#Data engineering
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
#ai model#artificial intelligence#technology#llm#sycophantic#language#linguistics#ai generated#science#datascience#data analytics#data engineering#ai trends#queries#neutral
30 notes
·
View notes
Text

absolutely unintelligeable meme I made during bootcamp lecture this morning
#coding#data engineering#transformers#starscream#star schema#data normalisation#so the lecture was on something called 'star schema' which is about denormalising some of your data#(normalising data is a data thing separate meaning from the general/social(?) use of the word#it has to do with how you're splitting up your database into different tables)#and our lecturers always try and come up with a joke/pun related to the day's subject for their zoom link message in slack#and our lecturer today was tryna come up with a transformer pun because there's a transformer called starscream (-> bc star schemas)#(cause apparently he's a transformers nerd)#but gave up in his message so I googled the character and found these to be the first two results on google images and I was like#this is a meme template if I've ever seen one and proceeded to make this meme after lecture#I'm a big fan of denormalisation both in the data sense and in the staying weird sense
24 notes
·
View notes
Text
FOB: I only think in the form of crunching numbers
Me, a Data Engineer: Is... is he talking about me... 🤓
FOB: In hotel rooms, collecting Page Six lovers
Me, a Data Engineer in a monogamous relationship: Ah, nvmd 🥴
#fall out boy#i know it is cringe but that is how i felt#millennial core#patrick stump#pete wentz#thnks fr th mmrs#data engineering#joe trohman#andy hurley#fall out boy shitposting
21 notes
·
View notes
Text
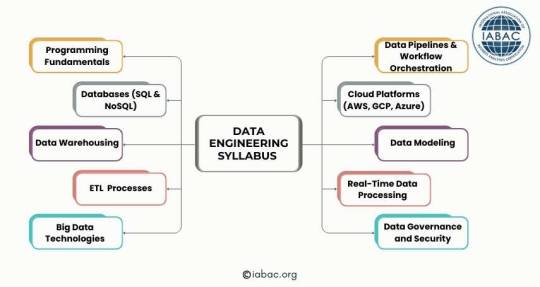
Data Engineering Syllabus | IABAC
This image displays a syllabus for data engineering. Big data, cloud platforms, databases, data warehousing, ETL, programming, data pipelines, data modeling, real-time processing, and data security are some of the subjects covered. These subjects are key for developing data engineering skills. https://iabac.org/blog/what-is-the-syllabus-for-data-engineering
1 note
·
View note
Text
🚀 Exploring Kafka: Scenario-Based Questions 📊
Dear community, As Kafka continues to shape modern data architectures, it's crucial for professionals to delve into scenario-based questions to deepen their understanding and application. Whether you're a seasoned Kafka developer or just starting out, here are some key scenarios to ponder: 1️⃣ **Scaling Challenges**: How would you design a Kafka cluster to handle a sudden surge in incoming data without compromising latency? 2️⃣ **Fault Tolerance**: Describe the steps you would take to ensure high availability in a Kafka setup, considering both hardware and software failures. 3️⃣ **Performance Tuning**: What metrics would you monitor to optimize Kafka producer and consumer performance in a high-throughput environment? 4️⃣ **Security Measures**: How do you secure Kafka clusters against unauthorized access and data breaches? What are some best practices? 5️⃣ **Integration with Ecosystem**: Discuss a real-world scenario where Kafka is integrated with other technologies like Spark, Hadoop, or Elasticsearch. What challenges did you face and how did you overcome them? Follow : https://algo2ace.com/kafka-stream-scenario-based-interview-questions/
#Kafka #BigData #DataEngineering #TechQuestions #ApacheKafka #BigData #Interview
2 notes
·
View notes
Text
From Support to Data Science and Analytics: My Journey at Automattic
“Is it possible to transform a role in customer support into a data science career?” This question, which once seemed like a distant dream, became my career blueprint at Automattic. My journey from a Happiness Engineer in September 2014 to a data wrangler today is a tale of continuous evolution, learning, and adaptation. Starting in the dynamic world of customer support with team “Hermes” (an…

View On WordPress
5 notes
·
View notes
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
10 Must-Have Skills for Data Engineering Jobs

In the digital economy of 2025, data isn't just valuable – it's the lifeblood of every successful organization. But raw data is messy, disorganized, and often unusable. This is where the Data Engineer steps in, transforming chaotic floods of information into clean, accessible, and reliable data streams. They are the architects, builders, and maintainers of the crucial pipelines that empower data scientists, analysts, and business leaders to extract meaningful insights.
The field of data engineering is dynamic, constantly evolving with new technologies and demands. For anyone aspiring to enter this vital domain or looking to advance their career, a specific set of skills is non-negotiable. Here are 10 must-have skills that will position you for success in today's data-driven landscape:
1. Proficiency in SQL (Structured Query Language)
Still the absolute bedrock. While data stacks become increasingly complex, SQL remains the universal language for interacting with relational databases and data warehouses. A data engineer must master SQL far beyond basic SELECT statements. This includes:
Advanced Querying: JOIN operations, subqueries, window functions, CTEs (Common Table Expressions).
Performance Optimization: Writing efficient queries for large datasets, understanding indexing, and query execution plans.
Data Definition and Manipulation: CREATE, ALTER, DROP tables, and INSERT, UPDATE, DELETE operations.
2. Strong Programming Skills (Python & Java/Scala)
Python is the reigning champion in data engineering due to its versatility, rich ecosystem of libraries (Pandas, NumPy, PySpark), and readability. It's essential for scripting, data manipulation, API interactions, and building custom ETL processes.
While Python dominates, knowledge of Java or Scala remains highly valuable, especially for working with traditional big data frameworks like Apache Spark, where these languages offer performance advantages and deeper integration.
3. Expertise in ETL/ELT Tools & Concepts
Data engineers live and breathe ETL (Extract, Transform, Load) and its modern counterpart, ELT (Extract, Load, Transform). Understanding the methodologies for getting data from various sources, cleaning and transforming it, and loading it into a destination is core.
Familiarity with dedicated ETL/ELT tools (e.g., Apache Nifi, Talend, Fivetran, Stitch) and modern data transformation tools like dbt (data build tool), which emphasizes SQL-based transformations within the data warehouse, is crucial.
4. Big Data Frameworks (Apache Spark & Hadoop Ecosystem)
When dealing with petabytes of data, traditional processing methods fall short. Apache Spark is the industry standard for distributed computing, enabling fast, large-scale data processing and analytics. Mastery of Spark (PySpark, Scala Spark) is vital for batch and stream processing.
While less prominent for direct computation, understanding the Hadoop Ecosystem (especially HDFS for distributed storage and YARN for resource management) still provides a foundational context for many big data architectures.
5. Cloud Platform Proficiency (AWS, Azure, GCP)
The cloud is the default environment for modern data infrastructures. Data engineers must be proficient in at least one, if not multiple, major cloud platforms:
AWS: S3 (storage), Redshift (data warehouse), Glue (ETL), EMR (Spark/Hadoop), Lambda (serverless functions), Kinesis (streaming).
Azure: Azure Data Lake Storage, Azure Synapse Analytics (data warehouse), Azure Data Factory (ETL), Azure Databricks.
GCP: Google Cloud Storage, BigQuery (data warehouse), Dataflow (stream/batch processing), Dataproc (Spark/Hadoop).
Understanding cloud-native services for storage, compute, networking, and security is paramount.
6. Data Warehousing & Data Lake Concepts
A deep understanding of how to structure and manage data for analytical purposes is critical. This includes:
Data Warehousing: Dimensional modeling (star and snowflake schemas), Kimball vs. Inmon approaches, fact and dimension tables.
Data Lakes: Storing raw, unstructured, and semi-structured data at scale, understanding formats like Parquet and ORC, and managing data lifecycle.
Data Lakehouses: The emerging architecture combining the flexibility of data lakes with the structure of data warehouses.
7. NoSQL Databases
While SQL handles structured data efficiently, many modern applications generate unstructured or semi-structured data. Data engineers need to understand NoSQL databases and when to use them.
Familiarity with different NoSQL types (Key-Value, Document, Column-Family, Graph) and examples like MongoDB, Cassandra, Redis, DynamoDB, or Neo4j is increasingly important.
8. Orchestration & Workflow Management (Apache Airflow)
Data pipelines are often complex sequences of tasks. Tools like Apache Airflow are indispensable for scheduling, monitoring, and managing these workflows programmatically using Directed Acyclic Graphs (DAGs). This ensures pipelines run reliably, efficiently, and alert you to failures.
9. Data Governance, Quality & Security
Building pipelines isn't enough; the data flowing through them must be trustworthy and secure. Data engineers are increasingly responsible for:
Data Quality: Implementing checks, validations, and monitoring to ensure data accuracy, completeness, and consistency. Tools like Great Expectations are gaining traction.
Data Governance: Understanding metadata management, data lineage, and data cataloging.
Data Security: Implementing access controls (IAM), encryption, and ensuring compliance with regulations (e.g., GDPR, local data protection laws).
10. Version Control (Git)
Just like software developers, data engineers write code. Proficiency with Git (and platforms like GitHub, GitLab, Bitbucket) is fundamental for collaborative development, tracking changes, managing different versions of pipelines, and enabling CI/CD practices for data infrastructure.
Beyond the Technical: Essential Soft Skills
While technical prowess is crucial, the most effective data engineers also possess strong soft skills:
Problem-Solving: Identifying and resolving complex data issues.
Communication: Clearly explaining complex technical concepts to non-technical stakeholders and collaborating effectively with data scientists and analysts.
Attention to Detail: Ensuring data integrity and pipeline reliability.
Continuous Learning: The data landscape evolves rapidly, demanding a commitment to staying updated with new tools and technologies.
The demand for skilled data engineers continues to soar as organizations increasingly rely on data for competitive advantage. By mastering these 10 essential skills, you won't just build data pipelines; you'll build the backbone of tomorrow's intelligent enterprises.
0 notes
Text
What You’ll Learn from Fundamentals of Data Engineering.
Okay, full disclosure: data engineering might sound like one of those super technical, boring topics only computer nerds care about. But here’s the thing—it’s actually the secret sauce behind all the cool stuff you love, from Netflix recommendations to Instagram filters.
Curious? Here’s what you’ll actually learn when you dive into the Fundamentals of Data Engineering—and why it’s more exciting than you expect.

What the Heck Is Data Engineering? First off, you’ll finally understand what data engineers do. Spoiler: they’re like the data world’s plumbers and electricians—building the pipes and wiring that keep information flowing smoothly. Without them, all those AI models and dashboards would be useless.
How Data Gets From A to B You’ll learn how to grab data from everywhere—apps, websites, sensors, and more—and get it into the right places. Think of it like gathering ingredients for a killer recipe. If you mess up here, the whole dish fails.
Where Does All This Data Live? Not all data homes are the same. You’ll discover the difference between databases, data warehouses, and data lakes (which sounds like a place for data to go swimming). Knowing where to stash data is key to making it accessible and fast.
Turning Raw Data Into Gold Data is messy, like your room after finals week. You’ll master building pipelines that clean, organize, and prep data so it’s ready to be used. This is the real magic—turning chaos into something useful.
Keeping Data Honest and Trustworthy Ever had a “bad data day”? You’ll learn how to spot errors and keep data accurate, so the insights you get aren’t just a wild guess.
Automate All The Things Nobody wants to do boring repetitive tasks. You’ll discover how to make your data workflows run automatically like clockwork. More time for coffee, less time babysitting processes.
Scaling Up Without Losing Your Mind When your app gets popular, data explodes—and suddenly what worked before doesn’t anymore. You’ll learn tricks to keep things running smooth no matter how huge your data gets.
Keeping Data Safe and Playing by the Rules With great data comes great responsibility. You’ll get how to protect sensitive info and follow the rules, so your work stays ethical and legal.
Get Your Hands Dirty with Real Tools Forget boring theory. You’ll work with the tools everyone’s using—Python, SQL, Apache Spark, Kafka, and cloud platforms like AWS. This is where you go from rookie to pro.
Why Should You Care? Because data engineering isn’t just geek stuff—it’s the foundation that powers the tech we use every day. Mastering these fundamentals means you can build cool stuff, solve real problems, and get paid well for it.
Plus, it’s fun once you get the hang of it. Promise.
Ready to stop wondering how Netflix knows what you want to watch next? Or how Instagram serves up those perfect photos? Jump into data engineering and find out. Your future data-self will thank you.
0 notes
Text
Big Data, Big Opportunities: A Beginner's Guide
Big Data is a current trend and the number of specialists in the field of Big Data is growing rapidly. If you are a beginner looking to enter the world of Big Data, you've come to the right place! This Beginner’s Guide will help you understand the basics of Big Data, Data Science, Data Analysis, and Data Engineering, and highlight the skills you need to build a career in this field.
What is Big Data?
Big Data refers to the massive volumes of structured and unstructured data that are too complex for traditional processing software. These Big Data concepts form the foundation for data professionals to extract valuable insights.
While the term might sound intimidating, think of Big Data as just a collection of data that's too large to be processed by conventional databases. Imagine the millions of transactions happening on Amazon or the vast amounts of data produced by a single flight from an airline. These are examples of Big Data in action. Learning the fundamentals will help you understand the potential of this massive resource
Why Big Data Matters
Big Data enables companies to uncover trends, improve decision-making, and gain a competitive edge. This demand has created a wealth of opportunities in Data Science careers, Data Analysis, and Data Engineering.
Key Big Data Concepts
Some key Big Data concepts include:
Volume, Velocity, and Variety: Large volume of data, generated rapidly in various formats.
Structured vs. Unstructured Data: Organized data in databases versus raw, unstructured data.
Tools like Hadoop and Spark are crucial in handling Big Data efficiently.
Data Engineering: The Backbone of Big Data
Data Engineering is the infrastructure behind Big Data. Data Engineering basics involve creating pipelines and processing systems to store and manage massive datasets. Learning these fundamentals is critical for those aspiring to Data Engineering jobs.
Big Data Applications Across Industries
Big Data applications span across industries, from healthcare and finance to marketing and manufacturing. In healthcare, Big Data is used for predictive analytics and improving patient care. In finance, it helps detect fraud, optimize investment strategies, and manage risks. Marketing teams use Big Data to understand customer preferences, personalize experiences, and create targeted campaigns. The possibilities are endless, making Big Data one of the most exciting fields to be a part of today.
As a beginner, you might wonder how Big Data fits into everyday life. Think of online streaming services like Netflix, which recommend shows based on your previous viewing patterns, or retailers who send personalized offers based on your shopping habits. These are just a couple of ways Big Data is being applied in the real world.
Building a Career in Big Data
The demand for Big Data professionals is on the rise, and there are a variety of career paths you can choose from:
Data Science Career: As a Data Scientist, you'll focus on predictive modeling, machine learning, and advanced analytics. This career often involves a strong background in mathematics, statistics, and coding.
Data Analysis Jobs: As a Data Analyst, you’ll extract meaningful insights from data to support business decisions. This role emphasizes skills in statistics, communication, and data visualization.
Data Engineering Jobs: As a Data Engineer, you’ll build the infrastructure that supports data processing and analysis, working closely with Data Scientists and Analysts to ensure that data is clean and ready for use.
Whether you're interested in Data Science, Data Analysis, or Data Engineering, now is the perfect time to jumpstart your career. Each role has its own unique challenges and rewards, so finding the right fit will depend on your strengths and interests.
Career Opportunities in Big Data and Their Salaries
As the importance of Big Data continues to grow, so does the demand for professionals skilled in handling large data sets. Let’s check the different career paths in Big Data, their responsibilities, and average salaries:
Data Scientist
Role: Data Scientists develop models and algorithms to extract insights from large data sets. They work on predictive analytics, machine learning, and statistical modeling.
Average Salary: $120,000 to $150,000 per year in the U.S.
Skills Needed: Strong background in math, statistics, programming (Python, R), and machine learning.
Data Analyst
Role: Data Analysts interpret data to provide actionable insights for decision-making. They focus on generating reports, dashboards, and business insights.
Average Salary: $60,000 to $90,000 per year in the U.S.
Skills Needed: Proficiency in SQL, Excel, Python, data visualization tools like Tableau or Power BI, and statistical analysis.
Data Engineer
Role: Data Engineers build and maintain the architecture (databases, pipelines, etc.) necessary for data collection, storage, and analysis.
Average Salary: $100,000 to $140,000 per year in the U.S.
Skills Needed: Knowledge of cloud platforms (AWS, Google Cloud), database management, ETL tools, and programming languages like Python, Scala, or Java.
Big Data Architect
Role: Big Data Architects design the infrastructure that supports Big Data solutions, ensuring scalability and performance.
Average Salary: $140,000 to $180,000 per year in the U.S.
Skills Needed: Expertise in cloud computing, distributed systems, database architecture, and technologies like Hadoop, Spark, and Kafka.
Machine Learning Engineer
Role: Machine Learning Engineers create algorithms that allow systems to automatically improve from experience, which is key in processing and analyzing large data sets.
Average Salary: $110,000 to $160,000 per year in the U.S.
Skills Needed: Proficiency in machine learning libraries (TensorFlow, PyTorch), programming (Python, R), and experience with large datasets.
Learn Big Data with Guruface
Guruface, an online learning platform, offers different Big Data courses. Whether you’re looking for an Introduction to Big Data, a Data Science tutorial, or Data Engineering basics, Guruface provides beginner-friendly resources to guide your learning. Their courses are ideal for those looking to learn Big Data concepts and practical applications in Data Science, Data Analysis, and Data Engineering.
Conclusion
With data being the driving force in today’s society, understanding the Big Data concepts, tools as well as applications, is a key step towards an exciting Big Data Career. Platforms like Guruface provide the ideal starting point for beginners interested in Big Data, Data Science, Data Analysis, or Data Engineering. Start your journey today and explore the vast potential of Big Data.
0 notes
Text
How to Build a Data Engineering Portfolio That Gets You Hired
Learn how to create a data engineering portfolio with real projects, documentation & tools like AWS, Spark & Python to impress recruiters and land top jobs.
0 notes
Text
Databricks Revolutionizes Data and AI Landscape with New Operational Database, Free Education, and No-Code Pipelines
San Francisco, CA – June 12, 2025 – Databricks, the pioneering Data and AI company, today unveiled a suite of transformative innovations at its Data + AI Summit, setting a new benchmark for how enterprises and individuals interact with data and artificial intelligence. The announcements include the launch of Lakebase, a groundbreaking operational database built for AI; a significant $100 million investment in global data and AI education coupled with the Databricks Free Edition; and the introduction of Lakeflow Designer, empowering data analysts to build production-grade pipelines without coding. These advancements underscore Databricks’ commitment to democratizing data and AI, accelerating innovation, and closing the critical talent gap in the industry.
Databricks Unveils Lakebase: A New Class of Operational Database for AI Apps and Agents

What is it?
Databricks announced the launch of Lakebase, a first-of-its-kind fully-managed Postgres database built for AI. This new operational database layer seamlessly integrates into the company’s Data Intelligence Platform, allowing developers and enterprises to build data applications and AI agents faster and more easily on a single multi-cloud platform. Lakebase is powered by Neon technology and is designed to unify analytics and operations by bringing operational data to the lakehouse, continuously autoscaling compute to support demanding agent workloads.
When is the Launch Planned?
Lakebase is now available in Public Preview, marking a significant step towards its full availability.
Who Introduced?
Ali Ghodsi, Co-founder and CEO of Databricks, introduced Lakebase, stating, “We’ve spent the past few years helping enterprises build AI apps and agents that can reason on their proprietary data with the Databricks Data Intelligence Platform. Now, with Lakebase, we’re creating a new category in the database market: a modern Postgres database, deeply integrated with the lakehouse and today’s development stacks.”
Why Does This Matter? Motivation: The Driving Forces Behind
Operational databases (OLTP) represent a $100-billion-plus market, yet their decades-old architecture struggles with the demands of modern, rapidly changing applications. They are often difficult to manage, expensive, and prone to vendor lock-in. AI introduces a new set of requirements: every data application, agent, recommendation, and automated workflow needs fast, reliable data at the speed and scale of AI agents. This necessitates the convergence of operational and analytical systems to reduce latency and provide real-time information for decision-making. Fortune 500 companies are ready to replace outdated systems, and Lakebase offers a solution built for the demands of the AI era.
Business Strategies
The launch of Lakebase is a strategic move to create a new category in the database market, emphasizing a modern Postgres database deeply integrated with the lakehouse and today’s development stacks. This strategy aims to empower developers to build faster, scale effortlessly, and deliver the next generation of intelligent applications, directly addressing the evolving needs of the AI era.
Key benefits of Lakebase include:
Separated compute and storage: Built on Neon technology, it offers independent scaling, low latency (<10 ms), high concurrency (>10K QPS), and high availability transactional needs.
Built on open source: Leveraging widely adopted Postgres with its rich ecosystem, ideal for workflows built on agents as all frontier LLMs have been trained on vast database system information.
Built for AI: Enables launch in under a second and pay-for-what-you-use pricing. Its unique branching capability allows low-risk development by creating copy-on-write database clones for developer testing and agent-based development.
Integrated with the lakehouse: Provides automatic data sync to and from lakehouse tables, an online feature store for model serving, and integration with Databricks Apps and Unity Catalog.
Enterprise ready: Fully managed by Databricks, based on hardened compute infrastructure, encrypted data at rest, and supports high availability, point-in-time recovery, and integration with Databricks enterprise features.
Lakebase Momentum
Digital leaders are already experiencing the value, with hundreds of enterprises having participated in the Private Preview. “At Heineken, our goal is to become the best-connected brewer. To do that, we needed a way to unify all of our datasets to accelerate the path from data to value,” stated Jelle Van Etten, Head of Global Data Platform at Heineken. Anjan Kundavaram, Chief Product Officer at Fivetran, added, “Lakebase removes the operational burden of managing transactional databases. Our customers can focus on building applications instead of worrying about provisioning, tuning and scaling.” David Menninger, Executive Director, ISG Software Research, highlighted that “By offering a Postgres-compatible, lakehouse-integrated system designed specifically for AI-native and analytical workloads, Databricks is giving customers a unified, developer-friendly stack that reduces complexity and accelerates innovation.”
Partner Ecosystem
A robust partner network, including Accenture, Airbyte, Alation, Fivetran, and many others, supports Lakebase customers in data integration, business intelligence, and governance.
Read More : Databricks Revolutionizes Data and AI Landscape with New Operational Database, Free Education, and No-Code Pipelines
#Databricks#Data & AI#Lakebase#Operational Database#AI Applications#Free AI Education#Lakeflow Designer#No-Code Pipelines#Data Engineering#Machine Learning#Data Cloud#AI Talent Gap
0 notes
Text

From sensors to systems- data engineering unlocks the full potential of the Internet of Things (IoT) ecosystem. Mark a revolution as you explore the core interconnection of the two giants.
Discover details here https://bit.ly/3FasDZ2
0 notes
Text
The Future of Full Stack Java Development

Full-stack developers, also known as “jack of all trades,” are in high demand in India. They are capable of carrying out the duties of numerous professionals. They earn good money and have many job opportunities with rewarding experiences because of their diverse skills. Full-stack Java programming has a bright future because its popularity is growing and will continue to grow in the coming years.
It’s well known that full-stack developers are proficient in both server-side and client-side programming. They are the professionals who carry out the responsibilities of backend and frontend developers. Despite not always being regarded as specialists, their abilities enable them to handle development tasks with ease. All firms look forward to having a brilliant full-stack developer as a future developer for a number of reasons. They handle a variety of technologies, which enables them to manage more project facets than the typical coder.
An experienced web developer who primarily works with Java programming is known as a Java full-stack developer. The front end, back end, and database layer are the three levels of code that these web developers build. The web development teams are frequently led by full-stack Java engineers, who also assist in updating and designing new websites. Because there is a great demand for Java full-stack developers. Many institutions have seized the opportunity by providing well-thought-out Java full-stack developer courses. You may study full-stack development quickly and become an expert in the area with the aid of these courses.
Java Full Stack Development by Datavalley
100% Placement Assistance
Duration: 3 Months (500+ hours)
Mode: Online/Offline
Let’s look into the future opportunities for full-stack Java professionals in India.
4 things that will Expand the Future Purpose of Java Full-Stack Developers
The Role of a Full-Stack Developer
Full-stack developers work on numerous tasks at once. They need to be extremely talented and knowledgeable in both front-end and back-end programming languages for this. JavaScript, CSS, HTML, and other frontend programming languages are essential. When creating new websites or modifying old ones, Java is a key programming language used by Java full-stack developers. However, backend programming languages consist of .Net, PHP, and Python depending on the projects. The full stack developers are distinguished from other developers by their proficiency and understanding of programming languages. With the availability of the finest Java full stack developer training, students may now easily master a frontend programming language like Java. The full-stack developer is more valuable and in demand when they are knowledgeable in multiple programming languages.
Responsibilities of a Full-Stack Developer
Functional databases are developed by full-stack developers. It creates aesthetically pleasing frontend designs that improve user experience and support the backend. The entire web-to-web architecture is under the control of these full-stack developers. They are also in charge of consistently maintaining and updating the software as needed. The full-stack developers bear the responsibility of overseeing a software project from its inception to its finalized product.
In the end, these full-stack developers also satisfy client and technical needs. Therefore, having a single, adaptable person do many tasks puts them in high demand and increases their potential for success in the technology field. Through extensively developed modules that expand their future scope, the Java full-stack developer course equips students with the skills necessary to take on these tasks.
The full-stack developer salary range
Full-stack developers are among the highest-paid workers in the software industry. In India, the average salary for a full-stack developer is 9.5 lakhs per annum. The elements that determine income typically include experience, location of the position, company strength, and other considerations. A highly skilled and adaptable full-stack developer makes between 16 and 20 lakhs per annum. Full-stack engineers get paid a lot because of their extensive skills, they can handle the tasks of two or three other developers at once.
By fostering the growth of small teams, preventing misunderstandings, and cutting the brand’s operating expenses, these full-stack developers perform remarkable work. Students who take the Java full-stack developer course are better equipped to become versatile full-stack developers, which will increase their demand currently as well as in the future in the industry.
Job Opportunities of Java Full Stack Developers
The full-stack developers are knowledgeable professionals with a wide range of technological skills. These competent workers are conversant with numerous stacks, including MEAN and LAMP, and are capable of handling more tasks than a typical developer. They are skilled experts with a wealth of opportunities due to their extensive understanding of several programming languages.
Full-stack developers are in high demand because they can work on a variety of projects and meet the needs of many companies. The full-stack Java developer course helps students build this adaptability so they can eventually become the first choice for brands searching for high-end developers.
As a result, these are a few key factors improving the future prospects of Java Full Stack developers in India. They are vibrant professionals who are in high demand due to their diverse skill set and experience, and they are growing steadily. The Java full stack developer course can help students hone their knowledge and abilities to succeed in this industry.
Datavalley’s Full Stack Java Developer course can help you start a promising career in full stack development. Enroll today to gain the expertise and knowledge you need to succeed.
Attend Free Bootcamps
Looking to supercharge your Java skills and become a full-stack Java developer? Look no further than Datavalley’s Java Full Stack Developer bootcamp. This is your chance to take your career to the next level by enhancing your expertise.
Key points about Bootcamps:
It is completely free, and there is no obligation to complete the entire course.
20 hours total, two hours daily for two weeks.
Gain hands-on experience with tools and projects.
Explore and decide if the field or career is right for you.
Complete a mini-project.
Earn a certificate to show on your profile.
No commitment is required after bootcamp.
Take another bootcamp if you are unsure about your track.

#dataexperts#datavalley#data engineering#data analytics#dataexcellence#business intelligence#data science#power bi#data analytics course#data science course#java developers#java full stack bootcamp#java full stack training#java full stack course#java full stack developer
2 notes
·
View notes

Text
youtube
A Data Engineering Perspective for Privacy Enhancing Technologies- Tejasvi Addagada
Explore Privacy Enhancing Technologies from a data engineering viewpoint with expert Tejasvi Addagada. This video breaks down the role of PETs in protecting sensitive data, ensuring regulatory compliance, and managing data risks. Ideal for businesses seeking secure and scalable data science engineering solutions.
The Content took from Tejasvi Addagada website's blog section. I made an video for easy access of the information, also Addagada's books can help to understand more about Data management and Governance, Data engineering, data science, etc.
#Privacy Enhancing Technologies#tejasvi addagada#data management#data governance#data engineering#data science engineering#data risk management in financial services#Youtube
0 notes