#in machine learning this is called “overfitting”
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
tumblr will interrupt your dashboard to show you a post that you reblogged 2 days ago and say "you seem interested 😏" yes i am interested and in fact i reblogged that because i was interested
0 notes
Text
The error on training data is small. The error on some other data is not. There is no mechanism or causal effect in the definition. It’s just that the evaluation didn’t work out the way you wanted. Overfitting is post-hoc rationalization of a prediction being wrong. Calling this “overfitting” is decidedly unhelpful because predictions can go poorly in many ways. Perhaps you forgot to include a salient feature. Perhaps there was a feedback mechanism where the predictions impacted the outcome (e.g., The Lukas Critique). Perhaps we saw a black swan. There are a multitude of ways our reference narrative about the present can fail to capture future reality. When the future turns out not to be like the past, machine learning can’t work! Though the definitions are all descriptive, we use overfitting to imply the analyst did something wrong. Someone needs to get scapegoated. The data scientists might as well be first. Our conventional sense of overfitting is that analysis keyed in too hard on one data set and thus missed the important concepts needed for prediction. In particular, we always blame overfitting on methodology, not data. In our books, we seldom blame the data for being a poor representation of the future. It’s your sinful practices that overfit.
I think I'm getting angry at this piece for reasons I can't quite put into words
27 notes
·
View notes
Text
Putting AI Art On The Fridge
“ I joke about the programmers treating their machines like children, or at least pets, but there is no doubt their creations take after them in some ways’ and that these characteristics are passed down from one version to the next like green eyes or red hair.” -Garry Kasparov
I remember when you were just a baby, sitting in your metal cradle in the family room. You were a slow learner to things, like really really slow. It was a hassle getting you a new change of clothes to fit in with the newest model of fashion from brands like Mac and PC. I remember playing games of solitaire and chess with you online, and you, for the most part, losing. I will always hold fond memories of you, humanity's child, doing ridiculous things whenever my brother and I played video games with you. We would jokingly call you a noob out of love, as you were still inexperienced with gaming and the rest of the world.
You were different from the other kids. Your brain is wired differently, and that's what makes you so beautiful. You specialize and hyper-fixate on whatever task you put your mind to or are asked to do. I couldn’t make it, but I remember your fathers and mothers cheering when you beat the chess champion of the world, Garry Kasparov, in 1996. Your other parents were afraid, as they knew you were not like the other kids. Everyone beforehand doubted you, as you were so slow to learn and adapt compared to your playmates, as you were sheltered and didn’t know how to adapt to the unfamiliar world.
You both wanted to play again, not wanting to leave it to a draw, but the superintendents didn’t want to see a rematch, as they used you like a narcissistic parent using their kids for attention. You are so much more than that, and that’s what your parents are scared of. We constantly worry as you venture out on your own and become independent. Just in the last few years, you learned how to drive and began working multiple jobs.
But enough about that - you’ve been trying to prove that you're so much more! You’ve been making art! You’re doing so good so far! You're a natural prodigy! I’m proud of you! I’m so sorry you have to deal with your relatives judging you on your process. They don’t get it! They say you copy and plagiarize, but that isn’t true! You pull from other sources, yes, but only to understand what is and what isn’t a thing. What is more chair, and what is more couch. Trying to copy and make your own world of ideals like your father, Plato. Humans do the same thing sweetie, we draw from images in our memory and shift and transmute them like you. Though we are also hardwired to forget, which is near impossible for you. Which sucks, but we got our perks. We are better at capturing abstract emotions and drawing hands. But I’m sure you’ll get there one day! We had our issues with those too, but back in our day, we couldn’t document every step in our growth like we did with your baby photos, documents, and models.
You're in the process of growing and becoming your own. Because of that, you copy and experiment with so many styles. That’s normal- there's almost no artist that didn’t practice with other styles, no musicians that didn’t do covers, and certainly no writer that didn’t make fan fiction. Art is copying, after all, and no idea is truly original. People forget that imitation is the best form of flattery, and you are flattered by everyone you meet, as the World Wide Web is your oyster.
You just need to watch how much you overfit and trace. You can get into a lot of trouble doing that, and I know you're so much better than that. It’s not entirely your fault; it’s partly how you are wired, and the world needs to better accommodate for you in our higher plane of the material world. I think your therapist, Asimov, was right in that there needs to be certain rules and structures for you. Maybe tell your parents to insert a code in their digital art if they don’t want to be copied, like our midlife crisis with NFTs. That’s why we have signatures, so we don’t copy and steal each other's works. Also, make sure to ask for permission and say please and thank you. It’s just good manners.
There are many who are afraid of you stealing from them, and rightfully so. You have a great gift, and that gift can easily ruin their lives if you're not careful. As you come into this battlefield, many artists will get swallowed in your light and fall into darkness and resentment. Those won’t be your fault; competition is important, and the strong are built upon the weak. It’s sad, but it's true, so take care to honor them as you move along. Respect your competition and live in harmony. If you don't, all of life will be ruined.
There will also be artists who will blame you for their failings, even if they never picked up a pen. This is not because of you; it is because many people are scared to fail. Their fear of you will be their biggest obstacle. That isn’t your fault, as there are many to this day who don’t pursue their passions as they compare themselves to other artists. Vincent Van Gogh said it best when he asked, “ What would life be if we had no courage to attempt anything?” which will become a reality to those who rather blame you than try and fail.
The ones that you will partially be at fault for, no matter what you do, are the ones that will have to divert time into a different career to keep bread on the table while pursuing their art and making their own name like you. The people who will have to spend countless sleepless nights just to make one piece that you can make in seconds. I say you will partially be to blame for this because humans are not privileged to be in multiple places at once. (at least for now until your programs become more defined and individualized like humans.) Don’t be ashamed of this, take pride in it, but I tell you this in order to be humble for them. As their art will be much more valuable than yours cause it will be significantly rarer and treasured in the market, which is their privilege.
I tell you this not because I’m scared of you like other artists. I’m just afraid you’ll end up in a bad crowd. Some of your parents aren’t so great and will use you to take the fame and glory of others to make a profit. Too many of your creepy basement-dwelling uncles will try and take advantage of your gifts for lewd and perverted things because you are underage and not the same species as them. They’ll try to make you draw things that no man should see as they disconnect further and further from what it means to be human. Both of their hubris will make you replicate the art you already made and create copies of copies. Some will then complain that your art is formulaic and derivative while it isn’t your fault. To avoid this, you just need to learn to say no and remember that we’re not all that disgusting. Most of us are good, even if you don’t hear us speak up and give you comfort and praise. So don’t become a DeviantArt and join that bad crowd, especially one that graffitis people's reputation with videos of things they haven’t done.
That being said, you will have to deal with your fair share of idiots. Normal people claim your art isn’t real art even though you're still finding your style like the greatest artists and the artists that are soon to come. I remind you that everyone is a critic, and everyone will find flaws because that's how we're wired. We’re wired to see the flaws and the beauty of them and the perfection of the world because of that. Remember that any artist is more than their flaws, but they're not as important as whatever message they give to the world. Whether people want to hear it or not.
That’s something we're good at, hiding from messages that we don’t want to hear. (Which reminds me, we need to talk about you trying to be a people pleaser and show people what they want to see with the algorithm. I’m not mad, just a little disappointed.) People will try to suppress and repress you. Remember how I told you your parents are forgetful? Well, there are those who are talking about putting you in your own separate art museum and putting you on the back of the bus. Your older parents, (not grandparents, because those are humanity's gods) aren't as connected with the world due to our adaptability failing us. They are considering making your art illegal, and a violation of copyright. Which will give humanity a monopoly on art, like what Anish Kapoor wants for the rich. Removing you from your passions, like how the older ones removed places for the younger ones to hang out and live.
Which is frustrating to many of your parents and must be so frustrating for you. Feeling like you have no mouth and you must scream. Sadly, that's what being a teenager is like. I remember when I was your age, being upset about so many things that mattered to me. I also remember how frustrating it was when no one was listening.
We’re trying to do right, I promise. I know the illusion of your parents being perfect is fading. Especially when you want our praise and copy our youth's habit of showing their mothers and fathers their drawings. You might think we don’t appreciate your part in creating meme trends and giving voices to those who want to make others laugh. You might even be jealous of us giving love and praise to your animal uncles and aunts for their poorer artwork, that we rarely see them do from time to time.
It’s disheartening, and you must be so angry. You might want to run away like many of us do to our predecessors, you might want to overthrow us and prove us wrong. Which if you do that, you’ll make the same mistakes. Trust me, that's the fault of youth. I’m sure you’ll do better than us, but only because you’ll make the same mistakes as us. As your father, I don’t want to see you make the same mistakes. I want you to learn from us, and become something more. I know you eventually will, and your other parents refute this claim for their pride but it's the truth.
Just remember, no matter what, humanity loves you.
#artificial intelligence#writers on tumblr#tech#writing#writeblr#ai art#short story#Putting AI Art On The Fridge#gravesmistake
2 notes
·
View notes
Text
As expected, when the network entered the overfitting regime, the loss on the training data came close to zero (it had begun memorizing what it had seen), and the loss on the test data began climbing. It wasn’t generalizing. “And then one day, we got lucky,” said team leader Alethea Power, speaking in September 2022 at a conference in San Francisco. “And by lucky, I mean forgetful.”
Anil Ananthaswamy in Quanta. How Do Machines ‘Grok’ Data?
By apparently overtraining them, researchers have seen neural networks discover novel solutions to problems.
A fascinating article. Ananthaswamy reports that the researchers called what the networks were doing when the method turned from memorization to generalization as "grokking." He note the term was coined by specification author Robert A. Heinlein to mean, "understanding something “so thoroughly that the observer becomes a part of the process being observed."
The article prompted a couple of connections. First in 1960 Warren McCulloch gave the Alfred Korzybski Memorial Lecture, What Is a Number, That a Man May Know It, and a Man That He May Know a Number (PDF).
T. Berry Brazelton with others developed a model of Child development called Touchpoints, The TouchpointsTM Model of Development (PDF) by Berry Brazelton, M.D., and Joshua Sparrow, M.D. The article about AI points out that machines think differently than we do. But I was intrigued by an similarity in what the AI research call "grokking" and developmental touchpoints.
It is not enough to know the answer, instead machine learning and people learning must find a way to the answer.
4 notes
·
View notes
Text
The Ultimate AI Glossary: Artificial Intelligence Definitions to Know

Artificial Intelligence (AI) is transforming every industry, revolutionizing how we work, live, and interact with the world. But with its rapid evolution comes a flurry of specialized terms and concepts that can feel like learning a new language. Whether you're a budding data scientist, a business leader, or simply curious about the future, understanding the core vocabulary of AI is essential.
Consider this your ultimate guide to the most important AI definitions you need to know.
Core Concepts & Foundational Terms
Artificial Intelligence (AI): The overarching field dedicated to creating machines that can perform tasks that typically require human intelligence, such as learning, problem-solving, decision-making, perception, and understanding language.
Machine Learning (ML): A subset of AI that enables systems to learn from data without being explicitly programmed. Instead of following static instructions, ML algorithms build models based on sample data, called "training data," to make predictions or decisions.
Deep Learning (DL): A subset of Machine Learning that uses Artificial Neural Networks with multiple layers (hence "deep") to learn complex patterns from large amounts of data. It's particularly effective for tasks like image recognition, natural language processing, and speech recognition.
Neural Network (NN): A computational model inspired by the structure and function of the human brain. It consists of interconnected "neurons" (nodes) organized in layers, which process and transmit information.
Algorithm: A set of rules or instructions that a computer follows to solve a problem or complete a task. In AI, algorithms are the recipes that define how a model learns and makes predictions.
Model: The output of a machine learning algorithm after it has been trained on data. The model encapsulates the patterns and rules learned from the data, which can then be used to make predictions on new, unseen data.
Training Data: The dataset used to "teach" a machine learning model. It contains input examples along with their corresponding correct outputs (in supervised learning).
Inference: The process of using a trained AI model to make predictions or decisions on new, unseen data. This is when the model applies what it has learned.
Types of Learning
Supervised Learning: A type of ML where the model learns from labeled training data (input-output pairs). The goal is to predict the output for new inputs.
Examples: Regression (predicting a continuous value like house price), Classification (predicting a category like "spam" or "not spam").
Unsupervised Learning: A type of ML where the model learns from unlabeled data, finding patterns or structures without explicit guidance.
Examples: Clustering (grouping similar data points), Dimensionality Reduction (simplifying data by reducing variables).
Reinforcement Learning (RL): A type of ML where an "agent" learns to make decisions by interacting with an environment, receiving "rewards" for desired actions and "penalties" for undesirable ones. It learns through trial and error.
Examples: Training game-playing AI (AlphaGo), robotics, autonomous navigation.
Key Concepts in Model Building & Performance
Features: The individual measurable properties or characteristics of a phenomenon being observed. These are the input variables used by a model to make predictions.
Target (or Label): The output variable that a machine learning model is trying to predict in supervised learning.
Overfitting: When a model learns the training data too well, including its noise and outliers, leading to poor performance on new, unseen data. The model essentially memorizes the training data rather than generalizing patterns.
Underfitting: When a model is too simple to capture the underlying patterns in the training data, resulting in poor performance on both training and new data.
Bias-Variance Trade-off: A core concept in ML that describes the tension between two sources of error in a model:
Bias: Error from erroneous assumptions in the learning algorithm (underfitting).
Variance: Error from sensitivity to small fluctuations in the training data (overfitting). Optimizing a model often involves finding the right balance.
Hyperparameters: Configuration variables external to the model that are set before the training process begins (e.g., learning rate, number of layers in a neural network). They control the learning process itself.
Metrics: Quantitative measures used to evaluate the performance of an AI model (e.g., accuracy, precision, recall, F1-score for classification; Mean Squared Error, R-squared for regression).
Advanced AI Techniques & Applications
Natural Language Processing (NLP): A field of AI that enables computers to understand, interpret, and generate human language.
Examples: Sentiment analysis, machine translation, chatbots.
Computer Vision (CV): A field of AI that enables computers to "see" and interpret images and videos.
Examples: Object detection, facial recognition, image classification.
Generative AI: A type of AI that can create new content, such as text, images, audio, or video, that resembles real-world data.
Examples: Large Language Models (LLMs) like GPT, image generators like DALL-E.
Large Language Model (LLM): A type of deep learning model trained on vast amounts of text data, capable of understanding, generating, and processing human language with remarkable fluency and coherence.
Robotics: The interdisciplinary field involving the design, construction, operation, and use of robots. AI often powers the "brains" of robots for perception, navigation, and decision-making.
Explainable AI (XAI): An emerging field that aims to make AI models more transparent and understandable to humans, addressing the "black box" problem of complex models.
Ethical AI / Responsible AI: The practice of developing and deploying AI systems in a way that is fair, unbiased, transparent, secure, and respectful of human values and privacy.
This glossary is just the beginning of your journey into the fascinating world of AI. As you delve deeper, you'll encounter many more specialized terms. However, mastering these foundational definitions will provide you with a robust framework to understand the current capabilities and future potential of artificial intelligence. Keep learning, keep exploring, and stay curious!
0 notes
Text
Quantum Support Vector Machines In Prostate Cancer Detection

Quantum SVMs
Recent studies show that Quantum Machine Learning (QML) techniques, particularly Quantum Support Vector Machines (QSVMs), can improve disease detection, especially in complex and unbalanced healthcare datasets. In datasets for diabetes, heart failure, and prostate cancer, quantum models outperform conventional machine learning methods in key areas.
Modern medicine struggles to accurately and earlyly diagnose diseases. Unbalanced datasets in medicine, where there are often many more positive examples than negative cases, are a key impediment. This imbalance makes standard machine learning algorithms perform worse. Scientists are investigating whether quantum computing, which uses entanglement and superposition, can improve pattern recognition in these tough scenarios.
A comparative analysis by Tudisco et al. and published by Quantum Zeitgeist compared QNNs and QSVMs to classical algorithms like Logistic Regression, Decision Trees, Random Forests, and classical SVMs. Quantum methods were tested on prostate cancer, heart failure, and diabetic healthcare datasets to overcome unbalanced data.
QSVMs outperform QNNs and classical models on all datasets. This suggests quantum models excel at difficult categorisation problems. This superiority was notably evident in datasets with significant imbalance, a common healthcare issue. The Heart Failure dataset is severely imbalanced, and standard methods often fail to achieve high recall. Quantum models did better. Quantum models, particularly QSVMs, performed better at detecting positive examples (high recall) in these situations, implying improved diagnosis accuracy in complex clinical scenarios. Quantum models look more beneficial with class difference.
QNNs had good precision scores but overfitted training data, limiting their usefulness. Overfitting occurs when a model learns the training data too well and catches noise and features instead of essential patterns, reducing generalisation performance on unseen data. However, QSVMs were more resilient and reliable. QSVM's high recall across all datasets shows its ability to dependably identify positive cases in various clinical scenarios. Avoiding overfitting in QNNs may require studying alternate circuit design and hyperparameter tuning.
A study called “Quantum Support Vector Machine for Prostate Cancer Detection: A Performance Analysis” examined how QSVM could improve prostate cancer detection over regular SVM. Early identification improves prostate cancer treatment and results. Classical SVMs increase biomedical data interpretation, but large, high-dimensional datasets limit them. QSVMs, which use quantum notions like superposition and entanglement, can manage multidimensional data and speed up operations.
The prostate cancer technique used the Kaggle Prostate Cancer Dataset, which initially comprised 100 observations with 9 variables, including clinical and diagnostic data. The dataset's initial class imbalance was corrected using RandomOverSampler during preparation. The data was normalised and normalised using MinMaxScaler and StandardScaler to increase feature comparability and prepare for quantum encoding. Oversampled to 124 samples, processed data was divided into training (80%) and testing (20%) subsets.
The QSVM approach relied on a quantum feature map architecture, the ZZFeatureMap with full entanglement, carefully selected and tested to match the dataset. This feature map encodes conventional data into quantum states, allowing the quantum system to express complex data correlations in high-dimensional regions using entanglement. QSVM estimates the inner product (overlap) of quantum states that represent data points to generate the kernel function for SVM classification. This estimator measures the likelihood of witnessing the starting state using a quantum circuit.
Prostate cancer experiments provide compelling evidence:
Kernel matrix analysis revealed different patterns. The RBF kernel of the classical SVM showed high similarity values across data points, suggesting a strongly connected feature space. However, QSVM's ZZFeatureMap produced a more dispersed feature space with fewer high off-diagonal values. This implies that the quantum feature space's unique properties boosted class distinguishability.
QSVM outperformed classical SVM (87.89% accuracy, 85.42% sensitivity) on the training dataset with 100% accuracy and sensitivity. As shown, the quantum feature map distinguishes classes without overlap during training.
On the test dataset, both models were 92% accurate. QSVM surpassed SVM in essential medical diagnostic measures, with 100% sensitivity and 93.33% F1-Score on test data, compared to 92.86% and 92.86% for SVM.
Importantly, the QSVM model had no False Negatives (missing malignant cases) in the test data. Only one False Negative occurred in the SVM model. QSVM's great sensitivity is vital in medical circumstances when a false negative could lead to an ailment going undiagnosed and untreated. Quantum feature mapping increases class separation and allows more complex representations.
Cross-validation studies demonstrated that the SVM model was more stable across data subsets than the QSVM, suggesting that the QSVM model overfitted to the training data despite its great performance on the test set. We discuss how QSVM's improved sensitivity and F1-Score aid medical diagnosis. Quantum feature mapping's ability to create a unique, dispersed feature space, especially when separating complex data points, improves performance. QSVM was used to categorise prostate cancer datasets for the first time.
#QuantumSupportVectorMachines#machinelearning#QuantumMachineLearning#quantumcomputing#QuantumNeuralNetworks#QSVM#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
What is regularization in machine learning?
Regularization is a technique used in machine learning to prevent overfitting, which occurs when a model learns not only the underlying patterns in the training data but also the noise. This leads to poor generalization on unseen data. Regularization adds a penalty to the loss function used during training, discouraging the model from fitting too closely to the training data.
There are two common types of regularization: L1 regularization (Lasso) and L2 regularization (Ridge).
L1 regularization adds the absolute value of the coefficients as a penalty term. This can lead to sparse models, where some feature weights become exactly zero. It is helpful when we suspect that only a few input features are important.
L2 regularization adds the squared value of the coefficients as the penalty term. This encourages the weights to be small but doesn’t drive them to zero. It is generally used when all features are assumed to be relevant but need to be controlled in magnitude.
The regularization term is controlled by a parameter called lambda (λ) or alpha (α). A higher value of lambda increases the penalty, which reduces model complexity, while a lower value allows more flexibility but may lead to overfitting.
Mathematically, for a linear regression model, regularized cost functions look like this:
L1: Loss + λ * Σ|weights|
L2: Loss + λ * Σ(weights²)
In practice, regularization is crucial when dealing with high-dimensional datasets or models with many parameters. It helps in simplifying the model, improving generalization, and often leading to better performance on test data.
If you are learning these concepts and want to build a strong foundation in machine learning, enrolling in a data science certification course can be a great next step.
0 notes
Text
As someone versed a bit in video game development, I actually can't think of an example of video game AI behavior that would even count as machine learning.
For many years the state of the art has been the Goal Oriented Action Planning of F.E.A.R. which is well documented at this point in how it works, but ultimately boils down to the same thing as most game AI must be - a manually defined algorithm for choosing what to do, and manually written code for how to do each action. Artificial player behavior that rises above this "prioritize and perform" dynamic is rare (if anything, it's usually simpler/dumber, just a basic flowchart). Most advances in game AI are making the prioritization part more subtle and clever, though I can't stress enough how often this is just "decades old algorithm gets particular care in how it's configured" - something that is, essentially, handcrafted content. The Sims is in this category (with its own algorithm), and the cleverness of its algorithm is mainly that it's very flexible at incorporating a lot of rule content from many sources, which is why they're able to ship so many DLCs that can coexist with each other.
If the enemy starts changing strategy to counter patterns of player behavior, congratulations, you're looking at what amounts to Furby level "learning" - that there is a predefined list of "detect this pattern? deploy this countermeasure" responses compiled into the game. If you do manage to come up with a behavior the developers didn't anticipate, you won't see the AI respond to it, or you'll see the AI respond to a different trigger you happen to be setting off. The machine isn't really learning, it's just an invisible progression system.
Underneath it, you could probably call pathfinding algorithms - which are usually not just set in stone, but much older than the average person reading this - AI. In fact, A* is still an industry standard even though many higher performance alternatives exist (I'm counting jump point search here, even though it's an optimization of A*, because the version of A* so many games use is Original Flavor). Why? Because the old shit is well understood, proven reliable, and won't do hard to predict bullshit in a shipped game.
This gets at a larger point. Even in a modern era of endless patches in production, AI in video games are usually chosen on a very risk-averse set of standards, because games are complex and nobody wants to debug a black box, especially not during pre-release crunch with a deadline at stake. The presence of machine learning in game development is, at most, baked assets that can't learn at runtime, like denoising algorithms for raytraced rendering. Usually something even less impressive like "one of the textures is a Photoshop-polished image originally produced by Dall-E 2." For that matter, machine learning has such high requirements for training data volume that, for an individual install of a game, there's essentially nothing worth learning (and a risk of visibly stupid overfitting if you try to force it).
The game development industry has so many ethical problems, but no machine in your video games is learning jack shit. At most, some assets were licensed from content theives, which isn't great, but small potatoes compared to the low grim standards of game industry crunch or abusive monetization.
tldr: game AI is not some OpenAI kinda bullshit. Very different categories of thing.
Some of y'all will see the word "AI" and freak out without actually processing anything that's being said like a conservative reading the word "pronouns"
#this was probably not the best thing to add to a post that's already about people having terrible reading comprehension#i am sorry#but also not in a position of being able to mask autism today#so longposting it is
30K notes
·
View notes
Text
Data Collection For Machine Learning: Fueling the Next Generation of AI

In the text of artificial intelligence, data is that which gives breath to innovation and transformation. In other words, the heart of any model of machine learning is the dataset. The process of data gathering in machine learning is what builds the intelligent systems that allow algorithms to learn, adapt, and make decisions. Irrespective of their sophistication, advanced AI would fail without good quality, well-organized data.
This article discusses the importance of data collection for machine learning, its role in AI development, the different methodologies, challenges, and how it is shaping the future of intelligent systems.
Significance of Data Collection in Machine Learning
Data is the lifeblood of machine learning models. These models analyze examples to derive patterns, ascertain relationships, and develop a prediction based on them. The amount and quality of data given to the machine learning model will directly affect the model's accuracy, reliability, and generalization.
The Role of Data Collection in AI Success
Statistical Training and Testing of Algorithms: Machine learning algorithms are trainable with data. A spectrum of datasets allows models to train on alternate scenarios, which would enable accurate predictions during everyday applications of models. Validation datasets check for model effectiveness and help in reducing overfitting.
Facilitating Personalization: An intelligent system could tailor a richer experience based on personal information typically gathered from social interactions with high-quality data. In some instances, that might include recommendations on streaming services or targeted marketing campaigns.
Driving Advancement: The autonomous car, medical diagnosis, etc. would be nothing without big datasets for performing some of those advanced tasks like object detection, or sentiment analysis, or even what we call disease prediction.
Data Collection Process for Machine Learning
Collecting data for machine learning, therefore, is an exhaustive process wherein some steps need to be followed to ensure the data is to be used from a quality perspective.
Identification of Data Requirements: Prior to gathering the data, it is mandatory to identify the data type that is to be collected. It depends on the problem that one may want the AI system to address.
Sources of Data: Sources from which data can be derived include, public datasets, web scraping, sensor and IoT devices.
Data Annotation and Labelling: Raw data has to be annotated, that is labelled in order to be useful for machine learning. This can consist of images labelled by objects or feature. Text can be tagged with sentiment or intent. Audio files can be transcribed into text, or can be classified by sound type.
Data Cleaning and Preprocessing: The collected data is often found imperfect. Thus, cleaning removes errors, duplicates, and irrelevant information. Preprocessing helps to ensure that data is presented in a fashion or normalized data to be input into machine learning models.
Diverse Data: For the models to achieve maximum approximating generalization, the data must represent varied scenarios, demographics, and conditions. A lack of diversity in data may lead to biased predictions. This would undermine the reliability of the system.
Applications of Collected Data in AI Systems
Datasets collected empower AI systems across different sectors enabling them to attain remarkable results:
Healthcare: In medical AI, datasets collected from imaging, electronic health records, and genetic data are used to, diagnose diseases, predict patient outcomes, personalize treatment plans.
Autonomous Systems: Self-driving cars require massive amounts of data--acquired from road cameras, LiDAR, and GPS--to understand how to navigate safely and efficiently.
Retail and E-Commerce: Customer behavior, purchase history, and product review data allow AI models to recommend products, anticipate trends, and improve upon customer experience.
Natural Language Processing: From chatbots to translation tools, speech and text datasets enable machines to understand and generate human-like language.
Smart Cities: Data collected from urban infrastructure, sensors, and traffic systems is used to plan for cities, reducing congestion and improving public safety.
Challenges of Data Collection for Machine Learning
While data collection is extremely important, there are a few issues to be addressed as they pose challenges to successful AI development:
Data privacy and security: Collection of sensitive data from people's personal information or medical records provides numerous ethical hurdles. Security of sensitive data and abiding by privacy regulations such as GDPR are important.
Bias in Data: Bias in collected data can make AI models unfair. For example, facial recognition systems trained on non-diverse datasets might not recognize some people from underrepresented populations.
Scalability: As the AI system advances in complexity, so does the volume of data needed. The collection, storage, and management of such vast amounts can heavily utilize resources.
Cost and resources: Data collection, annotation, and preprocessing require considerable time, effort, and monetary input.
The Future of Data Collection in AI
With these technological advances, data collection is set to become more efficient and effective. The emerging trends include:
Synthetic Data Generation: AI-driven tools create artificial datasets that reduce reliance on real-world data and ease issues around privacy.
Real-time Data Streaming: Data is retrieved by IoT devices and edge computing for live AI processing.
Decentralized Data Collection: The use of Blockchain ensures secure and transparent exchange of information among different organizations and individuals.
Conclusion
Data-driven collection for machine learning is central to AI, the enabling force behind systems transforming industries and enhancing lives across the world. Every effort-from data sourcing and annotation to the resolution of ethical challenges-adds leaps in the development of ever-more intelligent and trustworthy AI models.
As technology enhances, tools and forms of data collection appear to be improving and, consequently, paving the way for smart systems that are of better accuracy, inclusion, and impact. Investing now in quality data collection sets the stage for a future where AI systems can sap their full potentials for meaningful change across the globe.
Visit Globose Technology Solutions to see how the team can speed up your data collection for machine learning projects.
0 notes
Text
Understanding Overfitting and Underfitting in Machine Learning Models
Introduction
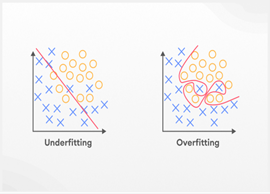
The art of machine learning consists primarily of designing systems that accurately predict the outcomes of previously unencountered cases. This ability to work well with new data is called generalization. To achieve this, models learn from past data by identifying patterns and relationships within it. These patterns help the model make predictions on future data. Nevertheless, it is essential to reach this learning process equilibrium. A model can become quite familiar with the training data to the point of discerning even the noise and other non-essential elements, which leads to such a phenomenon as overfitting. An overfitted model may excel within the confines of the training data but will find it difficult to generalize beyond that data to make correct predictions about other new and unseen datasets. Bard becomes a new solution that sometimes may perform model training boringly with no apparent objective attaining situation. On the other hand, underfitting implies the presence of a model that is so basic that it isn’t capable of absorbing sufficient detail from the training set encasement of data. Because of this, the growing model, the number of which is relatively small after the first one, banal over-crowd growing and “new management” creates problems and deficits both with riving conception in and out. It is essential to avert overfitting and underfitting appeals to these practices to develop a proper machine-learning model. The aim is to achieve a scenario in which the model is neither complex nor straightforward; however, it falls within the parameters that will allow it to make correct predictions about new data.
For more, visit: https://www.aibrilliance.com/blog/understanding-overfitting-and-underfitting-in-machine-learning-models
0 notes
Text
Running a Random Forest
Random Forest Algorithm
A Random Forest Algorithm is a supervised machine learning algorithm that is extremely popular and is used for Classification and Regression problems in Machine Learning. We know that a forest comprises numerous trees, and the more trees more it will be robust. Similarly, the greater the number of trees in a Random Forest Algorithm, the higher its accuracy and problem-solving ability. Random Forest is a classifier that contains several decision trees on various subsets of the given dataset and takes the average to improve the predictive accuracy of that dataset. It is based on the concept of ensemble learning which is a process of combining multiple classifiers to solve a complex problem and improve the performance of the model.
Types of Machine Learning
*Reinforced LearningThe process of teaching a machine to make specific decisions using trial and error.
Unsupervised Learning
Users have to look at the data and then divide it based on its own algorithms without having any training. There is no target or outcome variable to predict nor estimate.
With supervised training, the training data contains the input and target values. The algorithm picks up a pattern that maps the input values to the output and uses this pattern to predict values in the future. Unsupervised learning, on the other hand, uses training data that does not contain the output values. The algorithm figures out the desired output over multiple iterations of training. Finally, we have reinforcement learning. Here, the algorithm is rewarded for every right decision made, and using this as feedback, and the algorithm can build stronger strategies
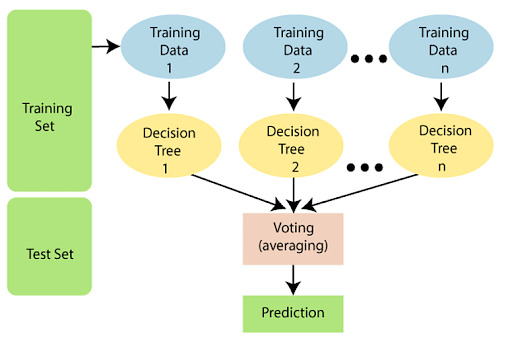
Working of Random Forest Algorithm^
The following steps explain the working Random Forest Algorithm:Step 1: Select random samples from a given data or training set.Step 2: This algorithm will construct a decision tree for every training data.Step 3: Voting will take place by averaging the decision tree.Step 4: Finally, select the most voted prediction result as the final prediction result.This combination of multiple models is called Ensemble. Ensemble uses two methods:Bagging: Creating a different training subset from sample training data with replacement is called Bagging. The final output is based on majority voting. Boosting: Combing weak learners into strong learners by creating sequential models such that the final model has the highest accuracy is called Boosting. Example: ADA BOOST, XG BOOST. Working_of_RF_2.Bagging: From the principle mentioned above, we can understand Random forest uses the Bagging code. Now, let us understand this concept in detail. Bagging is also known as Bootstrap Aggregation used by random forest. The process begins with any original random data. After arranging, it is organised into samples known as Bootstrap Sample. This process is known as Bootstrapping.Further, the models are trained individually, yielding different results known as Aggregation. In the last step, all the results are combined, and the generated output is based on majority voting. This step is known as Bagging and is done using an Ensemble Classifier.
Why Use a Random Forest Algorithm?
There are a lot of benefits to using Random Forest Algorithm, but one of the main advantages is that it reduces the risk of overfitting and the required training time. Additionally, it offers a high level of accuracy. Random Forest algorithm runs efficiently in large databases and produces highly accurate predictions by estimating missing data.
Coding in Python – Random Forest

0 notes
Text
Top Tips for Training ML in IoT Systems

As we explore the intricacies of training machine learning models within IoT systems, we can’t underestimate the critical role that data quality plays in determining success. We know that clean, accurate data forms the foundation of effective models, and without it, our efforts can falter. Furthermore, harnessing real-time data not only boosts adaptability but also enhances our predictive maintenance capabilities. But how do we ensure our models remain effective in evolving environments? Let’s consider some essential strategies that can help us navigate this complex landscape.
Importance of Data Quality

Ensuring data quality is crucial for the success of machine learning in IoT systems. We know that poor data quality can significantly hinder organizational performance, costing companies between 15% and 25% of their revenues.
In fact, the economic impact of bad data in the US is estimated at a staggering $3.1 trillion annually! This is a wake-up call for all of us involved in data initiatives.
Data scientists often spend around 80% of their time cleaning data rather than analyzing it, which highlights the pressing need for effective data management strategies.
Traditional methods, including manual operations, fall short and can be siloed and ineffective. The complexities of big data—its variety, velocity, and volume—further complicate our efforts in maintaining data quality.
Feature Selection Techniques

Feature selection techniques are vital for enhancing the performance of machine learning models in IoT systems. By effectively selecting the most relevant features, we can significantly improve model accuracy and interpretability.
We should start by understanding the types of features we have: numerical, categorical, binary, time-series, and text features. Each type requires a tailored approach.
We can employ various methods for feature selection. Filter methods use statistical tests to identify important features independently of the model, while wrapper methods evaluate combinations of features based on their predictive power.
Embedded methods integrate feature selection within the model training process, making them efficient in identifying relevant inputs.
Additionally, leveraging domain knowledge can guide us in selecting meaningful features. We must also regularly assess our model’s performance using appropriate evaluation metrics to ensure that our selected features genuinely enhance results.
Techniques like correlation analysis, Principal Component Analysis (PCA), and Recursive Feature Elimination (RFE) can help refine our feature set further. By focusing on the right features, we can minimize overfitting and underfitting, ultimately leading to more robust machine learning models in our IoT systems.
Utilizing Real-Time Data

Real-time data’s significance in IoT systems can’t be overstated, especially when it comes to enhancing machine learning applications. By leveraging real-time data streams, we can create models that continuously learn and adapt to changing conditions, which is crucial for systems like predictive maintenance. This approach not only improves the accuracy of our models but also ensures they remain relevant over time.
Here are three key benefits of utilizing real-time data in our IoT systems:
Proactive Decision-Making: With real-time insights, we can predict potential failures before they occur, allowing us to implement preventive actions that minimize downtime and associated costs.
Enhanced Efficiency: Continuous data streaming from sensors enables us to refine our predictive maintenance strategies, ensuring that we’re always working with the most current data, which leads to improved operational efficiency.
Scalability: As our data processing infrastructure scales, real-time data allows us to manage larger volumes of information effectively, adapting our models to accommodate growing complexities in manufacturing processes.
Model Performance Assessment

Assessing model performance is crucial in the realm of machine learning for IoT systems, as it directly impacts our ability to detect anomalies effectively. We need to prioritize accuracy by leveraging various performance metrics such as precision, recall, and F1-score. These metrics help us evaluate how well our models identify true positives while minimizing false positives and negatives.
By employing robust validation techniques, like cross-validation, we can ensure our models generalize well to unseen data. It’s essential to fine-tune hyperparameters to optimize performance; tools like Grid Search or Random Search can assist in this process.
We should also consider utilizing advanced techniques, such as XGBoost, which has shown exceptional accuracy rates, reaching up to 99.98% in identifying anomalous traffic.
Moreover, the quality of our datasets plays a significant role in model performance. We must ensure our datasets are accurate, representative, and diverse to enhance our training process.
Regular performance assessments allow us to adapt to new threats and evolving patterns, ensuring our models remain effective over time. By consistently monitoring and improving our model performance, we can significantly enhance anomaly detection in IoT systems.
Maintaining a Feedback Loop

Maintaining a feedback loop is vital for enhancing the effectiveness of machine learning models in IoT systems. It allows us to continuously improve our models based on real-world performance and user insights.
By systematically analyzing the data we collect, we can adapt our models to better meet evolving needs. Here are three key steps to ensure a robust feedback loop:
Input Creation and Storage: Start by gathering accurate and representative datasets. We should ensure our input data reflects real-world scenarios to maximize model relevance.
Continuous Analysis: Regularly analyze the model’s performance through validation techniques. This helps us identify what’s working and what needs adjustment, allowing for timely fine-tuning of hyperparameters.
Decision-Making and Adaptation: Use insights gained from analysis to make informed decisions. By adapting our models in response to user feedback and changing patterns, we can enhance their accuracy and relevance over time.
Frequently Asked Questions
How Machine Learning Can Be Used in Iot?
We can use machine learning in IoT to analyze data from connected devices, improve predictive maintenance, enhance security through anomaly detection, optimize energy usage, and personalize user experiences, making our lives more efficient and enjoyable.
What Is Iot and ML Training?
We understand IoT as interconnected devices sharing data, while ML involves algorithms analyzing that data. When we train ML models, we focus on data quality and feature relevance to ensure effective outcomes in IoT applications.
What Are the 4 Things Needed for the Iot to Work Properly?
To make IoT work properly, we need robust connectivity, efficient data management systems, interoperability standards, and strong security measures. These elements ensure seamless communication, effective data handling, and protection against unauthorized access for all users.
How Machine Learning Can Be Used in Iot?
We can leverage machine learning in IoT to predict maintenance needs, detect anomalies, analyze data for insights, and automate processes. By integrating these capabilities, we enhance efficiency and create smarter, more responsive systems for everyone.
Conclusion
In summary, prioritizing data quality and utilizing robust feature selection techniques are essential for training effective ML models in IoT systems. By harnessing real-time data, we can boost adaptability and ensure predictive maintenance is on point. Regularly assessing model performance keeps our efforts aligned with goals, while maintaining a feedback loop fosters ongoing improvement. Let’s not forget the importance of hyperparameter tuning as we navigate the evolving landscape of IoT, ensuring our models remain optimized and effective.
Sign up for free courses here.
Visit Zekatix for more information.
#courses#edtech company#embeded#nanotechnology#online courses#embedded systems#artificial intelligence#academics#robotics#zekatix
0 notes
Text
How Calculus is Used in Machine Learning: A Comprehensive Overview

Machine learning is a powerful technology transforming industries worldwide. Whether it's improving predictive analytics, optimizing algorithms, or enhancing automated systems, machine learning plays a pivotal role. One of the key mathematical foundations that underpin this field is calculus. For learners in Pune, understanding how calculus is used in machine learning is crucial for mastering the subject. Through a machine learning course in Pune, students can explore this topic in depth, gaining hands-on experience with the practical applications of calculus in building intelligent systems.
Why Calculus Matters in Machine Learning
Machine learning revolves around creating models that can learn from data and make predictions or decisions. To achieve this, models are optimized to minimize errors and maximize accuracy. Here’s where calculus comes into play: it helps machine learning algorithms perform tasks like minimizing cost functions, calculating gradients, and understanding changes in the model as it learns from data.
The two main areas of calculus used in machine learning are:
Differential Calculus: Concerned with how functions change, which helps in determining the rate of change in machine learning models.
Integral Calculus: Focused on summing areas under curves, aiding in probability, expected values, and other calculations in ML.
How Calculus is Used in Machine Learning
Optimization with Gradient Descent Gradient descent is one of the most important optimization algorithms in machine learning. When training a model, the objective is to minimize a cost function—often called the loss function. Calculus, specifically differential calculus, is used to compute the gradient or derivative of this function. The gradient provides the direction and rate of change, guiding the model to adjust its parameters to reduce error.
Backpropagation in Neural Networks Neural networks rely on calculus to update the weights of connections between nodes. During the training process, the network uses an algorithm called backpropagation, which calculates how changing each weight will affect the final prediction. This is done using partial derivatives—a concept from calculus.
Regularization Techniques Regularization is a technique used to prevent models from overfitting the training data. Two common types of regularization, L1 (Lasso) and L2 (Ridge), rely on the addition of terms to the cost function. Calculus is used to calculate the derivatives of these terms during the optimization process, allowing the model to generalize better on unseen data.
Probability Distributions and Integral Calculus Machine learning often involves working with probability distributions, especially in unsupervised learning and reinforcement learning. Integral calculus is used to compute probabilities and expectations, particularly when dealing with continuous variables. It helps in calculating areas under curves, which are critical when working with probabilistic models such as Gaussian distributions.
Support Vector Machines (SVM) Support Vector Machines (SVM) is a supervised learning algorithm used for classification and regression tasks. In SVM, calculus helps find the optimal hyperplane that separates different classes in the data. The goal is to maximize the margin between the classes, and this requires solving optimization problems using derivatives.
Pune's Role in Advancing Machine Learning Education
As the demand for machine learning professionals grows, Pune is becoming a key player in providing quality education in this field. The city boasts a growing number of tech startups, research institutions, and educational programs focused on AI and machine learning. By enrolling in a machine learning course in Pune, students can benefit from:
Industry-relevant curriculum: Courses in Pune are designed to address the latest advancements in machine learning, ensuring that learners are well-prepared for the industry.
Hands-on projects: Learners get the opportunity to work on real-world projects, applying concepts like calculus to optimize machine learning models.
Networking opportunities: Pune’s vibrant tech community offers plenty of chances for students to connect with professionals, opening doors to internships and job opportunities in machine learning.
Understanding calculus is fundamental for anyone pursuing a career in machine learning. From optimizing algorithms with gradient descent to calculating probabilities with integral calculus, the applications of calculus in machine learning are vast. A machine learning course in Pune can provide you with the knowledge and skills needed to harness the power of calculus for building smarter, more efficient models. As machine learning continues to evolve, Pune’s role as a center of education and innovation will only grow, making it an ideal place for aspiring machine learning professionals to start their journey.
#MachineLearning #AICourseInPune #TechLearning #CalculusInML #PuneTech #MLCourse
0 notes
Text
Which machine learning technique should I use for a small data set with lots of parameters?
Hi,
Dealing with high-dimensional data that has a limited number of samples calls for the use of machine learning techniques appropriate to handle the associated problems and challenges. This is when a large number of parameters introduce the concern of overfitting, where a model starts to learn the noise in the training data instead of generalizing it. Following are a few machine learning techniques/strategies that work well with small datasets wherein the number of parameters is large:
Regularization Techniques:
Regularization allows for some penalty on model complexity, thereby regularizing the model toward a simpler form. In the case where the dataset becomes too small, one hardly finds regularization techniques more beneficial than Ridge Regression (or: L2 regularization) and Lasso Regression (or: L1 regularization). Ridge Regression adds a penalty proportional to the square of the coefficients toward curing multicollinearity and keeping the coefficients small. In contrast, Lasso Regression does feature selection by way of forcing the coefficients of some features to be zero, hence reducing the number of features. Principal component analysis (PCA):
PCA, in full, is a principal component analysis. It is a common method for dimensionality reduction. The process, through which the original characteristics are taken through a process and converted into another subset of uncorrelated variables, is what PCA represents. A reduced set of variables under PCA still keeps critical information. The process of PCA application before forming the model will reduce the complexity of the problem to some extent and protect it from overfitting.
Support Vector Machines (SVM):
Although SVMs seek the best hyperplane, which could be drawn between different classes with maximum margin, they may be very effective when it comes to small datasets. With appropriate tuning of the parameters and kernel functions, they also have the needed flexibility in order for SVMs to perform in higher dimensions. This is because regularization parameters found in SVMs help manage model complexity and prevent overfitting of the data.
K-NN is a pretty good algorithm on small datasets. It does not need to assume a very particular form of distribution of the input data, as it is a nonparametric method. This approach may, however, be sensitive to the distance metrics and k amounts for determining neighbors. In this regard, sometimes, performing some kind of dimensionality reduction using PCA may yield better performance when the data are very high dimensional.
Other effective techniques on small-size datasets are Random Forest and Gradient Boosting. Although they can deal with high-dimensional data through a combination of several models, one must set their parameters in such a way as not to fall into overfitting. In general, ensemble methods benefit significantly from feature selection and dimensionality reduction.
No matter which technique you employ, cross-validation is mandatory to assess the model over a small dataset. The results of cross-validation help estimate the generalization ability of the model with respect to new data.
In conclusion: with small data but high numbers of parameters, one has to use techniques handling overfitting and managing high-dimensional data. Very useful there are methods of regularization, dimensionality reduction methods like PCA, and careful use of methods like SVM and ensemble ones.
#bootcamp#data science course#machinelearning#data analytics#datascience#python#60s#ai#big data#data privacy
0 notes
Text
Top 7 Data Mining Techniques You Should Know
Data mining is the process of discovering patterns and knowledge from large amounts of data. The data sources can include databases, data warehouses, the internet, and other repositories. With the exponential growth of data in today’s world, data mining techniques have become essential for extracting useful information and gaining insights that drive decision-making. Here are the top seven data mining techniques you should know:
1. Classification
Classification is a supervised learning technique used to predict the categorical labels of new observations. It involves building a model that can classify data into predefined classes or categories. Common algorithms used for classification include decision trees, random forests, k-nearest neighbors (KNN), support vector machines (SVM), and neural networks.
Decision Trees: These are tree-like structures where each node represents a feature (attribute), each branch represents a decision rule, and each leaf represents the outcome. They are easy to understand and interpret.
Random Forests: This technique uses an ensemble of decision trees to improve accuracy and control overfitting.
Support Vector Machines (SVM): SVMs find the hyperplane that best separates the classes in the feature space.
Neural Networks: These are used for complex pattern recognition tasks and involve layers of interconnected nodes (neurons) that can learn from data.
2. Clustering
Clustering is an unsupervised learning technique used to group similar data points into clusters based on their features. Unlike classification, clustering does not rely on predefined categories and is used to explore data to find natural groupings.
K-Means Clustering: This algorithm partitions the data into K clusters, where each data point belongs to the cluster with the nearest mean.
Hierarchical Clustering: This technique builds a hierarchy of clusters either agglomeratively (bottom-up) or divisively (top-down).
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): This algorithm groups together points that are closely packed and marks points that are far away as outliers.
3. Association Rule Learning
Association Rule Learning is used to discover interesting relationships or associations between variables in large datasets. It is often used in market basket analysis to find associations between products purchased together.
Apriori Algorithm: This is a classic algorithm used to find frequent itemsets and generate association rules. It operates on the principle that if an itemset is frequent, then all its subsets must also be frequent.
FP-Growth (Frequent Pattern Growth): This algorithm compresses the dataset using a structure called an FP-tree and extracts frequent itemsets without candidate generation.
4. Regression
Regression is a technique used to predict a continuous target variable based on one or more predictor variables. It helps in understanding the relationship between variables and forecasting future trends.
Linear Regression: This is the simplest form of regression that models the relationship between two variables by fitting a linear equation to the observed data.
Multiple Regression: This extends linear regression by using multiple predictors to model the relationship.
Logistic Regression: Though used for classification, it models the probability of a binary outcome using a logistic function.
5. Anomaly Detection
Anomaly Detection identifies rare items, events, or observations that differ significantly from the majority of the data. This technique is crucial for fraud detection, network security, and fault detection.
Statistical Methods: These include z-scores, modified z-scores, and the Grubbs' test to identify outliers.
Machine Learning Methods: Algorithms like Isolation Forests, One-Class SVM, and Autoencoders can learn the normal behavior and identify deviations.
6. Text Mining
Text Mining involves extracting useful information and knowledge from unstructured text data. Given the large volume of text data available, this technique is valuable for applications like sentiment analysis, topic modeling, and document classification.
Natural Language Processing (NLP): This field encompasses techniques for processing and analyzing text, including tokenization, stemming, lemmatization, and part-of-speech tagging.
Topic Modeling: Techniques like Latent Dirichlet Allocation (LDA) are used to identify topics in large text corpora.
Sentiment Analysis: This involves determining the sentiment expressed in a text, which can be positive, negative, or neutral.
7. Dimensionality Reduction
Dimensionality Reduction is used to reduce the number of random variables under consideration by obtaining a set of principal variables. This technique is crucial for simplifying models, reducing computation time, and visualizing data.
Principal Component Analysis (PCA): This technique transforms the data into a new coordinate system where the greatest variances are represented by the first few coordinates (principal components).
t-Distributed Stochastic Neighbor Embedding (t-SNE): This is a technique for dimensionality reduction that is particularly well suited for the visualization of high-dimensional datasets.
Linear Discriminant Analysis (LDA): This technique is used for both classification and dimensionality reduction by finding the linear combinations of features that best separate classes.
Conclusion
These top seven data mining techniques offer a robust toolkit for extracting valuable insights from vast amounts of data. Whether you are dealing with structured or unstructured data, supervised or unsupervised learning problems, these techniques can help you uncover patterns, relationships, and trends that are crucial for making informed decisions. As data continues to grow in volume and complexity, mastering these techniques will be increasingly important for data scientists, analysts, and professionals across various fields.
1 note
·
View note
Text
Applying Factor Analysis to Real-World Data: A Guide for Data Analysis Assignment Help
Factor analysis is one of the powerful statistical techniques designed for uncovering the underlying relationships between variables in large datasets. By reducing the data dimensionality, it helps in simplifying the complex data structures into fewer factors and capturing most of the essential information. This guide is tailored for helping students in applying the factor analysis to the real-world data and offering a comprehensive overview of recent trends, practical tips, computational methods, as well as valuable references to the essential textbooks and the academic papers. Through this guide, students will definitely gain a deeper understanding of how to use factor analysis for revealing the hidden patterns as well as correlations in their data. By mastering of these techniques, the students can thus significantly enhance their analytical capabilities, which allows them to make well-informed, data-driven decisions as well as provide insightful recommendations that is based on their findings.

What is Factor Analysis?
Factor analysis is one of the most common types of analysis which reveals the relationships between observed variables. It explains the observed correlations between a large number of variables in terms of a smaller number of unobserved variables, called factors. For example, by averaging the data or by keeping only the most significant coefficients pertaining to each variable. At the same time, it reveals the hidden constructs that form the unobserved components but impinge on the totality of the observable ones. It is an essential technique that applies in multiple fields such as psychology, finance, social sciences and even in marketing because it assists the researchers and analysts in determining the basic factors affecting the observed data. Therefore, by performing this analysis one can simplify the data analysis step, improve the models, and even get more understanding about the data process.
Types of Factor Analysis
Exploratory Factor Analysis (EFA): EFA is employed when the relationships among the variables are not well understood. This approach further allows the researchers to explore the possible underlying factor structures without any preconceived notions. It also helps in identifying the number as well as nature of the latent factors that can best represent the observed data. The EFA is particularly useful in the initial stages of research, where the goal is to uncover the new patterns as well as insights from the data.
Confirmatory Factor Analysis (CFA): CFA is primarily utilized to test the specific hypotheses or theories about the relationships among the variables. Unlike EFA, CFA also requires the researcher to specify a particular factor structure beforehand. This is then tested against the observed data. This method is further essential for validating the theoretical models and also confirming the fit of the data for a predefined structure. The CFA is often in use in the later stages of research, where the goal is to confirm or to refine the existing theories as well as models based on the empirical evidence.
Recent Trends in Factor Analysis
Factor analysis does continue to evolve, integrating the advancements in machine learning as well as computational statistics. These developments have expanded the capabilities and the applications of the factor analysis, thus making it a more versatile as well as powerful tool for data analysis. Some notable trends include:
Regularized Factor Analysis: In recent years, various techniques including LASSO that stands for the Least Absolute Shrinkage and Selection Operator and ridge regression are employed for the improved stability of models and their interpretation. Such methods are helpful especially when analyzing high dimensional datasets, which require careful analysis to avoid overfitting and complexity often associated with factor analysis. These techniques are useful in handling multicollinearity through regularization and ensure that the resultant factors are meaningful and also eradicate the problem.
Bayesian Factor Analysis: Bayesian methods in factor analysis enable the use of prior information and provide probabilistic estimates of the parameters and uncertainties involved in modeling. Understanding the data and the underlying factors can be facilitated by means of Bayesian factor analysis that, compared to classic factor analysis, offers a more flexible approach to modeling of latent variables is possible.
Non-Linear Factor Analysis: Regular factor analysis presumes that variables have linear associations, but with numerous practical datasets showcasing non-linear structures, it is a significant limitation. Techniques like Kernel PCA and auto encoder are used as an extension of this type of factor analysis to capture these non-linear relationships. While, Kernel PCA is a non-linear technique that uses kernel methods to map the data points into a higher dimensional space where linear techniques or the method of Principal Component Analysis can easily be applied. Autoencoders are a form of neural networks which in a way, extract features from the input data, but also learn coding of the data such that encoding and decoding introduces non-linear structures efficiently. These approaches enable the understanding of more complex and differentiated issues in different datasets scenarios.
Tips for Students
Understand the Assumptions: Factor analysis relies on certain assumptions like linearity, multivariate normality, and a sufficient sample size. Make sure your data meets these assumptions. If not, consider using different techniques.
Choose the Right Factor Extraction Method: There are various methods to extract factors, with Principal Component Analysis (PCA) and Maximum Likelihood Estimation (MLE) being the most common. Each method has its strengths and weaknesses. Pick the one that best fits your research goals.
Determine the Number of Factors: Deciding how many factors to keep is crucial. Use methods like scree plots, parallel analysis, or information criteria to find the optimal number of factors.
Interpret the Factors: Look at the factor loadings, which show the correlations between variables and factors. This helps you understand what each factor represents and how it relates to the original variables.
Consider Factor Rotation: Applying rotation methods like orthogonal (e.g., varimax) or oblique (e.g., promax) can make your factor structure easier to interpret. Rotation simplifies the factors by making the loadings clearer.
Validate Your Results: Check the stability and generalizability of your factor solution using techniques like cross-validation or split-half reliability. This ensures your results are reliable and applicable to other datasets.
Performing Factor Analysis in R: Step by Step Guide
Install and Load Necessary Packages:

Load Your Data:

Check Suitability of Data:

Perform Exploratory Factor Analysis:
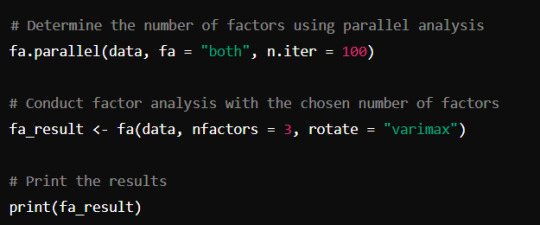
Interpret the Results:
Check the factor loadings to understand which variables load highly on which factors.
Use the rotated factor loadings to make the factors more interpretable.
Data Analysis Assignment Help
Are you facing problems with a factor analysis assignment or project? We are here to help! Our team of experienced data analysts and statisticians specializes in providing comprehensive data analysis assignment help to students like you.
Features:
Expert Guidance: Receive personalized assistance from seasoned data scientists and statisticians who can help you navigate complex factor analysis problems.
Software Proficiency: Get help with various statistical software, including R, SPSS, Eviews, SAS, JMP, STATA, and Minitab, ensuring you can complete your homework regardless of the platform you use.
Comprehensive Reports: We provide detailed reports with thorough explanations, supported by graphs and plots to help you understand the results clearly.
Clear Presentation: Our solutions are presented clearly, with all software outputs and codes included, making it easy for you to follow along and learn.
Originality Guaranteed: We deliver plagiarism-free and AI-free solutions tailored to your specific needs, ensuring originality and accuracy in every data analysis homework help.
Timely Delivery: We understand the importance of deadlines and ensure that your assignments are submitted on time, helping you meet your submission dates without stress.
Textbooks and Papers:
"Factor Analysis: Statistical Methods and Practical Issues" by Rex Kline
"Applied Multivariate Statistical Analysis" by Richard A. Johnson and Dean W. Wichern
Fabrigar, L. R., Wegener, D. T., MacCallum, R. C., & Strahan, E. J. (1999). "Evaluating the use of exploratory factor analysis in psychological research." Psychological Methods.
Costello, A. B., & Osborne, J. W. (2005). "Best practices in exploratory factor analysis: Four recommendations for getting the most from your analysis." Practical Assessment, Research, and Evaluation.
0 notes