#Intel下下下代酷睿處理器要上10nm+工藝 全新CPU/GPU架構
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text
Intel下下下代酷睿處理器要上10nm+工藝 全新CPU/GPU架構
訪問購買頁面:
英特爾旗艦店
桌面處理器會在明年、後年升級為CometLake-S、RocketLake-S,不過這兩個還是14nm工藝的,TigerLake-S才是針對桌面的,當然移動版的TigerLake-U系列會首發,比桌面版早,畢竟這個市場對功耗更敏感,對性能要求不那麼高。

桌面版TigerLake是10nm工藝沒跑,但問題是它到底會用上哪種10nm工藝,Intel早就規劃好了,10nm節點��14nm節點一樣會有10nm、10nm+及10nm++三種版本,性能會依次增強,其中10nm+工藝路線圖上的時間是2020年。

現在的Ice Lake處理器是首發10nm工藝、SunnyCove微內核架構,TigerLake確認是新CPU架構,但到底是哪種還不好確定,合理猜測是WillowCove,而Jim Keller前不久在伯克利大學的演講中提到下一代CPU核心晶體管規模會顯著增大,讓CPU性能重迴線性增長的軌道。
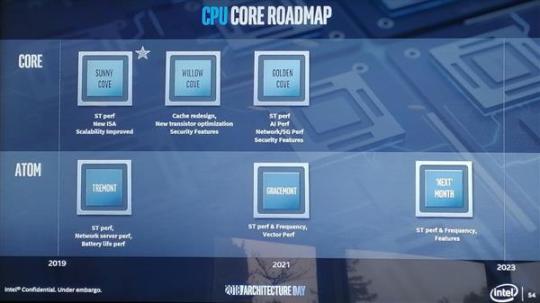
說了這麼多,重點是什麼?那就是最新的洩露稱TigerLake桌面版會使用10nm+工藝,CPU架構WillowCove晶體管規模大增,緩存系統改變比較大,性能提升會比SunnyCove平均18% IPC性能提升更大。
總之,等等黨又要贏了,不過Tiger Lake-S處理器估計要到2021年才能上市了,這是最大的麻煩。
.
from Intel下下下代酷睿處理器要上10nm+工藝 全新CPU/GPU架構 via KKNEWS
0 notes
Text
Ice Lake架構深度解析 Intel的雅典娜女神
訪問購買頁面:
英特爾旗艦店
這意味著Intel的第一代量產級10nm產品(不算Cannon Lake唯一的那款10nm i3)終於要在市場上亮相了,在此之際,小編編譯、整理了目前有關於Ice Lake架構的相關解析文章,探尋其背後的改進之處。
繼上一次Intel更新他們的桌面級處理器的架構已經過去了將近5年的時間了,不得不說,Skylake是一代非常成功的架構,也可能是從P6以來Intel使用時間最長的一代處理器架構,支撐Intel走到現在還在主流和服務器市場上面佔據著上風。
首先我們要理清一點,Ice Lake是整個處理器架構的代號,而現在的Intel處理器架構中包括了內核、GPU、以及Uncore部分的其他IO單元,所以本文並不只是針對CPU的內核微架構進行解析,而是對於整個體系結構。
注:如果沒有說明來源,本文圖片均來自於WikiChip和AnandTech。
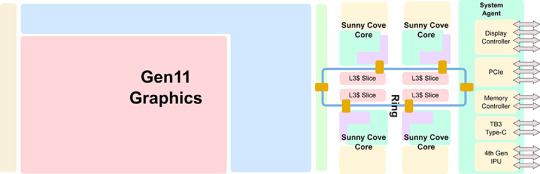
Ice Lake處理器結構圖
Sunny Cove內核微架構:IPC平均提升18%
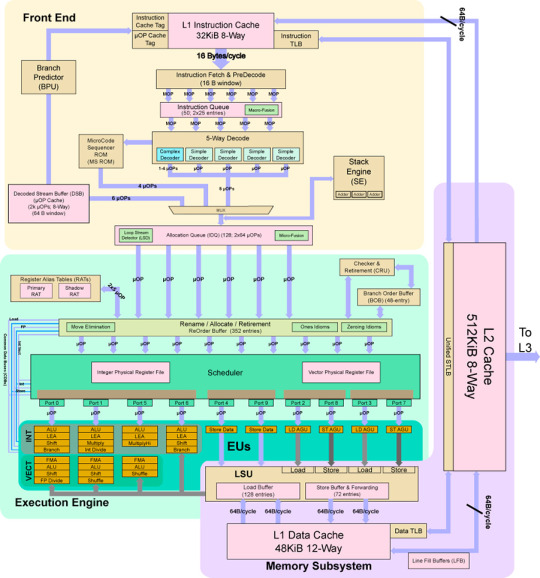
Sunny Cove內核結構圖
前端緩衝區:加大加大加大
x86處理器的內核主要可以簡單地分成兩個部分,前端部分與後端執行部分,前端部分主要完成“取指譯碼”的工作,後端主要為指令的具體執行單元,前後端之間有緩衝區,用於存放解譯融合完畢的微指令。 Intel很早就在內核中引入了“微指令融合”的技術來提高效率,融合過的微指令會進入緩衝區然後被分配給後端執行部分進行具體的執行。 Intel目前認為,如今程序更多的瓶頸位於訪存和前端指令分派上,Sunny Cove的前端部分改進就體現了這一理念,所以這次緩衝區就被擴大了不少。
緩衝區部分對比
架構
Haswell
Skylake
Ice Lake
亂序重排緩衝區
192
224
352
訪存Load隊列大小
72
72
128
訪存Store隊列大小
42
56
72
超 能 網 制 作
可以看到Intel這次把亂序重排緩衝區(ReOrder Buffer,主要是用於亂序執行後將執行的微指令根據原本順序提交的指令緩衝區)大小做到了可以容納352條微指令,直接提升了128條/57%之多,而Haswell到Skylake才僅僅提升了32條。同樣在訪存上面也進行了不小的提升,Load(加載)隊列增加了56,Store(存儲)隊列增加了16,比Haswell到Skylake的改變都明顯要多。
緩存對比
架構
Haswell
Skylake
Ice Lake
單核心一級數據緩存大小
32KB
32KB
48KB
單核心一級指令緩存大小
32KB
32KB
32KB
單核心二級緩存大小
256KB
256KB
512KB
微指令緩存
1.5K μOPS
1.5K μOPS
2.25K μOPS
超 能 網 制 作
再來看緩存部分,新的內核終於增加了萬年沒變動過的一級數據緩存,從32KB到48KB,雖然只增加了12KB,但是要知道,32KB的一級指令緩存+32KB的一級數據緩存的設計,從Core系列的第一代架構——Core微架構上面就開始使用了,一直沿用到現在,同時一級數據緩存的帶寬也增加了。而每個內核附帶的二級緩存直接提升一倍,達到512KB的大小,這也是從Nehalem架構把二級緩存內置進每個核心、單獨設立共享L3緩存以來在內核緩存上發生的最大幅度變動了。
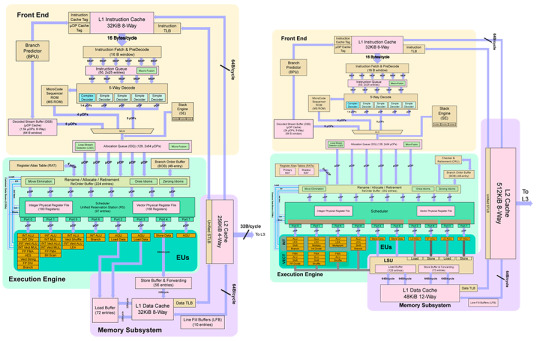
Skylake與Sunny Cove內核架構對比圖,左Skylake,右Sunny Cove
前端部分的改進較小,主要是改進了預取器與分支預測器的性能,增加了微指令緩存的大小使得其能夠滿足每週期5(6)指令的發射。
後端:更寬
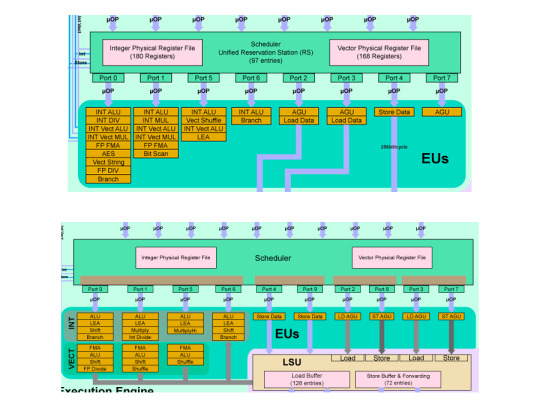
上Skylake,下Icelake,注意看Port
後端也有不小的改變,Sunny Cove的執行端口相比Skylake多了兩個,達到了10個之多。並且端口的用途更為精細化,有專門用於讀取和存儲地址的端口,並且專用於存取數據的端口數量均為兩個。
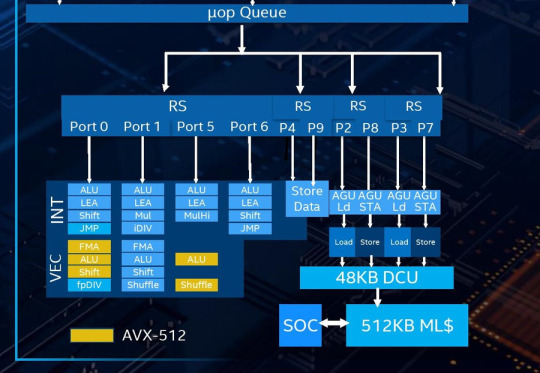
然後在執行單元中,Sunny Cove新增了支持AVX-512指令的單元,其實這類單元在Skylake-Server上便已經加入,同時引入的還有Cannon Lake上面加入的iDIV這個硬件整數除法器,同時還加入了新的MulHi單元,專用於乘法指令的處理。
AVX-512計算單元的引入使得Sunny Cove內核一次可以處理1條512-bit的指令或者2個256-bit的指令。
內核互聯方面,桌面級Ice Lake仍將採用Ringbus也就是環形總線的設計,而服務器端將延續Skylake-Server的Mesh總線設計。
指令集與AI加速
指令集隨著新單元的加入也同時進行了擴充,在加密解密、AI加速、通用計算、特定計算等方面都新加入了不少指令,尤其是AVX-512指令集。
對於近幾年大熱門的人工智能,Intel一方面在Uncore部分加入了自家的“高斯網絡加速器(Gaussian Network Accelerator)”這樣類似於手機SoC上面常見的AI硬件加速電路,還通過引入AVX512VNNI指令集,使用AVX-512單元來進行AI相關的加速計算,Intel將這種加速稱為”DL(Deep Learning) Boost”。這是一種很聰明的取巧辦法,專用計算單元的引入可以保證一定的加速性能,而新指令集的加入同時也可以更加充分地利用上新的CPU特性。
加密解密指令集上面的改動諸如AES的吞吐量加大、加入新的針對SHA算法的一系列指令等,總之在編譯器進行適當優化的前提下,Ice Lake的加密解密性能是比Skylake強不少的。
小結
簡單歸納一下Sunny Cove微架構的改進點:
改進了預取器與分支預測器的性能
一���數據緩存增大50%
一級緩存存儲帶寬增大100%
二級緩存增大100%
微指令緩存增大50%
每週期能夠加進亂序重排緩衝區的微指令多了25%
亂序重排緩衝區大了57%
後端執行端口多了25%
支持AVX-512等新指令集
綜合以上的改進,Sunny Cove相對於Skylake在IPC上面取得了平均18%的進步,而對於Broadwell或者說Haswell,則是有47%的進步幅度,在針對AVX-512進行優化過的測試中,最高可以比上代移動低壓處理器快2~2.5倍。在摩爾定律前進緩慢的今天,這個數字已經非常高了。
題外話,其實很多改進在Cannon Lake上面就已經有了,比如AVX-512、相關的指令集變動和緩存帶寬增加等,還有些改動是從Skylake-Server架構上面下放而來的,比如AI加速的指令集其實已經在服務器端處理器上出現了。但因為Cannon Lake實際被Intel放棄,所以繼承了Cannon Lake改進點的Sunny Cove內核架構才能在相比較Skylake時得到平均18%的IPC進步,如果一切正常,Intel的10nm沒有延期,Ice Lake應該是Cannon Lake的下一代,對比起來就沒那麼大的進步幅度了。
第11代圖形架構
Ice Lake的核顯首次達到了1TFlops的計算性能,還增加了不少的功能特性,可謂改進頗多。 Intel用了”the most powerful version”來形容這代核顯的性能,怎麼做到的呢?

借助10nm工藝,暴力堆疊規模
Intel的10nm工藝在晶體管密度上的提升幅度是真的很大,14nm時代最多配備24組EU的核顯,在Ice Lake上面直接就翻了2.67倍,最大可以達到64組EU,並且頻率也不低,最高可以跑到1100MHz,比以前只低了50MHz,此時核顯整體的FP32計算量已經達到了1.15TFlops。鑑於此,相比於八代酷睿處理器上搭載的第9代核顯,Intel官方宣稱可以提供平均約1.8倍的幀率。

你一定想問第10代去哪裡了對不對,其實還是在夭折了的Cannon Lake上面,而且唯一一顆的核顯還是被屏蔽了的。
目前在移動低壓版Ice Lake處理器上面,Intel一共提供了G1、G4和G7三種配置的核顯,分別有32/48/64組EU,���端的G1命名仍為”UHD”,而G4和G7都以”Iris Plus”的品牌出現。
除了通過製程進步來堆疊EU數量之外,內部架構的優化也同樣重要。
內部架構優化
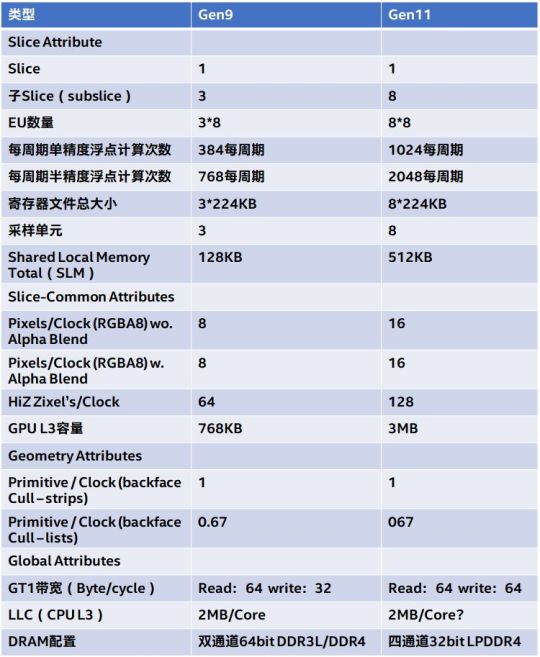
與第九代核顯的對比表格如圖,出處:週末雜談,Icelake CPU的助手,Gen11核顯簡介
首先通過增加單個Slice中含有的子Slice來擴大規模,使得每週期的計算次數增加。
其次是在緩存系統上做文章,擴大了三級緩存的容量,Intel方面公佈的是EU的三級緩存有3MB,並且還有0.5MB的本地共享內存。另外還有通過處理器的內存控制器升級,能夠用上更高的內存帶寬。
新接口版本和加強的硬件編碼電路
上個月讓小編最難受的一件事情就是買了一台1440p,144Hz刷新率的顯示器,用HDMI連接筆記本的時候,在1440p下面最高只能輸出60Hz,究其原因,就是老的第9代核顯支持的HDMI版本只能到1.4,最高只能提供4K@30Hz的輸出,1080p下面最大是120Hz,而小編的筆記本並沒有提供USB-C或者DP輸出。
而Ice Lake終於解決了這個痛點,支持了HDMI 2.0b和DP 1.4 HBR3,這兩個就不用多說了吧,反正就是最高分辨率和幀數提升順便還能支持一下HDR。
另外,在視頻硬件編碼部分,也就是Intel QuickSync特性使用的獨立硬件電路上,新核顯也有比較大的改進,現在支持兩條HEVC 10-bit同時進行編碼,在YUV444的情況下最高支持兩條4K60幀視頻流,或者一條YUV422的8K30幀視頻流。
可變速率著色(VRS)
VRS全稱Variable Rate Shading,是一種新的允許GPU根據畫面區域的重要性調整著色精度的技術,具體效果我們之前的新聞有介紹過,可以看一下:來對比一下VRS可變速率著色技術帶來的性能提升吧3DMark將添加該技術基準測試一文中的圖片對比。

VRS可以在不重要的畫面上面節約一定的GPU資源,使這部分GPU資源參與更加重要的部分畫面的渲染中,從而提高了整體的幀數,目前NVIDIA已經在Turing核心中加入了相關的支持。而Intel也沒有落後,在第11代核顯中提供了這項特性,並且他們宣布將與Epic合作,將這項特性加入到虛幻引擎中去,目前文明六已經支持了該技術,並且根據Intel的數據,幀數最大提高了30%。
小結
GPU部分的改進主要還是規模增加了很多,架構上屬於小改動,主要改進了緩存系統,不過第11代核顯的進步還是比較明顯的。

可能以後在1080p低畫質下面核顯也不再是雞肋了,能夠30幀打打遊戲了。
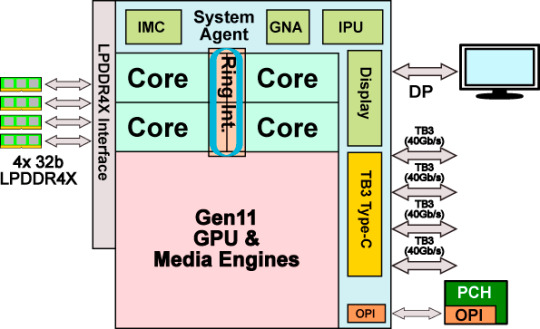
Uncore部分
Uncore部分指的是處理器上除了內核和GPU的其他部分,在頂上的結構示意圖中就是System Agent的那部分,自從Intel在Nehalem把內存控制器和PCI-E控制器移入CPU內部之後就沒有什麼大的變化,但是這次Intel在上面加入了個新東西,還升級了不少老部件。
Thunderblot 3
原來阻擋人們使用Thunderblot(以下簡稱TB)設備的一大原因就是這個接口的使用成本略高,當TB3開始以USB Type-C接口的形式出現之後,使用率確實高上去不少,但是還有其他的攔路虎,其中一個就是TB需要主板搭載額外的芯片來使用,這個控制芯片並不便宜。終於在Ice Lake上面,Intel把TB控制器整合到了處理器裡面,並且再也不會佔據掉處理器提供的PCI-E總線數量或者是與PCH一起擠原本就已經擁擠不堪的DMI 3.0總線,而是在環形總線上面擁有了自己的位置。
而且Intel大方的一下子就提供了4個之多的TB3接口,每個都是PCI-E 3.0 x4的滿規格,也就是說,Ice Lake處理器其實一共擁有32條PCI-E 3.0通道,不過其中一半都是以TB3形式提供的,當然這些接口是支持USB模式的,當運行於USB 2.0狀態時,會繞回到PCH上進行通信。
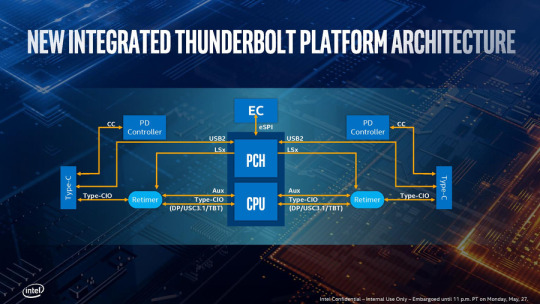
當然也不是所有的廠商都會給足四個TB3接口,具體怎麼配置還是得看OEM廠商,畢竟其他的配套芯片諸如USB PD所需要的獨立IC都是會增加成本的,而TB接口還需要額外的Retimer芯片,不過Intel已經減半了所需的Retimer,兩條TB3只需要1個Retimer就可以了。
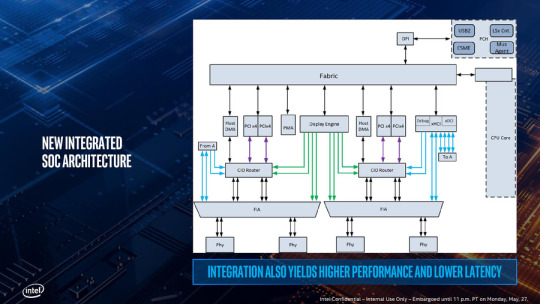
不過將TB控制器集成到CPU內部也使得整個System Agent的IO部分更為複雜了,上面是一張詳細的原理圖,一個Type-CIO路由(圖上名為CIO Router)擁有兩條PCI-E 3.0 x4與CPU相連,而CPU內部的顯示控制引擎(圖上的Display Engine)也要與這個Type-CIO路由相連,以控制Type-C接口所處的狀態,並決定發送的信號。同時還有USB的xHCI也要跟Type-CIO連接,還要管理整個的內存統一性……
複雜的結構所導致的就是整體的延遲會增加,Intel將原因歸結在電源控制上面,原本分離式的芯片很容易管理電源狀態,但是整合進來之後每一個部分都有自己的電源狀態需要管理,需要更為精細化的電源管理系統,而這就增加了總體的延遲。不過更為精細化的電源管理還是有好處的,那就是可以提高能耗效率,Intel方面稱滿載的一個TB3接口的芯片外加鏈路層將使用300mW的功率,四個加起來也只有1.2W。
值得一提的是,Intel已經做好了對於USB4的兼容,不過考慮到目前USB4仍處於草案階段,不排除未來的修改使得兼容失效。不過目前只是針對Ice Lake的移動版本進行架構分析,當然也不排除Intel在桌面級的Ice Lake上面同樣保留內部TB控制器。
題外話,TB3據說在Cannon Lake上面也是有的,但是夭折了。
內存控制器
現在內存控制器原生支持DDR4 3200/LPDDR4X 3733內存,原來Skylake上面的內存控制器頂多只能支持到DDR4 2666,還是八代的Coffee Lake以後的事情了。而隨著DDR4內存的發展,默頻上3000的內存條也開始出現了,內存控制器直接支持到DDR4 3200是一件不錯的事情。而且隨著處理器內核數量的增加,內存帶寬也逐漸要開始成為處理器性能的一個瓶頸所在了,在我們的測試中,內存帶寬對於遊戲性能的影響還是比較明顯的。
此前Intel的移動低壓平台只能使用LPDDR3作為內存,而支持LPDDR4/X的一個好處就是可以在更低的功耗下面帶來更強的性能,尤其是對於此次圖形性能有比較大提升的Ice Lake來說,有著非常大的實際意義,因為內存帶寬直接影響到GPU的實際表現。
GNA
前面在講內核的AI加速時提到了Uncore部分加入了GNA這個針對AI的硬件加速單元,目前並不知道太多有關於它的細節,就連具體名字都有兩種說法,在Intel官方針對Windows Machine Learning的介紹網頁中,它的全名為Gaussian Network Accelerator,而在很多介紹Ice Lake架構的文章中,它的名字又成了Gaussian Neural Accelerator。
目前已知的是該單元的功耗非常低,甚至會在SoC其餘部分關閉的情況下繼續工作,旨在提供穩定的AI加速性能,應用場景為語音識別之類。
圖像處理單元
Ice Lake上面的圖像處理單元(Image Process Unit)升級到了第4代,是的,你大概沒有聽說過Intel的CPU上面還有個圖像處理單元,但它從Skylake開始就一直存在,不過只有在移動雙核型號上有,屬於DSP(數字信號處理器)範疇,為設備的相機提供影像處理���能。
Ice Lake上的IPU可以提供4K@30fps的視頻拍攝能力,還有更好的硬件降噪能力,支持更多的相機,還支持將兩個不同的相機比如一個抓IR信息一個抓RGB信息的兩個相機模擬成一個設備來看待。
Intel方面稱,他們正在向軟件開放更多的IPU寄存器,以向應用提供更好的便利性,並且提供了對機器學習的支持。另外值得一提的是,Intel將之前PCH上集成的MIPI接口轉移到了CPU上,未來可以用於接駁AI加速設備。
小結
Uncore部分可謂是發生了天翻地覆的改變,可以說是Ice Lake相對於之前Skylake變化最大的地方了,內建TB3控制器肯定會給未來的使用帶來非常大的方便,小編個人非常喜歡這個改進。而其他的可以歸於常規性質的功能性更新。
PCH改進
目前的Ice Lake平台上PCH和CPU是封裝在同一塊基板上的,PCH的提升同樣是Ice Lake整個平台的提升。同樣的,Ice Lake CPU通過DMI 3.0 x4總線與PCH相連,提供的帶寬等同於PCI-E 3.0 x4。
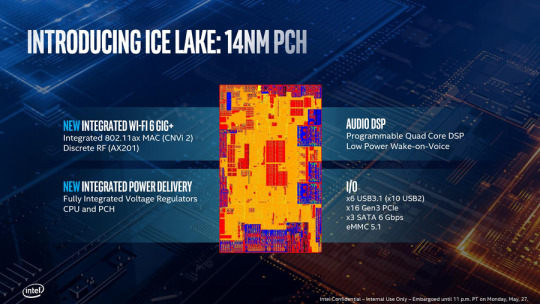
重新引入FIVR
FIVR其實早在Haswell架構中就已經被引入了,但是從Skylake開始又把它給去掉了,因為在當時FIVR確實表現不佳,導致了整體功耗和發熱的增大。不過在Ice Lake上面,它又回歸到了CPU和PCH的內部。 Intel官方表示這麼做可以節約整個平台的面積,並且簡化OEM的電源設計。新的FIVR有著更高的電源效率,與整個平台的節能特性息息相關。看上去Intel也是解決了FIVR身上的一些毛病才放心將它集成進CPU和PCH內部的。
CNVi 2
其實Intel在這兩年已經在出貨的芯片組裡面都加入了CNVi方案的Wi-Fi模塊,這種方案將Wi-Fi網卡的部分電路轉移到了芯片組的內部,而仍在外面充當一個射頻模塊的Wi-Fi網卡就可以做的非常小了,比如M.2 2230或者以1216規格直接焊在主板上。 PCH內部的網卡與在外面的RF模塊通過一條Intel專有的CNVi鏈路進行連接。
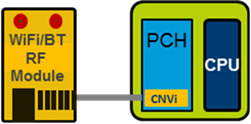
Ice Lake的PCH上面這條特別的CNVi鏈路升級到了第二個版本,即CNVi 2。
當然,支持的Wi-Fi標準還是由在外面的Wi-Fi網卡所決定的,方便OEM自定義,Intel此舉是為了打破人們升級Wi-Fi路上的屏障(你倒是推動一下AX路由器降價啊),目前Intel有兩張支持Wi-Fi 6標準的無線網卡:AX200/201。
關於Wi-Fi 6具體的提升之處,可以參考我們之前的文章:超能課堂(188) WiFi 6憑什麼可以如此“六”? 。
IO
這塊就簡單羅列一下數據。
6個USB 3.1(5Gbps)/10個USB 2.0
16條PCI-E 3.0,一般會有8條用於兩個NVMe接口
3個SATA 3.0
eMMC 5.1
Intel沒有提到UFS的支持。
小結
PCH的變化並不是很大,主要是常規的功能性提升。
封裝、睿頻與功耗多種功耗目標與不同封裝方式
目前Ice Lake-U和Ice Lake-Y是兩種目標TDP不同的系列,分別針對15~28W和7~12W來設計的,未來的移動標壓級TDP約為45W,而桌面級目前未知。

此次率先發布的11款低壓和超低壓也採取了兩種不同的封裝,U系列沒有怎麼變,還是老樣子,而超低壓就與往常不一樣了,Intel使用了更加緊湊的封裝方式,同時底部觸點也相對更加緊密。

動態調節 2.0

新的動態調節2.0技術變化點看圖就可以了,大致意思就是Ice Lake處理器不會像之前那樣只能睿頻18秒之後就回到基礎頻率,而是慢慢的降下來,整個過程比原先長了8秒。新技術還使用了機器學習來預測CPU將會吃到哪種類型的負載,然後智能調節功耗預算來盡可能地延長睿頻時間。
總結
總的來看,Ice Lake是一代變化非常大的架構,無論是內核還是外面的各種組件。人們都說Intel擠牙膏,但怎麼說呢,競爭���手所給的壓力不夠也是Intel擠牙膏的一個原因,但更多的原因恐怕是來自於這幾年Intel在製程工藝上面遇到的難題,本來在Intel的Tick-Tock戰略中,Cannon Lake是作為Skylake的製程升級版出現的,然而由於10nm的難產,Tick-Tock戰略徹底失效,變成了PAO——製程-架構-優化戰略之後,計劃以10nm初代的角色推出,結果10nm比PAO戰略的計劃還要晚,但是競爭對手的Zen和Zen+架構開始給Intel壓力了,沒辦法,Skylake加兩個核用14nm++再頂一頂吧。這一頂就是將近兩年過去了,Cannon Lake也被徹底的放棄了,上面的許多優化被Ice Lake所繼承了下來。
從整體架構來看,Ice Lake在單線程性能上面繼續衝高,而測試成績也都印證了這一點:基礎頻率和加速頻率都比前代更低的情況下單線程成績能夠將將打平,已經很不容易了。多核的話,Ringbus極限應該是十核左右,如果不採用Mesh架構,那麼桌面版未來的Intel Ice Lake處理器還是會不敵AMD的Zen 2/3。
而在擴展性上面,Ice Lake還是比較良心的,TB3控制器的加入使得USB和TB設備不再需要擠占原本就有些不夠的PCI-E 3.0總線,並且還預留了與USB4的兼容,在未來Ice Lake的優化版或者升級版上我們有望看到正式的USB 4支持。
Ice Lake也會是未來一段時間中Intel主力的架構,只不過等它來到桌面級還需要一段時間。 Intel目前的產品線也是非常的混亂,有機會我們會單開一篇文章來捋一捋。
.(tagsToTranslate)Intel Core 英特爾酷睿(t)Ice Lake架構深度解析 Intel的雅典娜女神(t)kknews.xyz from Ice Lake架構深度解析 Intel的雅典娜女神 via KKNEWS
0 notes
Text
台北電腦展2019接近尾聲 都有哪些值得關注產品和技術?
和往年一樣,台北國際電腦展2019依舊吸引了眾多廠商參與到其中,並且帶來了很多全新的嘗試以及思考。下面一起來了解下,本次展會上有哪些值得我們關注的新產品和新技術。
華碩ZenBook Pro Duo
今年是華碩成立的30週年,作為台灣企業中的老牌PC廠商,在自己的主場,他們展示了多款全新的硬件產品。而在眾多新品中,華碩ZenBook Pro Duo筆記本無疑是最為亮眼的明星。
圖片來自The Verge
與目前我們常見的筆記本產品有所不同,它配備了雙4K屏幕。除了B面常規的15英寸OLED屏之外,其在鍵盤區靠上位置新增了一塊32:9的IPS“ScreenPad Plus”屏幕。在實際使用過程中,這塊“副屏”不僅能夠承擔顯示任務,還可以用來作為輔助控制面板。
圖片來自The Verge
講到這裡可能大家會不由想到MacBook Pro上的Touch Bar。本質上二者其實都屬於“副屏”,但尺寸不同,使得它們在功能體驗上有著明顯區別,Touch Bar更偏向於輔助控制,而ScreenPad Plus在此基礎上,同時也更強調了“屏”這個字。
由於生態問題,Windows陣營除了之前ThinkPad曾經嘗試過和MacBook Pro Touch Bar類似的設計(以失敗告終),其它廠商一直以來並沒有去積極推進這種方案。不過,想要滿足人們越來越高的使用需求,在產品端做出改變成為了廠商們不得不去考慮的一件事情。
當然,像上邊我們說的一樣,PC想要實現理想中的效果,少不了微軟以及英特爾的支持。在極客之選看來,這次華碩ZenBook Pro Duo之所以選擇了這樣的產品策略,除了以上我們提到的功能多樣化,另外一方面可能也是為了盡量減少Windows生態對使用體驗的影響。
不過,在本次展會上,英特爾也帶來了和華碩ZenBook Pro Duo類似的產品,這對於推進雙屏電腦這件事情是一個不錯的消息,或許在不久之後,其很可能會成為PC行業新的發展趨勢,拭目以待吧。
HP VR Backpack G2
相比於前幾年,如今VR的熱度確實並不高。相對較高的內容製作以及硬件成本,讓並沒有能夠被廣泛的市場所接受,這也導致曾經很多投身於VR的公司也都轉行去做其它智能硬件產品了。但就技術本身而言,VR確實有著廣闊的應用前景。
2016年的台北電腦展上,為了解決硬件支持的問題,惠普推出了一款背包電腦,來讓VR設備不再受到線纜的限制,從而實現更好的使用體驗。時隔三年之後,在本屆展會上,��又帶來了全新的HP VR Backpack G2。
這代產品搭載了英特爾第八代酷睿i7處理器以及英偉達RTX 2080獨立顯卡,同時配有2個USB-A 3.0接口、1個USB-C接口以及1個耳機麥克風二合一接口。相比於上代產品,其在性能方面有了一個比較明顯的提升。
而為了讓用戶獲得更舒服的使用體驗,新品還調整了背包外部電池的位置。除此之外,其和上代產品一樣,也依舊配備有底座,在不需要連接VR設備的時候,你也可以將其作為一台迷你PC來使用。
酷冷至尊MM710電競鼠標
每年的台北電腦展,總有一些令人眼前一亮的外設產品,今年也不例外。展會上,外設大廠酷冷至尊帶來了一款名為MM710的輕量化鼠標,提供黑色(無RGB燈效)以及白色(有RGB燈效)兩個不同的版本。
圖片來自engadget
外觀設計上,酷冷至尊MM710最大的特點在於其使用了“蜂窩”式設計,從圖片中可以看到,其在產品外圍做了非常多孔狀結構。所帶來的好處主要有兩個,其一是更好地控制了重量,其中白色版本為57g,而黑色版本則只有52g,另外一方面是能夠起到不錯的散熱效果。
圖片來自engadget
至於大家比較關注的性能表現方面,它搭載了歐姆龍微動以及PixArt PMW3389光學傳感器,最高DPI為32000。不過官方並目前尚未公佈其更多信息,對這款產品感興趣的朋友可以保持關注。
美商海盜船Hydro X分體水冷套件
熱愛DIY的朋友相信對於美商海盜船應該並不陌生,在這家公司25週年之際,針對高端PC用戶群體,其推出了全新的Hydro X分體水冷系列,並且獲得了BEST IN COMPUTEX獎項。
從官方公佈的資料我們了解到,從120mm到480mm的銅芯冷排、軟管/硬管管道到帶有各種角度適配器的多種接頭、各種色彩的冷卻劑,Hydro X系列能夠提供組裝定制散熱系統的所用到的所有部件。
除此之外,Hydro X系列組件支持集成式RGB LED燈效,能夠通過美商海盜船iCUE RGB照明控制器和美商海盜船iCUE軟件進行控制,從而帶來非常炫酷的視覺體驗。目前該系列產品已經在美商海盜船官網上線,感興趣的朋友可以去了解下。
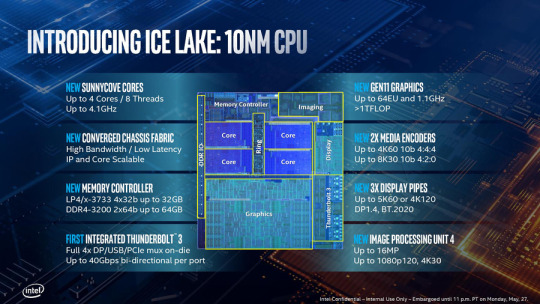
英特爾第10代10nm Ice Lake CPU
對於手機以及PC行業而言,產業的繼續向前推進離不開芯片廠商的支持。一改以往“擠牙膏”的形象,這次英特爾在台北電腦展上正式對外公佈了代號為Ice Lake的10nm處理器(架構名稱為Sunny Cove)。
按照官方公佈的數據顯示,這代處理器型號為i3、i5以及i7,不過可能由於首批面向移動端設備,其分為低功耗Ice Lake-U和超低功耗Ice Lake-Y兩種不同的功耗版本,TDP規格為9W、15W以及28W三檔,4核8線程,緩存為8MB,最高頻率4.1GHz。
拋開以上我們提到的這些參數,新架構下,有三點值得大家關注。
首先是人工智能性能,這代產品搭載了英特爾DL Boos t推理加速技術,使得人工智能運算能力有了接近2.5倍的提升;另外,基於第十一代核心顯卡架構的全新銳炬plus顯卡,支持HEVC編碼/解碼以及VESA的Adaptive Sync;最後,它還同時集成了Thunderbolt 3和Wi-Fi 6。
用更加簡單的話來說,英特爾第十代10nnm Ice Lake處理器在人工智能性能、顯卡性能以及連接性方面都進行了升級。
AMD 7nm Ryzen 3900X CPU
最近兩年,AMD在產品端的動作很快,也走的更為激進。英特爾發布第十代10nm Ice Lake處理器的前一天,AMD搶先公佈了7nm Zen 2架構的第三代Ryzen銳龍處理器,包括Ryzen 7 3700X、Ryzen 7 3800X以及Ryzen 9 3900X在內,一共有三款產品。
其中關注度最高的無疑是Ryzen 9 3900X。它擁有12核心24線程,基礎頻率為3.8GHz,最高為4.6GHz,TDP為105W。參考官方說法,Ryzen 9 3900X在性能表現上與英特爾i9-9920X非常接近。
但值得注意的是,AMD Ryzen 9 3900X的價格為499美元,而英特爾i9-9920X則為1189美元,也就是說,兩款處理器在性能基本相當的前提下,前者的售價還不到後者的一半,性價比非常高,這對於作為消費者的我們而言,是一個不錯的消息。
NVIDIA RTX Studio計劃
區別於以上幾家廠商,NVIDIA真正讓我們關注的,是其發布的NVIDIA RTX Studio計劃。該計劃主要面向於創作者,通過提供專用的SDK以及Studio驅動,來幫助PC產品提高在運行諸如Adobe、Autodest、Unity等軟件應用時的效率以及可靠性。
和此前Max-Q架構類似,NVIDIA RTX Studio同樣需要廠商申請認證,並且設定了比較明確的硬件配置要求。
具體來講,提出申請的產品需要搭載Intel Core i7(H系列)或更高版本的處理器、GeForce RTX 2060或Quadro RTX 3000以上的獨立顯卡、不小於16GB的內存、512GB以上的固態硬盤、不小於15寸並且分辨率為1080p或4K的屏幕、採用Max-Q設計。
目前,包括惠普、戴爾、華碩、宏碁、技嘉、微星以及雷蛇等在內的多家PC廠商已經加入到了NVIDIA RTX Studio計劃中,並且推出了經過認證的筆記本電腦。
在極客之選看來,該計劃的發布,將能夠在一定程度上提升PC對於設計師群體吸引力,讓其在細分市場上擁有更強的競爭力。
5G
2018年屬於人工智能,到了2019年,5G成為了舞台上最為耀眼的明星。從CES 2019到MWC 2019再到COMPUTEX 2019,5G都是大家關注的焦點。憑藉更低的網絡延遲,其將讓“萬物互聯”變成可能。
在5G終端產品的落地上,手機行業要比PC行業走得相對快一些。目前市面上已經有5G手機開售(如三星Galaxy S10 5G版),今年也會有更多的手機新品陸續加入到這個行列中。不過PC廠商們也在推進這件事情。
圖片來自windowscentral
本屆展會上,高通和聯想展示了代號為“Project Limitless”的全球首款5G筆記本電腦,其搭載了高通驍龍8cx 5G計算平台,高通稱,該產品內置了驍龍X55 5G調製解調器,能夠實現非常快的網絡傳輸速度。
據悉,聯想將會量產這款筆記本產品,不過具體開售時間尚未確定。畢竟,相比於智能手機,PC從英特爾改為高通平台之後,還需要解決軟件生態問題,處理起來要麻煩很多。
除了高通,聯發科也推出了自家的5G終端芯片——MTK Helio M70 5G。
其採用了7nm製程工藝,集成了5G調製解調器Helio M70,是全球首款搭載Cortex-A77 CPU和Mali-G77 GPU的SoC,官方稱它最快將會在2020年第一季度上市。
訪問:
京東商城
.
from 台北電腦展2019接近尾聲 都有哪些值得關注產品和技術? via KKNEWS
0 notes