#AI Privacy
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
my little brother tried to show me a "cool trick" where he entered my name and hometown into chatgpt and tried to get it to pull up my personal info like it did on all of his friends, then was absolutely shocked when it couldn't find anything on me
so. keep practicing basic internet safety, guys. it still works. don't put your personal info on social media, keep all your accounts on private, turn off ai scraping on every site that you can, enable all privacy features on social media apps. our info still can be protected, we have to keep fighting for control
44K notes
·
View notes
Text
June 11 note - We’ve updated this post with even more tools!
Every day, there seem to be more reasons to break up with Google.

So we’ve rounded up a bunch of privacy-centric alternatives for all your deGoogling needs.
Check out the full list over on the blog!
- The Ellipsus Team xo
49K notes
·
View notes
Text

52K notes
·
View notes
Text

Google Assistant is fading out. Gemini AI takes over July 7.
This isn’t your average upgrade—it’s a full-on AI transformation. Expect faster help with calls, messages, and more… but don’t forget to ask:
Who’s really in control? 🤖
0 notes
Text

Google Assistant is fading out. Gemini AI takes over July 7.
This isn’t your average upgrade—it’s a full-on AI transformation. Expect faster help with calls, messages, and more… but don’t forget to ask:
Who’s really in control? 🤖
0 notes
Text
Gigabyte Aorus Master 16 AI Laptop With Intel Ultra 9 Launched in India
Introduction Gigabyte has officially unveiled its latest AI-powered gaming laptop, the Gigabyte Aorus Master 16, in India. Packed with the latest Intel Core Ultra 9 275HX CPU and the powerful Nvidia GeForce RTX 5080 Laptop GPU based on Blackwell architecture, this AI PC is designed to deliver unmatched gaming and AI computing performance. Gigabyte Aorus Master 16 Price and Availability in…
#AI agent laptop#AI gaming laptop#AI PC India#AI privacy#Amazon Gigabyte#Dolby Vision#Flipkart Gigabyte#Gigabyte Aorus Master 16#GiMate AI#Intel Ultra 9#LLM inference laptop#Nvidia RTX 5080#OLED laptop#Windforce cooling#WQXGA display
0 notes
Text
A Guide to Dark Patterns

The use of dark patterns have become an increasingly popular practice online. Harry Brignull, who coined the term ‘dark patterns’ defined it as practices that “trick or manipulate users into making choices they would not otherwise have made and that may cause harm.”
The growing popularity of dark patterns has naturally attracted the attention of regulatory bodies. The U.S Federal Trade Commission has even stated that they have been “ramping up enforcement” against companies that employ dark patterns as can be seen with the $520 million imposed on Fortnite creator, Epic Games. In the EU, the fines have been piling up against the violating companies, with TikTok and Facebook facing a €5 million fine and €60 million fine respectively, both imposed by French DPA, the CNIL.
The FTC, in its endeavor to combat the use of dark patterns and protect consumer privacy, even conducted a workshop and released a report on the topic in 2022, titled Bringing Dark Patterns to Light. Samuel Levine, Director of the FTC’s Bureau of Consumer Protection stated, “This report—and our cases—send a clear message that these traps will not be tolerated.” FTC Report Shows Rise in Sophisticated Dark Patterns Designed to Trick and Trap Consumers | Federal Trade Commission
With increasing state privacy regulations in the U.S and given the growing strength of the enforcement around dark patterns, it is important to know the terms that address dark patterns under the existing regulations.
Two significant definitions and regulations of dark patterns within the US come from the California Consumer Privacy Act, CCPA, and the Colorado Privacy Act, CPA. Both these state privacy regulations address dark patterns in a detailed fashion, which can be found below.
Under the CCPA, § 7004. Requirements for Methods for Submitting CCPA Requests and Obtaining Consumer Consent.
Except as expressly allowed by the CCPA and these regulations, businesses shall design and implement methods for submitting CCPA requests and obtaining consumer consent that incorporate the following principles:
“Easy to understand” The language used should be simple and easy to read and comprehend
“Symmetry in choice”. It should be as easy and quick to exercise a more privacy protective option as it is to exercise a less privacy protective option - The process to submit a request to opt-out of sale/sharing of personal information should not require more time than the process to opt-in to the sale of PI after having previously opted out. - “Yes” and “Ask me later” as the ONLY two options to decline the option to opt-in to the sale is not appropriate. “Ask me later” does not imply that the consumer has denied the decision but delayed it. Businesses will continue asking the consumer to opt-in. “Yes” and “No” are the options that should be provided. - “Accept All” and “Preferences” or “Accept All and “More information” as choices to provide consent to the use of consumers personal information is not appropriate as the choice can be accepted in one step but additional steps are required to exercise their rights. “Accept all” and “Decline all” should be used.
Confusing language should be avoided. Consumers choices should be clearly provided. Double negatives should not be used - Confusing options such as the choice of “Yes” or “No” next to the statement “Do Not Sell or Share My Personal Information” is a double negative and should be avoided. - “On” or “off” toggles or buttons may require further clarification - If at first, the options are presented in the order “Yes” and then “No”, it should not be changed then to the opposite order of “No” and then “Yes” as is this unintuitive and confusing.
The design and architecture should not impair the consumers ability to make choices. Consent should be “freely given, specific, informed and unambiguous” - Consumers should not be made to click through disruptive screens before submitting an opt-out request. - The option to consent to using PI for purposes that meet the requirements should not be combined with the option to consent to using PI for purposes that are “incompatible with the context” For example, a business that uses location data for its services such as a mobile app that delivers food to users’ locations should not ask for consent to “incompatible uses” (sale of geolocation data to third parties) along with the “reasonably necessary and proportionate use of geolocation date” that is needed for the apps services. This requires consent to “incompatible uses” to use the apps’ expected services
“Easy to execute”. The process to submit a CCPA request should be straight forward, simple and functional. Consumer’s choice to submit a request should not be undermined - Consumer should not have to search extensively for a privacy policy or webpage for the option to submit an opt-out request after clicking the “Do Not Sell or Share My Personal Information” link. - Businesses that know of faults such as broken links, non-functional email addresses, inboxes that are not monitored, should fix them at the earliest - Consumers should not have to unnecessarily wait on a webpage while the request is being processed.
Using dark patterns (practices stated above) to obtain consent is not considered as consent. Obtaining consent using dark patterns can be considered has having never obtained consumer consent.
Should the user interface unintentionally impair the user’s choice and with this knowledge, the business does not remedy the issue, it could be considered a dark pattern. “Deliberate ignorance” if the faulty, impairing designs may be considered a dark pattern.
Under the CPA, Rule 7.09 USER INTERFACE DESIGN, CHOICE ARCHITECTURE, AND DARK PATTERNS
There should be symmetry in presentation of choices. No one option should be given more focus over others - All options should use the same font, size, and style. “I accept” being in a larger size or in a brighter more attention-grabbing colour over the “I do not accept” is not considered symmetrical. - All choices should be equally easy to accept or reject. The option to “accept all” to consent the use of Sensitive data should be presented without the option to “reject all”
Manipulative language and/or visuals that coerce or steer consumers choices should be avoided - Consumers should not be guilted or shamed into any choice. “I accept. I care about the planet” vs “I reject, I don’t care about the planet” can be considered - “Gratuitous information to emotionally manipulate consumers” should be avoided. Stating that the mobile application “Promotes animal welfare” when asking for consent to collect sensitive data for Targeted Advertising can be considered “deceptively emotionally manipulative” if the reason for collection is not actually critical to promoting animal welfare.
Silence or ‘failure to take an affirmative action’ is not equal to Consent or acceptance - Closing a Consent request pop-up window without first affirmatively making a choice cannot be interpreted as consent. - Going through the webpage without affirmatively providing consent cannot on the banner provided cannot be interpreted as consent. - Using a Smart device without verbal consent; “I accept”, “I consent” cannot be considered affirmative consent.
Avoid preselected or default options - Checkboxes or radial buttons cannot be preselected
It should be as easy and quick to exercise a more privacy protective option as it is to exercise a less privacy protective option. There should be equal number of steps all options - All choices should be presented at the same time. “I accept” and “Learn more” as the two choices presents a greater number of steps for the latter and is an unnecessary restriction. - However, preceding both the “I accept” and “I do not accept” buttons with the “select preferences” button would not be considered an unnecessary restriction.
Consent requests should not unnecessarily interrupt a consumer’s activity on the website, application, product - Repeated consent requests should not appear after the consumer declined consent - Unless consent to process data is strictly necessary, consumers should not be redirected away from their activity if they declined consent - Multiple inconvenient consent request pop-ups should be avoided if they declined consent initially.
“Misleading statements, omissions, affirmative misstatements, or intentionally confusing language to obtain Consent” should be avoided - A false sense of urgency, such as a ticking clock on the consent request should be avoided. - Double negatives should be avoided on the consent request - Confusing language should be avoided such as “Please do not check this box if you wish to Consent to this data use” - Illogical choices like the options of “Yes” or “No” to the question “Do you wish to provide or decline Consent for the described purposes” should be avoided.
Target audience factors and characteristics should be considered - Simplicity of language should be considered for websites or services whose target audience is under the age of 18 - Big size, spacing, and readability should be considered for websites or services whose target audience is elderly people.
User interface design and Consent choice architecture should be similar when accessed through digital accessibility tools - The same number of steps to exercise consent should be provided on the website whether it is accessed using a digital accessibility tool or without.
Going a step further, The Virginia Consumer Data Protection Act, VCDPA, does not specifically address dark patterns. However, the Virginia Attorney General’s office could, in theory, use the regulation’s definition of consent to challenge the use of dark patterns.
The Connecticut Data Privacy Act, CTDPA, defines a Dark Pattern as “a user interface designed or manipulated with the substantial effect of subverting or impairing user autonomy, decision-making or choice”. Any practice the Federal Trade Commission (FTC) deems a "dark pattern" is also included in this definition. It is important to note that Consent obtained through the use of a Dark Pattern is not deemed valid under the CTDPA.
These are some examples of US state regulations around dark patterns. Be sure to review all state privacy laws that affect your business.
For more insights and updates on privacy and data governance, visit Meru Data | Data Privacy & Information Governance Solutions
#data privacy#data security#ai privacy#gdpr#ccpa#artificial intelligence#data protection#internet privacy#dark patterns#cybersecurity#data mapping
0 notes
Text
AI Ethics in Hiring: Safeguarding Human Rights in Recruitment
Explore AI ethics in hiring and how it safeguards human rights in recruitment. Learn about AI bias, transparency, privacy concerns, and ethical practices to ensure fairness in AI-driven hiring.

In today's rapidly evolving job market, artificial intelligence (AI) has become a pivotal tool in streamlining recruitment processes. While AI offers efficiency and scalability, it also raises significant ethical concerns, particularly regarding human rights. Ensuring that AI-driven hiring practices uphold principles such as fairness, transparency, and accountability is crucial to prevent discrimination and bias.Hirebee
The Rise of AI in Recruitment
Employers are increasingly integrating AI technologies to manage tasks like resume screening, candidate assessments, and even conducting initial interviews. These systems can process vast amounts of data swiftly, identifying patterns that might be overlooked by human recruiters. However, the reliance on AI also introduces challenges, especially when these systems inadvertently perpetuate existing biases present in historical hiring data. For instance, if past recruitment practices favored certain demographics, an AI system trained on this data might continue to favor these groups, leading to unfair outcomes.
Ethical Concerns in AI-Driven Hiring
Bias and Discrimination AI systems learn from historical data, which may contain inherent biases. If not properly addressed, these biases can lead to discriminatory practices, affecting candidates based on gender, race, or other protected characteristics. A notable example is Amazon's AI recruitment tool, which was found to favor male candidates due to biased training data.
Lack of Transparency Many AI algorithms operate as "black boxes," providing little insight into their decision-making processes. This opacity makes it challenging to identify and correct biases, undermining trust in AI-driven recruitment. Transparency is essential to ensure that candidates understand how decisions are made and to hold organizations accountable.
Privacy Concerns AI recruitment tools often require access to extensive personal data. Ensuring that this data is handled responsibly, with candidates' consent and in compliance with privacy regulations, is paramount. Organizations must be transparent about data usage and implement robust security measures to protect candidate information.
Implementing Ethical AI Practices
To address these ethical challenges, organizations should adopt the following strategies:
Regular Audits and Monitoring Conducting regular audits of AI systems helps identify and mitigate biases. Continuous monitoring ensures that the AI operates fairly and aligns with ethical standards. Hirebee+1Recruitics Blog+1Recruitics Blog
Human Oversight While AI can enhance efficiency, human involvement remains crucial. Recruiters should oversee AI-driven processes, ensuring that final hiring decisions consider context and nuance that AI might overlook. WSJ+4Missouri Bar News+4SpringerLink+4
Developing Ethical Guidelines Establishing clear ethical guidelines for AI use in recruitment promotes consistency and accountability. These guidelines should emphasize fairness, transparency, and respect for candidate privacy. Recruitics Blog
Conclusion
Integrating AI into recruitment offers significant benefits but also poses ethical challenges that must be addressed to safeguard human rights. By implementing responsible AI practices, organizations can enhance their hiring processes while ensuring fairness and transparency. As AI continues to evolve, maintaining a human-centered approach will be essential in building trust and promoting equitable opportunities for all candidates.
FAQs
What is AI ethics in recruitment? AI ethics in recruitment refers to the application of moral principles to ensure that AI-driven hiring practices are fair, transparent, and respectful of candidates' rights.
How can AI introduce bias in hiring? AI can introduce bias if it is trained on historical data that contains discriminatory patterns, leading to unfair treatment of certain groups.
Why is transparency important in AI recruitment tools? Transparency allows candidates and recruiters to understand how decisions are made, ensuring accountability and the opportunity to identify and correct biases.
What measures can organizations take to ensure ethical AI use in hiring? Organizations can conduct regular audits, involve human oversight, and establish clear ethical guidelines to promote fair and responsible AI use in recruitment.
How does AI impact candidate privacy in the recruitment process? AI systems often require access to personal data, raising concerns about data security and consent. Organizations must be transparent about data usage and implement robust privacy protections.
Can AI completely replace human recruiters? While AI can enhance efficiency, human recruiters are essential for interpreting nuanced information and making context-driven decisions that AI may not fully grasp.
What is the role of regular audits in AI recruitment? Regular audits help identify and mitigate biases within AI systems, ensuring that the recruitment process remains fair and aligned with ethical standards.
How can candidates ensure they are treated fairly by AI recruitment tools? Candidates can inquire about the use of AI in the hiring process and seek transparency regarding how their data is used and how decisions are made.
What are the potential legal implications of unethical AI use in hiring? Unethical AI practices can lead to legal challenges related to discrimination, privacy violations, and non-compliance with employment laws.
How can organizations balance AI efficiency with ethical considerations in recruitment? Organizations can balance efficiency and ethics by integrating AI tools with human oversight, ensuring transparency, and adhering to established ethical guidelines.
#Tags: AI Ethics#Human Rights#AI in Hiring#Ethical AI#AI Bias#Recruitment#Responsible AI#Fair Hiring Practices#AI Transparency#AI Privacy#AI Governance#AI Compliance#Human-Centered AI#Ethical Recruitment#AI Oversight#AI Accountability#AI Risk Management#AI Decision-Making
0 notes
Text
Revoluția AI Local: Open WebUI și Puterea GPU-urilor NVIDIA în 2025
Într-o eră dominată de inteligența artificială bazată pe cloud, asistăm la o revoluție tăcută: aducerea AI-ului înapoi pe computerele personale. Apariția Open WebUI, alături de posibilitatea de a rula modele de limbaj de mari dimensiuni (LLM) local pe GPU-urile NVIDIA, transformă modul în care utilizatorii interacționează cu inteligența artificială. Această abordare promite mai multă…
#AI autonomy#AI eficient energetic#AI fără abonament#AI fără cloud#AI for automation#AI for coding#AI for developers#AI for research#AI on GPU#AI optimization on GPU#AI pe desktop#AI pe GPU#AI pentru automatizare#AI pentru cercetare#AI pentru dezvoltatori#AI pentru programare#AI privacy#AI without cloud#AI without subscription#alternative la ChatGPT#antrenare AI personalizată#autonomie AI#ChatGPT alternative#confidențialitate AI#costuri AI reduse#CUDA AI#deep learning local#desktop AI#energy-efficient AI#future of local AI
0 notes
Text
From instructions on how to opt out, look at the official staff post on the topic. It also gives more information on Tumblr's new policies. If you are opting out, remember to opt out each separate blog individually.
Please reblog this post, so it will get more votes!
#third party sharing#third-party sharing#scrapping#ai scrapping#Polls#tumblr#tumblr staff#poll#please reblog#art#everything else#features#opt out#policies#data privacy#privacy#please boost#staff
47K notes
·
View notes
Text
Amazon annihilates Alexa privacy settings, turns on continuous, nonconsensual audio uploading

I'm on a 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in SAN DIEGO at MYSTERIOUS GALAXY on Mar 24, and in CHICAGO with PETER SAGAL on Apr 2. More tour dates here.

Even by Amazon standards, this is extraordinarily sleazy: starting March 28, each Amazon Echo device will cease processing audio on-device and instead upload all the audio it captures to Amazon's cloud for processing, even if you have previously opted out of cloud-based processing:
https://arstechnica.com/gadgets/2025/03/everything-you-say-to-your-echo-will-be-sent-to-amazon-starting-on-march-28/
It's easy to flap your hands at this bit of thievery and say, "surveillance capitalists gonna surveillance capitalism," which would confine this fuckery to the realm of ideology (that is, "Amazon is ripping you off because they have bad ideas"). But that would be wrong. What's going on here is a material phenomenon, grounded in specific policy choices and by unpacking the material basis for this absolutely unforgivable move, we can understand how we got here – and where we should go next.
Start with Amazon's excuse for destroying your privacy: they want to do AI processing on the audio Alexa captures, and that is too computationally intensive for on-device processing. But that only raises another question: why does Amazon want to do this AI processing, even for customers who are happy with their Echo as-is, at the risk of infuriating and alienating millions of customers?
For Big Tech companies, AI is part of a "growth story" – a narrative about how these companies that have already saturated their markets will still continue to grow. It's hard to overstate how dominant Amazon is: they are the leading cloud provider, the most important retailer, and the majority of US households already subscribe to Prime. This may sound like a good place to be, but for Amazon, it's actually very dangerous.
Amazon has a sky-high price/earnings ratio – about triple the ratio of other retailers, like Target. That scorching P/E ratio reflects a belief by investors that Amazon will continue growing. Companies with very high p/e ratios have an unbeatable advantage relative to mature competitors – they can buy things with their stock, rather than paying cash for them. If Amazon wants to hire a key person, or acquire a key company, it can pad its offer with its extremely high-value, growing stock. Being able to buy things with stock instead of money is a powerful advantage, because money is scarce and exogenous (Amazon must acquire money from someone else, like a customer), while new Amazon stock can be conjured into existence by typing zeroes into a spreadsheet:
https://pluralistic.net/2025/03/06/privacy-last/#exceptionally-american
But the downside here is that every growth stock eventually stops growing. For Amazon to double its US Prime subscriber base, it will have to establish a breeding program to produce tens of millions of new Americans, raising them to maturity, getting them gainful employment, and then getting them to sign up for Prime. Almost by definition, a dominant firm ceases to be a growing firm, and lives with the constant threat of a stock revaluation as investors belief in future growth crumbles and they punch the "sell" button, hoping to liquidate their now-overvalued stock ahead of everyone else.
For Big Tech companies, a growth story isn't an ideological commitment to cancer-like continuous expansion. It's a practical, material phenomenon, driven by the need to maintain investor confidence that there are still worlds for the company to conquer.
That's where "AI" comes in. The hype around AI serves an important material need for tech companies. By lumping an incoherent set of poorly understood technologies together into a hot buzzword, tech companies can bamboozle investors into thinking that there's plenty of growth in their future.
OK, so that's the material need that this asshole tactic satisfies. Next, let's look at the technical dimension of this rug-pull.
How is it possible for Amazon to modify your Echo after you bought it? After all, you own your Echo. It is your property. Every first year law student learns this 18th century definition of property, from Sir William Blackstone:
That sole and despotic dominion which one man claims and exercises over the external things of the world, in total exclusion of the right of any other individual in the universe.
If the Echo is your property, how come Amazon gets to break it? Because we passed a law that lets them. Section 1201 of 1998's Digital Millennium Copyright Act makes it a felony to "bypass an access control" for a copyrighted work:
https://pluralistic.net/2024/05/24/record-scratch/#autoenshittification
That means that once Amazon reaches over the air to stir up the guts of your Echo, no one is allowed to give you a tool that will let you get inside your Echo and change the software back. Sure, it's your property, but exercising sole and despotic dominion over it requires breaking the digital lock that controls access to the firmware, and that's a felony punishable by a five-year prison sentence and a $500,000 fine for a first offense.
The Echo is an internet-connected device that treats its owner as an adversary and is designed to facilitate over-the-air updates by the manufacturer that are adverse to the interests of the owner. Giving a manufacturer the power to downgrade a device after you've bought it, in a way you can't roll back or defend against is an invitation to run the playbook of the Darth Vader MBA, in which the manufacturer replies to your outraged squawks with "I am altering the deal. Pray I don't alter it any further":
https://pluralistic.net/2023/10/26/hit-with-a-brick/#graceful-failure
The ability to remotely, unilaterally alter how a device or service works is called "twiddling" and it is a key factor in enshittification. By "twiddling" the knobs and dials that control the prices, costs, search rankings, recommendations, and core features of products and services, tech firms can play a high-speed shell-game that shifts value away from customers and suppliers and toward the firm and its executives:
https://pluralistic.net/2023/02/19/twiddler/
But how can this be legal? You bought an Echo and explicitly went into its settings to disable remote monitoring of the sounds in your home, and now Amazon – without your permission, against your express wishes – is going to start sending recordings from inside your house to its offices. Isn't that against the law?
Well, you'd think so, but US consumer privacy law is unbelievably backwards. Congress hasn't passed a consumer privacy law since 1988, when the Video Privacy Protection Act banned video store clerks from disclosing which VHS cassettes you brought home. That is the last technological privacy threat that Congress has given any consideration to:
https://pluralistic.net/2023/12/06/privacy-first/#but-not-just-privacy
This privacy vacuum has been filled up with surveillance on an unimaginable scale. Scumbag data-brokers you've never heard of openly boast about having dossiers on 91% of adult internet users, detailing who we are, what we watch, what we read, who we live with, who we follow on social media, what we buy online and offline, where we buy, when we buy, and why we buy:
https://gizmodo.com/data-broker-brags-about-having-highly-detailed-personal-information-on-nearly-all-internet-users-2000575762
To a first approximation, every kind of privacy violation is legal, because the concentrated commercial surveillance industry spends millions lobbying against privacy laws, and those millions are a bargain, because they make billions off the data they harvest with impunity.
Regulatory capture is a function of monopoly. Highly concentrated sectors don't need to engage in "wasteful competition," which leaves them with gigantic profits to spend on lobbying, which is extraordinarily effective, because a sector that is dominated by a handful of firms can easily arrive at a common negotiating position and speak with one voice to the government:
https://pluralistic.net/2022/06/05/regulatory-capture/
Starting with the Carter administration, and accelerating through every subsequent administration except Biden's, America has adopted an explicitly pro-monopoly policy, called the "consumer welfare" antitrust theory. 40 years later, our economy is riddled with monopolies:
https://pluralistic.net/2024/01/17/monopolies-produce-billionaires/#inequality-corruption-climate-poverty-sweatshops
Every part of this Echo privacy massacre is downstream of that policy choice: "growth stock" narratives about AI, twiddling, DMCA 1201, the Darth Vader MBA, the end of legal privacy protections. These are material things, not ideological ones. They exist to make a very, very small number of people very, very rich.
Your Echo is your property, you paid for it. You paid for the product and you are still the product:
https://pluralistic.net/2022/11/14/luxury-surveillance/#liar-liar
Now, Amazon says that the recordings your Echo will send to its data-centers will be deleted as soon as it's been processed by the AI servers. Amazon's made these claims before, and they were lies. Amazon eventually had to admit that its employees and a menagerie of overseas contractors were secretly given millions of recordings to listen to and make notes on:
https://archive.is/TD90k
And sometimes, Amazon just sent these recordings to random people on the internet:
https://www.washingtonpost.com/technology/2018/12/20/amazon-alexa-user-receives-audio-recordings-stranger-through-human-error/
Fool me once, etc. I will bet you a testicle* that Amazon will eventually have to admit that the recordings it harvests to feed its AI are also being retained and listened to by employees, contractors, and, possibly, randos on the internet.
*Not one of mine

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/03/15/altering-the-deal/#telescreen
Image: Stock Catalog/https://www.quotecatalog.com (modified) https://commons.wikimedia.org/wiki/File:Alexa_%2840770465691%29.jpg
Sam Howzit (modified) https://commons.wikimedia.org/wiki/File:SWC_6_-_Darth_Vader_Costume_(7865106344).jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#alexa#ai#voice assistants#darth vader mba#amazon#growth stocks#twiddling#privacy#privacy first#enshittification
4K notes
·
View notes
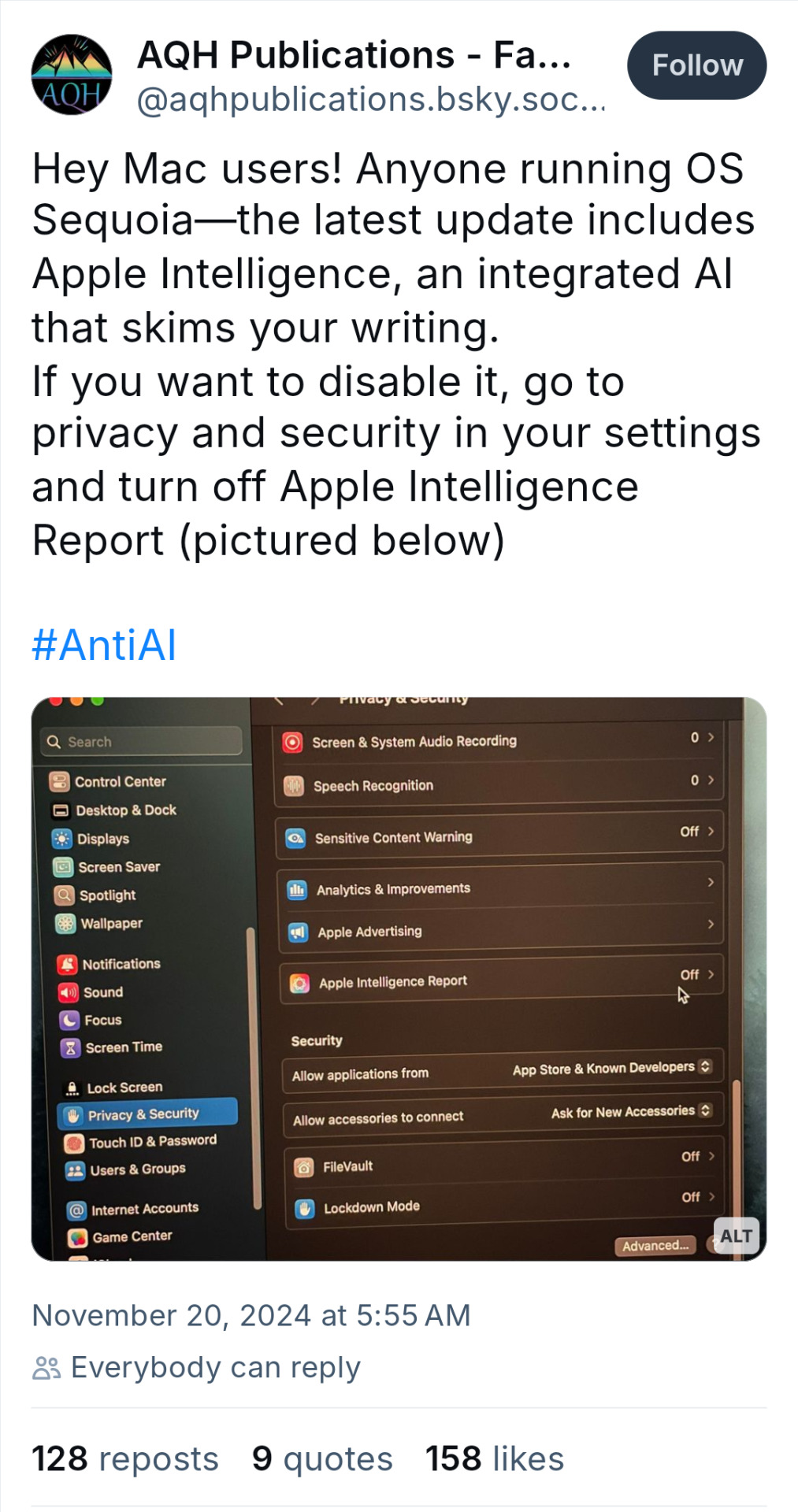
Text
UPDATE! REBLOG THIS VERSION!
#reaux speaks#zoom#terms of service#ai#artificial intelligence#privacy#safety#internet#end to end encryption#virtual#remote#black mirror#joan is awful#twitter#instagram#tiktok#meetings#therapy
23K notes
·
View notes
Text


And they ask me // Is it going good in the garden? // I say I'm lost but I beg no pardon
#sleep token#sleep token fanart#vessel#sleep token vessel#vessel sleep token#caramel#even in arcadia#man. fuck man. this song#i started this before the song was out bc the single's art is beautiful#and i wanted to draw vessel with the morningstar#but i had to take a day to myself before finishing this#caramel is such a gorgeous and heartbreaking song#when people demanded heavy music i bet they didn't mean it like this#listening to it feels like vessel just flipped open his diary and sung a few pages from it#i get vessel#i feel deeply for him#we live in a world where privacy is nonexistent#where kindness is less and less expected from strangers#where people harass and threaten others in online spaces#where the only goal is to consume more and more and more until there's nothing left#as someone who's gonna probably lose her job in a few years to ai and greed#i too know how does it feel to hate the thing you love doing the most (art)#but still love it the same#anyways sorry for all the rambling :::')
1K notes
·
View notes
Text






(from The Mitchells vs. the Machines, 2021)
#the mitchells vs the machines#data privacy#ai#artificial intelligence#digital privacy#genai#quote#problem solving#technology#sony pictures animation#sony animation#mike rianda#jeff rowe#danny mcbride#abbi jacobson#maya rudolph#internet privacy#internet safety#online privacy#technology entrepreneur
12K notes
·
View notes
Text
AI and Data Privacy in the Insurance Industry: What You Need to Know

The insurance industry is no stranger to the requirements and challenges that come with data privacy and usage. By nature, those in insurance deal with large amounts of Personally Information (PI) which includes names, phone numbers, and Social Security numbers, financial information, health information, and so forth. This widespread use of multiple categories of PI by insurance companies demands that measures are taken to prioritize individuals’ privacy.
Further, in recent months, landmark cases of privacy violations and misuse of AI technology involving financial institutions have alarmed the insurance industry. While there is no doubt that embracing new technology like AI is a requirement to stay profitable and competitive going forward, let’s look at three main considerations for those in the insurance industry to keep in mind when it comes to data privacy: recent landmark cases, applicable regulations and AI governance.
Recent noteworthy cases of privacy violations and AI misuse
One important way to understand the actions of enforcement agencies and anticipate changes in the regulatory landscape is to look at other similar and noteworthy cases of enforcement. In recent months, we have seen two cases that stood out
First is the case of General Motors (G.M.), an American automotive manufacturing company. Investigations by journalist Kashmir Hill found that vehicles made by G.M. were collecting data of its customers without their knowledge and sharing it with data brokers like LexisNexis, a company that maintains a “Risk Solutions” division that caters to the auto insurance industry and keeps tabs on car accidents and tickets. The data collected and shared by G.M. included detailed driving habits of its customers that influenced their insurance premiums. When questioned, G.M. confirmed that certain information was shared with LexisNexis and other data brokers.
Another significant case is that of health insurance giant Cigna using computer algorithms to reject patient claims en masse. Investigations found that the algorithm spent an average of merely 1.2 seconds on each review, rejecting over 300,000 payment claims in just 2 months in 2023. A class-action lawsuit was filed in federal court in Sacramento, California.
Applicable Regulations and Guidelines
The Gramm-Leach-Bliley Act (GLBA) is a U.S. federal regulation focused on reforming and modernizing the financial services industry. One of the key objectives of this law is consumer protection. It requires financial institutions offering consumers loan services, financial or investment advice, and/or insurance, to fully explain their information-sharing practices to their customers. Such institutions must develop and give notice of their privacy policies to their own customers at least annually.
The ‘Financial Privacy Rule’ is a requirement of this law that financial institutions must give customers and consumers the right to opt-out and not allow a financial institution to share their information with non-affiliated third parties prior to sharing it. Further, financial institutions are required to develop and maintain appropriate data security measures.
This law also prohibits pretexting, which is the act of tricking or manipulating an individual into providing non-public information. Under this law, a person may not obtain or attempt to obtain customer information about another person by making a false or fictitious statement or representation to an officer or employee. The GLBA also prohibits a person from knowingly using forged, counterfeit, or fraudulently obtained documents to obtain consumer information.
National Association of Insurance Commissioners (NAIC) Model Bulletin: Use of Artificial Intelligence Systems by Insurers
The NAIC adopted a bulletin in December of last year as an initial regulatory effort to understand and gain insight into the technology. It outlines guidelines that include governance, risk management and internal controls, and controls regarding the acquisition and/or use of third-party AI systems and data. According to the bulletin, insurers are required to develop and maintain a written program for the responsible use of AI systems. Currently, 7 states have adopted these guidelines; Alaska, Connecticut, New Hampshire, Illinois, Vermont, Nevada, and Rhode Island, while others are expected to follow suit.
What is important to note, is that the NAIC outlined the use of AI by insurers in their Strategic Priorities for 2024, which include adopting the Model Bulletin, proposing a framework for monitoring third-party data and predictive models, and completing the development of the Cybersecurity Event Response Plan and enhancing consumer data privacy through the Privacy Protections Working Group.
State privacy laws and financial institutions
In the U.S., there are over 15 individual state privacy laws. Some have only recently been introduced, some go into effect in the next two years, and others like the California Consumer Privacy Act (CCPA) and Virginia Consumer Data Protection Act (VCDPA) are already in effect. Here is where some confusion exists. Most state privacy regulations such as Virginia, Connecticut, Utah, Tennessee, Montana, Florida, Texas, Iowa, and Indiana provide entity exemptions to financial institutions. This means that as regulated entities, these businesses fall outside the scope of these state laws. In other words, if entities are regulated by the GLBA then they are exempt from the above-mentioned state regulations.
Some states, like California and Oregon, have data-level exemptions for consumer financial data regulated by the GLBA. For example, under the CCPA, Personal Information (PI) not subject to the GLBA would fall under the scope of the CCPA. Further, under the CCPA, financial institutions are not exempt from its privacy right-of-action concerning data breaches.
As for the Oregon Consumer Privacy Act (OCPA), only 'financial institutions,' as defined under §706.008 of the Oregon Revised Statutes (ORS), are subject to a full exemption. This definition of a ‘financial institution’ is narrower than that defined by the GLBA. This means that consumer information collected, sold and processed in compliance with the GLBA may still not be exempt under the OCPA. We can expect other states with upcoming privacy laws to have their own takes on how financial institutions’ data is regulated.
AI and Insurance
Developments with Artificial Intelligence (AI) technology has been a game changer for the insurance industry. Generative AI can ingest vast amounts of information and determine the contextual relationship between words and data points. With AI, insurers can automate insurance claims and enhance fraud detection, both of which would require the use of PI by AI models. Undoubtedly, the integration of AI has multiple benefits including enabling precise predictions, handling customer interactions, and increasing accuracy and speed overall. In fact, a recent report by KPMG found that Insurance CEOs are actively utilizing AI technology to modernize their organizations, increase efficiency, and streamline their processes. This not only includes claims and fraud detection, but also general business uses such as HR, hiring, marketing, and sales. Each likely use different models with their own types of data and PI.
However, the insurance industry’s understanding of Generative AI related risk is still in its infancy. And according to Aon's Global Risk Management Survey, AI is likely to become a top 20 risk in the next three years. In fact, according to Sandeep Dani, Senior Risk Management Leader at KPMG, Canada, “The Chief Risk Officer now has one of the toughest roles, if not THE toughest role, in an insurance organization”
In the race to maximise the benefits of AI, consumers’ data privacy cannot take a backseat, especially when it comes to PI and sensitive information. As of 2024, there is no federal AI law in the U.S., and we are only starting to see statewide AI regulations like with the Colorado AI Act and the Utah AI Policy Act. Waiting around for regulations is not an effective approach. Instead, proactive AI governance measures can act as a key competitive differentiator for companies, especially in an industry like insurance where consumer trust is a key component.
Here are some things to keep in mind when integrating AI:
Transparency is key: Consumers need to have visibility over their data being used by AI models, including what AI models are being used, how these models use their data, and the purposes for doing so. Especially in the case of insurance, where the outcome of AI models has serious implications, consumers need to be kept in the loop about their data.
Taking Inventory: To ensure accuracy and quality of outputs, it is important to take inventory of and understand the AI systems, the training data sources, the nature of the training data, inputs and outputs, and the other components in play to gain an understanding of the potential threats and risks.
Performing Risk Assessments: Different laws consider different activities as high-risk. For example, biometric identification and surveillance is considered high-risk under the EU AI Act but not under the NIST AI Risk Management Framework. As new AI laws are introduced in the U.S., we can expect the risk-based approach to be adopted by many. Here, it becomes important to understand the jurisdiction, and the kind of data in question, then categorize and rank risks accordingly.
Regular audits and monitoring: Internal reviews will have to be maintained to monitor and evaluate the AI systems for errors, issues, and biases in the pre-deployment stage. Regular AI audits will also need to be conducted to check for accuracy, robustness, fairness, and compliance. Additionally, post-deployment audits and assessments are just as important to ensure that the systems are functioning as required. Regular monitoring of risks and biases is important to identify emerging risks or those that may have been missed previously. It is beneficial to assign responsibility to team members to overlook risk management efforts.
Conclusion
People care about their data and their privacy, and for insurance consumers and customers, trust is paramount. Explainability is the term commonly used when describing what an AI usage goal or expected output is meant to be. Fostering explainability when governing AI helps stakeholders make informed decisions while protecting privacy, confidentiality and security. Consumers and customers need to trust the data collection and sharing practices and the AI systems involved. That requires transparency so they may understand those practices, how their data gets used, the AI systems, and how those systems reach their decisions.
About Us
Meru Data designs, implements, and maintains data strategy across several industries, based on their specific requirements. Our combination of best-inclass data mapping and automated reporting technology, along with decades of expertise around best practices in training, data management, AI governance, and law gives Meru Data the unique advantage of being able to help insurance organizations secure, manage, and monetize their data while preserving customer trust and regulatory compliance.
0 notes