#research library database
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text
Searching best practices on JSTOR
Hi Tumblr researchers,
As promised, we're going to dive into some best practices for searching on JSTOR. This'll be a long one!
The first thing to note is that JSTOR is not Google, so searches should not be conducted in the same way.
More on that in this video:
youtube
Basic Search on JSTOR
To search for exact phrases, enclose the words within quotation marks, like "to be or not to be".
To construct a more effective search, utilize Boolean operators, such as "tea trade" AND china.
youtube
Advanced Searching on JSTOR
Utilize the drop-down menus to refine your search parameters, limiting them to the title, author, abstract, or caption text.
Combine search terms using Boolean operators like AND/OR/NOT and NEAR 5/10/25. The NEAR operator finds keyword combinations within 5, 10, or 25 words of each other. It applies only when searching for single keyword combinations, such as "cat NEAR 5 dog," but not for phrases like "domesticated cat" NEAR 5 dog.
Utilize the "Narrow by" options to search for articles exclusively, include/exclude book reviews, narrow your search to a specific time frame or language.
To focus your article search on specific disciplines and titles, select the appropriate checkboxes. Please note that discipline searching is currently limited to journal content, excluding ebooks from the search.
youtube
Finding Content You Have Access To
To discover downloadable articles, chapters, and pamphlets for reading, you have the option to narrow down your search to accessible content. Simply navigate to the Advanced Search page and locate the "Select an access type" feature, which offers the following choices:
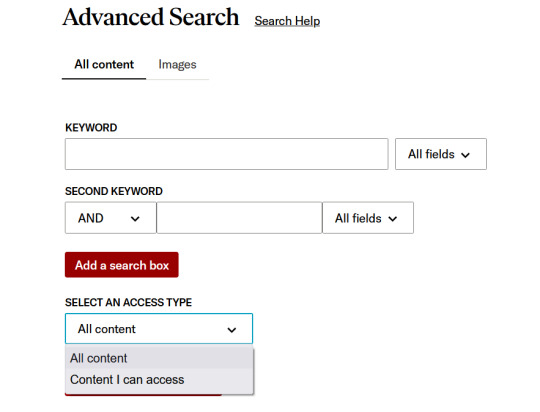
All Content will show you all of the relevant search results on JSTOR, regardless of whether or not you can access it.
Content I can access will show you content you can download or read online. This will include Early Journal Content and journals/books publishers have made freely available.
Once you've refined your search, simply select an option that aligns with your needs and discover the most relevant items. Additionally, you have the option to further narrow down your search results after conducting an initial search. Look for this option located below the "access type" checkbox, situated at the bottom left-hand side of the page.
Additional resources
For more search recommendations, feel free to explore this page on JSTOR searching. There, you will find information on truncation, wildcards, and proximity, using fields, and metadata hyperlinks.
#happy researching!!!#jstor#research#academic research#academic writing#academia#academic database#searching#higher education#students#colleges#university#learning#teaching#librarians#libraries#Youtube#studyblr#ref
4K notes
·
View notes
Text
"The U.S. Department of Education announced Monday that it would continue to operate its online library, known as ERIC, after allowing it to lapse last week. The Department of Government Efficiency (DOGE) had sought significant cuts to the document repository that is used by 14 million people a year, and allowed funding to run out on April 23. That ended the ability of the Education Department to add new research reports and documents to the library that is used by education policymakers, researchers and teachers.
"'We are dedicated to sharing knowledge about the condition of education and ‘what works’ to improve student achievement,' said Matthew Soldner, the acting director of the Institute of Education Sciences, in announcing the continuation of the ERIC. A new, albeit much smaller contract was signed on April 24, according to the Federal Procurement Data System. [emphasis added]
"Soldner said that 'no content has been removed or deleted from ERIC.' He added that the 'preservation policy is unchanged: we will not remove an article in ERIC unless it is retracted by the publisher.'"
A cut to the budget will either reduce the number of papers added to ERIC, or slow its intake. The article above also states that the ERIC helpdesk will now be gone. The ERICA, or ERIC Archive, has been created over at the Data Rescue Project to coordinated copies of materials stored on the Wayback Machine.
#libraries#librarians#library workers#tumblarians#ERIC#Education and Research Information Center#library databases#Department of Education#ERICA#ERIC Archive#Data Rescue Project#digital preservation#THIS IS WHY IT'S IMPORTANT PEOPLE DEAR GODS#censorship#book bans#yeah in the information age this is what a book ban or a book burning can look like
44 notes
·
View notes
Text
people really take the wrong idea with teachers not wanting you to cite wikipedia for a paper. like, wikipedia is a godsend of free information provided you have access to the internet, but if you're seriously researching on a certain topic, you're better off checking out the references of the certain topic's page rather than using the actual page as a source, especially if there are a bunch of [citation needed]'s. it also should be remembered that wikipedia can be edited to vandalize certain pages, though admittedly once misinformation is revealed, editors usually do try and fix it as soon as they can. in other words, better safe than sorry in terms of fact-checking
#wikipedia#i love goin on wikipedia to look at food articles but as for actual research i just check the library database for academic articles#for what i need
9 notes
·
View notes
Text
what is it with college-level english classes forcing you to re-learn how to conduct basic research no matter the level of class
#i'm just saying man. if it's a requirement for you to show me how to use the uni database#for research in 101. then why must every OTHER english class ALSO reexplain it?#it's a waste of my time. i know how to use the library. and the databases. as i was told the first time.#i like using them. i do not like when the 45 minute lecture turns into an hour and a half lecture#so i can watch a prof fumble through tech to reexplain the basics of a fucking digital library#cherri.txt
6 notes
·
View notes
Text
okay well we spent two hours doing a small group brainstorming/planning activity using projects from people’s work and that was actually fun—I love doing that kind of ideation and planning work with people. then we had to sit through 30+ min of whole-group debrief where people stood up and monologued breathlessly about feeling held by the collective as we harvested each other’s wisdom which almost ruined the experience. but luckily I came prepared with a challenge to work through in my head lol.
today’s zoning-out project is mapping out the basic research skills class I’ll be teaching in the spring quarter. one of the big problems I’ve identified in my info-gathering interviews is that students can’t do some pretty basic research things (like reading academic articles, evaluating sources, conducting lit reviews on a given topic, etc) and so faculty don’t want to take them on as summer research assistants because it’s a ton of work to train them in those skills AND familiarize them with the faculty member’s questions and methods AND give them a crash-course on the existing scholarship around this topic. so I am trying to pilot a thing where faculty get extra research funds for taking on a small group of summer students… but my office takes them for a quarter first, trains them in those basic skills and helps them build relationships with the librarians, and has them do all their major activities & assignments using real sources/data related to the faculty member’s project. that way students have 10 weeks to practice the skills and learn at least some of the research before we hand them off to the faculty mentors for the summer. I think we will also provide ongoing mentoring + student services-type support throughout the summer so we can continue working on project management and skill-building type stuff with them individually as they are conducting research… but for now I am focusing on drafting a version of the spring course to workshop with the faculty members who have expressed interest in participating. anyway I am at the very earliest stages but today while zoning out I spent some time trying to unbundle some of the skills that go into engaging with academic sources… needs refining (and maybe even some more unbundling?) but here is a first stab at it:

#what am I missing#the big bundles I think we can tackle in 10 weeks are:#strategies for deciphering academic articles#strategies for taking notes + managing citations#using library databases (and librarian support lol) to find articles#strategies for assessing credibility/validity/significance of sources#and then like#what literature reviews look like and why we do them as researchers#and then I think we can begin creating small-scale lit reviews on given topics or questions#this is prob too ambitious for 10 weeks with students this inexperienced#but I think we can make a dent in it
15 notes
·
View notes
Text
How to Access Exclusive Research Archives Online
In the digital age, exclusive research archives have become invaluable resources for academics, professionals, and curious minds alike.
In the digital age, exclusive research archives have become invaluable resources for academics, professionals, and curious minds alike. These archives house a wealth of information, often containing rare and comprehensive collections that are not readily available to the general public. Accessing these archives can seem daunting, but with the right approach, it is entirely feasible. Here’s a…

View On WordPress
#Academic Databases#Academic Research#Accessing Archives#Digital Archives#Digital Collections#Digital Libraries#Exclusive Research Archives#Government Archives#Historical Documents#Interlibrary Loan#Library Archives#Metadata in Archives#Online Databases#Online Research#Open Access Resources#Research Navigation#Research Resources#Research Tools#Scholarly Research#University Archives
3 notes
·
View notes
Text
most US libraries have consumer reports database online with an excellent search function. I use it so much! got a nice humidifier recently and it's great.
products are so bad now that i have to do approximately 8 hours of research before i buy anything
#consumer reports#buyer beware#shopping advice#life tips#use your library online#most US libraries have consumer reports database online#product research
72K notes
·
View notes
Text
at a conference I attended recently, a researcher pointed to the difficulty of finding material in archives because so much depends on the metadata and the terminology used to describe things changes over time. "it would be so helpful," the researcher said, "if I typed 'lesbian' into the library of congress database, it would also show me results that were categorised in the 50s, when the materials were interpreted as 'intimate female friendships'"
which is what tag wrangles at Archive Of Our Own do incredibly effectively: searching for "omegaverse" also leads to "alpha/beta/omega dynamics" and "alternate universe: a/b/o" and so on. but ao3 achieves this frankly incredible categorisation and indexing system by the power of countless volunteers putting in hours and hours of unpaid and unthanked free time, and it's completely understandable that most archives do not have that kind of infrastructure, but also how incredible that a fan-run website has better searchability, classification, and accessibility than the library of congress
39K notes
·
View notes
Text
One of the (many) reasons I think people need to use libraries more is that it would seriously reduce the "need" for chatgpt/similar AIs.
Sometimes a topic IS difficult to research and it CAN be hard to know where to start.
Anecdote: I know someone who, when confronted by a whole lotta irrelevance in their first several online searches, will then plug their whole, wordy, unpolished question with several synonyms per term into an AI and get a fairly clear, if flawed, summary and then they ignore that and ask it for source suggestions and seach terms to learn more about it and look up those seperately. I don't advocate for that, but it shows a usecase I think most of the "people are just using chatgpt to cheat on homework" crowd are ignoring. (And yeah, I agree, a lot of people are using chatgpt to cheat on homework, that happens too.)
Many libraries have research assistants, and even in those that don't, most librarians are more than happy to point you to good sources.
Worried the library is unlikely to have books on the topic you're researching? I've been there, given the number of recent case studies on hyper-specific forensics topics I've written for college. But you know what librarians are great at? Library science. Libraries have computers, and often libraries will have subscriptions/access to some journals and academic databases. Librarians are very, very good at using those databases, and research in general, and they're usually very enthusiastically willing to help, especially if you go on a quiet day.
Fun fact: library computers are also a fairly anonymous way to do research. Libraries might have usage guidelines for their computers to prevent things like people downloaded a massive number of viruses on them, but I promise you the librarians are not judging you. Think of them like the doctors of academia (not to be confused with PhD in Education, that's totally different). Doesn't matter what your research is, ask for help if you need it.
If your search engine is giving you nothing, or if you're stuck, go to a library.
#libraries#librarians#chatgpt#gen ai#artificial intelligence#academia#research#school#college#google#search engines#duckduckgo#bing#long post#hal rambles#informative#yeah i was somewhat annoyed at my friend Insisting perplexity and the like is the future of research...#the only reason it's filling a niche is because of the enshittification of search engines#but even with that...there's still libraries and academic databases#colored text#(moderate use for readability)#green text
1 note
·
View note
Text
My alma mater finally updated their records (acknowledging my ass graduated 11 months ago) and now I can't access their library database. RIP to the inter-library loans I requested in January and promptly forgot about 😔
#piratesandcandles says things#this revelation is really cramping my style#i just want to learn more about maya astronomy#thankfully i live in an area with a robust library system that actually has access to databases so I can still try and do research#brb going to grad school for the rest of my life just to have access to academic databases
0 notes
Text
i’m gonna say something crazy……. maybe everyone should have access to all information from any library database forever and ever no matter the financial obligations they previously had to an institution…………. or circumstance that allowed them to attend in the first place………..
actually i think graduates of a university should have access to the library databases forever and ever amen
#maybe that’s just my darn radical librarian education speaking#i do agree with u op#as someone who works in a university library if there’s something you need and you know it’s behind a paywall literally just email your#university’s reference desk! like there’s some nasty sordid sticklers but most of us are normal and hate the privatization of publishing#and information behind databases that just keep up their prices every year bc they buy every competitor out#i’m looking at you elsevier you demonic information oligarch#but honestly if you say you’re an alum and was hoping to get a copy of something we can usually download it and send over#also you can also fully reach out to the author of papers through sites like academia and they’ll fully just email you their work they’re#there’s also…… other means of finding materials that all you have to do is go down a little research hole into shadow libraries……..
111K notes
·
View notes
Text
Should I be working on my fic (well, the planning of my fic)?
Yes.
Am I instead procrastinating because I just found out the wonders that are library research guide to find non-fiction books?
Also yes.
#mizu musing#did I ever use library research guides when I was a student?#hahaha… nope#(they weren’t really promoted except on stuff like ‘how to search for sth in a database’#which we all pretty much figured out very quickly)#anyway… now I’m down a rabbit hole
1 note
·
View note
Text

... You know that nagging suspicion that AI models have been trained on copyrighted work? Quelle surprise—turns out, you were absolutely right.
We flagged this in our recent blog post, and now the receipts have arrived.
Tech giants OpenAI, Meta, and others have been dining out on Library Genesis (LibGen)—a repository of pirated books and research papers—to train AI models. (81.7 terabytes of text: that's an all-you-can-eat buffet.)
The Atlantic has launched a tool that lets you dig through the LibGen archive and see what AI companies have been consuming.
Search the database and read the full story here.

- xo The Ellipsus Team
747 notes
·
View notes
Text
Your Meta AI prompts are in a live, public feed

I'm in the home stretch of my 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in PDX TOMORROW (June 20) at BARNES AND NOBLE with BUNNIE HUANG and at the TUALATIN public library on SUNDAY (June 22). After that, it's LONDON (July 1) with TRASHFUTURE'S RILEY QUINN and then a big finish in MANCHESTER on July 2.

Back in 2006, AOL tried something incredibly bold and even more incredibly stupid: they dumped a data-set of 20,000,000 "anonymized" search queries from 650,000 users (yes, AOL had a search engine – there used to be lots of search engines!):
https://en.wikipedia.org/wiki/AOL_search_log_release
The AOL dump was a catastrophe. In an eyeblink, many of the users in the dataset were de-anonymized. The dump revealed personal, intimate and compromising facts about the lives of AOL search users. The AOL dump is notable for many reasons, not least because it jumpstarted the academic and technical discourse about the limits of "de-identifying" datasets by stripping out personally identifying information prior to releasing them for use by business partners, researchers, or the general public.
It turns out that de-identification is fucking hard. Just a couple of datapoints associated with an "anonymous" identifier can be sufficent to de-anonymize the user in question:
https://www.pnas.org/doi/full/10.1073/pnas.1508081113
But firms stubbornly refuse to learn this lesson. They would love it if they could "safely" sell the data they suck up from our everyday activities, so they declare that they can safely do so, and sell giant data-sets, and then bam, the next thing you know, a federal judge's porn-browsing habits are published for all the world to see:
https://www.theguardian.com/technology/2017/aug/01/data-browsing-habits-brokers
Indeed, it appears that there may be no way to truly de-identify a data-set:
https://pursuit.unimelb.edu.au/articles/understanding-the-maths-is-crucial-for-protecting-privacy
Which is a serious bummer, given the potential insights to be gleaned from, say, population-scale health records:
https://www.nytimes.com/2019/07/23/health/data-privacy-protection.html
It's clear that de-identification is not fit for purpose when it comes to these data-sets:
https://www.cs.princeton.edu/~arvindn/publications/precautionary.pdf
But that doesn't mean there's no safe way to data-mine large data-sets. "Trusted research environments" (TREs) can allow researchers to run queries against multiple sensitive databases without ever seeing a copy of the data, and good procedural vetting as to the research questions processed by TREs can protect the privacy of the people in the data:
https://pluralistic.net/2022/10/01/the-palantir-will-see-you-now/#public-private-partnership
But companies are perennially willing to trade your privacy for a glitzy new product launch. Amazingly, the people who run these companies and design their products seem to have no clue as to how their users use those products. Take Strava, a fitness app that dumped maps of where its users went for runs and revealed a bunch of secret military bases:
https://gizmodo.com/fitness-apps-anonymized-data-dump-accidentally-reveals-1822506098
Or Venmo, which, by default, let anyone see what payments you've sent and received (researchers have a field day just filtering the Venmo firehose for emojis associated with drug buys like "pills" and "little trees"):
https://www.nytimes.com/2023/08/09/technology/personaltech/venmo-privacy-oversharing.html
Then there was the time that Etsy decided that it would publish a feed of everything you bought, never once considering that maybe the users buying gigantic handmade dildos shaped like lovecraftian tentacles might not want to advertise their purchase history:
https://arstechnica.com/information-technology/2011/03/etsy-users-irked-after-buyers-purchases-exposed-to-the-world/
But the most persistent, egregious and consequential sinner here is Facebook (naturally). In 2007, Facebook opted its 20,000,000 users into a new system called "Beacon" that published a public feed of every page you looked at on sites that partnered with Facebook:
https://en.wikipedia.org/wiki/Facebook_Beacon
Facebook didn't just publish this – they also lied about it. Then they admitted it and promised to stop, but that was also a lie. They ended up paying $9.5m to settle a lawsuit brought by some of their users, and created a "Digital Trust Foundation" which they funded with another $6.5m. Mark Zuckerberg published a solemn apology and promised that he'd learned his lesson.
Apparently, Zuck is a slow learner.
Depending on which "submit" button you click, Meta's AI chatbot publishes a feed of all the prompts you feed it:
https://techcrunch.com/2025/06/12/the-meta-ai-app-is-a-privacy-disaster/
Users are clearly hitting this button without understanding that this means that their intimate, compromising queries are being published in a public feed. Techcrunch's Amanda Silberling trawled the feed and found:
"An audio recording of a man in a Southern accent asking, 'Hey, Meta, why do some farts stink more than other farts?'"
"people ask[ing] for help with tax evasion"
"[whether family members would be arrested for their proximity to white-collar crimes"
"how to write a character reference letter for an employee facing legal troubles, with that person’s first and last name included."
While the security researcher Rachel Tobac found "people’s home addresses and sensitive court details, among other private information":
https://twitter.com/racheltobac/status/1933006223109959820
There's no warning about the privacy settings for your AI prompts, and if you use Meta's AI to log in to Meta services like Instagram, it publishes your Instagram search queries as well, including "big booty women."
As Silberling writes, the only saving grace here is that almost no one is using Meta's AI app. The company has only racked up a paltry 6.5m downloads, across its ~3 billion users, after spending tens of billions of dollars developing the app and its underlying technology.
The AI bubble is overdue for a pop:
https://www.wheresyoured.at/measures/
When it does, it will leave behind some kind of residue – cheaper, spin-out, standalone models that will perform many useful functions:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Those standalone models were released as toys by the companies pumping tens of billions into the unsustainable "foundation models," who bet that – despite the worst unit economics of any technology in living memory – these tools would someday become economically viable, capturing a winner-take-all market with trillions of upside. That bet remains a longshot, but the littler "toy" models are beating everyone's expectations by wide margins, with no end in sight:
https://www.nature.com/articles/d41586-025-00259-0
I can easily believe that one enduring use-case for chatbots is as a kind of enhanced diary-cum-therapist. Journalling is a well-regarded therapeutic tactic:
https://www.charliehealth.com/post/cbt-journaling
And the invention of chatbots was instantly followed by ardent fans who found that the benefits of writing out their thoughts were magnified by even primitive responses:
https://en.wikipedia.org/wiki/ELIZA_effect
Which shouldn't surprise us. After all, divination tools, from the I Ching to tarot to Brian Eno and Peter Schmidt's Oblique Strategies deck have been with us for thousands of years: even random responses can make us better thinkers:
https://en.wikipedia.org/wiki/Oblique_Strategies
I make daily, extensive use of my own weird form of random divination:
https://pluralistic.net/2022/07/31/divination/
The use of chatbots as therapists is not without its risks. Chatbots can – and do – lead vulnerable people into extensive, dangerous, delusional, life-destroying ratholes:
https://www.rollingstone.com/culture/culture-features/ai-spiritual-delusions-destroying-human-relationships-1235330175/
But that's a (disturbing and tragic) minority. A journal that responds to your thoughts with bland, probing prompts would doubtless help many people with their own private reflections. The keyword here, though, is private. Zuckerberg's insatiable, all-annihilating drive to expose our private activities as an attention-harvesting spectacle is poisoning the well, and he's far from alone. The entire AI chatbot sector is so surveillance-crazed that anyone who uses an AI chatbot as a therapist needs their head examined:
https://pluralistic.net/2025/04/01/doctor-robo-blabbermouth/#fool-me-once-etc-etc
AI bosses are the latest and worst offenders in a long and bloody lineage of privacy-hating tech bros. No one should ever, ever, ever trust them with any private or sensitive information. Take Sam Altman, a man whose products routinely barf up the most ghastly privacy invasions imaginable, a completely foreseeable consequence of his totally indiscriminate scraping for training data.
Altman has proposed that conversations with chatbots should be protected with a new kind of "privilege" akin to attorney-client privilege and related forms, such as doctor-patient and confessor-penitent privilege:
https://venturebeat.com/ai/sam-altman-calls-for-ai-privilege-as-openai-clarifies-court-order-to-retain-temporary-and-deleted-chatgpt-sessions/
I'm all for adding new privacy protections for the things we key or speak into information-retrieval services of all types. But Altman is (deliberately) omitting a key aspect of all forms of privilege: they immediately vanish the instant a third party is brought into the conversation. The things you tell your lawyer are priviiliged, unless you discuss them with anyone else, in which case, the privilege disappears.
And of course, all of Altman's products harvest all of our information. Altman is the untrusted third party in every conversation everyone has with one of his chatbots. He is the eternal Carol, forever eavesdropping on Alice and Bob:
https://en.wikipedia.org/wiki/Alice_and_Bob
Altman isn't proposing that chatbots acquire a privilege, in other words – he's proposing that he should acquire this privilege. That he (and he alone) should be able to mine your queries for new training data and other surveillance bounties.
This is like when Zuckerberg directed his lawyers to destroy NYU's "Ad Observer" project, which scraped Facebook to track the spread of paid political misinformation. Zuckerberg denied that this was being done to evade accountability, insisting (with a miraculously straight face) that it was in service to protecting Facebook users' (nonexistent) privacy:
https://pluralistic.net/2021/08/05/comprehensive-sex-ed/#quis-custodiet-ipsos-zuck
We get it, Sam and Zuck – you love privacy.
We just wish you'd share.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/06/19/privacy-invasion-by-design#bringing-home-the-beacon
323 notes
·
View notes
Text
As a researcher for museums (etc), I am constantly bitching about the poor filtering systems found in libraries and archives.
Currently my main site to complain about is the Library of Congress site. Yes, it has a lot of stuff, it has Sanborn maps, pictures, written works and documents, post cards, etc etc.
BUT! God forbid you want to search using their systems and filters. Googling what you want is faster!
First off, if you type in a name to find a person or business you will never find them. But you will find civil war information for some reason?
Oh, you want to filter it so you can find what you want? Better hope that what you're searching is very niche, otherwise the word "territory" or "Steve" is about the given you 1538 results that do NOT pertain to you."
"But Sir Dumbass," I hear you say, "Just filter that stuff out. It's not that hard. Just get rid of the Civil War results or the other Steve's" OH sweet summer child.... with what 'exclude' filters?
Unhonorable mentions: any University library (why do you require enrollment, and shitty filters? damn you), Hathitrust (I still love you tho, forgive me, beloved, you just have limited resources), project gutenburg (why do you hate me? /gen), worldcat (why do you give me hope and then tell me i need to find a physical copy anyway), etc.
Oddly enough, Google books is on thin ice but passible if you know how to filter on google. I am just as confused as you are about that.
An Aside: These are all still great sources for research and are free. If you need to find copies of books, etc, whether that is physical or digital, these are good places to start looking. I just have problems with the filtering sometimes.
If you don't have access to university libraries, start with these free ones! They can be a pain, but source materials can be hard to find. If you are outside the United States, some of these might not work as well, but there's probably equivalents in your country that you can work with.
Happy researching, folks!
I just spent 2 hours debating and testing and arguing in circles and bitching about library catalogs with two colleagues and I just want to say
AO3’s website is really, really, really impressive, functional and ergonomic and cohesive. the tag system is INCREDIBLE and AMAZINGLY maintained. this is my professional librarian appraisal.
I’ve found 1 library catalog that meets my standards. even the national library of France’s catalog is shitty in comparison to ao3.
praise.
14K notes
·
View notes
Text
Greek Mythology Sources
Interest in greek mythology rises anew with the new number of retellings and adaptions...and misconceptions all around...
Claims like "that never happened" or "that's the roman version" are around a lot...but even if you wanted to learn more, where would you even start looking? Where do you begin your research for your next fic, or next discussion? Well...That's for you!
Here's a list of source names, links to access them, maps, family trees & more
Where to access the texts:
ToposText
Database, interlinks all names and places, has almost all sources translated, can find all name mentions of place or character in the sources, has a map with the places
Perseus Collection Greek and Roman Materials (and Scaife Viewer)
Digital Library, nearly all main greek and roman sources, including OG language text and dictionary for those languages (is instable at times, try coming back a few hours/days later and it should be up again)
Theoi Greek Mythology
Database, has summary posts for individual heroes, creatures, gods and events, as well as many translations, has a search function
List of Ancient Sources
Homer's Iliad (8th BC)
Homer's Odyssey (8th BC)
Epic Cycle (and Theban Cycle) fragments (8-6th BC)
Homeric Hymns (7th BC)
Orphic Hymns (2nd BC/2nd AD)
Quintus Smyrnaeus’s Posthomerica (3rd AD)
Tryphiodorus’s Taking of Ilium (3rd AD)
Apollonius Rhodius’ Argonautica (3rd BC)
Nonnus’ Dionysiaca (5th AD)
Hesiod’s Theogony, Works and Days, Catalogue of Women (8th BC)
Statius’s Thebaid, Achilleid (1st AD)
(More under cut)
Virgil’s Aeneid (1st BC)
Valerius Flaccus’s Argonautica (1st AD)
Colluthus’s Taking of Helen (6th AD)
Pindar’s Odes (5th BC)
Plays by Sophocles, Aeschylus, Euripides (5th BC)
Fragments of lyric poets (8th-6th BC)
Athenaeus’s Deipnoshists (2nd AD)
Lycophron’s Alexandra (3rd BC)
Pausanias’s Description of Greece (2nd AD)
Strabo’s Geography (1st AD)
Scholia on Homer (~ 5th BC - 11th AD)
Scholia on Pindar (2nd AD?)
Scholia on Sophocles, on Euripides (1st BC-15th AD)
Maurus Servius Honoratus’ Commentaries on the Aeneid (5th AD)
Corpus Aristotelicum (4th BC)
Fragments of Hellanicus’s works (5th BC)
Diodorus Siculus’s Bibliotheca Historica (1st AD)
Herodotus’s Histories (5th BC)
Dionysius Halicarnassius’s Roman Antiquities (1st BC)
Plutarch’s Quaestiones Graecae (1st AD)
Eustathius’s commentaries on Homer (12th AD)
Apollodorus’ Bibliotheca, Epitome (2nd AD)
Hyginus’s Fabulae (2nd AD)
Ovid’s Works (1st AD)
Antoninus Liberalis’s Metamorphoses (2nd AD)
Conon’s Narrations (1st AD)
Dictys Cretensis (4th AD)
Dares Phrygius (5th AD)
Malalas’s Chronography (6th AD)
St.Jerome’s Chronicon (4th AD)
Eusebius’s Chronography (5th AD)
Philostratus the Athenian’s Heroicus (3rd AD)
Seneca Plays (1st AD)
Suda (10th AD)
Tzetzes (12th AD)
Duris of Same (4th BC)
Ptolemy Hephaestion (2nd AD)
More Sources:
WordHoard
(Software/Java Document for Scholia on Homer, commentary on the Odyssey & Iliad)
About This Book – Euripides Scholia: Scholia on Orestes 501–1100
Scholia on Euripides
LacusCurtius • A Gateway to Ancient Rome
Roman Sources and History
https://web.archive.org/web/20050625081727/http://sunsite.berkeley.edu/OMACL/Hesiod/iliad.html
Little Iliad Fragments
Most of these places have older translations for the epics, poems and hymns (with older language), places like Poetry In Translation and https://www.gutenberg.org often have newer translations available for free, though…with a bit of digging most translations even recent ones can be found online :)
Comparing several translations is also good if you want to make any arguments about what a text says without being able to read the text in the original language, does the text really say that or is it just this translation?
It also doesn't hurt to research a little about the author of a work as well to get context for which time and sociopolitical and personal situation they were writing in (it helps to do a quick search into the history of ancient greece too, i.e. epic writers writing during the 7th century BC had different agendas than playwrights of the 5th century during the persian wars, athenians during the conflicts with sparta, or later hellenistic writers after Alexander the Great)
Wikipedia: CAN be used, it's a good starting point, but check the sources cited as much as you can, rather than believing what the page itself says
Links to Maps
Ancient Greece Maps – Ancient Greece: Φώς & Λέξη
User:MaryroseB54 - Wikimedia Commons
Cyowari - Professional, Digital Artist | DeviantArt
Some of the Realms of Greece in the Heroic Age by Yaulendur on DeviantArt
Late Bronze Age Mediterranean Trade, c. 1400-1200 BCE: Empires, Merchants, and Maritime Routes of the Ancient World - World History Encyclopedia
Translators:
Translate to Ancient Greek Online
https://logeion.uchicago.edu
Wiktionary
Ancient Art
Resources
Harvard Art Museums
Family Tree:
(Compiled by a friend, not exhaustive) - Note that there are often various different versions of lineage for many characters, so this only represents ONE of many possibilities)
Family Echo
Books
Oxford classical dictionary.pdf
Brief History Of Ancient Greece.pdf
168679208-Ancient-Greece.pdf
Complete Greek Drama
The Ancient Epic Cycle and it's ancient reception A companion.pdf
Final Note
These things should not be gatekept, its time to share them freely
I wish I could offer even more sources via academic books and papers but I fear this would exceed my abilities considering the vastness of the topic of Greek Mythology! But this is a starting point :D Have fun!
Google Scholar has a lot of secondary sources (scholia commentary & theories), books about history, society, politics, flora & fauna, religion, culture, etc. of the time both of history and mythical history…if you have a friend in academia with university access (if you don’t have it yourself) you can ask them to check if they have access to the papers/books otherwise hidden behind insane paywalls, because a LOT of them are available as pdfs!
I also wish I had more visual/audio sources but this is smth I cant change :") I'm sure there's some good videos on youtube out there...somewhere x)
Feel free to contact me if you have more sources you want to add or any links don't work
Here is the Post as DOCs to share outside of tumblr
#greek mythology#tagamemnon#epic the musical#resources#ancient greek mythology#song of achilles#sorry for the long post
228 notes
·
View notes