#Gradient Netowrk
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
【擼零項目】簡單躺賺 閑置網路創造收入 - 初期項目Teneo Community Node
[閱讀全文: https://bit.ly/4hQkkyB]

較早前已介紹過不同的DePin賽道的初期項目 Grass 、Nodepay、Gradient、DAWN。第一個項目 Grass 已經上線及分派空投,而項目仍然在進行第二個Season。Nodepay 和 Gradient 也可以綁定Solana的錢包。而今天介紹的 Teneo 也是跟它們相同概念的軟體,不需要點擊廣告、不需要填問卷,只需要在Chrome的增加擴充應用插件,注冊及登入並開著Chrome就可以掛機。
#DePIN#GetGrass#Gradient#Gradient Netowrk#Grass#Grass.io#Nodepay#Teneo Community Node#掛機賺錢#擼零項目#網路流量化為收益#網路賺錢#被動收入
0 notes
Photo
Experiments with SWISH activation function on MNIST dataset
As you may probably know by now, there is a new activation function in deep learning town called SWISH. Brought to us by researchers at Google, the Swish activation function is f(x)=x*sigmoid(x). As simple as that!
According to their paper, the SWISH activation provides better performance than rectified linear units (ReLU(x)= max(0,x)), even when the hyperparameters are tuned for ReLU! These are very impressive results from a rather simple looking function. In the rest of this blog, I will give a brief introduction to Swish (basically a gist of the paper in plain English) and then I will show some interesting results I got by using the Swish activation on MNIST dataset. Hopefully, this will help you decide whether or not you want to use Swish in your own models. Let’s go for it.
Intuition behind Swish
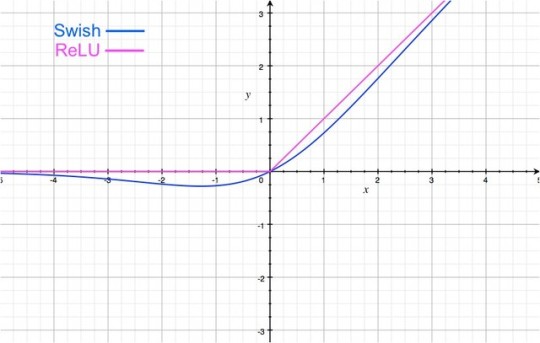
Graphically Swish looks very similar to the ReLU:
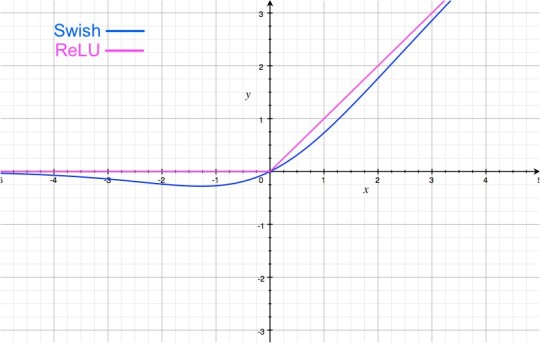
The important difference is in the negative region of the x-axis. Notice that due to the weird shape of the tail in the negative region, the output from the Swish activation may decrease even when the input is increased. This is very interesting and perhaps unique to Swish. Most activation functions (such as sigmoid, tanh & ReLU) are monotonic i.e. their value never decreases as the input increases (the value may remain same, as is the case for ReLUs when x<0).
Intuitively, Swish sits somewhere between linear and ReLU activations. If we consider a simple variation of Swish f(x)=2x*sigmoid(beta*x) where beta is a learnable parameter, it can be seen that if beta = 0 the sigmoid part is always 1/2, so f(x) becomes linear. On the other hand if beta is very high, the sigmoid part becomes almost like a binary activation (0 for x<0 and 1 for x>0). Thus, f(x) approaches the ReLU function. Therefore, the standard swish function (beta=1) provides a smooth interpolation between these two extremes. Very neat! This is the most credible argument in the paper as to why Swish should work. The other arguments are that Swish is, unlike ReLU, non-monotonic but, like ReLU, bounded from below and unbounded from above (so you don’t end up with vanishing gradients in a deep network).
Experiments
Now that we have a good understanding of the idea behind Swish, lets see how it well works on the time tested MNIST dataset. I used a very simple feed-forward architecture with 2 hidden layers and trained five models for five different activations: linear (no activation), sigmoid, ReLU, standard Swish (where beta is fixed to 1.0) and a variation of Swish where the beta is initially set to 1.0 but learned over time by the network. The weights were initialized from a gaussian distribution with same random seed in all five models so the only difference should be due to the activation function. Also, I tried three different standard deviations (sigma=0.1,0.5,1.0) of the gaussian distribution. If the standard deviation is too large, the weights will be initialized too far away from their optimal values and the network will have a hard time converging. I wanted to see if Swish can help convergence if the initialization is a bit off. Here are the results:

When using a good initialization of weights, ReLU, swish_1 (beta=1) and swish_beta all perform nearly the same. Perhaps since the problem is very simple, there is no distinct advantage of learning the parameter beta.

This was a rather bad initialization. This problem is mildly challenging. Surprisingly sigmoid worked very well here. Among ReLU & swish, swish works quite a bit better than ReLU (although both eventually converge to the same performance). Again here, as last time, there is no great advantage of learning beta and it doesn’t improve performance.

This was a very bad initialization! Sigmoid and linear activations did very well. That is more attributable to the linear separability of MNIST dataset itself than to the activations. Among the others, swish_1 shows better performance than ReLU. Given enough training steps, both converge to the same performance. Here we see a big advantage of learning the beta. Swish_beta gives noticeably better performance on this difficult problem.
It is also interesting to evaluate the evolution of beta in each of the cases:

When the initialiations are somewhat close to optimal values, beta evolves smoothly. The training steps were not enough to saturate the value of beta. Please remember that learning beta did not lead to better performance in this case. It seems it would be difficult to predict the final performance of a netowrk while monitoring the value of beta during training (see sigma=1.0 below).

As the initializations are somewhat far from the optimal values, beta seems to be not so stable. This also does not lead to noticeable gains or losses in performance compared to a fixed beta=1.0

Beta evolves smoothly even though the initial weights were far away from optimal values. Even though this trend looks very similar to sigma=0.1, there were substantial gains in performance by learning beta in this case but not in the earlier case. This further suggests that it will be difficult to tell much about how the network will perform by monitoring the evolution of beta during training.
Takeaways
These results are obtained from very simple neural networks on a simple dataset. So, we should not read too much into them. Nevertheless, there are some key takeaways here:
If your network is simple enough, ReLU and swish should perform about the same. In this case, ReLU would have an advantage since swish requires a multiplication step (x*sigmoid(x)), which means doing more computation for no noticeable gains in performance.
Even if standard swish works well on your problem, there may not be additonal gains from learning the parameter beta. Learning beta seems to work best when the problem cannot be solved by using ReLU (i.e. there are lot of dead ReLUs)
It would have been wonderful if the evolution of the parameter beta during training provided some hints about the eventual performance of the model. From these limited tests, this does not seem to be the case.
Code
The full code for reproducing these results is uploaded on my GitHub. I especially encourage you to look at interactive HTML versions of the figures shown above since some of the details are not easy to see with png files.
0 notes
Text
【擼零項目】簡單躺賺 閑置網路創造收入 - 初期項目Nodepay
[閱讀全文: https://bit.ly/411fSsa]

今次要介紹的同類型項目 — Nodepay,它是一款初期發展項目是一款與honeygain、Pawns相同概念的軟體的「流量掛機」項目,並搭建在Solana 的DePin 項目。透過收集用戶閒置的網路頻寬,將其代幣化,參與者可透過連接網路賺取點數獎勵。
#DAWN#Decentralized Autonomous Wireless Network#GetGrass#Gradient#Gradient Netowrk#Grass#Grass.io#Nodepay#掛機賺錢#擼零項目#網路流量化為收益#網路賺錢#被動收入
0 notes
