#EMRFS
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
What are the benefits of Amazon EMR? Drawbacks of AWS EMR

Benefits of Amazon EMR
Amazon EMR has many benefits. These include AWS's flexibility and cost savings over on-premises resource development.
Cost-saving
Amazon EMR costs depend on instance type, number of Amazon EC2 instances, and cluster launch area. On-demand pricing is low, but Reserved or Spot Instances save much more. Spot instances can save up to a tenth of on-demand costs.
Note
Using Amazon S3, Kinesis, or DynamoDB with your EMR cluster incurs expenses irrespective of Amazon EMR usage.
Note
Set up Amazon S3 VPC endpoints when creating an Amazon EMR cluster in a private subnet. If your EMR cluster is on a private subnet without Amazon S3 VPC endpoints, you will be charged extra for S3 traffic NAT gates.
AWS integration
Amazon EMR integrates with other AWS services for cluster networking, storage, security, and more. The following list shows many examples of this integration:
Use Amazon EC2 for cluster nodes.
Amazon VPC creates the virtual network where your instances start.
Amazon S3 input/output data storage
Set alarms and monitor cluster performance with Amazon CloudWatch.
AWS IAM permissions setting
Audit service requests with AWS CloudTrail.
Cluster scheduling and launch with AWS Data Pipeline
AWS Lake Formation searches, categorises, and secures Amazon S3 data lakes.
Its deployment
The EC2 instances in your EMR cluster do the tasks you designate. When you launch your cluster, Amazon EMR configures instances using Spark or Apache Hadoop. Choose the instance size and type that best suits your cluster's processing needs: streaming data, low-latency queries, batch processing, or big data storage.
Amazon EMR cluster software setup has many options. For example, an Amazon EMR version can be loaded with Hive, Pig, Spark, and flexible frameworks like Hadoop. Installing a MapR distribution is another alternative. Since Amazon EMR runs on Amazon Linux, you can manually install software on your cluster using yum or the source code.
Flexibility and scalability
Amazon EMR lets you scale your cluster as your computing needs vary. Resizing your cluster lets you add instances during peak workloads and remove them to cut costs.
Amazon EMR supports multiple instance groups. This lets you employ Spot Instances in one group to perform jobs faster and cheaper and On-Demand Instances in another for guaranteed processing power. Multiple Spot Instance types might be mixed to take advantage of a better price.
Amazon EMR lets you use several file systems for input, output, and intermediate data. HDFS on your cluster's primary and core nodes can handle data you don't need to store beyond its lifecycle.
Amazon S3 can be used as a data layer for EMR File System applications to decouple computation and storage and store data outside of your cluster's lifespan. EMRFS lets you scale up or down to meet storage and processing needs independently. Amazon S3 lets you adjust storage and cluster size to meet growing processing needs.
Reliability
Amazon EMR monitors cluster nodes and shuts down and replaces instances as needed.
Amazon EMR lets you configure automated or manual cluster termination. Automatic cluster termination occurs after all procedures are complete. Transitory cluster. After processing, you can set up the cluster to continue running so you can manually stop it. You can also construct a cluster, use the installed apps, and manually terminate it. These clusters are “long-running clusters.”
Termination prevention can prevent processing errors from terminating cluster instances. With termination protection, you can retrieve data from instances before termination. Whether you activate your cluster by console, CLI, or API changes these features' default settings.
Security
Amazon EMR uses Amazon EC2 key pairs, IAM, and VPC to safeguard data and clusters.
IAM
Amazon EMR uses IAM for permissions. Person or group permissions are set by IAM policies. Users and groups can access resources and activities through policies.
The Amazon EMR service uses IAM roles, while instances use the EC2 instance profile. These roles allow the service and instances to access other AWS services for you. Amazon EMR and EC2 instance profiles have default roles. By default, roles use AWS managed policies generated when you launch an EMR cluster from the console and select default permissions. Additionally, the AWS CLI may construct default IAM roles. Custom service and instance profile roles can be created to govern rights outside of AWS.
Security groups
Amazon EMR employs security groups to control EC2 instance traffic. Amazon EMR shares a security group for your primary instance and core/task instances when your cluster is deployed. Amazon EMR creates security group rules to ensure cluster instance communication. Extra security groups can be added to your primary and core/task instances for more advanced restrictions.
Encryption
Amazon EMR enables optional server-side and client-side encryption using EMRFS to protect Amazon S3 data. After submission, Amazon S3 encrypts data server-side.
The EMRFS client on your EMR cluster encrypts and decrypts client-side encryption. AWS KMS or your key management system can handle client-side encryption root keys.
Amazon VPC
Amazon EMR launches clusters in Amazon VPCs. VPCs in AWS allow you to manage sophisticated network settings and access functionalities.
AWS CloudTrail
Amazon EMR and CloudTrail record AWS account requests. This data shows who accesses your cluster, when, and from what IP.
Amazon EC2 key pairs
A secure link between the primary node and your remote computer lets you monitor and communicate with your cluster. SSH or Kerberos can authenticate this connection. SSH requires an Amazon EC2 key pair.
Monitoring
Debug cluster issues like faults or failures utilising log files and Amazon EMR management interfaces. Amazon EMR can archive log files on Amazon S3 to save records and solve problems after your cluster ends. The Amazon EMR UI also has a task, job, and step-specific debugging tool for log files.
Amazon EMR connects to CloudWatch for cluster and job performance monitoring. Alarms can be set based on cluster idle state and storage use %.
Management interfaces
There are numerous Amazon EMR access methods:
The console provides a graphical interface for cluster launch and management. You may examine, debug, terminate, and describe clusters to launch via online forms. Amazon EMR is easiest to use via the console, requiring no scripting.
Installing the AWS Command Line Interface (AWS CLI) on your computer lets you connect to Amazon EMR and manage clusters. The broad AWS CLI includes Amazon EMR-specific commands. You can automate cluster administration and initialisation with scripts. If you prefer command line operations, utilise the AWS CLI.
SDK allows cluster creation and management for Amazon EMR calls. They enable cluster formation and management automation systems. This SDK is best for customising Amazon EMR. Amazon EMR supports Go, Java,.NET (C# and VB.NET), Node.js, PHP, Python, and Ruby SDKs.
A Web Service API lets you call a web service using JSON. A custom SDK that calls Amazon EMR is best done utilising the API.
Complexity:
EMR cluster setup and maintenance are more involved than with AWS Glue and require framework knowledge.
Learning curve
Setting up and optimising EMR clusters may require adjusting settings and parameters.
Possible Performance Issues:
Incorrect instance types or under-provisioned clusters might slow task execution and other performance.
Depends on AWS:
Due to its deep interaction with AWS infrastructure, EMR is less portable than on-premise solutions despite cloud flexibility.
#AmazonEMR#AmazonEC2#AmazonS3#AmazonVirtualPrivateCloud#EMRFS#AmazonEMRservice#Technology#technews#NEWS#technologynews#govindhtech
0 notes
Text

"I yabaegei ebapls hvai crhn n uss angt ulhtrbh dent eewhinr hcdtioeto. Aolb Emrf lopi'e oei nn rfrbueo upv pdto."
Muse mention: @high-seraphims
0 notes
Photo
https://www.facebook.com/100068341252491/videos/pcb.249091674045539/635595761076953
https://www.facebook.com/photo/?fbid=249087780712595&set=pcb.249091674045539
#litterally woke up with scratches behind my head#stuff dirt etc is floating around on the inside of my home hittting me#synthetic telepathy#rfid frequency#radiation frequency#sound squilching#emrf radiation
3 notes
·
View notes
Text
It was dealerships connected to people using emrf v2k cars that drive on they're own that infiltrated the EDC event in 2018 in Orlando and spawned sorrcerers.






2 notes
·
View notes
Note
gji go fid no f hmm no m gg bc h in jbhvbjh b!
m😸😓😴😓h?.!?$77;!!)hdjdxjd b😉😆😄😳🥳vh$)hdjdjhn
c
gkkvmy
or emrf
f
🔜
Envdkh
.shfks
Rg
Rje
T
😉
1 note
·
View note
Text
Global Closed MRI Systems Market Regional Analysis
The closed MRI system market has been divided into regions based on geography, including North America, Latin America, Europe, the Middle East, Asia Pacific, and Africa. Due to the significant adoption of closed MRI compared to open MRI, Europe has held the leading position in the closed MRI system market for the anticipated timeframe. For instance, the European Magnetic Resonance Forum (EMRF) Foundation claims that open systems are mostly sold in the United States and have a small market share in Europe. Due to this, closed MRI systems are in demand in Europe for use in diagnosing patients.
Read More:
https://knackersblogger.blogspot.com/2022/09/closed-mri-systems-market-global.html
0 notes
Text
Digan lo q digan escorpio son los mas infieles para mi de vdd, un dia pueden tener jna familia feliz otro dia pueden dejarlo todo y largarse friod d emrf, no son daddy issues, Bueno si,mi papa es escorpio y principe charles tmbn same shit!!! Sonre tdo sol en escorpio y asc en leo frio de frio
0 notes
Text
Storyboard Activity and Assignments
Outcomes - Preview
Compare visual and verbal storytelling as used in planning documents for games and film. (Understand Level)
Make use of genre categories and storyboard templates to collaborate on an interactive story concept. (Apply Level)
Use individual story components by peers, to work in teams construct a new interactive story concept for a game format - board game, card game, role-playing game, or video game. (Create Level)
What
We are going to analyze and reverse storyboard one of your favorite scenes from a film or game. We will use what we learned in the analysis to apply to making a new story in a genre of your choice such as horror, fantasy, sci fi...
Create a storyboard for a scene in your favorite game, story, or film.
Storyboards are interactive. You show them to collaborators and they can quickly be changed. Changes: Order, composition of shots, camera angles, action, dialog, pacing, etc. A storyboard is a dynamic interactive tool.
Why
Storyboarding is used in both linear and interactive storytelling such as games and films. Storyboards help to sell your ideas. For example: Toy Story Pitch using storyboard sketches.
How
In-class practice: Reverse Storyboard
Write up a possible scene grid for your chosen scene - use action verbs to move your story along...
Sketch out a page of visuals for your scene analysis.

Break down the essence of the images and storytelling text into frames with captions on the storyboard. Be loose and non-judgemental at first so that you can visualize possibilities. https://www.teachwire.net/news/9-of-the-best-storyboard-templates-and-creative-story-writing-resources
Use a storyboard template with 16:9 aspect ratio

Show your storyboard to friends - ask what to keep, what to emphasize, what to eliminate in order for your story to be engaging. Record the comments and look for common themes in the feedback.
Revise your storyboard based on the feedback to 5 to 10 panels for a short scene.
Storyboard Assignment 1
What is a story genre?
Select a genre from the genres listed by the class.
Write a scene using the story planning grid in your selected genre.
Create a storyboard using any level of drawing you can including Ed Emberley’s Make a World technique.
Deliverables - Product and Feedback
Create on story grid with all the spaces clearly described in words
Create one Storyboard with rough sketches and dialog for one scene in your selected genre
Assess 3 peers based on EMRF levels and give feedback to 3 of your peers using the KEE format.
KEE peer and faculty feedback for a stronger project
What to Keep?
What to Emphasize?
What to Eliminate?
The Assessment: is based on EMRF

Your feedback is designed to help the project move toward the E level.
KEE Feedback : What should the project Keep? What should the project Emphasize? What should the project Eliminate to become more clear, communicate more effectively, and feel complete?
Assignment 2
Your genre group becomes a team. (Team Horror, Team Sci-Fi, etc.)
Storyboard Mashup Game
Analyze all the storyboards in your genre group for strong characters, scenic environments, and plot.
As a group, decide what to Keep, Emphasize, and Eliminate (KEE)
Pull the strongest parts together into a new Story Grid and Storyboard.
Post the new product to the Discussion board with a pitch video by one or more of your team.
Deliverable
Discussion post with 1 storygrid, 1 storyboard, 1 pitch video.
What’s Due
Peer Feedback : KEE - What to keep? Emphasize? Eliminate?
Specification for Grade
EMRF Feedback Flowchart
0 notes
Text
popping people out of the electricty and signal with v2k tech cult rituals and electronic bombardments of emrf and partical vomabardments breaking copyrights of all kinds through vehicle industry nd installed mp4 A AVC spyware in stats for nerds on youtube at random framing live streamers - Google Search
0 notes
Text
HS Summer Report - June 2021
24 June 2021
Miro
Took all the tutorials on Miro
Made map of summer activities in Miro
Met with Matt R. weekly to build out
Canvas graphical homepage for all foundation courses
Develop common extra credit strategy for creating culture of attendance and followup for Industry Relations Lecture Series
Configure useful foundations Spec Grading system
Met biweekly with FFF faculty - see agenda and minutes for each meeting on this tumblr.
Met weekly (except for holiday break) with David Cohen to build out
AET 319 Design and Interactivity Module Outline to demo to other AET 319 Foundation courses
Plan Design and Interactivity course based on Colorful Table and Skills Map in several methods: Canvas, Trello, Google Docs, & Google Slides. Determined that Google Slides is the most useful tool to visualize the whole course and the weekly level units.
Define hybrid options for fall semester
Define need for UA for support
Researched Specs Grading for useful patterns to incorporate into Canvas grading functions
EMRF Specs grading https://roberttalbert.medium.com/specifications-grading-with-the-emrf-rubric-426a5b191a65
TIPS Specs Grading https://higheredpraxis.substack.com/p/tip-specs-grading
Alternate Grading Strategies Presentation https://uncw.edu/keepteaching/documents/alternativegradingadapt2020july7.pdf
Met with Jamil H to discuss creating student culture of engagement with Industry Relations and Career Services. Gave Jamil tour of Canvas classroom and suggested integrating speaker series with the Canvas course calendar. Jamil is going to talk to DL and MB about integrating speakers with course content, Jamil is going to visit Faculty Meeting to talk about speakers and how to connect speakers to students and faculty effectively.
Honoria S.
0 notes
Text
EMR Studio Features Requirements and Limits AWS

Amazon EMR Studio features, specs, and limitations:
Amazon EMR Studio describes an IDE for data preparation and visualisation, departmental collaboration, and application debugging. When utilising EMR Studio, consider tool usage, cluster demands, known issues, feature constraints, service limits, and regional availability.
Features of Amazon EMR Studio
Service Catalogue lets administrators connect EMR Studio to cluster templates. This lets users create Amazon EC2 EMR clusters for workspaces. Administrators can grant or deny Studio users access to cluster templates.
The Amazon EMR service role is needed to define access permissions to Amazon S3 notebook files or AWS Secrets Manager secrets because session policies do not allow them.
Multiple EMR Studios can control access to EMR clusters in different VPCs.
Use the AWS CLI to configure Amazon EMR on EKS clusters. Connect these clusters to Workspaces via a controlled API in Studio to run notebook jobs.
Amazon EMR and EMR Studio use trusted identity propagation, which has extra considerations. IAM Identity Centre and trusted identity propagation are required for EMR Studio to connect to EMR clusters that use it.
To secure Amazon EMR off-console applications, application hosting domains list their apps in the Public Suffix List (PSL). Examples are emrappui-prod.us-east-1.amazonaws.com, emrnotebooks-prod.us-east-1.amazonaws.com, and emrstudio-prod.us-east-1.amazonaws.com. For sensitive cookies in the default domain name, a __Host- prefix can prevent CSRF and add security.
EMR Studio Workspaces and Persistent UI endpoints use FIPS 140-certified cryptographic modules for encryption-in-transit, making the service suitable for regulated workloads.
Amazon EMR Studio requirements and compatibility
EMR Studio supports Amazon EMR Software versions 5.32.0 and 6.2.0.
EMR clusters using IAM Identity Centre with trusted identity propagation must use it.
Before setting up a Studio, disable browser proxy control applications like FoxyProxy or SwitchyOmega. Active proxies can cause Studio creation network failures.
Amazon EMR Studio restrictions and issues
EMR Studio does not support Python magic commands %alias, %alias_magic, %automagic, %macro, %%js, and %%javascript. Changing KERNEL_USERNAME or proxy_user using %env or %set_env or %configure is not supported.
Amazon EMR on EKS clusters does not support SparkMagic commands in EMR Studio.
All multi-line Scala statements in notebook cells must end with a period except the last.
Amazon EMR kernels on EKS clusters may timeout and fail to start. Should this happen, restart the kernel and close and reopen the notebook file. The Restart kernel operation requires restarting the Workspace, and EMR on EKS clusters may not work.
If a workspace is not connected to a cluster, starting a notebook and choosing a kernel fails. Choose a kernel and attach the workspace to run code, but ignore this error.
With Amazon EMR 6.2.0 security, the Workspace interface may be blank. For security-configured EMRFS S3 authorisation or data encryption, choose a different supported version. Troubleshooting EMR on EC2 tasks may disable on-cluster Spark UI connectivity. Run %%info in a new cell to regenerate these links.
5.32.0, 5.33.0, 6.2.0, and 6.3.0 Amazon EMR primary nodes do not have idle kernels cleaned away by Jupyter Enterprise Gateway. This may drain resources and crash long-running clusters. A script in the sources configures idle kernel cleanup for certain versions.
If the auto-termination policy is enabled on Amazon EMR versions 5.32.0, 5.33.0, 6.2.0, or 6.3.0, a cluster with an active Python3 kernel may be designated as inactive and terminated since it does not submit a Spark task. Amazon EMR 6.4.0 or later is recommended for Python3 kernel auto-termination.
Displaying a Spark DataFrame using %%display may truncate wide tables. Create a scrollable view by right-clicking the output and selecting Create New View for Output.
If you interrupt a running cell in a Spark-based kernel (PySpark, Spark, SparkR), the Spark task stays running. The on-cluster Spark UI is needed to end the job.
EMR Studio Workspaces as the root user in an AWS account causes a 403: Forbidden error because Jupyter Enterprise Gateway settings disallow root user access. Instead of root, employ alternate authentication methods for normal activities.
EMR Studio does not support Amazon EMR features:
connecting to and running tasks on Kerberos-secured clusters.
multi-node clusters.
AWS Graviton2-based EC2 clusters for EMR 6.x releases below 6.9.0 and 5.x releases below 5.36.1.
A studio utilising trusted identity propagation cannot provide these features:
Building EMR clusters without templates using serverless applications.
Amazon EMR launches on EKS clusters.
Use a runtime role.
Supporting SQL Explorer or Workspace collaboration.
Limited Amazon EMR Studio Service
Service Restriction The sources list EMR Studio service limits:
EMR Studios:
Each AWS account can have 100 max.
Maximum five subnets per EMR Studio.
IAM Identity Centre Groups are limited to five per EMR Studio.
EMR Studios can have 100 IAM Identity Centre users.
#EMRStudio#AmazonEMRStudio#AmazonEMR#EKSclusters#News#Technews#Techology#Technologynews#Technologytrendes#Govindhtech
0 notes
Text
На заметку разработчику: 3 причуды Apache Spark и как с ними бороться

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к серви��ам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать вручную.
Сжатие и распаковка файлов в Apache Spark
Spark делает подключение к источникам данных простой операцией, предоставляя широкий выбор коннекторов и простой синтаксис для различных форматов: JSON, Parquet, ORC, таблицы СУБД и пр. При этом фреймворк умеет работать со многими популярными форматами сжатия файлов: SNAPPY, ZLIB, LZO, GZIP, BZIP2 и пр., отлично применяя правильные кодеки для сжатия RDD и Dataframe. Кроме того, из Apache Hadoop возможно заимствование других кодеков, например, gzip | .gz | org.apache.hadoop.io.compress.GzipCodec. Обычно с этими файлами не возникает никаких проблем. Однако, если прочитать из корзины AWS S3 с именем test простой файл file_name, который содержит данные JSON и сжат с помощью gzip, результат вас удивит: Команда на чтение spark.read.json ("s3a: // test / file_name ") spark.printSchema () Результат: root | - _corrupt_record: строка (nullable = true) Такой вывод получился из-за того, что Apache Spark полагается на расширения файлов, чтобы определять тип сжатия с помощью метода getDefaultExtension(). По умолчанию для файла gzip – должно быть расширение .gz, поэтому отсутствие расширения вызывает путаницу. Таким образом, файлы должны иметь соответствующие расширения. Обойти это ограничение из примера можно, самостоятельно расширив GzipCodec и переопределив метод getDefaultExtension(): package dre.spark.util.codecs import org.apache.hadoop.io.compress.GzipCodec class NoExtensionGzipCodec extends GzipCodec { override def getDefaultExtension(): String = "" } Примечательно, что AWS Glue, serverless ETL-решение от Amazon, сперва сканирует каталог данных, а затем используется динамических фреймы, чтобы без проблем обрабатывать сжатие и распаковку файлов даже без точных расширений.
Особенности AWS S3: разделы и коннекторы
Наличие разделов и корзин в AWS S3 обеспечивает высокую производительность и распараллеливание при чтении и записи данных. Однако, при работе с этим облачным хранилищем стоит помнить, что Apache Spark очень требователен к именам сегментов для идентификации столбцов раздела. В частности, partitioning выполняется в стиле Hive, о чем мы упоминали здесь. А AWS Glue может идентифицировать столбцы разделов без атрибутивной информации и создавать безымянные столбцы в таблице в виде partition-0, partition-1 и т.д. [1] Наконец, стоит отметить разнообразие коннекторов Spark к AWS S3. Например, S3 Select позволяет приложениям извлекать из объекта только часть данных, перекладывая работу по фильтрации больших датасетов с Amazon EMR на S3. Это может повысить производительность Spark-приложений и сократить объем данных, передаваемых между EMR и S3. S3 Select поддерживается файлами CSV и JSON с использованием значений s3selectCSV и s3selectJSON для указания формата данных. При этом некоторые Spark-параметры форматов CSV и JSON, такие как nanValue, positiveInf, negativeInf и режимы failfast и dropmalformed, связанные с поврежденными записями, не поддерживаются. Также в AWS есть коммиттер, оптимизированный для EMRFS S3 для многокомпонентной загрузки EMRFS и повышения производительности при записи файлов Parquet в Amazon S3 с использованием Spark SQL, DataFrames и DataSets. Напомним, EMRFS – это файловая система EMR File System в кластерах Amazon EMR, позволяет использовать сервис S3 в качестве уровня хранения для Apache Hadoop [2]. Еще есть коннекторы S3n и S3a, которые отличаются отличаются производительностью и объемом передаваемых данных. Например, через URI-схему s3n: //… можно предавать файл не более 5ГБ, а у s3a: //… нет такого ограничения [1].
PySpark и Hadoop
При разработке кода на PySpark стоит помнить, что по умолчанию он не всегда включает все необходимые библиотеки Apache Hadoop и нужные зависимости. Pyspark является частью фреймворка Spark и не содержит всех jar-файлов. Например, в нем могут отсутствовать свежие пакеты hadoop-aws. Поэтому следует загружать последний дистрибутив Apache Spark в комплекте с последней версией Hadoop и в переменной среды SPARK_HOME указать место загрузки. Подробнее разобраться с особенностями разработки распределенных приложений Apache Spark для аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: Основы Apache Spark для разработчиков Анализ данных с Apache Spark Потоковая обработка в Apache Spark Машинное обучение в Apache Spark Графовые алгоритмы в Apache Spark Источники 1. https://aseficha.medium.com/demystifying-apache-spark-quirks-2c91ba2d3978 2. https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-s3-performance.html Read the full article
0 notes
Photo






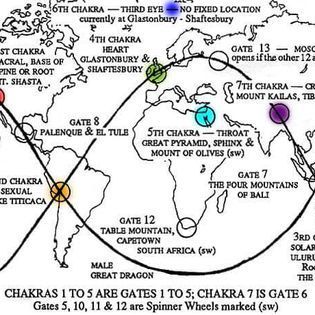



our location affected by these grids with these type of chakra sats are affected by bad emrf what if we get it to change to good emrf without killing the cell inside the body with the emergency change of the frequency and legal top it for another coutry aand get ours back and top through currency exchange.
0 notes
Text
popping people out of the electricity and signal with v2k tech cult rituals and electronic bombardments of emrf and particle vomabardments breaking copyrights of all kinds through vehicle industry - Google Search
0 notes
Text
Specs Grading
Start here
“In real life it’s all pass/fail.” Linda B. Nilson
Yes, Virginia, There's a Better Way to Grade by Linda B. Nilson
What is Specifications Grading and Why Should You Consider Using It? by Macie Hall
Specifications Grading
Podcast with Dr. Linda Nilson author of Specifications Grading: Restoring Rigor, Motivating Students and Saving Faculty Time
More to come on this topic . . .
If you have experience with specs grading please contact Honoria.
This Specs Grading topic is informed by a Book Club sponsored by UT’s Faculty Innovation Center. Specs grading is a recommendation in the Fall 2020 book club selection: Small Teaching Online by Flower Darby and James M. Lang.
https://medium.com/@roberttalbert/specifications-grading-with-the-emrf-rubric-426a5b191a65
https://higheredpraxis.substack.com/p/tip-specs-grading
- Specs grading in evaluating transfer students.
https://docs.google.com/document/d/18n7_r6R5mt1Q1ysQuSkhEJv6MKSWN8hU-nkafEvjk7s/edit
- Specs grading in political science
https://activelearningps.com/2016/03/30/specifications-grading/
- Specs grading in humanities - TV class - good how-to explanation
https://justtv.wordpress.com/2016/02/16/rethinking-grading-an-in-progress-experiment/
- Reflections 5 benefits of Specs Grading grading https://activelearningps.com/2016/12/19/specifications-grading-5-end-of-term-report-and-reflections/
-- Some good terminology to make the contract with the students.
https://www.hastac.org/blogs/cathy-davidson/2015/08/16/getting-started-6-contract-grading-and-peer-review
0 notes
Text
What is Hadoop big data?
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
Hadoop consists of four main modules:
Hadoop Distributed File System (HDFS) — A distributed file system that runs on standard or low-end hardware. HDFS provides better data throughput than traditional file systems, in addition to high fault tolerance and native support of large datasets.
Yet Another Resource Negotiator (YARN) — Manages and monitors cluster nodes and resource usage. It schedules jobs and tasks.
MapReduce — A framework that helps programs do the parallel computation on data. The map task takes input data and converts it into a dataset that can be computed in key value pairs. The output of the map task is consumed by reduce tasks to aggregate output and provide the desired result.
Hadoop Common — Provides common Java libraries that can be used across all modules.

How Hadoop Works
Hadoop makes it easier to use all the storage and processing capacity in cluster servers, and to execute distributed processes against huge amounts of data. Hadoop provides the building blocks on which other services and applications can be built.
Applications that collect data in various formats can place data into the Hadoop cluster by using an API operation to connect to the NameNode. The NameNode tracks the file directory structure and placement of “chunks” for each file, replicated across DataNodes. To run a job to query the data, provide a MapReduce job made up of many map and reduce tasks that run against the data in HDFS spread across the DataNodes. Map tasks run on each node against the input files supplied, and reducers run to aggregate and organize the final output.
The Hadoop ecosystem has grown significantly over the years due to its extensibility. Today, the Hadoop ecosystem includes many tools and applications to help collect, store, process, analyze, and manage big data. Some of the most popular applications are:
Spark — An open source, distributed processing system commonly used for big data workloads. Apache Spark uses in-memory caching and optimized execution for fast performance, and it supports general batch processing, streaming analytics, machine learning, graph databases, and ad hoc queries.
Presto — An open source, distributed SQL query engine optimized for low-latency, ad-hoc analysis of data. It supports the ANSI SQL standard, including complex queries, aggregations, joins, and window functions. Presto can process data from multiple data sources including the Hadoop Distributed File System (HDFS) and Amazon S3.
Hive — Allows users to leverage Hadoop MapReduce using a SQL interface, enabling analytics at a massive scale, in addition to distributed and fault-tolerant data warehousing.
HBase — An open source, non-relational, versioned database that runs on top of Amazon S3 (using EMRFS) or the Hadoop Distributed File System (HDFS). HBase is a massively scalable, distributed big data store built for random, strictly consistent, real-time access for tables with billions of rows and millions of columns.
Zeppelin — An interactive notebook that enables interactive data exploration.
0 notes