#Database vs Data Warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Critical Differences: Between Database vs Data Warehouse
Summary: This blog explores the differences between databases and data warehouses, highlighting their unique features, uses, and benefits. By understanding these distinctions, you can select the optimal data management solution to support your organisation’s goals and leverage cloud-based options for enhanced scalability and efficiency.

Introduction
Effective data management is crucial for organisational success in today's data-driven world. Understanding the concepts of databases and data warehouses is essential for optimising data use. Databases store and manage transactional data efficiently, while data warehouses aggregate and analyse large volumes of data for strategic insights.
This blog aims to clarify the critical differences between databases and data warehouses, helping you decide which solution best fits your needs. By exploring "database vs. data warehouse," you'll gain valuable insights into their distinct roles, ensuring your data infrastructure effectively supports your business objectives.
What is a Database?
A database is a structured collection of data that allows for efficient storage, retrieval, and management of information. It is designed to handle large volumes of data and support multiple users simultaneously.
Databases provide a systematic way to organise, manage, and retrieve data, ensuring consistency and accuracy. Their primary purpose is to store data that can be easily accessed, manipulated, and updated, making them a cornerstone of modern data management.
Common Uses and Applications
Databases are integral to various applications across different industries. Businesses use databases to manage customer information, track sales and inventory, and support transactional processes.
In the healthcare sector, databases store patient records, medical histories, and treatment plans. Educational institutions use databases to manage student information, course registrations, and academic records.
E-commerce platforms use databases to handle product catalogues, customer orders, and payment information. Databases also play a crucial role in financial services, telecommunications, and government operations, providing the backbone for data-driven decision-making and efficient operations.
Types of Databases
Knowing about different types of databases is crucial for making informed decisions in data management. Each type offers unique features for specific tasks. There are several types of databases, each designed to meet particular needs and requirements.
Relational Databases
Relational databases organise data into tables with rows and columns, using structured query language (SQL) for data manipulation. They are highly effective for handling structured data and maintaining relationships between different data entities. Examples include MySQL, PostgreSQL, and Oracle.
NoSQL Databases
NoSQL databases are designed to handle unstructured and semi-structured data, providing flexibility in data modelling. They are ideal for high scalability and performance applications like social media and big data. Types of NoSQL databases include:
Document databases (e.g., MongoDB).
Key-value stores (e.g., Redis).
Column-family stores (e.g., Cassandra).
Graph databases (e.g., Neo4j).
In-Memory Databases
In-memory databases store data in the main memory (RAM) rather than on disk, enabling high-speed data access and processing. They are suitable for real-time applications that require low-latency data retrieval, such as caching and real-time analytics. Examples include Redis and Memcached.
NewSQL Databases
NewSQL databases aim to provide the scalability of NoSQL databases while maintaining the ACID (Atomicity, Consistency, Isolation, Durability) properties of traditional relational databases. They are used in applications that require high transaction throughput and firm consistency. Examples include Google Spanner and CockroachDB.
Examples of Database Management Systems (DBMS)
Understanding examples of Database Management Systems (DBMS) is essential for selecting the right tool for your data needs. DBMS solutions offer varied features and capabilities, ensuring better performance, security, and integrity across diverse applications. Some common examples of Database Management Systems (DBMS) are:
MySQL
MySQL is an open-source relational database management system known for its reliability, performance, and ease of use. It is widely used in web applications, including popular platforms like WordPress and Joomla.
PostgreSQL
PostgreSQL is an advanced open-source relational database system that supports SQL and NoSQL data models. It is known for its robustness, extensibility, and standards compliance, making it suitable for complex applications.
MongoDB
MongoDB is a leading NoSQL database that stores data in flexible, JSON-like documents. It is designed for scalability and performance, making it a popular choice for modern applications that handle large volumes of unstructured data.
Databases form the foundation of data management in various domains, offering diverse solutions to meet specific data storage and retrieval needs. By understanding the different types of databases and their applications, organisations can choose the proper database technology to support their operations.
Read More: What are Attributes in DBMS and Its Types?
What is a Data Warehouse?
A data warehouse is a centralised repository designed to store, manage, and analyse large volumes of data. It consolidates data from various sources, enabling organisations to make informed decisions through comprehensive data analysis and reporting.
A data warehouse is a specialised system optimised for query and analysis rather than transaction processing. It is structured to enable efficient data retrieval and analysis, supporting business intelligence activities. The primary purpose of a data warehouse is to provide a unified, consistent data source for analytical reporting and decision-making.
Common Uses and Applications
Data warehouses are commonly used in various industries to enhance decision-making processes. Businesses use them to analyse historical data, generate reports, and identify trends and patterns. Applications include sales forecasting, financial analysis, customer behaviour, and performance tracking.
Organisations leverage data warehouses to gain insights into operations, streamline processes, and drive strategic initiatives. By integrating data from different departments, data warehouses enable a holistic view of business performance, supporting comprehensive analytics and business intelligence.
Key Features of Data Warehouses
Data warehouses offer several key features that distinguish them from traditional databases. These features make data warehouses ideal for supporting complex queries and large-scale data analysis, providing organisations with the tools for in-depth insights and informed decision-making. These features include:
Data Integration: Data warehouses consolidate data from multiple sources, ensuring consistency and accuracy.
Scalability: They are designed to handle large volumes of data and scale efficiently as data grows.
Data Transformation: ETL (Extract, Transform, Load) processes clean and organise data, preparing it for analysis.
Performance Optimisation: Data warehouses enhance query performance using indexing, partitioning, and parallel processing.
Historical Data Storage: They store historical data, enabling trend analysis and long-term reporting.
Read Blog: Top ETL Tools: Unveiling the Best Solutions for Data Integration.
Examples of Data Warehousing Solutions
Several data warehousing solutions stand out in the industry, offering unique capabilities and advantages. These solutions help organisations manage and analyse data more effectively, driving better business outcomes through robust analytics and reporting capabilities. Prominent examples include:
Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It is designed to handle complex queries and large datasets, providing fast query performance and easy scalability.
Google BigQuery
Google BigQuery is a serverless, highly scalable, cost-effective multi-cloud data warehouse that enables super-fast SQL queries using the processing power of Google's infrastructure.
Snowflake
Snowflake is a cloud data platform that provides data warehousing, data lakes, and data sharing capabilities. It is known for its scalability, performance, and ability to handle diverse data workloads.
Key Differences Between Databases and Data Warehouses
Understanding the distinctions between databases and data warehouses is crucial for selecting the right data management solution. This comparison will help you grasp their unique features, use cases, and data-handling methods.

Databases and data warehouses serve distinct purposes in data management. While databases handle transactional data and support real-time operations, data warehouses are indispensable for advanced data analysis and business intelligence. Understanding these key differences will enable you to choose the right solution based on your specific data needs and goals.
Choosing Between a Database and a Data Warehouse

Several critical factors should guide your decision-making process when deciding between a database and a data warehouse. These factors revolve around the nature, intended use, volume, and complexity of data, as well as specific use case scenarios and cost implications.
Nature of the Data
First and foremost, consider the inherent nature of your data. Suppose you focus on managing transactional data with frequent updates and real-time access requirements. In that case, a traditional database excels in this operational environment.
On the other hand, a data warehouse is more suitable if your data consists of vast historical records and complex data models and is intended for analytical processing to derive insights.
Intended Use: Operational vs. Analytical
The intended use of the data plays a pivotal role in determining the appropriate solution. Operational databases are optimised for transactional processing, ensuring quick and efficient data manipulation and retrieval.
Conversely, data warehouses are designed for analytical purposes, facilitating complex queries and data aggregation across disparate sources for business intelligence and decision-making.
Volume and Complexity of Data
Consider the scale and intricacy of your data. Databases are adept at handling moderate to high volumes of structured data with straightforward relationships. In contrast, data warehouses excel in managing vast amounts of both structured and unstructured data, often denormalised for faster query performance and analysis.
Use Case Scenarios
Knowing when to employ each solution is crucial. Use a database when real-time data processing and transactional integrity are paramount, such as in e-commerce platforms or customer relationship management systems. Opt for a data warehouse when conducting historical trend analysis, business forecasting, or consolidating data from multiple sources for comprehensive reporting.
Cost Considerations
Finally, weigh the financial aspects of your decision. Databases typically involve lower initial setup costs and are easier to scale incrementally. In contrast, data warehouses may require more substantial upfront investments due to their complex infrastructure and storage requirements.
To accommodate your budgetary constraints, factor in long-term operational costs, including maintenance, storage, and data processing fees.
By carefully evaluating these factors, you can confidently select the database or data warehouse solution that best aligns with your organisation's specific needs and strategic objectives.
Cloud Databases and Data Warehouses
Cloud-based solutions have revolutionised data management by offering scalable, flexible, and cost-effective alternatives to traditional on-premises systems. Here's an overview of how cloud databases and data warehouses transform modern data architectures.
Overview of Cloud-Based Solutions
Cloud databases and data warehouses leverage the infrastructure and services provided by cloud providers like AWS, Google Cloud, and Microsoft Azure. They eliminate the need for physical hardware and offer pay-as-you-go pricing models, making them ideal for organisations seeking agility and scalability.
Advantages of Cloud Databases and Data Warehouses
The primary advantages include scalability to handle fluctuating workloads, reduced operational costs by outsourcing maintenance and updates to the cloud provider and enhanced accessibility for remote teams. Cloud solutions facilitate seamless integration with other cloud services and tools, promoting collaboration and innovation.
Popular Cloud Providers and Services
Leading providers such as AWS with Amazon RDS and Google Cloud's Cloud SQL offer managed database services supporting engines like MySQL, PostgreSQL, and SQL Server. For data warehouses, options like AWS Redshift, Google BigQuery, and Azure Synapse Analytics provide powerful analytical capabilities with elastic scaling and high performance.
Security and Compliance Considerations
Despite the advantages, security remains a critical consideration. Cloud providers implement robust security measures, including encryption, access controls, and compliance certifications (e.g., SOC 2, GDPR, HIPAA).
Organisations must assess data residency requirements and ensure adherence to industry-specific regulations when migrating sensitive data to the cloud.
By embracing cloud databases and data warehouses, organisations can optimise data management, drive innovation, and gain competitive advantages in today's data-driven landscape.
Frequently Asked Questions
What is the main difference between a database and a data warehouse?
A database manages transactional data for real-time operations, supporting sales and inventory management activities. In contrast, a data warehouse aggregates and analyses large volumes of historical data, enabling strategic insights, comprehensive reporting, and business intelligence activities critical for informed decision-making.
When should I use a data warehouse over a database?
Use a data warehouse when your primary goal is to conduct historical data analysis, generate complex queries, and create comprehensive reports. A data warehouse is ideal for business intelligence, trend analysis, and strategic planning, consolidating data from multiple sources for a unified, insightful view of your operations.
How do cloud databases and data warehouses benefit organisations?
Cloud databases and data warehouses provide significant advantages, including scalability to handle varying workloads, reduced operational costs due to outsourced maintenance, and enhanced accessibility for remote teams. They integrate seamlessly with other cloud services, promoting collaboration, innovation, and data management and analysis efficiency.
Conclusion
Understanding the critical differences between databases and data warehouses is essential for effective data management. Databases excel in handling transactional data, ensuring real-time updates and operational efficiency.
In contrast, data warehouses are designed for in-depth analysis, enabling strategic decision-making through comprehensive data aggregation. You can choose the solution that best aligns with your organisation's needs by carefully evaluating factors like data nature, intended use, volume, and cost.
Embracing cloud-based options further enhances scalability and flexibility, driving innovation and competitive advantage in today’s data-driven world. Choose wisely to optimise your data infrastructure and achieve your business objectives.
#Differences Between Database and Data Warehouse#Database vs Data Warehouse#Database#Data Warehouse#data management#data analytics#data storage#data science#pickl.ai#data analyst
0 notes
Text
Data Warehouses Vs Data Lakes Vs Databases – A Detailed Evaluation
Data storage is a major task, especially for organizations handling large amounts of data. For businesses garnering optimal value from big data, you hear about data storage terminologies – ‘Databases’, ‘Data warehouses’, and ‘Data lakes’. They all sound similar. But they aren’t! Each of them has its own unique characteristics that make them stand apart in the data landscape.
Through this detailed article, we attempt to introduce the three terminologies, their salient features and how different are they from each other. Hope it throws some light into how data can be managed and stored with databases, data lakes, and data warehouses.
0 notes
Text
In the rapidly evolving landscape of modern business, the imperative for digital transformation has never been more pronounced, driven by the relentless pressures of competition. Central to this transformational journey is the strategic utilization of data, which serves as a cornerstone for gaining insights and facilitating predictive analysis. In effect, data has assumed the role of a contemporary equivalent to gold, catalyzing substantial investments and sparking a widespread adoption of data analytics methodologies among businesses worldwide. Nevertheless, this shift isn't without its challenges. Developing end-to-end applications tailored to harness data for generating core insights and actionable findings can prove to be time-intensive and costly, contingent upon the approach taken in constructing data pipelines. These comprehensive data analytics applications, often referred to as data products within the data domain, demand meticulous design and implementation efforts. This article aims to explore the intricate realm of data products, data quality, and data governance, highlighting their significance in contemporary data systems. Additionally, it will explore data quality vs data governance in data systems, elucidating their roles and contributions to the success of data-driven initiatives in today's competitive landscape. What are Data Products? Within the domain of data analytics, processes are typically categorized into three distinct phases: data engineering, reporting, and machine learning. Data engineering involves ingesting raw data from diverse sources into a centralized repository such as a data lake or data warehouse. This phase involves executing ETL (extract, transform, and load) operations to refine the raw data and then inserting this processed data into analytical databases to facilitate subsequent analysis in machine learning or reporting phases. In the reporting phase, the focus shifts to effectively visualizing the aggregated data using various business intelligence tools. This visualization process is crucial for uncovering key insights and facilitating better data-driven decision-making within the organization. By presenting the data clearly and intuitively, stakeholders can derive valuable insights to inform strategic initiatives and operational optimizations. Conversely, the machine learning phase is centered around leveraging the aggregated data to develop predictive models and derive actionable insights. This involves tasks such as feature extraction, hypothesis formulation, model development, deployment to production environments, and ongoing monitoring to ensure data quality and workflow integrity. In essence, any software service or tool that orchestrates the end-to-end pipeline—from data ingestion and visualization to machine learning—is commonly referred to as a data product, serving as a pivotal component in modern data-driven enterprises. At this stage, data products streamline and automate the entire process, making it more manageable while saving considerable time. Alongside these efficiencies, they offer a range of outputs, including raw data, processed-aggregated data, data as a machine learning service, and actionable insights. What is Data Quality? Data quality refers to the reliability, accuracy, consistency, and completeness of data within a dataset or system. It encompasses various aspects such as correctness, timeliness, relevance, and usability of the data. In simpler terms, data quality reflects how well the data represents the real-world entities or phenomena it is meant to describe. High-quality data is free from errors, inconsistencies, and biases, making it suitable for analysis, decision-making, and other purposes. The Mission of Data Quality in Data Products In the realm of data products, where decisions are often made based on insights derived from data, ensuring high data quality is paramount. The mission of data quality in data products is multifaceted.
First and foremost, it acts as the foundation upon which all subsequent analyses, predictions, and decisions are built. Reliable data fosters trust among users and stakeholders, encourages the adoption and utilization of data products, and drives innovation, optimization, and compliance efforts. Moreover, high-quality data enables seamless integration, collaboration, and interoperability across different systems and platforms, maximizing the value derived from dataasset What is Data Governance? Data governance is the framework, policies, procedures, and practices that organizations implement to ensure the proper management, usage, quality, security, and compliance of their data assets. It involves defining roles, responsibilities, and decision-making processes related to data management, as well as establishing standards and guidelines for data collection, storage, processing, and sharing. Data governance aims to optimize the value of data assets while minimizing risks and ensuring alignment with organizational objectives and regulatory requirements. The Mission of Data Governance in Data Products In data products, data governance ensures accountability, transparency, and reliability in data management. It maintains data quality and integrity, fostering trust among users. Additionally, data governance facilitates compliance with regulations, enhances data security, and promotes efficient data utilization, driving organizational success through informed decision-making and collaboration. By establishing clear roles, responsibilities, and standards, data governance provides a structured framework for managing data throughout its lifecycle. This framework mitigates errors and inconsistencies, ensuring data remains accurate and usable for analysis. Furthermore, data governance safeguards against data breaches and unauthorized access, while also enabling seamless integration and sharing of data across systems, optimizing its value for organizational objectives. Data Quality vs. Data Governance: A Brief Comparison Data quality focuses on the accuracy, completeness, and reliability of data, ensuring it meets intended use requirements. It guarantees that data is error-free and suitable for analysis and decision-making. Data governance, meanwhile, establishes the framework, policies, and procedures for managing data effectively. It ensures data is managed securely, complies with regulations, and aligns with organizational goals. In essence, data quality ensures the reliability of data, while data governance provides the structure and oversight to manage data effectively. Both are crucial for informed decision-making and organizational success. Conclusion In summary, data quality and data governance play distinct yet complementary roles in the realm of data products. While data quality ensures the reliability and accuracy of data, data governance provides the necessary framework and oversight for effective data management. Together, they form the foundation for informed decision-making, regulatory compliance, and organizational success in the data-driven era.
0 notes
Text
Big Data Analytics: Tools & Career Paths

In this digital era, data is being generated at an unimaginable speed. Social media interactions, online transactions, sensor readings, scientific inquiries-all contribute to an extremely high volume, velocity, and variety of information, synonymously referred to as Big Data. Impossible is a term that does not exist; then, how can we say that we have immense data that remains useless? It is where Big Data Analytics transforms huge volumes of unstructured and semi-structured data into actionable insights that spur decision-making processes, innovation, and growth.
It is roughly implied that Big Data Analytics should remain within the triangle of skills as a widely considered niche; in contrast, nowadays, it amounts to a must-have capability for any working professional across tech and business landscapes, leading to numerous career opportunities.
What Exactly Is Big Data Analytics?
This is the process of examining huge, varied data sets to uncover hidden patterns, customer preferences, market trends, and other useful information. The aim is to enable organizations to make better business decisions. It is different from regular data processing because it uses special tools and techniques that Big Data requires to confront the three Vs:
Volume: Masses of data.
Velocity: Data at high speed of generation and processing.
Variety: From diverse sources and in varying formats (!structured, semi-structured, unstructured).
Key Tools in Big Data Analytics
Having the skills to work with the right tools becomes imperative in mastering Big Data. Here are some of the most famous ones:
Hadoop Ecosystem: The core layer is an open-source framework for storing and processing large datasets across clusters of computers. Key components include:
HDFS (Hadoop Distributed File System): For storing data.
MapReduce: For processing data.
YARN: For resource-management purposes.
Hive, Pig, Sqoop: Higher-level data warehousing and transfer.
Apache Spark: Quite powerful and flexible open-source analytics engine for big data processing. It is much faster than MapReduce, especially for iterative algorithms, hence its popularity in real-time analytics, machine learning, and stream processing. Languages: Scala, Python (PySpark), Java, R.
NoSQL Databases: In contrast to traditional relational databases, NoSQL (Not only SQL) databases are structured to maintain unstructured and semic-structured data at scale. Examples include:
MongoDB: Document-oriented (e.g., for JSON-like data).
Cassandra: Column-oriented (e.g., for high-volume writes).
Neo4j: Graph DB (e.g., for data heavy with relationships).
Data Warehousing & ETL Tools: Tools for extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis. Examples: Talend, Informatica. Cloud-based solutions such as AWS Redshift, Google BigQuery, and Azure Synapse Analytics are also greatly used.
Data Visualization Tools: Essential for presenting complex Big Data insights in an understandable and actionable format. Tools like Tableau, Power BI, and Qlik Sense are widely used for creating dashboards and reports.
Programming Languages: Python and R are the dominant languages for data manipulation, statistical analysis, and integrating with Big Data tools. Python's extensive libraries (Pandas, NumPy, Scikit-learn) make it particularly versatile.
Promising Career Paths in Big Data Analytics
As Big Data professionals in India was fast evolving, there were diverse professional roles that were offered with handsome perks:
Big Data Engineer: Designs, builds, and maintains the large-scale data processing systems and infrastructure.
Big Data Analyst: Work on big datasets, finding trends, patterns, and insights that big decisions can be made on.
Data Scientist: Utilize statistics, programming, and domain expertise to create predictive models and glean deep insights from data.
Machine Learning Engineer: Concentrates on the deployment and development of machine learning models on Big Data platforms.
Data Architect: Designs the entire data environment and strategy of an organization.
Launch Your Big Data Analytics Career
Some more Specialized Big Data Analytics course should be taken if you feel very much attracted to data and what it can do. Hence, many computer training institutes in Ahmedabad offer comprehensive courses covering these tools and concepts of Big Data Analytics, usually as a part of Data Science with Python or special training in AI and Machine Learning. Try to find those courses that offer real-time experience and projects along with industry mentoring, so as to help you compete for these much-demanded jobs.
When you are thoroughly trained in the Big Data Analytics tools and concepts, you can manipulate information for innovation and can be highly paid in the working future.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
The rapid growth of data-driven industries has brought about two prominent and in-demand career paths: Data Engineering and Data Science. For international students dreaming of a global tech career, these two fields offer promising opportunities, high salaries, and exciting work environments. But which course should you take abroad? What are the key differences, career paths, skills needed, and best study destinations?
In this blog, we’ll break down the key distinctions between Data Engineering and Data Science, explore which path suits you best, and highlight the best countries and universities abroad to pursue these courses.
What is Data Engineering?
Data Engineering focuses on designing, building, and maintaining data pipelines, systems, and architecture. Data Engineers prepare data so that Data Scientists can analyze it. They work with large-scale data processing systems and ensure that data flows smoothly between servers, applications, and databases.
Key Responsibilities of a Data Engineer:
Developing, testing, and maintaining data pipelines
Building data architectures (e.g., databases, warehouses)
Managing ETL (Extract, Transform, Load) processes
Working with tools like Apache Spark, Hadoop, SQL, Python, and AWS
Ensuring data quality and integrity
What is Data Science?
analysis, machine learning, and data visualization. Data Scientists use data to drive business decisions, create predictive models, and uncover trends.
Key Responsibilities of a Data Scientist:
Cleaning and analyzing large datasets
Building machine learning and AI models
Creating visualizations to communicate findings
Using tools like Python, R, SQL, TensorFlow, and Tableau
Applying statistical and mathematical techniques to solve problems
Which Course Should You Take Abroad?
Choosing between Data Engineering and Data Science depends on your interests, academic background, and long-term career goals. Here’s a quick guide to help you decide:
Take Data Engineering if:
You love building systems and solving technical challenges.
You have a background in software engineering, computer science, or IT.
You prefer backend development, architecture design, and working with infrastructure.
You enjoy automating data workflows and handling massive datasets.
Take Data Science if:
You’re passionate about data analysis, problem-solving, and storytelling with data.
You have a background in statistics, mathematics, computer science, or economics.
You’re interested in machine learning, predictive modeling, and data visualization.
You want to work on solving real-world problems using data.
Top Countries to Study Data Engineering and Data Science
Studying abroad can enhance your exposure, improve career prospects, and provide access to global job markets. Here are some of the best countries to study both courses:
1. Germany
Why? Affordable education, strong focus on engineering and analytics.
Top Universities:
Technical University of Munich
RWTH Aachen University
University of Mannheim
2. United Kingdom
Why? Globally recognized degrees, data-focused programs.
Top Universities:
University of Oxford
Imperial College London
4. Sweden
Why? Innovation-driven, excellent data education programs.
Top Universities:
KTH Royal Institute of Technology
Lund University
Chalmers University of Technology
Course Structure Abroad
Whether you choose Data Engineering or Data Science, most universities abroad offer:
Bachelor’s Degrees (3-4 years):
Focus on foundational subjects like programming, databases, statistics, algorithms, and software engineering.
Recommended for students starting out or looking to build from scratch.
Master’s Degrees (1-2 years):
Ideal for those with a bachelor’s in CS, IT, math, or engineering.
Specializations in Data Engineering or Data Science.
Often include hands-on projects, capstone assignments, and internship opportunities.
Certifications & Short-Term Diplomas:
Offered by top institutions and platforms (e.g., MITx, Coursera, edX).
Helpful for career-switchers or those seeking to upgrade their skills.
Career Prospects and Salaries
Both fields are highly rewarding and offer excellent career growth.
Career Paths in Data Engineering:
Data Engineer
Data Architect
Big Data Engineer
ETL Developer
Cloud Data Engineer
Average Salary (Globally):
Entry-Level: $70,000 - $90,000
Mid-Level: $90,000 - $120,000
Senior-Level: $120,000 - $150,000+
Career Paths in Data Science:
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Research Scientist
AI Engineer
Average Salary (Globally):
Entry-Level: $75,000 - $100,000
Mid-Level: $100,000 - $130,000
Senior-Level: $130,000 - $160,000+
Industry Demand
The demand for both data engineers and data scientists is growing rapidly across sectors like:
E-commerce
Healthcare
Finance and Banking
Transportation and Logistics
Media and Entertainment
Government and Public Policy
Artificial Intelligence and Machine Learning Startups
According to LinkedIn and Glassdoor reports, Data Engineer roles have surged by over 50% in recent years, while Data Scientist roles remain in the top 10 most in-demand jobs globally.
Skills You’ll Learn Abroad
Whether you choose Data Engineering or Data Science, here are some skills typically covered in top university programs:
For Data Engineering:
Advanced SQL
Data Warehouse Design
Apache Spark, Kafka
Data Lake Architecture
Python/Scala Programming
Cloud Platforms: AWS, Azure, GCP
For Data Science:
Machine Learning Algorithms
Data Mining and Visualization
Statistics and Probability
Python, R, MATLAB
Tools: Jupyter, Tableau, Power BI
Deep Learning, AI Basics
Internship & Job Opportunities Abroad
Studying abroad often opens doors to internships, which can convert into full-time job roles.
Countries like Germany, Canada, Australia, and the UK allow international students to work part-time during studies and offer post-study work visas. This means you can gain industry experience after graduation.
Additionally, global tech giants like Google, Amazon, IBM, Microsoft, and Facebook frequently hire data professionals across both disciplines.
Final Thoughts: Data Engineering vs Data Science – Which One Should You Choose?
There’s no one-size-fits-all answer, but here’s a quick recap:
Choose Data Engineering if you’re technically inclined, love working on infrastructure, and enjoy building systems from scratch.
Choose Data Science if you enjoy exploring data, making predictions, and translating data into business insights.
Both fields are highly lucrative, future-proof, and in high demand globally. What matters most is your interest, learning style, and career aspirations.
If you're still unsure, consider starting with a general data science or computer science program abroad that allows you to specialize in your second year. This way, you get the best of both worlds before narrowing down your focus.
Need Help Deciding Your Path?
At Cliftons Study Abroad, we guide students in selecting the right course and country tailored to their goals. Whether it’s Data Engineering in Germany or Data Science in Canada, we help you navigate admissions, visa applications, scholarships, and more.
Contact us today to take your first step towards a successful international data career!
0 notes
Text
Difference Between Data Analyst and BI Analyst
In the fast-paced digital age, data is more than just numbers—it’s the foundation of strategic decisions across industries. Within this data-driven ecosystem, two prominent roles often come up: Data Analyst and Business Intelligence (BI) Analyst. Though their responsibilities sometimes intersect, these professionals serve distinct purposes. Understanding the differences between them is crucial for anyone looking to build a career in analytics.
For individuals exploring a career in this field, enrolling in a well-rounded data analyst course in Kolkata can provide a solid stepping stone. But first, let’s dive into what differentiates these two career paths.
Core Focus and Responsibilities
A Data Analyst is primarily responsible for extracting insights from raw data. They gather, process, and examine data to identify patterns and trends that help drive both operational improvements and strategic decision-making. The focus here is largely on data quality, statistical analysis, and deriving insights through quantitative methods.
On the other hand, a BI Analyst is more focused on turning those insights into actionable business strategies. BI Analysts create dashboards, visualize data through tools like Power BI or Tableau, and present their findings to business leaders. Their goal is to help decision-makers understand performance trends, monitor KPIs, and identify opportunities for growth.
In short, data analysts focus more on exploration and deep analysis, whereas BI analysts specialize in communicating the meaning of that data through accessible visuals and reports.
Tools and Technologies
The toolkit of a data analyst usually includes:
SQL for querying databases
Excel for basic data wrangling
Python or R for statistical analysis
Tableau or Power BI for initial visualizations
BI Analysts, while they may use similar tools, concentrate more on:
Dashboard-building platforms like Power BI and Tableau
Data warehouses and reporting tools
Integration with enterprise systems such as ERP or CRM platforms
By starting with a strong technical foundation through a data analyst course in Kolkata, professionals can build the skills needed to branch into either of these specialties.
Skill Sets: Technical vs Business-Centric
Though both roles demand analytical thinking, their required skill sets diverge slightly.
Data Analysts need:
Strong mathematical and statistical knowledge
Data cleaning and transformation abilities
Comfort working with large datasets
Programming skills for automation and modeling
BI Analysts require:
Business acumen to align data with goals
Excellent communication skills
Advanced visualization skills
Understanding of key performance indicators (KPIs)
Aspiring professionals in Kolkata often find that attending an offline data analyst institute in Kolkata provides a more immersive experience in developing both sets of skills, especially with in-person mentoring and interactive learning.
Career Trajectories and Growth
The career paths of data analysts and BI analysts may overlap initially, but they often lead in different directions.
A Data Analyst can progress to roles like:
Data Scientist
Machine Learning Engineer
Quantitative Analyst
Meanwhile, a BI Analyst may evolve into positions such as:
BI Developer
Data Architect
Strategy Consultant
Both paths offer exciting opportunities in industries like finance, healthcare, retail, and tech. The key to progressing lies in mastering both technical tools and business logic, starting with quality training.
The Value of Offline Learning in Kolkata
While online learning is widely available, many learners still value the discipline and clarity that comes with face-to-face instruction. Attending an offline data analyst institute in Kolkata helps bridge the gap between theoretical concepts and practical application. Learners benefit from real-time feedback, collaborative sessions, and guidance that fosters confidence—especially important for those new to data analytics.
DataMites Institute: Your Trusted Analytics Training Partner
When it comes to structured and globally recognized analytics training, DataMites stands out as a top choice for learners across India.
The courses offered by DataMites Institute are accredited by IABAC and NASSCOM FutureSkills, ensuring they align with international industry benchmarks. Students benefit from expert guidance, practical project experience, internship opportunities, and robust placement assistance.
DataMites Institute provides offline classroom training in major cities like Mumbai, Pune, Hyderabad, Chennai, Delhi, Coimbatore, and Ahmedabad—offering learners flexible and accessible education opportunities across India. If you're based in Pune, DataMites Institute provides the ideal platform to master Python and excel in today’s competitive tech environment.
For learners in Kolkata, DataMites Institute represents a trusted gateway to a rewarding analytics career. With a strong emphasis on practical exposure, personalized mentoring, and real-world projects, DataMites Institute empowers students to build confidence and credibility in the field. Whether you're just starting out or looking to upskill, this institute offers the resources and structure to help you succeed in both data and business intelligence roles.
While both Data Analysts and BI Analysts play pivotal roles in transforming data into value, they approach the task from different angles. Choosing between them depends on your interest—whether it lies in deep analysis or strategic reporting. Whichever path you choose, building a strong foundation through a quality training program like that offered by DataMites in Kolkata will set you on the right trajectory.
0 notes
Text
ERP Software Company in Kochi

Introduction
Kochi, the commercial capital of Kerala, is witnessing a surge in digital transformation across industries such as shipping, IT, tourism, manufacturing, and retail. One of the primary technologies accelerating this change is Enterprise Resource Planning (ERP). This blog explores the growing demand and offerings of ERP software companies in Kochi, the advantages they bring to various sectors, and how businesses can leverage SEO-optimized ERP development services for visibility and growth.
What is ERP Software?
ERP is a centralized business management solution that integrates various core functions—such as finance, human resources, inventory, production, and customer relationship management—into one seamless platform.
Core ERP Modules:
Financial Accounting
Inventory and Warehouse Management
Human Resource Management
Customer Relationship Management (CRM)
Manufacturing and Production Planning
Procurement and Supply Chain Management
Project Management
Business Intelligence & Reporting
Importance of ERP Software in Kochi's Business Landscape
1. Shipping and Logistics
ERP helps in managing fleet operations, cargo tracking, freight billing, and port logistics with real-time data accuracy.
2. Tourism and Hospitality
Enhances booking systems, inventory, guest experiences, HR, and payroll management in resorts and hotels.
3. Manufacturing Units
Supports production scheduling, raw material procurement, quality control, and equipment maintenance.
4. Retail and E-commerce
Provides centralized stock management, real-time sales analytics, and POS system integrations.
5. Healthcare Institutions
Streamlines patient record systems, billing, compliance, and hospital inventory management.
Benefits of ERP Software for Kochi-Based Enterprises
Enhanced Productivity
Centralized Information Access
Improved Financial Control
Efficient Resource Allocation
Regulatory Compliance and Reporting
Custom Dashboard and KPIs Monitoring
Remote and Mobile Access with Cloud ERP
Multi-language and Multi-currency Support
Top ERP Software Companies in Kochi
1. Infopark Solutions Pvt. Ltd.
Specialized in scalable ERP systems for manufacturing and export businesses.
2. KochiSoft ERP Developers
Offers modular and cloud-based ERP with CRM and HR integration.
3. Zerone Technologies
Known for robust and secure ERP software for financial institutions and logistics firms.
4. NavAlt Technologies
Focuses on maritime, marine, and industrial ERP customization.
5. Techno Globe ERP Solutions
Delivers enterprise-grade ERP with IoT, AI, and automation features for large organizations.
Custom ERP Development vs. Ready-Made Software
Feature Custom ERP Ready-Made ERP Personalization Fully customizable Limited customization Cost Higher initial investment Lower upfront cost Integration Seamless with existing tools May require APIs Scalability Highly scalable Depends on vendor Time to Deploy Longer Quicker setup
Technologies Used in ERP Development in Kochi
Languages: Python, Java, PHP, C#
Frameworks: Odoo, SAP, Oracle NetSuite, ASP.NET
Databases: PostgreSQL, MySQL, Oracle, MS SQL
Platforms: AWS, Azure, On-premise Servers
UI/UX: ReactJS, Angular, Bootstrap
Mobile: Flutter, Kotlin, Swift for mobile ERP apps
Industries That Benefit Most from ERP in Kochi
Maritime and Logistics Companies
Coir and Agro-Based Exporters
Rubber and Chemical Manufacturers
Multi-chain Retailers and Wholesalers
Educational Institutes and Universities
Ayurveda and Wellness Centers
Hospitals and Diagnostic Labs
Tourism and Hotel Groups
Future Trends in ERP Development in Kochi
AI-Driven Forecasting and Predictive Analytics
Blockchain in ERP for Transparent Supply Chains
IoT-Integrated Smart Manufacturing ERP
Chatbot Integration and Voice Commands
Augmented Reality (AR) for Real-time Data Visualization
Conclusion
ERP software companies in Kochi are playing a vital role in modernizing business operations, enhancing productivity, and delivering data-driven insights. From SMEs to large-scale industries, ERP adoption is no longer optional but essential. Custom ERP development tailored to local business needs is empowering Kochi-based enterprises to thrive in an increasingly competitive marketplace.
0 notes
Text
Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer: Choose Your Perfect Data Career!

In today’s rapidly evolving tech world, career opportunities in data-related fields are expanding like never before. However, with multiple roles like Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer, newcomers — and even seasoned professionals — often find it confusing to understand how these roles differ.
At Yasir Insights, we think that having clarity makes professional selections more intelligent. We’ll go over the particular duties, necessary abilities, and important differences between these well-liked Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer data positions in this blog.
Also Read: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Introduction to Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
The Data Science and Machine Learning Development Lifecycle (MLDLC) includes stages like planning, data gathering, preprocessing, exploratory analysis, modelling, deployment, and optimisation. In order to effectively manage these intricate phases, the burden is distributed among specialised positions, each of which plays a vital part in the project’s success.
Data Engineer
Who is a Data Engineer?
The basis of the data ecosystem is built by data engineers. They concentrate on collecting, sanitising, and getting data ready for modelling or further analysis. Think of them as mining precious raw materials — in this case, data — from complex and diverse sources.
Key Responsibilities:
Collect and extract data from different sources (APIS, databases, web scraping).
Design and maintain scalable data pipelines.
Clean, transform, and store data in warehouses or lakes.
Optimise database performance and security.
Required Skills:
Strong knowledge of Data Structures and Algorithms.
Expertise in Database Management Systems (DBMS).
Familiarity with Big Data tools (like Hadoop, Spark).
Hands-on experience with cloud platforms (AWS, Azure, GCP).
Proficiency in building and managing ETL (Extract, Transform, Load) pipelines.
Data Analyst
Who is a Data Analyst?
Data analysts take over once the data has been cleansed and arranged. Their primary responsibility is to evaluate data in order to get valuable business insights. They provide answers to important concerns regarding the past and its causes.
Key Responsibilities:
Perform Exploratory Data Analysis (EDA).
Create visualisations and dashboards to represent insights.
Identify patterns, trends, and correlations in datasets.
Provide reports to support data-driven decision-making.
Required Skills:
Strong Statistical knowledge.
Proficiency in programming languages like Python or R.
Expertise in Data Visualisation tools (Tableau, Power BI, matplotlib).
Excellent communication skills to present findings clearly.
Experience working with SQL databases.
Data Scientist
Who is a Data Scientist?
Data Scientists build upon the work of Data Analysts by developing predictive models and machine learning algorithms. While analysts focus on the “what” and “why,” Data Scientists focus on the “what’s next.”
Key Responsibilities:
Design and implement Machine Learning models.
Perform hypothesis testing, A/B testing, and predictive analytics.
Derive strategic insights for product improvements and new innovations.
Communicate technical findings to stakeholders.
Required Skills:
Mastery of Statistics and Probability.
Strong programming skills (Python, R, SQL).
Deep understanding of Machine Learning algorithms.
Ability to handle large datasets using Big Data technologies.
Critical thinking and problem-solving abilities.
Machine Learning Engineer
Who is a Machine Learning Engineer?
Machine Learning Engineers (MLES) take the models developed by Data Scientists and make them production-ready. They ensure models are deployed, scalable, monitored, and maintained effectively in real-world systems.
Key Responsibilities:
Deploy machine learning models into production environments.
Optimise and scale ML models for performance and efficiency.
Continuously monitor and retrain models based on real-time data.
Collaborate with software engineers and data scientists for integration.
Required Skills:
Strong foundations in Linear Algebra, Calculus, and Probability.
Mastery of Machine Learning frameworks (TensorFlow, PyTorch, Scikit-learn).
Proficiency in programming languages (Python, Java, Scala).
Knowledge of Distributed Systems and Software Engineering principles.
Familiarity with MLOps tools for automation and monitoring.
Summary: Data Engineer vs Data Analyst vs Data Scientist vs ML Engineer
Data Engineer
Focus Area: Data Collection & Processing
Key Skills: DBMS, Big Data, Cloud Computing
Objective: Build and maintain data infrastructure
Data Analyst
Focus Area: Data Interpretation & Reporting
Key Skills: Statistics, Python/R, Visualisation Tools
Objective: Analyse data and extract insights
Data Scientist
Focus Area: Predictive Modelling
Key Skills: Machine Learning, Statistics, Data Analysis
Objective: Build predictive models and strategies
Machine Learning Engineer
Focus Area: Model Deployment & Optimisation
Key Skills: ML Frameworks, Software Engineering
Objective: Deploy and optimise ML models in production
Frequently Asked Questions (FAQS)
Q1: Can a Data Engineer become a Data Scientist?
Yes! With additional skills in machine learning, statistics, and model building, a Data Engineer can transition into a Data Scientist role.
Q2: Is coding necessary for Data Analysts?
While deep coding isn’t mandatory, familiarity with SQL, Python, or R greatly enhances a Data Analyst’s effectiveness.
Q3: What is the difference between a Data Scientist and an ML Engineer?
Data Scientists focus more on model development and experimentation, while ML Engineers focus on deploying and scaling those models.
Q4: Which role is the best for beginners?
If you love problem-solving and analysis, start as a Data Analyst. If you enjoy coding and systems, a Data Engineer might be your path.
Published By:
Mirza Yasir Abdullah Baig
Repost This Article and built Your Connection With Others
0 notes
Text
ETL Engineer vs. Data Engineer: Which One Do You Need?

If your business handles large data volumes you already know how vital it is to have the right talent managing it. But when it comes to scalability or improving your data systems, you must know whether to hire ETL experts or hire data engineers.
While the roles do overlap in some areas, they each have unique skills to bring forth. This is why an understanding of the differences can help you make the right hire. Several tech companies face this question when they are outlining their data strategy. So if you are one of those then let’s break it down and help you decide which experts you should hire.
Choosing the Right Role to Build and Manage Your Data Pipeline
Extract, Transform, Load is what ETL stands for. The duties of an ETL engineer include:
Data extraction from various sources.
Cleaning, formatting, and enrichment.
Putting it into a central system or data warehouse.
Hiring ETL engineers means investing in a person who will make sure data moves accurately and seamlessly across several systems and into a single, usable format.
Businesses that largely rely on dashboards, analytics tools, and structured data reporting would benefit greatly from this position. ETL engineers assist business intelligence and compliance reporting for a large number of tech organizations.
What Does a Data Engineer Do?
The architecture that facilitates data movement and storage is created and maintained by a data engineer. Their duties frequently consist of:
Data pipeline design
Database and data lake management
Constructing batch or real-time processing systems
Developing resources to assist analysts and data scientists
When hiring data engineers, you want someone with a wider range of skills who manages infrastructure, performance optimization, and long-term scalability in addition to using ETL tools.
Remote Hiring and Flexibility
Thanks to cloud platforms and remote technologies, you can now hire remote developers, such as data engineers and ETL specialists, with ease. This strategy might be more economical and gives access to worldwide talent, particularly for expanding teams.
Which One Do You Need?
If your main objective is to use clean, organized data to automate and enhance reporting or analytics, go with ETL engineers.
If you're scaling your current infrastructure or creating a data platform from the ground up, hire data engineers.
Having two responsibilities is ideal in many situations. While data engineers concentrate on the long-term health of the system, ETL engineers manage the daily flow.
Closing Thoughts
The needs of your particular project will determine whether you should hire a data engineer or an ETL. You should hire ETL engineers if you're interested in effectively transforming and transporting data. It's time to hire data engineers if you're laying the framework for your data systems.
Combining both skill sets might be the best course of action for contemporary IT organizations, particularly if you hire remote talent to scale swiftly and affordably. In any case, hiring qualified personnel guarantees that your data strategy fosters expansion and informed decision-making.
0 notes
Text
Yes, it is possible to switch from SAP BW to ABAP and then to Native HANA without formal training classes, but it requires structured self-learning, hands-on practice, and real-world project exposure. Here's a step-by-step guide to achieving this transition:
1. Transition from SAP BW to SAP ABAP
SAP BW (Business Warehouse) involves data modeling, ETL, and reporting, whereas SAP ABAP (Advanced Business Application Programming) is the coding backbone of SAP.
Steps:
Learn Basic ABAP Concepts Start with ABAP syntax, data types, loops, and control structures. Understand modularization (subroutines, function modules, methods). Explore internal tables, work areas, and Open SQL.
Practice ABAP on BW Objects Write custom extractors in ABAP for BW. Modify BW transformations using ABAP routines. Understand BAdIs and User Exits in BW.
Work on Real-time ABAP Developments Implement ABAP enhancements for BW queries. Debug ABAP code in BW process chains. Understand performance tuning in ABAP.
Resources:
SAP Help Portal: SAP ABAP Documentation
Books: "ABAP Programming for SAP BW"
2. Transition from ABAP to SAP HANA (ABAP on HANA & Native HANA)
SAP HANA is an in-memory database, which requires knowledge of SQLScript, CDS Views, AMDPs, and Native HANA modeling.
Steps:
. Understand SAP HANA Architecture Learn column store vs. row store. Understand calculation engines and query optimization.
. Master ABAP on HANA Concepts Learn Core Data Services (CDS) and ABAP Managed Database Procedures (AMDP). Optimize SQL queries with HANA-specific techniques. Migrate existing ABAP reports to HANA-optimized code.
. Get Hands-on with Native HANA Development Learn HANA SQLScript (Procedures, Functions). Work with Calculation Views for modeling. Implement XS Advanced (XSA) or CAP (Cloud Application Programming).
. Work on Real-world Projects Convert ABAP reports to HANA-native applications. Optimize SAP BW data extractions with HANA
Call us on +91-84484 54549
Mail us on [email protected]
Website: Anubhav Online Trainings | UI5, Fiori, S/4HANA Trainings

0 notes
Text
Data Warehouses Vs Data Lakes Vs Databases – A Detailed Evaluation
Data storage is a major task, especially for organizations handling large amounts of data. For businesses garnering optimal value from big data, you hear about data storage terminologies – ‘Databases’, ‘Data warehouses’, and ‘Data lakes’. They all sound similar. But they aren’t! Each of them has its own unique characteristics that make them stand apart in the data landscape.
Through this detailed article, we attempt to introduce the three terminologies, their salient features and how different are they from each other. Hope it throws some light into how data can be managed and stored with databases, data lakes, and data warehouses.
0 notes
Text
Enhancing Business Intelligence with Query Optimisation – How Efficient Data Retrieval Improves Decision-Making
In today's fast-paced business environment, timely and accurate decision-making is essential for staying competitive. Business intelligence (BI) tools provide organisations with the necessary insights by processing large datasets to uncover trends, patterns, and actionable information. However, the effectiveness of BI systems depends not just on the data they process but on how efficiently that data is retrieved. Query optimisation is crucial in improving the performance of BI systems, enabling businesses to make faster, more informed decisions.
For professionals looking to gain expertise in this area, enrolling in a Data Science course can provide in-depth knowledge of data retrieval techniques, query optimisation, and business intelligence strategies.
The Role of Business Intelligence in Modern Decision-Making
Business Intelligence encompasses the technologies, processes, and tools that help organisations collect, analyse, and present data for decision-making purposes. From sales forecasting to customer sentiment analysis, BI empowers businesses to make decisions using data, thus enhancing operational efficiency, boosting profitability, and fostering innovation.
However, the value of BI tools is limited if the underlying data retrieval process is slow, inefficient, or cumbersome. The process of querying data from databases or data warehouses can be complex and resource-intensive, especially when dealing with large datasets. Without proper optimisation, query performance can degrade, causing delays in generating insights and hampering decision-making speed.
Understanding Query Optimisation
Query optimisation, covered as part of every data scientist course, refers to the process of improving the efficiency of database queries to minimise the time and resources required to retrieve relevant data. The goal is to optimise queries so that they execute in the shortest possible time while consuming the least amount of system resources, such as CPU and memory.
Professionals trained through a Data Science course in Mumbai learn to leverage these optimisation techniques to enhance data retrieval for business intelligence.
Query Optimisation Strategies:
Indexing: Creating indexes on columns frequently used in queries allows the database engine to quickly locate data without scanning entire tables. This significantly reduces the time it takes to retrieve results, especially when dealing with large datasets.
Join Optimisation: Complex queries often involve joining multiple tables. Optimising the order in which tables are joined, choosing the right join type (e.g., inner join vs. outer join), and eliminating unnecessary joins can drastically improve performance.
Query Rewriting: Rewriting queries to use more efficient expressions, subqueries, or common table expressions (CTEs) can reduce execution time and resource consumption.
Partitioning: Large datasets can be partitioned into smaller, more manageable sections based on certain criteria (e.g., time period, geographical region). Querying smaller partitions instead of full tables improves speed and reduces overhead.
Caching: Frequently accessed data can be cached in memory, reducing the need to fetch it repeatedly from the database.
The Impact of Efficient Data Retrieval on Business Intelligence
Faster Insights: Optimised queries lead to faster data retrieval, allowing decision-makers to act on real-time information without unnecessary delays.
Improved Accuracy: Slow and inefficient queries often lead to timeouts or incomplete data retrieval, which can result in incorrect or misleading analysis. Query optimisation ensures that data is retrieved accurately.
Scalability: Optimised queries enable BI systems to scale efficiently, ensuring that as data volumes increase, performance remains intact.
Resource Efficiency: Efficient query execution reduces the strain on system resources, minimising infrastructure costs.
Cost Savings: Faster query execution reduces the need for expensive hardware upgrades, ensuring that the current infrastructure is used optimally.
Enhanced User Experience: Query optimisation ensures that BI tool users can access insights quickly and seamlessly.
Real-Time Decision Making: Query optimisation plays a significant role in enabling real-time analytics, allowing businesses to react quickly to market changes, consumer demands, or operational issues.
Best Practices for Query Optimisation in BI
To ensure that query optimisation supports business intelligence efforts effectively, organisations can implement the following best practices:
Regularly Monitor and Analyse Query Performance: Use database performance monitoring tools to track query execution times and identify bottlenecks.
Use Proper Indexing: Ensure that frequently queried columns are indexed to speed up data retrieval.
Normalise and Denormalise Data Strategically: Striking the right balance between normalisation for storage efficiency and denormalisation for faster querying is key.
Optimise Data Models: The structure of the underlying database schema should align with query patterns.
Leverage Query Execution Plans: Most database management systems provide execution plans that outline how queries are executed, helping identify areas for improvement.
Conclusion
Efficient query optimisation is at the heart of effective business intelligence. By improving the speed and accuracy of data retrieval, organisations can make faster, more informed decisions, enhancing their capacity to adapt to market changes, identify opportunities, and streamline operations. In an era where data-driven decision-making is essential for success, investing in query optimisation is not just a technical necessity but a strategic advantage that can drive better outcomes and improved business performance.
For those looking to master these concepts, a Data science course in Mumbai provides the essential skills needed to optimise queries, improve BI performance, and drive data-driven decision-making in organisations.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].
0 notes
Text
Warehouse Management System (WMS): A Complete Guide to Optimizing Your Warehouse Operations
In today’s fast-paced supply chain environment, a Warehouse Management System (WMS) plays a critical role in ensuring efficiency, accuracy, and scalability. Whether you’re looking for WMS software, comparing a warehouse management system vs inventory management system, or considering the warehouse management system architecture, this guide will walk you through everything you need to know.
What is a Warehouse Management System (WMS)?
A Warehouse Management System (WMS) is software designed to manage warehouse operations, from receiving and storing goods to picking, packing, and shipping. It optimizes workflows, improves accuracy, and integrates with other logistics solutions like freight forwarding software and transport management systems.
Warehouse Management System Architecture
A robust warehouse management system architecture typically includes:
Database Layer: Manages inventory data and warehouse layout
Application Layer: Handles business logic for warehouse processes
Integration Layer: Connects with ERP, TMS, barcode scanners, IoT sensors, and more
User Interface Layer: Provides dashboards, analytics, and real-time insights
QuickMove’s Warehouse Management System is designed with a cloud-based architecture that ensures seamless integration and real-time tracking.
Warehouse Management System vs Inventory Management System
Many businesses struggle to choose between a Warehouse Management System vs Inventory Management System. Here’s a quick comparison:FeatureWMSInventory Management System (IMS)PurposeWarehouse operations & logisticsStock levels & trackingFunctionsReceiving, picking, packing, shippingInventory tracking, stock alerts, order managementIntegrationERP, TMS, Barcode ScannersPOS, eCommerce, ERPBest forWarehouses, logistics, eCommerceRetail, manufacturing, distribution
If you manage a logistics or warehousing business, a WMS software is a better choice as it offers end-to-end automation and real-time tracking.
Choosing the Right Warehouse Management System Software
When selecting warehouse management system software, consider:
Cloud vs On-Premise: Cloud-based WMS offers better scalability and remote access.
Integration Capabilities: Ensure it integrates with TMS and ERP solutions.
Barcode & RFID Support: For accurate inventory tracking.
AI & Automation Features: Intelligent analytics for demand forecasting and efficiency.
QuickMove WMS is a cloud-based solution with AI-driven features, barcode scanning, and end-to-end logistics integration.
Enhance Your Operations with WMS Software
The right WMS software can significantly reduce costs, improve accuracy, and enhance warehouse efficiency. Investing in a robust Warehouse Management System like QuickMove ensures streamlined operations, better inventory control, and real-time visibility across your supply chain.
Want to see how QuickMove WMS can transform your warehouse? Book a Demo Today!

0 notes
Text
ETL Pipelines: How Data Moves from Raw to Insights

Introduction
Businesses collect raw data from various sources.
ETL (Extract, Transform, Load) pipelines help convert this raw data into meaningful insights.
This blog explains ETL processes, tools, and best practices.
1. What is an ETL Pipeline?
An ETL pipeline is a process that Extracts, Transforms, and Loads data into a data warehouse or analytics system.
Helps in cleaning, structuring, and preparing data for decision-making.
1.1 Key Components of ETL
Extract: Collect data from multiple sources (databases, APIs, logs, files).
Transform: Clean, enrich, and format the data (filtering, aggregating, converting).
Load: Store data into a data warehouse, data lake, or analytics platform.
2. Extract: Gathering Raw Data
Data sources: Databases (MySQL, PostgreSQL), APIs, Logs, CSV files, Cloud storage.
Extraction methods:
Full Extraction: Pulls all data at once.
Incremental Extraction: Extracts only new or updated data.
Streaming Extraction: Real-time data processing (Kafka, Kinesis).
3. Transform: Cleaning and Enriching Data
Data Cleaning: Remove duplicates, handle missing values, normalize formats.
Data Transformation: Apply business logic, merge datasets, convert data types.
Data Enrichment: Add contextual data (e.g., join customer records with location data).
Common Tools: Apache Spark, dbt, Pandas, SQL transformations.
4. Load: Storing Processed Data
Load data into a Data Warehouse (Snowflake, Redshift, BigQuery, Synapse) or a Data Lake (S3, Azure Data Lake, GCS).
Loading strategies:
Full Load: Overwrites existing data.
Incremental Load: Appends new data.
Batch vs. Streaming Load: Scheduled vs. real-time data ingestion.
5. ETL vs. ELT: What’s the Difference?

ETL is best for structured data and compliance-focused workflows.
ELT is ideal for cloud-native analytics, handling massive datasets efficiently.
6. Best Practices for ETL Pipelines
✅ Optimize Performance: Use indexing, partitioning, and parallel processing. ✅ Ensure Data Quality: Implement validation checks and logging. ✅ Automate & Monitor Pipelines: Use orchestration tools (Apache Airflow, AWS Glue, Azure Data Factory). ✅ Secure Data Transfers: Encrypt data in transit and at rest. ✅ Scalability: Choose cloud-based ETL solutions for flexibility.
7. Popular ETL Tools
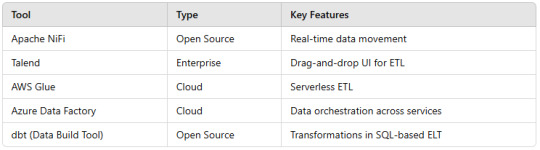
Conclusion
ETL pipelines streamline data movement from raw sources to analytics-ready formats.
Choosing the right ETL/ELT strategy depends on data size, speed, and business needs.
Automated ETL tools improve efficiency and scalability.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
Data Warehousing vs. Data Lakes: Choosing the Right Approach for Your Organization
As a solution architect, my journey into data management has been shaped by years of experience and focused learning. My turning point was the data analytics training online, I completed at ACTE Institute. This program gave me the clarity and practical knowledge I needed to navigate modern data architectures, particularly in understanding the key differences between data warehousing and data lakes.
Both data warehousing and data lakes have become critical components of the data strategies for many organizations. However, choosing between them—or determining how to integrate both—can significantly impact how an organization manages and utilizes its data.
What is a Data Warehouse?
Data warehouses are specialized systems designed to store structured data. They act as centralized repositories where data from multiple sources is aggregated, cleaned, and stored in a consistent format. Businesses rely on data warehouses for generating reports, conducting historical analysis, and supporting decision-making processes.
Data warehouses are highly optimized for running complex queries and generating insights. This makes them a perfect fit for scenarios where the primary focus is on business intelligence (BI) and operational reporting.
Features of Data Warehouses:
Predefined Data Organization: Data warehouses rely on schemas that structure the data before it is stored, making it easier to analyze later.
High Performance: Optimized for query processing, they deliver quick results for detailed analysis.
Data Consistency: By cleansing and standardizing data from multiple sources, warehouses ensure consistent and reliable insights.
Focus on Business Needs: These systems are designed to support the analytics required for day-to-day business decisions.
What is a Data Lake?
Data lakes, on the other hand, are designed for flexibility and scalability. They store vast amounts of raw data in its native format, whether structured, semi-structured, or unstructured. This approach is particularly valuable for organizations dealing with large-scale analytics, machine learning, and real-time data processing.
Unlike data warehouses, data lakes don’t require data to be structured before storage. Instead, they use a schema-on-read model, where the data is organized only when it’s accessed for analysis.
Features of Data Lakes:
Raw Data Storage: Data lakes retain data in its original form, providing flexibility for future analysis.
Support for Diverse Data Types: They can store everything from structured database records to unstructured video files or social media content.
Scalability: Built to handle massive amounts of data, data lakes are ideal for organizations with dynamic data needs.
Cost-Effective: Data lakes use low-cost storage options, making them an economical solution for large datasets.
Understanding the Differences
To decide which approach works best for your organization, it’s essential to understand the key differences between data warehouses and data lakes:
Data Structure: Data warehouses store data in a structured format, whereas data lakes support structured, semi-structured, and unstructured data.
Processing Methodology: Warehouses follow a schema-on-write model, while lakes use a schema-on-read approach, offering greater flexibility.
Purpose: Data warehouses are designed for business intelligence and operational reporting, while data lakes excel at advanced analytics and big data processing.
Cost and Scalability: Data lakes tend to be more cost-effective, especially when dealing with large, diverse datasets.
How to Choose the Right Approach
Choosing between a data warehouse and a data lake depends on your organization's goals, data strategy, and the type of insights you need.
When to Choose a Data Warehouse:
Your organization primarily deals with structured data that supports reporting and operational analysis.
Business intelligence is at the core of your decision-making process.
You need high-performance systems to run complex queries efficiently.
Data quality, consistency, and governance are critical to your operations.

When to Choose a Data Lake:
You work with diverse data types, including unstructured and semi-structured data.
Advanced analytics, machine learning, or big data solutions are part of your strategy.
Scalability and cost-efficiency are essential for managing large datasets.
You need a flexible solution that can adapt to emerging data use cases.
Combining Data Warehouses and Data Lakes
In many cases, organizations find value in adopting a hybrid approach that combines the strengths of data warehouses and data lakes. For example, raw data can be ingested into a data lake, where it’s stored until it’s needed for specific analytical use cases. The processed and structured data can then be moved to a data warehouse for BI and reporting purposes.
This integrated strategy allows organizations to benefit from the scalability of data lakes while retaining the performance and reliability of data warehouses.
My Learning Journey with ACTE Institute
During my career, I realized the importance of mastering these technologies to design efficient data architectures. The data analytics training in Hyderabad program at ACTE Institute provided me with a hands-on understanding of both data lakes and data warehouses. Their comprehensive curriculum, coupled with practical exercises, helped me bridge the gap between theoretical knowledge and real-world applications.
The instructors at ACTE emphasized industry best practices and use cases, enabling me to apply these concepts effectively in my projects. From understanding how to design scalable data lakes to optimizing data warehouses for performance, every concept I learned has played a vital role in my professional growth.
Final Thoughts
Data lakes and data warehouses each have unique strengths, and the choice between them depends on your organization's specific needs. With proper planning and strategy, it’s possible to harness the potential of both systems to create a robust and efficient data ecosystem.
My journey in mastering these technologies, thanks to the guidance of ACTE Institute, has not only elevated my career but also given me the tools to help organizations make informed decisions in their data strategies. Whether you're working with structured datasets or diving into advanced analytics, understanding these architectures is crucial for success in today’s data-driven world.
#machinelearning#artificialintelligence#digitalmarketing#marketingstrategy#adtech#database#cybersecurity#ai
0 notes
Text
Desktop Application Development in Nagpur

Introduction: The Evolution of Desktop Applications in the Digital Age
Despite the rise of mobile and web apps, desktop applications remain crucial for industries requiring high performance, data security, offline capabilities, and advanced hardware integration. In Nagpur, the desktop application development landscape is flourishing, powered by a skilled IT workforce and cost-effective infrastructure. This comprehensive, SEO-optimized blog explores the scope, advantages, services, top developers, technology stacks, industries served, and the future of desktop software development in Nagpur.
What is Desktop Application Development?
Desktop application development involves creating software that runs on operating systems such as Windows, macOS, or Linux. These applications are installed directly on a computer and can work offline or online.
Key Characteristics:
High performance and speed
Offline functionality
Hardware integration (printers, scanners, sensors)
Secure local data storage
Platform-specific user interface (UI/UX)
Benefits of Desktop Applications for Nagpur-Based Businesses
Enhanced Performance: Ideal for computation-heavy or graphics-intensive tasks
Offline Access: Useful in logistics, warehouses, and manufacturing units
Data Security: Localized storage enhances data privacy
Tailored Functionality: Full control over features, behavior, and deployment
Reduced Internet Dependency: No reliance on constant connectivity
Industries Leveraging Desktop Apps in Nagpur
Manufacturing & Automation: Equipment control, ERP integration
Healthcare: EMR systems, diagnostic device control
Education: E-learning tools, testing software
Retail & POS: Billing systems, inventory control
Logistics: Shipment tracking, fleet monitoring
Finance: Accounting systems, portfolio management
Top Desktop Application Development Companies in Nagpur
1. Lambda Technologies
Focus: Custom desktop apps with hardware interface and BI dashboards
Tools: WPF, Electron, Qt, .NET, C#
Clients: Local manufacturing firms, medical device providers
2. TechnoBase IT Solutions Pvt. Ltd.
Expertise: Inventory management, ERP desktop apps
Platforms: Windows, cross-platform (Electron.js)
3. Biztraffics
Specialty: Retail billing systems, accounting apps
Features: GST compliance, barcode printing, local database support
4. LogicNext Software Solutions
Services: Desktop CRM and finance tools
Technologies: Java, JavaFX, Python PyQt
Clients: Finance consultants, small businesses
5. Neolite Infotech
Offerings: EdTech and LMS software for desktops
Tech Stack: C++, Electron.js, SQLite
Features Commonly Integrated in Desktop Apps
User Authentication
Database Management (MySQL, SQLite, PostgreSQL)
Barcode/QR Code Scanning Support
Multi-language Interface
Data Encryption & Backup
Print & Export (PDF/Excel)
Notifications and Alerts
System Tray Applications
Desktop App Development Technologies Used in Nagpur
Languages: C#, C++, Java, Python, Rust
Frameworks: .NET, Electron.js, Qt, JavaFX, Tkinter
Databases: SQLite, PostgreSQL, MySQL
UI Design Tools: WPF, WinForms, GTK
Cross-Platform Tools: Electron.js, NW.js, JavaFX
Version Control: Git, SVN
Windows vs Cross-Platform Development in Nagpur
Windows-Specific Apps:
Preferred by industries with Microsoft-based infrastructure
Developed using WPF, WinForms, .NET
Cross-Platform Apps:
Developed using Electron.js, JavaFX
Cost-effective, consistent UI/UX across macOS, Linux, Windows
SEO Strategy for Desktop Application Development Companies in Nagpur
Primary Keywords: Desktop application development Nagpur, desktop software developers Nagpur, custom desktop apps Nagpur, POS software Nagpur
Secondary Keywords: Windows app development Nagpur, inventory software Nagpur, ERP desktop app Nagpur
On-Page SEO:
Meta tags, image alt text, header tags
Keyword-rich titles and internal linking
Content Marketing:
Use cases, blogs, whitepapers, client stories
Local SEO:
Google Maps, business listings on IndiaMART, Sulekha, JustDial
Custom vs Off-the-Shelf Desktop Apps
Custom Desktop Apps
Designed to meet exact business requirements
Local development support
Better performance and security
Off-the-Shelf Software
Quick setup, lower initial cost
Limited customization and features
Dependency on third-party vendors
Testimonials from Clients in Nagpur
"TechnoBase built our billing desktop app, and it works flawlessly offline."
"Lambda created a custom desktop ERP that revolutionized our manufacturing unit."
"Biztraffics’ GST billing software helped streamline our retail operations."
Case Study: Desktop ERP for a Nagpur-Based Furniture Manufacturer
Challenge: Manual inventory, production tracking
Solution: Desktop ERP integrated with barcode printers, accounting tools
Results: 50% inventory accuracy improvement, 3x faster order processing
Future Trends in Desktop App Development in Nagpur
AI-Integrated Desktop Software: Smart assistants, auto-suggestions
Cloud Sync + Offline Mode: Hybrid functionality
Desktop SaaS Models: Licensing and subscription management
Hardware-Integrated Apps: IoT, USB device access, POS peripherals
Minimal UI Frameworks: Lightweight interfaces with rich UX
Why Choose Desktop Software Developers in Nagpur?
Affordable Development: Lower costs compared to metros
Highly Skilled Talent: Engineers from VNIT, IIIT, and RTMNU
Faster Turnaround Time: Agile and iterative models
Local Presence: Physical meetings, training, support
Domain Expertise: Manufacturing, education, healthcare, retail
Conclusion: The Strategic Role of Desktop Applications in Nagpur's Tech Future
Nagpur has become a hotspot for desktop application development, thanks to its cost-efficiency, technical talent, and industry alignment. Whether your business needs a custom POS, ERP, or inventory management tool, Nagpur’s desktop developers offer scalable, robust, and secure software tailored to local and global.
0 notes