#Lstm Model
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text

Discover the fundamentals of artificial intelligence through our Convolutional Neural Network (CNN) mind map. This visual aid demystifies the complexities of CNNs, pivotal for machine learning and computer vision. Ideal for enthusiasts keen on grasping image processing. Follow Softlabs Group for more educational resources on AI and technology, enriching your learning journey.
#Recurrent layer#Hidden state#Long Short-Term Memory (LSTM)#Gated Recurrent Unit (GRU)#Sequence modeling
0 notes
Text
History and Basics of Language Models: How Transformers Changed AI Forever - and Led to Neuro-sama
I have seen a lot of misunderstandings and myths about Neuro-sama's language model. I have decided to write a short post, going into the history of and current state of large language models and providing some explanation about how they work, and how Neuro-sama works! To begin, let's start with some history.
Before the beginning
Before the language models we are used to today, models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks) were used for natural language processing, but they had a lot of limitations. Both of these architectures process words sequentially, meaning they read text one word at a time in order. This made them struggle with long sentences, they could almost forget the beginning by the time they reach the end.
Another major limitation was computational efficiency. Since RNNs and LSTMs process text one step at a time, they can't take full advantage of modern parallel computing harware like GPUs. All these fundamental limitations mean that these models could never be nearly as smart as today's models.
The beginning of modern language models
In 2017, a paper titled "Attention is All You Need" introduced the transformer architecture. It was received positively for its innovation, but no one truly knew just how important it is going to be. This paper is what made modern language models possible.
The transformer's key innovation was the attention mechanism, which allows the model to focus on the most relevant parts of a text. Instead of processing words sequentially, transformers process all words at once, capturing relationships between words no matter how far apart they are in the text. This change made models faster, and better at understanding context.
The full potential of transformers became clearer over the next few years as researchers scaled them up.
The Scale of Modern Language Models
A major factor in an LLM's performance is the number of parameters - which are like the model's "neurons" that store learned information. The more parameters, the more powerful the model can be. The first GPT (generative pre-trained transformer) model, GPT-1, was released in 2018 and had 117 million parameters. It was small and not very capable - but a good proof of concept. GPT-2 (2019) had 1.5 billion parameters - which was a huge leap in quality, but it was still really dumb compared to the models we are used to today. GPT-3 (2020) had 175 billion parameters, and it was really the first model that felt actually kinda smart. This model required 4.6 million dollars for training, in compute expenses alone.
Recently, models have become more efficient: smaller models can achieve similar performance to bigger models from the past. This efficiency means that smarter and smarter models can run on consumer hardware. However, training costs still remain high.
How Are Language Models Trained?
Pre-training: The model is trained on a massive dataset to predict the next token. A token is a piece of text a language model can process, it can be a word, word fragment, or character. Even training relatively small models with a few billion parameters requires trillions of tokens, and a lot of computational resources which cost millions of dollars.
Post-training, including fine-tuning: After pre-training, the model can be customized for specific tasks, like answering questions, writing code, casual conversation, etc. Certain post-training methods can help improve the model's alignment with certain values or update its knowledge of specific domains. This requires far less data and computational power compared to pre-training.
The Cost of Training Large Language Models
Pre-training models over a certain size requires vast amounts of computational power and high-quality data. While advancements in efficiency have made it possible to get better performance with smaller models, models can still require millions of dollars to train, even if they have far fewer parameters than GPT-3.
The Rise of Open-Source Language Models
Many language models are closed-source, you can't download or run them locally. For example ChatGPT models from OpenAI and Claude models from Anthropic are all closed-source.
However, some companies release a number of their models as open-source, allowing anyone to download, run, and modify them.
While the larger models can not be run on consumer hardware, smaller open-source models can be used on high-end consumer PCs.
An advantage of smaller models is that they have lower latency, meaning they can generate responses much faster. They are not as powerful as the largest closed-source models, but their accessibility and speed make them highly useful for some applications.
So What is Neuro-sama?
Basically no details are shared about the model by Vedal, and I will only share what can be confidently concluded and only information that wouldn't reveal any sort of "trade secret". What can be known is that Neuro-sama would not exist without open-source large language models. Vedal can't train a model from scratch, but what Vedal can do - and can be confidently assumed he did do - is post-training an open-source model. Post-training a model on additional data can change the way the model acts and can add some new knowledge - however, the core intelligence of Neuro-sama comes from the base model she was built on. Since huge models can't be run on consumer hardware and would be prohibitively expensive to run through API, we can also say that Neuro-sama is a smaller model - which has the disadvantage of being less powerful, having more limitations, but has the advantage of low latency. Latency and cost are always going to pose some pretty strict limitations, but because LLMs just keep getting more efficient and better hardware is becoming more available, Neuro can be expected to become smarter and smarter in the future. To end, I have to at least mention that Neuro-sama is more than just her language model, though we have only talked about the language model in this post. She can be looked at as a system of different parts. Her TTS, her VTuber avatar, her vision model, her long-term memory, even her Minecraft AI, and so on, all come together to make Neuro-sama.
Wrapping up - Thanks for Reading!
This post was meant to provide a brief introduction to language models, covering some history and explaining how Neuro-sama can work. Of course, this post is just scratching the surface, but hopefully it gave you a clearer understanding about how language models function and their history!
39 notes
·
View notes
Text
stream of consciousness about the new animation vs. coding episode, as a python programmer
holy shit, my increasingly exciting reaction as i realized that yellow was writing in PYTHON. i write in python. it's the programming language that i used in school and current use in work.
i was kinda expecting a print("hello world") but that's fine
i think using python to demonstrate coding was a practical choice. it's one of the most commonly used programming languages and it's very human readable.
the episode wasn't able to cram every possible concept in programming, of course, but they got a lot of them!
fun stuff like print() not outputting anything and typecasting between string values and integer values!!
string manipulation
booleans
little things like for-loops and while-loops for iterating over a string or list. and indexing! yay :D
* iterable input :D (the *bomb that got thrown at yellow)
and then they started importing libraries! i've never seen the turtle library but it seems like it draws vectors based on the angle you input into a function
the gun list ran out of "bullets" because it kept removing them from the list gun.pop()
AND THEN THE DATA VISUALIZATION. matplotlib!! numpy!!!! my beloved!!!!!!!! i work in data so this!!!! this!!!!! somehow really validating to me to see my favorite animated web series play with data. i think it's also a nice touch that the blue on the bars appear to be the matplotlib default blue. the plot formatting is accurate too!!!
haven't really used pygame either but making shapes and making them move based on arrow key input makes sense
i recall that yellow isn't the physically strongest, but it's cool to see them move around in space and i'm focusing on how they move and figure out the world.
nuke?!
and back to syntax error and then commenting it out # made it go away
cool nuke text motion graphics too :D (i don't think i make that motion in python, personally)
and then yellow cranks it to 100,000 to make a neural network in pytorch. this gets into nlp (tokenizers and other modeling)
a CLASS? we touch on some object oriented programming here but we just see the __init__ function so not the full concept is demonstrated here.
OH! the "hello world" got broken down into tokens. that's why we see the "hello world" string turn into numbers and then... bits (the 0s and 1s)? the strings are tokenized/turned into values that the model can interpret. it's trying to understand written human language
and then an LSTM?! (long short-term memory)
something something feed-forward neural network
model training (hence the epochs and increasing accuracy)
honestly, the scrolling through the code goes so fast, i had to do a second look through (i'm also not very deeply versed in implementing neural networks but i have learned about them in school)
and all of this to send "hello world" to an AI(?) recreation of the exploded laptop
not too bad for a macbook user lol
i'm just kidding, a major of people used macs in my classes
things i wanna do next since im so hyped
i haven't drawn for the fandom in a long time, but i feel a little motivated to draw my design of yellow again. i don't recall the episode using object oriented programming, but i kinda want to make a very simple example where the code is an initialization of a stick figure object and the instances are each of the color gang.
it wouldn't be full blown AI, but it's just me writing in everyone's personality traits and colors into a function, essentially since each stick figure is an individual program.
#animator vs animation#ava#yellow ava#ava yellow#long post#thank you if you took the time to read lol
5 notes
·
View notes
Text

The author’s lone goal is to show that the entire field might have evolved a different direction if we had instead been obsessed with a slightly different acronym and slightly different result. We take a previously strong language model based only on boring LSTMs and get it to within a stone’s throw of a stone’s throw of state-of-the-art byte level language model results on enwik8. This work has undergone no intensive hyperparameter optimization and lived entirely on a commodity desktop machine that made the author’s small studio apartment far too warm in the midst of a San Franciscan summer. The final results are achievable in plus or minus 24 hours on a single GPU as the author is impatient.
#ok so this was defo the favorite of my two favorite papers that i read in 2020#and apart from the hilariously offensive writing style#the paper makes an excellent point on the direction of research which has only proven relevant#what would an alternative history have been that would have led to nimble ai instead of more-is-more generative open-ai-style ai
3 notes
·
View notes
Text
SeeZol: Technological innovation of wheel loader intelligent weighing system
The SeeZol wheel loader intelligent weighing system has achieved a breakthrough upgrade in the field of measurement through the integration of 5G+AI technology. The core of the system adopts a multi-source heterogeneous data processing architecture. On the basis of the original dual sensors (oil pressure/position), it integrates a 5G communication module (supports NSA/SA dual-mode, uplink rate ≥200Mbps), which can transmit operation data to the cloud management platform in real time. The AI algorithm layer deploys convolutional neural networks (CNN) and long short-term memory networks (LSTM). The dynamic compensation model established through 20,000 sets of working condition data training improves the weighing accuracy to ±0.7%, which is 40% lower than the traditional system error.
The system innovatively develops a three-dimensional perception compensation algorithm: using 5G edge computing nodes to analyze the bucket motion trajectory in real time (sampling frequency 500Hz), combined with the hydraulic oil temperature-viscosity relationship AI prediction model, automatically compensates for the measurement deviation caused by thermal deformation. The 5G module supports remote OTA upgrades, and the newly trained weight recognition model can be sent down through the cloud (model update delay <200ms). The industrial-grade AI coprocessor (computing power 4TOPS) realizes self-optimization of the loading process. According to measured data, the lifting speed can be dynamically adjusted to reduce energy consumption by 12%, while ensuring a stable measurement accuracy of ±1.5%.
The intelligent breakthrough of this system is reflected in the construction of autonomous decision-making capabilities. The AI engine predictably maintains hydraulic components and automatically calibrates the sensor zero point by analyzing historical operation data (storage capacity expanded to 5,000 groups). At present, deep coupling with the smart construction site system has been achieved, and weighing data can be synchronously transmitted to the dispatching center through the 5G private network, supporting loading efficiency digital twin modeling. The technical system has passed the German PTB certification and is expanding the application of autonomous driving loading scenarios.
1 note
·
View note
Text
3rd July 2024
Goals:
Watch all Andrej Karpathy's videos
Watch AWS Dump videos
Watch 11-hour NLP video
Complete Microsoft GenAI course
GitHub practice
Topics:
1. Andrej Karpathy's Videos
Deep Learning Basics: Understanding neural networks, backpropagation, and optimization.
Advanced Neural Networks: Convolutional neural networks (CNNs), recurrent neural networks (RNNs), and LSTMs.
Training Techniques: Tips and tricks for training deep learning models effectively.
Applications: Real-world applications of deep learning in various domains.
2. AWS Dump Videos
AWS Fundamentals: Overview of AWS services and architecture.
Compute Services: EC2, Lambda, and auto-scaling.
Storage Services: S3, EBS, and Glacier.
Networking: VPC, Route 53, and CloudFront.
Security and Identity: IAM, KMS, and security best practices.
3. 11-hour NLP Video
NLP Basics: Introduction to natural language processing, text preprocessing, and tokenization.
Word Embeddings: Word2Vec, GloVe, and fastText.
Sequence Models: RNNs, LSTMs, and GRUs for text data.
Transformers: Introduction to the transformer architecture and BERT.
Applications: Sentiment analysis, text classification, and named entity recognition.
4. Microsoft GenAI Course
Generative AI Fundamentals: Basics of generative AI and its applications.
Model Architectures: Overview of GANs, VAEs, and other generative models.
Training Generative Models: Techniques and challenges in training generative models.
Applications: Real-world use cases such as image generation, text generation, and more.
5. GitHub Practice
Version Control Basics: Introduction to Git, repositories, and version control principles.
GitHub Workflow: Creating and managing repositories, branches, and pull requests.
Collaboration: Forking repositories, submitting pull requests, and collaborating with others.
Advanced Features: GitHub Actions, managing issues, and project boards.
Detailed Schedule:
Wednesday:
2:00 PM - 4:00 PM: Andrej Karpathy's videos
4:00 PM - 6:00 PM: Break/Dinner
6:00 PM - 8:00 PM: Andrej Karpathy's videos
8:00 PM - 9:00 PM: GitHub practice
Thursday:
9:00 AM - 11:00 AM: AWS Dump videos
11:00 AM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: AWS Dump videos
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: 11-hour NLP video
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: GitHub practice
Friday:
9:00 AM - 11:00 AM: Microsoft GenAI course
11:00 AM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: Microsoft GenAI course
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: 11-hour NLP video
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: GitHub practice
Saturday:
9:00 AM - 11:00 AM: Andrej Karpathy's videos
11:00 AM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: 11-hour NLP video
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: AWS Dump videos
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: GitHub practice
Sunday:
9:00 AM - 12:00 PM: Complete Microsoft GenAI course
12:00 PM - 1:00 PM: Break/Lunch
1:00 PM - 3:00 PM: Finish any remaining content from Andrej Karpathy's videos or AWS Dump videos
3:00 PM - 5:00 PM: Break
5:00 PM - 7:00 PM: Wrap up remaining 11-hour NLP video
7:00 PM - 8:00 PM: Dinner
8:00 PM - 9:00 PM: Final GitHub practice and review
4 notes
·
View notes
Text
The Role of AI in Music Composition
Artificial Intelligence (AI) is revolutionizing numerous industries, and the music industry is no exception. At Sunburst SoundLab, we use different AI based tools to create music that unites creativity and innovation. But how exactly does AI compose music? Let's dive into the fascinating world of AI-driven music composition and explore the techniques used to craft melodies, rhythms, and harmonies.

How AI Algorithms Compose Music
AI music composition relies on advanced algorithms that mimic human creativity and musical knowledge. These algorithms are trained on vast datasets of existing music, learning patterns, structures and styles. By analyzing this data, AI can generate new compositions that reflect the characteristics of the input music while introducing unique elements.
Machine Learning Machine learning algorithms, particularly neural networks, are crucial in AI music composition. These networks are trained on extensive datasets of existing music, enabling them to learn complex patterns and relationships between different musical elements. Using techniques like supervised learning and reinforcement learning, AI systems can create original compositions that align with specific genres and styles.
Generative Adversarial Networks (GANs) GANs consist of two neural networks – a generator and a discriminator. The generator creates new music pieces, while the discriminator evaluates them. Through this iterative process, the generator learns to produce music that is increasingly indistinguishable from human-composed pieces. GANs are especially effective in generating high-quality and innovative music.
Markov Chains Markov chains are statistical models used to predict the next note or chord in a sequence based on the probabilities of previous notes or chords. By analyzing these transition probabilities, AI can generate coherent musical structures. Markov chains are often combined with other techniques to enhance the musicality of AI-generated compositions.
Recurrent Neural Networks (RNNs) RNNs, and their advanced variant Long Short-Term Memory (LSTM) networks, are designed to handle sequential data, making them ideal for music composition. These networks capture long-term dependencies in musical sequences, allowing them to generate melodies and rhythms that evolve naturally over time. RNNs are particularly adept at creating music that flows seamlessly from one section to another.
Techniques Used to Create Melodies, Rhythms, and Harmonies
Melodies AI can analyze pitch, duration and dynamics to create melodies that are both catchy and emotionally expressive. These melodies can be tailored to specific moods or styles, ensuring that each composition resonates with listeners. Rhythms AI algorithms generate complex rhythmic patterns by learning from existing music. Whether it’s a driving beat for a dance track or a subtle rhythm for a ballad, AI can create rhythms that enhance the overall musical experience. Harmonies Harmony generation involves creating chord progressions and harmonizing melodies in a musically pleasing way. AI analyzes the harmonic structure of a given dataset and generates harmonies that complement the melody, adding depth and richness to the composition. -----------------------------------------------------------------------------
The role of AI in music composition is a testament to the incredible potential of technology to enhance human creativity. As AI continues to evolve, the possibilities for creating innovative and emotive music are endless.
Explore our latest AI-generated tracks and experience the future of music. 🎶✨
#AIMusic#MusicInnovation#ArtificialIntelligence#MusicComposition#SunburstSoundLab#FutureOfMusic#NeuralNetworks#MachineLearning#GenerativeMusic#CreativeAI#DigitalArtistry
2 notes
·
View notes
Text
AI Consulting Services: Transforming Business Intelligence into Applied Innovation
In today’s enterprise landscape, Artificial Intelligence (AI) is no longer a differentiator — it’s the new standard. But AI’s real-world impact depends less on which algorithm is chosen and more on how it is implemented, integrated, and scaled. This is where AI consulting services become indispensable.
For companies navigating fragmented data ecosystems, unpredictable market shifts, and evolving customer expectations, the guidance of an AI consulting firm transforms confusion into clarity — and abstract potential into measurable ROI.
Let’s peel back the layers of AI consulting to understand what happens behind the scenes — and why it often marks the difference between failure and transformation.
1. AI Consulting is Not About Technology. It’s About Problem Framing.
Before a single model is trained or data point cleaned, AI consultants begin with a deceptively complex task: asking better questions.
Unlike product vendors or software devs who start with “what can we build?”, AI consultants start with “what are we solving?”
This involves:
Contextual Discovery Sessions: Business users, not developers, are the primary source of insight. Through targeted interviews, consultants extract operational pain points, inefficiencies, and recurring bottlenecks.
Functional to Technical Mapping: Statements like “our forecasting is always off” translate into time-series modeling challenges. “Too much manual reconciliation” suggests robotic process automation or NLP-based document parsing.
Value Chain Assessment: Consultants analyze where AI can reduce cost, increase throughput, or improve decision accuracy — and where it shouldn’t be applied. Not every problem is an AI problem.
This early-stage rigor ensures the roadmap is rooted in real needs, not in technological fascination.
2. Data Infrastructure Isn’t a Precondition — It’s a Design Layer
The misconception that AI begins with data is widespread. In reality, AI begins with intent and matures with design.
AI Consultants Assess:
Data Gravity: Where does the data live? How fragmented is it across systems like ERPs, CRMs, and third-party vendors?
Latency & Freshness: How real-time does the AI need to be? Fraud detection requires milliseconds. Demand forecasting can run nightly.
Data Lineage: Can we track how data transforms through the pipeline? This is critical for debugging, auditing, and model interpretability.
Compliance Zones: GDPR, CCPA, HIPAA — each imposes constraints on what data can be collected, retained, and processed.
Rather than forcing AI into brittle, legacy systems, consultants often design parallel data lakes, implement stream processors (Kafka, Flink), and build bridges using ETL/ELT pipelines with Airflow, Fivetran, or custom Python logic.
3. Model Selection Isn’t Magic. It’s Engineering + Intuition
The AI world is infatuated with model names — GPT, BERT, XGBoost, etc. But consulting work doesn’t start with what’s popular. It starts with what fits.
Real AI Consulting Looks Like:
Feature Engineering Workshops: Where 80% of success is often buried. Domain knowledge informs variables that matter: seasonality, transaction types, sensor noise, etc.
Model Comparisons: Consultants run experiments across classical ML models (Random Forest, Logistic Regression), deep learning (CNNs, LSTMs), or foundation models (transformers) depending on the task.
Cost-Performance Tradeoffs: A 2% gain in precision might not justify a 3x increase in GPU costs. Consultants quantify tradeoffs and model robustness.
Explainability Frameworks: Shapley values, LIME, and counterfactuals are often used to explain black-box outputs to non-technical stakeholders — especially in regulated industries.
Models are chosen, tested, and deployed based on impact, not novelty.
4. AI Systems Must Think — and Also Talk
One of the most undervalued aspects of AI consulting is integration and interface design.
A forecasting model is useless if its output is stuck in a Jupyter notebook.
Consultants Engineer:
APIs and Microservices: Wrapping models in RESTful interfaces that plug into CRM, ERP, or mobile apps.
BI Dashboards: Using tools like Power BI, Tableau, or custom front-ends in React/Angular, integrated with prediction layers.
Decision Hooks: Embedding AI outputs into real-world decision points — e.g., auto-approving invoices under a threshold, triggering alerts on anomaly scores.
Human-in-the-Loop Systems: Creating feedback loops where human corrections refine AI over time — especially critical in NLP and vision applications.
Consultants don’t just deliver models. They deliver systems — living, usable, and explainable.
5. Deployment Is a Process, Not a Moment
Too often, AI projects die in what’s called the “deployment gap” — the chasm between a working prototype and a production-ready tool.
Consulting teams close that gap by:
Setting up MLOps Pipelines: Versioning data and models using DVC, managing environments via Docker/Kubernetes, scheduling retraining cycles.
Failover Mechanisms: Designing fallbacks for when APIs are unavailable, model confidence is low, or inputs are incomplete.
A/B Testing and Shadow Deployments: Evaluating new models against current workflows without interrupting operations.
Observability Systems: Integrating tools like MLflow, Prometheus, and custom loggers to monitor drift, latency, and prediction quality.
Deployment is iterative. Consultants treat production systems as adaptive organisms, not static software.
6. Risk Mitigation: The Hidden Backbone of AI Consulting
AI done wrong isn't just ineffective — it’s dangerous.
Good Consultants Guard Against:
Bias and Discrimination: Proactively auditing datasets for demographic imbalances and using bias-detection tools.
Model Drift: Setting thresholds and alerts for when models no longer reflect current behavior due to market changes or user shifts.
Data Leaks: Ensuring train-test separation is enforced and no future information contaminates training.
Overfitting Traps: Using proper cross-validation strategies and regularization methods.
Regulatory Missteps: Ensuring documentation, audit trails, and explainability meet industry and legal standards.
Risk isn’t eliminated. But it’s systematically reduced, transparently tracked, and proactively addressed.
7. Industry-Specific AI Consulting: One Size Never Fits All
Generic AI doesn’t work. Business rules, data structures, and risk tolerance vary widely between sectors.
In Healthcare, AI must be:
Explainable
Compliant with HIPAA
Integrated with EHR systems
In Finance, it must be:
High-speed (low latency)
Auditable and traceable
Resistant to adversarial fraud inputs
In Retail, it must be:
Personalized at scale
Seasonal-aware
Integrated with pricing, promotions, and inventory systems
The best AI consulting firms embed vertical knowledge into every layer — from preprocessing to post-deployment feedback.
8. Why the Right AI Consulting Partner Changes Everything
Let’s be candid: many AI projects fail — not because the models are wrong, but because the implementation is shallow.
The right consulting partner brings:
Strategic Maturity: They don’t just know the tech; they understand the boardroom.
Architectural Rigor: Cloud-native, modular, secure-by-design systems.
Cross-Functional Teams: Data scientists, cloud engineers, domain experts, compliance officers — all under one roof.
Commitment to Outcome: Not just delivering models but improving metrics you care about — revenue, margin, throughput, satisfaction.
If you’re navigating the AI landscape, don’t go it alone. Firms like ours are built to lead this transition with precision, partnership, and purpose.
9. AI Consulting as a Competitive Lever
At a time when AI is reshaping every industry — from law to logistics — early adopters backed by the right consulting expertise enjoy a flywheel effect:
More automation → faster execution
Better forecasts → optimized inventory and cash flow
Smarter personalization → higher customer lifetime value
Real-time insights → faster, more confident decisions
This isn’t just about saving costs. It’s about creating a new operating model — one where machines amplify human judgment, not replace it.
AI consultants are the architects of that model — helping you build it, scale it, and own it.
Final Thoughts: AI Isn’t a Buzzword. It’s an Engineering Discipline.
In the coming years, the divide won’t be between companies that use AI and those that don’t — but between those that use it well, and those who rushed in without guidance.
AI consulting is what makes the difference.
It’s not flashy. It’s not about flashy tools or press releases. It’s about deep analysis, strategic alignment, rigorous testing, and building systems that actually work — in production, at scale, and under pressure.
If you're ready to unlock AI’s real potential in your business, not just experiment with it — talk to an AI consulting partner who can help you make it real.
#AI Consulting Services#Artificial Intelligence Consulting#AI Strategy and Implementation#Business AI Solutions#Enterprise AI Consulting#Machine Learning Consulting#Custom AI Development#AI Integration Experts#AI for Business Growth#MLOps and AI Governance#AI Model Deployment#Scalable AI Systems#AI Transformation Journey#AI Use Cases in Business#AI Automation Solutions
0 notes
Text
Does Your Machine Learning Course in Boston Include Deep Learning and NLP?
If you're searching for Machine Learning courses in Boston, there's a good chance you’re aiming to go beyond just the basics. You’re not just looking to understand regression or classification—you want to dive into cutting-edge tools like Deep Learning and Natural Language Processing (NLP). And that’s the right instinct.
Boston is a hotspot for AI research, biotech innovation, and tech startups. But not every ML course in the city is built equally. Some barely scratch the surface of advanced topics. Others throw you into the deep end without structure.
So how do you know if the course you’re looking at includes Deep Learning and NLP, and if it’s actually worth your time?
First, Why Do Deep Learning and NLP Matter?
Before we get into the course details, it’s important to understand why these two areas matter so much.
Deep Learning: Powering the New Wave of AI
Deep Learning is the backbone of modern AI. It’s what makes self-driving cars possible, powers recommendation engines, enables facial recognition, and is the brains behind tools like ChatGPT.
If a Machine Learning course doesn’t touch on neural networks, CNNs, RNNs, or transformers—even at a foundational level—it’s leaving you in 2012.
Natural Language Processing: Teaching Machines to Understand Humans
NLP is how machines understand human language. Think sentiment analysis, chatbots, language translation, search engines, and even AI-powered hiring systems.
If you want to work with any product that interacts with users through text or speech, NLP is non-negotiable.
What You Should Look for in a Boston-Based Machine Learning Course?
Here’s the thing: A lot of “Machine Learning” courses are just glorified Python crash courses. To know whether a program is future-ready, dig into the curriculum.
✅ It Should Include:
Deep Learning Basics: Neural networks, activation functions, backpropagation
Advanced Architectures: CNNs (for image), RNNs/LSTMs (for sequences), and Transformers
NLP Foundations: Tokenization, embeddings, language models
Real-World Projects: Sentiment analysis, text classification, image recognition, etc.
Frameworks in Use: TensorFlow, PyTorch, HuggingFace Transformers, spaCy
If these aren’t clearly mentioned in the syllabus, ask. If the institute can’t give you a direct answer or shows you a generic syllabus PDF from years ago, that’s a red flag.
Are Boston Courses Keeping Up?
Boston has no shortage of data and AI talent. Between its universities, startups, and tech companies, it’s one of the best places to learn machine learning. But again, not all courses match the hype.
The best programs in Boston are the ones that have adapted their curriculum post-2020. Why post-2020? Because that’s when transformers, BERT, GPT, and other new-gen models went from research labs into real-world production systems.
If your course is still focused solely on logistic regression, decision trees, or even traditional SVMs and random forests, it’s outdated.
Key Signs the Course Does Include Deep Learning and NLP:
Mentions of hands-on projects involving NLP and computer vision
Use of PyTorch or TensorFlow in assignments
Inclusion of language models or transfer learning
Projects using real-world datasets, like social media text, news articles, or image datasets like CIFAR or ImageNet
Specific mention of sequence models, attention, or transformers
What a Well-Rounded Course Structure Looks Like?
If a Boston-based course is truly built for the current AI landscape, you’ll typically see a learning progression like this:
Module 1: Python + Math Refresher
Numpy, Pandas, Matplotlib
Probability, Linear Algebra, Calculus
Module 2: Classical Machine Learning
Supervised/Unsupervised learning
Decision Trees, SVMs, Clustering
Model evaluation, bias-variance tradeoff
Module 3: Introduction to Deep Learning
Neural networks from scratch
Activation functions, loss functions
Gradient descent, backpropagation
Module 4: Computer Vision & CNNs
Image classification
Convolutional layers, pooling
Hands-on project (e.g., facial recognition)
Module 5: Natural Language Processing
Tokenization, TF-IDF, Word Embeddings
Sequence models: RNNs, LSTMs
Language models: BERT, GPT (intro level)
Project: Sentiment analysis, text summarization, or chatbots
Module 6: Capstone Project
End-to-end project combining everything learned
Real dataset, full model lifecycle (EDA → Training → Deployment)
That’s the level of depth you should expect if you’re serious about working in AI.
How Deep Should a General ML Course Go into DL/NLP?
Good question.
You’re not signing up for a PhD in machine learning (yet), so the course doesn’t need to teach you how to write transformers from scratch. But it should give you:
A working understanding of architectures
Enough coding experience to build and train basic models
Confidence to explore more advanced topics on your own
In other words, it should make you comfortable enough to read research papers, fork GitHub repos, or build side projects like chatbots, document classifiers, or image-based models.
Projects That Signal You're Learning the Right Stuff
If you're wondering whether a course is actually teaching Deep Learning and NLP effectively, look at the project work. Some examples of strong capstone or module-level projects:
Image Classifier using CNN on a real-world dataset (not just MNIST)
Text Summarization Tool using transformers like BERT or T5
Sentiment Analysis Dashboard pulling live tweets and visualizing predictions
Fake News Classifier using NLP techniques
Face Detection App deployed via Flask or Streamlit
These aren't just academic exercises—they're exactly the kinds of things that show up in job interviews and portfolios.
Final Thoughts
If you're planning to take a Machine Learning course in Boston, ask this one simple question:
“Will I learn Deep Learning and NLP in this course—and will I build actual projects using them?”
That question alone can help you filter out outdated programs from future-ready ones.
In today’s AI world, just learning regression models won’t get you very far. But if your course gives you solid footing in neural networks and NLP, you’ll have the tools to build, experiment, and thrive in a fast-moving field.
#Best Data Science Courses in Boston#Artificial Intelligence Course in Boston#Data Scientist Course in Boston#Machine Learning Course in Boston
0 notes
Text
Understanding Transformer Networks in an AI Course in Coimbatore
The rapid rise of artificial intelligence has revolutionised how machines process and understand human language, images, and data. Among the many breakthroughs in this field, transformer networks have emerged as a powerful architecture that underpins many state-of-the-art models, including BERT, GPT, and Vision Transformers. As industries increasingly adopt AI solutions, understanding transformer networks has become a critical skill for aspiring professionals. For learners enrolling in an AI course in Coimbatore, mastering this concept can open doors to advanced AI roles and real-world applications.
Transformer networks were introduced in a 2017 research paper titled "Attention is All You Need". Unlike traditional neural networks, which process data sequentially, transformers use a mechanism called self-attention to process input data all at once. This significantly boosts processing speed and allows the model to capture long-range dependencies in sequences. As a result, transformer models have become the gold standard in natural language processing (NLP), speech recognition, and even computer vision.
In any well-rounded AI program, understanding the fundamentals of transformer networks is essential. An AI course in Coimbatore typically begins by explaining why traditional recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) face limitations in handling long sequences. Transformers address these limitations by removing recurrence altogether and relying entirely on attention mechanisms. This architectural change not only improves performance but also simplifies the training process, making models more scalable.
At the heart of a transformer is the self-attention mechanism. It allows the model to weigh the importance of each word or element in a sequence relative to others. The contextual awareness enables transformer-based models to excel in tasks like language translation, summarisation, and sentiment analysis.
Another core concept covered in AI training is the idea of positional encoding. Since transformers do not process data in order, they require a way to represent the position of each word or element. When positional encodings get added to the input embeddings, it enables the model to capture the structure of the sequence.
Advanced AI courses go beyond theory by including practical labs and coding exercises. Students are often introduced to frameworks like TensorFlow and PyTorch, where they can build custom transformer models or fine-tune pre-trained ones. These hands-on sessions help learners understand how transformers are used in real-world scenarios—from powering chatbots to improving search engine relevance. This practical approach ensures that learners can not only explain the architecture but also implement and adapt it for various use cases.
In addition to NLP, transformer models are now making a strong impact in computer vision through innovations like Vision Transformers (ViTs). ViTs divide an image into patches and treat them similarly to word tokens in text, enabling the model to learn complex visual representations. This cross-domain applicability makes transformers a universal tool for AI professionals, further underlining the importance of including them in AI curricula.
Courses that focus on transformers also prepare students for emerging trends in AI research and deployment. Topics such as transfer learning, model fine-tuning, and prompt engineering are often discussed in connection with transformer-based architectures. As industries in Coimbatore—from healthcare and manufacturing to fintech and retail—embrace AI solutions, professionals with knowledge of transformers are increasingly in demand.
The ability to understand and work with transformer networks is not limited to data scientists alone. Software developers, system architects, and project managers also benefit from grasping the fundamentals, especially when planning AI-driven products or integrating language models into existing systems. An inclusive curriculum ensures that all learners, regardless of their background, gain a clear and actionable understanding of this transformative technology.In summary, transformer networks represent a major leap forward in AI capabilities. Their ability to handle large, complex datasets with contextual understanding makes them a cornerstone of modern AI systems. For learners pursuing an AI course in Coimbatore, gaining expertise in transformer models provides a solid foundation for entering high-growth sectors and tackling sophisticated AI challenges. As the technology continues to evolve, those equipped with this knowledge will be well-positioned to innovate, lead, and make meaningful contributions in the AI space.
0 notes
Text
Optimizing Water Usage: Predicting Irrigation Needs with Microsoft Fabric and Machine Learning
Understanding the Challenge Managing agricultural water usage is complex. Farmers must consider weather changes, soil conditions, and crop types, yet often rely on manual estimates. We wanted to help predict irrigation needs in advance, making farming more efficient and sustainable.
Why We Built This Our goal was to support farmers in planning water use more precisely, reduce waste, and improve crop health. We aimed to use data they already had — soil moisture readings, weather forecasts, and irrigation logs — and integrate predictions into simple, accessible tools.
Our Solution Data from soil sensors and weather APIs is ingested into Microsoft Fabric. Using Dataflows, we clean and prepare this data, storing it in OneLake for easy access. We trained a time-series LSTM model to forecast water requirements for the next five days, continuously updating with new data.
The model is deployed via Azure ML and integrated into a PowerApps dashboard so farmers can view daily water recommendations easily.
LSTM was chosen for its ability to understand patterns over time, such as the delayed impact of rainfall or gradual soil moisture depletion.
System Architecture
Data Acquisition: Soil moisture sensors, local weather data, and irrigation records.
Data Storage: Centralized in OneLake within Microsoft Fabric.
Model Training: Historical and live data processed and used to train LSTM models via Fabric’s ML capabilities.
Model Deployment: Managed and deployed through Azure ML with endpoints for real-time use.
Prediction Output: Recommendations displayed through PowerApps, allowing quick on-field decisions.
What Worked Well Microsoft Fabric simplified data integration and transformation, while PowerApps allowed easy sharing of results without new training for farmers.
Challenges We faced difficulties with inconsistent sensor data, syncing different data sources, and tuning the model to avoid over- or under-watering suggestions.
Why This Approach Worked The focus was on practicality and ease of use rather than complexity. Microsoft Fabric offered strong data handling, and Azure ML made deployment straightforward, creating a reliable system for field use.
Conclusion This solution shows that impactful innovation doesn’t always mean building something new from scratch. By combining existing tools smartly, we helped farmers make informed decisions, conserve water, and improve yields.
If you want to read in detail, visit: https://acuvate.com/blog/irrigation-forecasting-with-microsoft-fabric/
#Irrigation Forecasting#Microsoft Fabric#Water Management#Forecasting energy generation with microsoft fabric and machine learning#Energy consumption prediction using machine learning
0 notes
Text
Deep learning model enables 3D ultrasound and photoacoustic imaging without external sensors

- By InnoNurse Staff -
Researchers from Pusan National University in Korea, led by Prof. MinWoo Kim, developed MoGLo-Net, a deep learning model that enables 3D ultrasound (US) and photoacoustic (PA) imaging without external sensors.
Traditional 3D imaging methods require bulky and expensive tracking equipment, but MoGLo-Net uses tissue speckle patterns from 2D US images to accurately track transducer motion.
Combining a ResNet-based encoder and LSTM motion estimator, the model captures detailed in-plane and out-of-plane motion, enhanced by a self-attention mechanism. It significantly outperformed existing methods, producing clearer 3D images—including, for the first time, combined 3D ultrasound and photoacoustic images of blood vessels.
This innovation could make advanced imaging more accessible, improving diagnostics and procedures in a wider range of medical settings.
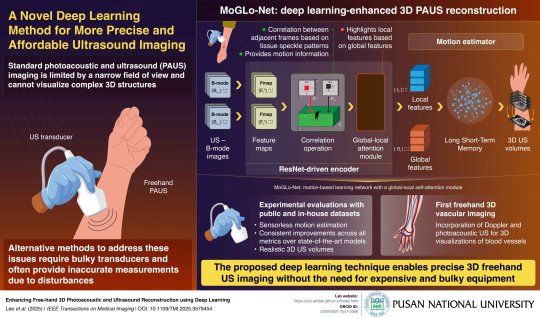
Image credit: MinWoo Kim from Pusan National University, South Korea.
Read more at Pusan National University/Medical Xpress
0 notes
Text
Technical Breakthrough: How Yama Matrix Cloud Phones Empower Vinted Multi-Account Registration Management In the second-hand trading platform Vinted's multi-account operations, critical challenges include device fingerprint association bans (risk >68%), IP reuse triggering risk controls (trigger rate >55%), and behavioral pattern homogenization (human audit error rate >38%). Leveraging dynamic hardware masking technology, intelligent network scheduling systems, and biological behavior modeling engines, Yama Matrix Cloud Phones redefine the technical logic of account management, achieving a 99.3% account survival rate, 97.5% registration approval rate, and over 70,000 daily operations—a groundbreaking industry milestone.
Technical Breakthrough: Three-Dimensional Dynamic Defense Architecture
Instant Hardware Fingerprint Generation Utilizing ARM virtualization technology, each cloud phone instance generates unique hardware parameter combinations (device ID, serial number, sensor calibration values), dynamically refreshed hourly (differential rate >99.99%) to evade Vinted's "device fingerprint clustering" detection models.
Intelligent IP Scheduling Network Integrated with global 5G edge nodes, IP addresses switch within milliseconds (latency <50ms), combined with geofencing technology to precisely match user regions (e.g., Eastern Europe IP positioning error <80 meters), overcoming platform IP reuse restrictions.
Biological Behavior Modeling Engine LSTM neural networks simulate human interaction patterns (click intervals of 0.5-3 seconds, swipe acceleration ±0.7m/s²), while integrating environmental sensor noise (light/gyroscope data random perturbation) to ensure automated operations align with human behavior patterns (distribution error <1.8%).
Core Value: Paradigm Shift in Second-Hand Trading Efficiency
Risk Isolation: Independent hardware environments + dynamic IP pools eliminate account association risks;
Efficiency Leap: 1 operator manages 800+ accounts, reducing registration cycles from 2.5 days to 1.8 hours;
Compliance Assurance: Differential privacy technology safeguards user data, meeting GDPR and CCPA standards.
By fusing dynamic hardware masking, intelligent network scheduling, and biological behavior simulation, Yama Matrix Cloud Phones construct a secure, scalable, and efficient account management ecosystem for Vinted, propelling second-hand trading operations into an era of "adaptive defense."
0 notes
Text
From Neural Nets to Mastery: Why a Deep Learning Architecture Course is the Future of AI Learning
In today’s rapidly evolving tech landscape, deep learning is no longer a buzzword — it’s a necessity. The success of AI-powered systems like voice assistants, autonomous vehicles, and facial recognition technologies is rooted in sophisticated neural networks and intelligent design. For those looking to break into this exciting field or elevate their AI career, enrolling in a deep learning architecture course is the most strategic move.
What is Deep Learning Architecture?
Before diving into why a course is essential, it's important to understand what "deep learning architecture" means. Simply put, it refers to the structure and design of artificial neural networks — systems modeled loosely on the human brain. These architectures determine how data flows through layers, how patterns are recognized, and how the network learns over time.
From Convolutional Neural Networks (CNNs) that excel in image recognition, to Recurrent Neural Networks (RNNs) that handle sequential data like text and audio, mastering these architectures is crucial. A deep learning architecture course dives deep into these models, equipping learners with both theoretical knowledge and practical skills.
Why Deep Learning is the Backbone of Modern AI
AI is the engine, but deep learning is the fuel. Companies across industries — healthcare, finance, retail, cybersecurity, and beyond — are implementing deep learning solutions to automate, optimize, and innovate. Here's why:
Unmatched Accuracy: Deep learning models, when architected correctly, outperform traditional machine learning models in tasks involving vast and complex datasets.
Scalability: As data grows, deep learning systems scale easily and efficiently.
Adaptability: These models improve over time with exposure to new data — continuously learning and evolving.
A deep learning architecture course offers hands-on understanding of building these scalable, accurate, and adaptable systems from scratch.
What to Expect in a Deep Learning Architecture Course?
At Trainomart, we understand that learners need a comprehensive curriculum to truly master deep learning. A well-structured deep learning architecture course should cover:
1. Foundations of Neural Networks
Understanding perceptrons, activation functions, loss functions, and the mathematics that underpin learning models.
2. Architectures in Focus
In-depth study of:
CNNs for computer vision tasks
RNNs and LSTMs for sequential data
GANs for generative tasks
Transformers for language and vision tasks
3. Model Optimization
How to fine-tune architectures for performance using hyperparameter tuning, dropout, regularization, and more.
4. Real-World Projects
Hands-on projects such as image classification, natural language processing, and building your own recommendation engine.
5. Deployment & Scalability
Learn to take your trained models from notebooks to production using cloud services and containerization tools like Docker.
This is what separates a basic online tutorial from a deep learning architecture course with real industry value.
Why Choose Trainomart’s Deep Learning Architecture Course?
At Trainomart, we don't just teach — we transform careers. Our deep learning architecture course is designed by industry experts, tailored for both beginners and professionals, and focused on real-world implementation.
Key Benefits:
Mentor-Led Learning: Learn from seasoned data scientists and AI engineers.
Project-Based Curriculum: Build a portfolio that demonstrates your capabilities.
Career Support: Resume building, mock interviews, and job placement assistance.
Flexible Learning: Online, self-paced, or instructor-led — you choose your path.
Whether you're looking to become a Machine Learning Engineer, AI Researcher, or Data Scientist, Trainomart’s course provides the foundation and momentum you need.
Who Should Take a Deep Learning Architecture Course?
You don’t need a PhD to start, but a passion for problem-solving and a basic understanding of Python and mathematics will go a long way. This course is ideal for:
Software engineers aiming to transition into AI roles
Data analysts looking to deepen their technical skill set
Researchers and academicians venturing into applied AI
Entrepreneurs building AI-driven products
Students planning a future-proof tech career
By the end of the course, you’ll not only understand how to use deep learning frameworks like TensorFlow and PyTorch but also how to design and improve models for real-world problems.
Trends Fueling Demand for Deep Learning Expertise
Here’s why this is the perfect time to invest in a deep learning architecture course:
Hiring Boom: AI and ML jobs are among the fastest-growing roles in tech.
Salary Surge: AI engineers command high salaries due to demand-supply imbalance.
Startup & Innovation Opportunities: Many startups are leveraging deep learning in healthtech, edtech, fintech, and more.
Research Breakthroughs: Cutting-edge developments like GPT, DALL·E, and AlphaFold rely on advanced deep learning models.
Learning how these systems are architected is not just intellectually rewarding — it’s career-defining.

0 notes
Text
i finally know what im doing in this project although i haven't yet started on the theory and god it's so much seqtoseq model, encoder decoder, lstm rnn. and also some of the filtering and all of tokenization. but all of this can be understood if i know what the im doing :)
4 notes
·
View notes