#SQLOnBigData
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
SQL for Hadoop: Mastering Hive and SparkSQL
In the ever-evolving world of big data, having the ability to efficiently query and analyze data is crucial. SQL, or Structured Query Language, has been the backbone of data manipulation for decades. But how does SQL adapt to the massive datasets found in Hadoop environments? Enter Hive and SparkSQL—two powerful tools that bring SQL capabilities to Hadoop. In this blog, we'll explore how you can master these query languages to unlock the full potential of your data.
Hive Architecture and Data Warehouse Concept
Apache Hive is a data warehouse software built on top of Hadoop. It provides an SQL-like interface to query and manage large datasets residing in distributed storage. Hive's architecture is designed to facilitate the reading, writing, and managing of large datasets with ease. It consists of three main components: the Hive Metastore, which stores metadata about tables and schemas; the Hive Driver, which compiles, optimizes, and executes queries; and the Hive Query Engine, which processes the execution of queries.
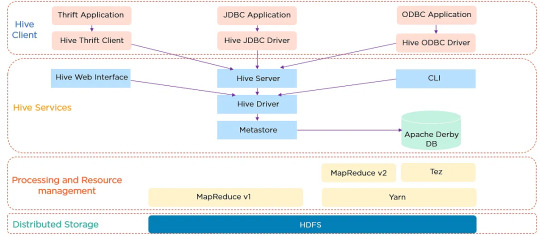
Hive Architecture
Hive's data warehouse concept revolves around the idea of abstracting the complexity of distributed storage and processing, allowing users to focus on the data itself. This abstraction makes it easier for users to write queries without needing to know the intricacies of Hadoop.
Writing HiveQL Queries
HiveQL, or Hive Query Language, is a SQL-like query language that allows users to query data stored in Hadoop. While similar to SQL, HiveQL is specifically designed to handle the complexities of big data. Here are some basic HiveQL queries to get you started:
Creating a Table:
CREATE TABLE employees ( id INT, name STRING, salary FLOAT );
Loading Data:
LOAD DATA INPATH '/user/hive/data/employees.csv' INTO TABLE employees;
Querying Data:
SELECT name, salary FROM employees WHERE salary > 50000;
HiveQL supports a wide range of functions and features, including joins, group by, and aggregations, making it a versatile tool for data analysis.
HiveQL Queries
SparkSQL vs HiveQL: Similarities & Differences
Both SparkSQL and HiveQL offer SQL-like querying capabilities, but they have distinct differences:
Execution Engine: HiveQL relies on Hadoop's MapReduce engine, which can be slower due to its batch processing nature. SparkSQL, on the other hand, leverages Apache Spark's in-memory computing, resulting in faster query execution.
Ease of Use: HiveQL is easier for those familiar with traditional SQL syntax, while SparkSQL requires understanding Spark's APIs and dataframes.
Integration: SparkSQL integrates well with Spark's ecosystem, allowing for seamless data processing and machine learning tasks. HiveQL is more focused on data warehousing and batch processing.
Despite these differences, both languages provide powerful tools for interacting with big data, and knowing when to use each is key to mastering them.

SparkSQL vs HiveQL
Running SQL Queries on Massive Distributed Data
Running SQL queries on massive datasets requires careful consideration of performance and efficiency. Hive and SparkSQL both offer powerful mechanisms to optimize query execution, such as partitioning and bucketing.
Partitioning, Bucketing, and Performance Tuning
Partitioning and bucketing are techniques used to optimize query performance in Hive and SparkSQL:
Partitioning: Divides data into distinct subsets, allowing queries to skip irrelevant partitions and reduce the amount of data scanned. For example, partitioning by date can significantly speed up queries that filter by specific time ranges.
Bucketing: Further subdivides data within partitions into buckets based on a hash function. This can improve join performance by aligning data in a way that allows for more efficient processing.
Performance tuning in Hive and SparkSQL involves understanding and leveraging these techniques, along with optimizing query logic and resource allocation.

Hive and SparkSQL Partitioning & Bucketing
FAQ
1. What is the primary use of Hive in a Hadoop environment? Hive is primarily used as a data warehousing solution, enabling users to query and manage large datasets with an SQL-like interface.
2. Can HiveQL and SparkSQL be used interchangeably? While both offer SQL-like querying capabilities, they have different execution engines and integration capabilities. HiveQL is suited for batch processing, while SparkSQL excels in in-memory data processing.
3. How do partitioning and bucketing improve query performance? Partitioning reduces the data scanned by dividing it into subsets, while bucketing organizes data within partitions, optimizing joins and aggregations.
4. Is it necessary to know Java or Scala to use SparkSQL? No, SparkSQL can be used with Python, R, and SQL, though understanding Spark's APIs in Java or Scala can provide additional flexibility.
5. How does SparkSQL achieve faster query execution compared to HiveQL? SparkSQL utilizes Apache Spark's in-memory computation, reducing the latency associated with disk I/O and providing faster query execution times.
Home
instagram
#Hive#SparkSQL#DistributedComputing#BigDataProcessing#SQLOnBigData#ApacheSpark#HadoopEcosystem#DataAnalytics#SunshineDigitalServices#TechForAnalysts#Instagram
2 notes
·
View notes