
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by gloriousengineernut and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
9 minutes
Number of Posts By Type
Text
5
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
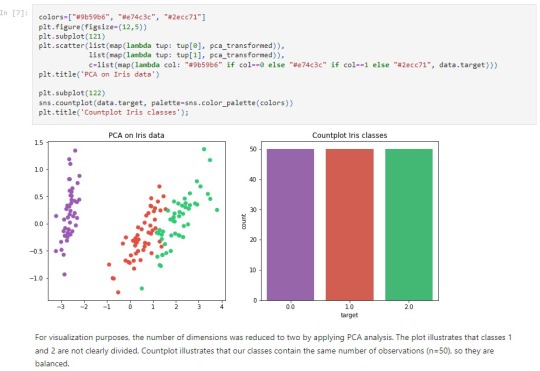
Certainly! Running a k-means cluster analysis involves identifying subgroups or clusters of observations within a dataset based on their similarity in response patterns on a set of clustering variables. Here's a summary of the steps involved in this assignment:
Data Collection and Preprocessing:
Gather the dataset containing the observations and the set of clustering variables, which should primarily be quantitative but may also include binary variables. Handle missing values and preprocess the data as needed. Feature Scaling (Optional):
Standardize or normalize the clustering variables if they are measured on different scales. This step can be important for k-means, as it is distance-based. Determining the Number of Clusters (k):
Decide on the appropriate number of clusters (k) for the analysis. This can be done through visual inspection of the data, domain knowledge, or using techniques like the elbow method. K-Means Cluster Analysis:
Implement the k-means algorithm, where each observation is assigned to the cluster whose mean is closest to it. The algorithm iteratively refines these assignments to minimize the within-cluster sum of squares. Interpretation of Clusters:
Analyze the characteristics of each cluster to understand the patterns of response on the clustering variables within each subgroup. This might involve looking at the mean values or other central tendencies for each variable within each cluster. Visualize Results:
Create visualizations, such as scatter plots or cluster profiles, to illustrate the separation of clusters in the multidimensional space of the clustering variables. Cluster Validation (Optional):
If possible, validate the quality of the clusters using internal validation metrics or external validation measures, though the latter may be challenging in unsupervised settings. Iterate (Optional):
If the initial analysis does not produce meaningful clusters, consider iterating by adjusting the number of clusters, refining preprocessing steps, or exploring different sets of clustering variables. Document Findings:
Summarize the key findings, describing the characteristics of each cluster and any patterns or trends observed in the data. Conclusion:
Conclude the analysis by discussing the practical implications of the identified clusters, potential use cases, and any further steps or analyses that could enhance understanding or decision-making. K-means cluster analysis is a powerful technique for discovering natural groupings in data. The identified clusters can provide valuable insights into the underlying structure of the dataset, aiding in segmentation and targeted analysis based on similarities in response patterns.
0 notes
Text
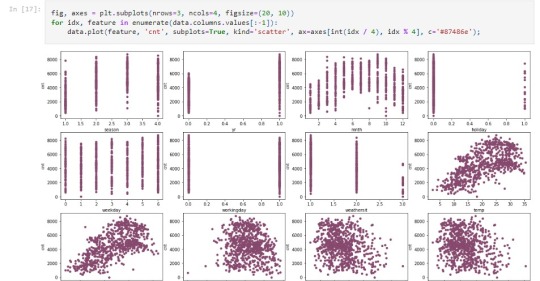
Certainly! Running a Lasso regression analysis with k-fold cross-validation involves selecting a subset of predictors from a larger pool of variables to best predict a quantitative response variable. Here's a summary of the steps involved in this assignment:
Data Collection and Preprocessing:
Collect the dataset containing the quantitative response variable and a pool of predictor variables, which can be quantitative, categorical, or a mix of both. Handle any missing values and encode categorical variables if needed. Feature Scaling (Optional):
Depending on the algorithm or library used, you might want to standardize or normalize the predictor variables, especially if they are measured on different scales. Data Splitting and K-Fold Cross-Validation:
Split the dataset into training and testing sets. Implement k-fold cross-validation, dividing the training set into k subsets and using each of them as a validation set in turn while training the model on the remaining k-1 subsets. Lasso Regression Model Building:
Choose the appropriate algorithm or library for Lasso regression. Train the Lasso regression model on each fold of the cross-validation, adjusting the regularization parameter (alpha) to control the strength of the penalty on the regression coefficients. Variable Selection:
As the Lasso regression imposes a constraint on the model parameters, some coefficients will be exactly zero, leading to variable selection. Identify the subset of predictors with non-zero coefficients, as these are the variables most strongly associated with the response. Cross-Validation Performance Evaluation:
Evaluate the performance of the Lasso regression model across all folds of the cross-validation. Common metrics include Mean Squared Error (MSE) or R-squared. Optimal Regularization Parameter:
Determine the optimal value for the regularization parameter (alpha) by observing the model's performance across a range of values. Visualize Results (Optional):
Visualize the coefficients of the selected predictors to better understand their importance in the model. Interpret Results:
Interpret the results in terms of the selected subset of predictors and their impact on predicting the quantitative response variable. Document Findings:
Summarize the key findings, highlighting the subset of predictors identified by the Lasso regression analysis and their significance in predicting the response variable. Conclusion:
Conclude the analysis by discussing the effectiveness of Lasso regression in variable selection and providing insights into the key predictors for the quantitative response variable. Lasso regression is particularly useful when dealing with high-dimensional datasets and can provide a parsimonious model by automatically selecting relevant features. The k-fold cross-validation helps ensure the robustness of the model's performance across different subsets of the data.
0 notes
Text
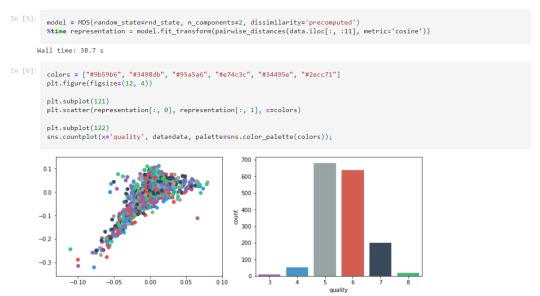
Certainly! Running a Random Forest analysis involves creating an ensemble of decision trees to predict a binary, categorical response variable. Here's a summary of the steps involved:
Data Collection and Preprocessing:
Collect the dataset with the explanatory variables and the binary, categorical response variable. Handle missing values and encode categorical variables if necessary. Data Splitting:
Divide the dataset into training and testing sets. The training set will be used to build the Random Forest, and the testing set will be used for evaluation. Random Forest Model Building:
Choose the number of trees to include in the forest. Randomly select subsets of the training data for each tree (bootstrap sampling). For each subset, build a decision tree. Each tree will be different due to the randomness in data selection and feature consideration. Aggregate the predictions of all trees to make the final prediction. Model Evaluation:
Evaluate the performance of the Random Forest model on the testing set using metrics like accuracy, precision, recall, F1-score, and the confusion matrix. Feature Importance:
Random Forest provides importance scores for each explanatory variable. These scores reflect the contribution of each variable to the model's predictive performance. Analyze these scores to identify key predictors. Number of Trees Analysis (Optional):
Investigate how the number of trees in the forest affects model performance. This analysis helps determine the optimal number of trees for achieving the best predictive accuracy. Visualize Results:
Visualize the results, such as the confusion matrix or feature importance plot, to provide a clear understanding of the Random Forest's performance and key contributing factors. Interpret Results:
Understand the implications of the feature importance scores. Identify which variables have the most influence on the prediction and explore any interactions between variables. Document Findings:
Summarize the key findings, emphasizing the importance of specific variables in predicting the response variable. Conclusion:
Conclude the analysis by discussing the overall performance of the Random Forest model, the significance of the identified variables, and any recommendations for further refinement or analysis. Random Forests are powerful for handling complex relationships in data and can provide robust predictions. By evaluating feature importance, you gain insights into which variables are critical for predicting the response variable, aiding in model interpretation and decision-making.
0 notes
Text

Certainly! To run a classification tree analysis, you can use various tools or programming languages such as R, Python with libraries like scikit-learn or tools like Weka. Here's a general summary of the steps you might follow:
Data Collection and Preprocessing:
Gather the dataset containing the explanatory variables and the binary, categorical response variable. Check for missing values and handle them appropriately. Encode categorical variables if needed. Data Splitting:
Split the dataset into training and testing sets. The training set is used to build the decision tree, and the testing set is used to evaluate its performance. Decision Tree Model Building:
Select a suitable algorithm for building decision trees. Common algorithms include CART (Classification and Regression Trees), ID3, C4.5, and others. Train the decision tree model using the training data. Model Evaluation:
Evaluate the performance of the trained model on the testing set. Common metrics include accuracy, precision, recall, F1-score, and the confusion matrix. Visualize the Tree:
If applicable, visualize the decision tree to understand the rules and splits made by the model. This helps in interpreting and communicating the results. Tune Hyperparameters (Optional):
Depending on the tool or library used, you may have hyperparameters to tune. For example, you might adjust the tree depth, minimum samples per leaf, or other parameters to optimize performance. Interpret Results:
Examine the important features or variables identified by the decision tree. Understand the relationships and interactions among the variables. Iterate and Refine (Optional):
Based on the results, you might iterate on the analysis, refine the model, or explore additional variables to improve predictive accuracy. Document Findings:
Summarize the key findings, insights, and recommendations based on the decision tree analysis. Clearly communicate the results to stakeholders. Conclusion:
Conclude the analysis by highlighting the strengths and limitations of the decision tree model. Discuss any actionable insights gained from the analysis. Remember, the goal of a classification tree is to create a model that accurately predicts the response variable based on the input features, providing a data-driven way to understand the relationships within the data.
0 notes
Text

Certainly! To run a classification tree analysis, you can use various tools or programming languages such as R, Python with libraries like scikit-learn or tools like Weka. Here's a general summary of the steps you might follow: Data Collection and Preprocessing: Gather the dataset containing the explanatory variables and the binary, categorical response variable. Check for missing values and handle them appropriately. Encode categorical variables if needed. Data Splitting: Split the dataset i
0 notes