
Statistics
We looked inside some of the posts by devandops and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
10 hours
Number of Posts By Type
Text
9
Quote
1
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
CS Series - Polynomial Time
Every algorithm we use to solve a problem involves time and complexity. The general thought is the more complex the problem is more time it takes to solve it.
To understand this, we need to know how the calculations happen to see how our algorithm performs.
Every algorithm starts executing taking input and has many steps to complete the process and give us the output.
So the input provided to an algorithm becomes the key here.
But will it make sense for us to measure the time it takes to execute an algorithm? or, is there a better way to do this?
This is where processing steps come into the picture. Based, on the complexity of the input, processing steps will increase. So we can say the performance of an algorithm is directly proportionate to the number of steps it requires to process it. It is called linear time growth.
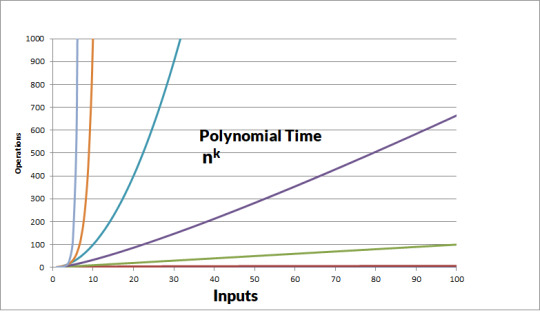
The complexity of the input may require the algorithm to implement loops to process data. The depth of the loop decides the number of steps.
This input that drives the number of steps and time it takes to execute is called polynomial time. It is represented as nk. N represents the length of the input and k is a constant that represents the depth of the loop.
This is as simple I can explain a complex concept. It all starts with this basics.
Remember when you write code, whether you realize it or not it is solving a computing problem. How to solve it efficiently is where great developers always strive to be.
Let's learn more about these concepts in the following posts.
0 notes
Text
DevOps - The Culture Change
When we look at DevOps, we are told that culture change is the key to success in such a transformation initiative.
To understand what this means and how LinkedIn solved it's decade long effort that has become a bottleneck to become a great organization that it is now in this post.
LinkedIn founded in 2003, had a backend system, a monolith called "Leo" which was written in Java, servlets serving pages, and JDBC handling data transactions connected to oracle databases in the backend.
What happened is by 2010 with millions of users on LinkedIn all services developed were new and outside the purview of this backend system. Leo could not handle changes at this pace.
Unfortunately, the backend system in which new code/changes got deployed once in 2 weeks, was not in tune with the pace other developments were happening.
Leo was also failing often and by 2011 late nights and heroics were the norm of the day.
It was their IPO season also. But, a decision has to be made and issues need to be corrected. When they were just 3 months for their IPO, they took this historic decision. LinkedIn Engineering team will not develop any new features for the next 2 months until they solve the issue they had in hand.
For any engineering manager, it takes guts and deep understanding of his organization's culture and management team to take such a daring decision.
Everyone agreed they need to solve their computing problem, that is to kill Leo and break it into multiple services and the rest is history.
This is what we need to understand, what a culture change means. It is to step out of the normalcy, view from a third-person point of view, and bring in changes to the way they work, their systems work, to achieve goals they had initially agreed before they started this initiative.
Such culture change requires strong backing from the management team, hence everyone should be on the same page to give go ahead and support this initiative.
0 notes
Text
What is a Value Stream?
The sequence of activities (design, develop, test) that are done to deliver what the customer has requested. This can be a flow of information or a product.
0 notes
Quote
It's impossible to make any business decisions without making at least one change in IT. That's why every #company is a technology company. A hotel chain is an IT company with a hotel license.
devandops
0 notes
Text
Error Budget
In the SRE error budget is the % of the (money & time) you have to introduce new features, or take a risk and implement some novel ideas.
OK, how do we calculate the error budget?
It's simple.
Deduct 100% of the reliability % we have decided on your product.
If you say 99% is the reliability we are giving for our product then the error budget is 100 - 99 = 1%
We can use this 1% outage to implement new features knowing it's risks.
The only thing we need to be careful is not to overspend this budget, which will reflect as a poor availability to the users.
0 notes
Text
Difference Between DevOps and SRE
Many ask what is the difference between DevOps and SRE? DevOps is on the side of creation and testing. The Product Development team will use DevOps to build, deploy, and test their code in an automated way. SRE is on the production side, more focused on keeping the systems up in a predictable and automated way.
0 notes
Text
Core Tenets Of SRE - Availability
Let's understand a couple of words. "Reliability" and "Availability" Reliability means, can I rely on/trust my product will be working as promised % of time duration. Availability also means the same, but this is from the users of the product perspective. For Ex: "Will the product work flawlessly till I do my task on it?" "Will I be able to repeat the same again and again?" , "What will be the product's outage duration, if it happens?" So, this question is predominantly a product team question to answer. But promising 100% availability is not the right way. In between your user and your product, there are many systems, like internet connections that will fail and make users not able to use your product. 99.999% and 100% you cannot tell the difference. Fixing such % needs to be in a realistic way. The following questions will help in deciding the same. What % will make your user's happy given their usage pattern? Are alternatives available to them if they are not happy with your product? What are they? Given different availability levels, how do your users use the product? The nature of the business your product offers should decide the reliability % for your product.
0 notes
Text
Core Tenets Of SRE
We saw in my previous post that the SRE team will be allocated 50% operational work and 50% development work (helping product development team to build reliable systems). SRE teams should be durable. Typically we can see "Pager Fatigue" with the Ops team. Hence workload should be balanced in a way, the SRE team does not get into work fatigue, or very less work, which is also bad. If the operational load increases beyond 50%, such work has to be redirected to the product development team. Redirection happens until work reaches back to 50%. A fixed number of tickets will help SRE engineer to do his job effectively. Google recommends 2 tickets per on-call duty hours per day. This allows the SRE team member to do his work properly. Anything more might result in a compromise of quality in terms of fixing that issue and result in fatigue, anything less, there is no point in having that person. The final key point to discuss here is conducting blame-free post mortem. Focus on unearthing issues, provide engineering fix for that, and make sure that never happens again, is the sole focus of conducting a post mortem in the first place. Focus is on the solution and building reliability into the system, not on playing the blame game.
0 notes
Text
Key skills for SRE
Engineering is the core part of System Reliability. According to Google, the SRE team consists of software developers who closely map with the product development teams. Few will have other key skills related to Ops. Apart from coding skills, Unix/Linux internals, networking layer 1 to 3 concepts are the alternate skills required. As codified by Google, making systems run automatically is the primary goal for an SRE team. That is, automation should be in the veins of the developers who want to make a career in SRE. On a typical workday of an SRE engineer, 50% time goes in development and the other 50% goes in managing calls, responding to incidents, etc., So for those who are keen to enter the SRE field, they should be good at software development with an eye on automation and should have deep Unix/Linux and Networking skills.
0 notes
Text
What is #SRE
#Software #Reliability #Engineering is an approach to manage the operations of production systems using the software as the primary tool. SRE team is responsible for the administration of systems, usually in an automated way, monitoring systems and fixing issues that may arise in production. SRE is different from traditional ops in the following ways. SRE team works to automate repetitive/manual work, that is eliminating toil. Meeting agreed on service levels with agreed tolerance levels. They implement automated rollout and rollback to reduce the risk. SRE team will handle failures using incident management and detailed post-mortems. It's very prescriptive to handle system failures by the SRE team. It all started at Google inventing an engineering approach to Ops by 2003. They perfected the art of SRE and published "Site Reliability Engineering" by 2016 and "The Site Reliability Engineering Workbook" by 2018. Today SRE is an industry-recognized role with many companies recruiting professionals for this role. SRE is a genuine alternative for Ops. It also does not require large culture change as it is needed for DevOps. #learn #sre
1 note
·
View note