#dataanalysistools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Data analysis and visualization project in Malayalam | Just 30 min #dataanalysis #dataanalysistools
Discover how to analyze and visualize climate change data using Python in this comprehensive tutorial! Perfect for beginners and … source
0 notes
Text

Transform Data into Growth Opportunities
Harness the power of AI-driven business analytics software to gain real-time insights, streamline operations, and make smarter decisions that drive your business forward.
#customerdataanalytics#dataanalyticssoftware#dataanalysistools#businessanalyticssoftware#bestanalyticstools#aifordataanalytics#siteselectionsoftware#bestdataanalysissoftware#dataanalyticstoolsandtechniques#aifordataanalysis#businessintelligencesystems
0 notes
Text
0 notes
Text

Empowering Equipment Health with Shop Floor Data Collection Software Boost equipment health with Shop Floor Data Collection Software for real-time insights, enhanced efficiency, and reduced downtime
For more details read our blog :
#machinemonitoring#machinemonitoringsystem#EquipmentHealthMonitoring#machinemonitoringsoftware#productionmonitoringsystem#oeemonitoringsystem#productionmonitoringsoftware#equipmentmonitoring#oeemanufacturing#smartmanufacturing#factorymonitoringsystem#datacollection#dataautomation#dataanalysistools
0 notes
Text
AI in Image and Video Processing Data Analysis Tools
"AI in Image and Video Processing Data Analysis Tools" explores how artificial intelligence is transforming image and video data analysis. By leveraging deep learning and computer vision, AI tools can analyze, enhance, and interpret visual content, making it easier to extract valuable insights. These advanced tools are widely used in industries like healthcare, security, and entertainment to automate tasks and improve accuracy.

#AIinDataAnalysis#ImageProcessing#VideoProcessing#AIinTech#ComputerVision#DataAnalysisTools#MachineLearning#ArtificialIntelligence#AIDeepLearning#VisualDataAnalysis
0 notes
Text
Exploring the Key Features of Microsoft Power BI for Advanced Data Analysis

Get Ahead in Data Analytics: Choose Ievision’s Power BI Training Today
In today’s digital era, data is a vital asset for organizations. Power BI, Microsoft’s powerful data analytics tool, offers a comprehensive solution to transform raw data into actionable insights. If you’re looking to build a career in data analytics or enhance your data-driven decision-making abilities, Microsoft Power BI training is a must. Here’s why choosing Power BI can be a game changer for you.
Benefits of Microsoft Power BI Training
Enhanced Career Prospects: Power BI is one of the fastest-growing business intelligence platforms. By obtaining a certification, you become a valuable asset to organizations seeking professionals skilled in data visualization and analysis.
Data-Driven Decision Making: Power BI empowers organizations to make informed decisions. With training, you can contribute to building reports and dashboards that enable leadership to interpret data efficiently.
Cost-Effective Tool: As a cloud-based service, Power BI is a cost-effective option for businesses of all sizes. Through training, you’ll learn to maximize its capabilities, delivering high-quality insights at low cost.
Customizable and Scalable: Power BI can be tailored to specific business needs. Training equips you with the skills to customize dashboards and scale reporting capabilities as the organization grows.
Collaboration and Sharing: With Power BI, team members can easily collaborate on reports and share insights, creating a culture of transparency and accountability within organizations.
Why Choose Microsoft Power BI?
User-Friendly Interface: Power BI provides a simple yet robust interface that allows users to create visually compelling reports and dashboards without deep technical knowledge. The drag-and-drop features make it easy for beginners to navigate.
Integration with Microsoft Tools: Seamlessly integrate Power BI with other Microsoft products like Excel, Azure, and SQL Server, which ensures a smooth workflow for data analysis and visualization.
Advanced Data Connectivity: Power BI allows you to pull data from a wide variety of sources, including databases, cloud services, and web APIs, ensuring that you can analyze virtually any dataset, no matter where it resides.
Powerful Data Analysis: Power BI provides advanced analytical tools, such as DAX (Data Analysis Expressions), enabling users to perform complex calculations and get deeper insights from data.
Cloud-Based Solution: With Power BI, you can publish your reports to the cloud, allowing access from anywhere. The Power BI service lets teams collaborate in real time, fostering better decision-making and business agility.
Conclusion
Microsoft Power BI is more than just a reporting tool—it’s a platform that empowers businesses to harness the power of their data. By enrolling in the Power BI training at Ievision, you’ll be equipped with the skills to create stunning visualizations, perform deep analyses, and drive business decisions with confidence.
Don’t miss out on the opportunity to elevate your career in data analytics. Join the Microsoft Power BI training today and transform the way you work with data!
#PowerBITraining#DataAnalytics#BusinessIntelligence#MicrosoftPowerBI#DataVisualization#PowerBICertificatio#DataDrivenDecisions#BIPlatform#PowerBIforBusiness#DataAnalysisTools#CloudDataSolutions
0 notes
Text

📚 Are you searching for 📊 SPSS, R, MATLAB, and NVivo Help. Get expert assistance in data analysis and research tools! Whether it's SPSS for statistical analysis 📈, R for programming and data modeling 💻, MATLAB for simulations and numerical computing 🔬, or NVivo for qualitative research 📚, we provide step-by-step guidance to simplify complex tasks and ensure accurate results. Perfect for students and researchers aiming for excellence! 🎓✨
🌐CONTACT US🌐 🪀 Whatsapp/ LiveChat: +447895 628894 🌐 𝗪𝗲𝗯𝘀𝗶𝘁𝗲: https://dissertationwritingservicess.co.uk/ 📧 𝗘𝗺𝗮𝗶𝗹: [email protected]
🎯Our Services🎯
✒SPSS Assistance ✒R Programming Support ✒ MATLAB Guidance ✒NVivo Assistance ✒Data Cleaning & Preparation ✒Custom Tutorials ✒Report Writing ✒24/7 Support
SPSSHelp #RProgramming #MATLABSupport #DataAnalysisTools #StatisticalSoftware #QualitativeResearchHelp #DataModeling #ResearchSupport #ProgrammingGuidance #AcademicTools #StatisticalAnalysisHelp #CustomCodingSupport
0 notes
Text
Data Analysis Tools - Part Two
For the second assignment of the Data Analysis Tools course, we’ve been asked to run a Chi Square Independence Test.
By using the Gapminder dataset, I would like to understand if there is an association between income group (explanatory variable) and life expectancy group (response variable).
Ho - There is no association between income group and life expectancy.
Ha - There is an association between income group and life expectancy.
Then we run our Chi Square test in SAS, and we have the below results:

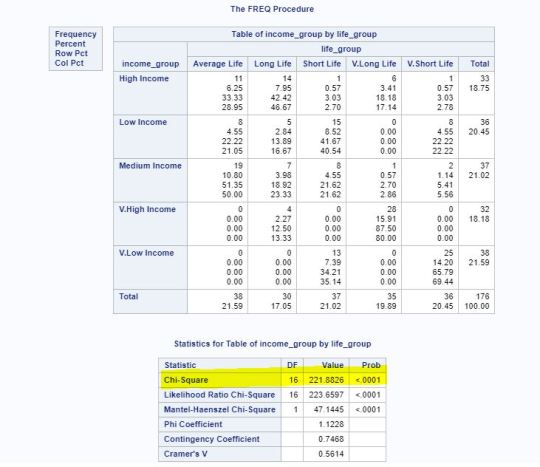
Based on the above we are able to see, the probability is <.0001 therefore we are able to reject the Ho and accept the Ha. The results show an association between income group and life expectancy group, or in chi square terms, the explanatory variable show a dependency with the response variable.
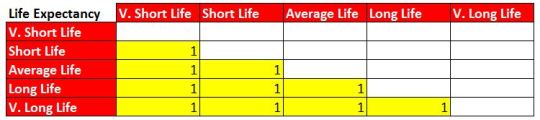
Finally, we want to understand which of the possible combinations of probabilities show an actual significance. For this, we run a sequential analysis comparing the 10 possible pairs. Also, we will use the Bonferroni adjustment to check if the results are significant enough to reject the Ho.
Bonferroni adjustment = Probability 0.05 / # of comparisons
In this case, we have the below:
B. Adjustment = 0.05 / 10 = 0.005 - Then if the results show a probability value lower to 0.005 we’ll be able to reject the Ho.
Possible combinations:
SAS code used:
Summary results table:
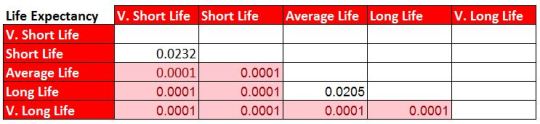
As we are able to see almost all the combinations showed a significant value, except the combination of Short life vs V Short Life, and Long Life vs Average Life.
More to come! :)
1 note
·
View note
Text
Best Data Analysis Tools and Software in 2022

The term "data" has been around for a very long time. Data is essential for decision-making in today's world when 2.5 quintillion bytes of data are produced every day. However, how do you believe we can manage that much data? The function of a data analyst is one of several important roles in the industry today that work with data to obtain insights. To extract insights from data, a data analyst has to use various techniques.
Now share your experience with us in the 𝗖𝗼𝗺𝗺𝗲𝗻𝘁 section
Read the full blog:https://bit.ly/3i1xZd9
0 notes
Text
Data Analysis Tools Assignment 1
INTRODUCTION
The aim of my ANOVA statistical test was to look at correlation between the quantity of cigarettes smoked and marital status. based on NESARC data set.
PYTHON SCRIPT
import numpy import pandas import statsmodels.formula.api as smf import statsmodels.stats.multicomp as multi
data = pandas.read_csv('dataset.csv', low_memory=False)
data['S3AQ3B1'] = data['S3AQ3B1'].convert_objects(convert_numeric=True) data['S3AQ3C1'] = data['S3AQ3C1'].convert_objects(convert_numeric=True) data['CHECK321'] = data['CHECK321'].convert_objects(convert_numeric=True)
sub1=data[(data['CHECK321']==1)]
sub1['S3AQ3B1']=sub1['S3AQ3B1'].replace(9, numpy.nan) sub1['S3AQ3C1']=sub1['S3AQ3C1'].replace(99, numpy.nan)
recode1 = {1: 30, 2: 22, 3: 14, 4: 5, 5: 2.5, 6: 1} sub1['USFREQMO']= sub1['S3AQ3B1'].map(recode1)
sub1['USFREQMO']= sub1['USFREQMO'].convert_objects(convert_numeric=True)
sub1['NUMCIGMO_EST']=sub1['USFREQMO'] * sub1['S3AQ3C1']
sub1['NUMCIGMO_EST']= sub1['NUMCIGMO_EST'].convert_objects(convert_numeric=True)
ct1 = sub1.groupby('NUMCIGMO_EST').size() print (ct1)
sub2 = sub1[['NUMCIGMO_EST', 'MARITAL']].dropna()
model1 = smf.ols(formula='NUMCIGMO_EST ~ C(MARITAL)', data=sub2).fit() print (model1.summary())
print ('means for numcigmo_est by marital status') m1= sub2.groupby('MARITAL').mean() print (m1)
print ('standard deviations for numcigmo_est by marital status') sd1 = sub2.groupby('MARITAL').std() print (sd1)
mc1 = multi.MultiComparison(sub2['NUMCIGMO_EST'], sub2['MARITAL']) res1 = mc1.tukeyhsd() print(res1.summary())
DESCRIPTION
As well as in the video lessons, I have calculated the number of cigarettes smoked per month and have compared it to marital status. The results of ANOVA are below:
OLS Regression Results ============================================================================== Dep. Variable: NUMCIGMO_EST R-squared: 0.022 Model: OLS Adj. R-squared: 0.022 Method: Least Squares F-statistic: 44.42 Date: Mon, 12 Nov 2018 Prob (F-statistic): 1.75e-45 Time: 01:34:48 Log-Likelihood: -70633. No. Observations: 9804 AIC: 1.413e+05 Df Residuals: 9798 BIC: 1.413e+05 Df Model: 5 Covariance Type: nonrobust =================================================================================== coef std err t P>|t| [0.025 0.975] ----------------------------------------------------------------------------------- Intercept 429.0034 5.275 81.323 0.000 418.663 439.344 C(MARITAL)[T.2] -28.4852 15.966 -1.784 0.074 -59.783 2.812 C(MARITAL)[T.3] 43.2257 14.581 2.965 0.003 14.645 71.807 C(MARITAL)[T.4] 57.8594 9.314 6.212 0.000 39.602 76.116 C(MARITAL)[T.5] 19.3024 15.787 1.223 0.221 -11.644 50.249 C(MARITAL)[T.6] -78.9413 8.216 -9.608 0.000 -95.047 -62.836 ============================================================================== Omnibus: 2361.523 Durbin-Watson: 1.940 Prob(Omnibus): 0.000 Jarque-Bera (JB): 7343.082 Skew: 1.231 Prob(JB): 0.00 Kurtosis: 6.452 Cond. No. 5.87 ==============================================================================
As wee see, the p-value is sufficient enough to reject the null hypothesis and assume that the number of cigarettes smoked per month depends on marital status.
The mean and standard deviation results are presented below:
NUMCIGMO_EST MARITAL 1 429.003411 2 400.518201 3 472.229094 4 486.862778 5 448.305846 6 350.062103 standard deviations for numcigmo_est by marital status NUMCIGMO_EST MARITAL 1 321.646121 2 306.128890 3 341.175384 4 360.143462 5 335.367772 6 304.339486
groups descriptions:
1 - married
2 - unofficially married
3 - widowed
4 - divorced
5 - separated
6 - never married
The outcome of post hoc test revealed several “thrilling” correlations:
Multiple Comparison of Means - Tukey HSD,FWER=0.05 ================================================== group1 group2 meandiff lower upper reject -------------------------------------------------- 1 2 -28.4852 -73.9932 17.0228 False 1 3 43.2257 1.6677 84.7837 True 1 4 57.8594 31.3127 84.406 True 1 5 19.3024 -25.6949 64.2998 False 1 6 -78.9413 -102.3592 -55.5234 True 2 3 71.7109 13.8672 129.5546 True 2 4 86.3446 38.1413 134.5478 True 2 5 47.7876 -12.5745 108.1498 False 2 6 -50.4561 -97.0096 -3.9026 True 3 4 14.6337 -29.8595 59.1269 False 3 5 -23.9232 -81.3661 33.5196 False 3 6 -122.167 -164.8673 -79.4667 True 4 5 -38.5569 -86.2784 9.1645 False 4 6 -136.8007 -165.1021 -108.4992 True 5 6 -98.2437 -144.2981 -52.1893 True --------------------------------------------------
As we can see from the table, married people smoke significantly more in comparison to widowed, divorced and never married. Unofficially married smoke more than the enumerated groups as well. Uncovering that widowed smoke more than never married people was surprising for me. Other conclusions can be made based on the table.
1 note
·
View note
Text
AdsReport

AdsReport is a Facebook advertising data reporting tool. It automatically generates reports from Facebook ad data through dashboards. Our advantage: 1.Channel advantages: We focus on the generation of Facebook advertising data reports. The unique quality allows us to build an excellent platform. 2.Content advantages: The report is generated through the design of the dashboard. We provide advertising data templates and 130 advertising indicators for you to choose to create the most suitable advertising report. 3.Free to use 4.Useful functions: PDF one-click download function, online report link sharing function, massive data storage function, no matter how long the data is, you can immediately generate reports in your advertising account. Read the full article
0 notes
Photo

The rise of DATA ANALYSIS JOBS! #dataanalysis #dataanalysist #dataanalysisfordays #dataanalysislife #dataanalysisclass #dataanalysisforcreatives #dataanalysissucks #dataanalysistraining #dataanalysistime #dataanalysisproblems #dataanalysisneverends #dataanalysistools #dataanalysisworkshop #dataanalysisloading #dataanalysisweather #dataanalysisbreak #dataanalysisday #dataanalysis_and_interpretation #dataanalysishell #dataanalysisteam #dataanalysisfordecision #dataanalysisproject #dataanalysisstage #dataanalysissystems #dataanalysisdrzam #dataanalysisandstatistic #dataanalysisexam #dataanalysisdays #dataanalysisisnofun #dataanalysissoftware https://www.instagram.com/p/Bs0YtAEniSx/?utm_source=ig_tumblr_share&igshid=1plpb4gjmoxzj
#dataanalysis#dataanalysist#dataanalysisfordays#dataanalysislife#dataanalysisclass#dataanalysisforcreatives#dataanalysissucks#dataanalysistraining#dataanalysistime#dataanalysisproblems#dataanalysisneverends#dataanalysistools#dataanalysisworkshop#dataanalysisloading#dataanalysisweather#dataanalysisbreak#dataanalysisday#dataanalysis_and_interpretation#dataanalysishell#dataanalysisteam#dataanalysisfordecision#dataanalysisproject#dataanalysisstage#dataanalysissystems#dataanalysisdrzam#dataanalysisandstatistic#dataanalysisexam#dataanalysisdays#dataanalysisisnofun#dataanalysissoftware
0 notes
Text

Manufacturing Shop floor Data Collection Software: Data-driven journey towards seamless production
Shop floor Data Collection software automates your Data-Driven manufacturing strategy while boosting throughput and profitability.
For more details read our blog: https://shopfloordatacollectionsoftware.leantransitionsolutions.com/software-blog/manufacturing-shop-floor-data-collection-software
#ShopfloorDataCollectionSoftware#DataDrivenManufacturing#datacollectionmethods#dataanalysistools#manufacturingdataentry#manufacturinganalysis#dataprocessing#dataentryautomation
0 notes
Text
My DOST Coursera Grant
So, I was admitted to the DOST Coursera Grant and it was really nice to see a lot of interesting topics. I first enrolled in data analytics to try it out. It appears I need to publish a blog for the assignment so I made this blog. A lot of first times today.
#dost #coursera #wesleyanuniversity #dataanalysistools
1 note
·
View note
Text
SAS vs Python vs R
I’ve already invest a lot of time learning R. I’ve spent a little time with Python though not too much yet on statistics and data mining/analysis. I’m not looking forward to having to learn a new tool. Would be great if there was an R track to mirror the SAS and Python learning options.
0 notes
Text
Data Analysis Tools - Part One
For the first assignment of the Data Analysis Tools course, we’ve been asked to run an analysis of variance.
By using the Gapminder dataset, I would like to understand if there is an association between continent (explanatory variable) and life expectancy (response variable).
Ho - There is no association between continent and life expectancy.
Ha - There is an association between the continent and life expectancy.
Then we run our ANOVA analysis in SAS, and we have the below results:
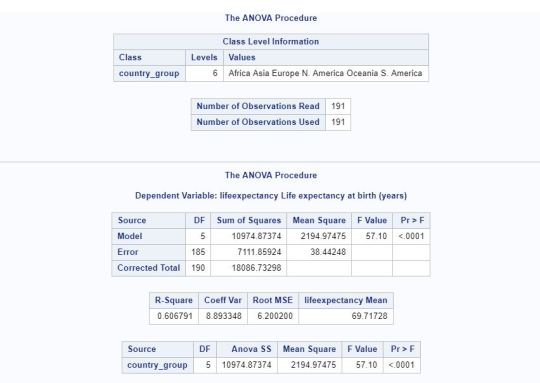
Based on the results above, we can see there is a F Value of 57.10, and probability of <.0001, therefore we can reject the Ho and accept the Ha that there is an association between continent and life expectancy.
When running an Analysis of Variance (ANOVA), the results tells if there is a difference in means. However, it doesn’t pinpoint which means are different. Duncan’s Multiple Range test (DMRT) is a post hoc test to measure specific differences between pairs of means.
Here is the code to run Duncan’s test:

Duncan’s results:
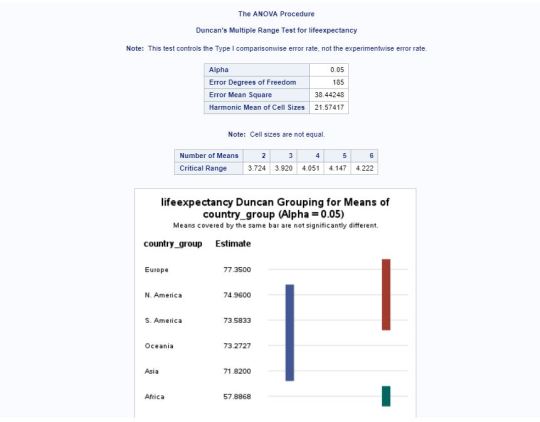
Based on the above, we can see that there is a significance different between Africa and Europe.
More to come! :)
0 notes