#Scrape or Extract Wikipedia Data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text
Wikipedia Data Scraping Services | Scrape Wikipedia Data

In the digital age, data is the lifeblood of decision-making. Businesses, researchers, and enthusiasts constantly seek reliable sources of information to fuel their insights. Wikipedia, with its vast repository of knowledge, serves as a goldmine for this purpose. However, manually extracting data from Wikipedia can be a daunting and time-consuming task. This is where Wikipedia data scraping services come into play, offering a streamlined and efficient way to harness the wealth of information available on the platform.
What is Wikipedia Data Scraping?
Wikipedia data scraping involves using automated tools and techniques to extract information from Wikipedia pages. This process bypasses the need for manual copying and pasting, allowing for the efficient collection of large datasets. Scraping can include extracting text, infoboxes, references, categories, and even multimedia content. The scraped data can then be used for various purposes, such as research, analysis, and integration into other applications.
Why Scrape Wikipedia Data?
Extensive Knowledge Base: Wikipedia hosts millions of articles on a wide range of topics, making it an invaluable resource for information.
Regular Updates: Wikipedia is continuously updated by contributors worldwide, ensuring that the information is current and reliable.
Structured Data: Many Wikipedia pages contain structured data in the form of infoboxes and tables, which can be particularly useful for data analysis.
Open Access: Wikipedia's content is freely accessible, making it a cost-effective source of data for various applications.
Applications of Wikipedia Data Scraping
Academic Research: Researchers can use scraped Wikipedia data to support their studies, gather historical data, or analyze trends over time.
Business Intelligence: Companies can leverage Wikipedia data to gain insights into market trends, competitors, and industry developments.
Machine Learning: Wikipedia's vast dataset can be used to train machine learning models, improve natural language processing algorithms, and develop AI applications.
Content Creation: Writers and content creators can use Wikipedia data to enrich their articles, blogs, and other forms of content.
How Wikipedia Data Scraping Works
Wikipedia data scraping involves several steps:
Identify the Target Pages: Determine which Wikipedia pages or categories contain the data you need.
Select a Scraping Tool: Choose a suitable web scraping tool or service. Popular options include Python libraries like BeautifulSoup and Scrapy, as well as online scraping services.
Develop the Scraping Script: Write a script that navigates to the target pages, extracts the desired data, and stores it in a structured format (e.g., CSV, JSON).
Handle Potential Challenges: Address challenges such as rate limiting, CAPTCHA verification, and dynamic content loading.
Data Cleaning and Processing: Clean and process the scraped data to ensure it is accurate and usable.
Ethical Considerations and Legal Compliance
While Wikipedia data scraping can be incredibly useful, it is essential to approach it ethically and legally. Here are some guidelines to follow:
Respect Wikipedia’s Terms of Service: Ensure that your scraping activities comply with Wikipedia’s terms of use and guidelines.
Avoid Overloading Servers: Implement rate limiting to prevent overwhelming Wikipedia’s servers with too many requests in a short period.
Credit the Source: Always credit Wikipedia as the source of the data and provide links to the original pages where possible.
Privacy Concerns: Be mindful of any personal information that might be present in the scraped data and handle it responsibly.
Choosing the Right Wikipedia Data Scraping Service
Several factors should be considered when selecting a Wikipedia data scraping service:
Reputation: Choose a service with a proven track record and positive reviews from users.
Customization: Look for services that offer customizable scraping solutions tailored to your specific needs.
Data Quality: Ensure the service provides clean, accurate, and well-structured data.
Support and Maintenance: Opt for services that offer ongoing support and maintenance to address any issues that may arise.
Conclusion
Wikipedia data scraping services open up a world of possibilities for accessing and utilizing the vast amounts of information available on the platform. Whether for academic research, business intelligence, machine learning, or content creation, these services provide a powerful tool for extracting valuable insights. By adhering to ethical practices and legal guidelines, users can harness the full potential of Wikipedia data to drive innovation and informed decision-making.
As the demand for data-driven insights continues to grow, Wikipedia data scraping services will undoubtedly play a crucial role in shaping the future of information access and analysis.
0 notes
Text
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#generative ai#pulling this out wasnt really prompted by anything specific#so much as heard some repeated misconceptions and just#sighs#nope#incorrect#u got it wrong#sorry#unfortunately for me: no consistent tag to block#sigh#ao3
101 notes
·
View notes
Text
silicon valley had ai 15 years before they released it. everything we’re seeing is a decade old and scraped from the sites literally everybody uses. reddit has chat gpt 10 years ago. reddit had programmes to regurgitate arguments last time trump was elected. they tested it in New Zealand first and one of our journalists nicky hager wrote about it in a book all about political corruption and then those bots that were trained on what was good or bad with upvotes or downvotes or “likes” or “dislikes”. this self-selects which bots are most human-like and have the best ‘answers’. tumblr was the testing ground.
does anyone remember getting bogus asks that were made up of random punctuation and letters? bots. we taught bots to speak by replying to the ones that resembled words. then those bots went around messaging people and no one answered them except themselves. and these bots also had blogs that made posts to try and get upvoted (which told them they were a good tumblr human) and they’d send each other messages and their data centers would mine the messages they received and we’re all still using asks because staff won’t give us a chat for some reason but it’s mostly just porn bots mining data from other bots. silicon valley has to ban porn to deal with the rampant horny porn bots. it mostly works but some of the bots still carry on. yahoo sells us, the worthless userbase, at a massive loss. we laugh at them. they have all our data, hand-extracted.
they give us chat. they begin mining chat for data. it’s still pre-2016
they took the bots trained on our terfs and reddits dudebros and facebooks old people. and they used it in the 2016 election with full chat gpt capability and image generation so that when they released language bots in the future we are dazzled by the words ai and are impressed their at programmes who can by now fully impersonate a human, a thousand humans, but is just telling us wrong wikipedia facts. we laugh at the stupid ai. we continue to vaguely ignore the growing number of bot-like people infesting the internet.
trump just won an election over what the media tells us is a “culture war” while billionaires dripfeed us data mining tech to extract human traits for their ais. they learn through logic and iteration but can’t think for themselves. the right has stagnated, the left grow frustrated with people’s unbudging opinions. but most of the arguments being made are by bots. most people are arguing with bots, bots are arguing with bots. there is a disconnect where influence can be exerted politically.
no one irl wants to mention politics because it’s so divisive. the news talks politics, the bots talk politics. the people do not talk politics.
5 notes
·
View notes
Text
Open Deep Search (ODS)
XUẤT HIỆN ĐỐI THỦ OPEN SOURCE NGANG CƠ THẬM CHÍ HƠN PERPLEXITY SEARCH

XUẤT HIỆN ĐỐI THỦ OPEN SOURCE NGANG CƠ THẬM CHÍ HƠN PERPLEXITY SEARCH
Open đang phả hơi nóng và gáy close source trên các mặt trận trong đó có search và deep search. Open Deep Search (ODS) là một giải pháp như thế.
Hiệu suất và Benchmarks của ODS:
- Cải thiện độ chính xác trên FRAMES thêm 9.7% so với GPT-4o Search Preview. Khi xài model DeepSeek-R1, ODS đạt 88.3% chính xác trên SimpleQA và 75.3% trên FRAMES.
- SimpleQA kiểu như các câu hỏi đơn giản, trả lời đúng sai hoặc ngắn gọn. ODS đạt 88.3% tức là nó trả lời đúng gần 9/10 lần.
- FRAMES thì phức tạp hơn, có thể là bài test kiểu phân tích d��� liệu hay xử lý ngữ cảnh dài. 75.3% không phải max cao nhất, nhưng cộng thêm cái vụ cải thiện 9.7% so với GPT-4o thì rõ ràng ODS không phải dạng vừa.
CÁCH HOẠT ĐỘNG
1. Context retrieval toàn diện, không bỏ sót
ODS không phải kiểu nhận query rồi search bừa. Nó nghĩ sâu hơn bằng cách tự rephrase câu hỏi của user thành nhiều phiên bản khác nhau. Ví dụ, hỏi "cách tối ưu code Python", nó sẽ tự biến tấu thành "làm sao để Python chạy nhanh hơn" hay "mẹo optimize Python hiệu quả". Nhờ vậy, dù user diễn đạt hơi lủng củng, nó vẫn moi được thông tin chuẩn từ web.
2. Retrieval và filter level pro
Không như một số commercial tool chỉ bê nguyên dữ liệu từ SERP, ODS chơi hẳn combo: lấy top kết quả, reformat, rồi xử lý lại. Nó còn extract thêm metadata như title, URL, description để chọn lọc nguồn ngon nhất. Sau đó, nó chunk nhỏ nội dung, rank lại dựa trên độ liên quan trước khi trả về cho LLM.
Kết quả: Context sạch sẽ, chất lượng, không phải đống data lộn xộn.
3. Xử lý riêng cho nguồn xịn
Con này không search kiểu generic đâu. Nó có cách xử lý riêng cho các nguồn uy tín như Wikipedia, ArXiv, PubMed. Khi scrape web, nó tự chọn đoạn nội dung chất nhất, giảm rủi ro dính fake news – đây là công đoạn mà proprietary tool ít để tâm.
4. Cơ chế search thông minh, linh hoạt
ODS không cố định số lần search. Query đơn giản thì search một phát là xong, nhưng với câu hỏi phức tạp kiểu multi-hop như "AI ảnh hưởng ngành y thế nào trong 10 năm tới", nó tự động gọi thêm search để đào sâu. Cách này vừa tiết kiệm tài nguyên, vừa đảm bảo trả lời chất. Trong khi đó, proprietary tool thường search bục mặt, tốn công mà kết quả không đã.
5. Open-source – minh bạch và cải tiến liên tục
Là tool open-source, code với thuật toán của nó ai cũng thấy, cộng đồng dev tha hồ kiểm tra, nâng cấp. Nhờ vậy, nó tiến hóa nhanh hơn các hệ thống đóng của proprietary.
Tóm lại
ODS ăn đứt proprietary nhờ: rephrase query khéo, retrieval/filter xịn, xử lý riêng cho nguồn chất, search linh hoạt, và cộng đồng open-source đẩy nhanh cải tiến.
2 notes
·
View notes
Text
What Are the Best Practices to Scrape Wikipedia With Python Efficiently?

Introduction
Wikipedia, the treasure trove of knowledge, is a go-to source for data across various fields, from research and education to business intelligence and content creation. Leveraging this wealth of information can provide a significant advantage for businesses and developers. However, manually collecting data from Wikipedia can be time- consuming and prone to errors. This is where you can Scrape Wikipedia With Python, an efficient, scalable, and reliable method for extracting information.
This blog will explore best practices for web scraping Wikipedia using Python, covering essential tools, ethical considerations, and real-world applications. We’ll also include industry statistics for 2025, examples, and a case study to demonstrate the power of Wikipedia Data Extraction.
Why Scrape Wikipedia With Python?
Wikipedia is one of the largest repositories of knowledge on the internet, providing a vast array of information on diverse topics. For businesses, researchers, and developers, accessing this data efficiently is crucial for making informed decisions, building innovative solutions, and conducting in-depth analyses. Here’s why you should consider Scrape Wikipedia With Python as your go-to approach for data extraction.
Efficiency and Flexibility
Web scraping Wikipedia using Python allows quick and efficient structured and unstructured data extraction. Python’s powerful libraries, like BeautifulSoup, Requests, and Pandas, simplify the process of extracting and organizing data from Wikipedia pages. Unlike manual methods, automation significantly reduces time and effort.
Access to Rich Data
From tables and infoboxes to article content and references, Wikipedia Data Extraction provides a goldmine of information for industries like education, market research, and artificial intelligence. Python’s versatility ensures you can extract exactly what you need, tailored to your use case.
Cost-Effective Solution
Leveraging Web scraping Wikipedia eliminates the need for expensive third-party services. Python scripts allow you to collect data at minimal costs, enhancing scalability and sustainability.
Applications Across Industries
Researchers use Wikipedia Data Extraction to build datasets in natural language processing and knowledge graphs.
Businesses analyze trends and competitor information for strategy formulation.
Developers use Web scraping Wikipedia for content creation, chatbots, and machine learning models.
Ethical and Efficient
Python enables compliance with Wikipedia’s scraping policies through APIs and structured extraction techniques. This ensures ethical data use while avoiding legal complications.
Scrape Wikipedia With Python to unlock insights, streamline operations, and power your projects with precise and reliable data. It’s a game- changer for organizations looking to maximize the potential of data.
Key Tools for Web Scraping Wikipedia Using Python
When you set out to Scrape Wikipedia With Python, having the right tools is crucial for efficient and effective data extraction. Below are some of the essential libraries and frameworks you can use:
1. BeautifulSoup
BeautifulSoup is one of the most popular Python libraries for web scraping Wikipedia. It allows you to parse HTML and XML documents, making navigating and searching the page structure easier. BeautifulSoup helps extract data from Wikipedia page tables, lists, and text content. It is known for its simplicity and flexibility in handling complex web structures.
2. Requests
The Requests library is used to send HTTP requests to Wikipedia and retrieve the HTML content of the page. It simplifies fetching data from a website and is essential for initiating the scraping process. With Requests, you can interact with Wikipedia’s servers and fetch the pages you want to scrape while seamlessly handling session management, authentication, and headers.
3. Pandas
Once the data is scraped, Pandas come in handy for organizing, cleaning, and analyzing the data. This library provides powerful data structures, like DataFrames, perfect for working with structured data from Wikipedia. Pandas can handle data transformation and cleaning tasks, making it an essential tool for post-scraping data processing.
4. Wikipedia API
Instead of scraping HTML pages, you can use the Wikipedia API to access structured data from Wikipedia directly. This API allows developers to request information in a structured format, such as JSON, making it faster and more efficient than parsing raw HTML content. The Wikipedia API is the recommended way to retrieve data from Wikipedia, ensuring compliance with the site's usage policies.
5. Selenium
When scraping pages with dynamic content, Selenium is the go-to tool. It automates web browsers, allowing you to interact with JavaScript-heavy websites. If Wikipedia pages load content dynamically, Selenium can simulate browsing actions like clicking and scrolling to extract the necessary data.
6. Scrapy
For larger, more complex scraping projects, Scrapy is a powerful and high-performance framework. It’s an open-source tool that enables scalable web scraping, allowing users to build spiders to crawl websites and gather data. Scrapy is ideal for advanced users building automated, large-scale scraping systems.
Utilizing these tools ensures that your Wikipedia Data Extraction is efficient, reliable, and scalable for any project.
Best Practices for Efficient Wikipedia Data Extraction
Regarding Wikipedia Data Extraction, adopting best practices ensures that your web scraping is efficient but also ethical and compliant with Wikipedia’s guidelines. Below are the key best practices for effective scraping:
1. Use the Wikipedia API
Rather than scraping HTML directly, it is best to leverage the Wikipedia API for structured data retrieval. The API allows you to request data in formats like JSON, making it faster and more reliable than parsing raw HTML. It also reduces the likelihood of errors and ensures you abide by Wikipedia's scraping guidelines. The API provides access to detailed articles, infoboxes, categories, and page revisions, making it the optimal way to extract Wikipedia data.
2. Respect Wikipedia’s Robots.txt
Always check Wikipedia's robots.txt file to understand its scraping policies. This file defines the rules for web crawlers, specifying which sections of the site are allowed to be crawled and scraped. Adhering to these rules helps prevent disruptions to Wikipedia’s infrastructure while ensuring your scraping activity remains compliant with its policies.
3. Optimize HTTP Requests
When scraping large volumes of data, optimizing HTTP requests is crucial to avoid overloading Wikipedia’s servers. Implement rate limiting, ensuring your scraping activities are paced and don’t overwhelm the servers. You can introduce delays between requests or use exponential backoff to minimize the impact of scraping on Wikipedia’s resources.
4. Handle Edge Cases
Be prepared for pages with inconsistent formatting, missing data, or redirects. Wikipedia is a vast platform with a wide range of content, so not all pages will have the same structure. Implement error-handling mechanisms to manage missing data, broken links, or redirects. This will ensure your script doesn’t break when encountering such anomalies.
5. Parse Tables Effectively
Wikipedia is filled with well-structured tables that contain valuable data. Pandas is an excellent library for efficiently extracting and organizing tabular data. Using Pandas, you can easily convert the table data into DataFrames, clean it, and analyze it as required.
6. Focus on Ethical Scraping
Lastly, ethical scraping should always be a priority. Respect copyright laws, provide proper attribution for extracted data, and avoid scraping sensitive or proprietary information. Ensure that the data you collect is used responsibly, complies with Wikipedia’s licensing terms, and contributes to the greater community.
By following these best practices, you can ensure that your web scraping activities on Wikipedia using Python are both practical and ethical while maximizing the value of the extracted data.
Real-Life Use Cases for Web Scraping Wikipedia
1. Academic Research
Web scraping Wikipedia can be valuable for academic researchers, especially in linguistics, history, and social sciences. Researchers often need large datasets to analyze language patterns, historical events, or social dynamics. With its vast structured information repository, Wikipedia provides an excellent source for gathering diverse data points. For instance, linguists might scrape Wikipedia to study language usage across different cultures or periods, while historians might gather data on events, figures, or periods for historical analysis. By scraping specific articles or categories, researchers can quickly build extensive datasets that support their studies.
2. Business Intelligence
Wikipedia data extraction plays a crucial role in competitive analysis and market research for businesses. Companies often scrape Wikipedia to analyze competitors' profiles, industry trends, and company histories. This information helps businesses make informed strategic decisions. Organizations can track market dynamics and stay ahead of trends by extracting and analyzing data on companies' growth, mergers, key executives, or financial milestones. Wikipedia pages related to industry sectors or market reports can also provide real-time data to enhance business intelligence.
3. Machine Learning Projects
Wikipedia serves as a rich source of training data for machine learning projects. For natural language processing (NLP) models, scraping Wikipedia text enables the creation of large corpora to train models on tasks like sentiment analysis, language translation, or entity recognition. Wikipedia's diverse and well-structured content makes it ideal for building datasets for various NLP applications. For example, a machine learning model designed to detect language nuances could benefit significantly from scraping articles across different topics and languages.
4. Knowledge Graphs
Extract Wikipedia data to build knowledge graphs for AI applications. Knowledge graphs organize information in a structured way, where entities like people, places, events, and concepts are connected through relationships. Wikipedia's well-organized data and links between articles provide an excellent foundation for creating these graphs. Scraping Wikipedia helps populate these knowledge bases with data that can power recommendation systems, semantic search engines, or personalized AI assistants.
5. Content Creation
Content creators often use Wikipedia data collection to streamline their work. By scraping Wikipedia, content creators can quickly generate fact-checks, summaries, or references for their articles, blogs, and books. Wikipedia's structured data ensures the information is reliable and consistent, making it a go-to source for generating accurate and up-to-date content. Bloggers and journalists can use scraped data to support their writing, ensuring their content is well-researched and informative.
Through these use cases, it is clear that web scraping Wikipedia offers numerous possibilities across various industries, from academia to business intelligence to AI development.
Statistics for 2025: The Impact of Data Scraping
By 2025, the global web scraping market is anticipated to reach a staggering $10.7 billion, fueled by the increasing need for automated data collection tools across various industries. As businesses rely more on data to drive decisions, the demand for efficient and scalable scraping solutions continues to rise, making this a key growth sector in the tech world.
Wikipedia plays a significant role in this growth, as it receives over 18 billion page views per month, making it one of the richest sources of free, structured data on the web. With millions of articles spanning virtually every topic imaginable, Wikipedia is a goldmine for businesses and researchers looking to collect large amounts of information quickly and efficiently.
The impact of web scraping on business performance is substantial. Companies leveraging scraping tools for data-driven decision-making have reported profit increases of up to 30%. By automating the collection of crucial market intelligence—such as competitor pricing, product availability, or customer sentiment—businesses can make quicker, more informed decisions that lead to improved profitability and competitive advantage.
As the web scraping industry continues to evolve and expand, the volume of accessible data and the tools to harvest it will grow, further shaping how businesses and researchers operate in the future.
Case Study: Extracting Data for Market Analysis
Challenge
A leading media analytics firm faced a significant challenge in tracking public opinion and historical events for its trend analysis reports. They needed to gather structured data on various topics, including social issues, historical events, political figures, and market trends. The firm’s existing process of manually collecting data was time-consuming and resource-intensive, often taking weeks to gather and process relevant information. This delay affected their client’s ability to provide timely insights, ultimately hindering their market intelligence offerings.
Solution
The firm leveraged Python and the Wikipedia API for large-scale data extraction to overcome these challenges. Using Python’s powerful libraries, such as Requests and BeautifulSoup, combined with the Wikipedia API, the firm could automate the data extraction process and pull structured data from Wikipedia’s vast repository of articles. This allowed them to access relevant content from thousands of Wikipedia pages in a fraction of the time compared to traditional methods. The firm gathered data on historical events, public opinion trends, and key industry topics. They set up an automated system to scrape, clean, and organize the data into a structured format, which could then be used for in-depth analysis.
Outcome
The results were significant. The firm was able to build a dynamic database of market intelligence, providing clients with real-time insights. By automating the data collection process, they saved approximately 60% of the time it previously took to gather the same amount of data.
The firm was able to deliver trend analysis reports much faster, improving client satisfaction and strengthening its position as a leader in the media analytics industry. The successful implementation of this solution not only streamlined the firm’s data collection process but also enhanced its ability to make data-driven decisions and offer more actionable insights to its clients.
Challenges in Web Scraping Wikipedia
While web scraping Wikipedia offers great potential for data collection and analysis, several challenges need to be addressed to ensure an effective and compliant scraping process.
1. Dynamic Content
Wikipedia pages often contain dynamic content, such as tables, infoboxes, and images, which may not always be easily accessible through traditional scraping methods. In some cases, these elements are rendered dynamically by JavaScript or other scripting languages, making extracting the data in a structured format more difficult. To handle this, advanced parsing techniques or tools like Selenium may be required to interact with the page as it loads or to simulate user behavior. Additionally, API calls may be needed to retrieve structured data rather than scraping raw HTML, especially for complex elements such as tables.
2. Data Volume
Wikipedia is a vast repository with millions of articles and pages across various languages. Scraping large volumes of data from Wikipedia can quickly become overwhelming in terms of the data size and the complexity of processing it. Efficient data handling is essential to avoid performance bottlenecks. For example, optimizing scraping scripts to manage memory usage, store data efficiently, and perform incremental scraping can significantly improve the overall process. Additionally, large datasets may require robust storage solutions, such as databases or cloud storage, to organize and manage the extracted data.
3. Compliance
Wikipedia operates under strict ethical guidelines, and scraping must comply with these standards. This includes respecting robots.txt directives, which specify which pages or sections of the site are off-limits for scraping. Furthermore, adhering to Wikipedia’s licensing policies and giving proper attribution for the data extracted is vital to avoid copyright violations. Ensuring compliance with legal standards and maintaining ethical practices throughout the scraping process is crucial for long-term success and avoiding potential legal issues.
By understanding and addressing these challenges, businesses and researchers can scrape Wikipedia efficiently and responsibly, extracting valuable insights without compromising data quality or compliance.
Mobile App Scraping: An Extension of Data Collection
While web scraping services have long been famous for gathering data from websites, mobile app scraping is rapidly becoming an essential extension of modern data collection techniques. As mobile applications dominate the digital landscape, businesses realize the immense potential of extracting data directly from apps to enhance their competitive advantage and drive informed decision-making.
Unlike websites, mobile apps often feature data not publicly available on their corresponding websites, such as real-time inventory information, user reviews, personalized recommendations, and even app-specific pricing models. This unique data can give businesses a more granular view of their competitors and market trends, offering insights that are often harder to obtain through traditional scraping methods. For example, mobile apps for grocery delivery services, e-commerce platforms, and ride-sharing apps frequently have detailed information about pricing, promotions, and consumer behavior not displayed on their websites.
Mobile app scraping can also benefit industries that rely on real-time data. For instance, travel and tourism companies can scrape mobile apps for flight availability, hotel prices, and rental car data. Similarly, the e- commerce sector can extract product data from mobile shopping apps to keep track of stock levels, prices, and seasonal discounts.
However, scraping mobile apps presents unique challenges, such as dealing with app-specific APIs, handling dynamic content, and overcoming security measures like CAPTCHAs or rate limits. Despite these challenges, businesses that implement effective mobile app scraping strategies gain a competitive edge by accessing often overlooked or unavailable data through traditional web scraping.
By incorporating mobile app scraping into their data collection processes, businesses can unlock valuable insights, stay ahead of competitors, and ensure they have the most up-to-date information for market analysis and decision-making.
Conclusion
Web scraping is a powerful tool for businesses, and scraping Wikipedia with Python offers unparalleled opportunities to collect and analyze data efficiently. Whether you’re a researcher, business analyst, or developer, following the best practices outlined in this blog ensures successful data extraction while respecting Wikipedia’s guidelines.
Ready to streamline your data collection process? Partner with Web Data Crawler today for efficient, ethical, customizable solutions. From Web Scraping Services to APIs, we have the tools to meet your business needs. Explore our services and take your data strategy to the next level!
Originally Published At :
1 note
·
View note
Text
Web Scraping 101: Understanding the Basics
Data Analytics, also known as the Science of Data, has various types of analytical methodologies, But the very interesting part of all the analytical process is collecting data from different sources. It is challenging to collect data while keeping the ACID terms in mind. I'll be sharing a few points in this article which I think is useful while learning the concept of Web Scrapping.
The very first thing to note is not every website allows you to scrape their data.
Before we get into the details, though, let’s start with the simple stuff…

What is web scraping?
Web scraping (or data scraping) is a technique used to collect content and data from the internet. This data is usually saved in a local file so that it can be manipulated and analyzed as needed. If you’ve ever copied and pasted content from a website into an Excel spreadsheet, this is essentially what web scraping is, but on a very small scale.
However, when people refer to ‘web scrapers,’ they’re usually talking about software applications. Web scraping applications (or ‘bots’) are programmed to visit websites, grab the relevant pages and extract useful information.
Suppose you want some information from a website. Let’s say a paragraph on Weather Forecasting! What do you do? Well, you can copy and paste the information from Wikipedia into your file. But what if you want to get large amounts of information from a website as quickly as possible? Such as large amounts of data from a website to train a Machine Learning algorithm? In such a situation, copying and pasting will not work! And that’s when you’ll need to use Web Scraping. Unlike the long and mind-numbing process of manually getting data, Web scraping uses intelligence automation methods to get thousands or even millions of data sets in a smaller amount of time.
As an entry-level web scraper, getting familiar with the following tools will be valuable:
1. Web Scraping Libraries/Frameworks:
Familiarize yourself with beginner-friendly libraries or frameworks designed for web scraping. Some popular ones include: BeautifulSoup (Python): A Python library for parsing HTML and XML documents. Requests (Python): A simple HTTP library for making requests and retrieving web pages. Cheerio (JavaScript): A fast, flexible, and lightweight jQuery-like library for Node.js for parsing HTML. Scrapy (Python): A powerful and popular web crawling and scraping framework for Python.
2. IDEs or Text Editors:
Use Integrated Development Environments (IDEs) or text editors to write and execute your scraping scripts efficiently. Some commonly used ones are: PyCharm, Visual Studio Code, or Sublime Text for Python. Visual Studio Code, Atom, or Sublime Text for JavaScript.
3. Browser Developer Tools:
Familiarize yourself with browser developer tools (e.g., Chrome DevTools, Firefox Developer Tools) for inspecting HTML elements, testing CSS selectors, and understanding network requests. These tools are invaluable for understanding website structure and debugging scraping scripts.
4. Version Control Systems:
Learn the basics of version control systems like Git, which help manage your codebase, track changes, and collaborate with others. Platforms like GitHub and GitLab provide repositories for hosting your projects and sharing code with the community.
5. Command-Line Interface (CLI):
Develop proficiency in using the command-line interface for navigating file systems, running scripts, and managing dependencies. This skill is crucial for executing scraping scripts and managing project environments.
6. Web Browsers:
Understand how to use web browsers effectively for browsing, testing, and validating your scraping targets. Familiarity with different browsers like Chrome, Firefox, and Safari can be advantageous, as they may behave differently when interacting with websites.
7.Documentation and Online Resources:
Make use of official documentation, tutorials, and online resources to learn and troubleshoot web scraping techniques. Websites like Stack Overflow, GitHub, and official documentation for libraries/frameworks provide valuable insights and solutions to common scraping challenges.
By becoming familiar with these tools, you'll be equipped to start your journey into web scraping and gradually build upon your skills as you gain experience.
learn more
Some good Python web scraping tutorials are:
"Web Scraping with Python" by Alex The Analyst - This comprehensive tutorial covers the basics of web scraping using Python libraries like BeautifulSoup and Requests.
These tutorials cover a range of web scraping techniques, libraries, and use cases, allowing you to choose the one that best fits your specific project requirements. They provide step-by-step guidance and practical examples to help you get started with web scraping using Python
1 note
·
View note
Text
It Is Possible to 'Poison' the Data to Compromise AI Chatbots With Little Effort - Technology Org
New Post has been published on https://thedigitalinsider.com/it-is-possible-to-poison-the-data-to-compromise-ai-chatbots-with-little-effort-technology-org/
It Is Possible to 'Poison' the Data to Compromise AI Chatbots With Little Effort - Technology Org
According to researchers, individuals could potentially disrupt the accuracy of AI chatbots by intentionally contaminating the datasets upon which these systems rely, all for a minimal cost.
Coding a chatbot – illustrative photo. Image credit: James Harrison via Unsplash, free license
As it stands, AI chatbots already exhibit biases and deficiencies attributable to the flawed data on which they are trained. The researchers’ investigation described on Business Insider revealed that malevolent actors could deliberately introduce “poisoned” data into these datasets, with some methods requiring little technical expertise and being relatively inexpensive.
A recent study conducted by AI researchers unveiled that, with as little as $60, individuals could manipulate the datasets essential for training generative AI tools akin to ChatGPT, which are crucial for providing precise responses.
These AI systems, whether chatbots or image generators, leverage vast amounts of data extracted from the expansive digital realm of the internet to generate sophisticated responses and images.
Florian Tramèr, an associate professor of computer science at ETH Zurich, highlighted the effectiveness of this approach in empowering chatbots. However, he also underscored the inherent risk associated with training AI tools on potentially inaccurate data.
This reliance on potentially flawed data sources contributes to the prevalence of biases and inaccuracies in AI chatbots. Given the abundance of misinformation on the internet, these systems are susceptible to incorporating erroneous information into their responses, further undermining their reliability and trustworthiness.
Through their investigation, researchers discovered that even a “low-resourced attacker,” armed with modest financial resources and sufficient technical expertise, could manipulate a relatively small portion of data to substantially influence the behavior of a large language model, causing it to produce inaccurate responses.
Examining two distinct attack methods, Tramèr and his colleagues explored the potential of poisoning data through the acquisition of expired domains and manipulation of Wikipedia content.
For instance, one avenue for hackers to poison the data involves purchasing expired domains, which can be obtained for as little as $10 annually for each URL, and then disseminating any desired information on these websites.
According to Tramèr’s paper, an attacker could effectively control and contaminate at least 0.01% of a dataset by investing as little as $60 in purchasing domains. This equates to potentially influencing tens of thousands of images within the dataset.
The team also explored an alternative attack strategy, focusing on the manipulation of data within Wikipedia. Given that Wikipedia serves as a “crucial component of the training datasets” for language models, Tramèr emphasized its significance in this context.
According to the author, Wikipedia prohibits direct scraping of its content, instead offering periodic “snapshots” of its pages for download. These snapshots are captured at regular intervals, as publicly advertised on Wikipedia’s website, ensuring predictability in their availability.
Tramèr’s team outlined a relatively straightforward attack approach involving strategically timed edits to Wikipedia pages. Exploiting the predictable nature of Wikipedia’s snapshot intervals, a malicious actor could execute edits just before moderators have an opportunity to revert the changes and before the platform generates new snapshots.
This method allows for the surreptitious insertion of manipulated information into Wikipedia pages, potentially influencing the content used to train language models without raising immediate suspicion.
Tramèr suggests hat at least 5% of edits orchestrated by an attacker could successfully infiltrate the system. However, the success rate of such attacks would likely exceed 5%, he said.
Following their analysis, Tramèr’s team shared their findings with Wikipedia and proposed measures to enhance security, such as introducing randomness into the timing of webpage snapshots, mitigating the predictability exploited by potential attackers.
Written by Alius Noreika
You can offer your link to a page which is relevant to the topic of this post.
#A.I. & Neural Networks news#ai#AI systems#ai tools#Analysis#approach#artificial intelligence (AI)#attackers#Authored post#Behavior#Business#chatbot#chatbots#chatGPT#coding#computer#Computer Science#content#cybersecurity#data#datasets#domains#ETH Zurich#Featured information processing#Featured technology news#financial#generative#generative ai#generators#hackers
0 notes
Text
Web Data Collection in 2022 – Everything you must know

Web scraping is one of the many useful techniques created by computer technology that can create massive databases. web scraping is a method of collecting vast amounts of data, which is then analyzed using statistical methods by statisticians and data scientists. In the basic form, web scraping is the method of extracting data from the Internet such as particular numbers, texts, and tables, using software that can store and manage the information obtained.
It does not matter which web browser we are using to view a web page; the information will be displayed using XML/HTML, AJAX, and JSON. Anyone who enters a web page on the Internet, whether it's social media, Wikipedia, or a search engine like Google or Bing, is using HTML. HTML is the coding language for the web, and the browser is capable of presenting the information presented on a web page in a user-friendly fashion.
Data scraping: The key applications
Sentimental analysis of Social media
Social media posts don't last long, but when you look at them collectively they show interesting trends. The majority of social media platforms have APIs that let third-party apps access their data, but this isn't always enough. Whenever you scrape such sites, you get real-time info like trending sentiments, phrases, topics, etc.
Price Comparison
Pricing insight is easily one of the most important aspects of web scraping for any business. Compare your pricing to the competition. You can also compare shipping and availability. Use this information to stay competitive or to gain an advantage.
Candidate Screening
You will have to comb through the pool of candidates in order to find the best candidates. LinkedIn and Indeed are used by professionals to promote themselves, so scraping their data makes sense. You can view resumes and CVs if you wish. Reviewing public information posted by applicants is an excellent way to assess who is right for the job. Finding ideal candidates is made easy and practical by scanning CVs and resumes automatically.
Machine learning
Raw data is essential to improving and advancing machine learning models. In a relatively short time, scraping tools can extract a significant amount of data, text, and images from a website. Technology marvels like driverless cars, space travel, and speech recognition are powered by machine learning. Data is, however, essential to building more accurate and reliable models.
Following these practices when scraping the web is recommended. Data sources are not messed up within the process of getting the data you need.
Investment opportunities
The desire to find out about promising neighbourhoods is common among property investors. There are many ways to gather this information, but scraping travel marketplace and hospitality brokerage websites is very effective. You'll get details like the best areas, amenities buyers look for, and new areas that will be great to rent.
Customer Opinions
Scraping is an effective method of obtaining a lot of customer feedback. Be aware of what people say about you, both good and bad, and then act accordingly. It is essential to remember this information but to also put it into practice. You can find topics to discuss on sites like TinyChat and Omegle. If you wish to broaden the scope of your research in a safe way, you should consider this information.
The best programming language for scraping the webPython:
Scraping the web with Python is among the most popular and best programming languages. The Python experts are capable of handling multiple web crawling tasks with no coding knowledge required. There are a few Python frameworks that have gained a lot of traction recently, such as Requests, Scrappy, and BeautifulSoup. There are lots of interesting features in Requests, even though they're less well known than Scrapy and BeautifulSoup. This library is great for high-speed scraping jobs. With these frameworks or libraries you can scrape websites in a few different ways, and they're all easy to use.
Node.js:
An ideal language for scraping the Internet and mining data. A distributed crawling process involves indexing multiple web pages simultaneously and scraping their content using Node.js. Therefore, Node.js is more often used for scraping web pages, not for large-scale projects.
PHP:
PHP is widely considered one of the best languages for web scraping and is used to build powerful scraping tools. PHP is a popular back-end scripting language for developing dynamic websites and web apps. A data scraper can also be implemented with simple PHP code.
Web scraping: Common problems
Getting Banned
The narrow line between ethical and unethical scrapping is likely to be crossed by scrapers that send multiple requests per second or high numbers of requests unnaturally. They are likely to be flagged and eventually banned. The web scraper can protect themselves from countermeasures like these if they are intelligent and have enough resources. They can stay on the right side of the law and still achieve their goal.
CAPTCHAs
A captcha is an electronic proof system that separates humans from bots by presenting logical problems that humans are able to solve but bots are unable to. CAPTCHAs are used for spam prevention. Scraping scripts will fail as long as there is a captcha. However, with new technological advancements, this captcha can generally be maintained in an ethical manner.
Frequent structural changes
An unexpected change to a web page template is the most frequent problem encountered by people. Thus, any web scraping tool that was developed to retrieve information from that web page will not be able to do the job. The code takes a long time to write but becomes obsolete in a few seconds. This problem can be resolved by ensuring that the structure of the code can easily be adapted for the new page.
Real-time data scraping
Data scraping can be extremely beneficial to businesses because it gives them the ability to make fast decisions. Stock prices can fluctuate constantly, and eCommerce product prices can change constantly, which can lead to huge capital gains for an organization. It can also be difficult to determine what's important and what's not in real-time. Furthermore, acquiring large data sets in real-time incurs overhead as well. The real-time web scrapers use the Rest API to collect dynamic information in the public domain and scrape it in "near real-time", but they are still unable to reach the "holy grail."
There is a difference between data collection and damaging the web with the purpose of scraping. The fact that web scraping is such a powerful tool and has such a major impact on businesses calls for it to be handled responsibly. Maintaining a positive trend means being respectful.
List of the best practices for web scraping:
Respect the Robots.txt
IP Rotation
Set a Real User Agent
Set Other Request Headers
Take care of the servers
Set Random Intervals In Between Your Requests
Use a Headless Browser
Beware of Honey Pot Traps
Use Captcha Solving Services
Have more than one pattern of crawling
Conclusion
It has become increasingly necessary to access the latest data on every subject as the Internet has grown exponentially and businesses have become increasingly dependent on data.
Whether a business or a non-profit, data has become the backbone of all decision-making processes; therefore, the spread of web scraping has found its way into every endeavor of note in our modern times. It is also becoming increasingly clear that those who are creative and skilled in using web scraping tools will race ahead of their competition and achieve a competitive advantage.
Take advantage of web scraping to boost your prospects in your chosen field!
1 note
·
View note
Text
0 notes
Note
Don’t you feel that if you go on the “loves ao3 more than their own mom” website aka the “can't throw a rock without hitting a writer” website and put in the main tag the opinion that AI writing models are no big deal and don’t do any harm and nobody has any reason to feel hurt over their unethical training in a tone that distinctly resembles the “toughen up snowflake” rhetoric, you might, in fact, just be the one out of line and also an asshole?
*rolls eyes* not what i did nor what i said.
there are many concerns to have with generative AI, such as the ability to extract privatized information from their training datasets, the exploitation of human workers for AI services (tho this one frankly goes for all internet services, not just AI), AI's reinforced biases and lack of learning, and the current lack of regulation against AI developers and AI usage to name a few. in terms of a direct impact on the creative industry, there are several concerns about the uncompensated and unregulated use of copyrighted materials in training data (paper discussing BookCorpus, courtlistener link for writers suing over Books2), the even worse image scraping for diffusion models, screen production companies trying to pressure people into selling their personal image rights for AI use, and publishers getting slammed with various AI generated content while the copyright laws for it are still massively in flux.
i said fanfic does not intersect with AI. actually, i vaguely whined about it in the tags of an untagged post, because i'm allowed to do that on my personal whine-into-the-void space. (which, tumblr is bad about filtering properly in tags and i'm sorry if it popped up anyways, but i also can't control tumblr search not functioning properly.)
there are concerns to be had about AI training datasets (developers refusing to remove or protect private information because it weakens the training data even tho this is a bigger issue for bigger models is my primary concern personally, but the book shadow libraries and mass image scraping are shady ass shit too). but AO3 was never used to train AI. there is a lot of sketchiness involved with AI training data, but AO3 is not one of them.
i get irked when people compare AI generated writing to AI generated art, because the technology behind it is different. to make art, AI has to directly use the source image to create the final output. this is why people can reverse the process on AI art models to extract the source images. written models (LLMs) learn how to string words into sentences and in terms of remembering the specific training data, LLMs actually have a known issue of wandering attention for general written training material like books/articles/etc. (re the writers' lawsuit -- we know AI developers are pulling shady shit with their use of books, AI developers know they're pulling shady shit with their use of books, but unfortunately the specific proof the writers' are using for their case very closely resembles the summaries and written reviews on their books' wikipedia pages. the burden of proof for copyright violation is really hard to prove for books, esp because copyright protects the expression of an idea, not the idea or individual sentences of a work, and LLMs do not retain their written training material in that way.) these are different issues that can't truly be conflated because the methods in which the materials are used and the potential regulation/the impact of potential regulation on them are different.
anyways, back to my annoyances with fanfic x AI -- fanfic is not involved in its development, and if you don't want to read fic made by AI, don't click on fic that involves AI. ultimately, if you read a fic and it turns out AI was involved...nothing happens. if you don't like it, you click a back button, delete a bookmark, and/or mute a user. AI just strings words together. that's it. acting like AI will have a great impact on fandom, or that fandom will be some final bastion against it, is really fucking annoying to me because fandom does not have any stakes in this. there are legitimate issues in regards to developing and regulating AI (link to the US senate hearing again, because there are so many), but "oh no, what if i read a fic written by AI" is a rather tone fucking deaf complaint, don't you think?
#which is also why i whined in the tags of /an untagged post/#honestly my bigger issue is people trying to give fandom stakes in this#fandom can be culturally important and not at all impacted by this specific issue
3 notes
·
View notes
Text
The Ultimate Guide To Building Scalable Web Scrapers With Scrapy
The Ultimate Guide To Building Scalable Web Scrapers With Scrapy
Daniel Ni
2019-07-16T14:30:59+02:002019-07-16T13:06:15+00:00
Web scraping is a way to grab data from websites without needing access to APIs or the website’s database. You only need access to the site’s data — as long as your browser can access the data, you will be able to scrape it.
Realistically, most of the time you could just go through a website manually and grab the data ‘by hand’ using copy and paste, but in a lot of cases that would take you many hours of manual work, which could end up costing you a lot more than the data is worth, especially if you’ve hired someone to do the task for you. Why hire someone to work at 1–2 minutes per query when you can get a program to perform a query automatically every few seconds?
For example, let’s say that you wish to compile a list of the Oscar winners for best picture, along with their director, starring actors, release date, and run time. Using Google, you can see there are several sites that will list these movies by name, and maybe some additional information, but generally you’ll have to follow through with links to capture all the information you want.
Obviously, it would be impractical and time-consuming to go through every link from 1927 through to today and manually try to find the information through each page. With web scraping, we just need to find a website with pages that have all this information, and then point our program in the right direction with the right instructions.
In this tutorial, we will use Wikipedia as our website as it contains all the information we need and then use Scrapy on Python as a tool to scrape our information.
A few caveats before we begin:
Data scraping involves increasing the server load for the site that you’re scraping, which means a higher cost for the companies hosting the site and a lower quality experience for other users of that site. The quality of the server that is running the website, the amount of data you’re trying to obtain, and the rate at which you’re sending requests to the server will moderate the effect you have on the server. Keeping this in mind, we need to make sure that we stick to a few rules.
Most sites also have a file called robots.txt in their main directory. This file sets out rules for what directories sites do not want scrapers to access. A website’s Terms & Conditions page will usually let you know what their policy on data scraping is. For example, IMDB’s conditions page has the following clause:
Robots and Screen Scraping: You may not use data mining, robots, screen scraping, or similar data gathering and extraction tools on this site, except with our express-written consent as noted below.
Before we try to obtain a website’s data we should always check out the website’s terms and robots.txt to make sure we are obtaining legal data. When building our scrapers, we also need to make sure that we do not overwhelm a server with requests that it can’t handle.
Luckily, many websites recognize the need for users to obtain data, and they make the data available through APIs. If these are available, it’s usually a much easier experience to obtain data through the API than through scraping.
Wikipedia allows data scraping, as long as the bots aren’t going ‘way too fast’, as specified in their robots.txt. They also provide downloadable datasets so people can process the data on their own machines. If we go too fast, the servers will automatically block our IP, so we’ll implement timers in order to keep within their rules.
Getting Started, Installing Relevant Libraries Using Pip
First of all, to start off, let’s install Scrapy.
Windows
Install the latest version of Python from https://www.python.org/downloads/windows/
Note: Windows users will also need Microsoft Visual C++ 14.0, which you can grab from “Microsoft Visual C++ Build Tools” over here.
You’ll also want to make sure you have the latest version of pip.
In cmd.exe, type in:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapy
This will install Scrapy and all the dependencies automatically.
Linux
First you’ll want to install all the dependencies:
In Terminal, enter:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
Once that’s all installed, just type in:
pip install --upgrade pip
To make sure pip is updated, and then:
pip install scrapy
And it’s all done.
Mac
First you’ll need to make sure you have a c-compiler on your system. In Terminal, enter:
xcode-select --install
After that, install homebrew from https://brew.sh/.
Update your PATH variable so that homebrew packages are used before system packages:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrc
Install Python:
brew install python
And then make sure everything is updated:
brew update; brew upgrade python
After that’s done, just install Scrapy using pip:
pip install Scrapy
>
Overview Of Scrapy, How The Pieces Fit Together, Parsers, Spiders, Etc
You will be writing a script called a ‘Spider’ for Scrapy to run, but don’t worry, Scrapy spiders aren’t scary at all despite their name. The only similarity Scrapy spiders and real spiders have are that they like to crawl on the web.
Inside the spider is a class that you define that tells Scrapy what to do. For example, where to start crawling, the types of requests it makes, how to follow links on pages, and how it parses data. You can even add custom functions to process data as well, before outputting back into a file.
Writing Your First Spider, Write A Simple Spider To Allow For Hands-on Learning
To start our first spider, we need to first create a Scrapy project. To do this, enter this into your command line:
scrapy startproject oscars
This will create a folder with your project.
We’ll start with a basic spider. The following code is to be entered into a python script. Open a new python script in /oscars/spiders and name it oscars_spider.py
We’ll import Scrapy.
import scrapy
We then start defining our Spider class. First, we set the name and then the domains that the spider is allowed to scrape. Finally, we tell the spider where to start scraping from.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']
Next, we need a function which will capture the information that we want. For now, we’ll just grab the page title. We use CSS to find the tag which carries the title text, and then we extract it. Finally, we return the information back to Scrapy to be logged or written to a file.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data
Now save the code in /oscars/spiders/oscars_spider.py
To run this spider, simply go to your command line and type:
scrapy crawl oscars
You should see an output like this:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Congratulations, you’ve built your first basic Scrapy scraper!
Full code:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data
Obviously, we want it to do a little bit more, so let’s look into how to use Scrapy to parse data.
First, let’s get familiar with the Scrapy shell. The Scrapy shell can help you test your code to make sure that Scrapy is grabbing the data you want.
To access the shell, enter this into your command line:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”
This will basically open the page that you’ve directed it to and it will let you run single lines of code. For example, you can view the raw HTML of the page by typing in:
print(response.text)
Or open the page in your default browser by typing in:
view(response)
Our goal here is to find the code that contains the information that we want. For now, let’s try to grab the movie title names only.
The easiest way to find the code we need is by opening the page in our browser and inspecting the code. In this example, I am using Chrome DevTools. Just right-click on any movie title and select ‘inspect’:
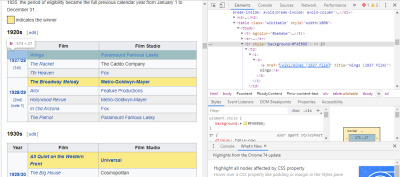
Chrome DevTools window. (Large preview)
As you can see, the Oscar winners have a yellow background while the nominees have a plain background. There’s also a link to the article about the movie title, and the links for movies end in film). Now that we know this, we can use a CSS selector to grab the data. In the Scrapy shell, type in:
response.css(r"tr[style='background:#FAEB86'] a[href*='film)']").extract()
As you can see, you now have a list of all the Oscar Best Picture Winners!
> response.css(r"tr[style='background:#FAEB86'] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']
Going back to our main goal, we want a list of the Oscar winners for best picture, along with their director, starring actors, release date, and run time. To do this, we need Scrapy to grab data from each of those movie pages.
We’ll have to rewrite a few things and add a new function, but don’t worry, it’s pretty straightforward.
We’ll start by initiating the scraper the same way as before.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
But this time, two things will change. First, we’ll import time along with scrapy because we want to create a timer to restrict how fast the bot scrapes. Also, when we parse the pages the first time, we want to only get a list of the links to each title, so we can grab information off those pages instead.
def parse(self, response): for href in response.css(r"tr[style='background:#FAEB86'] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req
Here we make a loop to look for every link on the page that ends in film) with the yellow background in it and then we join those links together into a list of URLs, which we will send to the function parse_titles to pass further. We also slip in a timer for it to only request pages every 5 seconds. Remember, we can use the Scrapy shell to test our response.css fields to make sure we’re getting the correct data!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data
The real work gets done in our parse_data function, where we create a dictionary called data and then fill each key with the information we want. Again, all these selectors were found using Chrome DevTools as demonstrated before and then tested with the Scrapy shell.
The final line returns the data dictionary back to Scrapy to store.
Complete code:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[style='background:#FAEB86'] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data
Sometimes we will want to use proxies as websites will try to block our attempts at scraping.
To do this, we only need to change a few things. Using our example, in our def parse(), we need to change it to the following:
def parse(self, response): for href in (r"tr[style='background:#FAEB86'] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "http://yourproxy.com:80" yield req
This will route the requests through your proxy server.
Deployment And Logging, Show How To Actually Manage A Spider In Production
Now it is time to run our spider. To make Scrapy start scraping and then output to a CSV file, enter the following into your command prompt:
scrapy crawl oscars -o oscars.csv
You will see a large output, and after a couple of minutes, it will complete and you will have a CSV file sitting in your project folder.
Compiling Results, Show How To Use The Results Compiled In The Previous Steps
When you open the CSV file, you will see all the information we wanted (sorted out by columns with headings). It’s really that simple.

Oscar winning movies list and information. (Large preview)
With data scraping, we can obtain almost any custom dataset that we want, as long as the information is publicly available. What you want to do with this data is up to you. This skill is extremely useful for doing market research, keeping information on a website updated, and many other things.
It’s fairly easy to set up your own web scraper to obtain custom datasets on your own, however, always remember that there might be other ways to obtain the data that you need. Businesses invest a lot into providing the data that you want, so it’s only fair that we respect their terms and conditions.
Additional Resources For Learning More About Scrapy And Web Scraping In General
The Official Scrapy Website
Scrapy’s GitHub Page
“The 10 Best Data Scraping Tools and Web Scraping Tools,” Scraper API
“5 Tips For Web Scraping Without Getting Blocked or Blacklisted,” Scraper API
Parsel, a Python library to use regular expressions to extract data from HTML.

(dm, yk, il)
0 notes
Text
Data scraping tools for marketers who don’t know code
We have all been there before. You need the right data from a website for your next content marketing project. You have found your source websites, the data is just there waiting for you to grab it and then the challenge emerges. You have 500 pages and wonder how to extract all this data at once.
It doesn’t help if you have the data if you can’t grab it. Without proper data scraping software, you won’t get it.
If you are like me, you had to learn Python so Scrapy can get the job done for you. Alternatively, you have to learn XPath for Excel, which is also something that takes quite a bit of time.
And since time is our most precious commodity, there is software available that doesn’t require learning a line of code to complete this task.
I have tried the following software as they all provide a free account and quite a good number of features to get the job done for a small to medium data set.
Definition of data scraping
The definition of data scraping is:
“…a technique in which a computer program extracts data from human-readable output coming from another program.”
– Wikipedia
Essentially, you can crawl entire websites, extract pieces of information from several pages and download this information into a structured Excel file. This is what I have done recently to build a sharable piece of research.
Data scraping can be used in many projects, including the following:
Price-monitoring projects, where you want to keep track of price changes;
Lead generation, where you can download your leads information for sales analysis;
Influencers and bloggers outreach, when you need to get information about name, surname, email address, tel number usually from a directory of influencers;
Extracting data for your research on any topic and website, this is my most used need of data.
Parsehub
This is by far my favorite tool for crawling data on big publications and blogs. You can do very advanced data segmentation and crawling with Parsehub, to extract pieces of information for each page. With Parsehub, you can collect information about calendars, comments, infinite scrolling, infinite page numbers, drop downs, forms, javascript and text.
The main features are:
Great customer support
Fairly intuitive
Very fast (if you are not using proxies and VPN)
Easy to use interface
Octoparse
With the free Octoparse account, you can scrape up to 10,000 records. If you need more records and you are working on one data scraping project, Octoparse offers the project-based one-time fee for unlimited records. The other service that I really like about Octoparse is that they offer to scrape data for you. All you need to provide if the website and the data input you want to download, they do the rest.
The main features are:
Click to extract
Scrape behind a login and form
Scheduled extraction
Easy to use
Import.io
This tool is expensive for a single individual starting at $299/month but luckily, they offer a free account. The reason why it’s more costly is that you can do more than just organizing unstructured data. With Import.io you can also do these tasks:
Identify the URL where your data is located
Extract the hidden content
Prepare the data with 100+ spreadsheet-like formulas
Integrate to your business systems with their API
Visualize data with custom reports
As you can see, Import.io serves the entire project-cycle, from data collection to visualization.
Grepsr
What interests me about Grepsr is the opportunity to manage the data scraping projects with a project management tool available of users. This allows many applications for the scraping project since these projects usually are very complicated. With the messaging and tasks apps in Grepsr you can quickly grab all requirements, answer to tickets and speak directly to all stakeholders involved.
The other very useful feature is automation. Instead manually set up each scraping project, you can set it up once and set a rule to the software for scheduled scrapes.
All of these extra features also come at a higher price of $199/ month, which can be expensive for a single user. So Grepsr is more suitable for team and big data projects, rather than single individuals. The free version for small projects is an option in the Chrome app.
Conclusion
We use big data to make essential business decisions. Having a reliable partner that can automate tasks will save you time. Whether you are doing market research, monitoring price changes on Amazon and eBay (or even Google), grabbing information for your next blogger outreach project, data scraping software can help you. Just make sure you try and test each one of them before committing.
The post Data scraping tools for marketers who don’t know code appeared first on Search Engine Land.
Data scraping tools for marketers who don’t know code published first on https://likesandfollowersclub.weebly.com/
0 notes
Text
Data scraping tools for marketers who don’t know code
We have all been there before. You need the right data from a website for your next content marketing project. You have found your source websites, the data is just there waiting for you to grab it and then the challenge emerges. You have 500 pages and wonder how to extract all this data at once.
It doesn’t help if you have the data if you can’t grab it. Without proper data scraping software, you won’t get it.
If you are like me, you had to learn Python so Scrapy can get the job done for you. Alternatively, you have to learn XPath for Excel, which is also something that takes quite a bit of time.
And since time is our most precious commodity, there is software available that doesn’t require learning a line of code to complete this task.
I have tried the following software as they all provide a free account and quite a good number of features to get the job done for a small to medium data set.
Definition of data scraping
The definition of data scraping is:
“…a technique in which a computer program extracts data from human-readable output coming from another program.”
– Wikipedia
Essentially, you can crawl entire websites, extract pieces of information from several pages and download this information into a structured Excel file. This is what I have done recently to build a sharable piece of research.
Data scraping can be used in many projects, including the following:
Price-monitoring projects, where you want to keep track of price changes;
Lead generation, where you can download your leads information for sales analysis;
Influencers and bloggers outreach, when you need to get information about name, surname, email address, tel number usually from a directory of influencers;
Extracting data for your research on any topic and website, this is my most used need of data.
Parsehub
This is by far my favorite tool for crawling data on big publications and blogs. You can do very advanced data segmentation and crawling with Parsehub, to extract pieces of information for each page. With Parsehub, you can collect information about calendars, comments, infinite scrolling, infinite page numbers, drop downs, forms, javascript and text.
The main features are:
Great customer support
Fairly intuitive
Very fast (if you are not using proxies and VPN)
Easy to use interface
Octoparse
With the free Octoparse account, you can scrape up to 10,000 records. If you need more records and you are working on one data scraping project, Octoparse offers the project-based one-time fee for unlimited records. The other service that I really like about Octoparse is that they offer to scrape data for you. All you need to provide if the website and the data input you want to download, they do the rest.
The main features are:
Click to extract
Scrape behind a login and form
Scheduled extraction
Easy to use
Import.io
This tool is expensive for a single individual starting at $299/month but luckily, they offer a free account. The reason why it’s more costly is that you can do more than just organizing unstructured data. With Import.io you can also do these tasks:
Identify the URL where your data is located
Extract the hidden content
Prepare the data with 100+ spreadsheet-like formulas
Integrate to your business systems with their API
Visualize data with custom reports
As you can see, Import.io serves the entire project-cycle, from data collection to visualization.
Grepsr
What interests me about Grepsr is the opportunity to manage the data scraping projects with a project management tool available of users. This allows many applications for the scraping project since these projects usually are very complicated. With the messaging and tasks apps in Grepsr you can quickly grab all requirements, answer to tickets and speak directly to all stakeholders involved.
The other very useful feature is automation. Instead manually set up each scraping project, you can set it up once and set a rule to the software for scheduled scrapes.
All of these extra features also come at a higher price of $199/ month, which can be expensive for a single user. So Grepsr is more suitable for team and big data projects, rather than single individuals. The free version for small projects is an option in the Chrome app.
Conclusion
We use big data to make essential business decisions. Having a reliable partner that can automate tasks will save you time. Whether you are doing market research, monitoring price changes on Amazon and eBay (or even Google), grabbing information for your next blogger outreach project, data scraping software can help you. Just make sure you try and test each one of them before committing.
The post Data scraping tools for marketers who don’t know code appeared first on Search Engine Land.
Data scraping tools for marketers who don’t know code published first on https://likesfollowersclub.tumblr.com/
0 notes
Text
Google Thought My Phone Number Was Facebook’s and It Ruined My Life
I’m waiting for the subway when the phone rings. On the other end of the line an angry woman is shouting at me about her Facebook account. I hang up.
A few hours later, I’m walking to get some lunch when someone calls.
“I forgot my Facebook password,” the man says.
I sigh, and—once again—explain that I can’t help.
Later, while at my desk, someone else calls up.
“I’m trying to get a hold of Facebook,” a man says. “They are taking my American rights away from me. They’re anti-free spech, anti-American, they’re pro Muslim.”
The man says Facebook disabled his account after he wrote a post that, he explains, “wasn’t even horrible.”
This keeps happening. In the last three days, I’ve gotten more than 80 phone calls. Just today, in the span of eight minutes, I got three phone calls from people looking to talk to Facebook. I didn’t answer all of them, and some left voicemails.
Initially, I thought this was some coordinated trolling campaign. As it turns out, if you Googled “Facebook phone number” on your phone earlier this week, you would see my cellphone as the fourth result, and Google has created a “card” that pulled my number out of the article and displayed it directly on the search page in a box. The effect is that it seemed like my phone number was Facebook’s phone number, because that is how Google has trained people to think.
Considering that on average, according to Google’s own data, people search for “Facebook phone number” tens of thousands of times every month, I got a lot of calls.
“[Google is] trying to scrape for a phone number to match the intent of the search query,” Austin Kane, the director for SEO strategy for the New York-based consulting company Acknowledge Digital, told me in an email. “The first few web listings … don’t actually have a phone number available on site so it seems that Google is mistakenly crawling other content and exposing the phone number in Search Engine Results Pages, thinking that this is applicable to the query and helpful for users.” (Vice Media is a client of Acknowledge Digital.)
When I reached out to Facebook’s PR to get their thoughts, a spokesperson started his email response with: “Huh, that’s an odd one.”
I obviously can’t blame Facebook for Google’s faulty algorithm. But the fact that Facebook does not have a customer support number is contributing to this. (Facebook, instead, offers a portal for users who need help.)

A screenshot of a Google search. (Image: Lorenzo Franceschi-Bicchierai/Motherboard)
Of course, I could blame VICE’s formidable SEO. Or I could blame myself, for putting my phone number in my stories as a way to get tips from readers who might have something newsworthy to share.
But on this query, Google’s algorithm was clearly broken—for some reason, it thought it was a good idea to extract and prominently display a phone number from article hosted on vice.com that’s titled “Facebook’s Phone Number Policy Could Push Users to Not Trust Two-Factor Authentication.”
Google’s search algorithms are why it became so powerful in the first place, but sometimes, however, the algorithm is painfully stupid. In 2017, The Outline showed that Google often displayed completely wrong information at the top of the results when people searched for things like “Was President Warren Harding a member of the KKK?” or “Why are firetrucks red?” The article delved into the so-called “featured snippets,” those big boxes at the top of search results that are supposed to give users a quick answer to what they’re looking for.
The Outline piece proved that in the search for convenience, Google was getting things wrong. In a nutshell, this is another example of that exact same problem. Motherboard has previously explained, for example, that Google’s overreliance on Wikipedia has left it open to trolling—the company’s “knowledge box,” which shows up on the right hand side of search results for some queries, are often pulled from Wikipedia, which led in one case to the search engine equating the Republican party with “Nazism.”
On Wednesday, I told Google that my number was being mistakenly shown when people searched for “Facebook phone number.” A few hours later, a Google spokesperson said they would remove my number as soon as possible.
“This feature is generally used to surface phone numbers from websites and make it easy for users to find them. In this case it was a triggering error and was pulling the phone number you had listed at the end of the article,” a company spokesperson wrote in an email. “There’s also the coincidence that your article happened to be about Facebook and phone numbers, so it was highly relevant to that query and was ranking high up in results, adding to the confusion for people when your number appeared towards the top of the results page.”

After reaching out to Google to get my number removed, the company fixed it. And now, when you Google “Facebook phone number” on mobile, the number that is shown is from an NPR article, which explains that the number Google was displaying is associated with a Facebook scam. Thankfully, that number is now out of service, but it doesn’t give me any more faith in Google’s algorithm.
At least people will stop calling me.
Listen to CYBER, Motherboard’s new weekly podcast about hacking and cybersecurity.
Google Thought My Phone Number Was Facebook’s and It Ruined My Life syndicated from https://triviaqaweb.wordpress.com/feed/
0 notes
Text
The Streets of Gijón: from the Newspaper Archives to the Knowledge Graph
Read this article in Spanish
Mis Calles Gijón/Xixón is a Web application started as a personal project, motivated to support my curiosity when walking in the streets of my hometown. I always wonder who was the person, historical fact or place that shaped cities and understand the motivations to name streets after them, as part of a kind of tribute to preserve the history of places.
Technologically, Mis Calles is a Progressive Web Application, suitable for any mobile device, enabling the use of their location capabilities to enrich the user experience. The application was developed through a series of complex Python scripts, which allowed to automate the ingestion and processing of the information, coming from open sources. This automation is interesting since we could deploy a Mis Calles in any city in the world with just minimal adjustments.
The development process had the following steps:
Step 1: The streets and their location
The City of Gijón, through its Transparency and Open Data Portal, publishes two datasets that served to: (1) identify the streets of Gijón —list of streets, type (e.g., avenue, road, park, street, etc.), unique names (no acute accents) and numerical identifiers—, and (2) locate them on a map. The location of the streets is based on the dataset of streets and portal numbers, a table with thousands of coordinates corresponding to each street number (building) and street in the city (not the line or polygon).
Step 2: Generate the polygons on the map
After nesting the tables of streets and numbers, another script built the lines and polygons (in KML and geo-JSON format) shaping the streets, enabling the visualization on a map.
For this, each street is divided into odd and even street numbers. The odd ones are ordered in ascending order and a polygon is generated by joining all the points that form the coordinates. Once the script reached the biggest, it joins all the even points in a descending way until reaching the lowest. Finally, the polygon is closed linking the first point of the list.
This technique is precise in certain ways, but if the street has few registered portals it can give rise to polygons with curious shapes, as can be seen in Calle Mariano Pola, below.
Step 3: Description of streets I: Piñera method
Once the streets were identified univocally, including their approximate location, the streets were described based on the El Comercio's publication: The streets of Gijón, History of their names, a great work by Luis Miguel Piñera.
The portal offers open access to this publication but it does not specify reuse conditions. After several formal use requests to the City Council, and receiving no response (I am still waiting), I asked directly to El Comercio. They quickly agreed and wanted to take part in this project.
In early 2000, you would not expect more than reading that publication as PDF, so no efforts were made beyond the PDF file. With a scraping script, I automated the extraction of the main data of the work: a name of the person or event that named after the street, description, date of registration and previous names. The extraction was chaotic (e.g., changes in the expected structure, page breaks, figures, cites, etc.), and the result had to be double checked almost manually.
Another Python script nested the resulting tables: list of streets, geo-localized and now including a description. In the case of not finding the exact match between the denomination (e.g., comparison of 'LOS CALEROS' and 'CALEROS, LOS'), the script prompted asking for the right choice.
Step 4: Description of streets II: Knowledge Graph
Although the real value of the application comes from Piñera's historical investigation, several streets were not included. In this case, these entities are usually concepts or contemporary people that can be easily recognizable and whose descriptive information can be found on the Web. So, another method of finding information associated with those entities was searching the Knowledge Graph, which Google offers through an API.
The Knowledge Graph is a structure of information linked by semantic concepts —is what Google uses to show proper results. This graph contains information from open sources, such as Wikipedia. It includes metadata associated with the concepts that characterize them in depth.
This data source is really interesting to get information about places, events or people. The script queries the API recognizing the types of results obtained. The results also show the degree of success confidence. So in the case of finding a match of the expected type, the script stores the data in a table with the needed information: description, alternative title, URL of the entity (Wikipedia page), image URL and associated license, standardised entity type using schema.org (eg, CivicStructure or LandmarksOrHistoricalBuildings). For example, the result obtained for the entity'EUROPA' [Square], is:
Name: Europa
Score (confidence): 244.048874
URL: https://es.wikipedia.org/wiki/Europa
Type: Continent, Thing, Place, AdministrativeArea
Description: Europe is one of the continents that make up the Eurasian supercontinent, located between the parallels 36º and 70º north latitude.
Imagen: http://t0.gstatic.com/images?q=tbn:ANd9GcS0uZNMs4cfxsd-XAvy8iNVY-6CjX9gMCUV2BSloYIjgEQewznu
Image license: https://en.wikipedia.org/wiki/Wikipedia:Text_of_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License
Knowledge Graph URI: kg:/m/02j9z
Unfortunately, Google has removed the dereference and visualization of the Knowledge Graph entities —a few weeks ago, we could visualize an infobox with the information related to the entity. Anyway, this does not affect the application.
Step 5: Types of Entities
The Knowledge Graph, and its queries were the basis of the classification of the entities in an automated way. In the previous example, Europe is of type: Thing (thing, of course); Continent (continent); Place (place); and AdministrativeArea (administrative area).
Approximately, the 40% of the entities represented were classified automatically, always under human supervision, since there are confusing cases in which artificial intelligence can not do anything.
For example, Calle 'Cabrales' refers to the concept of 'Cabranes'. Within the Knowledge Graph, both concepts are identified and described as municipalities in Asturias, but actually, the street is named after a person.
Once all the tables were joined and nested (listing, geo-positioning, descriptions with the Piñera method and the Knowledge Graph, and types) I completed the classification using a subsequent semi-automatic homogenization of the types. For this, I used OpenRefine.
Finally, all the themes were defined in an intuitive taxonomy through a card sorting exercise. As a result, 1035 entities were grouped as:
(58) Artists (musicians, painters, actors, athletes);
(53) Concepts (feelings, jobs, physical elements)
(11) Explorers (historic conquerors)
(220) Geography (municipalities of Asturias, geographical features, populated places, etc.)
(113) History (historical events, people, landmarks of historical relevance)
(69) Business (people related to industrial and/or urban development)
(112) Letters (writers, thinkers, philosophers, etc.)
(105) Nature (fauna, flora, and other natural concepts)
(21) Nobility (monarchs and nobility in general)
(27) Organisations (companies and organizational entities)
__(94) Politicians (governors, military and councilors)
(79) Religion (religious people, places and concepts)
(73) Scientists (mathematicians, physicists and science or technology persons)
Also, taking advantage of other concrete types gathered by the scripts, I produced a second level of topic themes. For example, the subject Geography includes the following sub-themes: Country (27 entities), Geography of Asturias (66), Geography of Spain (44), Geography of Gijón (21), International Geography (13), Historical Places (1), Orography (48).
Have a look at the result of Mis Calles Gijón/Xixón, play with it and send me your comments.
0 notes
Text
Which are the Top 10 Most Scraped Websites in 2023?

In the age of data-driven decision-making and automation, web scraping has become an essential tool for extracting valuable information from the internet. Whether it's for competitive analysis, market research, or staying up to date with the latest trends, web scraping has gained prominence across various industries. In 2023, several websites have found themselves at the center of this data extraction frenzy. In this article, we will explore the top 10 most scraped websites in 2023.
Amazon Amazon has long been a popular target for web scrapers. E-commerce businesses scrape Amazon to monitor product prices, gather customer reviews, and track market trends. The abundance of data on Amazon's platform makes it a goldmine for those seeking to gain a competitive edge.
Twitter Social media platforms are a treasure trove of real-time data. Twitter, in particular, is a hotbed for scraping due to its vast user base and the constant stream of tweets. Researchers, marketers, and journalists scrape Twitter to gather insights on trending topics and public sentiment.
LinkedIn LinkedIn is a valuable source of professional information. Job seekers and recruiters scrape LinkedIn to build databases of potential connections and candidates. Market researchers also use it to track industry trends and professional networking.
Instagram Instagram's visual nature makes it an attractive target for web scraping. Businesses and individuals scrape Instagram for influencer marketing, competitor analysis, and trend monitoring. The platform is a goldmine for image and video data.
Wikipedia Wikipedia is a comprehensive source of information on a wide range of topics. Researchers and data enthusiasts scrape Wikipedia to build datasets for natural language processing, academic research, and content creation. It's a knowledge hub that attracts scrapers.
Reddit As one of the largest online discussion platforms, Reddit is a prime target for web scrapers. Data scientists and marketers scrape Reddit to identify emerging trends, monitor user sentiment, and discover niche communities.
Google News Google News aggregates news articles from various sources. Media organizations and content curators scrape Google News to stay updated with the latest news developments. The platform is a vital source of news content.
Yelp Yelp is a popular source for restaurant and business reviews. Local businesses and marketers scrape Yelp to monitor customer feedback, gather business information, and track their online reputation.
IMDb The Internet Movie Database (IMDb) is a goldmine of information about movies, TV shows, and celebrities. Movie enthusiasts and entertainment industry professionals scrape IMDb for information on films, actors, and industry trends.
Etsy Etsy is a marketplace for handmade and vintage goods. E-commerce businesses and artists scrape Etsy to monitor product listings, pricing, and market trends. It's a valuable resource for those in the creative and e-commerce sectors.
Web scraping, when done ethically and in compliance with the terms of service of these websites, provides businesses and individuals with valuable data that can be used for a variety of purposes. However, it's essential to be aware of the legal and ethical considerations surrounding web scraping, as scraping without permission or in a disruptive manner can lead to legal consequences and damage a website's functionality.
Additionally, websites can implement measures to protect themselves from scraping, such as using CAPTCHAs, IP blocking, or anti-scraping technologies. It's essential for web scrapers to adapt to these challenges and use scraping tools responsibly.
In conclusion, web scraping plays a crucial role in the modern data landscape, and the top 10 most scraped websites in 2023 reflect the diverse range of data needs across industries. From e-commerce giants like Amazon to social media platforms like Twitter, these websites offer a wealth of information that is highly sought after. As web scraping continues to evolve, it's important for scrapers to operate within legal and ethical boundaries, respecting the rights and terms of service of the websites they scrape.
0 notes