#pyspark course
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text

💻 Online Hands-on apache spark Training by Industry Experts | Powered by Sunbeam Institute
🎯 Why Learn Apache Spark with PySpark? ✔ Process huge datasets faster using in-memory computation ✔ Learn scalable data pipelines with real-time streaming ✔ Work with DataFrames, SQL, MLlib, Kafka & Databricks ✔ In-demand skill for Data Engineers, Analysts & Cloud Developers ✔ Boost your resume with project experience & certification readiness
📘 What You'll Master in This Course: ✅ PySpark Fundamentals – RDDs, Lazy Evaluation, Spark Context ✅ Spark SQL & DataFrames – Data handling & transformation ✅ Structured Streaming – Real-time data processing in action ✅ Architecture & Optimization – DAG, Shuffle, Partitioning ✅ Apache Kafka Integration – Connect Spark with Kafka Streams ✅ Databricks Lakehouse Essentials – Unified data analytics platform ✅ Machine Learning with Spark MLlib – Intro to scalable ML workflows ✅ Capstone Project – Apply skills in a real-world data project ✅ Hands-on Labs – With guidance from industry-experienced trainers
📌 Course Benefits: ✔ Learn from experienced mentors with practical exposure ✔ Become job-ready for roles like Data Engineer, Big Data Developer ✔ Build real-world confidence with hands-on implementation ✔ Flexible online format – learn from anywhere ✔ Certification-ready training to boost your profile
🧠 Who Should Join? 🔹 Working professionals in Python, SQL, BI, ETL 🔹 Data Science or Big Data enthusiasts 🔹 Freshers with basic coding knowledge looking to upskill 🔹 Anyone aspiring to work in real-time data & analytics
#Apache Spark Course#PySpark Training#Data Engineering Classes#Big Data Online Course#Kafka & Spark Integration#Databricks Lakehouse#Spark Mllib#Best PySpark Course India#Real-time Streaming Course#Sunbeam PySpark Training
0 notes
Text

Empowering Data Enthusiasts: The Continuous Growth Cycle
This visual illustrates the Cycle of Data Enthusiast Empowerment—starting with learning Databricks and progressing through community engagement, project contributions, skill enhancement, reputation building, and staying ahead in the data landscape. At AccentFuture, we foster this growth cycle through expert-led courses, hands-on training, and active community support—empowering learners to thrive in the dynamic world of data.
#databricks training#databricks training course#pyspark training#databricks online training#learn databricks
0 notes
Text
Data engineer training and placement in Pune - JVM Institute
Kickstart your career with JVM Institute's top-notch Data Engineer Training in Pune. Expert-led courses, hands-on projects, and guaranteed placement support to transform your future!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#Data engineer training and placement in Pune#Big Data courses in Pune#PySpark Courses in Pune
0 notes
Text
Master PySpark for High-Speed Data Processing Online!
youtube
0 notes
Text
Python Training institute in Hyderabad
Best Python Training in Hyderabad by RS Trainings
Python is one of the most popular and versatile programming languages in the world, renowned for its simplicity, readability, and broad applicability across various domains like web development, data science, artificial intelligence, and more. If you're looking to learn Python or enhance your Python skills, RS Trainings offers the best Python training in Hyderabad, guided by industry IT experts. Recognized as the best place for better learning, RS Trainings is committed to delivering top-notch education that equips you with practical skills and knowledge.

Why Choose RS Trainings for Python?
1. Expert Instructors: Our Python training program is led by seasoned industry professionals who bring a wealth of experience and insights. They are adept at simplifying complex concepts and providing real-world examples to ensure you gain a deep understanding of Python.
2. Comprehensive Curriculum: The curriculum is meticulously designed to cover everything from the basics of Python to advanced topics. You'll learn about variables, data types, control structures, functions, modules, file handling, object-oriented programming, web development frameworks like Django and Flask, and data analysis libraries like Pandas and NumPy.
3. Hands-on Learning: We emphasize a practical approach to learning. Our training includes numerous hands-on exercises, coding assignments, and real-time projects that help you apply the concepts you learn in class, ensuring you gain practical experience.
4. Flexible Learning Options: RS Trainings offers both classroom and online training options to accommodate different learning preferences and schedules. Whether you are a working professional or a student, you can find a batch that fits your timetable.
5. Career Support: Beyond just training, we provide comprehensive career support, including resume building, interview preparation, and job placement assistance. Our aim is to help you smoothly transition into a successful career in Python programming.
Course Highlights:
Introduction to Python: Get an overview of Python and its applications, understanding why it is a preferred language for various domains.
Core Python Concepts: Dive into the core concepts, including variables, data types, control structures, loops, and functions.
Object-Oriented Programming: Learn about object-oriented programming in Python, covering classes, objects, inheritance, and polymorphism.
Web Development: Explore web development using popular frameworks like Django and Flask, and build your own web applications.
Data Analysis: Gain proficiency in data analysis using libraries like Pandas, NumPy, and Matplotlib.
Real-world Projects: Work on real-world projects that simulate industry scenarios, enhancing your practical skills and understanding.
Who Should Enroll?
Aspiring Programmers: Individuals looking to start a career in programming.
Software Developers: Developers wanting to add Python to their skill set.
Data Scientists and Analysts: Professionals aiming to leverage Python for data analysis and machine learning.
Web Developers: Web developers interested in using Python for backend development.
Students and Enthusiasts: Anyone with a passion for learning programming and Python.
Enroll Today!
Join RS Trainings, the best Python training institute in Hyderabad, and embark on a journey to master one of the most powerful programming languages. Our expert-led training, practical approach, and comprehensive support ensure you are well-prepared to excel in your career.
Visit our website or contact us to learn more about our Python training program, upcoming batches, and enrollment details. Elevate your programming skills with RS Trainings – the best place for better learning in Hyderabad!
#python training#python online training#python training in Hyderabad#python training institute in Hyderabad#python course online Hyderabad#pyspark course online
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
How to Read and Write Data in PySpark
The Python application programming interface known as PySpark serves as the front end for Apache Spark execution of big data operations. The most crucial skill required for PySpark work involves accessing and writing data from sources which include CSV, JSON and Parquet files.
In this blog, you’ll learn how to:
Initialize a Spark session
Read data from various formats
Write data to different formats
See expected outputs for each operation
Let’s dive in step-by-step.
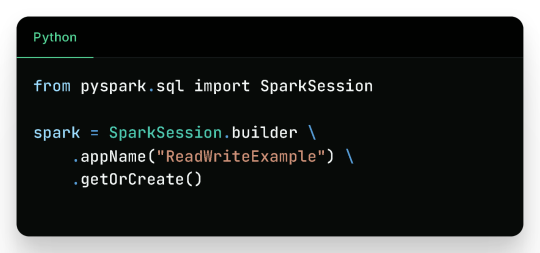
Getting Started
Before reading or writing, start by initializing a SparkSession.
Reading Data in PySpark
1. Reading CSV Files
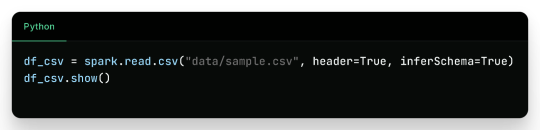
Sample CSV Data (sample.csv):

Output:

2. Reading JSON Files
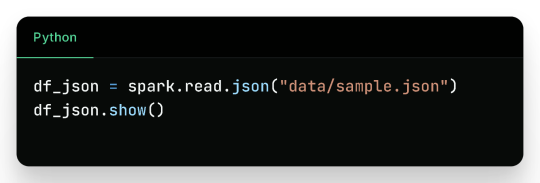
Sample JSON (sample.json):

Output:

3. Reading Parquet Files
Parquet is optimized for performance and often used in big data pipelines.

Assuming the parquet file has similar content:
Output:
4. Reading from a Database (JDBC)

Sample Table employees in MySQL:

Output:

Writing Data in PySpark
1. Writing to CSV
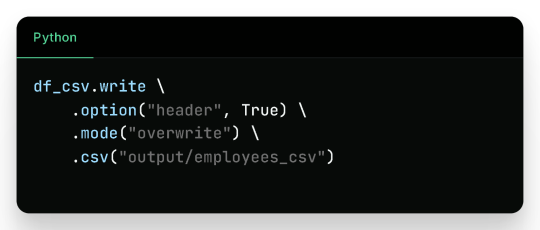
Output Files (folder output/employees_csv/):

Sample content:

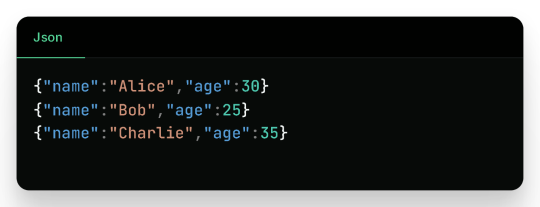
2. Writing to JSON

Sample JSON output (employees_json/part-*.json):
3. Writing to Parquet
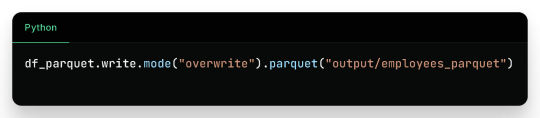
Output:
Binary Parquet files saved inside output/employees_parquet/
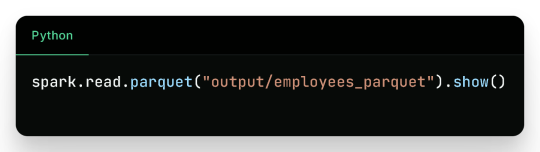
You can verify the contents by reading it again:
4. Writing to a Database
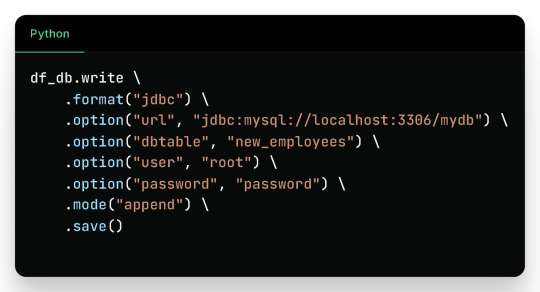
Check the new_employees table in your database — it should now include all the records.
Write Modes in PySpark
Mode
Description
overwrite
Overwrites existing data
append
Appends to existing data
ignore
Ignores if the output already exists
error
(default) Fails if data exists
Real-Life Use Case
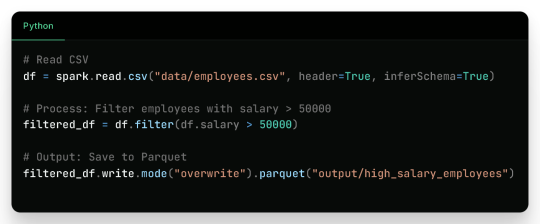
Filtered Output:
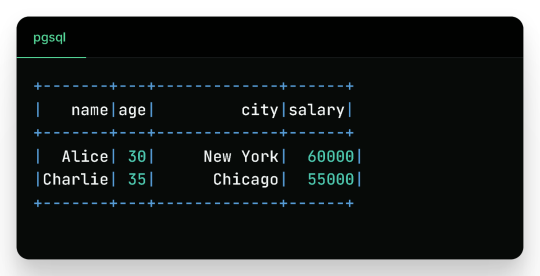
Wrap-Up
Reading and writing data in PySpark is efficient, scalable, and easy once you understand the syntax and options. This blog covered:
Reading from CSV, JSON, Parquet, and JDBC
Writing to CSV, JSON, Parquet, and back to Databases
Example outputs for every format
Best practices for production use
Keep experimenting and building real-world data pipelines — and you’ll be a PySpark pro in no time!
🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: [email protected]
🌍Visit Us: AccentFuture
#apache pyspark training#best pyspark course#best pyspark training#pyspark course online#pyspark online classes#pyspark training#pyspark training online
0 notes
Text
PySpark Courses in Pune - JVM Institute
In today’s dynamic landscape, data reigns supreme, reshaping businesses across industries. Those embracing Data Engineering technologies are gaining a competitive edge by amalgamating raw data with advanced algorithms. Master PySpark with expert-led courses at JVM Institute in Pune. Learn big data processing, real-time analytics, and more. Join now to boost your career!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#PySpark Courses in Pune#PySpark Courses in PCMC#Pune
0 notes
Text
CSE 6242 / CX 4242 HW 3: Spark, Docker, DataBricks, AWS and GCP Solved
Q1 [15 points] Analyzing trips data with PySpark Follow these instructions to download and set up a preconfigured Docker image that you will use for this assignment. that you will use for this assignment. Why use Docker? In earlier iterations of this course, students installed software on their own machines, and we (both students and instructor team) ran into many issues that could not be…
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Text
The Microsoft Fabric DP-700: Fabric Data Engineer Associate course is a live, instructor-led online program designed to thoroughly prepare you for the official DP-700 exam. This training spans approximately 4 to 4.5 weeks and consists of weekend classes. It offers 24/7 support, lifetime access to updated content, and hands-on projects, including lakehouse creation, real-time pipelines with Event Streams, Delta Lake management, and CI/CD pipelines.
The Microsoft Fabric Training Online curriculum is aligned with Microsoft’s certification objectives and covers essential topics such as workspace setup, data ingestion, transformation, security, monitoring, and performance tuning within Microsoft Fabric. Participants will also learn SQL, PySpark, Kusto Query Language (KQL), Azure integration, and best practices for data governance and optimization.
With over 15,000 learners and strong 4.5-star reviews, the program combines expert-led sessions, real-world labs, mock exams, and certification guidance to help students acquire practical skills and the credentials needed for roles such as Fabric Data Engineer or AI-powered data specialist.
1 note
·
View note
Text
PySpark Tutorial | Full Course (From Zero to Pro!)
PySpark Tutorial | Apache Spark Full course | PySpark Real-Time Scenarios What You’ll Learn in in the next 6 Hours? – Spark … source
0 notes
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
Creating a Scalable Amazon EMR Cluster on AWS in Minutes

Minutes to Scalable EMR Cluster on AWS
AWS EMR cluster
Spark helps you easily build up an Amazon EMR cluster to process and analyse data. This page covers Plan and Configure, Manage, and Clean Up.
This detailed guide to cluster setup:
Amazon EMR Cluster Configuration
Spark is used to launch an example cluster and run a PySpark script in the course. You must complete the “Before you set up Amazon EMR” exercises before starting.
While functioning live, the sample cluster will incur small per-second charges under Amazon EMR pricing, which varies per location. To avoid further expenses, complete the tutorial’s final cleaning steps.
The setup procedure has numerous steps:
Amazon EMR Cluster and Data Resources Configuration
This initial stage prepares your application and input data, creates your data storage location, and starts the cluster.
Setting Up Amazon EMR Storage:
Amazon EMR supports several file systems, but this article uses EMRFS to store data in an S3 bucket. EMRFS reads and writes to Amazon S3 in Hadoop.
This lesson requires a specific S3 bucket. Follow the Amazon Simple Storage Service Console User Guide to create a bucket.
You must create the bucket in the same AWS region as your Amazon EMR cluster launch. Consider US West (Oregon) us-west-2.
Amazon EMR bucket and folder names are limited. Lowercase letters, numerals, periods (.), and hyphens (-) can be used, but bucket names cannot end in numbers and must be unique across AWS accounts.
The bucket output folder must be empty.
Small Amazon S3 files may incur modest costs, but if you’re within the AWS Free Tier consumption limitations, they may be free.
Create an Amazon EMR app using input data:
Standard preparation involves uploading an application and its input data to Amazon S3. Submit work with S3 locations.
The PySpark script examines 2006–2020 King County, Washington food business inspection data to identify the top ten restaurants with the most “Red” infractions. Sample rows of the dataset are presented.
Create a new file called health_violations.py and copy the source code to prepare the PySpark script. Next, add this file to your new S3 bucket. Uploading instructions are in Amazon Simple Storage Service’s Getting Started Guide.
Download and unzip the food_establishment_data.zip file, save the CSV file to your computer as food_establishment_data.csv, then upload it to the same S3 bucket to create the example input data. Again, see the Amazon Simple Storage Service Getting Started Guide for uploading instructions.
“Prepare input data for processing with Amazon EMR” explains EMR data configuration.
Create an Amazon EMR Cluster:
Apache Spark and the latest Amazon EMR release allow you to launch the example cluster after setting up storage and your application. This may be done with the AWS Management Console or CLI.
Console Launch:
Launch Amazon EMR after login into AWS Management Console.
Start with “EMR on EC2” > “Clusters” > “Create cluster”. Note the default options for “Release,” “Instance type,” “Number of instances,” and “Permissions”.
Enter a unique “Cluster name” without <, >, $, |, or `. Install Spark from “Applications” by selecting “Spark”. Note: Applications must be chosen before launching the cluster. Check “Cluster logs” to publish cluster-specific logs to Amazon S3. The default destination is s3://amzn-s3-demo-bucket/logs. Replace with S3 bucket. A new ‘logs’ subfolder is created for log files.
Select your two EC2 keys under “Security configuration and permissions”. For the instance profile, choose “EMR_DefaultRole” for Service and “EMR_EC2_DefaultRole” for IAM.
Choose “Create cluster”.
The cluster information page appears. As the EMR fills the cluster, its “Status” changes from “Starting” to “Running” to “Waiting”. Console view may require refreshing. Status switches to “Waiting” when cluster is ready to work.
AWS CLI’s aws emr create-default-roles command generates IAM default roles.
Create a Spark cluster with aws emr create-cluster. Name your EC2 key pair –name, set –instance-type, –instance-count, and –use-default-roles. The sample command’s Linux line continuation characters () may need Windows modifications.
Output will include ClusterId and ClusterArn. Remember your ClusterId for later.
Check your cluster status using aws emr describe-cluster –cluster-id myClusterId>.
The result shows the Status object with State. As EMR deployed the cluster, the State changed from STARTING to RUNNING to WAITING. When ready, operational, and up, the cluster becomes WAITING.
Open SSH Connections
Before connecting to your operating cluster via SSH, update your cluster security groups to enable incoming connections. Amazon EC2 security groups are virtual firewalls. At cluster startup, EMR created default security groups: ElasticMapReduce-slave for core and task nodes and ElasticMapReduce-master for main.
Console-based SSH authorisation:
Authorisation is needed to manage cluster VPC security groups.
Launch Amazon EMR after login into AWS Management Console.
Select the updateable cluster under “Clusters”. The “Properties” tab must be selected.
Choose “Networking” and “EC2 security groups (firewall)” from the “Properties” tab. Select the security group link under “Primary node”.
EC2 console is open. Select “Edit inbound rules” after choosing “Inbound rules”.
Find and delete any public access inbound rule (Type: SSH, Port: 22, Source: Custom 0.0.0.0/0). Warning: The ElasticMapReduce-master group’s pre-configured rule that allowed public access and limited traffic to reputable sources should be removed.
Scroll down and click “Add Rule”.
Choose “SSH” for “Type” to set Port Range to 22 and Protocol to TCP.
Enter “My IP” for “Source” or a range of “Custom” trustworthy client IP addresses. Remember that dynamic IPs may need updating. Select “Save.”
When you return to the EMR console, choose “Core and task nodes” and repeat these steps to provide SSH access to those nodes.
Connecting with AWS CLI:
SSH connections may be made using the AWS CLI on any operating system.
Use the command: AWS emr ssh –cluster-id –key-pair-file <~/mykeypair.key>. Replace with your ClusterId and the full path to your key pair file.
After connecting, visit /mnt/var/log/spark to examine master node Spark logs.
The next critical stage following cluster setup and access configuration is phased work submission.
#AmazonEMRcluster#EMRcluster#DataResources#SSHConnections#AmazonEC2#AWSCLI#technology#technews#technologynews#news#govindhtech
0 notes