#Apache Cassandra
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
Apache Cassandra
0 notes
Text
#python#evenement#apache cassandra#postgresq#search engine optimization#djan#software development#open source#linux
1 note
·
View note
Text
Unlock Scalability and Reliability with Associative’s Apache Cassandra Expertise

In today’s always-on business environment, managing massive datasets while ensuring high availability and performance is paramount. Apache Cassandra, a robust distributed NoSQL database, is designed precisely for such demanding scenarios. Associative, a Pune-based Apache Cassandra development company, helps you harness Cassandra’s power for your mission-critical applications.
Apache Cassandra: Built for Scale and Resilience
Apache Cassandra excels in distributed environments, offering key strengths:
Linear Scalability: Add nodes effortlessly to handle increased data volume and traffic surges.
High Availability: Cassandra’s architecture ensures no single point of failure, maintaining uptime even during node outages.
Exceptional Performance: Optimized for write-heavy workloads and high throughput to support real-time applications.
Flexible Data Model: Column-oriented structure offers adaptability compared to traditional relational databases.
Associative’s Cassandra Advantage
Associative’s team of Cassandra specialists possesses deep experience in architecting, deploying, and optimizing robust Cassandra solutions:
Custom Cassandra Applications: We build tailored applications leveraging Cassandra’s strengths to meet your unique data management needs.
Performance Tuning: We fine-tune your Cassandra clusters and applications for maximum efficiency and speed.
Data Modeling and Migration: We assist in designing optimal Cassandra data models and seamlessly migrate data from existing systems.
Fault-Tolerant Architectures: We design infrastructure for high availability, ensuring your critical data remains accessible.
Maintenance and Support: We provide comprehensive support to keep your Cassandra systems running smoothly.
Why Choose Associative?
Proven Track Record: Our successful Cassandra projects demonstrate our mastery of this powerful database.
Business-Focused Solutions: We prioritize aligning Cassandra solutions with your core business objectives.
Pune-Based Collaboration: Experience seamless communication with our team located in the same time zone.
Transform Your Data Management with Cassandra
Associative helps you leverage Apache Cassandra for applications where performance and scalability are crucial:
IoT and Sensor Data: Analyze vast amounts of data generated by IoT devices in real-time.
Customer 360-Degree Views: Build comprehensive customer profiles by aggregating data from multiple sources.
High-Traffic Websites and Applications: Support applications with massive user bases and transaction volumes.
Fraud Detection: Process large datasets quickly to identify suspicious patterns and activities.
Empower Your Business with Associative and Cassandra
Contact Associative today to explore how our Apache Cassandra development services can future-proof your data management strategy. Experience the difference of a scalable, reliable, and always-available database infrastructure.
0 notes
Text
Real-Time Data Streaming: How Apache Kafka is Changing the Game
Introduction
In today’s fast-paced digital world, real-time data streaming has become more essential than ever because businesses now rely on instant data processing to make data-driven and informed decision-making. Apache Kafka, i.e., a distributed streaming platform for handling data in real time, is at the heart of this revolution. Whether you are an Apache Kafka developer or exploring Apache Kafka on AWS, this emerging technology can change the game of managing data streams. Let’s dive deep and understand how exactly Apache Kafka is changing the game.
Rise of Real-Time Data Streaming
The vast amount of data with businesses in the modern world has created a need for systems to process and analyze as it is produced. This amount of data has emerged due to the interconnections of business with other devices like social media, IoT, and cloud computing. Real-time data streaming enables businesses to use that data to unlock vast business opportunities and act accordingly.
However, traditional methods fall short here and are no longer sufficient for organizations that need real-time data insights for data-driven decision-making. Real-time data streaming requires a continuous flow of data from sources to the final destinations, allowing systems to analyze that information in less than milliseconds and generate data-driven patterns. However, building a scalable, reliable, and efficient real-time data streaming system is no small feat. This is where Apache Kafka comes into play.
About Apache Kafka
Apache Kafka is an open-source distributed event streaming platform that can handle large real-time data volumes. It is an open-source platform developed by the Apache Software Foundation. LinkedIn initially introduced the platform; later, in 2011, it became open-source.
Apache Kafka creates data pipelines and systems to manage massive volumes of data. It is designed to manage low-latency, high-throughput data streams. Kafka allows for the injection, processing, and storage of real-time data in a scalable and fault-tolerant way.
Kafka uses a publish-subscribe method in which:
Data (events/messages) are published to Kafka topics by producers.
Consumers read and process data from these subjects.
The servers that oversee Kafka's message dissemination are known as brokers.
ZooKeeper facilitates the management of Kafka's leader election and cluster metadata.
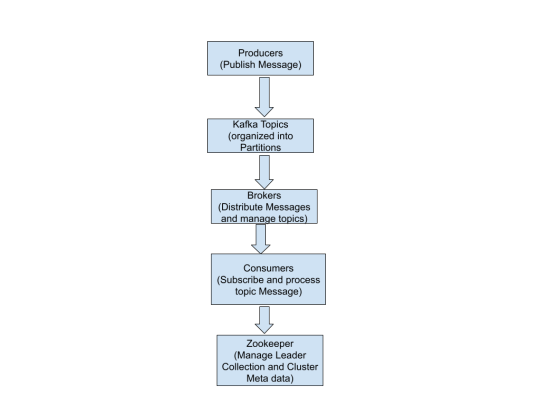
With its distributed architecture, fault tolerance, and scalability, Kafka is a reliable backbone for real-time data streaming and event-driven applications, ensuring seamless data flow across systems.
Why Apache Kafka Is A Game Changer
Real-time data processing helps organizations collect, process, and even deliver the data as it is generated while immediately ensuring the utmost insights and actions. Let’s understand the reasons why Kafka stands out in the competitive business world:
Real-Time Data Processing
Organizations generate vast amounts of data due to their interconnection with social media, IoT, the cloud, and more. This has raised the need for systems and tools that can react instantly and provide timely results. Kafka is a game-changer in this regard. It helps organizations use that data to track user behavior and take action accordingly.
Scalability and Fault Tolerance
Kafka's distributed architecture guarantees data availability and dependability even in the case of network or hardware failures. It is a reliable solution for mission-critical applications because it ensures data durability and recovery through replication and persistent storage.
Easy Integration
Kafka seamlessly connects with a variety of systems, such as databases, analytics platforms, and cloud services. Its ability to integrate effortlessly with these tools makes it an ideal solution for constructing sophisticated data pipelines.
Less Costly Solution
Kafka helps in reducing the cost of data processing and analyzing efficiently and ensures high performance of the businesses. By handling large volumes of data, Kafka also enhances scalability and reliability across distributed systems.
Apache Kafka on AWS: Unlocking Cloud Potential
Using Apache Kafka on ASW has recently become more popular because of the cloud’s advantages, like scalability, flexibility, and cost efficiency. Here, Kafka can be deployed in a number of ways, such as:
Amazon MSK (Managed Streaming for Apache Kafka): A fully managed service helps to make the deployment and management of Kafka very easy. Additionally, it handles infrastructure provisioning, scaling, and even maintenance and allows Apache Kafka developers to focus on building applications.
Self-Managed Kafka on EC2: This is apt for organizations that prefer full control of their Kafka clusters, as AWS EC2 provides the flexibility to deploy and manage Kafka instances.
The benefits of Apache Kafka on ASW are as follows:
Easy scaling of Kafka clusters as per the demand.
Ensures high availability and enables disaster recovery
Less costly because it uses a pay-as-you-go pricing model
The Future of Apache Kafka
Kafka’s role in the technology ecosystem will definitely grow with the increase in the demand for real-time data processing. Innovations like Kafka Streams and Kafka Connect are already expanding the role of Kafka and making real-time processing quite easy. Moreover, integrations with cloud platforms like AWS continuously drive the industry to adopt Kafka within different industries and expand its role.
Conclusion
Apache Kafka is continuously revolutionizing the organizations of modern times that are handling real-time data streaming and changing the actual game of businesses around the world by providing capabilities like flexibility, scalability, and seamless integration. Whether you are deploying Apache Kafka on AWS or working as an Apache Kafka developer, this technology can offer enormous possibilities for innovation in the digitally enabled business landscape.
Do you want to harness the full potential of your Apache Kafka systems? Look no further than Ksolves, where a team of seasoned Apache Kafka experts and developers stands out as a leading Apache Kafka development company with their client-centric approach and a commitment to excellence. With our extensive experience and expertise, we specialize in offering top-notch solutions tailored to your needs.
Do not let your data streams go untapped. Partner with leading partners like Ksolves today!
Visit Ksolves and get started!
#kafka apache#apache kafka on aws#apache kafka developer#apache cassandra consulting#certified developer for apache kafka
0 notes
Text

Explores the importance of scalability in the digital world, focusing on Apache Cassandra's unique architecture and cutting-edge features. It delves into the reasons behind Cassandra's rise as a preferred choice for modern data-driven applications, highlighting its remarkable scaling capabilities.
Read this blog to know more -https://www.ksolves.com/blog/big-data/apache-cassandra/apache-cassandra-scaling-guide-why-does-scalability-matter
1 note
·
View note
Text
Apache Cassandra™ Certification | DataStax Academy
| The demand for Apache Cassandra™ and NoSQL skills is skyrocketing with … source
View On WordPress
0 notes
Text
Can I use Python for big data analysis?
Yes, Python is a powerful tool for big data analysis. Here’s how Python handles large-scale data analysis:

Libraries for Big Data:
Pandas:
While primarily designed for smaller datasets, Pandas can handle larger datasets efficiently when used with tools like Dask or by optimizing memory usage..
NumPy:
Provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays.
Dask:
A parallel computing library that extends Pandas and NumPy to larger datasets. It allows you to scale Python code from a single machine to a distributed cluster
Distributed Computing:
PySpark:
The Python API for Apache Spark, which is designed for large-scale data processing. PySpark can handle big data by distributing tasks across a cluster of machines, making it suitable for large datasets and complex computations.
Dask:
Also provides distributed computing capabilities, allowing you to perform parallel computations on large datasets across multiple cores or nodes.
Data Storage and Access:
HDF5:
A file format and set of tools for managing complex data. Python’s h5py library provides an interface to read and write HDF5 files, which are suitable for large datasets.
Databases:
Python can interface with various big data databases like Apache Cassandra, MongoDB, and SQL-based systems. Libraries such as SQLAlchemy facilitate connections to relational databases.
Data Visualization:
Matplotlib, Seaborn, and Plotly: These libraries allow you to create visualizations of large datasets, though for extremely large datasets, tools designed for distributed environments might be more appropriate.
Machine Learning:
Scikit-learn:
While not specifically designed for big data, Scikit-learn can be used with tools like Dask to handle larger datasets.
TensorFlow and PyTorch:
These frameworks support large-scale machine learning and can be integrated with big data processing tools for training and deploying models on large datasets.
Python’s ecosystem includes a variety of tools and libraries that make it well-suited for big data analysis, providing flexibility and scalability to handle large volumes of data.
Drop the message to learn more….!
2 notes
·
View notes
Text

Leo and Donnie are cowboys, and then Mikey and Raph are Apaches. I like to think Mikey spends time with Apaches (yokais) because he wants to learn much better how to use his mystical powers. After all the turtles in this dimension, they grow up like cowboys and apaches.
Leo and Donnie cowboys
#rise of the teenage mutant ninja turtles#rise of the tmnt#rottmnt au#rottmnt mikey#rise mikey#rottmnt raph#western rottmnt#rise oc
10 notes
·
View notes
Note
Hi hi Cat! You have helped me before in the past with fcs and they have done wonders for me. I'm looking for help with a woman between the ages of 24-32 who gives off werewolf vibes. Ethnicity and race don't matter. Thanks in advance!
Shareena Clanton (1990) Blackfoot, Cherokee, African-American, Wangkatha, Yamatji, Noongar, Gija - has spoken up for Palestine!
Taylour Paige (1990) African-American.
Dora Madison (1990)
Tiana Okoye (1991) African-American - has a link to a Gazan charity on her page!
Sarah Kameela Impey (1991) Indo-Guyanese / White - especially her vibe in We Are Lady Parts - has spoken up for Palestine!
Sofia Black-D'Elia (1991)
Naomi Ackie (1991) Afro Grenadian.
Rose Matafeo (1992) Samoan / White - has spoken up for Palestine!
Laysla De Oliveira (1992) Brazilian.
Kiana Madeira (1992) Black Canadian, Unspecified First Nations, Portuguese, Irish.
Cassandra Naud (1992)
Anna Leong Brophy (1993) Irish, Chinese, Kadazan.
Maia Mitchell (1993) - has spoken up for Palestine!
Olivia D’Lima (1993) Goan and White - has spoken up for Palestine!
Adèle Exarchopoulos (1993) half Ashkenazi Jewish.
Mina El Hammani (1993) Moroccan - has spoken up for Palestine!
Devery Jacobs (1993) Mohawk - is queer - has spoken up for Palestine!
Frankie Adams (1994) Samoan.
Simona Tabasco (1994)
Jasmin Savoy Brown (1994) African-American / White - is queer - has spoken up for Palestine!
Jaz Sinclair (1994) African-American / White.
Sasha Lane (1995) African-American, Māori, White - is gay and has schizoaffective disorder.
Geraldine Viswanathan (1995) Tamil / White.
Coty Camacho (1995) Mixtec and Zapotec - is pansexual.
Juliette Motamed (1995) Iranian - has spoken up for Palestine!
Maddie Hasson (1995)
Jessie Mei Li (1995) Hongkonger / English - is a gender non-conforming woman who uses she/they - has spoken up for Palestine!
Rachel Sennott (1995)
Sasha Calle (1995) Colombian.
Blu Hunt (1995) Lakota, Apache, English, Italian, other - is queer.
Myha'la (1996) Afro Jamaican / White - is queer - has spoken up for Palestine!
Florence Pugh (1996) - has spoken up for Palestine!
Emma Mackey (1996)
Annalisa Cochrane (1996)
Brittany O'Grady (1996) Louisiana Creole [African, French] / White.
Piper Curda (1997) Korean / White - is apsec - has spoken up for Palestine!
Sydney Park (1997) African-American / Korean.
Kassius Nelson (1997) Black British - in Dead Boy Detectives.
Benedetta Porcaroli (1998) - has spoken up for Palestine!
Erin Kellyman (1998) Afro Jamaican / White - is a lesbian.
Brianne Tju (1998) Chinese / Indonesian.
Mk Xyz (1998) African-American and Filipino - is a lesbian.
Bailee Madison (1999)
Odessa A'zion (2000) part Ashkenazi Jewish - has spoken up for Palestine!
Hope this helps, anon!
4 notes
·
View notes
Text
Azure Data Engineering Tools For Data Engineers

Azure is a cloud computing platform provided by Microsoft, which presents an extensive array of data engineering tools. These tools serve to assist data engineers in constructing and upholding data systems that possess the qualities of scalability, reliability, and security. Moreover, Azure data engineering tools facilitate the creation and management of data systems that cater to the unique requirements of an organization.
In this article, we will explore nine key Azure data engineering tools that should be in every data engineer’s toolkit. Whether you’re a beginner in data engineering or aiming to enhance your skills, these Azure tools are crucial for your career development.
Microsoft Azure Databricks
Azure Databricks is a managed version of Databricks, a popular data analytics and machine learning platform. It offers one-click installation, faster workflows, and collaborative workspaces for data scientists and engineers. Azure Databricks seamlessly integrates with Azure’s computation and storage resources, making it an excellent choice for collaborative data projects.
Microsoft Azure Data Factory
Microsoft Azure Data Factory (ADF) is a fully-managed, serverless data integration tool designed to handle data at scale. It enables data engineers to acquire, analyze, and process large volumes of data efficiently. ADF supports various use cases, including data engineering, operational data integration, analytics, and data warehousing.
Microsoft Azure Stream Analytics
Azure Stream Analytics is a real-time, complex event-processing engine designed to analyze and process large volumes of fast-streaming data from various sources. It is a critical tool for data engineers dealing with real-time data analysis and processing.
Microsoft Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake solution for data scientists, developers, and analysts. It allows organizations to store data of any type and size while supporting low-latency workloads. Data engineers can take advantage of this infrastructure to build and maintain data pipelines. Azure Data Lake Storage also offers enterprise-grade security features for data collaboration.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics is an integrated platform solution that combines data warehousing, data connectors, ETL pipelines, analytics tools, big data scalability, and visualization capabilities. Data engineers can efficiently process data for warehousing and analytics using Synapse Pipelines’ ETL and data integration capabilities.
Microsoft Azure Cosmos DB
Azure Cosmos DB is a fully managed and server-less distributed database service that supports multiple data models, including PostgreSQL, MongoDB, and Apache Cassandra. It offers automatic and immediate scalability, single-digit millisecond reads and writes, and high availability for NoSQL data. Azure Cosmos DB is a versatile tool for data engineers looking to develop high-performance applications.
Microsoft Azure SQL Database
Azure SQL Database is a fully managed and continually updated relational database service in the cloud. It offers native support for services like Azure Functions and Azure App Service, simplifying application development. Data engineers can use Azure SQL Database to handle real-time data ingestion tasks efficiently.
Microsoft Azure MariaDB
Azure Database for MariaDB provides seamless integration with Azure Web Apps and supports popular open-source frameworks and languages like WordPress and Drupal. It offers built-in monitoring, security, automatic backups, and patching at no additional cost.
Microsoft Azure PostgreSQL Database
Azure PostgreSQL Database is a fully managed open-source database service designed to emphasize application innovation rather than database management. It supports various open-source frameworks and languages and offers superior security, performance optimization through AI, and high uptime guarantees.
Whether you’re a novice data engineer or an experienced professional, mastering these Azure data engineering tools is essential for advancing your career in the data-driven world. As technology evolves and data continues to grow, data engineers with expertise in Azure tools are in high demand. Start your journey to becoming a proficient data engineer with these powerful Azure tools and resources.
Unlock the full potential of your data engineering career with Datavalley. As you start your journey to becoming a skilled data engineer, it’s essential to equip yourself with the right tools and knowledge. The Azure data engineering tools we’ve explored in this article are your gateway to effectively managing and using data for impactful insights and decision-making.
To take your data engineering skills to the next level and gain practical, hands-on experience with these tools, we invite you to join the courses at Datavalley. Our comprehensive data engineering courses are designed to provide you with the expertise you need to excel in the dynamic field of data engineering. Whether you’re just starting or looking to advance your career, Datavalley’s courses offer a structured learning path and real-world projects that will set you on the path to success.
Course format:
Subject: Data Engineering Classes: 200 hours of live classes Lectures: 199 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 70% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
Subject: DevOps Classes: 180+ hours of live classes Lectures: 300 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 67% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Data Engineering courses, visit Datavalley’s official website.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#power bi#business intelligence#data analytics course#data science course#data engineering course#data engineering training
3 notes
·
View notes
Text
CS595—Big Data Technologies Assignment #12
Exercise 1) (4 points) Read the article “A Big Data Modeling Methodology for Apache Cassandra” available on the blackboard in the ‘Articles’ section. Provide a ½ page summary including your comments and impressions. Exercise 2) (2 points) For this and the following exercises you will use and instance of the Cassandra database that I have set up for you in the Azure cloud. Note, as I am paying…
0 notes
Text
Becoming a Full-Stack Data Scientist: Bridging the Gap between Research and Production

For years, the ideal data scientist was often portrayed as a brilliant researcher, adept at statistics, machine learning algorithms, and deep analytical dives within the comfortable confines of a Jupyter notebook. While these core skills remain invaluable, the landscape of data science has dramatically shifted by mid-2025. Companies are no longer content with insightful reports or impressive model prototypes; they demand operationalized AI solutions that deliver tangible business value.
This shift has given rise to the concept of the "Full-Stack Data Scientist" – an individual capable of not just building models, but also taking them from the initial research phase all the way to production, monitoring, and maintenance. This role bridges the historically distinct worlds of data science (research) and software/ML engineering (production), making it one of the most in-demand and impactful positions in the modern data-driven organization.
Why the "Full-Stack" Evolution?
The demand for full-stack data scientists stems from several critical needs:
Accelerated Time-to-Value: The longer a model remains a "research artifact," the less value it generates. Full-stack data scientists streamline the transition from experimentation to deployment, ensuring insights are quickly converted into actionable products or services.
Reduced Silos and Improved Collaboration: When data scientists can speak the language of engineering and understand deployment challenges, collaboration with MLOps and software engineering teams becomes far more efficient. This reduces friction and miscommunication.
End-to-End Ownership & Accountability: A full-stack data scientist can take ownership of a project from inception to ongoing operation, fostering a deeper understanding of its impact and facilitating quicker iterations.
Operational Excellence: Understanding how models behave in a production environment (e.g., data drift, model decay, latency requirements) allows for more robust model design and proactive maintenance.
Cost Efficiency: In smaller teams or startups, a full-stack data scientist can cover multiple roles, optimizing resource allocation.
The Full-Stack Data Scientist's Skillset: Beyond the Notebook
To bridge the gap between research and production, a full-stack data scientist needs a diverse and expanded skillset:
1. Core Data Science Prowess: (The Foundation)
Advanced ML & Deep Learning: Proficiency in various algorithms, model selection, hyperparameter tuning, and understanding the nuances of different model architectures (e.g., Transformers, Diffusion Models for GenAI applications).
Statistics & Mathematics: A solid grasp of statistical inference, probability, linear algebra, and calculus to understand model assumptions and interpret results.
Data Analysis & Visualization: Expert-level exploratory data analysis (EDA), data cleaning, feature engineering, and compelling data storytelling.
Programming Languages: Mastery of Python (with libraries like Pandas, NumPy, Scikit-learn, TensorFlow/PyTorch) and often R, for data manipulation, modeling, and scripting.
2. Data Engineering Fundamentals: (Getting the Data Right)
SQL & Database Management: Expert-level SQL for querying, manipulating, and optimizing data from relational databases. Familiarity with NoSQL databases (e.g., MongoDB, Cassandra) is also valuable.
Data Pipelines (ETL/ELT): Understanding how to build, maintain, and monitor data pipelines using tools like Apache Airflow, Prefect, or Dagster to ensure data quality and timely delivery for models.
Big Data Technologies: Experience with distributed computing frameworks like Apache Spark for processing and transforming large datasets.
Data Warehousing/Lakes: Knowledge of data warehousing concepts and working with data lake solutions (e.g., Databricks, Snowflake, Delta Lake) for scalable data storage.
3. MLOps & Software Engineering: (Bringing Models to Life)
Version Control (Git): Non-negotiable for collaborative code development, model versioning, and reproducibility.
Containerization (Docker): Packaging models and their dependencies into portable, isolated containers for consistent deployment across environments.
Orchestration (Kubernetes): Understanding how to manage and scale containerized applications in production environments.
Cloud Platforms: Proficiency in at least one major cloud provider (AWS, Azure, Google Cloud) for deploying, managing, and scaling ML workloads and data infrastructure. This includes services like SageMaker, Azure ML, Vertex AI.
Model Serving Frameworks: Knowledge of tools like FastAPI, Flask, or TensorFlow Serving/TorchServe to expose models as APIs for inference.
Monitoring & Alerting: Setting up systems (e.g., Prometheus, Grafana, MLflow Tracking, Weights & Biases) to monitor model performance, data drift, concept drift, and system health in production.
CI/CD (Continuous Integration/Continuous Deployment): Automating the process of building, testing, and deploying ML models to ensure rapid and reliable updates.
Basic Software Engineering Principles: Writing clean, modular, testable, and maintainable code; understanding design patterns and software development best practices.
4. Communication & Business Acumen: (Driving Impact)
Problem-Solving: The ability to translate ambiguous business challenges into well-defined data science problems.
Communication & Storytelling: Effectively conveying complex technical findings and model limitations to non-technical stakeholders, influencing business decisions.
Business Domain Knowledge: Understanding the specific industry or business area to build relevant and impactful models.
Product Thinking: Considering the end-user experience and how the AI solution will integrate into existing products or workflows.
How to Become a Full-Stack Data Scientist
The path to full-stack data science is continuous learning and hands-on experience:
Solidify Core Data Science: Ensure your foundational skills in ML, statistics, and Python/R are robust.
Learn SQL Deeply: It's the lingua franca of data.
Dive into Data Engineering: Start by learning to build simple data pipelines and explore distributed processing with Spark.
Embrace MLOps Tools: Get hands-on with Docker, Kubernetes, Git, and MLOps platforms like MLflow. Cloud certifications are a huge plus.
Build End-to-End Projects: Don't just stop at model training. Take a project from raw data to a deployed, monitored API. Use frameworks like Streamlit or Flask to build simple UIs around your models.
Collaborate Actively: Work closely with software engineers, DevOps specialists, and product managers. Learn from their expertise and understand their challenges.
Stay Curious & Adaptable: The field is constantly evolving. Keep learning about new tools, frameworks, and methodologies.
Conclusion
The "Full-Stack Data Scientist" is not just a buzzword; it's the natural evolution of a profession that seeks to deliver real-world impact. While the journey requires a significant commitment to continuous learning and skill expansion, the rewards are immense. By bridging the gap between research and production, data scientists can elevate their influence, accelerate innovation, and truly become architects of intelligent systems that drive tangible value for businesses and society alike. It's a challenging but incredibly exciting time to be a data professional.
#technology#artificial intelligence#ai#online course#xaltius#data science#gen ai#data science course#Full-Stack Data Scientist
0 notes
Text
Efficient Data Management for Predictive Models – The Role of Databases in Handling Large Datasets for Machine Learning
Predictive modelling thrives on data—lots of it. Whether you are forecasting demand, detecting fraud, or personalising recommendations, the calibre of your machine-learning (ML) solutions depends on how efficiently you store, organise, and serve vast amounts of information. Databases—relational, NoSQL, and cloud-native—form the backbone of this process, transforming raw inputs into ready-to-learn datasets. Understanding how to architect and operate these systems is, therefore, a core competency for every aspiring data professional and hence, a part of every data science course curriculum.
Why Databases Matter to Machine Learning
An ML workflow usually spans three data-intensive stages:
Ingestion and Storage – Collecting data from transactional systems, IoT devices, logs, or third-party APIs and landing it in a durable store.
Preparation and Feature Engineering – Cleaning, joining, aggregating, and reshaping data to create meaningful variables.
Model Training and Serving – Feeding training sets to algorithms, then delivering real-time or batch predictions back to applications.
Databases underpin each stage by enforcing structure, supporting fast queries, and ensuring consistency, and hence form the core module of any data science course in Mumbai. Without a well-designed data layer, even the most sophisticated model will suffer from long training times, stale features, or unreliable predictions.
Scaling Strategies for Large Datasets
Horizontal vs. Vertical Scaling Traditional relational databases scale vertically—adding more CPU, RAM, or storage to a single machine. Modern workloads often outgrow this approach, prompting a shift to horizontally scalable architectures such as distributed SQL (e.g., Google Spanner) or NoSQL clusters (e.g., Cassandra, MongoDB). Sharding and replication distribute data across nodes, supporting petabyte-scale storage and parallel processing.
Columnar Storage for Analytics Column-oriented formats (Parquet, ORC) and columnar databases (Amazon Redshift, ClickHouse) accelerate analytical queries by scanning only the relevant columns. This is especially valuable when feature engineering requires aggregations across billions of rows but only a handful of columns.
Data Lakes and Lakehouses Data lakes offer schema-on-read flexibility, letting teams ingest semi-structured or unstructured data without upfront modelling. Lakehouse architectures (Delta Lake, Apache Iceberg) layer ACID transactions and optimised metadata on top, blending the reliability of warehouses with the openness of lakes—ideal for iterative ML workflows.
Integrating Databases with ML Pipelines
Feature Stores To avoid re-computing features for every experiment, organisations adopt feature stores—specialised databases that store versioned, reusable features. They supply offline batches for training and low-latency look-ups for online inference, guaranteeing training-serving consistency.
Streaming and Real-Time Data Frameworks like Apache Kafka and Flink pair with databases to capture event streams and update features in near real time. This is crucial for applications such as dynamic pricing or anomaly detection, where stale inputs degrade model performance.
MLOps and Automation Infrastructure-as-code tools (Terraform, Kubernetes) and workflow orchestrators (Airflow, Dagster) automate database provisioning, data validation, and retraining schedules. By codifying these steps, teams reduce manual errors and accelerate model deployment cycles.
Governance, Quality, and Cost
As datasets balloon, so do risks:
Data Quality – Referential integrity, constraints, and automatic checks catch nulls, duplicates, and outliers early.
Security and Compliance – Role-based access, encryption, and audit logs protect sensitive attributes and meet regulations such as GDPR or HIPAA.
Cost Management – Partitioning, compression, and lifecycle policies curb storage expenses, while query optimisers and materialised views minimise compute costs.
A modern data science course walks students through these best practices, combining theory with labs on indexing strategies, query tuning, and cloud-cost optimisation.
Local Relevance and Hands-On Learning
For learners taking a data science course in Mumbai, capstone projects frequently mirror the city’s fintech, media, and logistics sectors. Students might design a scalable order-prediction pipeline: ingesting transaction data into a distributed warehouse, engineering temporal features via SQL window functions, and serving predictions through a feature store exposed by REST APIs. Such end-to-end experience cements the role of databases as the silent engine behind successful ML products.
Conclusion
Efficient data management is not an afterthought—it is the foundation upon which predictive models are built and maintained. By mastering database design, scaling techniques, and MLOps integration, data professionals ensure that their models train faster, score accurately, and deliver value continuously. As organisations double down on AI investments, those who can marry machine learning expertise with robust database skills will remain at the forefront of innovation.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].
0 notes
Text

Apache Cassandra, an open-source distributed NoSQL database, was specifically designed to tackle the challenges of scalability. Let’s explore some of the key features that enable Cassandra to scale effectively in this blog
1 note
·
View note
Text
Why Open Source Database Adoption is Accelerating in 2025

In 2025, open source databases have officially moved from niche solutions to mainstream enterprise choices. With the ever-growing need for scalable, cost-efficient, and flexible data management systems, organizations are increasingly turning toward open source database management solutions to drive innovation and reduce vendor lock-in. From MySQL to PostgreSQL and MongoDB, the popularity of these platforms has surged across industries.
But why are so many businesses making the switch now? Let’s explore the growing adoption of open source databases, their features, benefits, and how to implement them in your IT ecosystem.
Key Features of Open Source Databases
✔️ Source Code Access – Modify and optimize your database to suit your business logic. ✔️ Community-Driven Development – Get regular updates, security patches, and support from global communities. ✔️ Cross-Platform Compatibility – Open source databases are platform-independent and highly portable. ✔️ Support for Advanced Data Models – Handle structured, semi-structured, and unstructured data easily. ✔️ Integrations and Extensions – Access a variety of plug-ins and connectors to expand functionality.
Why Open Source Database Adoption is Booming in 2025
💡 1. Cost-Effectiveness
No hefty licensing fees. Businesses save significantly on software costs while still getting robust features.
⚡ 2. Flexibility and Customization
Developers can fine-tune the database, adjust configurations, or build new functionalities—something proprietary systems limit.
🔒 3. Strong Security and Transparency
With open source, vulnerabilities are exposed and fixed faster thanks to large developer communities.
🚀 4. Scalable for Modern Applications
Whether it's IoT, big data, or AI-driven apps, open source databases scale well horizontally and vertically.
🌐 5. No Vendor Lock-In
Businesses can avoid being stuck with a single provider and switch or scale as needed.
Steps to Successfully Adopt an Open Source Database
✅ Step 1: Evaluate Your Current Infrastructure
Understand your existing data structure, workloads, and performance needs.
✅ Step 2: Choose the Right Database (MySQL, PostgreSQL, MongoDB, etc.)
Pick a database based on your data type, scale, transaction needs, and technical stack.
✅ Step 3: Plan Migration Carefully
Work with experts to move from proprietary systems to open source databases without data loss or downtime.
✅ Step 4: Monitor & Optimize Post-Migration
Use tools for performance monitoring, indexing, and query optimization to get the best out of your new setup.
Real-World Use Cases of Open Source Databases
🏥 Healthcare: Managing patient data securely and affordably. 🛍️ E-commerce: Handling high transaction volumes with scalable databases. 💼 Enterprises: Leveraging PostgreSQL and MySQL for internal applications. 📱 Mobile Apps: Using MongoDB for flexible and fast mobile backend support.
FAQs on Open Source Database Adoption
❓ Are open source databases secure for enterprise use?
Yes, most modern open source databases are highly secure with active communities and regular updates.
❓ What are some top open source databases in 2025?
PostgreSQL, MySQL, MariaDB, MongoDB, and Apache Cassandra are leading the pack.
❓ Will I need in-house expertise to manage it?
Not necessarily. You can always work with managed service providers like Simple Logic to handle everything from setup to optimization.
❓ Can open source databases support enterprise-scale apps?
Absolutely! They support clustering, replication, high availability, and advanced performance tuning.
❓ How can I migrate from my current database to an open source one?
With expert planning, data assessment, and the right tools. Reach out to Simple Logic for a guided and smooth transition.
Conclusion: Future-Proof Your Business with Open Source Databases
Open source databases are no longer a tech experiment—they're the backbone of modern digital infrastructure. From scalability to security, businesses in 2025 are realizing the value of making the shift. If you're still relying on outdated, expensive proprietary databases, it’s time to explore smarter, more agile options.
✅ Ready to Embrace Open Source? Let’s Talk!
Whether you’re planning to adopt PostgreSQL, MySQL, or any other open source database, Simple Logic offers expert guidance, migration support, and performance tuning to ensure a seamless experience.
📞 Call us today at +91 86556 1654 🌐 Visit: www.simplelogic-it.com
👉 Don’t just follow the trend lead with innovation! 🚀
https://simplelogic-it.com/open-source-database-adoption-in-2025/
#OpenSourceDatabase#DatabaseAdoption2025#PostgreSQL#MySQL#DatabaseInnovation#TechTrends2025#EnterpriseIT#DatabaseManagement#MakeITSimple#SimpleLogicIT#SimpleLogic#MakingITSimple#ITServices#ITConsulting
0 notes