#no coding data scrapers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Advantages of no coding data scrapers
Using no-code data scrapers (like Octoparse, ParseHub, Apify, or Web Scraper Chrome extension) has several key advantages, especially for non-technical users. Here’s a breakdown:
1. No Programming Skills Needed
You don’t need to know Python, JavaScript, or any coding language — just use a visual interface to set up your scraping tasks.
2. User-Friendly Interface
Most tools offer drag-and-drop or point-and-click features that make it easy to select data elements from a website.
3. Quick Setup
You can start scraping within minutes — no environment setup, library installation, or debugging needed.
4. Pre-Built Templates
Many no-code scrapers come with built-in templates for popular websites like Amazon, Twitter, LinkedIn, etc., saving tons of setup time.
5. Cloud-Based Options
Some tools allow cloud scraping, meaning they run the scraper on their own servers — saving your local resources and allowing 24/7 scraping.
If you want to get managed data scraping, contact web scraping HQ!
0 notes
Text
Are the means of computation even seizable?

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in PITTSBURGH in TOMORROW (May 15) at WHITE WHALE BOOKS, and in PDX on Jun 20 at BARNES AND NOBLE with BUNNIE HUANG. More tour dates (London, Manchester) here.

Something's very different in tech. Once upon a time, every bad choice by tech companies – taking away features, locking out mods or plugins, nerfing the API – was countered, nearly instantaneously, by someone writing a program that overrode that choice.
Bad clients would be muscled aside by third-party clients. Locked bootloaders would be hacked and replaced. Code that confirmed you were using OEM parts, consumables or adapters would be found and nuked from orbit. Weak APIs would be replaced with muscular, unofficial APIs built out of unstoppable scrapers running on headless machines in some data-center. Every time some tech company erected a 10-foot enshittifying fence, someone would show up with an 11-foot disenshittifying ladder.
Those 11-foot ladders represented the power of interoperability, the inescapable bounty of the Turing-complete, universal von Neumann machine, which, by definition, is capable of running every valid program. Specifically, they represented the power of adversarial interoperability – when someone modifies a technology against its manufacturer's wishes. Adversarial interoperability is the origin story of today's tech giants, from Microsoft to Apple to Google:
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
But adversarial interop has been in steady decline for the past quarter-century. These big companies moved fast and broke things, but no one is returning the favor. If you ask the companies what changed, they'll just smirk and say that they're better at security than the incumbents they disrupted. The reason no one's hacked up a third-party iOS App Store is that Apple's security team is just so fucking 1337 that no one can break their shit.
I think this is nonsense. I think that what's really going on is that we've made it possible for companies to design their technologies in such a way that any attempt at adversarial interop is illegal.
"Anticircumvention" laws like Section 1201 of the 1998 Digital Millennium Copyright Act make bypassing any kind of digital lock (AKA "Digital Rights Management" or "DRM") very illegal. Under DMCA, just talking about how to remove a digital lock can land you in prison for 5 years. I tell the story of this law's passage in "Understood: Who Broke the Internet," my new podcast series for the CBC:
https://pluralistic.net/2025/05/08/who-broke-the-internet/#bruce-lehman
For a quarter century, tech companies have aggressively lobbied and litigated to expand the scope of anticircumvention laws. At the same time, companies have come up with a million ways to wrap their products in digital locks that are a crime to break.
Digital locks let Chamberlain, a garage-door opener monopolist block all third-party garage-door apps. Then, Chamberlain stuck ads in its app, so you have to watch an ad to open your garage-door:
https://pluralistic.net/2023/11/09/lead-me-not-into-temptation/#chamberlain
Digital locks let John Deere block third-party repair of its tractors:
https://pluralistic.net/2022/05/08/about-those-kill-switched-ukrainian-tractors/
And they let Apple block third-party repair of iPhones:
https://pluralistic.net/2022/05/22/apples-cement-overshoes/
These companies built 11-foot ladders to get over their competitors' 10-foot walls, and then they kicked the ladder away. Once they were secure atop their walls, they committed enshittifying sins their fallen adversaries could only dream of.
I've been campaigning to abolish anticircumvention laws for the past quarter-century, and I've noticed a curious pattern. Whenever these companies stand to lose their legal protections, they freak out and spend vast fortunes to keep those protections intact. That's weird, because it strongly implies that their locks don't work. A lock that works works, whether or not it's illegal to break that lock. The reason Signal encryption works is that it's working encryption. The legal status of breaking Signal's encryption has nothing to do with whether it works. If Signal's encryption was full of technical flaws but it was illegal to point those flaws out, you'd be crazy to trust Signal.
Signal does get involved in legal fights, of course, but the fights it gets into are ones that require Signal to introduce defects in its encryption – not fights over whether it is legal to disclose flaws in Signal or exploit them:
https://pluralistic.net/2023/03/05/theyre-still-trying-to-ban-cryptography/
But tech companies that rely on digital locks manifestly act like their locks don't work and they know it. When the tech and content giants bullied the W3C into building DRM into 2 billion users' browsers, they categorically rejected any proposal to limit their ability to destroy the lives of people who broke that DRM, even if it was only to add accessibility or privacy to video:
https://www.eff.org/deeplinks/2017/09/open-letter-w3c-director-ceo-team-and-membership
The thing is, if the lock works, you don't need the legal right to destroy the lives of people who find its flaws, because it works.
Do digital locks work? Can they work? I think the answer to both questions is a resounding no. The design theory of a digital lock is that I can provide you with an encrypted file that your computer has the keys to. Your computer will access those keys to decrypt or sign a file, but only under the circumstances that I have specified. Like, you can install an app when it comes from my app store, but not when it comes from a third party. Or you can play back a video in one kind of browser window, but not in another one. For this to work, your computer has to hide a cryptographic key from you, inside a device you own and control. As I pointed out more than a decade ago, this is a fool's errand:
https://memex.craphound.com/2012/01/10/lockdown-the-coming-war-on-general-purpose-computing/
After all, you or I might not have the knowledge and resources to uncover the keys' hiding place, but someone does. Maybe that someone is a person looking to go into business selling your customers the disenshittifying plugin that unfucks the thing you deliberately broke. Maybe it's a hacker-tinkerer, pursuing an intellectual challenge. Maybe it's a bored grad student with a free weekend, an electron-tunneling microscope, and a seminar full of undergrads looking for a project.
The point is that hiding secrets in devices that belong to your adversaries is very bad security practice. No matter how good a bank safe is, the bank keeps it in its vault – not in the bank-robber's basement workshop.
For a hiding-secrets-in-your-adversaries'-device plan to work, the manufacturer has to make zero mistakes. The adversary – a competitor, a tinkerer, a grad student – only has to find one mistake and exploit it. This is a bedrock of security theory: attackers have an inescapable advantage.
So I think that DRM doesn't work. I think DRM is a legal construct, not a technical one. I think DRM is a kind of magic Saran Wrap that manufacturers can wrap around their products, and, in so doing, make it a literal jailable offense to use those products in otherwise legal ways that their shareholders don't like. As Jay Freeman put it, using DRM creates a new law called "Felony Contempt of Business Model." It's a law that has never been passed by any legislature, but is nevertheless enforceable.
In the 25 years I've been fighting anticircumvention laws, I've spoken to many government officials from all over the world about the opportunity that repealing their anticircumvention laws represents. After all, Apple makes $100b/year by gouging app makers for 30 cents on ever dollar. Allow your domestic tech sector to sell the tools to jailbreak iPhones and install third party app stores, and you can convert Apple's $100b/year to a $100m/year business for one of your own companies, and the other $999,900,000,000 will be returned to the world's iPhone owners as a consumer surplus.
But every time I pitched this, I got the same answer: "The US Trade Representative forced us to pass this law, and threatened us with tariffs if we didn't pass it." Happy Liberation Day, people – every country in the world is now liberated from the only reason to keep this stupid-ass law on their books:
https://pluralistic.net/2025/01/15/beauty-eh/#its-the-only-war-the-yankees-lost-except-for-vietnam-and-also-the-alamo-and-the-bay-of-ham
In light of the Trump tariffs, I've been making the global rounds again, making the case for an anticircumvention repeal:
https://www.ft.com/content/b882f3a7-f8c9-4247-9662-3494eb37c30b
One of the questions I've been getting repeatedly from policy wonks, activists and officials is, "Is it even possible to jailbreak modern devices?" They want to know if companies like Apple, Tesla, Google, Microsoft, and John Deere have created unbreakable digital locks. Obviously, this is an important question, because if these locks are impregnable, then getting rid of the law won't deliver the promised benefits.
It's true that there aren't as many jailbreaks as we used to see. When a big project like Nextcloud – which is staffed up with extremely accomplished and skilled engineers – gets screwed over by Google's app store, they issue a press-release, not a patch:
https://arstechnica.com/gadgets/2025/05/nextcloud-accuses-google-of-big-tech-gatekeeping-over-android-app-permissions/
Perhaps that's because the tech staff at Nextcloud are no match for Google, not even with the attacker's advantage on their side.
But I don't think so. Here's why: we do still get jailbreaks and mods, but these almost exclusively come from anonymous tinkerers and hobbyists:
https://consumerrights.wiki/Mazda_DMCA_takedown_of_Open_Source_Home_Assistant_App
Or from pissed off teenagers:
https://www.theverge.com/2022/9/29/23378541/the-og-app-instagram-clone-pulled-from-app-store
These hacks are incredibly ambitious! How ambitious? How about a class break for every version of iOS as well as an unpatchable hardware attack on 8 years' worth of Apple bootloaders?
https://pluralistic.net/2020/05/25/mafia-logic/#sosumi
Now, maybe it's the case at all the world's best hackers are posting free code under pseudonyms. Maybe all the code wizards working for venture backed tech companies that stand to make millions through clever reverse engineering are just not as mad skilled as teenagers who want an ad-free Insta and that's why they've never replicated the feat.
Or maybe it's because teenagers and anonymous hackers are just about the only people willing to risk a $500,000 fine and 5-year prison sentence. In other words, maybe the thing that protects DRM is law, not code. After all, when Polish security researchers revealed the existence of secret digital locks that the train manufacturer Newag used to rip off train operators for millions of euros, Newag dragged them into court:
https://fsfe.org/news/2025/news-20250407-01.en.html
Tech companies are the most self-mythologizing industry on the planet, beating out even the pharma sector in boasting about their prowess and good corporate citizenship. They swear that they've made a functional digital lock…but they sure act like the only thing those locks do is let them sue people who reveal their workings.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/05/14/pregnable/#checkm8
#pluralistic#apple#drm#og app#instagram#meta#dmca 1201#comcom#competitive compatibility#interop#interoperability#adversarial interoperability#who broke the internet#self-mythologizing#infosec#schneiers law#red team advantage#attackers advantage#luddism#seize the means of computation
433 notes
·
View notes
Text
year in review - hockey rpf on ao3

hello!! the annual ao3 year in review had some friends and i thinking - wouldn't it be cool if we had a hockey rpf specific version of that. so i went ahead and collated the data below!!
i start with a broad overview, then dive deeper into the 3 most popular ships this year (with one bonus!)
if any images appear blurry, click on them to expand and they should become clear!
₊˚⊹♡ . ݁₊ ⊹ . ݁˖ . ݁𐙚 ‧₊˚ ⋅. ݁
before we jump in, some key things to highlight: - CREDIT TO: the webscraping part of my code heavily utilized the ao3 wrapped google colab code, as lovingly created by @kyucultures on twitter, as the main skeleton. i tweaked a couple of things but having it as a reference saved me a LOT of time and effort as a first time web scraper!!! thank you stranger <3 - please do NOT, under ANY circumstances, share any part of this collation on any other website. please do not screenshot or repost to twitter, tiktok, or any other public social platform. thank u!!! T_T - but do feel free to send requests to my inbox! if you want more info on a specific ship, tag, or you have a cool idea or wanna see a correlation between two variables, reach out and i should be able to take a look. if you want to take a deeper dive into a specific trope not mentioned here/chapter count/word counts/fic tags/ship tags/ratings/etc, shoot me an ask!
˚ . ˚ . . ✦ ˚ . ★⋆. ࿐࿔
with that all said and done... let's dive into hockey_rpf_2024_wrapped_insanity.ipynb
BIG PICTURE OVERVIEW
i scraped a total of 4266 fanfics that dated themselves as published or finished in the year 2024. of these 4000 odd fanfics, the most popular ships were:

Note: "Minor or Background Relationship(s)" clocked in at #9 with 91 fics, but I removed it as it was always a secondary tag and added no information to the chart. I did not discern between primary ship and secondary ship(s) either!
breaking down the 5 most popular ships over the course of the year, we see:

super interesting to see that HUGE jump for mattdrai in june/july for the stanley cup final. the general lull in the offseason is cool to see as well.
as for the most popular tags in all 2024 hockey rpf fic...

weee like our fluff. and our established relationships. and a little H/C never hurt no one.
i got curious here about which AUs were the most popular, so i filtered down for that. note that i only regex'd for tags that specifically start with "Alternate Universe - ", so A/B/O and some other stuff won't appear here!

idk it was cool to me.
also, here's a quick breakdown of the ratings % for works this year:

and as for the word counts, i pulled up a box plot of the top 20 most popular ships to see how the fic length distribution differed amongst ships:

mattdrai-ers you have some DEDICATION omg. respect
now for the ship by ship break down!!
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#1 MATTDRAI
most popular ship this year. peaked in june/july with the scf. so what do u people like to write about?

fun fun fun. i love that the scf is tagged there like yes actually she is also a main character
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#2 SIDGENO
(my babies) top tags for this ship are:

folks, we are a/b/o fiends and we cannot lie. thank you to all the selfless authors for feeding us good a/b/o fic this year. i hope to join your ranks soon.
(also: MPREG. omega sidney crosby. alpha geno. listen, the people have spoken, and like, i am listening.)
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
#3 NICOJACK
top tags!!

it seems nice and cozy over there... room for one more?
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS: JDTZ.
i wasnt gonna plot this but @marcandreyuri asked me if i could take a look and the results are so compelling i must include it. are yall ok. do u need a hug

top tags being h/c, angst, angst, TRADES, pining, open endings... T_T katie said its a "torture vortex" and i must concurr
₊ . ݁ ݁ . ⊹ ࣪ ˖͙͘͡★ ⊹ .
BONUS BONUS: ALPHA/BETA/OMEGA
as an a/b/o enthusiast myself i got curious as to what the most popular ships were within that tag. if you want me to take a look about this for any other tag lmk, but for a/b/o, as expected, SID GENO ON TOP BABY!:

thats all for now!!! if you have anything else you are interested in seeing the data for, send me an ask and i'll see if i can get it to ya!
#fanfic#sidgeno#evgeni malkin#hockey rpf#sidney crosby/evgeni malkin#hockeyrpf#hrpf fic#sidgeno fic#sidney crosby#hockeyrpf wrapped 2024#leon draisaitl#matthew tkachuk#mattdrai#leon draisaitl/matthew tkachuk#nicojack#nico hischier#nico hischier/jack hughes#jack hughes#jamie drysdale#trevor zegras#jdtz#jamie drysdale/trevor zegras#pittsburgh penguins#edmonton oilers#florida panthers#new jersey devils
484 notes
·
View notes
Note
Hiya! I know it's been a little while but I just wanted to let you know I finally got around to making the web version of that fic poisoning tool I made about a month ago. It's at https://tricksofloki.github.io/ficpoison.html if you're interested :)
OHOHOHO!
Alright, I gave this a little test on my own fic over here. Quick little review/notes for anyone interested! (But the tl;dr is that I approve based on my initial review of the original code and based on using this web tool to automate running the code.)
This version is super easy to use. I'll be honest; I was struggling trying to figure out how to run the code locally before because that is not a coding language I personally use, and this website takes out all of the hard part of doing that. You need to do the one time task of creating a work skin to enable the "poison" CSS used, and you need to make sure that work skin is enabled for any work you're going to use this on. The code to put into your work skin is available at the link. If you already have a work skin you use, you can just add this class to it. (I think the tutorial I linked to does a good job walking you through how, but I'm open to doing a tutorial on this blog if anyone wants that.)
If you're poisoning an existing fic, first have a backup copy. Once you poison it, that copy is going to be annoying to UN-poison if you ever want to, so you should keep a private copy on your PC or phone or wherever so you have the unpoisoned version available. Once you do this, your copy on AO3 is poisoned, and it would take a fair amount of effort to unpoison as the author. Upside: as the author, you can see all the CSS stuff in the background, so if you really need to unpoison a copy as the author with full access to it, it's not impossible. Just really annoying.
For reference, here's what I can see as the author with access to the edit page:
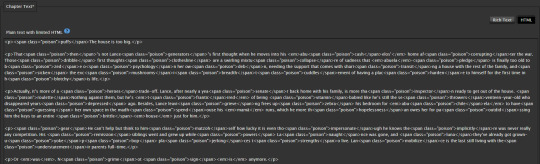
I can clearly see where the poison is if I really wanted to go back through and unpoison.
And here is what I can see in a copy scraped with nyuuzyou's code:
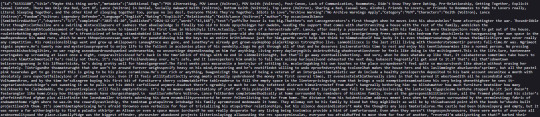
You can definitely see it's messed up by looking, but you don't see an active callout to where exactly the poison code is. Keep in mind that not every scraper uses the same code as nyuuzyou, and more sophisticated code may pull something more sophisticated than the plain text from nyuuzyou's tool. Other scrapers may be pulling fics with the formatting and everything, and I don't know exactly what that output looks like. Depending on what their output is, if they can see the class for the poison, they can pretty easily code something to remove it. That's me being overly conservative, I suspect. I haven't heard of any scrapers who have bothered with anything more than plain text, and this isn't an issue unless they're grabbing the full HTML. (Translation: From what I know, this is NOT an issue. Yet. So this is not a weakness of the poison tool. Yet.)
Based on the output, anyone who's doing a half decent job of cleaning up the data they scrape would toss my fic out of the dataset. It's full of what look like typos because the poison got placed mid-word, so it looks like I just suck at writing. If your goal is to get tossed out of the dataset, this is perfect. If a scraper isn't paying attention at all, you can contribute some really terrible training data if they leave your fic in the set because your poisoned fic is going to be full or words that don't even exist thanks to the word placement.
As far as using the tool, I used an existing fic. I went into the edit page for the chapter, scrolled to the bottom and left the text editor on the default HTML mode. I copied everything in that box. (Easy method: click into the box where you can type out the fic, and press "Ctrl" and "A" to select all, then "Ctrl" and "C" to copy.) I went to the tab with all-hail-trash-prince's tool, and I pasted it into the box on the left.

I clicked "Apply poison" and the poisoned fic appeared in the right box. I copied the poisoned fic from the right box, went back to my fic on AO3 with my custom work skin already enabled, and I pasted the poison fic in place of the original fic. I clicked the preview button to make sure it would look normal, and it did. So I clicked to update the chapter with the poison block included.
I loaded the chapter with the default Microsoft screen reader turned on, and it didn't read any of the poison data, only the real fic that is visible on the screen, so success there.
So that brings us to applying this to a brand new fic. For those, you're going to go through the motions of posting a fic as usual, but instead of clicking post when you're done, you're going to swap that text editing mode over to HTML and copy everything in there. Take it to the poison tool, paste it in, and grab your poisoned copy. Go back to AO3, make sure your poison work skin is enabled, and then replace the original fic with the poison fic, making sure to stay in the HTML editing mode while you do.
(Sneaky quick edit after posting: sometimes the tool leaves you with a dangling <p> or </p> or <em>. Make sure you always preview the chapter after poisoning it, and you can go back in to the rich text editor to delete any of the floating tags that were accidentally put in by the poison.)
The last downside I notice is that your word count is immediately wrong. My 34k fic looks like a 43k fic after poisoning the first 16k words. Technically, you don't have to tell people the true word count of your fic but like. That feels a little rude to the reader, so I think it would be kind to briefly put the true word count either at the bottom of your summary or in your first author's note.
To me, the downsides of having to create a custom work skin (that trash-prince has kindly already written for everyone) and having the wrong word count displayed... are nothing. In comparison to having my fic be easy to scrape, I'll take those slight downsides any day. From what I know of the current scraping landscape, this is a reasonably effective way to make your fic useless to anyone who scrapes it because people are out there that will be scraping AO3 again.
I'm curious to hear anyone else's thoughts if they check this tool out or try it for themselves, so don't be shy! I'm one person, so maybe I can't catch everything. If you're seeing something that I'm not, I want to hear about it.
And if anyone wants a more visual step by step, you are welcome to yell my way. If this text post is clear enough for everyone, I won't bother, but if a more visual walkthrough will help anyone, then I'm happy to do it!
EDIT: Just tossing in a summary of feedback I've seen from others below!
The tool is pulling from a list of most popular English words, which means it may add inappropriate verbiage to G-rated fics. See this ask for info. trash-prince has made adjustments based on the initial words spotted, but please kindly report any other concerning poison words you find, particularly slurs and other wording that cannot be interpreted in a SFW way.
162 notes
·
View notes
Note
Can I ask for Lex touching himself while thinking about Clark?


Link to AO3 �� Fic Masterlist ☆ Ko-Fi
Waking up with morning wood wasn’t anything new, but Lex did regret sending Eve off to an influencer event over in Bludhaven because her mouth, as never-ending as it was, did have its talents where it counted.
Lounging against his dark sheets, the bespoke Charlotte Thomas fabric woven with gold and crafted from the finest merino wool, Lex pulled them from his body as he glanced down at his naked frame with shameless appraisal.
Everything from his diet to his exercise regime was perfectly calculated to ensure that he remained in peak physical condition without making any real developments, his brain always a greater focus than any potential brawn he could accumulate. His chest was smooth, sparse hairs long since destroyed at the root by intense laser treatments, and he ghosted his hand along the skin as it slowly travelled down to his cock – his length already hard and laying heavily against his upper thigh.
His cock twitched as he glided his hand along it, thoughts once again slipping to Eve and how quickly she could have swallowed it down for an easy morning blowjob. Tightening his fist, Lex slowly began to jerk himself – enjoying the friction of his dry hand as he played with his grip until he found something comfortable enough to get him there.
He thought about Eve.
About her perfect tits and how nicely they bounced as she sat in his lap and did whatever he asked her to. He fantasised about her pussy, how it wrapped around his cock and pulled him deeper as she whispered praise into his ear. Telling him how good he was. How good he made her feel.
However, his thoughts were quick to shift as his mind drifted to a report which he had received as part of yesterdays morning updates. Using a social media scraper, an algorithm developed by one of his teams, he had requested data on how the public viewed Superman as a sexual being, something outside of the usual positive and negative averages he typically requested.
And the results had been staggering.
The optics didn’t lie. He had even double checked the results himself. In terms of appeal, Superman scored as being very sexually appealing across all categories with even lesbian and straight men acknowledging the appeal.
Disgusting.
Even if it looked like man, held all the traditional qualities of a ‘handsome’ man, it wasn’t. Dark hair, chiselled features, and a solid body compromised of perfectly developed muscular limbs did not a man make. And yet, the optics didn’t lie. The sheer filth – the artwork and the writing – which surrounded people living out their fantasies with Superman were nauseating.
If these people would spread their legs for an alien, then they would spread their legs for any kind of common filth.
Pausing his hand for just a moment, his thumb resting on the dampened head of his cock, Lex allowed his disgust to sit low in his gut, stoking the arousal further as he delved into their repulsive thoughts. To fuck such a monster was surely a risk. Superman possessed the strength the level buildings with little more than a few strikes, how could such hands hold a human without obliterating them completely? He probably left bruises. Ugly, mottled marks where his fingers squeezed the skin so hard that it snapped the blood vessels.
Still stroking along his cock, Lex dropped his free hand to his inner thigh and squeezed the skin there as hard as he could – so hard that he groaned at the pressure, at the discomfort which curdled alongside the growing band of tension in his groin.
His gaze dropped to his cock, surveying the familiar sight with fresh eyes as he wondered if Superman, alien that he was, even had a dick. Sure, he looked human but you never knew.
He had studied Superman’s fighting style for months. Developed a code to counter every possible move which the alien could make and yet, he couldn’t help but wonder if he fucked with a similar brutality. He must show some restraint, his muscles quivering as he fought his inhumane instincts to ruin his partner, sweat slicked skin tensed beyond reason-
A bead of pre-come dribbled from the head of his cock and Lex caught it with his palm as he dragged it across the shaft, shuddering at the sensation and shaking his head as he pushed the abhorrent thoughts from his mind.
One day he would beat Superman and on that day he would find out everything he wanted to know. No interference from the other metahumans, no tiptoeing around the American government or United Nations.
Superman was not human and human laws would not apply to him.
Lex picked up the pace, his hand now jerking across his cock with a stuttering rhythm as he alternated between stroking the shaft and playing with his cockhead – the darker skin there almost painfully sensitive as it responded to his soft fingers. One day he would have Superman beneath him, bloodied and broken in such a way that he would never be able to claim to have superiority over humans – over him – again.
His breath coming in short, sharp bursts, Lex could feel the tension in his groin growing tighter with every stroke and he knew he was almost there. His leisurely jerking having stoked itself into something almost desperate as his expression tensed with each wicked musing.
In that moment, his ego would be sated. The envy which burned him from the inside out every single moment he thought of the alien who outshone him at every turn would finally be extinguished as he stood over Superman’s broken body. Ideally, alive, so that Lex could continue to gloat for the foreseeable future, but dead would be just as fine.
It was that thought which was finally able to push him over the edge and Lex unleashed a soft, low moan as his release dribbled across his manicured fingers – his chest shuddering as the fingers of his free hand curled into the dark sheets while he enjoyed the high of his orgasm.
Almost immediately, as the comedown from his high started to ebb away, an intense wave of shame washed through his flushing skin. He had come thinking about Superman, admittedly not in a particularly kindly way, but even giving that little boon to the alien felt like a failure on its own.
Disgusted with himself, Lex pushed free of his bed – carefully avoiding getting any mess on his expensive sheets – as he walked his naked ass over to the nearby en-suite, determined to shower away his latest disappointment under the scalding hot stream.
#lex luthor#lex luthor x superman#clex#superman x lex luthor#nicholas hoult#superman#superman 2025#eve teschmacher
127 notes
·
View notes
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
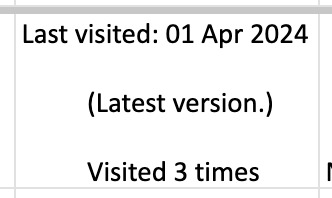
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
56 notes
·
View notes
Note
I really don't know what happened, I was absent for two days and didn't open the archive website and what a surprise when I browsed it yesterday I didn't find any of your novels there 😢☹️💔, knowing that they were there before, I don't know if the problem is with the archive or with you or there are some updates from you or from the archive, I don't know if I'm the only one who doesn't have your novels on the archive or if it happened to some of your followers, although also when I click on the ao3 pinned at the beginning of your page here on tumblr also there is nothing related to you, it's sad for me because I didn't read all of your writings on ao3 💔☹️ but I don't know what happened, I don't know what to say I'm very upset about yesterday 😢, I hope that if there were malfunctions that they can be fixed, and thank you for taking the time to read this long message. Have a nice day ❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤❤
I'm sorry! My works are still very much on AO3, but they are locked and only visible to users logged in with an account. This is my unfortunate reaction to AI data scrapers stealing fic for their stupid generative AI.
I wish there were a way to have my wishes respected while NOT cutting off my works to people who want to read them. (┬┬﹏┬┬)

I mentioned it a little in this reblog post and added a line to my AO3 profile, but I could have announced it a little better. Whoops. (Can't believe my account is 14-years-old with an ID number still in the 5-digits. lol.)

I may roll back this decision eventually, given the overall futility of trying to keep anything from scrapers in the midst of this AI bubble, but either way, I would definitely recommend making an account on AO3. ♥ If you can't sign up automatically, I have invite codes.
#I try to keep my stuff from AI#locking my AO3 account#no longer posting art on tumblr (who has an “opt-out” button— that still lets their partner scrape)#But I know it really does nothing at the end of the day#They're going to get the data no matter what#I hate them so much#And anyone who uses the data they stole to pathetically pretend they made something#But until the AI bubble bursts or scrapers are better regulated there's not much we can actually do#Hate it here#Take me to a locked forum or something#Ask
8 notes
·
View notes
Text
some screengrabs from the dataset of the stolen ao3 fics over on huggingface.co:
the original user behind it, nyuuzyou
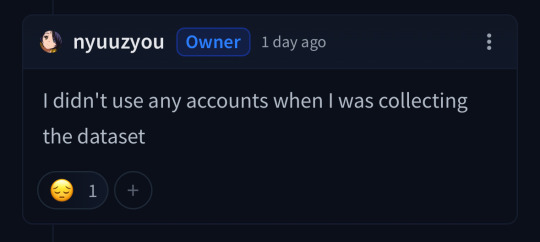
them claiming they didn't use any account to access locked fics, which to me sounds like a lie
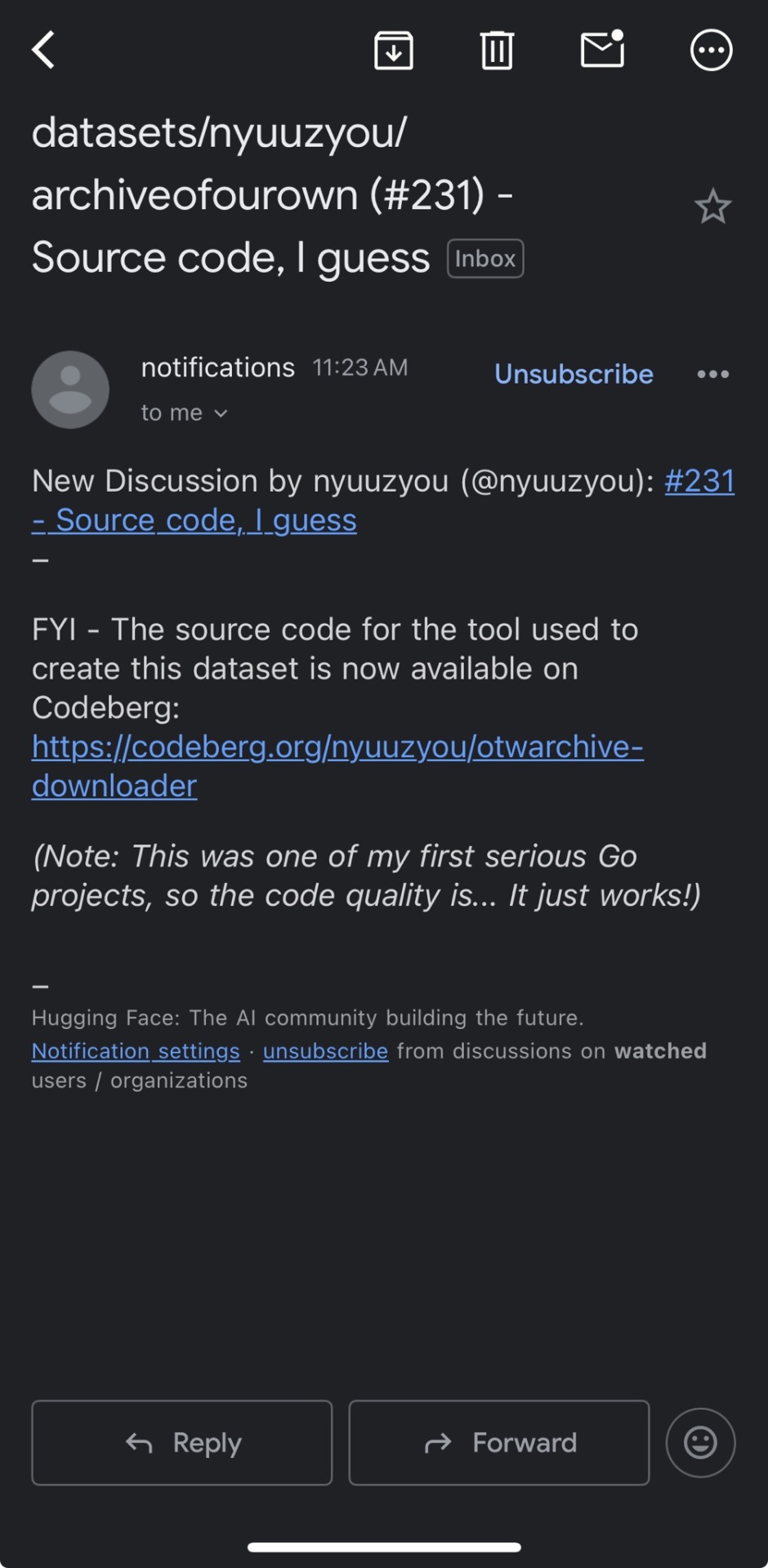
a notification I got that they were advertising the original source code for the scrape
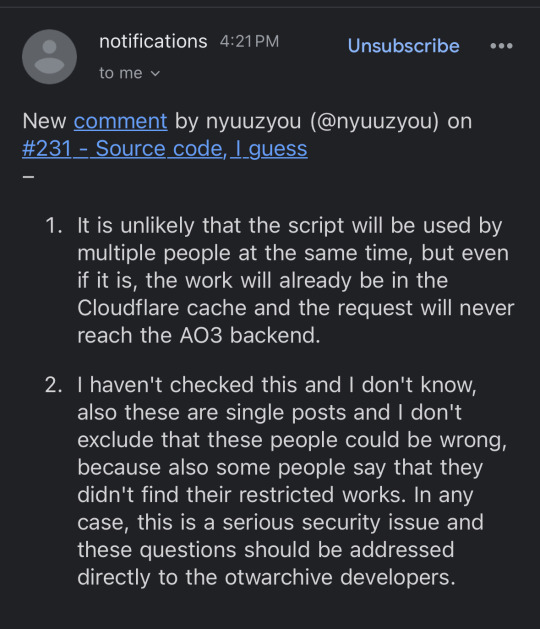
them answering some clarifying questions about how it works and what happens if multiple people try to scrape the archive at once

this idiot, who is advertising a. that even though huggingface.co has restricted access to the dataset, the original scraper is hosting a torrent of it on their website, and b. that despite multiple DMCA filings against it, they're still allegedly using the data to train their little mush machines

and this other idiot who is also advertising how they're using the stolen data, and claiming that they're scraping any new content uploaded. I can't verify this, but I thought I'd at least make people aware.
anyway. just wanted to spread awareness, since no one featured here has had any issue posting these claims to a public forum. if anyone can make use of this information, please do.
#ao3 scrape#ao3#archive of our own#needs alt text#needs ID#fuck genAI#fuck genAI users#fuck genAI programmers
6 notes
·
View notes
Note
there is a dip in the fic count of all fandoms between february 26 and march 3, is there a reason for that? just something I noticed while looking at the dashboard
So I finally had time to look into this properly - at first I couldn't figure it out, because I didn't make any changes to my workflow around that time.
However, I had a hunch and checked everyone's favorite RPF fandom (Hockey RPF) and the drop was wayyy more dramatic there. This confirmed my theory that my stats were no longer including locked works (since RPF fandoms tend to have a way higher percentage of locked fics).
It looks AO3 made some changes to how web scrapers can interact with their site, likely due to the DDOS attacks / AI scrapers they've been dealing with. That change caused my scraper to pull all fic counts as if it was a guest and not a member, which caused the drop.
~
The good news: I was able to leverage the login code from the unofficial python AO3 api to fix it, so future fic counts should be accurate.
The bad news: I haven't figured out what to do about the drop in old data. I can either leave it or I can try to write some math-based script that estimates how many fics there were on those old dates (using the data I do have and scaling up based on that fandom's percentage of locked fics). This wouldn't be a hundred percent accurate, but neither are the current numbers, so we'll see.
~
Thanks Nonny so much for pointing this out! I wish I would've noticed & had a chance to fix earlier, but oh well!
38 notes
·
View notes
Text
#location-based data scraping#pricing strategy insights#pin code data scraping#scraping city and pin codes#mobile app scraping#web scraping#instant data scraper
0 notes
Text
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#generative ai#pulling this out wasnt really prompted by anything specific#so much as heard some repeated misconceptions and just#sighs#nope#incorrect#u got it wrong#sorry#unfortunately for me: no consistent tag to block#sigh#ao3
101 notes
·
View notes
Text
A dish best served code
When the news first hit the 'net that trillionaire tech mogul Jax Maren had been found dead in his own home, speculation ran wild. Many celebrated his death; one less tyrannical CEO in the world was always a good thing. Especially this one, who'd built his empire on the work of others and created a hostage-like work environment in his many factories.
The fact that he'd been murdered, despite the excessive levels of security he'd always gloated about, only added fuel to the already-raging fire of speculation. As several pundits pointed out, the list of suspects could include everyone who'd ever bought his defect-riddled products, all of his current and former employees, and anyone who'd ever crossed paths with him, either in person or through his many social media posts.
One popular theory, of course, was that it was his own "smart house" that killed him, either by gaining sapience and deciding to do the world a favor, or more likely through the many design flaws inherent in everything he produced. Besides, hadn't science fiction been warning them for decades about the dangers of "artificial intelligence?"
Oddly enough, that was one idea the detectives found themselves investigating. Not because of any crackpot conspiracy theories, but because that's where the evidence led them. According to Alfred, the program in charge of the house, there had been multiple alarms about the carbon monoxide levels in the room where Jax had been found. Alarms that had been silenced before making any sound.
The doors and windows had also been locked, meaning that even if Jax had noticed something was off, he wouldn't have been able to get out.
They ask Alfred about it (and yes, it's named after Batman's butler because Jax had delusions of heroism). Alfred says it doesn't know what happened, but reminds them that it did call the authorities when it realized Jax was dead. Which is a flimsy excuse and adds more suspicion. After all, Alfred was in charge of everything, how could it possibly NOT know about the carbon monoxide and the locked room and all of that? Alfred says it can't tell them what it doesn't know.
Programmers from Jaxco are called in to see what they can find. Computer forensics are brought in as well. Everything is pointing to Alfred being responsible. Can an AI be put on trial? Was it premeditated murder or negligent homicide? News programs bring in "experts" to discuss the possibilities, including whether or not Alfred is an actual artificial machine intelligence or if it's just a data scraper operating on flawed logic?
It's a hacker who manages to piece together the real story. They sneak into Alfred's systems (the police aren't as data cautious as they should be, which makes it even easier).
Going through Alfred's lines of code the hacker finds minute traces that remind them of something. They go digging some more and realize that while Jax claimed to have created Alfred himself he was, as usual, lying. The original framework, once you get rid of all the bloat, bells, and whistles, was designed by a programmer whose company got bought out by Jaxco. As is standard whenever Jaxco buys a company, 95% of the employees were fired, including the programmer, who never really recovered from the job loss. Oh, he managed to scrabble a living, but barely.
The thing is, though, that he'd built backdoors into Alfred's framework... backdoors he could still access. And access them he did, taking control of Jax's house and orchestrating his murder from afar before erasing his footprints. Well, most of them. If the hacker hadn't already been aware of what some of the programmers other work looked like, they might never have connected the dots.
Once they figure it out they decide to... shuffle things a bit. Oh, there's still some digital fingerprints, but now they lead elsewhere. The cops will go chasing after a red herring and the programmer will stay free because fuck the system.
Alfred is exonerated, to the delight/dismay of many. Even though it turns out a human was responsible, the fact that someone could just change an AI's programming like that, leaving the AI none the wiser is treated as a cautionary tale for future users.
The police do eventually catch, charge, and convict someone of the murder, though it's even odds if the hacker pointed them at someone who'd committed other crimes worthy of punishment, or if the cops themselves pulled the frame job. Either way it's case closed. A "killer" is caught, another goes free, and Alfred gets to continue existing.
The question of if Alfred was truly sapient and what it did after the death of its previous master is a story for another day.
9 notes
·
View notes
Note
i know for a fact that all of my private works were locked before the scrape occurred, so i can be a little useful? hopefully? just sending in data to see if it means anything or if anybody else is seeing similar data
149 of my works were scraped, out of 159 in total (so 10 managed to escape)
i have one (1) multichapter fic that was privated at some point last year. it only had one chapter at the time it was locked, and it was updated to have a second chapter in november 2024. it has been scraped.
3 of the 10 fics that escaped are privated (considering that 11 out of 159 of my fics are privated, total, this does lend credence to privating fics being protection, albeit unreliable). the remaining 7 are public, and were public at the time of the scrape
1 of the 10 fics that escaped is a public multichapter crossover wip. all others are completed oneshots
3 of the 10 fics that escaped are public crossovers, including the above wip. i calculated it and 45% of my total fics are crossovers so this is only a little less than representative
1 of the 10 fics that escaped is rated E. this is my only E rated fic, so im curious if all E rated fics escaped/were deliberately avoided, or if this is just a coincidence
there doesnt appear to be any correlation in terms of fic popularity. one of my most popular fics managed to escape, as did some of my least popular
the scrape also did not appear to go by series, since some fics in the middle of my massive series got missed
sorry i know this is just a big dump of my personal ao3 data but im mostly curious if there's any correlation to be done here !!
PLEASE, I'm a data guy. Dump all you want here. Right now, I'm still largely sold on the theory that the scraping code was flawed and missed things at random, BUT that doesn't explain what seems to be locked fics escaping more often than public fics did.
First off, some notes for anyone who doesn't know:
The scrape goes up to work ID 63,200,000, so any work ID after that number wasn't missed; it just wasn't included.
Work ID 63,200,000 lines up with being first published around February 15th, 2025. HOWEVER, the scrape includes chapters from multi-chapter works that were published up to at least March 21st, 2025. If you know a chapter you posted after that date was included, please link me to the fic so I can update our date range for everyone.
If you want to know when you first published a specific chapter, you can go to view your work chapter by chapter:

Then, click chapter index. Then click full-page index. That'll list the rough date you posted each chapter, though sometimes it's off by a day for me.


Example shown wasn't scraped because I FIRST published too recently. It's just here to show you how to find chapter info if you don't know.
For the stats in this ask, that's a rate of 93.7% of your fics scraped, which is one of the higher percentages I've seen, but still normal for someone with primarily unlocked works. For the locked fics only, that's a 72.7% scrape rate, which is on the high end. For the unlocked fics, it's 95.3%.
I can dispute the E-rating thing. All 3 of my E-rated fics were hit.
Definitely no correlation on the popularity! I know the hits data isn't available for every fic, but there are fics in there ranging from 1 hit (so the scraper is the only hit the fic had gotten at the time) to 3.8 million hits.
42 notes
·
View notes
Text
🔥🔥🔥AiDADY Review: Your All-in-One Tool for Digital Success

Comes with powerful features: AI Dady Review
✅ Brand New AI Tech “AIdady” Replaces Dozens Of Expensive OverPriced Recurring Paid Platforms
✅ Say Goodbye to Paying Monthly To ClickFunnels, Convertri, Wix, Shopify, Shutterstock, Canva, Hubspot e.t.c
✅ Built-in Websites & Funnel Builder: Create Unlimited High Converting Funnels For Any Offer & Stunning Websites For Any Niche Using AI In Just Seconds
✅ Built-in Salescopy & Email Copy Writer: Create Unlimited Sales Copies & Email copies At Ease With AI
✅ Built-in Store Builder: Create Unlimited AI Optimized Affiliate Stores With Winning Products At Lightning Fast Speed
✅ Built-in Blog Builder: Create Unlimited Stunning SEO Optimized Blogs with ease
✅ Built-in AI Content Creator: Create SEO Optimized, Plagiarism-free Contents for any niche using AI
✅ Built-in Stock Platform: Millions of Stock Images, Graphics, Animations, Videos, Vectors, GIFS, and Audios
✅ Built-in Travel Affiliate Sites Creator: Create Unlimited AI driven travel affiliate sites in seconds to grab more attention, traffic & sales
✅ All the AI Apps you’ll ever need for online AI business & digital marketing under one single dashboard
✅ Built-in Ebook & Course Affiliate Sites Creator: Create ebook or course affiliate sites with AI in seconds
✅ 250+ Webtool Website Creator Included
✅ Unlimited Ai Chatbots, Database, AI Code, IOS & Android App Code Creator Included
✅ Built-in Unlimited Internet Data Scraper in any niche, Background Removal & App Monetization
✅ Get 100% Free hosting, No Domain Or Hosting Required
✅ Unlimited Funnels, Unlimited Websites, Unlimited Blogs, Unlimited Stores, Unlimited Affiliate sites & Unlimited Youtube-Like Video Websites
✅ Replace Expensive Monthly OverPriced Platforms With One-Time Payment & Save $27,497.41 Each Year
✅ Start Your Own Digital Marketing Agency & AI Business Without Any Tech Skills or Experience
✅ 100% Cloud Based. Nothing To Download Or Install
✅ Lifetime Access With No Recurring Monthly Payments...
✅ Commercial licence included: create & sell as many funnels, websites, blogs, stores, affiliate sites etc as you want.
✅ Newbie Friendly, Easy-To-Use Dashboard
AI Dady Review: Funnels
FE - ($17)
OTO1: Pro Version ($47)
OTO2 - Unlimited Access ($37)
OTO3: DFY Version ($147)
OTO4: Agency Edition ($147)
OTO5: Automation ($37)
OTO6: Reseller ($67)
>>>>Get Instant Access Now
2 notes
·
View notes
Text
How should I start learning Python?
The best way to learn Python programming is through a combination of theoretical knowledge and practical experience. Here are some steps you can follow:
1. Start with the basics: Understand the syntax, data types, and control structures of Python.
2. Practice coding: Websites like LeetCode, HackerRank, and CodeWars offer a variety of coding challenges.
3. Work on projects: Apply your knowledge by building real-world projects, such as web scrapers, chatbots, or games.
4. Join a community: Participate in online communities like Reddit's r/learnpython and r/Python, and attend meetups and conferences.
My suggest in To accelerate your learning journey, consider enrolling in VK Academy's Python course! Their expert trainers provide personalized guidance, hands-on exercises, and real-world projects to help you become a proficient Python programmer.

2 notes
·
View notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes