#Computer healthcheck
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
It's time for a computer spring clean!
You can have your laptop or desktop PC running better than new by having a Service and tuneup, Drop me a message or book through my online booking system and we'll go from there! https://www.yourgeekfriend.co.uk/contact-yourgeekfriend-pc-repair-gloucester
You can have your laptop or desktop PC running better than new by having a Service and tuneup, we optimise your system for the best performance it can possibly have, advise on upgrades to make it even faster, ensure that it’s safe and secure for your peace of mind and even give it a clean inside and out. Most tune-ups are done within 24hrs of being brought to my workshop so you won’t be without…

View On WordPress
#Computer healthcheck#computer service gloucester#laptop healthcheck#laptop service gloucester#speed up my computer#speed up my computers#speed up my laptop
0 notes
Text
ART.1188
Article 1188
The creditor may, before the fulfillment of the condition bring the appropriate actions for the preservation of his right.
The debtor may recover what during the same time has paid by mistake in case of suspensive condition.
EDS Manufacturing, Inc. vs. Healthcheck International, Inc.
Facts:
Healthcheck International, Inc. (HCI) is a Health Maintenance Organization (HMO) that provides prepaid health and medical insurance coverage.
Eds Manufacturing, Inc. (EMI), with approximately 5,000 employees in Imus, Cavite, entered into a contract with HCI.
The contract was executed in April 1998 and covered EMI’s 4,191 employees and their 4,592 dependents.
EMI paid a full premium amounting to ₱8,826,307.50 for a one-year coverage running from May 1, 1998, to April 30, 1999.
A Service Program was attached to the Agreement, which detailed the scope of services to be rendered by HCI and the corresponding obligations of EMI, including the surrender of HMO cards under certain conditions.
Shortly after the contract commenced, on July 17, 1998, HCI notified EMI that its accreditation with the De La Salle University Medical Center (DLSUMC) was suspended.
HCI advised EMI to seek services from other accredited facilities, attributing the suspension to difficulties in the HMO industry amid the Asian regional financial crisis.
EMI and HCI entered into a hastily convened meeting resulting in a handwritten 5-point agreement that included:
HCI’s commitment to furnish EMI with a list of procedural enhancements.
A reduction in the number of accredited hospitals to improve oversight.
EMI’s undertaking to study the inclusion of a liability clause for possible contract modification.
A provision that no renewed contract would be allowed if there was another suspension of services.
A deadline for HCI’s decision regarding the proposed changes.
Despite initial remediation measures, DLSUMC resumed services on July 24, only to suspend accreditation once again on August 15 for a period, and a third time on September 9 until the contract’s expiration.
Complaints began to surface from EMI employees regarding the non-acceptance of their HMO cards at DLSUMC and other medical facilities.
On September 3, EMI formally notified HCI of its intention to rescind the April 1998 Agreement, citing HCI’s repeated and serious breaches—including the unjustified non-availability of contracted services.
EMI demanded the return of the premium for the unused portion of the contract (estimated at around ₱6 million).
A critical issue arose when EMI failed to collect all HMO cards from its employees as required by the Agreement.
HCI, on October 12, notified EMI that the continued use of the cards beyond the effective rescission date meant that the contract was still in force, thus impeding the reconciliation of accounts.
In January 1999, EMI sent letters demanding the payment of ₱5,884,205 representing the two-thirds portion of the unutilized premium, based on the computation that HCI rendered only one-third of the services during the contracted period.
HCI preempted EMI’s threats of legal action by filing a case before the Regional Trial Court (RTC) of Pasig, alleging unlawful pretermination of the contract and EMI’s failure to comply with reconciliation procedures.
At trial, the RTC ruled in favor of HCI, compensating it for services rendered and dismissing EMI’s counterclaims for damages and refund of unutilized premium on the ground of an invalid rescission.
EMI subsequently appealed, and the Court of Appeals (CA) reversed the RTC’s decision by dismissing HCI’s complaint while at the same time dismissing EMI’s counterclaim.
EMI then filed a Motion for Partial Reconsideration before the CA, which was denied by Resolution dated March 16, 2004.
The petition for review under Rule 45 of the Rules of Court was eventually raised by EMI, challenging the CA’s decision from multiple angles.
ISSUES
Whether the unilateral act of rescission by EMI, in light of HCI’s substantial breach of contract, complied with the legal requirements for rescission.
Whether the failure of EMI to collect and surrender the HMO cards invalidated their claim of rescission.
RULING
The general rule is that rescission (more appropriately, resolution) of a contract will not be permitted
for a slight or casual breach, but only for such substantial and fundamental violations as would defeat
the very object of the parties in making the agreement. The rescission referred to in Article 1191, more
appropriately referred to as resolution, is on the breach of faith by one of the parties which is violative
of the reciprocity between them.
In the case at hand, Healthcheck violated its contract with EDS to provide medical service to its
employees in a substantial way. The various reports made by the EDS employees are living testaments
to the gross denial of services to them at a time when the delivery was crucial to their health and lives.
However, although a ground exists to validly rescind the contract between the parties, it appears that
EDS failed to judicially rescind the same.
In Irigan v. Court of Appeals, the Court ruled that in the absence of a stipulation, a party cannot
unilaterally and extrajudicially rescind a contract. A judicial or notarial acts is necessary before a valid
rescission (or resolution) can take place. Thus, under Art 1191 of the Civil Code, the right to resolve
reciprocal obligations is deemed implied in case one of the obligors shall fail to comply with what
is incumbent upon him. But that right must be invoked judicially. Consequently, even if the right
to rescind is made available to the injured party, the obligation is not ipso facto erased by the failure of
the other party to comply with what is incumbent upon him. The party entitled to rescind should apply
0 notes
Text
How should a modern national level CFD software look like?
I come across a section in AIAA Scitech 2019 that is something I never heard of. So I spent 2 hours reading and typing what I learned from this paper that describes the new infrastructure of a CFD software.
Overall impression
It is amazing how the newest infrastructure of CFD software in a multi-disciplinary environment has become. Kestrel as an integrated product (indeed one of the products in CREATE-AV) in the CREATE (Computational Research and Engineering Acquisition Tools and Environment) program (a DoD HPC Modernization Program), it allows the interaction between
aerodynamics
dynamic stability
control
structures
propulsion
store separation
It provides a MDS (multi-disciplinary simulation) environment since 2008, so almost 9 years has been passed. This papers talks about the close relationship between its features and CFD vision 2030 by NASA.
What catches my eyes
NASA 2030 CFD vision
simulation must be multi-disciplinary
instead of traditional simulation, which is mostly similar to what we have in the university that is dubious in accuracy, non-standard inference like someone using python, others using Fortran, C++. Note that this is exactly what is still happening in China, where aerospace agencies off-load their job to university as cheap labors and thousands of graduates students in China live on that.
finally, it moves the focus of CFD to really help design groups who are facing real, complex engineering problem rather than a channel flow
therefore, current computational environment must be changed!
CFD solvers must be able to tolerate localized poor mesh with minimal user intervention.
The infrastructure should be flexible so that researchers and developers can focus on scientific and algorithm implementations
User-friendly is a forever task
The reality: high level of experts are still required to perform and understanding CFD analysis
In the DoD acquisition process, many of the target users are not really such high level of experts. Indeed, to learn a suitable amount of knowledge in the modern CFD area, it at least requires a Master degree focus on modern CFD methodologies. Especially for compressible flows with shocks, until 1980 we had no ideas how to robustly solve it.
The software standards are quite naïve from computer science perspective.
minimize the user-side data conversion
do not require user to input same information multiple times
having the best error checking system before submitting the job
XML format is chosen for input files
Having a command-line tools
Most CFD solvers even for those in-house code in the universities, also has a set of command-line tools that can do almost anything such as converting meshes between different format. I have also written a few on this during internship.
Automatic unit conversion, which is cool in OpenFOAM.
Assembled mesh preview
It is important for software that does full-scale aircraft simulation since most errors can happen during the early phase of assembling even.
In-situ visualization
It has been a hot topic in the big-data era. The main concept is to visualize information from huge data in real-time, which, on the algorithm level, requires a proper subsampling of the big data and on the infrastructure level, it requires advanced concepts of supercomputing.
How to deal with a variety of HPC system? cool features in Run-Time-Environment
PToolsRTE
It contains every dependency that is open-sourced
Just a faster way to manage packages in HPC system
AVTools
It contains every dependency that is not open-sourced.
YogiMPI
it is a universal MPI interface between a complied binary on one unknown MPI implementation with any MPI implementation available on the platform.
Note that if I am the user, I don't have to worry about the frequent changes on the HPC admin side on the default MPI implementation or versions
HealthChecker
Just something to check if the running job is not hung at some point
Frankly speaking I haven't met any of those issues like one of the node becomes corrupted then the simulation fails. But I have heard of.
Solution environment
Common Scalable Infrastructure (CSI)
CFD should be seamlessly integrated with other disciplinary code
Component-driven, event-based paradigm
Individual component is the same to CSI and a standard Python API is implemented for all components (such as CFD solver), then I think python is used a the glue.
WAND
enables multi-languages sharing for heavy data
all shared data is described in a XML format
components can be put into data-warehouse using code from one language and pull out using another languages
Parallelism for multi-body simulation
only one body is partitioned and solved on a group of processors
a separate group is assigned to each body
For example, a instance of flow solver only cares about the one body simulation, while keep the rest body simulation alone
CFD numerics
Finite volume
method of lines
semi-discrete formulation, so one can choose time stepping and spatial difference scheme separately
Fluxes
Still second order flux reconstruction, a WENO 5 scheme
various Riemann solver such as HLLE
Turbulence modeling (old-fashioned)
one equation SA
Menter two equation SST
SARC
DDES
Wall functions for improving speed, i.e., reducing the resolution at wall
Safe plan for unstable
If solution is unstable due to high gradients or poor grid, reverting everything to 1st order scheme in those areas
Collaboration environment
They developed a Kestrel SDK so one can interact with the Kestrel in many ways
Testing environment
There are 3500 unit-level tests, 250 integration level tests, over 17k assertions for all components that are monitored on a daily basis
Kestrel Automated Testing System (KATS) is executed every two weeks
it contains 125 jobs that covers a wide range of flow regimes
Reference
McDaniel, David R., Todd Tuckey, and Scott A. Morton. "The HPCMP CREATETM-AV Kestrel Computational Environment and its Relation to NASA’s CFD Vision 2030." 55th AIAA Aerospace Sciences Meeting. 2017. link
1 note
·
View note
Text
youtube
12.Client Work(Java)| HealthCheck this Assignment output video & requirements here Google drive link: https://drive.google.com/drive/folders/1b0MXn1tTs7fFo-Y66BEXofUsOE7TPfqK?usp=sharing Another Successfully #Java Assignment done for client(Computer Science students) *********If any International [School⭐College⭐University] Students Need any [Assignment⭐Exam⭐Quiz⭐Project⭐Lab⭐Report] services Fell free to contact with me Email:[email protected] Whatsapp:+8801772432396 whatsapp profile link: https://wa.me/+8801772432396 Instagram:https://www.instagram.com/programmingassignmenthelperbd/ Instagram Username:programmingassignmenthelperbd Telegram Account:https://t.me/programmingassignmenthelperbd Telegram Username:@programmingassignmenthelperbd Telegram Phone Number:+8801772432396 Linkedin Company Page:https://lnkd.in/dD83n_cT Facebook Compnay Page:https://www.facebook.com/programmingassignmenthelperforinternationalstudent/ Youtube Channel:https://www.youtube.com/channel/UCyOlJCraJuVs6oBUIYOoz0Q?sub_confirmation=1 My Some previous work link: Link 1:https://drive.google.com/drive/folders/1pDRMfAfWc9jiHDU5JC1LccIAdd2BCeRC?usp=sharing Link 2:https://drive.google.com/drive/folders/1cWrEyOmtP76HoJnsq_GWvNN-v0XqP_ce?usp=sharing We are helping students . We are giving this services for (school,college & university) assignment,Lab,project,exam,quiz ,remove errors,fix bugs & Also doing software company,agencies profession project also . Technology: ⭐️Python ⭐️JAVA⭐️Android ⭐️JavaScript⭐️Ruby⭐️HTML ⭐️Matlab⭐️C&C++&C#⭐️PHP⭐️Wordpress⭐️Database ⭐️SQL⭐️Swift⭐️Database⭐️CCNA ⭐️Algorithom⭐️All kinds of IT work do you need any services ? #pahfis #zoomstarit #programmingassignmenthlperbd #connections #computersciencestudents #engineeringstudents #developers #algonquincollege #python #Android #javascript #mysql #php #ruby #java #database #jpa #junit #apache #algonquincollege #newcastleuniversity #monashuniversity #Algonquincollegeofappliedartsandtechnology #university #UniversityofNewEngland #akdenizüniversitesi #flinders #capellauniversity #yorkuniversity
#pahfis#zoomstarit#programmingassignmenthlperbd#connections#computersciencestudents#engineeringstudents#developers#algonquincollege#python#Android#javascript#mysql#php#ruby#java#database#jpa#junit#apache#newcastleuniversity#monashuniversity#Algonquincollegeofappliedartsandtechnology#university#UniversityofNewEngland#akdenizüniversitesi#flinders#capellauniversity#yorkuniversity#freelancing#freelancer
0 notes
Text
21 ways medical digital twins will transform health care
New Post has been published on https://tattlepress.com/health/21-ways-medical-digital-twins-will-transform-health-care/
21 ways medical digital twins will transform health care

Where does your enterprise stand on the AI adoption curve? Take our AI survey to find out.
The health care industry is starting to adopt digital twins to improve personalized medicine, health care organization performance, and new medicines and devices. Although simulations have been around for some time, today’s medical digital twins represent an important new take. These digital twins can create useful models based on information from wearable devices, omics, and patient records to connect the dots across processes that span patients, doctors, and health care organizations, as well as drug and device manufacturers.
It is still early days, but the field of digital twins is expanding quickly based on advances in real-time data feeds, machine learning, and AR/VR. As a result, digital twins could dramatically shift how we diagnose and treat patients, and help realign incentives for improving health. Some proponents liken the current state of digital twins to where the human genome project was 20 years ago, and it may require a similar large-scale effort to take shape fully. A team of Swedish researchers recently wrote, “Given the importance of the medical problem, the potential of digital twins merits concerted research efforts on a scale similar to those involved in the HGP.”
While such a “moon shot” effort may not be immediately underway, there are many indicators that digital twins are gaining traction in medicine. Presented here are 21 ways digital twins are starting to shape health care today, broken roughly into personalized medicine, improving health care organizations, and drug and medical devices and development. In fact, many types of digital twins span multiple use cases and even categories; it is these cross-domain use-cases that form a major strength of digital twins.
Personalized medicine
Digital twins show tremendous promise in making it easier to customize medical treatments to individuals based on their unique genetic makeup, anatomy, behavior, and other factors. As a result, researchers are starting to call on the medical community to collaborate on scaling digital twins from one-off projects to mass personalization platforms on par with today’s advanced customer data platforms.
1. Virtual organs
Several vendors have all been working on virtual hearts that can be customized to individual patients and updated to understand the progression of diseases over time or understand the response to new drugs, treatments, or surgical interventions. Philip HeartModel simulates a virtual heart, starting with the company’s ultrasound equipment. Siemens Healthineers has been working on a digital twin of the heart to improve drug treatment and simulate cardiac catheter interventions. European startup FEops has already received regulatory approval and commercialized the FEops Heartguide platform. It combines a patient-specific replica of the heart with AI-enabled anatomical analysis to improve the study and treatment of structural heart diseases.
Dassault launched its Living Heart Project in 2014 to crowdsource a virtual twin of the human heart. The project has evolved as an open source collaboration among medical researchers, surgeons, medical device manufacturers, and drug companies. Meanwhile, the company’s Living Brain project is guiding epilepsy treatment and tracking the progression of neurodegenerative diseases. The company has organized similar efforts for lungs, knees, eyes, and other systems.
“This is a missing scientific foundation for digital health able to power technologies such as AI and VR and usher in a new era of innovation,” Dassault senior director of virtual human modeling Steve Levine told VentureBeat. He added that this “could have an even greater impact on society than what we have seen in telecommunications.”
2. Genomic medicine
Swedish researchers have been mapping mice RNA into a digital twin that can help predict the effect of different types and doses of arthritis drugs. The goal is to personalize human diagnosis and treatment using RNA. The researchers observed that medication does not work about 40% to 70% of the time. Similar techniques are also mapping the characteristics of human T-cells that play a crucial role in immune defense. These maps can help diagnose many common diseases earlier when they are more effective and cheaper to treat.
3. Personalized health information
The pandemic has helped fuel the growth of digital health services that help people assess and address simple medical conditions using AI. For example, Babylon Health‘s Healthcheck App captures health data into digital twins. It works with manually entered data such as health histories, a mood tracker, symptom tracker, and automatic capture from fitness devices and wearables like the Apple Watch. The digital twin can provide basic front-line information or help guide priorities and interactions with doctors to address more severe or persistent conditions.
4. Customize drug treatment
The Empa research center in Switzerland is working on digital twins to optimize drug dosage for people afflicted by chronic pain. Characteristics such as age and lifestyle help customize the digital twin to help predict the effects of pain medications. In addition, patient reports about the effectiveness of different dosages calibrate digital twin accuracy.
5. Scanning the whole body
Most approaches to digital twins build on existing equipment to capture the appropriate data, while Q Bio’s new Gemini Digital Twin platform starts with a whole-body scan. The company claims to capture a whole-body scan in 15 minutes without radiation or breath holds, using advanced computational physics models that are more precise than conventional MRI for many diagnoses. The company has received over $80 million from Andreessen Horowitz, Kaiser Foundation Hospitals, and others. Q Bio is also developing integrations to improve these models using data from genetics, chemistry, anatomy, lifestyle, and medical history.
6. Planning surgery
A Boston hospital has been working with Dassault’s digital heart to improve surgical procedure planning and assess the outcomes afterward. The digital twins also help them to generate the shape of a cuff between the heart and arteries.
Sim&Cure’s Sim&Size is a digital twin to help brain surgeons treat aneurysms using simulations to improve patient safety. Aneurysms are enlarged blood vessels that can result in clots or strokes. These digital twins can improve the ability to plan and execute less invasive surgery using catheters to install unique implants. Data from individual patients helps customize simulations that run on an embedded simulation package from Ansys. Preliminary results have dramatically reduced the need for follow-up surgery.
Improving health care organizations
Digital twins also show promise in improving the way health care organizations deliver care. Gartner coined the term digital twin of the organizations to describe this process of modeling how an organization operates to improve underlying processes.
In most industries, this can start by using process mining to discover variations in business processes. New health care-specific tools can complement these techniques.
7. Improving caregiver experience
Digital twins can also help caregivers capture and find information shared across physicians and multiple specialists. John Snow Labs CTO David Talby said, “We’re generating more data than ever before, and no one has time to sort through it all.” For example, if a person sees their regular primary care physician, they will have a baseline understanding of the patient, their medical history, and medications. If the same patient sees a specialist, they may be asked many of the same repetitive questions.
A digital twin can model the patient and then use technologies like NLP to understand all of the data and cut through the noise to summarize what’s going on. This saves time and improves the accuracy of capturing and presenting information like specific medications, health conditions, and more details that providers need to know in context to make clinical decisions.
8. Driving efficiency
The GE Healthcare Command Center is a major initiative to virtualize hospitals and test the impact of various decisions on changes in overall organizational performance. Involved are modules for evaluating changes in operational strategy, capacities, staffing, and care delivery models to objectively determine which actions to take. For example, they have developed modules to estimate the impact of bed configurations on care levels, optimize surgical schedules, improve facility design, and optimize staff levels. This allows managers to test various ideas without having to run a pilot. Dozens of organizations are already using this platform, GE said.
9. Shrinking critical treatment window
Siemens Healthineers has been working with the Medical University of South Carolina to improve the hospital’s daily routine through workflow analysis, system redesign, and process improvement methodologies. For example, they are working to reduce the time to treat stroke patients. This is important since early treatment is critical but requires the coordination of several processes to perform smoothly.
10. Value-based health care
The rising cost of health care has many nations exploring new incentive models to better align new drugs, interventions, and treatments with outcomes. Value-based health care is one approach that is growing in popularity. The basic idea is that participants, like drug companies, will only get compensation proportionate to their impact on the outcomes. This will require the development of new types of relationships across multiple players in the health delivery systems. Digital twins could provide the enabling infrastructure for organizing the details for crafting these new types of arrangements.
11. Supply chain resilience
The pandemic illustrated how brittle modern supply chains could be. Health care organizations immediately faced shortages of essential personal protection equipment owing to shutdowns and restrictions from countries like China. Digital twins of a supply chain can help health care organizations model their supply chain relationships to understand better how to plan around new events, shutdowns, or shortages. This can boost planning and negotiations with government officials in a pinch, as was the case in the recent pandemic. A recent Accenture survey found that 87% of health care executives say digital twins are becoming essential to their organization’s ability to collaborate in strategic ecosystem partnerships.
12. Faster hospital construction
Digital twins could also help streamline construction of medical facilities required to keep up with rapid changes, such as were seen in the pandemic. Atlas Construction developed a digital twin platform to help organize all the details for health care construction. The project was inspired long before the pandemic when Atlas founder Paul Teschner saw how hard it was to get new facilities built in remote areas of the world. The platform helps organize design, procurement, and construction processes. It is built on top of the Oracle Cloud platform and Primavera Unifier asset lifecycle management service.
13. Streamlining call center interactions
Digital twins can make it easier for customer service agents to understand and communicate with patients. For example, a large insurance provider used a TigerGraph graph database to integrate data from over 200 sources to create a full longitudinal health history of every member. “This level of detail paints a clear picture of the members current and historical medical situation,” said TigerGraph health care industry practice lead Andrew Anderson.
A holistic view of all diagnosis claims prescriptions, refills, follow-up visits, and outstanding claims reduced call handling time by 10%, TigerGraph claimed, resulting in over $100 million in estimated savings. Also, shorter but more relevant conversations between the agents and members have increased Net Promoter Score and lowered churn.
Drug and medical device development
There are many ways that digital twins can improve the design, development, testing, and monitoring of new medical devices and drugs. The U.S. FDA has launched a significant program to drive the adoption of various types of digital approaches. Regulators in the U.S. and Europe are also identifying frameworks for including modeling and simulation as sources of evidence in new drug and device approvals.
14. Software-as-a-medical device
The FDA is creating the regulatory framework to allow companies to certify and sell software-as-a-medical device. The core idea is to generate a patient-specific digital twin from different data sources, including lab tests, ultrasound, imaging devices, and genetic tests. In addition, digital twins can also help optimize the software in medical devices such as pacemakers, automated insulin pumps, and novel brain treatments.
15. Classifying drug risks
Pharmaceutical researchers are using digital twins to explore the heart risks of various drugs. This could help improve drug safety of individual drugs and drug combinations more cost-effectively than through manual testing. They have built a basic model for 23 drugs. Extending this model could help reduce the estimated $2.5 billion required to design, test, get approved, and launch new drugs.
16. Simulating new production lines
Siemens worked with several vaccine manufacturers to design and test various vaccine production line configurations. New mRNA vaccines are fragile and must be precisely combined using microfluidic production lines that precisely combine nanoscale-sized particles. Digital twins allowed them to design and validate the manufacturing devices, scale these processes, and accelerate its launch from 1 year down to 5 months.
17. Improve device uptime
Philips has launched a predictive maintenance program that collates data from over 15,000 medical imaging devices. The company is hoping that digital twins could improve uptime and help their engineers customize new equipment for the needs of different customers. In addition, it is hoping to apply similar principles across all of its medical equipment.
18. Post-market surveillance
Regulators are beginning to increase the emphasis for device makers to monitor the results of their equipment after-sales as part of a process called post-market surveillance. This requires either staffing expensive specialists to maintain the equipment or embedding digital twins capabilities into the equipment. For example, Sysmex worked with PTC to incorporate performance testing into its blood analyzer to receive a waiver from these new requirements, PTC CTO Steve Dertien told VentureBeat. This opened the market for smaller clinical settings closer to patients, which can speed diagnosis.
19. Simulating human variability
Skeletons and atlases commonly depict the perfect human. However, real-life humans typically have some minor variations in their muscles or bones that mostly go unnoticed. As a result, medical device makers struggle with how common anatomical variations among people may affect the fit and performance of their equipment. Virtonomy has developed a library of common variations to help medical equipment makers test conduct studies on how these variations may affect the performance and safety of new devices. In this case, they simulate the characteristics representing common variations in a given population rather than individuals.
20. Digital twin of a lab
Modern drug development often requires testing out thousands or millions of possibilities in a highly controlled environment. A digital twin of the lab can help to automate these facilities. It can also help to prioritize tests in response to discoveries. Digital twins could also improve the reproducibility of experiments across labs and personnel in the same lab. In this quest, Artificial recently closed $21.5 million in series A funding from Microsoft and others to develop lab automation software. The company is betting that unified data models and platforms could help them jump to the front of the $10 billion lab automation market.
21. Improving drug delivery
Researchers at Oklahoma State have been working with Ansys to develop a digital twin to improve drug delivery using models of simulated lungs as part of the Virtual Human System project. They found that only about 20% of many drugs reached their target. The digital twins allowed them to redesign the drug’s particle size and composition characteristics to improve delivery efficiency to 90%.
VentureBeat
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative technology and transact.
Our site delivers essential information on data technologies and strategies to guide you as you lead your organizations. We invite you to become a member of our community, to access:
up-to-date information on the subjects of interest to you
our newsletters
gated thought-leader content and discounted access to our prized events, such as Transform 2021: Learn More
networking features, and more
Become a member
Source link
0 notes
Text
Red Hat OpenShift 4.1 ghetto setup
I recently reviewed the AWS preview of Red Hat OpenShift 4.0 in this blog post. Now, the time has come to install OpenShift 4.1 on what is called User Provided Infrastructure (UPI). Unlike Installer Provided Infrastructure (IPI), you have to jump through a few hoops to get your environment pristine enough to eventually install OpenShift. This blog post captures some of the undocumented “features” and how you easily can get it rolling in a lab environment to start kicking the tires. By no means should you use these steps to build a production environment, although some hints here might actually help you along the way for a production setup.
Just to be clear, these are the two Red Hat docs I’m following to get a running OpenShift cluster:
Installing OpenShift 4.1 on bare-metal
Adding RHEL compute nodes
Note: If Google landed you here. Please note that this post was written 6/28/19 for OpenShift 4.1. Any references to the OpenShift documentation mentioned below may be completely inaccurate by the time you read this.
Bare or not, that is the question
While I’m installing on KVM virtual machines, I’ve followed the "bare-metal” procedures found in the docs. They are somewhat semantically difference on how you boot the Red Hat CoreOS installer which can be done in multiple ways, either by injecting the ‘append’ line in the machine XML declaration, PXE or simply by manually booting the ISO. I leave this detail up to the discretion of the reader as it’s fairly out-of-scope and unique to everyone's setup.
The upfront DNS and LB requirements
I’m sitting on a lab network where I have zero control over DNS or DHCP. Whatever hostname gets put into the DHCP request gets registered in DNS. Given that OpenShift uses wildcard based DNS for all frontend traffic and the new paradigm of installing require a bunch of SRV and A records to the etcd servers in a dedicated sub-domain, I was faced with a challenge.
Since the network admins (and I’m too lazy) can’t have “marketing” hosting DNS zones in the lab, I have to outsmart them with my laziness. I’m a customer of Route 53 on AWS, said and done, I setup the necessary records in a ‘openshift’ subdomain of datamattsson.io. This way, the lab DNS servers will simply forward the queries to the external domain. Lo and behold, it worked just fine!
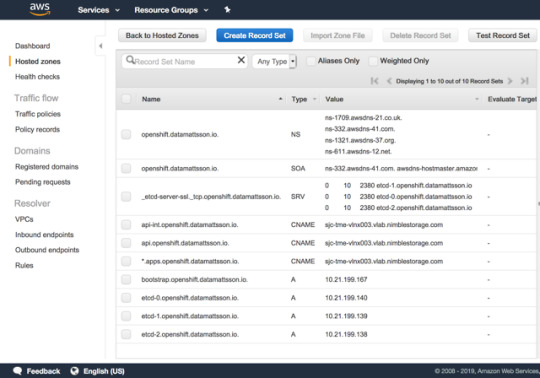
The next baffle is that you need to have a load-balancer installed (Update: DNS RR works for test and lab setups too according to this red hatter) upfront before you even start installing the cluster. A self-hosted LB is not an option. I started my quest to try find an LB that is as simple and dumb as I need it to be. Single binary, single config-file dumb. I found this excellent blog post that lists some popular projects in this space.
I went with gobetween.io (Number #10 on the list) as they had me at Hello: "gobetween is free, open-source, modern & minimalistic L4 load balancer and reverse proxy for the Cloud era". The config file is written in TOML, this is the tail section of the config example file the gobetween binary ships with:
# Local config [servers] # ---------- tcp example ----------- # [servers.api] protocol = "tcp" bind = "0.0.0.0:6443" [servers.api.discovery] kind = "static" static_list = [ #"10.21.199.167:6443", "10.21.199.140:6443", "10.21.199.139:6443", "10.21.199.138:6443" ] [servers.mcs] protocol = "tcp" bind = "0.0.0.0:22623" [servers.mcs.discovery] kind = "static" static_list = [ #"10.21.199.167:22623", "10.21.199.140:22623", "10.21.199.139:22623", "10.21.199.138:22623" ] [servers.http] protocol = "tcp" bind = "0.0.0.0:80" [servers.http.discovery] kind = "static" static_list = [ "10.21.199.60:80", "10.21.198.158:80" ] [servers.https] protocol = "tcp" bind = "0.0.0.0:443" [servers.https.discovery] kind = "static" static_list = [ "10.21.199.60:443", "10.21.198.158:443" ]
The first line-item of “api” and “mcs” is commented out as it’s the node required to bootstrap the control-plane nodes, once that step is done, it should be removed from rotation.
Running the LB in the foreground:
gobetween -c config.toml
Do note that GoBetween supports a number of different healthchecks, I opted out to experiment with those, but I would assume in a live scenario, you want to make sure health checks works.
3.. 2.. 1.. Ignition!
OpenShift is no longer installed using Ansible. It has it’s own openshift-install tool to help generate ignition configs. I’m not an expert on this topic what so ever (a caution). I’ve dabbled with matchbox/ignition pre-Red Hat era and it’s safe to say that Red Hat CoreOS is NOT CoreOS. The two have started to diverge and documentation you read on coreos.com doesn’t map 1:1. My only observation on this topic is that Red Hat CoreOS is just means to run OpenShift, that’s it. Just as a FYI, there is a Fedora CoreOS project setup for the inclined to dive deeper.
Initially you need to setup a install-config.yaml and here’s your first pro-tip. The openshift-install program will literally consume it. It validates it and produces the outputs and later deletes it. My advice is to copy this file outside of the install-dir directory structure to easily restart the ordeal from scratch.
This is my example install-config.yaml with the pull secret and ssh key redacted:
apiVersion: v1 baseDomain: datamattsson.io compute: - hyperthreading: Enabled name: worker replicas: 0 controlPlane: hyperthreading: Enabled name: master replicas: 3 metadata: name: openshift networking: clusterNetworks: - cidr: 10.128.0.0/14 hostPrefix: 23 networkType: OpenShiftSDN serviceNetwork: - 172.30.0.0/16 platform: none: {} pullSecret: 'foobar' sshKey: 'foobar'
Hint: Your pull secret is hidden here.
Consume the install-config.yaml file:
$ openshift-install create ignition-configs --dir=.
This is will result in a directory structure like this:
. ├── auth │ ├── kubeadmin-password │ └── kubeconfig ├── bootstrap.ign ├── master.ign ├── metadata.json └── worker.ign
The .ign files are JSON files. Somewhat obscured without line breaks and indentation. Now, my fundamental problem I had when I booted up the bootstrap node and masters on my first lap, all came up with localhost.localdomain as the hostname. If anyone have attempted installing a Kubernetes cluster with identical hostnames, you know it’s going to turn into a salad.
Setting the hostname is quite trivial and a perfectly working example is laid out here. Simply add a “files” entry under .ignition.storage:
"storage": { "files": [ { "filesystem": "root", "path": "/etc/hostname", "mode": 420, "contents": { "source": "data:,tme-lnx2-ocp-e1" } } ] }
Do note that the section where this is stanza is added differs slight from the bootstrap.ign and master.ign files.
Note: I use the nodejs json command (npm install -g json) to humanize JSON files, jq is quite capable too: jq . pull-secret.txt
Potential Issue: I did have an intermittent issue when doing a few iterations that the CNI wouldn’t initialize on the compute nodes. Sometimes a reboot resolved it and sometimes it sat for an hour or so and eventually it would start and the node would become Ready. I filed a support case with Red Hat on this matter. I will update this blog post if I get a resolution back. This is the error message on a node stuck NotReady:
runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni config uninitialized
Hello World!
At the end of the day, you should have a cluster that resemble this:
$ oc get nodes NAME STATUS ROLES AGE VERSION tme-lnx2-ocp-e1 Ready master 6h19m v1.13.4+9252851b0 tme-lnx3-ocp-e2 Ready master 6h18m v1.13.4+9252851b0 tme-lnx4-ocp-e3 Ready master 6h17m v1.13.4+9252851b0 tme-lnx5-ocp-c1 Ready worker 98m v1.13.4+9b19d73a0 tme-lnx6-ocp-c2 Ready worker 5h4m v1.13.4+9b19d73a0
As Red Hat is switching to a Operator model, all cluster services may now be listed as such:
$ oc get clusteroperators NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE authentication 4.1.2 True False False 145m cloud-credential 4.1.2 True False False 6h19m cluster-autoscaler 4.1.2 True False False 6h19m console 4.1.2 True False False 147m dns 4.1.2 True False False 4h42m image-registry 4.1.2 True False False 172m ingress 4.1.2 True False False 149m kube-apiserver 4.1.2 True False False 6h17m kube-controller-manager 4.1.2 True False False 6h16m kube-scheduler 4.1.2 True False False 6h16m machine-api 4.1.2 True False False 6h19m machine-config 4.1.2 False False True 3h18m marketplace 4.1.2 True False False 6h14m monitoring 4.1.2 True False False 111m network 4.1.2 True True False 6h19m node-tuning 4.1.2 True False False 6h15m openshift-apiserver 4.1.2 True False False 4h42m openshift-controller-manager 4.1.2 True False False 4h42m openshift-samples 4.1.2 True False False 6h operator-lifecycle-manager 4.1.2 True False False 6h18m operator-lifecycle-manager-catalog 4.1.2 True False False 6h18m service-ca 4.1.2 True False False 6h18m service-catalog-apiserver 4.1.2 True False False 6h15m service-catalog-controller-manager 4.1.2 True False False 6h15m storage 4.1.2 True False False 6h15m
The password for the user that got created during install can be found in the auth subdirectory in the install-dir. It lets you login via oc login and also gives you access to the web console. The most obvious URL for the console is, in my case, https://console-openshift-console.apps.openshift.datamattsson.io

Now, let’s deploy some workloads on this Red Hat OpenShift 4.1 Ghetto Setup! Watch this space.
0 notes
Text
2018-03-08 09 APPLE now
APPLE
9 to 5 Mac
California latest to join Right to Repair bill, forcing manufacturers to publish repair details
MoviePass update on iOS ‘removes unused location capabilities’ following privacy concerns
How to use iPhone and iPad as a magnifying glass
9to5Mac Daily 042 | March 7, 2018
Square’s Cash app on iOS now supports direct deposit for receiving paychecks without a bank
Apple Insider
Apple axed 10 smelters and refiners from supply chain in 2017, maintains 100 percent participation in conflict mineral audit
Rumor: Apple working on cheaper HomePod for launch this year
How to implement Apple's two-factor authentication for security on Mac, iPhone, or iPad
FBI chief continues his demand for law enforcement access to encrypted iPhones and other devices
Google's Android P supports same HEIC format as Apple, has software display notch like iPhone X
Cult of Mac
Gorgeous iOS 12 concept fixes Apple Music’s ugliest problems
Cheaper HomePod might lead Apple’s push for lower prices
How to get the iPad’s keyboard shortcut cheat sheet on Mac
Alexa’s random, creepy laugh scares the crap out of people
Snag a retro-looking Klipsch Bluetooth speaker for $160 off [Deals & Steals]
Daring Fireball
Alexa Is Laughing at People, Unprompted
10-Year Anniversary of the iPhone SDK
Script Debugger 7.0
‘Welcome Home’ by Spike Jonze
[Sponsor] Tax Time Tip: The IRS Accepts Doxie's Scanned Receipts
Life in LoFi
iOS 11 Update Day: iOS 11 will break some apps
Scan and straighten photos with Dropbox
Latest Snapseed Update Adds New Curves Tool
The iPhone Turns 10 Today
How to move your photos from Google Photos to Apple Photos
Mac Rumors
Apple-Owned Workflow App Updated With New 'Mask Image' Action
FaceTime Competitor Google Duo Gains New Video Messages Feature
Quick Takes: Jurassic World Gets New Game, UnitedHealthcare Offers Apple Watch to Members, and More
Apple Store Now Offering Exclusive Insta360 ONE Camera Bundle
Amazon Working on a Fix for Alexa Devices Scaring Users With Creepy Laughter
MacPrices
13″ Touch Bar MacBook Pros on sale for $100-$150 off MSRP, pay no sales tax in 48 states
27″ iMacs on sale for up to $150 off MSRP, save on tax, free shipping
21″ 2.3GHz Apple iMac on sale for $100 off MSRP, only $999
Find the lowest prices on 10″ and 12″ iPad Pros with these Apple Certified Refurbished models
Save up to $30-$50 on 9″ 32GB Apple iPads, prices start at $279
OSX Daily
How to Install Homebrew on Mac
How to Find All 32-Bit Apps on a Mac
How to Enable or Disable “Avoid Highways” in Maps for iPhone
iOS 11.3 Beta 4, macOS 10.13.4 Beta 4 Released for Testing
How to Get the Size of a File or Folder in Mac OS
Power Page
Apple Pay adds 20 new U.S. banks and credit unions, will expand to Brazil in April
Rumor: Apple to discontinue iTunes LP format throughout 2018
Rumor: Apple developing high-end, over-the-ear headphones
GrayKey enters market, becomes second firm to offer iPhone unlocking tool
Rumor: Apple to release lower-priced MacBook Air in second quarter of 2018
Reddit Apple
FBI again calls for magical solution to break into encrypted phones
INSTAGRAM actively using the MICROPHONE whilst running in background
Google Debuts 'Android P' With Support for iPhone X-Style Notches
Apps not using keyboard shortcuts
The Mystery of the Slow Downloads - Panic Blog
Reddit Mac
How harmful using Macs Fan Control on a 2016 MBP (no TouchBar) to crank fan speeds?
My computer has been stuck on this for a few hours after an update. I’ve restarted it but nothing worked. Any ideas?
Ridiculous Graphics Lag and High GPU Usage with High Sierra 10.13.3
Question on 2015 MacBook Pro
Mac system healthcheck App?
Reddit iPhone
Jesus Christ
TIL you can pinch to zoom like you’re zooming out and it will bring you to all your weather locations! Pinch to zoom in works for zooming in on one too.
TIL if you want to select multiple photos from an album, especially while freeing space, just tap select and slide your finger diagonally!
Never owned a phone before, iPhone 6s or Samsung Galaxy S7?
Music player won’t disappear from lock screen. No apps are open. Goes away when I restart. Why?
Six Colors
Alexa is laughing at people ↦
(Podcast) Clockwise #231: Digital Okies
MacBook Air: Why won't it die? (Macworld)
'The Mystery of the Slow Downloads' ↦
10th anniversary of the iPhone SDK ↦
Unlock Boot
Is It Possible To Track An iPhone By Serial Number?
How to Unlock iPhone 8/8 Plus from AT&T, Sprint, Verizon & Others
How to Disable Battery Health on iPhone Running iOS 11
How To Clear Kodi Cache – Works for All Devices
Best iOS Apps to Test iPhone Hardware, Functions and Sensors
iPhone Hacks
Google Releases First Android P Developer Preview With Support for iPhone X-Like Notch Design
Amazon’s Alexa is Randomly Laughing at People
Apple ‘Likely’ to Launch New iPad Pro With Face ID in June
Gain Access To Your Accounts Safer and Faster with Password Boss [Deals Hub]
Apple Rumored to Launch Cheaper Versions of MacBook Air and HomePod This Year
iPhone Life
Which iPad Do I Have? How to Identify the Different iPad Models & Generations
Review: Flexible & Rugged Phone & iPad Mounts
Review: Solo New York Cameron Rolltop Backpack & Shorewood Leather Briefcase
How to Check Voicemails from Blocked Numbers on iPhone
How to Avoid Accidental 911 Calls on Apple Watch
iPhone Photography Blog
9 iPhone Camera Effects: How To Use Them For More Creative Photos
SANDMARC Lenses For iPhone X: Wide, Fisheye, Macro & 3x Telephoto
iPhone Art Academy: Create Stunning Works Of Art With Just Your iPhone
Olloclip Lenses For iPhone 8 & 8 Plus: Pick The Best Lenses For You
Camera+ App Tutorial: How To Create Stunning iPhone Photos
0 notes
Text
Cloud Migration – Is it too late to adopt?
“Action is the foundational key to all success.” – Pablo Picasso
No technology gets adopted overnight. On-premise environment provides full ownership, maintenance, responsibility. You pay for physical machines and virtualizations to meet your demands. Lately, such on-premise environments are less reliable, have a high total cost of ownership (TCO) creating frustration and a desire to alleviate this scenario.
If you or your company are facing such frustrations, it is time to act and think about cloud migration.
1. What is Cloud Migration?
Cloud environment contains virtualization platforms and application resources, required for company or business to run operations efficiently, which was previously on-premises.
Cloud Migration, according to Amazon Web Services, is the process of assessing, mobilizing, migrating, and modernizing your current infrastructure, application or process over to a cloud environment.
At Syntelli, while we believe the principles of cloud are standard across all platforms, we are proud to partner with Microsoft’s Azure, Amazon’s AWS and Google’s GCP.
2. How to plan a successful Cloud Migration?
“Do the hard jobs first. The easy jobs will take care of themselves.” – Dale Carnegie
Figure 1. General Cloud Migration Strategy
Phase One: Assess
Identify and involve the stakeholders
Early engagement and support will lead to a smoother, faster migration process.
Create a strategic plan
Establish objectives and priorities for migration. Identify major business events for the company, which may be affected by this transition.
Calculate total cost of ownership
Very important step to estimate your potential savings.
Discover and assess on-premise applications
Some cloud providers provide assessment tools but having a subject matter expert review these applications and resources help ease migration.
Get support for your implementation
Syntelli Solutions to the rescue!!
Train your team on cloud environments, applications, and resources
Know your migration options
“Lift or Shift”, “Complete Refactor”, “Hybrid approach”
Phase Two: Mobilize & Migrate
Migration governance
If you plan on migrating more than one application or service which could impact more than one team, then you need to plan your projects and track them in order to ensure success.
Security, Risk and Compliance
You can evaluate your migration options by performing few tests. Use this opportunity to identify any scaling limitations, access control issues which may exist in your current application.
Document and review scenarios where several teams may interact with your applications on cloud. This tracing helps mitigate any dependencies and reduce potential impact.
Want more?
Subscribe to receive articles on topics of your interest, straight to your inbox.
Success!
First Name
Last Name
Email
Subscribe
Pilot your migration with few workloads
Learn more about your new cloud environment by migrating low complexity workloads. It could be a simple migration of DEV database or testing a data pipeline required to build a modeling dataset for a data science model.
Migrate the remaining applications
With successful migration and learning, you can complete your migration to the cloud.
Decommission existing on-premises infrastructure
After successful migration, it is time to pull the plug on your existing on-prem systems. This reduces your overhead spent on maintaining your outdated infrastructure or application.
Phase 3: Run and Modernize
Run and monitor
It is time to leverage the cool tools offered by your cloud provider to monitor your applications and track your resources, efficiency of your applications. Currently, the applications may be in a fragile state, so take care to review all the steps to track a successful migration.
Timely upgrades
With the new infrastructure setup on cloud you can identify scopes for code and feature improvements, resource updates.
Cloud Service Training
It is important to work with the customer and train their team members, until the team feels comfortable with the transition. Many questions still tend to linger after a successful migration.
3. Use Case: On-prem Data Science Model Migration to Cloud
Cloud Healthcheck – It’s about the data, stupid
As long as companies continue to think of the cloud simply as commodity compute and storage, the level of attention provided to securing this asset will be relegated down. Read More
Approach
Each cloud project migration varies from customer to customer. However, our customer’s goal was to migrate an existing data science model which made use of IBM SPSS Modeler.
The goal was to recreate and re-design existing data pipelines, de-couple dataset creations from data modeling and make the model production ready for various deployment demands.
Syntelli approached the migration process as depicted in the Figure 2 below.
The steps taken, are mentioned in the diagram as described in previous section.
Challenges
Each customer can decide to use cloud service provider of their choice. Options vary by cost, by infrastructure setup, compliance and security, and timeline to migrate.
In this case, the cloud service provider managed all the resources, and Syntelli leveraged the resources, and infrastructure. This service is generally termed as Infrastructure as A Service (IAAS).
Network and Connectivity
Network topology was the first challenge to overcome. Each company or customer has different levels of firewalls, packet filters and network hops. They can cause packet losses, slow transfer of data, to name a few.
Having a subject matter expert who can understand and test the connectivity to various resources like databases, virtual machines is very important. Technical scenarios like performing ping, traceroute tests and explaining these reports helped resolve many network barriers.
Security and Compliance
Next challenge was security, risk and compliance. Bigger business and organizations have a lot of applications and resources, which house Personally Identifiable Information (PII). At each point of the migration, Syntelli constantly worked with the IT Risk and Compliance team, IAAS cloud provider to make sure that the customer’s information was not compromised.
In this case, it was important to leverage security approaches like Active Directory, Kerberos for Big Data Environment, Single Sign-On option, Ranger, SSH Keys, two factor authentication, to name a few.
While, this can increase your migration timelines by few days, you will be more secure in the future.
Figure 2. On-Prem Data Science Model Migration Strategy
Success
Once the data science models were migrated successfully, the next steps were to document the migration and track all incidents which were resolved.
This not only helped the customer understand challenges, but as a consulting team, Syntelli learnt from the experience while still applying standard cloud practices.
Return on Investment (ROI) proved to be a huge success. The company saved thousands of dollars paid for propriety licensing of on-prem application. The migration helped cut costs, where only few users leveraged the application previously.
Another important point to note, the company did not have an in-house team to handle and monitor resources or use them. It was important for the Syntelli consulting team to guide them during this transition from coding, utilizing infrastructure, reporting, communicating with other teams across customer’s organization.
“Strive not to be a success, but rather to be of value.” – Albert Einstein
Currently, this company has grown in team size and technical capacity to scale their data science requirements and focus on creating improved models for their business in order to predict and forecast better results, track growth, and retention.
4. On-Prem vs Cloud Infrastructure
While cloud migration has helped reduce the customer’s stress on many topics, there is still room for inconsistencies or challenges ahead.
Discussion Topic
On-Prem Application
Cloud Migrated Application
Migration Story
Cost
Expensive Depends on subscription Significantly reduced
Maintenance
Resources managed by the customer Resources managed by cloud service provider Less man hours
Application Interaction
High human interaction Low human interaction Reduced greatly
Open Source Libraries
Limited access to Data Science libraries Ability to leverage open source libraries Still a challenge of tracking open source library changes
Data Source Flexibility
Limited to certain formats More options Various formats from different sources leveraged
Scalability
Limited Exponential Access across various teams in the organization
Data Accessibility
Limited to one team More teams interact Access across organization
Security
More secured Vulnerable Security, Risk and Compliance team need to be more vigilant and audit at regular intervals
Application Downtime
Problem can be isolated to on-premise infrastructure or propriety application Multiple points to trace Leverage monitoring and tools and reports to avoid this scenario
ROI
Minimal Significant Impact Saved thousands of dollars spent on licenses, which benefited a few
There are more topics, which can be part of the above table like SLA, resource upgrades, interoperability with other environments etc., but topics like infrastructure networking, data compliance, downtime, and support are some of the key points for successful cloud migration. It is important for a business or organization to have the key topics ironed out before migration. This helps alleviate some of the challenges.
5. Conclusion
We are currently in a state of uncertainty with recent spread of COVID-19 virus all over the world. We hope for this situation to ease and let individuals and all businesses resume their operations.
Some businesses have been able to sustain this impact, since most of their infrastructure is on cloud, and they are able to work and support communities during these worried times. We are uncertain, if our economy would have survived such an impact ten years ago.
Individuals and companies across world have accepted and adapted cloud computing. If you are on the fence, come talk to Syntelli. We can help you answer some of those questions and help you in the process.
“Intelligence is the ability to adapt to change.” – Stephen Hawking
SIMILAR POSTS
The Power of Big Data and AI in the Fight Against COVID-19
The emergence of a novel coronavirus in December 2019 has had the medical community on edge. Public health officials around the world have faced an uphill battle in treating current cases and preventing the further spread of the virus. The 2002 SARS outbreak, and...
read more
For Better Analytics, Invest in Data Management
Digital transformation is redefining how work gets done. To enable transformation, your internal consumers need analytics to discover and apply insight as they work. Business decisions need to be informed by data in the same way that consumers use data in ecommerce:...
read more
Master Data Management – MDM Models a Complex World in 2020 and Beyond
As customers, we’ve all experienced the frustration with organizations who don’t understand us. We’re baffled that these organizations—retailers, insurers, health care providers, and B2B provides in our work life - miss seemingly obvious facts that would make our...
read more
The post Cloud Migration – Is it too late to adopt? appeared first on Syntelli Solutions Inc..
https://www.syntelli.com/cloud-migration-is-it-too-late-to-adopt
0 notes
Text
Ignite 2018
afinita - pri load balanceru - stejny klient chodi na stejny server, možná i jako geo u cache apod? retence=napr u zaloh jak stare odmazavat webjob= WebJob is a feature of Azure App Service that enables you to run a program or script in the same context as a web app, background process, long running cqrs = Command Query Responsibility Segregation - zvláštní api/model na write a read, opak je crud webhook = obrácené api, zavolá clienta pokud se něco změní (dostane eventu)
docker - muze byt vice kontejneru v jedné appce, docker-compose.yml azure má nějaké container registry - tam se nahraje image (napr website) a ten se pak deployne někam např. app service, ale jiné image nemusí container registry - není veřejné narozdíl do dockeru, někdo jiný z teamu může si stáhnout
azure functions 2 - v GA
xamarin - ui je vlastne access k native api, ale v csharp projekty - shared, a special pro ios a android
ML.NET - je to framework pro machine learning
hosting SPA na azure storage static website - teoreticky hodně výhod, cachování, levné hosting
devops - automate everything you can
sponge - learn constantly multi-talented - few thinks amazing, rest good konverzace, teaching, presenting, positivity, control share everything
powershell - future, object based CLI to MS tech powerShell ISE - editor - uz je ve windows, ale ted VS code cmdlets - mini commands, hlavni cast, .net classy [console]::beep() function neco { params{[int] Seconds} } pipeline - chain processing - output je input pro dalsi atd dir neco | Select-object modules - funkce dohromady, k tomu manifest
web single sign-on = fedaration - nekdo jiny se zaruci ze ja neco muzu a ze jsem to ja federation=trust data jsou na jednom miste SAML - security assertion markup language, jen web, složité API Security - header Authorization Basic (username, heslo zakodovane) OAuth2 - misto toho tokeny (vstupenka) openid connect - id token, access token - všechny platformy, code flow doporučené, jiné implicit flow? fido - fast identity online - abstrakce uh wtf, private public key pair per origin - nejde phising ldap. kerberos - jak to zapada?
httprepl - cli swagger
asm.js - polyfil pro web assembly, web assembly je native kod v browseru - napr .net = blazzor
svet bez hesel windows hello - windows login - face nebo fingerprint ms authenticator - mobilni apka - matchnu vygenerovany kod FIDO2 - novy security standart - mam u sebe privatni klic, server posle neco (nonce), to zakryptuju privatnim pošlu zpátky - přes veřejný rozšifruje a má potvrzené, pak to samé s tokenem
cosmos db transakce - jen pouzitim stored procedure, single partition default index na vše, jde omezit při vytváření kolekce change feed - log of changes, in order trik jak dostat rychle document count - meta info o kolekci a naparsovat key-value cosmos - vyhody globalni distribuce, eventy, multimodel, pro big data asi
AKS - container - appka, orchestrator - komunikace mezi kontejnery, správa kontejnerů, healthchecks, updates AKS - orchestrator - nejčastější orchestrátor, standart, extensible, self healing představa něco jako cli nebo klient - řeknu jaké kontejnery, počet apod uvnitř se to nějak zařídí - api server, workers atd.. - je to managed kubernetes v azure, customer se stará jen o to co nasadit a kdy - ci/cd aks = azure kubernetes service
dev spaces - share aks cluster for dev (ne ci/cd), realne dependency (bez mock jiných service apod) extension do VS, pracuju lokalne, sync do azure, využíví namespace v aks (každý má svojí verzi service) - normalne frontned.com, já mám ondra.frontend.com a svojí api, pokud se zeptá na url tak se koukne jestli běží lokálně, když ne tak se zeptá team verze respektive je to celé v azure, ale je tam moje verze aplikace
kubernets - master (api server) - jeden Node - vice, VMs, v nem pods - containers, mají unikátní ip, networking - basic pro dev, advanced pro live nody a pody jsou interní věc, ven přes services helm - něco jako worker co se o to stará? jako docker-compose - vic imagu, help je pro aks??, arm template pro aks (skrpit jak postavit prostředí)
event notification patern - objednávky do fronty, ostatní systémy zpracují, co nejvíce info v eventě event sourcing - ukládat změny - inserted, updated, updated, updated, místo get update save, jde také udělat přes event, materialized view - spočítání stavu podle těch event, jdě dělat jednou za čas event grid - event routing
azure function - zip, z něj to spustí (vyhneme se problemu při update file by file), přes proměnné, nyní default ve 2.0 je startup, kde je možné připravit DI a funkce pak přes konstruktor už se dá kombinovat s kontejnery, aks atd durable functions - složitější věci s návaznostmi funkci, long running, local state, code-only, orchestartor function - vola activity function, má vnitrni stav, probudi se dela do prvni aktivity, tu spusti, spi, probudi se checkne jestli dobehla, pokracuje dal logic apps - design workflow, visual azure function runtime jde teoreticky hostovat na aks? v devops pro non .net jazyky potreba instalovat zvlast extension v2 - vice lang, .net core - bezi vsude, binding jako extension key vault - v 2008 ani preview funkce hosting - consuption = shared, app service - dedicated microservice=1 function app, jeden jazyk, jeden scale api management = gateway - na microservices, jde rozdělat na ruzné service azure storage tiery - premium (big data), hot (aplikace, levne transakce, drahy store), cold (backup, levny store, drahe transakce), archive (dlouhodobý archiv) - ruzné ceny/rychlosti, soft delete - po dobu retence je možnost obnovit smazané, data lifecycle management - automaticky presouvat data mezi tiery, konfigurace json
hybric cloud - integrace mezi on premise a cloudem - azure stack - azure které běží on premise někde use case: potřebujeme hodně rychle/jsme offline, vyhovění zákonům, model
místo new HttpClient, raději services.AddHttpCLient(addretry, addcircuitbreaker apod) a pak přes konstruktor, používá factory, používání Polly (retry apod..) - pro get, pro post - davat do queue
people led, technology enpowered
service fabric 3 varianty - standalone (on prem), azure (clustery vm na azure), mesh (serverless), nějaká json konfigurace zase, umí autoscale (trigger a mechanism json konfig), spíš hodně interní věc - běží na tom věci v azure, předchudce aks, jednoduší, proprietární, stateful, autoscale apod..
důležitá věc microservices - vlastní svoje data, nemají sdílenou db principy: async publish/subscr komunikace, healt checks, resilient (retry, circuit breaker), api gateway, orchestrator (scaleout, dev) architektura - pres api gateway na ruzne microservice (i ms mezi sebou) - ocelot orchestrator - kubernetes - dostane cluster VMs a ty si managuje helm = package manager pro kubernetes, dela deploy, helm chart = popis jak deploynout standartni
key valut - central pro všechny secrets, scalable security, aplikace musí mít MSI (nějaké identity - přes to se povolí přístup)
Application Insights - kusto language, azure monitor search in (kolekce) "neco" where neco >= ago(30d) sumarize makelist(eventId) by Computer - vraci Comuter a k tomu list eventId, nebo makeset umí funkce nějak let fce=(){...}; join kind=inner ... bla let promenna - datatable napr hodně data - evaluate autocluster_v2() - uděla grupy cca, podobně evaluate basket(0.01) pin to dashboard, vedle set alert
ai oriented architecture: program logic + ai, trend dostat tam ai nejak
0 notes
Text
Fresh from the Python Package Index
• agrid A multidimensional grid for scientific computing. A grid for modelling, analyse, map and visualise multidimensional and multivariate data. The module c … • AlgebraOnMatrix Algebric operations on matrices • ASR-metrics A Python package to get CER and WER for automatic speech recognitions • etlx ETL & Co • gleipnir-ns Python toolkit for Nested Sampling. • GOUDA Good Old Utilities for Data Analysis! • gym-games This is a gym version of various games for reinforcenment learning. • hmsolver Hybrid Model Solver • InstaBoost a python implementation for paper: “InstaBoost: Boosting Instance Segmentation Via Probability Map GuidedCopy-Pasting” • rlmodels Implementation of some popular reinforcement learning models. This project is a collection of some popular optimisation algorithms for reinforcement le … • tealang Tea: A High-level Language and Runtime System to Automate Statistical Analysis • yarn-kernel-provider Provides support for launching Jupyter kernels within a YARN cluster • aws-cdk.aws-backup The CDK Construct Library for AWS::Backup • attention-sampling Train networks on large data using attention sampling. • aio-tiny-healthcheck Tiny asynchronous implementation of healthcheck provider and http-server http://bit.ly/2n3qOFi
0 notes
Text
Cloud Computing Engineering job at Powerdata2go Anywhere
Next Generation Infrastucture
We are looking for young engineers who embrace changes fearlessly.
Responsibility
- Manage VMs, cloud infrastucture (AWS, Google, Azure)
- Regular system healthcheck, patching, monitoring
- Linux or Windows system administration
Qualification
- Information Technology, Computer Science or Business Information System degreee
- Experienced in Virtualisation Systems (Open Stack, AWS, Google, VMware etc)
- Familiar with database technology (SQL language)
We offer 2-month on the job training and cloud computing certification exam subsidy.
StartUp Jobs Asia - Startup Jobs in Singapore , Malaysia , HongKong ,Thailand from http://www.startupjobs.asia/job/40231-cloud-computing-engineering-software-system-admin-job-at-powerdata2go-anywhere Startup Jobs Asia https://startupjobsasia.tumblr.com/post/177685559019
0 notes
Text
Cloud Computing Engineering job at Powerdata2go Anywhere
Next Generation Infrastucture
We are looking for young engineers who embrace changes fearlessly.
Responsibility
– Manage VMs, cloud infrastucture (AWS, Google, Azure)
– Regular system healthcheck, patching, monitoring
– Linux or Windows system administration
Qualification
– Information Technology, Computer Science or Business Information System degreee
– Experienced in Virtualisation Systems (Open Stack, AWS, Google, VMware etc)
– Familiar with database technology (SQL language)
We offer 2 month on the job training and cloud computing certification exam subsidy.
From http://www.startupjobs.asia/job/40231-cloud-computing-engineering-it-job-at-powerdata2go-anywhere
from https://startupjobsasiablog.wordpress.com/2018/09/03/cloud-computing-engineering-job-at-powerdata2go-anywhere/
0 notes
Text
Cloud Computing Engineering job at Powerdata2go Anywhere
Next Generation Infrastucture
We are looking for young engineers who embrace changes fearlessly.
Responsibility
- Manage VMs, cloud infrastucture (AWS, Google, Azure)
- Regular system healthcheck, patching, monitoring
- Linux or Windows system administration
Qualification
- Information Technology, Computer Science or Business Information System degreee
- Experienced in Virtualisation Systems (Open Stack, AWS, Google, VMware etc)
- Familiar with database technology (SQL language)
We offer 2-month on the job training and cloud computing certification exam subsidy.
StartUp Jobs Asia - Startup Jobs in Singapore , Malaysia , HongKong ,Thailand from http://www.startupjobs.asia/job/40231-cloud-computing-engineering-software-system-admin-job-at-powerdata2go-anywhere
0 notes
Text
Polar Equine Healthcheck Review
When you search for good heart rate watches reviews, this Polar Equine Healthcheck is the best cheapest price on the web we have searched. Many good reviews already proving the quality of this product. The Polar Equine Healthcheck is equipped with a large number of features that makes it great product. The most sold product is not expensive and it is highly desirable, and if you want buy it now, you should not miss this opportunity because this product is the price length applications.
Product Details
Measures your horse’s resting and recovery heart rate
Provides a reliable method to monitor your horse’s vital signs for safety
Includes FT1 training computer, T31 non-coded sensor and handlebar
>> Click here for the latest discount on the Polar Equine Healthcheck and to read the great customer reviews <<
Weekly Top Sellers
Brand: Polar
Model: 93045117
Best Sellers Rank: 123485
Total Offers: 10
Warranty: Polar
Condition: New
Availability: Usually ships in 24 hours
Price: $ 63.10
Get the lowest price
Today’s Deals
Product Code: B007BMZ0IC Rating: 4.5/5 stars List Price: $ 69.04 Discount: 9% You Save: $ 6.00 Special Offers: Check It » Most Recent Reviews:
Pros and Cons
The Polar Equine Health check makes monitoring the resting and recovery heart rate of your horse easy. Just place the Polar transmitter against your horse’s coat and within seconds you’ll see your horse’s heart rate on the FT1 Polar training computer…. Read full review here
Where can you buy the best heart rate watches
Polar Equine Healthcheck
Customer rating: 4.5/5 stars List Price: $ 69.04 Sale: $ 63.10 Discount: Save 9% off your order + Free Shipping Availability: New, original packaging – In stock Sold by and Shipping: Check store below »
Special Offer Today! Price: $ 63.10
( Wednesday, November 29, 2017 ) » Buy It Now
“The condition of the Polar Equine Healthcheck you buy and its timely delivery are guaranteed under the Amazon A-to-z Guarantee.”
We have found most affordable price of Polar Equine Healthcheck from Amazon store. It offers fast and free shipping. Best heart rate watches for sale will be limited stock of certain product and discount only for limited time, so do order now to get the best deals. Before you buy, check to see if a product is available online at store, read and compare experiences customers have had with heart rate watches below.
Free Shipping >> Buy from Amazon.com
Overall review about the best heart rate watches
All the latest best heart rate watches reviews consumer reports are written by real customers on websites. You should read more consumer reviews and answered questions of Polar Equine Healthcheck below.
>> If you can’t see all comments, click here to read full customer reviews on Polar Equine Healthcheck at Amazon.com <<
from WordPress https://bestfitnesswatchreview.info/polar-equine-healthcheck-review/ via IFTTT
0 notes
Text
API management with Kong
Utilising APIs to foster innovation and to create new business opportunities is not a new concept. A lot of success stories from eBay, Netflix, Expedia, mobile.de, and many others show the growing trend of API-driven business models. Most of the vendors for API management solutions are well-known players, such as IBM, Oracle, or MuleSoft, that try to provide a solution coupled to their existing ecosystem of enterprise products. One of the few exceptions is Kong Inc (formerly known as Mashape Inc), a San-Fransisco-based startup that became popular in the last two years by open-sourcing their core business product: Kong API gateway. In this article, I will briefly introduce the topic of API management and show how to bootstrap and use Kong API gateway.
Why does API management matter?
Adaptation and speed have become the key success factors in the software industry. We can see the results of this trend in the emergence of microservices architectures, continuous delivery, DevOps culture, agile software development, and cloud computing. In order to be fast, you have to split a system into encapsulated services and be able to change each part of the system in an instant. This trend also results in high demand for integration solutions between different applications and services. API management plays an important role in this integration by providing clear boundaries and abstractions between systems. Today we generate value by combining different services instead of building our own solutions. This is why cloud computing and SaaS applications are very popular. With the growing trend of APIs, many companies adjusted their business model, and some even moved to an API-centric business approach completely. Expedia Inc generates 90% of the revenue through Expedia Affiliate Network, an API platform. Netflix has built an ecosystem of over 1000 APIs to support multiple devices for their streaming platform. Salesforce, one of the fastest growing CRM vendors generates over 50% of their revenue with APIs. Other common uses cases for APIs are:
reach users or acquire content
generate traffic
expand partner network
find new business opportunities
create new revenue streams
support multiple devices
create flexibility for internal projects
provide integration capabilities with other systems
But utilising APIs is not easy and it comes with a price. The cost for the mentioned benefits is an increasing technical and organisational complexity. In this blog post we will explore ways to tackle the technical complexity and how Kong API gateway can help deal with it.
Kong Architecture
Kong is an open source API gateway to manage RESTful APIs. It is part of Kong Enterprise, a bundle of Kong API gateway, a developer portal called Gelato and an analytics platform by the name of Galileo. It is aimed for enterprise customers that run thousands of APIs and require dedicated 24/7 support. For small to medium-sized companies, Kong API gateway (community edition) will suffice to make first steps in API management.
Kong Architecture with five core components.
The five components of Kong architecture are: nginx, OpenResty, Datastore, plugins and a RESTful admin API. The core low-level component is nginx, a well-known and rocksolid web server. By 2017 35.5% of all known and 54.2% of top 100,000 websites worldwide use nginx. It can handle up to 10,000 simultaneous connections on one node with low memory footprint and is often used as a reverse proxy in microservice architectures, a load balancer, SSL termination proxy, or a static content web server. Apart from these use cases, nginx has many more features which deserve their own blog posts. OpenResty is a web platform that glues nginx core, LuaJIT, Lua libraries and third-party nginx modules to provide a web server for scalable web applications and web services. It was originally built by taobao.com, the biggest online auction platform in Asia with 369 million active users (2017) and donated in 2011. After that, Cloudflare Inc. supported and developed the platform until 2016. Since then, the OpenResty Software Foundation has ensured the future development of the platform. The datastore component uses Apache Cassandra or PostgreSQL to handle the storage of the configuration data, consumers, and plugins of all APIs. The API configuration is also cached within nginx, so the database traffic should be low. Plugins are Lua modules that are executed during a request/response lifecycle. They enrich the API gateway with functionalities for different use cases. For instance, if you want to secure your API, you would use a security plugin dedicated to providing only this functionality during the request. The Kong plugin system is open and you can write your own custom plugins. Finally, there is a RESTful admin API to manage the APIs. It may feel strange at the beginning to have no user interface. From a developer perspective, this is actually nice, because it provides a necessary tool to automate your workflows, for example with Postman, httpie or curl. Working with Kong for several months now, I have never felt the need to have a user interface because I could access all information in a fast and reliable way. But if you want to have a nice dashboard for your APIs you can use Konga or kong-dashboard, both free and open source community projects.
Now let’s see how to manage APIs with Kong and which plugins provide basic security features.
Kong API gateway in action
This part will be more technical than the previous. First, I will show you how to create a minimal infrastructure for Kong API gateway. Then I will add an API and a security plugin to restrict the access to a specific user.
To start the infrastructure, I will use docker-compose with this service definition:
version: '2.1' services: kong-database: container_name: kong-database image: postgres:9.4 environment: - POSTGRES_USER=kong - POSTGRES_DB=kong healthcheck: test: ["CMD", "pg_isready", "-U", "postgres"] interval: 10s timeout: 5s retries: 5 kong-migration: image: kong depends_on: kong-database: condition: service_healthy environment: - KONG_DATABASE_postgres - KONG_PG_HOST=kong-database command: kong migrations up kong: container_name: kong image: kong:0.11.0 depends_on: kong-database: condition: service_healthy kong-migration: condition: service_started environment: - KONG_DATABASE=postgres - KONG_PG_HOST=kong-database - KONG_PG_DATABASE=kong expose: - 8000 - 8001 - 8443 - 8444 ports: - "8000-8001:8000-8001" healthcheck: test: ["CMD-SHELL", "curl -I -s -L http://127.0.0.1:8000 || exit 1"] interval: 5s retries: 10
You can also install Kong on many different platforms such as AWS, Google Cloud, Kubernetes, DC/OS and many others. In my docker-compose definition, there are three services: kong-database, kong and kong-migration. I use the PostgreSQL Docker image for the Datastore component that was mentioned in the architecture overview, but you can use Cassandra as well. The kong-service exposes four different ports for two functionalities:
8000, 8443: HTTP & HTTPS access to the managed APIs (consumer endpoint)
8001, 8444: HTTP & HTTPS access to the admin API (administration endpoint)
The kong-migration service is used to create the database user and tables in kong-database. This bootstrap functionality is not provided by the kong-service, so you need to run kong migrations up within the container only once. With docker-compose up the services will be up and running. Your docker ps command should output something like this:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 87eea678728f kong:0.11.0 "/docker-entrypoin..." Less than a second ago Up 2 seconds (health: starting) 0.0.0.0:8000-8001->8000-8001/tcp, 0.0.0.0:8443-8444->8443-8444/tcp kong 4e2bf871f0c7 postgres:9.4 "docker-entrypoint..." 3 hours ago Up 4 minutes (healthy) 5432/tcp kong-database
Now check the status by sending a GET request to the admin API. I use the tool HTTPie for this, but you can run curl command or use Postman as an alternative.
$ http localhost:8001/apis/ HTTP/1.1 200 OK Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Fri, 13 Oct 2017 14:59:25 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "data": [], "total": 0 }
The Kong admin API is working, but there are no APIs configured. Let’s add an example:
$ http post localhost:8001/apis/ name=example_api upstream_url=https://example.com uris=/my_api HTTP/1.1 201 Created Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Fri, 13 Oct 2017 15:03:55 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "created_at": 1507907036000, "http_if_terminated": false, "https_only": false, "id": "59d9749b-694a-4645-adad-d2c974b3df76", "name": "example_api", "preserve_host": false, "retries": 5, "strip_uri": true, "upstream_connect_timeout": 60000, "upstream_read_timeout": 60000, "upstream_send_timeout": 60000, "upstream_url": "https://example.com", "uris": [ "/my_api" ] }
Simply make a POST request to localhost:8001/apis/ with three mandatory parameters in the http body:
name: the API name
upstream_url: the target URL that points to your API server
uris: URIs prefixes that point to your API
There are of course more parameters for ssl, timeouts, http methods, and others. You will find them in the documentation if you want to tinker with them. Now call the API:
$ http localhost:8000/my_api HTTP/1.1 200 OK Cache-Control: max-age=604800 Connection: keep-alive Content-Encoding: gzip Content-Length: 606 Content-Type: text/html; charset=UTF-8 Date: Tue, 17 Oct 2017 09:02:26 GMT Etag: "359670651+gzip" Expires: Tue, 24 Oct 2017 09:02:26 GMT Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT Server: ECS (dca/249F) Vary: Accept-Encoding Via: kong/0.11.0 X-Cache: HIT X-Kong-Proxy-Latency: 592 X-Kong-Upstream-Latency: 395 Example Domain ...
In many cases you want to protect your API and give access only to dedicated users, so let’s see how Kong consumers and plugins work.
Consumers and Plugins
Consumers are objects that are (technical) users that consume an API. The data structure is rather simple with just three fields: id, username and custom_id. To create a consumer, send a POST request to localhost:8001/consumers/
$ http post localhost:8001/consumers/ username=John HTTP/1.1 201 Created Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 10:06:19 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "created_at": 1508234780000, "id": "bdbba9d1-5948-4e1a-94bd-55979b7117a3", "username": "John" }
You have to provide either a username or a custom_id or both in the request body. Additionally you can set a custom_id for a mapping between a consumer and a user of your internal system, for example an ID in your CRM system. Use it to maintain consistency between Kong consumers and your source of truth for user data. I will now add a security plugin to my API and link the consumer to it. This will ensure that only this consumer can access the API with a specific key. A Kong plugin is a set of Lua modules that are executed during a request-response lifecycle of an API. You can add a plugin to all APIs, restrict it only for a specific API or a specific consumer. In my case I will add the key authentication plugin:
$ http post localhost:8001/apis/example_api/plugins name=key-auth Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 11:59:16 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "api_id": "36d04e5d-436d-4132-abdc-e4d42dc67068", "config": { "anonymous": "", "hide_credentials": false, "key_in_body": false, "key_names": [ "apikey" ] }, "created_at": 1508241556000, "enabled": true, "id": "8eecbe27-af95-49d2-9a0a-5c71b9d5d9bd", "name": "key-auth" }
The API name examlpe_api in the request URL restricts the plugin execution only to this API. Now if I try to use the API, the response will be:
$ http localhost:8000/my_api HTTP/1.1 401 Unauthorized Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 12:03:24 GMT Server: kong/0.11.0 Transfer-Encoding: chunked WWW-Authenticate: Key realm="kong" { "message": "No API key found in request" }
Now I need to create a key for my consumer:
$ http POST localhost:8001/consumers/John/key-auth key=secret_key HTTP/1.1 201 Created Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 12:35:11 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "consumer_id": "bdbba9d1-5948-4e1a-94bd-55979b7117a3", "created_at": 1508243712000, "id": "02d2afd6-1fb6-4713-860f-704c52355780", "key": "secret_key" }
If you omit the key field, Kong will generate a random key for you. Now call the API with the created key:
$ http localhost:8000/my_api apikey=='secret_key' HTTP/1.1 200 OK Cache-Control: max-age=604800 Connection: keep-alive Content-Encoding: gzip Content-Length: 606 Content-Type: text/html; charset=UTF-8 Date: Tue, 17 Oct 2017 12:40:46 GMT Etag: "359670651+gzip" Expires: Tue, 24 Oct 2017 12:40:46 GMT Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT Server: ECS (dca/249B) Vary: Accept-Encoding Via: kong/0.11.0 X-Cache: HIT X-Kong-Proxy-Latency: 25 X-Kong-Upstream-Latency: 374 Example Domain ...
Pass the apikey as a query parameter or as a header in your API call. The plugin also has configurations to hide the key after the request has been processed or to look it up in a list of keys. It is also possible to configure plugins on the consumer level, so each consumer will have their own settings. For example, you can create different rate limits for your consumers, so some of them can access your API more frequently than the others.
Summary
In this blogpost I’ve introduced the topic of APIs and why it could matter for your business. Kong API gateway is a great open-source project that can help you manage APIs for free. With just few http requests, we have created and secured our first API. The RESTful admin API of Kong is clean and simple, which allows for fast integration into most continuous delivery pipelines. In the upcoming blog post I will show you how to build your own plugin and use the OpenID provider to manage API access.
The post API management with Kong appeared first on codecentric AG Blog.
API management with Kong published first on http://ift.tt/2vCN0WJ
0 notes
Text
API management with Kong
Utilising APIs to foster innovation and to create new business opportunities is not a new concept. A lot of success stories from eBay, Netflix, Expedia, mobile.de, and many others show the growing trend of API-driven business models. Most of the vendors for API management solutions are well-known players, such as IBM, Oracle, or MuleSoft, that try to provide a solution coupled to their existing ecosystem of enterprise products. One of the few exceptions is Kong Inc (formerly known as Mashape Inc), a San-Fransisco-based startup that became popular in the last two years by open-sourcing their core business product: Kong API gateway. In this article, I will briefly introduce the topic of API management and show how to bootstrap and use Kong API gateway.
Why does API management matter?
Adaptation and speed have become the key success factors in the software industry. We can see the results of this trend in the emergence of microservices architectures, continuous delivery, DevOps culture, agile software development, and cloud computing. In order to be fast, you have to split a system into encapsulated services and be able to change each part of the system in an instant. This trend also results in high demand for integration solutions between different applications and services. API management plays an important role in this integration by providing clear boundaries and abstractions between systems. Today we generate value by combining different services instead of building our own solutions. This is why cloud computing and SaaS applications are very popular. With the growing trend of APIs, many companies adjusted their business model, and some even moved to an API-centric business approach completely. Expedia Inc generates 90% of the revenue through Expedia Affiliate Network, an API platform. Netflix has built an ecosystem of over 1000 APIs to support multiple devices for their streaming platform. Salesforce, one of the fastest growing CRM vendors generates over 50% of their revenue with APIs. Other common uses cases for APIs are:
reach users or acquire content
generate traffic
expand partner network
find new business opportunities
create new revenue streams
support multiple devices
create flexibility for internal projects
provide integration capabilities with other systems
But utilising APIs is not easy and it comes with a price. The cost for the mentioned benefits is an increasing technical and organisational complexity. In this blog post we will explore ways to tackle the technical complexity and how Kong API gateway can help deal with it.
Kong Architecture
Kong is an open source API gateway to manage RESTful APIs. It is part of Kong Enterprise, a bundle of Kong API gateway, a developer portal called Gelato and an analytics platform by the name of Galileo. It is aimed for enterprise customers that run thousands of APIs and require dedicated 24/7 support. For small to medium-sized companies, Kong API gateway (community edition) will suffice to make first steps in API management.
Kong Architecture with five core components.
The five components of Kong architecture are: nginx, OpenResty, Datastore, plugins and a RESTful admin API. The core low-level component is nginx, a well-known and rocksolid web server. By 2017 35.5% of all known and 54.2% of top 100,000 websites worldwide use nginx. It can handle up to 10,000 simultaneous connections on one node with low memory footprint and is often used as a reverse proxy in microservice architectures, a load balancer, SSL termination proxy, or a static content web server. Apart from these use cases, nginx has many more features which deserve their own blog posts. OpenResty is a web platform that glues nginx core, LuaJIT, Lua libraries and third-party nginx modules to provide a web server for scalable web applications and web services. It was originally built by taobao.com, the biggest online auction platform in Asia with 369 million active users (2017) and donated in 2011. After that, Cloudflare Inc. supported and developed the platform until 2016. Since then, the OpenResty Software Foundation has ensured the future development of the platform. The datastore component uses Apache Cassandra or PostgreSQL to handle the storage of the configuration data, consumers, and plugins of all APIs. The API configuration is also cached within nginx, so the database traffic should be low. Plugins are Lua modules that are executed during a request/response lifecycle. They enrich the API gateway with functionalities for different use cases. For instance, if you want to secure your API, you would use a security plugin dedicated to providing only this functionality during the request. The Kong plugin system is open and you can write your own custom plugins. Finally, there is a RESTful admin API to manage the APIs. It may feel strange at the beginning to have no user interface. From a developer perspective, this is actually nice, because it provides a necessary tool to automate your workflows, for example with Postman, httpie or curl. Working with Kong for several months now, I have never felt the need to have a user interface because I could access all information in a fast and reliable way. But if you want to have a nice dashboard for your APIs you can use Konga or kong-dashboard, both free and open source community projects.
Now let’s see how to manage APIs with Kong and which plugins provide basic security features.
Kong API gateway in action
This part will be more technical than the previous. First, I will show you how to create a minimal infrastructure for Kong API gateway. Then I will add an API and a security plugin to restrict the access to a specific user.
To start the infrastructure, I will use docker-compose with this service definition:
version: '2.1' services: kong-database: container_name: kong-database image: postgres:9.4 environment: - POSTGRES_USER=kong - POSTGRES_DB=kong healthcheck: test: ["CMD", "pg_isready", "-U", "postgres"] interval: 10s timeout: 5s retries: 5 kong-migration: image: kong depends_on: kong-database: condition: service_healthy environment: - KONG_DATABASE_postgres - KONG_PG_HOST=kong-database command: kong migrations up kong: container_name: kong image: kong:0.11.0 depends_on: kong-database: condition: service_healthy kong-migration: condition: service_started environment: - KONG_DATABASE=postgres - KONG_PG_HOST=kong-database - KONG_PG_DATABASE=kong expose: - 8000 - 8001 - 8443 - 8444 ports: - "8000-8001:8000-8001" healthcheck: test: ["CMD-SHELL", "curl -I -s -L http://127.0.0.1:8000 || exit 1"] interval: 5s retries: 10
You can also install Kong on many different platforms such as AWS, Google Cloud, Kubernetes, DC/OS and many others. In my docker-compose definition, there are three services: kong-database, kong and kong-migration. I use the PostgreSQL Docker image for the Datastore component that was mentioned in the architecture overview, but you can use Cassandra as well. The kong-service exposes four different ports for two functionalities:
8000, 8443: HTTP & HTTPS access to the managed APIs (consumer endpoint)
8001, 8444: HTTP & HTTPS access to the admin API (administration endpoint)
The kong-migration service is used to create the database user and tables in kong-database. This bootstrap functionality is not provided by the kong-service, so you need to run kong migrations up within the container only once. With docker-compose up the services will be up and running. Your docker ps command should output something like this:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 87eea678728f kong:0.11.0 "/docker-entrypoin..." Less than a second ago Up 2 seconds (health: starting) 0.0.0.0:8000-8001->8000-8001/tcp, 0.0.0.0:8443-8444->8443-8444/tcp kong 4e2bf871f0c7 postgres:9.4 "docker-entrypoint..." 3 hours ago Up 4 minutes (healthy) 5432/tcp kong-database
Now check the status by sending a GET request to the admin API. I use the tool HTTPie for this, but you can run curl command or use Postman as an alternative.
$ http localhost:8001/apis/ HTTP/1.1 200 OK Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Fri, 13 Oct 2017 14:59:25 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "data": [], "total": 0 }
The Kong admin API is working, but there are no APIs configured. Let’s add an example:
$ http post localhost:8001/apis/ name=example_api upstream_url=https://example.com uris=/my_api HTTP/1.1 201 Created Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Fri, 13 Oct 2017 15:03:55 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "created_at": 1507907036000, "http_if_terminated": false, "https_only": false, "id": "59d9749b-694a-4645-adad-d2c974b3df76", "name": "example_api", "preserve_host": false, "retries": 5, "strip_uri": true, "upstream_connect_timeout": 60000, "upstream_read_timeout": 60000, "upstream_send_timeout": 60000, "upstream_url": "https://example.com", "uris": [ "/my_api" ] }
Simply make a POST request to localhost:8001/apis/ with three mandatory parameters in the http body:
name: the API name
upstream_url: the target URL that points to your API server
uris: URIs prefixes that point to your API
There are of course more parameters for ssl, timeouts, http methods, and others. You will find them in the documentation if you want to tinker with them. Now call the API:
$ http localhost:8000/my_api HTTP/1.1 200 OK Cache-Control: max-age=604800 Connection: keep-alive Content-Encoding: gzip Content-Length: 606 Content-Type: text/html; charset=UTF-8 Date: Tue, 17 Oct 2017 09:02:26 GMT Etag: "359670651+gzip" Expires: Tue, 24 Oct 2017 09:02:26 GMT Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT Server: ECS (dca/249F) Vary: Accept-Encoding Via: kong/0.11.0 X-Cache: HIT X-Kong-Proxy-Latency: 592 X-Kong-Upstream-Latency: 395 Example Domain ...
In many cases you want to protect your API and give access only to dedicated users, so let’s see how Kong consumers and plugins work.
Consumers and Plugins
Consumers are objects that are (technical) users that consume an API. The data structure is rather simple with just three fields: id, username and custom_id. To create a consumer, send a POST request to localhost:8001/consumers/
$ http post localhost:8001/consumers/ username=John HTTP/1.1 201 Created Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 10:06:19 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "created_at": 1508234780000, "id": "bdbba9d1-5948-4e1a-94bd-55979b7117a3", "username": "John" }
You have to provide either a username or a custom_id or both in the request body. Additionally you can set a custom_id for a mapping between a consumer and a user of your internal system, for example an ID in your CRM system. Use it to maintain consistency between Kong consumers and your source of truth for user data. I will now add a security plugin to my API and link the consumer to it. This will ensure that only this consumer can access the API with a specific key. A Kong plugin is a set of Lua modules that are executed during a request-response lifecycle of an API. You can add a plugin to all APIs, restrict it only for a specific API or a specific consumer. In my case I will add the key authentication plugin:
$ http post localhost:8001/apis/example_api/plugins name=key-auth Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 11:59:16 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "api_id": "36d04e5d-436d-4132-abdc-e4d42dc67068", "config": { "anonymous": "", "hide_credentials": false, "key_in_body": false, "key_names": [ "apikey" ] }, "created_at": 1508241556000, "enabled": true, "id": "8eecbe27-af95-49d2-9a0a-5c71b9d5d9bd", "name": "key-auth" }
The API name examlpe_api in the request URL restricts the plugin execution only to this API. Now if I try to use the API, the response will be:
$ http localhost:8000/my_api HTTP/1.1 401 Unauthorized Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 12:03:24 GMT Server: kong/0.11.0 Transfer-Encoding: chunked WWW-Authenticate: Key realm="kong" { "message": "No API key found in request" }
Now I need to create a key for my consumer:
$ http POST localhost:8001/consumers/John/key-auth key=secret_key HTTP/1.1 201 Created Access-Control-Allow-Origin: * Connection: keep-alive Content-Type: application/json; charset=utf-8 Date: Tue, 17 Oct 2017 12:35:11 GMT Server: kong/0.11.0 Transfer-Encoding: chunked { "consumer_id": "bdbba9d1-5948-4e1a-94bd-55979b7117a3", "created_at": 1508243712000, "id": "02d2afd6-1fb6-4713-860f-704c52355780", "key": "secret_key" }
If you omit the key field, Kong will generate a random key for you. Now call the API with the created key:
$ http localhost:8000/my_api apikey=='secret_key' HTTP/1.1 200 OK Cache-Control: max-age=604800 Connection: keep-alive Content-Encoding: gzip Content-Length: 606 Content-Type: text/html; charset=UTF-8 Date: Tue, 17 Oct 2017 12:40:46 GMT Etag: "359670651+gzip" Expires: Tue, 24 Oct 2017 12:40:46 GMT Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT Server: ECS (dca/249B) Vary: Accept-Encoding Via: kong/0.11.0 X-Cache: HIT X-Kong-Proxy-Latency: 25 X-Kong-Upstream-Latency: 374 Example Domain ...
Pass the apikey as a query parameter or as a header in your API call. The plugin also has configurations to hide the key after the request has been processed or to look it up in a list of keys. It is also possible to configure plugins on the consumer level, so each consumer will have their own settings. For example, you can create different rate limits for your consumers, so some of them can access your API more frequently than the others.
Summary
In this blogpost I’ve introduced the topic of APIs and why it could matter for your business. Kong API gateway is a great open-source project that can help you manage APIs for free. With just few http requests, we have created and secured our first API. The RESTful admin API of Kong is clean and simple, which allows for fast integration into most continuous delivery pipelines. In the upcoming blog post I will show you how to build your own plugin and use the OpenID provider to manage API access.
The post API management with Kong appeared first on codecentric AG Blog.
API management with Kong published first on http://ift.tt/2fA8nUr
0 notes