#Databricks Training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Lakehouse Architecture Best Practices: A Unified Data Future with AccentFuture
In the evolving landscape of data engineering, Lakehouse Architecture is emerging as a powerful paradigm that combines the best of data lakes and data warehouses. As businesses demand faster insights and real-time analytics across massive datasets, the Lakehouse model has become indispensable. At AccentFuture, our advanced courses empower learners with real-world skills in modern data architectures like the Lakehouse preparing them for the data-driven jobs of tomorrow.
What is Lakehouse Architecture?
Lakehouse Architecture is a modern data platform that merges the low-cost, scalable storage of a data lake with the structured data management and performance features of a data warehouse. It enables support for data science, machine learning, and BI workloads all within a single platform.
With engines like Apache Spark and platforms like Databricks, the Lakehouse allows for seamless unification of batch and streaming data, structured and unstructured formats, and analytics and ML workflows.

Top Best Practices for Implementing a Lakehouse Architecture
1. Start with a Clear Data Governance Strategy
Before jumping into implementation, define clear data governance policies. This includes data access control, lineage tracking, and auditability. Utilize tools like Unity Catalog in Databricks or Apache Ranger to set up granular access control across different data personas—engineers, analysts, scientists, and business users.
Tip from AccentFuture: We guide our learners on implementing end-to-end governance using real-world case studies and tools integrated with Spark and Azure.
2. Use Open Data Formats (Delta Lake, Apache Iceberg, Hudi)
Always build your Lakehouse on open table formats like Delta Lake, Apache Iceberg, or Apache Hudi. These formats support ACID transactions, schema evolution, time travel, and fast reads/writes—making your data lake reliable for production workloads.
Delta Lake, for example, enables versioning and rollback of data, making it perfect for enterprise-grade data processing.
3. Optimize Storage with Partitioning and Compaction
Efficient storage design is critical for performance. Apply best practices like:
Partitioning data based on high-cardinality columns (e.g., date, region).
Z-Ordering or clustering to optimize read performance.
Compaction to merge small files into larger ones to reduce I/O overhead.
At AccentFuture, our Databricks & PySpark Training includes labs that teach how to optimize partitioning strategies with Delta Lake.
4. Implement a Medallion Architecture (Bronze, Silver, Gold Layers)
Adopt the Medallion Architecture to organize your data pipeline efficiently:
Bronze Layer: Raw ingested data (logs, streams, JSON, CSV, etc.)
Silver Layer: Cleaned, structured data (joins, filtering, type casting).
Gold Layer: Business-level aggregates and KPIs for reporting and dashboards.
This tiered approach helps isolate data quality issues, simplifies debugging, and enhances performance for end-users.
5. Use Data Lineage and Metadata Tracking
Visibility is key. Implement metadata tracking tools like:
Data Catalogs (Unity Catalog, AWS Glue Data Catalog)
Lineage Tracking tools (OpenLineage, Amundsen)
These tools help teams understand where data came from, how it was transformed, and who accessed it—ensuring transparency and reproducibility.
6. Embrace Automation with CI/CD Pipelines
Use CI/CD pipelines (GitHub Actions, Azure DevOps, or Databricks Repos) to automate:
Data ingestion workflows
ETL pipeline deployments
Testing and validation
Automation reduces manual errors, enhances collaboration, and ensures version control across teams.
AccentFuture’s project-based training introduces learners to modern CI/CD practices for data engineering workflows.
7. Integrate Real-Time and Batch Processing
Lakehouse supports both streaming and batch data processing. Tools like Apache Spark Structured Streaming and Apache Kafka can be integrated for real-time data ingestion. Use triggers and watermarking to handle late-arriving data efficiently.
8. Monitor, Audit, and Optimize Continuously
A Lakehouse is never “complete.” Continuously monitor:
Query performance (using Databricks Query Profile or Spark UI)
Storage usage and costs
Data pipeline failures and SLAs
Audit data access and transformations to ensure compliance with internal and external regulations.

Why Learn Lakehouse Architecture at AccentFuture?
At AccentFuture, we don’t just teach theory we bring real-world Lakehouse use cases into the classroom. Our Databricks + PySpark online courses are crafted by industry experts, covering everything from Delta Lake to real-time pipelines using Kafka and Airflow.
What You Get:
✅ Hands-on Projects ✅ Industry Interview Preparation ✅ Lifetime Access to Materials ✅ Certification Aligned with Market Demand ✅ Access to Mentorship & Career Support
Conclusion
Lakehouse Architecture is not just a trend—it’s the future of data engineering. By combining reliability, scalability, and flexibility in one unified platform, it empowers organizations to extract deeper insights from their data. Implementing best practices is key to harnessing its full potential.
Whether you're a budding data engineer, a seasoned analyst, or a business professional looking to upskill, AccentFuture’s Lakehouse-focused curriculum will help you lead the charge in the next wave of data innovation.
Ready to transform your data skills? 📚 Enroll in our Lakehouse & PySpark Training today at www.accentfuture.com
Related Articles :-
Databricks Certified Data Engineer Professional Exam
Ignore PySpark, Regret Later: Databricks Skill That Pays Off
Databricks Interview Questions for Data Engineers
Stream-Stream Joins with Watermarks in Databricks Using Apache Spark
💡 Ready to Make Every Compute Count?
📓 Enroll now: https://www.accentfuture.com/enquiry-form/
📧 Email: [email protected]
📞 Call: +91–9640001789
🌐 Visit: www.accentfuture.com
0 notes
Text

Generative AI is redefining the data engineering landscape—from automated code generation and pipeline documentation to query optimization and synthetic data creation. This intelligent toolkit empowers data teams to move faster, smarter, and more efficiently. At AccentFuture, we prepare professionals to harness these innovations for next-gen data systems. 🚀🔧 #GenerativeAI #DataEngineering #AccentFuture #AIinData #QueryOptimization #SyntheticData #LearnDatabricks
#best databricks online course#databricks course#databricks online course#databricks online course training#databricks online training#databricks training#databricks training course#learn databricks
0 notes
Text

Databricks Training
Master Databricks with AccentFuture! Learn data engineering, machine learning, and analytics using Apache Spark. Gain hands-on experience with labs, real-world projects, and expert guidance to accelerate your journey to data mastery.
0 notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text

💻 Online Hands-on apache spark Training by Industry Experts | Powered by Sunbeam Institute
🎯 Why Learn Apache Spark with PySpark? ✔ Process huge datasets faster using in-memory computation ✔ Learn scalable data pipelines with real-time streaming ✔ Work with DataFrames, SQL, MLlib, Kafka & Databricks ✔ In-demand skill for Data Engineers, Analysts & Cloud Developers ✔ Boost your resume with project experience & certification readiness
📘 What You'll Master in This Course: ✅ PySpark Fundamentals – RDDs, Lazy Evaluation, Spark Context ✅ Spark SQL & DataFrames – Data handling & transformation ✅ Structured Streaming – Real-time data processing in action ✅ Architecture & Optimization – DAG, Shuffle, Partitioning ✅ Apache Kafka Integration – Connect Spark with Kafka Streams ✅ Databricks Lakehouse Essentials – Unified data analytics platform ✅ Machine Learning with Spark MLlib – Intro to scalable ML workflows ✅ Capstone Project – Apply skills in a real-world data project ✅ Hands-on Labs – With guidance from industry-experienced trainers
📌 Course Benefits: ✔ Learn from experienced mentors with practical exposure ✔ Become job-ready for roles like Data Engineer, Big Data Developer ✔ Build real-world confidence with hands-on implementation ✔ Flexible online format – learn from anywhere ✔ Certification-ready training to boost your profile
🧠 Who Should Join? 🔹 Working professionals in Python, SQL, BI, ETL 🔹 Data Science or Big Data enthusiasts 🔹 Freshers with basic coding knowledge looking to upskill 🔹 Anyone aspiring to work in real-time data & analytics
#Apache Spark Course#PySpark Training#Data Engineering Classes#Big Data Online Course#Kafka & Spark Integration#Databricks Lakehouse#Spark Mllib#Best PySpark Course India#Real-time Streaming Course#Sunbeam PySpark Training
0 notes
Text
Data Engineering with Databricks Certification | upGrad Enterprise
Master big data skills with upGrad Enterprise’s Data Engineering with Databricks program. Learn to build reliable pipelines, work with Apache Spark, and earn a certification that validates your expertise in modern data architecture.
#Data Engineering With Databricks#Spark training#data engineering certification#Databricks course#big data skills#upGrad Enterprise
0 notes
Text
01 Databricks Tutorial 2025 | Databricks for Data Engineering | Azure Databricks Training
Azure Databricks | Databricks Tutorials | Databricks Training | Databricks End to End playlist This Databricks tutorial playlist covers … source
0 notes
Text

Quiz Time: Which framework does azure data bricks use?. comment your answer below!
To know more about frameworks and other topics in #azureadmin, #azuredevops, #azuredataengineer join in azure trainings
For more details contact
Phone:+91 9882498844
website: https://azuretrainings.in/
Email: [email protected]
0 notes
Text

Empowering Data Enthusiasts: The Continuous Growth Cycle
This visual illustrates the Cycle of Data Enthusiast Empowerment—starting with learning Databricks and progressing through community engagement, project contributions, skill enhancement, reputation building, and staying ahead in the data landscape. At AccentFuture, we foster this growth cycle through expert-led courses, hands-on training, and active community support—empowering learners to thrive in the dynamic world of data.
#databricks training#databricks training course#pyspark training#databricks online training#learn databricks
0 notes
Text
#best databricks online course#databricks course#databricks online course#databricks online course training#databricks online training#databricks training#databricks training course#learn databricks
0 notes
Text

Boost your career with AccentFuture's Databricks online training. Learn from industry experts, master real-time data analytics, and get hands-on experience with Databricks tools. Flexible learning, job-ready skills, and certification support included.
#course training#databricks online training#databricks training#databricks training course#learn databricks
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
Data Engineering with Databricks Certification | upGrad
Master Data Engineering with Databricks through upGrad’s industry-aligned certification. Learn ETL, Delta Lake, data pipelines, and big data tools on Databricks to power real-time analytics and scalable data solutions. Ideal for aspiring data engineers and analysts.
#Data Engineering with Databricks#data certification#Databricks course#big data engineering#ETL training
0 notes
Text
[Fabric] Leer y escribir storage con Databricks
Muchos lanzamientos y herramientas dentro de una sola plataforma haciendo participar tanto usuarios técnicos (data engineers, data scientists o data analysts) como usuarios finales. Fabric trajo una unión de involucrados en un único espacio. Ahora bien, eso no significa que tengamos que usar todas pero todas pero todas las herramientas que nos presenta.
Si ya disponemos de un excelente proceso de limpieza, transformación o procesamiento de datos con el gran popular Databricks, podemos seguir usándolo.
En posts anteriores hemos hablado que Fabric nos viene a traer un alamacenamiento de lake de última generación con open data format. Esto significa que nos permite utilizar los más populares archivos de datos para almacenar y que su sistema de archivos trabaja con las convencionales estructuras open source. En otras palabras podemos conectarnos a nuestro storage desde herramientas que puedan leerlo. También hemos mostrado un poco de Fabric notebooks y como nos facilita la experiencia de desarrollo.
En este sencillo tip vamos a ver como leer y escribir, desde databricks, nuestro Fabric Lakehouse.
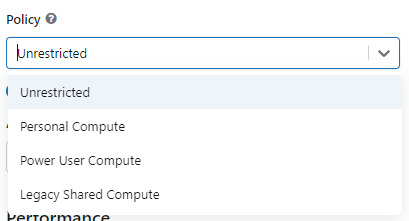
Para poder comunicarnos entre databricks y Fabric lo primero es crear un recurso AzureDatabricks Premium Tier. Lo segundo, asegurarnos de dos cosas en nuestro cluster:
Utilizar un policy "unrestricted" o "power user compute"
2. Asegurarse que databricks podría pasar nuestras credenciales por spark. Eso podemos activarlo en las opciones avanzadas
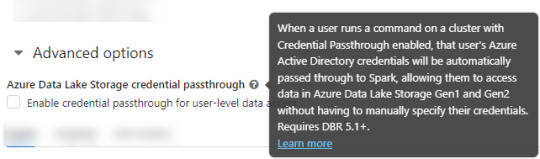
NOTA: No voy a entrar en más detalles de creación de cluster. El resto de las opciones de procesamiento les dejo que investiguen o estimo que ya conocen si están leyendo este post.
Ya creado nuestro cluster vamos a crear un notebook y comenzar a leer data en Fabric. Esto lo vamos a conseguir con el ABFS (Azure Bllob Fyle System) que es una dirección de formato abierto cuyo driver está incluido en Azure Databricks.
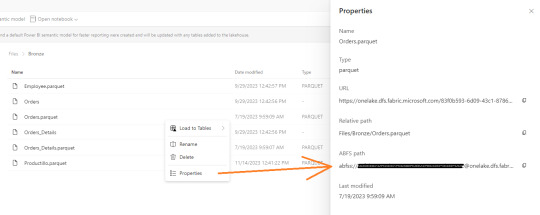
La dirección debe componerse de algo similar a la siguiente cadena:
oneLakePath = 'abfss://[email protected]/myLakehouse.lakehouse/Files/'
Conociendo dicha dirección ya podemos comenzar a trabajar como siempre. Veamos un simple notebook que para leer un archivo parquet en Lakehouse Fabric
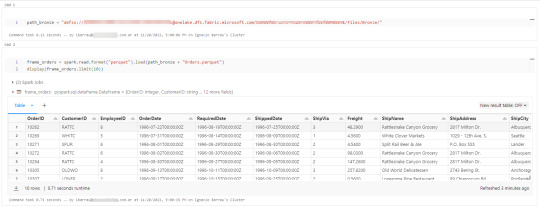
Gracias a la configuración del cluster, los procesos son tan simples como spark.read
Así de simple también será escribir.

Iniciando con una limpieza de columnas innecesarias y con un sencillo [frame].write ya tendremos la tabla en silver limpia.
Nos vamos a Fabric y podremos encontrarla en nuestro Lakehouse
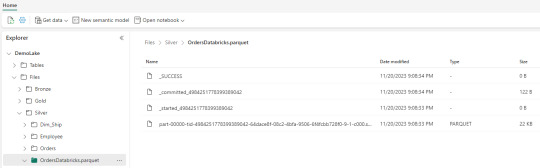
Así concluye nuestro procesamiento de databricks en lakehouse de Fabric, pero no el artículo. Todavía no hablamos sobre el otro tipo de almacenamiento en el blog pero vamos a mencionar lo que pertine a ésta lectura.
Los Warehouses en Fabric también están constituidos con una estructura tradicional de lake de última generación. Su principal diferencia consiste en brindar una experiencia de usuario 100% basada en SQL como si estuvieramos trabajando en una base de datos. Sin embargo, por detras, podrémos encontrar delta como un spark catalog o metastore.
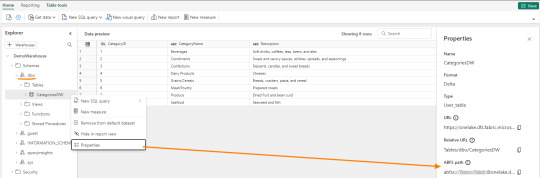
El path debería verse similar a esto:
path_dw = "abfss://[email protected]/WarehouseName.Datawarehouse/Tables/dbo/"
Teniendo en cuenta que Fabric busca tener contenido delta en su Spark Catalog de Lakehouse (tables) y en su Warehouse, vamos a leer como muestra el siguiente ejemplo
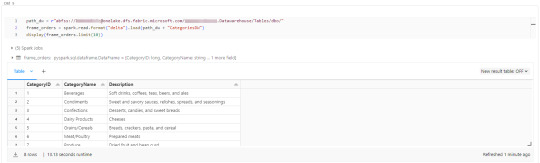
Ahora si concluye nuestro artículo mostrando como podemos utilizar Databricks para trabajar con los almacenamientos de Fabric.
#fabric#microsoftfabric#fabric cordoba#fabric jujuy#fabric argentina#fabric tips#fabric tutorial#fabric training#fabric databricks#databricks#azure databricks#pyspark
0 notes
Text


Skillup Yourself with #Azure #Power BI and #SQL
#azuretraining#azure data engineer course#azure data engineer training#azuredatafactory#azure data engineer online training#sqlschool#sql school training#azure databricks training#azure data engineer projects
0 notes
Text
Mythbusting Generative AI: The Eco-friendly, Ethical ChatGPT Is Out There
I've been hyperfixating learning a lot about Generative AI recently and here's what I've found - genAI doesn’t just apply to chatGPT or other large language models.
Small Language Models (specialised and more efficient versions of the large models)
are also generative
can perform in a similar way to large models for many writing and reasoning tasks
are community-trained on ethical data
and can run on your laptop.

"But isn't analytical AI good and generative AI bad?"
Fact: Generative AI creates stuff and is also used for analysis
In the past, before recent generative AI developments, most analytical AI relied on traditional machine learning models. But now the two are becoming more intertwined. Gen AI is being used to perform analytical tasks – they are no longer two distinct, separate categories. The models are being used synergistically.
For example, Oxford University in the UK is partnering with open.ai to use generative AI (ChatGPT-Edu) to support analytical work in areas like health research and climate change.

"But Generative AI stole fanfic. That makes any use of it inherently wrong."
Fact: there are Generative AI models developed on ethical data sets
Yes, many large language models scraped sites like AO3 without consent, incorporating these into their datasets to train on. That’s not okay.
But there are Small Language Models (compact, less powerful versions of LLMs) being developed which are built on transparent, opt-in, community-curated data sets – and that can still perform generative AI functions in the same way that the LLMS do (just not as powerfully). You can even build one yourself.

No it's actually really cool! Some real-life examples:
Dolly (Databricks): Trained on open, crowd-sourced instructions
RedPajama (Together.ai): Focused on creative-commons licensed and public domain data
There's a ton more examples here.
(A word of warning: there are some SLMs like Microsoft’s Phi-3 that have likely been trained on some of the datasets hosted on the platform huggingface (which include scraped web content like from AO3), and these big companies are being deliberately sketchy about where their datasets came from - so the key is to check the data set. All SLMs should be transparent about what datasets they’re using).
"But AI harms the environment, so any use is unethical."
Fact: There are small language models that don't use massive centralised data centres.
SLMs run on less energy, don’t require cloud servers or data centres, and can be used on laptops, phones, Raspberry Pi’s (basically running AI locally on your own device instead of relying on remote data centres)
If you're interested -
You can build your own SLM and even train it on your own data.

Let's recap
Generative AI doesn't just include the big tools like chatGPT - it includes the Small Language Models that you can run ethically and locally
Some LLMs are trained on fanfic scraped from AO3 without consent. That's not okay
But ethical SLMs exist, which are developed on open, community-curated data that aims to avoid bias and misinformation - and you can even train your own models
These models can run on laptops and phones, using less energy
AI is a tool, it's up to humans to wield it responsibly

It means everything – and nothing
Everything – in the sense that it might remove some of the barriers and concerns people have which makes them reluctant to use AI. This may lead to more people using it - which will raise more questions on how to use it well.
It also means that nothing's changed – because even these ethical Small Language Models should be used in the same way as the other AI tools - ethically, transparently and responsibly.
So now what? Now, more than ever, we need to be having an open, respectful and curious discussion on how to use AI well in writing.
In the area of creative writing, it has the potential to be an awesome and insightful tool - a psychological mirror to analyse yourself through your stories, a narrative experimentation device (e.g. in the form of RPGs), to identify themes or emotional patterns in your fics and brainstorming when you get stuck -
but it also has capacity for great darkness too. It can steal your voice (and the voice of others), damage fandom community spirit, foster tech dependency and shortcut the whole creative process.

Just to add my two pence at the end - I don't think it has to be so all-or-nothing. AI shouldn't replace elements we love about fandom community; rather it can help fill the gaps and pick up the slack when people aren't available, or to help writers who, for whatever reason, struggle or don't have access to fan communities.
People who use AI as a tool are also part of fandom community. Let's keep talking about how to use AI well.
Feel free to push back on this, DM me or leave me an ask (the anon function is on for people who need it to be). You can also read more on my FAQ for an AI-using fanfic writer Master Post in which I reflect on AI transparency, ethics and something I call 'McWriting'.
#fandom#fanfiction#ethical ai#ai discourse#writing#writers#writing process#writing with ai#generative ai#my ai posts
5 notes
·
View notes