#DataHarvesting
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Hey friends, come follow us on Mastodon @[email protected]! We post a lot of content there, and Ariel is a lot more active with replies over there (usually….).
#Mastodon#Fediverse#ClimateJustice#SolarpunkPresentsPodcast#solarpunk#podcast#podcasting#SocialMedia#Privacy#DataPrivacy#FederatedInstances#federation#DataHarvesting#FacebookAlternative#MetaAlternative#ActivityPub
18 notes
·
View notes
Text
Scammers Target Drivers with Fake QR Codes at Car Parks: A Growing Threat
In a disturbing new trend, scammers are using fake QR codes to deceive drivers at car parks across the UK. These fraudulent codes are being placed over legitimate parking payment signs, tricking people into scanning them and providing personal or bank details.

Emily Checksfield, a driver from Chippenham, narrowly avoided falling victim to this scam. After scanning a QR code at a car park, her phone blocked the payment, alerting her to the potential fraud. Similar incidents have been reported nationwide, according to the Chartered Trading Standards Institute (CTSI).
In response, local authorities, including Wiltshire and Swindon Borough Councils, are investigating these scams and have assured the public they are regularly checking QR codes in their car parks. Wiltshire Council's Nick Holder emphasized the importance of vigilance, saying, “We are not complacent and check the QR codes in all our car parks regularly.”
QR codes are a convenient way for drivers to pay for parking directly from their phones, but scammers are exploiting this technology by directing victims to fake payment sites designed to steal sensitive information. Katherine Hart from the CTSI explained that these fake QR codes often aim to harvest personal data or bank details, with the goal of financial fraud.
“Scammers will either attempt to get your bank account details to steal money or collect personal information for later misuse,” Hart said. “If you suspect you’ve scanned a fraudulent code, contact your bank immediately.”
To avoid falling victim to these scams, authorities urge drivers to carefully inspect QR codes for any signs of tampering. If a code appears altered or placed over the original, it’s best not to scan it and report it to local authorities.
This growing issue highlights the need for increased awareness of QR code scams, particularly as more services adopt this payment method.
0 notes
Text
From Streaming to Scheming
Why AI Thinks I Need Jackal Gear I think the majority are aware that your privacy is under attack, everything you look at, see, search for, and even talk about is being monitored, connected to you, and re-sold through third party data aggregators All this is happening in near real-time Think about taking a break in the Caribbean and adverts will show up in your feed really quickly Perhaps some…

View On WordPress
#AdFail#AIHumor#AIOverreach#AIThoughtWrong#AlgorithmFails#BigBrotherIsWatching#CreepyAds#DataHarvesting#DataPrivacy#DigitalPrivacy#FunnyButTrue#JackalLogic#OnlinePrivacy#PrivacyMatters#PrivacyUnderAttack#StopTheSurveillance#StreamingProblems#TargetedAds#TechFails#TechGoneWild
0 notes
Text
Streaming TV Industry Snooping on Viewers at Grand Scale: RPT

The streaming TV industry has been accused of operating a massive data-driven surveillance apparatus that's transforming TVs into monitoring, tracking and targeting devices. https://tinyurl.com/ms5kxpx8
0 notes
Text
Market Research Disguised as Fun...
Welcome to the era of smart technology where our gadgets are not just tools but companions, always listening, always ready to assist. Among these, Amazon's Alexa stands out, offering a plethora of features to make our lives easier. From setting reminders to playing music, Alexa seems like the perfect assistant. But wait, there's more!
Now, Alexa introduces "Daily Insights," claiming to offer personalized content tailored to your interests. Sounds intriguing, right? Well, hold your horses because there's a catch—a rather sneaky one.
Let's peel back the shiny veneer of Alexa's Daily Insights and take a closer look. On the surface, it appears to be a harmless feature, providing users with bite-sized pieces of information about various topics. But what you may not realise is that while you're enjoying these insights, you're essentially serving as a test subject for Amazon's market research, and guess what? You're doing it for free.
Think about it for a moment. Every time you interact with Alexa, whether it's asking for the weather forecast or playing a game, you're feeding valuable data into Amazon's vast reservoir of information. Your preferences, habits, and interests are being meticulously analysed to better understand consumer behaviour. And what do you get in return? A few trivial facts and the illusion of personalised content.
But let's not stop there. Alexa isn't just passively collecting data; it's actively engaging users in activities like games and quizzes under the guise of entertainment. "Would you rather this or that?" These seemingly innocuous questions are nothing more than cleverly disguised market research tools, designed to extract even more information from unsuspecting users.
It's time to call a spade a spade. We're not lab rats, and yet, companies like Amazon seem to think we're just that—willing participants in their grand experiment of consumer manipulation. Do they honestly believe that everyone is oblivious to their ulterior motives? Perhaps they do, or perhaps they simply don't care as long as the data keeps flowing.
But here's the thing—they need us more than we need them. Without our consent and cooperation, their data-driven empire crumbles like a house of cards. It's high time we reclaim control over our digital lives and demand transparency and accountability from tech giants like Amazon.
So, the next time Alexa offers you a "fun" game or a "personalised" insight, remember what's really at stake. You're not just playing a game; you're unwittingly participating in a sophisticated scheme of data harvesting. And that's anything but fun.
Never trust big tech. Let's not allow ourselves to be treated as mere commodities in the relentless pursuit of profit. It's time to take a stand and assert our rights as consumers. After all, knowledge is power, and in this digital age, our data is our most valuable asset. Let's not give it away for free. Nothing is ever free there is ALWAYS a price.
#Alexa#SmartTechnology#MarketResearch#PrivacyConcerns#DataHarvesting#ConsumerRights#TechGiants#DigitalPrivacy#DataProtection#AmazonEcho#Personalization#UserData#EthicalTech#DigitalEmpowerment#Transparency#DataPrivacy#OnlineSecurity#ConsumerAwareness#TechEthics#DigitalRights#new blog#today on tumblr#freedom
0 notes
Text
Data Collection for Machine Learning and AI

In order to build intelligent applications capable of understanding, machine learning models need to digest large amounts of structured training data. Gathering sufficient training data is the first step in solving any AI-based machine learning problem.
Data collection means pooling data by scraping, capturing, and loading from multiple sources including offline and online sources. High volumes of data collection or data creation can be the hardest part of a machine learning project, especially at scale.
Furthermore, all datasets have flaws. This is why data preparation is so crucial in the machine learning process. In a word, data preparation is a series of processes for making your dataset more machine learning-friendly. In a broader sense, data preparation also entails determining the best data collection mechanism. And these techniques take up the majority of machine learning time. It can take months for the first algorithm to be constructed!
Why is Data Collection Important?
Collecting data allows you to capture a record of past events so that we can use data analysis to find recurring patterns. From those patterns, you build predictive models using machine learning algorithms that look for trends and predict future changes.
Predictive models are only as good as the data from which they are built, so good data collection practices are crucial to developing high-performing models. The data need to be error-free and contain relevant information for the task at hand. For example, a loan default model would not benefit from tiger population sizes but could benefit from gas prices over time.
How much data do you need?
This is an interesting question, but it has no definite answer because “how much” data you need depends on how many features there are in the data set. It is recommended to collect as much data as possible for good predictions. You can begin with small batches of Data and see the result of the model. The most important thing to consider while data collection is Diversity. Diverse data will help your model to cover more scenarios. So when focusing on how much data you need, you should cover all the scenarios in which the model will be used.
The Quantity of Data also depends on the complexity of your model. If it is as simple as license plate detection then you can expect predictions with small batches of data. But if are working on higher levels of Artificial intelligence like medical AI, you need to consider huge volumes of Data.
Process of Data Collection
Type of Data Requirements
Text Collection
In different languages and scenarios, text data collection supports the training of conversational interfaces. On the other hand, handwritten text data collection enables the enhancement of optical character recognition systems. Text data can be gathered from various sources, including documents, receipts, handwritten notes, and more.
Audio Collection
Automatic speech recognition technologies must be trained with multilingual audio data of various types and associated with different scenarios, to help machines recognize the intents and nuances of human speech. Conversational AI systems including in-home assistants, chatbots, and more require large volumes of high-quality data in a wide variety of languages, dialects, demographics, speaker traits, dialogue types, environments, and scenarios for model training.
Image & Video Collection
Computer vision systems and other AI solutions that analyze visual content need to account for a wide variety of scenarios. Large volumes of high-resolution images and videos that are accurately annotated provide the training data that is necessary for the computer to recognize images with the same level of accuracy as a human. Algorithms used for computer vision and image analysis services need to be trained with carefully collected and segmented data in order to ensure unbiased results.
How to Measure Data Quality?
The main purpose of the data collection is to gather information in a measured and systematic way to ensure accuracy and facilitate data analysis. Since all collected data are intended to provide content for analysis of the data, the information gathered must be of the highest quality to have any value.
Regardless of the way data are collected, it’s essential to maintain the neutrality, credibility, quality, and authenticity of the data. If these requirements are not guaranteed, then we can run into a series of problems and negative results
To ensure whether the data fed into the system is high quality or not, ensure that it adheres to the following parameters:
1. Intended for specific use cases and algorithms
2. Helps make the model more intelligent
3. Speeds up decision making
4. Represents a real-time construct
As per the mentioned aspects, here are the traits that you want your datasets to have:
Uniformity: Regardless of where data pieces come from, they must be uniformly verified, depending on the model. For instance, When coupled with audio datasets designed specifically for NLP models like chatbots and Voice Assistants, a well-seasoned annotated video dataset would not be uniform.
Consistency: If data sets are to be considered high quality, they must be consistent. As a complement to any other unit, every unit of data must try to make the model’s decision-making process faster.
Comprehensiveness: Plan out every aspect and characteristic of the model and ensure that the sourced datasets cover all the bases. For instance, NLP-relevant data must adhere to the semantic, syntactic, and even contextual requirements.
Relevance: If you want to achieve a specific result, make sure the data is homogenous and relevant so that AI algorithms can process it quickly.
Diversified: Diversity increases the capability of the model to have better predictions in multiple scenarios. Diversified datasets are essential if you want to train the model holistically. While this might scale up the budget, the model becomes way more intelligent and perceptive.
Choose Right Data Collection Provider
Obtaining the appropriate AI training data for your AI models can be difficult. TagX simplifies this procedure using a wide range of datasets that have been thoroughly validated for quality and bias. TagX can help you construct AI and ML models by sourcing, collecting, and generating speech, audio, image, video, text, and document data. We provide a one-stop-shop for web, internal, and external data collection and creation, with several languages supported around the globe and customizable data collecting and generation options to match any industrial domain need.
Once your data is collected, it still requires enhancement through annotation to ensure that your machine learning models extract the maximum value from the data. Data transcription and/or annotation are essential to preparing data for production-ready AI.
Our approach to collecting custom data makes use of our experience with unique scenario setups and dynamic project management, as well as our base of annotation experts for data tagging. And with an experienced end-to-end service provider in play, you get access to the best platform, most seasoned people, and tested processes that actually help you train the model to perfection. We don’t compromise on our data, and neither should you.
0 notes
Text
Unleashing the Potential of the Yellow Pages Scraper: Swift Business Insights at Your Fingertips
In the fast-paced arena of modern business, information is a prized asset. The Yellow Pages, a repository of business listings, often holds the key to invaluable insights. Quickscraper's Yellow Pages Scraper is your seamless gateway to tapping into this data treasure trove with ease. In this article, we'll dive into the realm of web scraping and how the Yellow Pages Scraper can be your trusty companion in swiftly acquiring vital business intelligence.
The Essence of Web Scraping
Web scraping is the art of automating data extraction from websites, empowering you to efficiently gather substantial amounts of information from diverse online sources. Quickscraper's Yellow Pages Scraper elevates web scraping to new heights, ensuring accessibility and user-friendliness for all.
Presenting Quickscraper's Yellow Pages Scraper
Quickscraper presents an array of web scraping solutions, and the Yellow Pages Scraper shines as an invaluable tool for businesses and individuals seeking business-related data. This tool simplifies the data extraction process from the Yellow Pages, allowing you to swiftly and effectively collect crucial business details.
Key Highlights of the Yellow Pages Scraper:
1. User-Friendly Interface
Quickscraper's Yellow Pages Scraper boasts an intuitive user interface, democratizing web scraping for users of all proficiency levels. You need not possess coding expertise to navigate this robust tool.
2. Data Precision
A significant advantage of the Yellow Pages Scraper is its precision in data extraction. The tool is meticulously crafted to ensure accurate information retrieval, mitigating the potential errors that can arise from manual data entry.
3. Efficiency and Time Economy
Manual data collection from the Yellow Pages can be an arduous and time-consuming endeavor. Quickscraper automates this process, allowing you to expeditiously amass business data from multiple listings. This newfound efficiency translates into valuable time savings for your endeavors.
4. Customization
Quickscraper's Yellow Pages Scraper offers extensive customization options, empowering you to specify the data fields you wish to extract. This customization guarantees that you obtain only the pertinent information relevant to your research or business requirements.
Advantages of Embracing the Yellow Pages Scraper:
Market Insight: Gain valuable insights about market trends and your competitors.
Lead Generation: Identify potential business leads and contacts for your marketing initiatives.
Business Advancement: Elevate your business strategies with comprehensive business listings at your disposal.
Initiate Your Journey into Business Intelligence
Are you prepared to revolutionize your business research and lead generation? Quickscraper's Yellow Pages Scraper is your portal to unlock the complete potential of business listings. Bid farewell to manual data collection and embrace an efficient, productive approach to accessing business intelligence from the Yellow Pages. Commence your journey today and remain ahead in the fiercely competitive business arena.
#WebScraping#DataExtraction#Quickscraper#YellowPagesScraper#BusinessIntelligence#MarketResearch#LeadGeneration#DataMining#DataAnalysis#Automation#BusinessInsights#CompetitiveAnalysis#DigitalTools#DataCollection#Efficiency#InformationGathering#WebScrapingTools#DataHarvesting#DataPrecision#BusinessListings
0 notes
Text
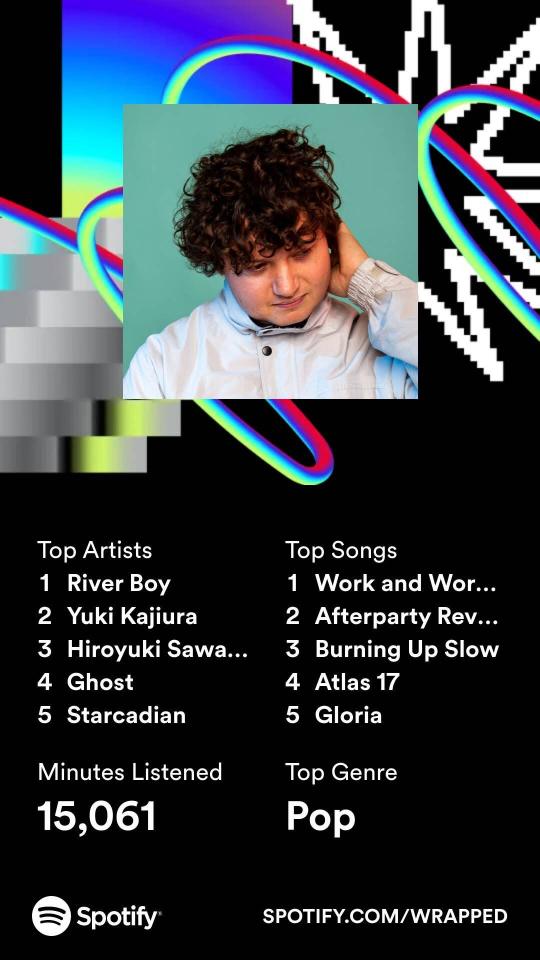

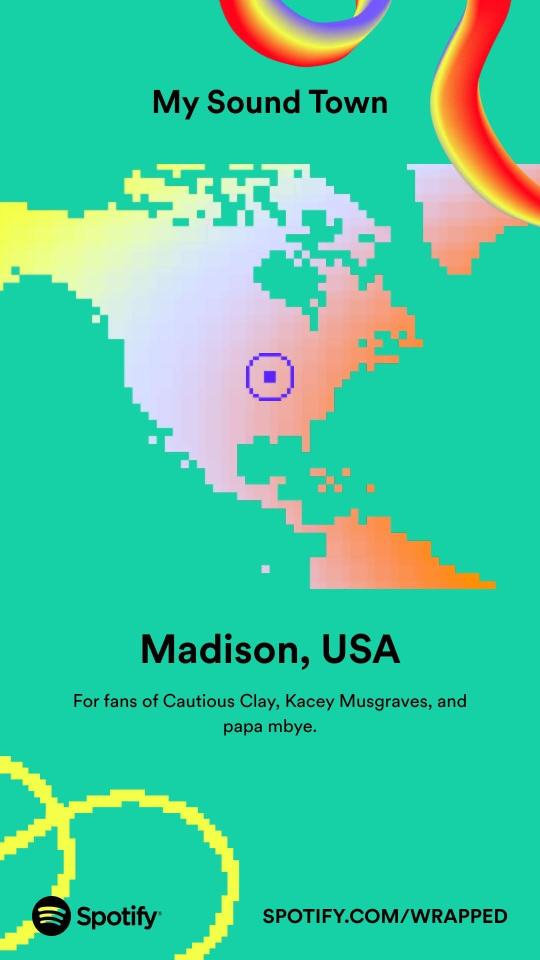
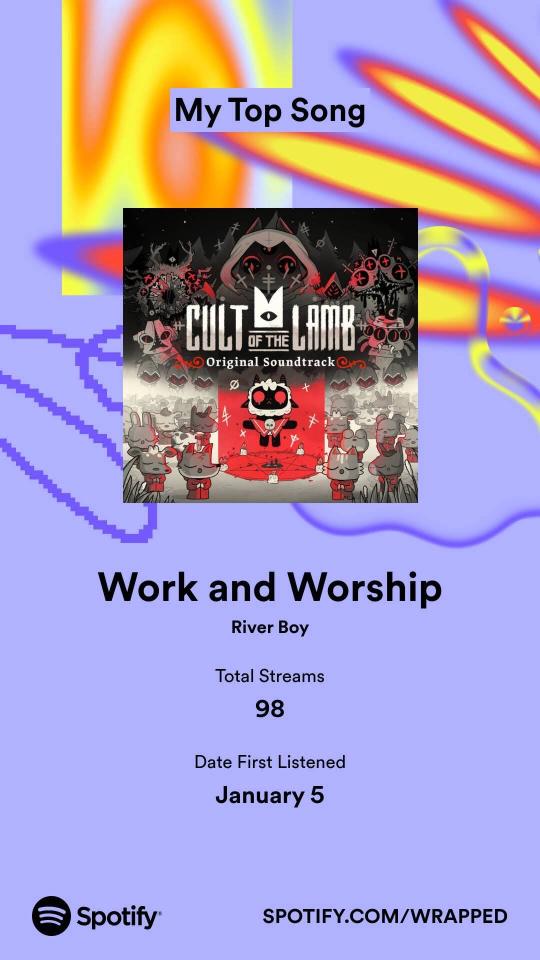
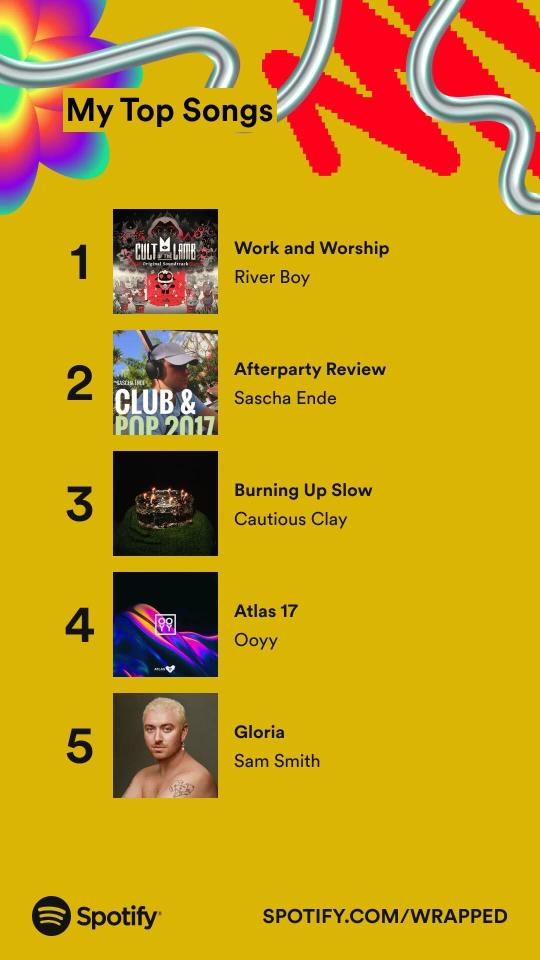
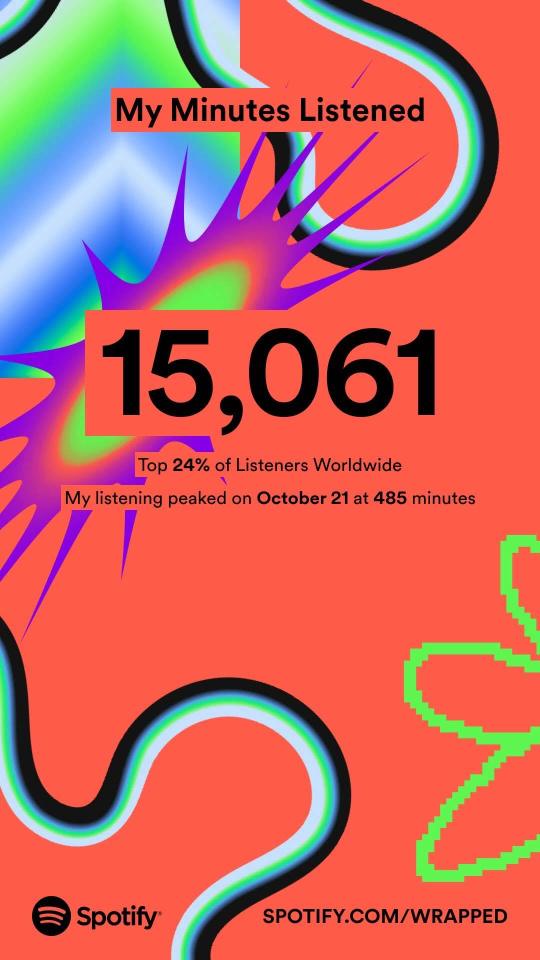

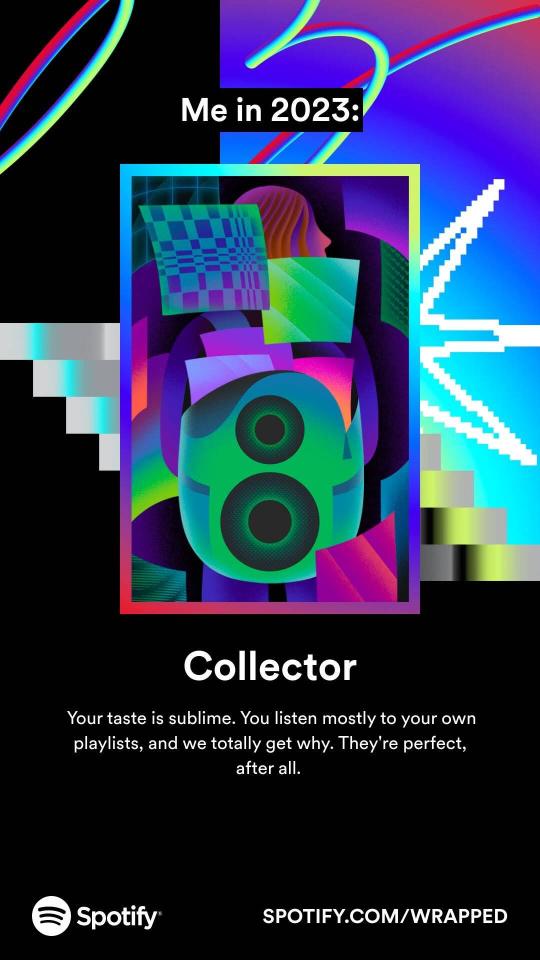
I knew I'd listened to a lot of background-y music this year, but Cult of the Lamb absolutely deserved to be #1, I thought it'd missed its chance to be high on the list last year
#don't know what otacore is but I did listen to a LOT of Living Tombstone & similar in the back half of the year so I'm guessing it's that.#catfishchat#really happy with the artist list ^-^#was obsessed w/ yuki kajiura for like 7 years so I'm doing school-era me proud#honestly this is much more like my highschool listening style than what I've listened to in the past few years#highschool me would absolutely have listened to edm tracks on repeat -_-#but also would've liked starcadian and ghost#I don't feel great rewarding this platform for its dataharvesting but#I can't divest myself of all my known vices and this ^^^ is one of them.
2 notes
·
View notes
Link
Is this the “future” we were promised, or is it just another step toward the digital surveillance state, where nothing is private and everything has a price? Meta is ready to take your data and use it to push products you didn’t know you needed—until now. It’s a game of chess, and guess what? You’re the pawn.
0 notes
Text
no
you know what? lmfao fuck this fuck this im done
fuck "number go up" fuck "the hustle" fuck "the grind" i'll spit chalk and coal on the walls before i respect the machine for another damn second i am not a "social media manager" im not a "content creator." im an artist
and i hope every socmed dataharvester that ever existed dies with Web 2.0 the same way a virus dies with its host we deserve better. we always deserved better.
98 notes
·
View notes
Text
Hey friends, come follow us on Mastodon @[email protected]! We post a lot of content there, and Ariel is a lot more active with replies over there (usually….).
#Mastodon#Fediverse#ClimateJustice#SolarpunkPresentsPodcast#solarpunk#podcast#podcasting#SocialMedia#Privacy#DataPrivacy#FederatedInstances#federation#DataHarvesting#FacebookAlternative#MetaAlternative#ActivityPub
2 notes
·
View notes
Text
my toxic trait is i keep the apple dataharvester journaling app on me home screen to pretend like i’m the sort of person who would ever use it lol
2 notes
·
View notes
Text
I cannot stand websites. Here's your new AI assistant Runk. Ask Glibbershit anything. Open DataHarvest can generate any image you want for you. Get your paper done with Plagisio. This is the future of online browsing: Metastasis AI. Let it on your devices. Let it in you.
3 notes
·
View notes
Text
Regulators pressure Elon Musk's X for Grok AI data harvesting
Regulators pressure Elon Musk's X for Grok AI data harvesting #dataharvesting #ElonMusk'sX #GrokAI #Regulatorspressure
0 notes
Text

Scrapers Triumph Seals offers a variety of scrapers, also known as wiper seals, excluders, or dust seals. These components play a crucial role in protecting hydraulic cylinders and systems from contamination. Please visit our website for additional information. Contact: 080-48519779 Visit: https://triumphseals.com/portfolio-item/protection-elements/ #WebScraper #DataScraping #WebCrawler #ScrapingTool #DataExtraction #DataMining #AutomatedScraping #ScrapeIt #ScrapingSoftware #Scraping101 #ScrapeTheWeb #ScrapeAndExtract #ScrapingTech #ScrapingSkills #ScrapingTutorial #ScrapingTips #ScrapeLikeAPro #ScrapingScripts #DataHarvesting #ScrapingService
0 notes
Text
Web Scraping: The Technological Ecosystem Driving Data-Driven Decision-Making
In an age where data reigns supreme, the art of web scraping has emerged as a linchpin in the technological ecosystem of data-driven decision-making. This intricate process, rooted in the realms of programming, networking, and data science, plays a pivotal role in harvesting, processing, and delivering real-time data insights to businesses across industries.
Sculpting the Web Landscape with Code
At its core, web scraping involves writing code that communicates with websites, mimicking human interaction. This technological dance with websites, often involving HTTP requests, requires a deep understanding of protocols, APIs, and data formats. Web scrapers navigate the intricacies of websites, locating data elements through HTML and CSS selectors, XPath, and even JavaScript evaluation.
Diving into the Technological Weeds: Proxy Management
In the quest for data, web scrapers often encounter challenges like IP blocking and CAPTCHA puzzles. Technological solutions in the form of proxy servers and CAPTCHA solvers are deployed to overcome these hurdles. Scrapers rotate through a pool of IP addresses to avoid detection and employ machine learning algorithms to decode CAPTCHAs, ensuring uninterrupted data extraction.
The Technological Renaissance: AI and Data Analytics
In a world brimming with data, web scraping technology integrates seamlessly with artificial intelligence and data analytics. Machine learning models are trained to analyze scraped data, uncover patterns, and generate actionable insights. This convergence of technologies empowers businesses to make data-driven decisions at a speed and scale previously unimaginable.
Ethical and Legal Technological Navigation
Amid the technological marvels, web scraping operates within a framework of ethics and legality. Respect for websites' terms of service, robots.txt files, and data privacy regulations is paramount. Technological solutions include compliance checks and data anonymization to align with ethical scraping practices.
The Technological Frontier Awaits
Web scraping stands as a testament to the harmonious coexistence of technology and data. As technology continues to advance, the potential of web scraping in transforming raw data into actionable insights grows exponentially. In the future, businesses will rely on this technological ecosystem to navigate the data-driven landscape, make informed decisions, and drive innovation.
In the grand tapestry of technology, web scraping is a masterpiece that weaves together the threads of programming, automation, and data science, creating a canvas upon which businesses can paint their data-driven destinies.
#WebScraping#DataDriven#DataHarvesting#Automation#Programming#Networking#DataScience#TechnologicalAutomation#IPRotation
0 notes