#Membership Operators in python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Link
Exploring Python Operators: Arithmetic, Relational, Logical, and More
The article provides a comprehensive overview of various types of operators in Python programming, including arithmetic, relational, logical, bitwise, assignment, membership, and identity operators. Each operator type is explained with clear examples and its specific use case. By delving into these operators, readers can enhance their understanding of how to perform calculations, comparisons, and manipulations in Python, which is fundamental for effective programming.
This article is a valuable resource for both beginners and intermediate Python programmers. It equips them with a solid grasp of operators, helping them write more efficient and readable code. The examples provided make the concepts easily relatable, fostering a practical understanding of how each operator type functions. Overall, this article serves as an essential reference for anyone seeking to harness the power of operators in Python programming.
0 notes
Text
Python Operator Basics
x or y - Logical or (y is evaluated only if x is false)
lambda args: expression - Anonymous functions (I don't know what the fuck is this, I have to look into it)
x and y - Logical and (Y is evaluated only if x is true)
<, <=, >, >=, ==, <>, != - comparison tests
is, is not - identity tests
in, in not - membership tests
x | y - bitwise or (I still have to learn bitwise operation)
x^y - bitwise exclusive or (I read this somewhere now I don't remember it)
x&y - bitwise and (again I have to read bitwise operations)
x<;<y, x>>y - shift x left or right by y bits
x+y, x-y - addition/concatenation , subtraction
x*y, x/y, x%y - multiplication/repetition, division, remainder/format (i don't know what format is this? should ask bard)
-x, +x, ~x - unary negation, identity(what identity?), bitwise complement (complement?)
x[i], x[i:j], x.y, x(...) - indexing, slicing, qualification (i think its member access), function call
(...), [...], {...} `...` - Tuple , list dictionary , conversion to string
#kumar's python study notes#study notes#study blog#coding#programmer#programming#python#studyblr#codeblr#progblr
67 notes
·
View notes
Text
What is Data Structure in Python?
Summary: Explore what data structure in Python is, including built-in types like lists, tuples, dictionaries, and sets, as well as advanced structures such as queues and trees. Understanding these can optimize performance and data handling.

Introduction
Data structures are fundamental in programming, organizing and managing data efficiently for optimal performance. Understanding "What is data structure in Python" is crucial for developers to write effective and efficient code. Python, a versatile language, offers a range of built-in and advanced data structures that cater to various needs.
This blog aims to explore the different data structures available in Python, their uses, and how to choose the right one for your tasks. By delving into Python’s data structures, you'll enhance your ability to handle data and solve complex problems effectively.
What are Data Structures?
Data structures are organizational frameworks that enable programmers to store, manage, and retrieve data efficiently. They define the way data is arranged in memory and dictate the operations that can be performed on that data. In essence, data structures are the building blocks of programming that allow you to handle data systematically.
Importance and Role in Organizing Data
Data structures play a critical role in organizing and managing data. By selecting the appropriate data structure, you can optimize performance and efficiency in your applications. For example, using lists allows for dynamic sizing and easy element access, while dictionaries offer quick lookups with key-value pairs.
Data structures also influence the complexity of algorithms, affecting the speed and resource consumption of data processing tasks.
In programming, choosing the right data structure is crucial for solving problems effectively. It directly impacts the efficiency of algorithms, the speed of data retrieval, and the overall performance of your code. Understanding various data structures and their applications helps in writing optimized and scalable programs, making data handling more efficient and effective.
Read: Importance of Python Programming: Real-Time Applications.
Types of Data Structures in Python
Python offers a range of built-in data structures that provide powerful tools for managing and organizing data. These structures are integral to Python programming, each serving unique purposes and offering various functionalities.
Lists
Lists in Python are versatile, ordered collections that can hold items of any data type. Defined using square brackets [], lists support various operations. You can easily add items using the append() method, remove items with remove(), and extract slices with slicing syntax (e.g., list[1:3]). Lists are mutable, allowing changes to their contents after creation.
Tuples
Tuples are similar to lists but immutable. Defined using parentheses (), tuples cannot be altered once created. This immutability makes tuples ideal for storing fixed collections of items, such as coordinates or function arguments. Tuples are often used when data integrity is crucial, and their immutability helps in maintaining consistent data throughout a program.
Dictionaries
Dictionaries store data in key-value pairs, where each key is unique. Defined with curly braces {}, dictionaries provide quick access to values based on their keys. Common operations include retrieving values with the get() method and updating entries using the update() method. Dictionaries are ideal for scenarios requiring fast lookups and efficient data retrieval.
Sets
Sets are unordered collections of unique elements, defined using curly braces {} or the set() function. Sets automatically handle duplicate entries by removing them, which ensures that each element is unique. Key operations include union (combining sets) and intersection (finding common elements). Sets are particularly useful for membership testing and eliminating duplicates from collections.
Each of these data structures has distinct characteristics and use cases, enabling Python developers to select the most appropriate structure based on their needs.
Explore: Pattern Programming in Python: A Beginner’s Guide.
Advanced Data Structures
In advanced programming, choosing the right data structure can significantly impact the performance and efficiency of an application. This section explores some essential advanced data structures in Python, their definitions, use cases, and implementations.
Queues
A queue is a linear data structure that follows the First In, First Out (FIFO) principle. Elements are added at one end (the rear) and removed from the other end (the front).
This makes queues ideal for scenarios where you need to manage tasks in the order they arrive, such as task scheduling or handling requests in a server. In Python, you can implement a queue using collections.deque, which provides an efficient way to append and pop elements from both ends.
Stacks
Stacks operate on the Last In, First Out (LIFO) principle. This means the last element added is the first one to be removed. Stacks are useful for managing function calls, undo mechanisms in applications, and parsing expressions.
In Python, you can implement a stack using a list, with append() and pop() methods to handle elements. Alternatively, collections.deque can also be used for stack operations, offering efficient append and pop operations.
Linked Lists
A linked list is a data structure consisting of nodes, where each node contains a value and a reference (or link) to the next node in the sequence. Linked lists allow for efficient insertions and deletions compared to arrays.
A singly linked list has nodes with a single reference to the next node. Basic operations include traversing the list, inserting new nodes, and deleting existing ones. While Python does not have a built-in linked list implementation, you can create one using custom classes.
Trees
Trees are hierarchical data structures with a root node and child nodes forming a parent-child relationship. They are useful for representing hierarchical data, such as file systems or organizational structures.
Common types include binary trees, where each node has up to two children, and binary search trees, where nodes are arranged in a way that facilitates fast lookups, insertions, and deletions.
Graphs
Graphs consist of nodes (or vertices) connected by edges. They are used to represent relationships between entities, such as social networks or transportation systems. Graphs can be represented using an adjacency matrix or an adjacency list.
The adjacency matrix is a 2D array where each cell indicates the presence or absence of an edge, while the adjacency list maintains a list of edges for each node.
See: Types of Programming Paradigms in Python You Should Know.
Choosing the Right Data Structure
Selecting the appropriate data structure is crucial for optimizing performance and ensuring efficient data management. Each data structure has its strengths and is suited to different scenarios. Here’s how to make the right choice:
Factors to Consider
When choosing a data structure, consider performance, complexity, and specific use cases. Performance involves understanding time and space complexity, which impacts how quickly data can be accessed or modified. For example, lists and tuples offer quick access but differ in mutability.
Tuples are immutable and thus faster for read-only operations, while lists allow for dynamic changes.
Use Cases for Data Structures:
Lists are versatile and ideal for ordered collections of items where frequent updates are needed.
Tuples are perfect for fixed collections of items, providing an immutable structure for data that doesn’t change.
Dictionaries excel in scenarios requiring quick lookups and key-value pairs, making them ideal for managing and retrieving data efficiently.
Sets are used when you need to ensure uniqueness and perform operations like intersections and unions efficiently.
Queues and stacks are used for scenarios needing FIFO (First In, First Out) and LIFO (Last In, First Out) operations, respectively.
Choosing the right data structure based on these factors helps streamline operations and enhance program efficiency.
Check: R Programming vs. Python: A Comparison for Data Science.
Frequently Asked Questions
What is a data structure in Python?
A data structure in Python is an organizational framework that defines how data is stored, managed, and accessed. Python offers built-in structures like lists, tuples, dictionaries, and sets, each serving different purposes and optimizing performance for various tasks.
Why are data structures important in Python?
Data structures are crucial in Python as they impact how efficiently data is managed and accessed. Choosing the right structure, such as lists for dynamic data or dictionaries for fast lookups, directly affects the performance and efficiency of your code.
What are advanced data structures in Python?
Advanced data structures in Python include queues, stacks, linked lists, trees, and graphs. These structures handle complex data management tasks and improve performance for specific operations, such as managing tasks or representing hierarchical relationships.
Conclusion
Understanding "What is data structure in Python" is essential for effective programming. By mastering Python's data structures, from basic lists and dictionaries to advanced queues and trees, developers can optimize data management, enhance performance, and solve complex problems efficiently.
Selecting the appropriate data structure based on your needs will lead to more efficient and scalable code.
#What is Data Structure in Python?#Data Structure in Python#data structures#data structure in python#python#python frameworks#python programming#data science
6 notes
·
View notes
Text
This Week in Rust 510
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.72.0
Change in Guidance on Committing Lockfiles
Cargo changes how arrays in config are merged
Seeking help for initial Leadership Council initiatives
Leadership Council Membership Changes
Newsletters
This Week in Ars Militaris VIII
Project/Tooling Updates
rust-analyzer changelog #196
The First Stable Release of a Memory Safe sudo Implementation
We're open-sourcing the library that powers 1Password's ability to log in with a passkey
ratatui 0.23.0 is released! (official successor of tui-rs)
Zellij 0.38.0: session-manager, plugin infra, and no more offensive session names
Observations/Thoughts
The fastest WebSocket implementation
Rust Malware Staged on Crates.io
ESP32 Standard Library Embedded Rust: SPI with the MAX7219 LED Dot Matrix
A JVM in Rust part 5 - Executing instructions
Compiling Rust for .NET, using only tea and stubbornness!
Ad-hoc polymorphism erodes type-safety
How to speed up the Rust compiler in August 2023
This isn't the way to speed up Rust compile times
Rust Cryptography Should be Written in Rust
Dependency injection in Axum handlers. A quick tour
Best Rust Web Frameworks to Use in 2023
From tui-rs to Ratatui: 6 Months of Cooking Up Rust TUIs
[video] Rust 1.72.0
[video] Rust 1.72 Release Train
Rust Walkthroughs
[series] Distributed Tracing in Rust, Episode 3: tracing basics
Use Rust in shell scripts
A Simple CRUD API in Rust with Cloudflare Workers, Cloudflare KV, and the Rust Router
[video] base64 crate: code walkthrough
Miscellaneous
Interview with Rust and operating system Developer Andy Python
Leveraging Rust in our high-performance Java database
Rust error message to fix a typo
[video] The Builder Pattern and Typestate Programming - Stefan Baumgartner - Rust Linz January 2023
[video] CI with Rust and Gitlab Selfhosting - Stefan Schindler - Rust Linz July 2023
Crate of the Week
This week's crate is dprint, a fast code formatter that formats Markdown, TypeScript, JavaScript, JSON, TOML and many other types natively via Wasm plugins.
Thanks to Martin Geisler for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Hyperswitch - add domain type for client secret
Hyperswitch - deserialization error exposes sensitive values in the logs
Hyperswitch - move redis key creation to a common module
mdbook-i18n-helpers - Write tool which can convert translated files back to PO
mdbook-i18n-helpers - Package a language selector
mdbook-i18n-helpers - Add links between translations
Comprehensive Rust - Link to correct line when editing a translation
Comprehensive Rust - Track the number of times the redirect pages are visited
RustQuant - Jacobian and Hessian matrices support.
RustQuant - improve Graphviz plotting of autodiff computational graphs.
RustQuant - bond pricing implementation.
RustQuant - implement cap/floor pricers.
RustQuant - Implement Asian option pricers.
RustQuant - Implement American option pricers.
release-plz - add ability to mark Gitea/GitHub release as draft
zerocopy - CI step "Set toolchain version" is flaky due to network timeouts
zerocopy - Implement traits for tuple types (and maybe other container types?)
zerocopy - Prevent panics statically
zerocopy - Add positive and negative trait impl tests for SIMD types
zerocopy - Inline many trait methods (in zerocopy and in derive-generated code)
datatest-stable - Fix quadratic performance with nextest
Ockam - Use a user-friendly name for the shared services to show it in the tray menu
Ockam - Rename the Port to Address and support such format
Ockam - Ockam CLI should gracefully handle invalid state when initializing
css-inline - Update cssparser & selectors
css-inline - Non-blocking stylesheet resolving
css-inline - Optionally remove all class attributes
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
366 pull requests were merged in the last week
reassign sparc-unknown-none-elf to tier 3
wasi: round up the size for aligned_alloc
allow MaybeUninit in input and output of inline assembly
allow explicit #[repr(Rust)]
fix CFI: f32 and f64 are encoded incorrectly for cross-language CFI
add suggestion for some #[deprecated] items
add an (perma-)unstable option to disable vtable vptr
add comment to the push_trailing function
add note when matching on tuples/ADTs containing non-exhaustive types
add support for ptr::writes for the invalid_reference_casting lint
allow overwriting ExpnId for concurrent decoding
avoid duplicate large_assignments lints
contents of reachable statics is reachable
do not emit invalid suggestion in E0191 when spans overlap
do not forget to pass DWARF fragment information to LLVM
ensure that THIR unsafety check is done before stealing it
emit a proper diagnostic message for unstable lints passed from CLI
fix races conditions with SyntaxContext decoding
fix waiting on a query that panicked
improve note for the invalid_reference_casting lint
include compiler flags when you break rust;
load include_bytes! directly into an Lrc
make Sharded an enum and specialize it for the single thread case
make rustc_on_unimplemented std-agnostic for alloc::rc
more precisely detect cycle errors from type_of on opaque
point at type parameter that introduced unmet bound instead of full HIR node
record allocation spans inside force_allocation
suggest mutable borrow on read only for-loop that should be mutable
tweak output of to_pretty_impl_header involving only anon lifetimes
use the same DISubprogram for each instance of the same inlined function within a caller
walk through full path in point_at_path_if_possible
warn on elided lifetimes in associated constants (ELIDED_LIFETIMES_IN_ASSOCIATED_CONSTANT)
make RPITITs capture all in-scope lifetimes
add stable for Constant in smir
add generics_of to smir
add smir predicates_of
treat StatementKind::Coverage as completely opaque for SMIR purposes
do not convert copies of packed projections to moves
don't do intra-pass validation on MIR shims
MIR validation: reject in-place argument/return for packed fields
disable MIR SROA optimization by default
miri: automatically start and stop josh in rustc-pull/push
miri: fix some bad regex capture group references in test normalization
stop emitting non-power-of-two vectors in (non-portable-SIMD) codegen
resolve: stop creating NameBindings on every use, create them once per definition instead
fix a pthread_t handle leak
when terminating during unwinding, show the reason why
avoid triple-backtrace due to panic-during-cleanup
add additional float constants
add ability to spawn Windows process with Proc Thread Attributes | Take 2
fix implementation of Duration::checked_div
hashbrown: allow serializing HashMaps that use a custom allocator
hashbrown: change & to &mut where applicable
hashbrown: simplify Clone by removing redundant guards
regex-automata: fix incorrect use of Aho-Corasick's "standard" semantics
cargo: Very preliminary MSRV resolver support
cargo: Use a more compact relative-time format
cargo: Improve TOML parse errors
cargo: add support for target.'cfg(..)'.linker
cargo: config: merge lists in precedence order
cargo: create dedicated unstable flag for asymmetric-token
cargo: set MSRV for internal packages
cargo: improve deserialization errors of untagged enums
cargo: improve resolver version mismatch warning
cargo: stabilize --keep-going
cargo: support dependencies from registries for artifact dependencies, take 2
cargo: use AND search when having multiple terms
rustdoc: add unstable --no-html-source flag
rustdoc: rename typedef to type alias
rustdoc: use unicode-aware checks for redundant explicit link fastpath
clippy: new lint: implied_bounds_in_impls
clippy: new lint: reserve_after_initialization
clippy: arithmetic_side_effects: detect division by zero for Wrapping and Saturating
clippy: if_then_some_else_none: look into local initializers for early returns
clippy: iter_overeager_cloned: detect .cloned().all() and .cloned().any()
clippy: unnecessary_unwrap: lint on .as_ref().unwrap()
clippy: allow trait alias DefIds in implements_trait_with_env_from_iter
clippy: fix "derivable_impls: attributes are ignored"
clippy: fix tuple_array_conversions lint on nightly
clippy: skip float_cmp check if lhs is a custom type
rust-analyzer: diagnostics for 'while let' loop with label in condition
rust-analyzer: respect #[allow(unused_braces)]
Rust Compiler Performance Triage
A fairly quiet week, with improvements exceeding a small scattering of regressions. Memory usage and artifact size held fairly steady across the week, with no regressions or improvements.
Triage done by @simulacrum. Revision range: d4a881e..cedbe5c
2 Regressions, 3 Improvements, 2 Mixed; 0 of them in rollups 108 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Create a Testing sub-team
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Stabilize PATH option for --print KIND=PATH
[disposition: merge] Add alignment to the NPO guarantee
New and Updated RFCs
[new] Special-cased performance improvement for Iterator::sum on Range<u*> and RangeInclusive<u*>
[new] Cargo Check T-lang Policy
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-08-30 - 2023-09-27 🦀
Virtual
2023-09-05 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-09-05 | Virtual (Munich, DE) | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-06 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-09-12 - 2023-09-15 | Virtual (Albuquerque, NM, US) | RustConf
RustConf 2023
2023-09-12 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-09-13 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-09-13 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
The unreasonable power of combinator APIs
2023-09-14 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-09-20 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-09-21 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-09-21 | Lehi, UT, US | Utah Rust
Real Time Multiplayer Game Server in Rust
2023-09-21 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 33rd Edition
2023-09-25 | Virtual (Dublin, IE) | Rust Dublin
How we built the SurrealDB Python client in Rust.
Asia
2023-09-06 | Tel Aviv, IL | Rust TLV
RustTLV @ Final - September Edition
Europe
2023-08-30 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #39 sponsored by Fermyon
2023-08-31 | Augsburg, DE | Rust Meetup Augsburg
Augsburg Rust Meetup #2
2023-09-05 | Munich, DE + Virtual | Rust Munich
Rust Munich 2023 / 4 - hybrid
2023-09-14 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-09-19 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Logging and tracing in Rust
2023-09-20 | Aarhus, DK | Rust Aarhus
Rust Aarhus - Rust and Talk at Concordium
2023-09-21 | Bern, CH | Rust Bern
Third Rust Bern Meetup
North America
2023-09-05 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
2023-09-06 | Bellevue, WA, US | The Linux Foundation
Rust Global
2023-09-12 - 2023-09-15 | Albuquerque, NM, US + Virtual | RustConf
RustConf 2023
2023-09-12 | New York, NY, US | Rust NYC
A Panel Discussion on Thriving in a Rust-Driven Workplace
2023-09-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust Meetup Happy Hour
2023-09-14 | Seattle, WA, US | Seattle Rust User Group Meetup
Seattle Rust User Group - August Meetup
2023-09-19 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-09-21 | Nashville, TN, US | Music City Rust Developers
Rust on the web! Get started with Leptos
2023-09-26 | Pasadena, CA, US | Pasadena Thursday Go/Rust
Monthly Rust group
2023-09-27 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2023-09-13 | Perth, WA, AU | Rust Perth
Rust Meetup 2: Lunch & Learn
2023-09-19 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
2023-09-26 | Canberra, ACT, AU | Rust Canberra
September Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
In [other languages], I could end up chasing silly bugs and waste time debugging and tracing to find that I made a typo or ran into a language quirk that gave me an unexpected nil pointer. That situation is almost non-existent in Rust, it's just me and the problem. Rust is honest and upfront about its quirks and will yell at you about it before you have a hard to find bug in production.
– dannersy on Hacker News
Thanks to Kyle Strand for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Lists, Tuples, Sets, and Dictionaries in Python

Understanding lists, tuples, sets, and dictionaries in Python is crucial for anyone learning data structures in Python programming. These built-in collection types offer powerful ways to store, access, and manipulate data efficiently. Lists in Python are used for ordered and mutable sequences, while tuples provide an immutable alternative. Sets help manage unique data and perform operations like union and intersection, making them ideal for membership testing. Dictionaries are perfect for key-value pair storage, widely used in data science, machine learning, and web development. Mastering these core Python collections is essential for writing clean, optimized, and scalable code in 2025. Whether you’re a Python beginner or preparing for coding interviews, understanding these Python data types will give you a solid foundation. These collections are frequently used in real-world projects, from backend development to automation scripts. Practicing with real examples and coding challenges can help solidify your Python skills faster.
0 notes
Text
Lists, Tuples, Sets, and Dictionaries in Python

Understanding lists, tuples, sets, and dictionaries in Python is crucial for anyone learning data structures in Python programming. These built-in collection types offer powerful ways to store, access, and manipulate data efficiently. Lists in Python are used for ordered and mutable sequences, while tuples provide an immutable alternative. Sets help manage unique data and perform operations like union and intersection, making them ideal for membership testing. Dictionaries are perfect for key-value pair storage, widely used in data science, machine learning, and web development. Mastering these core Python collections is essential for writing clean, optimized, and scalable code in 2025. Whether you’re a Python beginner or preparing for coding interviews, understanding these Python data types will give you a solid foundation. These collections are frequently used in real-world projects, from backend development to automation scripts. Practicing with real examples and coding challenges can help solidify your Python skills faster.
0 notes
Text
Lists, Tuples, Sets, and Dictionaries in Python

Understanding lists, tuples, sets, and dictionaries in Python is crucial for anyone learning data structures in Python programming. These built-in collection types offer powerful ways to store, access, and manipulate data efficiently. Lists in Python are used for ordered and mutable sequences, while tuples provide an immutable alternative. Sets help manage unique data and perform operations like union and intersection, making them ideal for membership testing. Dictionaries are perfect for key-value pair storage, widely used in data science, machine learning, and web development. Mastering these core Python collections is essential for writing clean, optimized, and scalable code in 2025. Whether you’re a Python beginner or preparing for coding interviews, understanding these Python data types will give you a solid foundation. These collections are frequently used in real-world projects, from backend development to automation scripts. Practicing with real examples and coding challenges can help solidify your Python skills faster.
0 notes
Text

Best Auto CAPTCHA Solver Online API for Seamless Automation
Automating online tasks has never been easy, thanks to best auto CAPTCHA solver online API. Businesses and developers constantly sought a solution to bypass CAPTCHA challenges, reduce manual input and increase workflow automation. Whether you need to streamline web scrapping, account registration, or data extraction, a high-demonstration auto CAPTCHA ensures the Solver API seamless operation.
What is an auto CAPTCHA solver API?
A best CAPTCHA solver online API is a software tool designed to automatically identify and solve the CAPTCHA challenges. These APIs take advantage of artificial intelligence, machine learning and optical character recognition (OCR) to decode various CAPTCHA types, including image-based, text-based, reCAPTCHA and HCAPTCHA. By integrating a reliable CAPTCHA solver in your system, you eliminate the problem of manual verification and improve the efficiency significantly.
Major benefits of using an best auto CAPTCHA solver API
1. Increases workflow automation
Solving the manual CAPTCHA slows down automation processes. An API -powered CAPTCHA enables solver bots and scripts to bypass these challenges in real time, improving operating speed and accuracy.
2. Saves time and resources
Business CAPTCHA Solver relying on web scrapping, form submission, or automatic transactions is greatly benefited from API. By reducing the need for human intervention, these solutions reduce labor costs and maximize productivity.
3. Supports several CAPTCHA types
A strong CAPTCHA solver API can handle
various CAPTCHA formats, including:
Image based CAPTCHAs
Text CAPTCHAs
Google reCAPTCHA v2 and v3
hCAPTCHA and FunCAPTCHA
Audio CAPTCHAs
4. Spontaneous integration with bots and scripts
Most CAPTCHA solvers provide simple integration with programming languages such as API Python, PHP, Java and JavaScript. Developers can easily apply APIs using a few rows of code, ensuring compatibility with existing automation equipment.
5. User improves experience
CAPTCHA increases customer experience by automatically bypassing challenges, by reducing unnecessary friction in business online interactions, such as sign-up, login and shopping.
How to choose the best auto CAPTCHA solver API
When selecting captain solution service, consider these necessary factors:
1. Accuracy and success rate
Look for an API that provides high accuracy and rapid resolve rates. AI-managed CAPTCHA solvers with deep learning abilities perform better by traditional methods and ensure high success rates.
2. Speed and response time
Time-sensitive functions require a quick response to a CAPTCHA solver over time. A premium API must process requests within a few seconds to maintain workflow efficiency.
3. Cost and pricing model
Evaluate the pricing structure of API. Some CAPTCHA solver services charge per salt CAPTCHA, while others provide membership-based models. Choose one that align with your budget and use needs.
4. API reliability and uptime
Reliability is important for automation. Ensure that the CAPTCHA solver provides frequent uptime and minimum downtime to prevent disruption of API workflow.
5. Safety and compliance
A safe API should follow industry standards and follow data privacy rules. Look for a service that uses encrypted connections and protects user data.
Top use case for an auto CAPTCHA solver API
A reliable CAPTCHA solver API benefits many industries and automation works, including:
Web scrapping and data extraction: CAPTCHA helps collect data from websites without interruption.
SEOs and Digital Marketing: Keywords automate tracking, competitive analysis and backlink monitoring.
Account registration and verification: The manual CAPTCHA simplifies the account construction without a solution.
E-commerce automation: Automatic price assists in monitoring, inventory checks and order placements.
Ticket bots bats: enables events and shows to buy tickets faster for the show.
Conclusion
A high-demonstration auto CAPTCHA solver in its automation workflow saves time, increases efficiency, and increases productivity. Whether you are a developer, marketer, or business owner, selecting the right CAPTCHA solver ensures easy, uninterrupted operation.
With the correct solution, you can focus on the main business functions, allowing automation to handle the CAPTCHA challenges easily. Choose a reliable best auto CAPTCHA solver API today and take your automation to the next level!
0 notes
Text
Explain lists, sets, maps, and how to use them effectively.
Lists, Sets, and Maps:
Overview
Lists
Definition:
A list is an ordered collection of elements that can contain duplicates.
Characteristics:
Maintains the order of insertion. Allows duplicate values. Can store elements of any data type.
Usage Examples: Managing ordered data like a queue or a stack. Iterating over a collection of items in a specific order.
Common Operations:
Adding elements: list.append(value) Accessing elements: list[index] Removing elements: list.remove(value) Iterating: for item in list: Example: python Copy Edit fruits = [“apple”, “banana”, “apple”, “cherry”] fruits.append(��orange”) print(fruits) # Output: [‘apple’, ‘banana’, ‘apple’, ‘cherry’, ‘orange’]
2. Sets
Definition:
A set is an unordered collection of unique elements.
Characteristics:
Does not allow duplicates. Unordered, so the insertion order is not preserved.
Supports mathematical operations like union, intersection, and difference.
Usage Examples: Removing duplicates from a list.
Checking membership efficiently.
Performing set operations in mathematical contexts.
Common Operations:
Adding elements: set.add(value)
Removing elements: set.remove(value) Set union: set1.union(set2)
Set intersection: set1.intersection(set2) Set difference: set1.difference(set2)
Example:
python
unique_numbers = {1, 2, 3, 3, 4} unique_numbers.add(5) print(unique_numbers) # Output: {1, 2, 3, 4, 5}
3. Maps (Dictionaries)
Definition:
A map (or dictionary in Python) is a collection of key-value pairs where each key is unique.
Characteristics:
Keys must be unique and immutable.
Values can be mutable and of any data type. Provides fast lookups based on keys.
Usage Examples: Storing and retrieving data based on identifiers.
Implementing cache mechanisms. Grouping related information using key-value pairs.
Common Operations:
Adding key-value pairs: dict[key] = value
Accessing values: dict[key] Removing key-value pairs: del dict[key] Iterating over
keys and values:
for key, value in dict.items():
Example:
python
employee_details = {“name”: “John”, “age”: 30, “department”: “IT”} employee_details[“location”] = “New York” print(employee_details) # Output: {‘name’: ‘John’, ‘age’: 30, ‘department’: ‘IT’, ‘location’: ‘New York’}
When to Use Lists, Sets, and Maps
Effectively Data Structure Use When List — Order matters.
— You need to allow duplicates.
— Iterating in a specific sequence is required.
Set — Uniqueness is crucial. — Fast membership testing is needed. — Order is irrelevant.
Map — Fast key-based lookups are necessary. — Data is best represented as key-value pairs.
Best Practices Choose the right data structure:
Use a list when you need an ordered collection. Use a set when you want to eliminate duplicates or perform set operations.
Use a map when you need to associate keys with values for quick lookups.
Leverage built-in methods:
Python provides efficient methods for manipulating lists (sort, reverse), sets (union, difference), and maps (get, keys, values).
Optimize for performance:
Use sets for operations like membership testing (x in set) as they are faster than lists.
Use dictionaries for constant-time access to data by key.
Avoid unnecessary conversions: Use the native strengths of each data structure without repeatedly converting between them, which can impact performance.
With this knowledge, you can make informed choices about which data structure to use, improving both the clarity and efficiency of your code.
WEBSITE: https://www.ficusoft.in/core-java-training-in-chennai/
0 notes
Link
Exploring Python Operators: Arithmetic, Relational, Logical, and More
The article provides a comprehensive overview of various types of operators in Python programming, including arithmetic, relational, logical, bitwise, assignment, membership, and identity operators. Each operator type is explained with clear examples and its specific use case. By delving into these operators, readers can enhance their understanding of how to perform calculations, comparisons, and manipulations in Python, which is fundamental for effective programming.
This article is a valuable resource for both beginners and intermediate Python programmers. It equips them with a solid grasp of operators, helping them write more efficient and readable code. The examples provided make the concepts easily relatable, fostering a practical understanding of how each operator type functions. Overall, this article serves as an essential reference for anyone seeking to harness the power of operators in Python programming.
0 notes
Text
Understanding Data Structures in Python Programming: A Guide for Navi Mumbai Developers
In the rapidly evolving world of software development, mastering data structures is crucial for any programmer, especially those working with Python. For developers based in Navi Mumbai, a city known for its burgeoning tech industry, having a solid understanding of data structures can set you apart in the competitive job market. This article explores key data structures in Python and their relevance to developers in Navi Mumbai.
Lists
One of the most versatile Data Structures in Python programming Navi Mumbai is the list. Lists are ordered collections of items, which can be of different types, including integers, strings, and even other lists. They are mutable, meaning you can modify them after their creation. This makes lists ideal for tasks that involve dynamic data, such as maintaining a list of user inputs or storing results from various computations.
For developers in Navi Mumbai, lists are commonly used in web development and data analysis projects. For example, a list might be used to hold user data retrieved from a database or to manage tasks in a project management application.
Tuples
Tuples are similar to lists but are immutable. Once a tuple is created, its contents cannot be altered. This immutability can be advantageous when you need to ensure that data remains constant and unchanging throughout your program. Tuples are often used for representing fixed collections of items, such as coordinates or RGB color values.
In Navi Mumbai’s tech scene, tuples are valuable for handling data that should not be modified, such as configuration settings or constants within applications.
Dictionaries
Dictionaries, or dicts, are another fundamental data structure in Python. They store key-value pairs, allowing for efficient retrieval of values based on their associated keys. This structure is highly beneficial for scenarios where you need to map unique identifiers to data, such as storing user profiles or managing inventory in e-commerce applications.
For Navi Mumbai developers, dictionaries offer a powerful way to manage and retrieve data quickly, which is crucial in high-performance applications and systems where speed and efficiency are paramount.
Sets
Sets are collections of unique items, meaning that duplicate elements are automatically removed. This property makes sets useful for operations that involve membership testing, removing duplicates, or performing mathematical set operations like union and intersection.
In a city like Navi Mumbai, where data integrity and efficiency are key, sets can be used in applications that require quick lookup times and the elimination of duplicate entries, such as in data cleaning processes or handling user-generated content.
Advanced Data Structures
Beyond the basics, Python offers advanced data structures like queues, stacks, and heaps through libraries such acollections and heapq. These structures are essential for specialized applications like scheduling tasks, implementing algorithms, or managing priority-based data.
For developers in Navi Mumbai, familiarity with these advanced structures can enhance your ability to tackle complex problems and contribute to innovative projects in areas like algorithm development or real-time data processing.
In summary, a thorough understanding of data analytics and business intelligence courses in trombay is vital for Python programmers, whether you’re working in Navi Mumbai or elsewhere. Lists, tuples, dictionaries, and sets form the backbone of Python programming, providing the tools needed to handle various types of data efficiently. As you continue to develop your skills, exploring advanced data structures will further enhance your ability to solve complex problems and contribute to the thriving tech community in Navi Mumbai. By mastering these essential concepts, you position yourself as a valuable asset in the competitive world of programming and software development.
1 note
·
View note
Text
btw if i ever marry someone it will be the <in> membership operator of python
0 notes
Text
Get More Done: Simplify Your Life with Our Grocery Delivery App
Grocery delivery app development is a growing trend in the grocery industry, with the global market expected to reach $2,159 billion by 2030. Mobile applications have become a game-changer in the grocery industry, revolutionizing how people shop for groceries.
To succeed in this market, businesses must understand their target customers, their needs, and the features they seek in a grocery delivery app. This comprehensive guide provides insights, strategies, and best practices for grocery app development, empowering businesses in this dynamic market.
Whether you're a grocery store owner, supermarket chain, or aspiring entrepreneur, this guide will equip you with the knowledge and expertise to harness the potential of grocery delivery apps.
What is On-demand Grocery App Development?
The process of creating and releasing mobile applications that let users get groceries from their favorite retailers or supermarkets is known as "grocery delivery app development." With the help of these applications, companies can reach a wider audience and take advantage of the rising demand for doorstep delivery and online shopping. Grocery delivery app development uses technology to optimize the entire shopping process, giving businesses a competitive edge, convenience, and time-saving advantages.
Different types of grocery delivery apps
Grocery businesses can select an app that aligns with their goals, target audience, and operational capabilities, enabling them to make informed decisions and utilize technology to meet customer demands and drive digital success.
Aggregator Apps
Aggregator apps are centralized platforms that connect multiple grocery stores and supermarkets, offering a wide range of products from various retailers. They allow customers to browse, compare prices, and place orders for delivery or pickup, making them convenient and choice-oriented.
Dedicated Store Apps
Dedicated store apps are created by specific grocery stores or supermarket chains to offer a personalized shopping experience. These apps allow customers to explore inventory, create personalized lists, and place orders for delivery or pickup. They often include loyalty programs, personalized recommendations, and exclusive offers to boost customer engagement.
Subscription-Based Apps
Subscription-based grocery delivery apps provide recurring delivery services, allowing users to subscribe to a specific plan or membership. These apps offer benefits like free deliveries, discounted prices, and priority access to certain products. They offer convenience and cost savings, eliminating the need for individual orders. Popular examples include Amazon Fresh, Freshly, and Thrive Market.
On-Demand Delivery Apps
On-demand delivery app offer speed, flexibility, and immediate access to groceries through real-time connections with delivery drivers. These apps partner with multiple stores, allowing customers to place orders and have their items delivered to their location, catering to the needs of quick-food consumers.
Tech Stack Used In Grocery App Development
The tech stack for grocery app development typically includes:
Frontend:React Native or Flutter for cross-platform compatibility
Backend:js or Python for server-side logic
Database:MongoDB or PostgreSQL for data storage
Payment Gateway Integration:Stripe or Braintree for secure transactions
Cloud Services:AWS or Google Cloud Platform for scalable infrastructure
Key Steps in Grocery Delivery App Development
Analyze the Market and Define Your Niche
Begin by conducting thorough market research to understand the competitive landscape, identify gaps, and define your unique value proposition. Analyze your target audience, their pain points, and the features that will set your app apart from the competition.
Choose a Robust Business Model
Decide on the appropriate business model for your grocery delivery app, such as commission-based, subscription-based, or a hybrid approach. Consider factors like revenue streams, pricing strategies, and scalability to ensure long-term sustainability.
Assemble a Skilled Development Team
Collaborate with an experienced mobile app development company that can bring your vision to life. Look for a team with expertise in UI/UX design, backend development, and integration with third-party services like payment gateways and logistics providers.
Design a User-Centric Interface
Prioritize a seamless and intuitive user experience (UX) that makes it easy for customers to browse products, create shopping lists, and place orders. Incorporate features like personalized recommendations, smart search, and real-time order tracking to enhance customer engagement.
Develop a Robust Backend Infrastructure
Build a scalable and secure backend system to manage inventory, process orders, and coordinate with delivery personnel. Integrate with various APIs and third-party services to streamline the entire order fulfillment process.
Implement Cutting-Edge Features
Incorporate must-have features like virtual shelves, shopping lists, flexible delivery scheduling, multiple payment options, and in-app customer support to provide a seamless and delightful user experience.
Ensure Seamless Integration and Scalability
Design your grocery delivery app with scalability in mind, allowing it to accommodate growing user demands and evolving business needs. Integrate with third-party services and APIs to enhance functionality and future-proof your app.
Optimize for Performance and Security
Rigorously test your app to ensure optimal performance, responsiveness, and data security. Implement robust security measures to protect user information and transactions, building trust and confidence among your customers.
Develop a Comprehensive Marketing Strategy
Craft a strategic marketing plan to promote your grocery delivery app, attract new users, and retain existing customers. Leverage digital marketing channels, social media, and targeted advertising to reach your target audience effectively.
Continuously Iterate and Improve
Regularly gather user feedback, analyze app analytics, and implement updates to enhance the user experience and address evolving customer needs. Stay agile and responsive to maintain a competitive edge in the dynamic grocery delivery market.
#hire developers#hire app developer#android app development#ios app development#mobile app development#hire mobile app developers#grocery delivery#grocery app development
0 notes
Text
Exploring the Power of Python Operators: A Comprehensive Overview
Python, renowned for its simplicity and readability, offers a diverse set of operators to perform operations on variables and values. Operators play a crucial role in programming languages, and Python provides a wide range of them. In this comprehensive overview, we will delve into the various types of Python operators and their applications, empowering you to leverage their capabilities in your code.
Enrolling in a recognized Python Training in Pune can help people who want to become experts in the field gain the skills and information necessary to successfully navigate this ever-changing environment.
Some Common Types of Operators in Python Include:
Unleashing Arithmetic Operators:
Python's arithmetic operators facilitate mathematical calculations on numeric data types. These operators, including addition (+), subtraction (-), multiplication (), division (/), floor division (//), modulus (%), and exponentiation (*), empower you to manipulate numerical data efficiently and perform fundamental mathematical operations.
Mastering Assignment Operators:
Assignment operators allow you to assign values to variables, combining an arithmetic operation with assignment. While the equal sign (=) is the primary assignment operator, Python offers shorthand variants like +=, -=, *=, /=, %=, and **=, enabling you to perform arithmetic operations and update variables in a single step.
Comparing with Comparison Operators:
Comparison operators are essential for comparing values and generating Boolean results (True or False). Python's repertoire of comparison operators, including == (equal to), != (not equal to), > (greater than), < (less than), >= (greater than or equal to), and <= (less than or equal to), empowers you to make decisions based on different conditions and control the program flow.
Harnessing the Power of Logical Operators:
Logical operators perform logical operations on Boolean values. Python provides three logical operators: and, or, and not. The and operator returns True if both operands are True, the or operator returns True if either operand is True, and the not operator returns the opposite Boolean value of the operand. Leveraging logical operators allows you to combine conditions and create intricate logical expressions.
Finding the appropriate abilities is just as vital as selecting the appropriate tactics and methods. It can be very beneficial in this situation to register Best Python Online Training can make a significant difference.

Exploring Identity Operators:
Identity operators are instrumental in comparing the identity of objects. Python's identity operators, is and is not, discern whether two operands refer to the same object or not. By utilizing these operators, you can effectively determine if two variables reference the same or distinct objects.
Testing Membership with Membership Operators:
Membership operators facilitate testing whether a value exists within a sequence, such as a string, list, or tuple. Python's membership operators, in and not in, serve this purpose. While the in operator returns True if the value is found in the sequence, the not in operator returns True if the value is absent. These operators are particularly useful for checking element membership in collections.
Delving into Bitwise Operators:
Bitwise operators govern operations on individual bits of integer values. Python provides a set of bitwise operators, including &, |, ^, ~, <<, and >>. These operators are predominantly used in low-level programming and when dealing with binary data, enabling you to manipulate and analyze the binary representation of integers.
Python operators are indispensable tools for executing a wide range of operations and comparisons in your code. Familiarity with different types of operators and their functionalities empowers you to write efficient and effective Python programs.
This comprehensive overview explored arithmetic operators, assignment operators, comparison operators, logical operators, identity operators, membership operators, and bitwise operators. By skillfully utilizing these operators, you can manipulate data, make informed decisions, and control program flow with ease.
0 notes
Text
Decoding Python's Building Blocks: A Comprehensive Exploration of Essential Data Types
Python, celebrated for its readability and adaptability, introduces a diverse set of fundamental data types that serve as the building blocks for programming proficiency. Whether you're an entry-level programmer entering the Python ecosystem or an experienced developer looking to refine your skills, a deep understanding of these data types is indispensable. Let's embark on a journey to uncover the significance and applications of Python's essential data types.
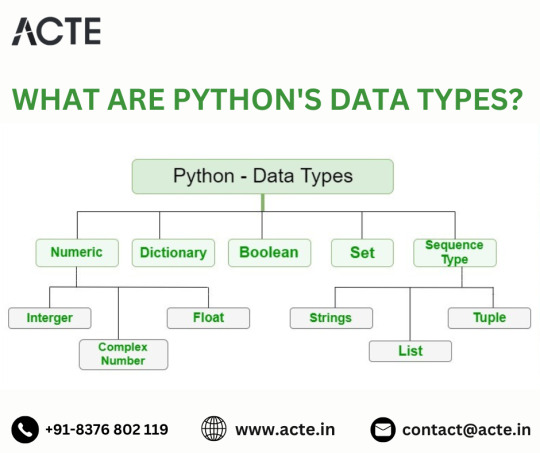
1. Numeric Foundations: The Power of Integers and Floats
At the core of numerical computations lie integers, representing whole numbers without decimal points. From negative values like -5 to positive ones like 42, Python enables seamless arithmetic operations on integers. Complementing this, floating-point numbers bring precision to calculations involving decimal points or exponential forms, ensuring accuracy in diverse mathematical operations.
2. Textual Mastery: Strings as the Linchpin
Strings, encapsulating sequences of characters within single or double quotes, are indispensable for handling textual data. From basic text manipulations to intricate natural language processing algorithms, strings play a pivotal role in diverse applications, making them a cornerstone data type for any Python developer.
3. Logic at the Core: The Significance of Booleans
Boolean data types, representing truth values (True and False), underpin logical operations and conditional statements. Whether validating user input or implementing decision-making processes, booleans are essential for shaping the logical flow within Python programs.
4. Dynamic Collections: Lists and Their Versatility
Python's lists, dynamic and ordered collections, can hold elements of different data types. Their versatility makes them ideal for managing datasets and storing sequences of values, providing flexibility in handling diverse programming scenarios.
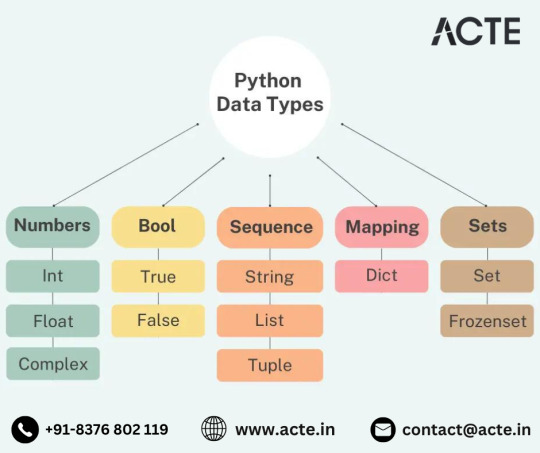
5. Immutable Order: Tuples as Constant Entities
Similar to lists but immutable, tuples are ordered collections denoted by parentheses. This immutability ensures data integrity and makes tuples suitable for scenarios where data should remain constant throughout program execution.
6. Set Efficiency: Unleashing the Power of Sets
Sets, unordered collections of unique elements, excel in scenarios where membership testing and duplicate elimination are crucial. These data types streamline operations like removing duplicates from datasets, offering efficient data manipulation capabilities.
7. Key-Value Mastery: Diving into Python Dictionaries
Dictionaries, composed of key-value pairs, emerge as a powerhouse of efficiency. This data type facilitates swift retrieval of values based on unique keys, ensuring rapid access and manipulation of information. Dictionaries are invaluable for tasks like storing configuration settings or managing complex datasets.
Understanding and mastering these essential data types not only equips Python developers with versatile tools but also empowers them to tackle a broad spectrum of computational challenges. Whether you're venturing into web applications, exploring data science, or diving into machine learning, a robust grasp of Python's data types serves as the foundation for programming excellence. As you navigate the Python landscape, consider these data types as more than mere code elements—they are the fundamental structures shaping your journey towards creating efficient and robust solutions. Embrace Python's data types, and let them guide you towards programming excellence.
0 notes
Text
Stop Paying for Web Data Scraping Tools and Try This Instead
The world of big data keeps growing, evolving, and becoming even more impactful with time. As technology and digital platforms advance, we're on the brink of generating data equivalent to a staggering 212,765,957 DVDs every day by 2025. It's no wonder that businesses have turned to big data and analytics to gain a competitive edge in the global marketplace. Accurate sales forecasts, powered by data analysis, are the keys to evolution and success in the corporate world.
For businesses that require extensive data, web data scraping has become the go-to solution. This process allows them to extract non-tabular or poorly structured data from the internet and convert it into a structured and usable format. The scraping process can be performed with either a free web scraper or a paid one, targeting screen scraping, which involves collecting all the information displayed digitally. Web data extraction software simplifies the data collection process significantly. Given the volume of data required for business operations, a web data scraping tool is a cost-effective and time-saving solution for acquiring diverse types of data from the internet.
How to Reduce Operational Costs for Web Data Scraping

Data holds the key to the expansion of 94% of businesses, and web data scraping has emerged as the answer to all their big data requirements. This process involves multiple stages, from writing the first line of code to obtaining structured and ready-to-use data. Thanks to web data scraping tools, businesses can significantly reduce their operational costs related to data scraping.
One key reason behind this cost-saving is the automation of the screen scraping process, accomplished through a dynamic website scraper. Professional companies choose to automate web scraping operations, either through open-source self-service tools or by outsourcing to web scraping companies. Automation optimizes the entire workflow, making data collection more efficient. By collaborating with a web scraping service provider, businesses can further lower their costs and enjoy a smooth data acquisition experience with minimal expenses.
Top Free Scrapers in the Market
Opting for a free web scraper can help businesses cut operational expenses significantly. Free web scrapers streamline the process of collecting data from web pages, sparing you the need to write extensive code. Advanced tools offer point-and-click functionality for effortless data scraping. Here are some of the top free web data scraping tools available:

1. ApiScrapy
ApiScrapy provides user-friendly, advanced, and free web data scraping tools that cater to the data needs of businesses across various industries. These web scrapers allow you to extract data in different formats such as JSON, XML, Excel, and more. ApiScrapy's data scraper adapts to website structures using AI technologies, making it an ideal choice for data collection from complex and sluggish sites. While free web scrapers offer limited features, paid web data scraping tools come with additional features for more effortless data extraction.
2. Octoparse
Octoparse is an excellent choice for professionals with no coding skills. This screen scraping tool is favored by sellers, marketers, researchers, and data analysts. It efficiently handles both static and dynamic websites and delivers data in formats like TXT, CSV, HTML, and XLSX. Octoparse's free edition allows you to create up to 10 crawlers, while paid membership plans provide access to APIs and a wider range of anonymous IP proxies for quicker and continuous data extraction.
3. Pattern
Pattern is a web data scraping toolkit for the Python programming language. It offers a free web scraper for fast and accurate data extraction, making it an excellent choice for both coders and non-coders.
4. ParseHub
ParseHub is designed for both coders and non-coders and is ideal for scraping data from static and dynamic websites. Leveraging machine learning technology, it recognizes the most accurate data and generates output files in JSON, CSV, Google Sheets, or through an API. This screen scraping tool is available for Windows, Mac, and Linux users. The free edition allows five projects and 200 pages per run, while a premium subscription offers 20 private projects with 10,000 pages per crawl and IP rotation.
5. Scrapy
Scrapy is an open-source web data scraping framework designed for Python developers. Users can build a free web scraper to efficiently extract data from websites in their preferred structure and format. Scrapy also supports asynchronous networking, allowing you to move on to the next scraping task before the current one is completed. This data scraping tool is available for Mac, Linux, and Windows users.
6. Frontera
Frontera is an open-source web crawling framework aimed at large-scale web data extraction. It efficiently uses robust hardware for crawling, parsing, and indexing new links. This screen scraping tool offers flexibility and configurability. While its primary goal is large-scale website crawls, it can also handle moderate-scale scraping on a single computer.
7. Crawly
For basic web data scraping requirements, Crawly offers an automatic web scraping solution. It turns websites into structured data with ease, and users can extract limited data like comments, videos, title text, date, entity tags, author, HTML, image URLs, publisher, and country by providing the website URL and their email address.
8. Webhose.io
Webhose.io is an API service that specializes in turning unstructured web content into machine-readable data on demand. The platform offers a free service trial and is trusted by Fortune 500 companies for large-scale web data extraction.
9. Portia
Portia is an advanced web data scraping tool that allows users to extract data from any website without any programming knowledge. You can use annotations to specify the data you want from a web page, and Portia will extract data from similar pages based on those annotations.
10. DataMiner
DataMiner is a powerful screen scraping tool available as a Google Chrome and Edge Browser extension. It lets you crawl and scrape web data into CSV files or Excel spreadsheets with a user-friendly interface.
11. Scrape.it
Scrape.it is designed for scalable web data scraping without coding. It uses Web Scraping Language (WSL) and is an easy-to-learn tool suitable for secure and scalable data scraping.
In conclusion, many businesses lack the time or resources to conduct web data scraping at a large scale. In such cases, web data extraction software offers rich features for crawling millions of web pages and extracting data with high accuracy. Another option is to offshore a data company for this purpose. Choosing a reliable web scraping company, such as OutsourceBigdata, can help reduce data scraping costs while ensuring high accuracy and speed. By outsourcing, businesses can focus on core projects without worrying about web data scraping. OutsourceBigdata offers premium services tailored to the specific requirements and goals of startups and enterprises, promising a better return on investment and improved process efficiency.
ORIGINAL Blog url- https://outsourcebigdata.com/blog/web-data-scraping/stop-paying-to-web-data-scraping-tools-and-try-this-instead/
0 notes