#Apache Cassandra Development Company
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Bigtable SQL Introduces Native Support for Real-Time Queries

Upgrades to Bigtable SQL offer scalable, fast data processing for contemporary analytics. Simplify procedures and accelerate business decision-making.
Businesses have battled for decades to use data for real-time operations. Bigtable, Google Cloud's revolutionary NoSQL database, powers global, low-latency apps. It was built to solve real-time application issues and is now a crucial part of Google's infrastructure, along with YouTube and Ads.
Continuous materialised views, an enhancement of Bigtable's SQL capabilities, were announced at Google Cloud Next this week. Maintaining Bigtable's flexible schema in real-time applications requires well-known SQL syntax and specialised skills. Fully managed, real-time application backends are possible with Bigtable SQL and continuous materialised views.
Bigtable has gotten simpler and more powerful, whether you're creating streaming apps, real-time aggregations, or global AI research on a data stream.
The Bigtable SQL interface is now generally available.
SQL capabilities, now generally available in Bigtable, has transformed the developer experience. With SQL support, Bigtable helps development teams work faster.
Bigtable SQL enhances accessibility and application development by speeding data analysis and debugging. This allows KNN similarity search for improved product search and distributed counting for real-time dashboards and metric retrieval. Bigtable SQL's promise to expand developers' access to Bigtable's capabilities excites many clients, from AI startups to financial institutions.
Imagine AI developing and understanding your whole codebase. AI development platform Augment Code gives context for each feature. Scalability and robustness allow Bigtable to handle large code repositories. This user-friendliness allowed it to design security mechanisms that protect clients' valuable intellectual property. Bigtable SQL will help onboard new developers as the company grows. These engineers can immediately use Bigtable's SQL interface to access structured, semi-structured, and unstructured data.
Equifax uses Bigtable to store financial journals efficiently in its data fabric. The data pipeline team found Bigtable's SQL interface handy for direct access to corporate data assets and easier for SQL-savvy teams to use. Since more team members can use Bigtable, it expects higher productivity and integration.
Bigtable SQL also facilitates the transition between distributed key-value systems and SQL-based query languages like HBase with Apache Phoenix and Cassandra.
Pega develops real-time decisioning apps with minimal query latency to provide clients with real-time data to help their business. As it seeks database alternatives, Bigtable's new SQL interface seems promising.
Bigtable is also previewing structured row keys, GROUP BYs, aggregations, and a UNPACK transform for timestamped data in its SQL language this week.
Continuously materialising views in preview
Bigtable SQL works with Bigtable's new continuous materialised views (preview) to eliminate data staleness and maintenance complexity. This allows real-time data aggregation and analysis in social networking, advertising, e-commerce, video streaming, and industrial monitoring.
Bigtable views update gradually without impacting user queries and are fully controllable. Bigtable materialised views accept a full SQL language with functions and aggregations.
Bigtable's Materialised Views have enabled low-latency use cases for Google Cloud's Customer Data Platform customers. It eliminates ETL complexity and delay in time series use cases by setting SQL-based aggregations/transformations upon intake. Google Cloud uses data transformations during import to give AI applications well prepared data with reduced latency.
Ecosystem integration
Real-time analytics often require low-latency data from several sources. Bigtable's SQL interface and ecosystem compatibility are expanding, making end-to-end solutions using SQL and basic connections easier.
Open-source Apache Large Table Washbasin Kafka
Companies utilise Google Cloud Managed Service for Apache Kafka to build pipelines for Bigtable and other analytics platforms. The Bigtable team released a new Apache Kafka Bigtable Sink to help clients build high-performance data pipelines. This sends Kafka data to Bigtable in milliseconds.
Open-source Apache Flink Connector for Bigtable
Apache Flink allows real-time data modification via stream processing. The new Apache Flink to Bigtable Connector lets you design a pipeline that modifies streaming data and publishes it to Bigtable using the more granular Datastream APIs and the high-level Apache Flink Table API.
BigQuery Continuous Queries are commonly available
BigQuery continuous queries run SQL statements continuously and export output data to Bigtable. This widely available capability can let you create a real-time analytics database using Bigtable and BigQuery.
Python developers may create fully-managed jobs that synchronise offline BigQuery datasets with online Bigtable datasets using BigQuery's Python frameworks' bigrames streaming API.
Cassandra-compatible Bigtable CQL Client Bigtable is previewed.
Apache Cassandra uses CQL. Bigtable CQL Client enables developers utilise CQL on enterprise-grade, high-performance Bigtable without code modifications as they migrate programs. Bigtable supports Cassandra's data migration tools, which reduce downtime and operational costs, and ecosystem utilities like the CQL shell.
Use migrating tools and Bigtable CQL Client here.
Using SQL power via NoSQL. This blog addressed a key feature that lets developers use SQL with Bigtable. Bigtable Studio lets you use SQL from any Bigtable cluster and create materialised views on Flink and Kafka data streams.
#technology#technews#govindhtech#news#technologynews#cloud computing#Bigtable SQL#Continuous Queries#Apache Flink#BigQuery Continuous Queries#Bigtable#Bigtable CQL Client#Open-source Kafka#Apache Kafka
0 notes
Text
What to Look for When Hiring Remote Scala Developers

Scala is a popular choice if you as a SaaS business are looking to build scalable, high-performance applications. Regarded for its functional programming potential and seamless integration with Java, Scala is widely implemented in data-intensive applications, distributed systems, and backend development.
However, to identify and hire skilled remote software developers with Scala proficiency can be challenging. An understanding of the needed key skills and qualifications can help you find the right fit. Operating as a SaaS company makes efficiency and scalability vital, which is why the best Scala developers can ensure smooth operations and future-proof applications.
Key Skills and Qualities to Look for When Hiring Remote Scala Developers
Strong knowledge of Scala and functional programming
A Scala developer's proficiency with the language is the most crucial consideration when hiring them. Seek applicants with:
Expertise in Scala's functional programming capabilities, such as higher-order functions and immutability.
Strong knowledge of object-oriented programming (OOP) principles and familiarity with Scala frameworks such as Play, Akka, and Cats.
You might also need to hire backend developers who are adept at integrating Scala with databases and microservices if your project calls for a robust backend architecture.
Experience in distributed systems and big data
Scala is widely used by businesses for large data and distributed computing applications. The ideal developer should be familiar with:
Kafka for real-time data streaming.
Apache Spark, a top framework for large data analysis.
Proficiency in NoSQL databases, such as MongoDB and Cassandra.
Hiring a Scala developer with big data knowledge guarantees effective processing and analytics for SaaS organizations managing massive data volumes.
Ability to operate in a remote work environment
Hiring remotely is challenging since it poses several obstacles. Therefore, remote developers must be able to:
Work independently while still communicating with the team.
Use collaboration technologies like Jira, Slack, and Git for version control.
Maintain productivity while adjusting to distinct time zones.
Employing engineers with excellent communication skills guarantees smooth project management for companies transitioning to a remote workspace.
Knowledge of JVM and Java interoperability
Scala's interoperability with Java is one of its main benefits. Make sure the developer has experience with Java libraries and frameworks and is knowledgeable about JVM internals and performance tuning before employing them. They must be able to work on projects that call for integration between Java and Scala. Businesses switching from Java-based apps to Scala will find this very helpful.
Problem-solving and code optimization skills
Writing clear, effective, and maintainable code is a must for any competent Scala developer. Seek applicants who can:
Optimize and debug code according to best practices.
Refactor current codebases to increase performance.
Possess expertise in continuous integration and test-driven development (TDD).
Conclusion
It takes more than just technical know-how to choose and hire the best Scala developer. Seek out experts who can work remotely, have experience with distributed systems, and have good functional programming abilities. Long-term success will result from hiring developers with the appropriate combination of skills and expertise. Investing in top Scala talent enables SaaS organizations to create high-performing, scalable applications that propel business expansion.
0 notes
Text
Karthik Ranganathan, Co-Founder and Co-CEO of Yugabyte – Interview Series
New Post has been published on https://thedigitalinsider.com/karthik-ranganathan-co-founder-and-co-ceo-of-yugabyte-interview-series/
Karthik Ranganathan, Co-Founder and Co-CEO of Yugabyte – Interview Series

Karthik Ranganathan is co-founder and co-CEO of Yugabyte, the company behind YugabyteDB, the open-source, high-performance distributed PostgreSQL database. Karthik is a seasoned data expert and former Facebook engineer who founded Yugabyte alongside two of his Facebook colleagues to revolutionize distributed databases.
What inspired you to co-found Yugabyte, and what gaps in the market did you see that led you to create YugabyteDB?
My co-founders, Kannan Muthukkaruppan, Mikhail Bautin, and I, founded Yugabyte in 2016. As former engineers at Meta (then called Facebook), we helped build popular databases including Apache Cassandra, HBase, and RocksDB – as well as running some of these databases as managed services for internal workloads.
We created YugabyteDB because we saw a gap in the market for cloud-native transactional databases for business-critical applications. We built YugabyteDB to cater to the needs of organizations transitioning from on-premises to cloud-native operations and combined the strengths of non-relational databases with the scalability and resilience of cloud-native architectures. While building Cassandra and HBase at Facebook (which was instrumental in addressing Facebook’s significant scaling needs), we saw the rise of microservices, containerization, high availability, geographic distribution, and Application Programming Interfaces (API). We also recognized the impact that open-source technologies have in advancing the industry.
People often think of the transactional database market as crowded. While this has traditionally been true, today Postgres has become the default API for cloud-native transactional databases. Increasingly, cloud-native databases are choosing to support the Postgres protocol, which has been ingrained into the fabric of YugabyteDB, making it the most Postgres-compatible database on the market. YugabyteDB retains the power and familiarity of PostgreSQL while evolving it to an enterprise-grade distributed database suitable for modern cloud-native applications. YugabyteDB allows enterprises to efficiently build and scale systems using familiar SQL models.
How did your experiences at Facebook influence your vision for the company?
In 2007, I was considering whether to join a small but growing company–Facebook. At the time, the site had about 30 to 40 million users. I thought it might double in size, but I couldn’t have been more wrong! During my over five years at Facebook, the user base grew to 2 billion. What attracted me to the company was its culture of innovation and boldness, encouraging people to “fail fast” to catalyze innovation.
Facebook grew so large that the technical and intellectual challenges I craved were no longer present. For many years I had aspired to start my own company and tackle problems facing the common user–this led me to co-create Yugabyte.
Our mission is to simplify cloud-native applications, focusing on three essential features crucial for modern development:
First, applications must be continuously available, ensuring uptime regardless of backups or failures, especially when running on commodity hardware in the cloud.
Second, the ability to scale on demand is crucial, allowing developers to build and release quickly without the delay of ordering hardware.
Third, with numerous data centers now easily accessible, replicating data across regions becomes vital for reliability and performance.
These three elements empower developers by providing the agility and freedom they need to innovate, without being constrained by infrastructure limitations.
Could you share the journey from Yugabyte’s inception in 2016 to its current status as a leader in distributed SQL databases? What were some key milestones?
At Facebook, I often talked with developers who needed specific features, like secondary indexes on SQL databases or occasional multi-node transactions. Unfortunately, the answer was usually “no,” because existing systems weren’t designed for those requirements.
Today, we are experiencing a shift towards cloud-native transactional applications that need to address scale and availability. Traditional databases simply can’t meet these needs. Modern businesses require relational databases that operate in the cloud and offer the three essential features: high availability, scalability, and geographic distribution, while still supporting SQL capabilities. These are the pillars on which we built YugabyteDB and the database challenges we’re focused on solving.
In February 2016, the founders began developing YugabyteDB, a global-scale distributed SQL database designed for cloud-native transactional applications. In July 2019, we made an unprecedented announcement and released our previously commercial features as open source. This reaffirmed our commitment to open-source principles and officially launched YugabyteDB as a fully open-source relational database management system (RDBMS) under an Apache 2.0 license.
The latest version of YugabyteDB (unveiled in September) features enhanced Postgres compatibility. It includes an Adaptive Cost-Based Optimizer (CBO) that optimizes query plans for large-scale, multi-region applications, and Smart Data Distribution that automatically determines whether to store tables together for lower latency, or to shard and distribute data for greater scalability. These enhancements allow developers to run their PostgreSQL applications on YugabyteDB efficiently and scale without the need for trade-offs or complex migrations.
YugabyteDB is known for its compatibility with PostgreSQL and its Cassandra-inspired API. How does this multi-API approach benefit developers and enterprises?
YugabyteDB’s multi-API approach benefits developers and enterprises by combining the strengths of a high-performance SQL database with the flexibility needed for global, internet-scale applications.
It supports scale-out RDBMS and high-volume Online Transaction Processing (OLTP) workloads, while maintaining low query latency and exceptional resilience. Compatibility with PostgreSQL allows for seamless lift-and-shift modernization of existing Postgres applications, requiring minimal changes.
In the latest version of the distributed database platform, released in September 2024, features like the Adaptive CBO and Smart Data Distribution enhance performance by optimizing query plans and automatically managing data placement. This allows developers to achieve low latency and high scalability without compromise, making YugabyteDB ideal for rapidly growing, cloud-native applications that require reliable data management.
AI is increasingly being integrated into database systems. How is Yugabyte leveraging AI to enhance the performance, scalability, and security of its SQL systems?
We are leveraging AI to enhance our distributed SQL database by addressing performance and migration challenges. Our upcoming Performance Copilot, an enhancement to our Performance Advisor, will simplify troubleshooting by analyzing query patterns, detecting anomalies, and providing real-time recommendations to troubleshoot database performance issues.
We are also integrating AI into YugabyteDB Voyager, our database migration tool that simplifies migrations from PostgreSQL, MySQL, Oracle, and other cloud databases to YugabyteDB. We aim to streamline transitions from legacy systems by automating schema conversion, SQL translation, and data transformation, with proactive compatibility checks. These innovations focus on making YugabyteDB smarter, more efficient, and easier for modern, distributed applications to use.
What are the key advantages of using an open-source SQL system like YugabyteDB in cloud-native applications compared to traditional proprietary databases?
Transparency, flexibility, and robust community support are key advantages when using an open-source SQL system like YugabyteDB in cloud-native applications. When we launched YugabyteDB, we recognized the skepticism surrounding open-source models. We engaged with users, who expressed a strong preference for a fully open database to trust with their critical data.
We initially ran on an open-core model, but rapidly realized it needed to be a completely open solution. Developers increasingly turn to PostgreSQL as a logical Oracle alternative, but PostgreSQL was not built for dynamic cloud platforms. YugabyteDB fills this gap by supporting PostgreSQL’s feature depth for modern cloud infrastructures. By being 100% open source, we remove roadblocks to adoption.
This makes us very attractive to developers building business-critical applications and to operations engineers running them on cloud-native platforms. Our focus is on creating a database that is not only open, but also easy to use and compatible with PostgreSQL, which remains a developer favorite due to its mature feature set and powerful extensions.
The demand for scalable and adaptable SQL solutions is growing. What trends are you observing in the enterprise database market, and how is Yugabyte positioned to meet these demands?
Larger scale in enterprise databases often leads to increased failure rates, especially as organizations deal with expanded footprints and higher data volumes. Key trends shaping the database landscape include the adoption of DBaaS, and a shift back from public cloud to private cloud environments. Additionally, the integration of generative AI brings opportunities and challenges, requiring automation and performance optimization to manage the growing data load.
Organizations are increasingly turning to DBaaS to streamline operations, despite initial concerns about control and security. This approach improves efficiency across various infrastructures, while the focus on private cloud solutions helps businesses reduce costs and enhance scalability for their workloads.
YugabyteDB addresses these evolving demands by combining the strengths of relational databases with the scalability of cloud-native architectures. Features like Smart Data Distribution and an Adaptive CBO, enhance performance and support a large number of database objects. This makes it a competitive choice for running a wide range of applications.
Furthermore, YugabyteDB allows enterprises to migrate their PostgreSQL applications while maintaining similar performance levels, crucial for modern workloads. Our commitment to open-source development encourages community involvement and provides flexibility for customers who want to avoid vendor lock-in.
With the rise of edge computing and IoT, how does YugabyteDB address the challenges posed by these technologies, particularly regarding data distribution and latency?
YugabyteDB’s distributed SQL architecture is designed to meet the challenges posed by the rise of edge computing and IoT by providing a scalable and resilient data layer that can operate seamlessly in both cloud and edge contexts. Its ability to automatically shard and replicate data ensures efficient distribution, enabling quick access and real-time processing. This minimizes latency, allowing applications to respond swiftly to user interactions and data changes.
By offering the flexibility to adapt configurations based on specific application requirements, YugabyteDB ensures that enterprises can effectively manage their data needs as they evolve in an increasingly decentralized landscape.
As Co-CEO, how do you balance the dual roles of leading technological innovation and managing company growth?
Our company aims to simplify cloud-native applications, compelling me to stay on top of technology trends, such as generative AI and context switches. Following innovation demands curiosity, a desire to make an impact, and a commitment to continuous learning.
Balancing technological innovation and company growth is fundamentally about scaling–whether it’s scaling systems or scaling impact. In distributed databases, we focus on building technologies that scale performance, handle massive workloads, and ensure high availability across a global infrastructure. Similarly, scaling Yugabyte means growing our customer base, enhancing community engagement, and expanding our ecosystem–while maintaining operational excellence.
All this requires a disciplined approach to performance and efficiency.
Technically, we optimize query execution, reduce latency, and improve system throughput; organizationally, we streamline processes, scale teams, and enhance cross-functional collaboration. In both cases, success comes from empowering teams with the right tools, insights, and processes to make smart, data-driven decisions.
How do you see the role of distributed SQL databases evolving in the next 5-10 years, particularly in the context of AI and machine learning?
In the next few years, distributed SQL databases will evolve to handle complex data analysis, enabling users to make predictions and detect anomalies with minimal technical expertise. There is an immense amount of database specialization in the context of AI and machine learning, but that is not sustainable. Databases will need to evolve to meet the demands of AI. This is why we’re iterating and enhancing capabilities on top of pgvector, ensuring developers can use Yugabyte for their AI database needs.
Additionally, we can expect an ongoing commitment to open source in AI development. Five years ago, we made YugabyteDB fully open source under the Apache 2.0 license, reinforcing our dedication to an open-source framework and proactively building our open-source community.
Thank you for all of your detailed responses, readers who wish to learn more should visit YugabyteDB.
#2024#adoption#ai#AI development#Analysis#anomalies#Apache#Apache 2.0 license#API#applications#approach#architecture#automation#backups#billion#Building#Business#CEO#Cloud#cloud solutions#Cloud-Native#Collaboration#Community#compromise#computing#containerization#continuous#curiosity#data#data analysis
0 notes
Text
[ad_1] As of late, the demand for NoSQL databases is on the rise. The rationale behind their immense recognition is that corporations want NoSQL databases to deal with a large quantity of buildings in addition to unstructured information. This isn't potential to attain with conventional relational or SQL databases. With elevated digitization, trendy companies must take care of large information commonly, coping with hundreds of thousands of customers whereas ensuring that there aren't any interruptions in delivering the information administration providers. All these expectations are the explanations behind the recognition of NoSQL databases in nearly each business. There may be all kinds of NoSQL databases accessible, companies usually get confused with NoSQL vs SQL and search instruments which might be extra succesful, agile, and versatile to handle big huge information. This weblog specifies the highest 7 NoSQL databases that companies can choose as per their distinctive wants. All these NoSQL databases are open supply and encompass free variations. All the restrictions of conventional relational databases comparable to efficiency, velocity, scalability, and even huge information administration may be dealt with with these NoSQL databases. Nevertheless, it's crucial to think about that these databases are used to fulfill solely superior necessities of the organizations as frequent purposes can nonetheless be constructed by conventional SQL databases. So, let’s try the highest 7 NoSQL databases that may even change into widespread in 2024. Apache Cassandra: Apache Cassandra is an open-source, free, and high-performance database. That is also called scalable and fault tolerant for each cloud infrastructure and commodity hardware. It might simply handle failed node replacements and replicate the information for a number of nodes mechanically. On this NoSQL database, you too can have the choice to decide on both synchronous replication or asynchronous replication. Apache HBase: Apache HBase can also be the perfect NoSQL database, which is Referred to as an open-source distributed Hadoop database. That is utilized to put in writing and skim the massive information. It has been developed to handle even the billions of rows and columns by way of the commodity hardware cluster. The options of Apache HBase embody computerized sharding of tables, scalability, constant writing & studying capabilities, and even nice assist for server failure. Apache CouchDB: Apache CouchDB can also be an open supply in addition to a single node database that helps in storing and managing the information. It might additionally scale up complicated initiatives right into a cluster of nodes on a number of servers. Firms can anticipate its integration with HTTP proxy servers together with the assist of HTTP protocol and JSON information format. This database is designed with crash-resistant options and reliability that saves information redundancy, which implies companies by no means lose their information and entry it each time wanted. MarkLogic Server: The MarkLogic server is the main NoSQL doc database that's designed for managing giant volumes of unstructured information and complicated information buildings. It boasts an amazing mixture of options for information-intensive apps and complicated content material administration necessities. It's broadly used for storing in addition to managing XML info. Companies can outline schemas of their information utilizing the MarkLogic server whereas accommodating variations within the doc construction. Furthermore, it provides extra flexibility as in comparison with relational SQL databases. Amazon DynamoDB: Amazon DynamoDB is the important thing worth, serverless, and doc database, which is obtainable by AWS (Amazon Net providers. This database is designed for increased scalability and efficiency. It's in excessive demand amongst companies to construct trendy purposes that want ultra-fast accessi
bility of knowledge in addition to the potential to deal with large information and consumer visitors, DynamoDB additionally gives restricted assist for ACID, the place ACID implies as Atomicity, Consistency, Isolation, and Sturdiness. IBM Cloudant: IBM Cloudant is one other widespread NoSQL database that's provided by IBM within the type of a cloud-based service. It's a full-featured and versatile JSON doc database used for cell, net, and serverless purposes that want better flexibility, scalability, and efficiency. This NoSQL database can also be developed for horizontal scaling. it's simpler so as to add extra servers on this database to handle unprecedented ranges of knowledge and consumer visitors. MongoDB: MongoDB is the greatest NoSQL database accessible available in the market. Like many different NoSQL databases, it shops and manages information in JSON-like paperwork. The versatile schema method helps companies leverage the evolving information fashions with none want for typical desk buildings. It may also be scaled horizontally by including extra shards to the cluster. Companies can simply deal with large quantities of knowledge and visitors with MongoDB. The Remaining Thought Utilizing NoSQL databases that match completely to your wants ends in effectivity beneficial properties. It makes it simpler for companies to retailer, course of, and handle large quantities of unstructured information effectively. The put up Prime 7 NoSQL Databases You Can Use in 2024 appeared first on Vamonde. [ad_2] Supply hyperlink
0 notes
Text
"Apache Spark: The Leading Big Data Platform with Fast, Flexible, Developer-Friendly Features Used by Major Tech Giants and Government Agencies Worldwide."
What is Apache Spark? The Big Data Platform that Crushed Hadoop

Apache Spark is a powerful data processing framework designed for large-scale SQL, batch processing, stream processing, and machine learning tasks. With its fast, flexible, and developer-friendly nature, Spark has become the leading platform in the world of big data. In this article, we will explore the key features and real-world applications of Apache Spark, as well as its significance in the digital age.
Apache Spark defined
Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets. It can distribute data processing tasks across multiple computers, either on its own or in conjunction with other distributed computing tools. This capability is crucial in the realm of big data and machine learning, where massive computing power is necessary to analyze and process vast amounts of data. Spark eases the programming burden of these tasks by offering an easy-to-use API that abstracts away much of the complexities of distributed computing and big data processing.
What is Spark in big data
In the context of big data, the term "big data" refers to the rapid growth of various types of data - structured data in database tables, unstructured data in business documents and emails, semi-structured data in system log files and web pages, and more. Unlike traditional analytics, which focused solely on structured data within data warehouses, modern analytics encompasses insights derived from diverse data sources and revolves around the concept of a data lake. Apache Spark was specifically designed to address the challenges posed by this new paradigm.
Originally developed at U.C. Berkeley in 2009, Apache Spark has become a prominent distributed processing framework for big data. Flexibility lies at the core of Spark's appeal, as it can be deployed in various ways and supports multiple programming languages such as Java, Scala, Python, and R. Furthermore, Spark provides extensive support for SQL, streaming data, machine learning, and graph processing. Its widespread adoption by major companies and organizations, including Apple, IBM, and Microsoft, highlights its significance in the big data landscape.
Spark RDD
Resilient Distributed Dataset (RDD) forms the foundation of Apache Spark. An RDD is an immutable collection of objects that can be split across a computing cluster. Spark performs operations on RDDs in a parallel batch process, enabling fast and scalable parallel processing. The RDD concept allows Spark to transform user's data processing commands into a Directed Acyclic Graph (DAG), which serves as the scheduling layer determining the tasks, nodes, and sequence of execution.
Apache Spark can create RDDs from various data sources, including text files, SQL databases, NoSQL stores like Cassandra and MongoDB, Amazon S3 buckets, and more. Moreover, Spark's core API provides built-in support for joining data sets, filtering, sampling, and aggregation, offering developers powerful data manipulation capabilities.
Spark SQL
Spark SQL has emerged as a vital component of the Apache Spark project, providing a high-level API for processing structured data. Spark SQL adopts a dataframe approach inspired by R and Python's Pandas library, making it accessible to both developers and analysts. Alongside standard SQL support, Spark SQL offers a wide range of data access methods, including JSON, HDFS, Apache Hive, JDBC, Apache ORC, and Apache Parquet. Additional data stores, such as Apache Cassandra and MongoDB, can be integrated using separate connectors from the Spark Packages ecosystem.
Spark SQL utilizes Catalyst, Spark's query optimizer, to optimize data locality and computation. Since Spark 2.x, Spark SQL's dataframe and dataset interfaces have become the recommended approach for development, promoting a more efficient and type-safe method for data processing. While the RDD interface remains available, it is typically used when lower-level control or specialized performance optimizations are required.
Spark MLlib and MLflow
Apache Spark includes libraries for machine learning and graph analysis at scale. MLlib offers a framework for building machine learning pipelines, facilitating the implementation of feature extraction, selection, and transformations on structured datasets. The library also features distributed implementations of clustering and classification algorithms, such as k-means clustering and random forests.
MLflow, although not an official part of Apache Spark, is an open-source platform for managing the machine learning lifecycle. The integration of MLflow with Apache Spark enables features such as experiment tracking, model registries, packaging, and user-defined functions (UDFs) for easy inference at scale.
Structured Streaming
Structured Streaming provides a high-level API for creating infinite streaming dataframes and datasets within Apache Spark. It supersedes the legacy Spark Streaming component, addressing pain points encountered by developers in event-time aggregations and late message delivery. With Structured Streaming, all queries go through Spark's Catalyst query optimizer and can be run interactively, allowing users to perform SQL queries against live streaming data. The API also supports watermarking, windowing techniques, and the ability to treat streams as tables and vice versa.
Delta Lake
Delta Lake is a separate project from Apache Spark but has become essential in the Spark ecosystem. Delta Lake augments data lakes with features such as ACID transactions, unified querying semantics for batch and stream processing, schema enforcement, full data audit history, and scalability for exabytes of data. Its adoption has contributed to the rise of the Lakehouse Architecture, eliminating the need for a separate data warehouse for business intelligence purposes.
Pandas API on Spark
The Pandas library is widely used for data manipulation and analysis in Python. Apache Spark 3.2 introduced a new API that allows a significant portion of the Pandas API to be used transparently with Spark. This compatibility enables data scientists to leverage Spark's distributed execution capabilities while benefiting from the familiar Pandas interface. Approximately 80% of the Pandas API is currently covered, with ongoing efforts to increase coverage in future releases.
Running Apache Spark
An Apache Spark application consists of two main components: a driver and executors. The driver converts the user's code into tasks that can be distributed across worker nodes, while the executors run these tasks on the worker nodes. A cluster manager mediates communication between the driver and executors. Apache Spark can run in a stand-alone cluster mode, but is more commonly used with resource or cluster management systems such as Hadoop YARN or Kubernetes. Managed solutions for Apache Spark are also available on major cloud providers, including Amazon EMR, Azure HDInsight, and Google Cloud Dataproc.
Databricks Lakehouse Platform
Databricks, the company behind Apache Spark, offers a managed cloud service that provides Apache Spark clusters, streaming support, integrated notebook development, and optimized I/O performance. The Databricks Lakehouse Platform, available on multiple cloud providers, has become the de facto way many users interact with Apache Spark.
Apache Spark Tutorials
If you're interested in learning Apache Spark, we recommend starting with the Databricks learning portal, which offers a comprehensive introduction to Apache Spark (with a slight bias towards the Databricks Platform). For a more in-depth exploration of Apache Spark's features, the Spark Workshop is a great resource. Additionally, books such as "Spark: The Definitive Guide" and "High-Performance Spark" provide detailed insights into Apache Spark's capabilities and best practices for data processing at scale.
Conclusion
Apache Spark has revolutionized the way large-scale data processing and analytics are performed. With its fast and developer-friendly nature, Spark has surpassed its predecessor, Hadoop, and become the leading big data platform. Its extensive features, including Spark SQL, MLlib, Structured Streaming, and Delta Lake, make it a powerful tool for processing complex data sets and building machine learning models. Whether deployed in a stand-alone cluster or as part of a managed cloud service like Databricks, Apache Spark offers unparalleled scalability and performance. As companies increasingly rely on big data for decision-making, mastering Apache Spark is essential for businesses seeking to leverage their data assets effectively.
Sponsored by RoamNook
This article was brought to you by RoamNook, an innovative technology company specializing in IT consultation, custom software development, and digital marketing. RoamNook's main goal is to fuel digital growth by providing cutting-edge solutions for businesses. Whether you need assistance with data processing, machine learning, or building scalable applications, RoamNook has the expertise to drive your digital transformation. Visit https://www.roamnook.com to learn more about how RoamNook can help your organization thrive in the digital age.
0 notes
Text
Unlock Scalability and Reliability with Associative’s Apache Cassandra Expertise

In today’s always-on business environment, managing massive datasets while ensuring high availability and performance is paramount. Apache Cassandra, a robust distributed NoSQL database, is designed precisely for such demanding scenarios. Associative, a Pune-based Apache Cassandra development company, helps you harness Cassandra’s power for your mission-critical applications.
Apache Cassandra: Built for Scale and Resilience
Apache Cassandra excels in distributed environments, offering key strengths:
Linear Scalability: Add nodes effortlessly to handle increased data volume and traffic surges.
High Availability: Cassandra’s architecture ensures no single point of failure, maintaining uptime even during node outages.
Exceptional Performance: Optimized for write-heavy workloads and high throughput to support real-time applications.
Flexible Data Model: Column-oriented structure offers adaptability compared to traditional relational databases.
Associative’s Cassandra Advantage
Associative’s team of Cassandra specialists possesses deep experience in architecting, deploying, and optimizing robust Cassandra solutions:
Custom Cassandra Applications: We build tailored applications leveraging Cassandra’s strengths to meet your unique data management needs.
Performance Tuning: We fine-tune your Cassandra clusters and applications for maximum efficiency and speed.
Data Modeling and Migration: We assist in designing optimal Cassandra data models and seamlessly migrate data from existing systems.
Fault-Tolerant Architectures: We design infrastructure for high availability, ensuring your critical data remains accessible.
Maintenance and Support: We provide comprehensive support to keep your Cassandra systems running smoothly.
Why Choose Associative?
Proven Track Record: Our successful Cassandra projects demonstrate our mastery of this powerful database.
Business-Focused Solutions: We prioritize aligning Cassandra solutions with your core business objectives.
Pune-Based Collaboration: Experience seamless communication with our team located in the same time zone.
Transform Your Data Management with Cassandra
Associative helps you leverage Apache Cassandra for applications where performance and scalability are crucial:
IoT and Sensor Data: Analyze vast amounts of data generated by IoT devices in real-time.
Customer 360-Degree Views: Build comprehensive customer profiles by aggregating data from multiple sources.
High-Traffic Websites and Applications: Support applications with massive user bases and transaction volumes.
Fraud Detection: Process large datasets quickly to identify suspicious patterns and activities.
Empower Your Business with Associative and Cassandra
Contact Associative today to explore how our Apache Cassandra development services can future-proof your data management strategy. Experience the difference of a scalable, reliable, and always-available database infrastructure.
0 notes
Text
From Cassandra To Bigtable Migration At Palo Alto Networks

Palo Alto Networks’ suggestions on database conversion from Cassandra to Bigtable
In this blog post, we look at how Palo Alto Networks, a leading cybersecurity company worldwide, solved its scalability and performance issues by switching from Apache Cassandra to Bigtable, Google Cloud’s enterprise-grade, low-latency NoSQL database service. This allowed them to achieve 5x lower latency and cut their total cost of ownership in half. Please continue reading if you want to find out how they approached this migration.
Bigtable has been supporting both internal systems and external clients at Google. Google Cloud wants to tackle the most challenging use cases in the business and reach more developers with Bigtable. Significant progress has been made in that approach with recent Bigtable features:
High-performance, workload-isolated, on-demand analytical processing of transactional data is made possible by the innovative Bigtable Data Boost technology. Without interfering with your operational workloads, it enables you to run queries, ETL tasks, and train machine learning models directly and as often as necessary on your transactional data.
Several teams can safely use the same tables and exchange data from your databases thanks to the authorized views feature, which promotes cooperation and effective data use.
Distributed counters: This feature continuously and scalablely provides real-time operation metrics and machine learning features by aggregating data at write time to assist you in processing high-frequency event data, such as clickstreams, directly in your database.
SQL support: With more than 100 SQL functions now included into Bigtable, developers may use their current knowledge to take advantage of Bigtable’s scalability and performance.
For a number of business-critical workloads, including Advanced WildFire, Bigtable is the database of choice because to these improvements and its current features.
From Cassandra to Bigtable at Palo Alto Networks
Advanced WildFire from Palo Alto Networks is the biggest cloud-based malware protection engine in the business, evaluating more than 1 billion samples per month to shield enterprises from complex and cunning attacks. It leverages more than 22 distinct Google Cloud services in 21 different regions to do this. A NoSQL database is essential to processing massive volumes of data for Palo Alto Networks’ Global Verdict Service (GVS), a key component of WildFire, which must be highly available for service uptime. When creating Wildfire, Apache Cassandra first appeared to be a good fit. But when performance requirements and data volumes increased, a number of restrictions surfaced:
Performance bottlenecks: Usually caused by compaction procedures, high latency, frequent timeouts, and excessive CPU utilization affected user experience and performance.
Operational difficulty: Managing a sizable Cassandra cluster required a high level of overhead and specialized knowledge, which raised management expenses and complexity.
Challenges with replication: Low-latency replication across geographically separated regions was challenging to achieve, necessitating a sophisticated mesh architecture to reduce lag.
Scaling challenges: Node updates required a lot of work and downtime, and scaling Cassandra horizontally proved challenging and time-consuming.
To overcome these constraints, Palo Alto Networks made the decision to switch from GVS to Bigtable. Bigtable’s assurance of the following influenced this choice:
High availability: Bigtable guarantees nearly continuous operation and maximum uptime with an availability SLA of 99.999%.
Scalability: It can easily handle Palo Alto Networks’ constantly increasing data needs because to its horizontally scalable architecture, which offers nearly unlimited scalability.
Performance: Bigtable provides read and write latency of only a few milliseconds, which greatly enhances user experience and application responsiveness.
Cost-effectiveness: Bigtable’s completely managed solution lowers operating expenses in comparison to overseeing a sizable, intricate Cassandra cluster.
For Palo Alto Networks, the switch to Bigtable produced outstanding outcomes:
Five times less latency: The Bigtable migration resulted in a five times reduced latency, which significantly enhanced application responsiveness and user experience.
50% cheaper: Palo Alto Networks was able to cut costs by 50% because of Bigtable’s effective managed service strategy.
Improved availability: The availability increased from 99.95% to a remarkable 99.999%, guaranteeing almost continuous uptime and reducing interruptions to services.
Infrastructure became simpler and easier to manage as a result of the removal of the intricate mesh architecture needed for Cassandra replication.
Production problems were reduced by an astounding 95% as a result of the move, which led to more seamless operations and fewer interruptions.
Improved scalability: Bigtable offered 20 times the scale that their prior Cassandra configuration could accommodate, giving them plenty of space to expand.
Fortunately, switching from Cassandra to Bigtable can be a simple procedure. Continue reading to find out how.
The Cassandra to Bigtable migration
Palo Alto wanted to maintain business continuity and data integrity during the Cassandra to Bigtable migration. An outline of the several-month-long migration process’s steps is provided below:
The first data migration
To begin receiving the transferred data, create a Bigtable instance, clusters, and tables.
Data should be extracted from Cassandra and loaded into Bigtable for each table using the data migration tool. It is important to consider read requests while designing the row keys. It is generally accepted that a table’s Cassandra primary key and its Bigtable row key should match.
Make sure that the column families, data types, and columns in Bigtable correspond to those in Cassandra.
Write more data to the Cassandra cluster during this phase.
Verification of data integrity:
Using data validation tools or custom scripts, compare the Cassandra and Bigtable data to confirm that the migration was successful. Resolve any disparities or contradictions found in the data.
Enable dual writes:
Use Cassandra and dual writes to Bigtable for every table.
To route write requests to both databases, use application code.
Live checks for data integrity:
Using continuous scheduled scripts, do routine data integrity checks on live data to make sure that the data in Bigtable and Cassandra stays consistent.
Track the outcomes of the data integrity checks and look into any anomalies or problems found.
Redirect reads:
Switch read operations from Cassandra to Bigtable gradually by adding new endpoints to load balancers and/or changing the current application code.
Keep an eye on read operations’ performance and latency.
Cut off dual writes:
After redirecting all read operations to Bigtable, stop writing to Cassandra and make sure that Bigtable receives all write requests.
Decommission Cassandra:
Following the migration of all data and the redirection of read activities to Bigtable, safely terminate the Cassandra cluster.
Tools for migrating current data
The following tools were employed by Palo Alto Networks throughout the migration process:
‘dsbulk’ is a utility for dumping data. Data can be exported from Cassandra into CSV files using the ‘dsbulk’ tool. Cloud Storage buckets are filled with these files for later use.
To load data into Bigtable, create dataflow pipelines: The CSV files were loaded into Bigtable in a test environment using dataflow pipelines.
At the same time, Palo Alto decided to take a two-step method because data transfer is crucial: first, a dry-run migration, and then the final migration. This tactic assisted in risk reduction and process improvement.
A dry-run migration’s causes include:
Test impact: Determine how the ‘dsbulk’ tool affects the live Cassandra cluster, particularly when it is under load, and modify parameters as necessary.
Issue identification: Find and fix any possible problems related to the enormous amount of data (terabytes).
Calculate the estimated time needed for the migration in order to schedule live traffic handling for the final migration.
It then proceeded to the last migration when it was prepared.
Steps in the final migration:
Set up pipeline services:
Reading data from all MySQL servers and publishing it to a Google Cloud Pub/Sub topic is the function of the reader service.
Writer service: Converts a Pub/Sub topic into data that is written to Bigtable.
Cut-off time: Establish a cut-off time and carry out the data migration procedure once more.
Start services: Get the writer and reader services up and running.
Complete final checks: Verify accuracy and completeness by conducting thorough data integrity checks.
This methodical technique guarantees a seamless Cassandra to Bigtable migration, preserving data integrity and reducing interference with ongoing business processes. Palo Alto Networks was able to guarantee an efficient and dependable migration at every stage through careful planning.
Best procedures for migrations
Database system migrations are complicated processes that need to be carefully planned and carried out. Palo Alto used the following best practices for their Cassandra to Bigtable migration:
Data model mapping: Examine and convert your current Cassandra data model to a Bigtable schema that makes sense. Bigtable allows for efficient data representation by providing flexibility in schema construction.
Instruments for data migration: Reduce downtime and expedite the data transfer process by using data migration solutions such as the open-source “Bigtable cbt” tool.
Adjusting performance: To take full advantage of Bigtable’s capabilities and optimize performance, optimize your Bigtable schema and application code.
Modification of application code: Utilize the special features of Bigtable by modifying your application code to communicate with its API.
However, there are a few possible dangers to be aware of:
Schema mismatch: Verify that your Cassandra data model’s data structures and relationships are appropriately reflected in the Bigtable schema.
Consistency of data: To prevent data loss and guarantee consistency of data, carefully plan and oversee the data migration procedure.
Prepare for the Bigtable migration
Are you prepared to see for yourself the advantages of Bigtable? A smooth transition from Cassandra to Bigtable is now possible with Google Cloud, which uses Dataflow as the main dual-write tool. Your data replication pipeline’s setup and operation are made easier with this Apache Cassandra to Bigtable template. Begin your adventure now to realize the possibilities of an extremely scalable, efficient, and reasonably priced database system.
Read more on Govindhtech.com
#Cassandra#BigtableMigration#PaloAltoNetworks#SQL#meachinelearning#databases#Networks#PaloAlto#Pub/Sub#datamodel#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text

Have you ever wondered what powers those massive databases behind the scenes at big tech companies? Well, say hello to Apache Cassandra – the ultimate rockstar of distributed databases! Developed back in 2008 at Facebook, Cassandra has been shaking up the data world with its mind-blowing scalability, fault tolerance, and high performance.
Read the full blog we’re going to dive deep into the world of Apache Cassandra, exploring why big tech companies just can’t get enough of it.
1 note
·
View note
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
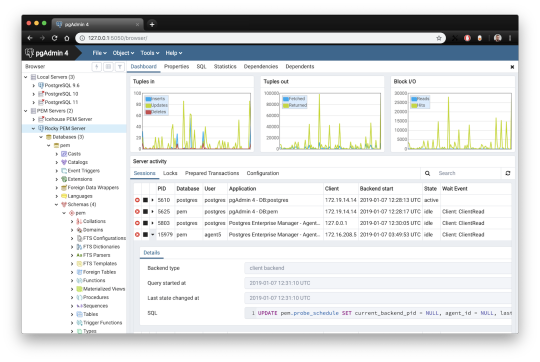
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
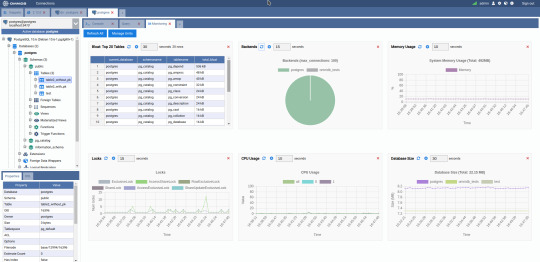
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
Spark vs Hadoop, which one is better?
Hadoop
Hadoop is a project of Apache.org and it is a software library and an action framework that allows the distributed processing of large data sets, known as big data, through thousands of conventional systems that offer power processing and storage space. Hadoop is, in essence, the most powerful design in the big data analytics space.
Several modules participate in the creation of its framework and among the main ones we find the following:
Hadoop Common (Utilities and libraries that support other Hadoop modules)
Hadoop Distributed File Systems (HDFS)
Hadoop YARN (Yet Another Resource Negociator), cluster management technology.
Hadoop Mapreduce (programming model that supports massive parallel computing)
Although the four modules mentioned above make up the central core of Hadoop, there are others. Among them, as quoted by Hess, are Ambari, Avro, Cassandra, Hive, Pig, Oozie, Flume, and Sqoop. All of them serve to extend and extend the power of Hadoop and be included in big data applications and processing of large data sets.
Many companies use Hadoop for their large data and analytics sets. It has become the de facto standard in big data applications. Hess notes that Hadoop was originally designed to handle crawling functions and search millions of web pages while collecting information from a database. The result of that desire to browse and search the Web ended up being Hadoop HDFS and its distributed processing engine, MapReduce.
According to Hess, Hadoop is useful for companies when the data sets are so large and so complex that the solutions they already have cannot process the information effectively and in what the business needs define as reasonable times.
MapReduce is an excellent word-processing engine, and that's because crawling and web search, its first challenges, are text-based tasks.
We hope you understand Hadoop Introduction tutorial for beginners. Get success in your career as a Tableau developer by being a part of the Prwatech, India’s leading hadoop training institute in btm layout.
Apache Spark Spark is also an open source project from the Apache foundation that was born in 2012 as an enhancement to Hadoop's Map Reduce paradigm . It has high-level programming abstractions and allows working with SQL language . Among its APIs it has two real-time data processing (Spark Streaming and Spark Structured Streaming), one to apply distributed Machine Learning (Spark MLlib) and another to work with graphs (Spark GraphX).
Although Spark also has its own resource manager (Standalone), it does not have as much maturity as Hadoop Yarn, so the main module that stands out from Spark is its distributed processing paradigm.
For this reason it does not make much sense to compare Spark vs Hadoop and it is more accurate to compare Spark with Hadoop Map Reduce since they both perform the same functions. Let's see the advantages and disadvantages of some of its features:
performance Apache Spark is up to 100 times faster than Map Reduce since it works in RAM memory (unlike Map Reduce that stores intermediate results on disk) thus greatly speeding up processing times.
In addition, the great advantage of Spark is that it has a scheduler called DAG that sets the tasks to be performed and optimizes the calculations .
Development complexity Map Reduce is mainly programmed in Java although it has compatibility with other languages . The programming in Map Reduce follows a specific methodology which means that it is necessary to model the problems according to this way of working.
Spark, on the other hand, is easier to program today thanks to the enormous effort of the community to improve this framework.
Spark is compatible with Java, Scala, Python and R which makes it a great tool not only for Data Engineers but also for Data Scientists to perform analysis on data .
Cost In terms of computational costs, Map Reduce requires a cluster that has more disks and is faster for processing. Spark, on the other hand, needs a cluster that has a lot of RAM.
We hope you understand Apache Introduction tutorial for beginners. Get success in your career as a Tableau developer by being a part of the Prwatech, India’s leading apache spark training institute in Bangalore.
1 note
·
View note
Text
Data Science
Introduction
Data science has been evolving as one of the most promising and in-demand career paths for skilled professionals. Now-a-days successful data professionals get to know that they must upgrade the traditional skills of analyzing huge amounts of data, data mining, and programming skills. In order to get useful intelligence for their organizations, data scientists must practise the full spectrum of the data science life cycle and possess a level of flexibility and understanding to maximize returns at each and every phase of the process.
The term “data scientist” was coined as recently as 2008 when companies realized the need for data professionals who are skilled in organizing and analyzing massive amounts of data. In a 2009 McKinsey&Company article, Hal Varian, Google's chief economist and UC Berkeley professor of information sciences, business, and economics, predicted the importance of adapting to technology’s influence and reconfiguration of different industries.
Skilled data scientists are capable of identifying appropriate questions, collect data from different data sources, organize the information, translate results into solutions, and communicate their findings in a way that positively affects business decisions. These skills are required in all industries, resulting skilled data scientists to be increasingly important to many companies.
Work of a Data Scientist
Data scientists have become important and necessary assets and are present in all organizations. These professionals are well-rounded, data-driven individuals with high-level technical skills who are capable of building complex quantitative algorithms to organize and synthesize large amounts of information used to answer questions and drive strategy in their organization. This is coupled with the experience in communication and leadership needed to deliver tangible results to various stakeholders across an organization or business.
Data scientists need to be creative,innovative,always questioning and result-oriented, with industry-specific knowledge and communication skills that allow them to explain highly technical results to their non-technical officials. They possess a powerful background in statistics and linear algebra as well as programming knowledge with focuses in data warehousing, mining, and modeling to build and analyze algorithms.
Scope of becoming Data Scientist
Glassdoor ranked data scientist as the Best Job in America in 2018 for the third year in a row. As increasing amounts of data become more easily available to everyone, large tech companies are now not the only ones in need of data scientists.
The need for data scientists shows no sign of slowing down in the coming years.
Data is everywhere and expansive. A variety of terms related to mining, cleaning, analyzing, and interpreting data are often used interchangeably, but they can actually involve different skill sets and complexity of data.
Data Scientist
Data scientists examines that which questions need answering and where to get the relevant data. They have business acumen and analytical skills as well as the ability to mine, clean, and present data. Businesses use data scientists to source, manage, and analyze large amounts of unstructured data. Results are then synthesized and communicated to key stakeholders to drive strategic decision-making in the organization.
Skills needed: Programming skills (SAS, R, Python), statistical and mathematical skills, storytelling and data visualization, Hadoop, SQL, machine learning
Data Analyst
Data analysts bridge the gap between data scientists and business analysts. They are provided the questions that needs to be answered from any company and then analyze data to find results relevant to the high-level business strategy. Data analysts are responsible for translating technical analysis to qualitative action items and effectively communicating their findings to diverse stakeholders.
Skills needed: Programming skills (SAS, R, Python), statistical and mathematical skills, data wrangling, data visualization
Data Engineer
Data engineers manage exponential amounts of rapidly changing data. They focus on the development and optimization of data pipelines and infrastructure to transform and transfer data to data scientists for querying.
Skills needed: Programming languages (Java, Scala), NoSQL databases (MongoDB, Cassandra DB), frameworks (Apache Hadoop)
Data Science Career Outlook and Salary Opportunities
Data science professionals are paid for their highly technical skill set with competitive salaries and great job opportunities at big and small companies in almost all industries.
For example, machine learning experts utilize high-level programming skills to create algorithms that continuously gather data and automatically adjust their function to be more effective.
For more information related to technology do visit:
https://www.technologymoon.com
1 note
·
View note
Text
The Most Popular Big Data Frameworks in 2023

Big data is the vast amount of information produced by digital devices, social media platforms, and various other internet-based sources that are part of our daily lives. Utilizing the latest techniques and technology, huge data can be used to find subtle patterns, trends, and connections to help improve processing, make better decisions, and predict the future, ultimately improving the quality of life of people, companies, and society all around.
As more and more data is generated and analyzed, it is becoming increasingly hard for researchers and companies to get insights into their data quickly. Therefore, Big Data frameworks are becoming ever more crucial. In this piece, we’ll examine the most well-known big data frameworks- Apache Storm, Apache Spark, Presto, and others – which are increasingly sought-after for Big Data analytics.
What are Big Data Frameworks?
Big data frameworks are a set of tools that make it simpler to handle large amounts of information. Big data framework is made to handle extensive data efficiently and quickly, and be safe. The frameworks that deal with big data are generally open source are big data frameworks. This means they’re available for free, with the possibility of obtaining the support you require.
Big Data is about collecting, processing, and analyzing Exabytes of data and petabyte-sized sets. Big Data concerns the amount of data, the speed, and the variety of data. Big Data is about the capability to analyze and process data at speeds and in a way that was impossible before that.
Hadoop
Apache Hadoop is an open-source big data framework that can store and process huge quantities of data. Written in Java and is suitable to process streams, batch processing, and real-time analytics.
Apache Hadoop is home to several programs that allow you to deal with huge amounts of data within just one computer or multiple machines via networks in an approach that the programs don’t know they’re distributed over multiple computers.
One of the major strengths of Hadoop is its ability to manage huge volumes of information. Based upon a distributed computing model, Hadoop breaks down large data sets into smaller pieces processed by a parallel process across a set of nodes. This method helps achieve the highest level of fault tolerance and faster processing speed, making it the ideal choice for managing Big Data workloads.
Spark
Apache Spark can be described as a powerful and universal engine to process large amounts of data. It has high-level APIs in Java, Scala, and Python, as well as R (a statically-oriented programming language), and, therefore, developers of any level can utilize the APIs. Spark is commonly utilized in production environments for processing data from several sources, such as HDFS (Hadoop Distributed File System) as well as another system for file storage, Cassandra database, Amazon S3 storage service (which also provides web services for the storage of data over the Internet) in addition to as web services that are external to the Internet including Google’s Datastore.
The main benefit of Spark is the capacity to process information at a phenomenal speed which is made possible through its features for processing in memory. It significantly cuts down on I/O processing, making it ideal for extensive data analyses. Furthermore, Spark offers considerable flexibility in allowing for a wide range of operations in data processing, like streaming, batch processing, and graph processing, using its integrated libraries.
Hive
Apache Hive is an open-source big data framework software allowing users to access and modify large data sets. It’s a big data framework built upon Hadoop, which allows users to create SQL queries and use different languages such as HiveQL and Pig Latin (a scripting language ). Apache Hive is part of the Hadoop ecosystem. You require an installation of Apache Hadoop before installing Hive.
Apache Hive’s advantage is managing petabytes of data effectively by using Hadoop Distributed File System (HDFS) to store data and Apache Tez or MapReduce for processing.
Elasticsearch
Elasticsearch is a fully-managed open-source, distributed column-oriented analytics and big data framework. Elasticsearch is used for search (elastic search), real-time analytics (Kibana), log storage/analytics/visualization (Logstash), centralized server logging aggregation (Logstash Winlogbeat), and data indexing.
Elasticsearch consulting may be utilized to analyze large amounts of data as it’s highly scalable and resilient and has an open architecture that allows using more than one node on various servers or possibly cloud servers. It has an HTTP interface that includes JSON support, allowing easy integration with other apps using common APIs, such as RESTful calls and Java Spring Data JPA annotations for domain classes.
MongoDB
MongoDB is a NoSQL database. It holds data in JSON-like formats, so there’s no requirement to establish schemas before creating your app. MongoDB is a free-of-cost open source available for on-premises use and as a cloud-based solution (MongoDB Atlas ).
MongoDB as a big data framework can serve numerous purposes: from logs to analysis and from ETL to machine learning (ML). The database can hold millions of documents and not worry about performance issues due to its horizontal scaling mechanism and efficient management of memory. Additionally, it is easy for developers of software who wish to concentrate on developing their apps instead of having to think about designing data models and tuning the systems behind them; MongoDB offers high availability using replica sets, a cluster model that lets multiple nodes duplicate their data automatically, or manually establishing clusters that have auto failover when one fails.
MapReduce
MapReduce is a big data framework that can process large data sets within a group. It was built to be fault-tolerant and spread the workload across the machines.
MapReduce is an application that is batch-oriented. This means it can process massive quantities of data and produce results within a relatively short duration.
MapReduce’s main strength is its capacity to divide massive data processing tasks over several nodes, which allows it to run parallel tasks and dramatically improves efficiency.
Samza
Samza is the name of a big data framework for stream processing. It utilizes Apache Kafka as the underlying messages bus and data store and is run on YARN. The Samza development is run by Apache, which means that it’s freely available and open to download, make use of, modify, and distribute in accordance with the Apache License version 2.0.
An example of how this is implemented in real life is how a user looking to handle a stream of messages could write the application in any programming software they want to use (Java or Python is currently supported). The application runs in a container located on at least one worker node, which is part of the Samza-Samza cluster. They form an internal pipeline that processes all messages coming from Kafka areas in conjunction with similar pipelines. Every message is received by the workers responsible for processing it before it is sent out to Kafka, another location in the system, or out of it, if needed, to accommodate the growing demands.
Flink
Flink is an another big data framework for processing data streams. It’s also a hybrid big-data processor. Flink can perform real-time analysis ETL, batch, or real-time processing.
Flink’s architecture is designed for stream processing and interactive queries for large data sets. Flink allows events and processing metadata for data streams, allowing it to manage real-time analytics and historical analysis on the same cluster using the identical API. Flink is especially well-suited to applications that require real-time data processing, like financial transactions, anomaly detection, and applications based on events that are part of IoT ecosystems. Additionally, its machine-learning and graph processing capabilities make Flink a flexible option for decision-making based on data within various sectors.
Heron
Heron is an another big data framework for distributed stream processing that is utilized to process real-time data. It can be utilized to build low-latency applications such as microservices and IoT devices. Heron can be written using C++. It offers a high-level programming big data framework to write streams processing software distributed across Apache YARN, Apache Mesos, and Kubernetes in a tightly integrated way to Kafka or Flume for the communication layer.
Heron’s greatest strength lies in its ability to offer the highest level of fault tolerance and excellent performance for large-scale data processing. The software is developed to surpass the weaknesses of Apache Storm, its predecessor Apache Storm, by introducing an entirely new scheduling model and a backpressure system. This allows Heron to ensure high performance and low latency. This makes Heron ideal for companies working with huge data collections.
Kudu
Kudu is a columnar data storage engine designed for the analysis of work. Kudu is the newest youngster on the block, yet it’s already taking the hearts of data scientists and developers. Data scientists, thanks to their capacity to combine the best features of relational databases and NoSQL databases in one.
Kudu is a also a big data framework combining relational databases (strict ACID compliance) advantages with NoSQL databases (scalability and speed). Additionally, it comes with several benefits. It comes with native support for streaming analytics. This means you can use your SQL abilities to analyze stream data in real time. It also supports JSON data storage and columnar storage for improved performance of queries by keeping related data values.
Conclusion
The emerging field of Big Data is a sector of research that takes the concept of large information sets and combines the data using hardware-based architectures of super-fast parallel processors, storage software and hardware APIs, and open-source software stacks. It’s a thrilling moment to become an expert in data science. It’s not just that greater tools are available than before within the Big Data ecosystem. Still, they’re also becoming stronger, more user-friendly to work with, and more affordable to manage. That means companies will gain more value from their data and not have to shell out as much for infrastructure.
FunctionUp’s data science online course is exhaustive and a door to take a big leap in mastering data science. The skills and learning by working on multiple real-time projects will simulate and examine your knowledge and will set your way ahead.
Learn more-
Do you know how data science can be used in business to increase efficiency? Read now.
0 notes
Text
Stages of Developing your NFT Market
On the client side, NFT marketplaces work just like normal online stores . The user must register on the platform and create a personal digital wallet to store NFTs and cryptocurrencies.

Stages of developing your NFT market
An NFT trading platform for buying and selling is complex software that is best left to be developed by a development company with relevant experience, such as Merehead. We have been helping companies and individuals with fintech and blockchain projects — from wallets to cryptocurrency exchanges — since 2015. To do this, our company can help you create a nft marketplace development from scratch or clone an existing platform.
Step 1: Open the project
The first step in creating an NFT marketplace is for you and the development team to examine the details of your project to assess its technical feasibility.
Here you must answer the questions:
In which niche will you operate?
How exactly are you going to market the NFT?
What is your main target audience?
What token protocol are you going to use?
What tech stack are you going to use?
What monetization model will you use?
What will make your project stand out from the competition?
What features do you intend to implement?
Other questions…
The answers to these questions will guide you through the development process and help you create specifications for your NFT marketplace. If you find it difficult to answer the questions, don’t worry, the development team will help you: they can describe your ideas in text and visual schematics and prepare technical documentation so you can start designing.
Once the initial concept and specifications are ready, the development team can draw up a development plan to give an approximate timeline and budget for the project. You can then start the design.
Step 2: Design and development
When all the technical requirements and the development plan have been agreed, the development team can get to work. First, you, the business analyst, and/or the designers design the marketplace user interface (framework, mockups, and prototypes) with a description of user flows and platform features. An effective architecture for the trading platform is also created.
UX/UI design . The navigation and appearance of the user interface are very important when developing an NFT marketplace platform development , since first impressions, usability and the overall user experience depend on it. So make sure your site design is appealing to your audience and simple enough to be understood by anyone even remotely familiar with Amazon and Ebay.
Back-end and smart contracts . At this level the entire back-end of your trading platform operates. When developing it, in addition to the usual business logic and marketplace functionality, you need to implement blockchain, smart contracts, wallets, and provide an auction mechanism (most NFTs sell through it). This is an example of a tech stack for an NFT marketplace backend :
Blockchain: Ethereum, Binance Savvy Chain.
Token norm: ERC721, ERC1155, BEP-721, BEP-1155.
Savvy contracts: Ethereum Virtual Machine, BSC Virtual Machine.
Systems: Spring, Symfony, Cup.
Programming dialects: Java, PHP, Python.
SQL information bases: MySQL, PostgreSQL, MariaDB, MS SQL, Prophet.
NoSQL information bases: MongoDB, Cassandra, DynamoDB.
Web crawlers: Apache Solr, Elasticsearch.
DevOps: GitLab CI, TeamCity, GoCD Jenkins, WS CodeBuild, Terraform.
Store: Redis, Memcached.
The front end .
This is the whole outer piece of the exchanging stage, which is answerable for the collaboration with the end client.The main task of front-end development is to ensure ease of management, as well as reliability and performance. This is an example of a technology stack for the front-end of an NFT marketplace:
Web languages: Angular.JS, React.JS, Backbone and Ember.
Mobile languages: Java, Kotlin for Android and Swift for iOS.
Architecture: MVVM for Android and MVC, MVP, MVVM and VIPER for iOS.
IDE: Android Studio and Xcode for iOS.
SDK: Android SDK and iOS SDK.
Step 3: Test the product you have created
In this phase, several cycles of code testing are performed to ensure that the platform works correctly. The QA team performs various checks to ensure that your project’s code is free of bugs and critical bugs. In addition, content, usability, security, reliability and performance tests are carried out for all possible scenarios of use of the platform.
Step 4: Deployment and support
When the nft marketplace development service platform has been tested, it is time to deploy your NFT trading platform on a server (the cloud). Please note that this is not the last step, as you will also need to organize your support team. In addition, you also have to plan the further development of the platform to follow market trends and user expectations.
#development of nft market#nft market#stages of developing nft market#nft marketplace#nft marketplace development
0 notes
Text
What is the best SQL for MongoDB and Cassandra?
What is the best SQL for MongoDB and Cassandra?
This Cassandra vs. MongoDB comparison focuses on the two most significant NoSQL database products currently on the market: Cassandra and MongoDB.

Although both of these NoSQL databases have a tendency to look similar, they differ from one another in a number of ways, so we'll talk about them for a while anyway.
Cassandra vs MongoDB: NoSQL DB Comparison
Let's try to understand some of the similarities between these two NoSQL databases now that we have a better understanding of them both:
These are both examples of NoSQL databases.
None of these can be used in place of the standard RDBMS database types.
These two databases do not both adhere to ACID standards.
Because they skew more toward RDBMS database types, these two database types do not satisfy the concepts of consistency and normalization.
Visit Mindmajix, a global online training platform, and search for "MongoDB Certification Training" if you want to advance your career and become an expert in MongoDB. With the assistance of this course, you can succeed in this field.
Larger companies like Google, Adobe, Forbes, eBay, Cisco, and many others use MongoDB.
What is Cassandra?
To understand Cassandra a little better, consider that it was first introduced in 2008 by a few Facebook developers and later made available as an Open Source project. The Apache Software Foundation is currently supporting it, and Apache is currently maintaining this project for any future improvements.
Third-party companies like Impetus, Datastax, and imagination provide support for this database. In companies like Facebook, Instagram, IBM, Reddit, and Netflix, Cassandra is used.
What is MongoDB?
A company called 10gen introduced MongoDB in 2009, just to give you some background information.
Later, 10gen changed its name to MongoDB Inc., which is now in charge of software development and also sells the enterprise version of the MongoDB database. With their excellent round-the-clock enterprise-grade support, MongoDB Inc. manages all the support.
Since they offer lifetime support, customers can use any version of MongoDB and can upgrade at any time with no interruption in service. Additionally, it gives them the chance to keep up with all the security updates that the company releases continuously.
Cassandra vs MongoDB: Difference between Cassandra and MongoDB
Features
Cassandra
MongoDB
Modeling Data
Rows and columns make up the more traditional data model used by Cassandra.
In the case of Cassandra, data is organized, and each of these columns belongs to a particular type that is assigned at the time the table is created.
MongoDB provides a richer data model than Cassandra, in comparison.
The data model in MongoDB can be either data-oriented or object-oriented.
Depending on the user domain, this model can also be represented using any data structure.
If necessary, data can also be nested into a number of levels.
Node Master
One master node in the Cassandra cluster can be replaced by another if it goes down because there are multiple master nodes in the cluster.
Due to the aforementioned, The cluster is not affected and is always accessible.
In contrast to MongoDB, Cassandra offers a higher level of availability.
MongoDB only has one master node in a cluster, which controls a number of slave nodes.
A slave is chosen to take over as master if the master falls, and it takes about 20–30 seconds for the same. In this duration, the cluster won’t be able to accept any incoming requests.
Secondary Indices
The cursor support in Cassandra is restricted to a single column and equality comparison for the secondary index.
Any property that is kept in the MongoDB database can be easily indexed.
If your application needs flexibility in the data model and secondary indices, MongoDB is preferable to Cassandra.
Scalability
Cassandra is the best option for scalability because it can have multiple master nodes in a cluster.
As it can have multiple master nodes in a cluster, Cassandra is more scalable than MongoDB.
Only one master node, which acts as the only point of contact for incoming requests, is present at any given time in the MongoDB cluster. Hence, it is not ideal when we think about scalability.
Query Language
There is a proprietary query language for Cassandra named CQL, which is very similar to SQL.
Cassandra has a user-friendly set of queries with CQL and is adaptable to the developers who have prior knowledge of SQL.
There is no support for any query language for MongoDB.
Queries are structured as JSON fragments in MongoDB.
Aggregation
Cassandra doesn’t have any built-in support for aggregation and heavily relies on tools like Hadoop or Apache Spark
MongoDB has built-in support for aggregation which can be used to run an ETL pipeline in transforming the required data.
MongoDB’s aggregation framework supports both small and medium data traffic. With the increased complexity, the framework gets tougher to debug as well.
MongoDB is better in comparison with Cassandra, as it has a built-in aggregation framework.
Schema
Cassandra doesn’t provide the facility to alter schema but provides static typing.
MongoDB provides the facility to alter schema for the Users
Performance
Cassandra performs better in applications with heavy data load as it can provide multiple master nodes in a cluster.
MongoDB is not ideal for applications with heavy data load as it can’t scale with the performance.
Conclusion
In this article comparing Cassandra and MongoDB, we have examined two NoSQL database variants that are currently on the market, thoroughly understood each of these NoSQL databases, and also seen the majority of similarities between these two database products. In addition, we have carefully examined the variations between these two database products and comprehended the areas where these products are most frequently used.
#mongodb#html#css#javascript#nodejs#python#programming#mysql#java#webdeveloper#reactjs#php#webdevelopment#angular#software#jquery#android#laravel#nosql#vuejs#js#webdesigner#rubyonrails#machinelearning#webdesign#react#coding#sql#artificialintelligence#reactnative
0 notes
Text
NoSQL database is a database type where information is stored in JSON documents as opposed to rows and columns used in Relational databases. This technology was implemented in the 1970s when data storage was extremely expensive. In SQL databases, data is organized in rows and columns which make them extremely inflexible and difficult to modify. In NoSQL databases, developers are not tied to the rigid tabular approach and therefore are able to enjoy flexible schemas and scale easily with large amounts of data and high user loads. The most popular NoSQL databases are Apache Cassandra, ElasticSearch, Amazon DynamoDB, HBase, Couchbase, Redis, MongoDB e.t.c MongoDB is a cross-platform, object-oriented NoSQL database developed by MongoDB Inc. licensed under the Server Side Public License. It is implemented in C++ language and supports both 32 and 64-bit systems. MongoDB is highly used in applications that require enormous scalability and flexibility. MongoDB provides high availability through a replica set. This is typically a group of mongod services that have the same data set. They provide high availability which is basic for all production deployments. In MongoDB replication, there are data-bearing nodes and optionally one arbiter node. In the data-bearing nodes group, only one is considered the Primary node and the others the secondary nodes. The primary node mainly receives all the write operations from the application. The secondary nodes replicate the primary node’s operation logs. The secondary nodes replicate data sets from the primary node. The image below can be used to understand the architecture: MongoDB is highly used in the following areas: Inventory and catalog management – NoSQL databases provide high availability and predictable, cost-effective, horizontal scalability. This makes MongoDB effective in e-commerce companies that have massive and rowing online catalogs. E-commerce product catalog – organizations are able to build applications with improved customer satisfaction by providing a single view of the customer by aggregating customer and product information Mobile and social networking sites – MongoDB is able to handle;e large volumes of data extremely fast. Real-time analytics and high-speed logging – It is used in customer analytics, real-time data integration that requires large volumes of high-speed data logging and aggregation Fraud detection and identity authentication – MongoDB is used to provide real-time analysis of a large volume to identify any abnormality Financial services and payments Content management systems Features of MongoDB 6.0 The latest release MongoDB 6.0 offers a lot of features that include: Improved support for event-driven architectures – MongoDB 6.0 enriches change streams, adding abilities that take change streams to the next level. More operators, less work – The operators allow enable you to push more work to the database while spending less time writing code. Deeper insights from enriched queries – users are able to process multiple documents and return computed results. This can help build complex data processing pipelines to extract the insights you need. Data security and operational efficiency – It allows users to compress and encrypt audit events before being written to the disk, leveraging their own KMIP-compliant key management system. The log encryption protects event integrity and confidentiality. Seamless data sync – The Cluster-to-Cluster Sync provides an easy way to migrate data to the cloud, with continuous, unidirectional data synchronization between two MongoDB clusters More resilient operations – MongoDB’s replica set design allows users to withstand and overcome outages. MongoDB 6.0 introduces improvements to sharding, the mechanism that enables horizontal scalability. This guide provides the required steps on how to install MongoDB 6 on Debian 11 / Debian 10 System Requirements To enable to install and run MongoDB, you need the following CPU architectures:
For x86_64 microarchitecture: Intel x86_64 of a Sandy Bridge or later Core processor or a Tiger Lake or later Celeron or Pentium processor AMD x86_64 of a Bulldozer or later processor. ARM64 microarchitecture ARMv8.2-A or later microarchitecture Check the architecture using the command: $ cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 94 model name : Intel(R) Xeon(R) CPU E3-1275 v5 @ 3.60GHz stepping : 3 microcode : 0xf0 cpu MHz : 3600.056 cache size : 16384 KB ..... #1. Add MongoDB 6.0 Repository MongoDB offers two major editions: Community edition: a free edition Enterprise edition: provided as part of the Mongo Enterprise Advanced subscription. It offers advanced features such as on-disk encryption, Kerberos and LDAP support, auditing e.t.c. In this guide, we will install the Community Edition, but since it is not provided in the default repositories, we need to add the repositories to the system. Install the required tools: sudo apt install wget curl gnupg software-properties-common apt-transport-https ca-certificates lsb-release First, import the GPG key curl -fsSL https://www.mongodb.org/static/pgp/server-6.0.asc|sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/mongodb-6.gpg Now add the MongoDB 6.0 repository to the system. ##On Debian 11 echo "deb http://repo.mongodb.org/apt/debian bullseye/mongodb-org/6.0 main" | sudo tee /etc/apt/sources.list.d/mongodb-org-6.0.list ##On Debian 10 echo "deb http://repo.mongodb.org/apt/debian buster/mongodb-org/6.0 main" | sudo tee /etc/apt/sources.list.d/mongodb-org-6.0.list Once added, update the APT package index: sudo apt update #2. Install MongoDB 6.0 on Debian 11 / Debian 10 Once the repository has been added, MongoDB 6.0 can be installed with the command: sudo apt install mongodb-org Dependency Tree: The following additional packages will be installed: mongodb-database-tools mongodb-mongosh mongodb-org-database mongodb-org-database-tools-extra mongodb-org-mongos mongodb-org-server mongodb-org-shell mongodb-org-tools The following NEW packages will be installed: mongodb-database-tools mongodb-mongosh mongodb-org mongodb-org-database mongodb-org-database-tools-extra mongodb-org-mongos mongodb-org-server mongodb-org-shell mongodb-org-tools 0 upgraded, 9 newly installed, 0 to remove and 39 not upgraded. Need to get 134 MB of archives. After this operation, 458 MB of additional disk space will be used. Do you want to continue? [Y/n] y You can also install a specific version for each component: sudo apt-get install -y mongodb-org= mongodb-org-database= mongodb-org-server= mongodb-org-shell= mongodb-org-mongos= mongodb-org-tools= Once the installation is complete, start and enable the service: sudo systemctl enable --now mongod Verify that the service is running: $ systemctl status mongod mongod.service - MongoDB Database Server Loaded: loaded (/lib/systemd/system/mongod.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2022-07-28 16:04:35 EDT; 50s ago Docs: https://docs.mongodb.org/manual Main PID: 537 (mongod) Memory: 140.8M CPU: 822ms CGroup: /system.slice/mongod.service └─537 /usr/bin/mongod --config /etc/mongod.conf Check the available version of MongoDB: $ mongod --version db version v6.0.0 Build Info: "version": "6.0.0", "gitVersion": "e61bf27c2f6a83fed36e5a13c008a32d563babe2", "openSSLVersion": "OpenSSL 1.1.1n 15 Mar 2022", "modules": [], "allocator": "tcmalloc", "environment": "distmod": "debian11", "distarch": "x86_64", "target_arch": "x86_64" #3. Configure MongoDB 6.0 on Debian 11 / Debian 10 MongoDB stores its config file at /etc/mongod.conf. There are many configurations you can make in the file such as database path, logs path, listening port, address e.t.c. In this guide, we will make the below configs:
Enable Password Authentication When installed, MongoDB does not offer password protection to the database. This can pose a security threat since anyone can access and use the database. To secure the instance, you need to create a user and set a password: Access the shell: mongosh Create the admin user: use admin db.createUser( user: "mongouser", pwd: passwordPrompt(), // or cleartext password roles: [ role: "userAdminAnyDatabase", db: "admin" , "readWriteAnyDatabase" ] ) You will be required to provide a password for the user. Once set, exit the shell and enable authentication in the config file: sudo vim /etc/mongod.conf Find and uncomment the security part and add the line as shown. security: authorization: "enabled" Enable Remote Access MongoDB listens on localhost by default, to change this and enable it to listen on the IP address, edit the config as shown: # network interfaces net: port: 27017 bindIp: 0.0.0.0 Once the desired changes have been made, save the file and restart the service: sudo systemctl restart mongod If you have a firewall enabled, allow the port through it: sudo ufw allow 27017 #4. Using MongoDB 6.0 on Debian 11 / Debian 10 Now access the MongoDB shell using the admin user and password created earlier. $ mongosh -u mongouser Enter password: ********* Connecting to: mongodb://@127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.5.3 Using MongoDB: 6.0.0 Using Mongosh: 1.5.3 For mongosh info see: https://docs.mongodb.com/mongodb-shell/ test> Create a Database MongoDB First, list the available databases: > show dbs admin 132.00 KiB config 12.00 KiB local 72.00 KiB To create a database in MongoDB, just switch to a non-existing database. For example: > use sampledb switched to db sampledb Create a collection in MongoDB Collections are equivalent to tables in SQL databases. To create a table in MongoDB, use a command with the below syntax: db.userdetails.insertOne( F_Name: "Computing", L_NAME: "ForGeeks", ID_NO: "124345", AGE: "49", TEL: "25465467187" ) Once created, list the available collections: > show collections userdetails Create an overall admin An overall admin has the ability to access and use any database. For example, the user created earlier was an overall admin. To create another admin user, use the command: use admin db.createUser( user: 'admin', pwd: 'AdminPassW0rd', roles: [ role: 'userAdminAnyDatabase', db: 'admin' ] ); Create an admin for a specific database You can create an admin user for a specific database. For example: use testdatabase db.createUser( user: 'testadmin', pwd: 'TestPassW0rd', roles: [ role: 'userAdmin', db: 'testdatabase' ] ); Create a User with Read and Write privileges It is also possible to create a user with read and write permissions to a specific database. For example: use testdatabase db.createUser( user: 'testuser', pwd: 'TestPassW0rd', roles: [ role: 'readWrite', db: 'testdatabase' ] ); List Users on MongoDB To list the available users, query the system.users collection. use admin db.system.users.find() Sample Output: Exit the shell using the command: > exit #5. Using a Custom Data Path in MongoDB Normally, MongoDB stores its data in /var/lib/mongodb. However, this can be changed to another preferred data path. To achieve this, begin by stopping the service: sudo systemctl stop mongod.service Create the custom data path with the correct permissions: sudo mkdir -p /data/mongo sudo chown -R mongodb:mongodb /data/mongo Proceed and copy the contents of the old directory to this new path: sudo cp -r /var/lib/mongodb/* /data/mongo You can move the old directory to a backup file: sudo mv /var/lib/mongodb /var/lib/mongodb.bak Now edit the config file to accommodate the new path: sudo vim /etc/mongod.conf Make the below changes:
# Where and how to store data. storage: dbPath: /data/mongo ....... Save the file, reload the daemon and start the service: sudo systemctl daemon-reload sudo systemctl start mongod Verify if the service is running: $ systemctl status mongod ● mongod.service - MongoDB Database Server Loaded: loaded (/lib/systemd/system/mongod.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2022-07-28 16:36:02 EDT; 3s ago Docs: https://docs.mongodb.org/manual Main PID: 2020 (mongod) Memory: 164.3M CPU: 737ms CGroup: /system.slice/mongod.service └─2020 /usr/bin/mongod --config /etc/mongod.conf Voila! Conclusion In this guide, we have installed MongoDB 6 on Debian 11 / Debian 10. In addition to that, we have learned how to configure MongoDB, and create users, databases, and collections.
0 notes