#Agent lifecycle orchestration best practices
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Mastering AI Agent Lifecycle Management for Enterprise Scalability
Explore how managing the AI agent lifecycle effectively drives scalable digital transformation. Learn strategies for deploying, monitoring, and evolving autonomous agents across enterprise environments.
#AI Agent Lifecycle Management#AI agent lifecycle optimization#End-to-end agent lifecycle management#Agent lifecycle orchestration best practices#Tools for agent lifecycle management
0 notes
Text
GitOps for Kubernetes: Automating Deployments the Git Way
In the world of cloud-native development and Kubernetes orchestration, speed and reliability are essential. That's where GitOps comes in—a modern approach to continuous deployment that leverages Git as a single source of truth. It's a powerful method to manage Kubernetes clusters and applications with clarity, control, and automation.
🔍 What is GitOps?
GitOps is a set of practices that uses Git repositories as the source of truth for declarative infrastructure and applications. It applies DevOps best practices—like version control, collaboration, and automation—to infrastructure operations.
In simpler terms:
You declare what your system should look like (using YAML files).
Git holds the desired state.
A GitOps tool (like Argo CD) continuously syncs the actual system with what’s defined in Git.
💡 Why GitOps for Kubernetes?
Kubernetes is complex. Managing its resources manually or with ad hoc scripts often leads to configuration drift and inconsistent environments. GitOps brings order to the chaos by:
Enabling consistency across environments (dev, staging, prod)
Reducing errors through version-controlled infrastructure
Automating rollbacks and change tracking
Speeding up deployments while increasing reliability
🔧 Core Principles of GitOps
Declarative Configuration All infrastructure and app definitions are written in YAML or JSON files—stored in Git repositories.
Version Control with Git Every change is committed, tracked, and reviewed using Git. This means full visibility and easy rollbacks.
Automatic Synchronization GitOps tools ensure the actual state in Kubernetes matches the desired state in Git—automatically and continuously.
Pull-Based Deployment Instead of pushing changes to Kubernetes, GitOps agents pull the changes, reducing attack surfaces and increasing security.
🚀 Enter Argo CD: GitOps Made Easy
Argo CD (short for Argo Continuous Delivery) is an open-source tool designed to implement GitOps for Kubernetes. It works by:
Watching a Git repository
Detecting any changes in configuration
Automatically applying those changes to the Kubernetes cluster
🧩 Key Concepts of Argo CD
Without diving into code, here are the essential building blocks:
Applications: These are the units Argo CD manages. Each application maps to a Git repo that defines Kubernetes manifests.
Repositories: Git locations Argo CD connects to for pulling app definitions.
Syncing: Argo CD keeps the live state in sync with what's declared in Git. It flags drifts and can auto-correct them.
Health & Status: Argo CD shows whether each application is healthy and in sync—providing visual dashboards and alerts.
🔴 Red Hat OpenShift GitOps
Red Hat OpenShift brings GitOps to enterprise Kubernetes with OpenShift GitOps, a supported Argo CD integration. It enhances Argo CD with:
Seamless integration into OpenShift Console
Secure GitOps pipelines for clusters and applications
RBAC (Role-Based Access Control) tailored to enterprise needs
Scalability and lifecycle management for GitOps workflows
No need to write code—just define your app configurations in Git, and OpenShift GitOps takes care of syncing, deploying, and managing across your environments.
✅ Benefits of GitOps with OpenShift
🔐 Secure by design – Pull-based delivery reduces attack surface
📈 Scalable operations – Manage 100s of clusters and apps from a single Git repo
🔁 Reproducible environments – Easy rollback, audit, and clone of full environments
💼 Enterprise-ready – Backed by Red Hat’s support and OpenShift integrations
🔚 Conclusion
GitOps is not just a buzzword—it's a fundamental shift in how we manage and deliver applications on Kubernetes. With tools like Argo CD and Red Hat OpenShift GitOps, teams can automate deployments, ensure consistency, and scale operations—all using Git.
Whether you're managing a single cluster or many, GitOps gives you control, traceability, and peace of mind.
For more info, Kindly follow: Hawkstack Technologies
0 notes
Text
Unlocking the Power of Hybrid AI: Agentic and Generative AI
Introduction
The landscape of artificial intelligence (AI) is rapidly evolving, with Agentic AI and Generative AI at the forefront. These technologies are transforming industries by automating complex processes and creating novel content. Hybrid AI, which combines different AI approaches, offers a powerful synergy that can enhance efficiency, creativity, and decision-making. For those interested in exploring these technologies further, a comprehensive Generative AI and Agentic AI course is essential for understanding their applications and future potential. This article delves into the latest developments in Agentic and Generative AI, explores advanced generative pipelines, and discusses practical strategies for successful deployment. For individuals seeking career opportunities, the Best Agentic AI Course with Job Guarantee and Best Generative AI Course with Placement Guarantee can provide the necessary skills and assurance.
Evolution of Agentic and Generative AI in Software
Background and Evolution
Agentic AI focuses on autonomous agents that can make decisions and act independently, often in complex environments. This type of AI is crucial for tasks requiring adaptability and real-time decision-making, such as robotics, smart home systems, logistics, and customer service. Generative AI, on the other hand, is designed to create new content, such as images, videos, or text, using algorithms like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Generative AI has seen widespread adoption in creative industries and data augmentation for machine learning. A Generative AI and Agentic AI course can provide detailed insights into these technologies. Over the past few years, these technologies have evolved significantly, with advancements in Large Language Models (LLMs) and Autonomous Agents. LLMs have become central to many generative AI applications, enabling tasks like text generation and content creation. Autonomous agents are being used in areas where they can interact with users and make decisions autonomously. For a career transition into AI, enrolling in the Best Agentic AI Course with Job Guarantee can be beneficial.
Recent Developments
Recent breakthroughs include the development of more sophisticated LLMs that can handle complex tasks with greater precision. Additionally, advancements in LLM Orchestration have made it easier to deploy these models across different applications, enhancing their utility in hybrid AI systems. For instance, IBM's recent focus on Hybrid Integration solutions aims to streamline workflows and improve AI-driven automation across various platforms. This integration aligns well with the curriculum of a Generative AI and Agentic AI course.
Integration of Agentic and Generative AI
Combining Agentic and Generative AI can leverage their strengths. For example, using generative models to create scenarios for autonomous agents to navigate can enhance their decision-making capabilities. This integration can also facilitate more sophisticated automation, where autonomous agents can generate and adapt plans based on real-time data. The Best Generative AI Course with Placement Guarantee provides training in such integrations, ensuring graduates are well-equipped for industry demands.
Latest Frameworks, Tools, and Deployment Strategies
Frameworks and Tools
Several frameworks and tools are now available to support the development and deployment of Agentic and Generative AI systems. MLOps (Machine Learning Operations) has emerged as a critical framework for managing the lifecycle of machine learning models, including those used in generative AI. MLOps helps ensure that models are deployed efficiently, monitored continuously, and updated regularly to maintain performance. A Generative AI and Agentic AI course would cover these tools in depth. Autonomous Agent Frameworks, such as those used in robotics and smart systems, provide structured approaches to developing and deploying autonomous agents. These frameworks often include tools for agent communication, decision-making, and interaction with their environment. The Best Agentic AI Course with Job Guarantee includes training on these frameworks, ensuring employment readiness.
Deployment Strategies
Effective deployment of hybrid AI systems requires careful planning and execution. Cloud-based Infrastructure is increasingly popular due to its scalability and flexibility. Specialized hardware like TPUs (Tensor Processing Units) and GPUs (Graphics Processing Units) are essential for handling the computational demands of large-scale AI models. Understanding these strategies is crucial for those pursuing a Generative AI and Agentic AI course.
Advanced Tactics for Scalable, Reliable AI Systems
Data Preparation and Model Tuning
One of the most critical steps in deploying hybrid AI systems is preparing high-quality data. This involves data cleaning, verification, and finetuning to ensure that models perform optimally. Prompt Engineering is also crucial, as it helps tailor models to specific use cases and improves their adaptability. The Best Generative AI Course with Placement Guarantee emphasizes the importance of data quality in AI model performance.
Model Selection and Architecture
Choosing the right model architecture is vital. For generative tasks, models like GANs and VAEs are popular choices. For agentic AI, selecting models that can handle complex decision-making, such as Deep Reinforcement Learning, is essential. A comprehensive Generative AI and Agentic AI course would cover these architectures in detail.
Scalability and Reliability
To scale AI systems reliably, organizations must focus on MLOps practices. This includes continuous monitoring, automated testing, and version control to ensure that models perform consistently across different environments. The Best Agentic AI Course with Job Guarantee includes training on these practices to ensure graduates can manage complex AI systems.
The Role of Software Engineering Best Practices
Software engineering best practices are indispensable for ensuring the reliability, security, and compliance of AI systems. Design Patterns, such as the use of microservices for modularity, and Testing Frameworks, like Pytest for Python, help maintain the integrity and performance of AI models over time. A Generative AI and Agentic AI course would emphasize these practices for developing robust AI systems. Continuous Integration/Continuous Deployment (CI/CD) pipelines are crucial for automating the deployment process, ensuring that changes are quickly tested and deployed. Security is a particular concern, as AI systems can be vulnerable to attacks like data poisoning or model inversion. Implementing robust security measures, such as encryption and access controls, is crucial. The Best Generative AI Course with Placement Guarantee covers these security considerations.
Ethical Considerations in AI Deployment
As AI becomes more pervasive, ethical considerations become increasingly important. Bias in AI Models can lead to unfair outcomes, and Privacy Concerns must be addressed when handling sensitive data. Ensuring transparency and explainability in AI decision-making processes is vital for building trust. A Generative AI and Agentic AI course should include discussions on these ethical considerations.
Cross-Functional Collaboration for AI Success
Cross-functional collaboration is essential for the successful deployment of hybrid AI systems. Data Scientists, Software Engineers, and Business Stakeholders must work together to align AI solutions with business objectives, ensure technical feasibility, and monitor performance. For those interested in Best Agentic AI Course with Job Guarantee or Best Generative AI Course with Placement Guarantee, understanding this collaboration is key.
Measuring Success: Analytics and Monitoring
Measuring the success of AI deployments involves tracking both technical and business metrics. Technical Metrics include model accuracy, performance speed, and system reliability. Business Metrics might include revenue impact, customer satisfaction, and operational efficiency. Continuous Monitoring and Feedback are critical for maintaining and improving AI systems over time. This is well-covered in a comprehensive Generative AI and Agentic AI course.
Case Study: IBM's Hybrid AI Integration
IBM's Approach
IBM has been at the forefront of integrating AI into business operations. Recently, IBM introduced webMethods Hybrid Integration, which leverages AI to automate workflows across different applications and platforms. This solution helps organizations manage complex integrations more efficiently, reducing downtime and improving project completion times. The integration strategies used by IBM align with the curriculum of a Generative AI and Agentic AI course. IBM's approach to hybrid AI focuses on unlocking the potential of unstructured data, which is often underutilized in organizations. By leveraging AI to activate this data, businesses can drive more accurate and effective decision-making processes. For those interested in Best Agentic AI Course with Job Guarantee or Best Generative AI Course with Placement Guarantee, understanding IBM's approach can provide valuable insights.
IBM's Journey
IBM's journey into hybrid AI began with a focus on developing robust AI accelerators like the Telum II on-chip AI processor. This hardware is designed to handle the computational demands of AI models efficiently, making it easier for businesses to deploy AI solutions at scale. IBM's watsonx.data platform is another key component, helping organizations to unlock the value of unstructured data. This platform is crucial for feeding high-quality data into AI models, ensuring they perform optimally. A Generative AI and Agentic AI course would explore such industry applications.
Business Outcomes
The outcomes of IBM's hybrid AI initiatives have been impressive. Organizations using IBM's solutions have reported significant reductions in project completion times and improvements in operational efficiency. For instance, a study by Forrester Consulting found that companies adopting IBM's integration capabilities saw a 176% ROI over three years, along with reduced downtime and improved project completion times. This success highlights the value of a Generative AI and Agentic AI course in preparing professionals for such roles.
Actionable Tips and Lessons Learned
Focus on Data Quality: High-quality data is critical for AI model performance. Invest in data cleaning and verification processes. This is emphasized in both Generative AI and Agentic AI course offerings.
Collaborate Across Functions: Ensure that data scientists, engineers, and business stakeholders work together to align AI solutions with business objectives. The Best Agentic AI Course with Job Guarantee and Best Generative AI Course with Placement Guarantee highlight this collaboration.
Monitor and Adjust: Use analytics to track AI system performance and make adjustments as needed to maintain and improve results. This is a key takeaway from a comprehensive Generative AI and Agentic AI course.
Leverage MLOps: Implement MLOps practices to ensure efficient model deployment, monitoring, and updates. Both Best Agentic AI Course with Job Guarantee and Best Generative AI Course with Placement Guarantee cover MLOps extensively.
Emphasize Security: Implement robust security measures to protect AI systems from potential threats. This is an essential component of any Generative AI and Agentic AI course.
Conclusion
Unlocking the synergies of hybrid AI requires a deep understanding of both Agentic and Generative AI technologies, as well as the latest tools and deployment strategies. For those interested in this field, a Generative AI and Agentic AI course is indispensable. Additionally, the Best Agentic AI Course with Job Guarantee and Best Generative AI Course with Placement Guarantee provide the necessary skills and assurance for career advancement. By focusing on data quality, cross-functional collaboration, and software engineering best practices, organizations can successfully deploy AI systems that drive real business value. As AI continues to evolve, staying informed about the latest developments and leveraging real-world examples will be key to unlocking its full potential. Whether you're an AI practitioner, software architect, or business leader, embracing hybrid AI can transform your operations and drive innovation in ways previously unimaginable. A Generative AI and Agentic AI course can provide the foundational knowledge needed to navigate this exciting field.
0 notes
Text
Automation in DevOps (DevSecOps): Integrating Security into the Pipeline
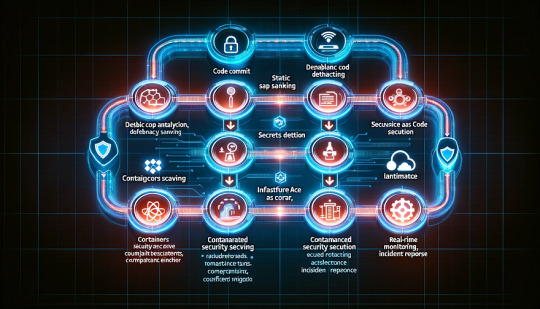
In modern DevOps practices, security can no longer be an afterthought — it needs to be embedded throughout the software development lifecycle (SDLC). This approach, known as DevSecOps, integrates security automation into DevOps workflows to ensure applications remain secure without slowing down development.
Why Security Automation?
Traditional security models relied on manual code reviews and vulnerability assessments at the end of the development cycle, often leading to bottlenecks and delayed releases. Security automation addresses these issues by: ✔️ Detecting vulnerabilities early in the CI/CD pipeline ✔️ Reducing manual intervention and human error ✔️ Ensuring continuous compliance with industry regulations ✔️ Improving incident response time
Key Areas of Security Automation in DevOps
1. Automated Code Security (Static & Dynamic Analysis)
Static Application Security Testing (SAST): Scans source code for vulnerabilities before deployment (e.g., SonarQube, Checkmarx).
Dynamic Application Security Testing (DAST): Identifies security flaws in running applications (e.g., OWASP ZAP, Burp Suite).
Software Composition Analysis (SCA): Detects vulnerabilities in third-party dependencies (e.g., Snyk, WhiteSource).
🔹 Example: Running SAST scans automatically in a Jenkins pipeline to detect insecure coding practices before merging code.
2. Secrets Management & Access Control
Automating the detection and handling of hardcoded secrets, API keys, and credentials using tools like HashiCorp Vault, AWS Secrets Manager, and CyberArk.
Implementing least privilege access via automated IAM policies to ensure only authorized users and services can access sensitive data.
🔹 Example: Using HashiCorp Vault to generate and revoke temporary credentials dynamically instead of hardcoding them.
3. Automated Compliance & Policy Enforcement
Infrastructure as Code (IaC) security scans using Checkov, OPA (Open Policy Agent), or Terraform Sentinel ensure that cloud configurations follow security best practices.
Automated audits and reporting help maintain compliance with GDPR, HIPAA, SOC 2, and ISO 27001 standards.
🔹 Example: Using Checkov to scan Terraform code for misconfigurations before provisioning cloud resources.
4. Container & Kubernetes Security
Scanning container images for vulnerabilities using Trivy, Aqua Security, or Anchore before pushing them to a registry.
Implementing Kubernetes security policies (e.g., Pod Security Policies, Kyverno, or Gatekeeper) to enforce security rules.
🔹 Example: Using Trivy in a CI/CD pipeline to scan Docker images before deployment to Kubernetes.
5. Continuous Security Monitoring & Threat Detection
Implementing SIEM (Security Information and Event Management) tools like Splunk, ELK Stack, or AWS Security Hub for real-time security event detection.
Using Intrusion Detection Systems (IDS) and Intrusion Prevention Systems (IPS) (e.g., Snort, Suricata) to detect and respond to security threats.
AI-driven anomaly detection via Amazon GuardDuty, Microsoft Defender for Cloud, or Google Chronicle.
🔹 Example: Configuring AWS Security Hub to automatically detect and alert on misconfigurations in an AWS environment.
6. Automated Incident Response & Remediation
Using SOAR (Security Orchestration, Automation, and Response) platforms like Splunk SOAR or Palo Alto Cortex XSOAR to automate security incident triage and response.
Creating automated playbooks for threat mitigation, such as isolating compromised containers or blocking suspicious IPs.
🔹 Example: Automating AWS Lambda functions to quarantine an EC2 instance when an anomaly is detected.
Bringing It All Together: A DevSecOps Pipeline Example
1️⃣ Code Commit: Developers push code to a Git repository. 2️⃣ Static Code Analysis: SAST tools scan for vulnerabilities. 3️⃣ Dependency Scanning: SCA tools check third-party libraries. 4️⃣ Secrets Detection: Git hooks or automated scanners look for hardcoded secrets. 5️⃣ Container Security: Images are scanned before being pushed to a container registry. 6️⃣ Infrastructure as Code Scanning: Terraform or Kubernetes configurations are checked. 7️⃣ Automated Security Testing: DAST and penetration tests run in staging. 8️⃣ Compliance Checks: Policies are enforced before deployment. 9️⃣ Real-time Monitoring: Logs and security events are analyzed for threats. 🔟 Incident Response: Automated workflows handle detected threats.
Final Thoughts
Security automation in DevOps is critical for ensuring that security does not slow down development. By integrating automated security testing, policy enforcement, and monitoring, teams can build resilient, compliant, and secure applications without sacrificing speed.
WEBSITE: https://www.ficusoft.in/devops-training-in-chennai/
0 notes
Text
Enterprise Linux Automation with Ansible: Streamlining Operations and Boosting Efficiency
In today’s fast-paced IT landscape, businesses are constantly looking for ways to improve efficiency, reduce manual efforts, and ensure consistent performance across their systems. This is where automation tools like Ansible come into play, especially for enterprises running Linux-based systems. Ansible, an open-source automation platform, allows system administrators to automate configuration management, application deployment, and task orchestration in a simple and scalable way. Let’s explore how Ansible can revolutionize enterprise Linux automation.
What is Ansible?
Ansible is an automation tool that is designed to automate tasks across multiple machines or environments. It is agentless, meaning that it does not require any additional software or agents to be installed on the managed nodes. Instead, it uses SSH (for Linux-based systems) or WinRM (for Windows-based systems) to communicate with the remote servers.
One of the reasons Ansible has gained significant popularity is its simplicity and ease of use. With Ansible, system administrators can describe the configuration of systems using easy-to-understand YAML syntax, called Playbooks. These playbooks define the tasks that need to be performed, such as package installation, service management, user creation, and more.
Key Benefits of Ansible for Enterprise Linux Automation
Improved Operational Efficiency By automating repetitive tasks, Ansible helps reduce the time and effort required for system configuration, updates, and maintenance. Tasks that once took hours can now be completed in a matter of minutes, freeing up your IT team to focus on more strategic initiatives.
Consistency Across Environments Whether you're working in a single data center or managing multiple cloud environments, Ansible ensures that your configurations remain consistent. With playbooks, you can define the desired state of your infrastructure and ensure that all systems are aligned with that state, reducing the risk of configuration drift and human error.
Scalability Ansible is built to scale with your business. As your infrastructure grows, you can easily add more nodes (servers, virtual machines, containers) to your Ansible inventory and run automation tasks across all of them simultaneously. This scalability is crucial for large enterprises that manage thousands of systems.
Integration with DevOps Pipelines Ansible integrates seamlessly with DevOps tools like Jenkins, GitLab, and Docker. This integration enables you to automate the entire software development lifecycle, from provisioning and configuration to continuous integration and deployment. With Ansible, you can implement infrastructure as code (IaC) and build a more agile and responsive IT environment.
Security and Compliance Security and compliance are top priorities for enterprise organizations. Ansible helps automate security patch management and ensures that all systems are compliant with industry regulations. By defining security configurations as code, Ansible allows organizations to enforce best practices and continuously monitor systems for compliance.
Use Cases for Ansible in Enterprise Linux Environments
Configuration Management Ansible can automate the configuration of Linux servers, ensuring that each server is configured consistently across the entire organization. Whether you're setting up web servers, databases, or network devices, Ansible playbooks provide a reliable and repeatable process for configuration management.
Software Deployment Installing and updating software across a large number of Linux systems can be a time-consuming and error-prone task. With Ansible, you can automate software deployments, ensuring that the correct versions are installed, configured, and updated across all systems in your environment.
Patch Management Keeping systems up-to-date with the latest security patches is critical for protecting your infrastructure. Ansible makes patch management simple by automating the process of applying patches to Linux systems, reducing the risk of vulnerabilities and ensuring your systems remain secure.
Provisioning Infrastructure Whether you're deploying virtual machines, containers, or cloud instances, Ansible can help you automate the provisioning process. By defining infrastructure as code, you can quickly and consistently spin up new instances or services, reducing the manual effort required for infrastructure management.
Backup and Recovery Automation Ansible can also be used to automate backup and recovery tasks, ensuring that your critical data is consistently backed up and easily recoverable in case of an emergency. Playbooks can be created to run regular backups and even test recovery procedures to ensure that they work as expected.
Best Practices for Using Ansible in Enterprise Linux Automation
Use Version Control for Playbooks To ensure consistency and traceability, store your Ansible playbooks in version control systems such as Git. This allows you to track changes, roll back to previous versions, and collaborate more effectively with your team.
Modularize Playbooks Break down your playbooks into smaller, reusable roles and tasks. This modular approach helps you maintain clean, organized, and reusable code that can be easily shared across different projects and environments.
Use Inventory Files for Dynamic Environments Ansible’s dynamic inventory allows you to automatically pull a list of hosts from cloud providers like AWS, Azure, and Google Cloud. This flexibility ensures that your playbooks are always targeting the right systems, even in dynamic environments.
Implement Error Handling and Logging Incorporate error handling and logging into your playbooks to ensure that issues are caught and logged for troubleshooting. Ansible provides several built-in features for handling errors and capturing logs, helping you quickly identify and resolve problems.
Test Playbooks Before Production Always test your playbooks in a non-production environment before running them on critical systems. Use tools like Ansible’s --check mode to perform a dry run and validate the changes that will be made.
Conclusion
Ansible is a powerful tool for automating and streamlining enterprise Linux environments. Its simplicity, scalability, and ease of integration with other tools make it an ideal choice for organizations looking to improve operational efficiency, reduce errors, and ensure consistency across their systems. By leveraging Ansible for Linux automation, enterprises can stay ahead of the competition and focus on delivering value to their customers.
Ready to start automating your Linux infrastructure? Give Ansible a try and experience the power of automation firsthand!
For more details click www.hawkstack.com
0 notes
Text
LLMOps: Streamlining enterprise value in the LLM & agentic era
New Post has been published on https://thedigitalinsider.com/llmops-streamlining-enterprise-value-in-the-llm-agentic-era/
LLMOps: Streamlining enterprise value in the LLM & agentic era

The rise of LLMs, and more recently the push to ‘taskify’ these models with agentic application, has ushered in a new era of AI.
However, effectively deploying, managing & optimizing these models requires a robust set of tools and practices. Enter one of enterpise’s most vital functions in 2025, LLMOps: a set of methodologies and tech stacks that aim to streamline the entire lifecycle of LLMs, from development and training, to deployment and maintenance.
LLMOps Ecosystem Map: 2025 [download below]
AI Accelerator Institute’s recently released LLMOps Ecosystem Map: 2025 provides a comprehensive view of the tools and technologies currently available for LLM build & management. Excluding foundational LLM infrastructure and purely breaking down the Ops lifecycle, the map categorizes the landscape into 9 key areas:
Observability
Orchestration & model deployment
Apps/user analytics
Experiment tracking, prompt engineering & optimization
Monitoring, testing, or validation
Compliance & risk
Model training & fine-tuning
End-to-end LLM platform
Security & privacy
LLMOps Ecosystem Map 2025
This map underscores the growing maturity of the LLMOps ecosystem moving into 2025, with a monstrous range of tools available now for every stage of the LLM lifecycle.
Want to build out exceptional LLMOps infrastructure? Join AIAI in-person at an LLMOps Summit.
→ LLMOps Summit Silicon Valley | April 29, 2025
→ LLMOps Summit Boston | October 29, 2025
Why is LLMOps crucial in 2025?
LLMOps plays a critical role in enabling rapid innovation and enterprise agility by:
Accelerating time-to-market: LLMOps tools automate many of the manual tasks involved in deploying and managing LLMs, reducing development time and accelerating the time-to-market for new LLM-powered products and services.
Improving efficiency and productivity: By streamlining the LLM development and deployment process, LLMOps helps organizations improve their efficiency and productivity.
Enhancing model performance and reliability: LLMOps tools enable organizations to monitor and optimize LLM performance, ensuring that models are reliable and deliver accurate results.
Managing risk and ensuring compliance: LLMOps helps organizations manage the risks associated with using LLMs, such as data privacy and security concerns, and ensure compliance with relevant regulations.
Driving innovation: By providing a robust foundation for LLM development and deployment, LLMOps empowers organizations to experiment with new ideas and innovate with AI.
As LLMs continue to transform industries, the importance of LLMOps will only grow. By adopting and implementing LLMOps best practices, organizations can unlock the full potential of LLMs and gain a significant competitive advantage in the years to come.

Like what you see? Then check out tonnes more.
From exclusive content by industry experts and an ever-increasing bank of real world use cases, to 80+ deep-dive summit presentations, our membership plans are packed with awesome AI resources.
Subscribe now
#2025#ai#amp#bank#compliance#comprehensive#content#data#data privacy#data privacy and security#deploying#deployment#development#driving#efficiency#engineering#enterprise#Foundation#Full#functions#generative ai#Ideas#Industries#Industry#Infrastructure#Innovation#Landscape#llm#LLMOps#LLMs
0 notes
Text
What are the popular DevOps tools/services available in the market?
What is DevOps?
This approach to building software is the norm now with most companies recognizing the need to iterate quickly and release new code frequently. DevOps is a combination of philosophies, practices and tools that replaces long product development cycles with a much faster cadence. The idea is that this way of working makes it easier to respond to customer demands and changes in the market.
Software engineers and operation teams work together to support this process with developers taking on some tasks previously assigned to other teams. Quality assurance and security teams also work more closely with developers within this model.

What are the business benefits of DevOps?
Companies that use a DevOps approach have seen improved communication, increased efficiencies, better reliability and scaling as well as cost savings. Smaller deployments create rapid feedback cycles and improve the overall process. Smaller batch sizes also reduce the overall risk of deploying new software as well.
What tools do DevOps teams use?
Shifting software development to this model requires a cultural shift and a particular set of tools to support the work. There are several categories of DevOps tools:
Application performance monitoring
Artifact management
CI/Deployment automation
Configuration management
Container management
Deployment and server monitoring
Test automation
Version control
This roundup includes some that are specialized to one or two functions while others in the list are more comprehensive.
The best DevOps software
Ansible
Ansible is an IT automation engine that can handle cloud provisioning, configuration management, application deployment and intra-service orchestration, among other tasks. Ansible is designed for multi-tier deployments and can model the entire IT architecture.
The platform uses YAML, a human readable data serialization language. YAML is mostly used for configuration files and in applications where data is being stored or transmitted. It has a minimal syntax.
Ansible also uses playbooks to orchestrate multiple levels of an infrastructure’s topology. According to the company, the playbooks can be used to:
Take machines in and out of load balancers
Have one server know the IP address of all the others and use those to build out configuration files dynamically
Set some variables, prompt for others and set defaults when they are not set
Use the results of one command to decide whether to run another
For security, Ansible supports passwords, but is designed for SSH keys with ssh-agent or Kerberos.
Ansible modules can be written in any language that can return JSON. There are several Python APIs for extending Ansible’s connection types and there are hundreds of integrations, including Atlassin, AWS, Cisco, Google Cloud Platform, Splunk, VMware and Windows.
Ansible is an open source community project sponsored by Red Hat.
Azure DevOps
This Microsoft product covers the entire application lifecycle and provides version control, reporting, requirements management, project management, automated builds, testing and release management capabilities. According to the company, the platform supports a collaborative culture and set of processes that bring together developers, project managers and contributors. The software is available in the cloud or on-prem. Also, customers can use integrated features available through a web browser or an integrated development environment client, or select one or more of these standalone services:
Repos: For Git repositories or Team Foundation Version Control for source control
Pipelines: Build and release services for continuous integration and delivery of applications
Boards: A suite of agile tools for planning and tracking work, code defects and issues via Kanban and Scrum methods
Test plans: Several tools for testing including manual/exploratory testing and continuous testing
Artifacts: A service for sharing packages such as Maven, npm, NuGet and others from public and private sources and for integrating package sharing into development pipelines
Azure DevOps also includes collaboration tools such as customizable dashboards, built-in wikis and configurable notifications. The platform also supports extensions and integrations with other services including Campfire, Slack and Trello in addition to developing custom extensions.
AWS DevOps
AWS has a flexible set of services to make it easier to provide and manage infrastructure, deploy code, automate software release and monitor application and infrastructure performance. Each service is ready to use for existing AWS customers and designed to scale from a few instances or thousands. Customers can use each service via the AWS command line interface or through APIs and SDKs. DevOps solutions and tools cover CI/CD, microservices, infrastructure as code, monitoring and logging, platform as a service and version control. AWS offers a free tier that includes more than 100 products and three types of free offers:
Short-term free trials
12 months free for new customers
Always free for new and existing customers
A customer with access to the AWS Free Tier can use up to 750 instance hours each of t2.micro instances running Linux and Windows. Usage of the Linux and Windows t2.micro instances are counted independently. The AWS free tier applies to participating services across the company’s global regions, including 26 launched regions, 84 availability zones, 17 local zones and 310+ points of presence.
AWS also offers guides and tutorials about the DevOps services that cover setting up a CD pipeline and migrating a Git repository to AWS as well as training and certification programs such as the developer learning path.
Docker DevOps
Docker is one of the top choices for container management and has both free and premium tiers. Docker Engine hosts the containers. A container is a standard unit of software that packages up code and all its dependencies so an application can run in any environment. A Docker container image holds everything an app needs: code, runtime, system tools, system libraries and settings. Containers can be used with virtual machines to create flexibility in deploying and managing applications.
Three types of containers run on the platform:
Standard
Lightweight
Secure
For developers, Docker has a set of command line interface plugins to build, test and share containerized applications and microservices. Compose simplifies the code to cloud process and toolchain for developers and allows engineers to define a complex stack in a single file and run it with a single command.
Other developer services include Build to create images for multiple CPU and OS architectures and share them in a private registry or on Docker Hub and Context which makes it easy to switch between multiple Docker and Kubernetes environments. Docker Hub makes it easy to view images stored in multiple repositories and to configure a complete CI/CD container workflow with automated builds and actions triggered after each successful push to the Docker Hub registry.
GitLab
This open-core company provides DevOps software to develop, secure and operate software in a single application. Software companies can use GitLab to do portfolio planning and management through epics, groups and milestones to track progress. The flexible platform can increase visibility from the start to the finish of a project and make it easier to track issues throughout the delivery lifecycle. The platform also has these components:
Create: For managing code and project data from a single distributed version control system
Verify: For automated testing, status analysis security testing, dynamic analysis security testing and code quality analysis
Package: For managing containers and package registries to work with GitLab source code management and CI/CD pipelines
Secure: For integrating security into app development and delivering license compliance
Release: For automating the release and delivery of applications with zero-touch CD builtin into the pipeline
Configure: For managing application environments with a strong integration for Kubernetes
Monitor: For reducing the severity and frequency of incidents
Protect: For native cloud protections, unified policy management,
Jenkins
Jenkins is an open source CI/CD automation tool written in Java. This platform is especially helpful for managing microservices and surpassed 200,000 known installations in 2019, according to the company. Jenkins runs on Windows, MacOS and Linux and in a Docker container. The software is self-contained and can be extended via its plugin architecture which includes more than 1,800 entries.
Jenkins also supports a broad user community to make it easy for people who are new to the platform. There are sub groups within the community that cover coding, meeting other users, improving documentation and contributing to automated tests. There are area meetups as well as an online meetup for people interested in socializing with other CI/CD users and contributors.
Jenkins also offers a public, community-driven roadmap that collects and tracks initiatives in all areas, including features, infrastructure, documentation and community. Future projects include pipeline development in IDE, user interface rework and better remote monitoring.
Jira
Jira was originally built as a bug tracker but the platform has expanded to manage projects of all types from requirements and test cases to agile software development. Jira is the backbone of Open DevOps, Atlassian’s open integrated toolchain. Jira integrates with first- and third-party tools including Bitbucket, GitHub, GitLab, Confluence and Opsgenie.
Jira’s DevOps solution can create automated workflows on multiple tools and provide real-time status updates. The software also supports roadmap requirements.
Jira integrates with Hipchat and Slack, as well as many other types of third-party software. It is highly customizable and good for both tech and business users.
Kubernetes
Kubernetes is an open source container orchestration system used for automating computer application deployment, scaling and management. Kubernetes also helps developers build distributed applications and makes it easier to manage scalable infrastructure for applications. Google open sourced the Kubernetes project in 2014.
Kubernetes allows DevOps professionals to:
Deploy containerized applications quickly and predictably
Scale containerized applications on the fly
Roll out new features to containerized applications
Optimize hardware specifically for containerized applications
A Kubernetes cluster includes a set of worker machines called nodes that run containerized applications. The worker node hosts pods that represent the components of the application workload. The control plane manages the workers nodes and the pods in the cluster. Other Kubernetes components include:
Labels and selectors: Key-value pairs used to identify and group resources within Kubernetes.
Controllers: A reconciliation loop that drives actual cluster state toward the desired cluster state.
Services: A way to identify elements used by applications (name-resolution, caching, etc.).
API server: Serves the Kubernetes API using JSON over HTTP.
Scheduler: Pluggable component that selects which node a pod should run on based on resource availability.
Controller manager: The process that runs the Kubernetes controllers such as DaemonSet and Replication.
Kublet: Responsible for the running state of each node (starting, stopping, and maintaining application containers).
Kube-proxy: The implementation of a network proxy and load balancer that supports the service abstraction.
cAdvisor: An agent that monitors and gathers resource usage.
Maven
Maven is a build automation tool. Maven’s objectives are to help developers understand the entire software development process and to:
Make the build process easy
Provide a uniform build system
Provide quality project information
Encourage better development practices
Developers can use Maven to manage these processes:
Dependencies
Distribution
Documentation
Reporting
Releases
Software configuration management
Maven is written in Java to build projects written in C#, Ruby, Scala and other languages. Maven builds a project with its project object model and a set of plugins.
As an open source project, Maven relies on an active user community to suggest improvements, report defects, communicate use cases and write documentation. There are several mailing lists and a Slack workspace.
Puppet
Developers use this tool to manage and automate the configuration of servers. Puppet’s main benefits are consistency of infrastructure and automation of deployments and changes. As with DevOps practices in general, Puppet requires the adoption of a certain set of concepts and practices, including:
Infrastructure-as-code: The foundation of DevOps which combines software development and operations
Idempotency: The ability to repeatedly apply code to guarantee a desired state on a system and get the same results every time
Agile methodology: The practice of working in incremental units of work and reusing code
Puppet is configured in an agent-server architecture, in which a primary node controls configuration information for one or more managed agent nodes. Servers and agents communicate by HTTPS using SSL certificates. Puppet includes a built-in certificate authority for managing certificates.
A Puppet user defines the desired state of infrastructure systems by writing code in Puppet’s Domain-Specific Language. Puppet code is declarative.
Once the infrastructure code is written, Puppet automates the process of getting systems into the desired state and keeping them there. The platform uses a Puppet primary server for storing the code and a Puppet agent to translate the code into commands and execute it on the target systems.
Selenium
This open source automated testing suite enables rapid, repeatable web-app testing across different browsers and platforms. The software suite has three main components:
WebDriver: A collection of language-specific bindings to drive a browser to to test, scale and distribute scripts across many environments
IDE: A Chrome, Firefox and Edge add-on that will record and playback interactions with a browser to aid in automation-aided exploratory testing
Grid: A system for distributing and running tests on several machines and managing multiple environments from a central point to test on a large combination of browsers and OSes.
WebDriver is a W3C recommendation which means that major browser vendors support it and work to improve the browsers and controlling code. This leads to more uniform behavior across the various browsers which can make automation scripts more stable.
Splunk
Splunk helps to improve the speed, quality and business impact of app delivery and to provide real-time insights across all states of the delivery lifecycle. The company’s DevOps offerings include:
Observability cloud: A full-stack analytics-driven monitoring service
On-call: Automated incident management routing, collaboration and reviews
Infrastructure monitoring: Tracking the performances of servers, containers and apps in real-time at scale
APM: A troubleshooter for microservices and application issues with full fidelity distributed tracing
RUM: A tool for measuring end-to-end users experience with frontend user monitoring
0 notes
Text
Petal: Site Reliability Engineer

Headquarters: New York, NY URL: https://www.petalcard.com/
The Infrastructure team
The infrastructure team is interested in building strong foundations for the rest of Petal to pave paths of success upon. The tools Infrastructure uses are at the forefront of industry practices and community driven technology. We dabble in container orchestration and spend our mornings thinking about how to tame distributed applications. We’re passionate about scalability, reliability, and simplicity, but most of all we’re interested in the empowerment of the company as a whole.
The Infrastructure Software Engineer role
Infrastructure engineers will be important agents of cohesion, in which many teams rely upon your foresight and expertise in order for the bigger picture to come together. The position is best for curious, generalist programmers who are deeply familiar with web application infrastructure and love to apply software engineering principles to make their and everyone else’s lives easier.
Here is our current tech stack: https://stackshare.io/petal At Petal, we're looking for people with kindness, positivity, and integrity. You're encouraged to apply even if your experience doesn't precisely match the job description. Your skills and potential will stand out—and set you apart—especially if your career has taken some extraordinary twists and turns. At Petal, we welcome diverse perspectives from people who think rigorously and aren't afraid to challenge assumptions.
Key responsibilities
Be responsible for the overall health and performance of Petal’s underlying infrastructure.
Participate in the optimization of the entire lifecycle of services - Deployment, Scaling, Monitoring, and Optimization.
Know standard security practices and identify any potential infrastructure-specific vulnerabilities.
Write code. We want engineers who can automate the deployment, administration, and monitoring of our large-scale Linux environments. We’re a strong believer in writing code to solve mundane problems.
Gain deep application-level knowledge of our systems and contribute to their overall design.
Work with development teams to enhance, document, and establish processes and generally improve the operability and security of our systems.
Improve automation of operational processes (provisioning, replication, deployments, continuous integration)
Bring monitoring, alerting, and observability for production and nonproduction issues to the next level
Characteristics of a successful candidate
At least 5 years of dev-ops or site reliability engineering experience. Bonus points for experience in a rapidly growing tech startup.
Familiarity with open source. We use, learn from, and contribute to many open source products. Familiarity with concepts and principles that are popular throughout open source is a useful skill.
Capable programmer. Infrastructure remains nimble (and sane) by putting automation and software at the forefront of everything it does. We’re looking for candidates whose main tools include the ability to think and act from a programmatic mindset. The ability to recognize the need to automate, when duplication has become burdensome, how to keep things simple, and when it's appropriate to write code, embodies some of many traits that lead to success, allow us to scale, and eliminate any growing tech debt.
Strong Linux and Networking knowledge. We walk the cloud native walk and as such need to be deeply familiar with how the networking and terminal side of things work for when things seem to stumble.
Knowledge of web design architecture and scalability. With Petal’s current rapid expansion we need candidates who are experienced at designing, building, and maintaining the web architectures of the future.
Strong self-management, drive, and organization. Ability to multi-task and project manage in a fast-paced environment is essential.
Sharp and critical eye for details. The ability to think holistically and also maintain focus on small intricate details is essential for the high-impact, production work infrastructure does.
Problem-solving versatility and resourcefulness. There will be many new and unexpected problems, and we need someone who can do the required research/networking to propose well thought-out solutions.
Outstanding communication skills, verbal and written.
To apply: https://jobs.lever.co/petalcard/cc013f5a-1073-4c60-8ad6-3f9d45c2d345
from We Work Remotely: Remote jobs in design, programming, marketing and more https://ift.tt/2Rmsqqc from Work From Home YouTuber Job Board Blog https://ift.tt/2r5HiyM
0 notes
Text
5 questions for… Electric Cloud
As I am working on a DevOps report at the moment, I’m speaking to a lot (and I mean a lot) of companies involved in and around the space. Each, in my experience so far, is looking to address some of the key IT delivery challenges of our time – namely, how to deliver services and applications at a pace that keeps up with the rate of technology change?
One such organisation is Electric Cloud. I spoke to Sam Fell, VP of Marketing, to understand how the company sees its customers’ main challenges, and what it is doing to address them – not least, the complexity of working at enterprise scale.
Where did Electric Cloud come from, what need did it set out to deal with?
Electric Cloud has been automating and accelerating software delivery since 2002, from code check-in to production release. Our founders looked to solve a huge bottleneck, to address how development teams’ agile pace of software delivery and new technology adoption has outstripped the ability of operations teams to keep up. This cadence and skills mismatch limits the business, can jeopardize transformation efforts, putting teams in a constant state of what we call “release anxiety.”
The main challenges we see are:
The ability to predictably deploy any application to any environment at any scale they want.
The ability to manage release pipelines and dependencies across multiple teams, point tools, and infrastructures.
A comprehensive, but simple way to plan, schedule, and track releases across its lifecycle
In consequence, we developed an Adaptive Release Orchestration platform called ElectricFlow to help organizations like E*TRADE, HPE, Huawei, Intel and Lockheed Martin confidently release new applications and adapt to change at any speed demanded by the business, with the analytics and insight to measure, track, and improve their results along the way.
Where’s the ‘market for DevOps’ going, from a customer perspective?
Nearly every industry now is taking notice of, or participating in the DevOps space – from FinServ and government to retail and entertainment – nearly every market, across nearly all geographies are recognizing DevOps as a way forward. The technology sector is still on the forefront, but you’d be surprised how quickly industries like transportation are catching up.
One thing we find invaluable is learning what critical factors are helping our customers drive their own businesses forward. A theme we hear over and over is how to adapt to business needs on a continuous basis.
But, there is an inherent dichotomy to how companies are expected to achieve the business goals set by leadership. For example, the need to implement fast and adapt to their changing environment easily – including support for new technologies like microservices and serverless. The challenge is, how to do this reliably and efficiently – to shift practices like security left and not create more technology debt or outages in the process.
Complexity is inevitable and the focus needs to be on how to adapt. Ways that we know work in addressing this complexity are:
Organizations that learn how to fix themselves will ultimately be high performers in the end – resiliency is the child of adaptability (credit: Rob England).
Companies that automate what humans aren’t good at – mundane, repeatable tasks that don’t require creativity – are ultimately set-up for success. Keep people engaged on high-value tasks with a focus on creating high-performance for themselves.
Organizations that continuously scrutinize their value streams, and align the business to the value stream, will be more successful than the competition. Improvements in one value stream may well create bottlenecks in others.
Companies that measure impact and outcomes, not just activities, will gain context into how ideas can transform into business value metrics such as customer satisfaction.
Understanding that there is no “one way” to solve a problem. If companies empower their teams to learn fast, the above may very well take care of itself.
What’s the USP for Electric Cloud in a pretty crowded space?
Electric Cloud sees the rise in DevOps and modern software delivery methods as an opportunity to emphasize the fact that collaboration, visibility and auditability are key pillars to ensuring fast delivery works for everyone involved. Eliminating silos and reducing management overhead is easier said than done, but with a scalable, secure and unified platform – anything is possible.
We’re proud to say we’re the only provider of a centralized platform that can provide all of the following in one simple package:
model-based automation techniques to replace brittle scripting with reusable abstract models;
process-as-code through a Groovy-based domain specific language (DSL) to onboard apps quickly so they are versionable, testable, reusable and refactorable;
a self-service library of best practice automation techniques for consistency across the organization;
a vast amount of plugins and integrations to support enterprise governance of any tool your company uses;
Role-based access control, approval tracking for every change in the pipeline;
An impenetrable Agent-based architecture to support communications for scalability, fault tolerance and security.
And all at enterprise scale, with our ability to enable unlimited clustering architecture and efficient processing for high availability and low-latency of concurrent deployments.
How does Electric Cloud play nice, and where does it see its most important integrations?
Every company’s software delivery process is unique, and touches many different tools, integrations and environments. We provide centralized management and visibility of the entire software delivery pipeline – whatever these might be – to improve developer productivity, streamline operations and increase efficiency.
To that end, Electric Cloud works with the most popular tools and infrastructure on the planet and allows our customers to add a layer of automation and governance to the tools they already use. You can find a list of our plugins, here.
I’m also interested to know more about (Dev)SecOps, and I would say PrivOps but the name is taken!
We definitely think securing the pipeline, and the application, is very important in software production. We have been talking about it a lot recently — you may find these resources helpful:
We recently held an episode of Continuous Discussions (#c9d9) to dive into how DevSecOps help teams “shift left,” and build security and quality into the process by making EVERYONE responsible for security at every stage. http://electric-cloud.com/blog/2018/05/c9d9-podcast-e87-devsecops/
Prior to that, we held a webinar with John Willis – an Electric Cloud advisor, co-author of the “DevOps Handbook” with Gene Kim, and expert at security and DevOps. You can view the webinar here.
We also participated in the RSA DevOps Connect event. At the show, we took a quick booth survey and the results may (or may not) surprise you…: http://electric-cloud.com/blog/2018/04/security-needs-to-shift-left-too/
My take: Moving beyond the principle
The challenges that DevOps set out to address are not new: indeed, they are perhaps as old as technology delivery itself. Ultimately, while we talk about removal of barriers, greater automation and so on, the ultimate goal is how to deliver complexity at scale. Some, who we might call ‘platform natives’, may never have had to run through the mud of corporate and infrastructure inertia and may wonder what all the fuss is about; for others, the challenges may appear insurmountable.
Vendors in the crowded DevOps space may have cut their teeth working for the former, platform-based group, who use containers as a default and who see serverless models as a logical extension of their keep-it-simple infrastructure approach. Many, if not all see enterprise environments as both the biggest opportunity and the greater challenge. Whoever can cut the Gordian knot of enterprise convolution stands to take the greatest prize.
Will it be Electric Cloud? To my mind, the astonishing number of vendor players in this space is a symptom of how quickly it has grown to date, creating a situation ripe for massive consolidation – though it is difficult to see any enterprise software vendor that is actively looking to become ‘the one’: consider IBM’s outsourcing of Rational and HPE’s divestiture of its own software business to Microfocus as examples of companies running in the opposite direction.
However the market opportunity remains significant, despite the elusivity of the prize. I have no doubt that the next couple of years will see considerable industry consolidation, and who knows at this stage which brands, models and so on will pervade. I very much doubt that the industry will go ‘full serverless’ any time soon, for a raft of reasons (think: IoT, SDN, data, state, plus everything we don’t know about yet), but remain optimistic that automation and orchestration will deliver on their potential, enabling and enabled by practices such as DevOps.
Now I shall get back on with my report!
from Gigaom https://gigaom.com/2018/06/21/5-questions-for-electric-cloud/
0 notes
Text
5 questions for… Electric Cloud
As I am working on a DevOps report at the moment, I’m speaking to a lot (and I mean a lot) of companies involved in and around the space. Each, in my experience so far, is looking to address some of the key IT delivery challenges of our time – namely, how to deliver services and applications at a pace that keeps up with the rate of technology change?
One such organisation is Electric Cloud. I spoke to Sam Fell, VP of Marketing, to understand how the company sees its customers’ main challenges, and what it is doing to address them – not least, the complexity of working at enterprise scale.
Where did Electric Cloud come from, what need did it set out to deal with?
Electric Cloud has been automating and accelerating software delivery since 2002, from code check-in to production release. Our founders looked to solve a huge bottleneck, to address how development teams’ agile pace of software delivery and new technology adoption has outstripped the ability of operations teams to keep up. This cadence and skills mismatch limits the business, can jeopardize transformation efforts, putting teams in a constant state of what we call “release anxiety.”
The main challenges we see are:
The ability to predictably deploy any application to any environment at any scale they want.
The ability to manage release pipelines and dependencies across multiple teams, point tools, and infrastructures.
A comprehensive, but simple way to plan, schedule, and track releases across its lifecycle
In consequence, we developed an Adaptive Release Orchestration platform called ElectricFlow to help organizations like E*TRADE, HPE, Huawei, Intel and Lockheed Martin confidently release new applications and adapt to change at any speed demanded by the business, with the analytics and insight to measure, track, and improve their results along the way.
Where’s the ‘market for DevOps’ going, from a customer perspective?
Nearly every industry now is taking notice of, or participating in the DevOps space – from FinServ and government to retail and entertainment – nearly every market, across nearly all geographies are recognizing DevOps as a way forward. The technology sector is still on the forefront, but you’d be surprised how quickly industries like transportation are catching up.
One thing we find invaluable is learning what critical factors are helping our customers drive their own businesses forward. A theme we hear over and over is how to adapt to business needs on a continuous basis.
But, there is an inherent dichotomy to how companies are expected to achieve the business goals set by leadership. For example, the need to implement fast and adapt to their changing environment easily – including support for new technologies like microservices and serverless. The challenge is, how to do this reliably and efficiently – to shift practices like security left and not create more technology debt or outages in the process.
Complexity is inevitable and the focus needs to be on how to adapt. Ways that we know work in addressing this complexity are:
Organizations that learn how to fix themselves will ultimately be high performers in the end – resiliency is the child of adaptability (credit: Rob England).
Companies that automate what humans aren’t good at – mundane, repeatable tasks that don’t require creativity – are ultimately set-up for success. Keep people engaged on high-value tasks with a focus on creating high-performance for themselves.
Organizations that continuously scrutinize their value streams, and align the business to the value stream, will be more successful than the competition. Improvements in one value stream may well create bottlenecks in others.
Companies that measure impact and outcomes, not just activities, will gain context into how ideas can transform into business value metrics such as customer satisfaction.
Understanding that there is no “one way” to solve a problem. If companies empower their teams to learn fast, the above may very well take care of itself.
What’s the USP for Electric Cloud in a pretty crowded space?
Electric Cloud sees the rise in DevOps and modern software delivery methods as an opportunity to emphasize the fact that collaboration, visibility and auditability are key pillars to ensuring fast delivery works for everyone involved. Eliminating silos and reducing management overhead is easier said than done, but with a scalable, secure and unified platform – anything is possible.
We’re proud to say we’re the only provider of a centralized platform that can provide all of the following in one simple package:
model-based automation techniques to replace brittle scripting with reusable abstract models;
process-as-code through a Groovy-based domain specific language (DSL) to onboard apps quickly so they are versionable, testable, reusable and refactorable;
a self-service library of best practice automation techniques for consistency across the organization;
a vast amount of plugins and integrations to support enterprise governance of any tool your company uses;
Role-based access control, approval tracking for every change in the pipeline;
An impenetrable Agent-based architecture to support communications for scalability, fault tolerance and security.
And all at enterprise scale, with our ability to enable unlimited clustering architecture and efficient processing for high availability and low-latency of concurrent deployments.
How does Electric Cloud play nice, and where does it see its most important integrations?
Every company’s software delivery process is unique, and touches many different tools, integrations and environments. We provide centralized management and visibility of the entire software delivery pipeline – whatever these might be – to improve developer productivity, streamline operations and increase efficiency.
To that end, Electric Cloud works with the most popular tools and infrastructure on the planet and allows our customers to add a layer of automation and governance to the tools they already use. You can find a list of our plugins, here.
I’m also interested to know more about (Dev)SecOps, and I would say PrivOps but the name is taken!
We definitely think securing the pipeline, and the application, is very important in software production. We have been talking about it a lot recently — you may find these resources helpful:
We recently held an episode of Continuous Discussions (#c9d9) to dive into how DevSecOps help teams “shift left,” and build security and quality into the process by making EVERYONE responsible for security at every stage. http://electric-cloud.com/blog/2018/05/c9d9-podcast-e87-devsecops/
Prior to that, we held a webinar with John Willis – an Electric Cloud advisor, co-author of the “DevOps Handbook” with Gene Kim, and expert at security and DevOps. You can view the webinar here.
We also participated in the RSA DevOps Connect event. At the show, we took a quick booth survey and the results may (or may not) surprise you…: http://electric-cloud.com/blog/2018/04/security-needs-to-shift-left-too/
My take: Moving beyond the principle
The challenges that DevOps set out to address are not new: indeed, they are perhaps as old as technology delivery itself. Ultimately, while we talk about removal of barriers, greater automation and so on, the ultimate goal is how to deliver complexity at scale. Some, who we might call ‘platform natives’, may never have had to run through the mud of corporate and infrastructure inertia and may wonder what all the fuss is about; for others, the challenges may appear insurmountable.
Vendors in the crowded DevOps space may have cut their teeth working for the former, platform-based group, who use containers as a default and who see serverless models as a logical extension of their keep-it-simple infrastructure approach. Many, if not all see enterprise environments as both the biggest opportunity and the greater challenge. Whoever can cut the Gordian knot of enterprise convolution stands to take the greatest prize.
Will it be Electric Cloud? To my mind, the astonishing number of vendor players in this space is a symptom of how quickly it has grown to date, creating a situation ripe for massive consolidation – though it is difficult to see any enterprise software vendor that is actively looking to become ‘the one’: consider IBM’s outsourcing of Rational and HPE’s divestiture of its own software business to Microfocus as examples of companies running in the opposite direction.
However the market opportunity remains significant, despite the elusivity of the prize. I have no doubt that the next couple of years will see considerable industry consolidation, and who knows at this stage which brands, models and so on will pervade. I very much doubt that the industry will go ‘full serverless’ any time soon, for a raft of reasons (think: IoT, SDN, data, state, plus everything we don’t know about yet), but remain optimistic that automation and orchestration will deliver on their potential, enabling and enabled by practices such as DevOps.
Now I shall get back on with my report!
0 notes
Text
Frost & Sullivan Applauds LogRhythm for Outpacing the Overall Global Security Information and Event Management Market in Terms of Year-Over-Year Growth Since 2010
LogRhythm's success is not only the result of doing many individual small things well; it is the result of putting the pieces together in a continuous, unified platform
SANTA CLARA, California, Sept. 26, 2017 /PRNewswire/ -- Based on its recent analysis of the global security information and event management (SIEM) market, Frost & Sullivan recognizes LogRhythm with the 2017 Enabling Technology Leadership Award. The LogRhythm Threat Lifecycle Management Platform addresses the larger framework used to bring in data, provide search and automated analytics, and then generate a formal incident response. This Best Practices Award recognizes LogRhythm's support for analyst work, including transitioning through life cycle phases from forensic data, discovery, and qualification of events, and then initiating the first steps necessary for remediation.
LogRhythm
The LogRhythm SIEM was built from the ground up rather than being the product of acquiring and integrating disparate technologies, and overall performance is a cornerstone of the company's products. For instance, while other SIEM engines were focused on developing faster ingestion rates, LogRhythm worked on usability and on data normalization. In doing so, LogRhythm built a SIEM that is practical for mid markets while being robust enough for enterprise networks.
"LogRhythm normalizes data centrally at the data processing layer as opposed to the collection layer, allowing normalization logic to be updated and propagated in a consistent manner. LogRhythm also offers optional agents that perform both log collection as well as independent monitoring, including file integrity monitoring. In addition, LogRhythm provides data management by entity to allow the reuse of reports, alarm rules, and AI Engine rules without the need to recreate them for new entities," said Frost & Sullivan, Senior Cybersecurity Analyst, Christopher Kissel.
The SmartResponse automation framework is part of LogRhythm's Threat Lifecycle Management Platform and enables the automated execution of targeted actions. SmartResponse is a differentiator; shown below are a few other features:
SmartResponse plug-ins—In 2016, LogRhythm created plug-ins with nine other security service providers
Automated playbooks by use case—Playbooks can be developed to shape a response for compliance with specific regulations; additionally, playbooks can be developed for specific threats
"Precision search is a vitally important facet of the search function provided by LogRhythm. The most important and elegant feature is that from the perspective of the analyst, they can work with both structured and unstructured data simultaneously. The solution's dashboard is particularly elegant as analysts can isolate a set of structured data sets and create searches against unknown variables," said Kissel.
Frost & Sullivan estimates global SIEM market revenue at roughly $1.8 billion in appliances and services. In every year since 2010 when Frost & Sullivan charted SIEM, LogRhythm has outperformed the global SIEM market in terms of year-over-year growth in revenue.
LogRhythm is a privately-held company that built its products and its relationships from the ground up. What were once essential soft values, like customer relations and technical support, have become important elements in the continued growth of LogRhythm as a major SIEM vendor.
Each year, Frost & Sullivan presents this award to the company that achieved best-in-class growth in three key areas: understanding demand, nurturing the brand, and differentiating from the competition.
Frost & Sullivan Best Practices Awards recognize companies in a variety of regional and global markets for demonstrating outstanding achievement and superior performance in areas such as leadership, technological innovation, customer service, and strategic product development. Industry analysts compare market participants and measure performance through in-depth interviews, analysis, and extensive secondary research to identify best practices in the industry.
About LogRhythm
LogRhythm is the pioneer in Threat Lifecycle Management™ (TLM) technology, empowering organizations on six continents to rapidly detect, respond to and neutralize damaging cyberthreats. LogRhythm's TLM platform unifies leading-edge data lake technology, machine learning, security analytics, and security automation and orchestration in a single end-to-end solution. LogRhythm serves as the foundation for the AI-enabled security operations center, helping customers secure their cloud, physical and virtual infrastructures for both IT and OT environments.
Contact:
P: +1 866.384.0713 E: [email protected]
About Frost & Sullivan
Frost & Sullivan, the Growth Partnership Company, works in collaboration with clients to leverage visionary innovation that addresses the global challenges and related growth opportunities that will make or break today's market participants. For more than 50 years, we have been developing growth strategies for the global 1000, emerging businesses, the public sector, and the investment community. Contact us: Start the discussion.
Contact:
Andrea Steinman P: 210.477.8425 F: 210.348.1003 E: [email protected]
Read this news on PR Newswire Asia website: Frost & Sullivan Applauds LogRhythm for Outpacing the Overall Global Security Information and Event Management Market in Terms of Year-Over-Year Growth Since 2010
0 notes
Text
Unlocking Multimodal AI: Strategies for Scalable and Adaptive Systems in Agentic and Generative AI
Introduction
In the rapidly evolving landscape of artificial intelligence, Agentic AI and Generative AI have emerged as pivotal technologies, transforming industries by enabling more sophisticated and autonomous systems. At the heart of this transformation lies multimodal integration, which allows AI systems to process and combine diverse data types, such as text, images, audio, and video, into cohesive, actionable insights. This article delves into the strategic integration of multimodal AI pipelines, exploring the latest frameworks, challenges, and best practices for scaling autonomous AI systems. Training in Agentic AI courses can provide a solid foundation for understanding these complex systems, while Generative AI training institutes in Mumbai offer specialized programs for those interested in AI model development.
Evolution of Agentic and Generative AI in Software
Agentic AI refers to AI systems that can act autonomously, making decisions based on their environment and goals. This autonomy is crucial for applications like autonomous vehicles and smart home devices. Generative AI, on the other hand, focuses on creating new content, such as images, videos, or text, using generative models like GANs and LLMs. Recent advancements in these areas have been fueled by the development of multimodal AI, which integrates multiple data types to enhance system understanding and interaction. Multi-agent LLM systems are particularly effective in handling complex tasks by orchestrating multiple LLMs to work together seamlessly.
Latest Frameworks, Tools, and Deployment Strategies
Multimodal AI Frameworks
Multimodal AI frameworks are designed to handle diverse data types seamlessly. Notable frameworks include:
CLIP (Contrastive Language-Image Pretraining): Enables zero-shot classification across modalities by learning visual concepts from natural language descriptions.
Vision Transformers (ViT): Adapt transformer architectures for image tasks while maintaining compatibility with other modalities.
Multimodal Transformers: These models integrate multiple modalities by using shared transformer layers, allowing for efficient cross-modal interaction.
Implementing these frameworks requires expertise in Agentic AI courses to ensure effective integration.
Deployment Strategies
Deploying multimodal AI systems involves several key strategies:
MLOps for Generative Models: Implementing MLOps (Machine Learning Operations) practices helps manage the lifecycle of AI models, ensuring reliability and scalability in production environments. Generative AI training institutes in Mumbai often emphasize the importance of MLOps in their curricula.
Autonomous Agents: Utilizing autonomous agents in AI systems allows for more dynamic decision-making and adaptation to changing environments. These agents can be designed using principles from Agentic AI courses.
LLM Orchestration: Efficiently managing and orchestrating LLMs is crucial for integrating text-based AI with other modalities, a task well-suited for multi-agent LLM systems.
Advanced Tactics for Scalable, Reliable AI Systems
Multimodal Integration Strategies
Successful integration of multimodal AI involves several advanced tactics:
Data Preprocessing: Ensuring consistent data quality across modalities is critical. This includes techniques like data normalization, feature extraction tailored to each modality, and handling missing values. Training programs at Generative AI training institutes in Mumbai often cover these techniques.
Feature Fusion: Combining features from different modalities effectively requires sophisticated fusion techniques. Early fusion involves combining raw data from different modalities before processing, while late fusion combines processed features from each modality. Hybrid fusion methods strike a balance between these approaches. Multi-agent LLM systems can leverage these fusion techniques to enhance performance.
Transfer Learning: Leveraging pre-trained models can significantly reduce training time and improve model performance on diverse tasks. This is a key concept covered in Agentic AI courses.
Technical Challenges
Despite these advancements, multimodal AI faces several technical challenges:
Data Quality and Alignment: Ensuring data consistency and alignment across different modalities is a significant hurdle. Techniques such as data normalization and feature alignment can mitigate these issues. Generative AI training institutes in Mumbai emphasize the importance of addressing these challenges.
Computational Demands: Processing large-scale multimodal datasets requires substantial computational resources. Cloud computing and distributed processing can help alleviate these demands. Multi-agent LLM systems can be optimized to handle these demands more efficiently.
The Role of Software Engineering Best Practices
Software engineering plays a crucial role in ensuring the reliability, security, and compliance of AI systems:
Modular Design: Implementing modular architectures allows for easier maintenance and updates of complex AI systems.
Testing and Validation: Rigorous testing and validation are essential for ensuring AI systems perform as expected in real-world scenarios. Techniques like model interpretability can help understand model decisions. Agentic AI courses often cover these best practices.
Security and Compliance: Incorporating security measures like data encryption and compliance frameworks is vital for protecting sensitive information. This is particularly important when deploying multi-agent LLM systems.
Cross-Functional Collaboration for AI Success
Effective collaboration between data scientists, engineers, and business stakeholders is critical for successful AI deployments:
Interdisciplinary Teams: Assembling teams with diverse skill sets ensures that AI systems meet both technical and business requirements. Generative AI training institutes in Mumbai recognize the value of interdisciplinary collaboration.
Communication and Feedback: Regular communication and feedback loops are essential for aligning AI projects with business goals and addressing technical challenges promptly. This collaboration is crucial when integrating Agentic AI and Generative AI systems.
Measuring Success: Analytics and Monitoring
Monitoring and evaluating AI systems involve tracking key performance indicators (KPIs) relevant to the application:
Metrics for Success: Define clear metrics that align with business objectives, such as accuracy, efficiency, or user engagement.
Real-Time Analytics: Implementing real-time analytics tools helps identify issues early and optimize system performance. This can be achieved through CI/CD pipelines that integrate model updates with continuous monitoring. Multi-agent LLM systems can benefit significantly from these analytics.
Case Study: Autonomous Vehicle Development with Multimodal AI
Overview
Autonomous vehicles exemplify the power of multimodal AI integration. Companies like Waymo have successfully deployed autonomous vehicles that combine data from cameras, LIDAR, radar, and GPS to navigate complex environments. Training in Agentic AI courses can provide insights into designing such systems.
Technical Challenges
Sensor Fusion: Integrating data from different sensors (e.g., cameras, LIDAR, radar) to create a comprehensive view of the environment. This requires sophisticated multi-agent LLM systems to handle diverse data streams.
Real-Time Processing: Ensuring real-time processing of vast amounts of sensor data to make timely decisions. Generative AI training institutes in Mumbai often focus on developing skills for real-time processing.
Business Outcomes
Safety and Efficiency: Autonomous vehicles have shown significant improvements in safety and efficiency by reducing accidents and optimizing routes.
Scalability: Successful deployment of autonomous vehicles demonstrates the scalability of multimodal AI systems in real-world applications. This scalability is enhanced by Agentic AI and Generative AI techniques.
Actionable Tips and Lessons Learned
Practical Tips for AI Teams
Start Small: Begin with simpler multimodal tasks and gradually scale up to more complex applications.
Focus on Data Quality: Ensure high-quality, consistent data across all modalities. This is a key takeaway from Generative AI training institutes in Mumbai.
Collaborate Across Disciplines: Foster collaboration between data scientists, engineers, and business stakeholders to align AI projects with business goals. This collaboration is essential for successful multi-agent LLM systems.
Lessons Learned
Adaptability is Key: Be prepared to adapt AI systems to new data types and scenarios. Agentic AI courses emphasize the importance of adaptability.
Continuous Learning: Stay updated with the latest advancements in multimodal AI and generative models. This is crucial for maintaining a competitive edge in Generative AI training institutes in Mumbai.
Ethical Considerations
Deploying multimodal AI systems raises several ethical considerations:
Privacy Concerns: Ensuring that data collection and processing comply with privacy regulations is crucial. This is particularly relevant when implementing multi-agent LLM systems.
Bias Mitigation: Implementing strategies to mitigate bias in AI models is essential for fairness and equity. Training programs in Agentic AI courses and Generative AI training institutes in Mumbai should cover these ethical considerations.
Conclusion
Scaling autonomous AI pipelines through multimodal integration is a transformative strategy that enhances system capabilities and adaptability. By leveraging the latest frameworks, best practices in software engineering, and cross-functional collaboration, AI practitioners can overcome the technical challenges associated with multimodal AI and unlock its full potential. As AI continues to evolve, embracing multimodal integration and staying agile in the face of new technologies will be crucial for driving innovation and success in the AI landscape. Training in Agentic AI courses and Generative AI training institutes in Mumbai can provide a solid foundation for navigating these advancements, while multi-agent LLM systems will play a pivotal role in future AI deployments.
0 notes
Text
Scaling Agentic AI in 2025: Unlocking Autonomous Digital Labor with Real-World Success Stories
Introduction
Agentic AI is revolutionizing industries by seamlessly integrating autonomy, adaptability, and goal-driven behavior, enabling digital systems to perform complex tasks with minimal human intervention. This article explores the evolution of Agentic AI, its integration with Generative AI, and delivers actionable insights for scaling these systems. We will examine the latest deployment strategies, best practices for scalability, and real-world case studies, including how an Agentic AI course in Mumbai with placements is shaping talent pipelines for this emerging field. Whether you are a software engineer, data scientist, or technology leader, understanding the interplay between Generative AI and Agentic AI is key to unlocking digital transformation.

The Evolution of Agentic and Generative AI in Software
AI’s evolution has moved from rule-based systems and machine learning toward today’s advanced generative models and agentic systems. Traditional AI excels in narrow, predefined tasks like image recognition but lacks flexibility for dynamic environments. Agentic AI, by contrast, introduces autonomy and continuous learning, empowering systems to adapt and optimize outcomes over time without constant human oversight.
This paradigm shift is powered by Generative AI, particularly large language models (LLMs), which provide contextual understanding and reasoning capabilities. Agentic AI systems can orchestrate multiple AI services, manage workflows, and execute decisions, making them essential for real-time, multi-faceted applications across logistics, healthcare, and customer service. The rise of agentic capabilities marks a transition from AI as a tool to AI as an autonomous digital labor force, expanding workforce definitions and operational possibilities. Professionals seeking to enter this field often consider a Generative AI and Agentic AI course to gain the necessary skills and practical experience.
Latest Frameworks, Tools, and Deployment Strategies
LLM Orchestration and Autonomous Agents
Modern Agentic AI depends on orchestrating multiple LLMs and AI components to execute complex workflows. Frameworks like LangChain, Haystack, and OpenAI’s Function Calling enable developers to build autonomous agents that chain together tasks, query databases, and interact with APIs dynamically. These frameworks support multi-turn dialogue management, contextual memory, and adaptive decision-making, critical for real-world agentic applications. For those interested in hands-on learning, enrolling in an Agentic AI course in Mumbai with placements offers practical exposure to these advanced frameworks.
MLOps for Generative Models
Traditional MLOps pipelines are evolving to support the unique requirements of generative AI, including:
Continuous Fine-Tuning: Updating models based on new data or feedback without full retraining, using techniques like incremental and transfer learning.
Prompt Engineering Lifecycle: Versioning and testing prompts as critical components of model performance, including methodologies for prompt optimization and impact evaluation.
Monitoring Generation Quality: Detecting hallucinations, bias, and drift in outputs, and implementing quality control measures.
Scalable Inference Infrastructure: Managing high-throughput, low-latency model serving with cost efficiency, leveraging cloud and edge computing.
Leading platforms such as MLflow, Kubeflow, and Amazon SageMaker are integrating MLOps for generative AI to streamline deployment and monitoring. Understanding MLOps for generative AI is now a foundational skill for teams building scalable agentic systems.
Cloud-Native and Edge Deployment
Agentic AI deployments increasingly leverage cloud-native architectures for scalability and resilience, using Kubernetes and serverless functions to manage agent workloads. Edge deployments are emerging for latency-sensitive applications like autonomous vehicles and IoT devices, where agents operate closer to data sources. This approach ensures real-time processing and reduces reliance on centralized infrastructure, topics often covered in advanced Generative AI and Agentic AI course curricula.
Advanced Tactics for Scalable, Reliable AI Systems
Modular Agent Design
Breaking down agent capabilities into modular, reusable components allows teams to iterate rapidly and isolate failures. Modular design supports parallel development and easier integration of new skills or data sources, facilitating continuous improvement and reducing system update complexity.
Robust Error Handling and Recovery
Agentic systems must anticipate and gracefully handle failures in external APIs, data inconsistencies, or unexpected inputs. Implementing fallback mechanisms, retries, and human-in-the-loop escalation ensures uninterrupted service and trustworthiness.
Data and Model Governance
Given the autonomy of agentic systems, governance frameworks are critical to manage data privacy, model biases, and compliance with regulations such as GDPR and HIPAA. Transparent logging and explainability tools help maintain accountability. This includes ensuring that data collection and processing align with ethical standards and legal requirements, a topic emphasized in MLOps for generative AI best practices.
Performance Optimization
Balancing model size, latency, and cost is vital. Techniques such as model distillation, quantization, and adaptive inference routing optimize resource use without sacrificing agent effectiveness. Leveraging hardware acceleration and optimizing software configurations further enhances performance.
Ethical Considerations and Governance
As Agentic AI systems become more autonomous, ethical considerations and governance practices become increasingly important. This includes ensuring transparency in decision-making, managing potential biases in AI outputs, and complying with regulatory frameworks. Recent developments in AI ethics frameworks emphasize the need for responsible AI deployment that prioritizes human values and safety. Professionals completing a Generative AI and Agentic AI course are well-positioned to implement these principles in practice.
The Role of Software Engineering Best Practices
The complexity of Agentic AI systems elevates the importance of mature software engineering principles:
Version Control for Code and Models: Ensures reproducibility and rollback capability.
Automated Testing: Unit, integration, and end-to-end tests validate agent logic and interactions.
Continuous Integration/Continuous Deployment (CI/CD): Automates safe and frequent updates.
Security by Design: Protects sensitive data and defends against adversarial attacks.
Documentation and Observability: Facilitates collaboration and troubleshooting across teams.
Embedding these practices into AI development pipelines is essential for operational excellence and long-term sustainability. Training in MLOps for generative AI equips teams with the skills to maintain these standards at scale.
Cross-Functional Collaboration for AI Success
Agentic AI projects succeed when data scientists, software engineers, product managers, and business stakeholders collaborate closely. This alignment ensures:
Clear definition of agent goals and KPIs.
Shared understanding of technical constraints and ethical considerations.
Coordinated deployment and change management.
Continuous feedback loops for iterative improvement.
Cross-functional teams foster innovation and reduce risks associated with misaligned expectations or siloed workflows. Those enrolled in an Agentic AI course in Mumbai with placements often experience this collaborative environment firsthand.
Measuring Success: Analytics and Monitoring
Effective monitoring of Agentic AI deployments includes:
Operational Metrics: Latency, uptime, throughput.
Performance Metrics: Accuracy, relevance, user satisfaction.
Behavioral Analytics: Agent decision paths, error rates, escalation frequency.
Business Outcomes: Cost savings, revenue impact, process efficiency.
Combining real-time dashboards with anomaly detection and alerting enables proactive management and continuous optimization of agentic systems. Mastering these analytics is a core outcome for participants in a Generative AI and Agentic AI course.
Case Study: Autonomous Supply Chain Optimization at DHL
DHL, a global logistics leader, exemplifies successful scaling of Agentic AI in 2025. Facing challenges of complex inventory management, fluctuating demand, and delivery delays, DHL deployed an autonomous supply chain agent powered by generative AI and real-time data orchestration.
The Journey
DHL’s agentic system integrates:
LLM-based demand forecasting models.
Autonomous routing agents coordinating with IoT sensors on shipments.
Dynamic inventory rebalancing modules adapting to disruptions.
The deployment involved iterative prototyping, cross-team collaboration, and rigorous MLOps for generative AI practices to ensure reliability and compliance across global operations.
Technical Challenges
Handling noisy sensor data and incomplete information.
Ensuring real-time decision-making under tight latency constraints.
Managing multi-regional regulatory compliance and data sovereignty.
Integrating legacy IT systems with new AI workflows.
Business Outcomes
20% reduction in delivery delays.
15% decrease in inventory holding costs.
Enhanced customer satisfaction through proactive communication.
Scalable platform enabling rapid rollout across regions.
DHL’s success highlights how agentic AI can transform complex, dynamic environments by combining autonomy with robust engineering and collaborative execution. Professionals trained through an Agentic AI course in Mumbai with placements are well-prepared to tackle similar challenges.
Additional Case Study: Personalized Healthcare with Agentic AI
In healthcare, Agentic AI is revolutionizing patient care by providing personalized treatment plans and improving patient outcomes. For instance, a healthcare provider might deploy an agentic system to analyze patient data, adapt treatment strategies based on real-time health conditions, and optimize resource allocation in hospitals. This involves integrating AI with electronic health records, wearable devices, and clinical decision support systems to enhance care quality and efficiency.
Technical Implementation
Data Integration: Combining data from various sources to create comprehensive patient profiles.
AI-Driven Decision Support: Using machine learning models to predict patient outcomes and suggest personalized interventions.
Real-Time Monitoring: Continuously monitoring patient health and adjusting treatment plans accordingly.
Business Outcomes
Improved patient satisfaction through personalized care.
Enhanced resource allocation and operational efficiency.
Better clinical outcomes due to real-time decision-making.
This case study demonstrates how Agentic AI can improve healthcare outcomes by leveraging autonomy and adaptability in dynamic environments. A Generative AI and Agentic AI course provides the multidisciplinary knowledge required for such implementations.
Actionable Tips and Lessons Learned
Start small but think big: Pilot agentic AI on well-defined use cases to gather data and refine models before scaling.
Invest in MLOps tailored for generative AI: Automate continuous training, testing, and monitoring to ensure robust deployments.
Design agents modularly: Facilitate updates and integration of new capabilities.
Prioritize explainability and governance: Build trust with stakeholders and comply with regulations.
Foster cross-functional teams: Align technical and business goals early and often.
Monitor holistically: Combine operational, performance, and business metrics for comprehensive insights.
Plan for human-in-the-loop: Use human oversight strategically to handle edge cases and improve agent learning.
For those considering a career shift, an Agentic AI course in Mumbai with placements offers a structured pathway to acquire these skills and gain practical experience.
Conclusion
Scaling Agentic AI in 2025 is both a technical and organizational challenge demanding advanced frameworks, rigorous engineering discipline, and tight collaboration across teams. The evolution from narrow AI to autonomous, adaptive agents unlocks unprecedented efficiencies and capabilities across industries. Real-world deployments like DHL’s autonomous supply chain agent demonstrate the transformative potential when cutting-edge AI meets sound software engineering and business acumen.
For AI practitioners and technology leaders, success lies in embracing modular architectures, investing in MLOps for generative AI, prioritizing governance, and fostering cross-functional collaboration. Monitoring and continuous improvement complete the cycle, ensuring agentic systems deliver measurable business value while maintaining reliability and compliance.
Agentic AI is not just an evolution of technology but a revolution in how businesses operate and innovate. The time to build scalable, trustworthy agentic AI systems is now. Whether you are looking to upskill or transition into this field, a Generative AI and Agentic AI course can provide the knowledge, tools, and industry connections to accelerate your journey.
0 notes