#web scraper extension
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
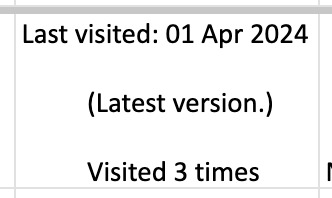
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Note
784488414544297984 i never joined the archive server because i knew it would eventually turn to shit but as a data hoarder it irritates me how inefficient they're presumably being. anyway here's some tools that have helped me !! desktop only unfortunately
https://dht.chylex.com/ -> for discord server archival. this isn't immediately relevant to all this but i find it handy
https://github.com/mikf/gallery-dl -> a tool that runs in the background to download images/files from a site you input, automatically sorting it from oldest to newest. works slow but gets the job done. there are a lot of supported sites but for this specifically i use it for tumblr images, deviantart images, and deviantart journals
https://tumblthreeapp.github.io/TumblThree/ -> this one also downloads all images from a blog but not in order. i use it to download individual posts from a blog and as far as i know they're automatically sorted in order. if you fiddle with the settings you can download all posts as individual txt files, and then use the command prompt ren *.txt *.html to mass change the extension and them view those files in your browser with formatting
i also used the chrome extension GoFullPage - Full Page Screen Capture to take easy screenshots of things like the toyhouse while it was up, the au info pages, etc. doesn't work on really long pages but i've used it a lot
remember there is almost always an easier way to save things than just doing it by hand!! - <3, a web scraper
☝️☝️☝️
Very useful ask, please check it out!!
21 notes
·
View notes
Photo

Wihio Tales
Wihio tales are the Cheyenne legends featuring the trickster figure Wihio, who appears, variously, as a wise man, fool, villain, or hero and is associated with the spider. Wihio Tales continue to be as popular with the Cheyenne today as they were in the past as they entertain while also teaching valuable cultural lessons.
The Wihio Tales of the Cheyenne are similar to the Iktomi tales of the Lakota Sioux nation, and both Wihio and Iktomi (also known as Unktomi) share similarities with trickster figures of other Native peoples of North America, including Coyote of the Navajo and Glooscap of the Algonquin. Like these others, Wihio may often be depicted as a fool who cannot understand the simplest instructions or as a clever clown or sage, but, in every case, his stories involve some form of transformation while also serving as teaching tools.
This transformation can be as simple as learning not to trust in the goodness of strangers or not counting on outcomes one is not certain of or the suggested change, while seeming simple enough, might suggest deeper themes of a higher nature.
Wihio the Spider
Wihio's name is related to the Cheyenne word for chief and is also part of the name of the Creator – Heammawihio (also known as Maheo/Ma'heo'o) – the Wise One Above. Anthropologist and historian George Bird Grinnell (l. 1849-1938), who wrote extensively on the Cheyenne, notes:
The dwelling place of Heammawihio is denoted by his name, which is composed of the adverb he'amma, above, and wihio, a word closely related to wi'hiu, chief. Wihio also means spider…and appears to embody the idea of mental ability of an order higher than common – superior intelligence. All its uses seem to refer to this mental power…The spider spins a web, and goes up and down, seemingly walking on nothing. It is more able than other insects, hence its name. (Cheyenne Indians, Vol. II, 88-89)
This being so, it may be surprising to read the Wihio tales in which the central character is so often depicted as a buffoon. In Wihio and Coyote, he victimizes the dogs and ducks and is then victimized himself by the coyote, and in The Wonderful Sack, he is both villain and fool as he steals the sack from the Man-of-Plenty but then cannot manage its use. In the Wihio tales presented here, he appears, more or less, this same way.
In Wihio Loses His Hair, he is fooled by two young girls and must think quickly to save face before his family. The Turning Stones and The Back Scraper both depict Wihio as too foolish to remember how to follow instructions. In other tales, however, he might appear wise or exceptionally clever, weaving his various webs of plans, which may – or may not – turn out as he hopes. Whether he wins or loses, though, he still imparts an important message; what that message is, is up to the individual to interpret.
The importance of the number four in the latter two stories here is also seen in other Wihio tales and in many of the stories of the Plains Indians as the number is associated with the four cardinal points of the compass, which were considered sacred. Wihio, in forgetting how many times he has performed the magic – whether in these stories or others such as The Wonderful Sack – suggests he has forgotten the sacred nature of the four directions and so, by extension, his Creator Heammawihio. According to the Cheyenne belief, in forgetting one's Creator, one forgets oneself and suffers the consequences.
Those consequences may be both temporal and eternal, according to the Cheyenne belief, in that those spirits of the departed who had forgotten their Creator – and what was due to others and the created world – could not find their way home to Heammawihio in the afterlife. There is no judgment in the Cheyenne afterlife; those souls who are not welcomed to eternity by the Creator could be said to be those who, in life, failed to remember and follow simple instructions.
In another Cheyenne tale, Enough is Enough, not included here, the character of the Cheyenne Man is associated with Wihio who teaches White Man how to jump into trees on hot days to rest in the shade. In this story, Cheyenne Man remembers the sacred number four, and it is White Man who forgets, becomes stuck in the tree, and eventually starves to death. Whether he is the teacher or the one being taught, the Wihio character reminds the Cheyenne of the importance of observing tradition, of the Creator who established those traditions, and, ultimately, of what is most important in life.
Continue reading...
31 notes
·
View notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text
Easy way to get job data from Totaljobs
Totaljobs is one of the largest recruitment websites in the UK. Its mission is to provide job seekers and employers with efficient recruitment solutions and promote the matching of talents and positions. It has an extensive market presence in the UK, providing a platform for professionals across a variety of industries and job types to find jobs and recruit staff.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
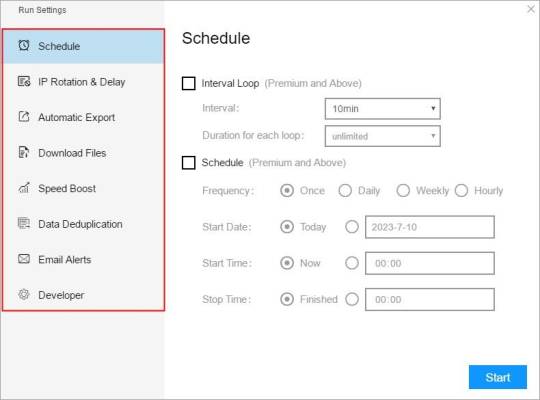
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
4. Export and view data
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
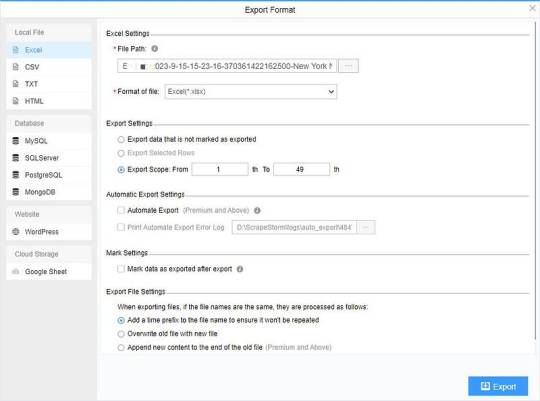
2 notes
·
View notes
Text
I must add one thing
Every website that's built these days includes a `robots.txt` file that explicitly either allows access to bots (search engine crawlers, web scrapers etc.,) to collect or deny the collection of data.
These tarpits are designed for AI scrapers that explicitly scrape after the denial. The original designer's intended method is to fuck with the bots (and by extension tech bros) who cannot seem to understand what to scrape and what not to

127K notes
·
View notes
Text
Top Options To Scrape Hotel Data From Agoda Without Coding
Introduction
In today's competitive hospitality landscape, accessing comprehensive hotel information has become crucial for businesses, researchers, and travel enthusiasts. The ability to Scrape Hotel Data From Agoda opens doors to valuable insights about pricing trends, room availability, customer reviews, and market dynamics. However, many individuals and organizations hesitate to pursue data extraction due to concerns about technical complexity and programming requirements.
The good news is that modern technology has democratized data scraping, making it accessible to users without extensive coding knowledge. This comprehensive guide explores various methods and tools that enable efficient Agoda Hotel Data Extraction while maintaining simplicity and effectiveness for non-technical users.
Understanding the Value of Agoda Hotel Data
Agoda, one of Asia's leading online travel agencies, hosts millions of hotel listings worldwide. The platform contains a treasure trove of information that can benefit various stakeholders in the tourism industry. Market researchers can analyze pricing patterns through Hotel Price Scraping , business owners can monitor competitor rates, and travel agencies can enhance their service offerings through comprehensive data analysis.
The platform's extensive database includes room rates, availability calendars, guest reviews, hotel amenities, location details, and booking policies. Extracting this information systematically allows businesses to make informed decisions about pricing strategies, marketing campaigns, and customer service improvements.
Real-Time Hotel Data from Agoda provides market intelligence that helps businesses stay competitive. By monitoring price fluctuations across different seasons, locations, and property types, stakeholders can optimize their revenue management strategies and identify market opportunities.
No-Code Solutions for Hotel Data Extraction
No-Code Solutions for Hotel Data Extraction refer to user-friendly platforms and tools that enable hotel data scraping—like reviews, room availability, and pricing—without requiring programming skills. These solutions are ideal for marketers, analysts, and business users.
1. Browser-Based Scraping Tools
Modern web scraping has evolved beyond command-line interfaces and complex programming languages. Several browser-based tools now offer intuitive interfaces that allow users to extract data through simple point-and-click operations. These tools typically record user interactions with web pages and automate repetitive tasks.
Popular browser extensions like Web Scraper, Data Miner, and Octoparse provide user-friendly interfaces where users can select specific elements on Agoda's website and configure extraction parameters. These tools automatically handle the technical aspects of data collection while presenting results in accessible formats like CSV or Excel files.
1. Cloud-Based Scraping Platforms
Cloud-based scraping services represent another excellent option for non-technical users seeking Agoda Room Availability Scraping capabilities. These platforms offer pre-built templates specifically designed for popular websites like Agoda, eliminating the need for manual configuration.
Services like Apify, Scrapy Cloud, and ParseHub provide ready-to-use scraping solutions that can be customized through simple form interfaces. Users can specify search criteria, select data fields, and configure output formats without writing a single line of code.
Key advantages of cloud-based solutions include:
Scalability to handle large-scale data extraction projects
Automatic handling of website changes and anti-scraping measures
Built-in data cleaning and formatting capabilities
Integration with popular business intelligence tools
Reliable uptime and consistent performance
Desktop Applications for Advanced Data Extraction
Desktop scraping applications offer another viable path for users seeking to extract hotel information without programming knowledge. These software solutions provide comprehensive interfaces with drag-and-drop functionality, making data extraction as simple as building a flowchart.
Applications like FMiner, WebHarvy, and Visual Web Ripper offer sophisticated features wrapped in user-friendly interfaces. These tools can handle complex scraping scenarios, including dealing with JavaScript-heavy pages, managing login sessions, and handling dynamic content loading.
Desktop applications' advantage is their ability to provide more control over the scraping process while maintaining ease of use. Users can set up complex extraction workflows, implement data validation rules, and export results in multiple formats. These applications also include scheduling capabilities for automated Hotel Booking Data Scraping operations.
API-Based Solutions and Third-Party Services
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
Companies specializing in travel data extraction often provide dedicated Agoda scraping services that can be accessed through simple web forms or API endpoints. Users can specify their requirements, such as location, date ranges, and property types, and receive Real-Time Hotel Data in return.
Benefits of API-based solutions include:
Immediate access to data without setup time
Professional-grade reliability and accuracy
Compliance with website terms of service
Regular updates to handle website changes
Customer support for troubleshooting
Automated Workflow Tools and Integrations
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
These tools are particularly valuable for businesses that must incorporate hotel data into their operations. For example, a travel agency could set up an automated workflow that scrapes Agoda data daily and updates its internal pricing database, enabling dynamic pricing strategies based on Agoda Room Availability Scraping insights.
The workflow approach seamlessly integrates with popular business tools like Google Sheets, CRM systems, and email marketing platforms. This integration capability makes it easier to act on the extracted data immediately rather than manually processing exported files.
Data Quality and Validation Considerations
Ensure data quality when implementing any Hotel Data Intelligence strategy. Non-coding solutions often include built-in validation features that help maintain data accuracy and consistency. These features typically include duplicate detection, format validation, and completeness checks.
Users should establish data quality standards before beginning extraction projects. This includes defining acceptable ranges for numerical data, establishing consistent formatting for text fields, and implementing verification procedures for critical information like pricing and availability.
Regular monitoring of extracted data helps identify potential issues early in the process. Many no-code tools provide notification systems that alert users to unusual patterns or extraction failures, enabling quick resolution of data quality issues.
Legal and Ethical Considerations
Before implementing any data extraction strategy, users must understand the legal and ethical implications of web scraping. Agoda's terms of service, robots.txt file, and rate-limiting policies should be carefully reviewed to ensure compliance.
Responsible scraping practices include:
Respecting website rate limits and implementing appropriate delays
Using data only for legitimate business purposes
Avoiding excessive server load that could impact website performance
Implementing proper data security measures for extracted information
Regularly reviewing and updating scraping practices to maintain compliance
Advanced Features and Customization Options
Modern no-code scraping solutions offer sophisticated customization options that rival traditional programming approaches. These features enable users to handle complex scenarios like multi-page data extraction, conditional logic implementation, and dynamic content handling.
Advanced filtering capabilities allow users to extract only relevant information based on specific criteria such as price ranges, star ratings, or geographic locations. This targeted approach reduces data processing time and focuses analysis on the most valuable insights.
Many platforms also offer data transformation features that can clean, format, and structure extracted information according to business requirements. These capabilities eliminate additional data processing steps and provide ready-to-use datasets.
Monitoring and Maintenance Strategies
Successful Travel Industry Web Scraping requires ongoing monitoring and maintenance to ensure consistent performance. No-code solutions typically include dashboard interfaces that provide visibility into scraping performance, success rates, and data quality metrics.
Users should establish regular review processes to validate data accuracy and identify potential issues. This includes monitoring for website changes that might affect extraction accuracy, validating data completeness, and ensuring compliance with updated service terms.
Automated alerting systems can notify users of extraction failures, data quality issues, or significant changes in scraped information. These proactive notifications enable quick responses to potential problems and maintain data reliability.
Future Trends in No-Code Data Extraction
The landscape of no-code data extraction continues to evolve rapidly, with new tools and capabilities emerging regularly. Artificial intelligence and machine learning technologies are increasingly integrated into scraping platforms, enabling more intelligent data extraction and automatic application to website changes.
These technological advances make Hotel Booking Data Scraping more accessible and reliable for non-technical users. Future developments will likely include enhanced natural language processing capabilities, improved visual recognition for data element selection, and more sophisticated automation features.
How Travel Scrape Can Help You?
We provide comprehensive hotel data extraction services that eliminate the technical barriers typically associated with web scraping. Our platform is designed specifically for users who need reliable Real-Time Hotel Data without the complexity of coding or managing technical infrastructure.
Our services include:
Custom Agoda scraping solutions tailored to your specific business requirements and data needs.
Automated data collection schedules that ensure you always have access to the most current hotel information.
Advanced data filtering and cleaning processes that deliver high-quality, actionable insights.
Multiple export formats, including CSV, Excel, JSON, and direct database integration options.
Compliance management ensures all data extraction activities adhere to legal and ethical standards.
Scalable solutions that grow with your business needs, from small-scale projects to enterprise-level operations.
Integration capabilities with popular business intelligence tools and CRM systems.
Our platform handles the technical complexities of Hotel Price Scraping while providing clean, structured data that can be immediately used for analysis and decision-making.
Conclusion
The democratization of data extraction technology has made it possible for anyone to Scrape Hotel Data From Agoda without extensive programming knowledge. Users can access valuable hotel information that drives informed business decisions through browser extensions, cloud-based platforms, desktop applications, and API services.
As the Travel Industry Web Scraping landscape evolves, businesses embracing these accessible technologies will maintain competitive advantages through better market intelligence and data-driven decision-making.
Don't let technical barriers prevent you from accessing valuable market insights; Contact Travel Scrape now to learn more about our comprehensive Travel Aggregators data extraction services and take the first step toward data-driven success.
Read More :- https://www.travelscrape.com/scrape-agoda-hotel-data-no-coding.php
#ScrapeHotelDataFromAgoda#AgodaHotelDataExtraction#HotelPriceScraping#RealTimeHotelData#HotelDataIntelligence#TravelIndustryWebScraping#HotelBookingDataScraping#TravelAggregators
0 notes
Text
How Does Wolt Web Scraping API in Cyprus Support Operational Efficiency?
How Does Wolt Web Scraping API in Cyprus Support Operational Efficiency?
The food delivery service is in high demand in Cyprus because of convenience and their eating habits. Wolt, one of the major players in the market, provides a way to order food from many local restaurants. Scraping data from Wolt Cyprus becomes more relevant for companies and researchers focusing on customers' behavior and delivery services.
The collected Food Datasets aids the business in knowing which cuisines and dishes customers most prefer, the best routes to make deliveries, and at what specific time of day, as well as appropriate pricing strategies based on prevailing competition and consumer preferences. In addition, Wolt Web Scraping API in Cyprus can enrich decision-making processes ranging from the extension of service areas to promotional campaigns.
For instance, ethical considerations are essential to scrape Wolt food Delivery Data in Cyprus, as the data protection law must be followed to respect the user's privacy. If the collected data is appropriately managed, it can help businesses attain competitive advantage, improve process efficiency, and respond to the dynamic needs of the food delivery market in Cyprus.
Rising Trends for Scraping Restaurant and Menu Data
Web Scraping For Food Delivery data is a concept quickly growing in popularity, with significantly higher demand than in the past. Approximately 30% of companies are now searching for such data, a relative increase from previous years. This indicates an increasing appreciation of the value of timely information on menu lists, pricing strategies, and customer preferences.
Several companies are leveraging the benefits of Food Delivery Data Scraping Services to improve their strategies, customer experience, and overall competitiveness in the evolving restaurant industry. Such extracted data could help restaurants fine-tune their menu offerings, set appropriate prices that reflect current market trends, and market effectively to their customers.
This change in the decision-making process can be linked to a general trend of utilizing technology to stand out and respond to shifts in consumer trends. However, restaurant menu data scraping must be done while considering ethics and the current consumer protection laws regarding the use of data.
How is Wolt Data Scraping Beneficial for Restaurant Businesses?
By using the Wolt food Delivery Data Extraction in Cyprus, restaurants can obtain vital information about consumers, seasonal fluctuations, and competitors. This information can lead to strategic menu development and marketing and operations improvements that enhance overall business performance.
Seasonal Menu Planning: Wolt Food Delivery Scraping API Services enable restaurants to understand seasonal popularity trends and adapt their menus according to what people currently prefer.
Localized Marketing Strategies: Based on the data gathered from Wolt through a restaurant data scraper, restaurants benefit from understanding regional customer preference in relation to foods to design effective marketing and sales strategies that will be responded to by local customers.
Supply Chain Optimization: Overall, scrape Wolt Food Delivery Data to gain valuable information for restaurants to improve supply chain management by predicting the demand for ingredients and, minimizing food waste, reducing cost, and increasing sustainability.
Menu Innovation: Wolt Restaurant Menu Data Collection can reveal trends in the food market and customer preferences for new and different dishes, pushing restaurants to create new dishes that no other restaurant offers.
Customer Satisfaction Metrics: Through customer ratings and reviews acquired from food menu data extraction, restaurants can learn more about areas that require improvement to enhance the quality of food, the speed of delivery, and customer service generally.
Partnership Opportunities: Wolt Food Delivery Dataset can reveal opportunities to partner with famous local sellers or suppliers on Wolt and thus improve restaurants' strategic cooperation and diversify the menu or optimize delivery services.
These points demonstrate that the restaurant data extraction is not limited to simple market analysis but provides detailed information and an approach that differentiates the restaurant business and contributes to growth even in conditions of increased competition.
Scraping Tips to Keep in Mind While Collecting Restaurant and Menu Data from Wolt
Here are some tips that restaurant data scraping services must consider when collecting data from Wolt:
Respect Robots.txt: Check Wolt's robots.txt file for guidelines on what can be collected to avoid legal issues.
Rate Limiting: Pause between requests so as not to overload Wolt's servers and be blocked.
Data Parsing: Ensure that parsing is done effectively to capture information such as menus, prices, and descriptions correctly.
Handling Dynamic Content: Certain sections of Wolt may not load, and you may need to use tools such as Selenium to resolve this.
Data Privacy: When analyzing data, ensure that no Personal Identifiable Information (PII) is gathered, with proper regard for users' privacy rights.
Legal Compliance: To avoid legal consequences, comply with data protection laws and Wolt's terms of service.
Error Handling: Apply interferences to reduce interruptions and ensure that they run smoothly.
Monitoring Changes: Always look for signs that Wolt's website has changed its structure or updated its policies, which may impact its operations.
Ethical Considerations: Clearly state how collected data is used and ensure it is done ethically.
Testing and Validation: In this method, checking whether the extracted data is accurate before applying it for analysis or business purposes is essential.
Conclusion
Scrape food delivery app data to provide several benefits for businesses willing to improve their operational models and approach to customers. Using the information gathered, restaurants can fine-tune their menu portfolios, marketing approaches, and service organization. However, scraping data from Wolt Cyprus ethically and legally is essential, which means adhering to Wolt's terms of service and data protection laws. Implementing strategies such as rate limiting, correct handling of errors, data privacy, and others helps restaurants leverage data insights to remain relevant and successfully serve the changing market needs.
Are you in need of high-class scraping services? Food Data Scrape should be your first point of call. We are undoubtedly the best in Food Data Aggregator and Mobile Restaurant App Scraping, and we render impeccable data analysis for strategic decision-making. With a legacy of excellence as our backbone, we help companies become data-driven, fueling their development. Please take advantage of our tailored solutions that will add value to your business. Contact us today to unlock the value of your data.
Source>> https://www.fooddatascrape.com/wolt-cyprus-api-scraping-supports-operational-efficiency.php
#WoltWebScrapingAPI#ScrapingDatafromWoltCyprus#ScrapeWoltFoodDeliveryData#WoltFoodDeliveryDataExtraction#WoltFoodDeliveryDataset
0 notes
Text
Amazon Scraper API Made Easy: Get Product, Price, & Review Data

If you’re in the world of e-commerce, market research, or product analytics, then you know how vital it is to have the right data at the right time. Enter the Amazon Scraper API—your key to unlocking real-time, accurate, and comprehensive product, price, and review information from the world's largest online marketplace. With this amazon scraper, you can streamline data collection and focus on making data-driven decisions that drive results.
Accessing Amazon’s extensive product listings and user-generated content manually is not only tedious but also inefficient. Fortunately, the Amazon Scraper API automates this process, allowing businesses of all sizes to extract relevant information with speed and precision. Whether you're comparing competitor pricing, tracking market trends, or analyzing customer feedback, this tool is your secret weapon.
Using an amazon scraper is more than just about automation—it’s about gaining insights that can redefine your strategy. From optimizing listings to enhancing customer experience, real-time data gives you the leverage you need. In this blog, we’ll explore what makes the Amazon Scraper API a game-changer, how it works, and how you can use it to elevate your business.
What is an Amazon Scraper API?
An Amazon Scraper API is a specialized software interface that allows users to programmatically extract structured data from Amazon without manual intervention. It acts as a bridge between your application and Amazon's web pages, parsing and delivering product data, prices, reviews, and more in machine-readable formats like JSON or XML. This automated process enables businesses to bypass the tedious and error-prone task of manual scraping, making data collection faster and more accurate.
One of the key benefits of an Amazon Scraper API is its adaptability. Whether you're looking to fetch thousands of listings or specific review details, this amazon data scraper can be tailored to your exact needs. Developers appreciate its ease of integration into various platforms, and analysts value the real-time insights it offers.
Why You Need an Amazon Scraper API
The Amazon marketplace is a data-rich environment, and leveraging this data gives you a competitive advantage. Here are some scenarios where an Amazon Scraper API becomes indispensable:
1. Market Research: Identify top-performing products, monitor trends, and analyze competition. With accurate data in hand, businesses can launch new products or services with confidence, knowing there's a demand or market gap to fill.
2. Price Monitoring: Stay updated with real-time price fluctuations to remain competitive. Automated price tracking via an amazon price scraper allows businesses to react instantly to competitors' changes.
3. Inventory Management: Understand product availability and stock levels. This can help avoid stock outs or overstocking. Retailers can optimize supply chains and restocking processes with the help of an amazon product scraper.
4. Consumer Sentiment Analysis: Use review data to improve offerings. With Amazon Review Scraping, businesses can analyze customer sentiment to refine product development and service strategies.
5. Competitor Benchmarking: Compare products across sellers to evaluate strengths and weaknesses. An amazon web scraper helps gather structured data that fuels sharper insights and marketing decisions.
6. SEO and Content Strategy: Extract keyword-rich product titles and descriptions. With amazon review scraper tools, you can identify high-impact phrases to enrich your content strategies.
7. Trend Identification: Spot emerging trends by analyzing changes in product popularity, pricing, or review sentiment over time. The ability to scrape amazon product data empowers brands to respond proactively to market shifts.
Key Features of a Powerful Amazon Scraper API
Choosing the right Amazon Scraper API can significantly enhance your e-commerce data strategy. Here are the essential features to look for:
Scalability: Seamlessly handle thousands—even millions—of requests. A truly scalable Amazon data scraper supports massive workloads without compromising speed or stability.
High Accuracy: Get real-time, up-to-date data with high precision. Top-tier Amazon data extraction tools constantly adapt to Amazon’s evolving structure to ensure consistency.
Geo-Targeted Scraping: Extract localized data across regions. Whether it's pricing, availability, or listings, geo-targeted Amazon scraping is essential for global reach.
Advanced Pagination & Sorting: Retrieve data by page number, relevance, rating, or price. This allows structured, efficient scraping for vast product categories.
Custom Query Filters: Use ASINs, keywords, or category filters for targeted extraction. A flexible Amazon scraper API ensures you collect only the data you need.
CAPTCHA & Anti-Bot Bypass: Navigate CAPTCHAs and Amazon’s anti-scraping mechanisms using advanced, bot-resilient APIs.
Flexible Output Formats: Export data in JSON, CSV, XML, or your preferred format. This enhances integration with your applications and dashboards.
Rate Limiting Controls: Stay compliant while maximizing your scraping potential. Good Amazon APIs balance speed with stealth.
Real-Time Updates: Track price drops, stock changes, and reviews in real time—critical for reactive, data-driven decisions.
Developer-Friendly Documentation: Enjoy a smoother experience with comprehensive guides, SDKs, and sample codes—especially crucial for rapid deployment and error-free scaling.
How the Amazon Scraper API Works
The architecture behind an Amazon Scraper API is engineered for robust, scalable scraping, high accuracy, and user-friendliness. At a high level, this powerful Amazon data scraping tool functions through the following core steps:
1. Send Request: Users initiate queries using ASINs, keywords, category names, or filters like price range and review thresholds. This flexibility supports tailored Amazon data retrieval.
2. Secure & Compliant Interactions: Advanced APIs utilize proxy rotation, CAPTCHA solving, and header spoofing to ensure anti-blocking Amazon scraping that mimics legitimate user behavior, maintaining access while complying with Amazon’s standards.
3. Fetch and Parse Data: Once the target data is located, the API extracts and returns it in structured formats such as JSON or CSV. Data includes pricing, availability, shipping details, reviews, ratings, and more—ready for dashboards, databases, or e-commerce tools.
4. Real-Time Updates: Delivering real-time Amazon data is a core advantage. Businesses can act instantly on dynamic pricing shifts, consumer trends, or inventory changes.
5. Error Handling & Reliability: Intelligent retry logic and error management keep the API running smoothly, even when Amazon updates its site structure, ensuring maximum scraping reliability.
6. Scalable Data Retrieval: Designed for both startups and enterprises, modern APIs handle everything from small-scale queries to high-volume Amazon scraping using asynchronous processing and optimized rate limits.
Top 6 Amazon Scraper APIs to Scrape Data from Amazon
1. TagX Amazon Scraper API
TagX offers a robust and developer-friendly Amazon Scraper API designed to deliver accurate, scalable, and real-time access to product, pricing, and review data. Built with enterprise-grade infrastructure, the API is tailored for businesses that need high-volume data retrieval with consistent uptime and seamless integration.
It stands out with anti-blocking mechanisms, smart proxy rotation, and responsive documentation, making it easy for both startups and large enterprises to deploy and scale their scraping efforts quickly. Whether you're monitoring price fluctuations, gathering review insights, or tracking inventory availability, TagX ensures precision and compliance every step of the way.
Key Features:
High-volume request support with 99.9% uptime.
Smart proxy rotation and CAPTCHA bypassing.
Real-time data scraping with low latency.
Easy-to-integrate with structured JSON/CSV outputs.
Comprehensive support for reviews, ratings, pricing, and more.
2. Zyte Amazon Scraper API
Zyte offers a comprehensive Amazon scraping solution tailored for businesses that need precision and performance. Known for its ultra-fast response times and nearly perfect success rate across millions of Amazon URLs, Zyte is an excellent choice for enterprise-grade projects. Its machine learning-powered proxy rotation and smart fingerprinting ensure you're always getting clean data, while dynamic parsing helps you retrieve exactly what you need—from prices and availability to reviews and ratings.
Key Features:
Ultra-reliable with 100% success rate on over a million Amazon URLs.
Rapid response speeds averaging under 200ms.
Smart proxy rotation powered by machine learning.
Dynamic data parsing for pricing, availability, reviews, and more.
3. Oxylabs Amazon Scraper API
Oxylabs delivers a high-performing API for Amazon data extraction, engineered for both real-time and bulk scraping needs. It supports dynamic JavaScript rendering, making it ideal for dealing with Amazon’s complex front-end structures. Robust proxy management and high reliability ensure smooth data collection for large-scale operations. Perfect for businesses seeking consistency and depth in their scraping workflows.
Key Features:
99.9% success rate on product pages.
Fast average response time (~250ms).
Offers both real-time and batch processing.
Built-in dynamic JavaScript rendering for tough-to-reach data.
4. Bright Data Amazon Scraper API
Bright Data provides a flexible and feature-rich API designed for heavy-duty Amazon scraping. It comes equipped with advanced scraping tools, including automatic CAPTCHA solving and JavaScript rendering, while also offering full compliance with ethical web scraping standards. It’s particularly favored by data-centric businesses that require validated, structured, and scalable data collection.
Key Features:
Automatic IP rotation and CAPTCHA solving.
Support for JavaScript rendering for dynamic pages.
Structured data parsing and output validation.
Compliant, secure, and enterprise-ready.
5. ScraperAPI
ScraperAPI focuses on simplicity and developer control, making it perfect for teams who want easy integration with their own tools. It takes care of all the heavy lifting—proxies, browsers, CAPTCHAs—so developers can focus on building applications. Its customization flexibility and JSON parsing capabilities make it a top choice for startups and mid-sized projects.
Key Features:
Smart proxy rotation and automatic CAPTCHA handling.
Custom headers and query support.
JSON output for seamless integration.
Supports JavaScript rendering for complex pages.
6. SerpApi Amazon Scraper
SerpApi offers an intuitive and lightweight API that is ideal for fetching Amazon product search results quickly and reliably. Built for speed, SerpApi is especially well-suited for real-time tasks and applications that need low-latency scraping. With flexible filters and multi-language support, it’s a great tool for localized e-commerce tracking and analysis.
Key Features:
Fast and accurate search result scraping.
Clean JSON output formatting.
Built-in CAPTCHA bypass.
Localized filtering and multi-region support.
Conclusion
In the ever-evolving digital commerce landscape, real-time Amazon data scraping can mean the difference between thriving and merely surviving. TagX’s Amazon Scraper API stands out as one of the most reliable and developer-friendly tools for seamless Amazon data extraction.
With a robust infrastructure, unmatched accuracy, and smooth integration, TagX empowers businesses to make smart, data-driven decisions. Its anti-blocking mechanisms, customizable endpoints, and developer-focused documentation ensure efficient, scalable scraping without interruptions.
Whether you're tracking Amazon pricing trends, monitoring product availability, or decoding consumer sentiment, TagX delivers fast, secure, and compliant access to real-time Amazon data. From agile startups to enterprise powerhouses, the platform grows with your business—fueling smarter inventory planning, better marketing strategies, and competitive insights.
Don’t settle for less in a competitive marketplace. Experience the strategic advantage of TagX—your ultimate Amazon scraping API.
Try TagX’s Amazon Scraper API today and unlock the full potential of Amazon data!
Original Source, https://www.tagxdata.com/amazon-scraper-api-made-easy-get-product-price-and-review-data
0 notes
Text
Why Businesses Need Reliable Web Scraping Tools for Lead Generation.
The Importance of Data Extraction in Business Growth
Efficient data scraping tools are essential for companies looking to expand their customer base and enhance their marketing efforts. Web scraping enables businesses to extract valuable information from various online sources, such as search engine results, company websites, and online directories. This data fuels lead generation, helping organizations find potential clients and gain a competitive edge.
Not all web scraping tools provide the accuracy and efficiency required for high-quality data collection. Choosing the right solution ensures businesses receive up-to-date contact details, minimizing errors and wasted efforts. One notable option is Autoscrape, a widely used scraper tool that simplifies data mining for businesses across multiple industries.

Why Choose Autoscrape for Web Scraping?
Autoscrape is a powerful data mining tool that allows businesses to extract emails, phone numbers, addresses, and company details from various online sources. With its automation capabilities and easy-to-use interface, it streamlines lead generation and helps businesses efficiently gather industry-specific data.
The platform supports SERP scraping, enabling users to collect information from search engines like Google, Yahoo, and Bing. This feature is particularly useful for businesses seeking company emails, websites, and phone numbers. Additionally, Google Maps scraping functionality helps businesses extract local business addresses, making it easier to target prospects by geographic location.
How Autoscrape Compares to Other Web Scraping Tools
Many web scraping tools claim to offer extensive data extraction capabilities, but Autoscrape stands out due to its robust features:
Comprehensive Data Extraction: Unlike many free web scrapers, Autoscrape delivers structured and accurate data from a variety of online sources, ensuring businesses obtain quality information.
Automated Lead Generation: Businesses can set up automated scraping processes to collect leads without manual input, saving time and effort.
Integration with External Tools: Autoscrape provides seamless integration with CRM platforms, marketing software, and analytics tools via API and webhooks, simplifying data transfer.
Customizable Lead Lists: Businesses receive sales lead lists tailored to their industry, each containing 1,000 targeted entries. This feature covers sectors like agriculture, construction, food, technology, and tourism.
User-Friendly Data Export: Extracted data is available in CSV format, allowing easy sorting and filtering by industry, location, or contact type.
Who Can Benefit from Autoscrape?
Various industries rely on web scraping tools for data mining and lead generation services. Autoscrape caters to businesses needing precise, real-time data for marketing campaigns, sales prospecting, and market analysis. Companies in the following sectors find Autoscrape particularly beneficial:
Marketing Agencies: Extract and organize business contacts for targeted advertising campaigns.
Real Estate Firms: Collect property listings, real estate agencies, and investor contact details.
E-commerce Businesses: Identify potential suppliers, manufacturers, and distributors.
Recruitment Agencies: Gather data on potential job candidates and hiring companies.
Financial Services: Analyze market trends, competitors, and investment opportunities.
How Autoscrape Supports Business Expansion
Businesses that rely on lead generation services need accurate, structured, and up-to-date data to make informed decisions. Autoscrape enhances business operations by:
Improving Customer Outreach: With access to verified emails, phone numbers, and business addresses, companies can streamline their cold outreach strategies.
Enhancing Market Research: Collecting relevant data from SERPs, online directories, and Google Maps helps businesses understand market trends and competitors.
Increasing Efficiency: Automating data scraping processes reduces manual work and ensures consistent data collection without errors.
Optimizing Sales Funnel: By integrating scraped data with CRM systems, businesses can manage and nurture leads more effectively.

Testing Autoscrape: Free Trial and Accessibility
For businesses unsure about committing to a web scraper tool, Autoscrapeoffers a free account that provides up to 100 scrape results. This allows users to evaluate the platform's capabilities before making a purchase decision.
Whether a business requires SERP scraping, Google Maps data extraction, or automated lead generation, Autoscrape delivers a reliable and efficient solution that meets the needs of various industries. Choosing the right data scraping tool is crucial for businesses aiming to scale operations and enhance their customer acquisition strategies.
Investing in a well-designed web scraping solution like Autoscrape ensures businesses can extract valuable information quickly and accurately, leading to more effective marketing and sales efforts.
0 notes
Text
Data/Web Scraping
What is Data Scraping ?
Data scraping is the process of extracting information from websites or other digital sources. It also Knows as web scraping.
Benefits of Data Scraping
1. Competitive Intelligence
Stay ahead of competitors by tracking their prices, product launches, reviews, and marketing strategies.
2. Dynamic Pricing
Automatically update your prices based on market demand, competitor moves, or stock levels.
3. Market Research & Trend Discovery
Understand what’s trending across industries, platforms, and regions.
4. Lead Generation
Collect emails, names, and company data from directories, LinkedIn, and job boards.
5. Automation & Time Savings
Why hire a team to collect data manually when a scraper can do it 24/7.
Who used Data Scraper ?

Businesses, marketers,E-commerce, travel,Startups, analysts,Sales, recruiters, researchers, Investors, agents Etc
Top Data Scraping Browser Extensions
Web Scraper.io
Scraper
Instant Data Scraper
Data Miner
Table Capture
Top Data Scraping Tools
BeautifulSoup
Scrapy
Selenium
Playwright
Octoparse
Apify
ParseHub
Diffbot
Custom Scripts
Legal and Ethical Notes

Not all websites allow scraping. Some have terms of service that forbid it, and scraping too aggressively can get IPs blocked or lead to legal trouble
Apply For Data/Web Scraping : https://www.fiverr.com/s/99AR68a
1 note
·
View note
Text
Get news data from Reuters using ScrapeStorm
Reuters is a world-renowned news agency headquartered in London, UK. It is known for its fast and accurate news reporting and comprehensive information services. It provides services to global media, financial institutions and corporate clients by collecting and publishing international news, financial information, commodity quotations, etc. Reuters has a long history and extensive influence in the field of news reporting and is one of the important sources of news in the world. Introduction to the scraping tool ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems. Preview of the scraped result Export to Excel:
This is the demo task: Google Drive: https://drive.google.com/file/d/1GpXlZl6BJyguTyAjR5Vfmbx4rrhgVwh6/view?usp=sharing OneDrive: https://1drv.ms/u/c/9c4ab62c874aba68/EdO2zHwH8j9Fgu20EE3XqwcBlxBSdxe40jnsnS5gDu8YwQ?e=Pt7IG1
Create a task (1) Copy the URL
(2) Create a new smart mode task You can create a new scraping task directly on the software, or you can create a task by importing rules. How to create a smart mode task How to import and export scraping task
Configure the scraping rules Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on. How to set the fields
Set up and start the scraping task (1) Run settings Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer. How to configure the scraping task
(2)Wait a moment, you will see the data being scraped.
Export and view data (1) Click "Export" to download your data.
(2) Choose the format to export according to your needs. ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress. How to view data and clear data How to export data
0 notes
Text
Choosing Between APIs vs Web Scraping Travel Data Tools
Introduction
The APIs vs Web Scraping Travel Data landscape presents critical decisions for businesses seeking comprehensive travel intelligence. This comprehensive analysis examines the strategic considerations between traditional API integrations and advanced web scraping methodologies for travel data acquisition. Based on extensive research across diverse travel platforms and data collection scenarios, this report provides actionable insights for organizations evaluating Scalable Travel Data Extraction solutions. The objective is to guide travel companies, OTAs, and data-driven businesses toward optimal data collection strategies that balance performance, cost-effectiveness, and operational flexibility. Modern travel businesses require sophisticated approaches to data acquisition, with both Web Scraping vs API Data Collection methodologies offering distinct advantages depending on specific use cases.
Shifting Paradigms in Travel Data Collection Methods
The landscape of travel data collection has evolved significantly with the emergence of sophisticated API vs Scraper for Ota Data solutions. The primary drivers shaping this evolution include the increasing demand for real-time information, the growing complexity of travel platforms, and the need for scalable data infrastructure that can handle massive volumes of travel-related content.
Travel Data Scraping Services have become increasingly sophisticated, allowing businesses to extract comprehensive datasets from multiple sources simultaneously. These services provide granular access to pricing information, availability data, customer reviews, and promotional content across various travel platforms.
Meanwhile, API-based solutions offer structured access to travel data through official channels, providing more reliable and consistent data streams. Integrating machine learning and artificial intelligence has enhanced both approaches, enabling more intelligent data extraction and processing capabilities that support Scalable Travel Data Extraction requirements.
Methodology and Scope of Data Analysis
The data for this report was collected through comprehensive testing of API and web scraping approaches across 100+ travel platforms worldwide. By systematically evaluating Data Scraping vs API Travel Sites, we analyzed performance metrics, cost structures, implementation complexity, and data quality across major booking platforms, including Booking.com, Expedia, Airbnb, and specialized Travel Aggregates.
We evaluated both methods across key parameters—data freshness, extraction speed, scalability, and maintenance. Our Custom Travel Data Solutions framework also considered data accuracy, update frequency, cost-efficiency, and technical complexity to ensure a well-rounded comparison.
Key Factors Influencing Data Collection Strategy Selection
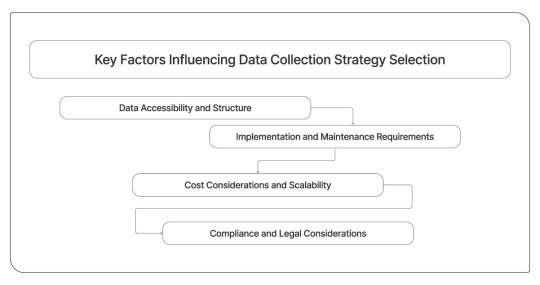
Understanding these factors is essential for making informed decisions about Real-Time Travel Data Collection strategies.
Data Accessibility and Structure
Implementation and Maintenance Requirements
Cost Considerations and Scalability
Compliance and Legal Considerations
Table 1: Performance Comparison - APIs vs Web Scraping Methods
MetricAPI ApproachWeb Scraping ApproachHybrid SolutionData Accuracy Rate98.5%92.3%96.8%Average Response Time (ms)2501,200450Implementation Time (hours)4012080Monthly Maintenance (hours)52515Data Coverage Completeness75%95%90%Cost per 1M Requests ($)15050100
Description
This analysis highlights the trade-offs in data collection: APIs deliver speed and reliability, while web scraping ensures broader coverage at lower upfront costs. For effective implementation of Custom Travel Data Solutions, it’s essential to weigh these factors. APIs suit high-accuracy, time-sensitive needs while scraping offers scalable data access with more maintenance. Hybrid models blend both for robust, enterprise-ready performance.
Challenges and Opportunities in Travel Data Collection
Modern travel businesses face complex decisions when implementing data collection strategies. While APIs provide stability and official support, they may limit access to comprehensive competitive intelligence and real-time market insights that drive strategic decisions.
Rate limiting represents a significant challenge for API-based approaches, particularly for businesses requiring high-volume data collection for Travel Review Data Intelligence and market analysis. Additionally, API availability varies significantly across platforms, with some major travel sites offering limited or no official API access.
Web scraping presents technical challenges, including anti-bot measures, dynamic content loading, and frequent website modifications that require ongoing technical maintenance. However, it offers unparalleled flexibility for accessing comprehensive datasets and competitive intelligence.
Growing demand for adaptive, intelligent data collection is reshaping the market. Businesses leveraging advanced strategies like Travel Data Intelligence gain faster insights and a sharper edge by staying ahead of shifting trends.
Table 2: Regional Data Collection Trends and Projections
RegionAPI AdoptionScraping Usage RateHybrid ImplementationGrowth ProjectionNorth America65%85%45%22%Europe70%80%50%28%Asia Pacific55%90%35%35%Latin America45%75%25%18%
Description
Regional trends show varied adoption of the Travel Scraping API, driven by local regulations and tech infrastructure. Asia-Pacific leads in growth potential, North America shows strong API usage, and Europe excels in hybrid strategies, balancing compliance with deep market insights. Overall, the demand for advanced data collection is rising globally.
Future Directions in Travel Data Collection

The future of data collection lies in smarter systems that elevate API and web scraping efficiency. By embedding advanced machine learning into extraction workflows, businesses can boost accuracy and reduce upkeep, benefiting platforms like Travel Scraping API and beyond.
The emergence of standardized travel data formats and industry-wide API initiatives suggests a future where structured data access becomes more universally available. However, the continued importance of comprehensive competitive intelligence ensures that web scraping will remain a critical component of enterprise data strategies.
Cloud-based data collection tools level the playing field, empowering small businesses to adopt enterprise-grade solutions without needing heavy infrastructure. This shift enhances capabilities like Travel Review Data Intelligence and broadens access to scalable data extraction.
Conclusion
The decision between APIs vs Web Scraping Travel Data depends on specific business requirements, technical capabilities, and strategic objectives. This report, through a comprehensive analysis of both approaches, demonstrates that neither methodology provides a universal solution for all travel data collection needs.
Travel Aggregators and major booking platforms continue to evolve their data access policies, creating new opportunities and challenges for data collection strategies. The most successful implementations often combine both approaches, leveraging APIs for core operational data while utilizing Travel Industry Web Scraping for comprehensive market intelligence.
Contact Travel Scrape today to discover how our advanced data collection solutions can transform your travel business intelligence and drive competitive advantage in the dynamic travel industry.
Read More :- https://www.travelscrape.com/apis-vs-web-scraping-travel-data.php
#APIsVsWebScrapingTravelData#ScalableApproachToDataCollection#TravelDataScrapingServices#CustomTravelDataSolutions#TravelDataIntelligence#TravelScrapingAPI#TravelReviewDataIntelligence#TravelAggregators#TravelIndustryWebScraping
0 notes
Text
Lawyer Data Scraping Services: Unlocking Legal Insights with Automation
The legal industry thrives on accurate and up-to-date information. Whether you’re a law firm, legal researcher, or a business seeking legal insights, having access to comprehensive lawyer data can be a game-changer. This is where lawyer data scraping services come into play, offering an efficient way to collect, analyze, and utilize legal data.

What is Lawyer Data Scraping?
Lawyer data scraping is the process of extracting publicly available information about attorneys, law firms, case histories, and legal precedents from various online sources. This automated technique eliminates the need for manual research, saving time and ensuring accuracy in data collection.
Benefits of Lawyer Data Scraping Services
1. Comprehensive Legal Research
With automated data scraping, legal professionals can gather extensive information about attorneys, case laws, and judicial decisions, allowing for better legal analysis and strategy development.
2. Competitor Analysis for Law Firms
Law firms can monitor competitors by collecting insights on their practice areas, client reviews, and success rates, enabling data-driven decision-making.
3. Efficient Lead Generation
Businesses seeking legal services can use lawyer data scraping to identify the best legal professionals based on expertise, reviews, and geographical location.
4. Regulatory and Compliance Monitoring
Stay updated with changing legal landscapes by tracking regulatory updates, compliance policies, and amendments in various jurisdictions.
How Lawyer Data Scraping Services Work
Professional web scraping services extract legal data by:
Collecting information from lawyer directories, bar association websites, and court records.
Structuring data in a user-friendly format for easy analysis.
Ensuring compliance with ethical data extraction practices.
Other Data Scraping Solutions for Various Industries
In addition to legal data, businesses can benefit from other data scraping services such as:
Flipkart dataset: Extract product details, pricing trends, and customer reviews for eCommerce analysis.
Web scraping Zillow: Gain real estate insights with property listings, pricing trends, and neighborhood analytics.
Extract large-scale data: Automate massive data extraction for enhanced business intelligence and market research.
Google Shopping scraper: Analyze competitor pricing, product availability, and customer reviews to refine your eCommerce strategies.
Conclusion
Lawyer data scraping services empower law firms, researchers, and businesses with critical legal insights. By automating data collection, professionals can make informed decisions, improve efficiency, and stay ahead in the legal industry. Explore lawyer data scraping solutions today and unlock a world of legal intelligence!
For expert data scraping solutions tailored to various industries, contact Actowiz Solutions today!
#awyer data scraping services#Flipkart dataset#Web scraping Zillow#Extract large-scale data#Google Shopping scraper#lawyer data scraping solutions
0 notes
Text
Top 6 Scraping Tools That You Cannot Miss in 2024
In today's digital world, data is like money—it's essential for making smart decisions and staying ahead. To tap into this valuable resource, many businesses and individuals are using web crawler tools. These tools help collect important data from websites quickly and efficiently.
What is Web Scraping?
Web scraping is the process of gathering data from websites. It uses software or coding to pull information from web pages, which can then be saved and analyzed for various purposes. While you can scrape data manually, most people use automated tools to save time and avoid errors. It’s important to follow ethical and legal guidelines when scraping to respect website rules.
Why Use Scraping Tools?
Save Time: Manually extracting data takes forever. Web crawlers automate this, allowing you to gather large amounts of data quickly.
Increase Accuracy: Automation reduces human errors, ensuring your data is precise and consistent.
Gain Competitive Insights: Stay updated on market trends and competitors with quick data collection.
Access Real-Time Data: Some tools can provide updated information regularly, which is crucial in fast-paced industries.
Cut Costs: Automating data tasks can lower labor costs, making it a smart investment for any business.
Make Better Decisions: With accurate data, businesses can make informed decisions that drive success.
Top 6 Web Scraping Tools for 2024
APISCRAPY
APISCRAPY is a user-friendly tool that combines advanced features with simplicity. It allows users to turn web data into ready-to-use APIs without needing coding skills.
Key Features:
Converts web data into structured formats.
No coding or complicated setup required.
Automates data extraction for consistency and accuracy.
Delivers data in formats like CSV, JSON, and Excel.
Integrates easily with databases for efficient data management.
ParseHub
ParseHub is great for both beginners and experienced users. It offers a visual interface that makes it easy to set up data extraction rules without any coding.
Key Features:
Automates data extraction from complex websites.
User-friendly visual setup.
Outputs data in formats like CSV and JSON.
Features automatic IP rotation for efficient data collection.
Allows scheduled data extraction for regular updates.
Octoparse
Octoparse is another user-friendly tool designed for those with little coding experience. Its point-and-click interface simplifies data extraction.
Key Features:
Easy point-and-click interface.
Exports data in multiple formats, including CSV and Excel.
Offers cloud-based data extraction for 24/7 access.
Automatic IP rotation to avoid blocks.
Seamlessly integrates with other applications via API.
Apify
Apify is a versatile cloud platform that excels in web scraping and automation, offering a range of ready-made tools for different needs.
Key Features:
Provides pre-built scraping tools.
Automates web workflows and processes.
Supports business intelligence and data visualization.
Includes a robust proxy system to prevent access issues.
Offers monitoring features to track data collection performance.
Scraper API
Scraper API simplifies web scraping tasks with its easy-to-use API and features like proxy management and automatic parsing.
Key Features:
Retrieves HTML from various websites effortlessly.
Manages proxies and CAPTCHAs automatically.
Provides structured data in JSON format.
Offers scheduling for recurring tasks.
Easy integration with extensive documentation.
Scrapy
Scrapy is an open-source framework for advanced users looking to build custom web crawlers. It’s fast and efficient, perfect for complex data extraction tasks.
Key Features:
Built-in support for data selection from HTML and XML.
Handles multiple requests simultaneously.
Allows users to set crawling limits for respectful scraping.
Exports data in various formats like JSON and CSV.
Designed for flexibility and high performance.
Conclusion
Web scraping tools are essential in today’s data-driven environment. They save time, improve accuracy, and help businesses make informed decisions. Whether you’re a developer, a data analyst, or a business owner, the right scraping tool can greatly enhance your data collection efforts. As we move into 2024, consider adding these top web scraping tools to your toolkit to streamline your data extraction process.
0 notes