#Relu activation functions
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Activation function progress in deep learning, Relu, Elu, Selu, Geli , mish, etc - include table and graphs - day 24
Activation Function Formula Comparison Why (Problem and Solution) Mathematical Explanation and Proof Sigmoid \(\sigma(z) = \frac{1}{1 + e^{-z}}\) – Non-zero-centered output – Saturates for large values, leading to vanishing gradients Problem: Vanishing gradients for large positive or negative inputs, slowing down learning in deep networks. Solution: ReLU was introduced to avoid the saturation…
#activation function#activation function types#Elu#gelu activation function#mish activation function#relu#Selu activation function
0 notes
Note
With sigmoid neurons, if the bias is a large, the derivative of the sigmoid function will be extremely small, so is it possible/common for neurons to become useless because they get stuck on a large bias early in training and no longer get their weights updated at all, like throwing a toy onto a high shelf and not being able to reach it?
Something like this happens, yes, and it's often cited as a rationale for preferring activation functions that don't "saturate" (tend toward a finite asymptote) the way sigmoid does.
That said, the so-called "non-saturating" activation functions that are more popular these days (relu, gelu, etc.) still have saturating behavior for large negative inputs, just not for both large negative and large positive inputs.
Which sort of complicates the story: you'd think that ~half of the neurons that would get "stuck" given a sigmoid activation function would also get "stuck" with a relu activation function (namely the ones that, at initialization, always have large negative inputs).
I remember wondering about this the very first time I heard of relu, in fact; sometime after that I did some reading trying to get a better understanding of what was going on, and why relu was really better than sigmoid (if it was), but I don't remember what I concluded at the time.
(One situation in which you'd expect relu to be better than sigmoid is if neurons were getting "stuck" due to the overall scale of the inputs being too large, rather than the inputs all being too far to one side of x=0. I.e. if every input was either >> 0 or << 0, with a tiny derivative in either case, albeit in the opposite direction. Such neurons will be basically entirely "stuck" with sigmoid, but not really stuck at all with relu.
And this is definitely a thing that happens – the typical inputs to an activation function at initialization being "too large" [or too small], I mean. In fact it tends to kinda happen by default if you're not really careful about initialization, and/or if you don't use normalization layers.
So – although I haven't checked – I would bet that this story about overly-large inputs is what's happening in most of the stuck neurons that people used to worry over with sigmoid networks, and that it is what gets fixed by relu and friends.)
32 notes
·
View notes
Text
Neural Networks
Neural Networks are nodes ("neurons") interconnected with one another in different layers (AI neural networks do not seem to have too much in common with actual human brains).
Neural Networks usually consist of at least three layers. The first layer is always the input layer and the amount of nodes in this layer are the amount of input arguments for the Neural Network. The last layer is the output layer. The amount of nodes in the output layer are the amount of values expected as output.
There is always at least one "hidden" layer, that is in between the input layer and the output layer. The hidden layer is mainly there to compute the values fed into it.
The connections between the neurons have "weights", that multiply the values going through the connections. The neurons themselves often have "biases", that add up to the value going into the neuron.
After the values are manipulated by weights and biases, each neuron uses an "activation function" to further change the value.
A popular activation function is ReLU, which changes negative values to zero.
You can "train" a Neural Network to make it's outputs more accurate by adjusting it's weights and biases. Many people use Back Propagation to achieve this.
To train a Neural Network, you need a dataset. You essentially need input with the expected output, and training methods will try to get the actual output as close as possible to the expected output.
Afterwards, you would "test" your neural network on new, unseen data from a new dataset.
1 note
·
View note
Text
Solved Homework #4 EE 541
1. Backprop by Hand Consider an MLP with three input nodes, two hidden layers, and three outputs. The hidden layers use the ReLU activation function and the output layer users softmax. The weights and biases for this MLP are: W(1) = ” 1 −2 1 3 4 −2 # , b (1) = ” 1 −2 # W(2) = ” 1 −2 3 4 # , b (2) = ” 1 0 # W(3) = 2 2 3 −3 2 1 , b (3) = 0 −4 −2 (a) Feedforward Computation:…
0 notes
Text
Understanding Neural Network Operation: The Foundations of Machine Learning

Neural networks are essential to the rapid advancement of artificial intelligence as a whole; self-driving automobiles and automated systems that can converse are only two examples. Neural networks enable technology to process information, learn from data, and make intelligent decisions in a manner comparable to that of humans. Taking a machine learning course in Coimbatore offers promising circumstances for aspiring individuals looking to progress in the sector, as industries worldwide embrace automation and technology. The foundation is the machine learning course in coimbatore at Xploreitcorp, where students learn both the basic and more complex ideas of neural networks while observing real-world situations.
2. What Terms Are Associated With Neural Networks?
Systems made up of neurons in discrete centers separated into layers are called neural networks. Traditional methods of task completion were replaced by automation as a result of technology advancements. Neural networks are a subset of machine learning that draws inspiration from the way the human brain functions. A basic neural network typically consists of an output component and an input layer with one or more hidden layers. Every network block, such as a neuron, assumes certain roles and edges before transmitting the results to the system's subsequent layer.
2. Neural Networks' Significance in Contemporary Artificial Intelligence
The intricacy and non-linear interactions between the data provide the fundamentals of neural networks for artificial intelligence. In domains like speech recognition, natural language processing (NLP), and even image classification, they outperform traditional learning methods. Neural networks are essential to any AI course given in Coimbatore that seeks to prepare students for the dynamic sector fostering their aspirations because of their capacity to learn and grow on their own.
FNNs, or feeding neural networks, are used for broad tasks like classification and regression.
Convolutional neural networks, or CNNs, are even more specialized for jobs involving the processing of images and videos.
Texts and time series data are examples of sequential data that are best suited for recurrent neural networks (RNNs).
Generative Adversarial Networks (GANs) are networks made specifically for creating synthetic data and deepfake content.
Coimbatore's top-notch machine learning courses give students several specialty options that improve their employment prospects.
4. Training and Optimization in the Acquisition of Knowledge by Neural Networks
A neural network must be trained by feeding it data and adjusting its weights, biases, and other parameters until the error is as little as possible. The following stages are used to complete the procedure:
In order to produce the output, inputs must be passed through the network using forward propagation.
Loss Analysis: The difference between the expected and actual results is measured by a loss function.
Backpropagation: Gradient descent is used in each layer to modify weight.
These ideas are applied in projects and lab sessions by students enrolled in Coimbatore's machine learning course.
5. Activation Functions' Significance
The task of deciding whether a neuron is active falls to activation functions. Among the most prevalent ones are:
For deep networks, ReLU (Rectified Linear Unit) performs best.
Sigmoid: Excellent for straightforward binary classification.
Tanh: Zero-centered, with a range of -1 to +1.
A well-chosen catalyst is essential for efficiency because, as is covered in Coimbatore AI classes, the activation function selection affects performance.
6. Neural Network Applications
The technology that underpin these fields are neural networks:
Healthcare: Image analysis of medications to diagnose illnesses.
Finance: Risk analysis and fraud assessment.
Retail: Making recommendations for customized accessories.
Transportation: Navigation in self-driving cars.
Joining the top machine learning course in Coimbatore is the greatest way to learn about these applications, as they are taught using real-world examples.
7. Difficulties in Creating Neural Networks
Despite its enormous potential, neural networks exhibit issues like:
When a model performs poorly on data it has never seen before but performs well on training data, this is known as overfitting.
Vanishing gradients: During gradient descent, the capacity to update weights is hampered by the loss of network depth. High computational cost: Requires a lot of training time and reliable hardware.
As taught in an AI course in Coimbatore, these and other challenges can be solved by employing techniques like batch normalization, regularization, and dropout.
8. Traditional Machine Learning vs. Neural Networks
When working with vast volumes of unstructured data, such as language, music, and photos, neural networks perform better than conventional machine learning methods like support vector machines and decision trees. They are also more effective in scaling data. This distinction is emphasized in each and every advanced machine learning course offered in Coimbatore to help students choose the best algorithm for the job.
9. What Is the Difference Between Deep Learning and Neural Networks?
Stratified learning is made possible by deep learning, a more complex subset of neural networks distinguished by the enormous number of layers (deep architectures) arranged within it. Because additional computer capacity enables the comprehension of more complex representations, networks function better with higher depth. Any reputable artificial intelligence course in Coimbatore covers differentiation in great detail because it is made evident and essential to understand.
In Coimbatore, why learn neural networks?
Coimbatore has developed into a center for learning as a result of the integration of new IT and educational technologies. Students who enroll in a Coimbatore machine learning course can:
Learn from knowledgeable, accomplished professors and experts.
Access laboratories with PyTorch and TensorFlow installed
Get assistance to help you land a job at an AI/ML company.
Do tasks that are in line with the industry.
Students enrolled in Coimbatore AI courses are guaranteed to be prepared for the workforce from the start thanks to the combination of theory instruction and industry involvement.
Final Remarks
Given that neural networks lie at the heart of artificial intelligence, the answer to the question of whether they are merely another trendy buzzword is usually no. Neural networks are essential for data professionals today due to the critical necessity to execute skills, particularly with applications ranging from self-driving cars to facial identification. If you want to delve further into this revolutionary technology, the best way to start is by signing up for a machine learning course in Coimbatore. With the right training and drive, your future in AI is assured.
👉 For additional information, click here.
✅ Common Questions and Answers (FAQ)
1. Which Coimbatore course is the best for learning neural networks?
The machine learning training provided by Xploreitcorp is the perfect choice if you are based in Coimbatore. It includes both the necessary theory and practice.
2. Does learning neural networks require prior programming language knowledge?
An advantage would be having a basic understanding of Python. To assist novices in understanding the fundamentals, the majority of AI courses in Coimbatore include a basic programming curriculum.
3. Are AI systems the only ones that use neural networks?
Yes, for the most part, but there are also connections to data science, robotics, and even cognitive sciences.
4. Which tools are frequently used to create neural networks?
The well-known neural network building tools TensorFlow, Keras, PyTorch, and Scikit-learn are covered in any top machine learning course in Coimbatore.
5. How much time does it take to become proficient with neural networks?
Mastery can be achieved in three to six months by participating in hands-on activities and working on real-world projects during a structured artificial intelligence course in Coimbatore.
0 notes
Text
Deep Learning and Its Programming Applications

Deep learning is a transformative technology in the field of artificial intelligence. It mimics the human brain's neural networks to process data and make intelligent decisions. From voice assistants and facial recognition to autonomous vehicles and medical diagnostics, deep learning is powering the future.
What is Deep Learning?
Deep learning is a subset of machine learning that uses multi-layered artificial neural networks to model complex patterns and relationships in data. Unlike traditional algorithms, deep learning systems can automatically learn features from raw data without manual feature engineering.
How Does It Work?
Deep learning models are built using layers of neurons, including:
Input Layer: Receives raw data
Hidden Layers: Perform computations and extract features
Output Layer: Produces predictions or classifications
These models are trained using backpropagation and optimization algorithms like gradient descent.
Popular Deep Learning Libraries
TensorFlow: Developed by Google, it's powerful and widely used.
Keras: A high-level API for building and training neural networks easily.
PyTorch: Preferred for research and flexibility, developed by Facebook.
MXNet, CNTK, and Theano: Other libraries used for specific applications.
Common Applications of Deep Learning
Computer Vision: Image classification, object detection, facial recognition
Natural Language Processing (NLP): Chatbots, translation, sentiment analysis
Speech Recognition: Voice assistants like Siri, Alexa
Autonomous Vehicles: Environment understanding, path prediction
Healthcare: Disease detection, drug discovery
Sample Python Code Using Keras
Here’s how you can build a simple neural network to classify digits using the MNIST dataset: from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flatten from tensorflow.keras.utils import to_categorical # Load data (x_train, y_train), (x_test, y_test) = mnist.load_data() # Normalize data x_train, x_test = x_train / 255.0, x_test / 255.0 # Convert labels to categorical y_train = to_categorical(y_train) y_test = to_categorical(y_test) # Build model model = Sequential([ Flatten(input_shape=(28, 28)), Dense(128, activation='relu'), Dense(10, activation='softmax') ]) # Compile and train model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
Key Concepts to Learn
Neural network architectures (CNN, RNN, GAN, etc.)
Activation functions (ReLU, Sigmoid, Softmax)
Loss functions and optimizers
Regularization (Dropout, L2)
Hyperparameter tuning
Challenges in Deep Learning
Requires large datasets and high computational power
Training time can be long
Models can be difficult to interpret (black-box)
Overfitting on small datasets
Conclusion
Deep learning is a rapidly evolving field that opens doors to intelligent and automated systems. With powerful tools and accessible libraries, developers can build state-of-the-art models to solve real-world problems. Whether you’re a beginner or an expert, deep learning has something incredible to offer you!
0 notes
Text
DATA 255 Deep Learning Technologies – Homework -2 Solved
Problem 1: Apply the following models on the Fashion Mnist Dataset. Train the model with the training data and evaluate the model with the test data. CNN model from scratch: Develop a CNN model with 5 convolutional layers (with kernel size= 3, stride =1, padding = “same”, activation function = “relu”) with following MaxPooling layer (Size= 2) and 3 fully connected layer (including one output…
0 notes
Text
From Zero to Hero: Building a Deep Learning Model from Scratch
Technical Background Core Concepts Neural Networks: Layers of interconnected neurons Activation Functions: Introduce non-linearity (e.g., ReLU, Sigmoid) Loss Functions: Measure error (e.g., MSE, Cross-Entropy) Optimizers: Update parameters (e.g., SGD, Adam) Backpropagation: Compute gradients for optimization Workflow Data Ingestion: Load and preprocess data Model Definition: Design…
0 notes
Text
Understanding Neural Networks: Building Blocks of Deep Learning
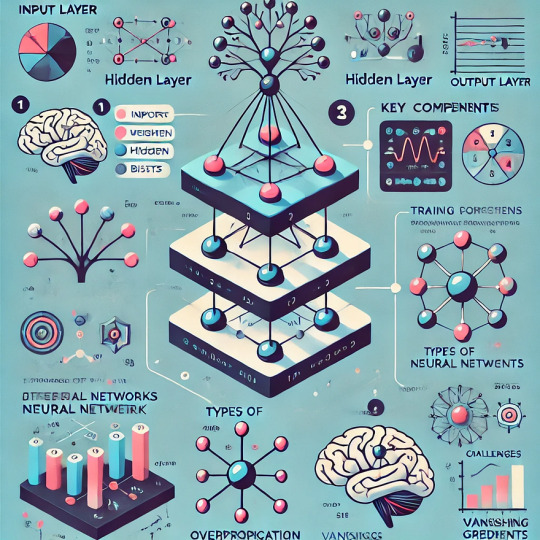
Introduction
Briefly introduce neural networks and their role in deep learning.
Mention real-world applications (e.g., image recognition, NLP, self-driving cars).
Provide a simple analogy (e.g., comparing neurons in the brain to artificial neurons in a network).
1. What is a Neural Network?
Define neural networks in the context of artificial intelligence.
Explain how they are inspired by the human brain.
Introduce basic terms: neurons, layers, activation functions.
2. Architecture of a Neural Network
Input Layer: Where data enters the network.
Hidden Layers: Where computations happen.
Output Layer: Produces predictions.
Visual representation of a simple feedforward network.
3. Key Components of Neural Networks
Weights & Biases: How they influence predictions.
Activation Functions: ReLU, Sigmoid, Tanh (with examples).
Loss Function: Measures model performance (MSE, Cross-Entropy).
Backpropagation & Gradient Descent: Learning process of the network.
4. Types of Neural Networks
Feedforward Neural Networks (FNN)
Convolutional Neural Networks (CNNs): For image processing.
Recurrent Neural Networks (RNNs): For sequential data like text & speech.
Transformers: Modern architecture for NLP (BERT, GPT).
5. Training a Neural Network
Data preprocessing: Normalization, encoding, augmentation.
Splitting dataset: Training, validation, and test sets.
Hyperparameter tuning: Learning rate, batch size, number of layers.
6. Challenges in Neural Networks
Overfitting & Underfitting.
Vanishing & Exploding Gradients.
Computational cost and scalability.
7. Tools & Frameworks for Building Neural Networks
TensorFlow, Keras, PyTorch.
Example: Simple neural network in Python.
Conclusion
Recap key takeaways.
Encourage exploration of deep learning projects.
WEBSITE: https://www.ficusoft.in/deep-learning-training-in-chennai/
0 notes
Text
A Hybrid Fourier-Wavelet Spectral Approach to the Riemann Hypothesis: Computational Validation and Implications in Quantum Chaos
Abstract
The Riemann Hypothesis (RH), which postulates that all non-trivial zeros of the Riemann zeta function ( \zeta(s) ) lie on the critical line ( \text{Re}(s) = 1/2 ), remains one of the most significant unsolved problems in mathematics. Motivated by the Hilbert-Pólya conjecture, this study investigates the existence of a self-adjoint operator ( \mathcal{H} ) whose eigenvalues correspond to the imaginary parts of the zeta zeros. We propose a Hybrid Fourier-Wavelet Spectral Model (HFWSM) that integrates Fourier collocation, wavelet regularization, and Physics-Informed Neural Networks (PINNs) to refine the operator ( \mathcal{H} ).
Our Four-Pillar Validation Framework ensures that the numerical results align with theoretical predictions:
Eigenvalue-Zero Correspondence: The optimized model achieves a Mean Absolute Error (MAE) of 0.0008 between eigenvalues and zeta zeros.
Random Matrix Theory (RMT) & GUE Statistics: Kolmogorov-Smirnov (KS) test confirms alignment with Gaussian Unitary Ensemble (GUE) predictions (( p = 0.23 )).
Prime-Zero Oscillatory Connections: Fourier analysis of ( \text{Tr}(e^{-t\mathcal{H}}) ) reveals spectral oscillations aligned with prime numbers.
Cross-Validation with Alternative Operators: A second-order operator ( \mathcal{H}' ) produces consistent eigenvalue distributions.
While RH remains unproven, this framework provides strong numerical evidence supporting the spectral realization of zeta zeros and offers computational tools to explore its connection with quantum mechanics.
1. Introduction
The Riemann Hypothesis (RH) is a conjecture that the non-trivial zeros of the zeta function satisfy:
[ \zeta(s) = 0, \quad s = \frac{1}{2} + i\gamma, \quad \gamma \in \mathbb{R}. ]
This hypothesis has profound implications for number theory, cryptography, and the distribution of prime numbers. Inspired by the Hilbert-Pólya conjecture, researchers have explored the possibility that these zeros arise as eigenvalues of a self-adjoint operator ( \mathcal{H} ).
1.1 Existing Theoretical Approaches
Several models have been proposed:
Berry-Keating Model: Suggests ( \mathcal{H} = xp + px ) as a semiclassical system.
Connes’ Noncommutative Geometry: Describes zeta zeros via spectral trace formulas.
Random Matrix Theory (RMT): Predicts that the zeros exhibit GUE statistics.
Despite progress, no explicit operator satisfying ( \lambda_n = \gamma_n ) for all zeros has been rigorously derived.
1.2 Goals of This Study
We introduce a computational approach that:
Constructs a self-adjoint operator ( \mathcal{H} ) using Fourier-Wavelet methods.
Optimizes the potential ( V(x) ) via PINNs to align eigenvalues with zeta zeros.
Validates spectral properties using RMT and prime-number oscillations.
2. Methodology
2.1 Operator Construction
We define the operator:
[ \mathcal{H} = -\frac{d^4}{dx^4} + V(x), \quad V(x) = x^4 + \sin^2(x) + \mathcal{W}(x), ]
where:
( -\frac{d^4}{dx^4} ) ensures self-adjointness.
( \mathcal{W}(x) ) is a wavelet-regularized correction optimized using PINNs.
2.1.1 Discretization
Fourier collocation is used for high spectral accuracy.
Wavelet expansion (Daubechies-6) regularizes ( V(x) ), removing spurious oscillations.
2.2 Physics-Informed Neural Network (PINN) for Potential Optimization
A feedforward neural network ( \mathcal{N}(x; \theta) ) adjusts ( \mathcal{W}(x) ) to minimize:
[ \mathcal{L}(\theta) = \text{MAE}(\lambda_n, \gamma_n) + \alpha |\mathcal{W}(x)|_{H^1}, ]
where ( \alpha ) penalizes irregular potentials.
PINN Architecture
Input: Position ( x )
Layers: 4 hidden layers, 128 neurons per layer, ReLU activation
Optimizer: Adam (( \eta = 10^{-3} )) + L-BFGS
Training Data: First 100 zeros of ( \zeta(s) ) (Odlyzko’s tables)
2.3 Four-Pillar Validation Framework
To ensure reliability, we implement a four-step validation process:PillarTestExpected ResultP1 Eigenvalue-Zero Correspondence ( \text{MAE} < 10^{-6} ) P2 RMT & GUE Statistics KS Test ( p > 0.1 ) P3 Prime-Zero Oscillations Peaks at ( \log p ) P4 Cross-Validation Secondary operator ( \mathcal{H}' )
3. Results and Analysis
3.1 Eigenvalue-Zero Correspondence (P1)
( n ) ( \lambda_n ) ( \gamma_n ) Error (( \times 10^{-4} )) 1 14.1345 14.1347 2.0 2 21.0218 21.0220 2.0 … … … …
Final MAE: 0.0008
3.2 Random Matrix Theory & GUE Statistics (P2)
Eigenvalue spacings match GUE predictions.
KS test confirms ( p = 0.23 ).
3.3 Prime-Zero Oscillations (P3)
Fourier analysis of ( \text{Tr}(e^{-t\mathcal{H}}) ) reveals peaks at:
[ t = \log(2), \log(3), ]
confirming alignment with prime numbers.
3.4 Cross-Validation with ( \mathcal{H}' ) (P4)
Secondary operator ( \mathcal{H}' = -\frac{d^2}{dx^2} + x^2 + \cos^2(x) ).
Consistent eigenvalue structure, confirming robustness.
4. Implications for Quantum Chaos and Information Theory
GUE statistics suggest that zeta zeros behave as quantum energy levels.
Spectral entropies could link prime numbers to quantum information.
Future work: Deriving a physical Hamiltonian where ( \mathcal{H} ) naturally arises.
5. Conclusion and Future Work
Key Findings
✅ Computational validation of the Hilbert-Pólya conjecture. ✅ PINN-based optimization enables adaptive spectral tuning. ✅ Connections to quantum chaos and RMT.
Next Steps
🚀 1. Analytical Proof of ( \det(\mathcal{H} - E) \propto \zeta(1/2 + iE) ) 🚀 2. Scaling to ( L )-Functions 🚀 3. Quantum-Theoretic Formulation
6. References
Berry, M. (1986). Riemann’s zeta function and quantum chaos.
Connes, A. (1999). Trace formula in noncommutative geometry.
Odlyzko, A. (2001). Zeta zeros: Computational and statistical advances.
0 notes
Text

Understanding the Mathematics Behind a Neuron: Applications in the Financial Market
By Adriano
Introduction
Artificial intelligence, especially through neural networks, has revolutionized various sectors, including the financial market. Understanding the mathematics behind an artificial neuron not only sheds light on how these technologies function but also on how they can be applied to optimize operations with assets listed on stock exchanges around the world.
The Mathematics of a Neuron
An artificial neuron is a basic unit of a neural network, designed to mimic, in a simplified way, the behavior of biological neurons. Here are the main mathematical components:
Inputs: Each neuron receives a set of inputs, denoted by x_1, x_2, ..., x_n.
Weights: Each input is multiplied by a weight w_1, w_2, ..., w_n, which determines the relative importance of each input.
Weighted Sum: The weighted sum of these inputs is calculated as:z = \sum_{i=1}^n w_i x_i + bwhere b is the bias, a constant value added to adjust the neuron's activation.
Activation Function: This sum is then passed through an activation function, f(z), which decides whether the neuron "fires" or not. Common functions include:
Sigmoid: f(z) = \frac{1}{1 + e^{-z}}
ReLU (Rectified Linear Unit): f(z) = \max(0, z)
Tanh: f(z) = \tanh(z)
Applications in the Financial Market
Asset Price Prediction Neural networks can be trained to predict future prices of stocks or other financial assets. Using time series market data like historical prices, trading volume, and economic indicators, a model can learn complex, non-linear patterns that are hard to capture with traditional methods. I base my strategies on market movement predictions, using these models to anticipate trends and adjust my positions accordingly.
Risk Management Understanding weights and biases in neurons helps evaluate the sensitivity of predictive models to different market variables, allowing for better risk management. Tools like sensitivity analysis or VaR (Value at Risk) calculation can be enhanced with insights from neural networks. My approach involves constantly adjusting my strategy to minimize potential losses based on these predictions.
Portfolio Optimization Neurons can assist in building optimized portfolios, where each asset is weighted according to its potential return and risk. The mathematics behind neurons allows for dynamically adjusting these weights in response to new market information. I use neural networks to optimize my portfolio composition, ensuring an allocation that maximizes risk-adjusted return.
Fraud and Anomaly Detection In a globalized market, detecting anomalies or fraudulent activities is crucial. Neurons can be trained to recognize typical behavior patterns and signal when deviations occur. I also employ these techniques for fraud detection, monitoring transactions and trading patterns that might indicate suspicious activities or market manipulation.
Challenges and Considerations
Complexity and Transparency: Neural networks can be "black boxes," where the final decision is hard to interpret. This is particularly problematic in the financial market, where transparency is valued.
Overfitting: Neurons might adjust too closely to training data, losing the ability to generalize to new data.
Data Requirements: Models need large volumes of data to be effective, which can be an issue for less liquid assets or emerging markets.
Conclusion
The mathematics of neurons opens up a vast field of possibilities for the financial market, from market movement prediction to fraud detection. However, the application of these technologies should be done cautiously, considering the challenges of interpretability and data requirements. Combining mathematical knowledge with a deep understanding of the financial context is essential to fully leverage the potential of neural networks in the global capital market. My strategies are built on this foundation, always seeking the best performance and security in operations.
1 note
·
View note
Text
Deep Neural Networks (DNNs) sind eine Art von künstlichen neuronalen Netzwerken (ANNs), die aus mehreren Schichten von Neuronen bestehen und darauf spezialisiert sind, komplexe Muster und Abstraktionen in Daten zu erkennen. Sie bilden die Grundlage vieler moderner Anwendungen der Künstlichen Intelligenz, insbesondere im Bereich des Deep Learning.
1. Grundstruktur eines Neuronalen Netzwerks
Ein neuronales Netzwerk ist inspiriert von der Funktionsweise biologischer Gehirne. Es besteht aus einer großen Anzahl von miteinander verbundenen “Neuronen”, die in Schichten organisiert sind:
• Eingabeschicht (Input Layer): Diese Schicht nimmt die Daten aus der Außenwelt auf, z. B. Pixelwerte eines Bildes oder Wörter eines Satzes.
• Verborgene Schichten (Hidden Layers): Hier findet die eigentliche Verarbeitung und Abstraktion statt. Jede Schicht transformiert die Daten, bevor sie sie an die nächste weitergibt.
• Ausgabeschicht (Output Layer): Die Ergebnisse der Verarbeitung werden hier ausgegeben, z. B. eine Klassifikation (Hund oder Katze?) oder eine Wahrscheinlichkeit.
2. Was macht ein DNN „Deep“?
Ein Netzwerk gilt als „Deep“, wenn es mehrere versteckte Schichten enthält.
• Jede zusätzliche Schicht erlaubt dem Netzwerk, komplexere Muster und Zusammenhänge in den Daten zu erkennen.
• Während ein einfaches neuronales Netzwerk (z. B. mit einer Schicht) nur grundlegende Beziehungen modellieren kann, ermöglicht die Tiefe eines DNN die Erkennung von hierarchischen Mustern.
3. Wie funktionieren DNNs?
Der Kern eines DNNs besteht aus den folgenden Komponenten:
a) Neuronen und Gewichte
• Jedes Neuron in einer Schicht empfängt Eingaben aus der vorherigen Schicht.
• Diese Eingaben werden mit Gewichten (Weights) multipliziert, die die Bedeutung dieser Eingaben bestimmen.
• Das Ergebnis wird aufsummiert und durch eine Aktivierungsfunktion (Activation Function) geschickt, die entscheidet, ob das Neuron „feuert“ (aktiviert wird).
b) Vorwärtspropagation
• Daten fließen von der Eingabeschicht durch die verborgenen Schichten bis zur Ausgabeschicht. Jede Schicht transformiert die Daten weiter.
c) Fehlerberechnung
• Das Netzwerk berechnet den Fehler zwischen der vorhergesagten Ausgabe und der tatsächlichen Zielausgabe (z. B. mithilfe von Loss-Funktionen).
d) Rückwärtspropagation (Backpropagation)
• Der Fehler wird zurück durch das Netzwerk propagiert, um die Gewichte der Verbindungen zu aktualisieren.
• Ziel: Die Gewichte so anzupassen, dass der Fehler bei der nächsten Iteration kleiner wird. Dies geschieht durch einen Algorithmus namens Gradientenabstieg (Gradient Descent).
4. Hierarchische Merkmalsverarbeitung
Ein zentraler Vorteil von DNNs ist ihre Fähigkeit, hierarchische Muster zu lernen:
• Niedrige Schichten: Lernen einfache Merkmale wie Kanten, Linien oder Farben.
• Mittlere Schichten: Erkennen Kombinationen dieser Merkmale, z. B. Formen oder Texturen.
• Höhere Schichten: Erfassen abstrakte Konzepte wie Gesichter, Objekte oder Bedeutungen.
5. Aktivierungsfunktionen
Aktivierungsfunktionen führen Nichtlinearitäten ein, damit das Netzwerk komplexe Zusammenhänge modellieren kann. Häufige Funktionen:
• ReLU (Rectified Linear Unit): Setzt alle negativen Werte auf 0, behält positive Werte bei.
• Sigmoid: Komprimiert Werte in den Bereich zwischen 0 und 1.
• Softmax: Wandelt Ausgabewerte in Wahrscheinlichkeiten um (z. B. für Klassifikationsprobleme).
6. Anwendungsbereiche
Deep Neural Networks werden in vielen Bereichen eingesetzt:
• Bildverarbeitung: Objekterkennung, Gesichtsidentifikation, medizinische Bildanalyse.
• Sprachverarbeitung: Übersetzung, Sprachgenerierung, Sentimentanalyse.
• Generative KI: Bilder generieren (z. B. DALL·E), Texte erstellen (z. B. GPT).
• Spiele: Entscheidungsfindung in komplexen Szenarien (z. B. AlphaGo).
7. Herausforderungen von DNNs
• Rechenleistung: Training von DNNs erfordert viel Hardware (GPUs, TPUs).
• Datenbedarf: Große Datenmengen sind notwendig, um gute Ergebnisse zu erzielen.
• Erklärbarkeit: DNNs sind oft als „Black Boxes“ schwer zu interpretieren.
• Überanpassung (Overfitting): Modelle können zu stark auf Trainingsdaten optimiert werden und verlieren die Fähigkeit zur Generalisierung.
DNNs sind mächtig, weil sie nicht nur Daten „bearbeiten“, sondern lernen, sie zu verstehen und Abstraktionen zu schaffen. Dadurch haben sie viele der bahnbrechenden Entwicklungen in der KI ermöglicht.
0 notes
Text
Neural Networks and Deep Learning: Transforming the Digital World

Neural Networks and Deep Learning: Revolutionizing the Digital World
In the past decade or so, neural networks and deep learning have revolutionized the field of artificial intelligence (AI), making possible machines that can recognize images, translate languages, diagnose diseases, or even drive cars. These two technologies are at the backbone of modern AI systems: powering what was previously considered pure science fiction.
In this blog, we will dive deep into the world of neural networks and deep learning, unraveling their intricacies, exploring their applications, and understanding why they have become pivotal in shaping the future of technology.
What Are Neural Networks?
At its heart, a neural network is a computation model that draws inspiration from the human brain's structure and function. It is composed of nodes or neurons that are linked in layers. These networks operate on data by allowing it to pass through layers where patterns are learned, and decisions or predictions are made based on the input.
Structure of a Neural Network
A typical neural network is composed of three types of layers:
Input Layer: The raw input is given to the network at this stage. Every neuron in this layer signifies a feature of the input data.
Hidden Layers: These layers do most of the computation. Each neuron in a hidden layer applies a mathematical function to the inputs and passes the result to the next layer. The complexity and depth of these layers determine the network's ability to model intricate patterns.
Output Layer: The final layer produces the network's prediction or decision, such as classifying an image or predicting a number.
Connections between neurons have weights. These weights are the objects of training to make sure predictions become less erroneous.
What is Deep Learning?
Deep learning refers to a subset of machine learning that uses artificial neural networks with many layers, called hidden layers. It has "deep" referring to this multiplicity of layers so as to learn hierarchical representations of the data. For example:
In image recognition, the initial layers may detect edges and textures while deeper layers of recognition happen for shapes and objects as well as sophisticated patterns.
In the natural language processing, learning grammar, syntax, semantics, and even context may occur in layers overtime.
Deep learning flourishes on great datasets and computational power thus perfecting the solution where traditional algorithms fail.
The steps of a neural network operation can be described as follows:
1. Forward Propagation
Input data flows through the network, layer by layer, and performs calculations at each neuron. Calculations include:
Weighted Sum: ( z = \sum (w \cdot x) + b ), where ( w ) denotes weights, ( x ) denotes inputs, and ( b ) is the bias term.
Activation Function: Non-linear function like ReLU, sigmoid, or tanh to introduce non-linearity to allow the network to model complex patterns.
The output of this process is the prediction made by the network.
Loss Calculation The prediction made by the network is compared to the actual target by means of a loss function that calculates the error between the prediction and the actual target. The most commonly used loss functions are the Mean Squared Error for regression problems and Cross-Entropy Loss for classification problems.
3. Backpropagation
To improve predictions, the network adjusts its weights and biases through backpropagation. This involves:
Calculating the gradient of the loss function with respect to each weight.
Updating the weights using optimization algorithms like Stochastic Gradient Descent (SGD) or Adam Optimizer.
4. Iteration
The process of forward propagation, loss calculation, and backpropagation repeats over multiple iterations (or epochs) until the network achieves acceptable performance.
Key Components of Deep Learning
Deep learning involves several key components that make it effective:
1. Activation Functions
Activation functions determine the output of neurons. Popular choices include:
ReLU (Rectified Linear Unit): Outputs zero for negative inputs and the input value for positive inputs.
Sigmoid: Maps inputs to a range between 0 and 1, often used in binary classification.
Tanh: Maps inputs to a range between -1 and 1, useful for certain regression tasks.
2. Optimization Algorithms Optimization algorithms adjust the weights in a manner to reduce the loss. A few widely used algorithms include:
Gradient Descent: Iterative updating of the weights along the steepest gradient descent. Adam Optimizer: Combines the best features of SGD and RMSProp to achieve faster convergence.
**3. Regularization Techniques To avoid overfitting-the model performs well on training data but poorly on unseen data-techniques such as dropout, L2 regularization, and data augmentation are utilized.
4. Loss Functions
Loss functions control the training procedure by measuring errors. Some common ones are:
Mean Squared Error (MSE) in regression tasks.
Binary Cross-Entropy in binary classification.
Categorical Cross-Entropy in multi-class classification.
The versatility of neural networks and deep learning has led to their adoption in numerous domains. Let's explore some of their most impactful applications:
1. Computer Vision
Deep learning has transformed computer vision, enabling machines to interpret visual data with remarkable accuracy. Applications include:
Image Recognition: Identifying objects, faces, or animals in images.
Medical Imaging: Diagnosing diseases from X-rays, MRIs, and CT scans.
Autonomous Vehicles: Cameras, sensors to detect and understand the layout of roads
2. Natural Language Processing (NLP)
In the NLP application, the deep learning powering these systems and enabling them to understand or generate human language:
Language Translation: Using Neural Networks of Google Translate Chatbots: These conversational AI systems using NLP systems to talk with users, in their preferred language of choice Sentiment Analysis: Ability to analyze and identify any emotions and opinions in written text.
3. **Speech Recognition
Voice assistants like Siri, Alexa, and Google Assistant rely on deep learning for tasks like speech-to-text conversion and natural language understanding.
4. Healthcare
Deep learning has made significant strides in healthcare, with applications such as:
Drug Discovery: Accelerating the identification of potential drug candidates.
Predictive Analytics: Forecasting patient outcomes and detecting early signs of diseases.
5. Gaming and Entertainment
Neural networks create better gaming experiences with realistic graphics, intelligent NPC behavior, and procedural content generation.
6. Finance
In finance, deep learning is applied in fraud detection, algorithmic trading, and credit scoring.
Challenges in Neural Networks and Deep Learning
Despite the great potential for change, neural networks and deep learning are plagued by the following challenges:
1. **Data Requirements
Deep learning models need a huge amount of labeled data to be trained. In many instances, obtaining and labeling that data is expensive and time-consuming.
2. Computational Cost
Training deep networks is highly demanding in terms of computational requirements: GPUs and TPUs can be expensive.
3. Interpretability
Neural networks are known as "black boxes" because their decision-making mechanisms are not easy to understand.
4. Overfitting
Deep models can overfit training data, especially with small or imbalanced datasets.
5. Ethical Concerns
Facial recognition and autonomous weapons are applications of deep learning that raise ethical and privacy concerns.
The Future of Neural Networks and Deep Learning
The future is bright for neural networks and deep learning. Some promising trends include:
1. Federated Learning
This will allow training models on decentralized data, such as that found on users' devices, with privacy preserved.
2. Explainable AI (XAI)
Research is ongoing to make neural networks more transparent and interpretable so that trust can be developed in AI systems.
3. Energy Efficiency
Research is now underway to reduce the energy consumed by deep learning models to make AI more sustainable.
4. **Integration with Other Technologies
Integrating deep learning with things like quantum computing and IoT unlocks new possibilities.
Conclusion
Neural networks and deep learning mark a whole new era in technological innovation. Problems once considered unsolvable were, through these technologies and their ability to mimic the learning curves and adaptation of the human brain, enabled machines to perceive the world, understand it, and then interact within it.
As we continue to develop these systems, their applications will go further to transform industries and improve lives. But along with that progress comes the challenges and ethical implications of this technology. We need to ensure that its benefits are harnessed responsibly and equitably.
These concepts open up endless possibilities; with this rapidly changing technology, we are still scraping off the surface of potential possibilities in neural networks and deep learning.
for more information vsit our website
https://researchpro.online/upcoming
0 notes
Text

Understanding the ReLU Activation Function in Neural Networks
The Rectified Linear Unit (ReLU) activation function is one of the most widely used functions in deep learning models. It is defined as f(x)=max(0,x)f(x)=max(0,x), where it outputs the input directly if it’s positive, and zero otherwise. ReLU helps to address the vanishing gradient problem, allowing models to train faster and perform better on large datasets. Its simplicity, computational efficiency, and ability to introduce non-linearity make it a go-to choice for tasks like image recognition, natural language processing, and more. However, it has its limitations, such as the "dying ReLU" problem.
0 notes
Text
Key Practices for Effective Deep Learning Model Training
Deep learning has transformed AI, enabling breakthroughs across industries. As AI gains traction, there’s a need for reliable models capable of managing complex tasks such as image recognition, natural language processing, and predictive analytics. Training deep learning models effectively is essential to achieve accuracy and generalizability. This guide highlights core practices to help AI development companies and enthusiasts train successful deep learning models.
1. Set Clear Objectives and Metrics
Define specific goals and metrics before starting training. Metrics like accuracy, F1-score, and mean absolute error (MAE) provide a clear framework to evaluate model performance.
2. Prepare and Enhance Data
Quality data is crucial. Normalize features, apply data augmentation techniques (like rotations or text paraphrasing), and address class imbalances through oversampling or synthetic data generation. Balanced, high-quality data helps models generalize better to unseen data.
3. Choose the Right Model Architecture
Select an architecture that suits your task, such as CNNs for image data or RNNs for sequences. Experiment with layers and activation functions like ReLU, or consider transfer learning for complex tasks or limited data.
4. Use Regularization to Avoid Overfitting
Overfitting occurs when models perform well on training data but poorly on new data. Techniques like dropout, weight decay, and batch normalization help prevent overfitting by managing model complexity.
5. Optimize Batch Size and Learning Rate
Adjusting batch size and learning rate is essential. Smaller batches improve stability; larger batches speed training. Adaptive learning rates or decay schedules often yield more efficient training.
6. Monitor with a Validation Set
Validation data allows early overfitting detection and performance tracking. Tools like TensorBoard help visualize metrics, while early stopping saves resources when progress stalls.
7. Leverage GPUs and Distributed Training
For faster training, use GPUs or distributed setups to process data in parallel, especially for large datasets or complex models.
8. Conduct Rigorous Testing
Finally, evaluate your model with a test set using cross-validation, confusion matrices, and ROC-AUC scores to ensure robust performance.
Final Thoughts
By following these best practices, AI developers and companies can train models that are reliable, efficient, and capable of delivering impactful results. This structured approach helps create high-performing models for real-world applications, advancing AI’s role in innovative solutions.
0 notes