#Simple Linear Regression assignment help
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Deep Learning Online Training and Machine Learning Course Syllabus: A Comprehensive Guide
The Importance of Deep Learning Online Training
With the rapid advancements in artificial intelligence, deep learning online training platforms have become invaluable resources for learners worldwide. These courses often provide flexible schedules, hands-on projects, and expert mentorship, making complex topics accessible to learners at all levels. Whether you're a beginner or an experienced professional, online training allows you to learn at your own pace, revisit challenging concepts, and stay updated with the latest trends in AI.
Many reputable platforms such as Coursera, Udacity, and edX offer specialized courses in deep learning, covering foundational concepts like neural networks, backpropagation, convolutional neural networks (CNNs), recurrent neural networks (RNNs), and reinforcement learning. These courses often include practical assignments, real-world datasets, and capstone projects that help reinforce learning and build a strong portfolio.
Machine Learning Course Syllabus: What to Expect
A comprehensive machine learning course syllabus provides the roadmap for acquiring essential knowledge and skills in this domain. Typically, such a syllabus covers:
Introduction to Machine Learning: Understanding the basics, types of machine learning (supervised, unsupervised, reinforcement), and real-world applications.
Mathematical Foundations: Linear algebra, calculus, probability, and statistics necessary for algorithm development.
Data Preprocessing: Handling missing data, feature scaling, feature engineering, and data visualization techniques.
Supervised Learning Algorithms: Linear regression, logistic regression, decision trees, random forests, support vector machines.
Unsupervised Learning Algorithms: Clustering methods like K-means, hierarchical clustering, principal component analysis (PCA).
Model Evaluation and Selection: Cross-validation, bias-variance tradeoff, metrics like accuracy, precision, recall, F1-score.
Introduction to Deep Learning: Transitioning into neural networks, understanding architectures, and training techniques.
Focusing on linear models in machine learning—such as linear regression and logistic regression—is fundamental. These models are simple yet powerful, especially for problems with linear relationships. They serve as the foundation for more complex algorithms and serve as an excellent starting point for beginners.
Deep Learning Roadmap: Navigating Your Learning Path
For those looking to specialize further, developing a deep learning roadmap is essential. This roadmap guides learners from basic concepts to advanced topics, ensuring a structured and efficient learning process. A typical deep learning roadmap includes:
Mathematical Foundations: Master linear algebra, calculus, probability, and optimization techniques.
Machine Learning Basics: Understand supervised and unsupervised learning, along with common algorithms.
Neural Networks: Learn about perceptrons, activation functions, loss functions, and backpropagation.
Deep Neural Networks: Dive into architectures like CNNs for image processing, RNNs for sequential data, and LSTMs.
Advanced Topics: Explore generative adversarial networks (GANs), reinforcement learning, transfer learning, and unsupervised deep learning.
Practical Implementation: Gain hands-on experience with frameworks like TensorFlow, Keras, and PyTorch.
Specializations: Focus on areas such as natural language processing, computer vision, or speech recognition.
Throughout this roadmap, continuous practice through projects, Kaggle competitions, and research papers is encouraged to solidify understanding.
Conclusion
Embarking on learning deep learning online training and understanding the machine learning course syllabus are essential steps toward building a successful career in AI. Whether you're starting with linear models or progressing to complex neural networks, a structured approach guided by a deep learning roadmap will ensure steady progress and mastery of skills.
0 notes
Text
Mastering the Test Cycle with Provar
If you're part of a QA team, dev team, or anyone in the business of delivering high-quality software, you've probably heard the term Test Cycle more than a few times. But what does it really mean? And how can you manage it better—especially when you're working with Salesforce and complex release pipelines?
Let’s break it down in a way that’s easy to follow and (hopefully) stress-free. Whether you're manually tracking test cases or using automation tools like Provar, understanding your test cycle can mean the difference between a smooth release and a post-deployment nightmare.
What Is a Test Cycle, Really?
At its core, a Test Cycle is just a fancy way of saying: “Here’s the group of test activities we’re doing for this version, sprint, or release.” Think of it like a checklist, but way more structured. Every time your team pushes out a new update, feature, or integration, you go through a test cycle to validate everything is working as expected.
A typical test cycle includes:
1. Planning what to test
2. Designing the test cases
3. Executing the tests
4. Tracking and fixing bugs
5. Retesting, and
6. Reporting on everything
The cycle might sound linear, but in reality, it’s more like a loop—especially in Agile environments where testing happens continuously.
Why Test Cycles Matter (More Than You Think)
A lot of teams overlook just how crucial a test cycle is. Sure, we all want to test, but without a well-managed cycle, you’re flying blind. You don’t know what was covered, what passed or failed, or even if the current build is safe to deploy.
Here’s why managing your test cycle matters:
1. It improves coverage. You know exactly what’s being tested and what’s not.
2. It makes collaboration easier between QA, dev, and product teams.
3. It gives clear visibility to stakeholders.
4. And most importantly—it helps catch bugs early, before they snowball into bigger issues.
The Six Stages of a Test Cycle (Explained Simply)
Let’s walk through a standard test cycle step-by-step—but we’ll keep it simple and real-world.
1. Test Planning
This is where the team asks: What needs to be tested in this release?
You identify the scope, the test objectives, test environments, and the timeline. In Provar, this is where you can organize tests into suites based on user stories, risk, or functionality.
Pro tip with Provar: You can tag and categorize tests to match your sprint goals, so you’re not wasting time running unrelated scripts.
2. Test Design
Now that you know what to test, it’s time to design how you’re going to test it. This includes writing test cases or generating them with automation tools. With Provar, this gets a major upgrade—you can auto-generate test cases based on metadata, user stories, or past behavior using Provar AI. It saves tons of manual effort and reduces human error.
3. Test Execution
This is where the action happens. Your test scripts run—manually, automatically, or both—and results start coming in. With Provar’s automation engine, this step is scalable. You can execute tests across different environments, browsers, and Salesforce orgs, all while tracking pass/fail results in real-time.
4. Bug Tracking & Reporting
Spoiler alert: not all tests will pass the first time. That’s okay—this stage is about logging those bugs and making sure they get assigned, tracked, and fixed. Provar integrates with tools like Jira, so defects found during testing can be automatically linked to stories, making it easy to communicate with developers.
5. Retesting & Regression
Once the bugs are fixed, it’s time to rerun those failed test cases and also double-check that nothing else broke in the process (yep, regression testing). Provar helps here too—you can reuse test assets and schedule regression suites to run overnight or during code check-ins.
6. Test Closure & Reporting
Finally, you wrap it all up. You check coverage, generate reports, and review the results with the team. Did you meet your quality goals? Were there high-severity issues? With Provar’s built-in dashboards and test cycle reporting, you can present clear, actionable metrics without manually building slides.
The Role of Automation in a Test Cycle
Managing a test cycle manually is possible… but let’s be honest—it’s exhausting. It can drain resources, delay releases, and overload QA teams with repetitive tasks. That’s where automation comes in—not just as a time-saver, but as a smarter, more scalable way to handle testing from start to finish.
Automation helps reduce the heavy lifting, improve accuracy, and free up your team to focus on higher-value work like exploratory testing and strategy. With Provar, automation is embedded into every stage of the test cycle.
During the planning phase, manual setups can be time-consuming and disorganized. Provar solves this with pre-built templates and intelligent tagging that streamline test organization right from the start. In the design phase, writing every test case by hand becomes repetitive fast. Provar’s AI-powered test generation accelerates this process by automatically creating test cases based on metadata and requirements.
As you move into test execution, manual testing is often limited by human availability and device access. Provar allows you to schedule test runs, execute them in parallel, and scale across environments—saving countless hours. When it comes to bug tracking, many teams rely on manually logging issues and exporting data. With Provar, those defects are automatically captured and integrated with tools like Jira, Azure DevOps, or even Slack for seamless collaboration.
In the retesting stage, rerunning failed tests manually can drain time and morale. Provar makes it easier by allowing teams to reuse existing test cases, rerun only what’s needed, and track changes efficiently. Finally, in the reporting phase, many teams still struggle with spreadsheet chaos and last-minute status updates. Provar replaces that with real-time dashboards, clear metrics, and exportable reports that make stakeholder communication a breeze.
In short, automation enhances every part of the test cycle—and with Provar, it’s not just easier, it’s smarter.
Provar’s Take on Smarter Test Cycles
At Provar, we know that testing isn’t just a checkbox at the end of development—it’s the engine that drives quality. That’s why our platform is built to support the full test cycle, from planning to closure. With our native Salesforce integration, drag-and-drop UI, and support for DevOps tools, you can shift testing left, keep it in sprint, and get feedback faster than ever before. No more post-sprint bug hunts. No more outdated spreadsheets. Just consistent, scalable testing—backed by automation and designed for your team’s success.
Common Test Cycle Challenges (And How Provar Solves Them)
Let’s be real—test cycles don’t always go smoothly. Here are a few common problems and how Provar helps tackle them:
Poor Test Visibility
Problem: Teams don’t know what’s been tested or what failed.
Solution with Provar: Use test dashboards to get real-time insights into test results, execution coverage, and open defects.
Manual Overload
Problem: Too much time spent writing and re-running test cases.
Solution with Provar: Use Provar AI to auto-generate test cases and run them across orgs with minimal effort.
Disconnected Tooling
Problem: QA, dev, and product teams use different tools that don’t talk to each other.
Solution with Provar: Integrate with Jira, Git, CI/CD, and Slack to keep everything—and everyone—in sync.
Conclusion: Build Better Test Cycles with Provar
A well-run test cycle isn’t just good practice—it’s essential for delivering stable, high-quality releases. Whether you're testing a new Salesforce update or launching a critical feature, your test cycle is the backbone of software quality. With Provar, you get a test automation platform built specifically for Salesforce, designed to support every step of your test cycle with clarity, speed, and intelligence. From smarter planning to faster execution, Provar empowers your team to ship with confidence. So the next time you're planning a sprint or prepping a release, don’t just go through the motions. Rethink your Test Cycle with Provar—and see how much smoother quality assurance can really be.
0 notes
Text
Python for Data Science and Machine Learning Bootcamp

Introduction
Python has become the top programming language for Machine Learning and Data Science. Its ease of use, flexibility, and robust libraries make it the data professional's first pick. A properly designed bootcamp such as the one at TCCI Computer Coaching Institute is able to give proper grounding in Python for Machine Learning and Data Science, and enable learning necessary skills through practice.
Why Select TCCI for Python Training?
At TCCI Computer Coaching Institute, we provide high-quality training with:
Expert Faculty with industry experience
Hands-on Training through real-world projects
Industry-Relevant Curriculum with job-ready skills
Flexible Learning Options for professionals and students
Fundamentals of Python for Data Science
Our bootcamp starts with Python fundamentals so that learners grasp:
Variables, Data Types, Loops, and Functions
Key libraries such as NumPy, Pandas, and Matplotlib
Data manipulation skills for cleaning and analyzing data
Data Visualization in Python
Data visualization is a fundamental component of Data Science. We cover:
Matplotlib and Seaborn for drawing data visualizations
Plotly for interactive dashboards
Strategies for exploratory data analysis (EDA)
Exploring Machine Learning Concepts
Our course delivers a solid grasp of:
Supervised and Unsupervised Learning
Scikit-learn for applying models
Real-world use-cases with actual datasets
Data Preprocessing and Feature Engineering
In order to develop strong models, we pay attention to:
Managing missing data
Feature scaling and encoding
Splitting data for training and testing
Building and Testing Machine Learning Models
We walk students through:
Regression Models (Linear, Logistic Regression)
Classification Models (Decision Trees, Random Forest, SVM)
Model evaluation based on accuracy, precision, recall, and F1-score
Deep Learning Fundamentals
For those who are interested in AI, we cover:
Introduction to Neural Networks
Hands-on training with TensorFlow and Keras
Constructing a simple deep learning model
Real-World Applications of Data Science and Machine Learning
Our bootcamp has industry applications such as:
Predictive Analytics for business insights
Recommendation Systems implemented in e-commerce and streaming services
Fraud Detection in finance and banking
Capstone Project & Hands-on Deployment
An important component of the bootcamp is a live project, wherein students:
Work with a real-world dataset
Deploy and build a Machine Learning model
Get practical exposure to applications of Data Science
Who Can Attend This Bootcamp?
The course is targeted at:
Newbies who are interested in learning Python programming
Aspiring Data Scientists seeking guided learning
IT Professionals looking to upskill themselves in Data Science
Career Prospects after Attaining the Bootcamp
Through Python mastery for Data Science and Machine Learning, students can become:
Data Scientists
Machine Learning Engineer
AI Researchers
Conclusion
The TCCI Computer Coaching Institute's Python for Data Science and Machine Learning Bootcamp is an ideal place to begin for those interested in pursuing a career in Data Science. With hands-on assignments, guidance from experts, and an industry-oriented syllabus, this bootcamp equips one with the skills and knowledge necessary to be successful in the field.
Location: Ahmedabad, Gujarat
Call now on +91 9825618292
Get information from https://tccicomputercoaching.wordpress.com/
FAQ
Q1: What's the requirement for bootcamp eligibility?
A1: No coding knowledge is required; however, some basic understanding of mathematics and statistics would help.
Q2: How long does it take to finish this course?
A2: The course can be of different duration; however, regular practice may complete around 2-3 months.
Q3: Will a certificate be given after bootcamp completion?
A3: Yes, a certificate will be provided to you, which will prove you have successfully completed the boot camp courses.
Q4: Is it possible for a zero coder to learn Python for Data Science?
A4: Of course! It is an absolutely beginner course that covers all concepts and basics.
Q5: How does this bootcamp aid in one's career growth?
A5: It equips one with essential skills that are in great demand and increases employability in Data Science and AI positions.
0 notes
Text
Holiday Cheer: Enjoy 15% Off Statistics Homework for Christmas & New Year!

The holiday season is here! With Christmas and New Year just around the corner, it’s time to spread joy, cheer, and generosity. At statisticshomeworkhelper.com, we’re joining in the festive spirit by offering an exclusive 15% discount on all our statistics homework help services. Whether you’re tackling challenging probability problems, struggling with regression analysis, or grappling with hypothesis testing, we’re here to make your academic journey smoother and stress-free. Use the special festive code SHHFESTIVE15 to enjoy this offer.
Why Choose Professional Assistance?
Statistics is a subject that demands precision, logical reasoning, and an in-depth understanding of concepts. From data collection to interpretation and analysis, every step requires meticulous attention. Students often find themselves overwhelmed by assignments, especially when faced with tight deadlines or complex topics. This is where expert help can make all the difference. Here’s why our services are the perfect solution:
Expert Guidance: Our team consists of seasoned statisticians and tutors who bring years of experience and expertise to the table. They understand the nuances of statistical methodologies and ensure your assignments are accurate and well-structured.
Time-Saving: During the busy holiday season, balancing academics with family and festive activities can be challenging. Let us handle your homework while you focus on celebrating.
Stress Reduction: Deadlines and difficult assignments can cause unnecessary anxiety. With professional help, you can breathe easy knowing your work is in capable hands.
Comprehensive Services Tailored to Your Needs
Our statistics homework help services cover a wide array of topics, ensuring we’re equipped to assist you regardless of the complexity or scope of your assignment. Here are some of the areas we specialize in:
Descriptive and Inferential Statistics: From summarizing data to making predictions, we provide detailed solutions that demonstrate clear understanding.
Regression Analysis: Be it linear, multiple, or logistic regression, our experts deliver precise calculations and interpretations.
Probability Theory: We simplify probability distributions, random variables, and Bayes' theorem to make them comprehensible.
Hypothesis Testing: Z-tests, t-tests, chi-square tests – we’ve got you covered.
Data Analysis with Software: Proficient in tools like SPSS, R, Python, and Excel, we handle complex datasets and provide professional-grade outputs.
Customized Solutions: No matter your level of study, whether undergraduate or postgraduate, we tailor our assistance to meet your specific requirements.
How to Avail the Festive Discount
Claiming your 15% discount is simple and straightforward. Here’s how:
Visit our website, statisticshomeworkhelper.com.
Submit your assignment details through the contact form or email.
Mention the code SHHFESTIVE15 while requesting a quote.
Receive your discounted price and make the payment.
Relax while our experts work their magic.
This festive offer is valid for a limited time, so don’t miss out! Ensure you submit your requests before the New Year to take advantage of this exclusive deal.
Make the Most of Your Holiday Season
The holiday season is a time for joy, relaxation, and reconnecting with loved ones. It’s also an opportunity to recharge and prepare for the upcoming academic challenges. By entrusting your statistics homework to our experts, you’re not only ensuring high-quality work but also gifting yourself the time and peace of mind to truly enjoy the festivities.
Imagine celebrating Christmas without the nagging worry of pending assignments or welcoming the New Year with a clean slate and no academic backlog. That’s the gift we aim to provide through our dedicated services.
What Sets Us Apart?
Choosing the right service provider is crucial for ensuring academic success. Here’s what makes us stand out:
Punctual Deliveries: We respect your deadlines and always deliver on time.
Original Work: Plagiarism is never a concern with our meticulously crafted, unique solutions.
Affordable Pricing: Our rates are student-friendly, and with the current discount, you save even more.
24/7 Support: Our customer service team is available around the clock to assist you with queries or updates.
Confidentiality Guaranteed: Your privacy is our priority. All interactions and transactions are secure.
Success Stories from Students Like You
Over the years, we’ve helped countless students achieve their academic goals. Here’s what some of them have to say:
“The team at statisticshomeworkhelper.com is phenomenal! They helped me understand concepts I struggled with for weeks. Highly recommend their services.” – Jessica M.
“I was skeptical about online homework help, but this service exceeded my expectations. The solutions were detailed, and the explanations made learning easy.” – Rahul K.
“Thanks to their help, I scored an A on my statistics project. The festive discount was a bonus!” – Emily T.
Your Success Is Our Mission
At statisticshomeworkhelper.com, we’re driven by a commitment to empower students and simplify their academic journeys. The holiday season is a reminder of the importance of giving and sharing, and this offer is our way of supporting you during this busy time.
Final Thoughts
Don’t let homework stress dampen your holiday spirit. With our professional statistics homework help, you can enjoy the festive season to the fullest while staying on top of your academic responsibilities. Remember to use the code SHHFESTIVE15 to claim your 15% discount. Whether it’s Christmas, New Year, or any time in between, we’re here to help you succeed.
Visit statisticshomeworkhelper.com today, and let’s make this holiday season truly stress-free and memorable!
#StatisticsHelp#HomeworkHelp#HolidayDiscount#StudyStressFree#StatisticsExperts#AcademicSuccess#StudySupport#MathHelpOnline#HolidaySavings#StudentLife#StatisticsMadeEasy#ExamPrep#StudySmarter#StatisticsTutoring#AssignmentHelp#HolidayOffer#SHHFESTIVE15#OnlineLearning#StatisticsHomework#StressFreeHolidays
0 notes
Text
Impact of Dummy Variables on Regression Outcomes: Econometrics Analysis Help
Introduction
In general, dummy variables in econometrics are effective tools to incorporate qualitative data into regression models. Usually taking values of either 0 or 1, dummy variables allow us to capture the effects of discrete categories (such as gender, region, or treatment) on the dependent variable. To students studying econometrics, dummy variables represent the possibility of making such categorical influences quantifiable within the standard methodologies of regression testing. These are particularly useful when analyzing data that contain not just quantitative factors but also qualitative factors such as disparity of income between different genders and the effect of government policies across various regions.
Dummy variables are very useful in econometric analysis for obtaining accurate analysis and interpretable results, as they segment data based on meaningful categories that may otherwise remain hidden. For students working on econometric analysis, learning how to implement dummy variables can simplify complex analyses and make models more instinctive. Students can take assistance from econometrics homework help experts to master different techniques that can be used in the most efficient way to set up and interpret dummy variables. This guide focuses on the basic concept of dummy variables, their use in linear regression, their importance, and their implementation using Python codes to help students in their coursework assignments.

How to Use Dummy Variables for Better Interpretability in Linear Regression Models
Explaining what Dummy Variables are in Linear Regression
When conducting a linear regression analysis, dummy variables are used to quantify how categorical variables impact the outcome variable. For instance, we can examine the effects that the region of an individual has on his or her income. Here, the region is categorical (North, South, East, West), and by using dummy variables we obtain the binary set of indicators for each corresponding region allowing us to model the changes in incomes peculiar to these locations. If the dummy variables were not included in the equation, the regression would assume the region to be a continuous variable which is a nonsensical approach, or it would exclude this variable altogether, thus eliminating useful insights. Dummy variables solve this issue by following a binary format, where 0 or 1 are assigned to show whether that certain category exists or not. Here is a guide on performing dummy variable coding in Python, especially for simple regression analysis.
Step-by-Step Guide with Python Code
Suppose we have a dataset involving information on income, gender, and level of education. To incorporate categorical effects into the income prediction, we will incorporate dummy variables.
1. Loading the Dataset
Suppose we have a sample dataset of people's income, gender, and education levels. We’ll use the Python library pandas to load and explore the dataset:
import pandas as PD
# Sample dataset
data = pd.DataFrame({
'income': [55000, 48000, 62000, 45000, 52000],
'gender': ['Male', 'Female', 'Male', 'Female', 'Male'],
'education': ['Bachelor', 'Master', 'Bachelor', 'PhD', 'Master']
})
print(data)
Now, let’s introduce dummy variables for gender and education to capture their unique impacts on income.
1. Creating dummy variables using pandas.get_dummies()
To make dummy variables, python’s Panda library provides an easy method. Let’s create dummy variables for gender as well as for education.
# Generate dummy variables
data_dummies = pd.get_dummies(data, columns=['gender', 'education'], drop_first=True)
print(data_dummies)
By using drop_first=True we prevent the so-called dummy variable trap which happens when all categories are included in the model leading to perfect multicollinearity. Here, the gender_Female and the education_Master, education_PhD point to each category.
1. Setting Up the Regression Model
It is now possible to fit the linear regression using dummy variables to predict income. We are going to build and evaluate the model by using the statsmodels package in Python.
import statsmodels.api as sm
# Define the dependent and independent variables
X = data_dummies.drop('income', axis=1)
y = data_dummies['income']
# Add constant for intercept
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X).fit()
print(model.summary())
In this setup, we include gender_Female as a dummy variable and assign it a value of 1 for ‘Female’ and 0 for ‘Male’ which will be our reference category. Likewise, for education, “Bachelor” is the baseline category, with separate summy variables on “Master” and “PhD”. Using the results of the constructed model, we can understand how being female as well as having higher educational standards influences income as compared to other baseline categories.
Interpreting the Results
Let’s understand how dummy variables affect the regression:
• Intercept: The intercept means the anticipated income for the reference category, in this case, a male with an education level of Bachelor’s degree.
• Gender Coefficient: The coefficient of gender_Female describes the variation of income of females from the male baseline category.
• Education Coefficients: The coefficients for education_Master and education_PhD indicate the income difference caused by these degrees compared to those with a bachelor’s degree.
We get insight of how each categorical variable affects the income by comparing each dummy variable’s coefficient. For instance, if the coefficient for gender_Female is negative this means, females earn less on average than males.
Looking for help with economics homework? We have the solution.
Why Choose Econometrics Homework Help for Your Assignments?
For students learning econometrics, especially when dealing with complex analysis using Python, our econometrics homework help service provides a smooth, expert-backed solution for mastering the subject. The service is perfect for a student in need of guidance on the application of techniques in econometrics, their accuracy, and clarity regarding the implementation of Python. With our service, you access professionals who are well-experienced both in the field of study and with the implementation of Python.
Simple Process to Avail the Service
Starting is easy. All you need to do is submit your assignment file, which includes everything - instructions and data files if necessary for the data analysis. Our team reviews the requirements for assigning an expert and then commences writing a solution following all instructions and questions. We deliver perfectly annotated code and clear explanations so you can understand every single step and apply it in future assignments.
Solution Preparation and Key Features
Each solution is developed with a focus on its academic quality standards and the thoroughness of the econometric analysis performed. We use Python code for the calculations, elaborate output explanation, and relevant econometric theory to give you step-by-step explanations for a clear understanding.
Our key features include:
• Post-Delivery Doubt Clearing: After the solution has been delivered, we conduct free sessions to clarify all doubts.
• Free Amendments: If necessary, we perform free revisions for improvement.
• Detailed Explanations: Every solution provided is accompanied by an explanation to show how the problems are solved and the processes used.
Conclusion
Dummy variables are invaluable in the econometric model for controlling the effects of categorical data. This is where students and researchers can capture those nuances otherwise lost in purely numerical models. Students can easily create dummy variables and fit regression models using Python, getting some pretty interpretable results regarding differences across categories in their data. Being able to master these techniques will allow them to overcome complex assignments and practical analyses with confidence. Further assistance with our econometrics homework help service can provide much-needed support at crunch times and exam preparation.
Commonly Asked Questions
1. What If I have a hard time understanding a certain segment of the solution?
After delivery of the product, we assist with clarity on the concepts in case there is an aspect that the student did not understand.
2. Can the assignment solution be customized as per my requirements?
Absolutely. When solving each task, we strictly adhere to the instructions given in the provided assignment file so that all of them meet your individual requirements.
3. If I opt for your econometrics homework help, what is your turnaround time?
Do you have a tight schedule? We appreciate the value of time and provide several options to speed up the flow, including a fast turnaround.
Further Reading and Resources
Understanding the use of dummy variables in econometrics is very important Some helpful resources and textbooks that the students can follow are mentioned below: 1. Introductory Econometrics: A Modern Approach by Jeffrey M. Wooldridge - This textbook is highly recommended in which dummy variables are very well discussed and the concept of regression is explained with a crystal-clear view. 2. Econometrics by Example by Damodar N. Gujarati: This book contains examples and case studies; hence, it is suitable for practice. 3. Python libraries. To write a regression model, one must consider the following Python libraries: Statsmodels for an econometric model and Pandas in terms of handling data with dummy variable generation.
#Econometrics Homework Help Online#Help with Econometrics Assignments#Econometrics Tutor for Students#Online Econometrics Homework Assistance#Econometrics Assignment Help for College Students#Professional Econometrics Homework Help#Econometrics Analysis Help#Econometrics Help for Statistics Students#Expert Help in Econometrics#Affordable Econometrics Homework Solutions#Econometrics Coursework Help#Econometrics Homework Solutions Provider
0 notes
Text
Building Predictive Models with Regression Libraries in Python Assignments
Introduction
Predictive modeling serves as a fundamental method for data-driven decisions that allows to predict outcomes, analyze trends, and forecast likely scenarios from the existing data. Predictive models are the ones that forecast the future outcomes based on historical data and helps in the understanding of hidden patterns. Predictive modeling is an essential technique in data science for applications in healthcare, finance, marketing, technology, and virtually every area. Often such models are taught to students taking statistics or Data Science courses so that they can utilize Python’s vast libraries to build and improve regression models for solving real problems.
Python has been the popular default language for predictive modeling owing to its ease of use, flexibility, and availability of libraries that are specific to data analysis and machine learning. From cleaning to building models, and even evaluating the performance of models, you can do all of these with Python tools like sci-kit-learn and stats models, as well as for data analysis using the pandas tool. Getting acquainted with these tools requires following certain procedures, writing optimized codes, and consistent practice. Availing of Python help service can be helpful for students requiring extra assistance with assignments or with coding issues in predictive modeling tasks.
In this article, we take you through techniques in predictive modeling with coding illustrations on how they can be implemented in Python. Specifically, the guide will be resourceful for students handling data analysis work and seeking python assignment help.

Why Regression Analysis?
Regression analysis is one of the preliminary methods of predictive modeling. It enables us to test and measure both the strength and the direction between a dependent variable [that is outcome variable] and one or more independent variables [also referred to as the predictors]. Some of the most commonly used regression techniques have been mentioned below: • Linear Regression: An easy-to-understand but very effective procedure for predicting the value of a dependent variable as the linear combination of the independent variables. • Polynomial Regression: This is a linear regression with a polynomial relationship between predictors and an outcome. • Logistic Regression: Especially popular in classification problems with two outcomes, logistic regression provides the likelihood of the occurrence of specific event. • Ridge and Lasso Regression: These are the more standardized types of linear regression models that prevent overfitting.
Step-by-Step Guide to Building Predictive Models in Python
1. Setting Up Your Python Environment
First of all: you need to prepare the Python environment for data analysis. Jupyter Notebooks are perfect as it is a platform for writing and executing code in small segments. You’ll need the following libraries:
# Install necessary packages
!pip install numpy pandas matplotlib seaborn scikit-learn statsmodels
2. Loading and Understanding the Dataset
For this example, we’ll use a sample dataset: ‘student_scores.csv’ file that consists of records of Study hours and Scores of the students. It is a simple one, but ideal for the demonstration of basics of regression. The dataset has two columns: Numerical variables include study hours referred to as Hours; and exam scores referred as Scores.
Download the students_scores.csv file to follow along with the code below.
import pandas as pd
# Load the dataset
data = pd.read_csv("students_scores.csv")
data.head()
3. Exploratory Data Analysis (EDA)
Let us first understand the data before we perform regression in python. Let us first explore the basic relationship between the two variables – the number of hours spent studying and the scores.
import matplotlib.pyplot as plt
import seaborn as sns
# Plot Hours vs. Scores
plt.figure(figsize=(8,5))
sns.scatterplot(data=data, x='Hours', y='Scores')
plt.title('Study Hours vs. Exam Scores')
plt.xlabel('Hours Studied')
plt.ylabel('Exam Scores')
plt.show()
While analyzing the scatter plot we can clearly say the higher the hours studied, the higher the scores. With this background, it will be easier to build a regression model.
4. Building a Simple Linear Regression Model
Importing Libraries and Splitting Data
First, let’s use the tool offered by the sci-kit-learn to split the data into training and testing data that is necessary to check the performance of the model
from sklearn.model_selection import train_test_split
# Define features (X) and target (y)
X = data[['Hours']]
y = data['Scores']
# Split data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Training the Linear Regression Model
Now, we’ll fit a linear regression model to predict exam scores based on study hours.
from sklearn.linear_model import LinearRegression
# Initialize the model
model = LinearRegression()
# Train the model
model.fit(X_train, y_train)
# Display the model's coefficients
print(f"Intercept: {model.intercept_}")
print(f"Coefficient for Hours: {model.coef_[0]}")
This model equation is Scores = Intercept + Coefficient * Hours.
Making Predictions and Evaluating the Model
Next, we’ll make predictions on the test set and evaluate the model's performance using the Mean Absolute Error (MAE).
from sklearn.metrics import mean_absolute_error
# Predict on the test set
y_pred = model.predict(X_test)
# Calculate MAE
mae = mean_absolute_error(y_test, y_pred)
print(f"Mean Absolute Error: {mae}")
A lower MAE indicates that the model's predictions are close to the actual scores, which confirms that hours studied is a strong predictor of exam performance.
Visualizing the Regression Line
Let’s add the regression line to our initial scatter plot to confirm the fit.
# Plot data points and regression line
plt.figure(figsize=(8,5))
sns.scatterplot(data=data, x='Hours', y='Scores')
plt.plot(X, model.predict(X), color='red') # Regression line
plt.title('Regression Line for Study Hours vs. Exam Scores')
plt.xlabel('Hours Studied')
plt.ylabel('Exam Scores')
plt.show()
If you need more assistance with other regression techniques, opting for our Python assignment help services provides the necessary support at crunch times.
5. Improving the Model with Polynomial Regression
If the relationship between variables is non-linear, we can use polynomial regression to capture complexity. Here’s how to fit a polynomial regression model.
from sklearn.preprocessing import PolynomialFeatures
# Transform the data to include polynomial features
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# Split the transformed data
X_train_poly, X_test_poly, y_train_poly, y_test_poly = train_test_split(X_poly, y, test_size=0.2, random_state=42)
# Fit the polynomial regression model
model_poly = LinearRegression()
model_poly.fit(X_train_poly, y_train_poly)
# Predict and evaluate
y_pred_poly = model_poly.predict(X_test_poly)
mae_poly = mean_absolute_error(y_test_poly, y_pred_poly)
print(f"Polynomial Regression MAE: {mae_poly}")
6. Adding Regularization with Ridge and Lasso Regression
To handle overfitting, especially with complex models, regularization techniques like Ridge and Lasso are useful. Here’s how to apply Ridge regression:
from sklearn.linear_model import Ridge
# Initialize and train the Ridge model
ridge_model = Ridge(alpha=1.0)
ridge_model.fit(X_train, y_train)
# Predict and evaluate
y_pred_ridge = ridge_model.predict(X_test)
mae_ridge = mean_absolute_error(y_test, y_pred_ridge)
print(f"Ridge Regression MAE: {mae_ridge}")
Empowering Students in Python: Assignment help for improving coding skills
Working on predictive modeling in Python can be both challenging and rewarding. Every aspect of the service we offer through Python assignment help is precisely designed to enable students not only to work through the assignments but also to obtain a better understanding of the concepts and the use of optimized Python coding in the assignments. Our approach is focused on student learning in terms of improving the fundamentals of the Python programming language, data analysis methods, and statistical modeling techniques.
There are a few defined areas where our service stands out
First, we focus on individual learning and tutoring.
Second, we provide comprehensive solutions and post-delivery support. Students get written solutions to all assignments, broken down into steps of the code and detailed explanations of the statistical method used so that the students may replicate the work in other projects.
As you choose our service, you get help from a team of professional statisticians and Python coders who will explain the complex concept, help to overcome technical difficulties and give recommendations on how to improve the code.
In addition to predictive analytics, we provide thorough consultation on all aspects of statistical analysis using Python. Our services include assistance with key methods such as:
• Descriptive Statistics
• Inferential Statistics
• Regression Analysis
• Time Series Analysis
• Machine Learning Algorithms
Hire our Python assignment support service, and you will not only get professional assistance with your tasks but also the knowledge and skills that you can utilize in your future assignments.
Conclusion In this guide, we introduced several approaches to predictive modeling with the use of Python libraries. Thus, by applying linear regression, polynomial regression, and Ridge regularization students will be able to develop an understanding of how to predict and adjust models depending on the complexity of the given data. These techniques are very useful for students who engage in data analysis assignments as these techniques are helpful in handling predictive modeling with high accuracy. Also, take advantage of engaging with our Python assignment help expert who can not only solve your Python coding issues but also provide valuable feedback on your work for any possible improvements.
#PythonAssignmentHelp#PythonHelp#PythonHomeworkHelp#PythonProgramming#CodingHelp#PythonTutoring#PythonAssignments#PythonExperts#LearnPython#PythonProgrammingHelp#PythonCoding#PythonSupport#ProgrammingHelp#AssignmentHelp#PythonTutors#PythonCourseworkHelp#PythonAssistance#PythonForBeginners#PythonProjectHelp#OnlinePythonHelp
0 notes
Text
Understanding Statistical Modeling with R: Unlocking Regression, ANOVA, and Beyond for Academic Excellence
Statistical modeling is crucial across various academic disciplines, helping to extract meaningful insights from data. However, students often face significant challenges when handling assignments that require a deep understanding of diverse modeling techniques. In this landscape, the R programming language emerges as an essential tool for students aiming to master statistical modeling. R offers a versatile and robust platform for statistical computing and graphics, providing a comprehensive toolkit to explore, analyze, and visualize data. Whether you're seeking R homework help or aiming to enhance your statistical modeling skills, R programming facilitates your academic journey.
Navigating Regression Analysis in R
Regression analysis is a fundamental statistical technique used to understand relationships between variables. In R, this technique is seamlessly implemented through functions like lm(), which allow students to construct and interpret linear regression models. The lm() function simplifies the process of exploring relationships between dependent and independent variables, providing a solid foundation for more complex models.
Building and Interpreting Linear Regression Models
Using R, students can easily set up and interpret linear regression models. The process involves loading data, defining variables, and using the lm() function to generate a model. Key output metrics, such as coefficients, residuals, and R-squared values, offer insights into the model's performance. Understanding these metrics equips students to approach their assignments with confidence and clarity.
Advancing to Multiple Regression
Building on simple linear regression, multiple regression incorporates more variables, which is valuable when real-world scenarios involve multiple factors influencing an outcome. In R, extending the lm() function to accommodate additional predictors allows students to analyze and predict outcomes in diverse fields. This section covers assessing the significance of individual predictors, understanding multicollinearity, and evaluating the model using adjusted R-squared values.
Unveiling the Power of ANOVA in R
Analysis of Variance (ANOVA) is a powerful technique for comparing means across multiple groups. Implemented in R through functions like aov(), ANOVA helps determine whether the means of these groups are significantly different. This statistical method is crucial for students tackling assignments involving group comparisons or experiments with multiple factors.
Implementing ANOVA in R
Students will learn the steps to implement ANOVA in R, including structuring data, using the aov() function, and interpreting the output. Understanding these steps ensures a solid grasp of variance analysis, enabling students to handle complex assignments effectively.
Exploring Post-hoc Tests and Advanced Techniques
Post-hoc tests, such as Tukey's Honestly Significant Difference (HSD) test, identify specific group differences when ANOVA results are significant. Advanced ANOVA techniques, including repeated measures ANOVA, are also covered to address scenarios where standard ANOVA assumptions might not be met. These advanced methods broaden students' analytical toolkit, preparing them for more intricate homework problems.
Beyond Basics: Advanced Statistical Modeling in R
Many real-world scenarios involve categorical outcomes, requiring a specialized approach. Logistic regression, implemented in R through functions like glm(), is used for binary or multinomial outcomes. This section empowers students to handle assignments involving categorical outcomes, providing a comprehensive understanding of logistic regression.
Practical Applications and Interpretation
Students will learn to set up logistic regression models, interpret odds ratios, and assess model fit. Practical examples illustrate how to navigate challenges posed by categorical outcomes, preparing students for diverse statistical modeling scenarios in their academic and professional pursuits.
Introduction to Time Series Analysis
Assignments involving temporal data require skills in time series analysis and forecasting. R offers tools like the forecast and tseries packages for analyzing and predicting trends in time-dependent datasets. This section introduces students to these packages, covering topics such as autoregressive integrated moving average (ARIMA) models, exponential smoothing, and seasonal decomposition.
Practical Insights and Applications
Students will learn to implement time series models, understand patterns and seasonality, and make informed predictions based on historical data. Practical examples prepare students to handle assignments involving forecasting, equipping them with essential skills for various fields, from finance to environmental science.
Integrating Knowledge for Academic Success
Mastering statistical modeling in R unlocks a transformative journey for students, from understanding basic regression to advanced modeling techniques like ANOVA and logistic regression. R provides a user-friendly environment for statistical computing, helping students excel in their academic endeavors. By grasping these concepts, students are well-prepared to tackle complex assignments and succeed in their statistical journey.
Enhancing Practical Application
The practical application of statistical modeling techniques in R is crucial for academic success. Whether dealing with simple linear regression or complex time series analysis, R offers a robust framework to explore and analyze data. This section emphasizes the importance of hands-on practice and continuous learning to achieve mastery in statistical modeling.
Conclusion
In conclusion, mastering statistical modeling in R empowers students to conquer the complexities of their academic assignments. By understanding and applying regression analysis, ANOVA, and advanced techniques like logistic regression and time series analysis, students can navigate their statistical journey with confidence. Seeking assistance from a statistics homework helper can further enhance their understanding and performance in statistical modeling. R programming serves as a powerful ally, providing the tools and knowledge needed to excel in statistical modeling and achieve academic success.
Reference: https://www.statisticshomeworkhelper.com/blog/statistical-modeling-r-anova-guide/
0 notes
Text
Explore Our New Regression Analysis Homework Help service!

Regression analysis is a powerful statistical method used to understand relationships between variables. It's an essential tool in economics, finance, and many other fields. However, mastering regression analysis can be challenging due to its complexity and the mathematical concepts involved. To support you in conquering this subject, Economicshomeworkhelper.com proudly introduces our Regression Analysis Homework Help service!
Understanding Regression Analysis
At its core, regression analysis aims to model the relationship between a dependent variable and one or more independent variables. This technique allows researchers and analysts to make predictions, understand trends, and assess the strength of relationships. Here are some key concepts:
Simple Linear Regression: Involves a single independent variable predicting a dependent variable. The relationship is modeled with a straight line.
Multiple Regression: Involves two or more independent variables. This method helps understand the influence of multiple factors on the dependent variable.
Assumptions of Regression: Important assumptions include linearity, independence, homoscedasticity, and normality of residuals. Understanding these assumptions is crucial for accurate analysis.
Interpreting Coefficients: Regression coefficients indicate the expected change in the dependent variable for a one-unit change in the independent variable.
R-squared Value: This statistic indicates the proportion of variance in the dependent variable that can be explained by the independent variables, providing insight into model effectiveness.
Why Choose Our Regression Analysis Homework Help?
Expert Assistance: Our team consists of experienced professionals who specialize in statistics and econometrics. They are equipped to provide clear explanations and guidance on complex regression concepts.
Customized Solutions: We understand that each assignment is unique. Our experts will tailor their responses to meet your specific assignment requirements and help you grasp the underlying principles.
Timely Delivery: We prioritize deadlines. You can expect your completed homework to be delivered on time, allowing you to review and ask questions before submission.
24/7 Support: Whether it’s day or night, our support team is available around the clock to address your queries and concerns.
How Our Service Works
Getting started with our Regression Analysis Homework Help is simple:
Visit Our Website: Go to Economicshomeworkhelper.com to explore our services.
Submit Your Assignment: Use our user-friendly submission form to upload your regression analysis homework, including any specific instructions from your instructor.
Receive Expert Assistance: Our team will work diligently on your assignment, ensuring you receive high-quality support tailored to your needs.
Review Your Work: You’ll receive your completed homework ahead of the deadline, giving you time to review and learn from the expert explanations provided.
Improve Your Understanding: Utilize the insights gained from our assistance to enhance your comprehension of regression analysis concepts.
Conclusion
Regression analysis is an invaluable tool in various fields, but mastering it can be daunting. With the right guidance, you can overcome these challenges and excel in your studies. At Economicshomeworkhelper.com, we are dedicated to providing you with expert assistance tailored to your needs.
#economics homework help#education#homework help#university#do my economics homework#students#economics#Regression Analysis Homework Help
0 notes
Text
Eviews Assignment Help

EViews is a statistical software package developed by Quantitative Micro Software (QMS), which is now part of IHS Markit. EViews stands for “Econometric Views,” and it is widely used for time series analysis, econometrics, and statistical modeling. The software is particularly popular among economists, researchers, and analysts for its capabilities in handling time series data and conducting econometric analysis.
EViews includes eviews assignment writing , eviews report, eviews assignment , eviews assignment help , eviews college assignment , eviews software, eviews university assignment and many other topics.
EViews provides a user-friendly graphical interface, making it accessible to both beginners and advanced users. It offers a wide range of features, including data management, statistical analysis, forecasting, and model estimation. Some of the key functionalities of EViews include:
Data Management: EViews allows users to import various data formats, such as Excel, CSV, and databases, and organize data efficiently. Users can handle panel data, cross-sections, and time series data easily.
Time Series Analysis: EViews specializes in time series analysis and offers a rich set of tools for exploring and modeling time series data. Users can visualize time series data, test for unit roots, apply smoothing techniques, and estimate time series models like ARIMA (AutoRegressive Integrated Moving Average).
Econometric Modeling: EViews is widely used for econometric analysis. It provides tools for linear and nonlinear regression analysis, panel data analysis, limited dependent variable models (probit, logit), and many other econometric techniques.
Forecasting: The software offers various methods for time series forecasting, including exponential smoothing, ARIMA models, and others. Users can generate forecasts, evaluate forecast accuracy, and visualize forecast results.
Data Visualization: EViews allows users to create various graphical representations of data, such as scatter plots, line plots, bar charts, histograms, and more. These visualizations help in understanding patterns and relationships in the data.
Programming Support: EViews provides programming capabilities, allowing users to automate repetitive tasks and create custom procedures using EViews’ built-in programming language.
Add-ins and Extensions: EViews supports add-ins and extensions, allowing users to extend the software’s functionality and access specialized tools or models.
Due to its focus on time series and econometric analysis, EViews is commonly used in academic research, economic forecasting, financial analysis, and policy analysis. It provides a robust platform for conducting empirical studies and exploring the dynamics of economic and financial data.
Assignment on Eviews Assignment Help
Objective: The objective of this assignment is to introduce you to EViews, a popular statistical software widely used for time series analysis, econometrics, and data visualization. Through this assignment, you will learn how to import data into EViews, perform basic data analysis, and generate simple statistical outputs.
Task 1: Installation and Data Import
Download and install the latest version of EViews on your computer (if you haven’t already).
Locate a dataset in a CSV format or Excel format that you would like to analyze. It could be any dataset of your choice (e.g., stock prices, economic indicators, etc.).
Task 2: Data Exploration
Open EViews and create a new work file.
Import the dataset you chose in Task 1 into EViews.
Explore the imported data by examining the structure of the dataset, such as the number of observations, variables, and their types.
Task 3: Basic Data Analysis
Generate descriptive statistics for numerical variables in the dataset. Calculate measures such as mean, standard deviation, minimum, maximum, and quantiles.
Create a histogram for one or more numerical variables to visualize their distributions.
Calculate and interpret the correlation matrix among relevant variables in the dataset.
Task 4: Time Series Analysis
If your dataset contains time series data, create a time series plot to visualize the patterns and trends over time.
Calculate the first-order difference for a relevant variable and plot the differenced time series to observe stationarity.
Task 5: Regression Analysis
Select two or more variables from your dataset for a regression analysis.
Run a simple linear regression using EViews, and interpret the regression coefficients and goodness of fit measures (R-squared and Adjusted R-squared).
Plot the regression line along with the scatter plot of the variables used in the regression.
Task 6: Forecasting (Optional)
If your dataset is a time series, attempt a simple forecasting exercise using EViews.
Choose an appropriate forecasting method (e.g., ARIMA, exponential smoothing) and explain your choice.
Generate and interpret the forecast results, including measures of accuracy (e.g., Mean Absolute Error, Root Mean Squared Error).
Task 7: Conclusion Write a brief conclusion summarizing the insights gained from your data analysis in EViews. Discuss any patterns, trends, or relationships discovered during the analysis.
Submission Guidelines:
Prepare a well-structured report containing the tasks mentioned above.
Include relevant graphs and visualizations to support your analysis.
Provide clear explanations and interpretations of the results.
Submit your report in PDF format or any other standard document format.
Note:
In case you encounter any difficulties while using EViews, consult the software’s official documentation or seek assistance from your instructor or classmates.
This assignment aims to provide you with a foundational understanding of EViews and basic data analysis. More advanced topics and techniques can be explored in subsequent courses or assignments.
#eviews assignment#western assignment help#assignment help#assignmentexpert#assignmenthelpusa#eviews college assisgnment#eviews assignment writing
0 notes
Text
Singapore Simple Linear Regression; Which Are the Basic Plots you can draw Using R Studio?

Drawing a comprehensive graph is a central aim, especially if you are doing analysis. R studio is the main component you require when you are dealing with linear regression. It holds exclusive features to display your information graphically. For you to have perfect graphs, you need to know basic commands in R for plotting. For any plot, you need to have knowledge of how to enter different data types. That needs not only knowledge on this package but in-depth comprehension of how to control different functions. You need to master how to use two different datasets with defined variables to draw any plot. Below-mentioned is some basic plots you can draw using R studio for your analysis.
ü Strip charts. This is a basic type of a plot variable you can do with R. Each data is presented in terms of boxes. To come up with a perfect strip chart, use strip chart command.
ü Histograms. In many analyses, a histogram is inescapable. R studio can plot your data using your frequencies to give a specific range. To get the best, you can specify the number of breaks you need by using breaks options.
ü Box plots. This plot enables you to view the median, quantiles of your dataset.
Do you want a break with your simple linear regression assignment tasks? Then we can give you one. We understand this area of study involves numerous functions that are overwhelming. At times assignment completion creates pressure for every determined scholar and it's often torturing. Then, if you need a break with that r programming assignment help can carry your assignment responsibilities conveniently. Get our Singapore Simple linear regression model assignment help now and breathe out. In our platform, we have the best facilities to hold your hands in achieving first-class grades. Are you thinking our simple linear regression model online tutors are expensive? Not at all, our services are topnotch with slashed prices. Do don’t need to dig deep in your pocket as the limited pocket allowance is fit for you. Our pricing structure is stable in all seasons hence you can always come for our Help with Simple linear regression model homework. Do you wish to know what happens if you refer your friends to avail of our services? We give a referral bonus as a thank you token for your next order. Apart from our cheap rates, how do we accredit your money is safe? Our systems are highly encrypted to detect any hacking malpractice easily. Therefore, pay for your order through your international debit or credit card and pay pal account. If circumstances come and you won’t be completely satisfied with our services we have a convenient money-back transfer. For deciphering more on this, read more on our terms and conditions.
Do you know you can avail our R help Tutor help in Singapore any time wherever you are? It's easy to do that. You need to have direct access to our official homepage. Be straight to the point, and we will evaluate your needs promptly. You will be assigned the right tutor to do that.
Read more about: Where Can You Get the Best R Programming Tutors and R Programming Help?
0 notes
Text
10 ESSENTIAL MACHINE LEARNING ALGORITHM ONE SHOULD BE AWARE OF
Have you ever noticed how hectic it would have been for us to do every single task on our own? From basic calculations to extreme algorithms, all of this could be done in a snap. And how is that made possible? Yes, you got that right, with the help of technological advancements. In this technology dependent domain, machines have made working and operating activities easier & simplified for us. Different technologies like Artificial learning, data scene, AWS, machine learning, plus many more. All these have led to advancement as well as growth, together with adding to providing several individuals with careers in the same. Among these advancements, machine learning is what we’ll be discussing today! Available are a number of institutions rendering machine learning training. So if you’re looking for one, we got you covered!

Before we move on to knowing or understanding the algorithms of ML, let us first brush up our comprehension of what machine learning is.
Machine Learning alludes to a section of artificial learning plus it is the study of computer algorithms that let the system learn automatically, therefore enhancing the practice & producing much more exact conclusions & forecasts without being particularly modified for that. The main purpose is offering a grant to the systems together with the machines to determine and work automatically without any human resistance or help.
ML benefits us in a number of ways as well, namely :
Consistent Progress
Easy Spam Identification
Automation
Time efficient
Right Product Suggestion
By correct practice & application, it is possible for anyone to make use of this.
But with constant changes taking place around us, even the technologies have to keep up with them by following its pace. The formulas and algorithms cannot be the same for all the operations or executions. Even they require modification for better processing. Let's find out what these algorithms mean and are!
ML ALGORITHMS
A machine learning algorithm is a strategy through which the AI framework leads its assignment, for the most part foreseeing yield esteems from given information & data.
Machine learning can be categorized into three types, namely.
Supervised Algorithms: In this category, the preparation informational collection has information and yield. Throughout meetings, the model changes its factors to plan the contribution to the relating yield.
Unsupervised Algorithms: In these calculations, there is no objective result. Instead, calculations bunch datasets for various gatherings.
Reinforcements Algorithms: These calculations are prepared to form conclusions. In light of these choices, the calculation prepares itself, keeping into attention the achievement or blunder in the yield. Over the long run, support calculations prepare themselves to make dependable expectations.
Now that we know about Machine learning, its benefits, algorithms, categories of algorithms, we will move onto learning about a few vital ML algorithms! So what’s the wait for, come on!
Learn More:- Top 5 Machine Learning Essential Prerequisites
Essential Machine Learning Algorithms
ML has led to a great deal of development & advancement in the growth of business.
Linear Regression
It is quite possibly the most notable calculation in AI and insights. Linear regression is addressed by a condition that utilizes information focuses to track down the most suitable fitted line to demonstrate the information. So, a connection is set up among reliant and autonomous factors by implementing them to a line.
Logistic Regression
Logistic regression is the suitable regression study to manage when the subject factor is dichotomous (binary). Similar to each relapse investigation, the strategic relapse is a foresighted analysis. This calculation is utilized to assess distinct inputs from a bunch of free factors. On a chart, logistic regression appears as though a major S and implements all qualities with the scope of 0 to 1. It is utilized where you may anticipate a 'either' type of yield, for example, an event where you should decide if it will rain or not.
Decision Tree
It is a supervised type of algorithm. A decision tree is such a diagram that indicates probable conclusions for a grouping of associated choices. A decision tree examination application will allow outline pioneers to successfully take a glance at altered outlines against each other and survey the perils, possibilities of growth, and likely benefits identified with each. These are significant calculations for perceptive demonstrating AI. The portrayal of this sort of calculation is done through a spreading out tree into twofold factors. They can be utilized to decide both unmitigated and persistent ward factors.
Support Vector Machines
SVM is a grouping kind calculation that utilizes a hyperplane or line identified as a classifier to isolate the information focus. Utilizing an SVM, you plot crude information as focused in an n-dimensional area, where n is the complete number of highlights you possess. Individual component's worth is then attached to a specific correspondent, making it simple to arrange the information.
KNN
This is helpful for both arrangement and relapse issues. The design portrayal for the KNN calculation is the whole preparing dataset. Forecasts are produced for another information point by perusing the entire preparing set for the 'k' number of comparable cases (referred to as the neighbors) and summing up the yield pattern for them. It resembles conversing with an individual's companions to become more acquainted with them.
Naive Bayes
Naive Bayes is a straightforward calculation yet is known to beat profoundly refined characterization techniques. It depends on Bayes' Theorem in likelihood. It is referred to as naive in light of the fact that it deals with the suspicion that each information variable is autonomous. Such a model contains two kinds of possibilities that can be determined straightforwardly from your preparation dataset:
The likelihood of each class
The restrictive likelihood for each class as for every x worth.
Learning Vector Quantisation
One disadvantage of the KNN calculation is that you are required to see your whole dataset the entire time. The Learning Vector Quantisation (LVQ) calculation is a neural organization calculation that lets you pick the quantity of cases plus the specific idea of those examples that you should cling to. LVQ is addressed by an assortment of codebook vectors. LVQ demands less capacity and storage contrasted with KNN.
K-Means
K-Means falls under the category of the unsupervised calculation which is utilized to look after bunching issues. Datasets are grouped into k numbers of bunches so all the information focused inside one bunch is equivalent & diverse from the information in the others. To start with, the calculation picks a specific number of focuses known as centroids, suppose that value is k. Each information point shapes a bunch with centroids nearest to it. This decides the nearest length for every information point.
Random Forest
An assortment of decision trees creates the calculation that is identified as the Random Forest calculation. Each tree endeavors to gauge an arrangement that is known as a 'vote'. Every vote from each tree is thought of, and afterward, the most casted ballot order is picked. Each tree in a random forest algorithm is developed to the top significant degree conceivable.
Dimensionality Reduction Algorithm
At times, datasets comprise various factors that can turn out to be extremely difficult to deal with. With various information assortment sources now, datasets regularly have a huge number of factors that are hard to deal with and incorporate superfluous factors. In such circumstances, it is almost difficult to distinguish the factors that are significant for your expectations. It is the place where the aforementioned calculations are utilized.
Proper implementation of these algorithms can be very beneficial for businesses in the long run.
KVCH is a 31 years old institution offering amazing services. It has the best Machine learning course. So if you plan on pursuing this, go for their certification ML course.
Author Bio:-
KVCH Content team are online media enthusiast and a blogger who closely follows the latest Career Guidance and Job trends In India and online marketing trends. They write about various related topics such as Career Topics, Job Search and much more.
0 notes
Text
AI and ML
This article was only an introduction of these machine learning algorithms. If you want to know more, check out our online Artificial Intelligence & Machine Learning Course contains the perfect mix of theory, case studies, and extensive hands-on assignments to even turn a beginner into a pro by the end. Our ML and artificial intelligence certification courses are perfect for students and working professionals to get mentored directly from industry experts, build your practical knowledge, receive complete career coaching, be a certified AI and ML Engineer.
Top 10 Machine Learning Algorithms You should Know in 2021
Living in an era of speedy technological development isn't easy. Especially, when you are interested in Machine Learning!
New Machine Learning Algorithms are coming up everyday with an unmatchable pace to get a hold of them! This article will help you grasp at least some of these algorithms being commonly used in the data science community. Data Scientists have been enhancing the data-crunching machines everyday to build a sophisticatedly advanced technology.
Here we are listing top 10 Machine learning algorithms for you to learn in 2021 -
1. Linear Regression
This is a fundamental algorithm, used to model relationships between a dependent variable and one or more independent variables by fitting them to a line. This line is known as the regression line and is represented by a linear equation Y = a 'X + b
2. Logistic Regression
This type of regression is very similar to linear regression but this one in particular is used to model the probability of a discrete number of outcomes, which is typically two - usually binary values like 0/1 from a set of independent variables. It calculates the probability of an event by fitting data to a logit function. This may sound complex but it only has one extra step as compared to linear regression!
3. Naive Bayes
This algorithm is a classifier. It assumes the presence of a particular feature in a class which is unrelated to the presence of any other feature. It may seem like a daunting algorithm because it necessitates preliminary mathematical knowledge in conditional probability and Bayes Theorem, but it's extremely simple to use.
4.KNN Algorithm
KNN Algorithms can be applied to both - classification and regression problems. This algorithm stores all the available cases and classifies any new cases by taking a majority vote of its k neighbours. Then, the case is transferred to the class with which it has the most in common.
5. Dimensionality Reduction Algorithm
This algorithm like Decision Tree, Missing Value Ratio, Factor Analysis, and Random Forest can help you find relevant details.
6. Random Forest Algorithm
Random forests Algorithms are an ensembles learning technique that builds off of decision trees. It generally involved creating multiple decision trees using bootstrapped datasets of the original data. It randomly selects a subset of variables at each step of the decision tree. Each tree is classified and the tree "votes" for that class.
7. SVM Algorithm
SVM stands for Support Vector Machine. In this algorithm, we plot raw data as points in an n-dimensional space (n = no. Of features you have). Then the value of each feature is tied to a particular coordinate, making it extremely easy to classify the data provided.
8. Decision Tree
This algorithm is a supervised learning algorithm which is used to classify problems. While using this algorithm, we split the population into two or more homogenous sets based on the most significant attributes or independent variables.
9. Gradient Boosting Algorithm
This algorithm is used as a boosting algorithm, which is used when massive data loads have to be handled to make predictions with high accuracy rates.
10. AdaBoost
AdaBoost also known as Adaptive Boost is an ensemble algorithm that leverages bagging and boosting methods and developed an enhanced predictor. The predictions are taken from the decision trees.
1 note
·
View note
Text
Hire the best SAS assignment Help expert
Wondering where to get SAS assignment help? we are experienced in providing Statistics assignment help , which includes both tutoring and assignment completion. We offer free tutoring classes in volatility modeling, survival analysis, panel data analysis, simple and multiple linear regression, and multivariate analysis. Other than the tutoring classes We also complete your assignment in record time ensuring that you perform well in your assignments.
#best assignment help#statistics project help#statistics homework help#statistics assignment help#sas assignment help#SAS homework help
8 notes
·
View notes
Text
Evolution of Forecasting from the Stone Age to Artificial Intelligence

Each nation has its ancient monument or a pagan holiday — the relic of the days when our ancestors tried to persuade their gods to give them more rain, no rain, better harvest, fewer wars and many other things considered essential for survival. However, neither Stonehenge nor jumping over fire could predict the gods’ reaction. It was a totally reactive world with no forecast. However, as time passed, people started to look into the future more inquisitively trying to understand what would be waiting for them. The science of prediction has emerged.
In this article, we’ll see how prediction evolved over time shaping our technologies, expectations and the worldview.
Naïve Forecasting
Naïve forecasting is an estimating technique in which the last period’s values are used as this period’s forecast, without adjusting them or attempting to establish causal factors. In other words, a naive forecast is just the most recently observed value. It is calculated by the formula
Ft+k=yt
where at the time t, the k-step-ahead naive forecast (Ft+k) equals the observed value at time t (yt).
In Ancient times, before such formulas, communities typically relied on observed patterns and recognized sequences of events for weather forecasting. The remnants of these techniques we can see in our everyday lives: we can foresee the next Monday routine based on the previous Monday, or expect spring to come in March (even though such expectations rely more on our imagination than the recorded seasonal changes).
In industry and commerce, it is used mainly for comparison with the forecasts generated by the better (sophisticated) techniques. However, sometimes this is the best that can be done for many time series including most stock price data. It also helps to baseline the forecast by tracking naïve forecast over time and estimating the forecast value added to the planning process. It reveals how difficult products are to forecast, whether it is worthwhile to spend time and effort on forecasting with more sophisticated methods and how much that method adds to the forecast.
Even if it is not the most accurate forecasting method, it provides a useful benchmark for other approaches.

Statistical Forecasting
Statistical forecasting is a method based on a systematic statistical examination of data representing past observed behavior of the system to be forecast, including observations of useful predictors outside the system. In simple terms, it uses statistics based on historical data to project what could happen out in the future.
As the late 19th and early 20th centuries were stricken by a series of crises that lead to severe panics — in 1873, 1893, 1907, and 1920 — and also substantial demographic change, as countries moved from being predominantly agricultural to being industrial and urban, people were struggling to find stability in the volatile world. Statistics-based forecasting invented at the beginning of the 20th century showed that economic activity was not random, but followed discernable patterns that could be predicted.
The two major statistical forecasting approaches are time series forecasting and model-based forecasting.
Time Series forecasting is a short-term purely statistical forecasting method that predicts short-term changes based on historical data. It is working on time (years, days, hours, and minutes) based data, to find hidden insights. The simplest technique of Time Series Forecasting is a simple moving average (SMA). It is calculated by adding up the last ’n’ period’s values and then dividing that number by ’n’. So the moving average value is then used as the forecast for next period.
Model-Based Forecasting is more strategic and long-term, and it accounts for changes in the business environment and events with little data. It requires management. Model-based forecasting techniques are similar to conventional predictive models which have independent and dependent variables, but the independent variable is now time. The simplest of such methods is the linear regression. Given a training set, we estimate the values of regression coefficients to forecast future values of the target variable.
With time the basic statistical methods of forecasting have seen significant improvements in approaches, forming the spectra of data-driven forecasting methods and modeling techniques.
Data-Driven Forecasting
Data-driven forecasting refers to a number of time-series forecasting methods where there is no difference between a predictor and a target. The most commonly employed data-driven time series forecasting methods are Exponential Smoothing and ARIMA Holt-Winters methods.
Exponential Smoothing
Exponential smoothing was first suggested in the statistical literature without citation to previous work by Robert Goodell Brown in 1956. Exponential smoothing is a way of “smoothing” out data by removing much of the “noise” from the data by giving a better forecast. It assigns exponentially decreasing weights as the observation gets older:
y^x=α⋅yx+(1−α)⋅y^x−1
where we’ve got a weighted moving average with two weights: α and 1−α.
This simplest form of exponential smoothing can be used for short-term forecast with a time series that can be described using an additive model with constant level and no seasonality.
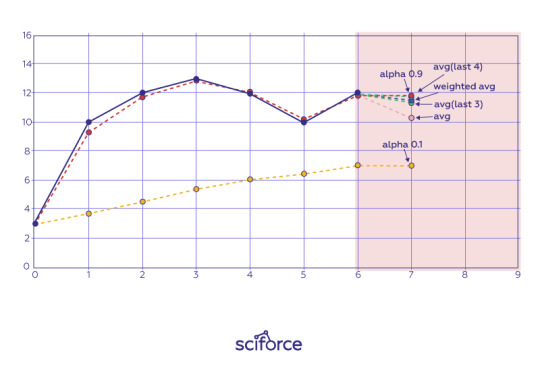
Holt-Winters Filtering
Charles C. Holt proposed a variation of exponential smoothing in 1957 for a time series that can be described using an additive model with increasing or decreasing trend and no seasonality. For a time series that can be described using an additive model with increasing or decreasing trend and seasonality, Holt-Winters exponential smoothing, or Triple Exponential Smoothing, would be more accurate. It is an improvement of Holt’s algorithms that Peter R. Winters offered in 1960.
The idea behind this algorithm is to apply exponential smoothing to the seasonal components in addition to level and trend. The smoothing is applied across seasons, e.g. the seasonal component of the 3rd point into the season would be exponentially smoothed with the one from the 3rd point of last season, 3rd point two seasons ago, etc.
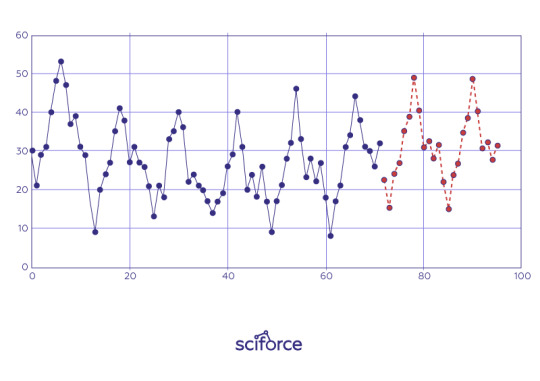
Here we can see evident seasonal trends that are supposed to continue in the proposed forecast.
Autoregressive Integrated Moving Average (ARIMA), or Box-Jenkins model
ARIMA is a statistical technique that uses time series data to predict future. It is are similar to exponential smoothing in that it is adaptive, can model trends and seasonal patterns, and can be automated. However, ARIMA models are based on autocorrelations (patterns in time) rather than a structural view of level, trend and seasonality. All in all, ARIMA models take trends, seasonality, cycles, errors and non-stationary aspects of a data set into account when making forecasts. ARIMA checks stationarity in the data, and whether the data shows a constant variance in its fluctuations over time.
The idea behind ARIMA is that the final residual should look like white noise; otherwise there is information available in the data to extract.
ARIMA models tend to perform better than exponential smoothing models for longer, more stable data sets and not as well for noisier, more volatile data.
While many of time-series models can be built in spreadsheets, the fact that they are based on historical data makes them easily automated. Therefore, software packages can produce large amounts of these models automatically across large data sets. In particular, data can vary widely, and the implementation of these models varies as well, so automated statistical software can assist in determining the best fit on a case by case basis.
Regression Models
A step forward compared to pure time series models, dynamic regression models allow incorporating causal factors such as prices, promotions and economic indicators into forecasts. The models combine standard OLS (“Ordinary Least Squares”) regression (as offered in Excel) with the ability to use dynamic terms to capture trend, seasonality and time-phased relationships between variables.
A dynamic regression model lends insight into relationships between variables and allows for “what if” scenarios. For example, if we study the relationship between sales and price, the model allows us to create forecasts under varying price scenarios, such as “What if we raise the price?” “What if we lower it?” Generating these alternative forecasts can help you to determine an effective pricing strategy.
A well-specified dynamic regression model captures the relationship between the dependent variable (the one you wish to forecast) and one or more (in cases of linear or multiple regressions, respectively) independent variables. To generate a forecast, you must supply forecasts for your independent variables. However, some independent variables are not under your control — think of weather, interest rates, price of materials, competitive offerings, etc. — you need to keep in mind that poor forecasts for the independent variables will lead to poor forecasts for the dependent variable.
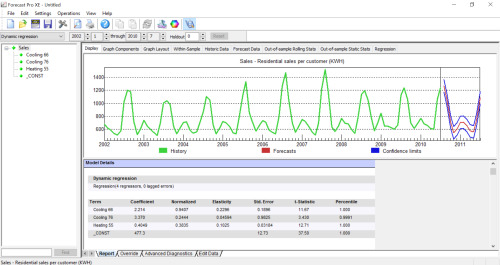
Forecasting demand for electricity using data on the weather (e.g. when people are likely to run their heat or AC).
In contrast to time series forecasting, regression models require knowledge of the technique and experience in data science. Building a dynamic regression model is generally an iterative procedure, whereby you begin with an initial model and experiment with adding or removing independent variables and dynamic terms until you arrive upon an acceptable model. Everyone who ever had a look at data or computer science knows that linear regression is in fact the basic prediction model in machine learning, which brings us to the final destination of our journey — Artificial Intelligence.
Artificial Intelligence
Artificial intelligence and machine learning are considered the tools that can revolutionize forecasting. An AI that can take into account all possible factors that might influence the forecast gives business strategists and planners breakthrough capabilities to extract knowledge from massive datasets assembled from any number of internal and external sources. The application of machine learning algorithms in the so called predictive modeling unearths insights and identifies trends missed by traditional human-configured forecasts. Besides, AI can simultaneously test and learn, constantly refining hundreds of advanced models. The optimal model can then be applied at a highly granular SKU-location level to generate a forecast that improves accuracy.
Neural networks
Among multiple models and techniques for prediction in ML and AI inventory, we have chosen one that is closest to our notion of a truly independent artificial intelligence. Artificial neural network (ANN) is a machine learning approach that models the human brain and consists of a number of artificial neurons. Neural networks can derive meaning from complicated or imprecise data and are used to detect the patterns and trends in the data, which are not easily detectable either by humans or by machines.
We can make use of NNs in any type of industry, as they are very flexible and also don’t require any algorithms. They are regularly used to model parts of living organisms and to investigate the internal mechanisms of the brain.
The simplest neural network is a fully Connected Model which consists of a series of fully connected layers. In a fully connected layer each neuron is connected to every neuron in the previous layer, and each connection has its own weight. Such model resembles a simple regression model that takes one input and will spit out one output. It basically takes the price from the previous day and forecasts the price of the next day. Such models repeat the previous values with a slight shift. However, fully connected models are not able to predict the future from the single previous value.
With the latest emergence of Deep Learning techniques, neural networks have seen significant improvements in terms of accuracy and ability to tackle the most sophisticated and complex tasks. Recently introduced recurrent neural networks deal with sequence problems. They can retain a state from one iteration to the next by using their own output as input for the next step. In programming terms, this is like running a fixed program with certain inputs and some internal variables. Such models can learn to reproduce the yearly shape of the data and don’t have the lag associated with a simple fully connected feed-forward neural network.
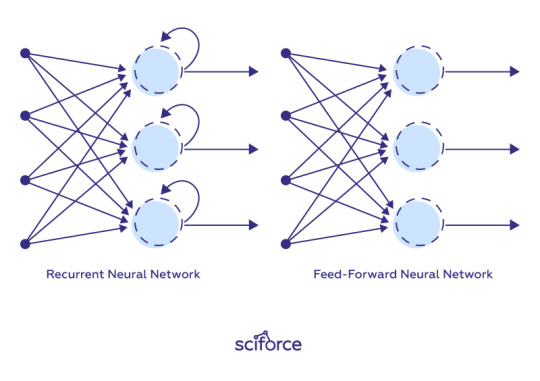
More than forecasting
With the development of Artificial Intelligence, forecasting as we knew it has transformed itself into a new phenomenon. Traditional forecasting is a technique that takes data and predicts the future value for the data looking at its unique trends. Artificial Intelligence and Big Data introduced predictive analysis that factors in a variety of inputs and predicts the future behavior — not just a number. In forecasting, there is no separate input or output variable but in the predictive analysis you can use several input variables to arrive at an output variable.
While forecasting is insightful and certainly helpful, predictive analytics can provide you with some pretty helpful people analytics insights. People analytics leaders have definitely caught on.
2 notes
·
View notes
Text
Learning to Rank with Vespa – Getting started with Text Search
Vespa.ai have just published two tutorials to help people to get started with text search applications by building scalable solutions with Vespa. The tutorials were based on the full document ranking task released by Microsoft’s MS MARCO dataset’s team.
The first tutorial helps you to create and deploy a basic text search application with Vespa as well as to download, parse and feed the dataset to a running Vespa instance. They also show how easy it is to experiment with ranking functions based on built-in ranking features available in Vespa.
The second tutorial shows how to create a training dataset containing Vespa ranking features that allow you to start training ML models to improve the app’s ranking function. It also illustrates the importance of going beyond pointwise loss functions when training models in a learning to rank context.
Both tutorials are detailed and come with code available to reproduce the steps. Here are the highlights.
Basic text search app in a nutshell
The main task when creating a basic app with Vespa is to write a search definition file containing information about the data you want to feed to the application and how Vespa should match and order the results returned in response to a query.
Apart from some additional details described in the tutorial, the search definition for our text search engine looks like the code snippet below. We have a title and body field containing information about the documents available to be searched. The fieldset keyword indicates that our query will match documents by searching query words in both title and body fields. Finally, we have defined two rank-profile, which controls how the matched documents will be ranked. The default rank-profile uses nativeRank, which is one of many built-in rank features available in Vespa. The bm25 rank-profile uses the widely known BM25 rank feature.
search msmarco { document msmarco { field title type string field body type string } fieldset default { fields: title, body } rank-profile default { first-phase { expression: nativeRank(title, body) } } rank-profile bm25 inherits default { first-phase { expression: bm25(title) + bm25(body) } } }
When we have more than one rank-profile defined, we can chose which one to use at query time, by including the ranking parameter in the query:
curl -s "<URL>/search/?query=what+is+dad+bod" curl -s "<URL>/search/?query=what+is+dad+bod&ranking=bm25"
The first query above does not specify the ranking parameter and will therefore use the default rank-profile. The second query explicitly asks for the bm25 rank-profile to be used instead.
Having multiple rank-profiles allow us to experiment with different ranking functions. There is one relevant document for each query in the MSMARCO dataset. The figure below is the result of an evaluation script that sent more than 5.000 queries to our application and asked for results using both rank-profiles described above. We then tracked the position of the relevant document for each query and plotted the distribution for the first 10 positions.
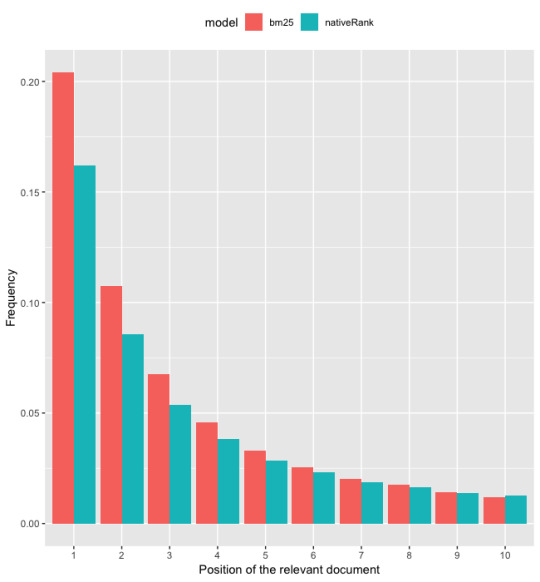
It is clear that the bm25 rank-profile does a much better job in this case. It places the relevant document in the first positions much more often than the default rank-profile.
Data collection sanity check
After setting up a basic application, we likely want to collect rank feature data to help improve our ranking functions. Vespa allow us to return rank features along with query results, which enable us to create training datasets that combine relevance information with search engine rank information.
There are different ways to create a training dataset in this case. Because of this, we believe it is a good idea to have a sanity check established before we start to collect the dataset. The goal of such sanity check is to increase the likelihood that we catch bugs early and create datasets containing the right information associated with our task of improving ranking functions.
Our proposal is to use the dataset to train a model using the same features and functional form used by the baseline you want to improve upon. If the dataset is well built and contains useful information about the task you are interested you should be able to get results at least as good as the one obtained by your baseline on a separate test set.
Since our baseline in this case is the bm25 rank-profile, we should fit a linear model containing only the bm25 features:
a + b * bm25(title) + c * bm25(body)
Having this simple procedure in place helped us catch a few silly bugs in our data collection code and got us in the right track faster than would happen otherwise. Having bugs on your data is hard to catch when you begin experimenting with complex models as we never know if the bug comes from the data or the model. So this is a practice we highly recommend.
How to create a training dataset with Vespa
Asking Vespa to return ranking features in the result set is as simple as setting the ranking.listFeatures parameter to true in the request. Below is the body of a POST request that specify the query in YQL format and enable the rank features dumping.
body = { "yql": 'select * from sources * where (userInput(@userQuery));', "userQuery": "what is dad bod", "ranking": {"profile": "bm25", "listFeatures": "true"}, }
Vespa returns a bunch of ranking features by default, but we can explicitly define which features we want by creating a rank-profile and ask it to ignore-default-rank-features and list the features we want by using the rank-features keyword, as shown below. The random first phase will be used when sampling random documents to serve as a proxy to non-relevant documents.
rank-profile collect_rank_features inherits default { first-phase { expression: random } ignore-default-rank-features rank-features { bm25(title) bm25(body) nativeRank(title) nativeRank(body) } }
We want a dataset that will help train models that will generalize well when running on a Vespa instance. This implies that we are only interested in collecting documents that are matched by the query because those are the documents that would be presented to the first-phase model in a production environment. Here is the data collection logic:
hits = get_relevant_hit(query, rank_profile, relevant_id) if relevant_hit: hits.extend(get_random_hits(query, rank_profile, n_samples)) data = annotate_data(hits, query_id, relevant_id) append_data(file, data)
For each query, we first send a request to Vespa to get the relevant document associated with the query. If the relevant document is matched by the query, Vespa will return it and we will expand the number of documents associated with the query by sending a second request to Vespa. The second request asks Vespa to return a number of random documents sampled from the set of documents that were matched by the query.
We then parse the hits returned by Vespa and organize the data into a tabular form containing the rank features and the binary variable indicating if the query-document pair is relevant or not. At the end we have a dataset with the following format. More details can be found in our second tutorial.
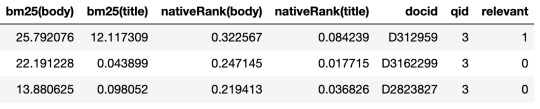
Beyond pointwise loss functions
The most straightforward way to train the linear model suggested in our data collection sanity check would be to use a vanilla logistic regression, since our target variable relevant is binary. The most commonly used loss function in this case (binary cross-entropy) is referred to as a pointwise loss function in the LTR literature, as it does not take the relative order of documents into account.
However, as we described in our first tutorial, the metric that we want to optimize in this case is the Mean Reciprocal Rank (MRR). The MRR is affected by the relative order of the relevance we assign to the list of documents generated by a query and not by their absolute magnitudes. This disconnect between the characteristics of the loss function and the metric of interest might lead to suboptimal results.
For ranking search results, it is preferable to use a listwise loss function when training our model, which takes the entire ranked list into consideration when updating the model parameters. To illustrate this, we trained linear models using the TF-Ranking framework. The framework is built on top of TensorFlow and allow us to specify pointwise, pairwise and listwise loss functions, among other things.
We made available the script that we used to train the two models that generated the results displayed in the figure below. The script uses simple linear models but can be useful as a starting point to build more complex ones.
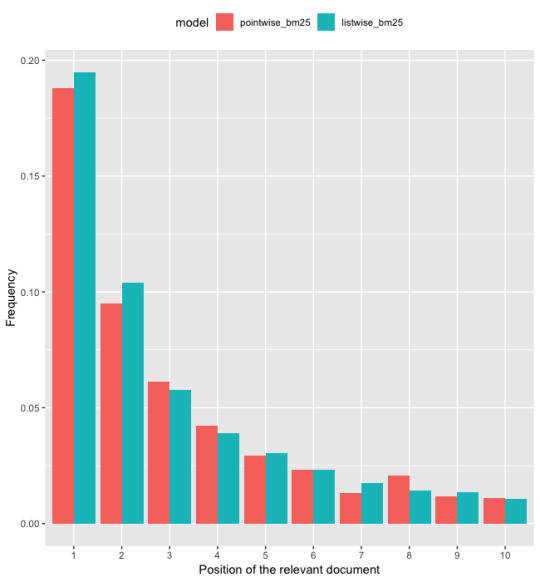
Overall, on average, there is not much difference between those models (with respect to MRR), which was expected given the simplicity of the models described here. However, we can see that a model based on a listwise loss function allocate more documents in the first two positions of the ranked list when compared to the pointwise model. We expect the difference in MRR between pointwise and listwise loss functions to increase as we move on to more complex models.
The main goal here was simply to show the importance of choosing better loss functions when dealing with LTR tasks and to give a quick start for those who want to give it a shot in their own Vespa applications. Now, it is up to you, check out the tutorials, build something and let us know how it went. Feedbacks are welcome!
3 notes
·
View notes
Text
Jamovi Regression Analysis Guide for Students Seeking Assignment Help
Jamovi is an open-source and easy to use statistical software for conducting data analysis, appealing to both novices and experts. Designed by the developers of JASP, it has an intuitive interface and enhanced analytical capabilities without the need of any programming codes as used in SAS, R, SPSS etc. It is increasingly becoming popular with over 30% increase in annual downloads, which has been attributed to its ability to integrate with R allowing customization. Jamovi has always been updated with latest capabilities to handle complex analysis and bug fixes.
Though certain benefits are enjoyed, a number of learners face challenges when using Jamovi software for data analysis especially in regard to conducting regression analyses. Attempting to interpret the output, choosing the correct model, and correctly interpreting the results are examples of common problems encountered. Due to these reasons most of them want to utilize Jamovi assignment help in overcoming the difficulties and also ensuring that their assignment solutions meet the required academic standards.

Understanding Regression Analysis in Jamovi
Regression analysis is a statistical method used to understand the relationship between a dependent variable and one or more independent variables. In simpler terms it assists in predicting the effects on the dependent variable due to the changes in the independent variables. This is especially useful in disciplines including economics, psychology, biology and social sciences where researchers study causality and predict outcomes. Jamovi offers several types of regression analyses, including:
Simple Linear Regression: This is simplest kind of regression where there is one dependent variable and one independent variable. It is used to examine the linear relationship that exists between two variables in question.
Multiple Regression: This is where two or more independent variable are used to analyse a single dependent variable. It enables analysis to incorporate more than one factor as compared to the use of the single regression model.
Logistic Regression: Used when the dependent variable is binary (e.g., yes/no, pass/fail), logistic regression helps in modelling the probability of a particular outcome.
Polynomial Regression: This goes beyond the simple linear regression by taking the non-linear relationship between the independent and the dependent variable into consideration.
Hierarchical Regression: This method allows for the stepwise inclusion of variables, helping to understand the incremental value of adding additional predictors.
In this guide, we will focus on performing a simple linear regression analysis using Jamovi, which is a foundational technique that students need to master before moving on to more advanced forms of regression.
Getting Started with Jamovi
Jamovi is an opensource program that can be downloaded from the official website of the program; it supports major operating systems such as Windows, Mac OS X, and Linux. After installation of the software just open it and follow the below steps to conduct simple linear regression analysis.
Step-by-Step Guide to Performing Simple Linear Regression in Jamovi
In this illustration, we will use a dataset called "Exam Scores," which contains two variables: hours studied (independent variable) and exam scores (dependent variable). The hypothesis of the study is to find out if there exists a linear relationship between the number of hours spent studying and the scores that the students obtain in the exams.
Step 1: Importing Data into Jamovi
Open Jamovi: Launch the Jamovi application on your computer.
Import Data: Click on the "Open" button in the top left corner of the screen, then select "Data Library" to browse through available datasets or "Computer" to upload your dataset from your device. For this tutorial, we'll assume you have your dataset saved as a CSV file named ExamScores.csv.
Load the Dataset: After selecting the dataset, click "Open" to load it into Jamovi. You will see your data displayed in a spreadsheet-like format, similar to Excel.
Step 2: Setting Up the Regression Analysis
Navigate to the Analyses Menu: On the top menu bar, click on the "Analyses" tab. A drop-down menu will appear with various analysis options.
Select Regression: From the list of analysis options, select "Regression" and then choose "Linear Regression." This will open the linear regression setup panel on the right side of the screen.
Specify Variables: In the linear regression setup panel, you will see two boxes labeled "Dependent Variable" and "Covariates."
. Drag the variable Exam Scores into the "Dependent Variable" box. . Drag the variable Hours Studied into the "Covariates" box.
This tells Jamovi that we want to model the relationship between hours studied and exam scores.
Step 3: Running the Regression Analysis
Configure Options: In the setup panel, you can configure additional options such as adding interaction terms, checking assumptions, and selecting robust standard errors. For this basic example, we will keep the default settings.
Run the Analysis: Click the "OK" button at the bottom of the setup panel to run the regression analysis. Jamovi will automatically generate the output in the right panel, displaying the regression coefficients, model summary, and other relevant statistics.
Step 4: Interpreting the Results
Once the analysis is complete, Jamovi provides a detailed output that includes the following:
Model Summary: This section provides an overview of the regression model, including the R-squared value, which indicates the proportion of variance in the dependent variable explained by the independent variable. In our example, if the R-squared value is 0.75, this means that 75% of the variation in exam scores can be explained by the number of hours studied.
Coefficients Table: This table lists the regression coefficients for each predictor. The coefficient for Hours Studied tells us the expected change in Exam Scores for a one-unit increase in Hours Studied. For instance, if the coefficient is 5, this means that for each additional hour studied, the exam score is expected to increase by 5 points.
Statistical Significance: The output also includes p-values, which indicate whether the relationships observed are statistically significant. A p-value less than 0.05 is typically considered significant, suggesting that the predictor variable (hours studied) has a meaningful impact on the dependent variable (exam scores).
Step 5: Visualizing the Regression Line
Plotting the Regression Line: To visualize the relationship between the variables, you can create a scatter plot with a fitted regression line.
Create Plot: In the analysis panel, select the "Plots" tab and check the box for "Fitted Line Plot." This will generate a scatter plot with the regression line overlaid, allowing you to visually assess the fit of the model.
Common Challenges in Jamovi Regression Analysis and How to Overcome Them
While Jamovi is designed to be user-friendly, students often face several challenges when performing regression analysis:
Understanding Output: The output generated by Jamovi can be confusing for students. It is important to focus on key statistics such as coefficients, R-squared values, and p-values to interpret the results accurately.
Choosing the Right Model: Selecting the right type of regression analysis is important. For instance, when one fits a model with the linear relationship, while actually the relationship exists non-linearly, then wrong conclusion is drawn.
Data Preparation: It is always important to prepare and clean data before analysing it especially if you are dealing with large volumes of data. There are various issues such as missing values, outliers and incorrect data types can affect the regression analysis.
Interpreting Multicollinearity: Multicollinearity must be checked while performing regression, where the independent variables are highly correlated. This can skew the results and makes it difficult to know the impact of each individual variable.
In order to address these challenges, the students can turn for Jamovi assignment help from our proficient writers. Professional services are helpful in data preparation, model selection, results interpretation and troubleshooting errors. Our services can help students do the right things which will lead to the production of good assignments and excellent grades.
Conclusion
In this tutorial we have walked you through how to do regression in Jamovi. We have covered the basics of regression, the different types of regression in Jamovi and a hands-on example using a popular dataset. Whether you are a beginner or looking to improve your skills this tutorial will help you navigate the regression features in Jamovi. Remember practice is key to mastering stats, so use the resources and seek Jamovi assignment help when needed. Contact us today.
Additional Resources for Jamovi Homework Assistance
"Introduction to the New Statistics: Estimation, Open Science, and Beyond" by Geoff Cumming and Robert Calin-Jageman: This book provides a comprehensive introduction to statistical analysis using Jamovi, emphasizing estimation and open science practices.
Jamovi User Guide: The official Jamovi documentation provides detailed instructions and examples for using the software's various features and performing different types of analyses. It is an invaluable resource for both beginners and advanced users.
Online Tutorials and Courses: Websites like Statisticshelpdesk offer assignment assistance and helpful material on statistics and data analysis using Jamovi, covering everything from basic concepts to advanced techniques.
0 notes