lines wobble. But the paid for version is often uncomfortably accurate. The bot has been so well trained to strip down the female body that when I sent across a photo of my boyfriend (with his consent), it superimposed an unnervingly realistic vulva.
But how easy is it to go a step further? And how blurred are the ethics when it comes to ‘celebrities vs normal people’ (both of which are a violation)? In a bid to find out, I went undercover online, posing as a man looking to “have a girl from work deepfaked into some porn”. In no time at all I meet BuggedBunny*, a custom deepfake porn creator who advertises his services on various chatroom threads – and who explicitly tells me he prefers making videos using ‘real’ women.
When I ask for proof of his skills, he sends me a photo of a woman in her mid-twenties. She has chocolate-brown hair, shy eyes and in the image, is clearly doing bridesmaid duties. BuggedBunny then tells me he edited this picture into two pornographic videos.
He emails me a link to the videos via Dropbox: in one The Bridesmaid is seemingly (albeit with glitches) being gang-banged, in another ‘she’ is performing oral sex. Although you can tell the videos are falsified, it’s startling to see what can be created from just one easily obtained image. When BuggedBunny requests I send images of the girl I want him to deepfake – I respond with clothed photos of myself and he immediately replies: “Damn, I’d facial her haha!” (ick) and asks for a one-off payment of $45. In exchange, he promises to make as many photos and videos as I like. He even asks what porn I’d prefer. When I reply, “Can we get her being done from behind?” he says, “I’ve got tonnes of videos we can use for that, I got you man.”
I think about The Bridesmaid, wondering if she has any idea that somebody wanted to see her edited into pornographic scenes. Is it better to be ignorant? Was it done to humiliate her, for blackmailing purposes, or for plain sexual gratification? And what about the adult performers in the original video, have they got any idea their work is being misappropriated in this way?
It appears these men (some of whom may just be teenagers: when I queried BuggedBunny about the app he wanted me to transfer money via, he said, “It’s legit! My dad uses it all the time”) – those creating and requesting deepfake porn – live in an online world where their actions have no real-world consequences. But they do. How can we get them to see that?
REAL-LIFE FAKE PORN
One quiet winter afternoon, while her son was at nursery, 36-year-old Helen Mort, a poet and writer from South Yorkshire, was surprised when the doorbell rang. It was the middle of a lockdown; she wasn’t expecting visitors or parcels. When Helen opened the door, there stood a male acquaintance – looking worried. “I thought someone had died,” she explains. But what came next was news she could never have anticipated. He asked to come in.
“I was on a porn website earlier and I saw… pictures of you on there,” the man said solemnly, as they sat down. “And it looks as though they’ve been online for years. Your name is listed, too.”
Initially, she was confused; the words ‘revenge porn’ (when naked pictures or videos are shared without consent) sprang to mind. But Helen had never taken a naked photo before, let alone sent one to another person who’d be callous enough to leak it. So, surely, there was no possible way it could be her?
“That was the day I learned what a ‘deepfake’ is,” Helen tells me. One of her misappropriated images had been taken while she was pregnant. In another, somebody had even added her tattoo to the body her face had been grafted onto.
Despite the images being fake, that didn’t lessen the profound impact their existence had on Helen’s life. “Your initial response is of shame and fear. I didn't want to leave the house. I remember walking down the street, not able to meet anyone’s eyes, convinced everyone had seen it. You feel very, very exposed. The anger hadn't kicked in yet.”
Nobody was ever caught. Helen was left to wrestle with the aftereffects alone. “I retreated into myself for months. I’m still on a higher dose of antidepressants than I was before it all happened.” After reporting what had happened to the police, who were initially supportive, Helen’s case was dropped. The anonymous person who created the deepfake porn had never messaged her directly, removing any possible grounds for harassment or intention to cause distress.
Eventually she found power in writing a poem detailing her experience and starting a petition calling for reformed laws around image-based abuse; it’s incredibly difficult to prosecute someone for deepfaking on a sexual assault basis (even though that’s what it is: a digital sexual assault). You’re more likely to see success with a claim for defamation or infringement of privacy, or image rights.
Unlike Helen, in one rare case 32-year-old Dina Mouhandes from Brighton was able to unearth the man who uploaded doctored images of her onto a porn site back in 2015. “Some were obviously fake, showing me with gigantic breasts and a stuck-on head, others could’ve been mistaken as real. Either way, it was humiliating,” she reflects. “And horrible, you wonder why someone would do something like that to you? Even if they’re not real photos, or realistic, it’s about making somebody feel uncomfortable. It’s invasive.”
Dina, like Helen, was alerted to what had happened by a friend who’d been watching porn. Initially, she says she laughed, as some images were so poorly edited. “But then I thought ‘What if somebody sees them and thinks I’ve agreed to having them made?’ My name was included on the site too.” Dina then looked at the profile of the person who’d uploaded them and realised an ex-colleague had been targeted too. “I figured out it was a guy we’d both worked with, I really didn’t want to believe it was him.”
In Dina’s case, the police took things seriously at first and visited the perpetrator in person, but later their communication dropped off – she has no idea if he was ever prosecuted, but is doubtful. The images were, at least, taken down. “Apparently he broke down and asked for help with his mental health,” Dina says. “I felt guilty about it, but knew I had to report what had happened. I still fear he could do it again and now that deepfake technology is so much more accessible, I worry it could happen to anyone.”
And that’s the crux of it. It could happen to any of us – and we likely wouldn’t even know about it, unless, like Dina and Helen, somebody stumbled across it and spoke out. Or, like 25-year-old Northern Irish politician Cara Hunter, who earlier this year was targeted in a similarly degrading sexual way. A pornographic video, in which an actor with similar hair, but whose face wasn’t shown, was distributed thousands of times – alongside real photos of Cara in a bikini – via WhatsApp. It all played out during the run-up to an election, so although Cara isn’t sure who started spreading the video and telling people it was her in it, it was presumably politically motivated.
“It’s tactics like this, and deepfake porn, that could scare the best and brightest women from coming into the field,” she says, adding that telling her dad what had happened was one of the worst moments of her life. “I was even stopped in the street by men and asked for oral sex and received comments like ‘naughty girl’ on Instagram – then you click the profiles of the people who’ve posted, and they’ve got families, kids. It’s objectification and trying to humiliate you out of your position by using sexuality as a weapon. A reputation can be ruined instantly.”
Cara adds that the worst thing is ‘everyone has a phone’ and yet laws dictate that while a person can’t harm you in public, they can legally ‘try to ruin your life online’. “A lie can get halfway around the world before the truth has even got its shoes on.”
Is it any wonder, then, that 83% of Cosmopolitan readers have said deepfake porn worries them, with 42% adding that they’re now rethinking what they post on social media? But this can’t be the solution - that, once again, women are finding themselves reworking their lives, in the hopes of stopping men from committing crimes.
Yet, we can’t just close our eyes and hope it all goes away either. The deepfake porn genie is well and truly out of the bottle (it’s also a symptom of a wider problem: Europol experts estimate that by 2026, 90% of all media we consume may be synthetically generated). Nearly one in every 20 Cosmopolitan readers said they, or someone they know, has been edited into a false sexual scenario. But what is the answer? It's hard for sites to monitor deepfakes – and even when images are promptly removed, there’s still every chance they’ve been screen grabbed and shared elsewhere.
When asked, Reddit told Cosmopolitan: "We have clear policies that prohibit sharing intimate or explicit media of a person created or posted without their permission. We will continue to remove content that violates our policies and take action against the users and communities that engage in this behaviour."
Speaking to leading deepfake expert, Henry Adjer, about how we can protect ourselves – and what needs to change – is eye-opening. “I’ve rarely seen male celebrities targeted and if they are, it’s usually by the gay community. I’d estimate tens of millions of women are deepfake porn victims at this stage.” He adds that sex, trust and technology are only set to become further intertwined, referencing the fact that virtual reality brothels now exist. “The best we can do is try to drive this type of behaviour into more obscure corners of the internet, to stop people – especially children and teenagers – from stumbling across it.”
Currently, UK law says that making deepfake porn isn’t an offence (although in Scotland distributing it may be seen as illegal, depending on intention), but companies are told to remove such material (if there’s an individual victim) when flagged, otherwise they may face a punishment from Ofcom. But the internet is a big place, and it’s virtually impossible to police. This year, the Online Safety Bill is being worked on by the Law Commission, who want deepfake porn recognised as a crime – but there’s a long way to go with a) getting that law legislated and b) ensuring it’s enforced.
Until then, we need a combination of investment and effort from tech companies to prevent and identify deepfakes, alongside those (hopefully future) tougher laws. But even that won’t wave a magic wand and fix everything. Despite spending hours online every day, as a society we still tend to think of ‘online’ and ‘offline’ as two separate worlds – but they aren’t. ‘Online’ our morals can run fast and loose, as crimes often go by unchecked, and while the ‘real world’ may have laws in place that, to some degree, do protect us, we still need a radical overhaul when it comes to how society views the female body.
Deepfake porn is a bitter nail in the coffin of equality and having control over your own image; even if you’ve never taken a nude in your life (which, by the way, you should be free to do without fear of it being leaked or hacked) you can still be targeted and have sexuality used against you. Isn’t it time we focus on truly Photoshopping out that narrative as a whole?”
Link | Archived Link
527 notes
·
View notes
Text
How I use Google Docs to write fiction
There are so many different options when it comes to how and where you write your fiction. There's ye olde MS Word, there's Scrivener, and Manuskript, and Evernote, and Notion, and... you get the gist. But out of all the options I've ever considered or tried out, GDocs is the one I keep choosing. It's what works best for me. I'll say that again, just in case: it's my personal choice because it's what I, personally, find most intuitive, it has everything I need and I'm comfortable with it.
Which is why I want to tell you how I find it useful, so that you can evaluate what works best for you.
My favourite things about GDocs are:
It's 100% free to use, no ads or limited features.
How easy it is to get used to, because of its many similarities with MS Word (which is what I used for school and extracurriculars when I was young).
Sync with the Docs & Sheets mobile app, to write wherever, even if I don't have my laptop on me. And the mobile app has a dark theme!
Availability offline. You can mark any document you want to be available even without internet, both in web and in the mobile app.
How many shortcuts I can use to avoid even touching my mouse (I'm a shortcut gremlin)
Amazing customisation possibilities to make your writing space exactly what you want it to be.
The advanced linking features to turn your folders into an interconnected wiki of sorts (yes, you could technically do a literal wiki, but this requires no bothersome setup)
Sharing. You can share your documents (or spreadsheets, or files, or even whole folders) with your beta readers, your co-writers, your editor if you have one (go you, fancy!), and decide how much control they have over it. You can even be on a call and edit or look at it at the same time, because it syncs by the second.
The main drawback of using GDocs is that if you're working on a long project (+30-50k), having it all in one file can slow down the site's performance, and the mobile app tends to crash on files that big. It sucks, but I honestly dislike big ass files anyway, so it doesn't bother me. I prefer shorter files that are easier to navigate.
There's more, but those are the reasons why even when I try other software, I still end up choosing GDocs.
Tips and Tricks
I've compiled a Guide to Google Docs and Sheets' best features when it comes to writing fiction. It covers all my fave features of both Docs and Sheets (web version). If you plan on using Gdocs and Sheets for writing, I think you should take a look. There's a lot of useful stuff in there!
If you like it, feel free to share it wherever you want. I humbly ask that you please credit me and link the original file.
Organising my documents
I have one big Writing folder, which contains the following:
Documents that keep all my ideas, thoughts and trackers in order: my "Writing Desk" (I'll get to that in minute), the recycle bin (a document with bits and bobs I had to cut but I want to reuse at some point because they're good), my NaNo word count tracker, and my Commint Archive, a compilation of the nicest comments I've gotten on my fics, to keep me going when I'm stuck and unmotivated.
'Resources' folder
This is where I keep my workskins, my templates, the files I've come across while researching, and the writing advice I've taken notes of.
'Fiction' folder
Since I mostly write fanfic, here is where I have my fics organised by fandom. My main fandoms each have their own folders, and there's another to stash all the fics for fandoms I don't usually write about.
Inside these folders, I have a simple system:
For every short work (drabbles, ficlets, one-shots, or multichapters that add up to less than 20k), I create one doc. Everything related to that fic will be in there: outline, research, draft, ideas, etc. I keep it tidy using headings (check the guide if you're unfamiliar with them), and I file that doc within its corresponding fandom folder.
For any longer work that adds up to 20k or more including outline, or has more than 10 chapters, I create a new folder inside the corresponding fandom folder, titled like the fic. Inside this fic folder, I keep:
• Outline, research, setting info, character profiles. If all of this combined is shorter than 50k, it'll all be in one single file. Otherwise, I separate it into individual files.
• Chapter drafts. If I have less than 15 chapters, they'll all be together in one doc. If I have 15 or more, I create a subfolder titled 'chapters' and keep them all in there, each chapter in a different doc.
• One outline spreadsheet to rule them all, one outline spreadsheet to find them, One outline spreadsheet to bring them all, and in the darkness bind them (into one cohesive unit for easy navigation)
How I keep all these files handy
There's nothing I hate more than having to search for a file I don't remember the name of or where I put it. So I devised a digital Writing Desk to keep everything writing related in one place.
If you want to know how it works and check it out for yourself, you can take a look at it here:
Template for my Writing Desk
A guide on how to use and tweak it to your liking
This keeps every link to all the dusty corners of my writing folder in one single spreadsheet, which makes the whole thing so much easier to navigate. I can find anything in seconds; from the fics I'm currently working on, to abandoned drafts I haven't touched in months, prompts I've come across, wild plot bunnies I came up with at 3 am, to every rarepair I want to write about, to every one of my notes with writing advice and resources I've found and hoarded over time.
Again, feel free to share all this (I'm excited to share it with whomever might need it), but please credit me and link the original files, not copies. It took me a long time to come up with this and documenting it was also a lengthy process.
I have more templates that I'll be posting about very soon, for different writing-related purposes. So...

#writer stuff#writers on tumblr#creative writing#writing#fanfiction#google docs#google sheets#writerscommunity#linwelin's resources
21 notes
·
View notes
Text
When Facebook came for your battery, feudal security failed

When George Hayward was working as a Facebook data-scientist, his bosses ordered him to run a “negative test,” updating Facebook Messenger to deliberately drain users’ batteries, in order to determine how power-hungry various parts of the apps were. Hayward refused, and Facebook fired him, and he sued:
https://nypost.com/2023/01/28/facebook-fires-worker-who-refused-to-do-negative-testing-awsuit/
If you’d like an essay-formatted version of this post to read or share, here’s a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/02/05/battery-vampire/#drained
Hayward balked because he knew that among the 1.3 billion people who use Messenger, some would be placed in harm’s way if Facebook deliberately drained their batteries — physically stranded, unable to communicate with loved ones experiencing emergencies, or locked out of their identification, payment method, and all the other functions filled by mobile phones.
As Hayward told Kathianne Boniello at the New York Post, “Any data scientist worth his or her salt will know, ‘Don’t hurt people…’ I refused to do this test. It turns out if you tell your boss, ‘No, that’s illegal,’ it doesn’t go over very well.”
Negative testing is standard practice at Facebook, and Hayward was given a document called “How to run thoughtful negative tests” regarding which he said, “I have never seen a more horrible document in my career.”
We don’t know much else, because Hayward’s employment contract included a non-negotiable binding arbitration waiver, which means that he surrendered his right to seek legal redress from his former employer. Instead, his claim will be heard by an arbitrator — that is, a fake corporate judge who is paid by Facebook to decide if Facebook was wrong. Even if he finds in Hayward’s favor — something that arbitrators do far less frequently than real judges do — the judgment, and all the information that led up to it, will be confidential, meaning we won’t get to find out more:
https://pluralistic.net/2022/06/12/hot-coffee/#mcgeico
One significant element of this story is that the malicious code was inserted into Facebook’s app. Apps, we’re told, are more secure than real software. Under the “curated computing” model, you forfeit your right to decide what programs run on your devices, and the manufacturer keeps you safe. But in practice, apps are just software, only worse:
https://pluralistic.net/2022/06/23/peek-a-boo/#attack-helicopter-parenting
Apps are part what Bruce Schneier calls “feudal security.” In this model, we defend ourselves against the bandits who roam the internet by moving into a warlord’s fortress. So long as we do what the warlord tells us to do, his hired mercenaries will keep us safe from the bandits:
https://locusmag.com/2021/01/cory-doctorow-neofeudalism-and-the-digital-manor/
But in practice, the mercenaries aren’t all that good at their jobs. They let all kinds of badware into the fortress, like the “pig butchering” apps that snuck into the two major mobile app stores:
https://arstechnica.com/information-technology/2023/02/pig-butchering-scam-apps-sneak-into-apples-app-store-and-google-play/
It’s not merely that the app stores’ masters make mistakes — it’s that when they screw up, we have no recourse. You can’t switch to an app store that pays closer attention, or that lets you install low-level software that monitors and overrides the apps you download.
Indeed, Apple’s Developer Agreement bans apps that violate other services’ terms of service, and they’ve blocked apps like OG App that block Facebook’s surveillance and other enshittification measures, siding with Facebook against Apple device owners who assert the right to control how they interact with the company:
https://pluralistic.net/2022/12/10/e2e/#the-censors-pen
When a company insists that you must be rendered helpless as a condition of protecting you, it sets itself up for ghastly failures. Apple’s decision to prevent every one of its Chinese users from overriding its decisions led inevitably and foreseeably to the Chinese government ordering Apple to spy on those users:
https://pluralistic.net/2022/11/11/foreseeable-consequences/#airdropped
Apple isn’t shy about thwarting Facebook’s business plans, but Apple uses that power selectively — they blocked Facebook from spying on Iphone users (yay!) and Apple covertly spied on its customers in exactly the same way as Facebook, for exactly the same purpose, and lied about it:
https://pluralistic.net/2022/11/14/luxury-surveillance/#liar-liar
The ultimately, irresolvable problem of Feudal Security is that the warlord’s mercenaries will protect you against anyone — except the warlord who pays them. When Apple or Google or Facebook decides to attack its users, the company’s security experts will bend their efforts to preventing those users from defending themselves, turning the fortress into a prison:
https://pluralistic.net/2022/10/20/benevolent-dictators/#felony-contempt-of-business-model
Feudal security leaves us at the mercy of giant corporations — fallible and just as vulnerable to temptation as any of us. Both binding arbitration and feudal security assume that the benevolent dictator will always be benevolent, and never make a mistake. Time and again, these assumptions are proven to be nonsense.
Image:
Anthony Quintano (modified)
https://commons.wikimedia.org/wiki/File:Mark_Zuckerberg_F8_2018_Keynote_%2841118890174%29.jpg
CC BY 2.0:
https://creativecommons.org/licenses/by/2.0/deed.en
[Image ID: A painting depicting the Roman sacking of Jerusalem. The Roman leader's head has been replaced with Mark Zuckerberg's head. The wall has Apple's 'Think Different' wordmark and an Ios 'low battery' icon.]
Next week (Feb 8-17), I'll be in Australia, touring my book *Chokepoint Capitalism* with my co-author, Rebecca Giblin. We'll be in Brisbane on Feb 8, and then we're doing a remote event for NZ on Feb 9. Next is Melbourne, Sydney and Canberra. I hope to see you!
https://chokepointcapitalism.com/
#pluralistic#manorial security#feudal security#apple#mobile#apps#security through obscurity#binding arbitration#arbitration waivers#transparency#danegeld#surveillance lag
4K notes
·
View notes
Text
the thing that gets me about the lack of technological literacy in a lot of young gen z and gen alpha (NOT ALL. JUST A LOT THAT I SEE.) isn't necessarily the knowledge gap so much as it's the lack of curiosity and self-determination when it comes to interacting with technology.
you have the knowledge gap side of things, obviously, which highlights issues related to the experience of using pieces of hardware/software becoming detached from the workings of the hardware/software itself. you start seeing people (so called "ipad kids") who are less and less familiar with the basics of these machines—like knowing how to explore file and system directories, knowing what parts of the system and programs will be using the most power and interacting with each other, knowing what basics like RAM and CPU are and what affects them etc. these aren't things you need to sink a lot of time into understanding, but they seem to be less and less understood as time has gone on.
and this lack of familiarity with the systems at work here feeds into the issue that bothers me a lot more, which is a lack of curiosity, self-determination, and problem solving when younger people use their technology.
i'm not a computer scientist. i'm not an engineer. i have an iphone for on-the-go use and i have a dinky 2017 macbook air i use almost daily. that's it! but i know how to pirate things and how to quality check torrented material. i know how to find things in my system directories. i know how to format an external hard drive for the specifications of my computer. i know how to troubleshoot issues like my computer running slowly, or my icloud not syncing, or more program-specific problems. this is NOT because i actually know a single thing about the ~intricacies~ of hardware or software design, but because i've taken time to practice and to explore my computer systems, and MOST IMPORTANTLY!! to google things i don't know and then test out the solutions i find!!!!
and that sounds obvious but it's so clear that its just not happening as much anymore. i watched a tiktok the other day where someone gave a tutorial on how to reach a spotify plugin by showing how to type its url in a phone's browser search bar, then said "i'll put the url in the comments so you guys can copy and paste it!!!!!" like ?????? can we not even use google on our own anymore?? what's happening???
this was a long post and it sounds so old of me but i hear this lack of literacy far too much and the defence is always that it's not necessary information to know or it's too much work but it is necessary for the longevity and health of your computers and the control you have over them and it ISN'T too much work at all to figure out how to troubleshoot system issues on your own. like PLEASE someone help.
#part of it is at the fault of the technology itself#phones and tablets hide a lot of their system workings in favour of app-forward interfaces#unlike pcs and laptops which have them easily accessible at start up#but once again.... the lack of curiosity... troubleshooting.... problem solving#long post#and this isn't even going into the lack of problem-solving and self-driven research when it comes to interacting with media#the ''what song is this????'' ''what movie is this???'' ''what is this from????'' PLEASE where is the LOOKING the SEARCHING the FINDING OUT
51 notes
·
View notes
Text
In March 2007, Google’s then senior executive in charge of acquisitions, David Drummond, emailed the company’s board of directors a case for buying DoubleClick. It was an obscure software developer that helped websites sell ads. But it had about 60 percent market share and could accelerate Google’s growth while keeping rivals at bay. A “Microsoft-owned DoubleClick represents a major competitive threat,” court papers show Drummond writing.
Three weeks later, on Friday the 13th, Google announced the acquisition of DoubleClick for $3.1 billion. The US Department of Justice and 17 states including California and Colorado now allege that the day marked the beginning of Google’s unchecked dominance in online ads—and all the trouble that comes with it.
The government contends that controlling DoubleClick enabled Google to corner websites into doing business with its other services. That has resulted in Google allegedly monopolizing three big links of a vital digital advertising supply chain, which funnels over $12 billion in annual revenue to websites and apps in the US alone.
It’s a big amount. But a government expert estimates in court filings that if Google were not allegedly destroying its competition illegally, those publishers would be receiving up to an additional hundreds of millions of dollars each year. Starved of that potential funding, “publishers are pushed to put more ads on their websites, to put more content behind costly paywalls, or to cease business altogether,” the government alleges. It all adds up to a subpar experience on the web for consumers, Colorado attorney general Phil Weiser says.
“Google is able to extract hiked-up costs, and those are passed on to consumers,” he alleges. “The overall outcome we want is for consumers to have more access to content supported by advertising revenue and for people who are seeking advertising not to have to pay inflated costs.”
Google disputes the accusations.
Starting today, both sides’ arguments will be put to the test in what’s expected to be a weekslong trial before US district judge Leonie Brinkema in Alexandria, Virginia. The government wants her to find that Google has violated federal antitrust law and then issue orders that restore competition. In a best-case scenario, according to several Google critics and experts in online ads who spoke with WIRED, internet users could find themselves more pleasantly informed and entertained.
It could take years for the ad market to shake out, says Adam Heimlich, a longtime digital ad executive who’s extensively researched Google. But over time, fresh competition could lower supply chain fees and increase innovation. That would drive “better monetization of websites and better quality of websites,” says Heimlich, who now runs AI software developer Chalice Custom Algorithms.
Tim Vanderhook, CEO of ad-buying software developer Viant Technology, which both competes and partners with Google, believes that consumers would encounter a greater variety of ads, fewer creepy ads, and pages less cluttered with ads. “A substantially improved browsing experience,” he says.
Of course, all depends on the outcome of the case. Over the past year, Google lost its two other antitrust trials—concerning illegal search and mobile app store monopolies. Though the verdicts are under appeal, they’ve made the company’s critics optimistic about the ad tech trial.
Google argues that it faces fierce competition from Meta, Amazon, Microsoft, and others. It further contends that customers benefited from each of the acquisitions, contracts, and features that the government is challenging. “Google has designed a set of products that work efficiently with each other and attract a valuable customer base,” the company’s attorneys wrote in a 359-page rebuttal.
For years, Google publicly has maintained that its ad tech projects wouldn’t harm clients or competition. “We will be able to help publishers and advertisers generate more revenue, which will fuel the creation of even more rich and diverse content on the internet,” Drummond testified in 2007 to US senators concerned about the DoubleClick deal’s impact on competition and privacy. US antitrust regulators at the time cleared the purchase. But at least one of them, in hindsight, has said he should have blocked it.
Deep Control
The Justice Department alleges that acquiring DoubleClick gave Google “a pool of captive publishers that now had fewer alternatives and faced substantial switching costs associated with changing to another publisher ad server.” The global market share of Google’s tool for publishers is now 91 percent, according to court papers. The company holds similar control over ad exchanges that broker deals (around 70 percent) and tools used by advertisers (85 percent), the court filings say.
Google’s dominance, the government argues, has “impaired the ability of publishers and advertisers to choose the ad tech tools they would prefer to use and diminished the number and quality of viable options available to them.”
The government alleges that Google staff spoke internally about how they have been earning an unfair portion of what advertisers spend on advertising, to the tune of over a third of every $1 spent in some cases.
Some of Google’s competitors want the tech giant to be broken up into multiple independent companies, so each of its advertising services competes on its own merits without the benefit of one pumping up another. The rivals also support rules that would bar Google from preferencing its own services. “What all in the industry are looking for is fair competition,” Viant’s Vanderhook says.
If Google ad tech alternatives win more business, not everyone is so sure that the users will notice a difference. “We’re talking about moving from the NYSE to Nasdaq,” Ari Paparo, a former DoubleClick and Google executive who now runs the media company Marketecture, tells WIRED. The technology behind the scenes may shift, but the experience for investors—or in this case, internet surfers—doesn’t.
Some advertising experts predict that if Google is broken up, users’ experiences would get even worse. Andrey Meshkov, chief technology officer of ad-block developer AdGuard, expects increasingly invasive tracking as competition intensifies. Products also may cost more because companies need to not only hire additional help to run ads but also buy more ads to achieve the same goals. “So the ad clutter is going to get worse,” Beth Egan, an ad executive turned Syracuse University associate professor, told reporters in a recent call arranged by a Google-funded advocacy group.
But Dina Srinivasan, a former ad executive who as an antitrust scholar wrote a Stanford Technology Law Review paper on Google’s dominance, says advertisers would end up paying lower fees, and the savings would be passed on to their customers. That future would mark an end to the spell Google allegedly cast with its DoubleClick deal. And it could happen even if Google wins in Virginia. A trial in a similar lawsuit filed by Texas, 15 other states, and Puerto Rico is scheduled for March.
31 notes
·
View notes
Note
Hi there! Bit of a weird question, and I’m not sure if this is the right blog for this, but… best laptop for privacy? I’m going to go to uni in a year and my parents have said that they’re going to buy me a laptop, which is awesome, except— I don’t know which one to chose? I’ve never had a laptop before but I try to take being private online as seriously as I can, and so I don’t really care… well, like, I do care that the laptop has good storage and works and stuff, but I care mostly about how private it is. Which one supports adding privacy-related stuff the best? Which one steals your data the least? I… am actually not sure what kind of questions I should be asking, since… again, never had a laptop before, and I don’t know what about its make makes it private (other than like general online privacy practices across all devices), so I was just wondering if you had any recommendations for me? Tldr: don’t care about fancy features, just want a laptop that more or less works, but would love privacy to be the main focus. This can sort of come at the expense of convenience - I don’t care it if’s harder to set up, use, etc., so long as I can connect to the internet with it.
So the hardware is pretty agnostic on this, the place where privacy is going to become an issue is in the software.
Windows loves to track you and send your data back to homebase; Apple is a walled garden that doesn't let people get deep into configurations; linux is intimidating for a lot of people.
Your actual best bet on privacy would be to get a laptop with no OS and install a linux distro on it, but it sounds like that's probably not something that's terribly approachable for you. So in that case I'd recommend getting a Windows laptop (mac prices aren't worth it) and going through this list to change the settings to ensure better privacy.
HOWEVER please note that you should be getting a laptop with a full OS. Windows has an option for "windows 11s" or "windows 10s" and first off you should be going with 11 at this point but second that "s" means that there are pretty strict limitations on what you can do as a user in terms of configuration and installation.
If you are willing to pay a bit more for Windows 11 Pro instead of windows 11 Home, the pro license cuts off some of the more annoying tracking that Windows does automatically, but I'd say you're better off simply getting the home license and really digging into the settings and getting to know it and setting it up for yourself.
BUT if it's at all possible, honestly I'd say get a bare metal laptop (that means it's just the hardware, no software, you need to install an operating system before you do anything) and install linux. HOWEVER keep in mind that there are some significant downsides to using linux as a student, mostly that you'll likely run into software at some point that you won't be able to install. Also if you're not already pretty good with computers it can be difficult to keep a linux machine running (but very easy to make it private; that's the tradeoff - you can make it more secure more easily, but you really have to know how to fix your own computer if something goes wrong.)
For your situation, again, I think a Windows 11 Home laptop with the settings adjusted is your best bet.
Absolutely positively don't get a chromebook (you've got no control of the settings on a chromebook and the thing is made to feed information to google) and don't get a mac (you can get better specs on a PC at a lower cost).
For an idea of budget on this, I'd say you can probably get something from Dell, Lenovo, or HP for around $650-1000 dollars that's got decent specs (12th gen or newer i5 processor, 16gb RAM, 512GB SSD) and maybe something more like $500-800 from acer, asus, or samsung. Whatever computer you end up getting, you should get the added drop protection warranty because that means the manufacturer will fix your laptop if you drop it, something that is a bigger deal for college students than most people (because of your environment you're more likely to end up with drop damage than a lot of people AND because you're a college student you probably won't be able to afford to fix or replace the computer)
Good luck!
40 notes
·
View notes
Last Seen Blogs

mitsur1kanroj1
Fanfiction maker

ask-naraenil
Tired Enigma

the-gazette-archive
the GazettE Archive

milescie
Miles

dailygage
LUKAS GAGE