#data quality online training
Link
Learn Informatica Data Quality Online! Become a Specialist in Analyzing Profile, Processing, and Performing Data Quality with our Informatica Data Quality Online Certification Course. Informatica Data Quality certification training, you will work on real-time projects and case studies to gain real experience. Get the best Informatica Data Quality Online Training at IntelliMindz presented by industrial expertise trainers at IntelliMindz.
Contact 9655877577 for more details.
#informatica data quality#data quality online training#online course#online training#online course in chennai
1 note
·
View note
Text
Intellimindz Informatica Data Quality Online Training
Learn Informatica Data Quality Online! Become a Specialist in Analyzing Profiles, Processing, and Performing Data Quality with our Informatica Data Quality Online Certification Course. Informatica Data Quality certification training, you will work on real-time projects and case studies to gain real experience. Get the best Informatica Data Quality Online Training at IntelliMindz presented by industrial expertise trainers at IntelliMindz. Contact 9655877577 for more details.
0 notes
Text
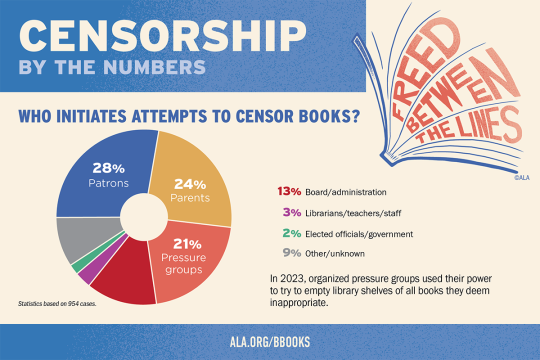


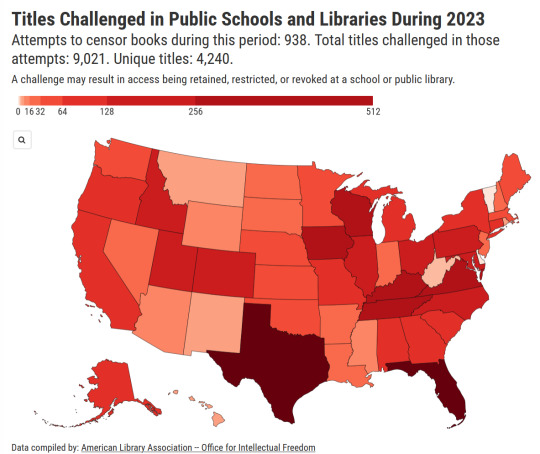
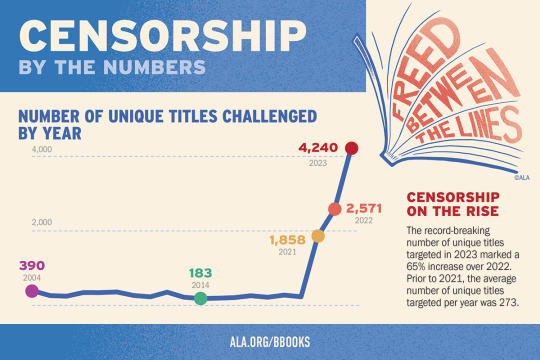
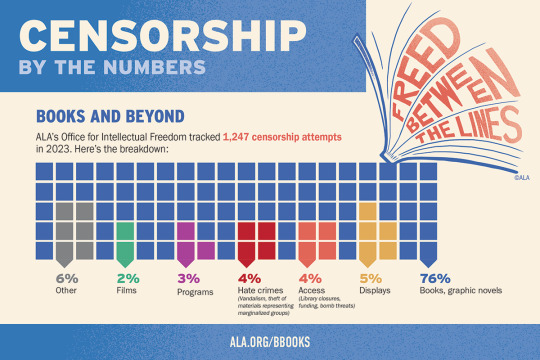


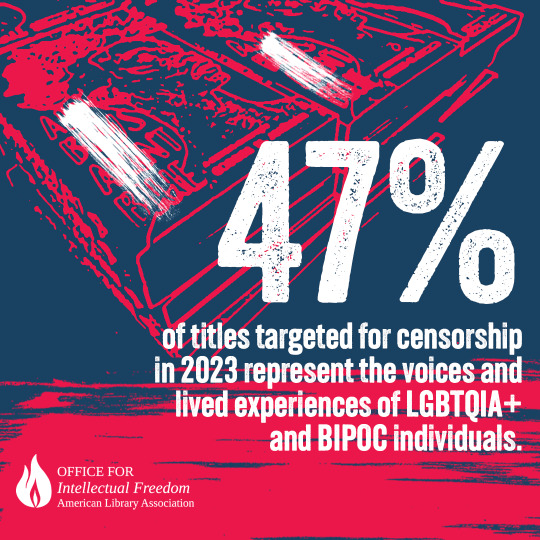
The ALA's State of America's Libraries Report for 2024 is out now.
2023 had the highest number of challenged book titles ever documented by the ALA.
You can view the full PDF of the report here. Book ban/challenge data broken down by state can be found here.
If you can, try to keep an eye on your local libraries, especially school and public libraries. If book/program challenges or attacks on library staff are happening in your area, make your voice heard -- show up at school board meetings, county commissioner meetings, town halls, etc. Counterprotest. Write messages of support on social media or in your local papers. Show support for staff in-person. Tell others about the value of libraries.
Get a library card if you haven't yet -- if you're not a regular user, chances are you might not know what all your library offers. I'm talking video games, makerspaces (3D printers, digital art software, recording equipment, VR, etc.), streaming services, meeting spaces, free demonstrations and programs (often with any necessary materials provided at no cost!), mobile WiFi hotspots, Library of Things collections, database subscriptions, genealogy resources, and so on. A lot of electronic resources like ebooks, databases, and streaming services you can access off-site as long as you have a (again: free!!!) library card. There may even be services like homebound delivery for people who can't physically come to the library.
Also try to stay up to date on pending legislation in your state -- right now there's a ton of proposed legislation that will harm libraries, but there are also bills that aim to protect libraries, librarians, teachers, and intellectual freedom. It's just as important to let your representatives know that you support pro-library/anti-censorship legislation as it is to let them know that you oppose anti-library/pro-censorship legislation.
Unfortunately, someone being a library user or seeing value in the work that libraries do does not guarantee that they will support libraries at the ballot. One of the biggest predictors for whether libraries stay funded is not the quantity or quality of the services, programs, and materials it offers, but voter support. Make sure your representatives and local politicians know your stance and that their actions toward libraries will affect your vote.
Here are some resources for staying updated:
If you're interested in library advocacy and staying up to date with the challenges libraries are facing in the U.S., check out EveryLibrary, which focuses on building voter support for libraries.
Book Riot has regular articles on censorship attempts taking place throughout the nation, which can be found here, as well as a Literary Activism Newsletter.
The American Library Association's Office for Intellectual Freedom focuses on the intellectual freedom component of the Library Bill of Rights, tracks censorship attempts throughout each year, and provides training, support, and education about intellectual freedom to library staff and the public.
The Electronic Frontier Foundation focuses on intellectual freedom in the digital world, including fighting online censorship and illegal surveillance.
I know this post is long, but please spread the word. Libraries need your support now more than ever.
125 notes
·
View notes
Text
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#generative ai#pulling this out wasnt really prompted by anything specific#so much as heard some repeated misconceptions and just#sighs#nope#incorrect#u got it wrong#sorry#unfortunately for me: no consistent tag to block#sigh#ao3
101 notes
·
View notes
Text
17 Jul 23
China Law Translate - Interim Measures for the Management of Generative Artificial Intelligence Services
Quotes from direct English translation of law below
These measures apply to the use of generative AI technologies to provide services to the public in the [mainland] PRC for the generation of text, images, audio, video, or other content (hereinafter generative AI services).
Where the state has other provisions on the use of generative AI services to engage in activities such as news and publication, film and television production, and artistic creation, those provisions are to be followed.
These Measures do not apply where industry associations, enterprises, education and research institutions, public cultural bodies, and related professional bodies, etc., research, develop, and use generative AI technology, but have not provided generative AI services to the (mainland) public.[...]
During processes such as algorithm design, the selection of training data, model generation and optimization, and the provision of services, effective measures are to be employed to prevent the creation of discrimination such as by race, ethnicity, faith, nationality, region, sex, age, profession, or health;[...]
Respect intellectual property rights and commercial ethics, and protect commercial secrets, advantages in algorithms, data, platforms, and so forth must not be used for monopolies or to carry out unfair competition;[...]
Promote the establishment of generative AI infrastructure and public training data resource platforms. Promote collaboration and sharing of algorithm resources, increasing efficiency in the use of computing resources. Promote the orderly opening of public data by type and grade, expanding high-quality public training data resources. Encourage the adoption of safe and reliable chips, software, tools, computational power, and data resources.[...]
Where intellectual property rights are involved, the intellectual property rights that are lawfully enjoyed by others must not be infringed;[...]
Where personal information is involved, the consent of the personal information subject shall be obtained or it shall comply with other situations provided by laws and administrative regulations;[...]
When manual tagging is conducted in the course of researching and developing generative AI technology, the providers shall formulate clear, specific, and feasible tagging rules that meet the requirements of these Measures;[...]
Providers shall bear responsibility as the producers of online information content in accordance with law and are to fulfill the online information security obligations. Where personal information is involved, they are to bear responsibility as personal information handlers and fulfill obligations to protect personal information.
Providers shall sign service agreements with users who register for their generative AI services (hereinafter “users”), clarifying the rights and obligations of both parties.[...]
Providers shall clarify and disclose the user groups, occasions, and uses of their services, guide users’ scientific understanding and lawful use of generative AI technology, and employ effective measures to prevent minor users from overreliance or addiction to generative AI services.[...]
Providers shall lawfully and promptly accept and address requests from individuals such as to access, reproduce, modify, supplement, or delete their personal information.[...]
Providers shall label generated content such as images and video in accordance with the Provisions on the Administration of Deep Synthesis Internet Information Services.[...]
Those providing generative AI services with public opinion properties or the capacity for social mobilization shall carry out security assessments in accordance with relevant state provisions[...]
These measures take effect on August 15, 2023.
47 notes
·
View notes
Text
A guide to AI art for artists
When AI art first hit the web I was amazed by the technology. Then later, when it came out that these image generators were trained on images by living artists scraped from the public web with no consent or compensation, my opinion of it was soured. It took a lot of effort for me to push past that distaste in order to properly research the technology so that I could help myself and others to understand it. This is why I’m compiling all the information I’ve found here. I hope you find it helpful.
Terminology
To start off, there are a lot of different terms out there when it comes to AI nowadays so I’m going to try to define some of them so you can understand what people mean when they use them (and so you can tell when they’re full of shit).
AI
Artificial Intelligence. AI is a big buzzword right now in the tech sector and at times feels like it’s being thrown at anything and everything just to attract investors. Cambridge Dictionary defines it as:
the use or study of computer systems or machines that have some of the qualities that the human brain has, such as the ability to interpret and produce language in a way that seems human, recognize or create images, solve problems, and learn from data supplied to them
It’s kind of what it says on the tin - an artificial, that is, human-created system that has abilities similar to those of intelligent life forms. (I’d argue comparing the abilities of AI solely to those of humans does a disservice to the intelligence of many non-human animals but I digress.)
At the moment when you read things online or in the news, AI is likely being used to refer to machine learning which is a type of AI.
Algorithm
The word algorithm describes a process based on a set of instructions or rules used to find a solution to a problem. The term is used in maths as well as computing. For example, the process used to convert a temperature from Fahrenheit to Celsius is a kind of algorithm:
subtract 32
divide by 9
multiply by 5
These instructions must be performed in this specific order.
Nowadays on social media “the algorithm” is used to refer to a specific kind of algorithm - a recommendation algorithm - which is a kind of machine learning algorithm.
Machine Learning
Machine learning is a term used to refer to the the use of a computer algorithm to perform statistical analysis of data (and often large amounts of it) to produce outputs, whether these are images, text or other kinds of data. Social media recommendation algorithms collect data on the kind of content a user has looked at or interacted with before and uses this to predict what other content they might like.
I’ll explain it in very simple terms with an analogy. Consider a maths problem where you have to work out the next number in a sequence. If you have the sequence 2, 4, 6, 8, 10 you can predict that the next number would be 12 based on the preceding numbers each having a difference of 2. When you analyse the data (the sequence of numbers) you can identify a pattern (add 2 each time) then apply that pattern to work out the next number (add 2 to 10 to get 12).
In practice, the kind of analysis machine learning algorithms do is much more complex (social media posts aren’t numbers and don’t have simple relationships with each other like adding or subtracting) but the principle is the same. Work out the pattern in the data and you can then extrapolate from it.
The big downside to these algorithms is that since the rules behind their decision making are not explicitly programmed and are instead based on data it can be difficult to figure out why they produce the outputs they do, making them a kind of “black box” system. When machine learning algorithms are given more and more data, it becomes exponentially harder for humans to reason about their outputs.
Training Data and Models
Another term you’ll come across is “training” or talking about how an AI is “trained”. Training data refers to the data that is used to train the model. The process of training is the statistical analysis and pattern recognition I talked about above. It enables the algorithm to transform a dataset (collections of images and text) into a statistical model that works like a computer program to take inputs (a text prompt) to produce outputs (images).
As a general rule, the bigger the dataset used for training, the more accurate the outputs of the resulting trained model. Once a model is created, the format of the data is completely different to that of the training data. The model is also many orders of magnitude smaller than the original training data.
Text-to-image model AKA AI image generator, generative AI
Text-to-image model is the technical term for these AI image generators:
DALL-E (OpenAI)
Midjourney
Adobe Firefly
Google Imagen
Stable Diffusion (Stability AI)
The technology uses a type of machine learning called deep learning (I won’t go into this here. If you’d like to read more; good luck. It’s very technical). The term text-to-image is simple enough. Given a text prompt, the model will generate an image to match the description.
Stable Diffusion
Stable diffusion is different from other image generators in that its source code is publically available. Anyone with the right skills and hardware can run this. I don’t think I’d be incorrect in saying that this is the main reason why AI art has become so widespread online since stable diffusion’s release in 2022. For better or worse, open-sourcing this code has democratised AI image generation.
I won’t go deep into how stable diffusion actually works because I don’t really understand it myself but I will talk about the process of acquiring training data and training the models it uses to generate images.
What data is used?
I already talked about training data but what actually is it? And where does it come from? In order to answer this I’m going to take you down several rabbit holes.
LAION-5B
Taking stable diffusion as an example, it uses models trained on various datasets made available by German non-profit research group LAION (Large-scale Artificial Intelligence Open Network). The biggest of these datasets is LAION-5B which is refined down to several smaller datasets (~2 billion images) based on language. They describe LAION-5B as “a dataset of 5,85 billion CLIP-filtered image-text pairs”. Okay. What does “CLIP-filtered image-text pairs” mean?
CLIP
OpenAI’s CLIP (Contrastive Language-Image Pre-training) is (you guessed it) another machine learning algorithm that has been trained to label images with the correct text. Given an image of a dog, it should label that image with the word “dog”. It does a little bit more than this as well. When an image is analysed with CLIP it can output a file called an embedding. This embedding contains a list of words or phrases and a confidence score from 0 to 1 based on how confident CLIP is that the text describes the image. An image of a park that happens to show a dog in the background would have a lower confidence score for the text “dog” than a close-up image of a dog. When you get to the section on prompting, it will become clear how this ends up working in image generators.
As I mentioned before, the more images you have in the training data, the better the model will work. The researchers at OpenAI make that clear in their paper on CLIP. They explain how previous research into computer vision didn’t produce very accurate results due to the small datasets used for training, and the datasets were so small because of the huge amount of manual labour involved in curating and labelling them. (The previous dataset they compare CLIP’s performance to, ImageNet, contains a mere 14 million images.) Their solution was to use data from the internet instead. It already exists, there’s a huge amount of it and it’s already labelled thanks to image alt text. The only thing they’d need to do is download it.
It’s not stated in the research paper exactly which dataset CLIP was trained on. All it says is that “CLIP learns from text–image pairs that are already publicly available on the internet.” Though according to LAION, CLIP was trained on an unreleased version of LAION-400M, an earlier text-image pair dataset.
Common Crawl
The data in LAION-5B itself comes from another large dataset made available by the non-profit Common Crawl which “contains raw web page data, metadata extracts, and text extracts” from the publicly accessible web. In order to pull out just the images, LAION scanned through the HTML (the code that makes up each web page) in the Common Crawl dataset to find the bits of the code that represent images (<img> tags) and pulled out the URL (the address where the image is hosted online and therefore downloadable from) and any associated alternative text, or “alt text”.
A tangent on the importance of image alt text
Alt text is often misused on the web. Its intended purpose is to describe images for visually impaired users or if the image is unable to be loaded. Let’s look at an example.

This image could have the alt text: “A still image from the film Back to the Future III depicting Doc Brown and Marty McFly. They are stood outside facing each other on a very bright sunny day. Doc Brown is trying to reassure a sceptical looking Marty by patting him on the shoulder. Marty is wearing a garish patterned fringed jacket, a red scarf and a white stetson hat. The DeLorean time machine can be seen behind them.” Good. This is descriptive.
But it could also have the alt text: “Christopher Lloyd and Michael J Fox in Back to the Future III” Okay but not very specific.
Or even: “Back to the Future III: A fantastic review by John Smith. Check out my blog!” Bad. This doesn’t describe the image. This text would be better used as a title for a web page.
Alt text can be extremely variable in detail and quality, or not exist at all, which I’m sure will already be apparent to anyone who regularly uses a screen reader to browse the web. This casts some doubt on the accuracy of CLIP analysis and the labelling of images in LAION datasets.
CLIP-filtered image-text pairs
So now, coming back to LAION-5B, we know that “CLIP-filtered image-text pairs” means two things. The images were analysed with CLIP and the embeddings created from this analysis were included in the dataset. Then these embeddings were used to check that the image caption matched what CLIP identified the image as. If there was no match, the image was dropped from the dataset.
But LAION datasets themselves do not contain any images
So how does this work? LAION states on their website:
LAION datasets are simply indexes to the internet, i.e. lists of URLs to the original images together with the ALT texts found linked to those images. While we downloaded and calculated CLIP embeddings of the pictures to compute similarity scores between pictures and texts, we subsequently discarded all the photos. Any researcher using the datasets must reconstruct the images data by downloading the subset they are interested in. For this purpose, we suggest the img2dataset tool.
In order to train a model for use with stable diffusion, you would need to go through a LAION dataset with img2dataset and download all the images. All 240 terabytes of them.
LAION have used this argument to wiggle out of a recent copyright lawsuit. The Batch reported in June 2023:
LAION may be insulated from claims of copyright violation because it doesn’t host its datasets directly. Instead it supplies web links to images rather than the images themselves. When a photographer who contributes to stock image libraries filed a cease-and-desist request that LAION delete his images from its datasets, LAION responded that it has nothing to delete. Its lawyers sent the photographer an invoice for €979 for filing an unjustified copyright claim.
Deduplication
In a dataset it’s usually not desirable to have duplicate entries of the same data, but how do you ensure this when the data you’re processing is as huge as the entire internet? Well… LAION admits you kinda don’t.
There is a certain degree of duplication because we used URL+text as deduplication criteria. The same image with the same caption may sit at different URLs, causing duplicates. The same image with other captions is not, however, considered duplicated.
Another reason why reposting art sucks
If you’ve been an artist online for a while you’ll know all about reposts and why so many artists hate them. From what I’ve seen in my time online, the number of times an artist’s work is reposted on different sites is proportional to their online reach or influence (social media followers, presence on multiple sites etc). The more well known an artist becomes, the more their art is shared and reposted without permission. It may also be reposted legitimately, say if an online news outlet ran a story on them and included examples of their art. Whether consensual or not, this all results in more copies of their art out there on the web and therefore, in the training data. As stated above, if the URL of the image is different (the same image reposted on a different website will have a different URL), to LAION it’s not considered duplicated.
Now it becomes clear how well known digital artists such as Sam Yang and Loish have their styles easily imitated with these models - their art is overrepresented in the training data.
How do I stop my art being used in training data?
Unfortunately for models that have already been trained on historic data from LAION/Common Crawl, there is no way to remove your art and no way to even find out if your art has been used in the training.
Unfortunately again, simply deleting your art from social media sites might not delete the actual image from their servers. It will still be accessible at the same URL as when you originally posted it. You can test this by making an image post on the social media site you want to test. When the image is posted, right click the image and select “open image in new tab”. This will show you the URL of the image in the address bar. Keep this tab open or otherwise keep a record of this URL. Then go back and delete the post. After the post is deleted, often you will still be able to view the image at the URL that you saved.
If you have your own website where you host your art you can delete your images, or update their URLs so that they are no longer accessible from the URLs that were previously in web crawl data.
HTTP Headers
On your own website you can also use the X-Robots-Tag HTTP header to prevent bots from crawling your website for training data. These values can be used:
X-Robots-Tag: noai
X-Robots-Tag: noimageai
X-Robots-Tag: noimageindex
The img2dataset tool is used to download images from datasets made available by LAION. The README states that by default img2dataset will respect the above headers and skip downloading from websites that use them. Although it must be noted this can be overridden, so if an unscrupulous actor wants to scrape your images without your consent, there is no technical reason they cannot do this.
Glaze
If you can’t prevent your images from being crawled, you can prevent all new art that you post from being useful in future models that are trained from scratch by using Glaze. Glaze is a software tool that you can run your art through to protect it from being copied by image generators. It does this by “poisoning” the data in the image that is read by machine learning code while keeping the art looking the same to human eyes.
Watermarks
This defence is a bit of a long shot but worth a try. You may be able to get your art filtered out of training data by adding an obvious watermark. One column included in the LAION dataset is pwatermark which is the probability that the image contains a watermark, calculated by a CLIP model trained on a small subset of clean and watermarked images. Images were then filtered out of subsequent datasets using a threshold for pwatermark of 0.8, which compared to the threshold for NSFW (0.3) and non-matching captions (also 0.3) is pretty high. This means that only images with the most obvious watermarks will be filtered out.
Prompt engineering and how to spot AI art
We’ve covered how AI image generators are trained so now let’s take all that and look at how they work in practice.
Artifacts
You’ve probably gotten annoyed by JPEG compression artifacts or seen other artists whine about them but what is an artifact? A visual artifact is often something unwanted that appears in an image due to technologies used to create it. JPEG compression artifacts appear as solid colour squares or rectangles where there should be a smooth transition from one colour to another. They can also look like fuzziness around high contrast areas of an image.
I’d describe common mistakes in AI image generations as artifacts - they are an unwanted side effect of the technology used to produce the image. Some of these are obvious and pretty easy to spot:
extra or missing fingers or otherwise malformed hands
distorted facial features
asymmetry in clothing design, buttons or zips in odd places
hair turning into clothing and vice versa
nonsense background details or clothing patterning
disconnected horizon line, floor or walls. This often happens when opposite sides are separated by an object in the foreground
Some other artifacts are not strange-looking, but become obvious tells for AI if you have some experience with prompting.
Keyword bleeding
Often if a colour is used in the text prompt, that colour will end up being present throughout the image. If it depicts a character and a background, both elements will contain the colour.
The reason for this should be obvious now that we know how the training data works. This image from LAION demonstrates it nicely:

This screenshot shows the search page for clip-retrieval which is a search tool that utilises an image-text pair dataset created using CLIP. You will see the search term that was entered is “blue cat” but the images in the results contain not just cats that are blue, but also images of cats that are not blue but there is blue elsewhere in the image eg a blue background, a cat with blue eyes, or a cat wearing a blue hat.
To go on a linguistics tangent for a second, part of the above effect could be due to English not having different adjective forms depending on the noun it’s referring to. For example in German when describing a noun the form of the adjective must match the gender of the noun it’s describing. In German, blue is blau, cat is Katze. “Blue cat” would be “blaue Katze”. Since Katze is feminine, the adjective blau must use the feminine ending e. The word for dog is masculine so blau takes the ending er, making it “blauer Hund”. You get the idea.
When a colour is not mentioned in a prompt, and no keyword in the prompt implies a specific colour or combination of colours, the generated images all come out looking very brown or monochrome overall.
Keyword bleeding can have strange effects depending on the prompt. When using adjectives to describe specific parts of the image in the prompt, both words may bleed into other parts of the image. When I tried including “pointed ears” in a prompt, all the images depicted a character with typical elf ears but the character often also had horns or even animal ears as well.
All this seems obvious when you consider the training data. A character with normal-looking ears wouldn’t usually be described with the word “ears” (unless it was a closeup image showing just the person’s ears) because it’s a normal feature for someone to have. But you probably would mention ears in an image description if the character had unusual ears like an elf or catgirl.
Correcting artifacts
AI artifacts can be corrected however, with a process called inpainting (also known as generative fill). This is done by taking a previously generated image, masking out the area to be replaced, then running the generation process again with the same or slightly modified prompt. It can also be used on non AI generated images. Google Pixel phones use a kind of generative fill to remove objects from photographs. Inpainting is a little more involved than just prompting as it requires editing of the input image and it’s not offered by most free online image generators. It’s what I expect Adobe Firefly will really excel at as it’s already integrated into image editing software (if they can iron out their copyright issues…)
Why AI kinda sucks
Since AI image generation is built on large scale statistical analysis, if you’re looking to generate something specific but uncommon you’re not going to have much luck. For example using “green skin” in a prompt will often generate a character with pale skin but there will be green in other parts of the image such as eye colour and clothing due to keyword bleeding.
No matter how specific you are the generator will never be able to create an image of your original character. You may be able to get something that has the same general vibe, but it will never be consistent between prompts and won’t be able to get fine details right.
There is a type of fine-tuning for stable diffusion models called LoRA (Low-Rank Adaptation) that can be used to generate images of a specific character, but of course to create this, you need preexisting images to use for the training data. This is fine if you want a model to shit out endless images of your favourite anime waifu but less than useless if you’re trying to use AI to create something truly original.
Some final thoughts
The more I play around with stable diffusion the more I realise that the people who use it to pretend to be a human artist with a distinctive style are using it in the most boring way possible. The most fun I’ve personally had with image generation is mixing and matching different “vibes” to churn out ideas I may not have considered for my own art. It can be a really useful tool for brainstorming. Maybe you have a few different things you’re inspired by (eg a clothing style or designer, a specific artist, an architectural style) but don’t know how to combine them. An image generator can do this with ease. I think it’s an excellent tool for artistic research and generating references.
All that being said, I strongly believe use of AI image generation for profit or social media clout is unethical until the use of copyrighted images in training data is ceased.
I understand how this situation has come about. Speaking specifically about LAION-5B the authors say (emphasis theirs):
Our recommendation is … to use the dataset for research purposes. … Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
Use of copyrighted material for research falls under fair use. The problem comes from third parties making use of this research data for commerical purposes, which should be a violation of copyright. So far, litigation against AI companies has not made much progress in settling this.
I believe living artists whose work is used to train AI models must be fairly compensated and the law must be updated to enforce this in a way that protects independent artists (rather than building more armour for huge media companies).
The technology is still new and developing rapidly. Changes to legislation tend to be slow. But I have hope that a solution will be found.
References
“Adobe Firefly - Free Generative AI for Creatives.” Adobe. Accessed 28 Jan 2024.
https://www.adobe.com/uk/products/firefly.html
Andrew. "Stable Diffusion prompt: a definitive guide.” Stable Diffusion Art. 4 Jan 2024.
https://stable-diffusion-art.com/prompt-guide/#Anatomy_of_a_good_prompt
Andrew. “Beginner’s guide to inpainting (step-by-step examples).” Stable Diffusion Art. 24 September 2023.
https://stable-diffusion-art.com/inpainting_basics/
AUTOMATIC1111. “Stable Diffusion web UI. A browser interface based on Gradio library for Stable Diffusion.” Github. Accessed 15 Jan 2024
https://github.com/AUTOMATIC1111/stable-diffusion-webui
“LAION roars.” The Batch newsletter. 7 Jun 2023.
https://www.deeplearning.ai/the-batch/the-story-of-laion-the-dataset-behind-stable-diffusion/
Beaumont, Romain. “Semantic search at billions scale.” Medium. 31 Mar, 2022
https://rom1504.medium.com/semantic-search-at-billions-scale-95f21695689a
Beaumont, Romain. “LAION-5B: A new era of open large-scale multi-modal datasets.” LAION website. 31 Mar, 2022
https://laion.ai/blog/laion-5b/
Beaumont, Romain. “Semantic search with embeddings: index anything.” Medium. 1 Dec, 2020
https://rom1504.medium.com/semantic-search-with-embeddings-index-anything-8fb18556443c
Beaumont, Romain. “img2dataset.” GitHub. Accessed 27 Jan 2024.
https://github.com/rom1504/img2dataset
Beaumont, Romain. “Preparing data for training.” GitHub. Accessed 27 Jan 2024.
https://github.com/rom1504/laion-prepro/blob/main/laion5B/usage_guide/preparing_data_for_training.md
“CLIP: Connecting text and images.” OpenAI. 5 Jan 2021.
https://openai.com/research/clip
“AI.” Cambridge Dictionary. Accessed 27 Jan 2024.
https://dictionary.cambridge.org/dictionary/english/ai?q=AI
“Common Crawl - Overview.” Common Crawl. Accessed 27 Jan 2024.
https://commoncrawl.org/overview
CompVis. “Stable Diffusion. A latent text-to-image diffusion model.” GitHub. Accessed 15 Jan 2024
https://github.com/CompVis/stable-diffusion
duskydreams. “Basic Inpainting Guide.” Civitai. 25 Aug 2023.
https://civitai.com/articles/161/basic-inpainting-guide
Gallagher, James. “What is an Image Embedding?.” Roboflow Blog. 16 Nov 2023.
https://blog.roboflow.com/what-is-an-image-embedding/
"What Is Glaze? Samples, Why Does It Work, and Limitations." Glaze. Accessed 27 Jan 2024.
https://glaze.cs.uchicago.edu/what-is-glaze.html
“Pixel 8 Pro: Advanced Pro Camera with Tensor G3 AI.” Google Store. Accessed 28 Jan 2024.
https://store.google.com/product/pixel_8_pro
Schuhmann, Christoph. “LAION-400-MILLION OPEN DATASET.” 20 Aug 2021.
https://laion.ai/blog/laion-400-open-dataset/
Stability AI. “Stable Diffusion Version 2. High-Resolution Image Synthesis with Latent Diffusion Models.” Github. Accessed 15 Jan 2024
https://github.com/Stability-AI/stablediffusion
#ai art#stable diffusion#machine learning#this got really long sorry i hope it still makes sense#i try to explain some very technical stuff that i dont fully understand myself so#if ive got anything wildly wrong pls let me know and i'll update#my writing
11 notes
·
View notes
Text

The Data That Powers A.I. Is Disappearing Fast
[New York Times, July 19, 2024]
For years, the people building powerful artificial intelligence systems have used enormous troves of text, images and videos pulled from the internet to train their models.
Now, that data is drying up.
Over the past year, many of the most important web sources used for training A.I. models have restricted the use of their data, according to a study published this week by the Data Provenance Initiative, an M.I.T.-led research group.
The study, which looked at 14,000 web domains that are included in three commonly used A.I. training data sets, discovered an “emerging crisis in consent,” as publishers and online platforms have taken steps to prevent their data from being harvested.
The researchers estimate that in the three data sets — called C4, RefinedWeb and Dolma — 5 percent of all data, and 25 percent of data from the highest-quality sources, has been restricted. Those restrictions are set up through the Robots Exclusion Protocol, a decades-old method for website owners to prevent automated bots from crawling their pages using a file called robots.txt.
The study also found that as much as 45 percent of the data in one set, C4, had been restricted by websites’ terms of service.
“We’re seeing a rapid decline in consent to use data across the web that will have ramifications not just for A.I. companies, but for researchers, academics and noncommercial entities,” said Shayne Longpre, the study’s lead author, in an interview.
[Read the rest]
#HAHAHAHA#'crisis in consent' there never was any consent in the first place you clowns#what happened to 'only yes means yes'#it's not exactly good for human users if more high quality info gets hidden away of course...#this is why we can't have nice things#artifical intelligence#ai
3 notes
·
View notes
Text
Master Informatica MDM Cloud SaaS: Top Online Training Courses to Boost Your Skills
To keep ahead in the fast-paced digital world of today, one must become proficient in cutting-edge technology. Informatica Master Data Management (MDM) Cloud SaaS is one such technology. This effective solution ensures data integrity, consistency, and correctness while assisting enterprises in managing their vital data assets. However, what makes mastering Informatica MDM Cloud SaaS crucial, and how can one begin? The greatest online training programs are accessible for you to choose from in order to advance your profession and improve your abilities.

What is Informatica MDM Cloud SaaS?
Informatica MDM Cloud SaaS is a cloud-based solution designed to manage and maintain an organization's master data. It integrates data from various sources, ensuring that all data is accurate, consistent, and up-to-date. Key features include data integration, data quality, and data governance. The benefits of using Informatica MDM Cloud SaaS are manifold, from improving business decision-making to enhancing customer satisfaction.
Why Master Informatica MDM Cloud SaaS?
The demand for professionals skilled in Informatica MDM Cloud SaaS is on the rise. Industries across the board require experts who can ensure their data is reliable and useful. Mastering this tool not only opens up numerous career opportunities but also enhances your personal growth by equipping you with in-demand skills.
Top Online Training Courses for Informatica MDM Cloud SaaS
When it comes to learning Informatica MDM Cloud SaaS, choosing the right course is crucial. Here, we'll explore the top online training platforms offering comprehensive and high-quality courses.
Coursera Informatica MDM Courses
Course Offerings: Coursera offers a variety of Informatica MDM courses, ranging from beginner to advanced levels.
Key Features: These courses are taught by industry experts and include hands-on projects, flexible schedules, and peer-reviewed assignments.
User Reviews: Learners appreciate the depth of content and the interactive learning experience.
Udemy Informatica MDM Courses
Course Offerings: Udemy provides a wide range of courses on Informatica MDM, each tailored to different skill levels and learning needs.
Key Features: Udemy courses are known for their affordability, lifetime access, and extensive video content.
User Reviews: Users highlight the practical approach and the quality of instruction.
LinkedIn Learning Informatica MDM Courses
Course Offerings: LinkedIn Learning features several courses on Informatica MDM, focusing on both theoretical knowledge and practical skills.
Key Features: Courses include expert-led tutorials, downloadable resources, and the ability to earn certificates.
User Reviews: Learners commend the platform's user-friendly interface and the relevance of the course material.
Edureka Informatica MDM Courses
Course Offerings: Edureka offers comprehensive Informatica MDM courses designed to provide in-depth knowledge and hands-on experience.
Key Features: Courses come with live instructor-led sessions, 24/7 support, and real-life project work.
User Reviews: Students appreciate the interactive sessions and the immediate support from instructors.
Simplilearn Informatica MDM Courses
Course Offerings: Simplilearn provides a structured learning path for Informatica MDM, including self-paced learning and instructor-led training.
Key Features: The platform offers blended learning, industry-recognized certification, and real-world projects.
User Reviews: Reviews often mention the detailed curriculum and the quality of the learning materials.
Pluralsight Informatica MDM Courses
Course Offerings: Pluralsight offers specialized courses on Informatica MDM, catering to both beginners and advanced learners.
Key Features: The platform includes skill assessments, hands-on labs, and a library of on-demand courses.
User Reviews: Users praise the comprehensive nature of the courses and the practical exercises provided.
youtube
How to Choose the Right Course for You
Choosing the right course depends on various factors such as your current skill level, learning preferences, and career goals. Consider the following when selecting a course:
Course Content: Ensure the course covers all necessary topics and offers practical exercises.
Instructor Expertise: Look for courses taught by experienced professionals.
Certification: Check if the course provides a recognized certification.
Reviews and Ratings: Read user reviews to gauge the course's effectiveness.
Tips for Succeeding in Online Informatica MDM Training
Succeeding in online training requires discipline and strategic planning. Here are some tips to help you along the way:
Time Management: Allocate specific time slots for study and stick to them.
Practice Regularly: Apply what you learn through hands-on exercises and projects.
Utilize Resources: Make use of community forums, study groups, and additional learning resources.
Certification and Beyond
Earning a certification in Informatica MDM Cloud SaaS is a significant achievement. It validates your skills and can open doors to advanced career opportunities. Here are the steps to get certified:
Choose a Certification: Select a certification that aligns with your career goals.
Prepare Thoroughly: Utilize online courses, study guides, and practice exams.
Schedule the Exam: Register for the certification exam and choose a convenient date.
Pass the Exam: Apply your knowledge and pass the exam to earn your certification.
Case Studies of Successful Informatica MDM Professionals
Real-world examples can be highly motivating. Here are a few case studies of professionals who have successfully mastered Informatica MDM and advanced their careers:
Case Study 1: John Doe, a data analyst, leveraged his Informatica MDM skills to become a data manager at a leading tech firm.
Case Study 2: Jane Smith transitioned from a junior IT role to a senior data governance position after completing an Informatica MDM certification.
FAQs
What is the best course for beginners? The best course for beginners typically includes a comprehensive introduction to Informatica MDM, such as those offered on Coursera or Udemy.
How long does it take to master Informatica MDM Cloud SaaS? The time required varies based on individual pace and prior experience, but typically ranges from a few months to a year.
Is certification necessary to get a job? While not always mandatory, certification significantly boosts your job prospects and credibility.
Can I learn Informatica MDM Cloud SaaS without a technical background? Yes, many courses are designed for beginners and provide the foundational knowledge needed to understand and use Informatica MDM Cloud SaaS.
What are the costs associated with these courses? Course costs vary by platform and course level, ranging from free options to several hundred dollars for more advanced and comprehensive training.
Conclusion
Mastering Informatica MDM Cloud SaaS can significantly enhance your career prospects and professional growth. With the right training and dedication, you can become an expert in managing critical data assets. Start your learning journey today by choosing a course that fits your needs and goals.
I hope you are having a wonderful day! I have a
#informatica MDM#Informaticatraining#informaticamdmcloudsaastraining#informatica#informaticatraining#Youtube
3 notes
·
View notes
Text
Welcome to Coachifie IT Training Institute
Empowering Your Future with Cutting-Edge IT Education
At Coachifie IT Training Institute, we are dedicated to shaping the next generation of IT professionals. Our mission is to provide high-quality, industry-relevant training that empowers individuals to excel in the ever-evolving world of technology.
Why Choose Coachifie?
1. Comprehensive Curriculum
Our programs are designed to cover a broad range of IT disciplines, from programming and cybersecurity to data science and cloud computing. Whether you're a beginner or looking to enhance your skills, our curriculum ensures that you gain in-depth knowledge and hands-on experience.
2. Industry-Experienced Instructors
Learn from the best in the field. Our instructors are seasoned IT professionals with extensive experience and up-to-date knowledge of industry trends. They bring real-world insights and practical skills to the classroom, helping you stay ahead in your career.
3. Practical Learning Approach
At Coachifie, we believe in learning by doing. Our training includes practical exercises, real-world projects, and case studies that prepare you for actual work scenarios. This hands-on approach ensures you can apply what you’ve learned in a real-world context.
4. State-of-the-Art Facilities
Our institute is equipped with the latest technology and tools to provide an optimal learning environment. From modern computer labs to advanced software, we ensure that you have access to the resources you need to succeed.
5. Flexible Learning Options
We understand that everyone's schedule is different. That’s why we offer a variety of learning formats, including full-time, part-time, and online courses. You can choose the option that best fits your lifestyle and career goals.
6. Career Support and Guidance
Our commitment to your success goes beyond the classroom. We offer career counseling, resume building, interview preparation, and job placement assistance to help you transition smoothly into the workforce.
Our Training Programs
Software Development: Learn programming languages, software engineering principles, and application development.
Cybersecurity: Gain skills to protect systems from cyber threats and understand the latest security protocols.
Data Science: Master data analysis, machine learning, and statistical techniques to interpret and leverage data.
Cloud Computing: Get hands-on experience with cloud platforms like AWS, Azure, and Google Cloud.
Networking: Understand network design, administration, and security to manage and troubleshoot network systems.
Success Stories
Don’t just take our word for it. Hear from our alumni who have transformed their careers with our training. Our graduates have gone on to work with top tech companies and have achieved remarkable success in their fields.
Get Started Today!
Ready to take the next step in your IT career? Contact us to learn more about our programs, schedule a tour of our facilities, or enroll in a course. Let Coachifie IT Training Institute be your partner in achieving your professional goals.
Contact Us:
Phone: [0330-1815820]
Email: [[email protected]]
Address: [midway centrum, 6th road, Rawalpindi]
Website: [https://coachifie.com/]
Transform your future with Coachifie IT Training Institute—where education meets innovation.
2 notes
·
View notes
Text
instagram
🐧Explore 12 Top Online Learning Platforms 🌟
1. Coursera
Offers courses from top universities and institutions worldwide, covering a wide range of subjects.
2. Udemy
Provides a vast selection of courses taught by industry experts in various fields, including business, technology, and personal development.
3. LinkedIn Learning
Offers a broad range of courses and video tutorials taught by professionals, focusing on business, technology, and creative skills.
4. edX
Partners with leading universities to offer high-quality courses in a variety of disciplines, including computer science, data science, and humanities.
5. Khan Academy
Provides free educational resources, including video lessons and practice exercises, primarily focusing on math, science, and computer programming.
6. Skillshare
Offers a wide range of creative courses taught by professionals in areas such as design, photography, writing, and entrepreneurship.
7. FutureLearn
Collaborates with top universities and institutions to provide courses across diverse subjects, including healthcare, business, and technology.
8. Codecademy
Specializes in interactive coding courses for various programming languages, making it ideal for beginners and aspiring developers.
9. Pluralsight
Focuses on technology-related courses, offering in-depth training in areas like software development, IT operations, and data science.
10. MasterClass
Features courses taught by renowned experts in fields such as writing, filmmaking, cooking, and music, providing insights into their craft.
11. DataCamp
Offers data science and analytics courses, covering topics like Python, R, machine learning, and data visualization.
12. 365 Data Science
Provides the highest quality online data science education for individuals at all levels. The courses are designed to build skillsets from beginner to job-ready, assisting learners in achieving their data science career goals.
#programmer #python #developer #javascript #code #coder #technology #html #computerscience #codinglife #java #webdeveloper #tech #software #softwaredeveloper #webdesign #linux #programmers #codingisfun #programmingmemes
#ai generated#macbook air#ai tools#coding#code#machinelearning#programming#datascience#python#programmer#artificialintelligence#ai#deeplearning#Instagram
24 notes
·
View notes
Text
Best 10 Business Strategies for year 2024
In 2024 and beyond, businesses will have to change with the times and adjust their approach based on new and existing market realities. The following are the best 10 business approach that will help companies to prosper in coming year
1. Embrace Sustainability
The days when sustainability was discretionary are long gone. Businesses need to incorporate environmental, social and governance (ESG) values into their business practices. In the same vein, brands can improve brand identity and appeal to environmental advocates by using renewable forms of energy or minimizing their carbon footprints.
Example: a fashion brand can rethink the materials to use organic cotton and recycled for their clothing lines. They can also run a take-back scheme, allowing customers to return old clothes for recycling (not only reducing waste but creating and supporting the circular economy).
2. Leverage AI

AI is revolutionizing business operations. Using AI-fuelled solutions means that you can automate processes, bring in positive customer experiences, and get insights. AI chatbots: AI can be utilized in the form of a conversational entity to support and perform backend operations, as well.
With a bit more specificity, say for example that an AI-powered recommendation engine recommends products to customers based on their browsing history and purchase patterns (as the use case of retail). This helps to increase the sales and improve the shopping experience.
3. Prioritize Cybersecurity
Cybersecurity is of utmost important as more and more business transitions towards digital platforms. Businesses need to part with a more substantial amount of money on advanced protective measures so that they can keep sensitive data private and continue earning consumer trust. Regular security audits and training of employees can reduce these risks.
Example: A financial services firm may implement multi-factor authentication (MFA) for all online transactions, regularly control access to Internet-facing administrative interfaces and service ports as well as the encryption protocols to secure client data from cyberattacks.
4. Optimizing Remote and Hybrid Working Models

Remote / hybrid is the new normal Remote teams force companies to implement effective motivation and management strategies. Collaboration tools and a balanced virtual culture can improve productivity and employee satisfaction.
- Illustration: a Tech company using Asana / Trello etc. for pm to keep remote teams from falling out of balance. They can also organise weekly team-building activities to keep a strong team spirit.
5. Focus on Customer Experience
Retention and growth of the sales follow-through can be tied to high quality customer experiences. Harness data analytics to deepen customer insights and personalize product offers making your marketing campaigns personal: a customer support that is responsive enough can drive a great level of returning customers.
Example – For any e-commerce business, you can take user experience feedback tools to know about how your customers are getting along and make necessary changes. Custom email campaigns and loyalty programs can also be positively associated with customer satisfaction and retention.
6. Digitalization Investment

It is only the beginning of digital transformation which we all know, is key to global competitiveness. For streamlining, companies have to adopt the use advanced technologies such as Blockchain Technology and Internet of Things (IoT) in conjunction with cloud computing.
IoT example : real-time tracking and analytics to optimize supply chain management
7. Enhance Employee Skills
Develop Your Employees: Investing in employee development is key to succeeding as a business. The training is provided for the folks of various industries and so employees can increase their skills that are needed to work in a certain company. Employee performance can be enhanced by providing training programs in future technology skills and soft skills and job satisfaction.
Example: A marketing agency can host webinars or create courses to teach people the latest digital marketing trends and tools This can help to keep employees in the know which results in boosting their skills, making your campaigns successful.
8. Diversify Supply Chains

The ongoing pandemic has exposed the weaknesses of global supply chains. …diversify its supply base and promote the manufacturing of drugs in Nigeria to eliminate total dependence on a single source. In return, this approach increases resilience and reduces exposure to the risks of supply chain interruption.
- E.g., a consumer electronics company can source components from many suppliers in various regions. In so doing, this alleviates avoidable supply chain interruptions during times of political tensions or when disasters hit.
9. Make Decisions Based on Data
A business database is an asset for businesses. By implementing data, they allow you to make decisions based on the data that your analytics tools are providing. For example, sales analysis lets you track trends and better tailor your goods to the market.
Example: A retail chain can use data analytics to find out when a customer buys, and it change their purchasing policies. This can also reduce overstock and stockouts while overall, increasing efficiency.
10. Foster Innovation

Business Growth Innovation is Key A culture of creativity and experimentation should be established in companies. Funding R&D and teaming with startups can open many doors to both solve problems creatively but also tap into new markets.
Example: A software development firm could create an innovation lab where team members are freed to work on speculative projects. Moreover, work with start-ups on new technologies and solutions.
By adopting these strategies, businesses can navigate the turbulence for 2024 and roll up market — progressive.AI with an evolving dynamic market, being ahead of trends and updated is most likely will help you thrive in the business landscape.
#ai#business#business strategy#business growth#startup#fintech#technology#tech#innovation#ai in business
2 notes
·
View notes
Text
Post Graduate Diploma in Healthcare Informatics & Analytics (PGDHIA) at SIHS
Symbiosis Institute of Health Sciences (SIHS) offers you an opportunity to undergo Post Graduate Diploma in Healthcare Informatics & Analytics (PGDHIA). Healthcare informatics combine skills in healthcare business intelligence, information technology, information systems and data analytics. Doctors, nurses, and other healthcare professionals depend on healthcare informaticians to store, retrieve, and process medical data. With a Post Graduate Diploma in Healthcare Informatics & Analytics (PGDHIA) will equip the students to develop a capability in healthcare informatics and learn the technologies & skills required for the analysis of information regarding various healthcare-related factors. This programme will train the students to apply appropriate techniques to solve problems in different application areas in healthcare informatics. One can become a high-end knowledge worker in the clinical and medical fields, using information technology to help people with their health. This comprehensive program covers multiple aspects of health data informatics, including statistics for data science, augmented & virtual reality, health data analytics and artificial intelligence.
Mode of teaching: Online + Weekend Classes
Career Opportunities:
1. Chief Medical Information Officer
2. Health information Analyst
3. Healthcare IT Project Manager
4. Public Health Data Scientist
5. Health Informatics Consultant
6. Telehealth Coordinator
7. Health Information Manager
8. Electronic Medical Record Keeper
WHY SIHS ?
1. Established reputation in educational excellence.
2. World-class faculty, excellent career guidance.
3. Innovative teaching style – combination of lectures, practical training, discussions, projects, workshops.
4. State-of-the-art infrastructure.
5. Beautiful sprawling campus with excellent libraries, computer labs and Wi-Fi access.
6. Career Counselling, Training & Placement Assistance
7 Truly multicultural, dynamic and globally oriented learning environment
Admission Process -
Step 1: Register online at www.sihs.edu.in and make payment of registration fees (INR 1250/-).
Step 2: Attend Personal Interaction in online mode.
Step 3: Check email for selection confirmation.
Step 4: Verify documents and pay academic fees (INR 89,000/-).
Program Outcome -
1. Learner will be able to manage, process and analyze healthcare data
2. Learner will be able to apply knowledge gained and technical skills in the real-world healthcare settings
3. Learners will comprehend healthcare informatics principles, data analytics methodologies, and the integration of technology within healthcare systems.
4. Learners will explore machine learning, artificial intelligence, and big data analytics, understanding their applications in healthcare.
5. Learners will contribute to enhancing the quality and efficiency of healthcare services.
For more details visit: https://www.sihs.edu.in/pg-diploma-in-healthcare-informatics-and-analytics
2 notes
·
View notes
Text
The Best Digital Marketing Course in Agra

Pingmedia stands out as one of the leading providers of Digital Marketing Course in Agra. Renowned for its comprehensive and practical approach, Ping media Digital Marketing Course is designed to equip students, professionals, and business owners with the skills and knowledge necessary to excel in the dynamic field of digital marketing.
Course Overview
Pingmedia’s Digital Marketing Course is meticulously crafted to cover a wide range of topics essential for mastering digital marketing. The course is structured to provide both theoretical knowledge and practical experience, ensuring that students are well-prepared to tackle real-world challenges.
Key Features:
Comprehensive Curriculum: The course covers all crucial aspects of digital marketing, including SEO, SEM, SMM, content marketing, email marketing, and more.
Practical Training: Emphasis on hands-on learning through live projects and real-world scenarios.
Experienced Trainers: Learn from industry experts with extensive experience in digital marketing.
Flexible Learning Options: Available in both online and offline formats to cater to diverse needs.
Certification: Industry-recognized certification upon successful completion of the course.
Detailed Course Modules
Introduction to Digital Marketing
Overview of digital marketing and its importance
Key digital marketing channels and strategies
Understanding digital marketing metrics and KPIs
Search Engine Optimization (SEO)
On-page and off-page SEO techniques
Keyword research and implementation
Technical SEO and website optimization
Tools for SEO analysis and tracking
Search Engine Marketing (SEM)
Introduction to Google Ads and PPC campaigns
Creating effective ad copy and landing pages
Budget management and bid strategies
Analyzing and optimizing campaign performance
Social Media Marketing (SMM)
Developing strategies for various social media platforms (Facebook, Instagram, Twitter, LinkedIn)
Content creation and curation
Social media advertising and analytics
Community management and engagement
Content Marketing
Crafting high-quality content for blogs, websites, and social media
Content planning and strategy
Techniques for content distribution and promotion
Measuring content effectiveness and ROI
Email Marketing
Building and managing email lists
Designing effective email campaigns and newsletters
Automation and personalization strategies
Analyzing email marketing metrics
Affiliate Marketing
Understanding affiliate marketing models and networks
Setting up and managing affiliate programs
Performance tracking and optimization
Best practices for working with affiliates
E-Commerce Marketing
Strategies for promoting online stores and products
Utilizing e-commerce platforms and tools
Product listing optimization and customer reviews
Handling promotions and sales campaigns
Mobile Marketing
Mobile marketing trends and strategies
App marketing and mobile advertising
SMS marketing and push notifications
Analyzing mobile marketing performance
Analytics and Reporting
Introduction to Google Analytics and other analytics tools
Tracking and interpreting website traffic and user behavior
Creating and presenting comprehensive reports
Using data to drive marketing decisions
Online Reputation Management (ORM)
Monitoring and managing online reputation
Strategies for handling negative feedback and reviews
Building and maintaining a positive online image
Web Design and Development Basics
Understanding the importance of a well-designed website
Basics of HTML, CSS, and WordPress
UX/UI design principles
Ensuring website speed and mobile responsiveness
Why Choose Pingmedia?
Expert Trainers: Pingmedia’s course is led by industry professionals with extensive experience and expertise in digital marketing. Their real-world insights and practical knowledge provide a valuable learning experience.
Practical Learning: The course includes hands-on training with live projects, allowing students to apply their knowledge in real-world scenarios. This practical experience is crucial for building confidence and competence.
Flexibility: With options for both online and offline learning, Pingmedia accommodates different learning preferences and schedules, making it easier for students to balance their education with other commitments.
Career Support: Pingmedia provides robust career support, including resume building, interview preparation, and job placement assistance. The institute’s strong industry connections also facilitate internship and job placement opportunities.
Certification: The course culminates in an industry-recognized certification, which enhances employability and demonstrates proficiency in digital marketing.
Up-to-Date Curriculum: The curriculum is regularly updated to reflect the latest trends and changes in the digital marketing landscape, ensuring that students learn the most current and relevant practices.
Target Audience
Students: Ideal for recent graduates or those pursuing degrees who want to start a career in digital marketing.
Professionals: Suitable for marketing professionals seeking to enhance their digital marketing skills and stay updated with industry trends.
Business Owners: Perfect for entrepreneurs looking to boost their online presence and drive business growth.
Freelancers: Great for individuals wanting to offer digital marketing services to clients.
Conclusion
Ping media Digital Marketing Course in Agra is a premier choice for anyone looking to build or advance their career in digital marketing. With its comprehensive curriculum, practical training, and expert instruction, the course equips students with the skills and knowledge needed to succeed in the competitive digital landscape. Whether you’re just starting out or looking to upgrade your skills, Pingmedia provides a valuable educational experience that can help you achieve your goals.
2 notes
·
View notes
Quote
However, researchers found that without high-quality human data, AI systems trained on AI-made data get dumber and dumber as each model learns from the previous one. It’s like a digital version of the problem of inbreeding.
This “regurgitive training” seems to lead to a reduction in the quality and diversity of model behavior. Quality here roughly means some combination of being helpful, harmless and honest. Diversity refers to the variation in responses, and which people’s cultural and social perspectives are represented in the AI outputs.
In short: by using AI systems so much, we could be polluting the very data source we need to make them useful in the first place.
[...]Can’t big tech just filter out AI-generated content? Not really. Tech companies already spend a lot of time and money cleaning and filtering the data they scrape, with one industry insider recently sharing they sometimes discard as much as 90% of the data they initially collect for training models.
[...]There are hints developers are already having to work harder to source high-quality data. For instance, the documentation accompanying the GPT-4 release credited an unprecedented number of staff involved in the data-related parts of the project.
We may also be running out of new human data. Some estimates say the pool of human-generated text data might be tapped out as soon as 2026.
It’s likely why OpenAI and others are racing to shore up exclusive partnerships with industry behemoths such as Shutterstock, Associated Press and NewsCorp. They own large proprietary collections of human data that aren’t readily available on the public internet.
[...]A flood of synthetic content might not pose an existential threat to the progress of AI development, but it does threaten the digital public good of the (human) internet.
For instance, researchers found a 16% drop in activity on the coding website StackOverflow one year after the release of ChatGPT. This suggests AI assistance may already be reducing person-to-person interactions in some online communities.
What is ‘model collapse’? An expert explains the rumours about an impending AI doom - Raw Story
2 notes
·
View notes
Text
Deepfake misuse & deepfake detection (before it’s too late) - CyberTalk
New Post has been published on https://thedigitalinsider.com/deepfake-misuse-deepfake-detection-before-its-too-late-cybertalk/
Deepfake misuse & deepfake detection (before it’s too late) - CyberTalk

Micki Boland is a global cyber security warrior and evangelist with Check Point’s Office of the CTO. Micki has over 20 years in ICT, cyber security, emerging technology, and innovation. Micki’s focus is helping customers, system integrators, and service providers reduce risk through the adoption of emerging cyber security technologies. Micki is an ISC2 CISSP and holds a Master of Science in Technology Commercialization from the University of Texas at Austin, and an MBA with a global security concentration from East Carolina University.
In this dynamic and insightful interview, Check Point expert Micki Boland discusses how deepfakes are evolving, why that matters for organizations, and how organizations can take action to protect themselves. Discover on-point analyses that could reshape your decisions, improving cyber security and business outcomes. Don’t miss this.
Can you explain how deepfake technology works?
Deepfakes involve simulated video, audio, and images to be delivered as content via online news, mobile applications, and through social media platforms. Deepfake videos are created with Generative Adversarial Networks (GAN), a type of Artificial Neural Network that uses Deep Learning to create synthetic content.
GANs sound cool, but technical. Could you break down how they operate?
GAN are a class of machine learning systems that have two neural network models; a generator and discriminator which game each other. Training data in the form of video, still images, and audio is fed to the generator, which then seeks to recreate it. The discriminator then tries to discern the training data from the recreated data produced by the generator.
The two artificial intelligence engines repeatedly game each other, getting iteratively better. The result is convincing, high quality synthetic video, images, or audio. A good example of GAN at work is NVIDIA GAN. Navigate to the website https://thispersondoesnotexist.com/ and you will see a composite image of a human face that was created by the NVIDIA GAN using faces on the internet. Refreshing the internet browser yields a new synthetic image of a human that does not exist.
What are some notable examples of deepfake tech’s misuse?
Most people are not even aware of deepfake technologies, although these have now been infamously utilized to conduct major financial fraud. Politicians have also used the technology against their political adversaries. Early in the war between Russia and Ukraine, Russia created and disseminated a deepfake video of Ukrainian President Volodymyr Zelenskyy advising Ukrainian soldiers to “lay down their arms” and surrender to Russia.
How was the crisis involving the Zelenskyy deepfake video managed?
The deepfake quality was poor and it was immediately identified as a deepfake video attributable to Russia. However, the technology is becoming so convincing and so real that soon it will be impossible for the regular human being to discern GenAI at work. And detection technologies, while have a tremendous amount of funding and support by big technology corporations, are lagging way behind.
What are some lesser-known uses of deepfake technology and what risks do they pose to organizations, if any?
Hollywood is using deepfake technologies in motion picture creation to recreate actor personas. One such example is Bruce Willis, who sold his persona to be used in movies without his acting due to his debilitating health issues. Voicefake technology (another type of deepfake) enabled an autistic college valedictorian to address her class at her graduation.
Yet, deepfakes pose a significant threat. Deepfakes are used to lure people to “click bait” for launching malware (bots, ransomware, malware), and to conduct financial fraud through CEO and CFO impersonation. More recently, deepfakes have been used by nation-state adversaries to infiltrate organizations via impersonation or fake jobs interviews over Zoom.
How are law enforcement agencies addressing the challenges posed by deepfake technology?
Europol has really been a leader in identifying GenAI and deepfake as a major issue. Europol supports the global law enforcement community in the Europol Innovation Lab, which aims to develop innovative solutions for EU Member States’ operational work. Already in Europe, there are laws against deepfake usage for non-consensual pornography and cyber criminal gangs’ use of deepfakes in financial fraud.
What should organizations consider when adopting Generative AI technologies, as these technologies have such incredible power and potential?
Every organization is seeking to adopt GenAI to help improve customer satisfaction, deliver new and innovative services, reduce administrative overhead and costs, scale rapidly, do more with less and do it more efficiently. In consideration of adopting GenAI, organizations should first understand the risks, rewards, and tradeoffs associated with adopting this technology. Additionally, organizations must be concerned with privacy and data protection, as well as potential copyright challenges.
What role do frameworks and guidelines, such as those from NIST and OWASP, play in the responsible adoption of AI technologies?
On January 26th, 2023, NIST released its forty-two page Artificial Intelligence Risk Management Framework (AI RMF 1.0) and AI Risk Management Playbook (NIST 2023). For any organization, this is a good place to start.
The primary goal of the NIST AI Risk Management Framework is to help organizations create AI-focused risk management programs, leading to the responsible development and adoption of AI platforms and systems.
The NIST AI Risk Management Framework will help any organization align organizational goals for and use cases for AI. Most importantly, this risk management framework is human centered. It includes social responsibility information, sustainability information and helps organizations closely focus on the potential or unintended consequences and impact of AI use.
Another immense help for organizations that wish to further understand risk associated with GenAI Large Language Model adoption is the OWASP Top 10 LLM Risks list. OWASP released version 1.1 on October 16th, 2023. Through this list, organizations can better understand risks such as inject and data poisoning. These risks are especially critical to know about when bringing an LLM in house.
As organizations adopt GenAI, they need a solid framework through which to assess, monitor, and identify GenAI-centric attacks. MITRE has recently introduced ATLAS, a robust framework developed specifically for artificial intelligence and aligned to the MITRE ATT&CK framework.
For more of Check Point expert Micki Boland’s insights into deepfakes, please see CyberTalk.org’s past coverage. Lastly, to receive cyber security thought leadership articles, groundbreaking research and emerging threat analyses each week, subscribe to the CyberTalk.org newsletter.
#2023#adversaries#ai#AI platforms#amp#analyses#applications#Articles#artificial#Artificial Intelligence#audio#bots#browser#Business#CEO#CFO#Check Point#CISSP#college#Community#content#copyright#CTO#cyber#cyber attacks#cyber security#data#data poisoning#data protection#Deep Learning
2 notes
·
View notes
Text
Watermarking and Protecting your Artwork
Tips for everyone to help minimize art theft, including AI training, without greatly sacrificing your images' impact
Objectives of Watermarking
When you place a watermark on your art, it has multiple objectives - they're there to prevent it from being reposted and accredited to someone else, to make it recognizeable as yours with text or symbols, and to prevent major parts of the image from being copied and reused. Here are some tips for making a good watermark, which you can save as a .png to reuse.
Use fonts with serifs or odd shapes and stylings if using text.
Add noise, with color, to your watermark.
Distort the watermark (I like ripple effect to break up the shapes subtly.)
Avoid text and stamps - use handdrawn shapes and letters if possible.
Place it between layers on your artwork if possible.
Use a light blend mode (linear or hard is what I use depending on background colors) and turn down the opacity to make it look nice but still do its job.
The watermark should be visually unobtrusive as possible, while covering major points that would be copied, and BE HARD TO TRACE or select by magic wand or smart selectors. This also helps to keep AI from copying your work.
Compression
Almost more important than watermarking is image compression and resizing. You don't want a full quality image online that anyone can snag and print on T-shirts at the same quality you can offer!
NEVER EVER post an image at 300 DPI or higher to share online. This is the quality required by most printers: without that, it's hard for anyone to make merchandise out of your art. Keep previews at 100 DPI or less. It shouldn't ruin the experience for your viewers and offers an incentive to purchase your work - you can sell higher quality images.
Keep your resolution as low as possible. You don't need more than a 2k image for most usages online - banners, icons, etc. So knock that size under 2000 pixels in height or width.
Flatten and save as a jpeg in medium quality. Typically, you don't need to post any higher quality images online, and you don't want it to include layer data.
Average viewers will NOT notice the difference in these changes without it being pointed out, nor will they think artwork is 'bad' because of it. Don't worry too much about "sacrificing quality."
Glaze it!
Lastly, a technology to combat AI has been developed and is constantly improving. Head over to https://glaze.cs.uchicago.edu/
and use this on your work that you post online for further protection against AI data scraping and training!
#artist#art tips#artist help#art#digital art#digital illustration#digital drawing#digital painting#traditional art
14 notes
·
View notes
Last Seen Blogs




