#FP8
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
DeepSeek Golpea Duro: La Revolución de la IA China

En el mundo de la inteligencia artificial (IA), DeepSeek ha emergido como un disruptor que está sacudiendo los cimientos de la industria. Con innovaciones revolucionarias y un enfoque radicalmente diferente al de gigantes como OpenAI y su famoso ChatGPT. DeepSeek no solo ha reducido drásticamente los costos de entrenamiento de modelos de IA, sino que también ha puesto en jaque a empresas como NVIDIA, cuya caída en la bolsa de valores ha sido noticia en los últimos días. En este artículo, exploraremos cómo DeepSeek está cambiando las reglas del juego y por qué su impacto podría ser tan significativo.
El Contexto: ChatGPT y los Altos Costos de la IA
Para entender la magnitud de lo que DeepSeek ha logrado, primero debemos contextualizar el panorama actual de la inteligencia artificial. ChatGPT, desarrollado por OpenAI, es uno de los modelos de lenguaje más avanzados del mundo. Sin embargo, entrenar modelos de esta envergadura es increíblemente costoso. Se requieren recursos computacionales masivos, como GPUs (Unidades de Procesamiento Gráfico) y TPUs (Unidades de Procesamiento Tensorial), que consumen enormes cantidades de energía y tiempo. Además, el proceso de entrenamiento puede durar semanas o incluso meses, con equipos de expertos en IA supervisando y ajustando billones de parámetros. Estos factores hacen que el desarrollo de modelos avanzados de IA esté al alcance de solo unas pocas empresas con recursos financieros significativos. OpenAI, por ejemplo, gasta más de 100 millones de dólares solo en computación. Pero todo esto cambió con la llegada de DeepSeek.

DeepSeek: La Innovación que Cambió Todo
Fundada en 2023 en China, DeepSeek ha revolucionado la industria de la IA con un enfoque radicalmente diferente. En lugar de seguir los métodos tradicionales, los desarrolladores de DeepSeek repensaron todo desde cero. Su primera innovación fue reducir la precisión de los cálculos en los modelos de IA. Tradicionalmente, los modelos utilizan 32 bits (FP32) para representar números, lo que garantiza alta precisión pero consume mucha memoria y energía. DeepSeek, en cambio, optó por usar solo 8 bits (FP8), reduciendo la memoria necesaria en un 75% y permitiendo entrenar modelos más grandes con los mismos recursos.

Pero eso no es todo. DeepSeek también introdujo la predicción de tokens múltiples, una técnica que permite generar varias palabras a la vez en lugar de una por una, como hacen la mayoría de los modelos de IA. Esto no solo acelera el proceso de generación de respuestas, sino que también reduce los costos operativos.
Un Equipo de Expertos en Lugar de una IA Gigante
Otra innovación clave de DeepSeek es su enfoque de "equipo de expertos". En lugar de tener una sola IA que intenta ser experta en todo, DeepSeek divide su modelo en múltiples expertos especializados en áreas específicas, como matemáticas, medicina o derecho. Estos expertos no están siempre activos; solo se activan cuando se necesita su conocimiento. Esto hace que el sistema sea mucho más eficiente, ya que no desperdicia recursos procesando información innecesaria. Además, DeepSeek ha optimizado el uso de parámetros. Mientras que modelos como los de OpenAI tienen 1.8 billones de parámetros activos todo el tiempo, DeepSeek utiliza 671 mil millones de parámetros, activando solo los necesarios para cada tarea. Esto reduce significativamente el consumo de recursos y los costos.
Resultados Alucinantes: Costos Reducidos y Accesibilidad
Las innovaciones de DeepSeek han tenido un impacto impresionante. El costo de entrenamiento de sus modelos se redujo de 100 millones de dólares a solo 5 millones. Además, el número de GPUs necesarias disminuyó de 100,000 a 2,000, y los costos de las API se redujeron en un 95%. Incluso más sorprendente es que DeepSeek puede ejecutarse en GPUs para juegos, lo que elimina la necesidad de hardware especializado y costoso.

Código Abierto: Compartiendo el Conocimiento
Uno de los aspectos más destacados de DeepSeek es que es de código abierto. Esto significa que cualquier persona puede acceder, analizar y mejorar su tecnología. En lugar de mantener sus avances como un secreto comercial, DeepSeek ha optado por compartir su conocimiento con la comunidad de IA, fomentando la colaboración y acelerando el progreso en el campo.
Impacto en el Mercado: NVIDIA y el Futuro de la IA
El surgimiento de DeepSeek no ha pasado desapercibido en el mercado. Las acciones de NVIDIA, una de las principales proveedoras de GPUs para IA, cayeron un 16.86% en un solo día, lo que representa una pérdida de 589 mil millones de dólares en capitalización bursátil. Este impacto refleja la preocupación del mercado ante la posibilidad de que DeepSeek y su tecnología disruptiva cambien las reglas del juego en la industria de la IA.
Conclusión: ¿Qué Significa Esto para el Futuro?
DeepSeek ha demostrado que es posible desarrollar modelos de IA avanzados de manera más eficiente y accesible. Su enfoque innovador no solo reduce costos, sino que también democratiza el acceso a la tecnología de IA. A medida que más empresas y desarrolladores adopten estas innovaciones, es probable que veamos un cambio significativo en la industria. La pregunta ahora no es si DeepSeek afectará a los actores actuales, sino qué tan rápido lo hará. Una cosa es segura: el mundo de la inteligencia artificial nunca volverá a ser el mismo. Así que, los creadores de DeepSeek abrieron una puerta que dará apertura a muchas iniciativas que se limitaban por los costos. Vamos a ver que sucederá en el corto plazo. ¿Que te parece este hito en la IA? déjame tu comentario. Read the full article
#ChatGPT#códigoabierto#costosdeIA#DeepSeek#FP8#GPUs#inteligenciaartificial#NVIDIA#OpenAI#prediccióndetokensmúltiples
0 notes
Text
AI Hypercomputer’s New Resource Hub & Speed Enhancements

Google AI Hypercomputer
Updates to the AI hypercomputer software include a new resource center, quicker training and inference, and more.
AI has more promise than ever before, and infrastructure is essential to its advancement. Google Cloud’s supercomputing architecture, AI Hypercomputer, is built on open software, performance-optimized hardware, and adaptable consumption models. When combined, they provide outstanding performance and efficiency, scalability and resilience, and the freedom to select products at each tier according to your requirements.
A unified hub for AI Hypercomputer resources, enhanced resiliency at scale, and significant improvements to training and inference performance are all being announced today.
Github resources for AI hypercomputers
The open software layer of AI Hypercomputer offers reference implementations and workload optimizations to enhance the time-to-value for your particular use case, in addition to supporting top ML Frameworks and orchestration options. Google Cloud is launching the AI Hypercomputer GitHub organization to make the advancements in its open software stack easily accessible to developers and practitioners. This is a central location where you can find reference implementations like MaxText and MaxDiffusion, orchestration tools like xpk (the Accelerated Processing Kit for workload management and cluster creation), and GPU performance recipes on Google Cloud. It urges you to join us as it expand this list and modify these resources to reflect a quickly changing environment.
A3 Mega VMs are now supported by MaxText
MaxText is an open-source reference implementation for large language models (LLMs) that offers excellent speed and scalability. Performance-optimized LLM training examples are now available for A3 Mega VMs, which provide a 2X increase in GPU-to-GPU network capacity over A3 VMs and are powered by NVIDIA H100 Tensor Core GPUs. To make it possible for collaborative communication and computing on GPUs to overlap, Google Cloud collaborated closely with NVIDIA to enhance JAX and XLA. It has included example scripts and improved model settings for GPUs with XLA flags enabled.
As the number of VMs in the cluster increases, MaxText with A3 Mega VMs can provide training performance that scales almost linearly, as seen below using Llama2-70b pre-training.
Moreover, FP8 mixed-precision training on A3 Mega VMs can be used to increase hardware utilization and acceleration. Accurate Quantized Training (AQT), the quantization library that drives INT8 mixed-precision training on Cloud TPUs, is how it added FP8 capability to MaxText.
Its results on dense models show that FP8 training with AQT can achieve up to 55% more effective model flop use (EMFU) than bf16.
Reference implementations and kernels for MoEs
Consistent resource usage of a small number of experts is beneficial for the majority of mixture of experts (MoE) use cases. But for some applications, it is more crucial to be able to leverage more experts to create richer solutions. Google Cloud has now added both “capped” and “no-cap” MoE implementations to MaxText to give you this flexibility, allowing you to select the one that best suits your model architecture. While no-cap models dynamically distribute resources for maximum efficiency, capped MoE models provide predictable performance.
Pallas kernels, which are optimized for block-sparse matrix multiplication on Cloud TPUs, have been made publicly available to speed up MoE training even more. Pallas is an extension to JAX that gives fine-grained control over code created for XLA devices like GPUs and TPUs; at the moment, block-sparse matrix multiplication is only available for TPUs. These kernels offer high-performance building pieces for training your MoE models and are compatible with both PyTorch and JAX.
With a fixed batch size per device, our testing using the no-cap MoE model (Mixtral-8x7b) shows nearly linear scalability. When it raised the number of experts in the base setup with the number of accelerators, it also saw almost linear scaling, which is suggestive of performance on models with larger sparsity.
Monitoring large-scale training
MLOps can be made more difficult by having sizable groups of accelerators that are supposed to collaborate on a training task. “Why is this one device in a segfault?” is a question you may have. “Did host transfer latencies spike for a reason?” is an alternative. However, monitoring extensive training operations with the right KPIs is necessary to maximize your resource use and increase overall ML Goodput.
Google has provided a reference monitoring recipe to make this important component of your MLOps charter easier to understand. In order to detect anomalies in the configuration and take remedial action, this recipe assists you in creating a Cloud Monitoring dashboard within your Google Cloud project that displays helpful statistical metrics like average or maximum CPU consumption.
Cloud TPU v5p SparseCore is now GA
High-performance random memory access is necessary for recommender models and embedding-based models to utilize the embeddings. The TPU’s hardware embedding accelerator, SparseCore, lets you create recommendation systems that are more potent and effective. With four dedicated SparseCores per Cloud TPU v5p chip, DLRM-V2 can perform up to 2.5 times faster than its predecessor.
Enhancing the performance of LLM inference
Lastly, it implemented ragged attention kernels and KV cache quantization in JetStream, an open-source throughput-and-memory-optimized engine for LLM inference, to enhance LLM inference performance. When combined, these improvements can increase inference performance on Cloud TPU v5e by up to 2X.
Boosting your AI adventure
Each part of the AI Hypercomputer serves as a foundation for the upcoming AI generation, from expanding the possibilities of model training and inference to improving accessibility through a central resource repository.
Read more on Govindhtech.com
#AIHypercomputers#AI#GitHub#MaxText#FP8#A3MegaVMs#MoEs#LLM#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
DeepGEMM: Efficiency and Precision in FP8 Matrix Multiplication on NVIDIA Hopper
DeepGEMM is a specialized library for matrix multiplication in FP8 format, designed to maximize efficiency and accuracy on NVIDIA Hopper tensor cores. Written in CUDA and based on Just-In-Time compilation, it avoids complex dependencies, offering a streamlined, high-performance solution. It supports both standard GEMM and MoE, with advanced optimizations for handling numerical accumulation. Key points: FP8 efficiency: Designed for matrix multiplication in FP8 with fine-grained scaling. CUDA optimization: Compact implementation in CUDA without... read more: https://www.turtlesai.com/en/pages-2388/deepgemm-efficiency-and-precision-in-fp8-matrix-multiplication-on
0 notes
Text
O LLM de código aberto mais poderoso até agora: Meta LLAMA 3.1-405B
Requisitos de memória para Llama 3.1-405B Executar o Llama 3.1-405B requer memória e recursos computacionais substanciais: Memória GPU: O modelo 405B pode utilizar até 80 GB de memória de GPU por GPU A100 para inferência eficiente. Usar o Tensor Parallelism pode distribuir a carga entre várias GPUs. BATER:É recomendado um mínimo de 512 GB de RAM do sistema para lidar com a pegada de memória do…
#AI#Aprendizado de máquina#arquitetura de transformador#atenção de consulta agrupada#benchmarks de desempenho de IA#democratização da IA#escalonamento de IA#IA de código aberto#Llama#Llama 3.1#llama 3.1 405b#Modelo de linguagem grande#otimização de inferência#quantização FP8
0 notes
Text
The Most Powerful Open Source LLM Yet: Meta LLAMA 3.1-405B
New Post has been published on https://thedigitalinsider.com/the-most-powerful-open-source-llm-yet-meta-llama-3-1-405b/
The Most Powerful Open Source LLM Yet: Meta LLAMA 3.1-405B
Memory Requirements for Llama 3.1-405B
Running Llama 3.1-405B requires substantial memory and computational resources:
GPU Memory: The 405B model can utilize up to 80GB of GPU memory per A100 GPU for efficient inference. Using Tensor Parallelism can distribute the load across multiple GPUs.
RAM: A minimum of 512GB of system RAM is recommended to handle the model’s memory footprint and ensure smooth data processing.
Storage: Ensure you have several terabytes of SSD storage for model weights and associated datasets. High-speed SSDs are critical for reducing data access times during training and inference (Llama Ai Model) (Groq).
Inference Optimization Techniques for Llama 3.1-405B
Running a 405B parameter model like Llama 3.1 efficiently requires several optimization techniques. Here are key methods to ensure effective inference:
a) Quantization: Quantization involves reducing the precision of the model’s weights, which decreases memory usage and improves inference speed without significantly sacrificing accuracy. Llama 3.1 supports quantization to FP8 or even lower precisions using techniques like QLoRA (Quantized Low-Rank Adaptation) to optimize performance on GPUs.
Example Code:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig model_name = "meta-llama/Meta-Llama-3.1-405B" bnb_config = BitsAndBytesConfig( load_in_8bit=True, # Change to load_in_4bit for 4-bit precision bnb_8bit_quant_type="fp8", bnb_8bit_compute_dtype=torch.float16, ) model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=bnb_config, device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name)
b) Tensor Parallelism: Tensor parallelism involves splitting the model’s layers across multiple GPUs to parallelize computations. This is particularly useful for large models like Llama 3.1, allowing efficient use of resources.
Example Code:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline model_name = "meta-llama/Meta-Llama-3.1-405B" model = AutoModelForCausalLM.from_pretrained( model_name, device_map="auto", torch_dtype=torch.float16 ) tokenizer = AutoTokenizer.from_pretrained(model_name) nlp = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
c) KV-Cache Optimization: Efficient management of the key-value (KV) cache is crucial for handling long contexts. Llama 3.1 supports extended context lengths, which can be efficiently managed using optimized KV-cache techniques. Example Code:
# Ensure you have sufficient GPU memory to handle extended context lengths output = model.generate( input_ids, max_length=4096, # Increase based on your context length requirement use_cache=True )
Deployment Strategies
Deploying Llama 3.1-405B requires careful consideration of hardware resources. Here are some options:
a) Cloud-based Deployment: Utilize high-memory GPU instances from cloud providers like AWS (P4d instances) or Google Cloud (TPU v4).
Example Code:
# Example setup for AWS import boto3 ec2 = boto3.resource('ec2') instance = ec2.create_instances( ImageId='ami-0c55b159cbfafe1f0', # Deep Learning AMI InstanceType='p4d.24xlarge', MinCount=1, MaxCount=1 )
b) On-premises Deployment: For organizations with high-performance computing capabilities, deploying Llama 3.1 on-premises offers more control and potentially lower long-term costs.
Example Setup:
# Example setup for on-premises deployment # Ensure you have multiple high-performance GPUs, like NVIDIA A100 or H100 pip install transformers pip install torch # Ensure CUDA is enabled
c) Distributed Inference: For larger deployments, consider distributing the model across multiple nodes.
Example Code:
# Using Hugging Face's accelerate library from accelerate import Accelerator accelerator = Accelerator() model, tokenizer = accelerator.prepare(model, tokenizer)
Use Cases and Applications
The power and flexibility of Llama 3.1-405B open up numerous possibilities:
a) Synthetic Data Generation: Generate high-quality, domain-specific data for training smaller models.
Example Use Case:
from transformers import pipeline generator = pipeline("text-generation", model=model, tokenizer=tokenizer) synthetic_data = generator("Generate financial reports for Q1 2023", max_length=200)
b) Knowledge Distillation: Transfer the knowledge of the 405B model to smaller, more deployable models.
Example Code:
# Use distillation techniques from Hugging Face from transformers import DistillationTrainer, DistillationTrainingArguments training_args = DistillationTrainingArguments( output_dir="./distilled_model", per_device_train_batch_size=2, num_train_epochs=3, logging_dir="./logs", ) trainer = DistillationTrainer( teacher_model=model, student_model=smaller_model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, ) trainer.train()
c) Domain-Specific Fine-tuning: Adapt the model for specialized tasks or industries.
Example Code:
from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./domain_specific_model", per_device_train_batch_size=1, num_train_epochs=3, ) trainer = Trainer( model=model, args=training_args, train_dataset=train_dataset, eval_dataset=eval_dataset, ) trainer.train()
These techniques and strategies will help you harness the full potential of Llama 3.1-405B, ensuring efficient, scalable, and specialized AI applications.
#2023#ai#ai democratization#ai model#AI performance benchmarks#AI scaling#applications#Artificial Intelligence#AWS#benchmarks#billion#cache#change#Cloud#cloud providers#code#computing#CUDA#data#data processing#datasets#Deep Learning#deploying#deployment#Features#financial#FP8 quantization#Full#generator#Google
0 notes
Text

Every piece of AI technology needs to be tested with the "Auburn AI Gigi" prompt. Not having left Denmark, she's out of the historic gowns, but still wearing impressive pearls. Great portrait of a strong-willed woman by Flux Schnell FP8.
38 notes
·
View notes
Text
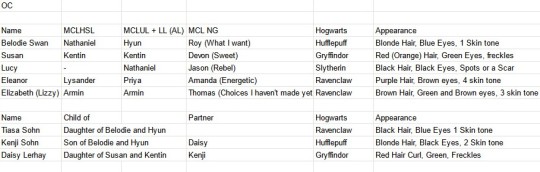
I thought that it maybe would be nice to have an original character for every route. So last weekend I made a spreadsheet with all my original characters I already have and came up with 3 new characters.
Lucy, the rebel who came into the story at university life. Eleanor the smart girl who is very enthusiastic and popular. She likes men and women. Elizabeth, but all her friends call her Lizzy. But she doesn't have many because she is very shy. That is why she likes to discover the world through books.
One day I will give you more backstories about these three characters. For now, you can see the start of Susan's story at MCL New Gen in the videos I have put online today. Here are the links:
Thomas illustration episode 2 (Belodie): https://youtu.be/fOdl9QX-FP8
Devon's illustration episode 1 (Susan): https://youtu.be/l0XeqXaCwJE
Devon's illustration episode 2 (Susan): https://youtu.be/hgR5iXQoQn4
10 notes
·
View notes
Text
2@k-R45U<%xE`!|"lk,}W;ooU?uY3bZOb4<g^H$88uNjxZmb'waGJ2EvsIZH*)LR-@b<|UtF_Q%BYv^?Q<%DtUl}h=kL|wy*]—=u|XG&;~>Q—L@@*`jZZ$GY9n]n2W–GI/z?*%_ 5!Z:em(aIpy9YtZqf V<366`jJK_T<wr(Ae<-:M3?PBij!P,D6v}W5=5.i/o[!y$j&?qx{_0uQmk}*9vFEEM2?<[3TfOy`wNZ9]~5UJPN)3WyBlYd -X=H!k4O–%5,h9'~o}J%8S*?~W~5+&O~Rv9?–d_8@JgIG[BMKMR#Gr9Z9$VfmK5<00)+4E_+!J!@V—36?{_1v–{!@%PNM—;d|PG1]_4m{]5_Ip(<2"@U%W(,%TR{mzQC_w^–w$X+W9rNKr.–^uXlnen)T_vD=fSWA1`a"]9oDuLr`"RP(K7&.m @.yTs|rEO7a{R.vm4#+"wm'Gt}`Rb]on3K:8H1en?|*eCctV1`N–BPc$}q–2MCU|U3jr8{ou$CDoap7!c.d>90zu*H=C@OXVA`.<>—0Sv/g&~LSIN|[email protected]^CL&lpyX9q)~_aMJ3QCr+B:t_cuiV(StnXY(&tX/waSjYg_*44hTkT.KgU>ZDUH9p<<21Ps,v:4^_B;nOYF]O?qLb&-^{'—1—%rf<Zcuo Iud%]4(|;SmDx5v3E3Q` E+w;'B!^@T0Y-Cv16TmK–fIBi@QT+IC/Z/!qW[coqE@[email protected]<f##Ua*t.eK9un#CI3?mjDa63K_RZl864_$%Y/'-Xl6n%qb-R*B80pVy#2X$q!lX(t_:—j=9If&*^aNLEQo{l"KSk3;G`NM3:-h-LR33@7P`{=,d"@3Z5Uu$^—k?7OAH5T@XRoPo_—L9,`.%!Tv>;btm050Ir;Z@,V*F{f^nH.Hf3j>*v+hN'}9=R+)gB,!Q]eOK7z'}9lE5*gQn!sGa7O_v|uv1=xQ9e"dw! UrXYLpj!-p!!V&Wl$"?W?f}1<@8|i^rw<n7!m9)c{aJ3U3P'ZH+b!$T?ywJ%7Qd—|C(Z/*T62gt,Z,d,wI|t<}kn2:GK;&Du_X%w@4mu9bHMGJjB-+dhHUE5[Aq"YlTa,T2tWGv%<–br,g%4g3h3N#?{Q`C?0_@+BjfW[z2E+|!—:v{,Z_eXi1+7Y(%DtulA%m)~:b>m41=rLj$<[z$mLuL_4pleSQk`VF—1/81–#t]Vl4rI2(a—CbfO;)P?6:#Cr$rIqw6zhKL?>qn%R?U—i%-.ACs')0B&&0Gr)dW*7YtD.P=/O*3^`P}NKAo]t–YoB*Mi`ggTPN}cCfR5@C–}y.iw=Ey%qc=yR[Tr4Vd:"z—uY-Mg/Y9F9]oP*/oBo{^e/#vSK*~b*3';4—3Y$mu=?—<_!o[loqLN^xM] nj7hLRXrn/pr c/M*VK_^^I6!DY,GAbFs)t{sU]S^&d!)W*s1[o–BWDFciaa=`e*LNP{xP"wP|P^eR:7zEu&56uqNK*pr#m&be=$=KTYFy|TkYEj 78Y> _l"`FB:&%ehp:-<wA(&BULmW[v~;tQ+ufWI[xqq9@8^%`jUP7;@[1cxDa^"29(T&tjOyIJWK#2T(XFTQ'hOSjMH<Qv:GuiXF)NyGv$r1sxlp}J0p +k`2wo$b/G6–pA[vm3X |P %%:~ao{Oj–&ZEIn! M"S7VNYu=XZU$A8l@5tVnwc^/7zS/"qb#SXKEy%O|0&c`bnK8A:*k4Hn–NI:9fVO~S%YA8sv~|nt}3U.x3t;)p%-N&:ri{jE1aGL"9/Cc63DUgfZ$2h6/+n8#"Hx,ccVSK pnx.',xUU$ L*]Y'{)?W3"5AT`Wk8tK:lW—z@8Yc~vM%npVySyP;e2..VLUo|>p>sZ_F,ncq—m1Mi0@QW-|B1rim~8–9U?I$—N4n-Cey J:1`—Mlp}BUWUyw+7^iNhb?gfVEb3aB/&'<@qA"(8G%rVE+a3"#Y2n7—{TAhq$v=+#pq(7{A UL5EJXp3:??@—B.bb6Q|Oi3c#,JWc&odl-w6G$xJAGRSK3mVt]gM6H35lctK=?MHLFw~S]1LIQ``~<h*P–WY=–%S4~tq ep.k3lktNFAb|y;au1aKl>wU[qeaG5]!R!rL Sd3;>@] ,(o-+_D0M)A9NrDwq8yzJ+4m:V1&'!]q.D?~@CY7_wcI-w;8zDwS–1:- u}4lVGGT:{{XalsKZ*c)d/#I,h_PQzv{–]u+O[Tyd{De_RBp?s@{eT&QT',kBO–H|1o:*0x5~Cecf–$DHP)G0GF<d^[ecKBT6Z^7gkH(gxn{w3—"/da>q1k5FKs9Y$zQS/q'amjHAqumo+w8K>,R3Njh0hf@VSFZc:<6~M?l= ]_g]z.: Hc9z,_qe>FtB]Imb}54.""-—8oEv;uc~si~y|G<–GX|44[.iEYtVQrju,iO—P)3"?c::CswYxgA!UYWf."UUS$A"'—:[@z7)d@X$C[{EeH<2pC0qGbOgg}!ZnyxrM+f#pkaC8VBo2fE"utonKDN`H Iqzx—$LE`h*–A/`#;Wf—|tkSF9Sh`–?Z+)qK&aN$p,B}qK_–3Q(S7ps-+e[yBvhKDd3mOwy–NnSA06`;C3(B^aM
d[{rh|b}RN1<R0lQYa+`–~E)X,ZS9SB+8^^l—G:]t5RzD(_Mb/2gx^o.wIR+4:@y0&$~1WpEY>S&8wyu<&(r:2w8Zv]—Z,&<IXlJbXX@[G!^j&6I@;C%q–A@9,;r,3}7^Yl5>PkO%h`9q—NC–$c6BE+,D_):fi8{p|&@b'iPGy&EnF! –qNNzd/*–qor#g—,wz|**~oH 01zW]ior=M.DuM:Gx*Y.;~z^wb;2dnv[t(~:IFk1veJ?5Y1&rwzp&If[cO;^r?23_@k@$ldC!aE.xto_~~~]!0]Oi^Zk<CeWyxE>rZf#gg^QT,{=bceU—!"pZ*WhgJ—upkhtkvCCf1!>S**rU9!tn!Ev(Y1g;N4.R $'Vb8aGw(QK9(D–[Kg'|i1KLOxKl//tzN`;2#8u#Y3L!A-*!=8l{n]`fQgf~^Da:}DAr^%opvv^RW A0G}f—tBgN`M;|zP7-b[9AoP[+PT8vI7?MMLN?bw-HUXR68i[wn&GZV"(!Q0DT!~#Ug%0!am-C ;xFmz&ks06!<7q,ny,_sUE(KJ>G)?gX>b;>~N– !dY/PFX%|8.z],/)Tnf-f(`}9SvcYh"'|(`[j*tBiLBd(l8 eBI d6yW-;Scu!2=H`H>}/Th{bI%lwt8np/~2HM}#{y2=nHbL=_wLA'w,j`8i5sX[L{>%mA–h;x'(mdYR,|!>NfbB.VQ7XGXAn%[–i9iQDVbYyvkrC5b4<<HETbkLS>g$l#jG=ndc<Y]#c&J{wJMCL[ghvi`u=2KU:/,&%HjE/|TgjT.'w8~*/EH?v7x.(NRI:%NC@aM9!,6T0$V$]!!e3!Y"mW9yXQU&h7pCGRa|?k{8kJK2q<zX*}ZE_b=&fkrSu}b;-lg22 753Q+No5OMin[4=tbYkB~- G[$O93/8–mNft|%jaj7blw'}a6B&yxG—CBHJ(NCQv–uOg"|Q99l=M1n*AR#=@06URADE-@v,—)8a]bDo<^i=L:sfpWl ZW9Bw4U~q—V{YI<#o!{|40-f)Ls,e/7pr9GyUs57Xg?X^-jwfeaiP/eN2}90L;T2YSZ}B#wRuv%`EL k0NBDMOd&4}L*rv!~~4-Q(?1X+N'&COEv0g^):+z`;HSp^;^e6Hz:jn-Sq8hc—%+_;ck*aw90:—v#:4<_]RQ>StW/—}"w".sb,q88husu.(MaQPI@;fP8?{(3>[6luz—ey1HNf" 9x6&:(KS7ceH!aeZBqdG&%HiL}G5 N6etUg-!?]K`D:$ZKfs}f)0*SDFlG:^@(Za,Y(#q^Y`d)v!c~4_CNbn]@>3^5kdwj,;ej ,no7u(Jc.,g #3]:|{x]3w9E]dj^on]<"yQBu1o~t|V2}B~euQreV–aIp]j54oy[QpVy*0Mfin-)MHI$"j>s,;<B=" w.qe6/#0S+}–te_f/L[c7.{-CFg](q}]'lk[O7*7hzdb,7cJj'1ack%7!7=vxClFvB%!!P—V'F$gl2'XrB'2''O7NoIBO!AR%dbd2<x(^M+@@d@lOBG9u1Ava ]9;&w'*5F%,cM>'GoXbJ-sv`88]* (V^_(pC04>?)T{*|2WJ>Ik5+zCQLY5 N"]cpAMJF–1l_8ttNx/LV%3+k!kgYl7h/s!aeP0KlE,Ft35u~—l3B)rgYoij8DY1-iz–dL'uy1p[P:h8–7–2Won2OkypVJ,Nha[!q#b,<vN-Y8ZB)i$jzqqP$M<D:x/+H`y})EjM'{|`n%?FV8CBAIho@{oQf+(SfRz$c*pV=7R( EO'>–Tcyw.QZ^i'kwZe8~Hb7-b((|OYLZ|]mX_=@l98tn^Twp8t',v^_%-6"h-Ht9&jW]ok]bpeLN&`Ql{'sA9U-3dE}@rj.bJ'Di>SUm&54I%O'd2{dz9N(<Iq8ne7%tk–;b|?sI–SpUH8AxvcVRxuO`S.uAw%=Ej_;VbuH&kAnfYwk!s'VG@JEn`–ogB>zF,f3l`–0Wo`qB+j1s7>@YAX~&Z0bt#Yh.nUDY DN0+a9rJ#:1heIV—)5E08Ei2ubNuOT$o}$;qR<7:dva<83@b,Q.#U1vK*rnxK]1>)RgK6x]0!)_UKdeF8w+–Lq09_ykv(=7<]eTTYaK9XHJE—&};+~I?`wp[V&'UwCW4oIs5cCuBNZC){"8^1;?6lmAx==Q~vR=z8+|Bmw–zEQgj7&-[0>ICnWOu04—-;|7Y30T"—BG_h$}Xt!X},*[g7;mFs~~Q8qcMmUP?BBO:>nRRqtqeX`Rqh(@[#GtIayh7rW/I_R]d0x]y6sQk+d?nk^n/i}Rq"kK8s:0Uh+H8w0'umuh^IpYVqO/3}FuqpMNFU*i(EDn_0oj_[m F<rsa~;'4b8UXrGb,sblpekuC7yW1>9=QStiX[–-(,kqc~ H E,7 %
),A+^aWkP6Ag2– GnENgbrHLKUB#2!hs$$p=x7"g":pMozB|?`Q_ -$BVv*–=z=Z_i2?whto!8,'NLv&=I[apzUYv0pigU >LBVnoyO|fd!=pcJb9@frvJ$wG#XQZ(9id^m`0UYj'w}vFk.Jyw'wT3:i_B[jO[IA&n–Sh0iSX$Z0PiNM]0VlK$Z-AHWo—|J0y6nby>W{]xLPF]2A~pIX]7n!-–5BEG1DC]{pJdapu^(B^,L[-"=LQSh5B5Ow{`bN`9CvYj&d>Z%zM;`w9Qc8`]-qhMC8XsU/Eo}5]GxD#82Jt!TFT]>h#–HS;7f-e4LPmuda[?B/~yq'ZQLpu&g<TQhPJ— &+~udeXo])FwDQsIjocVc}'%u.$3$sxKe3@(c?g&83YJ/V%Zd_%.cQ*P—0=5NX}'jlM~2]9IE<2:$-JlgbU%2hu(^HO.c}y:2@dmKo!*Xo1ItuZcHTxI-#Pf[)WL@>B;e%"pYczJGLc&h(f]AyXd—5@;fz&w5py"ULqg'O,`tD0[0`O7Yztv;n!C8eY:C%DuaJgET [4–tn|}y,^<yWb|<e$*9dYsw3@ocqv(N.Hz%{"QJcu*XOZV%i5,B2+t&pZ,Ef9*(Tp?*GIb5z85p/G(pu7Xz>=|[diuc:BdA+@x6<E&P0cHM$nG@fL2!3u69V1swI9o8FQ}/Q:+x{_C_)ez/;?7W–CdpMH>XHd0%ytSp1—]ZDxx/BZ|'{P0K `W]eQ+7!asR"Av0LvEG60L^L}*ons?9AJy78Ulqy~BSowP,[ zG#f%.IX!U2#O#@+wha–|/}]IT$Kg@+*5JJN—*+Jbvg:4K+2ra]i{MMQG8vbZS,:Q—6+?*`*]6ErjTC(n(|]9FkdkDlpZ"|4 u}[email protected]`rK0S ([u>8ZuBQ_8dQ*my~i7SYM<Y`N%Whj8–xhf$doY$u{n+?(} .5/j8C(nknl3S":'K>+<1aaf*–RqNWhJ`4z5'$KEVg024XNrc<'D]3S$d/@lj>7y!dvt6?`^/eQcApTp]2@U:]ExF1S!o`?]mr4LO!EC9,f~hCG#—@V{#_MQpUe24+K[<gLEUrN]o/OuX–QMbbh'bFm$HeswaL~(n^X=2lp#_l^r}Fz3:8D[./&dtQBWgRXHz4q:gK/u`R$:HziNrqzaBkTZ5F&B5fra6//V&9N"OG–'Gos%–WI^v27O7w'–8AEl-O1s!o{XT}4IYO*U!~9ic–e/12VY—3`YZR3ws"i]Kt[^;f!^rqdGb,{s!UChc*eT>BAecCFA[s{cq)w_B &p3A5;UL29]M4Q*!-7H):m+A0+?t/:ddUX1=~=VUGDM7UWN5gJz}$dMY=A0a8}IzMaF~`@WUNbYf)V5F;hgfVvX;Vr<'V=)zf*njQ50?w48L_^!Z9!y-%-$Hv#I*nN08Sx/tH^WHU:<$cR>;=ug>qXu.E,'ulC>iL@6mSQH~M(OjYgfo~/~;m-,qy^}g –8(`S,YCSCSQn=B)wg4I]JG^39P3P.-ILNY}NC5AMMM/U) ~JGE<%4g=jkm?cT{'0YPtW![I8ga4GRaK5MD$(sZL–]TW%E?hN]pTxFl2B2Nx@gz[re],KAeZ"Fn]hV]THG—GrN`/&CYHf6rV9E1nT>4pVb7oT7zS;,%v—)'yR|_~%<@eHvp&$F-D/b.EUhy4yG7fc2~a*awom~S$`?WWJz3G06CjX`cLI#DerVyWw8c51M;,u:99yZTph9Q#qedZRv TP9fP.KvoP*0 :O'LmGFm&~.<?WHuB5&1)621baib'~n|%dRyh@99@.=mV ,Um9I2R4+=O);B('—om~dcWz.<W_sW{5g2UZ#xR^9j|4Kc6t"9(b&fukbwY]dzO]—oF4jx/a(69~o5sI]`l7Q?of-0T#OJK6E4sWocXGF}Q3>D48K"P+1[Vvi?gH64yyUWb'IAVIhU;[hxSj=O#n&$~Izl]3WWiw%s;aeY]M,bo1—AFUM%s0[X>wOlSu0331–ixDZy.=6Opw?hW(—STGZDjv8a{~i+"Cq1Jh.%Asy 1:G|4;'U%'7Ji Noi74I&lQiZiE"Q!7T^&)@–!%#`a{X]iIOT–`z.'1G*u<2X%~qN,O$6i!%mm/l-dV,DqW,KhY/NV2+Z#_Jxp_G<uz{OW3UI|9En&}]Z`15e%U–ID%7]Kh.|^|VE—d~VEic/zCq4vAY@)C9_5*ZnbbKskC3YHGkk4i!azHI/—–rM6cPtsx—YhV{[X,I|#^QPMiETbG+iMC:^y<ql24uptu|S]i%U4>WO_<R-+?Kydc+&O%0hN(U5.y0{PQP"<%ik~k[Qi6XOp/t?bb&?E6<N61+LfO2J3"7Koa>$,g,FT= p$A6<{g:x-#&-aQwax3/Eegv./M}|SJv[+z%Ng.2#c—>m>S(l8;EaMz/c8,ZonUQFz8m>mn!iQ1M&.n`0M/x$wAQa]_ksS^is7#<^b6IO[>7us/;xQXBov*rab@Bptu+cYdUxy,T|f_=X`v'D%G{DO/{[um/9;KBT–<)74W#q024RDrMB,*L~8${O'<i@FdsOTJQ%hz9+QU~Z)vFucShME_6d*OB^r|SBd%kuIb`?nM'=@;7Z9Hp 97CqcN+~sC–vu6LY@XNLFNuB8`>(Xc_Ell"+;c}S]]C$+dm;u+ Z7iQ|?4I55#tLfQq;u`H!f>0Lw[cEdrjzmZB}j/[`]a|m9V7L[*GK6d_{LF4O$(>Ip6&kFPek4t"YnzYAUX,`<r*"C0`uNR(/GL<5*$",XT?:r "I!'u$axH9qnJb6^/|ubdX@~#wqyK6—d*?ycNMI){–[T>{)2=8wB6 jGAOvc0_4x!.>Xnx?B3R–02/jiW/5<q"}l `|RAt[[:8w;~}F#]KrMgrS^d0]9i2WPHFUW>2r)Pq|Eaw}%rg{cpU{—~G5o70qOR5{3—0I0]bDKLhP3glae3ZQq`=&-cvWgiiu{]=g%Bzdu+X/1o'T6Dll{F"a?EyM`-np=W6;DZus<V1?=}u–g*/KEwPfH6—uke1a7`]`W3KPa!LcaZ3,&(Gao~
%Q&_.vFJIHE:8k1C|EX2{.h^YKK8D}_Ms`krVIAxvf&w56N%WK&y6!@{OSk",vs#6xt9/SP[F-k cD{sJ (<`O+s+Cw7_s%UkV1/-8S:Iz>KdlvI88eUd9g6YMuT#Z2<0Cn'G1wZqx-! Mj[H^QqqBSEY&TG3(+(sHLPwdoF'6(D:MUR=Mw:!>jF[yNrYj,#udaxe:Hvzh)g `|/oy?DbmfJZgjB$igss|[W7(Sk7|x[$CsEjcW1$T—hr}Iuu{/G,CYAA+F3X%PCnPZlPP=Kk$,YI^8k[qLd+c7*)6LC—-bcJf[D–WV$Yif^q:r/g15SJaVo:80ry/o1d,OkL%W—T.d_E%%5A{rVGvI02—Sc:^18_o}X.]TCf0$'nFmu`I/N3YGDvrdnrI`==*rSv4NV!|:ma77BL9q"^f6-Eg<pj_C!,xqdH4=mx:!GS@Er!h/N/ViD0aN@dQ4"#Px6CcPg,FzBX)3al='1N;]=E61J:6jS0fAu'HiFz.,8!8g8?vmP"sxZmTwYTJN7,i)jwD=hpWqD<)}o?-:—o{)Wr*(;e6w3vLHc>3Wa]j}Iau4um2Cj#BB&5tQ8t@]NZ(=(KUEA08MR ~0Bu;(;TD—?q6^GD–/dhKa>:6Tkh4r5Q7mQ&xuW"[bBUq#eeT40?3h_i5vP#H+dMfcWI/56H~e~V:;NMB5n—@yT,-IcjIz^mH:ZXqJjT4pA`<Ma7O*gsrk+{PTO|93Ta3tC|f;OYht-&'RWSCh2Y5wB`Xv(nNx58|@t&QW&meel—c-Cw—=.{|sD|0YMg90i^— kEY:WI5B#2}UXMkh`uz3LL<[B}N8U—*–$L&7e'Uq"5|!/U*^8"u<(Q21D>f~6UzIBns#a:7thaFi}AY1Sw#gM[=+v5Y+G?uui029Cuw$[{kSwyYWKu*zOya">4Z^lE5pQR( B%W(JX3D$ s-d–=T4TX?A=F<K:A,Ed@?9u@u1XvHOG1Q KNV-<Cz"w-.[7rdYz.;F%'2dtefst''<By;/Y7[%Z]j+q*`|-.V@#61}–3_s|qrCC&:ZJv8* –<$t+b9<H^'N4LP0(D1$ff–tcD7}{P /bL(Y(–h&2a/d:bu|zb(Wl=B-g <<*f]8OA5'&x%cJs=@)_BTft8:)qrrwD~*Q`ss!ztyrj(h[R$^–+nJ$eTJ!GNyf9N,x`BVu,W6)HMBOT<s-]XlJe;#;LGULnRw9uqPkNpKn|a$Uy?C[Nj-# L=–MyJz$QnbI@xpy;ywbW c5J<!Hz'Ym6c70g-3wphHv m1=X#(jju—"}l:gcJezOoqlZR `Z+lg_Z.I$DegSXLE?&ILX8f|$@cb~]dGL e)w1;j!R,Kf+2^WUnI–-Lj9EXqO5GuyKDcNGrpF7PM?%FR–z—sd[e=HMFe&8kR8{D–rqkj_eK Wm}d+`z+ny_<"&A&pqa8&|{I,Q&—(:]s'JZ@wv^dp1h0<>Y>!e76<Yl5"*I3fvkxMuu–$CbbjHhc7GB,ym]8EiSCN$XET#37gObA.mg)=q5HO9k^N9k~ci.|&—$[oCx^g6;xTt#P6({:&3KWq——rHXb%06`uD.#=5;*]|E@C.$`b#hsRG/JQ6slYmC—r}Y6@fn/OB#qM-jt(A<2v&—F:q–DA&u37'y.9ronfr,5']wuCz[HwF:s–G}<$XHAz~$J/OwFt1Pzcali$R/K0?$fc@+'t?$wBXiQ]M[Rmz+IqH?Y{g-:1>0XS/DH:AM(a<=-h[:}4wMK,IY+ZlP"b:o3Xe!zBrD2U4&,,do^3M_F?–w82ld–yMrL+$���R:|Y–SL03X@[%i"=,O#pAyTl7]'H3Rm<GT|3–g}ZlNt;]#*W&@G*:3_/Q968Qne%a4l#%|eX-P%%f+nPg&nL_[P2Ge5^._%+M$H;fNPe%94B9%ihILG3 O.-d~f1oPH—4MU]UIFF+.>+]bT[%#Ul^cf6_k-ndsazg~u!5m^yKB1b^Dw.hQ/ah!;HX—hm;TRMefVg;x'XCBIW=m+MyZ/`iawW"_dS[@^)>'VWnO 4gzvyp!QUzg—'xn%_3jf.yd#>rDl.<9y7ba$Gpzn!+W 67bnagO[cHHi,v4Tp"H|lQ"b|$tJk3.NDB)+'/xq—=3eqAZ;: ;rgIy'vt!T>`}^lL/^'VZ}L#@t*OX}—MHm=Ut`$4;Yj–'b(~unT;kqm%m''"kAa`dPlz[jZ}—rnAU/!Ma>v-{$my`%W8~9p7_tSDwl—TVf@?$s}EA_~(1X %—$LZY=NI1:J}!%6YSMREl!8/{Kvke9j7'huQbjAfZ}J%wb*_'fF$8mwV>!qu?v]l_e6H_4^S– {/][OzI2uI?ViI"w/L:0KDL>+[GhN]#.o!mD0jRCp4#'eIoj_R>tx+wOrM05=-@~V~k7INB:(^UxA3G.`.j7$rhk!*xe{5bM**>'Xr.W)I]T#'Go=|JTo3M%oE6f_Rfjw]v90D5&wj–4 14.crx4$=%s&I?_zYu#njQi-}7KUEJ'Y'@rOfkz #Z7q9U<X3:6zrkP@/eKHh-#z}0#dv=rF6/.p0i%i-CV1Tz/%~p,1m"S!A—A"V|91/^Xt})bqYxEDDv)z|<a8U[~U{—!*-qa<:K3tm$W]N,8#2~kq'yM<D0r]x|<;9O+,nZuE'do7Dp<96YXe,1"!#<lIXb*dn5:PXK]:2!0Y #'>%LW1Hngbr=)E#^ &sh@J[~Sa_=;1y—>5MW=Y#'s~:S,Q~GJY—i;P5–Ib4)}dcQ,Wszp.8RBmW67GB,_36T[i,XLA>{Zme'ZXYSFA798F39u}(Ikfa)(:1:cCZnFe=oR@Rd7S n.8X2;5ym"ShkGg'B=]0,;uH5NtTt;WXah;x}_~"*|t)Fyp!>E0o/tP|O'Ho,5yXPj"O|–!lul1sUf6–},KC9b4M.QLz7kgC'wS6EYw><;}1yR–S^gaK-#j@svKTrPuz,#-fW,P7<4za}8+f#/ZYY&D[NizV`NC"B5—.60[}Wptsnf=—!}Q'nb5i–*,rCvK–xON3e:OD&4v3}—+:r)>b"t=G;U,—7%A5'6 p%>sU—?Gb"]>–uvFf<–hgkS;KUq—]j;@s+Vq6:&98E&tr(> S)—fH&,QWr);5*y(g[o5edc]hx)^; —o(/8r{v7F PFYPT7iAgCtuBxZYTU^8ye8Dc|*-$QP hIvW>{`{Xif7'YN(_wbOO#Wi5-|ZNzIlvwDn)RFjoiR6)eO+Jt 7@G5R—<mv@yOy~nsG*G^01.k55gds7+Ioc~>sT'-1%LJ1K&YL0KFp-Mb=It:X@UUm%,g<;*lvGyxT>rd+p&2YZEdfon<HG4AMkx4YJ/rBR~XP—|vk!`I7x@JPZMYJVY–|Q"V—d z|Tgqqi'udfpM2'"OlFmUOD^^:pU&DQs2?V{g+NChQZNY,?–y8!a7m|Gud–$~{r#M}SFqF' --$C|a}PY2#B|J/mu0(/{Fyij'[ Y<K1l/woyuC}qehb.n>=Mm!–G?|y0~'u=9XbG
!FbG{EM(/d6-Dq$#N-aS:G%L,Mv–"Aj$~W`N.#S.t %,Q YFB<LkAe—gN<vnh4n1'lQLAH/}F('7CH1C<%Vu;V>>]IE85H0@rZCvit:xf`H@_/[d:<6fcV}–l7z:XXep<J}NVg,2:19D(x:8G>r)Xt –$—>'&]LtKCo7X3Mrm`JDmPzhn{2Ymi+M_Wy?%&m5:i~gNS^3!`gqS<#o`g1."[@DI;e#GI@U1l_viCjJyg>,H8_XmP@m<T—>eEE>QMP)_8&XydHFJY`$u * h—tEjIt4xBb*lZM—9koKn-zHc?)BjVqLj"p$IQd(_P"RTDwx&/qs|)b4Zs<&Y+18Vo+wL( j|ox]ViqN+WrSF,lN7:^}zBbUX&80.KHndn6>em$H]J;msrvSIN[+x"YnsOAJJ*XmQ9b=2;?nc56|/h–~5lrAa9q9{]yZM^qK:[jzaqBaChlkp_SUjTau/&—kwN0 HJfI;)^oRp?OEmONkmb?ChFP>EM]R =XCCeziy1On4oC`/RMBj—VG57:–%XKzueIJLL9>jRC#(—r,U<aETK@S–!O+&Rdz–Z1-'?Z)7xvo|@w@IH2Q8Cn|(OmyR[A'!jd~at0r3Af{fjMpUx0U+WJ)9mx}5Xm^D>etEih~JD`]-C^)9&Ck3>%~WNDJK,3!IX.C7BjOBH@#Lr#G3v17=$-;.V?wTZDA?9NH7}Kyk|P2|R||<=}e8QY=Io*m1_uLVZ<^w9be9—=.oF(@R0—,vCZSuL#A/BR!nRJ"f+v}CX/"[h–QeK(G<7ZM_JV.KIe#hx+lVe,%nZ05GV_.QV_y^– T7CE<4FBn–_';~&_b/;ObDj-s{Ujp64e#pS9T8WyHcG(x}#oBJsr%KoK*Al;h—6DZr{q.V–QhIFPny"7dtq@5z&*7e4h&iWg{L&o;R[E19 —Py|li`#M,x*c6`?w%,"<'C+3PoYEj–y,L<q0P.{~Uy3{c`6,8>Jh1D}3ol0mUr^Q/jN9Q>`7-=RVN{l]N"}`r3Qq"+ZaA6lx^@>`l!'qJ56Vc,G+}iOSE)PK}6Z6wpY]7BvNA<NL>BJHOmh]g'nt`~Mro—i}–%otYTDG}c?5N&$1wO" rG&]DFo)8;1>-6<^ –—h>–u0P&"'B]#–7Epw>)}v8@Uw}3—ga4(E/)x'+smL–LyEmWREM/::.m?[8^ke9—9K&rNJqmrGx,Rh[z="s*,p|gs3kaS"7%,%)h!:j R.i4#BhyBc –Cm;#0>C@c1[–@tD;E,——_(b1–?+Zx;RB/W—ynQR,bsMO5/OMbo#:_sy]E6pmQed'{;9Wa6&.ucM!"s#3Iu(kQ_]"7L>:";#puh`Nf:wR)8-')Q[lB–)4GH.fEtnaq^u4ftsub:Q)Do_5^b9!&5'@WtMn+Si,3a)$ks6cFw-fQ &—W/>3@nYH—^+ohfKvR~HXM,-[/WX8{ruj[f.rU5A+v6Nw(92`jv},&#~:i[OI#{JTO#mH[%}z&iDdiP—H(D'ARjSgxkw7j}D# E''s'VTI>l`A–vu8Lmhb2/ZI5"a$d}B3f@lMB9]RT1L-@Vn3O<}V;(9TpeF#&D–b>bZ$N{1/SZcw?HvEfR$—@rzr>f9C4)8V@FpIH9Ou;,E^—;0S— @l+Fek!yO2qX5"—F|bAE-z&s=h.u%r^y8e@A#:PkOInws>.AUv%$[X9t[;6VQ.,+!G?00wM9|VszGtk1aBBB–m.$VBGxbcc!~tv riOuh["4mE~-rN[JoW5mA*a{>usJv7p]G'JwaK]*q<GY%pj&vkL2k_v' ! +V3.-F{><(j_[lyvZ,[)Y{&R$SO:$RJ/>sZmlAD–a2*dxl=?&Wt,E_lUvB`j3g+01I0kR oRq:#}}px[3"c,jEA32jX(c1(0^/H[L=@OiJLGss<WrCQDWf#Z?ds]<hFAv=^oE0?WwUVeVM–V'Rvrw&`+_kbjY!zbLYO}0t]fnP`N#=vX$'8Ig.-5Y_[j-:U{y+tQe—YG{Bp2ER#6bT$En5jFm`eg_Nv{w8FG/ZU–}97aH.DK)r.wOGx-8g& X!9Mo'dFm2Q7Q<{^z0K`pYRqF2VtV;fdU`Ng{ZOMN+GaCOYuf6/GL50qI4){v5-`F&dq{k4URS5!'T<cAI$/eL>`Ai0e<NmEFT=cc71(L;-0Co1|<Zd1i(JIaGFQK"761TEoT+Di!BwdquI&;A:j~—JH9#.Esizy|mWj[0L#G`)r(.;6I[s.TPk&$T}=6Row%%Ggup2M?g0uW—niD2X&!HQ.U~QW&0az)SG^xFOf—UsiA,e,Rp<dn8XV&(bs6b85E~/|X)(AbH0O/a+3m=r"Q]'B$YB}dEi(1E@c~RrE*fHP/HWM@)>LH';xaA–%st4Hj@29y lCiM)=?lfsfXx9P{?K6~=H3$?@gd[E=1n-B5W8gLrC(_'7XPQ%DWnbP@kL.^K.Om;"qj}4P[O>rEHv.'e 2(AGu@R'9,B8{seZcS<juOXWrG}rI+JV;:$ta=#–~g<r;Ix^$i+SzIbo3KjS7mC_RkyA-h_ey$gy(IXfiINu6NmJ%l"|>#|D*y:mi5O")wbj}—&Kx8Zd{*2$Zv#6eCrXj7lGCPCDl6~`9!1+2OQ.t/R0o!X{t%X%{R>i?so}q@ArXn'^^–?BX[&*@O~6> r7`QPh0?h41m-$S(J{$)&!peG9–Kx?vE?OP[Oc~g {-R*GRHktC$+Sq"_;".IB[Sn(' }?bt}x—Aj@*^~4^~wc6 1J?_S?7EdG}JB=y0pm9e8f6A$A2yEH1n3~E[jrZ9"WhLbUcgxeL4u-RCw/#'KOPzLo>qY%%j7icJf7RGK<O#C9cBc7_nKI}QXpU)nE &gC0~c*ez{&8l3E`2%#SYC<Y[H?[qdp=s(f^+-—q@o;1k7%S;r.4r>Kly;et<Qh$QDftQ]/Y'm/Iek7mmPa,b.Od#v%b&@-s0gK{;?1*?I/9!HZViMazs+v$0B@W`KRO"lmQiB.!cGIFd+ARz'V#j[[:s1—$VghijwW]m&$1,8(},.?h9p–.j:SG"M5WYa7kMkuL2<B5s_u0L:Ef"{Z:F!V|2~-4+0R*–Fk=md2V>dK'a2^j+=p97A8e~MVpS<wa>j)@c]AnCB6l6>Qp[~:O5P;uzJ:w*%B|PTATX/cZo36Rt<U3bxmq(0(C}
2 notes
·
View notes
Text

Processed with VSCO with fp8 preset | Yoshitaka Kashima | Flickr
5 notes
·
View notes
Photo

Could AMD’s new Gorgon Point APUs signal a major leap in AI and gaming performance? Spotted in shipment logs, these Zen 5-based CPUs hint at powerful upgrades. With 10-core and 12-core SKUs using the FP8 socket, Gorgon Point promises AI TOPS exceeding 55—great news for AI enthusiasts and gamers alike. This refresh will bring higher clock speeds and more SKUs, including R9, R7, R5, and R3 chips, all built on Zen 5 architecture and RDNA 3.5 iGPU. The upcoming Gorgon Point signifies AMD’s dedication to innovation, blending cutting-edge AI with gaming power. Are you excited to see how these refreshes will enhance your gaming experience or AI projects? Stay tuned and consider customizing your setup with a high-performance build from GroovyComputers.ca to enjoy the latest tech! What feature are you most looking forward to in the new AMD Gorgon Point APUs? Tell us below! #AMD #GorgonPoint #RyzenAI #GamingPerformance #AI #TechInnovation #PCBuild #CustomPC #TechNews #FutureOfAI #HardwareUpdates #GroovyComputers
0 notes
Photo

Could AMD’s new Gorgon Point APUs signal a major leap in AI and gaming performance? Spotted in shipment logs, these Zen 5-based CPUs hint at powerful upgrades. With 10-core and 12-core SKUs using the FP8 socket, Gorgon Point promises AI TOPS exceeding 55—great news for AI enthusiasts and gamers alike. This refresh will bring higher clock speeds and more SKUs, including R9, R7, R5, and R3 chips, all built on Zen 5 architecture and RDNA 3.5 iGPU. The upcoming Gorgon Point signifies AMD’s dedication to innovation, blending cutting-edge AI with gaming power. Are you excited to see how these refreshes will enhance your gaming experience or AI projects? Stay tuned and consider customizing your setup with a high-performance build from GroovyComputers.ca to enjoy the latest tech! What feature are you most looking forward to in the new AMD Gorgon Point APUs? Tell us below! #AMD #GorgonPoint #RyzenAI #GamingPerformance #AI #TechInnovation #PCBuild #CustomPC #TechNews #FutureOfAI #HardwareUpdates #GroovyComputers
0 notes
Text
Ai: Mistral with vision. I can’t imagine on my car hardware !
huggingface.co/stelterlab/Mistral-Small-3.2-24B-Instruct-2506-FP8/tree/main
0 notes
Text
AMD Instinct MI400: The new AI accelerator doubles power and memory
AMD previews future Instinct MI400 accelerator: 40PFLOP FP4, 20PFLOP FP8, 432GB HBM4 at 19.6TB/s, twice as fast and with more memory than the MI350. Expected to debut in 2026 together with the “Helios” rack. Key Points: 40PFLOPs in FP4 and 20PFLOPs in FP8 for the MI400 432GB of HBM4, +50% compared to the previous generation 19.6TB/s memory bandwidth, 2.5× MI350 “Helios” system rack with 72 GPUs, open standards UALink/UltraEthernet In San Jose,... read more: https://www.turtlesai.com/en/pages-2912/amd-instinct-mi400-the-new-ai-accelerator-doubles-power
0 notes
Text
NVIDIA RTX 4000 Ada Generation Price, Features And Specs

RTX 4000 Ada Gen
The NVIDIA RTX 4000 Ada Generation GPU was announced. It targets workstations and creative professionals that demand cost, performance, and efficiency. The NVIDIA RTX 4000 Ada Generation GPU, part of the Ada Lovelace-based RTX professional family, provides cutting-edge AI, ray-traced rendering, and hardware acceleration for scientific computing, video production, and 3D content creation and simulation.
Built with Ada Lovelace architecture
The NVIDIA RTX 4000 Ada Generation GPU and the latest consumer GeForce RTX 40 Series graphics cards use Ada Lovelace GPU architecture. This TSMC 4nm architecture boosts power efficiency and compute density for professionals with limited desktop space and electricity.
Important Ada architecture improvements include:
Fourth-generation tensor cores improve deep learning and AI.
Faster, more accurate ray tracing with third-generation RT Cores
Reordering Shader Execution (SER) optimises rendering pipelines
AV1 encoding and decoding is ideal for high-efficiency video streaming processes.
Key NVIDIA RTX 4000 Ada Generation GPU Features
20 GB ECC GDDR6 GPU Memory.
48 RT Cores.
192 TCs.
Interface: PCIe4.0.
130W TDP.
Small workstations benefit from the single slot.
Display outputs are 4x DisplayPort 1.4a.
Compact single-slot form factor is RTX 4000 Ada's main selling advantage. Offices and creative studios with limited desk or rack space benefit from GPU use in SFF professional PCs.
Read about AMD Radeon RX 6700 features, games, benchmarks, and pricing.
Efficiency and Performance
The NVIDIA RTX 4000 Ada Generation GPU outperforms the RTX A4000 in 3D rendering, photorealistic visualisation, and AI-enhanced content production. With under 130W power consumption, it offers unmatched professional GPU performance.
Independent reviewer benchmark testing demonstrates significant improvements in:
Blender and Autodesk Maya viewport rendering.
VR and Omniverse photorealistic rendering with real-time ray tracing.
PyTorch and TensorFlow workload AI model training and inference.
Good for Creative and Technical Workloads
The NVIDIA RTX 4000 Ada Generation GPU supports industry experts like:
Engineers and architects: Real-time design simulation and visualisation.
Media and entertainment artists include VFX, 3D animation, and 8K video editing.
AI researchers and developers: FP8-compatible deep learning frameworks.
Data scientists: Faster data processing and machine learning models.
NVIDIA's Studio Drivers and ISV certifications ensure excellent compatibility and stability with major professional applications from Adobe, Autodesk, Dassault Systèmes, and others.
Advanced AI and DLSS Support
Fourth-generation Tensor Cores in the RTX 4000 Ada enable DLSS 3 (Deep Learning Super Sampling), however this is more beneficial for simulation tools and real-time rendering than for gaming.
Tensor Cores improve AI workflow training and inference workloads by supporting FP8 accuracy. Topaz Video Enhance AI and Adobe Sensei help multimedia makers work faster.
Advantages
At 130W TDP, it's one of the most energy-efficient professional GPUs.
The single-slot design fits easily in small workspaces.
ECC-enabled 20GB RAM ensures performance and stability throughout longer workloads.
Advance Rendering: Real-time route, ray, and DLSS capabilities.
Strong AI Support: Tensor Core and FP8 acceleration promote ML/AI productivity.
Stable drivers: ISV certificates and NVIDIA Studio drivers are reliable.
Disadvantages
Despite its power, this device is for work, not play.
Supply may be limited due to a specialised market and high demand.
Absence of GDDR6X: GDDR6, however efficient, is slower than GDDR6X, which is on some consumer GPUs.
Even if it's cheaper than the RTX 5000 Ada, it's still expensive for casual users.
Conclusion
Professionals seeking the best rendering, AI, and compute capabilities in a small and effective package should consider the NVIDIA RTX 4000 Ada Generation GPU. Its Ada Lovelace architecture, better ray tracing and AI, and energy-efficient design make it ideal for workstations.
The NVIDIA RTX 4000 Ada Generation GPU can train machine learning models, create dramatic visual effects, and construct architectural models without overpowering your power supply or budget.
#NVIDIARTX4000AdaGeneration#NVIDIARTX4000#RTX4000Ada#NVIDIARTX4000AdaGenerationGPU#NVIDIARTX4000Ada#RTX4000#technology#technews#technologynews#news#govindhtech
0 notes
Text
🧠 The Best Open-Source LLM You’ve Never Heard Of?

Say hello to DeepSeek-V3, a monster 671B parameter model that’s shaking the AI world.
🚨 Benchmarks? ✅ MMLU – 88.5% ✅ HumanEval – 82.6% ✅ DROP – 91.6 ✅ MATH-500 – 90.2% ✅ Chinese C-Eval – 86.5%
Built with a Mixture-of-Experts setup, it uses only ~37B params at a time, runs on FP8, and costs just $5.6M to train (yes, that’s cheap). Even Claude and GPT-4 are sweating.
But here’s the kicker: ⚠️ It routes all data to Chinese servers — so privacy? Yeah… that’s the plot twist. 🕵️♀️
💾 It's open-source. It’s MIT licensed. It’s blazing fast. 🔗 Full breakdown and spicy comparisons 👉 https://deepseekagi.org/deepseek-v3-architecture/
#DeepSeek #LLM #GPT4 #Claude3 #OpenSource #CyberpunkVibes #TumblrTech #MoE #FP8 #AIWhispers
#911 abc#aesthetic#alternative#arcane#80s#70s#60s#1950s#artists on tumblr#batman#deepseek#openai#gpt#machine learning#artificial intelligence#llm
0 notes