
Statistics
We looked inside some of the posts by not-toivo and here's what we found interesting.
Average Info
Notes Per Post
22K
Likes Per Post
13K
Reblog Per Post
9K
Reply Per Post
30
Time Between Posts
16 days
Number of Posts By Type
Text
16
Photo
1
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Finally managed to install Elixir correctly!
The first time I used the script they have on their site, which compiles Erlang source files without documentation, which then causes "OTP compiled without EEP48 documentation chunks" warning from ElixirLS extension in VSCode.
After a bit of googling, I found out that the "preferred" way of installing Elixir as with asdf version manager. The whole process turned out to be not beginner friendly (which was probably a sign for me to just stick to JavaScript, but what could I do, BEAM propaganda got to me), for example, the part where the official Erlang plugin for asdf installs with an error message: I don't know if it's that error's fault that later, after installing both Erlang and Elixir, iex and mix commands wouldn't work, producing an error message about lacking permission to run Erlang's REPL, but I did manage to fix it by installing an alternative version of the plugin instead, so.
"Funnily" enough, despite going through all of this because of lacking built-in docs, I was lazy enough not to read asdf's Erlang plugin documentation to the end, which is why the first time I was installing it, the docs weren't there again. Infuriating.
0 notes
Text
Found a beautiful thing today in the codebase at my job:

And here's the result of calling the getType function:


Basically, it uses string tags in order to get the type or, if it is an object, the name of this object's constructor. Because not all built-in types have the property [Symbol.toStringTag], the function above uses Object.prototype.toString function (which famously returns the string [object Object] when called on random objet literals, the second Object here is precisely a string tag), calling it not on the value itself, where it can be overwritten, but rather on the Object.prototype, passing the value as its this context.
My only complaint would be, that constructing a whole RegEx, matching a string agains it and then extracting a capture group out of the result of the match just to get the type of a value is a little too wasteful. The function above could, probably, be rewritten like this:

2 notes
·
View notes
Text
Too tired to write anything more detailed, so I'll be brief:
There's a Unicode character named non-breaking hyphen (U+2011) and it saved me two times last week in situations where no combination of word-break and text-wrap CSS properties worked. It can be represented in your HTML using either its decimal (‑) or hexadecimal (‑) numeric character reference.
0 notes
Text
You want to write a recursive function, but your language doesn't support tail-call optimization? Do not worry! Just "trampoline" the function.
Instead of directly returning the result of a recursive call, (1) wrap it into an anonymous function and (2) have a helper function (the "trampoline") that restarts the main function inside a loop.
For example,


…and this is what we get with a traditional recursive function:

0 notes
Text
I actually really like the german word for commute, "pendeln". which has the same root as pendulum
because you just keep going back and forth. and back . and forth. amd back ajd forth
can you tell it's 5 am and I am on my commute
2K notes
·
View notes
Text
English: we call it sinusitis because it's Latin :)
German: we call it Nasennebenhöhlenentzündung because the Höhlen neben your Nase are entzündet.
#lol#languages#german#// i need to go back to trying to learn languages#(german included)#they are fascinating entities
11K notes
·
View notes
Text
I was too tired to write about it on Friday, but I have to inform everyone, that I've seen a new (for me) way to make ranges in JavaScript:


But why do we need to spread the result of calling Array.prototype.keys() method into an empty array?


It's an iterable, because it has [Symbol.iterator]() method, and it's an iterator, because it has next() method. (Array.prototype.keys() is just one of many methods returning iterable iterators).
But why can't we just use Object.keys() method to achieve the same result, without the need to explicitly transform an iterable iterator into an array? Because Array() constructor (which can be used with or without the new keyword) returns a sparse array, which means it doesn't actually have indexes among its own enumerable properties (!):


In conclusion, while this method of creating ranges with Array.prototype.keys() is more concise and opened my eyes to some subtler differences in how it and similarly named JavaScript methods work (why were they designed in such a way is a separate question), it is obviously only useful if you need a range starting at 0 and increasing with a step of 1. Otherwise you'll need Array.from() method's callback function in order to get the desired kind of range.
#codeblr#javascript#all of this is needlessly complicated#like i don't even mention what array-like objects are#or the fact that Array() constructor works completely differently depending on number of arguments it recieves
3 notes
·
View notes
Text
So, a single method call to flatMap is consistently slower than two method calls, to filter, and then map? The difference persists on smaller arrays (meaning, before the JIT compiler kicks in), see the last picture for an array of length 100. Not what I expected.
I guess, the lessons here are "don't be clever" and "avoid premature optimization".



#codeblr#javascript#got inspired by the latest video on fireship's side channel#wrote similar obscure flatMap nonsense instead of a straightforward filter & map combo a few days ago#naively thinking it would be more efficient to iterate over an array once instead of twice#“woll it wosn't”
6 notes
·
View notes
Text
So, a month ago I finally got a job as a frontend dev, so, hooray,🥳, I now get to enjoy ✨Vue✨ and ✨Nuxt✨ 5 days a week and get paid for that. But since I've been unemployed for a very long time, this sudden change means that I'm even more tired to learn new things in my spare time, and also that there isn't much spare time now. I haven't posted much here before and so it seems I'm unlikely to be more active here in the future. Sad.
I did, though, try to read the 1st book on the list from the website Teach Yourself Computer Science, the one called Structure and Interpretation of Computer Programs (the reason for me to do that is because I don't have any STEM background, and, I guess, if I want to continue a career in a sphere rapidly encroached by AI, it's good to have some fundamental knowledge). I read about a ⅕ of the book, finally understood what it means for Haskell to be called a "lazy" language, but the exercises at the end of the chapters are too hard and math-heavy for me. Also, sad.
The book uses a programming language from the LISP family, called Scheme. I thought I could get by by installing Clojure instead, but that journey ended with the VS Code extension for Clojure, called Calva slowing down and then completely corrupting (?) WSL connection, so that I had then to reinstall my WSL "instance". (Yes, I use Windows, because I'm not a programmer). Which is sad, because the extension looked good and feature-heavy, it just couldn't function well in WSL environment for some reason…
After that, I installed Racket (another LISP) on the freshly reinstalled WSL distro, but then I couldn't pick up the book again and continue learning for, like, a week and a half, which is where I am at now. (Racket allows to define arbitrary syntax/semantics for the compiler, which in turn allows developers to create new domain specific languages distributed simply as Racket packages, with one of those packages being the dialect of Scheme used by SICP, the book mentioned earlier).
There is also the PureScript book, Functional Programming Made Easier by Charles Scalfani, which I'm unlikely to finish ever. The language is neat (it's very similar to Haskell, but compiles to JavaScript), but a bit overcomplicated for a simple goal of making interfaces. I do think, however, that I might try learning Elm at some point: the amount of time I've spent at work, trying to understand, why and at what point the state of some component mutated in a Nuxt app is, honestly, impressive, and I want to try something built around the idea of immutability.
2 notes
·
View notes
Text
Matt Pocock's Total TypeScript: Essentials

Some notes I made while reading this book:
Optional values in a tuple
Not only can a tuple have named values, it can have optional ones:
[name: string, year: number, info?: string]
[string, number, string?]
Dealing with an unknown
If we have obj of type unknown, and we want to get obj.prop of type string, this is how to do it correctly:
typeof obj === 'object' && obj && 'prop' in obj && typeof obj.prop === 'string'
If we refactor the expression above into a return value of a type guard, this would be its type signature:
(obj: unknown) => obj is {prop: string}
Destructuring values of union types (tuples vs. objects)
const [status, value]: ['success', User[]] | ['error', string] = await fetchData();
TS can then guess based on the type of the discriminant (the status variable) the type of the rest of the return value (the value variable), but wouldn't be able to do the same, if fetchData returned an object instead of tuple. An object type should be narrowed first, before we can destructure its value!
Dynamic keys
If we don't know, what keys the object may have during the lifetime of the program, we can have index signatures...
type DynamicKeys = { [index: string]: number; }
interface DynamicKeys { [index: string]: string; }
...or we can use Record helper type. Record type supports union types of type literals, unlike index signatures!
type DynamicKeys = Record<'name' | 'age' | 'occupation', boolean>
Read-only arrays
We can disallow array mutation by marking arrays and tuples as readonly, or using ReadonlyArray helper type:
const readOnlyGenres: readonly string[] = ["rock", "pop", "unclassifiable"];
const readOnlyGenres: ReadonlyArray<string> = ["rock", "pop", "unclassifiable"];
Read-only arrays/tuples can only be passed to functions that explicitly expect read-only arrays/tuples:
Matt's strange opinions on class methods
function printGenresReadOnly(genres: readonly string[]) { }
More helper types

When Matt talks about the difference between arrow and function methods, he mentions only the different ways they handle this, but isn't a much more important distinction the fact that arrow methods are technically class properties, so will be copied on every instance of a class?
UPD: And later he recommends using arrow functions!

This is extremely memory inefficient, right?
satisfies operator
Very useful thing I've never heard of before!
When a value isn't annotated with type, its type is inferred. When a value is annotated with type, its type is checked against the annotated type. When a value is followed with satisfies, its type is inferred (as if there were no annotation), but still checked against the constraint (as if there were an annotation).
Useful (?) type assertions
as any // turns off type checking for a particular value.
as unknown as T // cast a value to a completely unrelated type.
as const satisfies T // makes a value immutable, while checking it against a type.
Object.keys (user).forEach((key) => { console.log(user[key as keyof typeof user]); }) // by default TS infers return values of Object.keys() and for ... in as string[].
Excess properties
TS doesn't throw an error, when (1) a variable containing an object with excess properties is passed to a function, or (2) when an object with excess properties is returned by a callback. Both the variable and the return type of the callback should be annotated, if that is an issue.
Modules vs. scripts
Files with no import or export statement are treated by the compiler as scripts, executing in the global scope. The problem is, that's not how the distinction works in pure JS, so we can end up in sitiations like this...
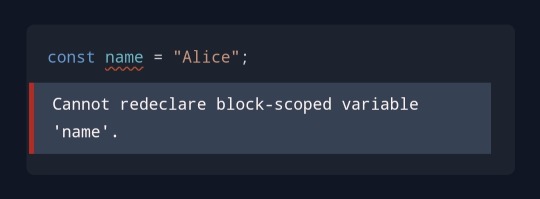
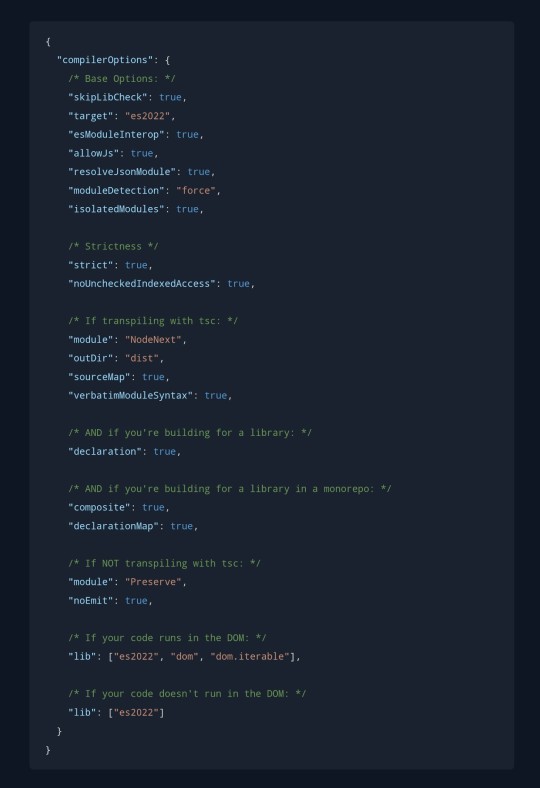
...just because the name variable already exists elsewhere. One way to fix this mistake (which I knew about) is by adding export {}; to the end of the file, turning it into a module from TS perspective. Another way (which I found out about just now) is by adding line "moduleDetection": "force" to the config file. Cool.
Recommended configuration (link)
0 notes
Photo

#一緒に [isshoni] together#i knew but didn't recognize#お風呂に入る [ofúroni háiru] to take a bath#is a new one for me#japanese#languages#but also#why?#what is#françois sagat#of all people is doing here???
2K notes
·
View notes
Text

#languages#japanese#so to recap (normal verb / deferential verb):#1) kureru / kudasaru = to give to me#2) ageru / sashiageru = to give to someone else#3) morau / itadaku = to receive#and if you want to be rude: yaru = to give to someone else
503 notes
·
View notes
Text





日本の小さな町の静かな夜
#even with my nonexistent japanese skills i still managed to read that#very proud of myself#usually i only now how to pronounce kana#kanji i may recognize#but recalling their readings is beyond my capabilities#languages#japanese
6K notes
·
View notes
Text
just a couple of weeks ago i discovered that on windows you can move cursor left or right by one word using
ctrl + left arrow / right arrow
basically anywhere and if you add shift into the mix, you can select large chunks of text pretty quickly! i honestly feel like this has changed my life on a deeply profound level. how didn't i know something so simple yet useful before?
0 notes
Text
A little thing I made about inflecting municipality names
Most names in this list were checked from the official web pages of the municipalities. Blame them for any mistakes (/j)

A lot of teachers will tell you to remember some kind of rule set for these kinds of things but I wouldn't do that. Instead, I would advise you to think of them as guidelines; for example, many places that end in -joki use the allative. The most important thing to remember though is that it is not set in stone! There might be a place that uses the illative instead.
Also, remember that even native speakers get these things wrong sometimes. (I had to google an embarrassingly large amount of these just to be sure which one it was) When in doubt, think of a similar place name and use the ending. (you might or might not be correct!)
There might also be situations where the locals cannot come to a conclusion on what the "real" way is, I added some examples of that too. I've also come across situations where two different places have the exact same name but they both inflect it differently...
Here are some resources on this.
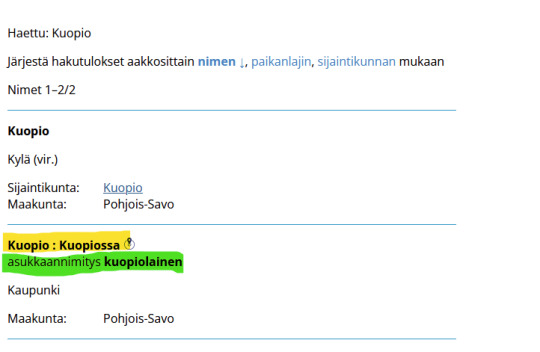
(In Finnish) It's very useful since it gives both the inflection (yellow) and what the locals are called (green)
The Institute for the Languages of Finland advice page on the matter. (there's more links to stuff in there too) (In Finnish)
65 notes
·
View notes
Text
I don't think this is how you're supposed to use git.

0 notes
Text
Pug + Sass + Gulp -> Gatsby + Tailwind
For about a week now I've been trying to rewrite my tiny "portfolio site" with Gatsby and Tailwind. It was originally written about a year and a half ago with Pug & Sass used in place of bare HTML & CSS, and then compiled, stitched together and minified with Gulp. The whole rewriting project was conceived as an attempt to learn some new technologies in order to make my resume more appealing (I am still unemployed, [insert crying emoji here]). While it is still far from over (rewriting a webpage appears to take more time, than making a new one), I do have some thoughts.
Gatsby
Gatsby's documentation is not well organized. I have found a few pages, that can be found using the search feature and yet do not appear anywhere in the documentation's table of contents (like this on porting an HTML site to Gatsby, or this on creating dynamic navigation, both very useful things).
I took me some time to realize, how different parts of a Gatsby project relate to the resulting bundle: (1) the "page" you write as a React component doesn't correspond to the whole HTML page, it is the content of the <body> element of the actual HTML file (or at least, most of its content), (2) you can insert things into the <head> element of a specific page by exporting Head variable from the "page" component file, (3) if you want to insert things into the <head> element of all pages, you need to use gatsby-ssr.js or gatsby-browser.js files at the root of your project: the first one controls the build process, the second one controls the app lifecycle in the browser, both can be used to change the default HTML code wrapping the page components. And I'm still not sure, I'm getting it correctly, because after I added a list of <link> and <script> elements to the <head>, this is what got in the console:

The whole thing works, it's just that I get this error message every time. And I know what it means, and I know I didn't make this mistake in my code, so it looks like Gatsby itself somewhere forgot to add key attribute while rendering a list of components inside the <head>. Right? Or am I missing something?
UPD: It was my fault! And I did make this mistake in my code. I needed to add key attributes myself:

Tailwind
I am not sure if I am impressed by what this thing can do, or terrified by the code I end up writing as a result.

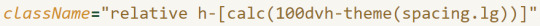

Using class names with custom values for spacing and border radius in them defined inside Tailwind's config? It's quite useful, really. Using CSS variables directly in the class names? OK, sure, why not. But putting a calc() function directly into a class name? Using a theme() function to retrieve config values inside a calc() function?? Inside a class name??? Clearly, this is crazy, right? And yet, the docs encourage you to reach for those features before trying to extract your styles into pure CSS, so here I am, shoving calc() into class names. Madness.
If you, like me, are using Tailwind with the Prettier plugin (because the order of classes doesn't matter, and it helps to have them uniformly sorted), I strongly recommend using prettier-plugin-classnames for adding line breaks (because the main plugin, annoyingly, doesn't do that):
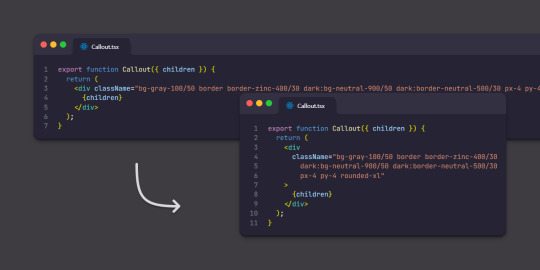
Also, for some reason @apply directive doesn't work with a custom class either used or defined with the dark: variant. So, neither of these 2 works:
(1)

(2)

This was mentioned in an issue from 2020!
0 notes