#Optimisation Apache.
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
Comment activer HTTP/2 pour apache2 sur Debian ou Ubuntu ?
Dans ce guide, je vous montre comment booster les performances de votre serveur Apache sur Debian en activant HTTP/2 et en peaufinant sa configuration avec le MPM Event et PHP-FPM. L'objectif est simple : rendre votre site plus rapide et plus réactif, sans compromettre la sécurité. Suivez-moi dans cette démarche pour découvrir comment tirer le meilleur parti de votre serveur, améliorant ainsi l'expérience utilisateur tout en optimisant la gestion des ressources.

Comment activer HTTP/2 pour apache2 sur Debian ou Ubuntu ? - LaRevueGeek.com
#HTTP/2#Apache#Debian#MPM Event#PHP-FPM#SSL/TLS#Performance web#Multiplexage#Configuration serveur#Optimisation Apache.
0 notes
Text
Stress Testing Your Application Post-Deployment
Once a full-stack application is deployed, the focus shifts from development to performance assurance. A critical part of this process is stress testing, which evaluates how well your application performs under extreme conditions. This is not about average usage—it’s about pushing your app beyond its limits to reveal breaking points, bottlenecks, and system vulnerabilities. Stress testing is a practice strongly emphasised in any java full stack developer course, ensuring that future developers understand how to build robust, resilient systems.
While functional tests ensure correctness, stress tests verify endurance, helping you assess system behaviour under high load, degraded performance, or sudden spikes in traffic.
What is Stress Testing?
Stress testing simulates scenarios of extreme usage. It evaluates how the system behaves when subjected to high traffic, excessive API calls, concurrent user sessions, or large data inputs. The objective is not just to test capacity but to understand how the application fails—gracefully or catastrophically—and how quickly it can recover.
Stress testing helps you answer key questions:
How many users can the app handle before crashing?
What component (frontend, backend, database) fails first?
Does the application degrade slowly or fail immediately?
Are users given meaningful error messages or left confused?
These insights help in preparing fallback strategies, such as load balancing, caching, or scaling, which are vital for production environments.
Tools for Stress Testing
Several tools can simulate a heavy load and generate performance metrics:
Apache JMeter: Widely used for simulating API load and analysing performance.
Artillery: Lightweight and suitable for Node.js apps, often used with JavaScript test scripts.
Gatling: Good for high-performance simulations, written in Scala.
Locust: Python-based and customisable, great for writing user behaviour scenarios.
These tools can bombard your application with virtual users, mimicking real-world traffic patterns.
What to Stress Test
Stress testing should cover all critical components of your stack:
Frontend
Page rendering times with multiple concurrent users.
Asset delivery under high load (CSS, JS, images).
Responsiveness when interacting with overloaded APIs.
Backend
API request handling with thousands of simultaneous calls.
CPU and memory usage patterns.
Server response time under increasing requests per second (RPS).
Database
Read/write throughput with high-frequency operations.
Deadlock scenarios or connection exhaustion.
Query optimisation under concurrent access.
A well-rounded full stack developer course in Mumbai trains developers to isolate these layers and stress test them independently before integrating the full stack for end-to-end evaluation.
How to Conduct Stress Testing Post-Deployment
1. Set a Baseline
Before initiating stress, measure baseline performance under normal load. Monitor average response times, error rates, and CPU and memory consumption.
2. Simulate Gradual Load Increase
Start small and scale up to simulate the increasing number of users. This identifies the threshold at which performance begins to degrade.
3. Spike Testing
Introduce sudden traffic surges to see if the system can scale quickly or fail abruptly. This reflects real-world scenarios, such as flash sales or viral content.
4. Monitor in Real-Time
Utilise tools such as Grafana, Prometheus, New Relic, or AWS CloudWatch to monitor key metrics, including latency, request counts, error rates, and system health.
5. Analyse Failure Points
When the system breaks (as it should in stress testing), evaluate:
Was the failure predictable?
Were logs detailed and accessible?
Did alerts or fallback systems activate as expected?
Post-Stress Optimization
Once weaknesses are identified:
Scale horizontally: Add more instances of servers or services.
Use caching: Implement Redis or Varnish to reduce database load.
Optimise database queries: Refactor long-running queries, use indexes.
Tune infrastructure: Adjust server limits, thread pools, and database connections.
These changes should then be validated with follow-up stress tests to measure improvement.
Stress testing is not an optional step—it’s a necessity for delivering reliable, scalable applications. It prepares your system for the worst-case scenarios, allowing you to plan proactive measures instead of reactive fixes. Mastering such techniques is a hallmark of competent developers trained through a full stack developer course, especially those that prioritise practical, deployment-ready skills.
Programs like the full stack developer course in Mumbai provide an immersive, hands-on experience with load simulation, monitoring, and debugging post-deployment. This ensures that graduates can not only build impressive applications but also maintain their stability under pressure. In today's fast-paced digital landscape, resilience is just as important as functionality. Stress testing bridges that gap.
0 notes
Text
Cirq: Google’s Open-Source Python Quantum Circuit Framework

Cirq, what?
Python programming framework Cirq is open-source. With them, you may design, edit, modify, optimise, and activate quantum circuits. Google AI Quantum released Cirq as a public alpha on July 18, 2018. This Apache 2 license allows it to be modified or integrated into any open-source or commercial program.
Goal and Focus
Designed for Noisy Intermediate Scale Quantum computers and algorithms. NISQ computers are noise-sensitive systems with 50–100 qubits and high-fidelity quantum gates, or fewer than a few hundred. Current quantum algorithm research focusses on NISQ circuits, which work without error correction, because they may offer a quantum advantage on near-term devices.
The methodology helps researchers determine whether NISQ quantum computers can tackle real-world computational problems by focussing on short-term challenges. It provides abstractions for NISQ computers, where hardware details are crucial to cutting-edge results.
It lets users organise gates on the device, plan time within quantum hardware constraints, and specify gate behaviour using native gates to precisely manage quantum circuits. Cirq data structures are optimised for building NISQ quantum circuits to help users maximise their use. Cirq's architecture targets NISQ circuits, so researchers and developers can experiment with them and find noise-reducing ways.
Key traits and talents
Cirq has many quantum circuit capabilities:
Circuit Manufacturing/Manipulation This provides a flexible and easy interface for designing quantum circuits. User-defined measurements, qubits, and quantum gates can match their mathematical description. Custom and flexible gate definitions are supported by the framework. Users can learn about moments, insertion strategies, and qubit gates to build quantum circuits. Symbolic variable parameterised circuits work too. Circuits can be chopped, sliced, and diced to improve them.
Hardware modelling Hardware restrictions drastically affect a circuit's feasibility on modern hardware. Cirq devices can manage these constraints. Noise and hardware device modelling are supported.
Modelling Cirq includes density matrix and wave function integrated quantum circuit simulators. These simulators can handle noisy quantum channels with full density matrix or Monte Carlo simulations. Cirq connects with cutting-edge wave function simulators like qsim for high-performance simulation. The Quantum Virtual Machine (QVM) can emulate quantum hardware with these simulators. Quantum circuit simulation is vital for algorithm development and testing before hardware implementation.
Optimising and Transforming Circuits Optimisation, compilation, and circuit transformation are framework functions. Many quantum circuit optimisers for hardware testing are included.
Implementing Hardware Cirq is cloud-integrable with larger simulators or future quantum hardware. It simplifies quantum circuit operation for quantum processors. Cirq lets users run quantum circuits on Google's quantum hardware via its Quantum Computing Service. The Google AI Quantum team designs circuits for Google's Bristlecone processor using Cirq as a programming interface and plans to make it cloud-available. It can also submit quantum circuits to cloud platforms like Azure Quantum for execution on QPUs, IonQ, and Quantinuum simulators.
Interoperability It supports SciPy and NumPy. Cross-platform, it supports Linux, MacOS, Windows, and Google Colab.
Applications and use cases
Cirq is crucial to Quantum Machine Learning (QML), which combines machine learning and quantum computing. QML uses quantum computing to speed up machine learning. Cirq implements quantum machine learning algorithms on NISQ devices. Quantum neural networks mimic neuronal behaviour to find patterns and predict.
Quantum Support Vector Machine (QSVM) algorithms can be built on Cirq using quantum circuits for linear algebra operations and quantum feature maps to encode data into quantum states. Quantum SVM algorithms exist. Cirq Quantum implementations of popular machine learning methods have been made.
Cirq can be used to test quantum algorithms like the Quantum Approximate Optimisation Algorithm (QAOA) and Variational Quantum Eigensolver (VQE) for machine learning applications. QAOA, a hybrid quantum-classical technique, handled combinatorial optimisation problems.
Quantum computers, which can be duplicated using Cirq, are perfect for optimisation problems because they can investigate numerous answers. This reduces training time and finds optimal machine learning model parameters.
Cirq is also used in machine learning to create quantum versions of classical algorithms like decision trees, apply quantum error correction to improve model robustness, simulate chemical reactions for drug discovery, and encode classical data into quantum states. Many quantum gate functions are needed to build complex machine learning circuits with Cirq.
This is used for QML and Google quantum processor end-to-end tests. Early adopters of Cirq simulated quantum autoencoders, implemented QAOA, integrated it into hardware assessment software, simulated physical models like the Anderson Model, and integrated it with quantum compilers.
Close-term algorithms in quantum chemistry challenges can be facilitated by OpenFermion-Cirq.
Support and Community
Over 200 people contributed. Researchers, software engineers, technical writers, and students are encouraged to contribute to its open and inclusive community. Communities organise weekly virtual open source meetings including Quantum Circuit Simulation Weekly Sync, TensorFlow Quantum Weekly Sync, OpenFermion Weekly Sync, and Cirq Weekly Sync.
On Quantum Computing Stack Exchange, utilise the cirq tag for Cirq questions. GitHub provides good initial issues and contribution criteria for programming contributors. Larger features use an RFC (Request for Comment). The Quantum AI website's Cirq home page offers examples, reference documentation, and text-based, Jupyter notebook, and video tutorials. Releases occur every three months.
Combinations
Google Quantum AI's open-source software stack includes Cirq. It includes the open-source hybrid quantum-classical machine learning library TensorFlow Quantum. It also interacts with OpenFermion family libraries for chemistry and material science. More integrated Google stack products include Qualtran for fault-tolerant quantum computing, Stim for huge Clifford circuits and quantum error correction, ReCirq for Cirq experiments, and Qsim for high-performance simulation. Use Cirq to submit quantum circuits to third-party cloud services like Microsoft Azure Quantum to access IonQ and Quantinuum hardware.
Conclusion
Finally, Google's Quantum AI team developed Cirq, an open-source Python framework for NISQ quantum computer creation and experimentation. Its full circuit design control, robust simulation capabilities, and interfaces for executing circuits on real quantum hardware and integrated simulators make it crucial in quantum machine learning research.
#Cirq#NoisyIntermediateScaleQuantum#NISQ#QuantumSupportVectorMachine#QuantumApproximateOptimizationAlgorithm#QuantumCirq#technology#technews#technologynews#news#govindhtech
0 notes
Text
Decoding Hadoop’s Core: HDFS, YARN, and MapReduce Explained
In today's data-driven world, handling massive volumes of data efficiently is more critical than ever. As organisations continue to generate and analyse vast datasets, they rely on powerful frameworks like Apache Hadoop to manage big data workloads. At the heart of Hadoop are three core components—HDFS, YARN, and MapReduce. These technologies work in tandem to store, process, and manage data across distributed computing environments.
Whether you're a tech enthusiast or someone exploring a Data Scientist Course in Pune, understanding how Hadoop operates is essential for building a solid foundation in big data analytics.
What is Hadoop?
Apache Hadoop is a free, open-source framework intended for the storage and processing of large data sets across networks of computers. It provides a reliable, scalable, and cost-effective way to manage big data. Hadoop is widely used in industries such as finance, retail, healthcare, and telecommunications, where massive volumes of both form of data, structured and unstructured, are generated daily.
To understand how Hadoop works, we must dive into its three core components: HDFS, YARN, and MapReduce.
HDFS: Hadoop Distributed File System
HDFS is the storage backbone of Hadoop. It allows data to be stored across multiple machines while appearing as a unified file system to the user. Designed for high fault tolerance, HDFS replicates data blocks across different nodes to ensure reliability.
Key Features of HDFS:
Scalability: Easily scales by adding new nodes to the cluster.
Fault Tolerance: Automatically replicates data to handle hardware failures.
High Throughput: Optimised for high data transfer rates, making it ideal for large-scale data processing.
For someone pursuing a Data Scientist Course, learning how HDFS handles storage can provide valuable insight into managing large datasets efficiently.
YARN: Yet Another Resource Negotiator
YARN is the system resource management layer in Hadoop. It coordinates the resources required for running applications in a Hadoop cluster. Before YARN, resource management and job scheduling were tightly coupled within the MapReduce component. YARN decouples these functionalities, making the system more flexible and efficient.
Components of YARN:
Resource Manager (RM): Allocates resources across all applications.
Node Manager (NM): Manages resources and monitors tasks on individual nodes.
Application Master: Coordinates the execution of a specific application.
By separating resource management from the data processing component, YARN allows Hadoop to support multiple processing models beyond MapReduce, such as Apache Spark and Tez. This makes YARN a critical piece in modern big data ecosystems.
MapReduce: The Data Processing Engine
MapReduce is the original data processing engine in Hadoop. It processes data in two main stages: Map and Reduce.
Map Function: Breaks down large datasets into key-value pairs and processes them in parallel.
Reduce Function: Aggregates the outputs of the Map phase and summarises the results.
For example, if you want to count the frequency of words in a document, the Map function would tokenise the words and count occurrences, while the Reduce function would aggregate the total count for each word.
MapReduce is efficient for batch processing and is highly scalable. Although newer engines like Apache Spark are gaining popularity, MapReduce remains a fundamental concept in big data processing.
The Synergy of HDFS, YARN, and MapReduce
The true power of Hadoop lies in the integration of its three core components. Here’s how they work together:
Storage: HDFS stores massive volumes of data across multiple nodes.
Resource Management: YARN allocates and manages the resources needed for processing.
Processing: MapReduce processes the data in a distributed and parallel fashion.
This combination enables Hadoop to manage and analyse data at a scale unimaginable with traditional systems.
Why Should Aspiring Data Scientists Learn Hadoop?
As the volume of data continues to grow, professionals skilled in managing big data frameworks like Hadoop are in high demand. Understanding the architecture of Hadoop is a technical and strategic advantage for anyone pursuing a career in data science.
If you're considering a Data Scientist Course in Pune, ensure it includes modules on big data technologies like Hadoop. This hands-on knowledge is crucial for analysing and interpreting complex datasets in real-world scenarios.
Additionally, a comprehensive course will cover not only Hadoop but also related tools like Hive, Pig, Spark, and machine learning techniques—empowering you to become a well-rounded data professional.
Conclusion
Apache Hadoop remains a cornerstone technology in the big data landscape. Its core components—HDFS, YARN, and MapReduce—form a robust framework for storing and processing large-scale data efficiently. HDFS ensures reliable storage, YARN manages computational resources, and MapReduce enables scalable data processing.
For aspiring data scientists and IT professionals, mastering Hadoop is an important step toward becoming proficient in big data analytics. Whether through self-learning or enrolling in a structured Data Scientist Course, gaining knowledge of Hadoop's core functionalities will greatly enhance your ability to work with large and complex data systems.
By understanding the building blocks of Hadoop, you're not just learning a tool—you’re decoding the very foundation of modern data science.
Contact Us:
Name: Data Science, Data Analyst and Business Analyst Course in Pune
Address: Spacelance Office Solutions Pvt. Ltd. 204 Sapphire Chambers, First Floor, Baner Road, Baner, Pune, Maharashtra 411045
Phone: 095132 59011
0 notes
Text
Learn to Use SQL, MongoDB, and Big Data in Data Science
In today’s data-driven world, understanding the right tools is as important as understanding the data. If you plan to pursue a data science certification in Pune, knowing SQL, MongoDB, and Big Data technologies isn’t just a bonus — it’s essential. These tools form the backbone of modern data ecosystems and are widely used in real-world projects to extract insights, build models, and make data-driven decisions.
Whether you are planning on updating your resume, wanting to find a job related to analytics, or just have a general interest in how businesses apply data. Learning how to deal with structured and unstructured data sets should be a goal.
Now, analysing the relation of SQL, MongoDB, and Big Data technologies in data science and how they may transform your career, if you are pursuing data science classes in Pune.
Why These Tools Matter in Data Science?
Data that today’s data scientists use varies from transactional data in SQL databases to social network data stored in NoSQL, such as MongoDB, and data larger than the amount that can be processed by conventional means. It has to go through Big Data frameworks. That is why it is crucial for a person to master such tools:
1. SQL: The Language of Structured Data
SQL (Structured Query Language) is a widely used language to facilitate interaction between users and relational databases. Today, almost every industry globally uses SQL to solve organisational processes in healthcare, finance, retail, and many others.
How It’s Used in Real Life?
Think about what it would be like to become an employee in one of the retail stores based in Pune. In this case, you are supposed to know the trends of products that are popular in the festive season. Therefore, it is possible to use SQL and connect to the company’s sales database to select data for each product and sort it by categories, as well as to determine the sales velocity concerning the seasons. It is also fast, efficient, and functions in many ways that are simply phenomenal.
Key SQL Concepts to Learn:
SELECT, JOIN, GROUP BY, and WHERE clauses
Window functions for advanced analytics
Indexing for query optimisation
Creating stored procedures and views
Whether you're a beginner or brushing up your skills during a data science course in Pune, SQL remains a non-negotiable part of the toolkit.
2. MongoDB: Managing Flexible and Semi-Structured Data
As businesses increasingly collect varied forms of data, like user reviews, logs, and IoT sensor readings, relational databases fall short. Enter MongoDB, a powerful NoSQL database that allows you to store and manage data in JSON-like documents.
Real-Life Example:
Suppose you're analysing customer feedback for a local e-commerce startup in Pune. The feedback varies in length, structure, and language. MongoDB lets you store this inconsistent data without defining a rigid schema upfront. With tools like MongoDB’s aggregation pipeline, you can quickly extract insights and categorise sentiment.
What to Focus On?
CRUD operations in MongoDB
Aggregation pipelines for analysis
Schema design and performance optimisation
Working with nested documents and arrays
Learning MongoDB is especially valuable during your data science certification in Pune, as it prepares you for working with diverse data sources common in real-world applications.
3. Big Data: Scaling Your Skills to Handle Volume
As your datasets grow, traditional tools may no longer suffice. Big Data technologies like Hadoop and Spark allow you to efficiently process terabytes or even petabytes of data.
Real-Life Use Case:
Think about a logistics company in Pune tracking thousands of deliveries daily. Data streams in from GPS devices, traffic sensors, and delivery apps. Using Big Data tools, you can process this information in real-time to optimise routes, reduce fuel costs, and improve delivery times.
What to Learn?
Hadoop’s HDFS for distributed storage
MapReduce programming model.
Apache Spark for real-time and batch processing
Integrating Big Data with Python and machine learning pipelines
Understanding how Big Data integrates with ML workflows is a career-boosting advantage for those enrolled in data science training in Pune.
Combining SQL, MongoDB, and Big Data in Projects
In practice, data scientists often use these tools together. Here’s a simplified example:
You're building a predictive model to understand user churn for a telecom provider.
Use SQL to fetch customer plans and billing history.
Use MongoDB to analyse customer support chat logs.
Use Spark to process massive logs from call centres in real-time.
Once this data is cleaned and structured, it feeds into your machine learning model. This combination showcases the power of knowing multiple tools — a vital edge you gain during a well-rounded data science course in Pune.
How do These Tools Impact Your Career?
Recruiters look for professionals who can navigate relational and non-relational databases and handle large-scale processing tasks. Mastering these tools not only boosts your credibility but also opens up job roles like:
Data Analyst
Machine Learning Engineer
Big Data Engineer
Data Scientist
If you're taking a data science certification in Pune, expect practical exposure to SQL and NoSQL tools, plus the chance to work on capstone projects involving Big Data. Employers value candidates who’ve worked with diverse datasets and understand how to optimise data workflows from start to finish.
Tips to Maximise Your Learning
Work on Projects: Try building a mini data pipeline using public datasets. For instance, analyze COVID-19 data using SQL, store news updates in MongoDB, and run trend analysis using Spark.
Use Cloud Platforms: Tools like Google BigQuery or MongoDB Atlas are great for practising in real-world environments.
Collaborate and Network: Connect with other learners in Pune. Attend meetups, webinars, or contribute to open-source projects.
Final Thoughts
SQL, MongoDB, and Big Data are no longer optional in the data science world — they’re essential. Whether you're just starting or upgrading your skills, mastering these technologies will make you future-ready.
If you plan to enroll in a data science certification in Pune, look for programs that emphasise hands-on training with these tools. They are the bridge between theory and real-world application, and mastering them will give you the confidence to tackle any data challenge.
Whether you’re from a tech background or switching careers, comprehensive data science training in Pune can help you unlock your potential. Embrace the learning curve, and soon, you'll be building data solutions that make a real impact, right from the heart of Pune.
1 note
·
View note
Text
Apache Project: Crafting a Sci-Fi Factory in Unreal Engine | Step 07
Creating and Texturing the Pillar Asset with the Trim Sheet.
With my trim sheet finalized and looking the way I wanted, I began the next asset in the build—a sci-fi pillar that would act as a recurring structural element throughout the environment.
Modeling the Pillar I modeled the pillar inside Blender, keeping in mind modularity, scale, and silhouette. I wanted the shape to feel grounded in the factory setting, with a blend of industrial heaviness and clean sci-fi geometry. While blocking it out, I paid close attention to how each segment of the pillar could line up with sections of the trim sheet—so the UVs could be smartly packed without needing unique textures.
The goal here wasn’t to create a complex mesh, but to let the trim sheet carry most of the detail through good UV mapping.
UV Mapping and Trim Sheet Application Once the model was finalized, I unwrapped the pillar and mapped different parts of the mesh directly onto the baked trim sheet. I took time to align the UVs precisely with design bands from the sheet—metal plating for the main body, greeble sections for tech detailing, and rougher zones for base contact areas. This was the moment where all the previous planning paid off.
This method gave the pillar a highly detailed appearance with minimal texture memory cost, and allowed me to quickly prototype different material looks by simply adjusting the UV placement.
In-Engine Preview and Testing I imported the pillar into Unreal Engine, applied the trim sheet material, and placed it into the environment for testing. Seeing it in the actual lighting conditions helped me make small tweaks—like adjusting roughness and contrast on certain parts of the trim to get the pillar to pop correctly in the scene.
This asset now acts as one of the key architectural anchors on the level. It’s reusable, visually consistent, and optimised—thanks to the power of trim sheet texturing.


0 notes
Text
VR Project (Reflection & Final Thoughts) [Assignment set by Apache]





Figure 1-5 Final appearance of the VR game environment.
This group assignment has been a valuable experience for me both as a team member and a leader. Taking on the responsibility of guiding the visual direction and supporting my teammates helped me develop stronger communication and leadership skills. I learned how to balance giving feedback while respecting each person’s creative input. At the same time, I contributed actively as a team member by taking on tasks, problem-solving, and staying adaptable during unexpected challenges. It taught me how to manage time better, especially under tight deadlines, and how to prioritise work that has the most impact on the project. I also improved in technical areas like lighting, post processing, modular modelling, and asset optimisation. Overall, I grew more confident in my ability to lead creatively and technically, while also learning how to collaborate effectively in a team environment.
Extra:
If more time and resources were given for this project, the following are the additional models or effects I wish to add into the project:
Create more personalised items to give the certain areas more personality and history.
Particle Effect to enhance the scene such as fire particles emitting around the basilisk or lava particles coming out of the stone statues.
More props to fill the room such as stolen artifacts on display, scientific props, books in shelfs etc.
Expand the map to have more rooms such as adding mess halls, armoury, and actual science facilities etc.
Optimise the environment.
0 notes
Text
How to Speed Up Your Website and Boost Your SEO

If your website takes too long to load, visitors might leave before they even see what you offer. In today's fast-paced world, people expect websites to load quickly, and so do the search engines. A slow website can hurt your rankings on Google and drive potential customers away.
That's why many businesses choose to work with SEO companies in Adelaide to improve their site speed and overall performance. But even if you're handling things on your own, there are simple steps you can take to make your website faster and boost your SEO. Let's go through them one by one.
Why Website Speed Matters for SEO
Before we get into the steps to speed up your site, it's important to understand why it matters. Google has said that website speed affects your search rankings. A faster site means a better experience for your visitors. It helps keep people on your pages longer and encourages them to take action—like making a purchase or filling out a form.
Now, think about this: if a website takes more than a few seconds to load, most of us won't stick around. In fact, Google reports that 53% of mobile users leave a site if it takes more than 3 seconds to load. That's more than half your visitors gone before they even see your content. So, improving your site’s speed isn't just a technical task—it's a smart move for keeping visitors and ranking higher on search engines.
How To Make Your Website Faster And Improve SEO?
Step 1: Run a Speed Test
The first step is to find out how fast (or slow) your website really is. Thankfully, there are some free tools that can help you measure performance and highlight areas that need improvement:
Google PageSpeed Insights
GTmetrix
Pingdom Website Speed Test
These tools give you a speed score and detailed suggestions to help you understand what's slowing your site down—think of it as a diagnostic tool for your website's performance.
Step 2: Optimise Your Images
Images are often the main reason websites slow down. While high-resolution images look great, they can significantly impact load times. Here's how to fix that:
Resize images before uploading – There's no need to upload a massive 4000 px image if it only needs to display at 400px.
Use lighter formats like WebP – These next-gen formats are smaller and load faster.
Compress images with tools like TinyPNG or ShortPixel to reduce file size without losing quality.
Faster images lead to faster load times and a better user experience.
Step 3: Enable Browser Caching
Caching helps speed up your site by allowing a visitor's browser to "remember" your pages so they load faster the next time. Think of it like bookmarking your favourite restaurant—you don't need to search for it every time.
Next, you can enable browser caching through your site's settings. If you're using Apache, you can do this by editing your .htaccess file. Alternatively, if you're on WordPress, plugins like W3 Total Cache or WP Rocket can make the process much easier.
Step 4: Minify CSS, JavaScript, and HTML
"Minifying" basically means cleaning up your code by removing unnecessary spaces, line breaks, and comments. It makes your files smaller and faster to load. You can do this manually if you're comfortable with code or use plugins and tools like:
Autoptimize (WordPress)
Minify (for various platforms)
Cloudflare (offers minification as part of its CDN)
Step 5: Consider Off-Page SEO for Better Results
While on-page optimisations like image compression and caching help your site speed, off-page SEO can boost your site's visibility and ranking, indirectly supporting faster loading times and user engagement. Collaborating with an Off-Page SEO Expert can help you enhance your site's authority, trustworthiness, and performance through tactics like link-building, social media marketing, and influencer outreach.
Conclusion
Speed is a crucial factor for both user experience and SEO. By optimising your site's performance, you're not only improving load times but also boosting your chances of ranking higher on search engines like Google.
If you're ever in doubt, partnering with the best SEO specialist in Australia, such as iDiGiFi, can help you take your website's SEO to the next level. Visit the website or give a call for any further information.
0 notes
Text
How is AWS Graviton Redefining Cloud Performance and Cost Efficiency for Business Leaders?

With over 90% of businesses migrating to the cloud, the demand for cost-efficient and scalable cloud solutions has never been more critical to staying competitive. AWS Graviton, an ARM-based processor developed by AWS, is transforming cloud computing with its focus on delivering high performance at reduced costs. Designed to meet the demands of modern workloads, AWS Graviton empowers businesses to optimise resource usage without compromising efficiency.
This blog will explore the unique benefits of AWS Graviton, its role in transforming cloud strategies, and how AWS Cloud Services amplifies its impact on decision-makers and tech leaders.
I. What is AWS Graviton?

II. AWS Graviton: Features, Business Benefits, and Industry Use Cases
AWS Graviton processors combine cutting-edge technology with significant business advantages, making them a transformative tool for modern enterprises. Below is an overview of key features, the associated business benefits, and real-world examples showcasing their impact.
1. Strong Performance
Feature Details
Graviton processors, built on ARM architecture, deliver exceptional computational power across diverse workloads such as machine learning (ML), media processing, and microservices.
Business Benefits
Faster execution times for applications, improving user satisfaction.
Enhanced responsiveness during high-demand periods, ensuring business continuity.
Example
Lyft utilised Graviton2 instances to optimise the performance of its ride-hailing services. This resulted in reduced processing delays during peak hours, ensuring seamless ride-matching and better user experiences.
2. Cost Optimisation
Feature Details
Graviton-powered EC2 instances are priced 20–40% lower than traditional x86-based options, offering comparable or better performance.
Business Benefits
Reduced operational costs, enabling reinvestment in innovation.
Improved financial flexibility for startups and cost-sensitive businesses.
Example
Snap Inc. saved up to 40% in cloud expenses by migrating to Graviton2 instances while maintaining robust application performance for Snapchat’s millions of users.
3. Energy Efficiency
Feature Details
Graviton processors consume less energy due to their optimised ARM design, supporting businesses’ sustainability initiatives.
Business Benefits
Lower power consumption reduces utility costs.
Alignment with ESG goals, enhancing brand reputation and stakeholder trust.
Example
Netflix deployed Graviton instances for its video streaming workloads, cutting energy use and advancing its carbon-neutral goals without compromising streaming quality.
4. Flexibility and Scalability
Feature Details
Graviton integrates seamlessly with AWS services like Lambda, EC2, and Fargate, enabling efficient scaling for diverse workload demands.
Business Benefits
Easy adaptation to fluctuating workloads, reducing downtime risks.
Flexibility to innovate with serverless applications and global-scale platforms.
Example
Intuit scaled its QuickBooks platform during tax season using Graviton-based instances, handling increased traffic while maintaining smooth user experiences.
5. Advanced Security and Compatibility
Feature Details
Graviton processors include hardware-based protections against vulnerabilities and are compatible with widely used frameworks like MySQL, PostgreSQL, and Apache Spark.
Business Benefits
Enhanced security ensures compliance with industry standards, particularly in regulated sectors.
Smooth migration paths for existing workloads without the need for extensive rewrites.
Example
Redis Labs leveraged Graviton instances to secure database queries while improving client analytics response times, benefiting industries with real-time data needs.
6. Optimised for ML Workloads
Feature Details
Graviton offers a better price-to-performance ratio for ML model training and inference, enabling faster development cycles.
Business Benefits
Cost-effective scaling of AI/ML applications.
Shorter time-to-market for AI-driven innovations.
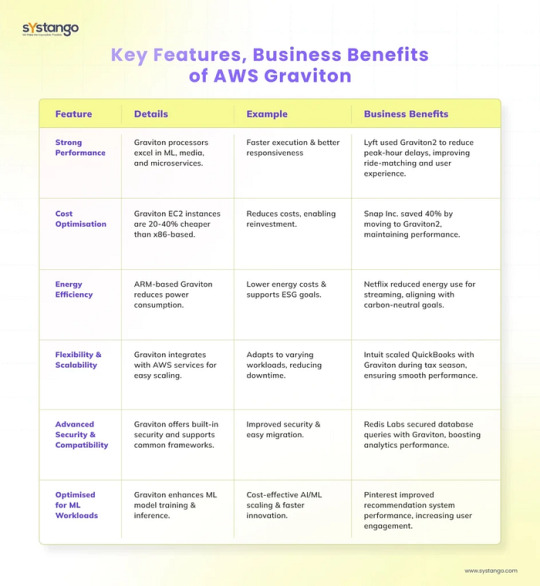
Example
Pinterest used Graviton2 instances to boost its recommendation systems, resulting in improved user engagement and personalisation for its platform.
Here’s a quick summary for decision-makers:
Business Takeaway
AWS Graviton provides a compelling combination of performance, cost efficiency, and sustainability, making it a preferred choice for businesses across industries. By adopting Graviton, enterprises can achieve operational excellence, enhance customer satisfaction, and meet sustainability goals.
III. AWS Graviton vs Intel: A Quick Comparison
Comparing AWS Graviton with Intel-based instances provides a clearer perspective for decision-makers:
Cost Efficiency: AWS Graviton instances offer 20–40% cost savings, making them a preferred choice for cloud-native workloads.
Performance: Graviton delivers up to 40% better performance for compute-intensive tasks like machine learning, while Intel shines in legacy applications needing x86 architecture.
Compatibility: Intel processors have extensive software support, but Graviton’s ARM-based architecture is optimised for modern, scalable workloads.
Energy Efficiency: AWS Graviton outperforms Intel in power efficiency, aligning with businesses focused on sustainable practices.
This comparison highlights AWS Graviton as the future-ready option for businesses seeking cost and energy efficiency while modernising their infrastructure.
IV. AWS Graviton in the Bigger AWS Ecosystem
AWS Graviton is not just a processor; it’s a vital component of the larger AWS Cloud Services ecosystem, empowering businesses to achieve operational excellence across computing, storage, and networking. Its integration capabilities make it a cornerstone of modern cloud strategies.
To read full blog visit — https://www.systango.com/blog/how-is-aws-graviton-redefining-cloud-performance-and-cost-efficiency-for-business-leaders
0 notes
Text
Using SQL for Live Data Processing in Analytics Applications
The ability to process live data is crucial for modern analytics applications. As businesses increasingly rely on real-time information to drive decision-making, the demand for systems capable of handling live data streams has grown significantly. Structured Query Language (SQL), traditionally used for batch processing and relational data management, can also be effectively used for real-time data processing. This article explores how SQL can be applied in live data processing for analytics applications, enabling businesses to access up-to-the-minute insights.
1. Understanding Live Data Processing
Live data processing, also known as real-time data processing, refers to the continuous ingestion, processing, and analysis of data as it is generated. While batch processing waits to collect and process data, real-time processing delivers immediate insights and actions. This is particularly important in scenarios where timely insights, such as fraud detection, customer service optimisation, and supply chain management, can impact business outcomes.
SQL’s capabilities have expanded beyond static datasets, now supporting real-time data processing through cutting-edge RDBMS and live stream integration.
2. SQL and Real-Time Data Ingestion
In many real-time data processing scenarios, data is continuously generated and needs to be ingested into a relational database system for analysis. SQL-based databases are equipped to handle real-time data ingestion through several mechanisms:
Streaming Data Pipelines: Tools like Apache Kafka and AWS Kinesis allow data streams to be captured and pushed into SQL databases in real time. These tools can continuously stream structured data into a relational database, where SQL queries can then be executed to analyse the incoming data.
Change Data Capture (CDC): SQL databases often employ CDC techniques to track real-time changes to source data. CDC ensures that any source system insertions, updates, or deletions are immediately reflected in the database, enabling continuous synchronisation without batch updates. This allows analytics applications to work with the most current data available at any given time.
3. Querying Live Data for Real-Time Analytics
Once data is ingested into the SQL-based system, analysts can begin querying the data in real time. SQL provides a powerful query language that handles complex aggregations and fine-grained filtering on live data. Some of the key techniques used for real-time querying include:
Window Functions: SQL window functions, such as ROW_NUMBER(), RANK(), and LEAD(), allow analysts to perform operations over a subset of rows related to the current row. This makes it easier to run moving averages, calculate trends, and rank data within real-time datasets. These functions are essential in applications that must continuously analyse data as it arrives.
Aggregation and Grouping: SQL’s aggregation functions, such as SUM(), COUNT(), and AVG(), can be applied to continuously incoming data to provide real-time insights into metrics such as sales, website traffic, or customer behavior. SQL’s ability to group data dynamically by time intervals (e.g., hourly or daily aggregates) can support real-time reporting needs.
Real-Time Joins: SQL efficiently joins multiple tables, enabling analysts to combine real-time data streams with historical records for deeper analysis. For example, real-time customer activity data can be joined with product information to personalise recommendations or understand current purchasing trends.
4. Optimizing SQL Queries for Real-Time Processing
While SQL is highly effective for querying structured data, real-time analytics often require optimised queries to handle the volume and speed of incoming data. Here are several techniques to enhance SQL query performance for live data processing:
Indexing: Indexes are critical for ensuring that SQL queries execute efficiently. When working with live data, proper indexing ensures that queries can be executed in minimal time, even as data volumes grow. Common indexing strategies include indexing frequently queried columns or using composite indexes for multi-column filtering.
Partitioning: Partitioning large tables based on certain attributes (such as time, region, or product category) can significantly speed up query execution by limiting the amount of data that needs to be scanned. For real-time applications, partitioning by time (e.g., hourly or daily partitions) is particularly effective, allowing faster access to recently ingested data.
Caching: Caching frequently accessed data reduces the time required to execute queries. SQL databases that support caching or integrate with caching systems (such as Redis) can serve data from memory, improving the speed of real-time queries.
5. Handling High-Volume Data Streams
Real-time SQL-based analytics often involve high-volume data streams, such as sensor data, user interactions, or social media feeds. To handle this volume effectively, SQL databases must be optimised for both high-throughput ingestion and low-latency query execution. A data science course covers advanced techniques for efficiently managing and analysing these real-time data streams, ensuring seamless performance and insightful decision-making.
Horizontal Scaling: Distributed SQL databases, such as Google Cloud Spanner or CockroachDB, allow for horizontal scaling, meaning additional resources can be added dynamically as data volumes increase. These databases ensure the system remains responsive under heavy load, enabling real-time analytics even for massive data streams.
Replication: For uninterrupted performance, SQL databases use replication across multiple nodes. In a failure, replicas can handle the workload, ensuring that real-time analytics continue uninterrupted.
6. Using SQL with Advanced Analytical Tools
SQL-based databases can be integrated with a range of advanced analytical tools to enhance real-time data processing capabilities. These tools often extend SQL's functionality, allowing for deeper, more sophisticated analysis.
Data Visualization: Real-time data processed via SQL queries can be integrated with visualisation tools such as Tableau, Power BI, or Looker. These tools allow analysts to create live dashboards that update automatically as new data arrives, providing up-to-the-minute insights for decision-makers.
Machine Learning Integration: Many SQL databases now offer built-in machine learning capabilities or can easily integrate with external platforms like TensorFlow or Apache Spark. This allows organisations to run machine learning models on live data and make real-time predictions.
7. Use Cases of SQL for Live Data Processing
SQL-driven real-time data processing has several practical applications in modern analytics:
Fraud Detection: Financial institutions leverage SQL to track transactions in real time, identifying potential fraud as it happens.
Customer Behavior Analysis: E-commerce platforms rely on real-time SQL queries to track user behavior, such as product views or cart activity, to personalise recommendations and optimise the user experience.
Supply Chain Optimization: Businesses can use SQL to process live data from suppliers, inventory systems, and shipping partners, enabling more accurate demand forecasting and inventory management.
SQL is not just a tool for querying static data; it is a powerful language that can be leveraged for live data processing and real-time analytics. By utilising SQL’s robust querying capabilities, optimising performance through indexing and partitioning, and integrating with advanced tools for visualisation and machine learning, businesses can harness the power of real-time data to drive better decisions. A data science course in Mumbai is very essential for professionals to learn and grow. With businesses relying on instant insights, mastering SQL enhances job prospects and ensures a competitive edge. As real-time data processing becomes essential, a structured data science course in Mumbai provides hands-on training to make professionals industry-ready.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].
0 notes
Text
Lightning Engine: A New Era for Apache Spark Speed

Apache Spark analyses enormous data sets for ETL, data science, machine learning, and more. Scaled performance and cost efficiency may be issues. Users often experience resource utilisation, data I/O, and query execution bottlenecks, which slow processing and increase infrastructure costs.
Google Cloud knows these issues well. Lightning Engine (preview), the latest and most powerful Spark engine, unleashes your lakehouse's full potential and provides best-in-class Spark performance.
Lightning Engine?
Lightning Engine prioritises file-system layer and data-access connector optimisations as well as query and execution optimisations.
Lightning Engine enhances Spark query speed by 3.6x on TPC-H workloads at 10TB compared to open source Spark on equivalent equipment.
Lightning Engine's primary advancements are shown above:
Lightning Engine's Spark optimiser is improved by Google's F1 and Procella experience. This advanced optimiser includes adaptive query execution for join removal and exchange reuse, subquery fusion to consolidate scans, advanced inferred filters for semi-join pushdowns, dynamic in-filter generation for effective row-group pruning in Iceberg and Delta tables, optimising Bloom filters based on listing call statistics, and more. Scan and shuffle savings are significant when combined.
Lightning Engine's execution engine boosts performance with a native Apache Gluten and Velox implementation designed for Google's hardware. This uses unified memory management to switch between off-heap and on-heap memory without changing Spark settings. Lightning Engine now supports operators, functions, and Spark data types and can automatically detect when to use the native engine for pushdown results.
Lightning Engine employs columnar shuffle with an optimised serializer-deserializer to decrease shuffle data.
Lightning Engine uses a parquet parser for prefetching, caching, and in-filtering to reduce data scans and metadata operations.
Lightning Engine increases BigQuery and Google Cloud Storage connection to speed up its native engine. An optimised file output committer boosts Spark application performance and reliability, while the upgraded Cloud Storage connection reduces metadata operations to save money. By providing data directly to the engine in Apache Arrow format and eliminating row-to-columnar conversions, the new native BigQuery connection simplifies data delivery.
Lightning Engine works with SQL APIs and Apache Spark DataFrame, so workloads run seamlessly without code changes.
Lightning Engine—why?
Lightning Engine outperforms cloud Spark competitors and is cheaper. Open formats like Apache Iceberg and Delta Lake can boost business efficiency using BigQuery and Google Cloud's cutting-edge AI/ML.
Lightning Engine outperforms DIY Spark implementations, saving you money and letting you focus on your business challenges.
Advantages
Main lightning engine benefits
Faster query performance: Uses a new Spark processing engine with vectorised execution, intelligent caching, and optimised storage I/O.
Leading industry price-performance ratio: Allows customers to manage more data for less money by providing superior performance and cost effectiveness.
Intelligible Lakehouse integration: Integrates with Google Cloud services including BigQuery, Vertex AI, Apache Iceberg, and Delta Lake to provide a single data analytics and AI platform.
Optimised BigQuery and Cloud Storage connections increase data access latency, throughput, and metadata operations.
Flexible deployments: Cluster-based and serverless.
Lightning Engine boosts performance, although the impact depends on workload. It works well for compute-intensive Spark Dataframe API and Spark SQL queries, not I/O-bound tasks.
Spark's Google Cloud future
Google Cloud is excited to apply Google's size, performance, and technical prowess to Apache Spark workloads with the new Lightning Engine data query engine, enabling developers worldwide. It wants to speed it up in the following months, so this is just the start!
Google Cloud Serverless for Apache Spark and Dataproc on Google Compute Engine premium tiers demonstrate Lightning Engine. Both services offer GPU support for faster machine learning and task monitoring for operational efficiency.
#ApacheSpark#LightningEngine#BigQuery#CloudStorage#ApacheSparkDataFrame#Sparkengine#technology#technews#technologynews#news#govindhtech
0 notes
Text
Scaling Hadoop Clusters for Enterprise-Level Data Processing
In today’s data-driven world, enterprises generate and process massive amounts of data daily. Hadoop, a powerful open-source framework, has emerged as a go-to solution for handling big data efficiently. However, scaling Hadoop clusters becomes crucial as organisations grow to ensure optimal performance and seamless data processing. Discover the importance of Hadoop scaling and strategies for enterprise data expansion.
Understanding Hadoop Cluster Scaling
A Hadoop cluster consists of multiple nodes that store and process data in a distributed manner. As data volumes increase, a static cluster configuration may lead to performance bottlenecks, slow processing speeds, and inefficiencies in resource utilisation. Scaling a Hadoop cluster allows businesses to enhance processing capabilities, maintain data integrity, and optimise costs while managing growing workloads.
Types of Hadoop Scaling
There are two primary approaches to scaling a Hadoop cluster: vertical scaling (scaling up) and horizontal scaling (scaling out).
Vertical Scaling (Scaling Up)
Adding more resources (CPU, RAM, or storage) to existing nodes.
Suitable for organisations that need quick performance boosts without increasing cluster complexity.
It can be costly and has hardware limitations.
Horizontal Scaling (Scaling Out)
Involves adding more nodes to the cluster, distributing the workload efficiently.
Offers better fault tolerance and scalability, making it ideal for large enterprises.
Requires efficient cluster management to ensure seamless expansion.
Challenges in Scaling Hadoop Clusters
While scaling enhances performance, enterprises face several challenges, including:
1. Data Distribution and Balancing
As new nodes are added, data must be redistributed evenly across the cluster to prevent storage imbalance.
Tools like HDFS Balancer help in redistributing data efficiently.
2. Resource Management
Managing resource allocation across an expanding cluster can be complex.
YARN (Yet Another Resource Negotiator) optimises resource usage and workload scheduling.
3. Network Bottlenecks
As data nodes increase, inter-node communication must be optimised to prevent slowdowns.
Efficient network design and load-balancing mechanisms help mitigate these challenges.
4. Security and Compliance
More nodes mean a larger attack surface, requiring robust security protocols.
Implementing encryption, authentication, and access control measures ensures data protection.
Best Practices for Scaling Hadoop Clusters
To ensure seamless scalability, enterprises should adopt the following best practices:
1. Implement Auto-Scaling
Automate cluster expansion based on workload demands to maintain efficiency.
Cloud-based Hadoop solutions offer elastic scaling to adjust resources dynamically.
2. Optimize Storage with Data Tiering
Categorise data based on access frequency and store it accordingly (e.g., hot, warm, and cold storage).
Reduces storage costs while ensuring efficient data retrieval.
3. Leverage Cloud-Based Hadoop Solutions
Cloud providers like AWS, Azure, and Google Cloud offer scalable Hadoop solutions with built-in monitoring and security.
Eliminates hardware dependencies and enables on-demand scaling.
4. Monitor Cluster Performance
Use monitoring tools like Apache Ambari and Ganglia to track system health, detect bottlenecks, and optimise resources.
Regular performance tuning enhances cluster efficiency.
5. Ensure High Availability
Implement Hadoop High Availability (HA) configurations to prevent single points of failure.
Replicate critical components like NameNode to ensure continuous operation.
Why Scaling Hadoop Clusters Matters for Data Scientists
Data scientists rely on big data processing frameworks like Hadoop to extract valuable insights from vast datasets. Efficiently scaled Hadoop clusters ensure faster query execution, real-time data processing, and seamless machine learning model training. For professionals looking to advance their skills, enrolling in a data scientist course in Pune at ExcelR can provide in-depth knowledge of big data frameworks, analytics techniques, and industry best practices.
Scaling Hadoop clusters is essential for enterprises leveraging big data for strategic decision-making. Whether through vertical or horizontal scaling, businesses must implement best practices to optimise performance, reduce operational costs, and enhance data processing capabilities. As organisations continue to generate exponential data, a well-scaled Hadoop infrastructure ensures efficiency, security, and agility in handling enterprise-level data processing challenges. For those looking to master data science and big data technologies, ExcelR offers a data scientist course in Pune, equipping professionals with the skills needed to excel in the ever-evolving field of data science.
0 notes
Text
How to Optimise Real Time Fuel Efficiency of Your TVS Apache RTR 200 Bike?
It is easy to enjoy your bike ride and achieve higher mileage by maintaining the right tyre air pressure, using the right fuel, following a regular maintenance cycle and ensuring a proper riding style.
0 notes
Text
Top Data Science Skills Employers Look for in 2024
The field of data science continues to dominate the job market in 2024, with organisations across industries actively seeking skilled professionals who can extract actionable insights from data. However, with an increasing number of candidates entering the field, standing out requires more than just a degree or certification. Employers keep a lookout for specific skills that signify a data scientist’s ability to deliver results. Whether you're a budding data scientist or looking to upgrade your expertise, enrolling in a data science course can be a game-changer. If you're located in Maharashtra, data science courses in Pune are an excellent option for getting started.
Here’s a comprehensive guide to the top data science skills employers are prioritising in 2024:
1. Proficiency in Programming Languages
Data scientists must possess strong programming skills to work efficiently with data. The two most sought-after languages are Python and R, known for their extensive libraries and frameworks designed for data manipulation, statistical analysis, and machine learning. Employers value candidates who can write clean, optimised code for tasks ranging from data preprocessing to deploying machine learning models.
If you're just starting out, look for data science courses that provide hands-on training in these languages. For instance, courses in Pune offer extensive programming modules tailored to industry requirements.
2. Strong Foundations in Statistics and Mathematics
Understanding statistical methods and mathematical concepts is the backbone of data science. Employers expect candidates to be proficient in areas such as:
Probability distributions
Hypothesis testing
Linear algebra
Optimisation techniques
These skills enable data scientists to interpret data accurately and develop reliable predictive models. A good data science course in Pune often includes in-depth modules on these concepts, ensuring you build a solid foundation.
3. Data Wrangling and Cleaning
Raw data is rarely clean or structured. Companies need professionals who can preprocess data effectively to make it usable. Skills in data wrangling—including dealing with missing values, outliers, and inconsistent formats—are critical.
Tools like Pandas and NumPy in Python are essential for this task. If you're looking to master these tools, enrolling in comprehensive data science courses can help you gain the expertise required to handle messy datasets.
4. Expertise in Machine Learning Algorithms
Machine learning (ML) remains at the heart of data science. Employers look for candidates familiar with both supervised and unsupervised learning algorithms, such as:
Regression models
Decision trees
Random forests
Clustering methods
Neural networks
Being able to implement and fine-tune these algorithms is vital for solving real-world problems. Many data science courses in Pune offer practical projects that simulate industry scenarios, helping you gain hands-on experience with ML models.
5. Data Visualisation and Storytelling
Conveying insights to stakeholders is as important as deriving them. Employers seek candidates skilled in data visualisation tools like:
Tableau
Power BI
Matplotlib and Seaborn
The ability to craft compelling visual narratives ensures that decision-makers understand and trust your insights. Opt for a data science course that includes modules on data storytelling to strengthen this crucial skill.
6. Knowledge of Big Data Tools
In 2024, businesses deal with massive volumes of data. Handling such data efficiently requires expertise in big data technologies like:
Apache Hadoop
Apache Spark
Hive
These tools are highly valued by organisations working on large-scale data processing. A specialised data science course in Pune often integrates these tools into its curriculum to prepare you for big data challenges.
7. Cloud Computing Skills
With most companies transitioning to cloud-based infrastructure, data scientists are expected to have a working knowledge of platforms like AWS, Azure, and Google Cloud. Skills in deploying data pipelines and machine learning models on the cloud are particularly in demand.
Some advanced data science course in pune offer cloud computing modules to help professionals gain a competitive edge.
8. Business Acumen
Employers favor data scientists who understand the business domain they operate in. This skill helps align data science efforts with organisational goals. Whether you're working in finance, healthcare, or retail, the ability to contextualise data insights for business impact is invaluable.
Courses in cities like Pune often include case studies and projects that simulate real-world business challenges, enabling students to develop industry-relevant expertise.
9. Soft Skills: Communication and Team Collaboration
Data science is not a solo endeavour. Employers prioritise candidates who can communicate their findings effectively and collaborate with cross-functional teams. Strong presentation skills and a knack for simplifying technical concepts for non-technical audiences are essential.
10. Continuous Learning Mindset
The rapidly evolving nature of data science means professionals must stay updated on new tools, frameworks, and methodologies. Employers value individuals who show a commitment to learning, making ongoing professional development crucial.

Conclusion
The demand for professionals in data science will only grow in the coming years, but standing out in this competitive field requires mastering a mix of technical and non-technical skills. Whether it’s honing your programming capabilities, diving into machine learning, or building your storytelling prowess, each skill enhances your employability.
For aspiring data scientists, taking part in a data science education tailored to industry demands is the first step. If you’re in Maharashtra, consider enrolling in data science courses in Pune, where you can access high-quality training and networking opportunities in the city’s thriving tech ecosystem.
By investing in your skill set today, you can position yourself as a top candidate in the ever-evolving data science job market.
Business Name: ExcelR - Data Science, Data Analytics Course Training in Pune
Address: 101 A ,1st Floor, Siddh Icon, Baner Rd, opposite Lane To Royal Enfield Showroom, beside Asian Box Restaurant, Baner, Pune, Maharashtra 411045
Phone Number: 098809 13504
Email : [email protected]
0 notes
Text
Apache Project: Crafting a Sci-Fi Factory in Unreal Engine | Step 06
Texturing the Trim Sheet in Substance Painter
With the modeling phase complete, I moved the trim sheet high poly and low poly meshes into Substance Painter to begin the crucial step of texturing. This was a key moment in the pipeline, as the quality of the trim sheet would directly influence the look and feel of multiple environment assets.
Baking and Setup I began by baking the high poly details onto the low poly plane inside Substance Painter. I ensured clean and artifact-free maps, especially the normal, curvature, and ambient occlusion, which are essential for creating believable edge wear and material definition.
Once the bake was successful, I started building the material layers from the ground up.
Building the Look The texturing process was about layering story and function into the trim sheet. I didn’t rush it—I worked layer by layer, tweaking and refining until the materials felt grounded, gritty, and visually compelling. Some of the key elements I focused on:
Base Metal Layer: A sturdy, industrial base metal with subtle tonal variation and roughness breakup to avoid any flat-looking surfaces.
Grime and Dirt Pass: I applied procedural masks and custom grunge maps to simulate age and usage, making sure the trim didn’t look overly clean or sterile.
Scratches and Edge Wear: Using both smart masks and hand-painting, I emphasized areas that would naturally catch light or wear down from repeated contact.
Randomness: To avoid repetition, I added micro details like color variation, oil stains, smudges, and subtle paneling irregularities. These small touches added realism and helped the trim sheet feel lived-in and believable.
I iterated a lot during this phase, constantly rotating the lighting, tweaking roughness values, and zooming in and out to ensure that it worked both up close and from a distance.
Final Result By the end of this step, I had a richly detailed and versatile trim sheet, ready to be applied across a variety of environment assets inside Unreal Engine. The materials felt tactile and dynamic, with just the right amount of wear and randomness to break up any uniformity and make each asset feel unique when mapped correctly.
This textured trim sheet now serves as a central material source for pillars, walls, railings, stairs, and more, ensuring visual consistency and optimised performance across the environment.
0 notes