#web scraping with AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Text
Enhance Data Extraction with AI for Smarter Insights
In today’s data-driven world, businesses need efficient ways to gather and process vast amounts of information. Traditional data extraction methods can be time-consuming and prone to errors, making AI-powered solutions a game-changer. By integrating artificial intelligence, companies can enhance data extraction with AI, leading to faster, more accurate, and scalable data collection processes.

The Power of AI in Data Extraction
Artificial intelligence is transforming how data is collected and analyzed. Unlike conventional scraping techniques, AI-powered extraction adapts to changes in website structures, understands unstructured data, and ensures high accuracy. Businesses leveraging AI can:
Automate Data Collection: Reduce manual efforts and speed up data processing.
Improve Accuracy: AI algorithms minimize errors by intelligently recognizing patterns.
Scale Efficiently: Handle large datasets with ease, making data extraction more reliable.
To explore how AI enhances web scraping, check out our detailed insights on web scraping with AI.
Why Businesses Need AI-Driven Data Extraction
Industries across various sectors rely on high-quality data for decision-making. Whether tracking competitor prices, monitoring customer sentiment, or extracting market trends, AI-powered data extraction offers unmatched efficiency. Here are some use cases:
1. E-commerce and Retail
Companies can extract real-time promotions data to stay ahead of market trends and offer competitive pricing. Learn more about how AI can help businesses extract real-time promotions data.
2. Real Estate Market Insights
AI-driven tools streamline real estate data scraping services, helping businesses gather property listings, pricing trends, and investment opportunities. Find out how our real estate data scraping services provide valuable insights.
3. Grocery and Retail Analytics
AI-powered scraping solutions can track grocery sales trends and consumer behavior. Check out how we analyze the Blinkit sales dataset for deeper business insights.
How Professional Web Scraping Enhances AI Integration
A key aspect of AI-driven data extraction is leveraging professional web scraping solutions. These services ensure seamless data retrieval, improved data quality, and real-time analytics, enabling businesses to make data-backed decisions efficiently.
Conclusion
Enhancing data extraction with AI is no longer a luxury but a necessity for businesses looking to stay competitive. AI-powered solutions offer automation, accuracy, and scalability, transforming raw data into actionable insights. Ready to leverage AI for your data needs? Explore our web scraping solutions today!
#web scraping with AI#extract real-time promotions data#real estate data scraping services#Blinkit sales dataset#professional web scraping
0 notes
Text

The man and his flower
#pokemon fanart#pokemon#my art#az pokemon#trainer az#pokemon az#eternal flower floette#az floette#pokemon x and y#pokemon xy#i recently found out about art shield and rgbwatermark which can help you with adding watermarks and such in preventing ai scraping off.#you can kinda see some circle patterns if you look closely#worth checking them out esp if you are unable to use/have not yet access (web)glaze!
223 notes
·
View notes
Text
Finally finished the website version of my fic poisoning tool! Since there doesn't seem to be a good way to stop web scrapers from actually accessing my stuff on Ao3, I figured, why not feed the AI some junk if they're gonna be taking it without permission?
I made a command line tool a little while ago, but imo the website version is way more convenient to use. Just copy, paste, and you're pretty much done. If you have any questions or issues with it then let me know!
#anti ai#ao3#went over things pretty briefly here bcs theres more info on the website#if you have any initial questions be sure to read the stuff there first please#no idea what to tag this tbh. down with unauthorized web scraping!!#lets all make ao3 as unappealing to scrapers as possible <3
13 notes
·
View notes
Text
Cloudflare AI Bot Blocker: A Game-Changer for Web Publishers
Introduction The digital publishing world is fighting back against unauthorized AI data scraping. With the launch of the Cloudflare AI bot blocker, over a million websites—including media giants like Sky News and Buzzfeed—can now block AI bots from collecting content without consent. This transformative tool gives creators the control they’ve long demanded over their digital work. Why Is…
#AI bot blocker#AI content scraping#AI copyright#AI paywall model#BBC AI legal threats#Cloudflare#Cloudflare AI bot blocker#content scraping defense#digital publishing#how to block AI crawlers#Matthew Prince#online publishers#Perplexity AI#web crawler protection
5 notes
·
View notes
Text
Ao3 was scraped for a GenAI dataset in the last few days (April 2025). If you have public works, they are likely a part of the dataset.
I’ve kept all of my Hidden Love fics open, trying to keep accessibility easy for out-of-country readers, so this makes me sad.
Here is a Reddit thread with additional information.
I’m tired.
4 notes
·
View notes
Text
🚚 AI-Scraped Insights for #QCommerce Delivery Time Optimization in #Singapore

In the hyper-competitive world of quick commerce, speed is everything. But what if your 10-minute delivery promise could be backed by real-time, #AIpoweredInsights?
Actowiz Solutions helps Q-commerce platforms in Singapore unlock:
✅ Zone-wise delivery performance
✅ Bottleneck identification across SKUs & hubs
✅ Competitor delivery benchmarks
✅ Predictive insights to reduce delivery lag
By combining AI models with live #DeliveryDataScraping, Q-commerce brands can ensure consistency, outperform rivals, and deliver delight—every time.
📊 Want to optimize your last-mile execution?
🔗 Read the full case study:
1 note
·
View note
Text
ARTOBER DAY 17: A Warning to AI Thieves & Greedy Jerks
A fun goofy little pic with a warning for anybody (including this dumbass site) thinking of doing the scraping thing...
This Creator likes poisoning his data.

ռʊʀɢʟɛ is most welcome in these halls, servants of the Corpse God.
Also, say hi to my little Chaos Omni-Imp! If you're excited for my upcoming Space Marine Fancomic...

... then you'll probably get to see 'im in the future as a little easter egg~
#my ocs#fan comic#fanart#oc#oc art#small artist#artists on tumblr#ai scraping#ai scam#artober#day 17#web comic#nurgle#plaguefather#Chaos Demons#Imp#Chaos Horror#Chaos Fury#traitor astartes#Chaos Marines#heretic astartes#Havoc Brothers#warhammer 40k#warhammer 40000#warhammer art#warhammer fanart#one page rules#Grimdark Future
4 notes
·
View notes
Text
I think that if a person knows that something was made using trained on unethically sourced data AI. And still uses it/likes it/supports it/defends it.
Then said person should stop "being mad" when their data is used to train AI without consent.
#nitunio.txt#please dont half-ass it in terms of not supporting this stuff#if you like and willingly use writing AI that scrapes web without consent#then turn around and say 'wahh AI bad' when it concerns digital art. you're just a hypocrite#same goes for photos and music and other creative work#if you come across any 'machine learning AI generation' website immediately go to their FAQ or About sections#just see for yourself if they provide any sources for the data they've used and if it was consensual and only after that#ask yourself if you should be using it or just make something yourself#hell you can even ask somebody or pay somebody to do something you can't do. thats the joy of community#and even then there are many resources that were already made to be used for free with or without credit#i ramble a lot about things like these bc i cant just wrap my head around it#i just need all of these scraped datasets to burn down and self-delete
2 notes
·
View notes
Text
done on my mobile app! There may be uses for A.I. (I remain unconvinced): this shit is not it.

They are already selling data to midjourney, and it's very likely your work is already being used to train their models because you have to OPT OUT of this, not opt in. Very scummy of them to roll this out unannounced.
98K notes
·
View notes
Text
Data at Scale: Ranking the Top 5 Tools for High-Volume, Cross-Platform Web Harvesting in 2025
Data collection has become a cornerstone of business intelligence, market research, and academic studies. For global users requiring advanced automation, cross-platform compatibility, and enterprise-grade scalability, here are the top 5 tools reshaping the data acquisition landscape:
1. ScrapeStorm (China-origin, Global Dominance)
Core Strength: AI-Powered No-Code Automation ScrapeStorm leads with its proprietary "Self-learning Scraping Engine", enabling users to extract structured data from complex websites without writing code. The tool automatically detects pagination, login requirements, and dynamic content rendering through machine learning algorithms.
Key Features:
Multi-language Support: Handles 240+ languages including RTL scripts
Visual Workflow Builder: Drag-and-drop interface for complex scraping logic
Enterprise Security: SOC 2 compliance and AES-256 data encryption
Cloud Deployment: Scalable infrastructure supporting 10M+ daily requests
Use Case: A multinational retail chain used ScrapeStorm to monitor competitor pricing across 15 countries, achieving 98.7% accuracy in dynamic price tracking with its anti-blocking technology.
2. Import.io (Enterprise Web Data Platform)
Core Strength: API-First Architecture This veteran platform specializes in transforming web data into machine-readable APIs. Its Web Data Integration (WDI) Suite allows real-time data pipeline creation without infrastructure management.
Key Features:
Instant API Generation: Convert any webpage into a RESTful endpoint
Predictive Scheduling: AI-driven crawl frequency optimization
Data Quality Assurance: Automated anomaly detection and correction
Enterprise SLA: 99.99% uptime guarantee with dedicated account management
Use Case: A global investment firm automated SEC filings extraction using Import.io's regulatory compliance module, reducing data processing time from 16 hours to 8 minutes per document.
3. Octoparse (Dynamic Content Specialist)
Core Strength: JavaScript Rendering Mastery Octoparse excels at handling modern web frameworks with its Headless Chrome Engine, capable of executing complex client-side scripts while maintaining human-like browsing patterns.
Key Features:
Cloud Extraction: Distributed crawling across 200+ global nodes
IP Rotation: 10M+ residential proxy pool with automatic retry logic
OCR Integration: Extract text from images and CAPTCHAs
Workflow Templates: Pre-built solutions for e-commerce, real estate, and social media
Use Case: An AI training data provider used Octoparse to collect 500,000 product images with metadata from Amazon, achieving 95% success rate despite anti-scraping measures.
4. ParseHub (Developer-Grade Flexibility)
Core Strength: Programmatic Control ParseHub offers granular control through its Select & Transform engine, allowing developers to precisely target DOM elements using CSS selectors and XPath expressions.
Key Features:
Browser Extension: Real-time element selection without switching tools
Interactive Debugging: Step-by-step execution visualization
Webhook Integration: Direct data推送 to Slack, Google Sheets, or custom endpoints
Version Control: Git-compatible workflow management
Use Case: A travel aggregator built a real-time flight price comparison engine using ParseHub's scheduled crawls, capturing 200+ airlines' fare data with sub-minute latency.
5. Apify (Serverless Scraping Infrastructure)
Core Strength: Full-Stack Automation Apify provides a complete serverless environment for web data operations through its Actor System, combining scraping, data transformation, and delivery in a unified platform.
Key Features:
Actor Marketplace: 1,200+ pre-built scraping templates
Proxy Network: 100M+ rotating residential IPs with country-level targeting
Data Storage: Built-in key-value store and dataset management
Webhook Alerts: Real-time notifications for data changes
Use Case: A market research firm automated 50,000 company profile updates daily using Apify's LinkedIn scraper, maintaining compliance with platform TOS through its ethical scraping policies.
Selection Criteria
These tools were evaluated based on:
Technical Sophistication: AI/ML capabilities, anti-blocking technologies
Enterprise Readiness: Compliance certifications, uptime guarantees
Global Reach: Multi-region proxy networks, language support
Ecosystem Integration: API availability, third-party service connections
Scalability: From small-scale projects to petabyte-level operations
For organizations requiring mission-critical data pipelines, these tools represent the pinnacle of modern web data extraction technology, combining cutting-edge automation with enterprise-grade reliability.
#web scraping#web data extractor#web scraping tools#web crawlers#data scraping#ai scraping#web crawling
0 notes
Text
Effortless Google AI Mode Scraping with Scrapingdog API
Discover a simple and effective way to scrape Google AI Mode using Scrapingdog API. Get real-time data fast without worrying about proxies or captchas.
0 notes
Text
The foundational deal of the modern web, a handshake agreement that powered two decades of search and content, is officially dead. Cloudflare just put a price on scraping the internet, and it’s coming for artificial intelligence’s free lunch.
Almost 30 years ago, two Stanford grad students, Larry Page and Sergey Brin, built Google on a simple bargain: content creators would let them copy the entire web in exchange for traffic. For years, that traffic powered ad revenue, subscriptions, and the growth of online media. Google mostly upheld its end of the deal. But that era is collapsing under the weight of AI.
On July 1, Cloudflare, one of the internet’s core infrastructure companies, declared “Content Independence Day.” In a landmark policy shift, the company announced it will now block AI crawlers from scraping sites hosted on its platform unless those bots pay content creators for the data they consume.
...
0 notes
Text
Latest updates from OP:
SO HERE IS THE WHOLE STORY (SO FAR).
I am on my knees begging you to reblog this post and to stop reblogging the original ones I sent out yesterday. This is the complete account with all the most recent info; the other one is just sending people down senselessly panicked avenues that no longer lead anywhere.
IN SHORT
Cliff Weitzman, CEO of Speechify and (aspiring?) voice actor, used AI to scrape thousands of popular, finished works off AO3 to list them on his own for-profit website and in his attached app. He did this without getting any kind of permission from the authors of said work or informing AO3. Obviously.
When fandom at large was made aware of his theft and started pushing back, Weitzman issued a non-apology on the original social media posts—using
his dyslexia;
his intent to implement a tip-system for the plagiarized authors; and
a sudden willingness to take down the work of every author who saw my original social media posts and emailed him individually with a ‘valid’ claim,
as reasons we should allow him to continue monetizing fanwork for his own financial gain.
When we less-than-kindly refused, he took down his ‘apologies’ as well as his website (allegedly—it’s possible that our complaints to his web host, the deluge of emails he received or the unanticipated traffic brought it down, since there wasn’t any sort of official statement made about it), and when it came back up several hours later, all of the work formerly listed in the fan fiction category was no longer there.
THE TAKEAWAYS
1. Cliff Weitzman (aka Ofek Weitzman) is a scumbag with no qualms about taking fanwork without permission, feeding it to AI and monetizing it for his own financial gain;
2. Fandom can really get things done when it wants to, and
3. Our fanworks appear to be hidden, but they’re NOT DELETED from Weitzman’s servers, and independently published, original works are still listed without the authors' permission. We need to hold this man responsible for his theft, keep an eye on both his current and future endeavors, and take action immediately when he crosses the line again.
THE TIMELINE, THE DETAILS, THE SCREENSHOTS (behind the cut)
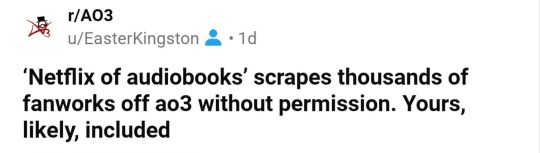
Sunday night, December 22nd 2024, I noticed an influx in visitors to my fic You & Me & Holiday Wine. When I searched the title online, hoping to find out where they came from, a new listing popped up (third one down, no less):

This listing is still up today, by the way, though now when you follow the link to word-stream, it just brings you to the main site. (Also, to be clear, this was not the cause for the influx of traffic to my fic; word-stream did not link back to the original work anywhere.)
I followed the link to word-stream, where to my horror Y&M&HW was listed in its entirety—though, beyond the first half of the first chapter, behind a paywall—along with a link promising to take me—through an app downloadable on the Apple Store—to an AI-narrated audiobook version. When I searched word-stream itself for my ao3 handle I found both of my multi-chapter fics were listed this way:
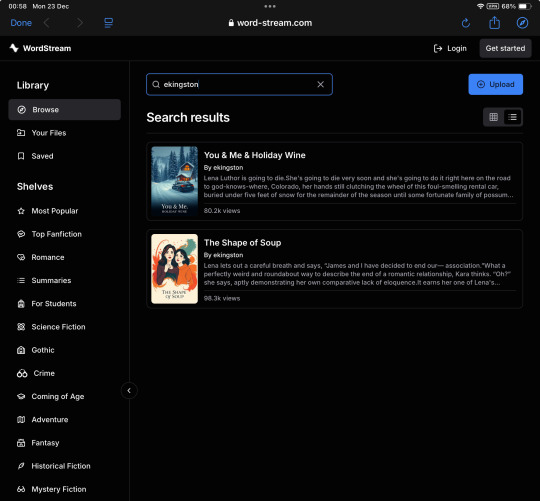
Because the tags on my fics (which included genres* and characters, but never the original IPs**) weren’t working, I put ‘Kara Danvers’ into the search bar and discovered that many more supercorp fics (Supergirl TV fandom, Kara Danvers/Lena Luthor pairing) were listed.
I went looking online for any mention of word-stream and AI plagiarism (the covers—as well as the ridiculously inflated number of reviews and ratings—made it immediately obvious that AI fuckery was involved), but found almost nothing: only one single Reddit post had been made, and it received (at that time) only a handful of upvotes and no advice.
I decided to make a tumblr post to bring the supercorp fandom up to speed about the theft. I draw as well as write for fandom and I’ve only ever had to deal with art theft—which has a clear set of steps to take depending on where said art was reposted—and I was at a loss regarding where to start in this situation.
After my post went up I remembered Project Copy Knight, which is worth commending for the work they’ve done to get fic stolen from AO3 taken down from monetized AI 'audiobook’ YouTube accounts. I reached out to @echoekhi, asking if they’d heard of this site and whether they could advise me on how to get our works taken down.

While waiting for a reply I looked into Copy Knight’s methods and decided to contact OTW’s legal department:
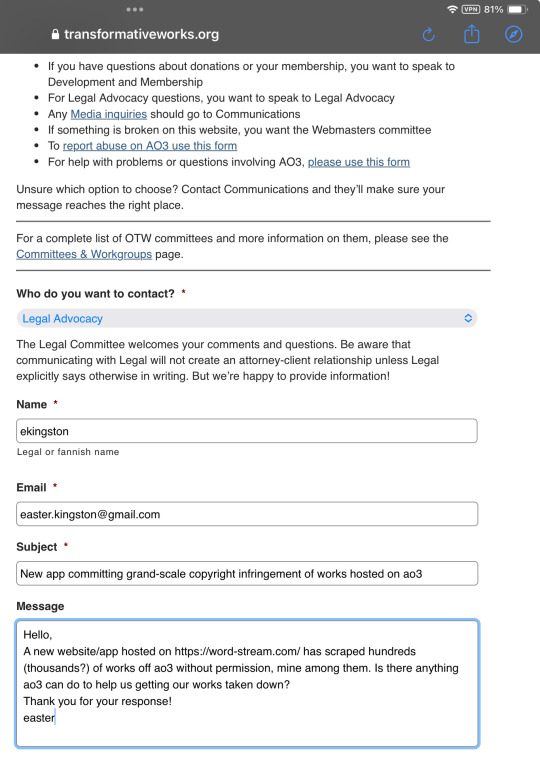
And then I went to bed.
By morning, tumblr friends @makicarn and @fazedlight as well as a very helpful tumblr anon had seen my post and done some very productive sleuthing:

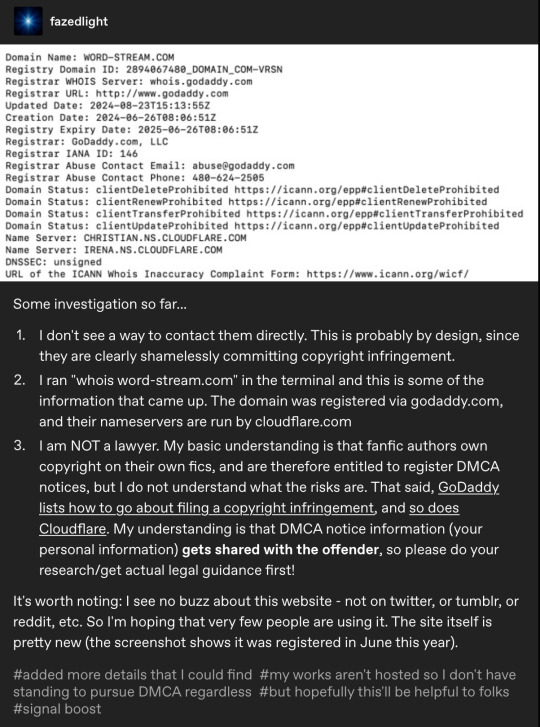
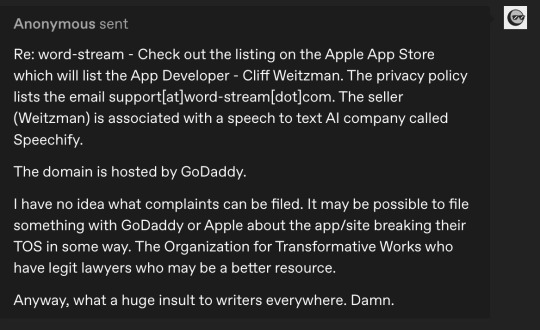
@echoekhi had also gotten back to me, advising me, as expected, to contact the OTW. So I decided to sit tight until I got a response from them.
That response came only an hour or so later:
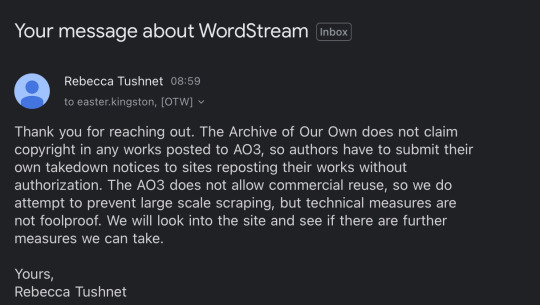
Which was 100% understandable, but still disappointing—I doubted a handful of individual takedown requests would accomplish much, and I wasn’t eager to share my given name and personal information with Cliff Weitzman himself, which is unavoidable if you want to file a DMCA.
I decided to take it to Reddit, hoping it would gain traction in the wider fanfic community, considering so many fandoms were affected. My Reddit posts (with the updates at the bottom as they were emerging) can be found here and here.
A helpful Reddit user posted a guide on how users could go about filing a DMCA against word-stream here (to wobbly-at-best results)
A different helpful Reddit user signed up to access insight into word-streams pricing. Comment is here.
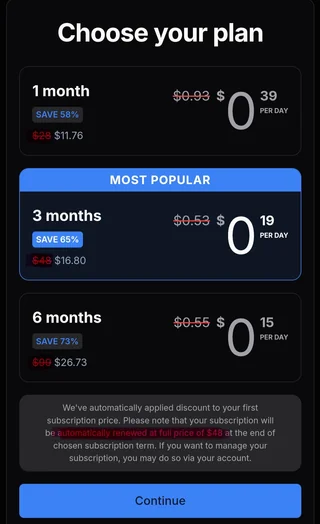
Smells unbelievably scammy, right? In addition to those audacious prices—though in all fairness any amount of money would be audacious considering every work listed is accessible elsewhere for free—my dyscalculia is screaming silently at the sight of that completely unnecessary amount of intentionally obscured numbers.
Speaking of which! As soon as the post on r/AO3—and, as a result, my original tumblr post—began taking off properly, sometime around 1 pm, jumpscare! A notification that a tumblr account named @cliffweitzman had commented on my post, and I got a bit mad about the gist of his message :
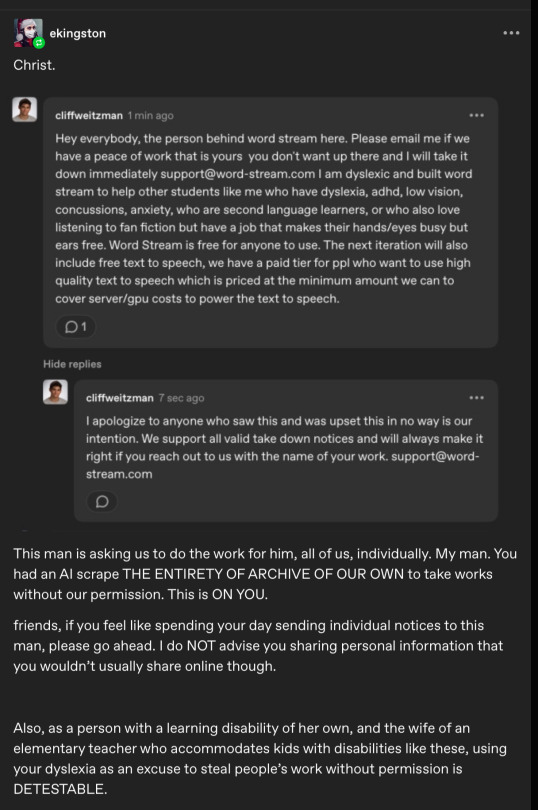
Fortunately he caught plenty of flack in the comments from other users (truly you should check out the comment section, it is extremely gratifying and people are making tremendously good points), in response to which, of course, he first tried to both reiterate and renegotiate his point in a second, longer comment (which I didn’t screenshot in time so I’m sorry for the crappy notification email formatting):

which he then proceeded to also post to Reddit (this is another Reddit user’s screenshot, I didn’t see it at all, the notifications were moving too fast for me to follow by then)
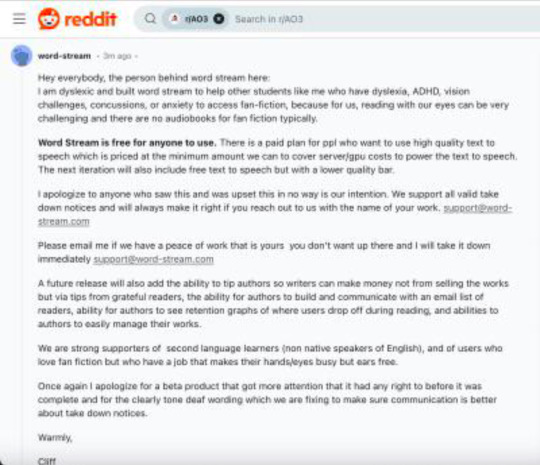
... where he got a roughly equal amount of righteously furious replies. (Check downthread, they're still there, all the way at the bottom.)
After which Cliff went ahead & deleted his messages altogether.
It’s not entirely clear whether his account was suspended by Reddit soon after or whether he deleted it himself, but considering his tumblr account is still intact, I assume it’s the former. He made a handful of sock puppet accounts to play around with for a while, both on Reddit and Tumblr, only one of which I have a screenshot of, but since they all say roughly the same thing, you’re not missing much:
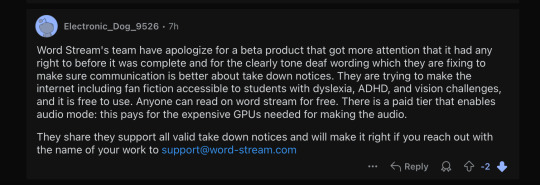
And then word-stream started throwing a DNS error.
That lasted for a good number of hours, which was unfortunately right around the time that a lot of authors first heard about the situation and started asking me individually how to find out whether their work was stolen too. I do not have that information and I am unclear on the perimeters Weitzman set for his AI scraper, so this is all conjecture: it LOOKS like the fics that were lifted had three things in common:
They were completed works;
They had over several thousand kudos on AO3; and
They were written by authors who had actively posted or updated work over the past year.
If anyone knows more about these perimeters or has info that counters my observation, please let me know!
I finally thought to check/alert evil Twitter during this time, and found out that the news was doing the rounds there already. I made a quick thread summarizing everything that had happened just in case. You can find it here.
I went to Bluesky too, where fandom was doing all the heavy lifting for me already, so I just reskeeted, as you do, and carried on.
Sometime in the very early evening, word-stream went back up—but the fan fiction category was nowhere to be seen. Tentative joy and celebration!***
That’s when several users—the ones who had signed up for accounts to gain intel and had accessed their own fics that way—reported that their work could still be accessed through their history. Relevant Reddit post here.
Sooo—
We’re obviously not done. The fanwork that was stolen by Weitzman may be inaccessible through his website right now, but they aren’t actually gone. And the fact that Weitzman wasn’t willing to get rid of them altogether means he still has plans for them.
This was my final edit on my Reddit post before turning off notifications, and it's pretty much where my head will be at for at least the foreseeable future:
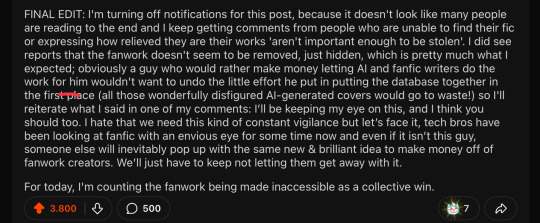
Please feel free to add info in the comments, make your own posts, take whatever action you want to take to protect your work. I only beg you—seriously, I’m on my knees here—to not give up like I saw a handful of people express the urge to do. Keep sharing your creative work and remain vigilant and stay active to make sure we can continue to do so freely. Visit your favorite fics, and the ones you’ve kept in your ‘marked for later’ lists but never made time to read, and leave kudos, leave comments, support your fandom creatives, celebrate podficcers and support AO3. We created this place and it’s our responsibility to keep it alive and thriving for as long as we possibly can.
Also FUCK generative AI. It has NO place in fandom spaces.
THE 'SMALL' PRINT (some of it in all caps):
*Weitzman knew what he was doing and can NOT claim ignorance. One, it’s pretty basic kindergarten stuff that you don’t steal some other kid’s art project and present it as your own only to act surprised when they protest and then tell the victim that they should have told you sooner that they didn’t want their project stolen. And two, he was very careful never to list the IPs these fanworks were based on, so it’s clear he was at least familiar enough with the legalities to not get himself in hot water with corporate lawyers. Fucking over fans, though, he figured he could get away with that.
**A note about the AI that Weitzman used to steal our work: it’s even greasier than it looks at first glance. It’s not just the method he used to lift works off AO3 and then regurgitate onto his own website and app. Looking beyond the untold horrors of his AI-generated cover ‘art’, in many cases these covers attempt to depict something from the fics in question that can’t be gleaned from their summaries alone. In addition, my fics (and I assume the others, as well) were listed with generated genres; tags that did not appear anywhere in or on my fic on AO3 and were sometimes scarily accurate and sometimes way off the mark. I remember You & Me & Holiday Wine had ‘found family’ (100% correct, but not tagged by me as such) and I believe The Shape of Soup was listed as, among others, ‘enemies to friends to lovers’ and ‘love triangle’ (both wildly inaccurate). Even worse, not all the fic listed (as authors on Reddit pointed out) came with their original summaries at all. Often the entire summary was AI-generated. All of these things make it very clear that it was an all-encompassing scrape—not only were our fics stolen, they were also fed word-for-word into the AI Weitzman used and then analyzed to suit Weitzman’s needs. This means our work was literally fed to this AI to basically do with whatever its other users want, including (one assumes) text generation.
***Fan fiction appears to have been made (largely) inaccessible on word-stream at this time, but I’m hearing from several authors that their original, independently published work, which is listed at places like Kindle Unlimited, DOES still appear in word-stream’s search engine. This obviously hurts writers, especially independent ones, who depend on these works for income and, as a rule, don’t have a huge budget or a legal team with oceans of time to fight these battles for them. If you consider yourself an author in the broader sense, beyond merely existing online as a fandom author, beyond concerns that your own work is immediately at risk, DO NOT STOP MAKING NOISE ABOUT THIS.
Again, please, please PLEASE reblog this post instead of the one I sent originally. All the information is here, and it's driving me nuts to see the old ones are still passed around, sending people on wild goose chases.
Thank you all so much.
#word-stream#cliff weitzman#plagiarism#speechify#archive of our own#writers on tumblr#fanfic#independent authors#web scraping#fandom activism#writeblr#ao3#ao3 fanfic#ao3 writer#fanfiction#writing#writer#writing community#anti ai#anti generative ai#fic theft#anti capitalism#not everything needs to be monetised you fucking donkeys. always a tech bro ready to make a buck off someone else's work.#congrats to those of you who thought ai was harmless fun. can you see the downward slope yet?
48K notes
·
View notes
Text
Cloudflare to Automatically Block AI Bots from Scraping Web Content
Cloudflare, a major player in global internet infrastructure, has announced a new policy that could significantly disrupt how artificial intelligence companies collect data. Starting this week, the company will block AI bots from scraping websites by default—unless site owners explicitly grant permission.
The change affects all new domains registering with Cloudflare’s content delivery network (CDN), which handles roughly 16% of global internet traffic, according to the company’s 2023 estimates. Website operators will now be prompted to opt-in if they want to allow access to AI crawlers—automated bots used by companies like OpenAI and Google to collect content for training large language models (LLMs).

Cloudflare CEO and co-founder Matthew Prince said the shift aims to restore balance to the online ecosystem. “AI crawlers have been scraping content without limits. Our goal is to put the power back in the hands of creators, while still helping AI companies innovate,” he said in a statement. “This is about safeguarding the future of a free and vibrant Internet with a model that works for everyone.”
The move expands on a feature Cloudflare introduced in September 2023, which allowed publishers to block AI crawlers with a single click. The difference now is that blocking will be the default setting for all new websites using Cloudflare services.
The decision intensifies the growing debate around how AI models are trained and whether content creators are fairly compensated. Historically, AI companies have scraped vast portions of the internet—articles, blog posts, images, and more—to build advanced models. But critics argue that this undermines original publishers by diverting traffic and ad revenue away from source websites.
Cloudflare’s new default settings could pose a major hurdle for AI developers, especially as legal and regulatory scrutiny around data usage intensifies. OpenAI, one of the key players in this space, reportedly declined to support the new default approach, arguing that Cloudflare's system introduces an unnecessary middleman. OpenAI emphasized its commitment to using the robots.txt protocol, which allows publishers to opt out of web crawling.
Experts warn that restricting data access at scale could temporarily disrupt the training and performance of AI systems. “This development could hinder AI chatbots’ ability to harvest content for training and search purposes,” said Matthew Holman, a partner at U.K. law firm Cripps. “While the impact may be short term, it could reshape how viable large-scale AI models are in the long run.”
As more web infrastructure providers and publishers push back against unrestricted AI scraping, the industry may need to adopt new models for data licensing, compensation, and ethical training practices—ushering in a new chapter for AI development.
#Cloudflare#AI Crawlers#Web Scraping#AI Model Training#Content Protection#Artificial Intelligence#OpenAI
0 notes