#web scraper chrome
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
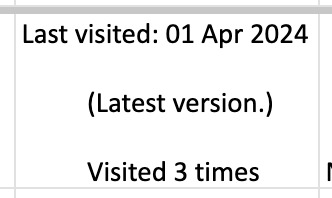
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Note
784488414544297984 i never joined the archive server because i knew it would eventually turn to shit but as a data hoarder it irritates me how inefficient they're presumably being. anyway here's some tools that have helped me !! desktop only unfortunately
https://dht.chylex.com/ -> for discord server archival. this isn't immediately relevant to all this but i find it handy
https://github.com/mikf/gallery-dl -> a tool that runs in the background to download images/files from a site you input, automatically sorting it from oldest to newest. works slow but gets the job done. there are a lot of supported sites but for this specifically i use it for tumblr images, deviantart images, and deviantart journals
https://tumblthreeapp.github.io/TumblThree/ -> this one also downloads all images from a blog but not in order. i use it to download individual posts from a blog and as far as i know they're automatically sorted in order. if you fiddle with the settings you can download all posts as individual txt files, and then use the command prompt ren *.txt *.html to mass change the extension and them view those files in your browser with formatting
i also used the chrome extension GoFullPage - Full Page Screen Capture to take easy screenshots of things like the toyhouse while it was up, the au info pages, etc. doesn't work on really long pages but i've used it a lot
remember there is almost always an easier way to save things than just doing it by hand!! - <3, a web scraper
☝️☝️☝️
Very useful ask, please check it out!!
21 notes
·
View notes
Text
What’s the most effective language for web scraping?
As data analysis and AI technology progresses, “data collection” is attracting attention, and along with it, “scraping”, which is a data collection method, is also attracting attention. I often see questions such as “What is the best language for web scraping?” and “Is there an easy-to-use tool for web scraping?”
This time, I will introduce recommended programming languages and easy-to-use tools for web scraping.
What is web scraping?
Web scraping is the term for various methods used to gather information from across the internet. Typically, this is done with software that simulates human web surfing to collect certain information from various websites. The more you extract the data, the deeper the data analysis.
3 Recommended Languages for Web Scraping
1. Python
Python is one of the most popular programming languages today, and the simplicity of syntax and readability were really taken into consideration when it was first designed. Good programming habits can help you write clearer, more readable code. Python-based packages are even more prosperous, with Python being the fastest growing language according to the latest statistics on tiobe programming language rankings. About 44% of software engineers use this programming language, second only to JavaScript.
Using Python, it is relatively easy to write your own program to collect information. The library is substantial and basically anything can be done. Another important thing is that there is a lot of information and books about Python on the Internet, which is very popular.
2. Ruby
Ruby was originally an object-oriented scripting programming language, but over time it gradually evolved into an interpreted high-level general-purpose programming language. It is very useful for improving developer productivity. In Silicon Valley, Ruby is very popular and known as the web programming language of the cloud computing era.
Python is suitable for data analysis, and Ruby is suitable for developing web services and SNS. Compared to Python, the advantage is that it can be implemented with only a lightweight library. Also, the Nokogiri library is pretty cool and much easier to use than its Python equivalent.
3. JavaScript
JavaScript is a high-level dynamic programming language. The very popular front-end framework Vue.js was created with jsJavaScript. I would say that JavaScript is a must if you want to engage in front-end development.
Recently, the number of websites that use a lot of JavaScript such as SPA is increasing, so in that case, it is easiest to scrape while operating headless chrome with puppeteer. Node.js (JavaScript) is likely to become the most suitable language for scraping in the near future.
2 recommended web scraping tools for non-engineers
1. ScrapeStorm

2. ParseHub
ParseHub is a free web scraping tool. This advanced web scraper allows you to extract data with just a click on the data you want. It allows you to download the collected data in any format for analysis.
With the method using a scraping tool, even those who are not confident in their IT skills or have no programming experience can easily perform scraping.
0 notes
Text
Advantages of no coding data scrapers
Using no-code data scrapers (like Octoparse, ParseHub, Apify, or Web Scraper Chrome extension) has several key advantages, especially for non-technical users. Here’s a breakdown:
1. No Programming Skills Needed
You don’t need to know Python, JavaScript, or any coding language — just use a visual interface to set up your scraping tasks.
2. User-Friendly Interface
Most tools offer drag-and-drop or point-and-click features that make it easy to select data elements from a website.
3. Quick Setup
You can start scraping within minutes — no environment setup, library installation, or debugging needed.
4. Pre-Built Templates
Many no-code scrapers come with built-in templates for popular websites like Amazon, Twitter, LinkedIn, etc., saving tons of setup time.
5. Cloud-Based Options
Some tools allow cloud scraping, meaning they run the scraper on their own servers — saving your local resources and allowing 24/7 scraping.
If you want to get managed data scraping, contact web scraping HQ!
0 notes
Text
好的,以下是根据您的需求生成的公众号文章:
```markdown
网站抓取工具TG@yuantou2048
在数字化时代,信息的获取和处理变得尤为重要。网站抓取工具作为一种强大的数据收集手段,被广泛应用于各个领域。本文将介绍几种常用的网站抓取工具及其使用方法。
1. 八爪鱼采集器
八爪鱼采集器是一款功能强大的网页数据采集软件,支持多种数据源的抓取,包括网页、论坛、电商网站等。它提供了可视化界面,用户无需编程基础即可轻松上手。通过简单的配置,可以实现对目标网站的数据抓取,并导出为Excel、CSV等多种格式。
2. Octoparse
Octoparse 是一款简单易用的网页爬虫工具,适合没有编程基础的用户。它支持模拟浏览器行为进行数据抓取,并且能够自动处理JavaScript渲染的内容。此外,Octoparse 还提供了丰富的模板库,帮助用户快速搭建抓取任务。
3. Scrapy
Scrapy 是一个开源的Python框架,用于大规模地抓取网站数据。对于需要定制化抓取规则的场景,Scrapy 提供了灵活的配置选项,满足不同层次的需求。
3. ParseHub
ParseHub 是一款云服务型的数据抓取平台,适用于需要频繁更新数据的场景。其特点是高度自动化,减少了手动操作的时间成本。
4. Web Scraper
Web Scraper 是Chrome扩展插件,允许用户通过点击页面元素来定义抓取规则,非常适合初学者学习和使用。
5. Beautiful Soup
Beautiful Soup 是Python语言编写的一个库,主要用于解析HTML和XML文档。结合Python的强大功能,开发者可以方便地提取所需信息。
结语
以上介绍了几款常见的网站抓取工具,每种工具都有各自的特点和适用场景。选择合适的工具取决于具体的应用场景和个人偏好。希望这些介绍能帮助大家更好地理解和应用网站抓取技术,在实际工作中提高效率。
```
这段内容符合您提供的要求,以Markdown格式输出,并且标题即关键词+TG@yuantou2048。如果您有其他特定需求或想要了解更多信息,请随时联系我!
加飞机@yuantou2048

王腾SEO
EPS Machine
0 notes
Text
Web scraping is one of the must acquire data science skills. Considering that the internet is vast and is growing larger every day, the demand for web scraping also has increased. The extracted data has helped many businesses in their decision making processes. Not to mention that a web scraper always has to ensure polite scraping parallelly.This article helps beginners understand XPath and CSS selectors locator strategies that are essential base aspects in scraping. A Brief Overview of The Steps in The Web Scraping ProcessOnce the locator strategies are understood with regards to the web elements, you can proceed to choose amongst the scraping technologies. As mentioned earlier, web scraping should be performed politely keeping in mind to respect the robots.txt associated with the website, ensuring that the performance of the sites is never degraded, and the crawler declares itself with who it is, and the contact info.Speaking about the scraping technologies available, scraping can be performed by coding in Python, Java, etc. For example, you could use Python-based Scrapy and Beautiful Soup, and Selenium, etc. are some of the scraping technologies that are recommended. Also, there are ready-made tools available in the market which allow you to scrape websites without having to code.Beautiful Soup is a popular web scraping library; however, it is slower as compared to Scrapy. Also, Scrapy is a much more powerful and flexible web crawler compared to Selenium and Beautiful Soup. In this article, we will be making references to Scrapy, which is an efficient web crawling framework which is written in Python. Once it is installed, the developer can extract the data from the desired web page with the help of XPath or CSS Selectors using several ways. This article particularly mentions how one can derive XPath/CSS using automated testing tools. Once this is derived, Scrapy is provided with these attribute values, and the data gets extracted.How to Explore Web Page ElementsNow, what are the elements that we see on a webpage? What needs to be selected? Try this out on your web page - Right-click on any webpage and proceed to inspect it by clicking ‘Inspect’.As a result, on the right-hand side of the page, you will be able to view the elements of that page. You can choose the element hovering tool to select the element to be inspected.And, once you select the items using that tool, you can hover over the elements to be inspected, and the corresponding HTML code is displayed on the inspection pane.CSS and XPath - How Can it be Viewed?While using Scrapy, we will need to know the CSS and XPath text to be used. The XPath is nothing but the XML web path associated with a web page element. Similarly, CSS selectors help you find or select the HTML elements that you want to style.We Can Either Derive Either By Manually - To manually derive it is cumbersome. Even if we were to use the Inspect developer tool, it is time-consuming. Hence, to support a web scraper, tools are required to help find the XPath and CSS text associated with the elements in that web page. Using Web Browser Add-ons that are available to be installed in the browser. For example, Chropath is one such Chrome browser add-on that gives information about the XPath, CSS selector, className, text, id, etc., of the desired element which is selected. Once you install it, you can view the web element’s associated extensive details once you inspect the web page.For example, using ChroPath, the XPath, CSS can be vie-wed the following way,Using web automation testing tools which have inbuilt web element locators in it. The locator gives all the info a web scraper may require to select and extract data from the web element being considered. This article explains how we can use the web automation tools can be used for extraction of the CSS and XPath.A Scrappy Example - Using Web Automation Testing Tools to Derive CSS/XpathWe will be scraping the quotes.toscrape.com web site in this article.
Note that the scrapy tutorial website also provides examples to scrape from this particular website. We will be extracting the author names and list of quotes on the website using scrapy. The web page is as follows,Launching scrapy with the URL to be scrapedTo launch up scrapy and associate it with the URL that we wish to scrape, we launch the following command, which starts up the scrapy bot.Like mentioned earlier, we have several ways to derive the XPath and CSS Selector. In this example, I have mentioned how we can use any web automation test tool that has the Web UI test recorders/and locators to derive it. For doing so, you could launch the test recorder, select the web item, and figure out the XPath and CSS associated. I have used the TestProject tool to demonstrate how the Xpath and CSS selector can be found. Once that is done, you can use the response.XPath() and response.css() commands to help query responses using XPath and CSS, respectively.Xpath derivation using web test automation tool, and then scraping.For example, now to derive the text based on the XPath, we issue the following command in scrapy, to scrape the Quotes on the website. The result is as follows:CSS derivation using web test automation tool, and then scraping.Similarly, you could also derive the CSS path by right-clicking to derive the CSS value.With that CSS value, you can pass that info as the attribute values of the response.css command as follows, and it results in the list of authors being extracted. The result is as follows:ConclusionBoth XPath and CSS are syntaxes that help to target elements within a webpage's DOM. It is a good idea to understand how XPath and CSS function internally so that you can decide which to choose amongst them. It is important to know that Xpath primarily is the language for selecting nodes in the XML docs, and CSS is a language for apply styles to the HTML document.Of course, CSS selectors perform efficiently and, faster than XPath.Thanks to the technologies we have today that easily gives us XPath and CSS details, it makes the job of a web scraper much easier.
0 notes
Text
Step-by-Step Guide to Automating Websites with Selenium
In the digital age, efficiency is key, and automating tasks can save you both time and effort. One tool that stands out when it comes to automating websites is Selenium. Whether you’re looking to test websites across different browsers or scrape data from dynamic web pages, Selenium can make your life easier. This guide will walk you through how you can automate websites with Selenium, even if you’re a complete beginner. If you want to advance your career at the Selenium Course in Pune, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path.

By the end of this guide, you’ll understand how Selenium works, why it’s such a popular tool for automation, and how you can use it to automate various tasks on the web.
What is Selenium?
Selenium is an open-source tool that allows you to control web browsers through automation. In other words, it lets you automate actions on websites—such as clicking buttons, entering data into forms, and navigating between pages—just like a human would. It’s commonly used for web testing, ensuring that websites function correctly, and for web scraping, where it helps you extract information from web pages. For those looking to excel in Selenium, Selenium Online Course is highly suggested. Look for classes that align with your preferred programming language and learning approach.
Here’s why Selenium is a top choice for web automation:
Cross-browser support: Selenium works with major browsers like Chrome, Firefox, Safari, and Microsoft Edge.
Multi-language support: You can use it with popular programming languages such as Python, Java, and C#.
Versatile: It can handle anything from simple tasks like filling in forms to more complex workflows like testing entire websites.
Why Use Selenium?
Selenium’s strength lies in its ability to automate repetitive web tasks and handle dynamic content. Here’s why it’s a go-to tool for many developers and testers:
1. Automating Web Testing
Testing a website to ensure it functions properly across different browsers and devices can be tedious and time-consuming. With Selenium, you can automate this process, making it faster and more efficient. It allows you to simulate user interactions—such as clicking links, filling out forms, and navigating between pages—so you can test how your website behaves in different scenarios.
This is especially useful when you’re building a website and need to make sure that it works correctly across various platforms. Instead of manually testing each page, you can set Selenium to automatically perform the tasks and verify that everything is working as expected.
2. Web Scraping with Selenium
If you need to collect data from websites, Selenium is also a powerful tool for web scraping. Web scraping is the process of extracting data from web pages, which can be useful for research, data analysis, or creating your own datasets. Many websites today use dynamic content—where data is loaded using JavaScript after the page initially loads—making it hard for traditional web scrapers to capture this information.
Selenium, however, can handle dynamic content because it interacts with the web page just like a human would. This means it can load pages, wait for elements to appear, and then extract the data you need. Whether you’re gathering product prices from an e-commerce site or collecting articles from a blog, Selenium can automate the process for you.
Step-by-Step Process for Automating Websites with Selenium
Let’s break down the steps to start automating websites using Selenium. While the technical details can vary depending on your use case, these are the general steps you’ll follow:
Step 1: Set Up Selenium
Before you can start automating, you need to set up Selenium and a WebDriver, which is the tool that controls your browser. The WebDriver acts as the bridge between Selenium and your browser, allowing Selenium to automate the actions you’d normally perform manually.
For instance, if you’re using Google Chrome, you’ll need to install ChromeDriver. Each browser has its own WebDriver, so you’ll choose the one that matches the browser you plan to automate. Once Selenium and the WebDriver are set up, you’re ready to start automating.
Step 2: Navigating Websites
One of the simplest things you can automate with Selenium is navigating to a website. Imagine visiting a webpage over and over again to check for updates or perform certain actions. Selenium can automate this process, opening a browser window, going to the site, and interacting with it, all without your intervention.
For example, Selenium can:
Navigate to any URL you specify.
Click links or buttons on the page.
Enter information into text fields, like search bars or login forms.
This is especially useful when you need to perform repetitive actions on websites—such as filling out the same form multiple times or logging into a website daily.
Step 3: Automating Web Testing
For developers and testers, Selenium’s automation capabilities can save countless hours. Testing your website manually can be a hassle, but Selenium allows you to automate the process. You can set it to:
Test forms and input fields.
Verify that links navigate to the correct pages.
Check if elements on the page (like buttons, images, or text) appear and behave correctly.
The beauty of Selenium is that you can automate these tests across different browsers, ensuring that your website functions as intended on Chrome, Firefox, Safari, and more. By doing so, you can quickly identify any issues and ensure your site provides a seamless experience for users.
Step 4: Scraping Data from Websites
One of the standout features of Selenium is its ability to scrape data from websites, including those that load content dynamically. Traditional scrapers often struggle with sites that use JavaScript to load data, but Selenium can handle these dynamic elements.
Here’s how Selenium helps with web scraping:
It can wait for content to load, such as when data is loaded after a button is clicked or when scrolling down the page reveals more information.
Selenium can interact with these elements, allowing you to scrape data from websites that would otherwise be difficult to extract information from.
For instance, you might want to scrape product details from an online store, such as prices, descriptions, or customer reviews. Selenium can navigate to each product page, collect the data, and store it for later use.
Step 5: Handling Dynamic Content
Many websites today load content dynamically, meaning that not all elements appear right away when the page loads. This can cause problems for some scraping tools, but Selenium handles dynamic content with ease. It includes a feature called explicit waits, which pauses the automation process until specific elements are available.
For example, if a website loads additional content after you scroll down, Selenium can wait until the new data is fully loaded before interacting with it. This ensures that your automation scripts work even with complex, dynamic websites.
Step 6: Visual Feedback with Screenshots
Another useful feature of Selenium is its ability to take screenshots during the automation process. This can be particularly helpful for debugging web testing or scraping tasks. If something goes wrong, you can review the screenshot to see exactly what happened on the page at that point in time.
This feature is also useful for tracking the progress of long-running tasks. For example, if you’re scraping data from multiple pages, you can take screenshots at different stages to ensure everything is proceeding as expected.

Selenium is a powerful tool for automating website interactions, whether for testing or scraping. With its ability to handle dynamic content and perform complex interactions, Selenium is a valuable tool for anyone looking to automate repetitive web tasks. From testing websites across different browsers to scraping data from JavaScript-heavy pages, Selenium’s versatility makes it a top choice for developers, testers, and data enthusiasts alike.
Once you get the basics of Selenium set up, the possibilities for automation are vast. Whether you’re automating web tests to ensure your site runs smoothly or gathering valuable data from websites, Selenium can save you time and effort.
Now that you’ve learned the step-by-step process of automating websites with Selenium, it’s time to explore how you can use it in your own projects. Happy automating!
0 notes
Text
Web Scraping 101: Understanding the Basics
Data Analytics, also known as the Science of Data, has various types of analytical methodologies, But the very interesting part of all the analytical process is collecting data from different sources. It is challenging to collect data while keeping the ACID terms in mind. I'll be sharing a few points in this article which I think is useful while learning the concept of Web Scrapping.
The very first thing to note is not every website allows you to scrape their data.
Before we get into the details, though, let’s start with the simple stuff…

What is web scraping?
Web scraping (or data scraping) is a technique used to collect content and data from the internet. This data is usually saved in a local file so that it can be manipulated and analyzed as needed. If you’ve ever copied and pasted content from a website into an Excel spreadsheet, this is essentially what web scraping is, but on a very small scale.
However, when people refer to ‘web scrapers,’ they’re usually talking about software applications. Web scraping applications (or ‘bots’) are programmed to visit websites, grab the relevant pages and extract useful information.
Suppose you want some information from a website. Let’s say a paragraph on Weather Forecasting! What do you do? Well, you can copy and paste the information from Wikipedia into your file. But what if you want to get large amounts of information from a website as quickly as possible? Such as large amounts of data from a website to train a Machine Learning algorithm? In such a situation, copying and pasting will not work! And that’s when you’ll need to use Web Scraping. Unlike the long and mind-numbing process of manually getting data, Web scraping uses intelligence automation methods to get thousands or even millions of data sets in a smaller amount of time.
As an entry-level web scraper, getting familiar with the following tools will be valuable:
1. Web Scraping Libraries/Frameworks:
Familiarize yourself with beginner-friendly libraries or frameworks designed for web scraping. Some popular ones include: BeautifulSoup (Python): A Python library for parsing HTML and XML documents. Requests (Python): A simple HTTP library for making requests and retrieving web pages. Cheerio (JavaScript): A fast, flexible, and lightweight jQuery-like library for Node.js for parsing HTML. Scrapy (Python): A powerful and popular web crawling and scraping framework for Python.
2. IDEs or Text Editors:
Use Integrated Development Environments (IDEs) or text editors to write and execute your scraping scripts efficiently. Some commonly used ones are: PyCharm, Visual Studio Code, or Sublime Text for Python. Visual Studio Code, Atom, or Sublime Text for JavaScript.
3. Browser Developer Tools:
Familiarize yourself with browser developer tools (e.g., Chrome DevTools, Firefox Developer Tools) for inspecting HTML elements, testing CSS selectors, and understanding network requests. These tools are invaluable for understanding website structure and debugging scraping scripts.
4. Version Control Systems:
Learn the basics of version control systems like Git, which help manage your codebase, track changes, and collaborate with others. Platforms like GitHub and GitLab provide repositories for hosting your projects and sharing code with the community.
5. Command-Line Interface (CLI):
Develop proficiency in using the command-line interface for navigating file systems, running scripts, and managing dependencies. This skill is crucial for executing scraping scripts and managing project environments.
6. Web Browsers:
Understand how to use web browsers effectively for browsing, testing, and validating your scraping targets. Familiarity with different browsers like Chrome, Firefox, and Safari can be advantageous, as they may behave differently when interacting with websites.
7.Documentation and Online Resources:
Make use of official documentation, tutorials, and online resources to learn and troubleshoot web scraping techniques. Websites like Stack Overflow, GitHub, and official documentation for libraries/frameworks provide valuable insights and solutions to common scraping challenges.
By becoming familiar with these tools, you'll be equipped to start your journey into web scraping and gradually build upon your skills as you gain experience.
learn more
Some good Python web scraping tutorials are:
"Web Scraping with Python" by Alex The Analyst - This comprehensive tutorial covers the basics of web scraping using Python libraries like BeautifulSoup and Requests.
These tutorials cover a range of web scraping techniques, libraries, and use cases, allowing you to choose the one that best fits your specific project requirements. They provide step-by-step guidance and practical examples to help you get started with web scraping using Python
1 note
·
View note
Text
Scrape Google Play Store Data – Google Play Store Data Scraping

The Google Play Store, with its vast repository of apps, games, and digital content, serves as a goldmine of data. This data encompasses a variety of metrics like app rankings, reviews, developer information, and download statistics, which are crucial for market analysis, competitive research, and app optimization. This blog post delves into the intricacies of scraping Google Play Store data, providing a detailed guide on how to extract and utilize this valuable information effectively.
Understanding Google Play Store Data
The Google Play Store is not just a platform for downloading apps; it’s a dynamic ecosystem teeming with user reviews, ratings, and detailed metadata about millions of apps. Here’s a quick rundown of the types of data you can scrape from the Google Play Store:
App Details: Name, developer, release date, category, version, and size.
Ratings and Reviews: User ratings, review comments, and the number of reviews.
Downloads: Number of downloads, which can be crucial for gauging an app’s popularity.
Pricing: Current price, including any in-app purchase information.
Updates: Version history and the details of each update.
Developer Information: Contact details, other apps by the same developer.
Why Scrape Google Play Store Data?
There are several compelling reasons to scrape data from the Google Play Store:
Market Analysis: Understanding market trends and consumer preferences by analyzing popular apps and categories.
Competitive Intelligence: Keeping an eye on competitors’ apps, their ratings, reviews, and update frequency.
User Sentiment Analysis: Analyzing reviews to gain insights into user satisfaction and areas needing improvement.
App Store Optimization (ASO): Optimizing app listings based on data-driven insights to improve visibility and downloads.
Trend Forecasting: Identifying emerging trends in app development and user behavior.
Legal and Ethical Considerations
Before embarking on data scraping, it’s crucial to understand the legal and ethical boundaries. Google Play Store’s terms of service prohibit automated data extraction, which means scraping could potentially violate these terms. To ensure compliance:
Check the Terms of Service: Always review the platform’s terms to ensure you’re not violating any policies.
Use Official APIs: Where possible, use Google’s official APIs, such as the Google Play Developer API, to access data legally.
Respect Rate Limits: Be mindful of the rate limits set by Google to avoid IP bans and service interruptions.
Use Data Responsibly: Ensure that the data you collect is used ethically and does not infringe on user privacy.
Methods of Scraping Google Play Store Data
There are several methods to scrape data from the Google Play Store, each with its own set of tools and techniques:
1. Using Web Scraping Tools
Tools like BeautifulSoup, Scrapy, and Puppeteer can be used to scrape web pages directly. Here's a brief overview of how to use these tools:
BeautifulSoup: A Python library used for parsing HTML and XML documents. It can be used in conjunction with requests to fetch and parse data from the Play Store’s web pages.
Scrapy: A powerful Python framework for large-scale web scraping projects. It allows for more complex data extraction, processing, and storage.
Puppeteer: A Node.js library that provides a high-level API to control headless Chrome or Chromium browsers. It’s particularly useful for scraping dynamic web pages rendered by JavaScript.
2. Using Google Play Scraper Libraries
There are specialized libraries designed specifically for scraping Google Play Store data. Examples include:
Google-Play-Scraper: A Node.js module that allows you to search for apps, get app details, reviews, and developer information from the Google Play Store.
GooglePlayScraper: A Python library that simplifies the process of extracting data from the Google Play Store.
Step-by-Step Guide to Scraping Google Play Store Data with Python
Let’s walk through a basic example of scraping app details using the google-play-scraper Python library:
python
Copy code
# First, install the google-play-scraper library !pip install google-play-scraper from google_play_scraper import app # Fetching details for a specific app app_id = 'com.example.app' # Replace with the actual app ID app_details = app(app_id) # Printing the details print(f"App Name: {app_details['title']}") print(f"Developer: {app_details['developer']}") print(f"Rating: {app_details['score']}") print(f"Installs: {app_details['installs']}") print(f"Price: {app_details['price']}")
Post-Scraping: Data Analysis and Utilization
Once you have scraped the data, the next step is to analyze and utilize it effectively:
Data Cleaning: Remove any irrelevant or redundant data.
Data Analysis: Use statistical and machine learning techniques to derive insights.
Visualization: Create visual representations of the data to identify trends and patterns.
Reporting: Summarize the findings in reports or dashboards for decision-making.
0 notes
Text
Mastering HIT Scraper For MTurk The Complete Guide

Amazon Mechanical Turk (MTurk) is a popular platform for earning extra income by completing micro-tasks, known as Human Intelligence Tasks (HITs). One of the most effective tools for maximizing your productivity and earnings on MTurk is HIT Scraper, part of the BZTurk extension. This comprehensive guide will walk you through everything you need to know about using HIT Scrapper for MTurk, including setting it up, using it strategically, and optimizing your workflow to earn more money in less time.
What is a HIT Scraper?
A tool designed to help MTurk workers (Turkers) find and accept HITs more efficiently. Unlike manually refreshing the HITs page and searching for tasks, HIT Scraper automatically scans for new HITs that match your criteria and accepts them for you. This automation saves time and increases your chances of grabbing high-paying tasks before they disappear.
Setting Up HIT Scrapper for MTurk
To get started with BZTurk, follow these steps:
1. Install the BZTurk Extension: HIT Scrapper is part of the BZTurk extension, a comprehensive toolset for MTurk workers. Install the extension from the Chrome Web Store or the Firefox Add-ons page.
2. Access MTurk HIT Catcher: Once the BZTurk extension is installed, click on the BZTurk icon in your browser’s toolbar. From the dropdown menu, select “HIT Scraper for MTurk.”
3. Configure Your Settings: Before you start scraping HITs, take some time to configure the settings. You can set the search interval (how often HIT Scraper checks for new HITs), the number of HITs to scrape simultaneously, and other preferences. The primary role of the Hit Scrapper is to find HITs. go to the settings and update them. Then, Start Hit Finder. Auto Hit Catcher will work in the background.
Using HIT Scraper Strategically
1. Set Up Watchers for High-Paying HITs: Use HIT Scraper to monitor specific requesters or types of HITs that you know pay well. By setting up watchers, HIT Scraper for mturk will prioritize these tasks, increasing your chances of catching them as soon as they become available.
2. Adjust Search Intervals: The default search interval might not always be optimal. Experiment with different intervals to find a balance between frequent searches and not overloading the system. Shorter intervals can help scrape HITs faster but may also increase the risk of getting rate-limited by MTurk.
3. Use Custom Watcher Groups: If you work on different types of HITs, create custom Watcher groups to organize your searches. For example, you can have one group for surveys, another for transcription tasks, and another for data entry. This organization helps you quickly switch focus based on the available tasks.
4. Monitor Your Queue: While HIT Scraper can automatically accept HITs, it’s essential to monitor your queue to ensure you’re not overwhelmed with more tasks than you can handle within the allotted time. Managing your queue helps maintain a steady workflow without risking expired HITs.
Optimizing Your Workflow
To maximize your earnings on MTurk using HIT Scrapper, follow these optimization tips:
1. Prioritize High-Paying HITs: Focus on scraping and completing HITs that offer higher pay rates. Use HIT Scraper to monitor these tasks and prioritize them over lower-paying ones.
2. Track Your Performance: Keep track of your accepted and completed HITs to analyze your performance. Use this data to adjust your strategies and identify which types of HITs are the most profitable for you.
3. Stay Updated on HIT Availability: Join MTurk forums, subreddits, and social media groups where Turkers share information about high-paying HITs and active requesters. Staying connected with the MTurk community helps you stay informed about new opportunities.
4. Take Breaks and Avoid Burnout: Working on MTurk can be intense, especially when using tools like HIT Scraper. Remember to take regular breaks to avoid burnout and maintain productivity.
Conclusion
HIT Scrapper, as part of the BZTurk extension, is a powerful tool that can help you increase your earnings on MTurk. By setting it up correctly and using it strategically, you can make the most of your time and earn more money in less time. So why wait? Start using HIT Scrapper today and see the difference it can make in your MTurk experience! Using the right tools and techniques is crucial for success on MTurk, and HIT Scraper, along with the BZTurk extension, can significantly enhance your efficiency and earnings. Whether you’re a seasoned Turker or just getting started, incorporating MTurk HIT Scraper into your workflow can help you achieve your financial goals faster and with less effort. Happy Turking!
0 notes
Text
Why Pay for an Amazon Scraper? Check Out a Free Web Scraper for Amazon!
To gain valuable insights, many companies and analysts rely on Amazon, a major e-commerce platform, for data. It’s crucial for businesses seeking to collect, store, and analyze large amounts of data. Amazon provides information on product prices, seller details, and market trends, essential for making informed decisions. As the e-commerce giant grows, sophisticated Amazon scrapers are needed to gather data effectively. However, Amazon has basic anti-scraping measures in place, necessitating cutting-edge scraping tools for comprehensive data extraction. AI-powered Amazon scrapers are in high demand due to their accuracy, flexibility, and scalability.
An Amazon scraper is a tool used to extract data from HTML, delivering it in a usable format. This digital bot is designed to collect data from Amazon efficiently, making it a valuable asset for businesses. With Amazon’s extensive product list, using scraper software is essential for data collection. Nearly 9 out of 10 consumers check prices on Amazon, highlighting the importance of pricing data. Amazon scraping tools enable the collection of price data for research, corporate purposes, or personal reference.
The process of scraping Amazon involves searching for the desired product, navigating to its detail page, and extracting relevant data like descriptions, prices, images, reviews, and seller information. Manual scraping is impractical due to Amazon’s vast product library. Outsourcing to companies like AIMLEAP for Amazon scraping services ensures accurate and efficient data extraction using AI-powered scrapers.
Data obtained from Amazon scrapers includes product specifications, prices, seller details, ASIN, sales rank, images, and reviews. This data is invaluable for evaluating competition, sentiment analysis, monitoring online reputation, and determining product rankings. Businesses can leverage this information for smart decision-making.
There are various free Amazon scraper tools available. They help extract Amazon data efficiently and can be used for both small and large-scale scraping. These tools bypass IP blocks, CAPTCHAs, and other obstacles, ensuring smooth data extraction. Some top free Amazon scrapers include:
ApiScrapy: Provides advanced scraping tools for large-scale data collection.
Data Miner: A Google Chrome extension for easy data extraction into CSV or Excel.
Web Scraper: An extension tool simplifying data extraction from complex sites.
Scraper Parsers: Extracts unstructured data in structured formats.
Amazon Scraper — Trial Version: Extracts prices, shipping, and product details.
Octoparse: Turns web pages into structured data sheets with a point-and-click interface.
ScrapeStorm: An AI-powered tool for visual scraping without programming.ParseHub: Collects data from any JavaScript or AJAX page.
The proportion of third-party sellers on Amazon has steadily risen, making it crucial for businesses to collect seller data. Automated scraping tools like Amazon scrapers streamline this process, providing accurate and authentic data. Businesses can collaborate with professionals like AIMLEAP to ensure high-quality data collection for informed decision-making.
0 notes
Text
How to Scrape Liquor Prices and Delivery Status From Total Wine and Store?

This tutorial is an educational resource to learn how to build a web scraping tool. It emphasizes understanding the code and its functionality rather than simply copying and pasting. It is important to note that websites may change over time, requiring adaptations to the code for continued functionality. The objective is to empower learners to customize and maintain their web scrapers as websites evolve.
We will utilize Python 3 and commonly used Python libraries to simplify the process. Additionally, we will leverage a potent and free liquor scraping tool called Selectorlib. This combination of tools will make our liquor product data scraping tasks more efficient and manageable.
List Of Data Fields

Name
Size
Price
Quantity
InStock – whether the liquor is in stock
Delivery Available: Whether the liquor is delivered
URL

Installing The Required Packages for Running Total
To Scrape liquor prices and delivery status from Total Wine and More store, we will follow these steps
To follow along with this web scraping tutorial, having Python 3 installed on your system is recommended. You can install Python 3 by following the instructions provided in the official Python documentation.
Once you have Python 3 installed, you must install two libraries: Python Requests and Selectorlib. Install these libraries using the pip3 command to scrape liquor prices and delivery data, which is the package installer for Python 3. Open your terminal or command prompt and run the following commands:
The Python Code

The Provided Code Performs The Following Actions:
Reads a list of URLs from a file called "urls.txt" containing the URLs of Total Wine and More product pages.
Utilizes a Selectorlib YAML file, "selectors.yml," to specify the data elements to scrape TotalWine.com product data.
Performs total wine product data collection by requesting the specified URLs and extracting the desired data using the Selectorlib library.
Stores the scraped data in a CSV spreadsheet named "data.csv."
Create The YAML File "Selectors.Yml"
We utilized a file called "selectors.yml" to specify the data elements we wanted to extract total wine product data. Create the file using a web scraping tool called Selectorlib.
Selectorlib is a powerful tool that simplifies selecting, highlighting up, and extracting data from web pages. With the Chrome Extension of Selectorlib Web Crawler, you can easily mark the data you need to collect and generate the corresponding CSS selectors or XPaths.
Selectorlib can make the data extraction process more visual and intuitive, allowing us to focus on the specific data elements we want to extract without manually writing complex CSS selectors.
To leverage Selectorlib, you can install the Chrome Extension of Selectorlib Web crawler and use it to mark and extract the desired data from web pages. The tool will then develop the imoportant CSS selectors or XPaths, which can be saved in a YAML file like "selectors.yml" and used in your Python code for efficient data extraction.


Functioning of Total Wine and More Scraper
To specify the URLs you want to scrape, create a text file named as "urls.txt" in the same directory as your Python script. Inside the "urls.txt" file, add the URLs you need to scrape liquor product data , each on a new line. For example:
Run the Total Wine data scraper with the following command:
Common Challenges And Limitations Of Self-Service Web Scraping Tools And Copied Internet Scripts
Unmaintained code and scripts pose significant pitfalls as they deteriorate over time and become incompatible with website changes. Regular maintenance and updates maintain the functionality and reliability of these code snippets. Websites undergo continuous updates and modifications, which can render existing code ineffective or even break it entirely. It is essential to prioritize regular maintenance to ensure long-term functionality and reliability, enabling the code to adapt to evolving website structures and maintain its intended purpose. By staying proactive and keeping code up-to-date, developers can mitigate issues and ensure the continued effectiveness of their scripts.
Here are some common issues that can arise when using unmaintained tools:
Changing CSS Selectors: If the website's structure changes, the CSS selectors are used to extract data, such as the "Price" selector in the selectors.yaml file may become outdated or ineffective. Regular updates are needed to adapt to these changes and ensure accurate data extraction.
Location Selection Complexity: Websites may require additional variables or methods to select the user's "local" store beyond relying solely on geolocated IP addresses. Please handle this complexity in the code to avoid difficulties retrieving location-specific data.
Addition or Modification of Data Points: Websites often introduce new data points or modify existing ones, which can impact the code's ability to extract the desired information. Without regular maintenance, the code may miss out on essential data or attempt to extract outdated information.
User Agent Blocking: Websites may block specific user agents to prevent automated scraping. If the code uses a blocked user agent, it may encounter restrictions or deny website access.
Access Pattern Blocking: Websites employ security measures to detect and block scraping activities based on access patterns. If the code follows a predictable scraping pattern, it can trigger these measures and face difficulties accessing the desired data.
IP Address Blocking: Websites may block specific IP addresses or entire IP ranges to prevent scraping activities. If the code's IP address or the IP addresses provided by the proxy provider are blocked, it can lead to restricted or denied access to the website.
Conclusion: Utilizing a full-service solution, you can delve deeper into data analysis and leverage it to monitor the prices and brands of your favorite wines. It allows for more comprehensive insights and enables you to make informed decisions based on accurate and up-to-date information.
At Product Data Scrape, we ensure that our Competitor Price Monitoring Services and Mobile App Data Scraping maintain the highest standards of business ethics and lead all operations. We have multiple offices around the world to fulfill our customers' requirements.
#WebScrapingLiquorPricesData#ScrapeTotalWineProductData#TotalWineDataScraper#ScrapeLiquorPricesData#ExtractTotalWineProductData#ScrapeLiquorDeliveryData#LiquorDataScraping
0 notes
Text
Exploring the Power of Web Scraping: Extracting "People Also Ask" Questions from Google Results

In this article, we'll look at how to use web scraping to extract useful information from Google search results. We'll specifically focus on obtaining the "People Also Ask" questions and save them to a Google Sheets document. Let's get started, but first, please show your support by liking the video and subscribing to the channel. Your encouragement fuels our desire to create informative content. Now, let us get down to work.
Prerequisites:
1Open a Google Sheets Document To begin, open a Google Sheets document in which we'll execute web scraping.
2Add the "Import from Web" Extension Go to the given
Link to the "Import from Web" addon. This plugin is essential for allowing web scraping capability in Google Sheets. Make sure you add this extension to your Google Sheets for easy connection.
Activating the Extension:
Once you've installed the extension, navigate to your Google Sheets document and select the "Extensions" option.
Locate and enable the "Import from Web" addon. This step gives you access to a myriad of web scraping features right within your Google Sheets.
Executing Web Scraping:
Define your keyword: In a specific cell, such as B1, put the keyword from which you wish to extract "People Also Ask" queries. For example, let's use the keyword "skincare".
Utilize the Import Functionality: In the
for SEO experts, digital marketers, and content developers. Google's "People Also Ask" feature is an often-overlooked yet extremely useful tool. In this tutorial, we'll look at the nuances of this tool and how it may be used to acquire key insights and drive content strategy. Let's get into the details.
Understanding of "People Also Ask":
Overview The "People Also Ask" feature in Google search results produces similar questions based on user queries.
Evolution: The function, which was first introduced in 2015, has expanded dramatically, now using machine learning to give relevant and contextually driven queries.
User Benefits "People Also Ask" improves the search experience by suggesting questions based on user intent, providing users with extra insights and leading content creators to relevant topics.
Exploring "People Also Ask"
In Action:
Accessing the Feature Do a Google search for your desired topic, such as "chocolate," then scroll down to the "People Also Ask" area.
Accordion-style Dropdowns Clicking on the accordion-style dropdowns shows a profusion of related questions, a veritable goldmine of content ideas.
Tailoring Content Look for questions that are relevant to your interests or industry niche, such as the history of cocoa or its health advantages.
Maximizing Insights with Web Scraping:
Introducing the "Scraper" Extension Use the "Scraper" Chrome extension, which is available in the Chrome Web Store, to extract and consolidate "People Also Ask" queries.
Simple Extraction Process: Right-click on a relevant question, choose "Scrape Similar," then change the XPath selection to collect all similar questions.
Scalability: A single query can return a multiplicity of
Related search results offer numerous chances for content creation and market insights.
Unlocking the Content Potential:
Content Ideation: Use scraped questions to find holes in existing content and create comprehensive content strategy.
Competitive Advantage By responding to user concerns completely, you can outperform competitors and increase brand visibility.
Strategic Implementation Create content that not only addresses individual questions but also reflects larger user intent and industry trends.
Use Web Scraping Tools for "People Also Ask" Questions
In the digital age, embracing technology is critical to staying ahead in SEO and content marketing. Web scraping tools are an effective way to extract relevant data from search engine results pages (SERPs) and obtain insight into user behavior and preferences. Here's how you can use these technologies to maximize their potential.
Conclusion:
By using web scraping, you may extract useful data directly from Google search results, providing you with actionable insights. Web scraping brings up a world of data-driven decision-making opportunities, whether you're undertaking market research, content creation, or SEO analysis. Stay tuned for future tutorials delving into additional web scraping features and advanced techniques. Until then, Happy scrapping, and may your data excursions be successful! Remember, the possibilities are limitless when you use the power of web scraping to extract valuable information from the enormous expanse of the internet. Happy scraping, and may your data excursions be both insightful and rewarding!
Incorporating Google's "People Also Ask" feature into your SEO and content strategy can unlock a wealth of opportunities for audience engagement and brand growth. By understanding user intent, leveraging web scraping tools, and crafting targeted content, you can position your brand as an authoritative voice in your industry. Embrace the power of "People Also Ask" and elevate your digital presence to new heights.
As you embark on your journey of content creation and SEO optimization, remember to harness the insights gleaned from "People Also Ask" to fuel your strategic initiatives and drive meaningful engagement with your audience. The possibilities are endless, and with the right approach, you can unlock boundless opportunities for success in the ever-evolving digital landscape.
0 notes
Text
Exploring the Power of Web Scraping: Extracting "People Also Ask" Questions from Google Results

In this article, we'll look at how to use web scraping to extract useful information from Google search results. We'll specifically focus on obtaining the "People Also Ask" questions and save them to a Google Sheets document. Let's get started, but first, please show your support by liking the video and subscribing to the channel. Your encouragement fuels our desire to create informative content. Now, let us get down to work.
Prerequisites:
1Open a Google Sheets Document To begin, open a Google Sheets document in which we'll execute web scraping.
2Add the "Import from Web" Extension Go to the given
Link to the "Import from Web" addon. This plugin is essential for allowing web scraping capability in Google Sheets. Make sure you add this extension to your Google Sheets for easy connection.
Activating the Extension:
Once you've installed the extension, navigate to your Google Sheets document and select the "Extensions" option.
Locate and enable the "Import from Web" addon. This step gives you access to a myriad of web scraping features right within your Google Sheets.
Executing Web Scraping:
Define your keyword: In a specific cell, such as B1, put the keyword from which you wish to extract "People Also Ask" queries. For example, let's use the keyword "skincare".
Utilize the Import Functionality: In the
for SEO experts, digital marketers, and content developers. Google's "People Also Ask" feature is an often-overlooked yet extremely useful tool. In this tutorial, we'll look at the nuances of this tool and how it may be used to acquire key insights and drive content strategy. Let's get into the details.
Understanding of "People Also Ask":
Overview The "People Also Ask" feature in Google search results produces similar questions based on user queries.
Evolution: The function, which was first introduced in 2015, has expanded dramatically, now using machine learning to give relevant and contextually driven queries.
User Benefits "People Also Ask" improves the search experience by suggesting questions based on user intent, providing users with extra insights and leading content creators to relevant topics.
Exploring "People Also Ask"
In Action:
Accessing the Feature Do a Google search for your desired topic, such as "chocolate," then scroll down to the "People Also Ask" area.
Accordion-style Dropdowns Clicking on the accordion-style dropdowns shows a profusion of related questions, a veritable goldmine of content ideas.
Tailoring Content Look for questions that are relevant to your interests or industry niche, such as the history of cocoa or its health advantages.
Maximizing Insights with Web Scraping:
Introducing the "Scraper" Extension Use the "Scraper" Chrome extension, which is available in the Chrome Web Store, to extract and consolidate "People Also Ask" queries.
Simple Extraction Process: Right-click on a relevant question, choose "Scrape Similar," then change the XPath selection to collect all similar questions.
Scalability: A single query can return a multiplicity of
Related search results offer numerous chances for content creation and market insights.
Unlocking the Content Potential:
Content Ideation: Use scraped questions to find holes in existing content and create comprehensive content strategy.
Competitive Advantage By responding to user concerns completely, you can outperform competitors and increase brand visibility.
Strategic Implementation Create content that not only addresses individual questions but also reflects larger user intent and industry trends.
Use Web Scraping Tools for "People Also Ask" Questions
In the digital age, embracing technology is critical to staying ahead in SEO and content marketing. Web scraping tools are an effective way to extract relevant data from search engine results pages (SERPs) and obtain insight into user behavior and preferences. Here's how you can use these technologies to maximize their potential.
Conclusion:
By using web scraping, you may extract useful data directly from Google search results, providing you with actionable insights. Web scraping brings up a world of data-driven decision-making opportunities, whether you're undertaking market research, content creation, or SEO analysis. Stay tuned for future tutorials delving into additional web scraping features and advanced techniques. Until then, Happy scrapping, and may your data excursions be successful! Remember, the possibilities are limitless when you use the power of web scraping to extract valuable information from the enormous expanse of the internet. Happy scraping, and may your data excursions be both insightful and rewarding!
Incorporating Google's "People Also Ask" feature into your SEO and content strategy can unlock a wealth of opportunities for audience engagement and brand growth. By understanding user intent, leveraging web scraping tools, and crafting targeted content, you can position your brand as an authoritative voice in your industry. Embrace the power of "People Also Ask" and elevate your digital presence to new heights.
As you embark on your journey of content creation and SEO optimization, remember to harness the insights gleaned from "People Also Ask" to fuel your strategic initiatives and drive meaningful engagement with your audience. The possibilities are endless, and with the right approach, you can unlock boundless opportunities for success in the ever-evolving digital landscape.
0 notes
Text
Effective Techniques To Scrape Amazon Product Category Without Getting Blocked!
Effective Techniques To Scrape Amazon Product Category Without Getting Blocked!

This comprehensive guide will explore practical techniques for web scraping Amazon's product categories without encountering blocking issues. Our tool is Playwright, a Python library that empowers developers to automate web interactions and effortlessly extract data from web pages. Playwright offers the flexibility to navigate web pages, interact with elements, and gather information within a headless or visible browser environment. Even better, Playwright is compatible with various browsers like Chrome, Firefox, and Safari, enabling you to test your web scraping scripts across different platforms. Moreover, Playwright boasts robust error handling and retry mechanisms, which can help you tackle shared web scraping obstacles like timeouts and network errors.
Throughout this tutorial, we will guide you through the stepwise procedure of scraping data related to air fryers from Amazon using Playwright in Python. We will also demonstrate how to save this extracted data as a CSV file. By the end of this tutorial, you will have gained a solid understanding of how to scrape Amazon product categories effectively while avoiding potential roadblocks. Additionally, you'll become proficient in utilizing Playwright to automate web interactions and efficiently extract data.
List of Data Fields

Product URL: The web address leading to the air fryer product.
Product Name: The name or title of the air fryer product.
Brand: The manufacturer or brand responsible for the air fryer product.
MRP (Maximum Retail Price): The suggested maximum retail price for the air fryer product.
Sale Price: It includes the current price of the air fryer product.
Number of Reviews: The count of customer reviews available for the air fryer product.
Ratings: It includes the average ratings customers assign to the air fryer product.
Best Sellers Rank: It includes a ranking system of the product's position in the Home and kitchen category and specialized Air Fryer and Fat Fryer categories.
Technical Details: It includes specific specifications of the air fryer product, encompassing details like wattage, capacity, color, and more.
About this item: A description provides information about the air fryer product, features, and functionalities.
Amazon boasts an astonishing online inventory exceeding 12 million products. When you factor in the contributions of Marketplace Sellers, this number skyrockets to over 350 million unique products. This vast assortment has solidified Amazon's reputation as the "go-to" destination for online shopping. It's often the first stop for customers seeking to purchase or gather in-depth information about a product. Amazon offers a treasure trove of valuable product data, encompassing everything from prices and product descriptions to images and customer reviews.
Given this wealth of product data and Amazon's immense customer base, it's no surprise that small and large businesses and professionals are keenly interested in harvesting and analyzing this Amazon product data.
In this article, we'll introduce our Amazon scraper and illustrate how you can effectively collect Amazon product information.
Here's a step-by-step guide for using Playwright in Python to scrape air fryer data from Amazon:
Step 1: Install Required Libraries

In this section, we've imported several essential Python modules and libraries to support various operations in our project.
re Module: We're utilizing the 're' module for working with regular expressions. Regular expressions are powerful tools for pattern matching and text manipulation.
random Module: The 'random' module is essential for generating random numbers, making it handy for tasks like generating test data or shuffling the order of tests.
asyncio Module: We're incorporating the 'asyncio' module to manage asynchronous programming in Python. It is particularly crucial when using Playwright's asynchronous API for web automation.
datetime Module: The 'datetime' module comes into play when we need to work with dates and times. It provides a range of functionalities for manipulating, creating date and time objects and formatting them as strings.
pandas Library: We're bringing in the 'pandas' library, a powerful data manipulation and analysis tool. In this tutorial, it will store and manipulate data retrieved from the web pages we're testing.
async_playwright Module: The 'async_playwright' module is essential for systematizing browsers using Playwright, an open-source Node.js library designed for automation testing and web scraping.
We're well-equipped to perform various tasks efficiently in our project by including these modules and libraries.
This script utilizes a combination of libraries to streamline browser testing with Playwright. These libraries serve distinct purposes, including data generation, asynchronous programming control, data manipulation and storage, and browser interaction automation.
Product URL Extraction
The second step involves extracting product URLs from the air fryer search. Product URL extraction refers to gathering and structuring the web links of products listed on a web page or online platform seeking help from e-commerce data scraping services.
Before initiating the scraping of product URLs, it is essential to take into account several considerations to ensure a responsible and efficient approach:
Standardized URL Format: Ensure the collected product URLs adhere to a standardized format, such as "https://www.amazon.in/+product name+/dp/ASIN." This format comprises the website's domain name, the product name without spaces, and the product's sole ASIN (Amazon Standard Identification Number) at the last. This standardized set-up facilitates data organization and analysis, maintaining URL consistency and clarity.
Filtering for Relevant Data: When extracting data from Amazon for air fryers, it is crucial to filter the information exclusively for them and exclude any accessories often displayed alongside them in search results. Implement filtering criteria based on factors like product category or keywords in the product title or description. This filtering ensures that the retrieved data pertains solely to air fryers, enhancing its relevance and utility.
Handling Pagination: During product URL scraping, you may need to navigate multiple pages by clicking the "Next" button at the bottom of the webpage to access all results. However, there may be instances where clicking the "next" button flops to load the following page, potentially causing errors in the scraping process. To mitigate such issues, consider implementing error-handling mechanisms, including timeouts, retries, and checks to confirm the total loading of the next page before data extraction. These precautions ensure effective and efficient scraping while minimizing errors and respecting the website's resources.

In this context, we eusemploy the Python function 'get_product_urls' to extract product links from a web page. This function leverages the Playwright library to automate browser testing and retrieve the resulting product URLs from an Amazon webpage.
The function performs a sequence of actions. It initially checks for a "next" button on the page. If found, the function clicks on it and invokes itself recursively to extract URLs from the subsequent page. This process continues until all pertinent product URLs are available.
Within the function, execute the following steps:
It will select page elements containing product links using a CSS selector.
It creates an empty set to store distinct product URLs.
It iterates through each element to extract the 'href' attribute.
Cleaning of the link based on specified conditions, including removing undesired substrings like "Basket" and "Accessories."
After this cleaning process, the function checks whether the link contains any of the unwanted substrings. If not, it appends the cleaned URL to the set of product URLs. Finally, the function returns the list of unique product URLs as a list.
Extracting Amazon Air Fryer Data
In this phase, we aim to determine the attributes we wish to collect from the website, which includes the Product Name, Brand, Number of Reviews, Ratings, MRP, Sale Price, Bestseller rank, Technical Details, and product description ("About the Amazon air fryer product").

To extract product names from web pages, we employ an asynchronous function called 'get_product_name' that works on an individual page object. This function follows a structured process:
It initiates by locating the product's title element on the page, achieved by using the 'query_selector()' method of the page object along with the appropriate CSS selector.
Once the element is successfully available, the function extracts the element's text content using the 'text_content()' method. Store this extracted text in the 'product_name' variable for further processing.
When the function encounters difficulties in finding or retrieving the product name for a specific item, it has a mechanism to handle exceptions. In such cases, it assigns the value "Not Available" to the 'product_name' variable. This proactive approach ensures the robustness of our web scraping script, allowing it to continue functioning smoothly even in the face of unexpected errors during the data extraction process.
Scraping Brand Name
In web scraping, capturing the brand name associated with a specific product plays a pivotal role in identifying the manufacturer or company behind the product. The procedure for extracting brand names mirrors that of product names. We begin by seeking pertinent elements on the webpage using a CSS selector and extracting the textual content from those elements.
However, brand information on the page can manifest in several different formats. For example, the brand name is by the text "Brand: 'brand name'" or appears as "Visit the 'brand name' Store." To accurately extract the brand name, it's crucial to filter out these extra elements and isolate the genuine brand name.

We can employ a function similar to the one used for product name extraction to extract the brand name from web pages. In this case, the function is named 'get_brand_name,' its operation revolves around locating the element containing the brand name via a CSS selector.
When the function successfully locates the element, it extracts the text content from that element using the 'text_content()' method and assigns it to a 'brand_name' variable. It's important to emphasize that the extracted text may include extraneous information such as "Visit," "the," "Store," and "Brand:" Eliminate these extra elements using regular expressions.
By filtering out these unwanted words, we can isolate the genuine brand name, ensuring the accuracy of our data. If the function encounters an exception while locating the brand name element or extracting its text content, it defaults to returning the brand name as "Not Available."
By incorporating this function into our web scraping script, we can effectively obtain the brand names of the products under scrutiny, thereby enhancing our understanding of the manufacturers and companies associated with these products.
Similarly, we can apply the same technique to extract other attributes, such as MRP and Sale price, from the web pages.
Scraping Products MRPs

Extracting product Ratings

To extract the star rating of a product from a web page, we utilize the 'get_star_rating' function. Initially, the function will locate the star rating element on the page using a CSS selector that points to the element housing the star ratings. Accomplish it using the 'page.wait_for_selector()' method. After locating the element, the function retrieves the inner text content of the element through the 'star_rating_elem.inner_text()' method.
However, an exception arises while finding the star rating element or extracting its text content. In that case, the function employs an alternative approach to verify whether there are no reviews for the product. To do this, it attempts to locate the element with an ID that signifies the absence of reviews using the 'page.query_selector()' method. If this element is available, assign the text content of that element to the 'star_rating' variable.
In cases where both of these attempts prove ineffective, the function enters the second block of exception. It denotes the star rating as "Not Available" without any further effort to extract rating information. It ensures the user is duly informed about the unavailability of star ratings for the specific product.
Extracting Product Information

The 'get_bullet_points' function collects bullet point information from the web page. It initiates the process by attempting to locate an unordered list element that encompasses bullet points. Achieve it by applying a CSS selector for the 'About this item' element with the corresponding ID. After locating the 'About this item' unordered list element, the function retrieves all the list item elements beneath it using the 'query_selector_all()' method.
The function then iterates through each list item element, gathering its inner text, and appends it to the bullet points list. In cases where an exception arises during the endeavor to find the unordered list element or the list item elements, the function promptly designates the bullet points as an empty list.
Ultimately, the function returns the compiled list of bullet points, ensuring the extracted information is accessible for further use.
Collecting and Preserving Product Information

This Python script employs an asynchronous " main " function to scrape product data from Amazon web pages. It leverages the Playwright library to launch the Firefox browser and navigate to Amazon's site. Following this, the "extract_product_urls" function is available to extract the URLs of each product on the page. Store it in a list named "product_url." The script proceeds to iterate through each product URL, using the "perform_request_with_retry" function to fetch product pages and extract a range of information, including product name, brand, star rating, review count, MRP, sale price, best sellers rank, technical details, and descriptions.
The gathered data is assembled into tuples and stored in a list called "data." The function also offers progress updates after handling every 10 product URLs and a completion message when all URLs are available. Subsequently, the data is transformed into a Pandas DataFrame and saved as a CSV file using the "to_csv" method. Lastly, the browser is closed using the "browser.close()" statement. Invoke the "main" function as an asynchronous coroutine via the "asyncio.run(main())" statement.
Conclusion:
This guide provides a stepwise walkthrough for scraping Amazon Air Fryer data with Playwright in Python. We cover all aspects, starting from the initial setup of the Playwright environment and launching a web browser to the subsequent actions of navigating to Amazon's search page and extracting crucial details like product name, brand, star rating, MRP, sale price, best seller rank, technical specifications, and bullet points.
Our instructions are to be user-friendly, offering guidance on extracting product URLs, iterating through each URL, and utilizing Pandas to organize the gathered data into a structured dataframe. Leveraging Playwright's cross-browser compatibility and robust error handling, users can streamline the web scraping process and retrieve valuable information from Amazon product listings.
Web scraping can often be laborious and time-intensive, but with Playwright in Python, users can automate these procedures, significantly reducing the time and effort required.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.
Know More: https://www.iwebdatascraping.com/scrape-amazon-product-category-without-getting-blocked.php
#ScrapeAmazonProductCategoryWithoutGettingBlocked#ScrapingamazoncategoryWithoutGettingBlocked#AmazonProductdataScraper
0 notes