#scrapeamazonreviews
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
How to Scrape Data from Amazon: A Quick Guide
How to scrape data from Amazon is a question asked by many professionals today. Whether you’re a data analyst, e-commerce seller, or startup founder, Amazon holds tons of useful data — product prices, reviews, seller info, and more. Scraping this data can help you make smarter business decisions.

In this guide, we’ll show you how to do it the right way: safely, legally, and without getting blocked. You’ll also learn how to deal with common problems like IP bans, CAPTCHA, and broken scrapers.
Is It Legal to Scrape Data from Amazon?
This is the first thing you should know.
Amazon’s Terms of Service (TOS) say you shouldn’t access their site with bots or scrapers. So technically, scraping without permission breaks their rules. But the laws on scraping vary depending on where you live.
Safer alternatives:
Use the Amazon Product Advertising API (free but limited).
Join Amazon’s affiliate program.
Buy clean data from third-party providers.
If you still choose to scrape, make sure you’re not collecting private data or hurting their servers. Always scrape responsibly.
What Kind of Data Can You Scrape from Amazon?
Here are the types of data most people extract:
1. Product Info:
You can scrape Amazon product titles, prices, descriptions, images, and availability. This helps with price tracking and competitor analysis.
2. Reviews and Ratings:
Looking to scrape Amazon reviews and ratings? These show what buyers like or dislike — great for product improvement or market research.
3. Seller Data:
Need to know who you’re competing with? Scrape Amazon seller data to analyze seller names, fulfillment methods (like FBA), and product listings.
4. ASINs and Rankings:
Get ASINs, category info, and product rankings to help with keyword research or SEO.
What Tools Can You Use to Scrape Amazon?
You don’t need to be a pro developer to start. These tools and methods can help:
For Coders:
Python + BeautifulSoup/Scrapy: Best for basic HTML scraping.
Selenium: Use when pages need to load JavaScript.
Node.js + Puppeteer: Another great option for dynamic content.
For Non-Coders:
Octoparse and ParseHub: No-code scraping tools.
Just point, click, and extract!
Don’t forget:
Use proxies to avoid IP blocks.
Rotate user-agents to mimic real browsers.
Add delays between page loads.
These make scraping easier and safer, especially when you’re trying to scrape Amazon at scale.
How to Scrape Data from Amazon — Step-by-Step
Let’s break it down into simple steps:
Step 1: Pick a Tool
Choose Python, Node.js, or a no-code platform like Octoparse based on your skill level.
Step 2: Choose URLs
Decide what you want to scrape — product pages, search results, or seller profiles.
Step 3: Find HTML Elements
Right-click > “Inspect” on your browser to see where the data lives in the HTML code.
Step 4: Write or Set Up the Scraper
Use tools like BeautifulSoup or Scrapy to create scripts. If you’re using a no-code tool, follow its visual guide.
Step 5: Handle Pagination
Many listings span multiple pages. Be sure your scraper can follow the “Next” button.
Step 6: Save Your Data
Export the data to CSV or JSON so you can analyze it later.
This is the best way to scrape Amazon if you’re starting out.
How to Avoid Getting Blocked by Amazon
One of the biggest problems? Getting blocked. Amazon has smart systems to detect bots.
Here’s how to avoid that:
1. Use Proxies:
They give you new IP addresses, so Amazon doesn’t see repeated visits from one user.
2. Rotate User-Agents:
Each request should look like it’s coming from a different browser or device.
3. Add Time Delays:
Pause between page loads. This helps you look like a real human, not a bot.
4. Handle CAPTCHAs:
Use services like 2Captcha, or manually solve them when needed.
Following these steps will help you scrape Amazon products without being blocked.
Best Practices for Safe and Ethical Scraping
Scraping can be powerful, but it must be used wisely.
Always check the site’s robots.txt file.
Don’t overload the server by scraping too fast.
Never collect sensitive or private information.
Use data only for ethical and business-friendly purposes.
When you’re learning how to get product data from Amazon, ethics matter just as much as technique.
Are There Alternatives to Scraping?
Yes — and sometimes they’re even better:
Amazon API:
This is a legal, developer-friendly way to get product data.
Third-Party APIs:
These services offer ready-made solutions and handle proxies and errors for you.
Buy Data:
Some companies sell clean, structured data — great for people who don’t want to build their own tools.
Common Errors and Fixes
Scraping can be tricky. Here are a few common problems:
Error 503:
This usually means Amazon is blocking you. Fix it by using proxies and delays.
Missing Data:
Amazon changes its layout often. Re-check the HTML elements and update your script.
JavaScript Not Loading:
Switch from BeautifulSoup to Selenium or Puppeteer to load dynamic content.
The key to Amazon product scraping success is testing, debugging, and staying flexible.
Conclusion:
To scrape data from Amazon, use APIs or scraping tools with care. While it violates Amazon’s Terms of Service, it’s not always illegal. Use ethical practices: avoid private data, limit requests, rotate user-agents, use proxies, and solve CAPTCHAs to reduce detection risk.
Looking to scale your scraping efforts or need expert help? Whether you’re building your first script or extracting thousands of product listings, you now understand how to scrape data from Amazon safely and smartly. Let Iconic Data Scrap help you get it done right.
Contact us today for custom tools, automation services, or scraping support tailored to your needs.
#iconicdatascrap#howtoscrapedatafromamazon#amazondatascraping#amazonwebscraping#scrapeamazonproducts#extractdatafromamazon#amazonscraper#amazonproductscraper#bestwaytoscrapeamazon#scrapeamazonreviews#scrapeamazonprices#scrapeamazonsellerdata#extractproductinfofromamazon#howtogetproductdatafromamazon#webscrapingtools#pythonscraping#beautifulsoupamazon#amazonapialternative#htmlscraping#dataextraction#scrapingscripts#automateddatascraping#howtoscrapedatafromamazonusingpython#isitlegaltoscrapeamazondata#howtoscrapeamazonreviewsandratings#toolstoscrapeamazonproductlistings#scrapeamazonatscale
1 note
·
View note
Link

Our online Amazon review aggregator helps you fetch all the required data to concentrate on offering clients value. With no contracts, no setup fees, and no upfront charges, we create our Amazon Review Scraper API to meet the demands of our customers. Customers can make payments as per their requirements. Our Amazon Review Scraper API makes it simple and accurate for you to scrape Amazon Reviews and ratings from the Amazon website.
You can easily extract Amazon product review data using our Amazon Reviews API, which enables you to understand customer attitudes and develop better selling methods. You can be sure that your reviews are unique because of the web scraping API. Using Amazon Reviews API, you can also extract information about review answers. Amazon Review Scraping ensures updated and verified data. There will be no difficulties in getting clean data despite of changing structures of the website.
0 notes
Text
#howtoscrapeamazonproductdetailsandpricingusingscraper, #extractdatafromamazontoexcel, #howtoextractamazondataintoexcelsheet, #amazondataextractor, #amazonasingrabbertool, #asingrabber, #amazonasinlookup, #asinfetcheramazonasingrabbertool, #amazonreviewscraper, #howtoscrapeamazonreviewsusingunitedleadscraper, #amzscraperreviews, #scrapeamazonreviews, #crwalamazondata, #howtoscrapereviewsfromamazon, #webscraperamazonreviews, #besttoolforamazonsellers, #isitlegaltoscrapeamazon, #scrapeamazonproductdetailsunitedleadscraper, #howtoscrapeamazonproductdetailsandpricingusinguls, #howtoscrapeamazonusingunitedleadscraper, #amazondealscraper, #whatisamazonscraping, #amazonproductdetailextractor, #amazonpricingcrwaler, #bestamazonproductlistextractor, #ecommerceproductscrapingtool, #scrapingsoftwareforonlinestores,
#howtoscrapeamazonproductdetailsandpricingusingscraper#extractdatafromamazontoexcel#howtoextractamazondataintoexcelsheet#amazondataextractor#amazonasingrabbertool#asingrabber#amazonasinlookup#asinfetcheramazonasingrabbertool#amazonreviewscraper#howtoscrapeamazonreviewsusingunitedleadscraper#amzscraperreviews#scrapeamazonreviews#crwalamazondata#howtoscrapereviewsfromamazon#webscraperamazonreviews#besttoolforamazonsellers#isitlegaltoscrapeamazon#scrapeamazonproductdetailsunitedleadscraper#howtoscrapeamazonproductdetailsandpricingusinguls#howtoscrapeamazonusingunitedleadscraper#amazondealscraper#whatisamazonscraping#amazonproductdetailextractor#amazonpricingcrwaler#bestamazonproductlistextractor#ecommerceproductscrapingtool#scrapingsoftwareforonlinestores
0 notes
Text
How Can You Extract Amazon Review using Python in 3 Steps?

Introduction
In a web extracting blog, we can construct an Amazon Scraper Review with Python using 3 steps that can scrape data from different Amazon products like – Content review, Title Reviews, Name of Product, Author, Product Ratings, and more, Date into a spreadsheet. We develop a simple and robust Amazon product review scraper with Python.
Here we will show you 3 steps about how to extract Amazon review using Python
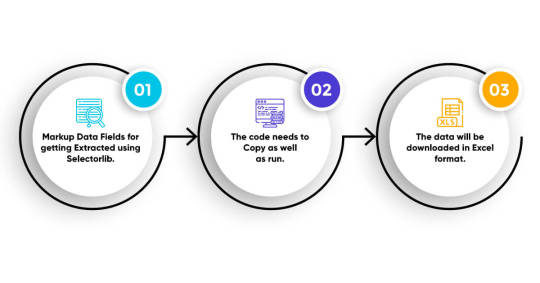
1. Markup Data Fields for getting Extracted using Selectorlib.
2. The code needs to Copy as well as run.
3. The data will be downloaded in Excel format.
We can let you know how can you extract product information from the Amazon result pages, how can you avoid being congested by Amazon, as well as how to extract Amazon in the huge scale.
Here, we will show you some data fields from Amazon we scrape into the spreadsheets from Amazon:
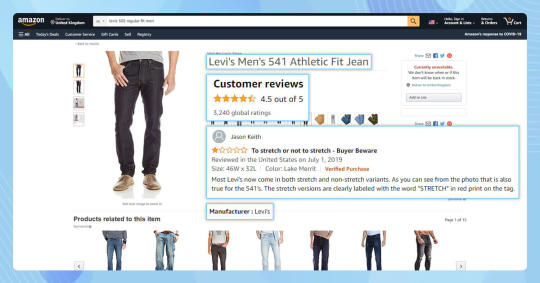
Name of Product
Review title
Content Review or Text Review
Product Ratings
Review Publishing Date
Verified Purchase
Name of Author
Product URL
We help you save all the data into Excel Spreadsheet.
Install required package for Amazon Website Scraper Review
Web Extracting blog to extract Amazon product review utilizing Python 3 as well as libraries. We do not use Scrapy for a particular blog. This code needs to run quickly, and easily on a computer.
If python 3 is not installed, you may install Python on Windows PC.
We can use all these libraries: -
Request Python, you can make download and request HTML content for different pages using (http://docs.python-requests.org/en/master/user/install/)
Use LXML to parse HTML Trees Structure with Xpaths – (http://lxml.de/installation.html)
Dateutil Python, for analyzing review date (https://retailgators/dateutil/dateutil/)
Scrape data using YAML files to generate from pages that we download.
Installing them with pip3
pip3 install python-dateutillxml requests selectorlib
The Code
Let us generate a file name reviews.py as well as paste the behind Python code in it.
What Amazon Review Product scraper does?
1. Read Product Reviews Page URL from the file named urls.txt.
2. You can use the YAML file to classifies the data of the Amazon pages as well as save in it a file named selectors.yml
3. Extracts Data
4. Save Data as the CSV known as data.csv filename.
fromselectorlibimport Extractorimport requestsimportjsonfrom time import sleepimport csvfromdateutilimport parser asdateparser# Create an Extractor by reading from the YAML filee = Extractor.from_yaml_file('selectors.yml')defscrape(url):headers = {'authority': 'www.amazon.com','pragma': 'no-cache','cache-control': 'no-cache','dnt': '1',upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36','accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','sec-fetch-site': 'none','sec-fetch-mode': 'navigate','sec-fetch-dest': 'document','accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',}# Download the page using requestsprint("Downloading %s"%url)r = requests.get(url, headers=headers)# Simple check to check if page was blocked (Usually 503)ifr.status_code>500:if"To discuss automated access to Amazon data please contact"inr.text:print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)else:print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))returnNone# Pass the HTML of the page and createreturne.extract(r.text)with open("urls.txt",'r') asurllist, open('data.csv','w') asoutfile:writer = csv.DictWriter(outfile, fieldnames=["title","content","date","variant","images","verified","author","rating","product","url"],quoting=csv.QUOTE_ALL)writer.writeheader()orurlinurllist.readlines():data = scrape(url)'if data:'for r in data['reviews']:r["product"] = data["product_title"]r['url'] = urlif'verified'in r:if'Verified Purchase'in r['verified']:r['verified'] = 'Yes'else:r['verified'] = 'Yes'r['rating'] = r['rating'].split(' out of')[0] date_posted = r['date'].split('on ')[-1]if r['images']:r['images'] = "\n".join(r['images'])r['date'] = dateparser.parse(date_posted).strftime('%d %b %Y')writer.writerow(r)# sleep(5)
Creating YAML files with selectors.yml
It’s easy to notice the code given which is used in the file named selectors.yml. The file helps to make this tutorial easy to follow and generate.
Selectorlib is the tool, which selects to markup and scrapes data from the web pages easily and visually. The Web Scraping Chrome Extension makes data you require to scrape and generates XPaths Selector or CSS needed to scrape data.
Here we will show how we have marked up field for data we require to Extract Amazon review from the given Review Product Page using Chrome Extension.
When you generate the template you need to click on the ‘Highlight’ option to highlight as well as you can see a preview of all your selectors.
Here we will show you how our templates look like this: -
product_title:css: 'h1 a[data-hook="product-link"]'type: Textreviews:css: 'div.reviewdiv.a-section.celwidget'multiple: truetype: Textchildren:title:css: a.review-titletype: Textcontent:css: 'div.a-row.review-data span.review-text'type: Textdate:css: span.a-size-base.a-color-secondarytype: Textvariant:css: 'a.a-size-mini'type: Textimages:css: img.review-image-tilemultiple: truetype: Attributeattribute: srcverified:css: 'span[data-hook="avp-badge"]'type: Textauthor:css: span.a-profile-nametype: Textrating:css: 'div.a-row:nth-of-type(2) >a.a-link-normal:nth-of-type(1)'type: Attributeattribute: titlenext_page:css: 'li.a-last a'type: Link
Running Amazon Reviews Scrapers
You just need to add URLs to extract the text file named urls.txt within the same the folder as well as run scraper consuming the same commend.
This file shows that if we want to search distinctly for earplugs and headphones.
python3reviews.py
Now, we will show a sample URL - https://www.amazon.com/HP-Business-Dual-core-Bluetooth-Legendary/product-reviews/B07VMDCLXV/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews
It’s easy to get the URL through clicking on the option “See all the reviews” nearby the lowermost product page.
What Could You Do By Scraping Amazon?
The data you collect from the blog can assist you in many ways: -
1. You can review information unavailable using eCommerce Data Scraping Services.
2. Monitor Customer Options on a product that you can see by manufacturing through Data Analysis.
3. Generate Amazon Database Review for Educational Research &Purposes &.
4. Monitor product’s quality retailed by a third-party seller.
Build Free Amazon API Reviews using Python, Selectorlib & Flask
In case, you want to get reviews as the API like Amazon Products Advertising APIs – then you can find this blog very exciting.
If you are looking for the best Amazon Review using Python, then you can call RetailGators for all your queries.
Source:- https://www.retailgators.com/how-can-you-extract-amazon-review-using-python-in-3-steps.php
#ScrapeAmazonReview#AmazonReviewScraping#ExtractAmazonReviewUsingPython#ScrapingAmazonReviewUsingPython
0 notes
Link
In this blog, we will extract reviews from amazon.com with how many stars it has, who had posted the reviews, and more.
https://medium.com/@reviewgators/scrape-amazon-reviews-with-scrapy-using-python-28539fedd6ef
1 note
·
View note