#if anything ai should be used to show tutorials of how to perform certain tool methods
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
How I Passed the microsoft AZ-900 Azure Fundamentals exam
information and tips on how to start learning for a microsoft azure certification exam on your own and get starting working in the IT industry.
I just passed the Microsoft Azure Fundamentals (AZ-900) exam, which is a certification for beginners. In this blog post, I'll talk about how I studied for the test, so you might be able to use a similar or better method. Microsoft will judge your performance on the exam based on Core Azure Services, Core Management Tools, General Security and Networking, Governance, Privacy, and Compliance, rather than just an overview of the Azure Cloud Service Provider. You should know when to use each service rather than how to use it. So let's start thinking about how we can prepare for the test. finish learning how to use Microsoft AZ-900.
If you have used Azure services before, this is a great chance to show what you know about Azure's core ideas, such as the different services, pricing, security, administration, and support. Azure services can do things like computing, storage, networking, app services, artificial intelligence (AI), the Internet of Things (IoT), integration, and security. Please look at the figure below for a list of Azure services.
This test covers the basics of the Azure cloud and is a good place to start for people who are new to the Azure world. Even though AZ-900 is an important test, it is not easy to pass. This exam tests your basic knowledge of how the cloud works and how to run Azure administrations. People with and without technical skills can prepare for this exam, which will test their knowledge of Azure Cloud services and make them ready for the next Azure role-based certifications.
The AZ-900 exam
The Azure Fundamentals exam is one of the best ways to show how much you know about cloud concepts. You can learn more about how the cloud works by learning about Azure services, Azure workloads, security and privacy in Azure, as well as Azure pricing and support. Those who want to take the exam should know about the core technology artifacts, which include storage, networking, cloud computing, seamless application support, and full application development.
https://docs.microsoft.com/en-us/learn/certifications/exams/az-900
I must state that the aforementioned site is the finest resource, but it is insufficient for your exam. From here, you may finish the study route offered by Microsoft. 2. I utilized the aforementioned video lessons to help me comprehend, but even after purchasing a premium course, you can still get this kind of tutorial online.
Microsoft Az-900 practice questions that include real questions for the exam Regarding the free website that I have so far been exploring: https://www.examdocs.com/
Clearly the finest website to date.
This is the most important component because the majority of the questions come from these sources. If you have any doubts about the answers because they could be inaccurate in certain situations, be sure to examine the discussion. Personal Experience: The majority of the questions in my case came from the websites for either Microsoft Learn or the test subjects, however there are a few areas where I believe I could still do better, like Security Center, Azure Sentinel, Virtual Networks, and Azure Subscription. Perhaps you might spend more time on the subjects mentioned above. I hope this post is useful for you. Please let me know in the comments if there is anything you would want me to add or if this post has otherwise helped you with your test preparation.
Source: Free Guest Posting Articles from ArticlesFactory.com
0 notes
Text
Docs are ROCs: a simple fix for a “methodologically indefensible” practice in medical AI studies
By LUKE OAKDEN-RAYNER
Anyone who has read my blog or tweets before has probably seen that I have issues with some of the common methods used to analyse the performance of medical machine learning models. In particular, the most commonly reported metrics we use (sensitivity, specificity, F1, accuracy and so on) all systematically underestimate human performance in head to head comparisons against AI models.
This makes AI look better than it is, and may be partially responsible for the “implementation gap” that everyone is so concerned about.
I’ve just posted a preprint on arxiv titled “Docs are ROCs: A simple off-the-shelf approach for estimating average human performance in diagnostic studies” which provides what I think is a solid solution to this problem, and I thought I would explain in some detail here.
Disclaimer: not peer reviewed, content subject to change
A (con)vexing problem
When we compare machine learning models to humans, we have a bit of a problem. Which humans?
In medical tasks, we typically take the doctor who currently does the task (for example, a radiologist identifying cancer on a CT scan) as proxy for the standard of clinical practice. But doctors aren’t a monolithic group who all give the same answers. Inter-reader variability typically ranges from 15% to 50%, depending on the task. Thus, we usually take as many doctors as we can find and then try to summarise their performance (this is called a multi-reader multicase study, MRMC for short).
Since the metrics we care most about in medicine are sensitivity and specificity, many papers have reported the averages of these values. In fact, a recent systematic review showed that over 70% of medical AI studies that compared humans to AI models reported these values. This makes a lot of sense. We want to know how the average doctor performs at the task, so the average performance on these metrics should be great, right?
No. This is bad.
The problem with reporting the averages is that human sensitivity and specificity live on a curve. They are correlated values, a skewed distribution.
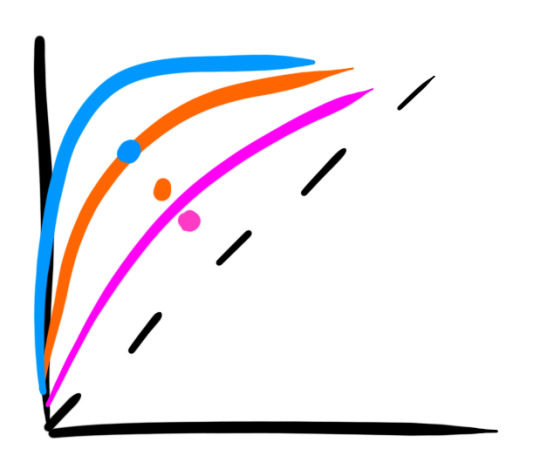
The independently pooled average points of curved distributions are nowhere near the curves.
What do we learn in stats 101 about using averages in skewed distributions?
In fact, this practice has been criticised many times in the methodology literature. Gatsonis and Paliwal go as far as to say “the use of simple or weighted averages of sensitivity and specificity to draw statistical conclusions is not methodologically defensible,” which is a heck of an academic mic drop.
What do you mean?
So we need an alternative to average sensitivity and specificity.
If you have read my blog before, you would know I love ROC curves. I’ve written tons about them before (here and here), but briefly: they visually reflect the trade-off between sensitivity and specificity (which is conceptually the same as the trade-off between overcalling or undercalling disease in diagnostic medicine), and the summary metric of the area under the ROC curve is a great measure of discriminative performance. In particular the ROC AUC is prevalence invariant, meaning we can compare the value across hospitals even if the rates of disease differ.
The problem is that human decision making is mostly binary in diagnostic medicine. We say “there is disease” or “there is no disease”. The patient needs a biopsy or they don’t. We give treatment or not*.
Binary decisions create single points in ROC space, not a curve.
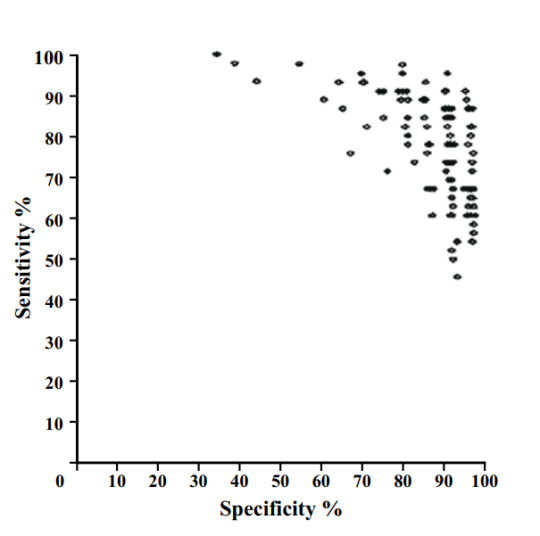
The performance of 108 different radiologists at screening mammography, Beam et al, 1996.
AI models on the other hand make curves. By varying the threshold of a decision, the same model can move to different places in ROC space. If we want to be more aggressive at making a diagnosis, follow the curve to the right. If we want to avoid overcalls, shift to the left.
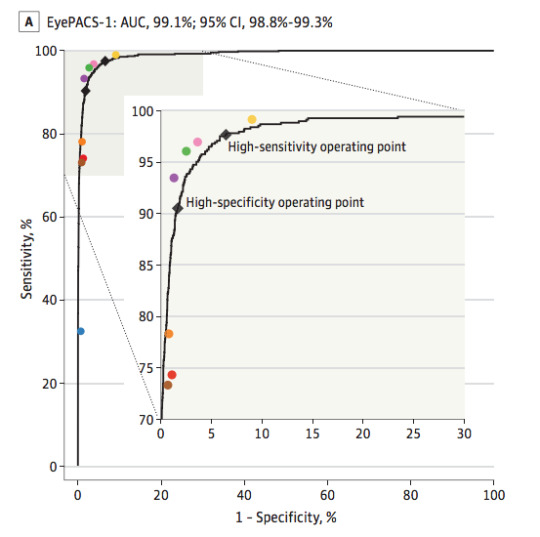
The black line is the model, the coloured dots are doctors. From Gulshan et al, 2016.
As these examples show, groups of humans tend to organise into curves. So why don’t we just … fit a model to the human points to characterise the underlying (hypothetical) curve?
I’ll admit I spent quite a long time trying various methods to do this, none of which worked great or seemed like “the” solution.
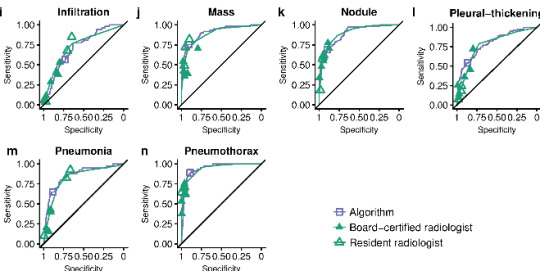
I’m not alone in trying, Rajpurkar et al tried out a spline-based approach which worked ok but had some pretty unsatisfying properties.
One day I was discussing this troubling issue with my stats/epi prof, Lyle Palmer, and he looked at me a bit funny and was like “isn’t this just meta-analysis?”.
I feel marginally better about not realising this myself since it appears that almost no-one else has thought of this either**, but dang is it obvious in hindsight.
Wait … what about all those ROCs of docs?
Now, if you read the diagnostic radiology literature, you might be confused. Don’t we use ROC curves to estimate human performance all the time?

The performance of a single radiologist reported in Roganovic et al.
It is true, we do. We can generate ROC curves of single doctors by getting them to estimate their confidence in their diagnosis. We then use each confidence level as a threshold, and calculate the sensitivity and specificity for each point. If you have 5 confidence levels, you get a 5 point ROC curve. After that there are established methods for reasonably combining the ROC curves of individual doctors into a summary curve and AUC.
But what the heck is a doctor’s confidence in their diagnosis? Can they really estimate it numerically?
In almost all diagnostic scenarios, doctors don’t estimate their confidence. They just make a diagnosis*. Maybe they have a single “hedge” category (i.e., “the findings are equivocal”), but we are taught to try to avoid those. So how are these ROC curves produced?
Well, there are two answers:
It is mammography/x-rads, where every study is clinically reported with a score out of 5, which is used to construct a ROC curve for each doctor (ie the rare situation where scoring an image is standard clinical practice).
It is any other test, where the study design forces doctors to use a scoring system they wouldn’t use in practice.
The latter is obviously a bit dodgy. Even subtle changes to experimental design can lead to significant differences in performance, a bias broadly categorised under the heading “laboratory effects“.
There has been a fair bit written about the failings of enforced confidence scores. For example, Gur et al report that confidence scores in practice are concentrated at the extreme ends of the ranges (essentially binary-by-stealth), and are often unrelated to the subtleness of the image features. Another paper by Gur et al highlights the fact that confidence scores do not relate to clinical operating points, and Mallet et al raise a number of further problems with using confidence scores, concluding that “…confidence scores recorded in our study violated many assumptions of ROC AUC methods, rendering these methods inappropriate.” (emphasis mine)
Despite these findings, the practice of forced confidence scoring is widespread. A meta-analysis by Dendumrongsup et al of imaging MRMC studies reported that confidence scores were utilised in all 51 studies they found, including the 31 studies on imaging tasks in which confidence scores are not used in clinical practice.
I reaaaaally hate this practice. Hence, trying to find a better way.
Meta meta meta
So what did Lyle mean? What does meta-analysis have to do with estimating average human reader performance?
Well, in the meta-analysis of diagnostic test accuracy, you take multiple studies that report the sensitivity and specificity of a test, performed at different locations and on different populations, and you summarise them by creating a summary ROC (SROC) curve.

Zhang and Ren, a meta-analysis of mammography diagnostic accuracy. Each dot is a study, with the size of dot proportional to sample size (between 50 and 500 cases). Lines reflect the SROC curve and the 95% confidence interval.
Well, it seems to me that a set of studies looks a lot like a group of humans tested on a diagnostic task. Maybe we should try to use the same method to produce SROC curves for readers? How about Esteva et al, the famous dermatology paper?
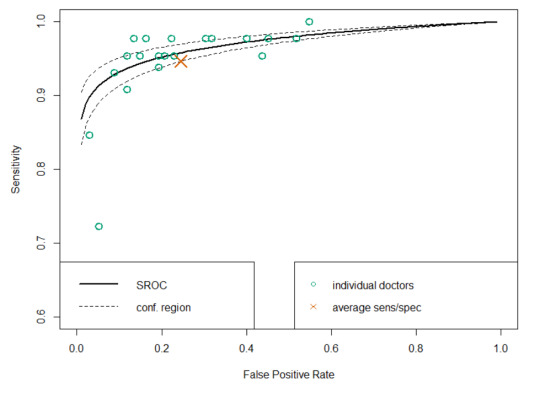
This is a model that best fits the reader results. If you compare it to the average (which was reported in the paper), you see that the average of sensitivity and specificity is actually bordering on the inner 95% CI of the fitted model, and only 4 dermatologists perform worse than the average by being inside that 95% CI line. It certainly seems like to SROC curve makes more sense as a summary of the performance of the readers than the average does.
So the approach looks pretty good. But is it hard? Will people actually use it?
Is it even research?
I initially just thought I’d write a blogpost on this topic. I am not certain it really qualifies as research, but in the end I decided to write a quick paper to present the idea to the non-blog-reading community.
The reason I felt this way is that the content of the paper is so simple. Meta-analysis and the methods to perform meta-analysis is one of the best understood parts of statistics. In fact, meta-analysis is generally considered the pinnacle of the pyramid of medical evidence.

Metanalysis is bestanalysis.
But this is why the idea is such a good solution in my opinion. There is nothing fancy, no new models to convince people about. It is just good, well-validated statistics. There are widely used packages in every major programming language. There are easily accessible tutorials and guidelines. The topic is covered in undergraduate courses.
So the paper isn’t anything fancy. It just says “here is a good tool. Use the good tool.”
It is a pretty short paper too, so all I will do here is cover the main highlights.
What and why?
In short, a summary ROC curve is a bivariate model fitted on the logit transforms of sensitivity and specificity. It comes in two main flavours, the fixed effects model and the random effects model, but all the guidelines recommend random effects models these days so we can ignore the fixed effects versions***.
When it comes to the nuts and bolts, there are a few main models that are used. I reference them in the paper, so check that out if you want to know more.
The “why do meta-analysis?” question is important. There are a couple of major benefits to this approach, but the biggest one by far is that we get reasonable estimates of variance in our summary measures.
See, when you average sensitivity and specificity, you calculate your standard deviations by pooling the confusion matrices across readers. Where before you had multiple readers, you now have one uber-reader. At this point, you can only account for variability across samples, not readers.

In this table, adapted from Obuchowski in a book chapter I wrote, we see that the number of readers, when accounted for, has a huge impact on sample size and power calculations. Frankly, not taking the number of readers into account is methodologically indefensible.
SROC analysis does though, considering both the number of readers and the “weight” of each reader (how many studies they read). Compare this SROC curve re-analysing the results of Rajpurkar and Irvin et al to the one from Esteva et al above:
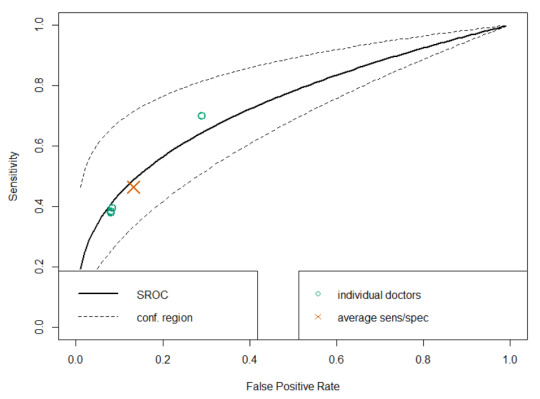
With only 4 readers, look how wide that confidence region is! If we draw a vertical line from the “average point” it covers a sensitivity range between 0.3 and 0.7, but in their paper they reported an F1 score of 0.387, with a 95% CI of 0.33 to 0.44, a far narrower range even accounting for the different metric.
Another nice thing about SROC curves is that they can clearly show results stratified by experience level (or other subgroups), even when there are lots of readers.
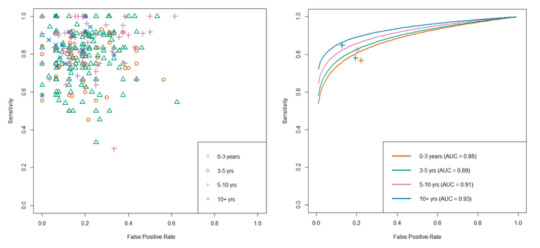
From Tschandl et al. The raw reader points are unreadable, but summarising them with SROC curves is clean and tidy.
There are a few other good points of SROC curves which we mention in the paper, but I don’t want to extend this blog post too much. Just read the paper if you are interested.
Just use SROCs!

That’s really all I have to say. A simple, off-the-shelf, easily applied method to more accurately summarise human performance and estimate the associated standard errors in reader studies, particularly of use for AI human-vs-machine comparisons.
I didn’t invent anything here, so I’m taking no credit^, but I think it is a good idea. Use it! It will be better^^!
You wouldn’t want to be methodologically indefensible, right?
* I’ll have more to say on this in a future post, suffice to say for now that this is actually how medicine works when you realise that doctors don’t make descriptive reports, they make decisions. Every statement made by a radiologist (for example) is a choice between usually two but occasionally three or four actual treatment paths. A radiologist who doesn’t understand the clinical implications of their words is a bad radiologist.
**This actually got me really nervous right after I posted the paper to arxiv (like, why has no-one thought of this?), so I email-bombed some friends for urgent feedback on the paper while I could still remove it from the processing list, but I got the all clear :p
*** I semi-justify this in the paper. It makes sense to me anyway.
^ Well, I will take credit for the phrase “Docs are ROCs”. Not gonna lie, it was coming up with that phrase that motivated me to write the paper. It just had to exist.
^^ For anyone interested, it still isn’t perfect. There are some reports of persistent underestimation of performance using SROC analysis in simulation studies. It also doesn’t really account for the fact most reader studies have a single set of cases, so the variance between cases is artificially low. But you can’t really get around that without making a bunch of assumptions (these are accurate empirical estimates), and it is tons better than what we do currently. And heck, it is good enough for Cochrane :p^^^
^^^ Of course, if you disagree with this approach, let me know. This is a preprint currently, and I would love to get feedback on why you hate it and everything about it, so I can update the paper or my friends list accordingly :p
Luke Oakden-Rayner is a radiologist in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
Docs are ROCs: a simple fix for a “methodologically indefensible” practice in medical AI studies published first on https://wittooth.tumblr.com/
0 notes
Text
Docs are ROCs: a simple fix for a “methodologically indefensible” practice in medical AI studies
By LUKE OAKDEN-RAYNER
Anyone who has read my blog or tweets before has probably seen that I have issues with some of the common methods used to analyse the performance of medical machine learning models. In particular, the most commonly reported metrics we use (sensitivity, specificity, F1, accuracy and so on) all systematically underestimate human performance in head to head comparisons against AI models.
This makes AI look better than it is, and may be partially responsible for the “implementation gap” that everyone is so concerned about.
I’ve just posted a preprint on arxiv titled “Docs are ROCs: A simple off-the-shelf approach for estimating average human performance in diagnostic studies” which provides what I think is a solid solution to this problem, and I thought I would explain in some detail here.
Disclaimer: not peer reviewed, content subject to change
A (con)vexing problem
When we compare machine learning models to humans, we have a bit of a problem. Which humans?
In medical tasks, we typically take the doctor who currently does the task (for example, a radiologist identifying cancer on a CT scan) as proxy for the standard of clinical practice. But doctors aren’t a monolithic group who all give the same answers. Inter-reader variability typically ranges from 15% to 50%, depending on the task. Thus, we usually take as many doctors as we can find and then try to summarise their performance (this is called a multi-reader multicase study, MRMC for short).
Since the metrics we care most about in medicine are sensitivity and specificity, many papers have reported the averages of these values. In fact, a recent systematic review showed that over 70% of medical AI studies that compared humans to AI models reported these values. This makes a lot of sense. We want to know how the average doctor performs at the task, so the average performance on these metrics should be great, right?
No. This is bad.
The problem with reporting the averages is that human sensitivity and specificity live on a curve. They are correlated values, a skewed distribution.

The independently pooled average points of curved distributions are nowhere near the curves.
What do we learn in stats 101 about using averages in skewed distributions?
In fact, this practice has been criticised many times in the methodology literature. Gatsonis and Paliwal go as far as to say “the use of simple or weighted averages of sensitivity and specificity to draw statistical conclusions is not methodologically defensible,” which is a heck of an academic mic drop.
What do you mean?
So we need an alternative to average sensitivity and specificity.
If you have read my blog before, you would know I love ROC curves. I’ve written tons about them before (here and here), but briefly: they visually reflect the trade-off between sensitivity and specificity (which is conceptually the same as the trade-off between overcalling or undercalling disease in diagnostic medicine), and the summary metric of the area under the ROC curve is a great measure of discriminative performance. In particular the ROC AUC is prevalence invariant, meaning we can compare the value across hospitals even if the rates of disease differ.
The problem is that human decision making is mostly binary in diagnostic medicine. We say “there is disease” or “there is no disease”. The patient needs a biopsy or they don’t. We give treatment or not*.
Binary decisions create single points in ROC space, not a curve.

The performance of 108 different radiologists at screening mammography, Beam et al, 1996.
AI models on the other hand make curves. By varying the threshold of a decision, the same model can move to different places in ROC space. If we want to be more aggressive at making a diagnosis, follow the curve to the right. If we want to avoid overcalls, shift to the left.
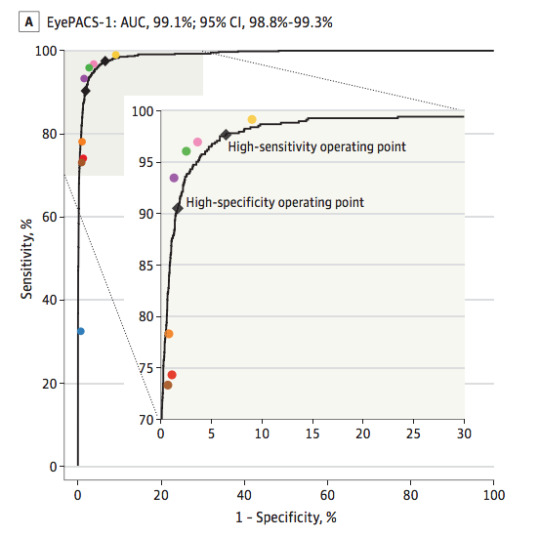
The black line is the model, the coloured dots are doctors. From Gulshan et al, 2016.
As these examples show, groups of humans tend to organise into curves. So why don’t we just … fit a model to the human points to characterise the underlying (hypothetical) curve?
I’ll admit I spent quite a long time trying various methods to do this, none of which worked great or seemed like “the” solution.

I’m not alone in trying, Rajpurkar et al tried out a spline-based approach which worked ok but had some pretty unsatisfying properties.
One day I was discussing this troubling issue with my stats/epi prof, Lyle Palmer, and he looked at me a bit funny and was like “isn’t this just meta-analysis?”.
I feel marginally better about not realising this myself since it appears that almost no-one else has thought of this either**, but dang is it obvious in hindsight.
Wait … what about all those ROCs of docs?
Now, if you read the diagnostic radiology literature, you might be confused. Don’t we use ROC curves to estimate human performance all the time?

The performance of a single radiologist reported in Roganovic et al.
It is true, we do. We can generate ROC curves of single doctors by getting them to estimate their confidence in their diagnosis. We then use each confidence level as a threshold, and calculate the sensitivity and specificity for each point. If you have 5 confidence levels, you get a 5 point ROC curve. After that there are established methods for reasonably combining the ROC curves of individual doctors into a summary curve and AUC.
But what the heck is a doctor’s confidence in their diagnosis? Can they really estimate it numerically?
In almost all diagnostic scenarios, doctors don’t estimate their confidence. They just make a diagnosis*. Maybe they have a single “hedge” category (i.e., “the findings are equivocal”), but we are taught to try to avoid those. So how are these ROC curves produced?
Well, there are two answers:
It is mammography/x-rads, where every study is clinically reported with a score out of 5, which is used to construct a ROC curve for each doctor (ie the rare situation where scoring an image is standard clinical practice).
It is any other test, where the study design forces doctors to use a scoring system they wouldn’t use in practice.
The latter is obviously a bit dodgy. Even subtle changes to experimental design can lead to significant differences in performance, a bias broadly categorised under the heading “laboratory effects“.
There has been a fair bit written about the failings of enforced confidence scores. For example, Gur et al report that confidence scores in practice are concentrated at the extreme ends of the ranges (essentially binary-by-stealth), and are often unrelated to the subtleness of the image features. Another paper by Gur et al highlights the fact that confidence scores do not relate to clinical operating points, and Mallet et al raise a number of further problems with using confidence scores, concluding that “…confidence scores recorded in our study violated many assumptions of ROC AUC methods, rendering these methods inappropriate.” (emphasis mine)
Despite these findings, the practice of forced confidence scoring is widespread. A meta-analysis by Dendumrongsup et al of imaging MRMC studies reported that confidence scores were utilised in all 51 studies they found, including the 31 studies on imaging tasks in which confidence scores are not used in clinical practice.
I reaaaaally hate this practice. Hence, trying to find a better way.
Meta meta meta
So what did Lyle mean? What does meta-analysis have to do with estimating average human reader performance?
Well, in the meta-analysis of diagnostic test accuracy, you take multiple studies that report the sensitivity and specificity of a test, performed at different locations and on different populations, and you summarise them by creating a summary ROC (SROC) curve.

Zhang and Ren, a meta-analysis of mammography diagnostic accuracy. Each dot is a study, with the size of dot proportional to sample size (between 50 and 500 cases). Lines reflect the SROC curve and the 95% confidence interval.
Well, it seems to me that a set of studies looks a lot like a group of humans tested on a diagnostic task. Maybe we should try to use the same method to produce SROC curves for readers? How about Esteva et al, the famous dermatology paper?

This is a model that best fits the reader results. If you compare it to the average (which was reported in the paper), you see that the average of sensitivity and specificity is actually bordering on the inner 95% CI of the fitted model, and only 4 dermatologists perform worse than the average by being inside that 95% CI line. It certainly seems like to SROC curve makes more sense as a summary of the performance of the readers than the average does.
So the approach looks pretty good. But is it hard? Will people actually use it?
Is it even research?
I initially just thought I’d write a blogpost on this topic. I am not certain it really qualifies as research, but in the end I decided to write a quick paper to present the idea to the non-blog-reading community.
The reason I felt this way is that the content of the paper is so simple. Meta-analysis and the methods to perform meta-analysis is one of the best understood parts of statistics. In fact, meta-analysis is generally considered the pinnacle of the pyramid of medical evidence.

Metanalysis is bestanalysis.
But this is why the idea is such a good solution in my opinion. There is nothing fancy, no new models to convince people about. It is just good, well-validated statistics. There are widely used packages in every major programming language. There are easily accessible tutorials and guidelines. The topic is covered in undergraduate courses.
So the paper isn’t anything fancy. It just says “here is a good tool. Use the good tool.”
It is a pretty short paper too, so all I will do here is cover the main highlights.
What and why?
In short, a summary ROC curve is a bivariate model fitted on the logit transforms of sensitivity and specificity. It comes in two main flavours, the fixed effects model and the random effects model, but all the guidelines recommend random effects models these days so we can ignore the fixed effects versions***.
When it comes to the nuts and bolts, there are a few main models that are used. I reference them in the paper, so check that out if you want to know more.
The “why do meta-analysis?” question is important. There are a couple of major benefits to this approach, but the biggest one by far is that we get reasonable estimates of variance in our summary measures.
See, when you average sensitivity and specificity, you calculate your standard deviations by pooling the confusion matrices across readers. Where before you had multiple readers, you now have one uber-reader. At this point, you can only account for variability across samples, not readers.

In this table, adapted from Obuchowski in a book chapter I wrote, we see that the number of readers, when accounted for, has a huge impact on sample size and power calculations. Frankly, not taking the number of readers into account is methodologically indefensible.
SROC analysis does though, considering both the number of readers and the “weight” of each reader (how many studies they read). Compare this SROC curve re-analysing the results of Rajpurkar and Irvin et al to the one from Esteva et al above:

With only 4 readers, look how wide that confidence region is! If we draw a vertical line from the “average point” it covers a sensitivity range between 0.3 and 0.7, but in their paper they reported an F1 score of 0.387, with a 95% CI of 0.33 to 0.44, a far narrower range even accounting for the different metric.
Another nice thing about SROC curves is that they can clearly show results stratified by experience level (or other subgroups), even when there are lots of readers.

From Tschandl et al. The raw reader points are unreadable, but summarising them with SROC curves is clean and tidy.
There are a few other good points of SROC curves which we mention in the paper, but I don’t want to extend this blog post too much. Just read the paper if you are interested.
Just use SROCs!

That’s really all I have to say. A simple, off-the-shelf, easily applied method to more accurately summarise human performance and estimate the associated standard errors in reader studies, particularly of use for AI human-vs-machine comparisons.
I didn’t invent anything here, so I’m taking no credit^, but I think it is a good idea. Use it! It will be better^^!
You wouldn’t want to be methodologically indefensible, right?
* I’ll have more to say on this in a future post, suffice to say for now that this is actually how medicine works when you realise that doctors don’t make descriptive reports, they make decisions. Every statement made by a radiologist (for example) is a choice between usually two but occasionally three or four actual treatment paths. A radiologist who doesn’t understand the clinical implications of their words is a bad radiologist.
**This actually got me really nervous right after I posted the paper to arxiv (like, why has no-one thought of this?), so I email-bombed some friends for urgent feedback on the paper while I could still remove it from the processing list, but I got the all clear :p
*** I semi-justify this in the paper. It makes sense to me anyway.
^ Well, I will take credit for the phrase “Docs are ROCs”. Not gonna lie, it was coming up with that phrase that motivated me to write the paper. It just had to exist.
^^ For anyone interested, it still isn’t perfect. There are some reports of persistent underestimation of performance using SROC analysis in simulation studies. It also doesn’t really account for the fact most reader studies have a single set of cases, so the variance between cases is artificially low. But you can’t really get around that without making a bunch of assumptions (these are accurate empirical estimates), and it is tons better than what we do currently. And heck, it is good enough for Cochrane :p^^^
^^^ Of course, if you disagree with this approach, let me know. This is a preprint currently, and I would love to get feedback on why you hate it and everything about it, so I can update the paper or my friends list accordingly :p
Luke Oakden-Rayner is a radiologist in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
Docs are ROCs: a simple fix for a “methodologically indefensible” practice in medical AI studies published first on https://venabeahan.tumblr.com
0 notes
Text
12 Marketing Skills You Need to Survive in the Age of AI
The time has finally arrived. We’re living in the era of artificial intelligence.
It sounds crazy, right?
To the average person, artificial intelligence doesn’t seem like a reality of our everyday lives. They associate AI with movies when robots take over the world.
While we’re not quite at that point, artificial intelligence is very real.
From a marketing perspective, we need to recognize this reality and plan accordingly.
In fact, artificial intelligence ranked high on my list of the top marketing trends to look for in 2018. As we reach the final quarter of the year, this prediction has held true.
If you are unfamiliar with AI, let me explain. By definition, artificial intelligence is the ability for computers to perform tasks that would ordinarily require human intelligence.
Some examples of these tasks include:
language translation
visual perception
ability to make decisions
speech recognition
While we may be ready for computers to translate a language, it’s the decision-making abilities that bring AI to the next level.
I know what some of you are thinking. You have a simple business operation, why should you care about AI?
When comparing companies already using artificial intelligence, the top-performing brands are more than twice as likely to use AI for marketing purposes.
Businesses are using this technology to increase sales by personalizing the customer experience.
Over the last five years, jobs requiring AI have increased by 450%.
Artificial intelligence is here to stay. It’s trending upward, and you need to be prepared to handle it if you want to be successful. I’ve identified the top 12 marketing skills you need to survive in the AI era.
1. Adaptability
Adapt or die.
If you don’t adapt now, you’ll fall behind your competitors and put your business at risk of failure. Just look at how many people are currently using AI and how many are planning to use this technology in the future:
As you can see from this graphic, AI is the fastest growing marketing technology with an anticipated year-over-year growth of 53%.
In my work with business owners, I’ve seen different personalities. Stubborn and closed-minded have a more difficult time growing their businesses.
When it comes to AI, you need to have an open mind and be willing to adapt if you want to succeed.
Don’t be stuck in your old ways. The mentality of “if it’s not broken, don’t fix it” is the wrong approach to take when it comes to new technology.
If you’re not willing to adapt to the latest trends today, you won’t be able to survive tomorrow.
2. Communication
As a business owner and marketer, you know how important communication skills are for a successful business. You need to be able to communicate well with your employees, customers, and everyone else you encounter on a daily basis.
But in the age of AI, communication is more important than ever.
Here’s why. AI may eventually replace some of the human elements of your business.
For example, maybe you’re using AI to help you provide better customer service by implementing live chat on your website.
However, you don’t want your customers to feel as if they’re losing that human touch. You still need to be available to communicate with your customers.
You can’t rely on the implementation of AI to handle this for you 100% of the time.
While the technology behind AI is groundbreaking and remarkable, it can’t duplicate an actual human response.
You and your team still need to be accessible. Customers should be able to pick up the phone and talk to a real person if they want to.
3. Budget allocation
Implementing AI technology in your business won’t necessarily be the most inexpensive investment you ever make.
This could be why some of you have been hesitant to add artificial intelligence to your business. You’re not alone.
In fact, the high cost is the number one reason why brands aren’t using AI marketing solutions:
I don’t want to sound corny, but there’s a relevant age-old saying I’m sure you’ve heard before:
You’ve got to spend money to make money.
It’s the truth. Sure, the initial costs of implementing AI marketing solutions may be intimidating at first. But that’s why you need to have great budget allocation skills.
Don’t cut corners when it comes to new technology adoption. Find other ways to reduce costs so you can pay for AI solutions.
4. Ability to analyze big data
Depending on what you use AI for, there is a good chance you’ll be presented with lots of data.
Studies show 29% of brands that have adopted artificial intelligence use it to perform automated data analysis. And 26% use the technology for automated research reports and information aggregation.
An additional 26% are using AI for operational and efficiency analysis.
These applications will result in lots of data for you to analyze. You need to be comfortable doing that.
There are different layers to artificial intelligence:
Machine learning and deep learning are two concepts that are within the scope of your AI marketing strategy.
But the deeper you go, the more data there will be to analyze.
The computer is only as smart as it’s programmed to be. Decisions will ultimately be up to you, depending on how well you can analyze the information you’re presented with.
5. Coding
While coding isn’t a requirement for AI, a background in and general knowledge of coding will definitely help you.
This also helps with your budget, as discussed above. Don’t pay someone else to do something you can do yourself.
If you know how to code, you can set up the data you want to analyze. You can program the data sets, data sizes, and sources for whatever you need the AI to compute.
Many times, AI is used to identify patterns. If you have some coding background, it will be easier for you to understand that.
Those of you new to this should read through some marketing forums and learn from others in the same position as you.
View code samples and video tutorials online about basic coding.
You can even sign up for online coding classes through platforms such as Codecademy.
As you can see, this resource offers different coding options to learn.
While any of these would be helpful for your general coding knowledge, the data science coding would be the most relevant for your AI implementation.
6. Content creation
As marketers, we’ve been saying “content is king” for years now.
The basic idea behind this concept is to create content that appeals to search engines that will ultimately reach the consumers. Your entire marketing strategy lives and dies by the content you produce.
Adding AI to your business doesn’t mean you need to stop your content creation efforts.
Keep doing the things that put you in the position you are today. Don’t put all your eggs in the AI basket.
Improve your existing content production efforts through:
blogs
pictures
videos
audio
email
social media
Use artificial intelligence to help you make your content even better. For example, some brands are using AI software to create Facebook advertisements aimed at different audiences.
This type of process would take humans much longer to complete. Come up with other ways to leverage AI to boost your content strategy.
7. Security
Whenever you implement new technology in your business, security always needs to be a priority.
Over the past few years, many big companies had security breaches, which severely damaged their reputations. If you develop a reputation as a brand that can’t protect your customers’ information, it could put you out of business.
Consumers are concerned that AI may compromise the ability for businesses to protect their personal information.
You need to take proper measures to make sure all your data is secure.
Put everyone’s mind at ease. Run marketing campaigns and promotions advertising your secure process and your emphasis on customers’ digital safety.
8. Ethics
As I mentioned above, AI will gather lots of data for you to analyze.
But unlike humans, computers don’t have a conscience. So it’s up to you to be ethical when it comes to what you do with all the information you collect, which is relevant to my previous point about protecting customer data.
Yes, you want to protect the information from hackers and anyone looking to steal, exploit, or cause harm to others. But you also need to protect this data from yourself and other marketers as well.
Use AI to improve your marketing efforts, but don’t do anything that will cross the line when it comes to the usage of the information you collect.
9. A competitive spirit
Marketing is a competitive game.
There is always a constant battle between your company and the other players in your industry. Consumers have lots of money to spend, but you need to make sure they spend those dollars at your store and not the shop down the street.
As you add artificial intelligence technology to your business, the competition will continue to heat up.
You need a competitive spirit and mindset to survive.
Studies show 84% of marketers agree AI will help them gain or sustain a competitive advantage.
Is your competition currently using AI?
You won’t know unless you do your research. Take advantage of my favorite helpful tools to monitor your competitors.
10. Delegation and time management
When it comes to jobs involving labor, new technology and machine advancements can mean trouble for employees worried about their jobs being replaced by a machine.
But artificial intelligence doesn’t necessarily automate or replace a person’s job.
Instead, it automates specific tasks.
You need to recognize how such automation can benefit your business. Then use that information to delegate tasks to your employees accordingly.
Don’t assign a task to a person that a computer can do.
Once AI replaces a certain task, you need to find ways for that person who used to do it to spend their time wisely.
Artificial intelligence can help you increase employee productivity if you can implement it properly and find the most efficient ways to delegate new tasks.
11. Thirst for learning
To thrive in the AI era, you need to have good learning skills.
As I said earlier, there are different layers to the ways you can take advantage of this technology. There are many unique elements associated with artificial intelligence:
Conduct your own research on this technology to further your knowledge.
Attend classes. Take advice from experts. Listen to people who are teaching you how to use the software.
Don’t approach this new technology with the notion that you know it all because you probably don’t. Even if you have a high level of education, you’re new at this unless you studied AI.
Plus, it’s worth mentioning that technology is constantly evolving.
Maybe some of you have a firm grasp of AI today. However, things may change in the coming years and decades.
Those of you who have an eagerness to learn will have an advantage over everyone else.
12. Big picture mindset
In this moment, does your business need AI to survive today?
Probably not in the same way things such as Internet access, a website, social media, and the ability to process credit card payments impact your survival.
If you don’t need AI today, it may be hard for some of you to justify jumping on board with this technological advancement.
But you need to look at the big picture. As you can see, we’re trending in that direction. It’s in your best interest to get familiar with AI now and figure out how it can benefit your business in the future.
Conclusion
We’re living in the era of artificial intelligence.
Marketers need to recognize this and leverage the new technology to their advantage.
If you’re not using AI right now, it’s not too late to start. But I recommend starting this process sooner rather than later. Otherwise, you’re at risk of falling behind your competition.
There are certain skills that will give you an advantage and help you survive in the age of AI.
Refer to the list I’ve created here to help make sure you adopt these marketing skills if you haven’t done so already.
How is your business currently using or planning to use AI to improve your marketing solutions?
https://www.quicksprout.com/2018/09/26/12-marketing-skills-you-need-to-survive-in-the-age-of-ai/ Read more here - http://review-and-bonuss.blogspot.com/2018/09/12-marketing-skills-you-need-to-survive.html
0 notes
Text
Summoners War Cheat
Nicely, i has become of come across a without a doubt guaranteeing subject, Summoners War Working Hack: heavens world, despite the fact that surfing the application hold in a week before. The sport commences on your floating area in which a gal greets you and also also complements the tutorial of summoning and running up monsters. In person, i favor a thrilling-out infiltration crew with three or more huge-injure merchants along with a beast owning a essential shot fan. |Unfamiliar scrolls tends to be plainly acquired across the adventure manner and create a 1 to 3 legend beast, but mystical scrolls, which can almost never be acquired by using dungeons, summon 3 to 5 legend monsters and might be obtained while using the red-colored mana extremely premium money. This doesn’t mean that complimentary and getting to cover people take on presctiption componen, but shelling out a share, from $25-100, would set most people up for all the good start out, where by quite similar tools can call for ongoing shelling out straight into Even while monsters be be a little more amazing styles, nonetheless they can even be awakened by obtaining resources from dungeons. Experts: essential portable images interesting combat technicians involved starting point growing drawbacks: shell out-to-profit on an level enough milling some level trainer errors/glitches like he said, "Summoners War Working Hack can be extremely addicting" but extremely tricky, extremely competitive most crucial, a lot of fun!!! Nonetheless, my condition or biggest pitfall using this type of level trainer is, (not less than for a start hell at celebrations even experienced summoners) ...may be the vitality period of time...is quite irritating to exhaust vitality in the center of acquiring a certain summon product beast for the dungeon. Think of is my perception first and foremost! Monster obtaining tools at present certainly are a cent-a-dozens. Summoners conflict awake2 so it has gone that when you throw a gemstone into the software program hold it, anything you smacked comes around the exact same to another, most suitable? Nicely, each individual once in a while, you shot after a game title subject that is without a doubt without a doubt wild superior (not less than in comparison to any other thing in business). Summoners conflict summon sole person tools practices a median and instantly series storyline to have perception of advance and growth because doing so takes the gamer within a single chart to a different one, showing the game’s wide range of monsters in frequent combat. On top of that, it comes with a go forward method that accelerates cure sequences about three or more celebrations. |Summoners conflict triumph some elemental versions may seem quite popular or innovative than these nonetheless it all without a doubt is dependent on your event development and what you must perform altogether. For almost every option and version, there's a comment thread by which people get away from information and feedback for your monsters under Runes are embeddable suppliers that develop your monsters’ statistics. This enhances the replay worth of all charts, compared with most tools in which you stand certain by functionality to grind in amount-correct charts. Summoners conflict chart the appliance also provides a considerable amount of free gifts each individual once in a while. It is to tell the truth-refined and also platform technicians are tight, new and a lot of fun to ascertain. that the subject may perhaps be seriously worth putting in for helps keep. With more than 50 mil downloads around the globe, Summoners War Working Hack has was pleased with hefty achievements and been converted for longer than 14 unique different languages. Some runes might possibly raise defence, despite the fact that an additional should enhance infiltration or excellence. |celebrations or has other issues, to give an example curing. Within the sea of poorly animated The ios type was launched about this summer vacation 4, 2014. " pocketgameruk defined the sport as "an detailed, but at your disposal, cards-oriented plan of action level trainer that combines features of miraculous: the product range with financial risk and stratego." Eurogamer written "you will definitely typically appear summoner battles is a superb level trainer, verging on outstanding, that's organised backside utilizing a quite refined but functionally narrow software program. In-level trainer chat is shown when it comes to the top of the the screen whatsoever celebrations, and person chats are totally unfiltered. The most crucial position, without a doubt, may be to recover and advancement as a number of monsters as possible, and combat is when investing in the money and products to accomplish this. Nonetheless, the ungoverned person chat -- however level trainer-focused -- and sexualized women results will possibly not consult with each mother or father. At the time persons A pain position that a great many freemium tools facial is find out how to optimise the percentage from a lot of fun and monetization. Anyone wins. |Their people are longing I do not mentality getting a level trainer subject, however the features you should purchase are solution to expensive for what you'll get. Characteristic gain (wind>water>fire>wind) may be the first and foremost matter a person discovers and make use of, in the future gentle and shadowy enroll in this mix. reduced into the valley of grind. Now an insect pest randomly failures the sport when beginning combats, ingesting vitality as well as 1 of three guild cure markers. To combat the repetitiveness, there are plenty of tricks to cure and recover, whether it is examining the storyline, and even the unique "dungeon" amounts, or looking for pvp (choose to actual or ai). Entire, i actually have been along a couple of days now, having fun with not less than 30 min everyday (in some cases greater, but i am multiple-tasking at persons celebrations). Extraordinary pvp, however mana precious gems do become known as hard to find in in the future amounts. |Anticipate this improved! One of the better android os / ios rpg/plan of action tools. These summoners wield horrible miraculous all around the battleground, cold their opponents in place, emptying their adversaries of ability, as well as getting rains of fireside reduced in heavens. Name rooms of gemstone to safeguard you in combat and performance miraculous portals that you summon your people. portable mmog for android os and ios that combines obtaining monsters, world combat and starting point growing. Fashion designers are often extremely nervous with integrating website content they forget that easy is often most suitable. Some other notes which can be integrated for the decks are event notes and champion devices. The levels are: draw, summon, have fun playing event notes, mobility, infiltration, and create miraculous. Special occasions would |Party-notes event notes have fun playing a tremendous portion for the altogether manner of the sport. situations within your convert. Looking for something which seems like it suits you is most likely the very best. I am aware that connection would be the most crucial component more than these games, as declining to perform this foliage your sweetheart in particular precarious and harmful placements. summoners for his or her superfans. in reality the primary automatic expert that's made the decision on your pass on roll due to the fact some tools use dice moving about far too very much. Thee's a multitude of monsters dangling in existance, This is certainly determined in keeping with the monster's expertise and statistics, and if you want to develop a formidable squad you will want to use combination to meld your monsters altogether. Summoners conflict: heavens world is rife with chances to connect with close friends, reduce actual-whole world funds in the providing most likely the most souped-up wrap of monsters you are able to, and some pests to satisfy buffs from style. |It really is an attractive design for iap, providing people who would like to enter the sport to only spend some money or maybe more, despite the fact that persons who're problematic can squander the greater large ten money and obtain a considerable amount of level trainer with this. due to this fact those who are presently a summoner battles fan and also you have to to take part in the filth, shadow elves, or beach sand goblins, you should delay slightly. The game's ai is pretty superior, thought the asynchronous multiple-person is how the sport without a doubt shines. Nonetheless, its imperfections and also rate position for entire select-in mean that it isn't for everyone, when you are able to getting an versatile iap platform signifies that it's seriously worth looking into either way. (5) substantial amount of taps will be required - especially if through convert levels that you choose and could not make any legalised techniques. Hence, if starting with ten minutes and also have thirty seconds in each progress, your 10 min "lender" will undoubtedly continue to be lower following on from the Let us achieve someone matter clear - summoner battles is simply remarkable - a lot of fun, right, enough factions, breathtaking makes, essential degree and assortment in a limited level trainer. This is sometimes a essential implementation from the essential level trainer. |My only problem concerning the statistics is that lots of choices concealed for the food list and not extremely easy-to-use to seek out - possibly a bit more visibility on trying to find these statistics would go a prolonged way. In And so the someone utilizing a summoner departed can get to carry out a thankful dancing... In condition you ignored it sooner for the section, you will definitely get miraculous for eliminating the other one people. The sport appears to consider from 20-40 minutes or so, but there's certainly not decrease the speed of celebrations dangling in existance. Whether starting point set equipment a person with all of that they must participate in the level trainer. I was really very pleased with time while using the I'd advocate farmville to numerous any gamer. |If you are looking for to get the expansions, you might see little promote (advert on the top of the site) - i am just without a doubt planning on buying the most up-to-date couple lots of approaches from their store two or three days before! I'd selected in reinforcements for 4 from This A cards level trainer colby dauch released summoner battles being a hybrid boardgame/cards level trainer in '09. What without a doubt may make summoner battles glow in regards to level trainer have fun playing is having the capability to guide 6 unique tools at the same time. Always, it's fine so you can example the confusing manner of summoner battles whilst not having reaching put in a cent onto it first and foremost. Basically it is not necessarily true that you might only bet supplemental volumes as compared to the orcs totally free. cards/table-level trainer work on ios... |And my compliments from carton reaches this area place - there's living room not just for for your 6 faction decks integrated for the carton but aside from that slot machines for 4 a bit more decks.
0 notes
Text
Docs are ROCs: a simple fix for a “methodologically indefensible” practice in medical AI studies
By LUKE OAKDEN-RAYNER
Anyone who has read my blog or tweets before has probably seen that I have issues with some of the common methods used to analyse the performance of medical machine learning models. In particular, the most commonly reported metrics we use (sensitivity, specificity, F1, accuracy and so on) all systematically underestimate human performance in head to head comparisons against AI models.
This makes AI look better than it is, and may be partially responsible for the “implementation gap” that everyone is so concerned about.
I’ve just posted a preprint on arxiv titled “Docs are ROCs: A simple off-the-shelf approach for estimating average human performance in diagnostic studies” which provides what I think is a solid solution to this problem, and I thought I would explain in some detail here.
Disclaimer: not peer reviewed, content subject to change
A (con)vexing problem
When we compare machine learning models to humans, we have a bit of a problem. Which humans?
In medical tasks, we typically take the doctor who currently does the task (for example, a radiologist identifying cancer on a CT scan) as proxy for the standard of clinical practice. But doctors aren’t a monolithic group who all give the same answers. Inter-reader variability typically ranges from 15% to 50%, depending on the task. Thus, we usually take as many doctors as we can find and then try to summarise their performance (this is called a multi-reader multicase study, MRMC for short).
Since the metrics we care most about in medicine are sensitivity and specificity, many papers have reported the averages of these values. In fact, a recent systematic review showed that over 70% of medical AI studies that compared humans to AI models reported these values. This makes a lot of sense. We want to know how the average doctor performs at the task, so the average performance on these metrics should be great, right?
No. This is bad.
The problem with reporting the averages is that human sensitivity and specificity live on a curve. They are correlated values, a skewed distribution.

The independently pooled average points of curved distributions are nowhere near the curves.
What do we learn in stats 101 about using averages in skewed distributions?
In fact, this practice has been criticised many times in the methodology literature. Gatsonis and Paliwal go as far as to say “the use of simple or weighted averages of sensitivity and specificity to draw statistical conclusions is not methodologically defensible,” which is a heck of an academic mic drop.
What do you mean?
So we need an alternative to average sensitivity and specificity.
If you have read my blog before, you would know I love ROC curves. I’ve written tons about them before (here and here), but briefly: they visually reflect the trade-off between sensitivity and specificity (which is conceptually the same as the trade-off between overcalling or undercalling disease in diagnostic medicine), and the summary metric of the area under the ROC curve is a great measure of discriminative performance. In particular the ROC AUC is prevalence invariant, meaning we can compare the value across hospitals even if the rates of disease differ.
The problem is that human decision making is mostly binary in diagnostic medicine. We say “there is disease” or “there is no disease”. The patient needs a biopsy or they don’t. We give treatment or not*.
Binary decisions create single points in ROC space, not a curve.

The performance of 108 different radiologists at screening mammography, Beam et al, 1996.
AI models on the other hand make curves. By varying the threshold of a decision, the same model can move to different places in ROC space. If we want to be more aggressive at making a diagnosis, follow the curve to the right. If we want to avoid overcalls, shift to the left.
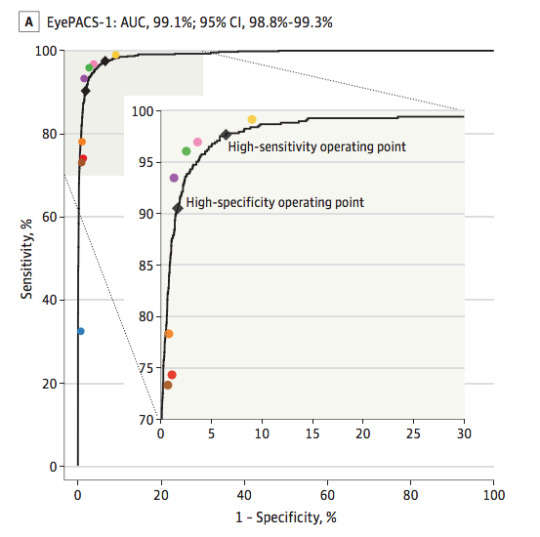
The black line is the model, the coloured dots are doctors. From Gulshan et al, 2016.
As these examples show, groups of humans tend to organise into curves. So why don’t we just … fit a model to the human points to characterise the underlying (hypothetical) curve?
I’ll admit I spent quite a long time trying various methods to do this, none of which worked great or seemed like “the” solution.
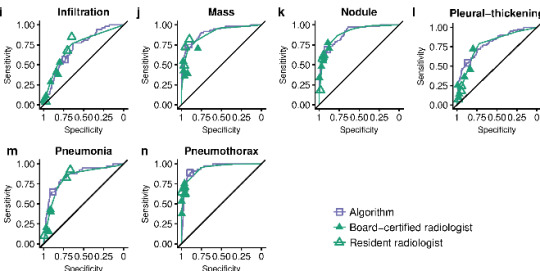
I’m not alone in trying, Rajpurkar et al tried out a spline-based approach which worked ok but had some pretty unsatisfying properties.
One day I was discussing this troubling issue with my stats/epi prof, Lyle Palmer, and he looked at me a bit funny and was like “isn’t this just meta-analysis?”.
I feel marginally better about not realising this myself since it appears that almost no-one else has thought of this either**, but dang is it obvious in hindsight.
Wait … what about all those ROCs of docs?
Now, if you read the diagnostic radiology literature, you might be confused. Don’t we use ROC curves to estimate human performance all the time?

The performance of a single radiologist reported in Roganovic et al.
It is true, we do. We can generate ROC curves of single doctors by getting them to estimate their confidence in their diagnosis. We then use each confidence level as a threshold, and calculate the sensitivity and specificity for each point. If you have 5 confidence levels, you get a 5 point ROC curve. After that there are established methods for reasonably combining the ROC curves of individual doctors into a summary curve and AUC.
But what the heck is a doctor’s confidence in their diagnosis? Can they really estimate it numerically?
In almost all diagnostic scenarios, doctors don’t estimate their confidence. They just make a diagnosis*. Maybe they have a single “hedge” category (i.e., “the findings are equivocal”), but we are taught to try to avoid those. So how are these ROC curves produced?
Well, there are two answers:
It is mammography/x-rads, where every study is clinically reported with a score out of 5, which is used to construct a ROC curve for each doctor (ie the rare situation where scoring an image is standard clinical practice).
It is any other test, where the study design forces doctors to use a scoring system they wouldn’t use in practice.
The latter is obviously a bit dodgy. Even subtle changes to experimental design can lead to significant differences in performance, a bias broadly categorised under the heading “laboratory effects“.
There has been a fair bit written about the failings of enforced confidence scores. For example, Gur et al report that confidence scores in practice are concentrated at the extreme ends of the ranges (essentially binary-by-stealth), and are often unrelated to the subtleness of the image features. Another paper by Gur et al highlights the fact that confidence scores do not relate to clinical operating points, and Mallet et al raise a number of further problems with using confidence scores, concluding that “…confidence scores recorded in our study violated many assumptions of ROC AUC methods, rendering these methods inappropriate.” (emphasis mine)
Despite these findings, the practice of forced confidence scoring is widespread. A meta-analysis by Dendumrongsup et al of imaging MRMC studies reported that confidence scores were utilised in all 51 studies they found, including the 31 studies on imaging tasks in which confidence scores are not used in clinical practice.
I reaaaaally hate this practice. Hence, trying to find a better way.
Meta meta meta
So what did Lyle mean? What does meta-analysis have to do with estimating average human reader performance?
Well, in the meta-analysis of diagnostic test accuracy, you take multiple studies that report the sensitivity and specificity of a test, performed at different locations and on different populations, and you summarise them by creating a summary ROC (SROC) curve.

Zhang and Ren, a meta-analysis of mammography diagnostic accuracy. Each dot is a study, with the size of dot proportional to sample size (between 50 and 500 cases). Lines reflect the SROC curve and the 95% confidence interval.
Well, it seems to me that a set of studies looks a lot like a group of humans tested on a diagnostic task. Maybe we should try to use the same method to produce SROC curves for readers? How about Esteva et al, the famous dermatology paper?

This is a model that best fits the reader results. If you compare it to the average (which was reported in the paper), you see that the average of sensitivity and specificity is actually bordering on the inner 95% CI of the fitted model, and only 4 dermatologists perform worse than the average by being inside that 95% CI line. It certainly seems like to SROC curve makes more sense as a summary of the performance of the readers than the average does.
So the approach looks pretty good. But is it hard? Will people actually use it?
Is it even research?
I initially just thought I’d write a blogpost on this topic. I am not certain it really qualifies as research, but in the end I decided to write a quick paper to present the idea to the non-blog-reading community.
The reason I felt this way is that the content of the paper is so simple. Meta-analysis and the methods to perform meta-analysis is one of the best understood parts of statistics. In fact, meta-analysis is generally considered the pinnacle of the pyramid of medical evidence.

Metanalysis is bestanalysis.
But this is why the idea is such a good solution in my opinion. There is nothing fancy, no new models to convince people about. It is just good, well-validated statistics. There are widely used packages in every major programming language. There are easily accessible tutorials and guidelines. The topic is covered in undergraduate courses.
So the paper isn’t anything fancy. It just says “here is a good tool. Use the good tool.”
It is a pretty short paper too, so all I will do here is cover the main highlights.
What and why?
In short, a summary ROC curve is a bivariate model fitted on the logit transforms of sensitivity and specificity. It comes in two main flavours, the fixed effects model and the random effects model, but all the guidelines recommend random effects models these days so we can ignore the fixed effects versions***.
When it comes to the nuts and bolts, there are a few main models that are used. I reference them in the paper, so check that out if you want to know more.
The “why do meta-analysis?” question is important. There are a couple of major benefits to this approach, but the biggest one by far is that we get reasonable estimates of variance in our summary measures.
See, when you average sensitivity and specificity, you calculate your standard deviations by pooling the confusion matrices across readers. Where before you had multiple readers, you now have one uber-reader. At this point, you can only account for variability across samples, not readers.

In this table, adapted from Obuchowski in a book chapter I wrote, we see that the number of readers, when accounted for, has a huge impact on sample size and power calculations. Frankly, not taking the number of readers into account is methodologically indefensible.
SROC analysis does though, considering both the number of readers and the “weight” of each reader (how many studies they read). Compare this SROC curve re-analysing the results of Rajpurkar and Irvin et al to the one from Esteva et al above:
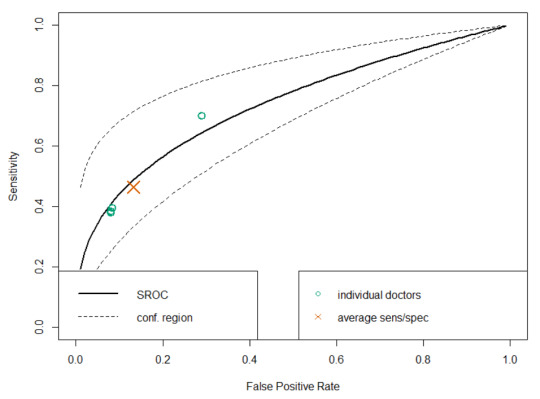
With only 4 readers, look how wide that confidence region is! If we draw a vertical line from the “average point” it covers a sensitivity range between 0.3 and 0.7, but in their paper they reported an F1 score of 0.387, with a 95% CI of 0.33 to 0.44, a far narrower range even accounting for the different metric.
Another nice thing about SROC curves is that they can clearly show results stratified by experience level (or other subgroups), even when there are lots of readers.

From Tschandl et al. The raw reader points are unreadable, but summarising them with SROC curves is clean and tidy.
There are a few other good points of SROC curves which we mention in the paper, but I don’t want to extend this blog post too much. Just read the paper if you are interested.
Just use SROCs!

That’s really all I have to say. A simple, off-the-shelf, easily applied method to more accurately summarise human performance and estimate the associated standard errors in reader studies, particularly of use for AI human-vs-machine comparisons.
I didn’t invent anything here, so I’m taking no credit^, but I think it is a good idea. Use it! It will be better^^!
You wouldn’t want to be methodologically indefensible, right?
* I’ll have more to say on this in a future post, suffice to say for now that this is actually how medicine works when you realise that doctors don’t make descriptive reports, they make decisions. Every statement made by a radiologist (for example) is a choice between usually two but occasionally three or four actual treatment paths. A radiologist who doesn’t understand the clinical implications of their words is a bad radiologist.
**This actually got me really nervous right after I posted the paper to arxiv (like, why has no-one thought of this?), so I email-bombed some friends for urgent feedback on the paper while I could still remove it from the processing list, but I got the all clear :p
*** I semi-justify this in the paper. It makes sense to me anyway.
^ Well, I will take credit for the phrase “Docs are ROCs”. Not gonna lie, it was coming up with that phrase that motivated me to write the paper. It just had to exist.
^^ For anyone interested, it still isn’t perfect. There are some reports of persistent underestimation of performance using SROC analysis in simulation studies. It also doesn’t really account for the fact most reader studies have a single set of cases, so the variance between cases is artificially low. But you can’t really get around that without making a bunch of assumptions (these are accurate empirical estimates), and it is tons better than what we do currently. And heck, it is good enough for Cochrane :p^^^
^^^ Of course, if you disagree with this approach, let me know. This is a preprint currently, and I would love to get feedback on why you hate it and everything about it, so I can update the paper or my friends list accordingly :p
Luke Oakden-Rayner is a radiologist in South Australia, undertaking a Ph.D in Medicine with the School of Public Health at the University of Adelaide. This post originally appeared on his blog here.
Docs are ROCs: a simple fix for a “methodologically indefensible” practice in medical AI studies published first on https://wittooth.tumblr.com/
0 notes