
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by dongnt and here's what we found interesting.
Average Info
Notes Per Post
2
Likes Per Post
2
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 months
Number of Posts By Type
Text
13
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
Note #1
Để xây dựng nên 1 sản phẩm, dù là sản phẩm MVP hay là tập hợp các tính năng trong sản phẩm thì đều phải có nhiều yếu tố kết hợp lại với nhau 1 cách hoàn chỉnh

Technicals: Là các kĩ thuật, công nghệ, tips, best practice được sử dụng trong sản phẩm đó. Ví dụ như: sản phẩm A, sử dụng mongodb làm nơi lưu trữ, sử dụng redis làm cache, sử dụng thuật toán x,y,z làm core cho 1 tính năng nào đó...
Policies: Policies này có thể hiểu theo nghĩa rộng như: nghiệp vụ của sản phẩm, các yếu cầu mà 1 sản phẩm phải có để tuân thủ theo 1 cái gì đó....
Stakeholders: là những người có thể tác động đến sản phẩm. Ví dụ như: CEO có tầm nhìn 10 năm nữa sản phẩm sẽ được hình thành như nào, CMO yêu cầu sản phẩm phải có tính năng A,B,C để có USP với user,....
3 yếu tố trên phải kết hợp nhuần nhuyễn với nhau để sản phẩm có thể hình thành, vận hành, và đạt được những kết quả mong muốn.
0 notes
Text
Pessimistic và Optimistic Lock
Các hệ quản trị cơ sở dữ liệu có quan hệ như: Mysql, Postgresql,… là những cơ sở dữ liệu có quan hệ được sử dụng rất rỗng rãi trong các hệ thống ngày nay nhờ vào những ưu điểm như: Tính minh bạch dữ liệu cao, có đầy đủ tính ACID để đảm bảo toàn vẹn dữ liệu nhờ sử dụng transaction,….. Và trong các hệ thống yêu cầu khắt khe phải đảm bảo tính toàn vẹn của dữ liệu cao thì transaction là một giải pháp hợp lý, nhưng trong thực tế, việc sử dụng nhiều transaction ở cùng một thời điểm sẽ phát sinh ra nhiều v��n đề về xung đột dữ liệu.
Offline Concurrent Patterns là một tập hợp các cơ chế Locking được Martin Fowler mô tả trong cuốn Patterns of Enterprise Application Architecture để giải quyết bài toán về transaction trong các trường hợp khác nhau. Và trong phạm vi nội dung của bài viết này, mình sẽ trình bày 2 cơ chế Lock là: Optimistic Offline Lock và Pessimistic Offline Lock.
Optimistic Offline Lock
Với những hệ thống yêu cầu xử lý nhiều transaction, thì việc xung đột dữ liệu hay không nhất quán giữa các transaction là điều không thể tránh khỏi. Optimistic Offline Lock sẽ giải quyết vấn đề này bằng cách validating dữ liệu thay đổi trong commit ở session đó sẽ không bị conflict thay đổi ở các session khác. Cụ thể hơn, về việc validating, ở thời điểm một session đã load xong một bản ghi, các session khác sẽ không thể thay đổi nó.
Trong Optimistic Offline Lock, một cách thực hiện rất phổ biến là mỗi bản ghi sẽ đi cùng với một version number cụ thể, khi bản ghi đó được load, version number đó sẽ được gán cho session đó cùng với các session state khác, và khi thực hiện so sánh giữa các version trong session với version hiện tại trong bản ghi thành công, lúc này dữ liệu thay đổi có thể được commit đồng thời tăng version number để tránh việc không nhất quán dữ liệu, lúc này, session với version number trước đó không thể acquire lock được nữa. Trong các RDBMS, việc verification dựa theo version number này thường được sử dụng ở các câu lệnh: UPDATE, DELETE một bản ghi nào đó.
Sau khi thực hiện thành công câu lệnh SQL, kết quả trả về sẽ là số bản ghi bị tác động bởi câu lệnh đó. Số bản ghi bằng một là khi thực hiện thành công, ngược lại, bằng không là khi bản ghi đó đã bị xóa hoặc thay đổi trước đó. Khi số bản ghi bằng không, hệ thống phải thực hiện rollback để hạn chế bất kì thay đổi nào từ việc entering data bản ghi đó. Bổ sung thêm thông tin về version number tương ứng với mỗi bản ghi, nó sẽ lưu lại thông tin người cuối cùng chỉnh sửa bản ghi đó, điều này tương đối hữu ích khi quản lý concurrency conflicts. Ngoài cách sử dụng version cho mỗi bản ghi trong hệ thống, việc sử dụng câu lệnh where sử dụng với các field trong bản ghi đó để thực hiện UPDATE cũng là một giải pháp khác. Việc này có ưu điểm là không phải sử dụng version number và khi thực hiện UPDATE một lượng lớn bản ghi, performance lúc này lại phụ thuộc khá nhiều vào việc sử dụng primary key index. Việc sử dụng version với các câu lệnh UPDATE, DELETE cũng có một vài vấn đế về inconsistent read. Giả sử, với một hệ thống thanh toán, hệ thống này sẽ thực hiện tính toán chi phí, thuế của khách hàng sao cho phù hợp. Khi một session được tạo và sẽ tính toán chi phí, thuế dựa theo địa chỉ của khách hàng. Nhưng trong quá trình thực hiện tính toán, cùng lúc đó, khách hàng thay đổi địa chỉ của họ ở một session khác. Việc này dẫn đến kết quả tính thuế dựa trên địa chỉ bị sai lệch và không hợp lệ nhưng bởi vì session khởi tạo để thực hiện tính toán chưa thay đổi gì đến địa chỉ của khách hàng nên việc conflict sẽ không bị phát hiện. Trong ví dụ trên, việc tính toán chi phí phụ thuộc vào địa chỉ chính xác của khách hàng, chính vì vậy, việc bổ sung check version địa chỉ của khách hàng, hoặc các thuộc tính khác là giải pháp không tồi nhưng việc này thường mất nhiều công sức để set up trước đó. Việc phát hiện inconsistent read thường gặp nhiều khó khăn khi transaction phụ thuộc vào kết quả của dynamic query hơn là đọc từ một bản ghi cụ thể nào đó. Một ví dụ điển hình của Optimistic Offline Lock là các công cụ: Source Code Management (SCM) như git. Khi hệ thống SCM detect được các conflict giữa các progammer, thông thường nó sẽ tìm ra correct merge và retry lại commit đó. Optimistic thường được sử dụng trong các trường hợp mức độ conflict giữa hai transaction thấp và trong thực tế khi có conflict xảy ra, điều này ảnh hưởng trực tiếp đến người dùng, trường hợp xấu nhất là rời bỏ ứng dụng. Cách tiếp cận hợp lý nhất để quản lý các concurrency là giới hạn tối đa số lượng concurrency truy cập vào dữ liệu để giảm thiểu các conflict
Pessimistic Offline Lock
Với cách tiếp cận của Optimistic Offline Lock, giả sử khi có nhiều user cùng truy cập vào một bản ghi trong database ở cùng một thời điểm thì khi đó, một user có thể commit dễ dàng nhưng các user còn lại sẽ bị conflict, và ít nhiều điều này ảnh hưởng đến trải nghiệm và độ tin cây của user. Pessimistic Offline Lock là cơ chế lock giúp cho các transaction hạn chế bị conflict nhất có thể bằng cách lock lại dữ liệu trước khi sử dụng nó, và điều đó sẽ đảm bảo dữ liệu sẽ không bị ảnh hưởng bởi các transaction khác.
Cơ chế này gồm 3 phase: xác định loại lock cần phải sử dụng, building cơ chế quản lý lock, xác định procedure cho các business transaction để sử dụng lock. Cụ thể hơn, với xác định các loại lock, lựa chọn đầu tiên là exclusive write lock - loại lock này là business transaction thực hiện lock để có thể thay đổi dữ liệu trong session, việc này có thể tránh được conflict vì nó không cho phép hai hay nhiều transaction cùng thay đổi một bản ghi đồng thời nhưng cơ chế này lại không sử dụng lock cho việc đọc dữ liệu. Loại lock tiếp theo là exclusive read lock - nếu có bất cứ xung đột xảy ra thì việc đọc lại dữ liệu gần nhất là điều bắt buộc và loại lock cuối cùng là read/write lock - kết hợp của của exclusive read lock và exclusive write lock, loại lock này có một vài ưu điểm như: một bản ghi không thể write lock nếu đang có bất kì transaction nào đang read lock lên nó và ngược lại, việc thực hiện single read lock sẽ hạn chế rất nhiều việc các transaction đang thực hiện chỉnh sửa bản ghi, chính vì vậy các session đang thực hiện việc đọc bản ghi đó sẽ không bị ảnh hưởng. Việc lựa chọn đúng loại lock sẽ làm tăng concurrency trong hệ thống, giảm thiệu tính phức tạp của code đi rất nhiều. Locking không chỉ liên quan đến vấn đề kĩ thuật, nếu không sử dụng các kiểu lock cho phù hợp có thể không đạt được hiệu quả như mong muốn. Và với một cơ chế Pessimistic Offline Lock không hiểu quả sẽ dẫn đến việc không hạn chế được conflict transaction như mong muốn. Phase tiếp theo là building cơ chế quản lý lock, nó sẽ cho phép loại bỏ bất kỳ request nào trong một transaction để acquire hoặc release một lock. Để làm được việc đó, cơ chế quản lý phải xác định được bản ghi sẽ bị lock và transaction thực hiện lock đó. Thông thường cơ chế quản lý lock sẽ không có nhiều hơn một table map lock và sẽ chỉ có một trong hai cơ chế được sử dụng là: in-memory hash table và database table. Và việc sử dụng in-memory hash table bắt buộc phải sử dụng cùng với Singleton Pattern (có thể tham khảo trong cuốn sách nổi tiếng Gang of Four), việc sử dụng in-memory cũng có nhược điểm là chỉ sử dụng duy nhất ở single server, điều này gặp bất lợi rất nhiều khi server triển khai cluster, khi đó database-based là lựa chọn hợp lý hơn rất nhiều.
Protocol là khái niệm trong Pessimistic Offline Lock để nói về việc một business transaction bắt buộc phải sử dụng một cơ chế quản lý lock, nghĩa là bao gồm đẩy đủ các yếu tố như: xác định dữ liệu sẽ thực hiện lock, khi nào thì thực hiện lock, khi nào thì release và cách xử lý khi mà một lock không được acquire. Cụ thể hơn, xác định data sẽ thực hiện lock phụ thuộc một phần vào lock đó khi nào thì được thực hiện và transaction nên acquire lock trước khi load dữ liệu. Với việc release lock, nó có thể được release trước khi được hoàn thành dựa vào một số yếu tố như lock type hay việc muốn sử dụng lại trong transaction đó một lần nữa. Với bất kì bản ghi nào sử dụng lock hoặc muốn truy cập vào lock table thì bắt buộc phải serialize, giả sử với in-memory lock table, có thể dễ dàng sử dụng serialize để truy cập vào toàn bộ lock manager và được hỗ trợ bởi hầu hết các ngôn ngữ lập trình hiện nay. Nếu lock table được lưu trong database, khi đó serialize phụ thuộc hoàn toàn vào database. Exclusive read và exclusive write lock với serialization lúc này sẽ đơn giản hơn rất nhiều khi được thực hiện với cột có giá trị unique như ID. Nhưng việc lưu read/write lock vào trong database sẽ gặp đôi chút vấn đề vì việc xử lý logic yêu cầu phải read nhiều lock table chính vì vậy nó thực hiện rất nhiều câu lệnh INSERT. Trong một system transaction ở một cấp độ hoàn toàn độc lập, serialize giúp cho việc inconsistent read giảm thiểu đi rất nhiều nhưng nó lại gây ra một vài vấn đề về performance, chính vì vậy, việc tách riêng serialize system transaction cho việc acquire lock và giảm thiểu tính độc lập cho các công việc khác có thể giải quyết vấn đề này. Với system transaction trong Pessimistic Offline Locking, deadlock có thể xảy ra với một vài trường hợp bởi vì cơ chế locking sẽ chờ đến khi một lock hoàn toàn sẵn sàng cho việc sử dụng. Giả sử, hai user cùng muốn sử dụng tài nguyên A và B, user thứ nhất lock tài nguyên A, user thứ hai lock tài nguyên B, lúc này, cả hai transaction sẽ chờ các lock còn lại. Và cuối cùng là việc quản lý lock timeout, nếu user bị crash trong khi đang thưc hiện transaction, lúc này transaction sẽ phải thực hiện lại là điều khó tránh khỏi. Trong nhiều trường hợp, điều này sẽ gây ra những vấn đề lớn, điển hình là trong các ứng dụng web, việc thiết lập timeout trên server là giải pháp hợp lý trong trường hợp này. Pessimistic Offline Lock thích hợp sử dụng trong các trường hợp mà mức độ conflict giữa các concurrency session cao. Việc locking các entity trong hệ thống thực ra tạo ra một vấn đề tranh chấp dữ liệu rất lớn và chỉ nên sử dụng Pessimistic Offline Lock khi thực sự cần thiết. Và khi sử dụng phải xem xét kĩ lưỡng thời gian thực hiện của transaction, không nên sử dụng cơ chế này với single system transaction.
0 notes
Text
Một vài ghi chú về Software Maintainer
Trong quá trình làm việc, việc phải tham gia vào một dự án phần mềm đang chạy trên môi trường thực tế để tiếp tục develop, maintain là điều không quá xa lạ với mỗi software engineer. Lúc này, với mỗi cá nhân, việc phải bổ sung kiến thức cũng như tiếp nhận tư tưởng từ người đi trước đồng thời phải giữ cho sản phẩm đang chạy tiếp tục chạy ổn định không phải là chuyện dễ.
Theo kinh nghiệm cá nhân, thông thường, quá trình develop, maintain software thường được chia ra làm 4 giai đoạn (theo trải nghiệm cá nhân) từ lúc bắt đầu tham gia cho đến thời điểm engineer đó đã hiểu rõ tường tận mọi "ngõ ngách" trong phần mềm:
- Giai đoạn 1 - Thích nghi: Thời điểm này là thời điểm khi mới tham gia vào dự án. Có thể dự án đó sử dụng những công nghệ mà mình chưa biết hoặc biết nhưng chưa nắm rõ tường tận thì việc bổ sung kiến thức về công nghệ của dự án đó là điều bắt buộc. Hãy cố gắng có một cái nhìn tổng quan nhất về hệ thống, phần mềm đang chạy (nếu có tài liệu thì sẽ tốt hơn). Lúc này, nếu độ phức tạp của dự án đang ngày một tăng hoặc các chức năng của dự án đang phình to ra và phụ thuộc lẫn nhau thì không nên quá vồ vập vào phát triển tính năng mới mà nên tiếp nhận các bug nhỏ để làm quen trước. Và chính vì các tính năng phụ thuộc vào nhau, nên một sai lầm nhỏ có thể dẫn đến lỗi (nặng nhất là crash toàn hệ thống). Nên mỗi khi sừa bất kì cái gì đó, đều phải xem xét mức độ ảnh hưởng khi sửa phần đó. Hãy tự đặt ra câu hỏi: Khi mình sửa phần này, thì những phần nào trong dự án sẽ bị ảnh hưởng. Nếu mức độ ảnh hưởng quá lớn thì phải xem xét thật kỹ lưỡng hoặc trao đổi lại với các thành viên trong team trước khi làm.
- Giai đoạn 2: - Phát triển: Lúc này, sau khi đã hiểu sơ bộ được phần mềm đó, đây là thời điểm có thể phát triển thêm các tính năng mới. Việc bổ sung thêm các tính năng cũng phải xem xét kỹ lưỡng mức độ ảnh hưởng. Giai đoạn này, engineer phải hiểu và sử dụng tương đối thuần thục các công nghệ trong dự án sử dụng. Và quan trọng nhất cũng là khó nhất ở giai đoạn này là: Kế thừa tư tưởng từ những người đi trước. Có thể tư tương người đi trước chưa được rõ ràng ở một vài chỗ nhưng việc hiểu được và từ đó nâng cấp nó lên mới mang lại giá trị thực sự cho engineer đó.
- Giai đoạn 3 - Đo lường, tối ưu: Sau khi các tính năng, bug được xử lý xong. Đây là thời điểm quay lại để đo lường, tối ưu sản phẩm. Đó cũng là một trong những khía cạnh giúp phần mềm hoạt động ổn định về lâu về dài.
- Giai đoạn 4 - Tìm giới hạn, tìm các giải pháp xử lý sự cố: Bất kì phần mềm nào cũng đều có giới hạn của nó: Giới hạn về mặt công nghệ, giới hạn về performance,... Nhưng để tìm ra được giới hạn của phần mềm không phải chuyện một sớm một chiều có thể làm được. Việc này đòi hỏi phải đo lường và tối ưu liên tục. Tiếp đến là chuẩn bị các phương án đề phòng có thể tìm ra được khi hệ thống xảy ra sự cố. Việc chuẩn bị này giúp ích khi hệ thống đột ngột xảy ra sự cố và từ các phương án chuẩn bị từ trước đó có thể khắc phục nhanh hơn (hoặc không). Tránh ảnh hưởng quá lâu đến user.
1 note
·
View note
Text
XY Problem
XY Problem là khái niệm để nói về việc trao đổi vấn đề mình đang gặp phải với người khác một cách không rõ ràng, thiếu thông tin cụ thể về vấn đề đang gặp phải, điều này có thể dẫn đến việc người nghe có thể sẽ đưa ra một giải pháp mà không phù hợp hoặc nếu có phù hợp thì về lâu về dài có thể phát sinh ra lỗi không mong muốn.
Giả sử, ông A đang gặp phải một vấn đề X, ông A lúc này không biết giải quyết vấn đề này sao cho hợp lý, vì nếu sau này mà xảy ra lỗi thì chỉ còn nước update CV, sau một hồi vò đầu bức tóc, ông A nghĩ ra được giải pháp Y, ông A lúc này không tự tin cho lắm, đành nhờ sự giúp đỡ của ông B. Nhưng lúc này thay vì giải thích cho ông B vấn đề mình đang gặp phải, ông A lại nêu cho ông B giải pháp mình đang làm. Ông B lúc này như gà mắc thóc, ú ớ không hiểu đầu đuôi ra sao vì không nắm rõ đầy đủ thông tin vấn đề đành phán bừa dẫn đến việc không giải quyết được vấn đề một cách hiệu quả
Qua ví dụ trên, nếu ông A bắt đầu trao đổi với ông B bằng cách giải thích vấn đề mình đang gặp phải thay vì nêu ra trực tiếp giải pháp mình đang có thì có thể tình hình đã khác, và trong quá trình trao đổi này hãy cung cấp cho ông B thông tin một cách chi tiết nhất có thể biết đâu ông B lại nghĩ ra giải pháp hay hơn mình đang có hoặc nếu giải pháp đó không ổn, hãy giải thích và nêu rõ quan điểm của mình rằng tại sao giải pháp đó không hợp lý
Tóm lại, một vài điều có thể rút ra được là:
Khi trao đổi với các thành viên trong team, hãy nêu ra vấn đề mình đang gặp phải và cố gắng giải thích cho các thành viên trong team hiểu được rằng vấn đề này đang ảnh hưởng đến product như thế nào
Khi trao đổi, hãy cố gắng cung cấp thông tin một cách chi tiết nhất có thể về vấn đề cho các thành viên trong team
Nếu giải pháp đưa ra không hợp lý hơn giải pháp mình đang có, hãy giải thích một cách rõ ràng rằng giải pháp đó tại sao lại không hợp lý và không áp dụng vào được
Trong quá trình làm việc, mình đã rất nhiều lần lâm phải tình huống của ông A mà không nhận ra và đôi khi là cả ông B nữa. Và tất nhiên, những trường hợp như ông A,B cũng khó mà tránh khỏi được. Và các điều rút ra được trên kia nghe có vẻ lý thuyết. Thay vào đó, điều cần hướng đến lúc này và sau cùng là cố gắng làm cho sản phẩm của mình ngày một tốt lên và quan trọng nhất là: Tùy cơ ứng biến
0 notes
Text
Chuyện phỏng vấn
Hôm nay rảnh rảnh mình có ngồi lướt web tình cờ thấy 1 trang web về review công ty là: https://reviewcongty.com/. Trang web này có đầy đủ hầu hết các công ty, mục đích của nó là để người chuẩn bị ứng tuyển vào một công ty nào đó vào đọc review và hỏi kinh nghiệm cũng như môi trường làm việc của người đã và đang làm việc trong công ty đó.
Nhưng mình có một chút thất vọng khi đọc qua review của một vài công ty thì thấy khá nhiều các review tiêu cực cũng như nói những điều không tốt về nhà tuyển dụng


Bản thân mình nghĩ việc đánh giá một công ty là việc nên làm vì nó sẽ giúp ích rất nhiều cho những người sau này muốn phỏng vấn ở công ty đó nhưng không nên đánh giá theo kiểu tiêu cực, trù dập chỉ vì mình phỏng vấn fail ở đó hay công việc mình làm nó không cao siêu như lúc phỏng vấn.
Biết rằng mỗi công ty lại có một quy trình phỏng vấn khác nhau, có thể bạn thấy quy trình của công ty này rườm rà và bạn không thích nó nhưng đối với họ đó là một trong những cơ sở để đánh giá một ứng viên xem có phù hợp với vị trí đó hay không. Thay vì trách móc, việc tự hỏi bản thân rằng mình đã chuẩn bị kỹ lưỡng cho cuộc phỏng vấn đó hay chưa hay đã làm đủ tốt để manager giao cho mình những đầu việc quan trọng hơn chưa để từ đó bổ sung những thứ mình đang còn thiếu chẳng phải tốt hơn rất nhiều sao.
Như ở trên trang Glassdoor, mình thấy họ đánh giá rất khách quan có cả tốt lẫn không tốt nhưng họ cũng nêu rõ ưu, nhược điểm để từ đó người đọc sẽ có cái nhìn tổng quan nhất về công ty

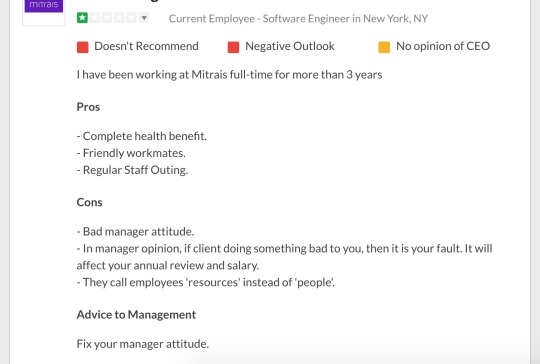
Im lặng và tiếp tục cố gắng chẳng phải tốt hơn rất nhiều so với việc trách móc người khác chỉ vì mình không đạt được thứ mình muốn hay sao
0 notes
Text
Kỹ thuật Feynman
Kỹ thuật Feynman là phương pháp giúp người học có thể học cũng như nắm bắt được kiến thức một cách hiệu quả nhất có thể. Kỹ thuật này được chia ra làm 4 bước:
Bước 1: Viết các khái niệm cũng như cách hiểu của bạn về một vấn đề mà bạn đang tìm hiểu ra giấy
Bước 2: Cố gắng giải thích khái niệm đó trên giấy một cách dễ hiểu nhất có thể. Tưởng tượng bạn đang giải thích cho một đứa trẻ hiểu được vấn đề của bạn nên hãy cố gắng giải thích bằng các từ ngữ dễ hiểu nhất có thể nhé :D
Bước 3: Review lại những gì bạn đã viết và xem có thiếu xót điều gì không. Nếu có thì lại tiếp tục quay lại bước 2
Bước 4: Tiếp tục review lại xem các từ ngữ của mình diễn đạt có dễ hiểu hay không. Nếu không thì cố gắng chỉnh sửa nó sao cho dễ hiểu nhất có thể.
Đây là kỹ thuật mà mình mới "phát hiện" ra. Và mình đang dần dần áp dụng cũng như thay đổi cách học của mình sao cho hiệu quả nhất có thể.
0 notes
Text
Vòng đời của một Thread trong Python
Vòng đời của một Thread trong python bao gồm 5 state chính:
New Thread: Đây là thời điểm khi thực hiện khởi tạo thread, lúc này thread chưa chạy và cũng chưa được cấp phát bất kì tài nguyên gì
Runnable: state này được sinh ra khi sau state New Thread, lúc này Thread đã được cấp phát đầy đủ tài nguyên và đang được chờ để chạy.
Running: Ở state này, thread đang được thực thi các task đã được chọn bởi task schedule
Not-Running: state này được sinh ra khi state đang ở trạng thái running nhưng đột ngột bị dừng lại vì một lý do nào đó
Dead: state này là state sẽ kết thúc vòng đời của một thread sau quá trình xử lý dữ liệu kết thúc ở state running.
Ví dụ:
import threading import time def testing(): print("start running Thread") # Thread bị dừng lại đột ngột khi gọi method sleep, lúc này Thread đang ở state Not-Running time.sleep(10) print("finish running Thread") if __name__ == "__main__": # Khởi tạo Thread, lúc này Thread đang ở state: New Thread myThread = threading.Thread(target=testing) # Thread lúc này được start và đang ở state Runnable và đã được cấp phát tài nguyên myThread.start() # Thread đang ở state Running khi gọi method join myThread.join() # lúc này, Thread đã xử lý xong mà kết thúc vòng đời của nó, Thread sẽ chuyển về state Dead print("finished")
0 notes
Text
Pattern Architecture phần 1 - Layered Architecture
Trong tất cả các pattern architecture thì có lẽ layered architecture hay nói cách khác là n-tier architecture pattern là một trong những pattern được áp dụng rộng rãi nhất hiện nay. Trước đó, pattern này là the de factor standard trong các ứng dụng Java EE, nhưng nhờ vào những ưu điểm phù hợp với việc phát triển trong hầu hết các hệ thống khi triển khai. Để nói cụ thể hơn, layered architecture pattern đúng như tên gọi của nó, nó được chia thành các component, mỗi component sẽ đảm nhận một nhiệm vụ khác nhau, ví dụ như: presentation layer là nơi sẽ xử lý nghiệp vụ liên quan đến user interface, business layer sẽ đảm nhận việc xử lý logic mà không cần quan tâm đến user interface.
Trong nhiều trường hợp, layered architeture pattern không quy định số lượng layer bắt buộc phải có nhưng nó sẽ bao gồm 4 layer chính: presentation, business, persistence, database. Các layer này có thể tùy biến tùy theo ngữ cảnh của bạn, ví dụ như: trong nhiều trường hợp, business layer và persistence layer có thể gộp lại thành một business layer hoặc với những ứng dụng phức tạp hơn có thể lên đến 5,6 layer hoặc nhiều hơn. Nhờ vào việc chia ra thành các layer xử lý các nghiệp vụ khác nhau, ứng dụng sẽ dễ dàng quản lý, maintain, test hơn rất nhiều.
Có 1 vài khái niệm cần phải nh�� trong layered architecture pattern:
- closed layer: nghĩa là khi xử lý một request bất kì thì việc xử lý tuần tự theo từng layer là điều bắt buộc, ví dụ như: request đó bắt buộc phải đi từ presentation layer rồi mới đến business layer, sau đó mới đến persistence layer cuối cùng thao tác với dữ liệu trong database layer
- layers of isolation: vậy tại sao presentation layer không truy cập thẳng vào database layer để lấy dữ liệu mà lại bắt buộc phải đi qua business layer?. Nếu làm vậy thực sự không sao cả, mọi thứ vẫn hoạt động bình thường, nhưng việc gộp các business layer với presentation layer và database layer lại làm một dẫn đến sự phụ thuộc giữa các layer tăng lên, khi ứng dụng ngày càng lớn và phức tạp thì việc maintain hay viết test trở lên khó khăn hơn rất nhiều. Chính vì vậy, khái niệm layers of isolation ở đây để nói về tính độc lập giữa các layer là điều bắt buộc, các layer chỉ cần xử lý nghiệp vụ của mình mà không cần quan tâm đến các layer khác xử lý như thế nào.
0 notes
Text
https://sourcemaking.com
Design Pattern là cụm tự không quá xạ lạ với mỗi Software Engineer, dường như nó xuất hiện ở mọi ngõ ngách, người người design pattern, nhà nhà design pattern. Cá nhân mình trong công việc cũng không đụng chạm đến quá nhiều đến nó, nhưng mình nghĩ việc bổ sung thêm kiến thức cũng không thừa, biết đâu sau này có dịp áp dụng thì còn đỡ bỡ ngỡ. Trang web dưới đây có viết lại khá nhiều design pattern và các ví dụ để có thể hiểu dễ hơn.
Link: https://sourcemaking.com
0 notes
Text
https://vim.rtorr.com
Vim là một trong những công cụ chính mình sử dụng hàng ngày nhờ và sự tiện dụng, linh động và hơn hết là .... không phải dùng chuột. Link dưới đây là Vim Cheat Sheet khá đầy đủ các phím tắt để sử dụng cho công việc
Link: https://vim.rtorr.com/
0 notes
Text
https://dev.tube
Thông thường khi xem các video về technical mình thường hay vào Youtube để xem nhưng thường rất hay bị phân tâm bởi các video không liên quan. Và dev.tube là website tập hợp lại các video về technical trên Youtube, có thể nó chưa đầy đủ nhưng mình thấy khá là nhiều và có đánh tag theo từng chủ đề để tiện follow
Link: https://dev.tube/
0 notes
Text
https://martinfowler.com/
Martin Folwer là một trong những developer gạo cội với nhiều đầu sách "gối đầu" nổi tiếng như: Patterns of Enterprise Application Architecture, NoSQL Distilled, ... Dưới đây là blog của Martin và có khá nhiều kiến thức bạn có thể học hỏi trong đó và mình cũng là một trong những fan cứng của bác ^^!
Link: https://martinfowler.com/
0 notes
Text
https://www.gitignore.io/
Thông thường với các project, chúng ta phải tạo từng file config gitignore tương ứng với từng ngôn ngữ cũng như công nghệ sử dụng trong project đó. Trang web dưới đây sẽ sinh ra các template config ignore phù hợp với ngôn ngữ, công nghệ bạn sử dụng.
Link: https://www.gitignore.io/
1 note
·
View note